motionbuilder_外部数据驱动基础入门

简介
MotionBuilder是业界最为重要的3D角色动画软件之一。它集成了众多优秀的工具,为制作高质量的动画作品提供了保证。此外,MotionBuilder中还包括了独特的实时架构,无损的动画层,非线性的故事板编辑环境和平滑的工作流程。
Alias MotionBuilder是用于游戏、电影、广播电视和多媒体制作的世界一流的实时三维角色动画生产力套装软件。利用实时的、以角色为中心的工具的集合,对于从传统的插入关键帧到运动捕捉编辑范围内的各种任务,该软件为技术指导和艺术家提供了处理最苛刻的、高容量的动画的功能。它的固有文件格式(FBX)使在创建三维内容的应用软件之间具有无与伦比的互用性—使MotionBuilder成为可以增强任何现有制作生产线的补充软件包。
1.MOTIONBUILDER模块介绍
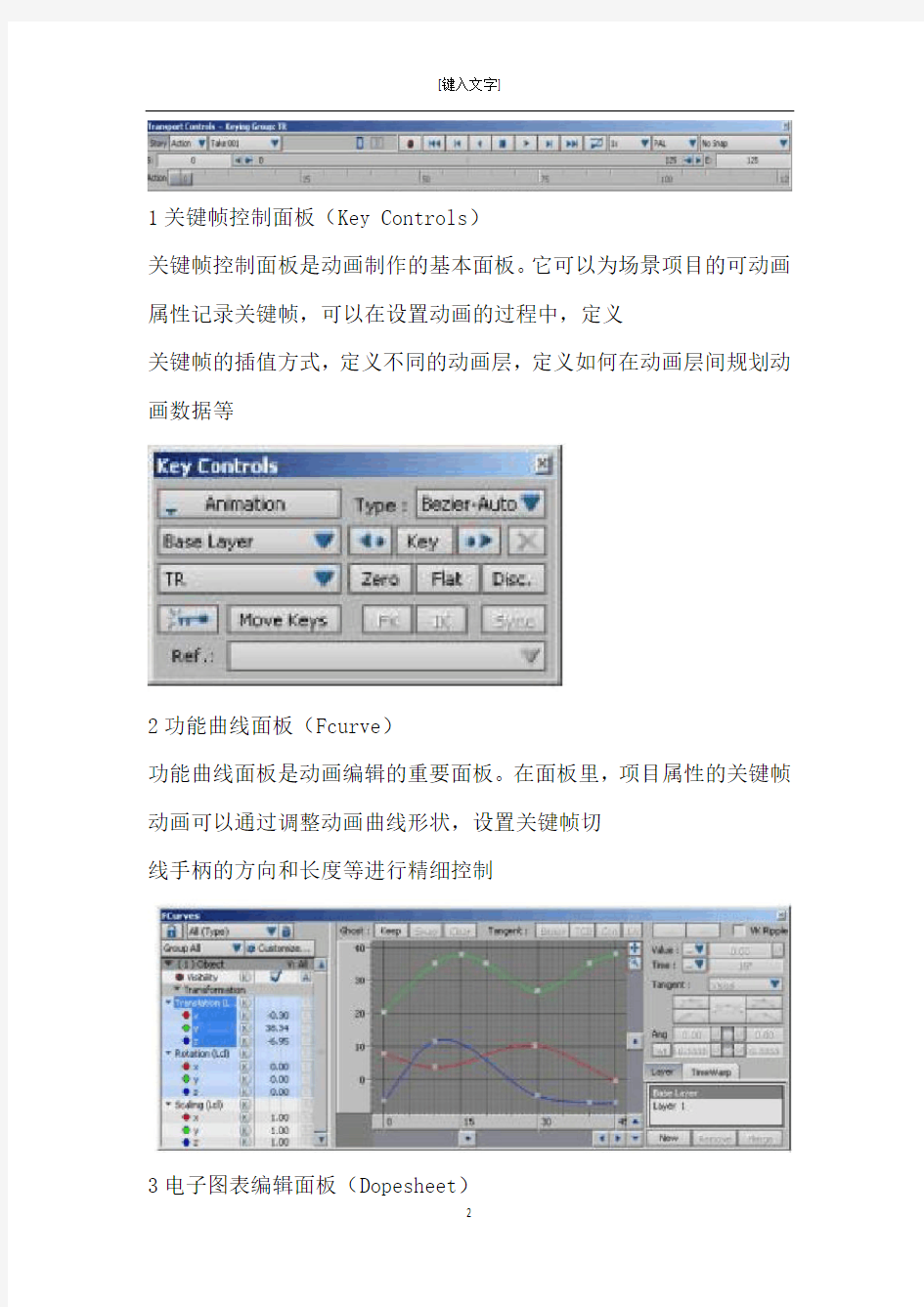
动画控制面板(Transport Control)
动画控制面板是播放场景动画的控制器。在场景项目设置动画以后,可以在面板里对动画进行正常播放,逐帧播放等
操作,还可以任意调整动画的时间,设置动画的帧速率,对动画进行简单的关键帧编辑等。
1关键帧控制面板(Key Controls)
关键帧控制面板是动画制作的基本面板。它可以为场景项目的可动画属性记录关键帧,可以在设置动画的过程中,定义
关键帧的插值方式,定义不同的动画层,定义如何在动画层间规划动画数据等
2功能曲线面板(Fcurve)
功能曲线面板是动画编辑的重要面板。在面板里,项目属性的关键帧动画可以通过调整动画曲线形状,设置关键帧切
线手柄的方向和长度等进行精细控制
3电子图表编辑面板(Dopesheet)
电子图表编辑面板显示场景中选择项目的运动属性动画设置,可以在面板里快速对项目的运动变换关键帧进行诸如移
动,复制,粘贴,缩放等编辑操作。
4数据过滤面板(Filters)
数据过滤面板提供对动画数据进行过滤,为动画曲线的关键帧进行诸如减少光滑度/噪点、减少关键点、切除关键
点、重新插入、解除循环等操作,
5角色/演员控制面板(Character/Actor Contorols)
角色/演员控制面板都是角色动画制作中重要的控制面板。其中,角色控制面板主要用于使用骨骼控制装配来设置角
色动画的情况,它能让你通过在面板里快速选择控制骨骼运动的效应器,设置动画的关键帧模式等来实现角色动画,
而在演员控制面板里,则可以在使用运动捕捉文件来动画角色的时候,通过选择演员的各个部分来和运动捕捉文件的数
据标记相匹配,从而帮助实现映射运动文件数据到演员上
6姿势控制面板(Pose Controls)
姿势控制面板可以保存角色动画在某个时刻的姿势,并且能够通过复制和粘贴操作等快速将所保存的角色姿势应用
数据库基本知识(自己整理,初学者可以看一下,基于某MySql)
数据库
1常见数据库 1.1MySql : 甲骨文 1.2Oracle: 甲骨文 1.3SQL Server: 微软 1.4Sybase: 赛尔斯 1.5DB2: IBM 2MySql基础知识 2.1关系结构数据模型数据库 2.2SQL(Structured Query Language)结构化查询语言2.2.1DDL(Data Definition Language):数据定义语言,用来定义数据库对象:库、表、列等 操作数据库 CREATE DATABASE [IF NOT EXISTS]mydb1 USE mydb1 DROP DATABASE [IF NOT EXISTS] mydb1
ALTER DATABASE mydb1 CHARACTER SET utf8 操作表 插入表 CREATE TABLE stu( sid CHAR(6), sname VARCHAR(20), age INT, gender VARCHAR(10) ); 更改表 ALTER TABLE t_user ADD (student varcher(20)) ALTER TABLE t_user MODIFY gender CHAR(20) ALTER TABLE t_user CHANGE gender VARCHER(20) ALTER TABLE t_user REMANE genderTO genders ALTER TABLE t_user DROP gender 删除表 DROP TABLE t_user 2.2.2DML(Data Manipulation Language):数据操作语言,用来定义数据库记录(数据) 插入数据 INSERT INTO t_user VALUES() INSERT INTO 表名 VALUES(值1,值2,…)
windows驱动开发和调试环境搭建
Windows驱动开发和环境搭建 【文章标题】: Windows驱动开发和调试的环境设置 【文章作者】: haikerenwu 【使用工具】: VC6.0,VMware6.0.3,Windbg 【电脑配置】: 惠普笔记本xp sp3 (一)VMWare安装篇 VMWare的安装一路Next即可,关于其序列号,百度一下就能找到,虚拟机安装完成之后,需要安装操作系统,我在虚拟机中安装的是windows xp sp2系统。 点击“文件”----“新建”----“虚拟机” 进入新建虚拟机的向导,配置虚拟系统参数
选择虚拟系统文件的兼容格式(新手推荐选择默认选项) 按照默认设置继续点击下一步,选择好您需要的操作系统,此处我选择的是Windows XP Prefessional。 设置虚拟机名称和虚拟操作系统安装路径,我单独空出来一个F 盘,将虚拟机和虚拟操作系统全部装在该盘。
配置网络模式(推荐选择NA T,一般主机不用做任何的设置虚拟机就可以利用主机上网)。 配置虚拟磁盘的容量。在这里可以直接单击完成,来完成基本操作设置,磁盘默认空间是8GB,用户可以根据自己的实际使用情况来调整大小,也可以自定义分区。
