试验设计与数据处理(第二版)课后习题答案
实验设计与数据处理心得
实验设计与数据处理心得体会 刚开始选这门课的时候,我觉得这门课应该就是很难懂的课程,首先我们做过不少的实验了,当然任何自然科学都离不开实验,大多数学科(化工、化学、轻工、材料、环境、医药等)中的概念、原理与规律大多由实验推导与论证的,但我觉得每次到处理数据的时候都很困难,所以我觉得这就是门难懂的课程,却也就是很有必要去学的一门课程,它对于我们工科生来说也就是很有用途的,在以后我们实验的数据处理上有很重要的意义。 如何科学的设计实验,对实验所观测的数据进行分析与处理,获得研究观测对象的变化规律,就是每个需要进行实验的人员需要解决的问题。“实验设计与数据处理”课程就就是就是以概率论数理统计、专业技术知识与实践经验为基础,经济、科学地安排试验,并对试验数据进行计算分析,最终达到减少试验次数、缩短试验周期、迅速找到优化方案的一种科学计算方法。它主要应用于工农业生产与科学研究过程中的科学试验,就是产品设计、质量管理与科学研究的重要工具与方法,也就是一门关于科学实验中实验前的实验设计的理论、知识、方法、技能,以及实验后获得了实验结果,对实验数据进行科学处理的理论、知识、方法与技能的课程。 通过本课程的学习,我掌握了试验数据统计分析的基本原理,并能针对实际问题正确地运用,为将来从事专业科学的研究打下基础。这门课的安排很合理,由简单到复杂、由浅入深的思维发展规律,先讲单因素试验、双因素试验、正交试验、均匀试验设计等常用试验设计
方法及其常规数据处理方法、再讲误差理论、方差分析、回归分析等数据处理的理论知识,最后将得出的方差分析、回归分析等结论与处理方法直接应用到试验设计方法。 比如我对误差理论与误差分析的学习:在实验中,每次针对实验数据总会有误差分析,误差就是进行实验设计与数据评价最关键的一个概念,就是测量结果与真值的接近程度。任何物理量不可能测量的绝对准确,必然存在着测定误差。通过学习,我知道误差分为过失误差,系统误差与随机误差,并理解了她们的定义。另外还有对准确度与精密度的学习,了解了她们之间的关系以及提高准确度的方法等。对误差的学习更有意义的应该就是如何消除误差,首先消除系统误差,可以通过对照试验,空白试验,校准仪器以及对分析结果的校正等方法来消除;其次要减小随机误差,就就是要在消除系统误差的前提下,增加平行测定次数,可以提高平均值的精密度。 比如我对方差分析的理解:方差分析就是实验设计中的重要分析方法,应用非常广泛,它就是将不同因素、不同水平组合下试验数据作为不同总体的样本数据,进行统计分析,找出对实验指标影响大的因素及其影响程度。对于单因素实验的方差分析,主要步骤如下:建立线性统计模型,提出需要检验的假设;总离差平方与的分析与计算;统计分析,列出方差分析表。对于双因素实验的方差分析,分为两种,一种就是无交互作用的方差分析,另一种就是有交互作用的方差分析,对于这两种类型分别有各自的设计方法,但就是总体步骤都与单因素实验的方差分析一样。
实验设计习题带答案
一、(10分)根据遗传物质的化学组成,可将病毒分为RNA病毒和DNA病毒两种类型。有些病毒对人类健康会造成很大危害。通常,一种新病毒出现后需要确定该病毒的类型。 假设在宿主细胞内不发生碱基之间的相互转换,请利用放射性同位素标记的方法,以体外培养的宿主细胞等为材料,设计实验以确定一种新病毒的类型,简要写出: (1)实验思路, (2)预期实验结果及结论即可。(要求:实验包含可相互印证的甲、乙两个组) 二、(12分)已知某种昆虫的有眼(A)与无眼(a)、正常刚毛(B)与小刚毛(b)、正常翅(E)与斑翅(e)这三对相对性状各受一对等位基因控制。现有三个纯合品系:①aaBBEE、②AAbbEE和③AABBee。假定不发生染色体变异和染色体交换,回答下列问题: (1)若A/a、B/b、E/e这三对等位基因都位于常染色体上,请以上述品系为材料,设计实验来确定这三对等位基因是否分别位于三对染色体上。(要求:写出实验思路、预期结果、得出结论) (2)假设A/a、B/b这两对等位基因都位于X染色体上,请以上述品系为材料,设计实验对这一假设进行验证。(要求:写出实验思路、预期结果、得出结论) 三、遗传学家在两个纯种小鼠品系中均发现了眼睛变小的隐形突变个体,欲通过一代杂交实验确定这两个隐性突变基因是否为同一基因的等位基因,写出实验思路。 四、等位基因A和a可能位于X染色体上,也可能位于常染色体上。假设某女孩的基因型是X A X A或AA,其祖父的基因型是或Aa,祖母的基因型是或Aa,外祖父的基因型是或Aa,外祖母的基因型是或Aa。 不考虑基因突变和染色体变异,请回答下列问题: (1)如果这对等位基因位于常染色体上,能否确定该女孩的2个显性基因A来自于祖辈4人中的具体哪两个人?为什么?。 (2)如果这对等位基因位于X染色体上,那么可判断该女孩两个中的一个必然来自 于(填“祖父”或“祖母”),判断依据是;此外,(填“能”或“不能”)确定另一个来自于外祖父还是外祖母。 五、果蝇是遗传学实验的好材料,某生物兴趣小组用果蝇做了如下实验。(12分) (1)该小组做染色体组型实验时,发现了一种性染色体组成为XYY的雄果蝇,你认为这种雄果蝇形成的原因为。(2分)
试验统计方法复习题集
