多线程网页抓取程序的分析与改进
一、GetWeb类源代码分析
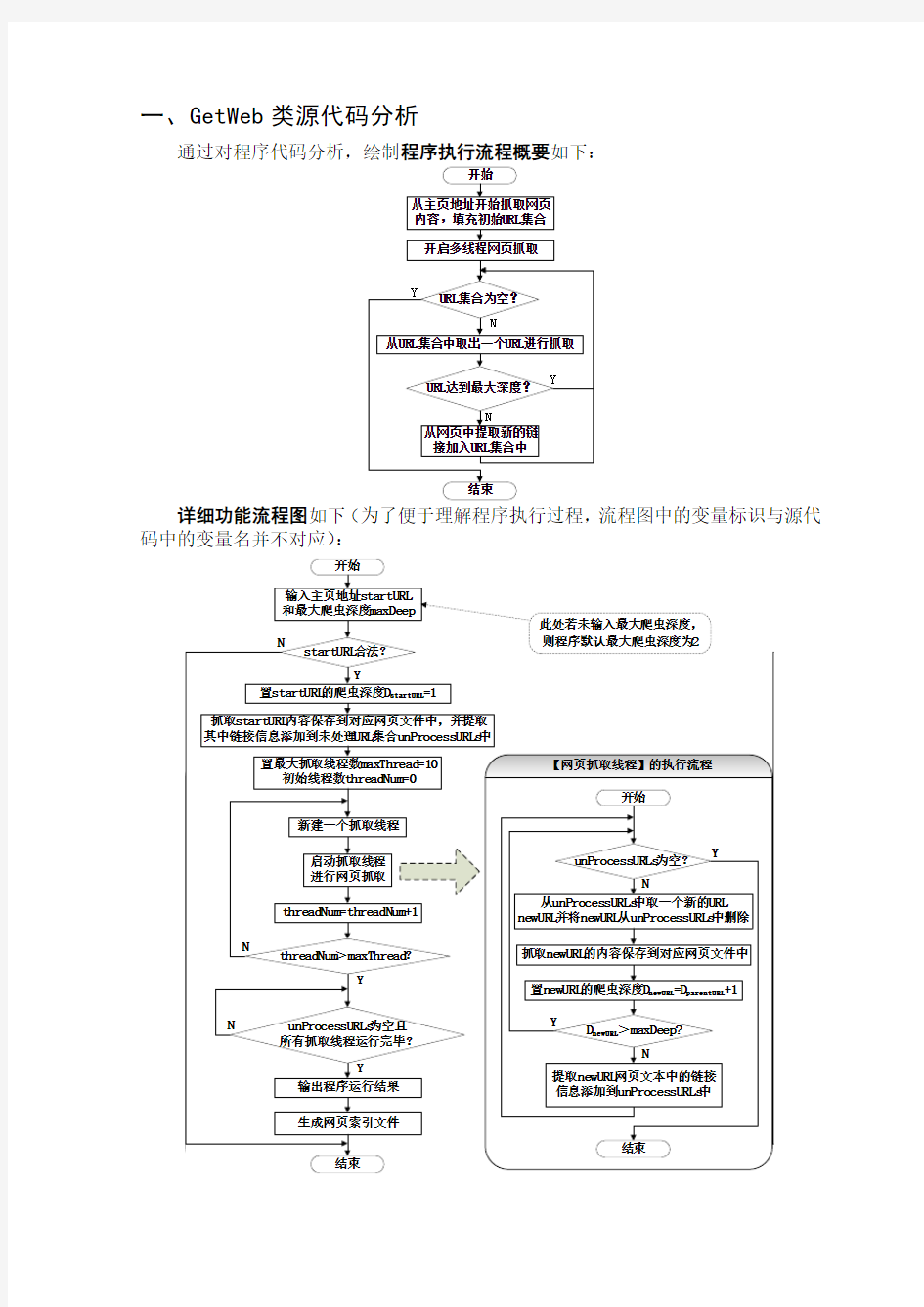
通过对程序代码分析,绘制程序执行流程概要如下:
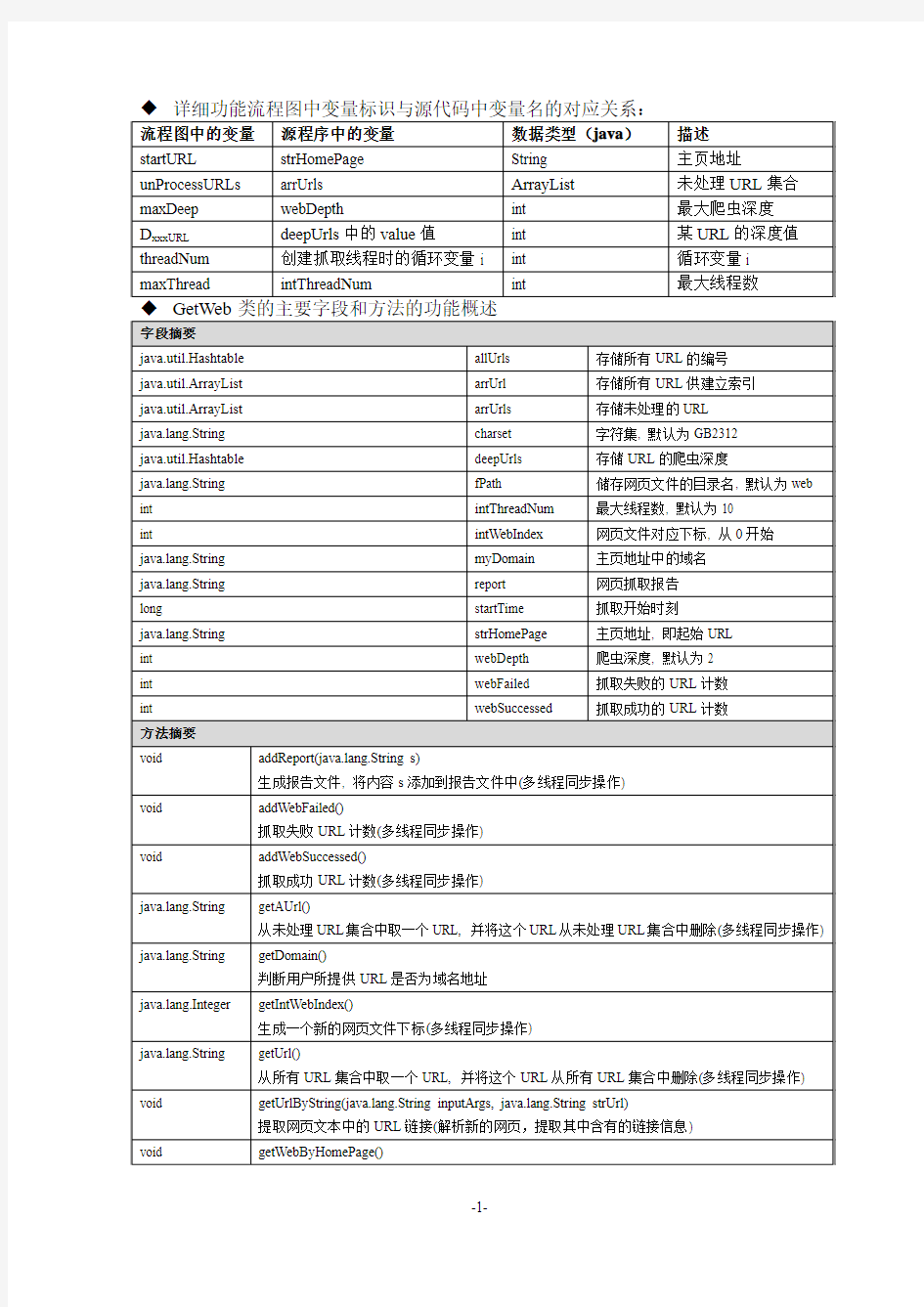
详细功能流程图如下(为了便于理解程序执行过程,流程图中的变量标识与源代码中的变量名并不对应):
getWebByHomePage 方法,首先将主页URL添加到arrUrl和allUrls队列中,为其分配初始编号0,并设置爬虫深度为1 ;然后调用getWebByUrl方法抓取主页内容,将其存入网页文件中,同时从抓回的网页文本中提取链接(使用getUrlByString方法)存入arrUrls队列和arrUrl队列中。同时在allUrls队列中为每个URL分配一个网页编号,在deepUrls 中添加并设置每个URL的爬虫深度(父链接爬虫深度+1,这里为1+1=2)。
接下来,循环创建10个抓取线程开始网页抓取。网页抓取线程不断从arrUrls队列中取出链接,抓取其网页内容。接着判断网页爬虫深度若大于最大爬虫深度则继续从arrUrls中取新的URL进行抓取,否则,要从刚刚抓取到的网页文本中提取链接,存入arrUrls队列和arrUrl队列,在allUrls队列中为每个URL分配网页编号,在deepUrls中设置每个URL的爬虫深度。然后才从arrUrls中取新的URL进行抓取。
值得强调的是,后续添加URL到arrUrls时,要判断这个URL是不是已经抓取过了,如果已经抓取过了就不再加入待抓取URL队列了。
最终,当arrUrls队列中的URL全部被取完时,程序终止抓取,从arrUrl提取网页文件索引信息输出到文件fileindex.txt中。
同时,在程序整个运行过程中,每一步的调试信息都输出在report.txt文件中。
二、存在问题及改进方法
通过对所给程序代码分析,结合真实的Internet网络环境,我们不难看出该程序仍有以下几点不足:
1.程序从网页文本中提取URL时,只考虑了完整格式的URL的提取,而忽略了相对地址和绝对地址的提取。这显然是不符合实际情况的。因为大多数网站的站内链接大多为相对地址或绝对地址,这种链接占Internet链接中的很大一部分。虽然同一个站点的页面爬虫的抓取深度有限,但忽略站内所有相对链接和绝对链接会失去很多页面信息,造成抓取页面不完整,这对后期网页索引等工作是很不利的。
完整格式的URL示例:Store
绝对地址的URL示例:iPhone
相对地址的URL示例:Mac
因此,我们可以在getUrlByString方法中添加相应的代码来对从a标签href域中提取出的链接信息进行分析处理,使之能够抓取到相对地址和绝对地址指向的页面。但在提取链接信息时,同时也会提取到一些诸如:JavaScript(JavaScript脚本)、mailto (电子邮箱地址)、#(本页面)之类的信息,对于这些信息我们需要丢弃。
2.在通过URL抓取网页过程中,程序没有考虑不同的HTTP连接状态,如:访问的URL暂时无法提供服务(HTTP状态码503:Service Unavailable)。这种情况下,原来的程序似乎无能为力。
对此,我们可以在getWebByUrl方法中添加相应的代码来获取HTTP连接状态码,然后根据不同的状态,做出相应的处理。一般常见的状态码是:200(正常)、3XX(重定向)、403(禁止访问)、404(未找到页面)、503(服务暂不可用)。显然只有在状态码为200或3XX时,我们才需要抓取对应网页内容,其他情况均无需抓取。
三、改进后程序流程
如下是对程序改进部分的流程概要:
1.对相对地址和绝对地址的处理如下图左(因为不是匹配完整格式的网页,所以需要从匹配到的链接中去除JavaScript、mailto、#等无效链接)
2.处理HTTP连接的不同状态码如下图右
注:其余部分代码功能与原程序基本相同,故未在下图中画出。
……
四、改进后程序代码及运行结果说明
GetWeb.java
import java.io.File;
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import https://www.360docs.net/doc/114388624.html,.HttpURLConnection;
import https://www.360docs.net/doc/114388624.html,.MalformedURLException;
import https://www.360docs.net/doc/114388624.html,.URL;
import java.util.ArrayList;
import java.util.regex.Pattern;
import java.util.Hashtable;
/**
* 网页抓取爬虫
* @author unknown
* 代码修改注释:
* 1. 代码改动主要在getWebByUrl方法和getUrlByString方法中
* 2. 修改了getDomain方法使之变为通用的获取主机域名的方法
* 3. 添加了三个方法:
* (1)getHomePage方法, 从指定URL中提取协议部分和主机部分(一般此部分即为站点主页地址) * (2)isRedirectStatusCode方法, 判断指定HTTP状态码是否为重定向状态码3XX
* (3)toFullAddress方法, 将指定URL转换为完整格式的URL并返回
*/
public class GetWeb {
/**
* 爬虫深度, 默认为2
*/
private int webDepth = 2;
/**
* 线程数,默认为10
*/
private int intThreadNum = 10;
/**
* 主页地址, 即起始URL
*/
private String strHomePage = "";
/**
* 域名
*/
private String myDomain;
/**
* 储存网页文件的目录名, 默认为web
*/
private String fPath = "web";
/**
* 存储未处理URL
*/
private ArrayList
/**
* 存储所有URL供建立索引
*/
private ArrayList
/**
* 存储所有URL的网页号
private Hashtable
/**
* 存储所有URL的深度
*/
private Hashtable
/**
* 网页对应文件下标, 从0开始
*/
private int intWebIndex = 0;
/**
* 字符集, 默认为GB2312
*/
private String charset = "GB2312";
/**
* 抓取网页报告
*/
private String report = "";
/**
* 开始时刻
*/
private long startTime;
/**
* 抓取成功的URL计数
*/
private int webSuccessed = 0;
/**
* 抓取失败的URL计数
*/
private int webFailed = 0;
/**
* 指定起始URL实例化网页抓取类的对象
* @param s 起始URL
*/
public GetWeb(String s) {
this.strHomePage = s;
}
/**
* 指定起始URL和爬虫深度实例化网页抓取类的对象
* @param s 起始URL
* @param i 爬虫深度
public GetWeb(String s, int i) {
this.strHomePage = s;
this.webDepth = i;
}
/**
* 抓取成功URL计数(多线程同步操作)
*/
public synchronized void addWebSuccessed() {
webSuccessed++;
}
/**
* 抓取失败URL计数(多线程同步操作)
*/
public synchronized void addWebFailed() {
webFailed++;
}
/**
* 生成报告文件, 将内容s添加到报告文件中(多线程同步操作)
* @param s 报告内容
*/
public synchronized void addReport(String s) {
try {
report += s;
PrintWriter pwReport = new PrintWriter(new FileOutputStream( "report.txt"));
pwReport.println(report);
pwReport.close();
} catch (Exception e) {
System.out.println("生成报告文件失败!");
}
}
/**
* 从未处理的URL集合中取一个URL, 并将这个URL从未处理URL集合中删除(多线程同步操作)
* @return一个URL
*/
public synchronized String getAUrl() {
String tmpAUrl = arrUrls.get(0);
arrUrls.remove(0);
return tmpAUrl;
/**
* 从所有URL集合中取一个URL, 并将这个URL从所有URL集合中删除(多线程同步操作) * @return一个URL
*/
public synchronized String getUrl() {
String tmpUrl = arrUrl.get(0);
arrUrl.remove(0);
return tmpUrl;
}
/**
* 生成一个新的网页文件下标(多线程同步操作)
* @return网页文件下标
*/
public synchronized Integer getIntWebIndex() {
intWebIndex++;
return intWebIndex;
}
public static void main(String[] args) {
if (args.length == 0 || args[0].equals("")) {
// 如果输入的起始URL为空, 则提示未输入URL, 程序退出
System.out.println("No input!");
System.exit(1);
} else if (args.length == 1) {
// 如果只输入了起始URL, 则默认爬虫深度为2, 开始网页抓取
GetWeb gw = new GetWeb(args[0]);
gw.getWebByHomePage();
} else {
// 如果输入了起始URL和爬虫深度, 则按指定的爬虫深度开始抓取网页
GetWeb gw = new GetWeb(args[0], Integer.parseInt(args[1]));
gw.getWebByHomePage();
}
}
/**
* 由用户提供的域名站点开始,对所有链接页面进行抓取
*/
public void getWebByHomePage() {
// 设置起始时刻
startTime = System.currentTimeMillis();
// 获取主页域名
this.myDomain = getDomain(strHomePage);
// 主页域名为空则出错返回
System.out.println("Wrong input!");
// System.exit(1);
return;
}
// 输出相关调试信息, 将主页地址添加到初始URL集合中
System.out.println("Homepage = " + strHomePage);
addReport("Homepage = " + strHomePage + "!\n");
System.out.println("Domain = " + myDomain);
addReport("Domain = " + myDomain + "!\n");
arrUrls.add(strHomePage);
arrUrl.add(strHomePage);
allUrls.put(strHomePage, 0);
// 设置初始URL的爬虫深度
deepUrls.put(strHomePage, 1);
// 建立存放网页文件的目录
File fDir = new File(fPath);
if (!fDir.exists()) {
fDir.mkdir();
}
// 开始抓取网页
System.out.println("Start!");
this.addReport("Start!\n");
String tmp = getAUrl(); // 取一个新的URL
// 对新URL所对应的网页进行抓取
this.getWebByUrl(tmp, charset, allUrls.get(tmp) + "");
// 建立多个线程, 从URL集合中取链接进行抓取
for (int i = 0; i < intThreadNum; i++) {
new Thread(new Processer(this)).start();
}
// 等待程序运行完成后输出运行结果信息
while (true) {
// 当未处理URL集合为空且抓取网页线程均已运行完毕时, 表示抓取已完成if (arrUrls.isEmpty() && Thread.activeCount() == 1) { // 设置程序结束时刻
long finishTime = System.currentTimeMillis();
// 计算程序运行时间
long costTime = finishTime - startTime;
// 输出程序运行结果
System.out.println("\n\n\n\n\nFinished!");
addReport("\n\n\n\n\nFinished!\n");
System.out.println("Start time = " + startTime + " "
+ "Finish time = " + finishTime + " " + "Cost time = "
+ costTime + "ms");
addReport("Start time = "+ startTime + " " + "Finish time = "
+ finishTime + " " + "Cost time = " + costTime + "ms"
+ "\n");
System.out.println("Total url number = "
+ (webSuccessed + webFailed) + " Successed: "
+ webSuccessed + " Failed: " + webFailed);
addReport("Total url number = " + (webSuccessed + webFailed) + " Successed: " + webSuccessed + " Failed: "
+ webFailed + "\n");
// 输出索引信息, 生成索引文件
String strIndex = "";
String tmpUrl = "";
while (!arrUrl.isEmpty()) {
tmpUrl = getUrl();
strIndex += "Web depth:" + deepUrls.get(tmpUrl)
+ " Filepath: " + fPath + "/web"
+ allUrls.get(tmpUrl) + ".htm" + " url:" + tmpUrl
+ "\n\n";
}
System.out.println(strIndex);
try {
PrintWriter pwIndex=new PrintWriter(new FileOutputStream(
"fileindex.txt"));
pwIndex.println(strIndex);
pwIndex.close();
} catch (Exception e) {
System.out.println("生成索引文件失败!");
}
break; // 程序运行结束
}
}
}
/**
* 抓取URL的网页文本并从中提取URL链接(对后续解析出的url进行抓取)
* @param strUrl 要抓取的URL
* @param charset 字符集
* @param fileIndex URL索引编号
*/
public void getWebByUrl(String strUrl,String charset,String fileIndex) {
try {
// 输出调试信息, 并将之添加到报告文件中
System.out.println("Getting web by url: " + strUrl);
addReport("Getting web by url: " + strUrl + "\n");
/**
* modify by yang 2011.12.23
*/
// 初始化URL和HttpURLConnction的对象
boolean isAccess = true; // URL是否可访问, 默认可以访问
URL url = new URL(strUrl);
HttpURLConnection conn =
(HttpURLConnection)url.openConnection();
conn.setInstanceFollowRedirects(false); // 设定不要自动跳转
conn.setReadTimeout(30000); // 设定timeout时间
conn.connect(); // 连线
// 以下分情况处理常见的HTTP状态码
int status = conn.getResponseCode(); // 获取HTTP状态码
String staStr = ""; // HTTP状态描述
