趋势外推法
一、实验课题
趋势外推法
二、实验目的与意义
学会利用修正指数曲线模型,指数曲线模型,皮尔曲线模型对数据进行分析解答
三、实验过程记录与结果分析
1,根据下列资料,用修正指数曲线模型预测2008年取暖器的销售量,并说明其最高限度。
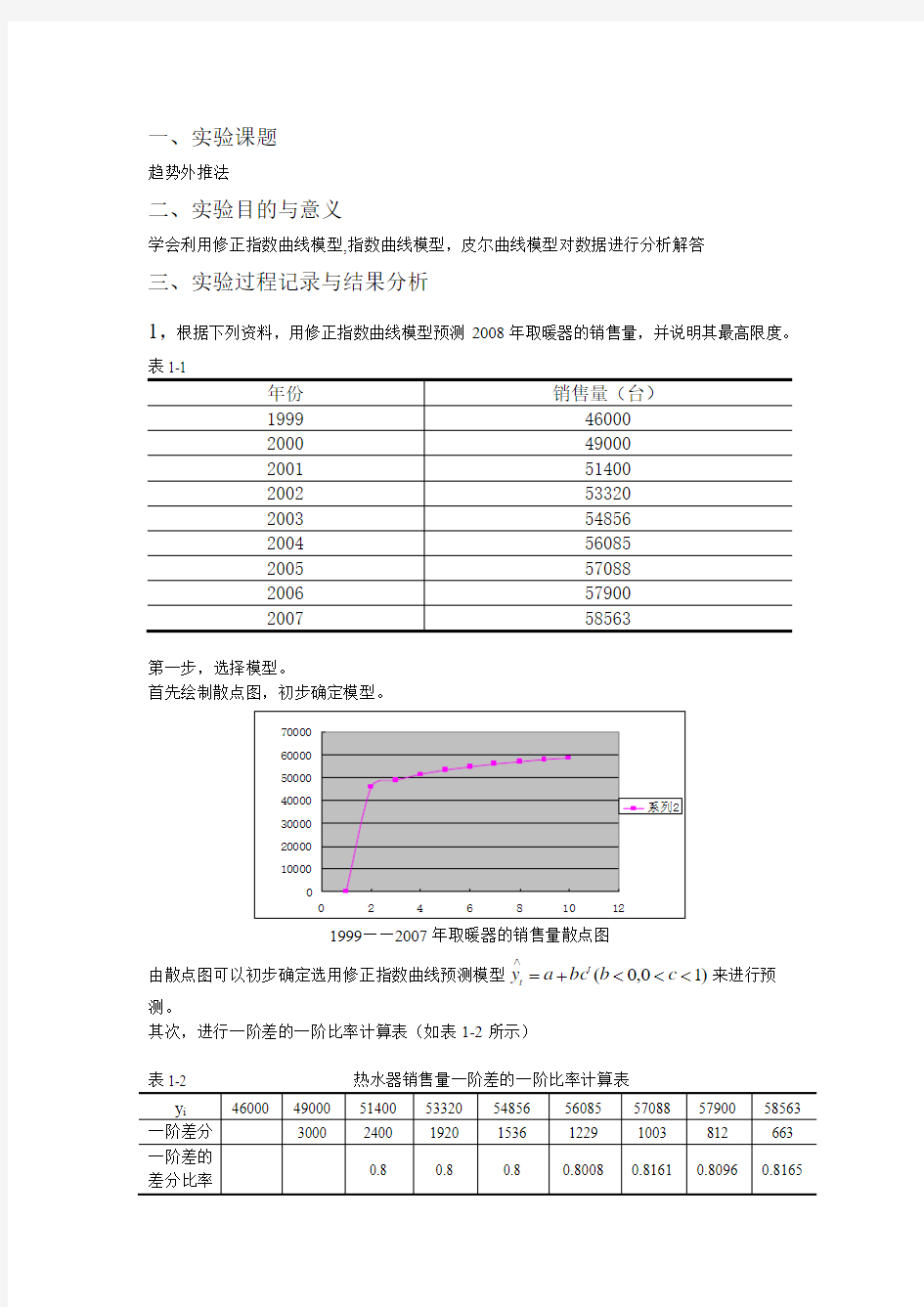
表1-1
年份
销售量(台)
1999 46000 2000 49000 2001 51400 2002 53320 2003 54856 2004 56085 2005 57088 2006 57900 2007
58563
第一步,选择模型。
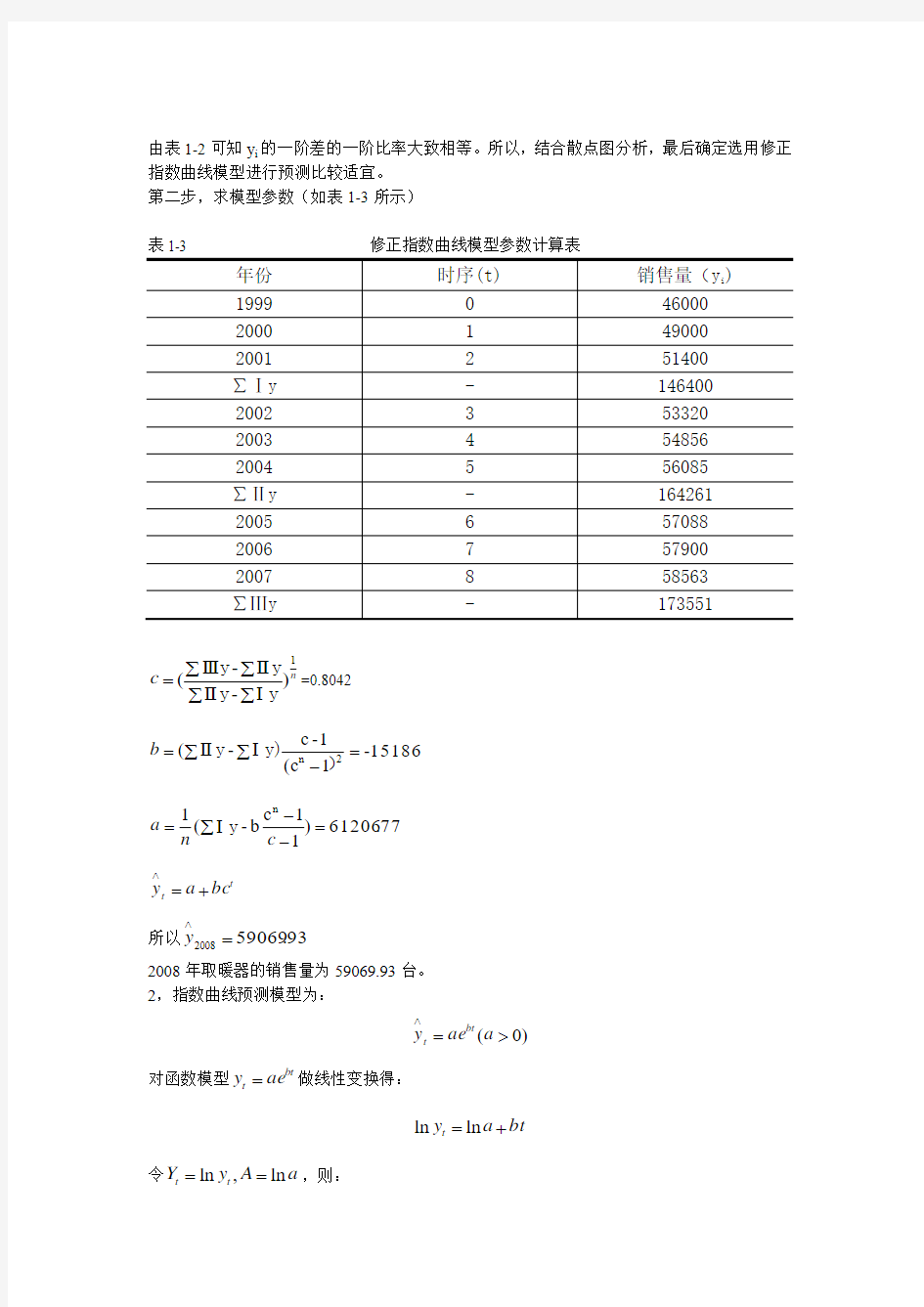
首先绘制散点图,初步确定模型。
010000
2000030000400005000060000700000
2
4
6
8
1012
系列2
1999——2007年取暖器的销售量散点图
由散点图可以初步确定选用修正指数曲线预测模型)10,0(<<<+=∧
c b bc a y t
t 来进行预测。
其次,进行一阶差的一阶比率计算表(如表1-2所示)
表1-2 热水器销售量一阶差的一阶比率计算表
y i 46000 49000 51400 53320 54856 56085 57088 57900 58563 一阶差分 3000 2400 1920 1536 1229 1003
812
663
一阶差的差分比率
0.8
0.8
0.8
0.8008
0.8161 0.8096 0.8165
由表1-2可知y i 的一阶差的一阶比率大致相等。所以,结合散点图分析,最后确定选用修正指数曲线模型进行预测比较适宜。 第二步,求模型参数(如表1-3所示)
表1-3 修正指数曲线模型参数计算表
年份 时序(t) 销售量(y i ) 1999 0 46000 2000 1 49000 2001 2 51400 ∑Ⅰy - 146400 2002 3 53320 2003 4 54856 2004 5 56085 ∑Ⅱy - 164261 2005 6 57088 2006 7 57900 2007 8 58563 ∑Ⅲy
-
173551
n
c 1
)Ⅰy
-Ⅱy Ⅱy -Ⅲy (∑∑∑∑==0.8042
15186-1(c 1
-c Ⅰy)
-Ⅱy (2
n =-∑∑=)
b 77.61206)11
c b -Ⅰy (1n =--∑=c n a
t t bc a y +=∧
所以93.59069
2008=∧
y 2008年取暖器的销售量为59069.93台。 2,指数曲线预测模型为:
)0(>=∧
a ae y bt t
对函数模型bt t ae y =做线性变换得:
bt a y t +=ln ln
令a A y Y t t ln ,ln ==,则:
bt A Y t +=
这样就把指数曲线模型转化为直线模型了。
例题:某市近6年灯具商品销售量资料如下表所示,试预测2008年的销售量。 表2-1
年份
2002
2003 2004 2005 2006 2007 销售量(万架)
8.7
10.6
13.3
16.5
20.6
26
第一步,选择预测模型。
首先,绘制散点图,根据散点图分布来选择模型。
图2-1灯具2002--2007年销售量散点图
根据图2-1,可以初步确定选用指数曲线预测模型)0,0(>>=∧