试验统计方法复习题 一、名词(术语、符号)解释: 1、总体:具有相同性质的个体所组成的集团特区为总体。 2、样本:从总体中抽出的一部分个体。 3、试验指标:用于衡量试验效果的指示性状称为试验指标。 4、试验因素:是人为控制并有待比较的一组处理因素,简称因素或因子。 5、试验水平:是在试验因素所设定的量的不同级别或质的不同状态称为试验水平,简称水平。 5、处理:单因素试验是指水平,多因素试验是水平与水平的组合。 6、简单效应:一个因素的水平相同,另一个因素不同水平间的性状(产量)差异属于简单效应。 7、参数:由总体的全部观察值而算得的特征数称为参数。 8、统计数:由样本观察值计算的特征数。 9、统计假设:是根据试验目的对试验总体提出两种彼此对立的假设称为统计假设。 10、无效假设:是指处理效应与假设值之间没有真实差异的假设称为无效假设。 11、准确度:是指试验中某一性状的观察值与其相应理论真值的接近程度。 12、精确度:是指试验中同一性状的重复观察值彼此之间的接近程度。 13、复置抽样:指将抽出的个体放回到原总体后再继续抽样的方法叫复置抽样或有放回抽样。 14、无偏估计:一个样本统计数等于所估计的总体参数,则该统计数为总体相应参数的无偏估计值。 15、第一类错误:否定一个正确H0 时所犯的错误。 16、第二类错误:接受一个不真实假设时所犯的错误。 17、互斥事件:事件A与B不可能同时发生,即AB为不可能事件,则称事件A与B为互斥事件。 18、随机事件:在一定条件下,可能发生也可能不发生,可能这样发生,也可能那样发生的事件。 19、标准差:方差的正根值称为标准差。 20、处理效应:是指因素的相对独立作用,亦是因素对性状所起的增进或减少的作用称为处理效应。 21、概率分布:随机变数可能取得每一个实数值或某一围的实数值是有一定概率的,这个概率称为 随机变数的概率分布。 22、随机抽样:保证总体中的每一个体,在每一次抽样中都有同等的概率被取为样本。 23、两尾测验:有两个否定区,分别位于分布的两尾。 24、显著水平:否定无效假设H0的概率标准。 25、试验方案:根据试验目的与要求拟定的进行比较一组试验处理的总称为试验方案。 26、随机样本:用随机抽样的方法,从总体中抽出的一个部分个体。 27、标准误:抽样分布的标准差称为标准误。 28、总体:具有相同性质的个体所组成的集团称为总体。 29、独立性测验:主要为探求两个变数间是否相互独立测验的假设。
实验设计与数据处理
《实验设计与数据处理》大作业 班级:环境17研 姓名: 学号: 1、 用Excel (或Origin )做出下表数据带数据点的折线散点图 余浊(N T U ) 加量药(mL) 总氮T N (m g /L ) 加量药(mL ) 图1 加药量与剩余浊度变化关系图 图2 加药量与总氮TN 变化关系图 总磷T P (m g /L ) 加量药(mL) C O D C r (m g /L ) 加量药(mL) 图3 加药量与总磷TN 变化关系图 图4 加药量与COD Cr 变化关系图 去除率(%) 加药量(mL)
图5 加药量与各指标去除率变化关系图
2、对离心泵性能进行测试的实验中,得到流量Q v 、压头H 和效率η的数据如表所示,绘制离心泵特性曲线。将扬程曲线和效率曲线均拟合成多项式(要求作双Y 轴图)。 η H (m ) Q v (m 3 /h) 图6 离心泵特性曲线 扬程曲线方程为:H=效率曲线方程为:η=+、列出一元线性回归方程,求出相关系数,并绘制出工作曲线图。 (1) 表1 相关系数的计算 Y 吸光度(A ) X X-3B 浓度(mg/L ) i x x - i y y - l xy l xx l yy R 10 -30 2800 20 -20 30 -10 40 ()() i i x x y y l R --= = ∑
50 10 60 20 70 30 平均值 40 吸光度 X-3B浓度(mg/L) 图7 水中染料活性艳红(X-3B )工作曲线 一元线性回归方程为:y=+ 相关系数为:R 2= (2) 代入数据可知: 样品一:x=样品二:x=、试找出某伴生金属c 与含量距离x 之间的关系(要求有分析过程、计算表格以及回归图形)。 表2 某伴生金属c 与含量距离x 之间的关系分析计算表 序号 x c lgx 1/x 1/c 1 2 2 3 3 4 4 5 5 7 6 8 7 10 1
试验设计与数据处理复习提纲
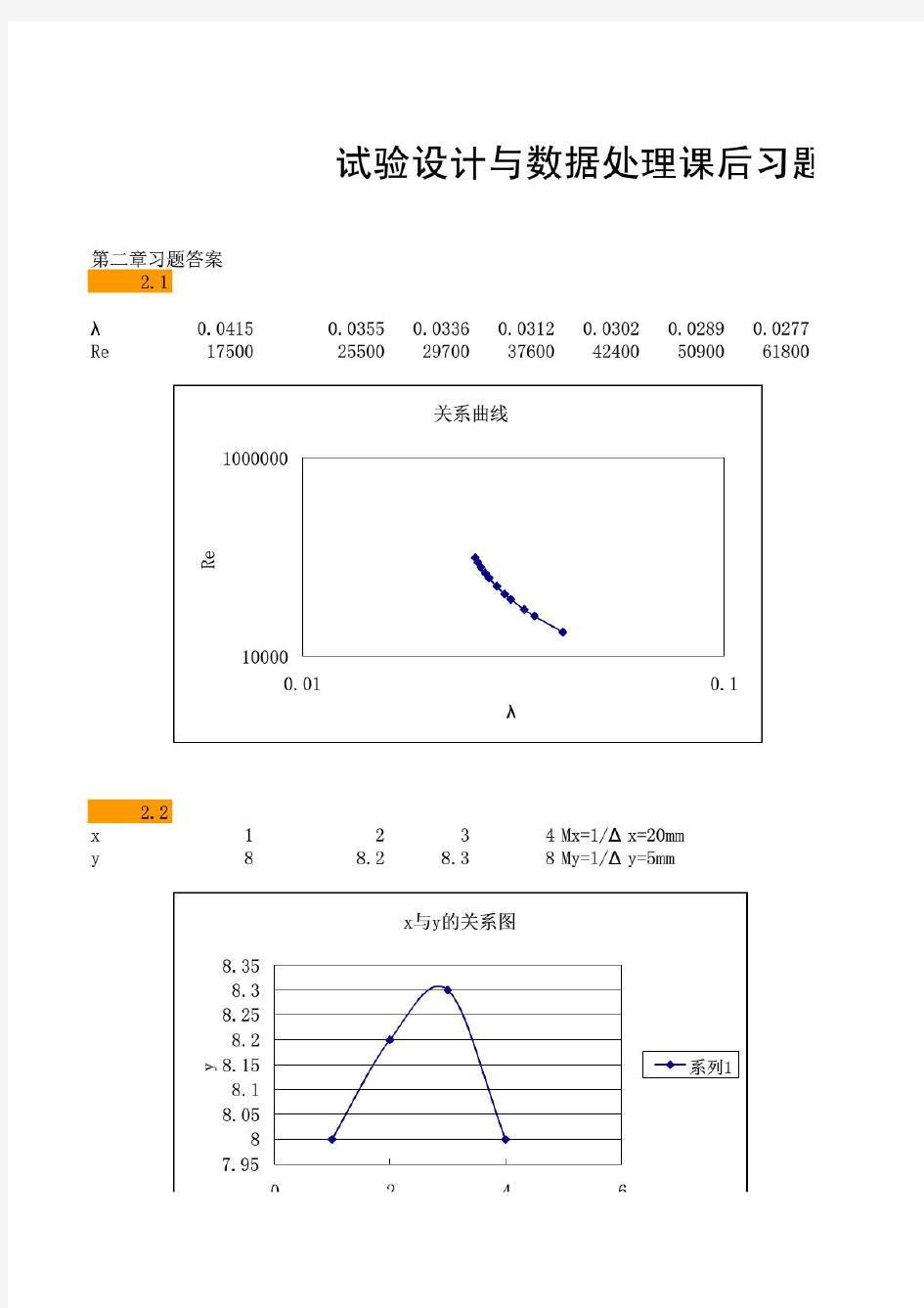
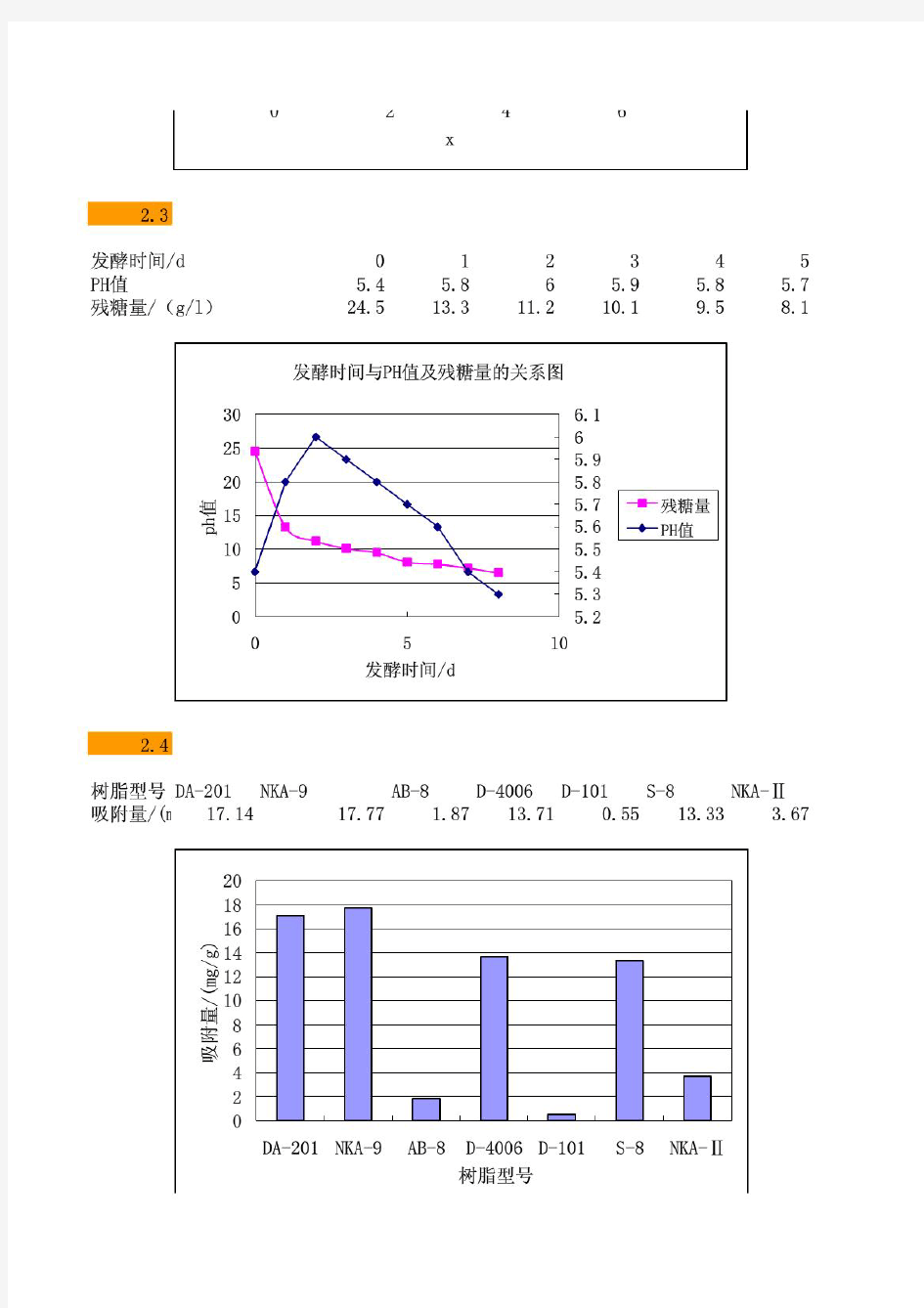
第0章 1 试验数据处理的主要作用 试验设计合理的规划试验,以通过较高效的试验方案获得更具代表性的数据 数据处理对试验数据进行分析研究,从而获得研究对象的变化规律,为生产和科研提供指导。 数据处理的具体作用: 第一章 2 真值的概念和特点 真值 某时刻和某一状态下,某量的可观值或实际值。 真值很多是位置的,但部分又是已知的。 3 平均值,尤其是算数平均值,加权平均值的概念。 平均值 科学实验中,经常将多次试验值得平均值作为真值的近似值。 (1) 算数平均值(arithmetic mean ) 同样试验条件下,如多次试验值服从正态分布,则算数平均值是这组等精度试验值中最佳或最可信赖的值。 (2) 加权平均值(weighted mean ) 若一组试验数据的精度或可靠度不一致,为了突出可靠性高的数值,可以采用加权平均值 权值的确定方法:①取试验值出现的频率ni/n ②若xi 为每组试验值的平均值,则权值为每组试验的次数 ③根据权与绝对误差的平方成反比确定 ④根据试验者的经验确定 4 误差的概念,包括绝对误差与相对误差。 判断影响结果的因素主次 优化试验或生产方案 确定试验因素与试验结果之间的近似函数关系 判断试验数据的可靠性 预测试验结果 控制试验结果 n n x i n ===121n x x x x i n ==+++= 121