switch (status) {
// 服务器返回200, 访问正常
case HttpURLConnection.HTTP_OK:
isAccess = true;
staStr = "Normal!";
break;
// 服务器返回403, 当前禁止访问该URL
case HttpURLConnection.HTTP_FORBIDDEN:
isAccess = false;
staStr = "Access is forbidden!";
break;
// 服务器返回404, URL指定页面未找到
case HttpURLConnection.HTTP_NOT_FOUND:
isAccess = false;
staStr = "Page not found!";
break;
// 服务器返回503, 服务暂不可用
case HttpURLConnection.HTTP_UNAVAILABLE:
isAccess = false;
staStr = "Service is unavailable!";
// 服务器返回3XX, 重定向到Location域所指定的URL
case HttpURLConnection.HTTP_MOVED_PERM: // 资源永久移位
case HttpURLConnection.HTTP_MOVED_TEMP: // 资源临时移位
case HttpURLConnection.HTTP_SEE_OTHER: // 资源重定向String urlStr = conn.getHeaderField("Location");
urlStr = toFullAddress(urlStr, strUrl); // 处理相对地址
url = new URL(urlStr);
conn = (HttpURLConnection) url.openConnection();
conn.setInstanceFollowRedirects(false);
conn.setReadTimeout(30000);// 设定timeout时间
conn.connect();// 连线
status = conn.getResponseCode();
int iterNum = 4; // 最大重定向次数
while (isRedirectStatusCode(status) && (iterNum--) > 0) { urlStr = conn.getHeaderField("Location");
urlStr = toFullAddress(urlStr, strUrl); // 处理相对地址
url = new URL(urlStr);
conn = (HttpURLConnection) url.openConnection();
conn.setInstanceFollowRedirects(false);
conn.setReadTimeout(30000);// 设定timeout时间
conn.connect();// 连线
status = conn.getResponseCode();
}
isAccess = true;
staStr = "Page has redirect!";
break;
}
/**
* modify end
*/
// 网页文件的路径
String filePath = fPath + "/web" + fileIndex + ".htm"; PrintWriter pw = null;
// 初始化网页文件及相关输入输出流
FileOutputStream fos = new FileOutputStream(filePath); OutputStreamWriter writer = new OutputStreamWriter(fos);
pw = new PrintWriter(writer);
if (isAccess == true) { // 如果URL访问正常, 则开始获取网页内容InputStream is = null;
is = url.openStream(); // 获取URL的输入流
new InputStreamReader(is));
StringBuffer sb = new StringBuffer();
String rLine = null;
String tmp_rLine = null;
// 开始读取网页文本内容
while ((rLine = bReader.readLine()) != null) {
tmp_rLine = rLine;
int str_len = tmp_rLine.length();
if (str_len > 0) { // 如果网页文本内容不为空
sb.append("\n" + tmp_rLine); // 将网页文本存入字符串变量
pw.println(tmp_rLine); // 将网页文本存入网页文件中
pw.flush();
if (deepUrls.get(strUrl) < webDepth)
// 如果URL深度未达到最大深度, 则从网页文本中提取URL链接
getUrlByString(tmp_rLine, strUrl);
}
tmp_rLine = null;
}
// 关闭相关输入输出流, 并输入调试信息, 写报告文件
is.close();
pw.close();
System.out.println("Get web successfully! " + strUrl
+ " [HTTP " + status + " " + staStr + "]");
addReport("Get web successfully! " + strUrl + " [HTTP "
+ status + " " + staStr + "]\n");
addWebSuccessed();
} else { // 如果网页访问不正常, 向网页文件中写入错误信息
pw.println("Get web occurred some problems! [HTTP " + status + staStr);
pw.flush();
pw.close();
System.out.println("Get web occurred some problems! [HTTP "
+ status + " " + staStr + "]");
addReport("Get web occurred some problems! [HTTP " + status + " " + staStr + "]\n");
addWebFailed(); // 抓取失败计数
}
} catch (Exception e) {
// 如果以过程出错, 则认为抓取失败, 输入失败信息, 并将之写入报告文件
System.out.println("Get web failed! " + strUrl
+ " [Internal program error!]");
addReport("Get web failed! " + strUrl
addWebFailed();
e.printStackTrace();
}
}
/**
* 判断HTTP状态码是不是3XX重定向
* @param status HTTP状态码
* @return若是状态码是300到307中的一个则返回true, 否则返回false
*/
public boolean isRedirectStatusCode(int status) {
return (status >= 300 && status <= 307) ? true : false;
}
/**
* 从URL中提取默认主页地址
* @param url URL链接
* @return URL中包含的主页地址
*/
public String getHomePage(String url) {
String homepage = url;
for (int i = 0, j = 0; i < homepage.length(); i++) { if (homepage.charAt(i) == '/') {
j++;
}
if (j == 3) {
homepage = homepage.substring(0, i);
break;
}
}
return homepage;
}
/**
* 将一个相对URL地址转换为绝对地址
* @param urlAddress 相对地址
* @param baseUrl 基地址
* @return若是相对地址则返回对应的绝对地址, 否则不做修改
* @throws MalformedURLException
*/
public String toFullAddress(String urlAddress, String baseUrl) throws MalformedURLException {
String absAddress = urlAddress;
// 相对地址与绝对地址
if (absAddress.indexOf("://") == -1) {
// 处理绝对地
if (absAddress.charAt(0) == '/') {
absAddress = "http://" + u.getHost() + absAddress;
} else {
String file = u.getFile();
// 处理相对地址
if (file.indexOf('/') == -1) {
absAddress = "http://" + u.getHost() + absAddress;
} else {
String path = file.substring(0, https://www.360docs.net/doc/114388624.html,stIndexOf('/') + 1);
absAddress = "http://" + u.getHost() + path + absAddress;
}
}
}
return absAddress;
}
/**
* 判断用户所提供URL是否为域名地址
* @return域名
*/
public String getDomain(String homePage) {
String reg =
"(?<=http\\://[a-zA-Z0-9]{0,100}[.]{0,1})[^.\\s]*?\\.(com|cn|net|org|biz| info|cc|tv)";
Pattern p = https://www.360docs.net/doc/114388624.html,pile(reg, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(homePage); // 使用指定正则表达式匹配主页地址
boolean blnp = m.find();
if (blnp == true) {
// 如果匹配成功则返回主页域名
return m.group(0);
}
return null;
}
/**
* 提取网页文本中的URL链接(解析新的网页,提取其中含有的链接信息)
* @param inputArgs URL对应的网页文本
* @param strUrl 网页文本对应的URL
* @throws MalformedURLException
*/
public void getUrlByString(String inputArgs, String strUrl)
throws MalformedURLException {
String regUrl = "(?<=(href=)[\"]?[\']?)[^\\s\"\'\\?]+[^\\s\"\'>]*"; Pattern p = https://www.360docs.net/doc/114388624.html,pile(regUrl, Pattern.CASE_INSENSITIVE); Matcher m = p.matcher(tmpStr);
