实验5 典型时间序列模型分析

实验5 典型时间序列模型分析
1、实验目的
熟悉三种典型的时间序列模型:AR 模型,MA 模型与ARMA 模型,学会运用Matlab 工具对对上述三种模型进行统计特性分析,通过对2阶模型的仿真分析,探讨几种模型的适用范围,并且通过实验分析理论分析与实验结果之间的差异。
2、实验原理
AR 模型分析
设有AR(2)模型,
X(n)=-0.3X(n-1)-0.5X(n-2)+W(n) W(n)是零均值正态白噪声,方差为4。
(1)用MATLAB 模拟产生X(n)的500观测点的样本函数,并绘出波形 (2)用产生的500个观测点估计X(n)的均值和方差 (3)画出理论的功率谱
(4)估计X(n)的相关函数和功率谱
【分析】给定二阶的AR 过程,可以用递推公式得出最终的输出序列。或者按照一个白噪声通过线性系统的方式得到,这个系统的传递函数为:
12
1
()10.30.5H z z z ??=
++
这是一个全极点的滤波器,具有无限长的冲激响应。 对于功率谱,可以这样得到,
2
2
12
12exp()
1()1x w
z j P a z a z ωωσ??==++
可以看出,()x P ω完全由两个极点位置决定。 对于AR 模型的自相关函数,有下面的公式:
2
11(0)
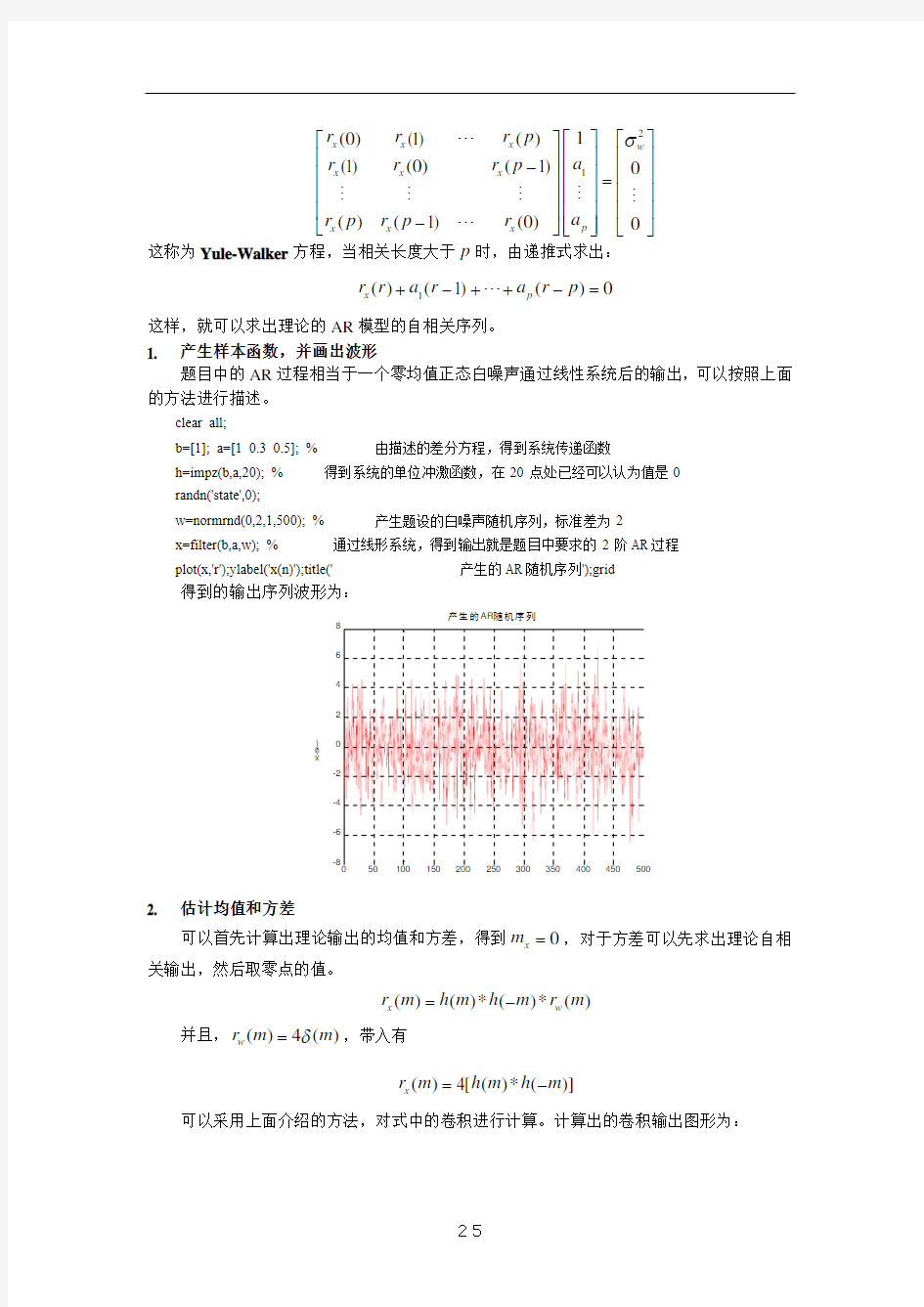
(1)()(1)(0)(1)0()(1)(0)0x x x w x x x p x x x r r r p a r r r p a r p r p r σ???????????????????=????????????????????
?"#####" 这称为Yule-Walker 方程,当相关长度大于p 时,由递推式求出:
1()(1)()0x p r r a r a r p +?++?="
这样,就可以求出理论的AR 模型的自相关序列。 1. 产生样本函数,并画出波形
题目中的AR 过程相当于一个零均值正态白噪声通过线性系统后的输出,可以按照上面的方法进行描述。
clear all;
b=[1]; a=[1 0.3 0.5]; % 由描述的差分方程,得到系统传递函数
h=impz(b,a,20); % 得到系统的单位冲激函数,在20点处已经可以认为值是0 randn('state',0);
w=normrnd(0,2,1,500); % 产生题设的白噪声随机序列,标准差为2 x=filter(b,a,w); % 通过线形系统,得到输出就是题目中要求的2阶AR 过程 plot(x,'r');ylabel('x(n)');title('产生的AR 随机序列');grid
得到的输出序列波形为:
x
(n )产生的AR 随机序列
2.
