K-means算法的实现与应用举例
K-means 算法的实现与应用举例
1 K-means 方法
K-means 算法如下:
S1:初始化,聚类中心k c ,,c c 21,标号集 k I I I 21; S2: 分类:
end
;i I I ;
c x c x j n
i for j j T
j i j i k
j **1*min arg :1
S3:重新计算聚类中心:
end
;x I c k j for
j
I i i
j
j 1
:1
S4:迭代S2-S3,直至收敛。 其matlab 程序见附录1。
2实验
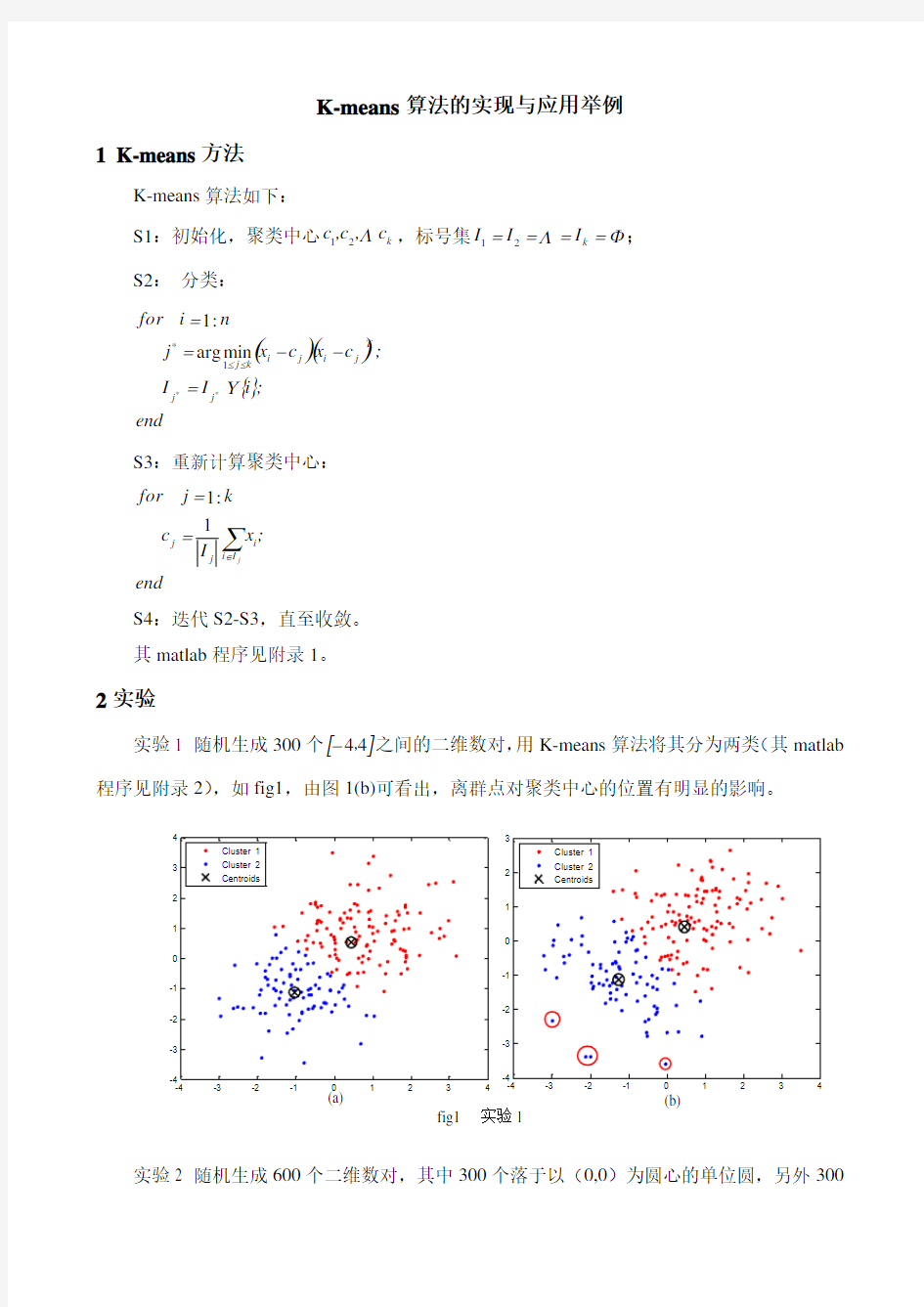
实验1 随机生成300个 44, 之间的二维数对,用K-means 算法将其分为两类(其matlab 程序见附录2),如fig1,由图1(b)可看出,离群点对聚类中心的位置有明显的影响。
实验2 随机生成600个二维数对,其中300个落于以(0,0)为圆心的单位圆,另外300
(a)
(b)
fig1 实验1
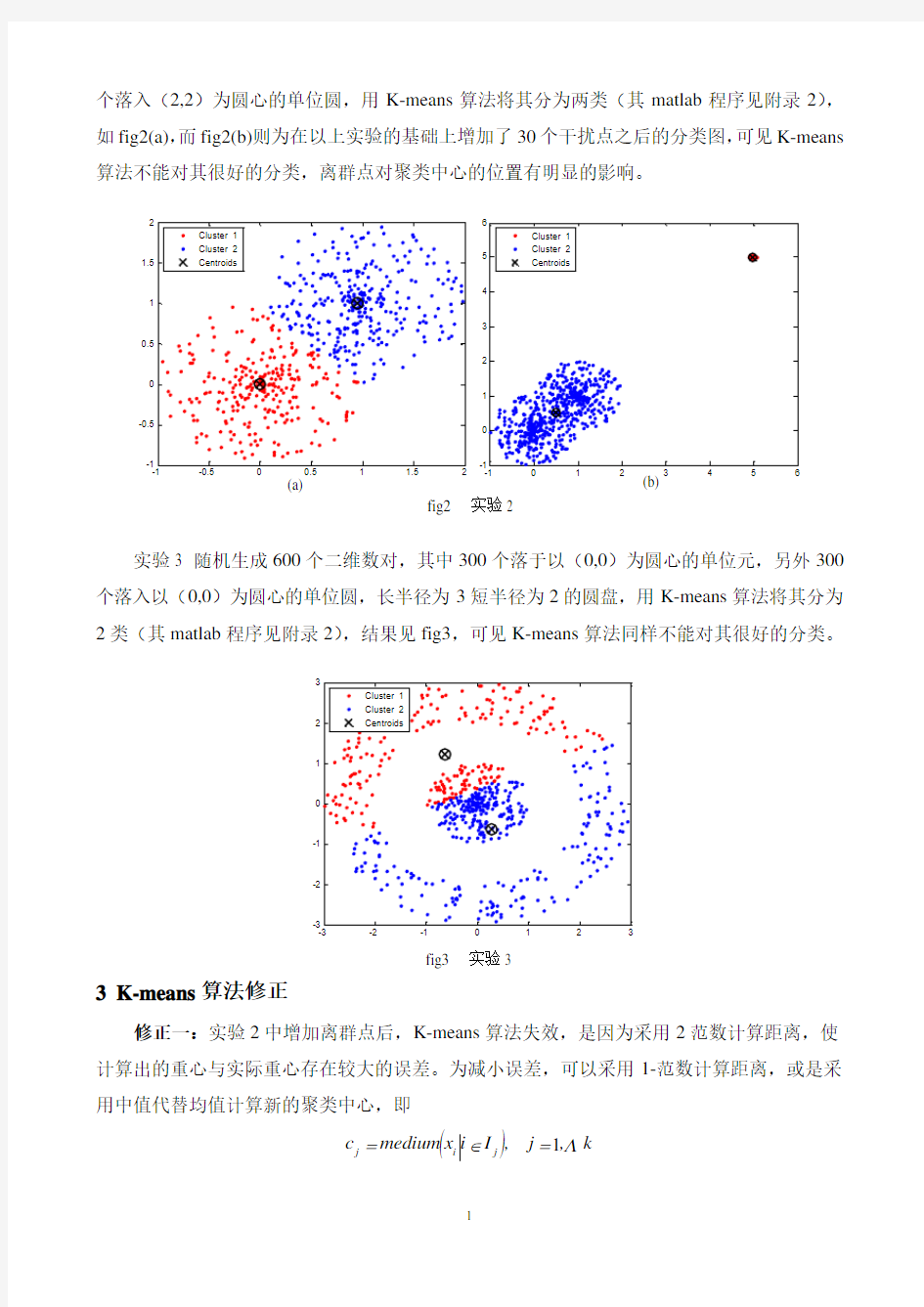
个落入(2,2)为圆心的单位圆,用K-means 算法将其分为两类(其matlab 程序见附录2),如fig2(a),而fig2(b)则为在以上实验的基础上增加了30个干扰点之后的分类图,可见K-means 算法不能对其很好的分类,离群点对聚类中心的位置有明显的影响。
实验3 随机生成600个二维数对,其中300个落于以(0,0)为圆心的单位元,另外300个落入以(0,0)为圆心的单位圆,长半径为3短半径为2的圆盘,用K-means 算法将其分为2类(其matlab 程序见附录2),结果见fig3,可见K-means 算法同样不能对其很好的分类。
3 K-means 算法修正
修正一:实验2中增加离群点后,K-means 算法失效,是因为采用2范数计算距离,使计算出的重心与实际重心存在较大的误差。为减小误差,可以采用1-范数计算距离,或是采用中值代替均值计算新的聚类中心,即
k ,j ,
I i x medium c j i j 1
(a)
(b)
fig2 实验2
fig3 实验3
通过实验可以知道,采用1-范数计算距离实验效果并没有很好的改进,而采用中值计算聚类中心取得较好的效果(matlab 程序见附录3),采用同实验2增加干扰后相同的实验数据用修正后的K-means 算法进行分类,得到实验结果如fig4(a),而实验3中结果产生的原因则是由于没有考虑数据点自身的结构特征与其他数据点之间关系引起,并且K-means 算法只考虑类内间距最小性并没有考虑类间间距的最大性,即只考虑了类内数据的相似性的最大性并没有考虑类间数据的差异性的最大性,所以单纯的改变聚类中心的选取方法,而没有对相关性(距离)进行本质的重新的定义,并不能对实验3的实验结果很好的改进,如fig4(b):
4附录
附录1
function [idx,C,D,sumD]=kmeans_mean(X,k) %kmeans2norm K-means clustering. % X:n*p 的数据矩阵 % k:将X 划分为几类
% startM:k*p 的矩阵,初始类中心
% idx:n*1的向量,存储每个点的聚类编号 % C:k*p 的矩阵,存储k 个聚类的中心位置
% sumD:1*k 的和向量,类间所有点与该类中心的距离之和 % D:n*k 的矩阵,每一点与所有中心的距离
%sumK:1*k 的和向量,记录第k 个类中点的个数 [n,p] = size(X); idx=zeros(n,1); C=zeros(k,p); startM=zeros(k,p); D=zeros(n,k);
fig4 中值修正
(a)
(b)
(b)
(a)
%-----------随机生成初始聚类中心
for i=1:k
bi=ceil(i*n/k*rand);
startM(i,:)=X(bi,:);
end
while sum(abs(startM-C))>0
C=startM;startM(:)=0;
sumD=zeros(1,k);
sumK=zeros(1,k);%记录第k个类中点的个数
% count=zeros(1,k);%计数器
% sortC=zeros(k,n);
for i=1:n
%------计算每一点与所有中心的距离------
for j=1:k
D(i,j)=(X(i,:)-C(j,:))*(X(i,:)-C(j,:))';
% D(i,j)=sum(abs(X(i,:)-C(j,:)));
end
%-----------标号------
mini=inf;
for j=1:k
if D(i,j) mini=D(i,j); idx(i)=j; end end sumD(idx(i))=sumD(idx(i))+D(i,idx(i)); sumK(idx(i))=sumK(idx(i))+1; end %---------计算新的聚类中心--------- %=======求解质心======= for i=1:n startM(idx(i),:)=startM(idx(i),:)+X(i,:)/sumK(idx(i));%求解质心end end 附录2 clear all % ------随机生成[-1,1]^2的数 % X = [randn(100,2)+ones(100,2);... % randn(100,2)-ones(100,2)]; % % %------随机生成圆盘内的数 % deg1=(2*rand(300,1)-1)*2*pi; % deg2=(2*rand(300,1)-1)*2*pi; % r1=rand(300,1); % r2=rand(300,1); % X1=[r1.*cos(deg1) r1.*sin(deg1)]; % X2=[(r2+2).*cos(deg2) (r2+2).*sin(deg2)]; % X=zeros(600,2); % for i=1:300 % X(2*i-1,:)=X1(i,:); % X(2*i,:)=X2(i,:); % end % %------随机生成两个圆--------- deg1=(2*rand(300,1)-1)*2*pi; r1=rand(300,1); deg2=(2*rand(30,1)-1)*2*pi; r2=0.1*rand(30,1); deg3=(2*rand(300,1)-1)*2*pi; r3=rand(300,1); X1=[r1.*cos(deg1) r1.*sin(deg1)]; X2=[r2.*cos(deg2)+5 r2.*sin(deg2)+5]; X3=[r3.*cos(deg3)+1 r3.*sin(deg3)+1]; X=[X1;X3]; %X=[X1;X2;X3]; %[idx,ctrs,D,sumD]=kmeans_mean(X,2); [idx,ctrs,D,sumD]=kmeans_medium(X,2); figure plot(X(idx==1,1),X(idx==1,2),'r.','MarkerSize',12) hold on plot(X(idx==2,1),X(idx==2,2),'b.','MarkerSize',12) plot(ctrs(:,1),ctrs(:,2),'kx',... 'MarkerSize',12,'LineWidth',2) plot(ctrs(:,1),ctrs(:,2),'ko',... 'MarkerSize',12,'LineWidth',2) legend('Cluster 1','Cluster 2','Centroids',... 'Location','NW') 附录3 function [idx,C,D,sumD]=kmeans_medium(X,k) %kmeans2norm K-means clustering. % X:n*p的数据矩阵 % k:将X划分为几类 % startM:k*p的矩阵,初始类中心 % idx:n*1的向量,存储每个点的聚类编号 % C:k*p的矩阵,存储k个聚类的中心位置 % sumD:1*k的和向量,类间所有点与该类中心的距离之和% D:n*k的矩阵,每一点与所有中心的距离 %sumK:1*k的和向量,记录第k个类点的个数 [n,p] = size(X); idx=zeros(n,1); C=zeros(k,p); startM=zeros(k,p); D=zeros(n,k); %-----------随机生成初始聚类中心 for i=1:k bi=ceil(i*n/k*rand); startM(i,:)=X(bi,:); end while sum(abs(startM-C))>0 C=startM;startM(:)=0; sumD=zeros(1,k); sumK=zeros(1,k);%记录第k个类中点的个数 % count=zeros(1,k);%计数器 % sortC=zeros(k,n); for i=1:n %------计算每一点与所有中心的距离------ for j=1:k % D(i,j)=sqrt(sum((X(i,:)-C(j,:)).^2)); D(i,j)=(X(i,:)-C(j,:))*(X(i,:)-C(j,:))'; %D(i,j)=sum(abs((X(i,:)-C(j,:)))); end %-----------标号------ mini=inf; for j=1:k if D(i,j) mini=D(i,j); idx(i)=j; end end sumD(idx(i))=sumD(idx(i))+D(i,idx(i)); sumK(idx(i))=sumK(idx(i))+1; end %---------计算新的聚类中心--------- %=======质心作为聚类中心======= % for i=1:n % startM(idx(i),:)=startM(idx(i),:)+X(i,:)/sumK(idx(i));%求解质心% end %=======中位数作为聚类中心======= for i=1:k inds=find(idx==i); tempX=X(inds,:); %-----------若标号为空则取离所在聚类中心最远的点为新的类中心------ if numel(tempX)==0 dist=0; for jj=1:n if D(jj,idx(jj))>dist dist=D(jj,idx(jj)); end end sumK(idx(jj))=sumK(idx(jj))-1; idx(jj)=i; D(jj,i)=0; sumK(i)=1; tempX=X(jj,:); end for j=1:p tempXj=tempX(:,j); tempXj=sort(tempXj); startM(i,j)=tempXj(round(sumK(i)/2)); end end end K-means聚类算法 K-means也是聚类算法中最简单的一种了,但是里面包含的思想却是不一般。最早我使用并实现这个算法是在学习韩爷爷那本数据挖掘的书中,那本书比较注重应用。看了Andrew Ng的这个讲义后才有些明白K-means后面包含的EM思想。 聚类属于无监督学习,以往的回归、朴素贝叶斯、SVM等都是有类别标签y的,也就是说样例中已经给出了样例的分类。而聚类的样本中却没有给定y,只有特征x,比如假设 宇宙中的星星可以表示成三维空间中的点集。聚类的目的是找到每个样本x潜在的类别y,并将同类别y的样本x放在一起。比如上面的星星,聚类后结果是一个个星团,星团里面的点相互距离比较近,星团间的星星距离就比较远了。 在聚类问题中,给我们的训练样本是,每个,没有了y。 K-means算法是将样本聚类成k个簇(cluster),具体算法描述如下: 1、随机选取k个聚类质心点(cluster centroids)为。 2、重复下面过程直到收敛 { 对于每一个样例i,计算其应该属于的类 对于每一个类j,重新计算该类的质心 } K是我们事先给定的聚类数,代表样例i与k个类中距离最近的那个类,的值 是1到k中的一个。质心代表我们对属于同一个类的样本中心点的猜测,拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,然后选取 距离最近的那个星团作为,这样经过第一步每一个星星都有了所属的星团;第二步对于 每一个星团,重新计算它的质心(对里面所有的星星坐标求平均)。重复迭代第一步和第二步直到质心不变或者变化很小。 下图展示了对n个样本点进行K-means聚类的效果,这里k取2。 K-means面对的第一个问题是如何保证收敛,前面的算法中强调结束条件就是收敛,可以证明的是K-means完全可以保证收敛性。下面我们定性的描述一下收敛性,我们定义畸变函数(distortion function)如下: J函数表示每个样本点到其质心的距离平方和。K-means是要将J调整到最小。假设当 前J没有达到最小值,那么首先可以固定每个类的质心,调整每个样例的所属的类别来让J函数减少,同样,固定,调整每个类的质心也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时,和c也同时收敛。(在理论上,可以有多组不同的和c值能够使得J取得最小值,但这种现象实际上很少见)。 K-means 算法的实现与应用举例 1 K-means 方法 K-means 算法如下: S1:初始化,聚类中心k c ,,c c 21,标号集 k I I I 21; S2: 分类: end ;i I I ; c x c x j n i for j j T j i j i k j **1*min arg :1 S3:重新计算聚类中心: end ;x I c k j for j I i i j j 1 :1 S4:迭代S2-S3,直至收敛。 其matlab 程序见附录1。 2实验 实验1 随机生成300个 44, 之间的二维数对,用K-means 算法将其分为两类(其matlab 程序见附录2),如fig1,由图1(b)可看出,离群点对聚类中心的位置有明显的影响。 实验2 随机生成600个二维数对,其中300个落于以(0,0)为圆心的单位圆,另外300 (a) (b) fig1 实验1 个落入(2,2)为圆心的单位圆,用K-means 算法将其分为两类(其matlab 程序见附录2),如fig2(a),而fig2(b)则为在以上实验的基础上增加了30个干扰点之后的分类图,可见K-means 算法不能对其很好的分类,离群点对聚类中心的位置有明显的影响。 实验3 随机生成600个二维数对,其中300个落于以(0,0)为圆心的单位元,另外300个落入以(0,0)为圆心的单位圆,长半径为3短半径为2的圆盘,用K-means 算法将其分为2类(其matlab 程序见附录2),结果见fig3,可见K-means 算法同样不能对其很好的分类。 3 K-means 算法修正 修正一:实验2中增加离群点后,K-means 算法失效,是因为采用2范数计算距离,使计算出的重心与实际重心存在较大的误差。为减小误差,可以采用1-范数计算距离,或是采用中值代替均值计算新的聚类中心,即 k ,j , I i x medium c j i j 1 (a) (b) fig2 实验2 fig3 实验3 k-means聚类算法的研究 1.k-means算法简介 1.1 k-means算法描述 给定n个对象的数据集D和要生成的簇数目k,划分算法将对象组织划分为k个簇(k<=n),这些簇的形成旨在优化一个目标准则。例如,基于距离的差异性函数,使得根据数据集的属性,在同一个簇中的对象是“相似的”,而不同簇中的对象是“相异的”。划分聚类算法需要预先指定簇数目或簇中心,通过反复迭代运算,逐步降低目标函数的误差值,当目标函数收敛时,得到最终聚类结果。这类方法分为基于质心的(Centroid-based)划分方法和基于中心的(Medoid-based)划分方法,而基于质心的划分方法是研究最多的算法,其中k-means算法是最具代表和知名的。 k-means算法是1967年由MacQueen首次提出的一种经典算法,经常用于数据挖掘和模式识别中,是一种无监督式的学习算法,其使用目的是对几何进行等价类的划分,即对一组具有相同数据结构的记录按某种分类准则进行分类,以获取若干个同类记录集。k-means聚类是近年来数据挖掘学科的一个研究热点和重点,这主要是因为它广泛应用于地球科学、信息技术、决策科学、医学、行为学和商业智能等领域。迄今为止,很多聚类任务都选择该算法。k-means算法是应用最为广泛的聚类算法。该算法以类中各样本的加权均值(成为质心)代表该类,只用于数字属性数据的聚类,算法有很清晰的几何和统计意义,但抗干扰性较差。通常以各种样本与其质心欧几里德距离总和作为目标函数,也可将目标函数修改为各类中任意两点间欧几里德距离总和,这样既考虑了类的分散度也考虑了类的紧致度。k-means算法是聚类分析中基于原型的划分聚类的应用算法。如果将目标函数看成分布归一化混合模型的似然率对数,k-means算法就可以看成概率模型算法的推广。 k-means算法基本思想: (1)随机的选K个点作为聚类中心; (2)划分剩余的点; (3)迭代过程需要一个收敛准则,此次采用平均误差准则。 (4)求质心(作为中心); (5)不断求质心,直到不再发生变化时,就得到最终的聚类结果。 k-means聚类算法是一种广泛应用的聚类算法,计算速度快,资源消耗少,但是k-means算法与初始选择有关系,初始聚类中心选择的随机性决定了算法的有效性和聚 k-means 算法 一.算法简介 k -means 算法,也被称为k -平均或k -均值,是一种得到最广泛使用的聚类算法。 它是将各个聚类子集内的所有数据样本的均值作为该聚类的代表点,算法的主要思想是通过迭代过程把数据集划分为不同的类别,使得评价聚类性能的准则函数达到最优,从而使生成的每个聚类内紧凑,类间独立。这一算法不适合处理离散型属性,但是对于连续型具有较好的聚类效果。 二.划分聚类方法对数据集进行聚类时包括如下三个要点: (1)选定某种距离作为数据样本间的相似性度量 k-means 聚类算法不适合处理离散型属性,对连续型属性比较适合。因此在计算数据样本之间的距离时,可以根据实际需要选择欧式距离、曼哈顿距离或者明考斯距离中的一种来作为算法的相似性度量,其中最常用的是欧式距离。下面我给大家具体介绍一下欧式距离。 假设给定的数据集 ,X 中的样本用d 个描述属性A 1,A 2…A d 来表示,并且d 个描述属性都是连续型属性。数据样本x i =(x i1,x i2,…x id ), x j =(x j1,x j2,…x jd )其中,x i1,x i2,…x id 和x j1,x j2,…x jd 分别是样本x i 和x j 对应d 个描述属性A 1,A 2,…A d 的具体取值。样本xi 和xj 之间的相似度通常用它们之间的距离d(x i ,x j )来表示,距离越小,样本x i 和x j 越相似,差异度越小;距离越大,样本x i 和x j 越不相似,差异度越大。 欧式距离公式如下: (2)选择评价聚类性能的准则函数 k-means 聚类算法使用误差平方和准则函数来评价聚类性能。给定数据集X ,其中只包含描述属性,不包含类别属性。假设X 包含k 个聚类子集X 1,X 2,…X K ; {} |1,2,...,m X x m total ==() ,i j d x x = 聚类分析K-means算法综述 摘要:介绍K-means聚类算法的概念,初步了解算法的基本步骤,通过对算法缺点的分析,对算法已有的优化方法进行简单分析,以及对算法的应用领域、算法未来的研究方向及应用发展趋势作恰当的介绍。 关键词:K-means聚类算法基本步骤优化方法应用领域研究方向应用发展趋势 算法概述 K-means聚类算法是一种基于质心的划分方法,输入聚类个数k,以及包含n个数据对象的数据库,输出满足方差最小标准的k个聚类。 评定标准:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算。 解释:基于质心的划分方法就是将簇中的所有对象的平均值看做簇的质心,然后根据一个数据对象与簇质心的距离,再将该对象赋予最近的簇。 k-means 算法基本步骤 (1)从n个数据对象任意选择k 个对象作为初始聚类中心 (2)根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分 (3)重新计算每个(有变化)聚类的均值(中心对象) (4)计算标准测度函数,当满足一定条件,如函数收敛时,则算法终止;如果条件不满足则回到步骤(2) 形式化描述 输入:数据集D,划分簇的个数k 输出:k个簇的集合 (1)从数据集D中任意选择k个对象作为初始簇的中心; (2)Repeat (3)For数据集D中每个对象P do (4)计算对象P到k个簇中心的距离 (5)将对象P指派到与其最近(距离最短)的簇; (6)End For (7)计算每个簇中对象的均值,作为新的簇的中心; (8)Until k个簇的簇中心不再发生变化 对算法已有优化方法的分析 (1)K-means算法中聚类个数K需要预先给定 这个K值的选定是非常难以估计的,很多时候,我们事先并不知道给定的数据集应该分成多少个类别才最合适,这也是K一means算法的一个不足"有的算法是通过类的自动合并和分裂得到较为合理的类型数目k,例如Is0DAIA算法"关于K一means算法中聚类数目K 值的确定,在文献中,根据了方差分析理论,应用混合F统计量来确定最佳分类数,并应用了模糊划分嫡来验证最佳分类数的正确性。在文献中,使用了一种结合全协方差矩阵RPCL算法,并逐步删除那些只包含少量训练数据的类。文献中针对“聚类的有效性问题”提出武汉理工大学硕士学位论文了一种新的有效性指标:V(k km) = Intra(k) + Inter(k) / Inter(k max),其中k max是可聚类的最大数目,目的是选择最佳聚类个数使得有效性指标达到最小。文献中使用的是一种称为次胜者受罚的竞争学习规则来自动决定类的适当数目"它的思想是:对每个输入而言不仅竞争获胜单元的权值被修正以适应输入值,而且对次胜单元采用惩罚的方法使之远离输入值。 (2)算法对初始值的选取依赖性极大以及算法常陷入局部极小解 不同的初始值,结果往往不同。K-means算法首先随机地选取k个点作为初始聚类种子,再利用迭代的重定位技术直到算法收敛。因此,初值的不同可能导致算法聚类效果的不稳定,并且,K-means算法常采用误差平方和准则函数作为聚类准则函数(目标函数)。目标函数往往存在很多个局部极小值,只有一个属于全局最小,由于算法每次开始选取的初始聚类中心落入非凸函数曲面的“位置”往往偏离全局最优解的搜索范围,因此通过迭代运算,目标函数常常达到局部最小,得不到全局最小。对于这个问题的解决,许多算法采用遗传算法(GA),例如文献中采用遗传算法GA进行初始化,以内部聚类准则作为评价指标。 (3)从K-means算法框架可以看出,该算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,因此当数据量非常大时,算法的时间开销是非常大 所以需要对算法的时间复杂度进行分析,改进提高算法应用范围。在文献中从该算法的时间复杂度进行分析考虑,通过一定的相似性准则来去掉聚类中心的候选集,而在文献中,使用的K-meanS算法是对样本数据进行聚类。无论是初始点的选择还是一次迭代完成时对数据的调整,都是建立在随机选取的样本数据的基础之上,这样可以提高算法的收敛速度。 机器学习算法day02_Kmeans聚类算法及应用课程大纲 Kmeans聚类算法原理Kmeans聚类算法概述 Kmeans聚类算法图示 Kmeans聚类算法要点 Kmeans聚类算法案例需求 用Numpy手动实现 用Scikili机器学习算法库实现 Kmeans聚类算法补充算法缺点 改良思路 课程目标: 1、理解Kmeans聚类算法的核心思想 2、理解Kmeans聚类算法的代码实现 3、掌握Kmeans聚类算法的应用步骤:数据处理、建模、运算和结果判定 1. Kmeans聚类算法原理 1.1 概述 K-means算法是集简单和经典于一身的基于距离的聚类算法 采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。 该算法认为类簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。 1.2 算法图示 假设我们的n个样本点分布在图中所示的二维空间。 从数据点的大致形状可以看出它们大致聚为三个cluster,其中两个紧凑一些,剩下那个松散一些,如图所示: 我们的目的是为这些数据分组,以便能区分出属于不同的簇的数据,给它们标上不同的颜色,如图: 1.3 算法要点 1.3.1 核心思想 通过迭代寻找k个类簇的一种划分方案,使得用这k个类簇的均值来代表相应各类样本时所得的总体误差最小。 k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。 k-means算法的基础是最小误差平方和准则, 其代价函数是: 式中,μc(i)表示第i个聚类的均值。 各类簇内的样本越相似,其与该类均值间的误差平方越小,对所有类所得到的误差平方求和,即可验证分为k类时,各聚类是否是最优的。 上式的代价函数无法用解析的方法最小化,只能有迭代的方法。 1.3.2 算法步骤图解 下图展示了对n个样本点进行K-means聚类的效果,这里k取2。 matlab实现Kmeans聚类算法 1.简介: Kmeans和应用于混合高斯模型的受限EM算法是一致的。高斯混合模型广泛用于数据挖掘、模式识别、机器学习、统计分析。Kmeans 的迭代步骤可以看成E步和M步,E:固定参数类别中心向量重新标记样本,M:固定均值只考虑(估计)了均值,而没有估计类别的方差,所以聚类的结构比较适合于特征协方差相等的类别。 Kmeans在某种程度也可以看成Meanshitf的特殊版本,Meanshift 是所以Meanshift可以用于寻找数据的多个模态(类别),利用的是梯度上升法。在06年的一篇CVPR文章上,证明了Meanshift方法是牛顿拉夫逊算法的变种。Kmeans和EM算法相似是指混合密度的形式已知(参数形式已知)情况下,利用迭代方法,在参数空间中搜索解。而Kmeans和Meanshift相似是指都是一种概率密度梯度估计的方法,不过是Kmean选用的是特殊的核函数(uniform kernel),而与混合概率密度形式是否已知无关,是一种梯度求解方式。 k-means是一种聚类算法,这种算法是依赖于点的邻域来决定哪些点应该分在点,也可以对高维的空间(3维,4维,等等)的点进行聚类,任意高维的空间都可以。 上图中的彩色部分是一些二维空间点。上图中已经把这些点分组了,并使用了不同的颜色对各组进行了标记。这就是聚类算法要做的事情。 这个算法的输入是: 1:点的数据(这里并不一定指的是坐标,其实可以说是向量) 2:K,聚类中心的个数(即要把这一堆数据分成几组) 所以,在处理之前,你先要决定将要把这一堆数据分成几组,即聚成几类。但并不是在所有情况下,你都事先就能知道需要把数据聚成几类的。意味着使用k-means就不能处理这种情况,下文中会有讲解。 把相应的输入数据,传入k-means算法后,当k-means算法运行完后,该算法的输出是: 1:标签(每一个点都有一个标签,因为最终任何一个点,总会被分到某个类,类的id号就是标签) 2:每个类的中心点。 标签,是表示某个点是被分到哪个类了。例如,在上图中,实际上有4中“标签”,每个“标签”使用不同的颜色来表示。所有黄色点我们可以用标签以看出,有3个类离的比较远,有两个类离得比较近,几乎要混合在一起了。 当然,数据集不一定是坐标,假如你要对彩色图像进行聚类,那么你的向量就可以是(b,g,r),如果使用的是hsv颜色空间,那还可以使用(h,s,v),当然肯定可以有不同的组合例如(b*b,g*r,r*b) ,(h*b,s*g,v*v)等等。 在本文中,初始的类的中心点是随机产生的。如上图的红色点所示,是本文随机产生的初始点。注意观察那两个离得比较近的类,它们几乎要混合在一起,看看算法是如何将它们分开的。 类的初始中心点是随机产生的。算法会不断迭代来矫正这些中心点,并最终得到比较靠5个中心点的距离,选出一个距离最小的(例如该点与第2个中心点的距离是5个距离中最小的),那么该点就归属于该类.上图是点的归类结果示意图. 经过步骤3后,每一个中心center(i)点都有它的”管辖范围”,由于这个中心点不一定是这个管辖范围的真正中心点,所以要重新计算中心点,计算的方法有很多种,最简单的一种是,直接计算该管辖范围内所有点的均值,做为心的中心点new_center(i). 如果重新计算的中心点new_center(i)与原来的中心点center(i)的距离大于一定的阈值(该阈值可以设定),那么认为算法尚未收敛,使用new_center(i)代替center(i)(如图,中心点从红色点 实验三报告实验三-Kmeans算法实现 北华大学开放实验报告 实验名称:实验三Kmeans算法实现 所属课程:模式识别 班级:信息10—1 学号:36 姓名:张慧 实验三、K_means算法实现 一、背景知识简介: Kmeans算法是一种经典的聚类算法,在模式识别中得到了广泛的应用,基于Kmeans的变种算法也有很多,模糊Kmeans、分层Kmeans 等。 Kmeans和应用于混合高斯模型的受限EM算法是一致的。高斯混合模型广泛用于数据挖掘、模式识别、机器学习、统计分析。Kmeans的迭代步骤可以看成E步和M步,E:固定参数类别中心向量重新标记样本,M:固定标记样本调整类别中心向量。K均值只考虑(估计)了均值,而没有估计类别的方差,所以聚类的结构比较适合于特征协方差相等的类别。 二、k-means聚类算法 k-means 算法接受参数 k ;然后将事先输入的n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。 K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。K-means算法的基本思想是:以空间中k个点 为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。 (1)算法思路: 首先从n个数据对象任意选择 k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用均方差作为标准测度函数. k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。 该算法的最大优势在于简洁和快速。算法的关键在于初始中心的选择和距离公式。 (2)算法步骤: step.1---初始化距离K个聚类的质心(随机产生) step.2---计算所有数据样本与每个质心的欧氏距离,将数据样本加入与其欧氏距离最短的那个质心的簇中(记录其数据样本的编号) step.3---计算现在每个簇的质心,进行更新,判断新质心是否与原质心相等,若相等,则迭代结束,若不相等,回到step2继续迭代。 (3)算法流程图 最大距离法选取初始簇中心的K-means文本聚类算法的研究 的评论 背景 随着计算机技术和网络技术的飞速发展,人们的生活方式产生了极大的改变。计算机从一个有几个房子大小的巨无霸,已经变成了小巧的笔记本。网络设备也已经从PC端走向移动端。越来越丰富的网络设备,让人们能在网络里畅游,网络对于人们来说触手可及,同时也产生了巨大的数据流量。人们如何从海量的数据中找到有用的信息,成为了现在计算机学科的研究热点。聚类是数据挖掘中重要的一支。由于聚类具有无需先验知识的优势,可以根据数据自然分部而获取知识。聚类成为数据挖掘领域一个非常活跃的领域,而且得到了广泛的应用。聚类就是把一个数据集合分成几个簇,在同一个簇里,数据相关性最高,但是在2个不同的簇里,数据相关性最低。K-means聚类算法主要针对处理大数据集时,处理快速简单,并且算法具有高效性和可伸缩性。但是,K-means聚类算法随机的选择初始簇中心会导致以下缺点:(1)得到的聚类结果中容易出现局部最优,而不是全局最优;(2)聚类结果不具有稳定性,很大程度上依赖于初始簇中心;(3)聚类过程中的迭代次数增加使聚类过程中的总耗时增加。 传统的k-means聚类算法 传统的聚类算法思想:首先从N个数据对象集合中随机选择k个对象,然后计算剩余的N-k个对象与k个对象的距离(相似度),与k个对象中哪个对象的距离最小,就把分给那个对象;然后在计算每个簇中的簇中心,即是每个簇中对象的均值;不断重复这一过程步骤,直到标准测度函数E开始收敛为止。 K-means算法描述如下: 输入:迭代终止条件ε,最大的迭代次数为max,簇的总数目是k,样本集有N个数据对象。 输出:满足迭代终止条件的k个簇和迭代次数s。 随机初始化k个簇中心: 对每个数据对象,分别计算该对象与k个簇中心均值的距离,并选择距离最小的簇将该对象加个到该簇里; 重新计算k个簇的中心,利用函数E计算出此时的函数值; 如果带到最大迭代次数或满足: 数据挖掘课程报告 班级 XXXXXX 学生姓名 XXXXXX 学号 2010100XXXXX 指导教师 XXXXXXX 日期 2013年10月15日 k-means 算法与猫群算法的聚类效果比较分析 摘要:本文在聚类个数k 值预先设定的前提下,分别应用了k-means 算法、猫群算法对储层含油性问题进行聚类分析,比较了这两种算法的聚类效果。实验结果显示:本文所采用的传统的k-means 算法常容易陷入局部最优。而猫群算法在样本数目较小时(如以表oilsk81为例时),是一种快速、高效的识别算法。当样本数目翻倍时,受实际算法代码设计的影响,识别的正确率将会下降,这也充分说明了猫群算法的运算效果受代码和样本大小的影响,有较大的不确定性。 关键词:k-means ;猫群算法;聚类分析; 1 引言 K-means 算法[1]是由J.B. Mac Queen 于1967 年提出的,该算法是一个经典的基于划分的聚类算法,因其算法效率较高,易于其它方法相结合,目前已成为数据挖掘、机器学习、模式识别和数量统计等领域应用最广的聚类算法之一。 近几年来提出了很多的群体智能算法,这些算法都是通过模仿生物界中某些动物的行为演化出来的智能算法[2]。猫群算法作为群体智能算法之一,具有良好的局部搜索和全局搜索能力[3],算法控制参数较少,通过两种模式的结合搜索,大大的提高了搜索优良解的可能性和搜索效率,较其他算法较容易实现,收敛速度快,具有较高的运算速度,易于其他算法结合。但也有出现“早熟”现象的弊端[4]。群体中个体的优化只是根据一些表层的信息,即只是通过适应度值来判断个体的好坏,缺乏深层次的理论分析和综合因素的考虑。由于猫群算法出现较晚,该算法目前主要应用于函数优化问题[5],故在聚类分析研究方面,很有必要对猫群算法进行深入研究。 传统的k-means 算法与新兴的聚类方法猫群算法相比较会有哪些异同点呢,接下来将具体阐述。 2 算法模型 2.1 K-means 算法模型 设对n 个m 维样本集进行聚类,n 个样本集表示为12{,,,}n X X X X = ,其中 12(,,,)i i i im X x x x = ,聚类成k 个分类表示为12{,,}k C C C C = ,其质心表示为1 ,1,2,....j j i x C j z X j k n ∈= =∑, j n 为 j C 中包含的数据点的个数,则聚类的目标是使k 个类满 足以下条件: K-means聚类算法研究综述 摘要:总结评述了K-means聚类算法的研究现状,指出K-means聚类算法是一个NP难优化问题,无法获得全局最优。介绍了K-means聚类算法的目标函数,算法流程,并列举了一个实例,指出了数据子集的数目K,初始聚类中心选取,相似性度量和距离矩阵为K-means聚类算法的3个基本参数。总结了K-means聚类算法存在的问题及其改进算法,指出了K-means 聚类的进一步研究方向。 关键词:K-means聚类算法;NP难优化问题;数据子集的数目K;初始聚类中心选取;相似性度量和距离矩阵 Review of K-means clustering algorithm Abstract: K-means clustering algorithm is reviewed. K-means clustering algorithm is a NP hard optimal problem and global optimal result cannot be reached. The goal,main steps and example of K-means clustering algorithm are introduced. K-means algorithm requires three user-specified parameters: number of clusters K,cluster initialization,and distance metric. Problems and improvement of K-means clustering algorithm are summarized then. Further study directions of K-means clustering algorithm are pointed at last. Key words: K-means clustering algorithm; NP hard optimal problem; number of clusters K; cluster initialization; distance metric K-means聚类算法是由Steinhaus1955年、Lloyed1957年、Ball & Hall1965年、McQueen1967年分别在各自的不同的科学研究领域独立的提出。K-means聚类算法被提出来后,在不同的学科领域被广泛研究和应用,并发展出大量不同的改进算法。虽然K-means聚类算法被提出已经超过50年了,但目前仍然是应用最广泛的划分聚类算法之一[1]。容易实施、简单、高效、成功的应用案例和经验是其仍然流行的主要原因。 文中总结评述了K-means聚类算法的研究现状,指出K-means聚类算法是一个NP难优化问题,无法获得全局最优。介绍了K-means聚类算法的目标函数、算法流程,并列举了一个实例,指出了数据子集的数目K、初始聚类中心选取、相似性度量和距离矩阵为K-means聚类算法的3个基本参数。总结了K-means聚类算法存在的问题及其改进算法,指出了K-means聚类的进一步研究方向。 1经典K-means聚类算法简介 1.1K-means聚类算法的目标函数 对于给定的一个包含n个d维数据点的数据集 12 {x,x,,x,,x} i n X=??????,其中d i x R ∈,以及要生成的数据子集的数目K,K-means聚类算法将数据对象组织为 K个划分{c,i1,2,} k C K ==???。每个划分代表一个类c k,每个类c k有一个类别中心iμ。选取欧氏距离作为相似性和 距离判断准则,计算该类内各点到聚类中心 i μ的距离平方和 2 (c) i i k i k x C J xμ ∈ =- ∑(1) 聚类目标是使各类总的距离平方和 1 (C)(c) K k k J J = =∑最小。 22 1111 (C)(c) i i K K K n k i k ki i k k k x C k i J J x d x μμ ==∈== ==-=- ∑∑∑∑∑ (2)其中, 1 i i ki i i x c d x c ∈ ? =? ? ? 若 若 ,显然,根据最小二乘 法和拉格朗日原理,聚类中心 k μ应该取为类别 k c类各数据点的平均值。 K-means聚类算法从一个初始的K类别划分开始,然 K-均值分类算法实例 第一步:取K=2,并选 z 1(1)=x 1=(0 0)T z 2(1)=x 2=(1 0)T 第二步:因)1()1(2111z x z x -<-,故)1(11S x ∈ 因)1()1(2212z x z x ->-,故)1(22S x ∈ 因)1()1(2313z x z x -<-,故)1(13S x ∈ …… 得到: S 1(1)={x 1, x 3} S 2(1)={x 2, x 4, x 5, …, x 20} 第三步:计算新的聚类中心 ∑∈??? ? ??=+==)1(311115.00.0)(211)2(S x x x x N z ∑∈???? ??=+++==)1(20422 2233.567.5)(1811)2(S x x x x x N z 第四步:因)1()2(j j z z ≠,j=1,2,返回第二步; 第二步(返回1):由新的聚类中心,得到: 8,,2,1,)2()2(21 =-<-l z x z x l l 20,,10,9,)2()2(21 =->-l z x z x l l 因此 S 1(2)={x 1, x 2, …, x 8} S 2(2)={x 9, x 10, …, x 20} 第三步(返回1):计算聚类中心 ∑∈??? ? ??=+++==)2(82111113.125.1)(811)3(S x x x x x N z ∑∈??? ? ??=+++==)2(2010922233.767.7)(1211 )3(S x x x x x N z 第四步(返回1):因)2()3(j j z z ≠,j=1,2,返回第二步; 第二步(返回2):分类结果与前一次迭代的结果相同,即S 1(4)=S 1(3), S 2(4)= S 2(3); 第三步(返回2):聚类中心与前一次迭代的结果相同; 第四步(返回2):因)3()4(j j z z =,j=1,2,算法收敛,得到最终的聚 类中心。 ??? ? ??=13.125.11z ???? ??=33.767.72z X-means:一种针对聚类个数的K-means算法改进 摘要 尽管K-means很受欢迎,但是他有不可避免的三个缺点:1、它的计算规模是受限的。2、它的聚类个数K必须是由用户手动指定的。3、它的搜索是基于局部极小值的。在本文中,我们引入了前两种问题的解决办法,而针对最后一个问题,我们提出了一种局部补救的措施。根据先前有关算法改进的工作,我们引入了一种根据BIC(Bayesian Information Criterion)或者AIC(Akaike information criterion)得分机制而确定聚类个数的算法,本文的创新点包括:两种新的利用充分统计量的方式,还有一种有效地测试方法,这种方法在K-means算法中可以用来筛选最优的子集。通过这样的方式可以得到一种快速的、基于统计学的算法,这种算法可以实现输出聚类个数以及他们的参量值。实验表明,这种技术可以更科学的找出聚类个数K值,比利用不同的K值而重复使用K-means算法更快速。 1、介绍 K-means算法在处理量化数据中已经用了很长时间了,它的吸引力主要在于它很简单,并且算法是局部最小化收敛的。但是它有三点不可避免的缺点:首先,它在完成每次迭代的过程中要耗费大量的时间,并且它所能处理的数据量也是很少的。第二,聚类个数K值必须由用户自身来定义。第三,当限定了一个确定的K值时,K-means算法往往比一个动态K值的算法表现的更差。我们要提供针对这些问题的解决办法,通过嵌入树型的数据集以及将节点存储为充分统计变量的方式来大幅度提高算法的计算速度。确定中心的分析算法要考虑到泰森多边形边界的几何中心,并且在估计过程的任何地方都不能存在近似的方法。另外还有一种估计方法,“黑名单”,这个列表中将会包含那些需要在指定的区域内被考虑的图心。这种方法不仅在准确度上以及处理数据的规模上都表现的非常好,而这个快速算法在X-means 聚类算法当中充当了结构算法的作用,通过它可以很快的估计K值。这个算法在每次使用 K-means算法之后进行,来决定一个簇是否应该为了更好的适应这个数据集而被分开。决定的依据是BIC得分。在本文中,我们阐述了“黑名单”方法如何对现有的几何中心计算BIC 得分,并且这些几何中心所产生的子类花费不能比一个单纯的K-means聚类算法更高。更进一步的,我们还通过缓存状态信息以及估计是否需要重新计算的方法来改善估计方法。 我们已经用X-means算法进行了实验,验证了它的确比猜K值更加科学有效。X-means 算法可以在人造的或者是真实数据中表现的更好,通过BIC得分机制。它的运行速度也是比K-means更快的。 2、定义 我们首先描述简单的K-means算法应该考虑哪些因素。通过K-means可以把一定量的数据集分为K个数据子集,这K个数据子集分别围绕着K个聚类中心。这种算法保持着K个聚类中心不变,并且通过迭代不断调整这K个聚类中心。在第一次迭代开始之前,K个聚类中心都是随机选取的,算法当聚类中心不再变化的时候返回最佳的结果,在每一次迭代中,算法都要进行如下的动作: 1、对于每一个节点向量,找到距离它最近的聚类中心,归入此类。 2、重新评估每一个图心的位置,对于每一个图心,必须是簇的质心。 K-means聚类算法通过局部最小化每个向量到对应图心的距离来实现聚类。同时,它处理真实数据时是非常慢的。许多情况下,真实的数据不能直接用K-means进行聚类,而要经过二次抽样筛选之后再进行聚类。Ester曾经提出了一种可以从树形数据中获得平衡的抽样数据的方法。Ng和Han曾经提出了一种可以指导概率空间对输入向量的检索模拟模型。 K-means算法简介 K-means算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,两个对象的距离越近,其相似度就越大。而簇是由距离靠近的对象组成的,因此算法目的是得到紧凑并且独立的簇。 假设要将对象分成k个簇,算法过程如下: (1) 随机选取任意k个对象作为初始聚类的中心(质心,Centroid),初始代表每一个簇; (2) 对数据集中剩余的每个对象根据它们与各个簇中心的距离将每个对象重新赋给最近的簇; (3) 重新计算已经得到的各个簇的质心; (4) 迭代步骤(2)-(3)直至新的质心与原来的质心相等或小于设定的阈值,算法结束。 随意找几个数据简单模拟(借用当年老师教的方法^_^)算法如下: ,A2,…,A6: 要聚成2类,算法过程如下: (1) 假设选择A1和A2为初始质心; (2) 计算A3-A6与A1和A2的距离,这里用欧氏距离公式d = sqrt((x1-x2)2+(y1- 2 距离的比较,A3、A4、A6都离A2近,A5与A1和A2距离相同,假设A5也分到A2这一簇,因此形成新的两簇: 簇1:A1 簇2:A2,A3,A4,A5,A6 (4) 计算新簇的质心 簇1质心:A1 簇2:新质心“C_temp”计算用每个维度的平均值 2簇: 簇1:A1,A2,A3 簇2:A4,A5,A6 新质心1“C_temp1”:((A1.x+A2.x+A3.x)/3 , (A1.y+A2.y+A3.y)/3)=(1.67, 2) bingoㄟ(??? )ㄏ 簇1:A1,A2,A3 簇2:A4,A5,A6 提示: (1) 在K-means 算法k值通常取决于人的主观经验; (2) 距离公式常用欧氏距离和余弦相似度公式,前者是根据位置坐标直接计算的,主要体现个体数值特征的差异,而后者更多体现了方向上的差异而不是位置上的,cos θ越接近1个体越相似,可以修正不同度量标准不统一的问题; (3) K-means算法获得的是局部最优解,在算法中,初始聚类中心常常是随机选择的,一旦初始值选择的不好,可能无法得到有效的聚类结果。 班级: 计算机127班 姓名: 潘** 学号: 12*****120 K-means 算法实验报告 K -means 算法, 也被称为k -平均或k -均值算法,是一种得到最广泛使用的聚类算法。 它是将各个聚类子集内的所有数据样本的均值作为该聚类的代表点,算法的主要思想是通过迭代过程把数据集划分为不同的类别,使得评价聚类性能的准则函数达到最优(平均误差准则函数E ),从而使生成的每个聚类(又称簇)内紧凑,类间独立。 欧氏距离 ? 假设给定的数据集 {}total m x X m ,...,2,1|==,X 中的样本用d 个描述属性A 1,A 2…A d (维度)来表示。 ? 数据样本x i =(x i1,x i2,…x id ), x j =(x j1,x j2,…x jd )其中, x i1,x i2,…x id 和x j1,x j2,…x jd 分别是样本x i 和x j 对应d 个描述属性A 1,A 2,…A d 的具体取值。 ? 样本xi 和xj 之间的相似度通常用它们之间的距离d(x i ,x j )来表示,距离越小,样本x i 和x j 越相似,差异度越小;距离越大,样本x i 和x j 越不相似,差异度越大。 欧式距离公式如下: ()()∑=-= d k jk ik j i x x x x d 1 2 , 平均误差准则函数 ? K-means 聚类算法使用误差平方和准则函数来评价聚类性能。给定数据集X ,其中只包含描述属性,不包含类别属性。假设X 包含k 个聚类子集X 1,X 2,…X K ;各个聚类子集中的样本数量分别为n 1,n 2,…,n k ;各个聚类子集的均值代表点(也称聚类中心)分别为m 1,m 2,…,m k 。 ? 误差平方和准则函数公式为: () 2 1 11 x x n d i n i -∑-= = K-means 算法过程 输入:簇的数目k 和包含n 个对象的数据库。 输出:k 个簇,使平方误差准则最小。 算法步骤: KMeans 算法及其修改 1.K-Means 算法原理 K-Means 算法的基本思想是:将N 个对象划分到k 个簇中,分类结果要使得相似度较高的对象划分到同一类簇中,而差异较大的对象存在于不同类簇中。 给定大小为n 的数据集,设V={v 1,v 2,…,v n },令I=1,将n 个对象划分到K 个不同的簇中,使用K-Means 算法聚类的具体算法步骤为: 步骤1 在数据集中随机选取K 个对象作为初始聚类中心c 1,c 2……c k ; 步骤2 计算数据集中每个对象到聚类中心的距离,选取最小距离min|V- c j |,分配到聚类中,其中V={v 1,v 2,…,v n },j=1,2……k; 步骤3 计算每个聚类中的所有对象均值,将此均值作为新的聚类中心,c j = 1 n j X i n j i =1,n j 为第j 类中对象的个数,j=1,2,……k; 步骤4如果每个簇的聚类中心不再发生变化,聚类准则函数 J c = |X i j ?c j |n j i =1k j =1收敛,则算法结束。否则返回步骤2继续迭代。 2.优缺点 K-Means 算法实现起来比较简单、运算速度较快,算法效率较高,能够处理大型数据集,空间复杂度和时间复杂度较低。但同时K-Means 算法也有不足之处,包含以下几点: (1) 聚类结果不确定 K-Means算法初始聚类中心是随机选择的,初始中心点的选择不同会导致最终聚类的效果不同。选取不同的初始聚类中心,会使得最终聚类得到的类簇发生变化。除此之外,K-Means算法一般采用准则函数为目标函数,准则函数中只存在一个全局最小值和N个极小值,这使得在进行计算时,使得算法陷入局部最小的情况,导致最终得到的不是全局最优解。 (2) 聚类个数不确定 K-Means算法中K表示聚类后簇的个数,K的取值决定着聚类的结果。K值的选取需要根据实际的需要来确定,但是通常情况下我们是不知道将原始数据集分为多少个类簇是合适的,所以需要针对不同的实验通过对比选取恰当的K值。 (3) 数据量大、算法时间复杂度较高 K-Means算法的计算过程是一个不断迭代的过程,为了寻找到合适的聚类中心,需要不断的计算和调整才能对数据对象进行有效的分类。这个过程中反复进行大量的对象间距离的计算,所以K-Means聚类算法过程会消耗大量的时间,降低聚类的效率。 3.改进点1: 普通kmeans算法是求出的聚簇之后对簇内的点取平均值,若这个簇形成的图像比较狭窄或其图像并不均匀,则使用平均值生成的点就极有可能偏离聚簇本身,所以本文希望通过求生成的簇的重心,以保证生成的中心点不会偏离聚簇本身并能够更好的代表整个簇。 Matlab的K-均值聚类Kmeans函数 K-means聚类算法采用的是将N*P的矩阵X划分为K个类,使得类内对象之间的距离最大,而类之间的距离最小。 使用方法: Idx=Kmeans(X,K) [Idx,C]=Kmeans(X,K) [Idc,C,sumD]=Kmeans(X,K) [Idx,C,sumD,D]=Kmeans(X,K) 各输入输出参数介绍: X---N*P的数据矩阵 K---表示将X划分为几类,为整数 Idx---N*1的向量,存储的是每个点的聚类标号 C---K*P的矩阵,存储的是K个聚类质心位置 sumD---1*K的和向量,存储的是类间所有点与该类质心点距离之和 D---N*K的矩阵,存储的是每个点与所有质心的距离 [┈]=Kmeans(┈,’Param1’,’Val1’,’Param2’,’Val2’,┈) 其中参数Param1、Param2等,主要可以设置为如下: 1、’Distance’---距离测度 ‘sqEuclidean’---欧氏距离 ‘cityblock’---绝对误差和,又称L1 ‘cosine’---针对向量 ‘correlation’---针对有时序关系的值 ‘Hamming’---只针对二进制数据 2、’Start’---初始质心位置选择方法 ‘sample’---从X中随机选取K个质心点 ‘uniform’---根据X的分布范围均匀的随机生成K个质心 ‘cluster’---初始聚类阶段随机选取10%的X的子样本(此方法初始使用’sample’方法)Matrix提供一K*P的矩阵,作为初始质心位置集合 3、’Replicates’---聚类重复次数,为整数 使用案例: data= 5.0 3.5 1.3 0.3 -1 5.5 2.6 4.4 1.2 0 6.7 3.1 5.6 2.4 1 5.0 3.3 1.4 0.2 -1 5.9 3.0 5.1 1.8 1 5.8 2.6 4.0 1.2 0 [Idx,C,sumD,D]=Kmeans(data,3,’dist’,’sqEuclidean’,’rep’,4) 运行结果: Idx = 1 2 3 1 3 2 C = 5.0000 3.4000 1.3500 0.2500 -1.0000 5.6500 2.6000 4.2000 1.2000 0 6.3000 3.0500 5.3500 2.1000 1.0000 sumD = 0.0300 0.1250 0.6300 D = 0.0150 11.4525 25.5350K-means算法简介
K-means算法的实现与应用举例
k-means聚类算法的研究全解
K-MEANS算法(K均值算法)
聚类分析K-means算法综述
机器学习kmeans聚类算法与应用
matlab实现Kmeans聚类算法
实验三报告实验三-Kmeans算法实现
K-means文本聚类算法
数据挖掘报告-Kmeans算法
K-means-聚类算法研究综述
第二章(K均值算法实例)
(完整版)X-means:一种针对聚类个数的K-means算法改进
K-means算法过程示意介绍
K-means算法分析实验报告
KMeans算法及其修改
Matlab中Kmeans函数的使用