b a ae y bt
t 。
其次,计算一阶差比率(如表2-2),并结合散点图最后确定选用哪一种模型。
表2-2 指数曲线模型差分预测表 销售量(万架) 8.7 10.6 13.3 16.5 20.6 26 一阶差比率
1.22
1.25
1.24
1.21
1.30
由表2-3知,观察值t y 的一阶差比率大致相等,符合指数曲线模型的数字特征。所以,选用模型bt
t ae y =∧
。 第二步,求模型参数
先将观察值t y 的数据进行变换,使其满足bt A Y bt a y t t +=?+=ln ln 。其变换数据如表2-3所示
表2-3 观察值数据转换表
年份 2002 2003 2004 2005 2006 2007 时序(t )
1 2 3 4 5 6 t t y Y ln =
2.16
2.36
2.59
2.80
2.99
3.25
经计算得
69
.21
,5.31,39.6040
.44,17.16,91,21,622==========∑∑∑∑∑∑∑Y n
Y t n t Y t Y Y t t n
根据直线模型公式
935
.1217
.02
2
=-==--=∑∑t b Y A t
n t Y t n tY b 因为a A ln =,所以93.6==A
e a 所以指数预测模型为t
t e
y 217.093.6=∧
第三步,预测2008年的销售量为31.64万架。
3,皮尔曲线预测模型的形式为:
bt
t ae
L
y -+=
1 式中,L 为变量t y 的极限值,a,b 为常数,t 为时间。
例题:已知某地区1998--2008年的人口资料,试用皮尔曲线模型预测该地区2013--2018年的人口总量。 表3-1
时序t
人口数(万
人)(y t ) t
y 1 1
1+t y
1
1*1+t t y y 2)1(t
y
1 2626 0.000380 0.000378 1.443E-0 1.45014E-07
2 2639 0.000378 0.000369 1.399E-07 1.43589E-07
3 2707 0.000369 0.000357 1.318E-07 1.36466E-07
4 2801 0.000357 0.000347 1.241E-07 1.2746E-07
5 2875 0.000347 0.000338 1.176E-07 1.20983E-07
6 295
7 0.00033
8 0.00032
9 1.115E-07 1.14366E-07 7 3033 0.000329 0.000322 1.062E-07 1.08706E-07 8 3103 0.000322 0.000315 1.015E-07 1.03857E-07 9 3172 0.000315 0.000307 9.691E-08 9.93879E-08 10 3253 0.000307 0.000301 9.270E-08 9.45E-08 11 3316 0.000301 0.000294 8.895E-08 9.09434E-08 12 3390 0.000294 0.000289 8.532E-08 8.70163E-08 13 3457 0.000289 0.000284 8.234E-08 8.36761E-08 14 3513 0.000284 0.000280 7.993E-08 8.10296E-08 15 3561 0.000280 0.000276 7.768E-08 7.88599E-08 16
3615
0.000276 0.000273 7.551E-08 7.65215E-08
17 3663 0.000273 0.000269 7.364E-08
7.45291E-08 18 3707 0.000269 0.000266 7.191E-08 7.27704E-08 19 3751 0.000266 0.000263 7.030E-08 7.10732E-08 20 3792 0.000263 0.000261
6.890E-08
6.95446E-08 21 3827 0.000261 0 0 6.82784E-08 ∑ 0.006509 0.006128 1.941E-06 2.04857E-06
第一步,根据实际人口数画出散点图,发现此散点图趋近于皮尔曲线,所以选皮尔曲线作为预测模型。
1988--2008年某地区人口数量散点图
第二步,估计模型的参数b ,L 和a 。 变换求得标准方程组为:
∑∑--++--=t
b
b t y e n L e y 1)1)(1(11
21)1(1)1()1*1(∑∑--++∑-=t b
t b t
t y e y L e y y 相对于b
e -和L
e b --1,解标准方程组,得:
∑∑∑∑∑----=
++-2
211)
1()1()1(1*1)1*1(
)1(t
t t
t t t b y y n y y y y n e
∑∑∑
∑∑∑---=-++-2
2121)
1()1()1()1*1(*1)1(*11t
t t
t t t t b
y y n y y y y y L
e
利用b,L 的值估算a 值:
)1(ln 12)1(ln -++=
∑t
y L
n n b a 根据表3-1的数据得a=4.3396,b=0.2761,L=4056.2707 所以,皮尔曲线的预测方程为t
t e y 2761.0)3396.4(12707
.4056-∧
+=
所以2013--2018年的人口总量分别为(万人):4016,4025,4033,4038,4043,4046
四、实验小结
学会利用修正指数曲线模型,指数曲线模型,皮尔曲线模型对数据进行分析预测,提高了对EXCEL 的操作能力。
人力需要预测之趋势外推预测法
人力需要预测之趋势外推预测法 将人力资源需求量的历史数据按时间顺序排列,即可形成一个时间数列。时间数列分为绝对数时间数列、相对数时间数列和平均数时间数列三种,人力资源需求量是绝对数,因而其数列是绝对数时间数列。按数列反映的现象性质不同,又可分为时期数列和时点数列,人力资源需求量是期末时点上的数据,因而其数列是时点数列。 在明确人力资源需求时点数列的性质后,考虑采用恰当的预测方法。针对时点数列,一般可选用三种方法:方法一,当时点数列不存在长期趋势和季节变动时,宜采用平滑方法预测;方法二,当时点数列存在长期趋势但不含季节变动时,宜采用趋势外推方法预测;方法三,当时点数列存在长期趋势和季节变化时,宜采用趋势季节模型方法预测。当人力资源需求时点数列不存在长期趋势,但中短期内有一定规律可循时,可采用方法一。但是当随时间变化的趋势不明显时,一般最好不要采用该类数量方法预测,所以方法一在人力资源需求预测方面运用较少。当人力资源需求呈现长期发展趋势,又随季节变化时,采用方法三。在组织中,一般人员是较为固定的,不会轻易随季节变化而变动,否则会严重地影响员工的忠诚度,甚至有些企业提倡经济萧条时也不裁员,因随便增减人员对企业危害巨大。也有符合该要求的人力资源需求数列,比如有淡旺季之分的产品促销员,这些促销员是临时招聘,而非正式员工,市场上供给充分,不需要过早预测,所以方法三更少运用。事实上,当正式员工需求呈现长期发展趋势时,不会考虑季节变动,一般选用方法二,所以趋势外推预测法(trend analysis)是人力资源需求预测中运用最广泛的时点数列预测方法。 趋势外推预测法中,最重要的是找出趋势线。找出趋势线的方法有多种,一般有绘图法、分段平均法、最小二乘法、指数平滑法等。 最简单、最直观的方法是绘图法。以人力资源需求量为纵轴,以时间为横轴,在坐标图上描出各年的历史数据。观察这些点是否有一定的发展规律,如果有,尝试在图上画出一条直线或曲线,使得大多数点尽可能地与这条线重合或接近。如果存在这样的线,则认为这条线就是趋势线。按这条线的发展趋势,延长趋势线。此后,在图上可以找到未来各年对应的人力资源需求。现以飞利浦一子公司人力资源需求预测为例,原始数据见表2-1,趋势图见图2-1。 表2-1 飞利浦一子公司年末在岗总人数 年份1999年2000年2001年2002年2003年员工总数4098人4104人3674人2553人2276人 注:所有数据已经过技术处理。 注:直线是实际人数连接线,虚线是趋势线。 从图2-1可见,飞利浦子公司的人力资源需求量是逐年下降,所以它的趋势线是一条斜率为负的直线。事实上,公司的规模和业务量是逐年上升,但由于管理水平和生产技术提高,使得需求人员反而下降,这体现了现代化工厂的特点。可以找到2004年在趋势线上的对应点,从而确定公司2004年的人力资源需求。可从图2-1上看出,2004年的需求大致为1650~1800人,此预测在2004年得到验证。 绘图法比较简单,但是绘制趋势线有较大的随意性,所以得出的结果也比较粗略。为了弥补这一缺点,可以用其它方法推出趋势线公式,从而得到更准确的数据。求出趋势线的方法很多,
趋势外推法
趋势外推法(trend projection)是生产预测中常用的一种方法。这种方法是找出一系列历史数据的趋势线并外推于将来做中长期预测。该方法的原理是:给趋势型时间数列拟合以时间单位为自变量的数学模型,然后以顺延的时间单位作已知条件,外推时间数列后续趋势值。外推预测的准确程度取决于所拟合模型的拟合优度,最小二乘法以其所拟合模型的预测标准误差最小的优势成为最常用的趋势模型的拟合方法。 趋势外推法又分为以下几类:增长型趋势模型外推法(又包括:等差增长趋势模型、二级等差增长趋势模型、等比增长趋势模型等),周期波动趋势模型外推法,生命周期趋势模型法等。 一、增长趋势模型 增长趋势模型包括等差增长趋势模型、二级等差趋势模型、等比增长趋势模型等,详述如下:
(三)等比增长趋势模型 当时间数列逐期变量值以同一比率增长时,可配以指数曲线增长模型:
二、周期波动趋势模型 季节型时间数列以日历时间为波动周期;循环型时间数列波动周期往往大于一年,且不稳定。尽管两者有所区别,但都呈周期性波动,因此宜以正弦曲线为基础,经修正波幅与周期拟合波动规律。正弦曲线预测模型的一般形式为:
只要对已知数据按上述各项要求加工填入以后,求解六元一次方程组,得β0~β5,代入预测方程即可开始预测。 三、生命周期趋势模型 当时间数列变化呈前期增长缓慢、中期增长逐渐加速、后期增长逐渐平缓、末期逐渐加速负增长时,可配以生命周期趋势模型。这类曲线包括能模拟生命周期的前期、中期和后期的龚珀资曲线、罗吉斯蒂曲线(蒲尔-里得)曲线以及能模拟生命周期中后期的修正指数曲线模型。
龚珀资曲线和罗吉斯蒂曲线是拟合从前期至后期的生命周期趋势,而后者是拟合从中后期至后期的生命周期趋势。 ----摘自《市场预测方法与案例》
时间序列趋势外推法
时间序列趋势外推法姓名:王茂林 学号:2014125104 班级:信息1411 组别:第一组
1.根据下列数据年取暖器的销售量,并对模型进行结果说明。 第一步:把数据导入excel做出能够反映数据变化趋势的散点图 ?从图可知,曲线呈现总体上升趋势,初期变化较快,随后增长比较缓慢,纵坐标在达到6000时,趋于一个固定队的值。接下来,我们通过散点图进行合理外推: 一:假设为指数曲线预测模型:
我们知道指数曲线其特点是环比发展速度为一个常数。 根据最小平方法的原理得 再求反对数,就能求出指数曲线预测模型的参数a,b的估计值。 (1)选择模型。计算序列的环比发展速度放在表格中, 从我计算的环比结果我们可以得知一个规律,就是环比发展速度的变化大体相近。因此,我可以用指数曲线预测模型来预测。 (2)建立指数曲线预测模型。 所求指数曲线预测模型为:^y=53644.47137(57129.80609)^t (3)预测。分别把t=9和t=10代入算出指数曲线预测模型。
当我计算前三年的预测值的时候,才发现和真实值相差太远,以至于后面的数据都无法输出。算这么多,我才醒悟过来,模型开始就假设错啦,而且错的不可理喻,因为指数曲线的趋势性是递增的,而本数据的散点图是开始递增,后来增长变得缓慢,到最后趋于一个固定的值。和指数曲线的趋势性相差十万八千里。所以,模型假设不成立。 二:假设为修正指数曲线预测模型. 由于修正指数曲线预测模型的一阶差分为 是指数函数形式,因此由指数曲线预测模型的特点,可知修正指数曲线预测模型的特征是:一阶差分的环比为一个常数。接下来我们来计算本数据的一阶差分和一阶差分环比。(1) 选择预测模型。计算序列一阶差分的环比放在表中,从环比数据可以看出:一阶差分环比基本上为一个常数,而这个常数为80; 所以,可配合修正指数曲线预测模型来预测。 (2)建立修正指数曲线预测模型。
第四章 时间序列的分解法和趋势外推法
第四章 时间序列的分解法和趋势外推法 基本内容 一、时间序列的分解 经济时间序列的变化受到长期趋势、季节变动和不规则变动这四个因素的影响。其中: (1) 长期趋势因素(T ) 长期趋势因素(T )反映了经济现象在一个较长时间内的发展方向,它可以在一个相当长的时间内表现为一种近似直线的持续向上或持续向下或平稳的趋势。 (2) 季节变动因素(S ) 季节变动因素(S )是经济现象受季节变动影响所形成的一种长度和幅度固定的周期波动。 (3) 周期变动因素(C ) 周期变动因素也称循环变动因素,它是受各种经济因素影响形成的上下起伏不定的波动。 (4) 不规则变动因素(I ) 不规则变动又称随机变动,它是受各种偶然因素影响所形成的不规则变动。 二、时间序列分解模型 时间序列Y 可以表示为以上四个因素的函数,即: (,,,)t t t t t y f T S C I = 时间序列分解的方法有很多,较常用的模型有加法模型和乘法模型。 加法模型为: t t t t t y T S C I =+++ 乘法模型为: t t t t t y T S C I =??? 乘法模型分解的基本步骤是: (1)运用移动平均法剔除长期趋势和周期变化,得到序列TC 。然后再用按月(季)平均法求出季节指数S 。 (2)作散点图,选择适合的曲线模型拟合序列的长期趋势,得到长期趋势T 。 (3)计算周期因素C 。用序列TC 除以T 即可得到周期变动因素C 。 (4)将时间序列的T 、S 、C 分解出来后,剩余的即为不规则变动,即: Y I TSC = 三、趋势外推法 当预测对象以时间变化呈现某种上升或下降趋势,没有明显的季节波动,且能找到一个合适的函数曲线反映这种变化趋势时,就可以用趋势外推法进行预测。 应用趋势外推法有两个假设条件:(1)假设事物发展过程没有跳跃式变化;(2)假定事物的发展因素也决定事物未来的发展,其条件是不变或变化不大。选择合适的趋势模型是应用趋势法的重要环节,图形识别和差分法是选择趋势模型的两种基本方法。 (1) 多项式曲线外推法模型的一般性形式为: 2012k t k y b b t b t b t =+++???+
直线趋势外推法
直线趋势外推法预测报告 某超市1995——2014年销售额如表,用直线趋势外推法预测2015年销售额(利用EXCEL软件预测)。 表一某超市1995——2014年销售额 年份销售额 1995 80 1996 81 1997 85 1998 84 1999 90 2000 92 2001 95 2002 89 2003 92 2004 99 2005 102 2006 110 2007 120 2008 140 2009 150 2010 155 2011 180 2012 175 2013 180 2014 200 一、将表1数据,按年份序号录入EXCEL工作表,形如表2 表2 年份序号及销售额表 年份销售额 -19 80 -17 81 -15 85 -13 84 -11 90 -9 92 -7 95 -5 89 -3 92
-1 99 1 102 3 110 5 120 7 140 9 150 11 155 13 180 15 175 17 180 19 200 二、使用“图表向导”绘制散点图,判断数列趋势 图1 销售额散点图 如图1所示,该公司九个年份的利润值基本围绕一条直线上下波动,可以认为数列呈直线趋势变动,因此配合直线趋势模型。 三、估算两个参数值 利用EXCEL软件中的“工具——数据分析——回归”求得两个参数值如表3所示。 表3 系数表
将的值带入理论模型:,得直线趋势模型: Y = 119.95 + 3.13*X 四、预测 依时间数列推算,到2015年,年份序号为21,即t=21,则2015年该公司利润预测值为: Y = 119.95 + 3.13*21 即该公司2015年利润预测值为189.46。
趋势外推预测法
趋势外推预测法 摘要:电力负荷预测是电力系统规划的重要组成部分,也是电力系统经济运行的基础,任何时候,电力负荷预测对电力系统规划和运行都极其重要。近年来,随着我国电力供需矛盾的突出及电力工业市场化营运机制的推进,电力负荷预测的准确性有待进一步提高;然而,由于社会运转速度的不断加快和信息量的膨胀,使准确的负荷预测变得愈加困难。 关键字:电力;负荷预测;预测方法;趋势外推。 负荷预测方法可分为确定性负荷预测方法和不确定性负荷预测方法。确定性负荷预测方法是把电力负荷预测用一个或者一组方程来描述,电力负荷与变量之间有明确的一一对应的关系。其中又可分为经验技术预测法、经典技术预测法、经济模型预测法、时间序列预测法、相关系数预测法和饱和曲线预测法等。不确定性预测方法基于类比对应等关系进行推理预测的,包括灰色理论预测法、专家系统法、模糊预测法、神经网络法、小波分析预测法等。 常用到的确定性负荷预测方法主要有:回归分析法;时间序列预测法;趋势外推预测法。本文主要介绍和分析趋势外推预测法。 一、回归分析法 回归分析法就是通过对历史数据的分析、研究,并考虑和电力负荷有关的各种影响因素,建立起适当的回归预测模型,用数理统计中的回归分析方法对变量的观测数据统计分析,从而预测未来的电力负荷。回归预测模型可以是线性的也可以是非线性的,可以是一元的也可以是多元的,其中一元线性回归预测是最基本的、最简单的预测方法。 回归分析法适用于中、短期预测,它的预测精度依赖于模型的准确性和影响因子(如国民生产总值、工农业生产总值、人口、气候等)预测值的准确度,该方法只能预测出综合用电负荷的发展水平,无法预测出各供电区的负荷发展水平,无法进行具体的电网建设规划。 二、时间序列法 时间序列预测方法就是根据到目前为止的历史资料数据,即时间序列所呈现出来的发展趋势和规律,设法建立一个数学模型,在该数学模型的基础上用数学方法进行延伸、外推,预测出今后各时期的指标值。时间序列法主要有移动平均法、指数平滑法等,其中指数平滑法是一种较为重要的方法,该方法是采取渐消记忆的方式,利用逐步衰减的不等权平均办法,用以往的历史数据的指数加权组
(1)趋势外推法
(一)趋势外推法 趋势外推法是利用惯性的原理,对企业人力资源需求总量进行预测。 根据调研结果,A企业人员总量的数据见表1—3,其中t表示年份,为自变量;L表示人员总数,为因变量。 1.定性分析 (1)根据近些年来的企业人力资源管理所采取的减员增效策略,可以作出“短期内该企业的人数将持续降低,至少将保持持平的发展状态”的推断; (2)实际上,企业人数不可能一直下降到0,因为在现实的生产条件下,企业要保证生产产品的销售量,赚取利润,还必须具备一定规模的员工人数,而不可能是“无人工厂”或采用“机器人”的生产模式。因此,做函数拟合的曲线不应具有一直向下的趋势。 2.函数拟合 将上表输入到SPSS,选用9种函数对企业员工总数的趋势做出拟合,见表1—4. (1)对数函数,其函数形式为:L=b。+ b1·ln(t) (2)双曲线,其函数形式为:L=b。+ b1/t (3)二次函数,其函数形式为:L=bo+ b1·t+ b2·t 2 (4)三次函数拟合,其函数形式为:L=b。+ b1·t+ b2·t 2+ b3·t 3 (5)复合模型,其函数形式为:L=b。×b1t (6)幂指数,其函数形式为:L=b。t o b1 (7)S曲线拟合,其函数形式为:L=e(bo+b1) (8)生长模型,其函数形式为:L=e(bo+b1·t) (9)指数函数,其函数形式为:L=b。·e b1·t 上述公式中,L为人员总数,t为时间变量,b。为系数。通过SPSS分析,上述9种函数做拟合的结果如表1-4所示。 表1—4 曲线拟合结果表 3.模型筛选