操作完成之后,在“VM”菜单下有个“setting。。。”菜单,点击此菜单,在CD-ROM中选择合适的选项,我使用的是Use ISO image 选项,将我的xp sp2操作系统的ISO映像路径设置好,安装操作系统。点击ok之后,启动虚拟机,即开始安装操作系统,安装过程跟普通装机过程相同。安装完成之后,启动操作系统,然后在VM菜单下点击“Install VMWare Tools”,把虚拟操作系统的驱动装好。 (二)VMWare设置篇
【EXCEL】数据分析那些事(菜鸟入门必看)
Q1:我现在的工作有一点数据分析的模块,自从上微薄后了解到还有专门从事数据分析工作,我现在想做这一行,但是经验、能力都还是菜鸟中的菜鸟,请问成为一名数据分析师还有需要哪些准备? A:很简单,我们可以看一下国内知名互联网数据分析师的招聘要求,进行自我对照,即可知道需要做哪些准备。 数据分析师职位要求: 1、计算机、统计学、数学等相关专业本科及以上学历; 2、具有深厚的统计学、数据挖掘知识,熟悉数据仓库和数据挖掘的相关技术,能够熟练地使用SQL; 3、三年以上具有海量数据挖掘、分析相关项目实施的工作经验,参与过较完整的数据采集、整理、分析和建模工作; 4、对商业和业务逻辑敏感,熟悉传统行业数据挖掘背景、了解市场特点及用户需求,有互联网相关行业背景,有网站用户行为研究和文本挖掘经验尤佳; 5、具备良好的逻辑分析能力、组织沟通能力和团队精神; 6、富有创新精神,充满激情,乐于接受挑战。 Q2:对数据分析有浓厚兴趣,希望从事数据分析、市场研究相关工作,但听说对学历要求较高,请问我是否要读研,读研的话应该读哪个方向? A:读研要看自身情况,但可明确:专业不是问题,本科学历就够。关键是兴趣与能力,以及自身的努力,兴趣是学习成长最好的老师! 当然如果是在校生考上研究生的话那是最好,如果考不上可以先工作,等你工作有经验了,你就知道哪方面的知识是自己需要,要考哪方面的研究生,也就更有方向性。 Q3:那么如何培养对数据分析的兴趣呢? A:建议如下: 1、先了解数据分析是神马? 2、了解数据分析有何用?可解决什么问题? 3、可以看看啤酒与尿布等成功数据分析案例; 4、关注数据分析牛人微博,听牛人谈数据分析(参考Q1的三个链接); 5、多思考,亲自动手分析实践,体验查找、解决问题的成就感; 6、用好搜索引擎等工具,有问题就搜索,你会有惊喜发现; 7、可以看看@李开复老师写的《培养兴趣:开拓视野,立定志向》; 有网友说:让数据分析变的有趣的方法是,把自己想象成福尔摩斯,数据背后一定是真相!Q4:我有点迷茫,是练好技能再找工作,还是找一个数据分析助理之类的要求不是特别高的工作,在工作中提升? A:建议在工作中进行学习实践,这才是最好的提升。看那么多书,没有实践都是虚的。 Q5:我是做电商的,对于数据分析这块,您有什么好的软件工具类推荐吗? A:做数据分析首先是熟悉业务及行业知识,其次是分析思路清晰,再次才是方法与工具,切勿为了方法而方法,为工具而工具!不论是EXCEL、SPSS还是SAS,只要能解决问题的工具就是好工具。 问题的高效解决开始于将待解决问题的结构化,然后进行系统的假设和验证。分析框架可以帮助我们:1、以完整的逻辑形式结构化问题;2、把问题分解成相关联的部分并显示它们之间的关系;3、理顺思路、系统描述情形/业务;4、然后洞察什么是造成我们正在解决的问题的原因。
面向对象设计之定义领域服务
面向对象设计之定义领域服务 若遵循基于面向对象设计范式的领域驱动设计,并用以应对纷繁复杂的业务逻辑,则强调领域模型的充血设计模型已成为社区不争事实。我将Eric提及的战术设计要素如EnTIty、Value Object、Domain Service、Aggregate、Repository与Factory视为设计模型。这其中,只有EnTIty、Value Object和Domain Service才能表达领域逻辑。 为避免贫血模型,在封装领域逻辑时,考虑设计要素的顺序为: Value Object -》EnTIty -》Domain Service 切记,我们必须将Domain Service作为承担业务逻辑的最后的救命稻草。之所以把Domain Service放在最后,是因为我太清楚领域服务的强大魔力了。开发人员总会有一种惰性,很多时候不愿意仔细思考所谓职责(封装领域逻辑的行为)的正确履行者,而领域服务恰恰是最便捷的选择。 就我个人的理解,只有满足如下三个特征的领域行为才应该放到领域服务中: 领域行为需要多个领域实体参与协作 领域行为与状态无关 领域行为需要与外部资源(尤其是DB)协作 假设某系统的合同管理功能允许客户输入自编码,该自编码需要遵循一定的编码格式。在创建新合同时,客户输入自编码,系统需要检测该自编码是否在已有合同中已经存在。针对该需求,可以提炼出两个领域行为: 验证输入的自编码是否符合业务规则 检查自编码是否重复 在寻找职责的履行者时,我们应首先遵循信息专家模式,即拥有信息的对象就是操作该信息的专家,因此可以提出一个问题:领域行为要操作的数据由谁拥有?针对第一个领域行为,就是要确认谁拥有自编码格式的验证规则?有两个候选: 拥有自编码信息的合同(Contract)对象
Windows驱动开发培训
Windows驱动开发培训 培训流程: 一、基础知识 在开始驱动开发之前,您应该知道操作系统原理以及驱动程序是如何在操作系统中进行工作的,了解这些基本原理将有助于您做出正确的设计决策并简化您的开发过程。 1、了解Windows操作系统构造\\ 可以链接进去 2、安装WDK,参考相关文档,熟悉WDK的内容\\ 可以链接进去 二、Windows驱动开发\\ 可以链接进去 一、基础知识 在开始驱动开发之前,您应该知道操作系统原理以及驱动程序是如何在操作系统中进行工作的,了解这些基本原理将有助于您做出正确的设计决策并简化您的开发过程。 1、了解Windows操作系统构造 (1)培训目标 深入了解Windows操作系统的系统结构以及工作原理 (2)培训内容 阅读书籍《深入解析Windows操作系统》的第3、4、6、7、9章,重点关注第九章“I/O系统” (3)培训任务 ①掌握Windows操作系统的系统结构 ②理解ISR、IRP、IRQL、DCP等概念的含义 ③了解注册表的用法,掌握注册表数据的查看和修改方法 ④了解进程和线程的内部机理以及线程的调度策略 ⑤了解I/O系统的内容,理解I/O请求以及I/O处理过程 注:以上相关内容,请在一周内完成。