boolean blnp = m.find();
while (blnp == true) {
/**
* modify by yang 2011.12.22
*/
String link = m.group(0);
// 跳过链到本页面内链接
if (link.charAt(0) == '#') {
continue;
}
// 跳过mailto链接
if (link.indexOf("mailto:") != -1) {
continue;
}
// 跳过JavaScript链接
if (link.toLowerCase().indexOf("javascript") != -1) { continue;
}
// 处理相对地址与绝对地址
link = toFullAddress(link, strUrl);
// 从link链接中提取域名
String tDomain = getDomain(getHomePage(link));
/**
* modify end
*/
// 如果解析到的URL没有包含在所有URL中,且URL中的域名与主页域名一致
// 则将之加入URL集合, 并向报告文件中添加相关记录信息
if (!allUrls.containsKey(link) && tDomain.equals(myDomain)) { // 输出调试信息, 同时将之记录到报告文件中
System.out.println("Find a new url,depth:"
+ (deepUrls.get(strUrl) + 1) + " " + link);
addReport("Find a new url,depth:"+ (deepUrls.get(strUrl) + 1) + " " + link + "\n");
// 将URL添加到未处理URL集合中
arrUrls.add(link);
// 将URL添加到所有URL集合中
arrUrl.add(link);
// 为URL生成一个网页号
// 设置URL深度为父结点的深度值加1
deepUrls.put(link, (deepUrls.get(strUrl) + 1));
}
// 截去已解析部分的网页文本, 开始下一次解析
tmpStr = tmpStr.substring(m.end(), tmpStr.length());
m = p.matcher(tmpStr);
blnp = m.find();
}
}
/**
* 独立的抓取线程
* @author unknown
*/
class Processer implements Runnable {
GetWeb gw;
public Processer(GetWeb g) {
this.gw = g;
}
public void run() {
// Thread.sleep(5000);
while (!arrUrls.isEmpty()) { // 如果未处理URL集中还有URL则继续
String tmp = getAUrl(); // 从未处理URL集合中取一个URL
getWebByUrl(tmp, charset, allUrls.get(tmp) + ""); // 抓取网页}
}
}
}
这里我们设定最大爬虫深度为2,然后用一个URL来对修改前后程序运行结果进行对比:https://www.360docs.net/doc/114388624.html,/。
抓取前先查看其主页源码,看到其中包含有一些绝对地址链接,如:
同时我们发现上图中第二条链接https://www.360docs.net/doc/114388624.html,/在直接访问时,会发生页面重定向(指定URL的HTTP响应状态可在https://www.360docs.net/doc/114388624.html,/pagestatus/上查询获得)。如下为地址https://www.360docs.net/doc/114388624.html,/的状态查询结果,显然会跳转到https://www.360docs.net/doc/114388624.html,/us
1.原来程序的运行结果(下图中省略号部分略去了部分不必要的内容)
可以看到总共抓回了14个网页,但其中并没有包含前面提到的绝对地址指向的页面(如:https://www.360docs.net/doc/114388624.html,/iphone/),而且对于链接https://www.360docs.net/doc/114388624.html,/,爬虫也并不知道这个页面是发生了重定向的,这对于把握页面详细状态显然不够。2.修改后程序的运行结果(下图中省略号部分略去了部分不必要的内容)
可以看到总共抓回了35个页面,相比原程序多抓取了21个页面,这些多出来的页面就是分析绝对地址和相对地址获得的。如下图中,在页面网页文本中均为绝对地
址的链接也被解析并抓取到了:
接状态。如下,有两个页面发生了重定向:
也是理解搜索引擎工作原理的一个重要的基础。
如何抓取网页数据,以抓取安居客举例
如何抓取网页数据,以抓取安居客举例 互联网时代,网页上有丰富的数据资源。我们在工作项目、学习过程或者学术研究等情况下,往往需要大量数据的支持。那么,该如何抓取这些所需的网页数据呢? 对于有编程基础的同学而言,可以写个爬虫程序,抓取网页数据。对于没有编程基础的同学而言,可以选择一款合适的爬虫工具,来抓取网页数据。 高度增长的抓取网页数据需求,推动了爬虫工具这一市场的成型与繁荣。目前,市面上有诸多爬虫工具可供选择(八爪鱼、集搜客、火车头、神箭手、造数等)。每个爬虫工具功能、定位、适宜人群不尽相同,大家可按需选择。本文使用的是操作简单、功能强大的八爪鱼采集器。以下是一个使用八爪鱼抓取网页数据的完整示例。示例中采集的是安居客-深圳-新房-全部楼盘的数据。 采集网站:https://https://www.360docs.net/doc/114388624.html,/loupan/all/p2/ 步骤1:创建采集任务 1)进入主界面,选择“自定义模式”
如何抓取网页数据,以抓取安居客举例图1 2)将要采集的网址复制粘贴到网站输入框中,点击“保存网址”
如何抓取网页数据,以抓取安居客举例图2 步骤2:创建翻页循环 1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。将页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”,以建立一个翻页循环
如何抓取网页数据,以抓取安居客举例图3 步骤3:创建列表循环并提取数据 1)移动鼠标,选中页面里的第一个楼盘信息区块。系统会识别此区块中的子元素,在操作提示框中,选择“选中子元素”
如何抓取网页数据,以抓取安居客举例图4 2)系统会自动识别出页面中的其他同类元素,在操作提示框中,选择“选中全部”,以建立一个列表循环
淘宝图片抓取工具使用方法
https://www.360docs.net/doc/114388624.html, 淘宝图片抓取工具使用方法 对于电商设计师来说,抓取竞品的宝贝的图片和店铺装修图片,来分析设计自己店铺的风格并做出差异化,是非常有用的方法哦。 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,以【淘宝图片】为例,教大家如何使用八爪鱼采集软件采集淘宝图片的方法。 本文介绍使用八爪鱼7.0采集淘宝商品图片的方法:首先将淘宝商品搜索结果网页中图片的URL采集下来,再通过八爪鱼专用的图片批量下载工具,将采集到的淘宝商品图片URL,下载并保存到本地电脑中。 采集网址:淘宝商品搜索页面 比如T恤(可更换其他关键词对淘宝商品图片进行采集): https://https://www.360docs.net/doc/114388624.html,/search?q=T%E6%81%A4&imgfile=&commend=all &search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taob ao-item.1&ie=utf8&initiative_id=tbindexz_20170306 采集数据内容:淘宝商品图片地址
https://www.360docs.net/doc/114388624.html, 使用功能点: ●翻页设置 ●图片链接采集 步骤1:创建淘宝商品图片采集任务1)进入八爪鱼采集器主界面,选择自定义模式 淘宝商品图片采集步骤1
https://www.360docs.net/doc/114388624.html, 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 淘宝商品图片采集步骤2 3)如下图红色框中的淘宝商品图片即为本次要采集的内容。
https://www.360docs.net/doc/114388624.html, 淘宝商品图片采集步骤3 步骤2:创建翻页循环 ●找到翻页按钮,设置翻页循环 ●设置ajax翻页时间 ●设置滚动页面 1)将淘宝商品搜索结果页页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中,选择“循环点击下一页”这个选项。
如何抓取网页数据
https://www.360docs.net/doc/114388624.html, 如何抓取网页数据 很多用户不懂爬虫代码,但是却对网页数据有迫切的需求。那么怎么抓取网页数据呢? 本文便教大家如何通过八爪鱼采集器来采集数据,八爪鱼是一款通用的网页数据采集器,可以在很短的时间内,轻松从各种不同的网站或者网页获取大量的规范化数据,帮助任何需要从网页获取信息的客户实现数据自动化采集,编辑,规范化,摆脱对人工搜索及收集数据的依赖,从而降低获取信息的成本,提高效率。 本文示例以京东评论网站为例 京东评价采集采集数据字段:会员ID,会员级别,评价星级,评价内容,评价时间,点赞数,评论数,追评时间,追评内容,页面网址,页面标题,采集时间。 需要采集京东内容的,在网页简易模式界面里点击京东进去之后可以看到所有关于京东的规则信息,我们直接使用就可以的。
https://www.360docs.net/doc/114388624.html, 京东评价采集步骤1 采集京东商品评论(下图所示)即打开京东主页输入关键词进行搜索,采集搜索到的内容。 1、找到京东商品评论规则然后点击立即使用
https://www.360docs.net/doc/114388624.html, 京东评价采集步骤2 2、简易模式中京东商品评论的任务界面介绍 查看详情:点开可以看到示例网址 任务名:自定义任务名,默认为京东商品评论 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组 商品评论URL列表:提供要采集的网页网址,即商品评论页的链接。每个商品的链接必须以#comment结束,这个链接可以在商品列表点评论数打开后进行复制。或者自己打开商品链接后手动添加,如果没有这个后缀可能会报错。多个商品评论输入多个商品网址即可。 将鼠标移动到?号图标可以查看详细的注释信息。 示例数据:这个规则采集的所有字段信息。
网页抓取工具如何进行http模拟请求
网页抓取工具如何进行http模拟请求 在使用网页抓取工具采集网页是,进行http模拟请求可以通过浏览器自动获取登录cookie、返回头信息,查看源码等。具体如何操作呢?这里分享给大家网页抓取工具火车采集器V9中的http模拟请求。许多请求工具都是仿照火车采集器中的请求工具所写,因此大家可以此为例学习一下。 http模拟请求可以设置如何发起一个http请求,包括设置请求信息,返回头信息等。并具有自动提交的功能。工具主要包含两大部分:一个MDI父窗体和请求配置窗体。 1.1请求地址:正确填写请求的链接。 1.2请求信息:常规设置和更高级设置两部分。 (1)常规设置: ①来源页:正确填写请求页来源页地址。 ②发送方式:get和post,当选择post时,请在发送数据文本框正确填写发布数据。 ③客户端:选择或粘贴浏览器类型至此处。 ④cookie值:读取本地登录信息和自定义两种选择。 高级设置:包含如图所示系列设置,当不需要以上高级设置时,点击关闭按钮即可。 ①网页压缩:选择压缩方式,可全选,对应请求头信息的Accept-Encoding。 ②网页编码:自动识别和自定义两种选择,若选中自定义,自定义后面会出现编
