CCNA2_chapter4(中文,图文)

ERouting Chapter 4 - ${COURSENAME} (版本${VERSION})
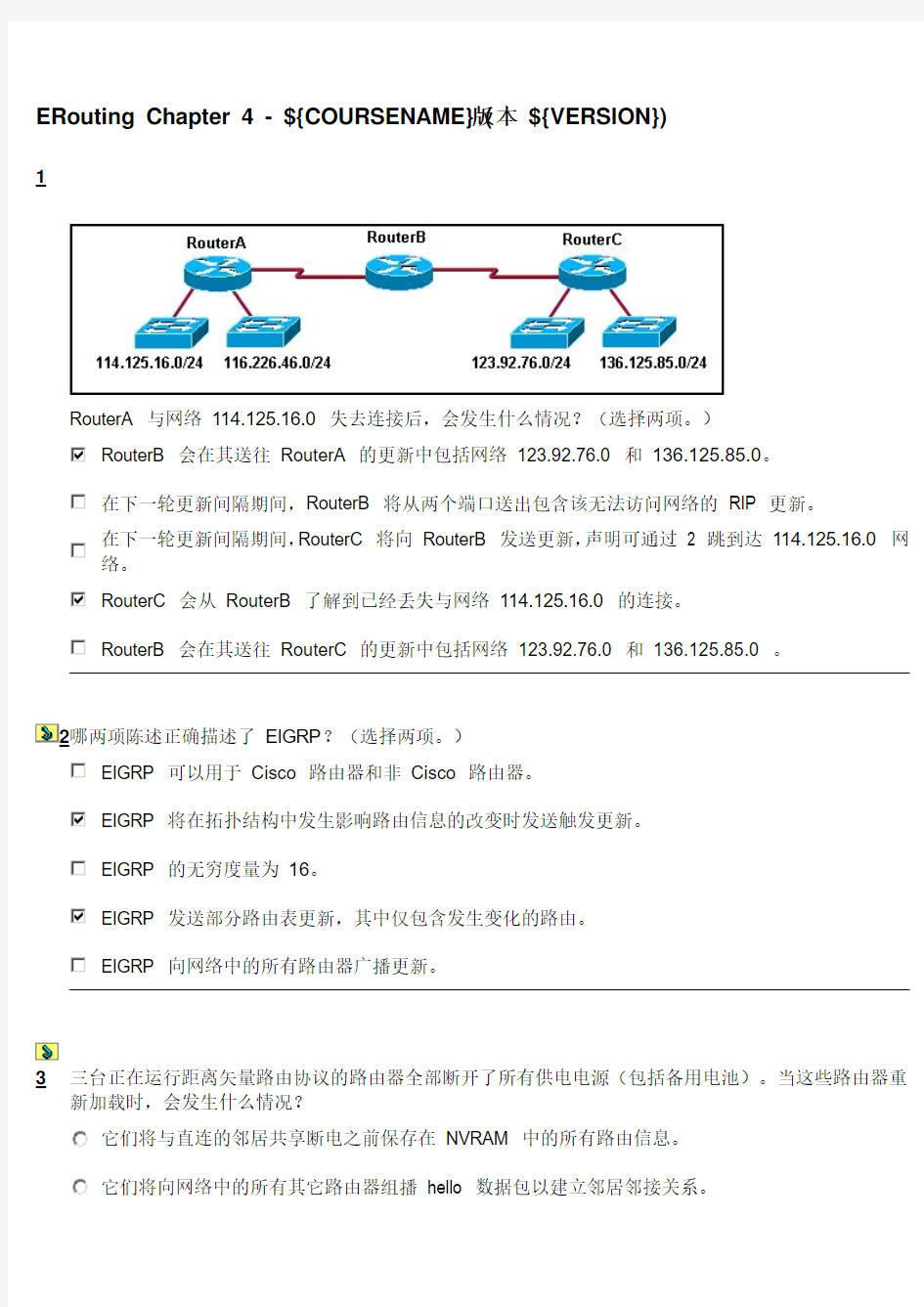
1
RouterA 与网络114.125.16.0 失去连接后,会发生什么情况?(选择两项。)
RouterB 会在其送往RouterA 的更新中包括网络123.92.76.0 和136.125.85.0。
在下一轮更新间隔期间,RouterB 将从两个端口送出包含该无法访问网络的RIP 更新。
在下一轮更新间隔期间,RouterC 将向RouterB 发送更新,声明可通过 2 跳到达114.125.16.0 网络。
RouterC 会从RouterB 了解到已经丢失与网络114.125.16.0 的连接。
RouterB 会在其送往RouterC 的更新中包括网络123.92.76.0 和136.125.85.0 。
2哪两项陈述正确描述了EIGRP?(选择两项。)
EIGRP 可以用于Cisco 路由器和非Cisco 路由器。
EIGRP 将在拓扑结构中发生影响路由信息的改变时发送触发更新。
EIGRP 的无穷度量为16。
EIGRP 发送部分路由表更新,其中仅包含发生变化的路由。
EIGRP 向网络中的所有路由器广播更新。
3三台正在运行距离矢量路由协议的路由器全部断开了所有供电电源(包括备用电池)。当这些路由器重新加载时,会发生什么情况?
它们将与直连的邻居共享断电之前保存在NVRAM 中的所有路由信息。
它们将向网络中的所有其它路由器组播hello 数据包以建立邻居邻接关系。
它们将向其直连的邻居发送仅包含直连路由的更新。
它们将向网络中的所有路由器广播其完整的路由表。
4
请参见图示。如果正在使用RIP 路由协议,来自192.168.1.0/24 网络的数据包会沿着哪一条路径到达10.0.0.0/8 网络?