2、安装WDK,参考相关文档,熟悉WDK的内容 (1)培训目标 了解WDK的安装过程,熟悉WDK的编译环境,掌握如何使用WDK的相关帮助文档;了解WDM驱动程序的基本结构 (2)培训内容 ①.阅读文档\\10.151.131.12\book\windows\MSWDM.chm,掌握WDM驱动程序的基本结构以及基本的编程技术。 ②.参考WDK的帮助文档:WDK documentation ,了解WDK的基本内容 (3)培训任务 ①理解分层驱动结构的含义,掌握设备和驱动程序的层次结构 ②理解“驱动对象”和“设备对象”的概念 ③理解2个基本例程:DriverEntry 和addDevice ④了解IRP的结构以及IRP处理的流程 ⑤初步了解I/O的控制操作 注:以上相关内容,请在一周内完成。 二、Windows驱动开发 学习如何基于WDK进行驱动程序的开发 1、培训目标 (1)学会根据WDK开发一个基本的Windows驱动程序和测试程序 (2)学会利用不同的IOCTL方式在内核模式和用户模式之间进行通讯 (3)学会如何在内核模式下和用户模式下访问注册表 (4)利用WinDbg跟踪程序,学会使用WinDbg进行调试 2、培训内容 (1)阅读
Stata软件基本操作和大数据分析报告入门
Stata软件基本操作和数据分析入门 第一讲 Stata操作入门 张文彤赵耐青 第一节概况 Stata最初由美国计算机资源中心(Computer Resource Center)研制,现在为Stata公司的产品,其最新版本为7.0版。它操作灵活、简单、易学易用,是一个非常有特色的统计分析软件,现在已越来越受到人们的重视和欢迎,并且和SAS、SPSS一起,被称为新的三大权威统计软件。 Stata最为突出的特点是短小精悍、功能强大,其最新的7.0版整个系统只有10M左右,但已经包含了全部的统计分析、数据管理和绘图等功能,尤其是他的统计分析功能极为全面,比起1G以上大小的SAS系统也毫不逊色。另外,由于Stata在分析时是将数据全部读入内存,在计算全部完成后才和磁盘交换数据,因此运算速度极快。 由于Stata的用户群始终定位于专业统计分析人员,因此他的操作方式也别具一格,在Windows席卷天下的时代,他一直坚持使用命令行/程序操作方式,拒不推出菜单操作系统。但是,Stata的命令语句极为简洁明快,而且在统计分析命令的设置上又非常有条理,它将相同类型的统计模型均归在同一个命令族下,而不同命令族又可以使用相同功能的选项,这使得用户学习时极易上手。更为令人叹服的是,Stata语句在简洁的同时又拥有着极高的灵活性,用户可以充分发挥自己的聪明才智,熟练应用各种技巧,真正做到随心所欲。
除了操作方式简洁外,Stata的用户接口在其他方面也做得非常简洁,数据格式简单,分析结果输出简洁明快,易于阅读,这一切都使得Stata成为非常适合于进行统计教学的统计软件。 Stata的另一个特点是他的许多高级统计模块均是编程人员用其宏语言写成的程序文件(ADO文件),这些文件可以自行修改、添加和下载。用户可随时到Stata网站寻找并下载最新的升级文件。事实上,Stata的这一特点使得他始终处于统计分析方法发展的最前沿,用户几乎总是能很快找到最新统计算法的Stata程序版本,而这也使得Stata自身成了几大统计软件中升级最多、最频繁的一个。 由于以上特点,Stata已经在科研、教育领域得到了广泛应用,WHO的研究人员现在也把Stata作为主要的统计分析工作软件。 第二节 Stata操作入门 一、Stata的界面 图1即为Stata 7.0启动后的界面,除了Windows版本的软件都有的菜单栏、工具栏,状态栏等外,Stata的界面主要是由四个窗口构成,分述如下: 1.结果窗口:位于界面右上部,软件运行中的所有信息,如所执行的命令、执行结果和出错信息等均在这里列出。窗口中会使用不同的颜色区分不同的文本,如白色表示命令,红色表示错误信息。 2.命令窗口:位于结果窗口下方,相当于DOS软件中的命令行,此处用于键入需要执行的命令,回车后即开始执行,相应的结果则会在结果窗口中显示出来。
操作系统与驱动开发试题
河北科技大学硕士学位研究生 2014——2015学年第1学期 《操作系统与驱动开发》课程期末考试试卷 学院信息学院专业电路与系统姓名程莉学号 2201414007 题号一二三四五六总分 得分 一.单项选择题(每小题1分,共10分) 1.操作系统的 D 管理部分负责对进程进行调度。 A.主存储器 B.控制器 C.运算器 D.处理机 2.分时操作系统通常采用 B 策略为用户服务。 A.可靠性和灵活性 B.时间片轮转 C.时间片加权分配 D.短作业优先 3.很好地解决了“零头”问题的存储管理方法是 A 。 A 页式存储管理 B 段式存储管理 C 多重分区管理 D 可变式分区管理 4.用WAIT、SIGNAL操作管理临界区时,信号量的初值应定义为 B 。 A.-1 B.0 C.1 D.任意值 5.在进程管理中,当 C 时,进程从阻塞状态变为就绪状态。 A.进程被进程调度程序选中 B.等待某一事件 C.等待的事件发生 D.时间片用完 6.某系统中有3个并发进程,都需要同类资源4个,试问该系统不会发生死锁的最少资源数 B 。 A.9 B.10 C.11 D.12 7.虚拟存储器管理系统的基础是程序的 B 理论。 A.全局性 B.局部性 C. 动态性 D.虚拟性 8.从用户的角度看,引入文件系统的主要目的是 D A.实现虚拟存储 B.保存系统文档
C.保存用户和系统文档 D.实现对文件的按名存取 9.操作系统中采用多道程序设计技术提高CPU和外部设备的 A A.利用率 B.可靠性 C.稳定性 D.兼容性 10.缓冲技术中缓冲池在 C 中。 A.主存 B. 外存 C. ROM D. 时间片轮转 二.填空(每空0.5分,共15分)。 11.进程存在的唯一标志是PCB 。 12.通常进程实体是由程序块、进程控制块和数据块三部分组成。 13.磁盘访问时间由寻道时间、旋转延迟时间和传输时间组成。 14.作业调度是从后备作业队列中选一些作业,为它们分配资源,并为它们创建进程。 15.文件的物理组织有顺序、链接和索引。 16.若一个进程已经进入临界区,则其它欲要进入临界区的进程必须___等待____。 17.信号量的物理意义是,当信号量值大于零时其值表示可分配资源的个数;当信号 量值小于零时,其绝对值表示等待使用该资源的进程的个数。 18.静态重定位在程序装入时进行; 而动态重定位在程序运行时进行。 19.分区管理中采用“最佳适应”分配算法时,宜把空闲区按长度递增次序登记在空闲 区表中。 20.所谓系统调用,就是用户在程序中调用操作系统所提供的一些子功能。 21.把逻辑地址映射为物理地址的工作称为地址映射。 22.设备管理中采用的数据结构有设备控制表、控制器控制表、通道控制表、 系统设备表等四种。 23.从资源管理(分配)的角度,I/O设备可分为独占设备、共享设备和虚 拟设备三种。 24.设备与控制器之间的接口信号主要包括数据、状态和控制。 25.DMA控制器由三部分组成,分别为主机与DMA控制器的接口、 DMA控制器与块设备的接 口和 I/O控制逻辑。 三.名词解释(每小题2.5分,共10分)。 26.虚拟存储器 答:虚拟存储器是指在具有层次结构存储器的计算机系统中,自动实现部分装入和部分替换功能,能从逻辑上为用户提供一个比物理贮存容量大得多,可寻址的“主存储器”。
领域驱动设计(DDD)架构的实践
领域驱动设计(DDD)架构的实践
前言 至少30年以前,一些软件设计人员就已经意识到领域建模和设计的重要性,并形成一种思潮,Eric Evans将其定义为领域驱动设计(Domain-Driven Design,简称DDD)。在互联网开发“小步快跑,迭代试错”的大环境下,DDD似乎是一种比较“古老而缓慢”的思想。 然而,由于互联网公司也逐渐深入实体经济,业务日益复杂,我们在开发中也越来越多地遇到传统行业软件开发中所面临的问题。本文就先来讲一下这些问题,然后再尝试在实践中用DDD的思想来解决这些问题。 问题 过度耦合 业务初期,我们的功能大都非常简单,普通的CRUD就能满足,此时系统是清晰的。随着迭代的不断演化,业务逻辑变得越来越复杂,我们的系统也越来越冗杂。模块彼此关联,谁都很难说清模块的具体功能意图是啥。修改一个功能时,往往光回溯该功能需要的修改点就需要很长时间,更别提修改带来的不可预知的影响面。
下图是一个常见的系统耦合病例。 订单服务接口中提供了查询、创建订单相关的接口,也提供了订单评价、支付、保险的接口。同时我们的表也是一个订单大表,包含了非常多字段。在我们维护代码时,牵一发而动全身,很可能只是想改下评价相关的功能,却影响到了创单核心路径。虽然我们可以通过测试保证功能完备性,但当我们在订单领域有大量需求同时并行开发时,改动重叠、恶性循环、疲于奔命修改各种问题。 上述问题,归根到底在于系统架构不清晰,划分出来的模块内聚度低、高耦合。
有一种解决方案,按照演进式设计的理论,让系统的设计随着系统实现的增长而增长。我们不需要作提前设计,就让系统伴随业务成长而演进。这当然是可行的,敏捷实践中的重构、测试驱动设计及持续集成可以对付各种混乱问题。重构——保持行为不变的代码改善清除了不协调的局部设计,测试驱动设计确保对系统的更改不会导致系统丢失或破坏现有功能,持续集成则为团队提供了同一代码库。 在这三种实践中,重构是克服演进式设计中大杂烩问题的主力,通过在单独的类及方法级别上做一系列小步重构来完成。我们可以很容易重构出一个独立的类来放某些通用的逻辑,但是你会发现你很难给它一个业务上的含义,只能给予一个技术维度描绘的含义。这会带来什么问题呢?新同学并不总是知道对通用逻辑的改动或获取来自该类。显然,制定项目规范并不是好的idea。我们又闻到了代码即将腐败的味道。 事实上,你可能意识到问题之所在。在解决现实问题时,我们会将问题映射到脑海中的概念模型,在模型中解决问题,再将解决方案转换为实际的代码。上述问题在于我们解决了设计到代码之间的重构,但提炼出来的设计模型,并不具有实际的业务含义,这就导致在开发新需求时,其他同学并不能很自然地将业务问题映射到该设计模型。设计似乎变成了重构者的自娱自乐,代码继续腐败,重新重构……无休止的循环。 用DDD则可以很好地解决领域模型到设计模型的同步、演化,最后再将反映了领域的设计模型转为实际的代码。
VB数据库基础知识
数据库基础知识 几乎所有的商业应用程序都需要处理大量的数据,并将其组织成易于读取的格式。这种要求通常可以通过数据库管理系统(MDBS)实现。MDBs是用高级命令操作表 格式数据的机制。数据库管理系统隐藏了数据在数据库中的存放方式之类的底层细节,使编程人员能够集中精力管理信息,而不是考虑文件的具体操作或数据连接关系的维护。 下面,先介绍几个基本的概念。 数据库:数据库就是一组排列成易于处理或读取的相关信息。数据库中的实际数据存放成表格(table),类似于随机访问文件。表格中的数据由行(row)和列(column)元素组成,行中包含结构相同的信息块,类似于随机访问文件中的记录,记录则是一组数值(或称为字段的集合),如图1所示: 图1:数据库和表格结构的图形表示 记录集:记录集(RecordSet)是表示一个或几个表格中的对象集合的多个对象。在数据库编程中,记录集等于程序中的变量。数据库中的表格不允许直接访问,而只能通过记录集对象进行记录的浏览和操作。记录集是由行和列构成的,它和表格相似,但可以包含多个表格中的数据。如图2所示网格中的内容来自于一个表格,形成一个记录集。图中所示的查询结果是所有作者的资料。 图2:BIBlIO数据库的Authors表,所选的行是Authors的相关记录 注意:可以把记录看成一种浏览数据库的工具,用户可以根据需要指定要选择的数据,记录集的类型有三类:
(1)DynaSets:这是可修改的显示数据; (2)SnapShots:这是静态(只读)的显示数据; (3)Tables:这是表格的直接显示数据。 DynaSets和SnapShots通常用SQL(结构化查询语言)语句生成,SQL将在以后介绍,但现在只要知道SQL语句是从指定数据库中读取数据的标准命令即可。DynaSets在每次用户数据库时更新,而对记录集的改变会反映在基础表格中。SnapShots是同一数据的静态显示,其中包含生成snapshots时请求的记录(基础表格中的改变不会在SnapShots中反映出来),自然也不会更改SnapShots。DynaSets是最灵活、最强大的记录集。虽然Table类型记录集需要大量间接成本。SnapShots是最缺少灵活性的记录集,但所要的间接成本最少。如果不需要更新数据库,只要浏览记录,可以用SnapShots这种类型。 SnapShots类型还有一个变形正向型SnapShots,这种类型SnapShots的限制更多,只能正向移动,但速度更快。正向型SnapShots可以用于要扫描多个记录并顺序处理(进行数值计算,复制所选记录到另一个表格中,等等)数据库记录的情况。这个记录集不提供反向方法,所以间接成本少。 Tables型记录组可以用于调用数据库表格。Tables比其他记录集类型的处理速度都快,可以保持表格与数据库中的数据同步,也可用于更新数据库。但Table 只限于一个表格。此外,通过Tables型记录集访问表格时,可以利用Tables 的索引值进行快速查找。 https://www.360docs.net/doc/0414781215.html,数据集(Datasets)的概念 1.基本概念 数据集是一种离线了的缓存存储数据,它的结构和数据库一样,具有表格、行、列的一种层次结构,另外还包括了为数据集所定义的数据间的约束和关联关系。用户可通过.NEt框架的命名空间(NameSpace)来创建和操作数据集。 用户可以通过一些诸如属性(properties)、集合(collections)这些标准的构成来了解Dataset这个概念。如: (1)数据集(DataSet)包括数据表格的Tables这个集合以及relation的"Relations"集合。 (2)DataTable类包括了数据表格row的"Rows"集合,数据columns的"Column" 集合,以及数据relation的"ChildRelations"和"ParentRelations"集合。(3)DataRow类包括"RowState"属性,这些值是用来显示数据表格首次从数据库 被加载后是否被修改过,这个属性的值可以为:"Deleted"、"Modified"、"New"以及"Unchanged"。 2.定义(Type)和未定义(Untyped)的数据集 数据集有定型的和未定型的之分,定型的数据集是基本的DataSet类的一个子类,并且含有图表(.xsd文件),它用来描述数据集所拥有的表格的结构。这些图表 文件,包括了表的名字和列名、列所代表的数据的类型信息,以及数据间的约束关系。而一个未定型的数据集则没有这些图表的描述。 在程序中用户可以使用任意两种类型的数据集,然而,定型的数据集可以使得用户对数据的操作更加明了,并且可以减少一些不必要的错误,定型的数据集可以生成一些对象模型,这些模型的第一层次的类(first-class)就是数据集所包含
[教程]-领域驱动设计(DDD)
本文内容提要: 1. 领域驱动设计之领域模型 2. 为什么建立一个领域模型是重要的 3. 领域通用语言(Ubiquitous Language) 4.将领域模型转换为代码实现的最佳实践 5. 领域建模时思考问题的角度 6.领域驱动设计的标准分层架构 7. 领域驱动设计过程中使用的模式 关联的设计 实体(Entity) 值对象(Value Object) 领域服务(Domain Service) 聚合及聚合根(Aggregate,Aggregate Root) 工厂(Factory) 仓储(Repository) 8. 设计领域模型的一般步骤 9. 领域驱动设计的其他一些主题 10. 一些相关的扩展阅读 领域驱动设计之领域模型 2004年Eric Evans发表Domain-Driven Design – Tackling Complexity in the Heart of Software (领域驱动设计),简称Evans DDD。领域驱动设计分为两个阶段: 1. 以一种领域专家、设计人员、开发人员都能理解的―通用语言‖作为相互交流的工具,在不断交流的过程中不断发现一些主要的领域概念,然后将这些概念设计成一个领域模型; 2. 由领域模型驱动软件设计,用代码来表现该领域模型。 由此可见,领域驱动设计的核心是建立领域模型。领域模型在软件架构中处于核心地位;软件开发过程中,必须以建立领域模型为中心。 为什么建立一个领域模型是重要的 领域驱动设计告诉我们,在通过软件实现一个业务系统时,建立一个领域模型是非常重要和必要的,因为领域模型具有以下特点: 1. 领域模型是对具有某个边界的领域的一个抽象,反映了领域内用户业务需求的本质;领域模型是有边界的,只反应了我们在领域内所关注的部分;
领域知识模型