根据表1-5所反映的信息,可以判断,在时间序列曲线估计的9种模型中,所有模型的F值都大于10,其显著度p都基本接近O,这说明用这些曲线做人数估计拟合是符合要求的,也就是说可以选用这些曲线做拟合。 表1—5各个模型的显著性、判定系数及标准误差值表 观察表1-5第二列的数据,发现双曲线与S曲线模型的R。比较小,而一般情况下,R。>0.8才认为有效,所以这两种曲线应舍弃。另外,还能从表中发现复合函数、生长模型和指数函数这三个模型的预测结果是完全相同的,这就是说,它们的判定系数、显著性以及标准误差值也是完全相同的,这三个函数只取一个就可以了。因此保留对数函数、二次函数、三次函数、复合模型、幂指数模型。
趋势外推法解读
一、实验课题 趋势外推法 二、实验目的与意义 学会利用修正指数曲线模型,指数曲线模型,皮尔曲线模型对数据进行分析解答 三、实验过程记录与结果分析 1,根据下列资料,用修正指数曲线模型预测2008年取暖器的销售量,并说明其最高限度。 表1-1 年份 销售量(台) 1999 46000 2000 49000 2001 51400 2002 53320 2003 54856 2004 56085 2005 57088 2006 57900 2007 58563 第一步,选择模型。 首先绘制散点图,初步确定模型。 010000 2000030000400005000060000700000 2 4 6 8 1012 系列2 1999——2007年取暖器的销售量散点图 由散点图可以初步确定选用修正指数曲线预测模型)10,0(<<<+=∧ c b bc a y t t 来进行预测。 其次,进行一阶差的一阶比率计算表(如表1-2所示) 表1-2 热水器销售量一阶差的一阶比率计算表 y i 46000 49000 51400 53320 54856 56085 57088 57900 58563 一阶差分 3000 2400 1920 1536 1229 1003 812 663 一阶差的差分比率 0.8 0.8 0.8 0.8008 0.8161 0.8096 0.8165
由表1-2可知y i 的一阶差的一阶比率大致相等。所以,结合散点图分析,最后确定选用修正指数曲线模型进行预测比较适宜。 第二步,求模型参数(如表1-3所示) 表1-3 修正指数曲线模型参数计算表 年份 时序(t) 销售量(y i ) 1999 0 46000 2000 1 49000 2001 2 51400 ∑Ⅰy - 146400 2002 3 53320 2003 4 54856 2004 5 56085 ∑Ⅱy - 164261 2005 6 57088 2006 7 57900 2007 8 58563 ∑Ⅲy - 173551 n c 1 )Ⅰy -Ⅱy Ⅱy -Ⅲy (∑∑∑∑==0.8042 15186-1(c 1 -c Ⅰy) -Ⅱy (2 n =-∑∑=) b 77.61206)11 c b -Ⅰy (1n =--∑=c n a t t bc a y +=∧ 所以93.59069 2008=∧ y 2008年取暖器的销售量为59069.93台。 2,指数曲线预测模型为: )0(>=∧ a ae y bt t 对函数模型bt t ae y =做线性变换得: bt a y t +=ln ln 令a A y Y t t ln ,ln ==,则: