计量经济学庞皓3版第四章练习题4.4参考解答要点
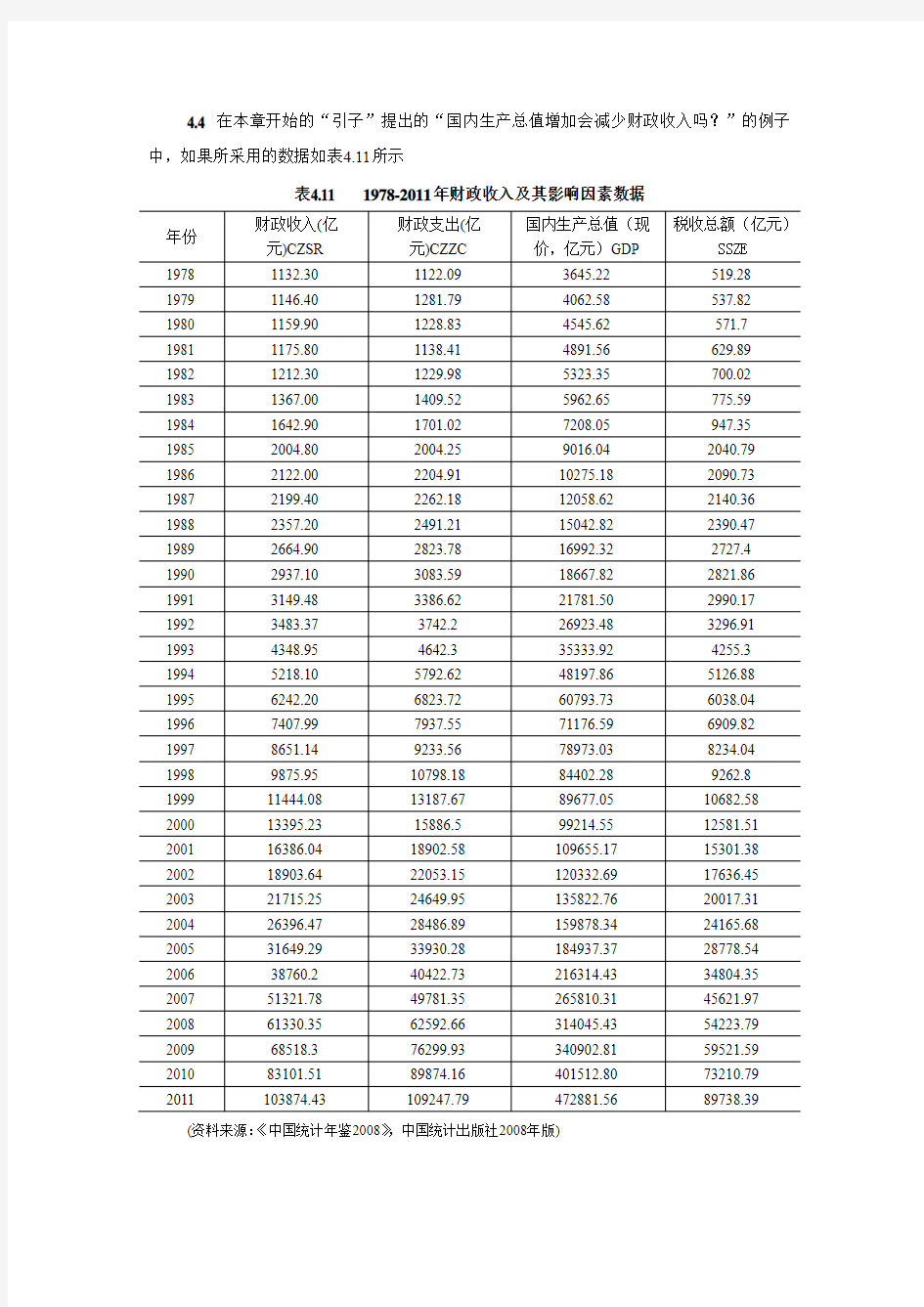

4.4 在本章开始的“引子”提出的“国内生产总值增加会减少财政收入吗?”的例子中,如果所采用的数据如表4.11所示
表4.11 1978-2011年财政收入及其影响因素数据
(资料来源:《中国统计年鉴2008》,中国统计出版社2008年版)
试分析:为什么会出现本章开始时所得到的异常结果?怎样解决所出现的问题? 【练习题4.4参考解答】 建议学生自己独立完成
由于模型存在严重的多重共线性,导致模型的回归系数不稳定,且回归系数的符号与相关图的分析不一致。
一、财政收入理论模型建立
由经济理论可知,一个国家或地区的经济发展是财政收入的来源,经济发展水平越高或者经济总量越大的地区,财政收入就越有充足的來源,一般地衡量一国的经济发展水平我们采用国内生产总值反映,故国内生产总值是影响财政收入的一个因素;税收是财政收入的主要形式,税收规模越大, 财政收入越多,税收收入是影响财政收入的一个重要因素;由以支定收财政理论可知,财政支出是政府为提供公共产品和服务,满足社会共同需要而进行的财政资金的支付,财政支出水平越高,政府提供公共产品与服务越多,需要的财政收入也越多,从这一角度而言,财政支出也是影响财政收入的一个因素。下列的相关图分析也说明了这一点。利用eviews 软件分别输入相关图命令:
scat czzc czsr scat gdp czsr scat ssze czsr
得财政支出与财政收入、国内生产总值与财政收入、税收收入与财政收入的相关图,如图一所示:
图一 变量之间的相关图
由相关图可知,财政支出、国内生产总值、税收收入分别与财政收入之间呈现出一种正的线性关系,综上所述,初步将财政收入理论模型定为线性回归模型:
t t t t t u ssze GDP czzc czsr +++=4321ββββ+
其中,czsr 表示财政收入、czzc 表示财政支出、GDP 表示国内生产总值、ssze 表示税
收收入、 u 表示随机扰动项
二、数据收集和处理
相关变量的数据均来源于《2012年中国统计年鉴》 三、模型估计
在预设模型满足基本假定的前提条件下,我们运用最小二乘法估计回归模型,eviews
软件估计回归模型的命令为
Ls cszr c czzc gdp ssze
得到回归模型估计结果,如图二所示
图二 财政收入三元线性回归模型1
根据图二数据,财政收入三元线性回归模型可用标准报告形式表示为:
t t t t ssze GDP czzc r
czs 1769.10253.00901.08540.221?+-+-=(模型1) (0.0444) (0.0051) (0.0622) T= (2.0311) (-4.9980) (18.9327)
2R =0.9999 2R =0.9998 F=53493.93 DW=1.4581
四、模型检验
1、经济意义及统计检验
由图二及报告形式,可以看出尽管模型判定系数2
R 高达0.9999,非常接近于1,模型拟合程度很高; F 统计量值达53493.93,其伴随概率接近于0,模型整体明显显著;回归系数的精确显著性水平均小于0.05;财政支出cczc 和税收总额ssze 的回归系数为正数,与理论分析相吻合,但GDP 的回归系数为负数,表明在其他解释变量不变的情况下,GDP 每增长一亿元,财政收入将减少0.0341亿元,这与前述的理论分析不吻合,也与相关图的分析不一致。这说明模型可能存在多重共线性,为此,我们进行多重共线性检验。
2、多重共线性检验
首先进行简单相关系数检验,输入命令:cor czsr czzc gdp ssze ,得到变量之间的相
关系数矩阵表,如表一所示:
表一 变量之间的相关系数矩阵表
由简单相关系数矩阵表可以看出,解释变量(财政支出、国内生产总值、税收总额)
之间的相关系数至少0.9925,大于0.8,表明模型存在严重的多重共线性;
但简单相关系数仅能检验两个变量的相关程度,而本例解释变量有三个,为了更好
地了解多重共线性的性质,需要建立辅助回归模型和计算方差膨胀因子来检验模型多重共线性,为此,分别建立每个解释变量对其他解释变量的辅助回归模型,即
i t t t ssze GDP czzc νααα+++=211101 i t t t ssze czzc gdp νααα+++=221202 i t t t gdp czzc ssze νααα+++=231303
利用eviews 软件分别运用最小二乘法估计辅助回归模型,依次输入命令: ls czzc c gdp ssze
ls gdp c czzc ssze ls ssze c czzc gdp
得到辅助回归模型估计结果,如图三、图四、图五所示:
图三czzc对其他解释变量辅助回归模型估计结果
图四gdp对其他解释变量辅助回归模型估计结果
图五ssze对其他解释变量辅助回归模型估计结果
由图三、图四、图五可以看出,尽管回归系数的T检验值表明:czzc与gdp、gdp与czzc
R都大于的T检验值较小,这些变量之间可能互相影响程度较小,但上述每个回归方程的2
0.9,F检验值都非常显著,其伴随概率均接近0,表明回归方程存在严重的多重共线性。
R,由公式方差膨胀因子进一步地我们可以根据辅助回归模型估计的可决系数2
vif=1/(1-2R )和容许度tol=1/vif ,依次计算出各自方差膨胀因子和容许度,如表二所示:
表二 各解释变量辅助回归模型的2R 、F 统计量及由此计算的各方差膨胀因子和容许度
由表二可知,Czzc 、gdp 和ssze 的方差膨胀因子均大于10,容许度均小于0.1,这与辅
助回归模型判断一样,也表明模型存在严重的多重共线性。
五、模型调整-对多重共线性的处理
上述检验表明财政收入回归模型存在严重的多重共线性,这导致模型1的回归系数估
计不稳定,gdp 的回归系数经济意义不合理,为此,我们应采用多种方法以降低回归模型的多重共线性。
(一) 逐步回归法
首先,根据表一的相关系数矩阵表,我们得知财政收入czsr 与税收总额ssze 最相关,为此,我们建立财政收入czsr 与税收总额ssze 的一元基本回归模型,即
t t t u ssze czsr +=2111ββ+
利用eviews 软件运用最小二乘法估计一元基本回归模型,输入命令: ls czsr c ssze
财政收入czsr 与税收总额ssze 的一元基本回归模型估计结果如图六
图六 财政收入czsr 与税收总额ssze 一元基本回归模型估计结果
根据图六数据,财政收入一元线性回归模型可用标准报告形式表示为:
t t ssze r
czs 1514.17687.734?+-=(模型2) (131.1949) (0.0042) T= (-5.6006) (273.1237)
2R =0.9997 2R =0.9997 F=74596.56 DW=0.8999