估计均值和方差
可以首先计算出理论输出的均值和方差,得到0x m =,对于方差可以先求出理论自相关输出,然后取零点的值。
()()*()*()x w r m h m h m r m =?
并且,()4()w r m m δ=,带入有
()4[()*()]x r m h m h m =?
可以采用上面介绍的方法,对式中的卷积进行计算。计算出的卷积输出图形为:
n
h
(n )*h (-n )
在最大值处就是输出的功率,也就是方差,为
2(0) 5.6x x r σ==
对实际数据进行估计,均值为mean(x)= -0.0703,而方差为var(x)= 5.2795,两者和理论值吻合的比较好。
3.
画出理论的功率谱密度曲线 理论的功率谱为,
22
()()()4()j j x w P P H e H e ωωωω==
用下面的语句产生:
delta=2*pi/1000;w_min=-pi;w_max=pi;Fs=1000;
w=w_min:delta:w_max; % 得到数字域上的频率取样点,范围是[-pi,pi]
Gx=4*(abs(1./(1+0.3*exp(-i*w)+0.5*exp(-2*i*w))).^2); % 计算出理论值 Gx=Gx/max(Gx); % 归一化处理
f=w*Fs/(2*pi); % 转化到模拟域上的频率 plot(f,Gx,’b’),grid on;
得到的图形为:
f (Hz)
G
x (w ) d B
可以看出,这个系统是带通系统。 4.
估计自相关函数和功率谱密度
用实际数据估计自相关函数和功率谱的方法前面已经讨论过,在这里仅给出最后的仿真
图形。
% 计算理论和实际的自相关函数序列 Mlag=20; % 定义最大自相关长度 Rx=xcorr(x,Mlag,'coeff'); m=-Mlag:Mlag; stem(m,Rx,'r.');
最终的值为
m
R
x (m )
可以看出,它和上面的理论输出值吻合程度很好。 实际的功率谱密度可以用类似于上面的方法进行估计,
window=hamming(20); % 采用hanmming 窗,长度为20 noverlap=10; % 重叠的点数 Nfft=512; % 做FFT 的点数 Fs=1000; % 采样频率,为1000Hz
[Px,f]=pwelch(x,window,noverlap,Nfft,Fs, 'onesided'); % 估计功率谱密度 f=[-fliplr(f) f(2:end)]; % 构造一个对称的频率,范围是[-Fs/2, Fs/2] Py=[-fliplr(Py) Py(2:end)]; % 对称的功率谱 plot(f,10*log10(Py),’b’);
估计出来的功率谱密度为,
f (Hz)
G
x (w ) d B
将两幅图画在一起,可以看到拟合的情况比较好:
f (Hz)
G
x (w ) d B
ARMA 模型分析
设有ARMA(2,2)模型,
X(n)+0.3X(n-1)-0.2X(n-2)=W(n)+0.5W(n-1)-0.2W(n-2) W(n)是零均值正态白噪声,方差为4。
(1)用MATLAB 模拟产生X(n)的500观测点的样本函数,并绘出波形 (2)用产生的500个观测点估计X(n)的均值和方差 (3)画出理论的功率谱
(4)估计X(n)的相关函数和功率谱
【分析】给定(2,2)的ARMA 过程,也可以用递推公式得出最终的输出序列。或者按照一个白噪声通过线性系统的方式得到,这个系统的传递函数为:
12
12
10.50.2()10.30.2z z H z z z
????+?=+? 对于功率谱,可以这样得到,
2
2
exp()()()x w z j P H z ωωσ==
对于ARMA 过程,当模型的所有极点均落在单位圆内时,才是一个渐进平稳的随机过程。这个过程的自相关函数不能简单地写成Yule-Walker 方程形式,它于模型的参数具有高度的非线性关系。
1.
产生样本函数,并画出波形
题目中的ARMA 过程相当于一个零均值正态白噪声通过线性系统后的输出,可以按照上面的方法进行描述。
clear all;
b=[1 0.5 -0.2]; a=[1 0.3 -0.2]; % 由描述的差分方程,得到系统传递函数 h=impz(b,a,10); % 得到系统的单位冲激函数,在10点处已经可以认为值是0 randn(‘state’,0);
w=normrnd(0,2,1,500); % 产生题设的白噪声随机序列,标准差为2
x=filter(b,a,w); % 通过线形系统,得到输出就是题目中要求的(2,2)阶ARMA 过程 plot(x,’r’);
得到的输出序列波形为:
n
X
(n )
2. 估计均值和方差
可以首先计算出理论输出的均值和方差,得到0x m =,对于方差可以先求出理论自相
关输出,然后取零点的值。
()()*()*()x w r m h m h m r m =?
并且,()4()w r m m δ=,带入有
()4[()*()]x r m h m h m =?
可以采用上面介绍的方法,对式中的卷积进行计算。计算出的卷积输出图形为:
n
h
(n )*h (-n )
f (Hz)G
x (w ) d B 在最大值处就是输出的功率,也就是方差,为
2(0) 4.2x x r σ==
对实际数据进行估计,均值为mean(x)= -0.0547,而方差为var(x)=3.8,两者和理论值吻合的比较好。
3.
画出理论的功率谱密度曲线 理论的功率谱为,
22
()()()4()j j x w P P H e H e ωωωω==
用下面的语句产生:
delta=2*pi/1000;w_min=-pi;w_max=pi;Fs=1000;
w=w_min:delta:w_max; % 得到数字域上的频率取样点,范围是[-pi,pi] NS=1+0.5*exp(-i*w)-0.2*exp(-2*i*w); % 分子 DS=1+0.3*exp(-i*w)-0.2*exp(-2*i*w); % 分母 Gx=4*(abs(NS./DS).^2); % 计算出理论值
Gx=Gx/max(Gx);f=w*Fs/(2*pi); % 转化到模拟域上的频率 plot(f,Gx,’b’),grid on;
4.