领域知识模型——企业应用系统的智慧中枢 摘要:企业应用系统有海量的领域对象和丰富的领域知识,这些领域知识一般被作为领域对象的业务逻辑或规则定义。本文认为领域知识是领域模型的一个知识切面且自成体系,结合领域驱动设计[DDD]和面向方面编程[AOP]的方法,对领域知识进行建模和应用,让面向业务活动的领域应用对象只需关注业务过程的组织和管理,用AOP技术把领域知识应用到具体的业务处理策略中,使领域应用对象和领域知识对象有更好内聚性且更轻量,不仅可大幅提升它们的可管理性和复用性,而且对系统开发效率、动态业务建模和装配能力也大有益处。 关键词:领域知识、领域模型、领域驱动设计、企业应用架构、DDD、AOP 1.前言 领域模型[Domain Model]和领域驱动设计[Domain-Driven Design][1]是目前在应用软件行业非常热门和前沿的话题,普遍认为这是构建高质量复杂系统最有效的方法和技术。领域模型在业界比较认可的定义是:领域模型是领域内的概念或者现实世界中对象的可视化表示,又称为概念模型、领域对象模型、分析对象模型,它专注于分析领域问题本身,领域对象是与技术无关的纯业务对象。领域建模的核心理念是把业务对象的属性、规则和职能封装在领域对象中,而不是被分散在用户界面层、应用层和持久化层中。 领域建模一般情况下是从应用功能或用例[Use Case]入手,因此,领域模型中的领域对象也是直接与应用功能或用例相关的业务对象,而这些领域对象模型涉及的领域知识,一般都作为领域对象的逻辑或者规则而存在。知识是应用领域问题的本质,是特定领域中一系列业务对象共有的知识切面,这个知识切面自成体系,本文中把这个知识体系的模型称为领域知识模型,与具体应用功能或者活动相关的领域对象模型称为领域应用模型。为了便于理解这些概念,我用一个与企业管理无关的通俗的例子来说明知识模型和应用模型的关系,比如对我喜欢的台球运动进行游戏建模,美式九球模型或者英式斯诺克模型是具体的领域应用模型,球台、球、球杆、运动员等是应用领域模型的核心领域对象,但要做出好玩的仿真游戏,台球碰撞中的基本物理知识是不可或缺的,用牛顿理论作为领域知识模型就涉及到质量、速度、动量等概念和动量守恒及能量守恒模型。知识模型是高度抽象并且可独立存在的模型,也是可以在各种业务情景中复用的模型,就如前面提到的台球游戏用到的牛顿理论模型,同样可以应用到保龄球游戏以及任何一款涉及到碰撞的游戏场景。企业管理领域也同样存在大量的知识模型,本文笔者致力于把企业管理领域涉及的领域知识进行分离、建模和应用的可行性分析和实践,希望以此进一步提升大型复杂企业应用系统的质量、动态业务建模和装配能力及组件复用水平。 2.企业应用系统中的领域知识问题分析 企业应用系统已逐渐成为企业经营管理的一体化应用平台,面向业务流程的行业深度应用
Windows驱动开发入门
接触windows驱动开发有一个月了,感觉Windows驱动编程并不像传说中的那么神秘。为了更好地为以后的学习打下基础,记录下来这些学习心得,也为像跟我一样致力于驱动开发却苦于没有门路的菜鸟朋友们抛个砖,引个玉。 我的开发环境:Windows xp 主机+ VMW ARE虚拟机(windows 2003 server系统)。编译环境:WinDDK6001.18002。代码编辑工具:SourceInsight。IDE:VS2005/VC6.0。调试工具:WinDBG,DbgView.exe, SRVINSTW.EXE 上面所有工具均来自互联网。 对于初学者,DbgView.exe和SRVINSTW.EXE是非常简单有用的两个工具,一定要装上。前者用于查看日志信息,后者用于加载驱动。 下面从最简单的helloworld说起吧。Follow me。 驱动程序的入口函数叫做DriverEntry(PDRIVER_OBJECT pDriverObj,PUNICODE_STRING pRegisgryString)。两个参数,一个是驱动对象,代表该驱动程序;另一个跟注册表相关,是驱动程序在注册表中的服务名,暂时不用管它。DriverEntry 类似于C语言中的main函数。它跟main的差别就是,main完全按照顺序调用的方法执行,所有东西都按照程序员预先设定的顺序依次发生;而DriverEntry则有它自己的规则,程序员只需要填写各个子例程,至于何时调用,谁先调,由操作系统决定。我想这主要是因为驱动偏底层,而底层与硬件打交道,硬件很多都是通过中断来与操作系统通信,中断的话就比较随机了。但到了上层应用程序,我们是看不到中断的影子的。说到中断,驱动程序中可以人为添加软中断,__asm int 3或者Int_3();前者是32位操作系统用的,后者是64位用的。64位驱动不允许内嵌汇编。下面是我的一个helloworld的源码:
数据库模型基础知识及数据库基础知识总结
数据库模型基础知识及数据库基础知识总结 数据库的4个基本概念 1.数据(Data):描述事物的符号记录称为数据。 2.数据库(DataBase,DB):长期存储在计算机内、有组织的、可共享的大量数据的集合。 3.数据库管理系统(DataBase Management System,DBMS 4.数据库系统(DataBase System,DBS) 数据模型 数据模型(data model)也是一种模型,是对现实世界数据特征的抽象。用来抽象、表示和处理现实世界中的数据和信息。数据模型是数据库系统的核心和基础。数据模型的分类 第一类:概念模型 按用户的观点来对数据和信息建模,完全不涉及信息在计算机中的表示,主要用于数据库设计现实世界到机器世界的一个中间层次 ?实体(Entity): 客观存在并可相互区分的事物。可以是具体的人事物,也可以使抽象的概念或联系 ?实体集(Entity Set): 同类型实体的集合。每个实体集必须命名。 ?属性(Attribute): 实体所具有的特征和性质。 ?属性值(Attribute Value): 为实体的属性取值。 ?域(Domain): 属性值的取值范围。 ?码(Key): 唯一标识实体集中一个实体的属性或属性集。学号是学生的码?实体型(Entity Type): 表示实体信息结构,由实体名及其属性名集合表示。如:实体名(属性1,属性2,…) ?联系(Relationship): 在现实世界中,事物内部以及事物之间是有联系的,这些联系在信息世界中反映为实体型内部的联系(各属性)和实体型之间的联系(各实体集)。有一对一,一对多,多对多等。 第二类:逻辑模型和物理模型 逻辑模型是数据在计算机中的组织方式
Windows驱动程序开发环境配置
Windows驱动程序开发笔记 一、WDK与DDK环境 最新版的WDK 微软已经不提供下载了这里:https://https://www.360docs.net/doc/0414781215.html,/ 可以下并且这里有好多好东东! 不要走进一个误区:下最新版的就好,虽然最新版是Windows Driver Kit (WDK) 7_0_0,支持windows7,vista 2003 xp等但是它的意思是指在windows7操作系统下安装能编写针对windows xp vista的驱动程序, 但是不能在xp 2003环境下安装Windows Driver Kit (WDK) 7_0_0这个高版本,否则你在build的时候会有好多好多的问题. 上文build指:首先安装好WDK/DDK,然后进入"开始"->"所有程序"->"Windows Driver Kits"->"WDK XXXX.XXXX.X" ->"Windows XP"->"x86 Checked Build Environment"在弹出来的命令行窗口中输入"Build",让它自动生成所需要的库 如果你是要给xp下的开发环境还是老老实实的找针对xp的老版DDK吧,并且xp无WDK 版只有DDK版build自己的demo 有个常见问题: 'jvc' 不是内部或外部命令,也不是可运行的程序。 解决办法:去掉build路径中的空格。 二、下载 WDK 开发包的步骤 1、访问Microsoft Connect Web site站点 2、使用微软 Passport 账户登录站点 3、登录进入之后,点击站点目录链接 4、在左侧的类别列表中选择开发人员工具,在右侧打开的类别:开发人员工具目录中找到Windows Driver Kit (WDK) and Windows Driver Framework (WDF)并添加到您的控制面板中 5、添加该项完毕后,选择您的控制面板,就可以看到新添加进来的项了。 6、点击Windows Driver Kit (WDK) and Windows Driver Framework (WDF),看到下面有下载链接,OK,下载开始。下载后的文件名为: 6.1.6001.18002.081017-1400_wdksp-WDK18002SP_EN_DVD.iso将近600M大小。
【新手入门】数据分析新手成长历程
表哥表姐的升级之路 Q1:什么是表哥表姐? A1:指市场部,运营部,业务部等部门专门负责数据提取,整理,出报表工作的基层员工。此类同学一般日常使用excel,简单的SQL工具,对基础数据进行筛选,整理,制作诸如:《XX公司业务月报》一类报表给对应部门查看。 Q2:表哥表姐为什么要升级 A2:因为这个岗位是一个高不成低不就的岗位,既不懂底层的数据仓储,数据库,没有编写分析代码,设计分析模型的能力,又不能跟市场,业务,运营部的老大汇报,参与决策,每天看的数据挺多,但大部分仅是输出简单的统计平均数,或者百分比,完全不知道这些数据是怎么来的,不知道是怎么用的,不知道有什么价值,想跳槽,一看应聘要求不是要求精通业务有实操经验,就是要求懂XX语言,会XX开发,内部升职无望,外部跳槽无力。 Q3:那表哥表姐该如何升级呢? A3:沉下去走技术线(学习系统,代码,开发知识,学习数据库,数据仓储等系统知识)或者浮上来走业务线(学习营销,策划,推广,销售,品牌,运营管理等知识)。 Q4:该选哪条线呢? A4:看个人能力,兴趣爱好及基础知识。理论上技术好的走技术,业务好的走业务。但是两条路都会有共同的困难:必须学习大量日常工作中用不到的知识才能升级,但一来日常工作用不到,非工作时间很难抽出空闲时间学习,二来日常工作用不到,所以学了也很容易忘,三来即使学会了,跳槽的时候想转型也很难说服HR相信,自己能适应一份过往X年内都没干过的岗位,十有八九不被HR认可,还是干回表姐。 Q5:但是我是一个有耐心,能牺牲业余时间,有主动学习精神,会编故事忽悠hr的好表哥,请指导我怎么升级吧! A5:技术线学习请咨询群主fly大神,业务线学习主要是提升业务能力,要懂业务。 Q6:我天天听人说:你懂不懂业务,业务要熟练,那么业务到底是个什么玩意? A6:业务就是怎么做生意,一个成功的生意包括:设计概念,研发产品,生产产品,品牌
数据库基础知识和Access入门习题答案
一、选择题 1.数据库系统的核心是。 A.数据库 B.数据库管理员 C.数据库管理系统 D.文件 2. A.记录 B.字段 C.域 3.Access数据库文件的扩展名是。 A.DOC B.XLS C.HTM D.MDB 4.DB、DBMS和DBS A.DB包括DBMS和DBS 包括DB和DBMS C.DBMS包括DBS和DB D.DBS与DB和DBMS无关 5.数据库管理系统位于。 A.硬件与操作系统之间 B.用户与操作系统之间 C.用户与硬件之间 D.操作系统与应用程序之间 6.使用二维表表示实体之间联系的数据模型是。 A.实体-联系模型 B.层次模型 C.关系模型 D.网状模型 7.一个学生可以选修多门课程,一门课程可以由多个学生选修,则学生—课程之间的联系为。 A.一对一 B.一对多 C.多对一 D.多对多 8.Access A.层次型 C.网状型 D.树型 9.关系数据库的基本关系运算有。 A.选择、投影和删除 B.选择、投影和添加 C.选择、投影和连接 D.选择、投影和插入 10.在E-R图中,用来表示联系的图形是。 A.矩形 B.三角形 C.椭圆形 D.菱形 二、填空题 1.常用的数据模型有层次模型、网状模型和关系模型。 2.实体与实体之间的联系有3种,它们是一对一、一对多和多对多。 3.二维表中的列称为关系的属性,二维表中的行称为关系的元组。 4.Access数据库中的7种数据库对象分别是表、查询、窗体、报表、数据访问页、宏和模块。 5.在关系数据库中,一个属性的取值范围为域。 三、简答题 1.什么是数据?什么是数据库?
答:数据是描述现实世界事物的符号记录形式,是利用物理符号记录下来可以识别的信息,数据的概念包括两个方面:一是描述事物特性的数据内容;二是存储在某一种媒体上的数据形式。 数据库是数据的集合,并按特定的组织方式将数据保存在存储介质上,同时可以被各种用户所共享。数据库不仅包含描述事物的数据本身,也包含数据之间的联系。
数据分析 数学基础
数据分析数学基础 统计学:科学方法收集、整理、汇总、描述和分析数据资料,并在此基础上进行推断和决策的科学; 归纳统计学/统计推断:通过样本分析来给总体下结论 描述性统计学/演绎统计学:值描述和分析特定对象而不下结论或推断 变量、常量、连续变量、离散变量、连续数据、离散数据 自变量、因变量、函数、单值函数、多值函数 数组阵列:原始数据按照数量大小升序或者降序排列,最大值与最小值的差为全距; 组距、组限、组界、组中值、直方图与频率多边形 频率分布=某一组频数/总频数 累计频数分布/累计频数表,累计频数多边形/卵形线 累计频率分布/百分率累计频数=累计频数/总频数 1、平均值/集中趋势的度量:趋向落在根据数值大小排列的数据的中心 算术平均: 加权算术平均: 2、中位数:一组数根据数量大小排列后的做兼职或者两个中间值的算术平均值 3、众数:一组数出现次数最多的那个数,众数不一定存在,也不唯一 均值、中位数和众数之间的关系: 4、几何平均G 5、调和平均H 算术平均、几何平均和平均之间的关系 6、均方根RMS 离差/变差:数值数据围绕其平均值分布的分数与集中程度,常用的有全距、平均偏差、半内四分位数间距,10-90百分位数间距、标准差; 1、全距:最大值-最小值 2、平均偏差 3、半内四分位数间距 4、10-90百分位数间距 5、标准差 6、方差:标准差的平方 离差度量间的关系 1、矩 2、r阶中心矩 3、偏度:分布不对称程度或偏离对称程度的反映 4、峰度:分布的陡峭程度,尖峰、扁峰、常峰态 1、概率 2、条件概率,独立和不独立事件 3、互不相容事件:两个或多个事件中,任意两个事件都不能同时发生 4、概率分布 离散型:离散型概率分布 连续型:概率密度函数、连续型概率分布 5、数学期望 如果一个人活得S美元的概率为p,则他的数学期望=pS
DDD领域驱动设计基本理论知识总结
?领域驱动设计之领域模型 ?为什么建立一个领域模型是重要的 ?领域通用语言(UBIQUITOUS LANGUAGE) ?将领域模型转换为代码实现的最佳实践 ?领域建模时思考问题的角度 ?领域驱动设计的经典分层架构 ?用户界面/展现层 ?应用层 ?领域层 ?基础设施层 ?领域驱动设计过程中使用的模式 ?所有模式的总揽图 ?关联的设计 ?实体(Entity) ?值对象(Value Object) ?领域服务(Domain Service) ?应用层服务 ?领域层服务 ?基础层服务 ?聚合及聚合根(Aggregate,Aggregate Root) ?聚合有以下一些特点: ?如何识别聚合? ?如何识别聚合根? ?工厂(Factory) ?仓储(Repository) ?设计领域模型的一般步骤 ?在分层架构中其他层如何与领域层交互 ?对于会影响领域层中领域对象状态的应用层功能 ?关于Unit of Work(工作单元)的几种实现方法 ?对于不会影响领域层中领域对象状态的查询功能 ?为什么面向对象比面向过程更能适应业务变化 ?领域驱动设计的其他一些主题 ?一些相关的扩展阅读 ?CQRS架构 ?Event Sourcing(事件溯源) ?DCI架构 ?四色原型分析模式 ?时刻-时间段原型(Moment-Interval Archetype) ?参与方-地点-物品原型(Part-Place-Thing Archetype)?描述原型(Description Archetype) ?角色原型(Role Archetype) 领域驱动设计之领域模型
加一个导航,关于如何设计聚合的详细思考,见这篇文章。 2004年Eric Evans 发表Domain-Driven Design –Tackling Complexity in the Heart of Software (领域驱动设计),简称Evans DDD。领域驱动设计分为两个阶段: 以一种领域专家、设计人员、开发人员都能理解的通用语言作为相互交流的工具,在交流的过程中发现领域概念,然后将这些概念设计成一个领域模型; 由领域模型驱动软件设计,用代码来实现该领域模型; 由此可见,领域驱动设计的核心是建立正确的领域模型。 为什么建立一个领域模型是重要的 领域驱动设计告诉我们,在通过软件实现一个业务系统时,建立一个领域模型是非常重要和必要的,因为领域模型具有以下特点: 1.领域模型是对具有某个边界的领域的一个抽象,反映了领域内用户业务需求的本质;领 域模型是有边界的,只反应了我们在领域内所关注的部分; 2.领域模型只反映业务,和任何技术实现无关;领域模型不仅能反映领域中的一些实体概 念,如货物,书本,应聘记录,地址,等;还能反映领域中的一些过程概念,如资金转 账,等; 3.领域模型确保了我们的软件的业务逻辑都在一个模型中,都在一个地方;这样对提高软 件的可维护性,业务可理解性以及可重用性方面都有很好的帮助; 4.领域模型能够帮助开发人员相对平滑地将领域知识转化为软件构造; 5.领域模型贯穿软件分析、设计,以及开发的整个过程;领域专家、设计人员、开发人员 通过领域模型进行交流,彼此共享知识与信息;因为大家面向的都是同一个模型,所以 可以防止需求走样,可以让软件设计开发人员做出来的软件真正满足需求; 6.要建立正确的领域模型并不简单,需要领域专家、设计、开发人员积极沟通共同努力, 然后才能使大家对领域的认识不断深入,从而不断细化和完善领域模型; 7.为了让领域模型看的见,我们需要用一些方法来表示它;图是表达领域模型最常用的方 式,但不是唯一的表达方式,代码或文字描述也能表达领域模型; 8.领域模型是整个软件的核心,是软件中最有价值和最具竞争力的部分;设计足够精良且 符合业务需求的领域模型能够更快速的响应需求变化; 领域通用语言(UBIQUITOUS LANGUAGE) 我们认识到由软件专家和领域专家通力合作开发出一个领域的模型是绝对需要的,但是,那种方法通常会由于一些基础交流的障碍而存在难点。开发人员满脑子都是类、方法、算法、模式、架构,等等,总是想将实际生活中的概念和程序工件进行对应。他们希望看到要建立哪些对象类,要如何对对象类之间的关系建模。他们会习惯按照封装、继承、多态等面向对象编程中的概念去思考,会随时随地这样交谈,这对他们来说这太正常不过了,开发人员就是开发人员。但是领域专家通常对这一无所知,他们对软件类库、框架、持久化甚至数据库没有什么概念。他们只了解他们特有的领域专业技能。比如,在空中交通监控样例中,领域专家知道飞机、路线、海拔、经度、纬度,知道飞机偏离了正常路线,知道飞机的发射。他们用他们自己的术语讨论这些事情,