由图六及报告形式,可以看出模型判定系数2R 高达0.9997,非常接近于1,模型拟合程度很高;回归系数的精确显著性水平接近于0; ssze 的回归系数为正数,表明在其他解释变量不变的情况下,ssze 每增长一亿元,财政收入平均将增加1.1514亿元,这与前述的理论分析吻合。
在此基础上,我们分别引入国内生产总值和财政支出,建立财政收入二元的回归模
型,即
t t t t u ssze GDP czsr ++=322212βββ+ t t t t u ssze czzc czsr ++=332313βββ+
利用eviews 软件运用最小二乘法估计分别估计上述二元回归模型,分别依次输入命令:
ls czsr c ssze gdp ls czsr c ssze czzc
得到财政收入czsr 与税收总额ssze 、国内生产总值的二元基本回归模型估计结果如图七EQ34,财政收入czsr 与税收总额ssze 、财政支出czzc 的二元基本回归模型估计结果如图八EQ35
图七财政收入czsr与税收总额ssze、国内生产总值的二元回归模型估计结果
图八财政收入czsr与税收总额ssze、财政支出czzc的二元回归模型估计结果
由图七和图八可以看出,尽管两个二元模型其判定系数均高达0.999以上,非常接近于,F统计量值很大,其伴随概率均接近于0,但这两个二元模型在经济意义和T检验中存在一定问题,引入国内生产总值的二元回归模型EQ34如图七所示,其回归系数为负数,经济意义不合理,而引入财政支出czzc的二元回归模型EQ35如图八所示,其T检验在显著性水平0.05和0.1下均没有通过。可见,财政收入的两个二元模型均没有通过统计检验。为什么没有通过统计检验?由于模型变量为时间序列数据,模型可能存在自相关。
进一步地我们检验财政收入二元模型的自相关性,对样本数n为27,解释变量个数k’为2,若给定的显著性水平 =0.05,查德宾-沃森d统计量表得d L=1.240,d U=1.556,而财政收入czsr与税收总额ssze、国内生产总值的二元回归模型EQ34如图七所示,d U<其DW统计量值=1.668678<4-d U,表明该模型不存在一阶自相关;财政收入czsr与税收总额ssze、财政支出czzc的二元回归模型EQ35如图八所示,0<其DW统计量值=0.810864< d L,显示该模型存在一阶自相关。
为此,我们运用广义差分法调整财政收入czsr与税收总额ssze、财政支出czzc的二元回归模型,输入广义差分法估计命令ls czsr c ssze czzc ar(1),估计结果如图九:
图九 财政收入czsr 与税收总额ssze 、财政支出czzc 的二元回归模型广义差分法估计结果
根据图九可得广义差分法估计的财政收入二元回归模型,其标准报告形式表示为:
]6895.0)1([1277.00101.1029.1061?=+++-=AR czzc ssze r czs t t t (模型3)
(459.6871) (0.06159) (0.0501) (0.1847)
T= (-2.3082) (16.4019) (2.5510) (3.7334)
2R =0.9999 2R =0.9998 F=40369.48 DW=2.0274
调整后模型经济意义合理,调整的可决系数2
R 比模型2有所改善,达0.9988,接近于1,表明模型对样本数据拟合较好;F 统计量为40369.48,其伴随概率为0.000000,接近于零,表明税收总额和财政支出共同对被解释变量财政收入有显著影响,模型总体线性关系显著;解释变量各自的回归系数均显著,且调整后模型AR(1)项的回归系数显著,表明回归模型确实存在一阶自相关;调整后模型经再检验已不存在一阶自相关,因为在显著性水平α=0.05下,n=26,k ’=2,d U =1.652 2、扩大样本容量,重新估计模型 重新收集数据,将数据向前扩充即1978年-2011年,输入扩充样本的命令 expand 1978 2011,再运用最小二乘法估计线性回归模型,输入命令:Ls cszr c czzc gdp ssze 得到线性回归模型估计结果,如图十所示 图十 财政收入三元线性回归模型4 根据图十可得财政收入三元线性回归模型,其标准报告形式表示为: t t t t ssze GDP czzc r czs 18116.10341.01224.00841.119?+-+=(模型4) (0.0489) (0.0051) (0.0697) T= (2.5049) (-6.7291) (16.9518) 2R =0.9998 2R =0.9998 F=47896.18 DW=1.02514 尽管模型判定系数2 R 高达0.9998,非常接近于1,模型拟合程度很高; F 统计量值达47896.18,其伴随概率接近于0,模型整体显著;回归系数的精确显著性水平均小于0.05;但GDP 的回归系数为负数,表明在其他解释变量不变的情况下,GDP 每增长一亿元,财政收入将减少0.0341亿元,这与前述的理论分析不吻合,也与相关图的分析不一致。究其原因,模型可能存在多重共线性,为此,我们改变模型函数形式。 3、改变模型函数形式,重新估计回归模型 将模型函数形式由线性变为双对数形式,重新估计模型,输入双对数模型命令 Ls log(cszr) c log(czzc) log(gdp) log(ssze) 得到双对数回归模型估计结果,如图十一所示 图十一 财政收入三元双对数回归模型5 根据图十一可得财政收入三元双对数回归模型,其标准报告形式表示为: )log(0940.0)log(1050.0)log(9966.02649.0)?log(t t t t ssze GDP czzc r czs +-+= (模型5)(0.0392) (0.0387) (0.0491) T= (25.4528) (-2.7132) (1.9150) 2R =0.9991 2R =0.9991 F=11823.06 DW=0.9960 尽管模型判定系数2 R 高达0.9991,非常接近于1,模型拟合程度很高; F 统计量值 达11823.06,其伴随概率接近于0,模型整体显著;回归系数的精确显著性水平均小于0.10;但对数GDP 的回归系数为负数,表明在其他解释变量不变的情况下,GDP 每增长1%,财政收入将减少0.105%,这与前述的理论分析不吻合,也与相关图的分析不一致,且n=34,k ’=3,0 4、检验自相关性,重新运用广义差分法估计回归双对数模型,输入双对数模型命令 Ls log(cszr) c log(czzc) log(gdp) log(ssze) ar(1) 得到双对数回归模型广义差分法估计结果,如图十二所示 图十二财政收入三元双对数回归模型广义差分法 (模型5) + + log(= .0 8431 + )? =AR r czs czzc GDP ssze .0 + [ ) log( )1( .0 ] 8839 6423 1678 ) log( .0 2272 ) log( .0 t t t t (0.0901)(0.1183)(0.0581)(0.0674)T= (7.1263)(1.9195)(2.8907)(13.1084)2 R=0.9995 2 R=0.9994 F=13983.07 DW=1.6770 R达0.9994,接近于1,表明模型对样本调整后模型经济意义合理,调整的可决系数2 数据拟合较好;F统计量为13983.07,其伴随概率为0.000000,接近于零,表明税收总额和 财政支出、国内生产总值共同对被解释变量财政收入有显著影响,模型总体显著;解释变量 各自的回归系数在显著性水平0.10下均显著,且调整后模型AR(1)项的回归系数显著,表明 回归模型确实存在一阶自相关;调整后模型经再检验已不存在一阶自相关,因为在显著性水 平α=0.05下,n=33,d U=1.651 模型估计结果说明,在其他因素不变的情况下,财政支出每增长1%,财政收入将增长 0.6423%;在其他因素不变的情况下,国内生产总值每增长1%,财政收入将增长0.2272%;在 其他因素不变的情况下,税收总额每增长1%,财政收入将增长0.1678%。 统计学2班 第三次作业 1、⑴存在.2 3223223232 322 ) ())(() )(())((?∑∑∑∑∑∑∑--=i i i i i i i i i i i x x x x x x x y x x y βΘ 当X 2和X 3之间的相关系数为0时,离差形式的 ∑i i x x 32=0 2 222232 22 322 ?) )(() )((??== =∴∑∑∑∑∑∑i i i i i i i i x x y x x x x y β 同理得:33 ??γβ= ⑵2 ?β会等于1?α和1?γ二者的线性组合。 33221???X X Y βββ--=Θ且221??X Y αα-=,331??X Y γγ-= 由⑴可得22 ??αβ=和33??γβ= 22221???X Y X Y βαα-=-=∴,3 3331???X Y X Y βγγ-=-= 212 ??X Y αβ-=∴,3 1 3??X Y γβ-= 则:33 1 2213 3221?????X X Y X X Y Y X X Y γαβββ----=--=Θ ⑶存在。∑-=)1()?(223 222 2 r x Var i σβΘ X 2和X 3之间相关系数为0,)?() 1()?(2222 223 2 22 2 α σσβVar x r x Var i i == -=∴∑∑ 同理可得)?()?(33 γβVar Var = 2、逐步向前回归和逐步向后回归的程序都存在不足,逐步向前法不能反映引进新的解释变量后的变化情况,即一旦引入新的变量,就保留在方程中,逐步向后法泽一旦剔除一个解释变量就再没有机会重新进入方程。而解释变量之间及其与被解释变量的相关关系与引入的变量个数及同时引入哪些变量而不同。所以采用逐步回归比较好。吸收了逐步向前和逐步向后的优点。 第二章简单线性回归模型 第一节回归分析与回归函数P15 (一)相关分析与回归分析 1、相关关系 2、相关系数 3、回归分析 (二)总体回归函数(条件期望) (三)随机扰动项 (四)样本回归函数 第二节简单线性回归模型参数的估计P26 (一)简单线性回归的基本假定 (二)普通最小二乘法求样本回归函数 (三)OLS回归线的性质 (四)最小二乘估计量的统计性质 1、参数估计量的评价标准(无偏性、有效性、一致性) 2、OLS估计量的统计特性(线性特性、无偏性、有效性、高斯-马尔可夫定理) 第三节拟合优度的度量(RSS、ESS、TSS)P35 (一)总变差的分解 (二)可决系数 (三)可决系数与相关系数的关系 第四节回归系数的区间估计与假设检验P38 (一)OLS估计的分布性质 (二)回归系数的区间估值 (三)回归系数的假设检验 1、Z检验 2、t检验 第五节回归模型预测P43 第六节案例分析P48 第三章多元线性回归模型 第一节多元线性回归模型及古典假定P64 一、多元线性回归模型 二、多元线性回归模型的矩阵形式 三、多元线性回归模型的古典假定 第二节多元线性回归模型的估计P68 一、多元线性回归性参数的最小二乘估计 二、参数最小二乘估计的性质(线性特性、无偏性、有效性) 三、OLS估计的分布性质 四、随机扰动项方差的估计 五、多元线性回归模型参数的区间估计 第三节多元线性回归模型的检验P74 一、拟合优度检验(多重可决系数、修正的可决系数) 二、回归方程的显著性检验(F-检验) 三、回归参数的显著性检验(t-检验) 第四节多元线性回归模型的预测P79 第五节案例分析P81 第四章多重共线性第一节什么是多重共线性P94 第二节多重共线性产生的后果 第三节多重共线性的检验 第四节多重共线性的补救措施 第五节案例分析P109 第二章简单线性回归模型 2.1 (1)①首先分析人均寿命与人均GDP的数量关系,用Eviews分析:Dependent Variable: Y Method: Least Squares Date: 12/27/14 Time: 21:00 Sample: 1 22 Included observations: 22 Variable Coefficient Std. Error t-Statistic Prob. C 56.64794 1.960820 28.88992 0.0000 X1 0.128360 0.027242 4.711834 0.0001 R-squared 0.526082 Mean dependent var 62.50000 Adjusted R-squared 0.502386 S.D. dependent var 10.08889 S.E. of regression 7.116881 Akaike info criterion 6.849324 Sum squared resid 1013.000 Schwarz criterion 6.948510 Log likelihood -73.34257 Hannan-Quinn criter. 6.872689 F-statistic 22.20138 Durbin-Watson stat 0.629074 Prob(F-statistic) 0.000134 有上可知,关系式为y=56.64794+0.128360x1 ②关于人均寿命与成人识字率的关系,用Eviews分析如下:Dependent Variable: Y Method: Least Squares Date: 11/26/14 Time: 21:10 Sample: 1 22 Included observations: 22 Variable Coefficient Std. Error t-Statistic Prob. C 38.79424 3.532079 10.98340 0.0000 X2 0.331971 0.046656 7.115308 0.0000 R-squared 0.716825 Mean dependent var 62.50000 Adjusted R-squared 0.702666 S.D. dependent var 10.08889 S.E. of regression 5.501306 Akaike info criterion 6.334356 Sum squared resid 605.2873 Schwarz criterion 6.433542 Log likelihood -67.67792 Hannan-Quinn criter. 6.357721 F-statistic 50.62761 Durbin-Watson stat 1.846406 Prob(F-statistic) 0.000001 由上可知,关系式为y=38.79424+0.331971x2 第四章:多重共线性 二、简答题 1、导致多重共线性的原因有哪些? 2、多重共线性为什么会使得模型的预测功能失效? 3、如何利用辅回归模型来检验多重共线性? 4、判断以下说法正确、错误,还是不确定?并简要陈述你的理由。 (1)尽管存在完全的多重共线性,OLS 估计量还是最优线性无偏估计量(BLUE )。 (2)在高度多重共线性的情况下,要评价一个或者多个偏回归系数的个别显著性是不可能的。 (3)如果某一辅回归显示出较高的2 i R 值,则必然会存在高度的多重共线性。 (4)变量之间的相关系数较高是存在多重共线性的充分必要条件。 (5)如果回归的目的仅仅是为了预测,则变量之间存在多重共线性是无害的。 12233i i i Y X X βββ=++ 来对以上数据进行拟合回归。 (1) 我们能得到这3个估计量吗?并说明理由。 (2) 如果不能,那么我们能否估计得到这些参数的线性组合?可以的话,写出必要的计 算过程。 6、考虑以下模型: 23 1234i i i i i Y X X X ββββμ=++++ 由于2X 和3 X 是X 的函数,那么它们之间存在多重共线性。这种说法对吗?为什么? 7、在涉及时间序列数据的回归分析中,如果回归模型不仅含有解释变量的当前值,同时还含有它们的滞后值,我们把这类模型称为分布滞后模型(distributed-lag model )。我们考虑以下模型: 12313233i t t t t t Y X X X X βββββμ---=+++++ 其中Y ——消费,X ——收入,t ——时间。该模型表示当期的消费是其现期的收入及其滞后三期的收入的线性函数。 (1) 在这一类模型中是否会存在多重共线性?为什么? (2) 如果存在多重共线性的话,应该如何解决这个问题? 8、设想在模型 12233i i i i Y X X βββμ=+++ 中,2X 和3X 之间的相关系数23r 为零。如果我们做如下的回归: name: 统计学2班 第二次作业 1、?i =-151.0263 + 0.1179X 1i + 1.5452X 2i T= (-3.066806) (6.652983) (3.378064) R 2=0.934331 R 2=0.92964 F=191.1894 n=31 ⑴模型估计结果说明,各省市旅游外汇收入Y 受旅行社职工人数X 1,国际旅游人数X 2的影响。由所估计出的参数可知,在假定其他变量不变的情况下,当旅行社职工人数每增加1人,各省市旅游外汇收入增加0.1179百万美元。在嘉定其他变量不变的情况下。当国际旅游人数每增加1万人,各省市旅游外汇收入增加1.5452百万美元。 ⑵由题已知,估计的回归系数β1的T 值为:t (β1)=6.652983。 β2的T 值分为: t (β2)=3.378064。 α=0.05.查得自由度为n-2=22-2=29的临界值t 0.025(29)=2.045229 因为t (β1)=6.652983≥t 0.025(29)=2.045229.所以拒绝原假设H 0:β1=0。 表明在显著性水平α=0.05下,当其他解释变量不变的情况下,旅行社职工人数X 1对各省市旅游外汇收入Y 有显著性影响。 因为 t (β2)=3.378064≥t 0.025(29)=2.045229,所以拒绝原假设H 0:β2=0 表明在显著性水平α=0.05下,当其他解释变量不变的情况下,和国际旅游人数X 2对各省市旅游外汇收入Y 有显著性影响。 ⑶正对H O :β1=β2=0,给定显著水性水平α=0.05,自由度为k-1=2,n-k=28的临界值 F 0.05(2,28)=3.34038。由题已知F=191.1894>F 0.05(2,28)=3.34038,应拒绝原假设 H O :β1=β2=0,说明回归方程显著,即旅行社职工人数和旅游人数变量联合起来对各省市旅游外汇收入有显著影响。 2、⑴样本容量n=15 残差平方和RSS=66042-65965=77 回归平方和ESS 的自由度为K-1=2 残差平方和RSS 的自由度为n-k=13 ⑵可决系数R 2=TSS ESS =6604265965 =0.99883 调整的可决系数R 2=1-(1-R 2)k n n --1=1-(1-0.99883)1214=0.99863 ⑶利用可决系数R 2=0.99883,调整的可决系数R 2=0.99863,说明模型对样本的拟合很好。不能确定两个解释变量X 2和X 3个字对Y 都有显著影响。 思考题答案 第一章 绪论 思考题 1.1怎样理解产生于西方国家的计量经济学能够在中国的经济理论研究和现代化建设中发挥重要作用? 答:计量经济学的产生源于对经济问题的定量研究,这是社会经济发展到一定阶段的客观需要。计量经济学的发展是与现代科学技术成就结合在一起的,它反映了社会化大生产对各种经济因素和经济活动进行数量分析的客观要求。经济学从定性研究向定量分析的发展,是经济学逐步向更加精密、更加科学发展的表现。我们只要坚持以科学的经济理论为指导,紧密结合中国经济的实际,就能够使计量经济学的理论与方法在中国的经济理论研究和现代化建设中发挥重要作用。 1.2理论计量经济学和应用计量经济学的区别和联系是什么? 答:计量经济学不仅要寻求经济计量分析的方法,而且要对实际经济问题加以研究,分为理论计量经济学和应用计量经济学两个方面。 理论计量经济学是以计量经济学理论与方法技术为研究内容,目的在于为应用计量经济学提供方法论。所谓计量经济学理论与方法技术的研究,实质上是指研究如何运用、改造和发展数理统计方法,使之成为适合测定随机经济关系的特殊方法。 应用计量经济学是在一定的经济理论的指导下,以反映经济事实的统计数据为依据,用计量经济方法技术研究计量经济模型的实用化或探索实证经济规律、分析经济现象和预测经济行为以及对经济政策作定量评价。 1.3怎样理解计量经济学与理论经济学、经济统计学的关系? 答:1、计量经济学与经济学的关系。联系:计量经济学研究的主体—经济现象和经济关系的数量规律;计量经济学必须以经济学提供的理论原则和经济运行规律为依据;经济计量分析的结果:对经济理论确定的原则加以验证、充实、完善。区别:经济理论重在定性分析,并不对经济关系提供数量上的具体度量;计量经济学对经济关系要作出定量的估计,对经济理论提出经验的内容。 2、计量经济学与经济统计学的关系。联系:经济统计侧重于对社会经济现象的描述性计量;经济统计提供的数据是计量经济学据以估计参数、验证经济理论的基本依据;经济现象不能作实验,只能被动地观测客观经济现象变动的既成事实,只能依赖于经济统计数据。区别:经济统计学主要用统计指标和统计分析方法对经济现象进行描述和计量;计量经济学主要利用数理统计方法对经济变量间的关系进行计量。 1.4在计量经济模型中被解释变量和解释变量的作用有什么不同? 答:在计量经济模型中,解释变量是变动的原因,被解释变量是变动的结果。被解释变量是模型要分析研究的对象。解释变量是说明被解释变量变动主要原因的变量。 1.5一个完整的计量经济模型应包括哪些基本要素?你能举一个例子吗? 答:一个完整的计量经济模型应包括三个基本要素:经济变量、参数和随机误差项。 例如研究消费函数的计量经济模型:u βX αY ++= 其中,Y 为居民消费支出,X 为居民家庭收入,二者是经济变量;α和β为参数;u 是随机误差项。 1.6假如你是中央银行货币政策的研究者,需要你对增加货币供应量促进经济增长提出建议, 第四章 经典单方程计量经济学模型:放宽基本假定的模型 一、内容提要 本章主要介绍计量经济模型的二级检验问题,即计量经济检验。主要讨论对回归模型的若干基本经典假定是否成立进行检验、当检验发现不成立时继续采用OLS 估计模型所带来的不良后果以及如何修正等问题。包括:异方差性问题、序列相关性问题、多重共线性问题。 1.异方差: 含义:随机扰动项的方差随样本点而不同。 后果:OLS 估计是线性、无偏、一致的但不有效;由于随机项异方差的存在而导致的参数估计值的标准差的偏误,通常的假设检验t 检验和F 检验失效;模型的预测变得无效。 检验:图示法、Goldfeld-Quandt 检验法以及White 检验法等。 修正:而当检测出模型确实存在异方差性时,通过采用加权最小二乘法进行修正的估计。 序列相关性也是模型随机扰动项出现序列相关时产生的一类现象。与异方差的情形相类似,在序列相关存在的情况下,OLS 估计量仍具无偏性与一致性,但通常的假设检验不再可靠,预测也变得无效。序列相关性的检测方法也有若干种,如图示法、回归检验法、Durbin-Watson 检验法以及Lagrange 乘子检验法等。存在序列相关性时,修正的估计方法有广义最小二乘法(GLS )以及广义差分法。 多重共线性是多元回归模型可能存在的一类现象,分为完全共线与近似共线两类。模型的多个解释变量间出现完全共线性时,模型的参数无法估计。更多的情况则是近似共线性,这时,由于并不违背所有的基本假定,模型参数的估计仍是无偏、一致且有效的,但估计的参数的标准差往往较大,从而使得t-统计值减小,参数的显著性下降,导致某些本应存在于模型中的变量被排除,甚至出现参数正负号方面的一些混乱。显然,近似多重共线性使得模型偏回归系数的特征不再明显,从而很难对单个系数的经济含义进行解释。多重共线性的检验包括检验多重共线性是否存在以及估计多重共线性的范围两层递进的检验。而解决多重共线性的办法通常有逐步回归法、差分法以及使用额外信息、增大样本容量等方法。 当模型中的解释变量是随机解释变量时,需要区分三种类型:随机解释变量与随机扰动项独立,随机解释变量与随机扰动项同期无关、但异期相关,随机解释变量与随机扰动项同期相关。第一种类型不会对OLS 估计带来任何问题。第二种类型则往往导致模型估计的有偏性,但随着样本容量的增大,偏误会逐渐减小,因而具有一致性。所以,扩大样本容量是克服偏误的有效途径。第三种类型的OLS 估计则既是有偏、也是非一致的,需要采用工具变量法来加以克服。 二、典型例题分析 1、下列哪种情况是异方差性造成的结果? (1)OLS 估计量是有偏的 (2)通常的t 检验不再服从t 分布。 (3)OLS 估计量不再具有最佳线性无偏性。 答: 第(2)与(3)种情况可能由于异方差性造成。异方差性并不会引起OLS 估计量出现偏误。 2、已知模型 i i i i u X X Y +++=22110βββ 式中,i Y 为某公司在第i 个地区的销售额;i X 1为该地区的总收入;i X 2为该公司在该地区投入的广告费用(i=0,1,2……,50)。 (1)由于不同地区人口规模i P 可能影响着该公司在该地区的销售,因此有理由怀疑随机误差项u i 是异方差的。假设i σ依赖于总体i P 的容量,请逐步描述你如何对此进行检验。需说明:1)零假 第四章一元线性回归 第一部分学习目的和要求 本章主要介绍一元线性回归模型、回归系数的确定和回归方程的有效性检验方法。回归方程的有效性检验方法包括方差分析法、t检验方法和相关性系数检验方法。本章还介绍了如何应用线性模型来建立预测和控制。需要掌握和理解以下问题: 1 一元线性回归模型 2 最小二乘方法 3 一元线性回归的假设条件 4 方差分析方法 5 t检验方法 6 相关系数检验方法 7 参数的区间估计 8 应用线性回归方程控制与预测 9 线性回归方程的经济解释 第二部分练习题 一、术语解释 1 解释变量 2 被解释变量 3 线性回归模型 4 最小二乘法 5 方差分析 6 参数估计 7 控制 8 预测 二、填空 ξ,目的在于使模型更1 在经济计量模型中引入反映()因素影响的随机扰动项 t 符合()活动。 2 在经济计量模型中引入随机扰动项的理由可以归纳为如下几条:(1)因为人的行为的()、社会环境与自然环境的()决定了经济变量本身的();(2)建立模型时其他被省略的经济因素的影响都归入了()中;(3)在模型估计时,()与归并误差也归入随机扰动项中;(4)由于我们认识的不足,错误的设定了()与()之间的数学形式,例如将非线性的函数形式设定为线性的函数形式,由此产生的误差也包含在随机扰动项中了。 3 ()是因变量离差平方和,它度量因变量的总变动。就因变量总变动的变异来源看,它由两部分因素所组成。一个是自变量,另一个是除自变量以外的其他因素。()是拟合值的离散程度的度量。它是由自变量的变化引起的因变量的变化,或称自变量对因变量变化的贡献。()是度量实际值与拟合值之间的差异,它是由自变量以外的其他因素所致,它又叫残差或剩余。 4 回归方程中的回归系数是自变量对因变量的()。某自变量回归系数β的意义,指 思考题答案 第一章绪论 思考题 1.1怎样理解产生于西方国家的计量经济学能够在中国的经济理论研究和现代化建设中发挥重要作用? 答:计量经济学的产生源于对经济问题的定量研究,这是社会经济发展到一定阶段的客观需要。计量经济学的发展是与现代科学技术成就结合在一起的,它反映了社会化大生产对各种经济因素和经济活动进行数量分析的客观要求。