路由器A -> 路由器 B -> 路由器 C -> 路由器E。
路由器A -> 路由器 D -> 路由器E。
路由器A 会在“路由器A -> 路由器 D -> 路由器E”和“路由器 A -> 路由器 B -> 路由器C -> 路由器E”之间实施负载均衡。
数据包会根据到达路由器A 的顺序交替选择路径。
5IP 报头中的TTL 字段有什么作用?
用于在发送到其它路由器的更新中将路由标记为不可达
防止定期更新消息错误地恢复已经不可用的路由
防止从收到更新的接口通告同一网络
限制数据包在被丢弃之前在网络中传输的时间或跳数
通过设置最大跳数来为每一距离矢量路由协议定义最大度量值
6R IP 抑制计时器的作用是什么?
确保无效路由的度量为15
对于在网络中造成路由环路的路由器,禁止其发送任何更新
在发送更新前确保每条新路由都有效
指示路由器在指定的时间内或特定事件下,忽略有关可能无法访问路由的更新
7下列路由协议中,哪三种属于距离矢量路由协议?(选择三项)。
R IPv1
EIGRP
OSPF
I S-IS
RIPv2
路由更新被对半分割,以减少更新时间。
从一个来源获知的信息不会发回给该来源。
只有从多个来源获知的新路由信息才能被接受。
更新之间的时间被对半分割,以加速收敛过程。
新路由信息被抑制,直到系统完成收敛。
9下列关于RIPv1 路由更新功能的陈述,哪两项是正确的?(选择两项。)
仅当拓扑结构发生变化时才广播更新
以一定的时间间隔广播更新
广播发送到0.0.0.0
广播发送到255.255.255.255
更新中包含整个网络拓扑结构
更新中仅包括所发生的变化
数据包在路由器的两个环回接口之间来回传递
从目的地返回的路径与出发路径不同而形成“环路”的情况
数据包在一系列路由器间不断传输却始终无法到达其真正的目的地的情况
路由从一种路由协议到另一种路由协议的分布
11
图中显示了一个配置为使用RIP 路由协议的网络。Router2 检测到与Router1 之间的链路断开。随后它将该链路网络的度量通告为16 跳。其使用的是哪种路由环路预防机制?
水平分割
错误条件
抑制计时器
路由毒化
计数至无穷
12
请参见图示。该网络中的路由器都运行RIP。路由器A 在三分钟内未接收到来自路由器B 的更新。
路由器 A 将如何作出响应?
抑制计时器将等候60 秒,之后将从路由表中删除该路由。
如果在180 秒后仍未收到更新,无效计时器将把该路由标记为不可用。
更新计时器将请求有关从路由器B 获知的路由的更新。
Hello 计时器将在10 秒之后超时,然后该路由将从路由表中清除。
13网络管理员正在考虑是为新网络部署RIP 还是EIGRP。该网络对拥塞敏感而且必须能够快速响应拓扑结构的变化。在这种情况下选择EIGRP 而不是RIP 的两项理由是什么?(选择两项。)
EIGRP 使用定期更新。
EIGRP 仅更新受影响的邻居。
EIGRP 使用广播更新。
EIGRP 更新为部分更新。
EIGRP 使用高效的贝尔曼-福特算法。
14
请参见图示。如果所有路由器都使用RIP,在所有路由器了解整个网络之前将发生多少轮更新?
1
2
3
4
5
6
15下列有关cisco RIP_JITTER 变量的陈述,哪一项是正确的?
它会在更新从路由器接口送出时缓冲更新,以此防止路由更新同步。
它会从下一次路由更新间隔中减去随机时间段(大小为指定间隔时间的0% 到15%),以此防止路由更新同步。
它会使路由器跳过每一个其它计划更新时间,以此防止路由更新同步。
它会强制路由器在发送自身更新之前侦听链路上的其它更新是何时发送的,以此防止路由更新同步。16以下哪种事件将导致触发更新?
更新路由计时器超时
接收到损坏的更新消息
路由表中安装了一条路由
网络已达到收敛
17哪两种情况最有可能导致路由环路?(选择两项。)
随机抖动
使用有类编址
路由表不一致
静态路由配置错误
网络收敛过快
18下列关于RIPv1 路由更新功能的陈述,哪两项是正确的?(选择两项。)
仅当拓扑结构发生变化时才广播更新
以一定的时间间隔广播更新
广播发送到0.0.0.0
广播发送到255.255.255.255
更新中包含整个网络拓扑结构
更新中仅包括所发生的变化
OB开发手册中文版
OB开发手册中文版
Contents [hide]1 简介 ? 1 简介 ? 1.1 开发概述 ? 1.2 开发方法 ? 1.3 组织开发工作 ? 1.4 标识符命名标准 ? 1.4.1 数据库元素 ? 1.4.2 MVC目录 ? 1.4.3 存储过程语法 ? 1.5 目录结构 ? 1.6 风格指南 ? 1.6.1 逻辑比较 ? 1.6.2 逗号分隔列表 ? 1.6.3 圆括号中的空格 ? 1.6.4 SELECT INTO和INSERT INTO ? 1.6.5 SQL关键字 ? 1.7 编译程序 ? 1.7.1 命令行编译任务 ? 1.7.2 开发环境 ? 1.7.3 生产环境 ? 1.8 从源代码构建 ? 1.8.1 安装Subversion ? 1.8.2 从Subversion中检出源代码 ? 1.8.3 快速构建指南 ? 1.9 集成开发环境 ? 2 Openbravo数据模型 ? 2.1 存储的数据库对象 ? 2.2 实体-关系(ER)图 ? 2.3 创建存储过程 ? 2.3.1 AD_PInstance和AD_PInstance_Para表 ? 2.3.2 存储过程的输入参数 ? 2.3.2.1 从AD_PInstance表中获取有用的信息 ? 2.3.2.2 AD_Update_PInstance存储过程 ? 2.3.2.3 例外和错误管理 ? 2.4 存储过程语法的建议 ? 2.4.1 通用规则 ? 2.4.1.1 游标 ? 2.4.1.2 数组 ? 2.4.1.3 ROWNUM ? 2.4.1.4 %ROWCOUNT ? 2.4.1.5 %ISOPEN,%NOTFOUND ? 2.4.2 表 ? 2.4.3 函数 ? 2.4.4 存储过程
PostgreSQL学习手册
tgreSQL学习手册(五) 函数和操作符 阿里云携手开源中国众包平台发布百万悬赏项目? 一、逻辑操作符: 常用的逻辑操作符有:AND、OR和NOT。其语义与其它编程语言中的逻辑操作符完全相同。 二、比较操作符: 下面是PostgreSQL中提供的比较操作符列表: 操作符描述 <小于 >大于 <=小于或等于 >=大于或等于 =等于 !=不等于 比较操作符可以用于所有可以比较的数据类型。所有比较操作符都是双目操作符,且返回boolean类型。除了比较操作符以外,我们还可以使用BETWEEN语句,如: a BETWEEN x AND y 等效于 a >= x AND a <= y a NOT BETWEEN x AND y 等效于 a < x OR a > y 三、数学函数和操作符: 下面是PostgreSQL中提供的数学操作符列表: 操作符描述例子结果 +加 2 + 35 -减 2 - 3-1 *乘 2 * 36 /除 4 / 22 %模 5 % 41 ^幂 2.0 ^ 3.08 |/平方根|/ 25.05 ||/立方根||/ 27.03 !阶乘 5 !120 !!阶乘!! 5120 @绝对值@ -5.05 &按位AND91 & 1511 |按位OR32 | 335