5 误差的类型及产生的原因。 随机误差 系统误差 过失误差 6 精密度、正确度和准确度的概念。 1精密度定义:一定条件下多次试验值得彼此符合程度或一致程度。 正确度定义:大量试验结果的算数平均值与真值的一致程度。 准确度定义:反映系统误差与随机误差的综合 正确度:大量试验结果的算数平均值与真值的一致程度。 反映试验系统随机误差的大小 准确度:反映系统误差与随机误差的综合 7随机误差的检验法F 检验法。 1)检验两组实验数据精密度是否一致—双侧检验 (2)检验两组实验数据精密度优劣—单侧检验 a. 左侧检验 ① 取统计量为: ②给定显著性水平α ③查表确定临界值: ④ 判断:若 且 结论:S12相对S12两无显著减小。 b. 右侧检验 8 系统误差的t 检验法。 2122S F S = ① 取统计量为: ②给定显著性水平α ③查表确定临界值: 1212 (1,1) F n n α - --122(1,1) F n n α--④ 判断:若 121212 2 (1,1)F (1,1) F n n F n n αα- --<<--结论:则两组数据方差无显著差异。 2 122 S F S =112(1,1)F n n α---F 1<12F (1 ,1)F n n α<--12(1,1)F n n α--12F (1 ,1)F n n α<--
试验设计习题及答案终审稿)
试验设计习题及答案文稿归稿存档编号:[KKUY-KKIO69-OTM243-OLUI129-G00I-FDQS58-
【西北农林科技大学试验设计与分析复习题】员海燕版 一、名词解释(15分) 1.重复:一个条件值的每一个实现。或因素某水平值的多次实现。 2.因素:试验中要考虑的可能会对试验结果产生影响的条件。常用大写字母表示。 3.水平:因素所处的不同状态或数值。 4.处理:试验中各个因素的每一水平所形成的组合 5.响应:试验的结果称为响应; 响应函数:试验指标与因素之间的定量关系用模型ε+=),,(1n x x f y 表示,其中 ),,(1n x x f y =是因素的值n x x ,,1 的函数,称为响应函数。 6.正交表:是根据均衡分散的思想,运用组合数学理论在拉丁方和正交拉丁方的基础上构造的一种表格。 7.试验指标:衡量试验结果好坏的指标 8.随机误差:在试验中总存在一些不可控制的因素,它们的综合作用称为~ 9.交互作用:一般地说,如果一个因素对试验指标的影响与另一个因素所取的水平有关,就称这两个因素有交互作用。 10.试验设计:是研究如何合理地安排试验,取得数据,然后进行综合的科学分析,从而达到尽快获得最优方案的目的。 11.试验单元:在试验中能施以不同处理的材料单元。 12.拉丁方格:用拉丁字母排列起来的方格,要求每个字母不论在方格的行内还是列内都只出现一次。 13.综合平衡法:先对各项指标进行分析,找出其较优生产条件,然后将各项指标的较优生产条件综合平衡,找出兼顾各项指标都尽可能好的生产条件的方法。 14.综合评分法:是用评分的方法,将多个指标综合成单一的指标---得分,用每次试验的得分来代表试验的结果,用各号试验的分数作为数据进行分析的方法。 15.信噪比:信号功率与噪声功率之比。 16.并列法:是由相同水平正交表构造水平数不同的正交表的一种方法。 17.拟水平法:是对水平数较少的因素虚拟一些水平使之能排在正交表的多水平列上 的一种方法。 18.直和法:是先把一部分因素和水平放在第一张正交表上进行试验,如果试验结果 达不到要求,再利用第一阶段试验结果提供的信息,在第二张正交表上安排下一 阶段的试验,最后再对两张正交表上的结果进行统一分析的方法。 19.直积法: 在某些试验设计中,试验因素常可分为几类,为了考察其中某两类因素 间的交互作用,常采用的把两类因素所用的两张正交表垂直叠在一起进行设计和 分析的一种方法。 20.稳健设计:为了减少质量波动,寻找使得质量波动达到最小的可控因素的水平组合 二、简答题(10分) 1.试验设计的基本原则是什么? 答:一是重复,即一个条件值的每一个实现。作用是提高估计和检验的精度 二是随机化,是通过试验材料的随机分配及试验顺序的随机决定来实现的 三是区组化,也就是局部控制。
试验设计与数据处理
试验设计与数据处理方法总述及总结 王亚丽 (数学与信息科学学院 08统计1班 081120132) 摘要:实验设计与数据处理是一门非常有用的学科,是研究如何经济合理安排 试验可以解决社会中存在的生产问题等,对现实生产有很重要的指导意义。因此本文根据试验设计与数据处理进行了总述与总结,以期达到学习、理解、掌握的以及灵活运用的目的。 1 试验设计与数据处理基本知识总述 1.1试验设计与数据处理的基本思想 试验设计与数据处理是数理统计学中的一个重要分支。它是以概率论、数理统计及线性代数为理论基础,结合一定的专业知识和实践经验,研究如何经济、合理地安排实验方案以及系统、科学地分析处理试验结果的一项科学技术,从而解决了长期以来在试验领域中,传统的试验方法对于多因素试验往往只能被动地处理试验数据,而对试验方案的设计及试验过程的控制显得无能为力这一问题。 1.2试验设计与数据处理的作用 (1)有助于研究者掌握试验因素对试验考察指标影响的规律性,即各因素的水平改变时指标的变化情况。 (2)有助于分清试验因素对试验考察指标影响的大小顺序,找出主要因素。(3)有助于反映试验因素之间的相互影响情况,即因素间是否存在交互作用。(4)能正确估计和有效控制试验误差,提高试验的精度。 (5)能较为迅速地优选出最佳工艺条件(或称最优方案),并能预估或控制一定条件下的试验指标值及其波动范围。 (6)根据试验因素对试验考察指标影响规律的分析,可以深入揭示事物内在规律,明确进一步试验研究的方向。