经济学从定性研究向定量分析的发展,是经济学逐步向更加精密、更加科学发展的表现。我们只要坚持以科学的经济理论为指导,紧密结合中国经济的实际,就能够使计量经济学的理论与方法在中国的经济理论研究和现代化建设中发挥重要作用。 1.2理论计量经济学和应用计量经济学的区别和联系是什么? 答:计量经济学不仅要寻求经济计量分析的方法,而且要对实际经济问题加以研究,分为理论计量经济学和应用计量经济学两个方面。 理论计量经济学是以计量经济学理论与方法技术为研究内容,目的在于为应用计量经济学提供方法论。所谓计量经济学理论与方法技术的研究,实质上是指研究如何运用、改造和发展数理统计方法,使之成为适合测定随机经济关系的特殊方法。 应用计量经济学是在一定的经济理论的指导下,以反映经济事实的统计数据为依据,用计量经济方法技术研究计量经济模型的实用化或探索实证经济规律、分析经济现象和预测经济行为以及对经济政策作定量评价。 1.3怎样理解计量经济学与理论经济学、经济统计学的关系? 答:1、计量经济学与经济学的关系。联系:计量经济学研究的主体—经济现象和经济关系的数量规律;计量经济学必须以经济学提供的理论原则和经济运行规律为依据;经济计量分析的结果:对经济理论确定的原则加以验证、充实、完善。区别:经济理论重在定性分析,并不对经济关系提供数量上的具体度量;计量经济学对经济关系要作出定量的估计,对经济理论提出经验的内容。 2、计量经济学与经济统计学的关系。联系:经济统计侧重于对社会经济现象的描述性计量;经济统计提供的数据是计量经济学据以估计参数、验证经济理论的基本依据;经济现象不能作实验,只能被动地观测客观经济现象变动的既成事实,只能依赖于经济统计数据。区别:经济统计学主要用统计指标和统计分析方法对经济现象进行描述和计量;计量经济学 计量经济学 第一章导论 一节什么是计量经济学 统计学,经济学,数学的结合 二节研究步骤 一、模型假定 估计解释变量与被解释变量的关系,设置随机扰动项μ 二、估计参数 通过变量的样本观测值合理的估计总体模型的参数,是计量经济学的核心内容三、模型检验 (1)经济意义检验,检验所估计的模型与经济理论是否相符 (2)统计推断信息,检验参数估计值是否是抽样的偶然结果,需要运用数理统计中统计推断方法对模型及参数的统计可靠性作出说明 (3)计量经济学检验,t检验和F检验 检验模型是否符合计量经济学假定,如多重共线性,随机扰动项的自相关和异方差性 (4)模型预测检验 四、模型应用 三节变量参数数据与模型 一、变量 经济变量:在不同的时间或空间有不同状态,回去不同的数值且可观测 eg.居民家庭收入X和居民消费支出Y 分类: (1)流量与存量(2)解释变量/自变量与被解释变量/因变量(3)内生变量(由模型所决定的变量,是模型求解的结果)和外生变量(由模型以外决定的变量)二、参数的估计 所得到的参数估计值迎“尽可能接近总体参数真实值”原则 三、计量经济学中应用的数据 (1)时间序列数据 (2)截面数据 (3)面板数据 (4)虚拟变量数据 二章简单线性回归模型 一节回归分析与回归函数 一、相关分析与回归分析 (一)经济变量之间的相关关系 经济变量之间有两种关系,一种是确定性的函数关系,另一种是不确定的统计关系,也叫相关关系。 当一个或若干个变量x取一定值时,与之对应的另一个变量Y的值虽然不确定,但按照某种规律在一定范围内变化,称这种变量之间的关系为不确定的统计关系或相关关系。 分类 (1)简单相关关系/多重相关关系 (2)线性相关/非线性相关 (3)正相关/负相关 (4)完全相关/不相关 第四章练习题及参考解答 假设在模型i i i i u X X Y +++=33221βββ中,32X X 与之间的相关系数为零,于是有人建议你进行如 下回归: i i i i i i u X Y u X Y 23311221++=++=γγαα (1)是否存在3 322????βγβα ==且?为什么? (2)1 11???βαγ会等于或或两者的某个线性组合吗? (3)是否有()()()()3 3 2 2 ?var ?var ?var ?var γβα β==且? 练习题参考解答: (1) 存在3 322????βγβα==且。 因为()()()() ()()() 2 3223223232322?∑∑∑∑∑∑∑--= i i i i i i i i i i i x x x x x x x y x x y β 当 32X X 与之间的相关系数为零时,离差形式的032=∑i i x x 有()()()()222223222322 ??αβ=== ∑∑∑∑∑∑i i i i i i i i x x y x x x x y 同理有:3 3??βγ= (2) 1 11???βαγ会等于或的某个线性组合 因为 12233???Y X X βββ=--,且122??Y X αα=-,133??Y X γγ=- 由于3322????βγβα ==且,则 112222 2 2 ?????Y Y X Y X X αααββ-=-=-= 则 11 122332 3112 3 ???????Y Y Y X X Y X X Y X X αγβββαγ--=--=--=+- (3) 存在()()()()3 3 2 2 ?var ?var ?var ?var γβα β==且。 因为()() ∑-= 223 2 22 2 1?var r x i σβ 当023=r 时,() ()()2222 2 23 222 2 ?var 1?var α σσβ== -=∑∑i i x r x 同理,有()()3 3 ?var ?var γβ= 在决定一个回归模型的“最优”解释变量集时人们常用逐步回归的方法。在逐步回归中既可采取每次引进一个解释变量的程序(逐步向前回归),也可以先把所有可能的解释变量都放在一个多元回归中,然后逐一地将它们剔 第四章课后习题 4.1 解 1)存在22β?α?=且3 3β?γ?=。因为2X 和3X 之间的相关系数为零,即2X 和3X 相互之间不存在线性关系,两者是相互独立的,所以分别一元回归和二元回归两者的系数都不会发生变 化。 利用公式证明如下: 2)会。 3)如第一问解释,22β?α?=,3 3β?γ?=是成立的,所以存在)α?()β?(22V a r V a r =,)α?()β?(33 Var Var =。 4.2 解: 根据我对多重共线性的认识,我认为任何一种逐步回归都存在弊端。根据课本上对多重共线性的定义,不仅包括解释变量之间精确的线性关系,还包括解释变量之间近似的线性关 系。而逐步回归法是通过逐步筛选并剔除引起多重共线性的变量。所以在采用逐步回归法时,难免会出现一些不符合要求的变量被剔除的情况,此变量岁引起多重共线性,但其对被解释变量也有一定的影响,直接剔除就是忽略其的影响,使得回归结果不够精确。误差增大。 4.3解:将数据输入到Eviews中,可得如下图所示: 图1 注释:X2表示国内生产总值GDP,X3表示居民消费价格指数CPI。 利用软件,采用最小二乘法进行回归,结果如下图所示: 图2 建立回归模型如下: i t X X Y μβββ+++33221ln ln ln = 1)从回归结果中,可知此模型的参数1β=﹣3.06015,2β=1.656675,3β=﹣1.057054 2) 利用软件求出lnx2和lnx3的相关系数,可得 由上图可知lnx2,lnx3之间存在很强的线性相关性。证实存在多重共线性。 根据题目要求分别进行三次回归: 第一章 1.计量分析的四个步骤:模型设定——参数估计——模型检验——模型应用 2.计量模型检验:经济意义检验——统计推断检验——计量经济学检验——模型预测检 验 3.计量模型的应用:结构分析——经济预测——政策评价——检验与发展经济理论 4.正确选择解释变量的原则:符合理论、规律——忽略众多次要因素,突出主要经济变 量——数据可得性——每个解释变量之间是独立的 5.参数的数据类型:时间序列数据——截面数据——面板数据——虚拟变量数据 第二章 1.总体相关系数:ρ=Cov(X,Y)/√Var(X)√Var(Y) 2.样本相关系数:rxy=Σ(Xi-X_)(Yi-Y_)/√Σ(Xi-X_)^2√Σ(Yi-Y_)^2 3.总体回归函数中引入随机扰动项的原因:作为未知影响因素的代表——作为无法取得 数据的已知因素代表——作为众多细小影响因素的综合代表——模型的设定误差——变量的观测误差——经济现象的内在随机性 4.简单线性回归模型的基本假定:1、对变量和模型的假定;2、对随机扰动项ui统计分 布的假定(古典假定):零均值假定——同方差假定——无自相关假定——随机扰动项ui与解释变量Xi不相关——正态性假定 5.违反零均值假定:影响截距上的估计(影响小) 6.违反正态性假定:不影响OLS估计是最佳无偏性,但会使t检验F检验失真(影响大) 7.样本回归函数的离差形式:yi^=β2^*xi 8.OLS估计值的离差表达式:β2^=Σ(Xi-X_)(Yi-Y_)/Σ(Xi-X_)^2=Σxiyi/Σxi^2 β1^=Y_-β2^*X_ 9.OLS回归线的性质:样本回归线过(X_,Y_)——估计值均值等于实际值均值——剩余 项ei的均值为零——Cov(Yi^,ei)=0——Cov(Xi,ei)=0 10.β^的评价标准:无偏性——有效性——一致性 11.β^的统计性质:线性——无偏性——有效性 12.Var(^β1)=?^2/Σxi^2——Var(^β2)=ΣXi^2/n*?^2/Σxi^2 13.^?^2=Σei^2/(n-2) 14.总变差平方和:Σ(Yi-Y_)^2=Σyi^2……TSS……n-1 回归平方和:Σ(Yi^-Y_)^2=Σ^yi^2……ESS……k-1 残差平方和:Σ(Yi-Yi^)^2=Σei^2……RSS……n-k 15.可决系数:R^2=ESS/TSS 16.SE(^β1)=√(?^2ΣXi^2)/(nΣxi^2) SE(^β2)=√?^2/Σxi^2 17.t=(^β1-β1)/^SE(^β1)~t(n-2) t=(^β2-β2)/^SE(^β2)~t(n-2) 18.区间估计: 1.当总体方差?^2已知,α=0.1—±1.645,α=0.05—±1.96,α=0.01—± 2.33, P[-tα 第四章习题 4.1 没有进行t检验,并且调整的可决系数也没有写出来,也就是没有考虑自由度的影响,会使结果存在误差。 一研究的目的和要求 我们知道,商品进口额与很多因素有关,了解其变化对进出口产品有很大帮助。为了探究和预测商品进口额的变化,需要定量地分析影响商品进口额变化的主要因素。 二、模型的设定及其估计 经分析,商品进口额可能与国内生产总值、居民消费价格指数有关。为此,考虑国内生产总值GDP、居民消费价格指数CPI为主要因素。各影响变量与商品进口额呈正相关。为此,设定如下形式的计量经济模型: =+ln+lnCP 式中,为第年中国商品进口额(亿元);lnGDP为第年国内生产总值(亿元);lnCPI为居民消费价格指数(以1985年为100)。各解释变量前的回归系数预期都大于零。 为估计模型,根据上表的数据,利用EViews软件,生成Y、lnGDP、lnCPI等数据,采用OLS方法估计模型参数,得到的回归结果如下图所示: 模型方程为: lnY=-3.111486+1.338533lnGDP-0.421791lnCPI (0.463010) (0.088610) (0.233295) t= (-6.720126) (15.10582) (-1.807975) =0.988051 =0.987055 F=992.2582 该模型=0.988051,=0.987055,可决系数很高,F检验值为992.2582,明显显著。但是当=0.05时,(n-k)=(27-3)=2.064,不仅lnCPI的系数不显著,而且,lnCPI的符号与预期相反,这表明可能存在 严重的多重共线性。 计算各解释变量的相关系数,选择lnGDP,lnCPI数据,“view/correlation”得相关系数矩阵。 1 由相关系数矩阵可以看出,各解释变量相互之间的相关系数较高,证实确实存在一定的多重共线性。 为了进一步了解多重共线性的性质,我们做辅助回归,即每个解释变量分别作为被解释变量都对剩余的解释变量进行回归。 第二章 简单线性回归模型 2.1 (1) ①首先分析人均寿命与人均GDP 的数量关系,用Eviews 分析: Dependent Variable: Y Method: Least Squares Date: 12/27/14 Time: 21:00 Sample: 1 22 Included observations: 22 Variable Coefficient Std. Error t-Statistic Prob. C 56.64794 1.960820 28.88992 0.0000 X1 0.128360 0.027242 4.711834 0.0001 R-squared 0.526082 Mean dependent var 62.50000 Adjusted R-squared 0.502386 S.D. dependent var 10.08889 S.E. of regression 7.116881 Akaike info criterion 6.849324 Sum squared resid 1013.000 Schwarz criterion 6.948510 Log likelihood -73.34257 Hannan-Quinn criter. 