估计相关函数和功率谱密度曲线
用实际数据估计自相关函数和功率谱的方法前面已经讨论过,在这里仅给出仿真图形。
% 计算理论和实际的自相关函数序列 Mlag=20; % 定义最大自相关长度 Rx=xcorr(x,Mlag,'coeff'); m=-Mlag:Mlag; stem(m,Rx,'r.');
最终的值为
n
R
x (n )
实际的功率谱密度可以用类似于上面的方法进行估计,
window=hamming(20); % 采用hanmming 窗,长度为20 noverlap=10; % 重叠的点数 Nfft=512; % 做FFT 的点数 Fs=1000; % 采样频率,为1000Hz
[Px,f]=pwelch(x,window,noverlap,Nfft,Fs, 'onesided'); % 估计功率谱密度 f=[-fliplr(f) f(2:end)]; % 构造一个对称的频率,范围是[-Fs/2, Fs/2] Py=[fliplr(Py) Py(2:end)]; % 对称的功率谱 plot(f,10*log10(Py),’b’);
估计出来的功率谱密度为,
f (Hz)
P
x (w ) d B
把两幅图画在一起,可以得到下面的图形,可以看出两者的吻合度比较高。
f (Hz)
G
x (w ) d B
3、实验内容
1、熟悉实验原理,将实验原理上的程序应用matlab工具实现;
2、设有MA(2)模型,x(n) =W(n)-0.3W(n-1)+0.2W(n-2)
W(n)是零均值正态白噪声,方差为4。
(1)用MATLAB模拟产生X(n)的500观测点的样本函数,并绘出波形(2)用产生的500个观测点估计X(n)的均值和方差
(3)画出理论的功率谱
(4)估计X(n)的相关函数和功率谱
4、实验要求
(1)用MATLAB编写程序。
(2)写出详细试验报告(要有自己对实验结果的结论)。
多元时间序列建模分析
应用时间序列分析实验报告
单位根检验输出结果如下:序列x的单位根检验结果:
1967 58.8 53.4 1968 57.6 50.9 1969 59.8 47.2 1970 56.8 56.1 1971 68.5 52.4 1972 82.9 64.0 1973 116.9 103.6 1974 139.4 152.8 1975 143.0 147.4 1976 134.8 129.3 1977 139.7 132.8 1978 167.6 187.4 1979 211.7 242.9 1980 271.2 298.8 1981 367.6 367.7 1982 413.8 357.5 1983 438.3 421.8 1984 580.5 620.5 1985 808.9 1257.8 1986 1082.1 1498.3 1987 1470.0 1614.2 1988 1766.7 2055.1 1989 1956.0 2199.9 1990 2985.8 2574.3 1991 3827.1 3398.7 1992 4676.3 4443.3 1993 5284.8 5986.2 1994 10421.8 9960.1 1995 12451.8 11048.1 1996 12576.4 11557.4 1997 15160.7 11806.5 1998 15223.6 11626.1 1999 16159.8 13736.5 2000 20634.4 18638.8 2001 22024.4 20159.2 2002 26947.9 24430.3 2003 36287.9 34195.6 2004 49103.3 46435.8 2005 62648.1 54273.7 2006 77594.6 63376.9 2007 93455.6 73284.6 2008 100394.9 79526.5 run; proc gplot; plot x*t=1 y*t=2/overlay; symbol1c=black i=join v=none; symbol2c=red i=join v=none w=2l=2; run; proc arima data=example6_4; identify var=x stationarity=(adf=1); identify var=y stationarity=(adf=1); run; proc arima; identify var=y crrosscorr=x; estimate methed=ml input=x plot; forecast lead=0id=t out=out; proc aima data=out; identify varresidual stationarity=(adf=2); run;
应用时间序列分析习题答案解析整理
第二章习题答案 2.1 (1)非平稳 (2)0.0173 0.700 0.412 0.148 -0.079 -0.258 -0.376 (3)典型的具有单调趋势的时间序列样本自相关图 2.2 (1)非平稳,时序图如下 (2)-(3)样本自相关系数及自相关图如下:典型的同时具有周期和趋势序列的样本自相关图
2.3 (1)自相关系数为:0.2023 0.013 0.042 -0.043 -0.179 -0.251 -0.094 0.0248 -0.068 -0.072 0.014 0.109 0.217 0.316 0.0070 -0.025 0.075 -0.141 -0.204 -0.245 0.066 0.0062 -0.139 -0.034 0.206 -0.010 0.080 0.118 (2)平稳序列 (3)白噪声序列 2.4 ,序列 LB=4.83,LB统计量对应的分位点为0.9634,P值为0.0363。显著性水平=0.05 不能视为纯随机序列。 2.5 (1)时序图与样本自相关图如下
(2) 非平稳 (3)非纯随机 2.6 (1)平稳,非纯随机序列(拟合模型参考:ARMA(1,2)) (2)差分序列平稳,非纯随机 第三章习题答案 3.1 解:1()0.7()()t t t E x E x E ε-=?+ 0)()7.01(=-t x E 0)(=t x E t t x ε=-)B 7.01( t t t B B B x εε)7.07.01()7.01(221Λ+++=-=- 229608.149 .011 )(εεσσ=-= t x Var 49.00212==ρφρ 022=φ 3.2 解:对于AR (2)模型: ?? ?=+=+==+=+=-3.05 .02110211212112011φρφρφρφρρφφρφρφρ 解得:???==15/115 /72 1φφ 3.3 解:根据该AR(2)模型的形式,易得:0)(=t x E 原模型可变为:t t t t x x x ε+-=--2115.08.0 2212122 ) 1)(1)(1(1)(σφφφφφφ-+--+-= t x Var 2) 15.08.01)(15.08.01)(15.01() 15.01(σ+++--+= =1.98232σ ?????=+==+==-=2209.04066.06957.0)1/(1221302112211ρφρφρρφρφρφφρ ?? ? ??=-====015.06957.033222111φφφρφ
时间序列分析实验报告(3)
《时间序列分析》课程实验报告
一、上机练习(P124) 1.拟合线性趋势 12.79 14.02 12.92 18.27 21.22 18.81 25.73 26.27 26.75 28.73 31.71 33.95 程序: data xiti1; input x@@; t=_n_; cards; 12.79 14.02 12.92 18.27 21.22 18.81 25.73 26.27 26.75 28.73 31.71 33.95 ; proc gplot data=xiti1; plot x*t; symbol c=red v=star i=join; run; proc autoreg data=xiti1; model x=t; output predicted=xhat out=out; run; proc gplot data=out; plot x*t=1 xhat*t=2/overlay; symbol2c=green v=star i=join; run; 运行结果:
分析:上图为该序列的时序图,可以看出其具有明显的线性递增趋势,故使用线性模型进行拟合:x t=a+bt+I t,t=1,2,3,…,12 分析:上图为拟合模型的参数估计值,其中a=9.7086,b=1.9829,它们的检验P值均小于0.0001,即小于显著性水平0.05,拒绝原假设,故其参数均显著。从而所拟合模型为:x t=9.7086+1.9829t.
分析:上图中绿色的线段为线性趋势拟合线,可以看出其与原数据基本吻合。 2.拟合非线性趋势 1.85 7.48 14.29 23.02 37.42 74.27 140.72 265.81 528.23 1040.27 2064.25 4113.73 8212.21 16405.95 程序: data xiti2; input x@@; t=_n_; cards; 1.85 7.48 14.29 23.02 37.42 74.27 140.72 265.81 528.23 1040.27 2064.25 4113.73 8212.21 16405.95 ; proc gplot data=xiti2; plot x*t; symbol c=red v=star i=none; run; proc nlin method=gauss; model x=a*b**t; parameters a=0.1 b=1.1; der.a=b**t; der.b=a*t*b**(t-1); output predicted=xh out=out; run; proc gplot data=out; plot x*t=1 xh*t=2/overlay;
时间序列分析资料报告——ARMA模型实验
基于ARMA模型的社会融资规模增长分析 ————ARMA模型实验
第一部分实验分析目的及方法 一般说来,若时间序列满足平稳随机过程的性质,则可用经典的ARMA模型进行建模和预则。但是, 由于金融时间序列随机波动较大,很少满足ARMA模型的适用条件,无法直接采用该模型进行处理。通过对数化及差分处理后,将原本非平稳的序列处理为近似平稳的序列,可以采用ARMA模型进行建模和分析。 第二部分实验数据 2.1数据来源 数据来源于中经网统计数据库。具体数据见附录表5.1 。 2.2所选数据变量 社会融资规模指一定时期(每月、每季或每年)实体经济从金融体系获得的全部资金总额,为一增量概念,即期末余额减去期初余额的差额,或当期发行或发生额扣除当期兑付或偿还额的差额。社会融资规模作为重要的宏观监测指标,由实体经济需求所决定,反映金融体系对实体经济的资金量支持。 本实验拟选取2005年11月到2014年9月我国以月为单位的社会融资规模的数据来构建ARMA模型,并利用该模型进行分析预测。 第三部分 ARMA模型构建 3.1判断序列的平稳性 首先绘制出M的折线图,结果如下图:
图3.1 社会融资规模M曲线图 从图中可以看出,社会融资规模M序列具有一定的趋势性,由此可以初步判断该序列是非平稳的。此外,m在每年同时期出现相同的变动趋势,表明m还存在季节特征。下面对m的平稳性和季节性·进行进一步检验。 为了减少m的变动趋势以及异方差性,先对m进行对数化处理,记为lm,其时序图如下: 图3.2 lm曲线图
对数化后的趋势性减弱,但仍存在一定的趋势性,下面观察lm的自相关图 表3.1 lm的自相关图 上表可以看出,该lm序列的PACF只在滞后一期、二期和三期是显著的,ACF随着滞后结束的增加慢慢衰减至0,由此可以看出该序列表现出一定的平稳性。进一步进行单位根检验,由于存在较弱的趋势性且均值不为零,选择存在趋势项的形式,并根据AIC自动选择之后结束,单位根检验结果如下: 表3.2 单位根输出结果 Null Hypothesis: LM has a unit root Exogenous: Constant, Linear Trend Lag Length: 0 (Automatic - based on SIC, maxlag=12) t-Statistic Prob.*
时间序列分析实验报告
时间序列分析实验报告 P185#1、某股票连续若干天的收盘价如表5-4 (行数据)所示。 表5-4 304 303 307 299 296 293301 293 301 295 284286 286 287 284 282278 281 278 277279 278 270 268 272 273 279 279280 275 271 277 278279 283 284 282 283279 280 280 279278 283 278 270 275 273 273 272275 273 273 272 273272 273 271 272 271273 277 274 274272 280 282 292 295 295 294 290 291 288 288 290 293 288 289 291 293 293 290 288 287 289 292 288 288 285 282 286 286 287 284 283 286 282 287 286 287 292 292 294 291 288 289 选择适当模型拟合该序列的发展,并估计下一天的收盘价。 解: (1)通过SA漱件画出上述序列的时序图如下: 程序: data example5_1; in put x@@; time=_ n_; cards ; 304 303 307 299296 293 301 293 301 295 284286286 287 284 282 278 281 278277 279 278 270 268 272 273279279 280 275 271 277 278 279283 284 282 283 279 280 280279278 283 278 270 275 273 273272 275 273 273 272 273 272273271 272 271 273 277 274 274272 280 282 292 295 295 294290291 288 288 290 293 288 289291 293 293 290 288 287 289292288 288 285 282 286 286 287284 283 286 282 287 286 287292292 294 291 288 289 proc gplot data =example5_1; plot x*time= 1; symbol1 c=black v=star i =join; run ; 上述程序所得时序图如下: 上述时序图显示,该序列具有长期趋势又含有一定的周期性,为典型的非平稳序列。又因为该序列呈现曲线形式,所以选择2阶差分。
典型时间序列模型分析
实验1典型时间序列模型分析 1、实验目的 熟悉三种典型的时间序列模型: AR 模型,MA 模型与ARMA 模型,学会运用Matlab 工具对 对上述三种模型进行统计特性分析,通过对2阶模型的仿真分析,探讨几种模型的适用范围, 并且通过实验分析理论分析与实验结果之间的差异。 2、实验原理 AR 模型分析: 设有AR(2)模型, X( n)=-0.3X( n-1)-0.5X( n-2)+W( n) 其中:W(n)是零均值正态白噪声,方差为 4。 (1 )用MATLAB 模拟产生X(n)的500观测点的样本函数,并绘出波形 (2) 用产生的500个观测点估计X(n)的均值和方差 (3) 画出理论的功率谱 (4) 估计X(n)的相关函数和功率谱 【分析】给定二阶的 AR 过程,可以用递推公式得出最终的输出序列。或者按照一个白噪声 通过线性系统的方式得到,这个系统的传递函数为: 这是一个全极点的滤波器,具有无限长的冲激响应。 对于功率谱,可以这样得到, 可以看出, FX w 完全由两个极点位置决定。 对于AR 模型的自相关函数,有下面的公式: \(0) 打⑴ 匚⑴… ^(0) ■ 1' G 2 W 0 JAP) 人9-1)… 凉0) _ 这称为Yule-Walker 方程,当相关长度大于 p 时,由递推式求出: r (r) + -1) + -■ + (7r - JJ )= 0 这样,就可以求出理论的 AR 模型的自相关序列。 H(z) 二 1 1 0.3z , P x w +W 1 1 a 才 a 2z^
1. 产生样本函数,并画出波形 2. 题目中的AR过程相当于一个零均值正态白噪声通过线性系统后的输出,可以按照上面的方法进行描述。 clear all; b=[1]; a=[1 0.3 0.5]; % 由描述的差分方程,得到系统传递函数 h=impz(b,a,20); % 得到系统的单位冲激函数,在20点处已经可以认为值是0 randn('state',0); w=normrnd(0,2,1,500); % 产生题设的白噪声随机序列,标准差为 2 x=filter(b,a,w); % 通过线形系统,得到输出就是题目中要求的2阶AR过程 plot(x,'r'); ylabel('x(n)'); title(' 邹先雄——产生的AR随机序列'); grid on; 得到的输出序列波形为: 邹先雄——产生的AR随机序列 2. 估计均值和方差 可以首先计算出理论输出的均值和方差,得到m x =0 ,对于方差可以先求出理论自相 关输出,然后取零点的值。
时间序列分析及VAR模型
Lecture 6 6. Time series analysis: Multivariate models 6.1Learning outcomes ?Vector autoregression (VAR) ?Cointegration ?Vector error correction model (VECM) ?Application: pairs trading 6.2Vector autoregression (VAR)向量自回归 The classical linear regression model assumes strict exogeneity; hence, there is no serial correlation between error terms and any realisation of any independent variable (lead or lag). As we discovered, serial correlation (or autocorrelation) is very common in financial time series and panel data. Furthermore, we assumed a pre-defined relation of causality: explanatory variable affect the dependent variable? 传统的线性回归模型假设严格的外主性,误差项与可实现的独立变量之间没有序列相关性。金融时间序列及面板数据往往都有很强的自相关性,假定解释变量影响因变量。 We now relax bo什]assumptions using a VAR model. VAR models can be regarded as a generalisation of AR(p) processes by adding additional time series. Hence, we enter the field of multivariate time series analysis. VAR模型可以'"l作是在一般的自回归过程中加入时间序列。 Lefs look at a standard AR(p) process for hvo variables (y( and xj? (1)%= Ql + 琅]仇『一 +仏 (2)x t = a2 + - + £2t The next step is to allow that lagged values of xt can affect y( and vice versa. This means that we obtain a system of equations for two dependent variables(y(and xj?Both dependent variables are influenced by past realisations of y(and x t. By doing that, we violate strict exogeneity (see Lecture 2); however, we can use a more relaxed concept, namely weak exogeneity?As we use lagged values of bodi dependent variables, we can argue that these lagged values are known to us, as we observed them in the previous period? We call these variables predetermined? Predetermined (lagged) variables fulfil weak exogeneity in the sense that they have to be uncorrelated with the contemporaneoiis error term in t? We can still use OLS to estimate the following system of equations, which is called a VAR in reduced form. (3)+y 仇1化_丫+sr=i ^12 +£it (4)X t = a2+2X1021”—, + _i + f2t
时间序列分析——最经典的
【时间简“识”】 说明:本文摘自于经管之家(原人大经济论坛) 作者:胖胖小龟宝。原版请到经管之家(原人大经济论坛) 查看。 1.带你看看时间序列的简史 现在前面的话—— 时间序列作为一门统计学,经济学相结合的学科,在我们论坛,特别是五区计量经济学中是热门讨论话题。本月楼主推出新的系列专题——时间简“识”,旨在对时间序列方面进行知识扫盲(扫盲,仅仅扫盲而已……),同时也想借此吸引一些专业人士能够协助讨论和帮助大家解疑答惑。 在统计学的必修课里,时间序列估计是遭吐槽的重点科目了,其理论性强,虽然应用领域十分广泛,但往往在实际操作中会遇到很多“令人发指”的问题。所以本帖就从基础开始,为大家絮叨絮叨那些关于“时间”的故事! Long long ago,有多long估计大概7000年前吧,古埃及人把尼罗河涨落的情况逐天记录下来,这一记录也就被我们称作所谓的时间序列。记录这个河流涨落有什么意义当时的人们并不是随手一记,而是对这个时间序列进行了长期的观察。结果,他们发现尼罗河的涨落非常有规律。掌握了尼罗河泛滥的规律,这帮助了古埃及对农耕和居所有了规划,使农业迅速发展,从而创建了埃及灿烂的史前文明。
好~~从上面那个故事我们看到了 1、时间序列的定义——按照时间的顺序把随机事件变化发展的过程记录下来就构成了一个时间序列。 2、时间序列分析的定义——对时间序列进行观察、研究,找寻它变化发展的规律,预测它将来的走势就是时间序列分析。 既然有了序列,那怎么拿来分析呢 时间序列分析方法分为描述性时序分析和统计时序分析。 1、描述性时序分析——通过直观的数据比较或绘图观测,寻找序列中蕴含的发展规律,这种分析方法就称为描述性时序分析 描述性时序分析方法具有操作简单、直观有效的特点,它通常是人们进行统计时序分析的第一步。 2、统计时序分析 (1)频域分析方法 原理:假设任何一种无趋势的时间序列都可以分解成若干不同频率的周期波动 发展过程: 1)早期的频域分析方法借助富里埃分析从频率的角度揭示时间序列的规律 2)后来借助了傅里叶变换,用正弦、余弦项之和来逼近某个函数 3)20世纪60年代,引入最大熵谱估计理论,进入现代谱分析阶段 特点:非常有用的动态数据分析方法,但是由于分析方法复杂,结果抽象,有一定的使用局限性 (2)时域分析方法
spss时间序列模型
《统计软件实验报告》SPSS软件的上机实践应用 时间序列分析
数学与统计学学院 一、实验内容: 时间序列是指一个依时间顺序做成的观察资料的集合。时间序列分析过程中最常用的方法是:指数平滑、自回归、综合移动平均及季节分解。 本次实验研究就业理论中的就业人口总量问题。但人口经济的理论和实践表明,就业总量往往受到许多因素的制约,这些因素之间有着错综复杂的联系,因此,运用结构性的因果模型分析和预测就业总量往往是比较困难的。时间序列分析中的自回归求积分移动平均法(ARIMA)则是一个较好的选择。对于时间序列的短期预测来说,随机时序ARIMA是一种精度较高的模型。 我们已辽宁省历年(1969-2005)从业人员人数为数据基础建立一个就业总量的预测时间序列模型,通过spss建立模型并用此模型来预测就业总量的未来发展趋势。 二、实验目的: 1.准确理解时间序列分析的方法原理 2.学会实用SPSS建立时间序列变量 3.学会使用SPSS绘制时间序列图以反应时间序列的直观特征。
4.掌握时间序列模型的平稳化方法。 5.掌握时间序列模型的定阶方法。 6.学会使用SPSS建立时间序列模型与短期预测。 7.培养运用时间序列分析方法解决身边实际问题的能力。 三、实验分析: 总体分析: 先对数据进行必要的预处理和观察,直到它变成稳态后再用SPSS对数据进行分析。 数据的预处理阶段,将它分为三个步骤:首先,对有缺失值的数据进行修补,其次将数据资料定义为相应的时间序列,最后对时间序列数据的平稳性进行计算观察。 数据分析和建模阶段:根据时间序列的特征和分析的要求,选择恰当的模型进行数据建模和分析。 四、实验步骤: SPSS的数据准备包括数据文件的建立、时间定义和数据期间的指定。 SPSS的时间定义功能用来将数据编辑窗口中的一个或多个变量指定为时间序列变量,并给它们赋予相应的时间标志,具体操作步骤是: 1.选择菜单:Date→Define Dates,出现窗口:
Eviews时间序列分析实例.