#按位XOR17 # 520 ~按位NOT~1-2 <<按位左移 1 << 416 >>按位右移8 >> 22 按位操作符只能用于整数类型,而其它的操作符可以用于全部数值数据类型。按位操作符还可以用于位串类型bit和bit varying, 下面是PostgreSQL中提供的数学函数列表,需要说明的是,这些函数中有许多都存在多种形式,区别只是参数类型不同。除非特别指明,任何特定形式的函数都返回和它的参数相同的数据类型。 函数返回类 型 描述例子结果 abs(x)绝对值abs(-17.4)17.4 cbrt(double)立方根cbrt(27.0)3 ceil(double/numeric)不小于参数的最小的整 数 ceil(-42.8)-42 degrees(double) 把弧度转为角度degrees(0.5)28.6478897565412 exp(double/numeric)自然指数exp(1.0) 2.71828182845905 floor(double/numeric)不大于参数的最大整数floor(-42.8)-43 ln(double/numeric)自然对数ln(2.0)0.693147180559945 log(double/numeric)10为底的对数log(100.0)2 log(b numeric,x numeric)numeric指定底数的对 数 log(2.0, 64.0) 6.0000000000 mod(y, x)取余数mod(9,4)1 pi() double"π"常量pi() 3.14159265358979 power(a double, b double)double求a的b次幂power(9.0, 3.0)729 power(a numeric, b numeric) numeric求a的b次幂power(9.0, 3.0)729 radians(double)double把角度转为弧度radians(45.0)0.785398163397448 random()double 0.0到1.0之间的随机 数值 random() round(double/numeric)圆整为最接近的整数round(42.4)42 round(v numeric, s int)numeric圆整为s位小数数字round(42.438,2)42.44 sign(double/numeric)参数的符号(-1,0,+1) sign(-8.4)-1 sqrt(double/numeric)平方根sqrt(2.0) 1.4142135623731 trunc(double/numeric)截断(向零靠近)trunc(42.8)42 trunc(v numeric, s int)numeric 截断为s小数位置的数 字 trunc(42.438,2)42.43 三角函数列表: 函数描述 acos(x)反余弦
PostgreSQL学习手册(PLpgSQL过程语言)
一、概述: PL/pgSQL函数在第一次被调用时,其函数内的源代码(文本)将被解析为二进制指令树,但是函数内的表达式和SQL命令只有在首次用到它们的时候,PL/pgSQL解释器才会为其创建一个准备好的执行规划,随后对该表达式或SQL命令的访问都将使用该规划。如果在一个条件语句中,有部分SQL命令或表达式没有被用到,那么PL/pgSQL解释器在本次调用中将不会为其准备执行规划,这样的好处是可以有效地减少为PL/pgSQL函数里的语句生成分析和执行规划的总时间,然而缺点是某些表达式或SQL命令中的错误只有在其被执行到的时候才能发现。 由于PL/pgSQL在函数里为一个命令制定了执行计划,那么在本次会话中该计划将会被反复使用,这样做往往可以得到更好的性能,但是如果你动态修改了相关的数据库对象,那么就有可能产生问题,如: CREATE FUNCTION populate() RETURNS integer AS $$ DECLARE -- 声明段 BEGIN PERFORM my_function(); END; $$ LANGUAGE plpgsql; 在调用以上函数时,PERFORM语句的执行计划将引用my_function对象的OID。在此之后,如果你重建了my_function函数,那么populate函数将无法再找到原有my_function函数的OID。要解决该问题,可以选择重建populate函数,https://www.360docs.net/doc/0214304402.html,或者重新登录建立新的会话,以使PostgreSQL重新编译该函数。要想规避此类问题的发生,在重建my_function时可以使用CREATE OR REPLACE FUNCTION命令。 鉴于以上规则,在PL/pgSQL里直接出现的SQL命令必须在每次执行时均引用相同的表和字段,换句话说,不能将函数的参数用作SQL命令的表名或字段名。如果想绕开该限制,可以考虑使用PL/pgSQL 中的EXECUTE语句动态地构造命令,由此换来的代价是每次执行时都要构造一个新的命令计划。 使用PL/pgSQL函数的一个非常重要的优势是可以提高程序的执行效率,由于原有的SQL调用不得不在客户端与服务器之间反复传递数据,这样不仅增加了进程间通讯所产生的开销,而且也会大大增加网络IO的开销。 二、PL/pgSQL的结构: PL/pgSQL是一种块结构语言,函数定义的所有文本都必须在一个块内,其中块中的每个声明和每条语句都是以分号结束,如果某一子块在另外一个块内,那么该子块的END关键字后面必须以分号结束,不过对于函数体的最后一个END关键字,分号可以省略,如: [ <
PostgreSQL+Linux 从入门到精通培训文档 2命令
本章大纲 1. 如何访问命令行 2. 使用命令行下的工具 非编辑模式 进入编辑模式 3. 正则表达式、管道和I/O 重定向 4. 管理用户账户 5. 文件访问控制 6. 管理进程 1,如何访问命令行 1.1 本地命令行的访问 在图形界面中,访问命令行的方法:打开Terminal,Console。或者:Ctrl+Alt+F1 ~ F6 1.2 使用SSH 访问命令行 同上 2,使用命令行下的工具 2.1 使用硬链接