1.3试验设计与数据处理应遵循的原则 (1)重复原则:重可复试验是减少和估计随机误差的的基本手段。 (2)随机化原则:随机化原则可有效排除非试验因素的干扰,从而可正确、无偏地估计试验误差,并可保证试验数据的独立性和随机性。 (3)局部控制原则:局部控制是指在试验时采取一定的技术措施方法减少非试验因素对试验结果的影响。用图形表示如下: 2试验设计与数据处理方法总述和总结 2.1方差分析 (1)概念:方差分析是用来检验两个或两个以上样本的平均值差异的显著程度。并由此判断样本究竟是否抽自具有同一均值的总体。 (2)优点:方差分析对于比较不同生产工艺或设备条件下产量、质量的差异,分析不同计划方案效果的好坏和比较不同地区、不同人员有关的数量指标差异是否显著时,是非常有用的。 (3)缺点:对所检验的假设会发生错判的情况,比如第一类错误或第二类错误的发生。 (4)基本原理:方差分析的基本思路是一方面确定因素的不同水平下均值之间的方差,把它作为对由所有试验数据所组成的全部总体的方差的第一个估计值;另一方面再考虑在同一水平下不同试验数据对于这一水平的均值的方差,由此计算出对由所有试验数据所组成的全部数据的总体方差的第 二个估计值。比较上述两个估计值,如果这两个方差的估计值比较接近就说明因素的不同水平下的均值间的差异并不大,就接受零假设;否则,说明因素的不同水平下的均值间的差异比较大。
试验统计方法复习题
试验统计方法复习题 1.何谓实验因素和实验水平?何谓简单效应、主要效应和交互效应?举例说明之。 实验因素: 被变动并设有待比较的一组处理的因子或试验研究的对象。 实验水平: 实验因素的量的不同级别或质的不同状态。 简单效应: 同一因素内俩种水平间实验指标的相差。 主要效应:一个因素内各简单效应的平均数。 交互效应:俩个因素简单效应间的平均差异。 2.什么是实验方案,如何制定一个正确的实验方案?试结合所学专业举例说明之。 试验指标:用于衡量试验效果的指示性状。 制定实验方案的要点○1.目的明确。 ○2. 选择适当的因素及其水平。 ○3设置对照水平或处理,简称对照(check,符号CK)。 ○4应用唯一差异原则。 3.什么是实验误差?实验误差与实验的准确度、精确度以及实验处理间的比较的可靠性有什么关系? ○1.试验误差的概念:试验结果与处理真值之间的差异. ○2随机误差影响了数据的精确性,精确性是指观测值间的符合程度,随机误差是偶然性的,整个试验过程中涉及的随机波动因素愈多,试验的环节愈多,时间愈长,随机误差发生的可能性及波动程度便愈大。系统误差是可以通过试验条件及试验过程的仔细操作而控制的。实际上一些主要的系统性偏差较易控制,而有些细微偏差则较难控制。 4.试分析田间实验误差的主要来源,如何控制田间实验的系统误差?如何降低田间实验的随机误差? 误差来源:(1)试验材料固有的差异 (2)试验时农事操作和管理技术的不一致所引起的差异 (3)进行试验时外界条件的差异 控制误差的途径:(1)选择同质一致的试验材料 (2) 改进操作和管理技术,使之标准化 (3) 控制引起差异的外界主要因素 选择条件均匀一致的试验环境; 试验中采用适当的试验设计和科学的管理技术; 应用相应的科学统计分析方法。 尽量减少实验中的随机波动因素、环节和时间可以有效的降低随机误差。 5.田间实验设计的基本原则是什么?完全随机设计、完全随机区组设计、拉丁设计各有何特点?各在什么情况下使用? (1)基本原则是:○1.重复○2随机排列○3局部控制 (2)完全随机设计的特点是设计分析简便,但是应用该设计的条件是要求试验的环境因素相当均匀,所以一般用于实验室培养试验及网、温室的盆钵试验。 完全随机区组设计○1.特点: 根据“局部控制”的原则,将试验地(或试验环境)按肥力变异梯度(或条件变异梯度)划分为等于重复次数的区组,一区组亦即一重复,区组内各处理都独立地随机排列。○2应用条件:对试验地的地形要求不严,必要时,不同区组亦可分散设置在不同地段上。 拉丁方设计的○1.特点:将处理从纵横二个方向排列为区组(或重复),使每个处理在每一
试验设计与数据处理课程论文
课 程 论 文 课程名称试验设计与数据处理 专业2012级网络工程 学生姓名孙贵凡 学号201210420136 指导教师潘声旺职称副教授