Eviews时间序列分析实例 时间序列是市场预测中经常涉及的一类数据形式,本书第七章对它进行了比较详细的介绍。通过第七章的学习,读者了解了什么是时间序列,并接触到有关时间序列分析方法的原理和一些分析实例。本节的主要内容是说明如何使用Eviews软件进行分析。 一、指数平滑法实例 所谓指数平滑实际就是对历史数据的加权平均。它可以用于任何一种没有明显函数规律,但确实存在某种前后关联的时间序列的短期预测。由于其他很多分析方法都不具有这种特点,指数平滑法在时间序列预测中仍然占据着相当重要的位置。 (-)一次指数平滑 一次指数平滑又称单指数平滑。它最突出的优点是方法非常简单,甚至只要样本末期的平滑值,就可以得到预测结果。 一次指数平滑的特点是:能够跟踪数据变化。这一特点所有指数都具有。预测过程中添加最新的样本数据后,新数据应取代老数据的地位,老数据会逐渐居于次要的地位,直至被淘汰。这样,预测值总是反映最新的数据结构。 一次指数平滑有局限性。第一,预测值不能反映趋势变动、季节波动等有规律的变动;第二,这种方法多适用于短期预测,而不适合作中长期的预测;第三,由于预测值是历史数据的均值,因此与实际序列的变化相比有滞后现象。 指数平滑预测是否理想,很大程度上取决于平滑系数。Eviews提供两种确定指数平滑系数的方法:自动给定和人工确定。选择自动给定,系统将按照预测误差平方和最小原则自动确定系数。如果系数接近1,说明该序列近似纯随机序列,这时最新的观测值就是最理想的预测值。 出于预测的考虑,有时系统给定的系数不是很理想,用户需要自己指定平滑系数值。平滑系数取什么值比较合适呢?一般来说,如果序列变化比较平缓,平滑系数值应该比较小,比如小于0.l;如果序列变化比较剧烈,平滑系数值可以取得大一些,如0.3~0.5。若平滑系数值大于0.5才能跟上序列的变化,表明序列有很强的趋势,不能采用一次指数平滑进行预测。 [例1]某企业食盐销售量预测。现在拥有最近连续30个月份的历史资料(见表l),试预测下一月份销售量。 表1 某企业食盐销售量单位:吨 解:使用Eviews对数据进行分析,第一步是建立工作文件和录入数据。有关操作在本
应用时间序列实验报告
河南工程学院课程设计 《时间序列分析课程设计》学生姓名学号: 学院:理学院 专业班级: 专业课程:时间序列分析课程设计指导教师: 2017年 6 月 2 日
目录 1. 实验一澳大利亚常住人口变动分析..... 错误!未定义书签。 实验目的............................................... 错误!未定义书签。 实验原理............................................... 错误!未定义书签。 实验内容............................................... 错误!未定义书签。 实验过程............................................... 错误!未定义书签。 2. 实验二我国铁路货运量分析........... 错误!未定义书签。 实验目的............................................... 错误!未定义书签。 实验原理............................................... 错误!未定义书签。 实验内容............................................... 错误!未定义书签。 实验过程............................................... 错误!未定义书签。 3. 实验三美国月度事故死亡数据分析...... 错误!未定义书签。 实验目的............................................... 错误!未定义书签。 实验原理............................................... 错误!未定义书签。 实验内容............................................... 错误!未定义书签。 实验过程............................................... 错误!未定义书签。课程设计体会 ............................ 错误!未定义书签。
现代时间序列分析模型
现代时间序列分析模型§1 时间序列平稳性和单位根检验§2 协整与误差修正模型经典时间序列分析模型: MA、AR、ARMA 平稳时间序列模型分析时间序列自身的变化规律现代时间序列分析模型:分析时间序列之间的关系单位根检验、协整检验现代宏观计量经济学§1 时间序列平稳性和单位根检验一、时间序列的平稳性二、单整序列三、单位根检验一、时间序列的平稳性 Stationary Time Series ⒈问题的提出经典计量经济模型常用到的数据有:时间序列数据(time-series data ;截面数据cross-sectional data 平行/面板数据(panel data/time-series cross-section data 时间序列数据是最常见,也是最常用到的数据。经典回归分析暗含着一个重要假设:数据是平稳的。数据非平稳,大样本下的统计推断基础――“一致性”要求――被破怀。数据非平稳,往往导致出现“虚假回归”(Spurious Regression)问题。表现为两个本来没有任何因果关系的变量,却有很高的相关性。例如:如果有两列时间序列数据表现出一致的变化趋势(非平稳的),即使它们没有任何有意义的关系,但进行回归也可表现出较高的可决系数。 2、平稳性的定义假定某个时间序列是由某一随机过程(stochastic process)生成的,即假定时间序列 Xt (t 1, 2, …)的每一个数值都是从一个概率分布中随机得到,如果满足下列条件:均值E Xt ?是与时间t 无关的常数;方差Var Xt ?2是与时间t 无关的常数;协方差Cov Xt,Xt+k ?k 是只与时期间隔k有关,与时间t 无关的常数;则称该随机时间序列是平稳的(stationary ,
时间序列实验报告
第三章平稳时间序列分析 选择合适的模型拟合1950-2008年我国邮路及农村投递线路每年新增里程数序列,见表1: 表1 1950-2008年我国邮路及农村投递线路每年新增里程数序列 一、时间序列预处理 (一)时间序列平稳性检验 1.时序图检验 (1)工作文件的创建。打开EViews6.0软件,在主菜单中选择File/New/Workfile, 在弹出的对话框中,在Workfile structure type中选择Dated-regular frequency(时间序列数据),在Date specification下的Frequency中选择Annual(年度数),在Start date中输入“1950”(表示起始年