硬链接,指在同一个文件系统中,对inode的引用,只要文件上存在至少1个硬链接,就可以找到对应的inode。 [digoal@digoal01 ~]$ echo "abc" > ./a [digoal@digoal01 ~]$ stat a File: `a' Size: 4 Blocks: 8 IO Block: 4096 regular file Device: 803h/2051d Inode: 656374 Links: 1 -- 硬链接数量 Access: (0664/-rw-rw-r--) Uid: ( 500/ digoal) Gid: ( 500/ digoal) Access: 2017-04-11 13:18:14.292848716 +0800 Modify: 2017-04-11 13:18:14.292848716 +0800 Change: 2017-04-11 13:18:14.292848716 +0800 创建硬链接 [digoal@digoal01 ~]$ ln -L ./a ./b [digoal@digoal01 ~]$ stat a File: `a' Size: 4 Blocks: 8 IO Block: 4096 regular file Device: 803h/2051d Inode: 656374 Links: 2 Access: (0664/-rw-rw-r--) Uid: ( 500/ digoal) Gid: ( 500/ digoal) Access: 2017-04-11 13:18:14.292848716 +0800 Modify: 2017-04-11 13:18:14.292848716 +0800 Change: 2017-04-11 13:18:34.631855044 +0800 [digoal@digoal01 ~]$ stat b File: `b' Size: 4 Blocks: 8 IO Block: 4096 regular file Device: 803h/2051d Inode: 656374 Links: 2 Access: (0664/-rw-rw-r--) Uid: ( 500/ digoal) Gid: ( 500/ digoal) Access: 2017-04-11 13:18:14.292848716 +0800 Modify: 2017-04-11 13:18:14.292848716 +0800 Change: 2017-04-11 13:18:34.631855044 +0800 删除一个硬链接,还能通过其他硬链接找到对应的inode。 [digoal@digoal01 ~]$ rm a rm: remove regular file `a'? y [digoal@digoal01 ~]$ cat b abc 2.2 归档和解压 常用的归档命令tar 归档-c (常用压缩库-j bz2, -z gzip) [digoal@digoal01 ~]$ tar -jcvf test.tar.bz2 b
PostgreSQL学习手册:SQL语言函数
PostgreSQL学习手册:SQL语言函数 一、基本概念: SQL函数可以包含任意数量的查询,但是函数只返回最后一个查询(必须是SELECT)的结果。在简单情况下,返回最后一条查询结果的第一行。如果最后一个查询不返回任何行,那么该函数将返回NULL值。如果需要该函数返回最后一条SELECT语句的所有行,可以将函数的返回值定义为集合,即SETOF sometype。 SQL函数的函数体应该是用分号分隔的SQL语句列表,其中最后一条语句之后的分号是可选的。除非函数声明为返回void,否则最后一条语句必须是SELECT。事实上,在SQL函数中,不仅可以包含SELECT查询语句,也可以包含INSERT、UPDATE和DELETE等其他标准的SQL 语句,但是和事物相关的语句不能包含其中,如BEGIN、COMMIT、ROLLBACK和SAVEPOINT 等。 CREATE FUNCTION命令的语法要求函数体写成一个字符串文本。通常来说,该文本字符串常量使用美元符($$)围住,如: CREATE FUNCTION clean_emp() RETURNS void AS $$ DELETE FROM emp WHERE salary < 0; $$ LANGUAGE SQL; 最后需要说明的是SQL函数中的参数,PostgreSQL定义$1表示第一个参数,$2为第二个参数并以此类推。如果参数是复合类型,则可以使用点表示法,即$https://www.360docs.net/doc/0214304402.html,访问复合类型参数中的name字段。需要注意的是函数参数只能用作数据值,而不能用于标识符,如:INSERT INTO mytable VALUES ($1); --合法 INSERT INTO $1 VALUES (42); --不合法(表名属于标示符之一) 二、基本类型: 最简单的SQL函数可能就是没有参数且返回基本类型的函数了,如: CREATE FUNCTION one() RETURNS integer AS $$ SELECT 1 AS result; $$ LANGUAGE SQL; 下面的例子声明了基本类型作为函数的参数。 CREATE FUNCTION add_em(integer, integer) RETURNS integer AS $$ SELECT $1 + $2; $$ LANGUAGE SQL; # 通过select调用函数。 postgres=# SELECT add_em(1,2) AS answer; answer -------- 3 (1 row) 在下面的例子中,函数体内包含多个SQL语句,它们之间是用分号进行分隔的。CREATE FUNCTION tf1 (integer, numeric) RETURNS numeric AS $$ UPDATE bank SET balance = balance - $2 WHERE accountno = $1; SELECT balance FROM bank WHERE accountno = $1; $$ LANGUAGE SQL;
Sqoop官方中文手册
Sqoop中文手册 1. 概述 本文档主要对SQOOP的使用进行了说明,参考内容主要来自于Cloudera SQOOP的官方文档。为了用中文更清楚明白地描述各参数的使用含义,本文档几乎所有参数使用说明都经过了我的实际验证而得到。 2. codegen 将关系数据库表映射为一个java文件、java class类、以及相关的jar包, 1、将数据库表映射为一个Java文件,在该Java文件中对应有表的各个字段。 2、生成的Jar和class文件在metastore功能使用时会用到。 基础语句: sqoop codegen –connect jdbc:mysql://localhost:3306/hive –username root –password 123456 –table TBLS2
3. create-hive-table 生成与关系数据库表的表结构对应的HIVE表 基础语句: sqoop create-hive-table –connect jdbc:mysql://localhost:3306/hive -username root -password 123456 –table TBLS –hive-table h_tbls2 4. eval
可以快速地使用SQL语句对关系数据库进行操作,这可以使得在使用import这种工具进行数据导入的时候,可以预先了解相关的SQL语句是否正确,并能将结果显示在控制台。 查询示例: sqoop eval –connect jdbc:mysql://localhost:3306/hive -username root -password 123456 -query ―SELECT * FROM tbls LIMIT 10″ 数据插入示例: sqoop eval –connect jdbc:mysql://localhost:3306/hive -username root -password 123456 -e ―INSERT INTO TBLS2 VALUES(100,1375170308,1,0,‘hadoop‘,0,1,‘guest‘,‘MANAGED_TABLE‘,‘abc‘,‘ddd‘)‖ -e、-query这两个参数经过测试,比如后面分别接查询和插入SQL语句,皆可运行无误,如上。 5. export 从hdfs中导数据到关系数据库中 sqoop export –connect jdbc:mysql://localhost:3306/hive –username root –password 123456 –table TBLS2 –export-dir sqoop/test
GP简明使用手册
GP服务启停 su - gpadmin gpstart #正常启动 gpstop #正常关闭 gpstop -M fast #快速关闭 gpstop –r #重启 gpstop –u #重新加载配置文件 登陆与退出Greenplum #正常登陆 psql gpdb psql -d gpdb -h gphostm -p 5432 -U gpadmin #使用utility方式 PGOPTIONS="-c gp_session_role=utility" psql -h -d dbname hostname -p port #退出 在psql命令行执行\q 参数查询 psql -c 'SHOW ALL;' -d gpdb gpconfig --show max_connections 创建数据库 createdb -h localhost -p 5432 dhdw 创建GP文件系统 # 文件系统名 gpfsdw # 子节点,视segment数创建目录 mkdir -p /gpfsdw/seg1 mkdir -p /gpfsdw/seg2 chown -R gpadmin:gpadmin /gpfsdw # 主节点 mkdir -p /gpfsdw/master chown -R gpadmin:gpadmin /gpfsdw gpfilespace -o gpfilespace_config
gpfilespace -c gpfilespace_config 创建GP表空间 psql gpdb create tablespace TBS_DW_DATA filespace gpfsdw; SET default_tablespace = TBS_DW_DATA; 删除GP数据库 gpdeletesystem -d /gpmaster/gpseg-1 -f 查看segment配置 select * from gp_segment_configuration; 文件系统 select * from pg_filespace_entry; 磁盘、数据库空间 SELECT * FROM gp_toolkit.gp_disk_free ORDER BY dfsegment; SELECT * FROM gp_toolkit.gp_size_of_database ORDER BY sodddatname;日志 SELECT * FROM gp_toolkit.__gp_log_master_ext; SELECT * FROM gp_toolkit.__gp_log_segment_ext; 表描述 /d+
H2Database中文教程(精编文档).doc
【最新整理,下载后即可编辑】 启动和使用H2管理系统 设置H2管理系统 通过JDBC连接到数据库 创建一个新的数据库 使用服务器模式 使用Hibernate 使用TopLink和Glassfish 使用EclipseLink 在WEB应用中使用数据库 CSV (逗号分隔文件)的支持 升级,备份,和恢复 命令行工具 使用OpenOffice基础框架 使用/ JNLP启动JAVA WEB 使用连接池 全文检索 用户自定义变量 日期和时间 使用Spring 使用和启动H2管理系统 H2管理系统让你能够通过一个浏览器对H2的SQL数据库进行管理操作。H2管理系统不仅可以连接H2数据库,也可以连接其他支持JDBC接口的数据库。
这是一个B/C/S应用,在服务器和浏览器上都要运行H2的管理程序。根据平台不同,H2管理系统支持多种启动应用的方式。在windows上有两种方式启动H2管理系统 方式一:单击[开始],[程序],[H2],和[H2 Console (Command Line)]。当使用SUN JDK1.5时,一个标题为'H2 Console'的窗口将弹出。当使用SUN JDK1.6时,一个数据库图标将被加入WINDOWS到系统托盘。如果既无窗口弹出也没有图标加入到系统托盘,很可能是你的JDK没有正确安装(如果确认自己的JDK 安装正确,可以尝试用另外一种方式启动控制台)。另外一个浏览器窗口将被打开,指向的URL是http://localhost:8082,是H2管理系统的登录页面。 方式二:打开文件浏览器,切换目录到h2/bin,双击运行h2.bat。一个控制台窗口将弹出,如果有问题,将有错误信息在这个窗口里显示。一个浏览器窗口将被打开,指向的URL是http://localhost:8082,是H2管理系统的登录页面。 其他操作系统启动H2管理系统 方式一:双击h2*.jar文件,如果.jar文件能正确的被java打开。
Postgresql配置文件
相比mysql单一的https://www.360docs.net/doc/0214304402.html,f,postgresql的访问认证配置主要涉及到两个主要的配置文件:postgresql.conf和pg_hba.conf,本文从安全设置角度讲述这两个配置文件的配置选项。部分文字、样例摘抄自postgresql的中文手册。 postgresql.conf postgresql.conf包含了许多的选项,这些选项控制了postgresql.conf的方方面面,中间影响访问认证的选项是: unix_socket_group 设置Unix 域套接字的组所有人,(套接字的所有权用户总是启动postmaster 的用户)与UNIX_SOCKET_PERMISSIONS 选项一起使用可以给这种套接字类型增加额外的访问控制机制,缺省时是一个空字串,也就是使用当前用户的缺省的组,这个选项只能在服务器启动时设置。 unix_socket_permissions 给Unix 域套接字设置访问权限,Unix 域套接字使用通常的Unix 文件系统权限集。可选的值可以是一个chmod 和umask 系统调用可以接受的数字模式。(要使用客户化的八进制格式,该数字必须以0 (零)开头) 缺省权限是0777,意即任何人都可以联接,合理的选则可能是0770 (只有用户和组,参阅UNIX_SOCKET_GROUP)和0700 (只有用户)。(请注意对于Unix 套接字而言,实际上只有写权限有意义,而且也没有办法设置或者取消读或执行权限) 这个选项只能在服务器启动时设置。 pg_hba.conf是设置访问认证的主要文件,格式为每条记录一行,每行指定一条访问认证。设定一条访问认证包含了7个部分:连接方式(type)、数据库(database)、用户名(user)、ip地址(ip-address)、子网掩码(ip-mask)、认证方法(authentication method)、认证配置(authentication-option),以下是这7个部分的详细说明: 连接方式(type) 连接方式共有三种:local、host、hostssl local 这条记录匹配通过Unix 域套接字进行的联接企图,没有这种类型的记录,就不允许Unix 域套接字的联接。 host
PostgreSQL数据库配置参数详解
十章数据库参数 PostgresSQL提供了许多数据库配置参数,本章将介绍每个参数的作用和如何配置每一个参数。 10.1 如何设置数据库参数 所有的参数的名称都是不区分大小写的。每个参数的取值是布尔型、整型、浮点型和字符串型这四种类型中的一个,分别用boolean、integer、floating point和string表示。布尔型的值可以写成ON、OFF、TRUE、FALSE、YES、NO、1和0,而且不区分大小写。 有些参数用来配置内存大小和时间值。内存大小的单位可以是KB、MB和GB。时间的单位可以是毫秒、秒、分钟、小时和天。用ms表示毫秒,用s表示秒,用min表示分钟,用h表示小时,用d表示天。表示内存大小和时间值的参数参数都有一个默认的单位,如果用户在设置参数的值时没有指定单位,则以参数默认的单位为准。例如,参数shared_buffers 表示数据缓冲区的大小,它的默认单位是数据块的个数,如果把它的值设成8,因为每个数据块的大小是8KB,则数据缓冲区的大小是8*8=64KB,如果将它的值设成128MB,则数据缓冲区的大小是128MB。参数vacuum_cost_delay 的默认单位是毫秒,如果把它的值设成10,则它的值是10毫秒,如果把它的值设成100s,则它的值是100秒。 所有的参数都放在文件postgresql.conf中,下面是一个文件实例: #这是注释 log_connections = yes log_destination = 'syslog' search_path = '"$user", public' 每一行只能指定一个参数,空格和空白行都会被忽略。“ #”表示注释,注释信息不用单独占一行,可以出现在配置文件的任何地方。如果参数的值不是简单的标识符和数字,应该用单引号引起来。如果参数的值中有单引号,应该写两个单引号,或者在单引号前面加一个反斜杠。 一个配置文件也可以包含其它配置文件,使用include指令能够达到这个目的,例如,假设postgresql.conf文件中有下面一行: include ‘my.confg’
Npgsql - 用户手册
Npgsql: 用户的手册 Copyright ?The Npgsql Development Team Last update: $Date: 2009/12/20 02:33:47 $ by $Author: fxjr $ Category: External documentation Intended Audience: Npgsql Users 1. What is Npgsql? Npgsql 是一个.net的资料提供者为postgresql的数据库服务器 它允许一个.net客户端应用程序(控制台,WinForms,ASP的。网络、网络服务…)发送和接收数据与postgresql的服务器。它正在积极开发基于指南规定在.net文档。 2. How to get and compile Npgsql 如何获得和编译Npgsql 2.1 Binary package 二进制包 你可以下载Npgsql编译为MS . 在里面编写.net的项目。 这个包裹里,你会发现下面的目录的布局。 Npgsql/bin/docs - Documentation Npgsql/bin/docs/apidocs - API Documentation Npgsql/bin/ms1.1 - Npgsql compiled for https://www.360docs.net/doc/0214304402.html, 1.1 Npgsql/bin/mono - Npgsql compiled for Mono As soon as Npgsql is released on other platforms/versions, they will be added accordingly to this layout. 2.2 Installing binary package 安装二进制包 为了查找到。net运行时,文件Npgsql.dll必须放置在你的应用程序目录——除非你指定另一个目录作为通往私营成分通过一个配置文件(使用探测单元)。请看看。net除有关如何运行(位于)总成,被载入。确切地说,前面可以称为”通往私人组件" 在ASP。网络和网络服务的应用程序中,必须有一个叫做“bin”的应用与https://www.360docs.net/doc/0214304402.html,目录. 举例来说,如果应用程序目录被称为“ASPNETApplication”,然后Npgsql.dll和Mono.Security.dll必须放置在“ASPNETApplication \bin”的目录. 如果这些文件是不正确的目录,你可以看到编译器生成错误代码,使用Npgsql类。 或者,你可以把Npgsql装配在解决。自从版本0.4,Npgsql强烈签字——这意味着你可以用“gacutil "安装它。 下列命令: gacutil - Npgsql.dll 请参阅“安装装配在全球缓存汇编”部分的单据MSDN来获得更多信息.利用gac的意义,你应该充分理解,沿着这条路。 注意,放置在……要求Npgsql设计时间支持.net可视化工作室。 (Npgsql编制单声道不需要Mono.Security.dll作为已经融入单声道运行。) 一旦你拷贝或设置组件,你准备去试试这个例子——跳转到section 3. 2.3 Getting Npgsql from CVS 获得Npgsql到CVS 让Npgsql到CVS,使用下列资料储存在你的客户信息 Server: https://www.360docs.net/doc/0214304402.html, Repository: /cvsroot/npgsql Module name: Npgsql2 User: anonymous Password:
SQLite学习手册 中文全本
SQLite学习手册 内容收集自网络 整理: zhoushuangsheng@https://www.360docs.net/doc/0214304402.html, 新浪微博:@_Nicky 开篇 一、简介: SQLite是目前最流行的开源嵌入式数据库,和很多其他嵌入式存储引擎相比(NoSQL),如BerkeleyDB、MemBASE等,SQLite可以很好的支持关系型数据库所具备的一些基本特征,如标准SQL语法、事务、数据表和索引等。事实上,尽管SQLite拥有诸多关系型数据库的基本特征,然而由于应用场景的不同,它们之间并没有更多的可比性。 下面我们将列举一下SQLite的主要特征: 1. 管理简单,甚至可以认为无需管理。 2. 操作方便,SQLite生成的数据库文件可以在各个平台无缝移植。 3. 可以非常方便的以多种形式嵌入到其他应用程序中,如静态库、动态库等。 4. 易于维护。 综上所述,SQLite的主要优势在于灵巧、快速和可靠性高。SQLite的设计者们为了达到这一目标,在功能上作出了很多关键性的取舍,与此同时,也失去了一些对RDBMS关键性功能的支持,如高并发、细粒度访问控制(如行级锁)、丰富的内置函数、存储过程和复杂的SQL语句等。正是因为这些功能的牺牲才换来了简单,而简单又换来了高效性和高可靠性。 二、SQLite的主要优点: 1. 一致性的文件格式: 在SQLite的官方文档中是这样解释的,我们不要将SQLite与Oracle或PostgreSQL去比较,而是应该将它看做fopen和fwrite。与我们自定义格式的数据文件相比,SQLite不仅提供了很好的移植性,如大端小端、32/64位等平台相关问题,而且还提供了数据访问的高效性,如基于某些信息建立索引,从而提高访问或排序该类数据的性能,SQLite提供的事务功能,也是在操作普通文件时无法有效保证的。 2. 在嵌入式或移动设备上的应用: 由于SQLite在运行时占用的资源较少,而且无需任何管理开销,因此对于PDA、智能手机等移动设备来说,SQLite的优势毋庸置疑。
PostgreSQL数据库学习手册之libpq
PostgreSQL数据库学习手册之libpq - C 库--介绍(转)[@more@] Chapter 1. libpq - C 库 Table of Contents 1.1. 介绍 1.2. 数据库联接函数 1.3. 命令执行函数 1.3.1. 主过程 1.3. 2. 为包含在 SQL 查询中逃逸字串 1.3.3. 逃逸包含在 SQL 查询中的二进制字串 1.3.4. 检索 SELECT 的结果信息 1.3.5. 检索 SELECT 结果数值 1.3.6. 检索非-SELECT 结果信息 1.4. 异步查询处理 1.5. 捷径接口 1.6. 异步通知 1.7. 与 COPY 命令相关的函数 1.8. libpq 跟踪函数 1.9. libpq 控制函数 1.10. 环境变量 1.11. 文件 1.1 2. 线程特性 1.13. 制作 Libpq 程序 1.14. 例子程序 1.1. 介绍 libpq 是 PostgreSQL的 C 应用程序员的接口. libpq 是一套允许客户程序向 PostgreSQL 后端服务进程发送查询并且获得查询返回的库过程. libpq 同时也是其他几个 PostgreSQL 应用接口下面的引擎,包括 libpq++ (C++), libpgtcl(Tcl),Perl,和 ecpg.所以如果你使用这些软件包, libpq某些方面的特性会对你非常重要. 本节末尾有三个小程序显示如何利用 libpq书写程序.在下面目录里面有几个完整的 libpq 应用的例子:src/test/examples src/bin/psql 使用 libpq 的前端程序必须包括头文件 libpq-fe.h 并且必须与 libpq 库链接. PostgreSQL数据库学习手册之libpq-C库---数据库联接函数(转)[@more@] 1.2. 数据库联接函数 下面的过程处理与 PostgreSQL 后端服务器联接的事情.一个应用程序一次可以与多个后端建立联接.(这么做的原因之一是访问多于一个数据库.)每个连接都是用一个从PQconnectdb()或PQsetdbLogin() 获得的PGconn对象表示.注意,这些函数总是返回一个非空的对象指针,除非存储器少得连个PGconn对象都分配不出来.在把查询发送给联接对象之前,可以调用PQstatus 函数来检查一下联接是否成功. * PQconnectdb 与后端数据库服务器建立一个新的联接. PGconn *PQconnectdb(const char *conninfo)
PostgreSQL部署文档