6.872689 F-statistic 22.20138 Durbin-Watson stat 0.629074 Prob(F-statistic) 0.000134 有上可知,关系式为y=56.64794+0.128360x 1 ②关于人均寿命与成人识字率的关系,用Eviews 分析如下: Dependent Variable: Y Method: Least Squares Date: 11/26/14 Time: 21:10 Sample: 1 22 Included observations: 22 Variable Coefficien t Std. Error t-Statistic Prob. C 38.79424 3.532079 10.98340 0.0000 X2 0.331971 0.046656 7.115308 0.0000 R-squared 0.716825 Mean dependent var 62.50000 Adjusted R-squared 0.702666 S.D. dependent var 10.08889 S.E. of regression 5.501306 Akaike info criterion 6.334356 Sum squared resid 605.2873 Schwarz criterion 6.433542 Log likelihood -67.67792 Hannan-Quinn criter. 6.357721 17 CHAPTER 4 SOLUTIONS TO PROBLEMS 4.2 (i) and (iii) generally cause the t statistics not to have a t distribution under H 0. Homoskedasticity is one of the CLM assumptions. An important omitted variable violates Assumption MLR.3. The CLM assumptions contain no mention of the sample correlations among independent variables, except to rule out the case where the correlation is one. 4.3 (i) While the standard error on hrsemp has not changed, the magnitude of the coefficient has increased by half. The t statistic on hrsemp has gone from about –1.47 to –2.21, so now the coefficient is statistically less than zero at the 5% level. (From Table G.2 the 5% critical value with 40 df is –1.684. The 1% critical value is –2.423, so the p -value is between .01 and .0 5.) (ii) If we add and subtract 2βlog(employ ) from the right-hand-side and collect terms, we have log(scrap ) = 0β + 1βhrsemp + [2βlog(sales) – 2βlog(employ )] + [2βlog(employ ) + 3βlog(employ )] + u = 0β + 1βhrsemp + 2βlog(sales /employ ) + (2β + 3β)log(employ ) + u , where the second equality follows from the fact that log(sales /employ ) = log(sales ) – log(employ ). Defining 3θ ≡ 2β + 3β gives the result. (iii) No. We are interested in the coefficient on log(employ ), which has a t statistic of .2, which is very small. Therefore, we conclude that the size of the firm, as measured by employees, does not matter, once we control for training and sales per employee (in a logarithmic functional form). (iv) The null hypothesis in the model from part (ii) is H 0:2β = –1. The t statistic is [–.951 – (–1)]/.37 = (1 – .951)/.37 ≈ .132; this is very small, and we fail to reject whether we specify a one- or two-sided alternative. 4.4 (i) In columns (2) and (3), the coefficient on profmarg is actually negative, although its t statistic is only about –1. It appears that, once firm sales and market value have been controlled for, profit margin has no effect on CEO salary. (ii) We use column (3), which controls for the most factors affecting salary. The t statistic on log(mktval ) is about 2.05, which is just significant at the 5% level against a two-sided alternative.庞皓计量经济学课后答案第四章(内容参考)
计量经济学第三版庞皓
计量经济学 庞皓 第三版课后答案
《计量经济学》第四章精选题及答案
伍德里奇计量经济学第四章
庞皓计量经济学课后答案第三章
计量经济学(庞皓)课后思考题答案
计量经济学第四章
第四章计量经济学答案范文
计量经济学 庞皓 第二版 思考题 答案
(完整word版)计量经济学总结第三版庞皓,推荐文档
计量经济学第四章练习题及参考解答
计量经济学第二版第四章课后习题
计量经济学复习提纲—庞皓版
计量经济学第四章习题详解
计量经济学庞皓第三版课后答案解析
计量经济学第4章课后答案