份为1950年),在End date中输入“2008”(表示样本数据的结束年份为2008年),然后单击“OK”,完成工作文件的创建。 (2)样本数据的录入。选择菜单中的Quick/Empty group(Edit Series)命令,在弹出的Group对话框中,直接将数据录入,并分别命名为year(表示年份),X(表示新增里程数)。 (3)时序图。选择菜单中的Quick/graph…,在弹出的Series List中输入“year x”,然后单击“确定”,在Graph Options中的Specifi中选择“XYLine”,然后按“确定”,出现时序图,如图1所示: 图1 我国邮路及农村投递线路每年新增里程数序列时序图从图1中可以看出,该序列始终在一个常数值附近随机波动,而且波动的围有界,因而可以初步认定序列是平稳的。为了进一步确认序列的平稳性,还需要分析其自相关图。 2.自相关图检验 选择菜单中的Quick/Series Statistics/Correlogram...,在Series Name 中输入x(表示作x序列的自相关图),点击OK,在Correlogram Specification 中的Correlogram of 中选择Level,在Lags to include中输入24,点击OK,得到图2:
时间序列分析实验报告
时间序列分析SAS软件实验报告: 以我国2002第一季度到2012年第一季度国内生产总值数据(季节效应模型)分析 班级:统计系统计0姓名: 学号: 指导老师: 20 年月日
时间序列分析报告 一、前言 【摘要】2012年3月5日温家宝代表国务院向大会作政府工作报告。温家宝在报告中提出,2012年国内生产总值增长7.5%。这是我国国内生产总值(GDP)预期增长目标八年来首次低于8%。 温家宝说,今年经济社会发展的主要预期目标是:国内生产总值增长7.5%;城镇新增就业900万人以上,城镇登记失业率控制在4.6%以内;居民消费价格涨幅控制在4%左右;进出口总额增长10%左右,国际收支状况继续改善。同时,要在产业结构调整、自主创新、节能减排等方面取得新进展,城乡居民收入实际增长和经济增长保持同步。 他指出,这里要着重说明,国内生产总值增长目标略微调低,主要是要与“十二五”规划目标逐步衔接,引导各方面把工作着力点放到加快转变经济发展方式、切实提高经济发展质量和效益上来,以利于实现更长时期、更高水平、更好质量发展。提出居民消费价格涨幅控制在4%左右,综合考虑了输入性通胀因素、要素成本上升影响以及居民承受能力,也为价格改革预留一定空间。 对于这一预期目标的调整,温家宝解释说,主要是要与“十二五”规划目标逐步衔接,引导各方面把工作着力点放到加快转变经济发展方式、切实提高经济发展质量和效益上来,以利于实现更长时期、更高水平、更好质量发展。 央行货币政策委员会委员李稻葵表示,未来若干年中国经济增长速度会有所放缓,这个放缓是必要的,是经济发展方式转变的一个必然要求。 【关键词】“十二五”规划目标国内生产总值增长率增速放缓提高发展质量附表:国内生产总值(2012年1季度) 绝对额(亿元)比去年同期增长(%) 国内生产总值107995.0 8.1 第一产业6922.0 3.8 第二产业51450.5 9.1 第三产业49622.5 7.5 注1:绝对额按现价计算,增长速度按不变价计算。注2:该表为初步核算数据。 GDP环比增长速度 环比增长速度(%) 2011年1季度 2.2 2季度 2.3 3季度 2.4 4季度 1.9 2012年1季度 1.8 注:环比增长速度为经季节调整与上一季度对比的增长速度。 此表是我国2012年第一季度国内生产总值及与2011年同期比较来源:前瞻网
应用时间序列实验报告
河南工程学院课程设计《时间序列分析课程设计》学生姓名学号: 学院:理学院 专业班级: 专业课程:时间序列分析课程设计 指导教师: 2017年6月2日
目录 1. 实验一澳大利亚常住人口变动分析 (1) 1.1 实验目的 (1) 1.2 实验原理 (1) 1.3 实验内容 (2) 1.4 实验过程 (3) 2. 实验二我国铁路货运量分析 (8) 2.1 实验目的 (8) 2.2 实验原理 (8) 2.3 实验内容 (9) 2.4 实验过程 (10) 3. 实验三美国月度事故死亡数据分析 (14) 3.1 实验目的 (14) 3.2 实验原理 (15) 3.3 实验内容 (15) 3.4 实验过程 (16) 课程设计体会 (19)
1.实验一澳大利亚常住人口变动分析 1971年9月—1993年6月澳大利亚常住人口变动(单位:千人)情况如表1-1所示(行数据)。 表1-1 (1)判断该序列的平稳性与纯随机性。 (2)选择适当模型拟合该序列的发展。 (3)绘制该序列拟合及未来5年预测序列图。 1.1 实验目的 掌握用SAS软件对数据进行相关性分析,判断序列的平稳性与纯随机性,选择模型拟合序列发展。 1.2 实验原理 (1)平稳性检验与纯随机性检验 对序列的平稳性检验有两种方法,一种是根据时序图和自相关图显示的特征做出判断的图检验法;另一种是单位根检验法。
(2)模型识别 先对模型进行定阶,选出相对最优的模型,下一步就是要估计模型中未知参数的值,以确定模型的口径,并对拟合好的模型进行显著性诊断。 (3)模型预测 模型拟合好之后,利用该模型对序列进行短期预测。 1.3 实验内容 (1)判断该序列的平稳性与纯随机性 时序图检验,根据平稳时间序列均值、方差为常数的性质,平稳序列的时序图应该显示出该序列始终在一个常识值附近波动,而且波动的范围有界。如果序列的时序图显示该序列有明显的趋势性或周期性,那么它通常不是平稳序列。 对自相关图进行检验时,可以用SAS 系统ARIMA 过程中的IDENTIFY 语句来做自相关图。 而单位根检验我们用到的是DF 检验。以1阶自回归序列为例: 11t t t x x φε-=+ 该序列的特征方程为: 0λφ-= 特征根为: λφ= 当特征根在单位圆内时: 11φ< 该序列平稳。 当特征根在单位圆上或单位圆外时: 11φ≥ 该序列非平稳。 对于纯随机性检验,既白噪声检验,可以用SAS 系统中的IDENTIFY 语句来输出白噪声检验的结果。 (2)选择适当模型拟合该序列的发展
实验·6时间序列分析报告地spss应用
实验6 时间序列分析的spss应用 6.1 实验目的 学会运用SPSS统计软件创建时间数列,熟练掌握长期趋势线性模型拟合和季节变动测定的SPSS方法与技能。 6.2 相关知识(略) 6.3 实验内容 6.3.1 用SPSS统计软件创建时间序列的创建 6.3.2用SPSS统计软件处理长期趋势线性模型的拟合(最小二乘法、指数平滑法)及预测。 6.3.3掌握测定季节变动规律的SPSS测定方法。 6.4实验要求 6.4.1准备实验数据 6.4.2用SPSS统计软件创建彩电出口数量的时间序列 6.4.3用最小二乘法测定长期趋势,拟合线性趋势方程,并进行趋势预测。 6.4.4测定彩电出口数量的季节变动规律。 6.4.5用指数平滑法预测2014和2015年的彩电出口数量。 6.5 实验步骤 6.5.1 实验数据 为了研究某国彩电出口的情况,某研究机构收集了从2003-2013年某国彩电出口的月度数据,如表6-1所示。 表6-1 我国2003-2013年的我国彩电出口的月度数据(单位:万台)1月2月3月4月5月6月7月8月9月10月11月12月2003年12.53 13.73 24.45 28.75 32.45 31.11 25.94 32.98 43.49 42.94 63.29 77.28 2004年30.01 39.63 29.77 42.74 32.25 31.94 32.27 32.59 32.92 30.98 47.44 52.82 2005年24.08 16.42 31.24 29.33 31.88 30.09 28.08 32.99 44.99 47.57 50.36 75.19 2006年39.02 25.81 43.38 37.34 39.22 39.87 51.10 50.99 55.16 62.78 57.75 72.20 2007年28.76 39.38 46.10 39.41 38.74 40.18 45.59 43.31 46.68 54.17 53.65 61.12 2008年28.87 21.23 35.82 26.97 32.33 24.53 29.39 31.96 38.22 39.24 52.95 68.41
时间序列建模案例VAR模型分析报告与协整检验
传统的经济计量方法是以经济理论为基础来描述变量关系的模型。但是,经济理论通常并不足以对变量之间的动态联系提供一个严密的说明,而且内生变量既可以出现在方程的左端又可以出现在方程的右端使得估计和推断变得更加复杂。为了解决这些问题而出现了一种用非结构性方法来建立各个变量之间关系的模型。本章所要介绍的向量自回归模型(vector autoregression ,VAR)和向量误差修正模型(vector error correction model ,VEC)就是非结构化的多方程模型。 向量自回归(VAR)是基于数据的统计性质建立模型,VAR 模型把系统中每一个内生变量作为系统中所有内生变量的滞后值的函数来构造模型,从而将单变量自回归模型推广到由多元时间序列变量组成的“向量”自回归模型。VAR 模型是处理多个相关经济指标的分析与预测最容易操作的模型之一,并且在一定的条件下,多元MA 和ARMA 模型也可转化成VAR 模型,因此近年来VAR 模型受到越来越多的经济工作者的重视。 VAR(p ) 模型的数学表达式是 t=1,2,…..,T 其中:yt 是 k 维内生变量列向量,xt 是d 维外生变量列向量,p 是滞后阶数,T 是样本个数。k ?k 维矩阵Φ1,…, Φp 和k ?d 维矩阵H 是待估计的系数矩阵。εt 是 k 维扰动列向量,它们相互之间可以同期相关,但不与自己的滞后值相关且不与等式右边的变量相关,假设 ∑ 是εt 的协方差矩阵,是一个(k ?k )的正定矩阵。 11t t p t p t t --=+???+++y Φy Φy Hx ε
注意,由于任何序列相关都可以通过增加更多的yt 的滞后而被消除,所以扰动项序列不相关的假设并不要求非常严格。 以1952一1991年对数的中国进、出口贸易总额序列为例介绍VAR 模型分析,其中包括;① VAR 模型估计;②VAR 模型滞后期的选择;③ VAR 模型平隐性检验;④VAR 模型预侧;⑤协整性检验 VAR 模型佑计 数据 εε εε
时间序列分析实验报告70946
时间序列分析实验报告 P185#1、某股票连续若干天的收盘价如表5—4(行数据)所示。 表5-4 304 303 307 299 296 293 301293 301 295 284 286 286 287 284 282 278 281278 277 279 278 270 268 272 273 279 279 280 275271 277 278 279 283284 282 283 279 280 280 279 278 283278270 275 273 273 272 275 273273272 273 272273 271 272 271 273 277 274 274 272280 282 292 295 295 294 290 291 288 288 290 293 288 289 291 293 293 290288 287 289 292 288 288 285 282 286 286 287 284 283 286 282 287 286 287 292 292 294 291 288 289 选择适当模型拟合该序列的发展,并估计下一天的收盘价。 解: (1)通过SAS软件画出上述序列的时序图如下: 程序: data example5_1; input x@@; time=_n_; cards; 304 303 307299 296293 301 293 301 295 284 286 286 287 284 282 278 281278 277 279 278 270268 272 273279 279 280275 271 277 278 279 283 284 282 283 279 280 280 279 278 283 278 270 275 273273 272 275 273 273 272 273 272 273 271272 271 273 277 274274 272 280 282 292295 295 294 290 291288 288 290 293288 289 291 293 293 290 288 287 289 292 288 288 285 282 286 286 287 284283 286 282 287 286 287 292 292 294 291 288 289 ; proc gplot data=example5_1; plotx*time=1; symbol1c=blackv=star i=join; run; 上述程序所得时序图如下: