补充习题(编译预处理)
C++基础习题(选择,循环,类与对象)

1.11.C++概述例题5:C++的合法注释是()。
A./*This is a C program/* B.// This is a C programC.“This is a C program”D.//This is a C program//答案:B分析:单行注释常采用“//”,多行注释采用“/*”和“*/”。
单行注释也可采用“/*”和“*/”,但答案A书写格式错误,不能选答案A。
注释和字符串的区别,双引号内的字符为字符串。
不能选答案C。
单行注释不需要结束符“//”,如果有,只能作为注释的一部分存在。
也不能选答案D。
例题6:下面标识符中正确的是()。
A._abc B.3ab C.int D.+ab答案:A分析:C++的标识符由字母、下划线和数字组成,而且第一个字符不能为数字。
答案B第一个字符为数字不能选B。
标识符不能为关键字,不能选答案C。
答案D第一个字符不是字母或下划线,也不能选。
例题7:分析下列该程序的错误。
输入数据格式为:2,5(回车)。
main(){ int sum=0;int a,b;cout<<"input a,b:";cin>>a>>b;sum=a+b;cout<<sum<<endl;}本程序把输入的两个数据进行累加并输出结果。
输入数据格式为:2 5。
正确程序:#include <iostream> // 编译预处理命令,以“#”开头。
把系统已经定义好的输入//输出功能包含到本程序中。
using namespace std; //使用std 名字空间int main() // 程序的主函数{ // 主函数开始int sum=0; // 定义一个变量sum存放累加结果,并且赋初值为0int a,b; // 定义两个变量,保存输入值cout<<"input a,b:"; // 提示输入cin>>a>>b; // 使用基本输入设备cin输入两个变量值sum=a+b; // 进行累加,结果保存到sum变量cout<<sum<<endl; // 使用基本输出设备cout输出累加结果sum}分析:(1)没有使用编译预处理命令:#include。
C++练习册答案

《C++语言程序设计》补充习题参考答案习题 11.分行书写2.;(分号)3./* */4.编译5. A6. B7. B ; C ; D 。
习题 2一、选择题1. C2. A3. B4. C5. C6. A7. C8. A9. D10. B11. B12. A13. C14.x值为10 ,y值为15 ,z值为10 。
15. D16. C17. C18. B ; A19. B20.x>2&&x<3||x<-10二、填空题1.正确2.正确3.double4. 6.55.186.307.1008.09. 510.'b'11. 512.1513.-3014.1315. 6(以下为“编译预处理命令”的相关习题)1. B2. A3. B4. D5.符号常量习题 3一、选择题1. B2. D3. A4. D5. C6. A7. C8. C (k的存储空间有限,溢出后出现负)二、填空题1. F2.493.输出2行:**1****3**4.36 。
5.x*2+y*4==90 或……6.********# (8个*)7.c!= '\n' c>='0'&&c<='9'8.i<=9 j%3!=09.1e-7 -s double(s)/n 或t=1.0*s/n pi*410.j=1 k<=6习题 4一、选择题1. B2. A3. D4. B5. D6. B7. C8. B9. C10. C11. B二、填空题1.函数头(函数说明部分)函数体2.声明语句执行语句3.不正确4.错误部分是void ,改正后为float5.i=7 , j=6 , x=7i=2 , j=7 , x=56.bool isLeap(int) ; 或int isLeap(int) ; //函数声明isLeap(year)bool 或intyear%4==0&&year%100!=0||year%400==07.f(r)*f(n)<0n-m<0.0018.j=1 ; y>=1 ; y--9.//程序的输出为15122010.817习题 5一、选择题1. A2. D3. C4. C5. C二、填空题1.输出结果是a[1]=6a[2]=9a[3]=92.①若给x输入5, 输出结果是10 8 6 5 4 2②若给x输入15, 输出结果是15 10 8 6 4 2③若给x输入10, 输出结果是10 10 8 6 4 23.i 或--j MAX-1-i 或ii //0行置10 //0列置1i-- ii-- MAX-1MAX-1MAX-1 !(i==j||(i+j)==(MAX-1)) 或i!=j&&(i+j)!=(MAX-1) cout<<endl4.去掉字符串尾部空格5.SWITCH*#WaMP*习题 6一、选择题1. D2. D3. B4. A5. C6. C7. D8. C二、填空题1. 22. 13.12 124.数组s[1]5.将数字字符串转换为整型数据6.分行输出其中的5个单词7.i 或i+1a+j8.*(a+i)<*(a+i)+j9.#910.p1++*p2return p习题71. A / B2. A / B3.union&stu[i].body.eye&stu[i]. body.f.length >> &stu[i]. body.f.weight习题8一、选择题1. D2. C3. B4. B5. D6. D7. D8. D9. C10. A二、填空题1. 12.static3.友元函数4.对象成员5.Date::bool Date::void Date::Date6.指出以下程序的错误:无参构造函数与带默认参数值的构造函数有冲突——出现二义性习题91. B2. C3. B4. B5. D6. C7. B8. D9.保护继承10.私有继承11.派生(子)12.protected:public:C(int i, int j, int k) : A(i) , b1(j)c=k ;cout<<a<<" "<<b1.b<<" "<<c<<endl;习题101. D2. A3. B4. D5. D6. D7. B8. A9.运行时10.抽象类习题111. A B2. D3. B4.输入流输出流5.文本文件(ASCII文件) / 顺序文件二进制文件/ 随机文件6.ASCII代码二进制代码7.字节/字符字节流/字符流(流式)8.“流”9.正好一致。
Java程序设计补充习题(2面向对象部分)