成绩 科学研究与数据处理 学院信息科学与技术学院专业网络工程姓名孙贵凡学号:201210420136 摘要:《实验设计与数据处理》这门课程列举典型实例介绍了一些常用的实验设计及实验数据处理方法在科学研究和工业生产中的实际应用,重点介绍了多因素优化实验设计——正交设计、回归分析方法以对目标函数进行模型化处理。其适于工艺、工程类本科生使用,尤其适用于化学化工、矿物加工、医学和环境学等学科的本科生使用。其对行实验设计可提供很大的帮助,也可供广大分析化学工作者应用。关键字:优化实验设计; 标函数进行模型化处理; 正交设计; 回归分析方法 1 引言 实验是一切自然科学的基础,科学界中大多数公式定理是由试验反复验证而推导出来的。只有经得起试验验证的定理规律才具有普遍实用性。而科学的试验设计是利用自己已有的专业学科知识,以大量的实践经验为基础而得出的既能减少试验次数,又能缩短试验周期,从而迅速找到优化方案的一种科学计算方法,就必然涉及到数据处理,也只有对试验得出的数据做出科学合理的选择,才能使实验结果更具说服力。实验设计与数据处理在水处理中发挥着不可估量的作用,通过科学合理的实验设计过程加上严谨规范的数据处理方法,可以使水处理原理,内在规律性被很好的发现,从而更好的应用于生产实践。 2 材料与方法 2.1 供试材料 1. 论文所围绕的目标和假设 研究的目标就是实验的目的,我们设计了这个实验是想来做什么以及想得到什么样的结论。要正确的识别问题和陈述问题,这些需要专业知识和大量的阅读文献综述等方法来获得我们所要提出的问题。需要对某一个具体的问题,并且对这个具体的问题提出假设。如水处理中混凝剂的最佳投加量,混凝剂的最佳投加量有一个适宜的PH值范围。
试验设计习题及答案
【西北农林科技大学试验设计与分析复习题】员海燕版 一、名词解释(15分) 1.重复:一个条件值的每一个实现。或因素某水平值的多次实现。 2.因素:试验中要考虑的可能会对试验结果产生影响的条件。常用大写字母表示。 3.水平:因素所处的不同状态或数值。 4.处理:试验中各个因素的每一水平所形成的组合 5.响应:试验的结果称为响应; 响应函数:试验指标与因素之间的定量关系用模型 ε+=),,(1n x x f y Λ表示,其中 ),,(1n x x f y Λ=是因素的值n x x ,,1Λ的函数,称为响应函数。 6.正交表:是根据均衡分散的思想,运用组合数学理论在拉丁方和正交拉丁方的基础上构造的一种表格。 7.试验指标:衡量试验结果好坏的指标 8.随机误差:在试验中总存在一些不可控制的因素,它们的综合作用称为~ 9.交互作用:一般地说,如果一个因素对试验指标的影响与另一个因素所取的水平有关,就称这两个因素有交互作用。 10.试验设计:是研究如何合理地安排试验,取得数据,然后进行综合的科学分析,从而达到尽快获得最优方案的目的。 11.试验单元:在试验中能施以不同处理的材料单元。 12.拉丁方格:用拉丁字母排列起来的方格,要求每个字母不论在方格的行内还是列内都只出现一次。 13.综合平衡法:先对各项指标进行分析,找出其较优生产条件,然后将各项指标的较优生产条件综合平衡,找出兼顾各项指标都尽可能好的生产条件的方法。 14.综合评分法:是用评分的方法,将多个指标综合成单一的指标---得分,用每次试验的得分来代表试验的结果,用各号试验的分数作为数据进行分析的方法。 15.信噪比:信号功率与噪声功率之比。 16.并列法:是由相同水平正交表构造水平数不同的正交表的一种方法。 17.拟水平法:是对水平数较少的因素虚拟一些水平使之能排在正交表的多水平列上 的一种方法。 18.直和法:是先把一部分因素和水平放在第一张正交表上进行试验,如果试验结果 达不到要求,再利用第一阶段试验结果提供的信息,在第二张正交表上安排下一 阶段的试验,最后再对两张正交表上的结果进行统一分析的方法。 19.直积法: 在某些试验设计中,试验因素常可分为几类,为了考察其中某两类因素 间的交互作用,常采用的把两类因素所用的两张正交表垂直叠在一起进行设计和 分析的一种方法。 20.稳健设计:为了减少质量波动,寻找使得质量波动达到最小的可控因素的水平组合 二、简答题(10分) 1.试验设计的基本原则是什么? 答:一是重复,即一个条件值的每一个实现。作用是提高估计和检验的精度 二是随机化,是通过试验材料的随机分配及试验顺序的随机决定来实现的 三是区组化,也就是局部控制。 2.试验设计的基本流程是什么? 1明确试验目的 2选择试验的指标,因素,水平 3设计试验方案 4实施试验 5对获得的数据进行分析和推断。 3.试验设计的相关分析有哪几种? 一是相关系数,即用数理统计中的两个量之间的相关程度来分析的一种方法。 二是等级相关,是把数量标志和品质标志的具体体现用等级次序排序,再测定标志等级和标志等级相关程度的一种方法。有斯皮尔曼等级差相关系数和肯德尔一致相关系数) 4.为什么要进行方差分析? 方差分析可检验有关因素对指标的影响是否显着,从而可确定要进行试验的因素; 另外,方差分析的观点认为,只需对显着因素选水平就行了,不显着的因素原则上可在试验范围内取任一水平,或由其它指标确定。 5.均匀设计表与正交表,拉丁方设计的关系 6.产品的三次设计是什么? 产品的三次设计是系统设计,参数设计,容差设计。 三、(15分) 1.写出所有3阶拉丁方格,并指出其中的标准拉丁方格和正交拉丁方格
实验设计与数据处理课后答案
《试验设计与数据处理》 专业:机械工程班级:机械11级专硕学号:S110805035 姓名:赵龙 第三章:统计推断 3-13 解:取假设H0:u1-u2≤0和假设H1:u1-u2>0用sas分析结果如下:Sample Statistics Group N Mean Std. Dev. Std. Error ---------------------------------------------------- x 8 0.231875 0.0146 0.0051 y 10 0.2097 0.0097 0.0031 Hypothesis Test Null hypothesis: Mean 1 - Mean 2 = 0 Alternative: Mean 1 - Mean 2 ^= 0 If Variances Are t statistic Df Pr > t ---------------------------------------------------- Equal 3.878 16 0.0013 Not Equal 3.704 11.67 0.0032 由此可见p值远小于0.05,可认为拒绝原假设,即认为2个作家所写的小品文中由3个字母组成的词的比例均值差异显著。 3-14 解:用sas分析如下: Hypothesis Test Null hypothesis: Variance 1 / Variance 2 = 1 Alternative: Variance 1 / Variance 2 ^= 1 - Degrees of Freedom - F Numer. Denom. Pr > F ---------------------------------------------- 2.27 7 9 0.2501 由p值为0.2501>0.05(显著性水平),所以接受原假设,两方差无显著差异 第四章:方差分析和协方差分析 4-1 解: Sas分析结果如下: Dependent Variable: y Sum of Source DF Squares Mean Square F Value Pr > F
试验设计与数据处理试验报告
试验设计与数据处理试验报告 正交试验设计 1.为了通过正交试验寻找从某矿物中提取稀土元素的最优工艺条件,使稀土元素提取率最高,选取的水平如下:
需要考虑交互作用有A×B,A×C,B×C,如果将A,B,C分别安排在正交表L8(2)的 1,2,4列上,试验结果(提取量/ml)依次是1.01,,1,33,1,13,1.06,,1.03,0.08,,0.76,0.56. 试用方差分析法(α=0.05)分析实验结果,确定较优工艺条件 解:(1)列出正交表L8(27)和实验结果,进行方差分析。 试验号 A B A×B C A×C B×C 空号提取量(ml) 1 1 1 1 1 1 1 1 1.01 2 1 1 1 2 2 2 2 1.33 3 1 2 2 1 1 2 2 1.13 4 1 2 2 2 2 1 1 1.06 5 2 1 2 1 2 1 2 1.03 6 2 1 2 2 1 2 1 0.8 7 2 2 1 1 2 2 1 0.76 8 2 2 1 2 1 1 2 0.56 K1 4.53 4.17 3.66 3.93 3.5 3.66 3.63 K2 3.15 3.51 4.02 3.75 4.18 4.02 4.05 k1 2.265 2.085 1.83 1.965 1.75 1.83 1.815 k2 1.575 1.755 2.01 1.875 2.09 2.01 2.025 极差R 1.38 0.66 0.36 0.18 0.68 0.36 0.42 因素主次 A A×C B A×B B×C 优选方案 A1B1C1 SS J 0.23805 0.05445 0.0162 0.00405 0.0578 0.0162 0.02205 Q 7.7816 总和T 7.68 P=T^2/n 7.3728 SS T 0.4088 差异源SS df MS F 显著性 A 0.23805 1 0.23805 19.5925 9259 * B 0.05445 1 0.05445 4.48148 1481 A*B 0.0162 1 0.0162 1.33333 3333 C 0.00405 1 0.00405 0.33333 3333 A*C 0.0578 1 0.0578 4.75720 1646
试验设计习题及答案
试验设计习题及答案. 【西北农林科技大学试验设计与分析复习题】员海燕版 一、名词解释(15分) 1.重复:一个条件值的每一个实现。或因素某水平值的多次实现。 2.因素:试验中要考虑的可能会对试验结果产生影响的条件。常用大写字母表示。3.水平:因素所处的不同状态或数值。 4.处理:试验中各个因素的每一水平所形成的组合 5.响应:试验的结果称为响应;
??),x,?f(x y n1表示,其中响应函数:试验指标与因素之间的定量关系用模型 y?f(x, ,x)x,,x nn11的函数,称为响应函数。是因素的值6.正交表:是根据均衡分散的思想,运用组合数学理论在拉丁方和正交拉丁方的基础上构造的一种表格。 7.试验指标:衡量试验结果好坏的指标 8.随机误差:在试验中总存在一些不可控制的因素,它们的综合作用称为~ 9.交互作用:一般地说,如果一个因素对试验指标的影响与另一个因素所取的水平有关,就称这两个因素有交互作用。10.试验设计:是研究如何合理地安排试验,取得数据,然后进行综合的科学分析,从而达到尽快获得最优方案的目的。11.试验单元:在试验中能施以不同处理的材料单元。 12.拉丁方格:用拉丁字母排列起来的方格,要求每个字母不论在方格的行内还是列内都只出现一次。 13.综合平衡法:先对各项指标进行分析,找出其较优生产条件,然后将各项指标的较优生产条件综合平衡,找出兼顾各项指标都尽可能好的生产条件的方法。 14.综合评分法:是用评分的方法,将多个指标综合成单一的指标---得分,用每次试验的得分来代表试验的结果,用各
号试验的分数作为数据进行分析的方法。 15.信噪比:信号功率与噪声功率之比。 16.并列法:是由相同水平正交表构造水平数不同的正交表的一种方法。 17.拟水平法:是对水平数较少的因素虚拟一些水平使之能排在正交表的多水平列上 的一种方法。 18.直和法:是先把一部分因素和水平放在第一张正交表上进行试验,如果试验结果 达不到要求,再利用第一阶段试验结果提供的信息,在第二张正交表上安排下一 阶段的试验,最后再对两张正交表上的结果进行统一分析的方法。 19.直积法: 在某些试验设计中,试验因素常可分为几类,为了考察其中某两类因素 间的交互作用,常采用的把两类因素所用的两张正交表垂直叠在一起进行设计和 分析的一种方法。 20.稳健设计:为了减少质量波动,寻找使得质量波动达到最小的可控因素的水平组合 二、简答题(10分) 1.试验设计的基本原则是什么? 答:一是重复,即一个条件值的每一个实现。作用是提高估计和检验的精度 二是随机化,是通过试验材料的随机分配及试验顺序的随机决定来实现的 三是区组化,也就是局部控制。 2.试验设计的基本流程是什么? 1明确试验目的 2选择试验的指标,因素,水平 3设计试验方案 4实施试验 5对获得的数据进行分析和推断。 3.试验设计的相关分析有哪几种? 一是相关系数,即用数理统计中的两个量之间的相关程度来分析的一种方法。 二是等级相关,是把数量标志和品质标志的具体体现用等级次序排序,再测定标志等级和标志等级相关程度的一种方法。有斯皮尔曼等级差相关系数和肯德尔一致相关系数) 4.为什么要进行方差分析? 方差分析可检验有关因素对指标的影响是否显著,从而可确定要进行试验的因素; 另外,方差分析的观点认为,只需对显著因素选水平就行了,不显著的因素原则上可在试验范围内取任一水平,或由其它指标确定。 5.均匀设计表与正交表,拉丁方设计的关系 6.产品的三次设计是什么? 产品的三次设计是系统设计,参数设计,容差设计。 三、(15分) 1.写出所有3阶拉丁方格,并指出其中的标准拉丁方格和正交拉丁方格
《实验设计与数据处理》教学大纲
《实验设计与数据处理》教学大纲 (Experiment Design and Data Analysis) 一、基本信息 课程代码: 学分:2 总课时:32 课程性质:硕士专业必修课 适用专业:环境工程 先修课程:高等数学、概率论、线性代数 二、本课程教学目的和任务 本课程是环境工程硕士生的专业课。数据分析作为一种研究手段,主要是通过从系统设计、参数设计和允许误差设计入手,运用一定的物质手段,在人为控制或模拟自然现象的条件下,使环境过程以纯粹的、典型的形式表现出来,以便进行观察、研究、探索环境本质及其规律,使试验设计建立在统计理论基础之上,试验设计与数据处理相并重。 三、大纲的教学体系 以课堂教学和上机操作为主,采用多媒体教学,辅以课堂讨论、专题讲解等内容。主要开展环境试验的优化设计、环境数据的展示分析、环境数据的比较分析、环境数据的关系分析、环境数据的类别分析、环境数据的序列分析、环境数据的序列分析、正交试验的数据分析、回归分析、数据分析软件学习等内容。 四、教学内容及要求 第一章环境实验设计与数据处理概论 要求掌握(1)环境试验研究的目的与任务;(2)环境试验研究的类型;(3)环境试验研究的程序 重点内容:准确理解环境试验研究类型的区分;理解环境试验研究的设计步骤,以及试验设计的基本要求。 难点内容:理解环境试验因子、水平、处理、重复、响应指标等要素,了解准确度、精密度等概念。 第二章环境试验的优化设计 要求掌握(1)非均分设计;(2)黄金分割设计;(3)纵横对折设计;(4)平行线设计;(5)环境试验的正交设计;(6)环境试验点均匀设计;熟悉单因子、双因子优选设计的基本方法,熟悉正交表的定义和类型;了解均匀设计与正交设计的区别。 重点内容:正交试验的设计步骤,常见的正交设计运用方法,均匀设计的步骤 难点内容:了解分数法设计;旋升设计;逐步提高设计;陡度法设计;单纯形法设计等。 第三章环境数据的展示分析
试验设计与数据处理(整理)
第四章 1、误差的来源: 主要有四个方面:1.设备仪表误差:包括所使用的仪器、器件、引线、传感器及提供检定用的标准器等,均可引入误差。2.环境误差:周围环境的温度、湿度、压力、振动及各种可能干扰测量的因素,均能使测量值发生变化,使测量失准,产生误差;3.人员误差:测量人员分辨能力、测量经验和习惯,影响测量误差的大小。4.方法误差:研究与实验方法引起的误差。 2、误差的分类: 粗大误差、系统误差、随机误差;粗大误差的特点是测量值显著异常。处理方法是在对实验结果进行数据处理之前,须先行剔除坏值。系统误差的特点是在测量条件一定时,误差的大小和方向恒定,当测量条件变化时,误差按某一确定规律变化。处理方法:由于误差是按某一确定规律变化的,即误差变化可用函数式或用曲线图形描述偶然出现,误差很大,数据异常。可以理论分析、实验验证,找到规律并修正。随机误差的特点是测量时,每一次测量的误差均不相同,时大时小,时正时负,不可预定,无确定规律。处理方法是采用数理统计的方法,来研究随机误差的特征,以判断它对测量结果的影响。 粗大误差或者坏值的判断方法:剔除方法有两种:1)格拉布斯准则。设对某物理 量进行N 次重复测量,得测量列x1,x2,···xn ,算术平均值11n i i x x n -==∑测量值与平均值之差称为残余误差或残差,用Vi 表示,即V i i x x - =- 测量列的标准差 σ= 若某测量值xi 的残差绝对值(,)V n αλασ>时,则判为坏值。(n 为测量次数,α为置信度)。2)3σ准则。确定其最大可能误差,并验证各测量值的误差是否超过最大可能误差。一般为简化计算,提出以+-3σ 为最大可能误差,也称为3σ准则。 3.误差传递公式及其应用(任意选取两个方面)
实验设计与数据处理(第二版部分答案)
试验设计与数据处理 学院 班级 学号 学生 指导老师
第一章 4、 相 故100g 中维生素C 的质量围为:。 5、1)、压力表的精度为1.5级,量程为0.2MPa , 则 2)、1mm 的汞柱代表的大气压为0.133KPa , 所以 3)、 1mm 则: 6. 样本测定值 3.48 算数平均值 3.421666667 3.37 几何平均值 3.421406894 3.47 调和平均值 3.421147559 3.38 标准差s 0.046224092 3.4 标准差σ 0.04219663 3.43 样本方差S 2 0.002136667 总体方差σ2 0.001780556 |||69.947|7.747 6.06 d x =-=>
算术平均误差△0.038333333 极差R 0.11 7、S?2=3.733,S?2=2.303 F=S?2/S?2=3.733/2.303=1.62123 而F 0.975(9.9)=0.248386,F0.025(9.9)=4.025994 所以F 0.975(9.9)< F 8.旧工艺新工艺 2.69% 2.62% 2.28% 2.25% 2.57% 2.06% 2.30% 2.35% 2.23% 2.43% 2.42% 2.19% 2.61% 2.06% 2.64% 2.32% 2.72% 2.34% 3.02% 2.45% 2.95% 2.51% t-检验: 双样本异方差假设 变量1 变量2 平均0.025684615 2.291111111 方差0.000005861 0.031611111 观测值13 9 假设平均差0 df 8 习题第一章 1、1 孟德尔豌豆试验 孟德尔做过这样一个实验:把一种开紫花的豌豆种与一种开白花的豌豆种结合在一起,第一次结出来的豌豆开紫花,第二次紫白相间,第三次全白。对此孟德尔没有充分的理由作出解释。后来,孟德尔从豌豆杂交实验结果,得出了相对性状中存在着显性与隐性的原理。虽然还有不少例外,但它仍然就是一个原理。孟德尔根据自己在实验中发现的原理,进一步做了推想。她认为决定豌豆花色的物质一定就是存在于细胞里的颗粒性的遗传单位,也就就是具有稳定性的遗传因子。她设想在身体细胞里,遗传因子就是成双存在的;在生殖细胞里,遗传因子就是成单存在的。例如,豌豆的花粉就是一种雄性生殖细胞,遗传因子就是成单存在的。在豌豆的根、茎、叶等身体细胞里,遗传因子就是成双存在的。这就就是说,孟德尔认为可以观察到的花的颜色就是由有关的遗传因子决定的。 如果用D代表红花的遗传因子,它就是显性;用d代表白花的遗传因子,它就是隐性。这样,豌豆花色的杂交实验,就可以这样解释: 红花×白花 (纯种)DD dd(身体细胞,遗传因子成双存在) ↓↓(杂交) D d(生殖细胞,遗传因子成单存在) \/ Dd(杂交) 自交Dd DD Dd dD dd 红花因为杂种的遗传基础物质就是由D与d组成的,因此,它的后代(子2)就可能出现白花(dd)了。 这就就是说,隐性的遗传因子在从亲代到后代的传递中,它可以不表现。但就是它就是稳定的,并没有消失。 遗传单位,叫做基因。研究基因的科学就就是遗传学。基因学说就就是现代遗传学的中心理论。很清楚,基因概念就是孟德尔在推想中提出来的,虽然当时她并没有提出“基因”这个科学名词。 孟德尔认为遗传单位(基因)具有高度的稳定性。一个显性基因与它相对的隐性基因在一起的时候,彼此都具有稳定性,不会改变性质。例如,豌豆的红花基因R与白花基因r 在一起,彼此不会因为相对基因在一起而发生变化,在一代一代的传递中,D与d都能长期保持自己的颜色特征。孟德尔的结论正好跟长期流传的融合遗传理论相对立。 融合遗传理论就是怎么回事儿呢?它的基本论点就是:遗传因子或遗传物质相遇的时候,彼此会相互混合,相互融化,而成为中间类型的东西。根据融合理论来推理,甲与乙杂交,就会产生出混血儿,甲的遗传因子与乙的遗传因子,都变成了中间类型的东西。好比两种液体混合在一起似的,亲代的遗传因子都因为融合而消失了。根据融合理论来推理,豌豆的红花遗传因子D跟白花遗传因子d在一起的时候也就会融合成为新的东西,D与d 都不再存在了。显然,融合理论就是错误的,因为它没有科学事实的支持。它只就是一种推测与猜想,不能解释所有的表现不同的遗传现象。然而中间类型就是有的。这就是相对的基因相互作用而产生的性状,基因本身并没有改变。例如,红花的紫茉莉与白花的紫茉莉杂交,子一代的花就是粉红色的。可就是子二代,这些粉红色茉莉的后代,却有三种不同的性状:粉红花、红花与白花。 从这里也可以瞧到,现象与本质虽然有着密切的关系,但就是它们之间就是有区别的,不能简单地把现象与本质等同起来。豌豆就是自花传粉植物,而且还就是闭花受粉,也就是豌豆花在未开放时,就已经完成了受粉,避免了外来花粉的干扰。所以豌豆在自然状态下一般都就是纯种,用豌豆做人工杂交实验,结果既可靠,又容易分析。 1、2比较植物在不同生长条件下生长速度 1、试验的目标植物的生长速度的快慢 2、因素及其试验范围不同的生长条件为因素,如,阳光、水分、空气、土壤…… 3、响应结果为试验的生长速度 4、试验误差如,温度的细小误差,土壤中微量元素的干扰,空气湿度…… 5、区组设立多的区组,可以使试验更加精确 6、随机化随机化试验顺序 7、重复重复多次试验,减小误差 8、统计模型建立统计模型,估计实验结果 9、追加试验追加试验,减小误差试验设计与建模第一章课后习题答案