yum安装PostgreSQL 下载PostgreSQL源: rpm -Uvh https://https://www.360docs.net/doc/0214304402.html,/pub/repos/yum/9.4/redhat/rhel-7-x86_64/pgdg-centos94-9.4-3.noarch.rpm 登录官网,选择适合自己的版本,本文选择的是PostgreSQL 9.4对应的CentOS7-x86_64版本。 执行安装命令: yum install postgresql94-server postgresql94-contrib 验证是否安装成功: rpm -aq| grep postgres 执行结果如下: postgresql94-libs-9.4.12-1PGDG.rhel7.x86_64 postgresql94-9.4.12-1PGDG.rhel7.x86_64 postgresql94-server-9.4.12-1PGDG.rhel7.x86_64 postgresql94-contrib-9.4.12-1PGDG.rhel7.x86_64 说明正确安装。 初始化数据库 /usr/pgsql-9.4/bin/postgresql94-setup initdb 一定要先初始化数据库,否则启动的时候会报如下错误: postgresql-check-db-dir[2994]: "/var/lib/pgsql/data"is missing or empty. postgresql-check-db-dir[2994]: Use"postgresql-setup initdb"to initialize the database cluster. 启动服务并设置为开机启动 systemctl enable postgresql-9.4 systemctl start postgresql-9.4
PostgreSQL注常见问题入总结
日本是一个多么让人联想翩翩浮想连连的词语,为啥我们要搞日本的大学捏?原因很简单,我们都爱日本妹子 国外的网站也不是坚不可摧,看完本系列文章你会发现,什么高深黑客技术,什么日本名牌大学的网站,也不过如此。都是五分钟从前台到服务器的货。 日本大学入侵系列篇章: 1) 《系列1之日本京都同志社大学 - php注入点写webshell,linux最简单提权》 2) 《系列2之日本共立女子大学 - 解决PostgreSQL连接问题完成脱众女子内裤》 3) 《系列3之日本东京大学 - PostgreSQL注入常见问题总结》 作者:YoCo Smart 来自:Silic Group Hacker Army https://www.360docs.net/doc/0214304402.html, 本文基于《PostgreSQL注入语法指南》而写,首先我们先来总结常见问题,常见问题有这样几个 如何判断数据库使用了PostgreSQL数据库,字段数和字段间编码问题,GPC为on时的字符型字段问题,注释符问题。我们一个一个讲 1) 如何判断php搭配数据库为PostgreSQL 我们假设一个php+PostgreSQL并且开启了错误回显的网站有一个注入点,我们在 xx.php?id=n后面加单引号',它的回显将会是这样的: Warning: pg_query() [function.pg-query]: Query failed: ERROR: unterminated quoted string at or near "'" LINE 1: select * from now where no = 111' ^ in /home/sites/web/school/detail.php on line 307 有这样几个关键字可以判断数据库为PostgreSQL: 操作PostgreSQL的函数pg_query() 关键字function.pg-query中的pg 看熟了MySQL的错误回显,有没有发现这个unterminated quoted string at or near不是MySQL的?MySQL的错误回显和这个区别太大了 2) 字段数和字段间编码问题 我们首先将上面的注入点order by 2可以确认now数据表的字段数大于2,当我们order by 2000的时候,显然不可能有那个表段中有2000条数据,当然会出错 Warning:pg_query() [function.pg-query]: Query failed: ERROR: ORDER BY position 2000 is not in select list in /home/sites/web/school/detail.php on line 307 这样大致可以确认可以猜出正确的字段数了。假设字段数为14,那么我们按照MySQL的步骤 1.xx.php?id=0+union+select+1,2,3,4,5,6,7,8,9,10,11,12,13,14 复制代码 这句没问题吧?但是它99%概率会出问题了:
PostgresXL使用说明文档
Postgres-XL使用说明文档 一、知识点介绍 Postgres-XL是一个基于PostgreSQL数据库的横向扩展开源SQL数据库集群,XL代表eXtensible Lattice,即可扩展的PG“格子”之意,以下简称PGXL。官方称其既适合写操作压力较大的OLTP1应用,又适合读操作为主的大数据应用。它的前身是Postgres-XC(简称PGXC),PGXC是在PG的基础上加入了集群功能,主要适用于OLTP2应用;PGXL是在PGXC的基础上的升级产品,加入了一些适用于OLAP应用的特性,如Massively Parallel Processing (MPP) 特性。通俗的说PGXL的代码是包含PG代码的,使用PGXL安装PG集群并不需要单独安装PG。 总体感觉PGXL这款工具还是相当成熟的,有官方网站,文档也比较完善,也有商业公司2ndQuadrant在支持。 上面这张图就是PGXL集群的架构图,来自官方网站。所有节点中分为三种角色:GTM (全局事务管理器)、Coordinator(协调器)和Datanode(数据节点)。需要注意一点是图中 1OLTP过程(On-Line Transaction Processing),也称为面向交易的处理过程,其基本特征是前台接收的用户数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果,是对用户操作快速响应的方式之一。OLTP系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作; 2OLAP,也叫联机分析处理(On-line Analytical Processing)系统,有的时候也叫DSS 决策支持系统,就是我们说的数据仓库。在这样的系统中,语句的执行量不是考核标准,因为一条语句的执行时间可能会非常长,读取的数据也非常多。所以,在这样的系统中,考核的标准往往是磁盘子系统的吞吐量(带宽),如能达到多少MB/s的流量。OLAP系统则强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等。