第二部分面向对象程序设计注意:选择题为不定项选择1、以下哪些是Java的修饰符()A. staticB. finalC. protectedD. const2、面向对象技术的特性是()A、继承性B、有效性C、多态性D、封装性3、下列哪个命题为真?()A、所有类都必须定义一个构造函数。
B、构造函数必须有返回值。
C、构造函数可以访问类的非静态成员。
D、构造函数必须初始化类的所有数据成员。
4、关于子类与父类关系的描述正确的是()A、子类型的数据可以隐式转换为其父类型的数据;B、父类型的数据可以隐式转换为其子类型的数据;C、父类型的数据必须通过显式类型转换为其子类型的数据;D、子类型实例也是父类型的实例对象。
5、读程序,以下可以在main()方法中添加的语句是哪些?()class Test{private float f=1.0f;int m=12;static int n=1;public static void main(String args[]){Test t=new Test();//...}}A. t.fB. this.nC. Test.mD. Test.n6、下面哪个关键字不是用来控制对类成员的访问的?()A、publicB、protectedC、defaultD、private7、Java语言正确的常量修饰符应该是()A、finalB、static finalC、staticD、public static final8、接口的所有成员域都具有、static和属性。
9、接口的所有成员方法都具有和属性。
10、编译下列源程序会得到哪些文件?()class A1{}class A2{}public class B{public static void main(String args[]){}}A. 只有B.classB. 只有A1.class和A2.class文件C. 有A1.class、A2.class和B.class文件D. 编译不成功11、下列哪种说法是正确的?()A、私有方法不能被子类重写。
C语言程序设计(第3版)第3章补充习题及答案

x=(a&&b)&&(c<’B’);
执行该程序段后,x的值为( )
AtureB falseC 0D 1
(9)以下程序的输出结果是( )
main()
{
int a=0,i=1;
switch(i)
{
case 0:
case 3:a+=2;
case 1:
case 2:a+=3;
default:a+=5;
(2)下面程序的输出结果是
iX=3
iX>3
。
#include "stdio.h"
main()
{intiX=3;
switch(iX)
{case 1:
case 2:printf("iX<3\n");
case 3:printf("iX=3\n");
case 4:
case 5:printf("iX>3\n");
}
}
(3)以下程序的运行结果是iM=3,iN=4,iT=3。
#include "stdio.h"
main()
{int iM,iN,iT,iA=2,iB=3;
iM=(++iA==--iB)?––iA:++iB;
iN=++iA;
iT=iB;
printf("iM=%d,iN=%d,iT=%d\n",iM,iN,iT);
(4)对switch后括号内的表达式,叙述正确的是C。
A.只能是数字B.可以是浮点数
C.只能是整型数据或字符型数据D.以上叙述都不对
部编版语文八年级下册补充习题答案-6阿西莫夫短文两篇

初中语文补充习题(八年级下册)参考答案6阿西莫夫短文两篇【夯实基础】1.领域膨胀流逝褶皱追溯劫难携带陨石2. A3.A(“天衣无缝”比喻事物周密完善,找不出什么毛病。
用在这里语意不符。
)4. B(恐龙化石之所以遍布于世界各地,是因为大陆在漂移。
)【研习文本】一、整体把握1.《恐龙无处不有》依据在南极发现恐龙化石的事实,佐证了大陆漂移说;《被压扁的沙子》通过对“被压扁的沙子"的反思,证明外星撞击导致恐龙灭绝。
2.科学发现-观点产生-科学研究发现-印证观点。
这是一种由果到因的逻辑思路。
3.将来一旦面临这种事情,我们可以采取某种应急措施。
4.逻辑顺序,重在说明事理,在短小的篇幅内,将抽象的科学知识层层剖析,既严谨又深入浅出地解释清楚。
二、片段研读1.恐龙遍布于世界各地;恐龙不适合在南极生存。
2.不能去掉,“都”是全部的意思,表范围,在这句话中指在地球的大陆上全部发现了恐龙的化石,具体说明了恐龙确实遍布于世界各地。
3.举例子。
具体说明了大陆漂移说,否定了恐龙迁移说。
4.“泛大陆”是板块在一段时期内将所有的大陆汇聚在一起形成一个主要陆地。
【拓展阅读】1.总领全文,点出本文的说明对象,交代说明对象的特点。
2.介绍了两种昆虫的历史、个性、种类、寓意、鸣叫的原因。
3.引用、打比方,列数字。
生动形象突出地说明了纺织娘叫声既有节奏、又富有变化。
引用《诗经》里的诗句增添文学色彩,吸引读者阅读兴趣。
4.写出了昆虫的鸣叫特点;运用比喻,生动形象。
【文化传承】1.诗人绘春草之象,含春光易逝之意,寓伤春之情(或对春天逝去的无可奈何);诗人借草伤己(人生),以草表达倦游思归的苦闷心情。
2.①咏物抒怀或寓情于物:将初入仕途的年轻人踌躇满志、英姿勃发的风采寄寓于青青春草之中;将倦于宦游,春末思归的苦闷情绪寄寓于暮春之草的凄凉衰败之中。
②对比:将初春之草的生机勃勃与暮春之草的凄凉衰败形成强烈对比,暗含伤春之意。
③衬托:用遍地春草映衬出宦游少年的春风得意。
汇编语言补充作业和答案汇总

汇编语⾔补充作业和答案汇总《微机系统与接⼝技术》汇编补充作业2.指出下列8088指令的错误:(1)MOV AH, BX(2)MOV [BX], [SI](3)MOV AX, [SI][DI](4)MOV MYDAT[BX][SI], ES:AX (5)MOV BL, 1000(6)MOV CS, AX(7)MOV DS, BP(8)XLAT BX(9)IN AX, 0382H(10)OUT AX, 20H答:(1 )两个操作数长度不⼀致(2 )两个操作数不能都是存储器操作数(3 )变址寻址⽅式不能使⽤两个变址寄存器(4 )寄存器寻址没有段超越⽤法(5 )两个操作数长度不⼀致(或1000 超出字节数据范围)(6 )CS不能做⽬的寄存器(9 )IN指令中16 位端⼝地址要⽤DX作为操作数(10)OUT指令两个操作数反了3. 按要求编写下⾯的程序段1)利⽤移位指令计算DX=3×AX+7×BX,假设为⽆符号数运算,⽆进位。
2)⽤逻辑运算指令实现数字0~9的ASCII码与⾮压缩BCD码的互相转换3)把DX.AX中的双字右移4位4)假设从4A00H:0000开始的4个字节中存放了4个⾮压缩的BCD 码,现在按照低地址对低位,⾼地址对⾼位的原则,将他们合并到DX中。
答:1)MOV CX, AXSHL AX, 1 ; AX*2ADD AX, CX ; AX*3MOV DX, BXMOV CL, 3SHL DX, CL ; BX*8SUB DX, BX ; BX*7ADD DX, AX2)MOV AL, ’0’LOP: AND AL, 0FHINC ALCMP AL, ‘:’JNE LOPMOV AL, 0LOP1: OR AL, 30HINC ALCMP AL, 0AHJNE LOP13) MOV CL,4SHR AX,CLMOV BL,DLSHR DX,CLSHL BL,CL4)MOV AX, 4A00HMOV DS, AXMOV CL, 4MOV SI, 0MOV AL, [SI]AND AL, 0FHMOV DL, ALINC SIMOV AL, [SI]SHL AL, CLOR DL, ALINC SIMOV AL, [SI]AND AL, 0FHMOV DH, ALINC SIMOV AL, [SI]SHL AL, CLOR DH, AL4. 请说明下⾯两段程序的功能1)mov si, 600hmov di, 601hmov ax, dsmov es, axmov cx, 256stdrep movsb2)cldmov ax, 0fefhmov cx, 5mov bx, 3000hmov es, bxmov di, 2000hrep stosw2 )从3000:2000h 开始连续存放5 个0fefh5.假设DS=2000H. BX=1256H, SI=528FH, 位移量TABLE=20A1H,[232F7H]=3280H, [264E5H]=2450H, 试问执⾏下列段内间接寻址的转移指令后,转移到有效地址是什么?i.JMP BXii.JMP TABLE[BX]iii.JMP [BX][SI]答: (1)1256H (2)3280H (3)2450H6.判断下列程序段跳转到条件(1)XOR AX, 1E1EHJE EQUAL(2)TEST AL, 10000001BJNZ THERE(3)CMP CX, 64HJB THERE答:(1) (AX)=1E1EH (2) (AL) 的最⾼位和/ 或最低位为1 (3) (CX)<64H7.如果条件跳转指令的跳转⽬标范围超出-128~127的范围,该如何处理?举例说明。
补充习题1

一、选择题1.()被称为动态主机配置协议。
A、HTTPB、DNSC、DHCPD、RAS2.在DHCP客户机上运行()命令用来显示TCP/IP的配置信息。
A、PINGB、IPCONFIGC、NETSTATD、ARP3.在DHCP客户机上运行()命令用来更新IP租约。
A、IPCONFIG /ALLB、IPCONFIG /RELEASEC、IPCONFIG /RENEWD、PING4.在DHCP客户机上运行()命令用来释放IP租约。
A、IPCONFIG /ALLB、IPCONFIG /RELEASEC、IPCONFIG /RENEWD、PING5.()是一种安全预防措施,使Windows Server 2003域中的DHCP服务器能在网络中正常运行。
A、作用域激活B、配置作用域选项C、授权DHCP服务器6.以下对DHCP描述正确的是()。
A、DHCP需要网络管理员手动配置客户机的TCP/IP信息B、DHCP减轻了网络管理员的负担,不需要手动配置TCP/IP信息C、DHCP租约过程分为两步:客户机请求IP,服务器分配IPD、DHCP服务器只需在服务器上运行Windows Server 2003即可,没有其他要求7.在DHCP服务器上为客户机配置选项时,应用范围最大的选项是( )。
A、服务器选项B、作用域选项C、保留选项8.DHCP服务器必须给客户机提供的TCP/IP信息有()。
A、IP地址B、子网掩码C、默认网关D、DNS服务器9.在DHCP客户机的IP地址配置中,备用配置信息的用途是()。
A、在使用动态IP地址的网络中,启用备用配置B、在使用静态IP地址的网络中,启用备用配置C、当动态IP地址有冲突时,启用备用配置D、当静态IP地址有冲突时,启用备用配置10.()称为域名系统,用来将域名解析为IP地址。
A、DNSB、CAC、RASD、DHCP11.下列属于域名空间结构的项目是()。
A、根域B、顶级域C、二级域D、主机E、反向域12.FQDN一般的格式为()。
编译预处理的名词解释

编译预处理的名词解释编译预处理(Compiler preprocessor)是计算机科学中一个重要概念,它是编译器的前处理步骤,用于在源代码被编译前对其进行一系列的转换和操作。
编译预处理器是编译过程中的一个组件,它处理源代码中的预处理指令,对代码进行一些宏展开、条件编译等操作,然后再将处理后的代码提交给编译器进行编译。
一、编译预处理的定义和作用编译预处理是指在编译过程中对源代码进行处理的一系列操作。
预处理器会通过扫描源代码中的特殊指令,执行相应的操作,并将结果替换回源代码中。
预处理器可以实现代码的复用、条件编译、宏定义等功能,大大提高了代码的灵活性和可维护性。
编译预处理器最常用的功能之一是宏展开(Macro expansion)。
宏是一段预定义的代码片段,在代码中使用宏可以简化重复的代码,提高代码的可读性和维护性。
预处理器会将所有使用宏的地方替换为宏的定义内容,以此实现代码的复用。
二、条件编译条件编译(Conditional Compilation)是编译预处理中的一项重要功能。
通过条件编译,我们可以根据不同的条件选择性地编译源代码中的一部分。
这对于不同平台、不同版本的代码兼容性是非常有用的。
条件编译使用预处理指令#if、#ifdef、#ifndef、#elif、#else和#endif来实现。
我们可以根据条件表达式的结果来选择编译不同的代码块,从而实现特定条件下的代码执行。
三、头文件包含头文件包含(Header File Inclusion)是编译预处理中的另一个重要功能。
头文件包含用于将一个源文件中的代码引入到另一个源文件中。
这样,我们可以在不同的源文件中共享函数、常量、宏等定义,提高代码的复用性。
头文件被放置在使用它的源文件中,通常使用#include指令来进行包含。
头文件包含具有层次结构,可以通过嵌套的方式来引入多个头文件。
四、预定义宏预定义宏(Predefined Macros)是编译预处理器提供的一些内置宏,在编译过程中可供我们使用。
补充习题(C语言概述)

第一章C语言概述之基本规则一、选择题1、C语言程序的基本单位是()(A)函数(B)过程(C)子程序(D)子例程2、下列各选项中,合法的C语言关键字是()(A)integer (B)sin (C)string (D)void3、下列选项中,是C语言提供的合法关键字是()(A)swicth (B)cher (C)default (D)Case4、C语言的程序一行写不下时,应该()(A)用回车符换行(B)在任意一个空格处换行(C)用分号换行(D)用逗号换行5、下列叙述不正确的是()(A)在C程序中,%是只能用于整数运算的运算符(B)在C程序中,无论是整数还是实数,都能正确无误地表示(C)若a是实型变量,C程序中a=20是正确的,因此实型变量允许被整型数赋值。
(D)在C程序中,语句之间必须用分号“;”分隔6、在C程序中,可以作为用户标识符的一组标识符是()(A)void define WORD (B)as_b3 _224 Else(C)Switch –wer case (D)4b DO SIG7、在C语言中,下列合法的字符常量是()(A)’\039’(B)’\x76’(C)’ab’(D)’\o’注:参见P14,3.字符常量。
8、以下说法正确的是()(A)C语言程序是从第一个定义的函数开始执行(B)在C语言程序中,要调用的函数必须在main()函数中定义(C)C语言程序是从main()函数开始执行(D)C语言程序中的main()函数必须放在程序的开始部分9、以下叙述中不正确的是()(A)在C程序中所有的变量必须先定义后使用(B)在程序中,aph和APH是两个不同的变量(C)若a和b类型相同,在执行了赋值语句a=b后,b中的值放入a中,b 中的值不变(D)当输入数值时,对于整型变量只能输入整型值,对于实型值只能输入实型值10、以下选项中合法的用户标识符是()(A)int (B)a# (C)5mem (D)_24311、C语言中的标识符只能由字母、数字和下划线3种字符组成,且第一个字符()(A)必须为字母(B)必须为下划线(C)必须为字母或下划线(D)可以是字母、数字、下划线中任意一种二、填空题1、C语言中的标识符可分为_____、_____和预定义标识符3类。
编译预处理习题与答案

编译预处理习题与答案第九章编译预处理9.1 选择题【题9.1】以下叙述中不正确的是。
A)预处理命令⾏都必须以#号开始B)在程序中凡是以#号开始的语句⾏都是预处理命令⾏C)C程序在执⾏过程中对预处理命令⾏进⾏处理D)以下是正确的宏定义#define IBM_PC【题9.2】以下叙述中正确的是。
A)在程序的⼀⾏上可以出现多个有效的预处理命令⾏B)使⽤带参的宏时,参数的类型应与宏定义时的⼀致C)宏替换不占⽤运⾏时间,只占编译时间D)在以下定义中C R是称为“宏名”的标识符#define C R 045【题9.3】请读程序:#define ADD(x) x+xmain(){int m=1,n=2,k=3;int sum=ADD(m+n)*k;printf(“sum=%d”,sum);}上⾯程序的运⾏结果是。
A)sum=9 B)sum=10 C)sum=12 D)sum=18【题9.4】以下程序的运⾏结果是。
#define MIN(x,y) (x)<(y)?(x):(y)main(){int i=10,j=15,k;k=10*MIN(i,j);printf(“%d\n”,k);}A)常量B)单精度数C)双精度数D)字符串【题9.6】以下程序的运⾏结果是。
#include#define FUDGE(y) 2.84+y#define PR(a) printf(“%d”,(int)(a))#define PRINT1(a) PR(a); putchar(‘\n’)main(){int x=2;PRINT1(FUDGE(5)*x);}A)11 B)12 C)13 D)15【题9.7】以下有关宏替换的叙述不正确的是。
A)宏替换不占⽤运⾏时间B)宏名⽆类型C)宏替换只是字符替换D)宏名必须⽤⼤写字母表⽰【题9.8】C语⾔的编译系统对宏命令的处理是。
A)在程序运⾏时进⾏的B)在程序连接时进⾏的C)和C程序中的其它语句同时进⾏编译的D)在对源程序中其它成份正式编译之前进⾏的【题9.9】若有宏定义如下:#define X 5#define Y X+1#define Z Y*X/2则执⾏以下printf语句后,输出结果是。
C语言程序设计(第3版)第5章补充习题及答案

第5章补充习题及答案习题5.1 选择题(1)对定义语句int iArr[2]; 的正确描述是:()A. 定义一维数组iArr,其中包含iArr[1]和iArr[2]两个元素B. 定义一维数组iArr,其中包含iArr[0]和iArr[1]两个元素C. 定义一维数组iArr,其中包含iArr[0]、iArr[1]和iArr[2]三个元素D. 定义一维数组iArr,其中包含iArr(0)、iArr(1)和iArr[2]三个元素(2)以下关于数组的说法,不正确的是:()A. C语言中可以通过通过数组名对数值型数组进行整体的输入或输出B. 数组中的各元素依次占据内存中连续的存储空间C. 同一数组中的元素具有相同的名称和类型D. 在使用数组前必须先对其进行定义(3)有以下程序()#include “stdio.h”void main( ){ int iArr[3]={1,2,3},i;for(i=3; i>=1; i++) printf(“ %d ” , iArr[i] );}则程序运行后的输出结果是:A. 1 2 3B. 不确定的值C. 编译出错D. 3 2 1(4)执行以下程序段后,iArr[2]的值是:()int iArr[10]={1,2,3,4,5,6,7,8,9,10},i,j,t; i = 0 ; j = 9;while( i < j){ t= iArr[i] ; iArr[i] = iArr[j]; iArr[j]=t;i++; j--; }A. 8B. 2C. 3D. 9(5)有以下程序:#include “stdio.h”void main(){ char chA[10]=”abcdef”, chB[5]=”AB\0c”;strcpy(chA,chB);printf(“%c”, chA[3]);}则程序的运行结果是:()A. dB. cC. \0D. 05.2 填空题(1)对于二维数组iA[5][10],判断下列对数组元素的引用正确的是。
习题参考答案-编译原理及实践教程(第3版)-黄贤英-清华大学出版社

附录部分习题参考答案第1章习题1. 解释下列术语。
翻译程序,编译程序,解释程序,源程序,目标程序,遍,前端,后端解答:略!2. 高级语言程序有哪两种执行方式?阐述其主要异同点。
描述编译方式执行程序的过程。
解答:略!3. 在你所使用的C语言编译器中,观察程序1.1经过预处理、编译、汇编、链接四个过程生成的中间结果。
解答:略!4. 编译程序有哪些主要构成成分?各自的主要功能是什么?解答:略!5. 编译程序的构造需要掌握哪些原理和技术?编译程序构造工具的作用是什么?解答:略!6. 复习C语言,其字母表中有哪些符号?有哪些关键字、运算符和界符?标识符、整数和实数的构成规则是怎样的?各种语句和表达式的结构是什么样的?解答:略!7.编译技术可应用在哪些领域?解答:略!8. 你能解释在Java编译器中,输入某个符号后会提示一些单词、某些单词会变为不同的颜色是如何实现的吗?你能解释在Code Blocks中在输入{后,会自动添加},输入do 会自动添加while()是为什么吗?解答:略!第2章习题1. 判断题,对下面的陈述,正确的在陈述后的括号内画√,否则画×。
(1) 有穷自动机识别的语言是正规语言。
()(2) 若r1和r2是Σ上的正则表达式,则r1|r2也是。
()(3) 设M是一个NFA,并且L(M)={x,y,z},则M的状态数至少为4个。
()(4) 令Σ={a,b},则所有以b开头的字构成的正规集的正则表达式为b*(a|b)*。
()(5) 对任何一个NFA M,都存在一个DFA M',使得L(M')=L(M)。
()1解答:略!2.从供选择的答案中,选出应填入下面叙述中?内的最确切的解答。
有穷自动机可用五元组(Q,V T,δ,q0,Q f)来描述,设有一有穷自动机M定义如下:V T={0,1},Q={q0,q1,q2},Q f={q2},δ的定义为:δ (q0,0)=q1δ (q1,0)=q2δ (q2,1)=q2δ (q2,0)=q2M是一个 A 有穷状态自动机,它所对应的状态转换图为 B ,它所能接受的语言可以用正则表达式表示为 C 。
compiler-习题解答-补充习题-自动机-正规式-文法
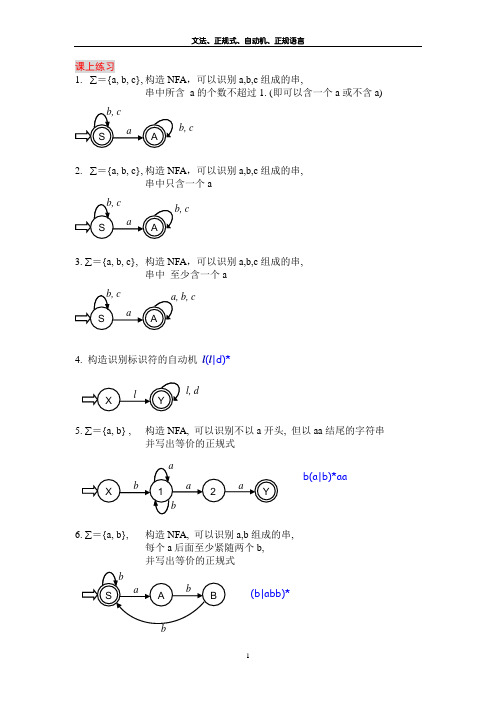
1. ∑={a, b, c}, 构造NFA ,可以识别a,b,c 组成的串,串中所含 a 的个数不超过1. (即可以含一个a 或不含a)2. ∑={a, b, c}, 构造NFA ,可以识别a,b,c 组成的串,串中只含一个a3. ∑={a, b, c}, 构造NFA ,可以识别a,b,c 组成的串,串中 至少含一个a4. 构造识别标识符的自动机 l (l |d)*5. ∑={a, b} , 构造NFA, 可以识别不以a 开头, 但以aa 结尾的字符串并写出等价的正规式b(a|b)*aa6. ∑={a, b},构造NFA, 可以识别a,b 组成的串, 每个a 后面至少紧随两个b, 并写出等价的正规式(b|abb)*b, cl, d1. 给语言 L={an|n≥0} , 写3型文法,并构造自动机可以构造出L 的自动机如下: 再将自动机转换成3型文法,G: S →aS |ε2. 给语言L={ an b m|n,m≥1},写3型文法,并构造自动机可以构造出L 的自动机如下: 再将自动机转换成3型文法,G: S →aAA →aA|bB B →bB|ε3. 构造自动机 L={ a2n+1b 2m a 2p+1| n≥0,m≥1, p≥0 }4. 给语言 L(G)={ an b m c k|n,m,k≥0} ,写3型文法,并构造自动机a*b*c*G: S →aS|BB →bB|C C →cC|ε 将DF A 1和DF A 2确定化最小化, 得到结果相同:a,b,cb5. 构造自动机,识别能被3整除的二进制数状态0: 被3整除状态1: 被3除余1状态2: 被3除余26. 构造自动机,识别含奇数个0 且 奇数个1 的二进制数串S: 偶数个0, 偶数个1A: 奇数个0, 偶数个1 B: 奇数个0, 奇数个1 C: 偶数个0, 奇数个17. 构造文法, 产生含有偶数个1的二进制数串, ∑={0,1} 解法一:G : S → 0S | 1A | ε A → 0A | 1S解法二:S: 偶数个0, 偶数个1 A: 奇数个0, 偶数个1 B: 奇数个0, 奇数个1 C: 偶数个0, 奇数个1确定化,最小化,则得到解法一中的DFA单元测试28. 构造自动机,识别满足以下条件的符号串:至少含有两个1, 又在任何两个1之间有偶数个09. 写出下图所示自动机所描述的语言100*|100*11*0|111*0化简得: 10*1*0L={10m1n0 | m≥0, n≥0}10. 证明题:正规集的子集不一定是正规集证明如下:a*b* 是正规集, L1={ a n b n |n≥0}是它的子集, 但是L1不是正规集, 因为找不到一个3型文法描述L1, 即只能用2型文法描述L1G: S→aSb|ε。
C语言程序设计(第3版)第10章补充习题及答案

第10章补充习题及答案习题10.1 选择题(1)当已存在一个abc.txt文件时,执行函数fopen("abc.txt","r+")的功能是。
A.打开abc.txt文件,清除原有的内容B.打开abc.txt文件,只能写入新的内容C.打开abc.txt文件,只能读取原有内容D.打开abc.txt文件,可以读取和写入新的内容(2)若用fopen()函数打开一个已存在的文本文件,保留该文件原有内容,且可以读,可以写。
则文件打开模式是。
A."ab+" B."w+" C."a+" D."a"(3)以下不能将文件指针重新移到文件开头位置的函数是。
A.rewind(fp); B.fseek(fp,0,SEEK_SET);C.fseek(fp,-(long)ftell(fp),SEEK_CUR); D.fseek(fp,0,SEEK_END);(4)若用fopen()函数打开一个新二进制文件,该文件可以读也可以写,则文件的打开模式为 B 。
A."ab+" B."wb+" C."rb+" D."a+"(5)fread(buffer,64,2,fp)的功能是。
A.从fp所指的文件中读取64并存入buffer中B.从fp所指的文件中读取64和2并存入buffer中C.从fp所指的文件中读取64个字节的数据并存入buffer中D.从fp所指的文件中读取2个64字节的数据并存入buffer中(6)以下程序的功能是。
提示:PRN是打印设备。
#include <stdio.h>void main(){ FILE * fp;char chStr[]="HELLO";fp=fopen("PRN","w");fputs(chStr,fp);fclose(fp);}A.在屏幕显示HELLO B.把HELLO存入PRN文件中C.在打印机上打印出HELLO D.以上都不对10.2 填空题(1)使用fopen("abc","r+")打开文件时,若"abc"文件不存在,则返回。
C++习题.jsp(1)

1. C++语言中有哪些数据类型?分别说明它们的类型关键字、取值范围、类型长度。 答:C++语言中的数据类型有:整型(短整型,整型,长整型);字符型;逻辑型;枚举型; 实型(单精度,双精度,长双精度);引用型(指针,引用);复合型(结构,联合);空类 型。 2. 字符常量与字符串常量的区别是什么? 答:字符常量与字符串常量的主要区别在于:(1)定界符不同。字符常量使用单引号,而字 符串常量使用双引号。(2)长度不同。字符常量的长度固定为 1,而字符串常量的长度,可 以是 0,也可以是某个整数。(3)存储要求不同。字符常量存储的是字符的 ASCII 码值,而
double
(5) ‗x‘+20 int
(6) (int )y
int
(7) y != 10 bool
(8) x<1 || x>10 bool
(9) x>10 ? x : sqrt (x) int 或 float (10) x && y
B.file
C.break
D.do
答案:B
(4) 运算符 +、<=、=、% 中,优先级最低的运算符是( )。
A. +
B.<=
C.=
D.%
答案:CΒιβλιοθήκη (5) 下列字符列中,可以作为“字符串常量”的是( )。
A. ABC
B.″xyz″ C.′uvw′
D. ′a′
答案:B
(6) 设变量 m,n,a,b,c,d 均为 0,执行(m = a==b)||(n=c==d)后,m,n 的值是( )。
答案:A
分析:%运算符要求式整型;关系运算值为 0;两个整数相除,商为为相除后的整数部分。
C++程序设计(第二版)课后习题解析_张树粹主编_清华大学出版社
C/C++程序设计(第二版)张树粹主编_清华大学出版社1-9章课后习题解析(修正错误版)第一章P42页一、选择:1.A 2.A 3.D 4.A 5.C 6.B 7.A二、填空1. .C.CPP.OBJ .EXE2. 主函数或main函数3. #include <iostream>#include <stdio.h>4. 顺序、选择、循环5. { }函数声明函数执行不能void三、分析理解1. 解答:C语言程序主要由函数组成,一般包括预处理命令、函数、全局变量声明等等。
2. 解答:函数由函数首部和函数体组成。
函数首部规定函数的返回值类型、函数名、函数的形参及类型;函数体包括用于实现功能的可执行语句,由{}括起。
3. 解答:基本的C语言语句由简单语句、复合语句、赋值语句、流程控制语句、非限定性转向语句等。
4. 解答:合法的一般标识符有:name,Int,File_name, DATA5. 解答:源程序需要经过编译程序编译转换成二进制程序,即:目标代码文件,再通过连接程序将目标文件盒其他目标文件及系统所提供的库函数等进行连接生成可执行程序。
6. 解答:两种:单行注释用//. 多行注释采用/* 和*/。
7. 解答:(此题注释和程序效果不一致需修改)。
源程序如图1-1所示:图1-1 ex1-7源程序运行结果如下图1-2所示:图1-2 ex1-7 运行结果分析:setprecison单独使用时用来输出实数的有效数字,若和fixed联用,则用来输出实数小数点后的数字位数。
(2)-33.7801 //setprecision(0)表示根据当前默认输出精度输出实数。
默认精度:实数输出6位有效数字。
(4) 122.1 //为num1输出4位有效数字(当实际数据位数大于所设置精度,则四舍五入)8. 解答:源程序如下图1-3所示:图1-3 ex1-8源程序运行结果如下图所示:图1-4 ex1-8 运行结果第二章P 67页一、选择1、B2、B3、A4、B5、C6、A7、B8、C9、D 10、D二、填空1、x>20 && x<30 ||x<-1002、x>y 或者a>b3、14、auto、extern、static、register5、函数内部6、int、float、double7、2,18、为最右边表达式的值9、710、前缀:先自增(自减)后使用;后缀:先使用后自增(自减)11、右结合性(自右向左)12、变量的数据类型、存储类型、变量名称13、是否整除14、全局变量,静态局部变量,静态局部变量15、const,初始值和数据类型三、阅读程序1、解答:输出结果是2,12、解答:输出结果是6,8,6,73、解答:输出结果是n=14、解答:输出结果是x=7,a=3,b=75、解答:输出结果是n=-46、解答:输出结果是07、解答:输出结果是2147483647,-21474836488、解答:输出结果是 2 3 1 2 (各数据均占8列)四、编程1、“china”译成密码问题。
C程复习资料

补充习题解答1:1.C 语言程序中可以对程序进行注释,注释部分必须用符号_____括起来。
A、‘{‘和’}’B、‘[‘和’]’C、“/*”和”*/”D、“*/”和”/*”答案:C,这题大家基本都没问题。
2.下列运算符中,优先级最低的是_____。
A、*B、!=C、+D、=答案:D。
本题考察的是运算符的优先级问题,顺序为:初等运算符>单目运算符>算术运算符>关系运算符>逻辑运算符>条件运算符>赋值运算符>逗号运算符.请大家记住这个顺序。
另外,大家在写程序的时候并不能够准确地确定优先级的时候,多加几对括号就可以了,因为在这种情况下读你程序的人可能也不确定优先级。
3.下列运算符中,优先级最低的是:_____A、*B、+C、==D、=答案:D,理由同上。
4.已知字符‘a’的ASCII码为97 ,执行下列语句的输出是_____。
printf ("%d, %c", ’b’, ’b’+1 ) ;A、98, bB、语句不合法C、98, 99D、98, c答案:D。
每一个字符都对应一个整型数值的ASCII码,故可以将字符以int型输出,反过来,也可以将符合ASCII码的int型数值进行字符。
关键在于输出格式控制。
5.有程序段如下:Int k=10;While(k=0)K=k-1;以下选项中描述正确的是_____。
A. 语句“k=k-1;”被执行10次。
B. 语句“k=k-1;”被执行1次。
C. 语句“k=k-1;”被执行无限多次。
D. 语句“k=k-1;”一次也不执行。
答案:D。
while循环体执行的条件为:while判断条件为真(非0为真0为假,特别注意,负数也为真)。
而本题的判断条件为k=0这个表达式的值,为0,故原题等价于while(0)。
所以在写程序的时候要特别避免类似的逻辑错误。
这两题很多同学有错。
6.写出判断一个年份为闰年的C语言表达式:______________________。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
编译预处理
一、选择题
1、以下叙述中正确的是()
(A)用#include包含的头文件的后缀不可以是”.a”
(B)若一些源程序中包含某个头文件,当该头文件有错时,只需对该头文件进行修改,包含此头文件的所有源程序不必重新进行编译(C)宏命令行可以看做是一行C语句
(D)C编译中的预处理是在编译之前进行的
2、下面是对宏定义的描述,不正确的是()
(A)宏不存在类型问题,宏名无类型,它的参数也无类型
(B)宏替换不占用运行时间
(C)宏替换时先求出实参表达式的值,然后代入形参运算求值
(D)宏替换只不过是字符替代而已
3、以下程序的输出结果是()
#include<stdio.h>
#define SQR(x) x*x
main()
{int a,k=3;
a=SQR(k+1);
printf(“%d\n”,a);}
(A)6 (B)7 (C)8 (D)9
4、以下程序的输出结果是()
#define MIN(x,y) (x)<(y)?(x):(y)
#include<stdio.h>
main()
{int i,j,k;
i=10;j=15;k=10*MIN(i,j);
printf(“%d\n”,k);}
(A)15 (B)100 (C)10 (D)150
5、以下程序的输出结果是()
#include<stdio.h>
#define N 2
#define M N+1
#define NUM (M+1)*M/2
main()
{int i;
for(i=1;i<=NUM;i++);
printf(“%d\n”,i);}
(A)5 (B)6 (C)8 (D)9
6、以下程序的输出结果是()
#define f(x) x*x
#include<stdio.h>
main()
{int a=6,b=2,c;
c=f(a)/f(b);
printf(“%d\n”,c);}
(A)9 (B)6 (C)36 (D)18 7、以下程序的输出结果是()
#define PT 5.5
#define S(x) PT*x*x
#include<stdio.h>
main()
{int a=1,b=2;
printf(“%4.1f\n”,S(a+b));}
(A)49.5 (B)9.5 (C)22.0 (D)45.0 8、以下程序的输出结果是()
#define MA(x) x*(x-1)
#include<stdio.h>
main()
{int a=1,b=2;
printf(“%d\n”,MA(1+a+b));}
(A)3 (B)4 (C)6 (D)8
9、有如下程序:()
#include<stdio.h>
#define N 2
#define M N+1
#define NUM 2*M+1
main()
{int i;
for(i=1;i<=NUM;i++)
printf(“%d\n”,i);}
该程序中的for循环执行的次数是()
(A)5 (B)6 (C)7 (D)8
10、以下程序的运行结果是()
#include <stdio.h>
#define F(y) 3.84+y
#define PR(a) printf(“%d”,(int)(a))
#define PRINT(a) PR(a);putchar(…\n‟)
main()
{ int x=2;
PRINT(F(3)*x);}
(A)8 (B)9 (C)10 (D)11
二、填空题
1、设有以下宏定义:
#define WIDTH 80
#define LENGTH WIDTH+40
则执行赋值语句:v=LENGTH*20;后,v的值是_____ 2、下列程序的输出结果是_____。
#include<stdio.h>
#define MAX(a,b) (a>b?a:b)+1
main()
{int i=6,j=8;
printf(“%d\n”,MAX(i,j));}。