快速流分类算法研究综述

快速流分类算法研究综述
李振强
(北京邮电大学信息网络中心,北京 100876)
摘要
本文对流分类算法进行了综述,包括流分类的定义,对流分类算法的要求,以及各种流分类算法的分析比较。文章的最后指出了在流分类方面还没有得到很好解决的问题,作为进一步研究的方向。
关键词
流分类;服务质量;IP
背景
当前的IP网络主要以先到先服务的方式提供尽力而为的服务。随着Internet的发展和各种新业务的出现,尽力而为的服务已经不能满足人们对Internet的要求,IP网络必须提供增强的服务,比如:SLA(Service Level Agreement)服务,VPN(Virtual Private Network)服务,各种不同级别的QoS (Quality of Service)服务,分布式防火墙,IP安全网关,流量计费等。所有这些增强服务的提供都依赖于流分类,即根据包头(packet header)中的一个或几个域(field)决定该包隶属的流(flow)。典型的,包头中可以用来分类的域包括:源IP地址(Source IP Address)、目的IP地址(Destination IP Address)、协议类型(Protocol Type)、源端口(Source Port)和目的端口(Destination Port)等。
流分类算法描述
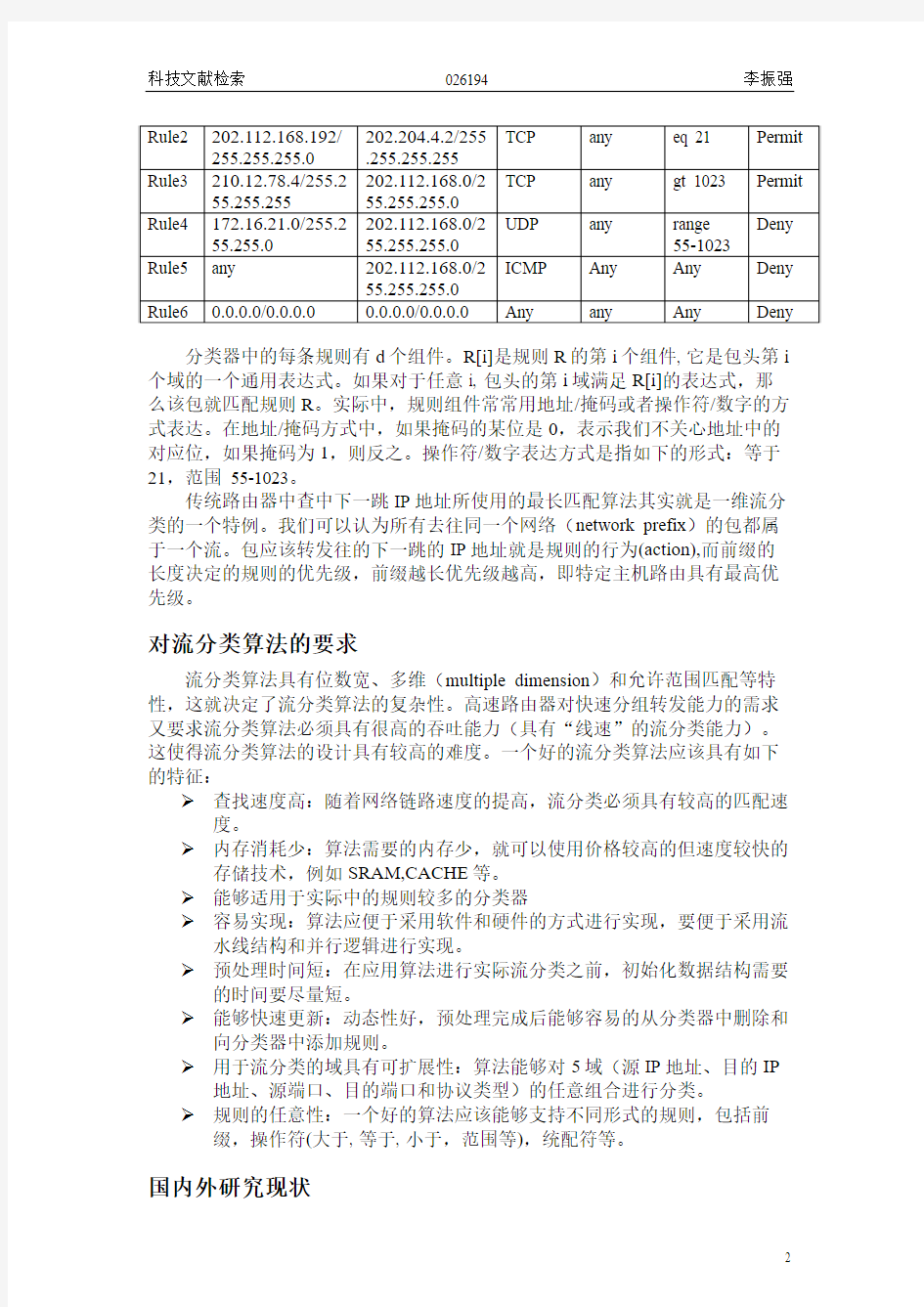
首先定义两个名词:规则(rule)和分类器(classifier)。用来对IP包进行分类的由包头中若干域组成的集合称之为规则,而若干规则的集合就是分类器。构成规则的域(我们称之为组件component)的值可以是某个范围,例如目的端口大于1023。流分类就是要确定和每个包最匹配的规则。表1是由6条规则组成的一个分类器。我们说这是一个5域分类器,因为每条规则由5个组件构成。我们假定分类器中的规则是有优先级的,越靠前的规则优先级越高,即规则1的优先级最高,规则6的最低。
分类器中的每条规则有d个组件。R[i]是规则R的第i个组件, 它是包头第i 个域的一个通用表达式。如果对于任意i, 包头的第i域满足R[i]的表达式,那么该包就匹配规则R。实际中,规则组件常常用地址/掩码或者操作符/数字的方式表达。在地址/掩码方式中,如果掩码的某位是0,表示我们不关心地址中的对应位,如果掩码为1,则反之。操作符/数字表达方式是指如下的形式:等于21,范围 55-1023。
传统路由器中查中下一跳IP地址所使用的最长匹配算法其实就是一维流分类的一个特例。我们可以认为所有去往同一个网络(network prefix)的包都属于一个流。包应该转发往的下一跳的IP地址就是规则的行为(action),而前缀的长度决定的规则的优先级,前缀越长优先级越高,即特定主机路由具有最高优先级。
对流分类算法的要求
流分类算法具有位数宽、多维(multiple dimension)和允许范围匹配等特性,这就决定了流分类算法的复杂性。高速路由器对快速分组转发能力的需求又要求流分类算法必须具有很高的吞吐能力(具有“线速”的流分类能力)。这使得流分类算法的设计具有较高的难度。一个好的流分类算法应该具有如下的特征:
查找速度高:随着网络链路速度的提高,流分类必须具有较高的匹配速度。
内存消耗少:算法需要的内存少,就可以使用价格较高的但速度较快的存储技术,例如SRAM,CACHE等。
能够适用于实际中的规则较多的分类器
容易实现:算法应便于采用软件和硬件的方式进行实现,要便于采用流水线结构和并行逻辑进行实现。
预处理时间短:在应用算法进行实际流分类之前,初始化数据结构需要的时间要尽量短。
能够快速更新:动态性好,预处理完成后能够容易的从分类器中删除和向分类器中添加规则。
用于流分类的域具有可扩展性:算法能够对5域(源IP地址、目的IP 地址、源端口、目的端口和协议类型)的任意组合进行分类。
规则的任意性:一个好的算法应该能够支持不同形式的规则,包括前缀,操作符(大于, 等于, 小于,范围等),统配符等。
国内外研究现状
目前流分类算法主要应用了三种数据结构:线性表,树和Hash表。这三种方法都是在预处理时建立相应的数据结构,流分类时通过一次或多次查找建立的数据结构和一些简单的处理获得最终的分类结果。使用线性表数据结构的算法包括:Linear Search、Ternary CAM、Crossproducting、Recursive Flow Classification等。使用树数据结构的算法包括:Hierarchical Tries、Set-Pruning Tries、Grid of Tries、Hierarchical Intelligent Cuttings、Aggregate Bit Vector等。使用Hash表数据结构的算法包括:Tuple Space Search等。下面对每一种算法进行简要的分析,指出各自的优缺点。
Linear Search
这种算法采用的数据结构最简单,规则以链表的方式降序存储。分类时数据包从表头开始依次和链表中的各个规则进行比较,直到找到一条匹配的规则或者达到链尾。尽管该算法存储效率高,简单,但是查找时间长,并且查找时间随规则数的增加而线性增加。
Ternary CAM
Ternary CAM算法具有最快的分类时间,只需要一个内存访问周期。但该算法只能由硬件实现,需要的CAM存储器的容量为dNW(d:分类器的维数,N:分类器中规则的个数,W:每一维的宽度,下同)。CAM存储器价格高,耗电量大,不能直接支持范围匹配,因而对d, N, W的扩展性均较差,只能用于较小的流分类问题。
CrossProducting[6]
CrossProducting算法将多维的流分类问题建立在多个一维流分类基础上,利用多个一维流分类的结果查找CrossProducting表获得最终的流分类结果。该方法便于实现,时间复杂度是dW,空间复杂度为Nd,对规则维数和数量的可扩展性较差。
Recursive Flow Classification[1]
RFC是由Pankaj Gupta和Nick McKeown提出的一种适合多域流分类问题的算法,具有流分类速度快,直接支持范围和前缀匹配等优点。但当d, N, W 增加时,所需存储空间太大。如果该算法所基于的特征在所用的分类器中不具有或不明显,每一维长度的压缩量将很小,这将严重影响流分类的性能。该算法的另一个缺点是动态性差,添加一条新规则在最坏的情况下需要重建整个数据结构,因而不适合规则频繁变化的流分类器。
Hierarchical Tries
Hierarchical Tries是对一维查找树的一种简单扩展,它从d维中任选一维生成第一级查找二叉树,对该二叉树中的每一个与分类器中第一维匹配的结点,按分类器中规则的第二维建立另一个二叉树,反复上述过程直到完成每一维的处理,就构成了多维分层查找树。该方法简单、直接,也便于硬件实现,但查找时间较长,对d的扩展性差,也不直接支持范围匹配。
Set-Pruning Tries[7]
Set-Pruning Tries通过对多维分层查找树中某些结点进行多次复制,减少多维分层查找树的层次,提高查找效率。但所需存储空间增加较多,对规则维数的扩展性差。
Grid of Tries[6]
Grid of Tries的主要思路是将Set-Pruning Tries中重复的子树删去,只保留一颗子树,这样存储空间的需求量由NddW降为NdW,时间复杂度仍为dW,但该方法动态性差,减少规则需要对整个树进行重建,并且只适用于d=2的情况。
Hierarchical Intelligent Cuttings[2]
Hierarchical Intelligent Cuttings的基本思想是以规则的每一字段为一层次将分类器中所有规则按范围空间进行循环分组,直到每一组中都只有少于NUM 条的规则,查找时在少于NUM条规则中通过线性匹配来找到匹配规则。在HiCuts中,整个分类器只建立一棵树:根节点表示整个d维空间,树中每个节点代表了查找空间的一部分,叶结点存储了位于这个查找空间的B条规则,
B<=NUM。HiCuts能够根据分类器本身的特征自动调节流分类算法使用的数据结构,最大限度的利用优化数据结构、减少冗余,降低算法的存储容量要求,提高流分类的速度。该算法对存储容量要求低,直接支持范围匹配,动态性好,规则的增删容易:产出规则时,只要把该规则打上“删除”标记即可,不用修改HiCuts树;增加规则时,在相应空间的叶结点加上该规则号,如果叶结点增加后的规则数大于NUM,则对该叶结点执行空间划分过程。
在规则空间均匀分布的情况下,HiCuts有很好的性能,但由于构造HiCuts 树时是循环依次对每一维进行空间划分,如果一个d维分类器中的大部分规则只通过某一维来划分,而其他维的值相似或相同,HiCuts树的深度和结点会大大增加,预处理时间和占用的内存空间都会成倍增加,大大影响算法的性能。
Aggregate Bit Vector[8]
ABV的基本思想是“分割-合并”,它将一个d维的流分类问题分割为d 个1维匹配的子问题,然后将子问题的结果进行合并得到最后的匹配规则。ABV为每一字段建立一棵非完全二叉树,二叉树的每个节点都表示了一个范围,二叉树的最高高度不大于该域的比特位数W。ABV利用比特向量记录符合该结点范围的规则,然后根据归并参数A对比特向量进行A位一组的逻辑或操作。通过归并ABV算法减少了访存次数,当分类器维数较大,规则较多时,采用多层归并可以大大减少算法的访存次数,提高匹配速度。但是归并带来的好处是受条件限制的。当规则无序排列使得归并后的向量为全1时,并不会减少访存的次数。所以,在ABV的预处理阶段需要对分类器中的规则按字段进行排序,但这会大大增加预处理时间。
ABV算法具有较好的动态性,对分类器中规则的增删改比较容易。删除规则时,只需遍历二叉树把向量中对应的比特位置0;修改与删除类似;增加规则时,可以占用被删除规则的位置或加到最后比特位的后面,并且能够较好的实现规则的冲突检测,这是ABV算法一个突出特性。
Tuple Space Search[10]
Tuple space search算法使用Hash表将一次匹配分解成几次严格匹配查询。该算法将一个d维规则映射成一个d元元组,d元元组的每个组件存储规则相应
域前缀的长度。该算法的时间复杂度是M(M是分类器中d元元组的个数),存储复杂度是O(N),因为每一个规则只在一个Hash表中存储。该算法支持规则的动态更新,在d元元组较少时有良好MF分类性能。但是该算法只支持前缀匹配,并且Hash算法的使用使得匹配和更新的时间具有不确定性,在最坏情况下,M= O(Wd)。
进一步研究方向
新算法的设计和验证
通过对已有流分类算法的研究和分析,借鉴其优秀的设计思想,对已有算法的不足进行改进,提出新的算法并进行验证。
IPv6流分类
以上所述各种算法都只适用于IPv4。对于IPv6的流分类问题现在很少有论文论及。IPv6的流分类和IPv4的流分类有些不同。首先,每一个地址域变成了128比特。一个典型的5域分类器用于分类的关键字将长达296比特。其次,确定TCP/UDP端口号需要顺着扩展头列表进行解析,直到分类器确定了
TCP/UDP净荷的开始位置或确定了分组不属于这两个协议。
对于IPv6流分类可以考虑利用IPv6包头中的流标号域。一个可能的用法是分组的发送源对所有要求网络给予同样排队和调度处理的分组分配一个随机但唯一的流标号值。这样分类关键字仅仅需要覆盖流标号和源地址域就能实现流层次上的分组隔离,而不需要检查目的地址域和TCP/UDP端口号。
但是流标号加源地址的分类方法限制了路由器将几个流进行汇聚的能力。产生分组的源负责为分组分配流标号并且可能为属于不同应用的流分配相同的流标号。由于流标号仅仅标识要求特殊排队和调度处理而没有其他附加语义,路由器就区分不出共享同一个流标号的不同的流,相反,由于不同的应用采用不同的TCP/UDP端口号,明确的端口号分类允许路由器从相关的应用中识别流。
分段后的流分类
MF分类的一个局限是分段的IPv4分组仅在第一段承载TCP/UDP端口号。因此,察看TCP/UDP端口号的MF分类器很可能遗漏同一个分组的后面的段(除非分类器使后面的段和承载端口号的第一个段关联)。
加密报文的分类
端到端的净荷加密给分类算法提出了挑战性的问题。网络加密隐藏尽可能多的信息以防止被窃听,而同时保留足够的信息以使路由器能正确的转发分组。如果IP的净荷被加密,则TCP和UDP端口号不能被识别。更复杂的情况是,应用的IP分组被全部加密且以隧道方式通过网络。网络内部的路由器将基于隧道的分组头分类,这意味着很少关心共享隧道的单个流的信息。
参考文献
1.Gupta P. and McKeown N., ―Packet Classification on Multiple fields‖, Proceedings of ACM Sigcomm, September 1999, pp. 147-160
2.Gupta P. and McKeown N., ―Classification Using Hierarchical Intelligent Cuttings‖, Hot Interconnects, August 1999
3.胡光岷,李乐民,“流分类算法研究综述”,通信技术,第一期,2002 4.Gupta P. and McKeown N., ―Algorithms for Packet Classification‖, IEEE Network, March/April 2001
5.隆克平,龚向阳等译,Grenville Armitage著,IP网络的服务质量—多业务互联网的基础,机械工业出版社,2001年1月
6.V. Srinivasan et al., ―Fast and Scalable Layer four Switching,‖ Proceedings of ACM Sigcomm, September 1998, pp. 203–14.
7.P. Tsuchiya, ―A Search Algorithm for Table Entries with Non-contiguous Wildcarding,‖ unpublished report, Bellcore.
8.Florin Baboescu, George Barghese, ―Scalable Packet Classification‖, Proceedings of ACM Sigcomm, 2001
9.Anja Feldmann, S. Muthukrishnan, ―Tradeoffs for Packet Classification‖, Proceedings of IEEE Infocom, 2000
10.V. Srinivasan, S. Suri, and G. Varghese, ―Packet Classification using Tuple Space Search‖, Proceedings of ACM Sigcomm, September 1999, pp. 135–46. 11.申震生,龚向阳等,“具有高速过滤算法的IP防火墙”,计算机应用,Vol. 21, No 5, May 2001
文本分类中的特征提取和分类算法综述
文本分类中的特征提取和分类算法综述 摘要:文本分类是信息检索和过滤过程中的一项关键技术,其任务是对未知类别的文档进行自动处理,判别它们所属于的预定义类别集合中的类别。本文主要对文本分类中所涉及的特征选择和分类算法进行了论述,并通过实验的方法进行了深入的研究。 采用kNN和Naive Bayes分类算法对已有的经典征选择方法的性能作了测试,并将分类结果进行对比,使用查全率、查准率、F1值等多项评估指标对实验结果进行综合性评价分析.最终,揭示特征选择方法的选择对分类速度及分类精度的影响。 关键字:文本分类特征选择分类算法 A Review For Feature Selection And Classification Algorithm In Text Categorization Abstract:Text categorization is a key technology in the process of information retrieval and filtering,whose task is to process automatically the unknown categories of documents and distinguish the labels they belong to in the set of predefined categories. This paper mainly discuss the feature selection and classification algorithm in text categorization, and make deep research via experiment. kNN and Native Bayes classification algorithm have been applied to test the performance of classical feature detection methods, and the classification results based on classical feature detection methods have been made a comparison. The results have been made a comprehensive evaluation analysis by assessment indicators, such as precision, recall, F1. In the end, the influence feature selection methods have made on classification speed and accuracy have been revealed. Keywords:Text categorization Feature selection Classification algorithm
基于机器学习的文本分类方法
基于机器学习算法的文本分类方法综述 摘要:文本分类是机器学习领域新的研究热点。基于机器学习算法的文本分类方法比传统的文本分类方法优势明显。本文综述了现有的基于机器学习的文本分类方法,讨论了各种方法的优缺点,并指出了文本分类方法未来可能的发展趋势。 1.引言 随着计算机技术、数据库技术,网络技术的飞速发展,Internet的广泛应用,信息交换越来越方便,各个领域都不断产生海量数据,使得互联网数据及资源呈现海量特征,尤其是海量的文本数据。如何利用海量数据挖掘出有用的信息和知识,方便人们的查阅和应用,已经成为一个日趋重要的问题。因此,基于文本内容的信息检索和数据挖掘逐渐成为备受关注的领域。文本分类(text categorization,TC)技术是信息检索和文本挖掘的重要基础技术,其作用是根据文本的某些特征,在预先给定的类别标记(label)集合下,根据文本内容判定它的类别。传统的文本分类模式是基于知识工程和专家系统的,在灵活性和分类效果上都有很大的缺陷。例如卡内基集团为路透社开发的Construe专家系统就是采用知识工程方法构造的一个著名的文本分类系统,但该系统的开发工作量达到了10个人年,当需要进行信息更新时,维护非常困难。因此,知识工程方法已不适用于日益复杂的海量数据文本分类系统需求[1]。20世纪90年代以来,机器学习的分类算法有了日新月异的发展,很多分类器模型逐步被应用到文本分类之中,比如支持向量机(SVM,Support Vector Machine)[2-4]、最近邻法(Nearest Neighbor)[5]、决策树(Decision tree)[6]、朴素贝叶斯(Naive Bayes)[7]等。逐渐成熟的基于机器学习的文本分类方法,更注重分类器的模型自动挖掘和生成及动态优化能力,在分类效果和灵活性上都比之前基于知识工程和专家系统的文本分类模式有所突破,取得了很好的分类效果。 本文主要综述基于机器学习算法的文本分类方法。首先对文本分类问题进行概述,阐述文本分类的一般流程以及文本表述、特征选择方面的方法,然后具体研究基于及其学习的文本分类的典型方法,最后指出该领域的研究发展趋势。 2.文本自动分类概述 文本自动分类可简单定义为:给定分类体系后,根据文本内容自动确定文本关联的类别。从数学角度来看,文本分类是一个映射过程,该映射可以是一一映射,也可以是一对多映射过程。文本分类的映射规则是,系统根据已知类别中若干样本的数据信息总结出分类的规律性,建立类别判别公式或判别规则。当遇到新文本时,根据总结出的类别判别规则确定文本所属的类别。也就是说自动文本分类通过监督学习自动构建出分类器,从而实现对新的给定文本的自动归类。文本自动分类一般包括文本表达、特征选取、分类器的选择与训练、分类等几个步骤,其中文本表达和特征选取是文本分类的基础技术,而分类器的选择与训练则是文本自动分类技术的重点,基于机器学习的文本分来就是通过将机器学习领域的分类算法用于文本分类中来[8]。图1是文本自动分类的一般流程。
蚁群算法综述
智能控制之蚁群算法 1引言 进入21世纪以来,随着信息技术的发展,许多新方法和技术进入工程化、产品化阶段,这对自动控制技术提出新的挑战,促进了智能理论在控制技术中的应用,以解决用传统的方法难以解决的复杂系统的控制问题。随着计算机技术的飞速发展,智能计算方法的应用领域也越来越广泛。 智能控制技术的主要方法有模糊控制、基于知识的专家控制、神经网络控制和集成智能控制等,以及常用优化算法有:遗传算法、蚁群算法、免疫算法等。 蚁群算法是近些年来迅速发展起来的,并得到广泛应用的一种新型模拟进化优化算法。研究表明该算法具有并行性,鲁棒性等优良性质。它广泛应用于求解组合优化问题,所以本文着重介绍了这种智能计算方法,即蚁群算法,阐述了其工作原理和特点,同时对蚁群算法的前景进行了展望。 2 蚁群算法概述 1、起源 蚁群算法(ant colony optimization, ACO),又称蚂蚁算法,是一种用来在图中寻找优化路径的机率型技术。它由Marco Dorigo于1992年在他的博士论文中引入,其灵感来源于蚂蚁在寻找食物过程中发现路径的行为。 Deneubourg及其同事(Deneubourg et al.,1990; Goss et al.,1989)在可监控实验条件下研究了蚂蚁的觅食行为,实验结果显示这些蚂蚁可以通过使用一种称为信息素的化学物质来标记走过的路径,从而找出从蚁穴到食物源之间的最短路径。 在蚂蚁寻找食物的实验中发现,信息素的蒸发速度相对于蚁群收敛到最短路径所需的时间来说过于缓慢,因此在模型构建时,可以忽略信息素的蒸发。然而当考虑的对象是人工蚂蚁时,情况就不同了。实验结果显示,对于双桥模型和扩展双桥模型这些简单的连接图来说,同样不需要考虑信息素的蒸发。相反,在更复杂的连接图上,对于最小成本路径问题来说,信息素的蒸发可以提高算法找到好解的性能。 2、基于蚁群算法的机制原理 模拟蚂蚁群体觅食行为的蚁群算法是作为一种新的计算智能模式引入的,该算法基于如下假设: (1)蚂蚁之间通过信息素和环境进行通信。每只蚂蚁仅根据其周围的环境作出反应,也只对其周围的局部环境产生影响。 (2)蚂蚁对环境的反应由其内部模式决定。因为蚂蚁是基因生物,蚂蚁的行为实际上是其基因的自适应表现,即蚂蚁是反应型适应性主体。 (3)在个体水平上,每只蚂蚁仅根据环境作出独立选择;在群体水平上,单
快速流分类算法研究综述
快速流分类算法研究综述 李振强 (北京邮电大学信息网络中心,北京 100876) 摘要 本文对流分类算法进行了综述,包括流分类的定义,对流分类算法的要求,以及各种流分类算法的分析比较。文章的最后指出了在流分类方面还没有得到很好解决的问题,作为进一步研究的方向。 关键词 流分类;服务质量;IP 背景 当前的IP网络主要以先到先服务的方式提供尽力而为的服务。随着Internet的发展和各种新业务的出现,尽力而为的服务已经不能满足人们对Internet的要求,IP网络必须提供增强的服务,比如:SLA(Service Level Agreement)服务,VPN(Virtual Private Network)服务,各种不同级别的QoS (Quality of Service)服务,分布式防火墙,IP安全网关,流量计费等。所有这些增强服务的提供都依赖于流分类,即根据包头(packet header)中的一个或几个域(field)决定该包隶属的流(flow)。典型的,包头中可以用来分类的域包括:源IP地址(Source IP Address)、目的IP地址(Destination IP Address)、协议类型(Protocol Type)、源端口(Source Port)和目的端口(Destination Port)等。 流分类算法描述 首先定义两个名词:规则(rule)和分类器(classifier)。用来对IP包进行分类的由包头中若干域组成的集合称之为规则,而若干规则的集合就是分类器。构成规则的域(我们称之为组件component)的值可以是某个范围,例如目的端口大于1023。流分类就是要确定和每个包最匹配的规则。表1是由6条规则组成的一个分类器。我们说这是一个5域分类器,因为每条规则由5个组件构成。我们假定分类器中的规则是有优先级的,越靠前的规则优先级越高,即规则1的优先级最高,规则6的最低。
贝叶斯分类多实例分析总结
用于运动识别的聚类特征融合方法和装置 提供了一种用于运动识别的聚类特征融合方法和装置,所述方法包括:将从被采集者的加速度信号 中提取的时频域特征集的子集内的时频域特征表示成以聚类中心为基向量的线性方程组;通过求解线性方程组来确定每组聚类中心基向量的系数;使用聚类中心基向量的系数计算聚类中心基向量对子集的方差贡献率;基于方差贡献率计算子集的聚类中心的融合权重;以及基于融合权重来获得融合后的时频域特征集。 加速度信号 →时频域特征 →以聚类中心为基向量的线性方程组 →基向量的系数 →方差贡献率 →融合权重 基于特征组合的步态行为识别方法 本发明公开了一种基于特征组合的步态行为识别方法,包括以下步骤:通过加速度传感器获取用户在行为状态下身体的运动加速度信息;从上述运动加速度信息中计算各轴的峰值、频率、步态周期和四分位差及不同轴之间的互相关系数;采用聚合法选取参数组成特征向量;以样本集和步态加速度信号的特征向量作为训练集,对分类器进行训练,使的分类器具有分类步态行为的能力;将待识别的步态加速度信号的所有特征向量输入到训练后的分类器中,并分别赋予所属类别,统计所有特征向量的所属类别,并将出现次数最多的类别赋予待识别的步态加速度信号。实现简化计算过程,降低特征向量的维数并具有良好的有效性的目的。 传感器 →样本及和步态加速度信号的特征向量作为训练集 →分类器具有分类步态行为的能力 基于贝叶斯网络的核心网故障诊断方法及系统 本发明公开了一种基于贝叶斯网络的核心网故障诊断方法及系统,该方法从核心网的故障受理中心采集包含有告警信息和故障类型的原始数据并生成样本数据,之后存储到后备训练数据集中进行积累,达到设定的阈值后放入训练数据集中;运用贝叶斯网络算法对训练数据集中的样本数据进行计算,构造贝叶斯网络分类器;从核心网的网络管理系统采集含有告警信息的原始数据,经贝叶斯网络分类器计算获得告警信息对应的故障类型。本发明,利用贝叶斯网络分类器构建故障诊断系统,实现了对错综复杂的核心网故障进行智能化的系统诊断功能,提高了诊断的准确性和灵活性,并且该系统构建于网络管理系统之上,易于实施,对核心网综合信息处理具有广泛的适应性。 告警信息和故障类型 →训练集 —>贝叶斯网络分类器
分类算法综述
《数据挖掘》 数据挖掘分类算法综述 专业:计算机科学与技术专业学号:S2******* 姓名:张靖 指导教师:陈俊杰 时间:2011年08月21日
数据挖掘分类算法综述 数据挖掘出现于20世纪80年代后期,是数据库研究中最有应用价值的新领域之一。它最早是以从数据中发现知识(KDD,Knowledge Discovery in Database)研究起步,所谓的数据挖掘(Data Mining,简称为DM),就从大量的、不完全的、有噪声的、模糊的、随机的、实际应用的数据中提取隐含在其中的、人们不知道的但又有用的信息和知识的过程。 分类是一种重要的数据挖掘技术。分类的目的是根据数据集的特点构造一个分类函数或分类模型(也常常称作分类器)。该模型能把未知类别的样本映射到给定类别中的一种技术。 1. 分类的基本步骤 数据分类过程主要包含两个步骤: 第一步,建立一个描述已知数据集类别或概念的模型。如图1所示,该模型是通过对数据库中各数据行内容的分析而获得的。每一数据行都可认为是属于一个确定的数据类别,其类别值是由一个属性描述(被称为类别属性)。分类学习方法所使用的数据集称为训练样本集合,因此分类学习又可以称为有指导学习(learning by example)。它是在已知训练样本类别情况下,通过学习建立相应模型,而无指导学习则是在训练样本的类别与类别个数均未知的情况下进行的。 通常分类学习所获得的模型可以表示为分类规则形式、决策树形式或数学公式形式。例如,给定一个顾客信用信息数据库,通过学习所获得的分类规则可用于识别顾客是否是具有良好的信用等级或一般的信用等级。分类规则也可用于对今后未知所属类别的数据进行识别判断,同时也可以帮助用户更好的了解数据库中的内容。 图1 数据分类过程中的学习建模 第二步,利用所获得的模型进行分类操作。首先对模型分类准确率进行估计,例如使用保持(holdout)方法。如果一个学习所获模型的准确率经测试被认为是可以接受的,那么就可以使用这一模型对未来数据行或对象(其类别未知)进行分类。例如,在图2中利用学习获得的分类规则(模型)。对已知测试数据进行模型
中文文本分类算法设计及其实现_毕业设计
毕业设计(论文)任务书 毕业设计(论文) 题目中文文本分类算法的设计及其实现 电信学院计算机系84班设计所在单位西安交通大学计算机系
西安交通大学本科毕业设计(论文) 毕业设计(论文)任务书 电信学院计算机系84 班学生丰成平 毕业设计(论文)工作自2013 年 2 月21 日起至2013 年 6 月20 日止毕业设计(论文)进行地点:西安交通大学 课题的背景、意义及培养目标 随着文本文件的增多,对其自动进行分门别类尤为重要。文本分类是指采用计算机程序对文本集按照一定的分类体系进行自动分类标记。文本分类器的设计通常包括文本的特征向量表示、文本特征向量的降维、以及文本分类器的设计与测试三个方面。本毕设论文研究文本分类器的设计与实现。通过该毕业设计,可使学生掌握文本分类器设计的基本原理及相关方法,并通过具体文本分类算法的设计与编程实现,提高学生的实际编程能力。 设计(论文)的原始数据与资料 1、文本语料库(分为训练集与测试集语料库)。 2、关于文本分类的各种文献(包括特征表示、特征降维、以及分类器设计)以及资料。 3、中科院文本分词工具(nlpir)。 4、文本分类中需要用到的各种分类方法的资料描述。 课题的主要任务 1.学习文本特征向量的构建方法及常用的降维方法。 2.学习各种分类器的基本原理及其训练与测试方法。 3.设计并编程实现文本分类器。
毕业设计(论文)任务书 4、对试验结果进行分析,得出各种结论。 5、撰写毕业论文。 6、翻译一篇关于文本分类的英文文献。 课题的基本要求(工程设计类题应有技术经济分析要求) 1、程序可演示。 2、对源代码进行注释。 3、给出完整的设计文档及测试文档。 完成任务后提交的书面材料要求(图纸规格、数量,论文字数,外文翻译字数等) 1、提交毕业论文 2、提交设计和实现的系统软件源程序及有关数据 3、提交外文资料翻译的中文和原文资料 主要参考文献: 自然语言处理与信息检索共享平台:https://www.360docs.net/doc/6c17863627.html,/?action-viewnews-itemid-103 Svm(支持向量机)算法:https://www.360docs.net/doc/6c17863627.html,/zhenandaci/archive/2009/03/06/258288.html 基于神经网络的中文文本分析(赵中原):https://www.360docs.net/doc/6c17863627.html,/p-030716713857.html TF-IDF的线性图解:https://www.360docs.net/doc/6c17863627.html,/blog-170225-6014.html 东南大学向量降维文献:https://www.360docs.net/doc/6c17863627.html,/p-690306037446.html 指导教师相明 接受设计(论文)任务日期2013-02-21~2013-06-20 学生签名:
特征选择算法综述20160702
特征选择方法综述 控制与决策2012.2 问题的提出 特征选择框架基于搜索策略划分特征选择方法基于评价准则划分特征选择方法结论 一、问题的提出特征选择是从一组特征中挑选出一些最有效的特征以降低特征空间维数的过程,是模式识别的关键问题之一。对于模式识别系统,一个好的学习样本是训练分类器的关键,样本中是否含有不相关或冗余信息直接影响着分类器的性能。因此研究有效的特征选择方法至关重要。 特征选择算法的目的在于选择全体特征的一个较少特征集合,用以对原始数据进行有效表达按照特征关系度量划分,可分为依赖基尼指数、欧氏距离、信息熵。 、特征选择框架 由于子集搜索是一个比较费时的步骤,一些学者基于相关和冗余分析,给出了下面一种特征选择框架,避免了子集搜索,可以高效快速地寻找最优子集。 从特征选择的基本框架看出,特征选择方法中有4 个基本步骤:候选特征子集的生成(搜索策略)、评价准则、停止准则和验证方法。目前对特征选择方法的研究主要集中于搜索策略和评价准则。因而,本文从搜索策略和评价准则两个角度对特征选择方法进行分类。 三、基于搜索策略划分特征选择方法 基本的搜索策略按照特征子集的形成过程,形成的特征选择方法如下:
图3 基于搜索策略划分特征选择方法 其中,全局搜索如分支定界法,存在问题: 1)很难确定优化特征子集的数目; 2)满足单调性的可分性判据难以设计; 3)处理高维多类问题时,算法的时间复杂度较高。 随机搜索法如模拟退火、遗传算法、禁忌搜索算法等,存在问题: 1)具有较高的不确定性,只有当总循环次数较大时,才可能找到较好的结果。 2)在随机搜索策略中,可能需对一些参数进行设置,参数选择的合适与否对最终结果的好坏起着很大的作用。 启发式搜索如SFS、SBS、SFFS、SFBS等,存在问题: 1)虽然效率高,但是它以牺牲全局最优为代价。 每种搜索策略都有各自的优缺点,在实际应用过程中,根据具体环境和准则函数来寻找一个最佳的平衡点。例如,特征数较少,可采用全局最优搜索策略;若不要求全局最优,但要求计算速度快,可采用启发式策略;若需要高性能的子集,而不介意计算时间,则可采用随机搜索策略。 四、基于评价准则划分特征选择方法
分类算法的研究进展
分类算法的研究进展 分类是数据挖掘、机器学习和模式识别中一个重要的研究领域,分类的目的是根据数据集的特点构造一个分类函数或分类模型,该分类模型能把未知类别的样本映射到给定类别中的某一个。分类和回归都可以用于预测,和回归方法不同的是,分类的输出是离散的类别值,而回归的输出是连续或有序值。 一、分类算法概述为了提高分类的准确性、有效性和可伸缩性,在进行分类之前,通常要对数据进行预处理,包括:(1)数据清理,其目的是消除或减少数据噪声处理空缺值。 (2)相关性分析,由于数据集中的许多属性可能与分类任务不相关,若包含这些属性将减慢和可能误导分析过程,所以相关性分析的目的就是删除这些不相关的或兀余 性。(3)数据变换,数据可以概化到较 高层概念,比如连续值属 为离散值:低、 可概化到高层概念“省”此外,数据也可以规范化,规 范化将给定的值按比例缩放,落入较小的区间,比如【0,1】等。
的属 性“收入”的数值可以概化 性“市” 中、高。又比如,标称值属 二、常见分类算法 2.1 决策树 决策树是用于分类和预测的主要技术之一,决策树学习是以实例为基础的归纳学习算法,它着眼于从一组无次序、无规则的实例中推理出以决策树表示的分类规则。构造决策树的目的是找出属性和类别间的关系,用它来预测将来未知类别的记录的类别。它采用自顶向下的递归方式,在决策树的内部节点进行属性的比较,并根据不同属性值判断从该节点向下的分支,在决策树的叶节点得到结论。 2.2贝叶斯分类贝叶斯分类是统计学分类方法,它足一类利用概率统计知识进行分类的算法。在许多场合,朴素贝叶斯(Naive Bayes, NB)分类算法可以与决策树和神经网络分类算法相媲美,该算法能运用到大型数据库中,且方法简单、分类准确率高、速度快。由于贝叶斯定理假设一个属性值对给定类的影响独立于其它属性的值,而此假设在实际情况中经常是不成立的,因此其分类准确率可能会下降。为此,就出现了许多降低独立性假设的贝叶斯分类算
数据挖掘中的文本挖掘的分类算法综述
数据挖掘中的文本挖掘的分类算法综述 摘要 随着Internet上文档信息的迅猛发展,文本分类成为处理和组织大量文档数据的关键技术。本文首先对数据挖掘进行了概述包括数据挖掘的常用方法、功能以及存在的主要问题;其次对数据挖掘领域较为活跃的文本挖掘的历史演化、研究现状、主要内容、相关技术以及热点难点问题进行了探讨;在第三章先分析了文本分类的现状和相关问题,随后详细介绍了常用的文本分类算法,包括KNN 文本分类算法、特征选择方法、支持向量机文本分类算法和朴素贝叶斯文本分类算法;;第四章对KNN文本分类算法进行深入的研究,包括基于统计和LSA降维的KNN文本分类算法;第五章对数据挖掘、文本挖掘和文本分类的在信息领域以及商业领域的应用做了详细的预测分析;最后对全文工作进行了总结和展望。 关键词:数据挖掘,文本挖掘,文本分类算法 ABSTRACT With the development of Web 2.0, the number of documents on the Internet increases exponentially. One important research focus on how to deal with these great capacity of online documents. Text classification is one crucial part of information management. In this paper we first introduce the basic information of data mining, including the methods, contents and the main existing problems in data mining fields; then we discussed the text mining, one active field of data mining, to provide a basic foundation for text classification. And several common algorithms are analyzed in Chapter 3. In chapter 4 thorough research of KNN text classification algorithms are illustrated including the statistical and dimension reduction based on LSA and in chapter 5 we make some predictions for data mining, text mining and text classification and finally we conclude our work. KEYWORDS: data mining, text mining, text classification algorithms,KNN 目录 摘要 (1) ABSTRACT (1) 目录 (1)
贝叶斯算法(文本分类算法)java源码
package com.vista; import java.io.IOException; import jeasy.analysis.MMAnalyzer; /** * 中文分词器 */ public class ChineseSpliter { /** * 对给定的文本进行中文分词 * @param text 给定的文本 * @param splitToken 用于分割的标记,如"|" * @return 分词完毕的文本 */ public static String split(String text,String splitToken) { String result = null; MMAnalyzer analyzer = new MMAnalyzer(); try { result = analyzer.segment(text, splitToken); } catch (IOException e) { e.printStackTrace(); } return result; } } 停用词处理 去掉文档中无意思的词语也是必须的一项工作,这里简单的定义了一些常见的停用词,并根据这些常用停用词在分词时进行判断。 package com.vista;
/** * 停用词处理器 * @author phinecos * */ public class StopWordsHandler { private static String stopWordsList[] ={"的", "我们","要","自己","之","将","“","”",",","(",")","后","应","到","某","后","个","是","位","新","一","两","在","中","或","有","更","好",""};//常用停用词public static boolean IsStopWord(String word) { for(int i=0;i 蚁群算法综述 控制理论与控制工程09104046 吕坤一、蚁群算法的研究背景 蚂蚁是一种最古老的社会性昆虫,数以百万亿计的蚂蚁几乎占据了地球上每一片适于居住的土地,它们的个体结构和行为虽然很简单,但由这些个体所构成的蚁群却表现出高度结构化的社会组织,作为这种组织的结果表现出它们所构成的群体能完成远远超越其单只蚂蚁能力的复杂任务。就是他们这看似简单,其实有着高度协调、分工、合作的行为,打开了仿生优化领域的新局面。 从蚁群群体寻找最短路径觅食行为受到启发,根据模拟蚂蚁的觅食、任务分配和构造墓地等群体智能行为,意大利学者M.Dorigo等人1991年提出了一种模拟自然界蚁群行为的模拟进化算法——人工蚁群算法,简称蚁群算法(Ant Colony Algorithm,ACA)。 二、蚁群算法的研究发展现状 国内对蚁群算法的研究直到上世纪末才拉开序幕,目前国内学者对蚁群算法的研究主要是集中在算法的改进和应用上。吴庆洪和张纪会等通过向基本蚁群算法中引入变异机制,充分利用2-交换法简洁高效的特点,提出了具有变异特征的蚊群算法。吴斌和史忠植首先在蚊群算法的基础上提出了相遇算法,提高了蚂蚁一次周游的质量,然后将相遇算法与采用并行策略的分段算法相结合。提出一种基于蚁群算法的TSP问题分段求解算法。王颖和谢剑英通过自适应的改变算法的挥发度等系数,提出一种自适应的蚁群算法以克服陷于局部最小的缺点。覃刚力和杨家本根据人工蚂蚁所获得的解的情况,动态地调整路径上的信息素,提出了自适应调整信息素的蚁群算法。熊伟清和余舜杰等从改进蚂蚁路径的选择策略以及全局修正蚁群信息量入手,引入变异保持种群多样性,引入蚁群分工的思想,构成一种具有分工的自适应蚁群算法。张徐亮、张晋斌和庄昌文等将协同机制引入基本蚁群算法中,分别构成了一种基于协同学习机制的蚁群算法和一种基于协同学习机制的增强蚊群算法。 随着人们对蚁群算法研究的不断深入,近年来M.Dorigo等人提出了蚁群优化元启发式(Ant-Colony optimization Meta Heuristic,简称ACO-MA)这一求解复杂问题的通用框架。ACO-MH为蚁群算法的理论研究和算法设计提供了技术上的保障。在蚁群优化的收敛性方面,W.J.Gutjahr做了开创性的工作,提出了基于图的蚂蚁系统元启发式(Graph-Based Ant System Metaheuristic)这一通用的蚁群优化 的模型,该模型在一定的条件下能以任意接近l的概率收敛到最优解。T.StBtzle 和M.Dorigo对一类ACO算法的收敛性进行了证明,其结论可以直接用到两类实验上,证明是最成功的蚁群算法——MMAs和ACS。N.Meuleau和M.Dorigo研究了 最近在面试中,除了基础& 算法& 项目之外,经常被问到或被要求介绍和描述下自己所知道的几种分类或聚类算法,而我向来恨对一个东西只知其皮毛而不得深入,故写一个有关聚类& 分类算法的系列文章以作为自己备试之用(尽管貌似已无多大必要,但还是觉得应该写下以备将来常常回顾思考)。行文杂乱,但侥幸若能对读者也起到一定帮助,则幸甚至哉。 本分类& 聚类算法系列借鉴和参考了两本书,一本是Tom M.Mitchhell所著的机器学习,一本是数据挖掘导论,这两本书皆分别是机器学习& 数据挖掘领域的开山or杠鼎之作,读者有继续深入下去的兴趣的话,不妨在阅读本文之后,课后细细研读这两本书。除此之外,还参考了网上不少牛人的作品(文末已注明参考文献或链接),在此,皆一一表示感谢。 本分类& 聚类算法系列暂称之为Top 10 Algorithms in Data Mining,其中,各篇分别有以下具体内容: 1. 开篇:决策树学习Decision Tree,与贝叶斯分类算法(含隐马可夫模型HMM); 2. 第二篇:支持向量机SVM(support vector machine),与神经网络ANN; 3. 第三篇:待定... 说白了,一年多以前,我在本blog内写过一篇文章,叫做:数据挖掘领域十大经典算法初探(题外话:最初有个出版社的朋友便是因此文找到的我,尽管现在看来,我离出书日期仍是遥遥无期)。现在,我抽取其中几个最值得一写的几个算法每一个都写一遍,以期对其有个大致通透的了解。 OK,全系列任何一篇文章若有任何错误,漏洞,或不妥之处,还请读者们一定要随时不吝赐教& 指正,谢谢各位。 基础储备:分类与聚类 在讲具体的分类和聚类算法之前,有必要讲一下什么是分类,什么是聚类,都包含哪些具体算法或问题。 常见的分类与聚类算法 简单来说,自然语言处理中,我们经常提到的文本分类便就是一个分类问题,一般的模式分类方法都可用于文本分类研究。常用的分类算法包括:朴素的贝叶斯分类算法(native Bayesian classifier)、基于支持向量机(SVM)的分类器,k-最近邻法(k-nearest neighbor, 特征选择常用算法综述 一.什么是特征选择(Featureselection ) 特征选择也叫特征子集选择 ( FSS , Feature SubsetSelection ) 。是指从已有的M个特征(Feature)中选择N个特征使得系统的特定指标最优化。 需要区分特征选择与特征提取。特征提取 ( Feature extraction )是指利用已有的特征计算出一个抽象程度更高的特征集,也指计算得到某个特征的算法。 特征提取与特征选择都能降低特征集的维度。 评价函数 ( Objective Function ),用于评价一个特征子集的好坏的指标。这里用符号J ( Y )来表示评价函数,其中Y是一个特征集,J( Y )越大表示特征集Y 越好。 评价函数根据其实现原理又分为2类,所谓的Filter和Wrapper 。 Filter(筛选器):通过分析特征子集内部的信息来衡量特征子集的好坏,比如特征间相互依赖的程度等。Filter实质上属于一种无导师学习算法。 Wrapper(封装器):这类评价函数是一个分类器,采用特定特征子集对样本集进行分类,根据分类的结果来衡量该特征子集的好坏。Wrapper实质上是一种有导师学习算法。 二.为什么要进行特征选择? 获取某些特征所需的计算量可能很大,因此倾向于选择较小的特征集特征间的相关性,比如特征A完全依赖于特征B,如果我们已经将特征B选入特征集,那么特征A 是否还有必要选入特征集?我认为是不必的。特征集越大,分类器就越复杂,其后果就是推广能力(generalization capability)下降。选择较小的特征集会降低复杂度,可能会提高系统的推广能力。Less is More ! 三.特征选择算法分类 精确的解决特征子集选择问题是一个指数级的问题。常见特征选择算法可以归为下面3类: 第一类:指数算法 ( Exponential algorithms ) 这类算法对特征空间进行穷举搜索(当然也会采用剪枝等优化),搜索出来的特征集对于样本集是最优的。这类算法的时间复杂度是指数级的。 分类算法综述 1 分类算法分类是数据挖掘中的一个重要课题。分类的目的是学会一个分类函数或分类模型(也常常称作分类器),该模型能把数据库中的数据项映射到给定类别中的某一个。分类可用于提取描述重要数据类的模型或预测未来的数据趋势。分类可描述如下:输入数据,或称训练集(Training Set),是一条条的数据库记录(Record)组成的。每一条记录包含若干个属性(Attribute),组成一个特征向量。训练集的每条记录还有一个特定的类标签(Class Label)与之对应。该类标签是系统的输入,通常是以往的一些经验数据。一个具体样本的形式可为样本向量:(v1,v2,…, vn ;c)。在这里vi表示字段值,c表示类别。分类的目的是:分析输入数据,通过在训练集中的数据表现出来的特性,为每一个类找到一种准确的描述或者模型。这种描述常常用谓词表示。由此生成的类描述用来对未来的测试数据进行分类。尽管这些未来的测试数据的类标签是未知的,我们仍可以由此预测这些新 数据所属的类。注意是预测,而不能肯定,因为分类的准确率不能达到百分之百。我们也可以由此对数据中的每一个类有更好的理解。也就是说:我们获得了对这个类的知识。 2 典型分类算法介绍解决分类问题的方法很多,下面介绍一些经典的分类方法,分析 各自的优缺点。 2.1 决策树分类算法决策树(Decision Tree)是一种有向无环图(Directed Acyclic Graphics,DAG)。决策树方法是利用信息论中 的信息增益寻找数据库中具有最大信息量的属性字段,建立决策树的一个结点,在根据该属性字段的 不同取值建立树的分支,在每个子分支子集中重复 建立树的下层结点和分支的一个过程。构造决策树 的具体过程为:首先寻找初始分裂,整个训练集作 为产生决策树的集合,训练集每个记录必须是已经 分好类的,以决定哪个属性域(Field)作为目前最 好的分类指标。一般的做法是穷尽所有的属性域, 对每个属性域分裂的好坏做出量化,计算出最好的 一个分裂。量化的标准是计算每个分裂的多样性(Diversity)指标。其次,重复第一步,直至每个叶 节点内的记录都属于同一类且增长到一棵完整的树。 南京航空航天大学金城学院毕业设计(论文)开题报告 题目基于蚁群算法的TSP问题研究 系部XXXX系 专业XXXX 学生姓名XXXX学号XXXX 指导教师XXXX职称讲师 毕设地点XXXX 年月日 填写要求 1.开题报告只需填写“文献综述”、“研究或解决的问题和拟采用的方法”两部分内容,其他信息由系统自动生成,不需要手工填写。 2.为了与网上任务书兼容及最终打印格式一致,开题报告采用固定格式,如有不适请调整内容以适应表格大小并保持整体美观,切勿轻易改变格式。 3.任务书须用A4纸,小4号字,黑色宋体,行距1.5倍。 4.使用此开题报告模板填写完毕,可直接粘接复制相应的内容到毕业设计网络系统。 1.结合毕业设计(论文)课题任务情况,根据所查阅的文献资料,撰写1500~2000字左右的文献综述: 1.1蚁群算法的发展和应用 在计算机自动控制领域中,控制和优化始终是两个重要问题。使用计算机进行控制和优化本质上都表现为对信息的某种处理。随着问题规模的日益庞大,特性上的非线性及不确定性等使得难以建立精确的“数学模型”。人们从生命科学和仿生学中受到启发,提出了许多智能优化方法,为解决复杂优化问题(NP-hard问题)提供了新途径。 蚁群算法(Ant Colony Algorithm,ACA)是Dorigo M等人于1991年提出的。 经观察发现,蚂蚁个体之间是通过一种称之为信息素的物质进行信息传递的。在运动过程中,蚂蚁能够在它所经过的路径上留下该种信息素,而且能够感知信息素的浓度,并以此指导自己的运动方向。蚁群的集体行为表现出一种信息正反馈现象:某一路径上走过的蚂蚁越多,则后来者选择该路径的概率就越大。蚂蚁个体之间就是通过这种信息的交流达到搜索食物的目的。它充分利用了生物蚁群通过个体间简单的信息传递,搜索从蚁巢至食物间最短路径的集体寻优特征,以及该过程与旅行商问题求解之间的相似性。同时,该算法还被用于求解二次指派问题以及多维背包问题等,显示了其适用于组合优化问题求解的优越特征。 蚁群算法应用于静态组合优化问题,其典型代表有旅行商问题(TSP)、二次分配问题(QAP)、车间调度问题、车辆路径问题等。在动态优化问题中的应用主要集中在通讯网络方面。这主要是由于网络优化问题的特殊性,如分布计算,随机动态性,以及异步的网络状态更新等。例如将蚁群算法应用于QOS组播路由问题上,就得到了优于模拟退火(SA)和遗传算法(GA)的效果。蚁群优化算法最初用于解决TSP 问题,经过多年的发展,已经陆续渗透到其他领域中,如图着色问题、大规模集成电路设计、通讯网络中的路由问题以及负载平衡问题、车辆调度问题等。蚁群算法在若干领域获得成功的应用,其中最成功的是在组合优化问题中的应用。 1.2蚁群算法求解TSP问题 (1)TSP问题的描述 TSP问题的简单形象描述是:给定n个城市,有一个旅行商从某一城市出发,访问各城市一次且仅有一次后再回到原出发城市,要求找出一条最短的巡回路径。 (2)TSP问题的理论意义 该问题是作为所有组合优化问题的范例而存在的。它已经成为并将继续成为测 贝叶斯分类器工作原理原理 贝叶斯分类器是一种比较有潜力的数据挖掘工具,它本质上是一 种分类手段,但是它的优势不仅仅在于高分类准确率,更重要的是,它会通过训练集学习一个因果关系图(有向无环图)。如在医学领域,贝叶斯分类器可以辅助医生判断病情,并给出各症状影响关系,这样医生就可以有重点的分析病情给出更全面的诊断。进一步来说,在面对未知问题的情况下,可以从该因果关系图入手分析,而贝叶斯分类器此时充当的是一种辅助分析问题领域的工具。如果我们能够提出一种准确率很高的分类模型,那么无论是辅助诊疗还是辅助分析的作用都会非常大甚至起主导作用,可见贝叶斯分类器的研究是非常有意义的。 与五花八门的贝叶斯分类器构造方法相比,其工作原理就相对简 单很多。我们甚至可以把它归结为一个如下所示的公式: 其中实例用T{X0,X1,…,Xn-1}表示,类别用C 表示,AXi 表示Xi 的 父节点集合。 选取其中后验概率最大的c ,即分类结果,可用如下公式表示 () ()()() ()( ) 0011111 00011111 0|,, ,|,,, ,C c |,i i n n n i i X i n n n i i X i P C c X x X x X x P C c P X x A C c P X x X x X x P P X x A C c ---=---========= ===∝===∏∏()() 1 0arg max |A ,i n c C i i X i c P C c P X x C c -∈=====∏ 上述公式本质上是由两部分构成的:贝叶斯分类模型和贝叶斯公式。下面介绍贝叶斯分类器工作流程: 1.学习训练集,存储计算条件概率所需的属性组合个数。 2.使用1中存储的数据,计算构造模型所需的互信息和条件互信息。 3.使用2种计算的互信息和条件互信息,按照定义的构造规则,逐步构建出贝叶斯分类模型。 4.传入测试实例 5.根据贝叶斯分类模型的结构和贝叶斯公式计算后验概率分布。6.选取其中后验概率最大的类c,即预测结果。 其流程图如下所示: 数据挖掘分类算法研究综述 程建华 (九江学院信息科学学院软件教研室九江332005 ) 摘要:随着数据库应用的不断深化,数据库的规模急剧膨胀,数据挖掘已成为当今研究的热点。特别是其中的分类问题,由于其使用的广泛性,现已引起了越来越多的关注。对数据挖掘中的核心技术分类算法的内容及其研究现状进行综述。认为分类算法大体可分为传统分类算法和基于软计算的分类法两类。通过论述以上算法优缺点和应用范围,研究者对已有算法的改进有所了解,以便在应用中选择相应的分类算法。 关键词:数据挖掘;分类;软计算;算法 1引言 1989年8月,在第11届国际人工智能联合会议的专题研讨会上,首次提出基于数据库的知识发现(KDD,Knowledge DiscoveryDatabase)技术[1]。该技术涉及机器学习、模式识别、统计学、智能数据库、知识获取、专家系统、数据可视化和高性能计算等领域,技术难度较大,一时难以应付信息爆炸的实际需求。到了1995年,在美国计算机年会(ACM)上,提出了数据挖掘[2](DM,Data Mining)的概念,由于数据挖掘是KDD过程中最为关键的步骤,在实践应用中对数据挖掘和KDD这2个术语往往不加以区分。 基于人工智能和信息系统,抽象层次上的分类是推理、学习、决策的关键,是一种基础知识。因而数据分类技术可视为数据挖掘中的基础和核心技术。其实,该技术在很多数据挖掘中被广泛使用,比如关联规则挖掘和时间序列挖掘等。因此,在数据挖掘技术的研究中,分类技术的研究应当处在首要和优先的地位。目前,数据分类技术主要分为基于传统技术和基于软计算技术两种。 2传统的数据挖掘分类方法 分类技术针对数据集构造分类器,从而对未知类别样本赋予类别标签。在其学习过程中和无监督的聚类相比,一般而言,分类技术假定存在具备环境知识和输入输出样本集知识的老师,但环境及其特性、模型参数等却是未知的。 2.1判定树的归纳分类 判定树是一个类似流程图的树结构,其中每个内部节点表示在一个属性上的测试,每个分支代表一个测试输出,而每个树叶节点代表类或类分布。树的最顶层节点是根节点。由判定树可以很容易得到“IFTHEN”形式的分类规则。方法是沿着由根节点到树叶节点的路径,路径上的每个属性-值对形成“IF”部分的一个合取项,树叶节点包含类预测,形成“THEN”部分。一条路径创建一个规则。 判定树归纳的基本算法是贪心算法,它是自顶向下递归的各个击破方式构造判定树。其中一种著名的判定树归纳算法是建立在推理系统和概念学习系统基础上的ID3算法。 2.2贝叶斯分类 贝叶斯分类是统计学的分类方法,基于贝叶斯公式即后验概率公式。朴素贝叶斯分类的分类过程是首先令每个数据样本用一个N维特征向量X={X1,X2,?X n}表示,其中X k是属性A k的值。所有的样本分为m类:C1,C2,?,C n。对于一个类别的标记未知的数据记录而言,若P(C i/X)>P(C j/X),1≤ j≤m,j≠i,也就是说,如果条件X下,数据记录属于C i类的概率大于属于其他类的概率的话,贝叶斯分类将把这条记录归类为C i类。 建立贝叶斯信念网络可以被分为两个阶段。第一阶段网络拓扑学习,即有向非循环图的——————————————————— 作者简介:程建华(1982-),女,汉族,江西九江,研究生,主要研究方向为数据挖掘、信息安全。蚁群算法研究综述
贝叶斯分类算法
特征选择综述
分类算法综述
基于蚁群算法的TSP问题研究
贝叶斯分类器工作原理
数据挖掘分类算法研究综述终板