码选择框,在选择框选择请求的编码。 ③Keep-Alive:决定当前请求是否与internet资源建立持久性链接。 ④自动跳转:决定当前请求是否应跟随重定向响应。 ⑤基于Windows身份验证类型的表单:正确填写用户名,密码,域即可,无身份认证时不必填写。 ⑥更多发送头信息:显示发送的头信息,以列表形式显示更清晰直观的了解到请求的头信息。此处的头信息供用户选填的,若要将某一名称的头信息进行请求,勾选Header名对应的复选框即可,Header名和Header值都是可以进行编辑的。 1.3返回头信息:将详细罗列请求成功之后返回的头信息,如下图。 1.4源码:待请求完毕后,工具会自动跳转到源码选项,在此可查看请求成功之后所返回的页面源码信息。 1.5预览:可在此预览请求成功之后返回的页面。 1.6自动操作选项:可设置自动刷新/提交的时间间隔和运行次数,启用此操作后,工具会自动的按一定的时间间隔和运行次数向服务器自动请求,若想取消此操作,点击后面的停止按钮即可。 配置好上述信息后,点击“开始查看”按钮即可查看请求信息,返回头信息等,为避免填写请求信息,可以点击“粘贴外部监视HTTP请求数据”按钮粘贴请求的头信息,然后点击开始查看按钮即可。这种捷径是在粘贴的头信息格式正确的前提下,否则会弹出错误提示框。 更多有关网页抓取工具或网页采集的教程都可以从火车采集器的系列教程中学习借鉴。
国内主要信息抓取软件盘点
国内主要信息抓取软件盘点 近年来,随着国内大数据战略越来越清晰,数据抓取和信息采集系列产品迎来了巨大的发展 机遇,采集产品数量也出现迅猛增长。然而与产品种类快速增长相反的是,信息采集技术相 对薄弱、市场竞争激烈、质量良莠不齐。在此,本文列出当前信息采集和数据抓取市场最具 影响力的六大品牌,供各大数据和情报中心建设单位采购时参考: TOP.1 乐思网络信息采集系统 乐思网络信息采系统的主要目标就是解决网络信息采集和网络数据抓取问题。是根据用户自定义的任务配置,批量而精确地抽取因特网目标网页中的半结构化与非结构化数据,转化为结构化的记录,保存在本地数据库中,用于内部使用或外网发布,快速实现外部信息的获取。 主要用于:大数据基础建设,舆情监测,品牌监测,价格监测,门户网站新闻采集,行业资讯采集,竞争情报获取,商业数据整合,市场研究,数据库营销等领域。 TOP.2 火车采集器 火车采集器是一款专业的网络数据采集/信息挖掘处理软件,通过灵活的配置,可以很轻松迅速地从网页上抓取结构化的文本、图片、文件等资源信息,可编辑筛选处理后选择发布到网站后台,各类文件或其他数据库系统中。被广泛应用于数据采集挖掘、垂直搜索、信息汇聚和门户、企业网信息汇聚、商业情报、论坛或博客迁移、智能信息代理、个人信息检索等领域,适用于各类对数据有采集挖掘需求的群体。 TOP.3 熊猫采集软件 熊猫采集软件利用熊猫精准搜索引擎的解析内核,实现对网页内容的仿浏览器解析,在此基础上利用原创的技术实现对网页框架内容与核心内容的分离、抽取,并实现相似页面的有效比对、匹配。因此,用户只需要指定一个参考页面,熊猫采集软件系统就可以据此来匹配类似的页面,来实现用户需要采集资料的批量采集。 TOP.4 狂人采集器 狂人采集器是一套专业的网站内容采集软件,支持各类论坛的帖子和回复采集,网站和博客文章内容抓取,通过相关配置,能轻松的采集80%的网站内容为己所用。根据各建站程序
网页数据抓取方法详解
https://www.360docs.net/doc/114388624.html, 网页数据抓取方法详解 互联网时代,网络上有海量的信息,有时我们需要筛选找到我们需要的信息。很多朋友对于如何简单有效获取数据毫无头绪,今天给大家详解网页数据抓取方法,希望对大家有帮助。 八爪鱼是一款通用的网页数据采集器,可实现全网数据(网页、论坛、移动互联网、QQ空间、电话号码、邮箱、图片等信息)的自动采集。同时八爪鱼提供单机采集和云采集两种采集方式,另外针对不同的用户还有自定义采集和简易采集等主要采集模式可供选择。
https://www.360docs.net/doc/114388624.html, 如果想要自动抓取数据呢,八爪鱼的自动采集就派上用场了。 定时采集是八爪鱼采集器为需要持续更新网站信息的用户提供的精确到分钟的,可以设定采集时间段的功能。在设置好正确的采集规则后,八爪鱼会根据设置的时间在云服务器启动采集任务进行数据的采集。定时采集的功能必须使用云采集的时候,才会进行数据的采集,单机采集是无法进行定时采集的。 定时云采集的设置有两种方法: 方法一:任务字段配置完毕后,点击‘选中全部’→‘采集以下数据’→‘保存并开始采集’,进入到“运行任务”界面,点击‘设置定时云采集’,弹出‘定时云采集’配置页面。
https://www.360docs.net/doc/114388624.html, 第一、如果需要保存定时设置,在‘已保存的配置’输入框内输入名称,再保存配置,保存成功之后,下次如果其他任务需要同样的定时配置时可以选择这个配置。 第二、定时方式的设置有4种,可以根据自己的需求选择启动方式和启动时间。所有设置完成之后,如果需要启动定时云采集选择下方‘保存并启动’定时采集,然后点击确定即可。如果不需要启动只需点击下方‘保存’定时采集设置即可。
网络文字抓取工具使用方法
https://www.360docs.net/doc/114388624.html, 网络文字抓取工具使用方法 网页文字是网页中常见的一种内容,有些朋友在浏览网页的时候,可能会有批量采集网页内容的需求,比如你在浏览今日头条文章的时候,看到了某个栏目有很多高质量的文章,想批量采集下来,下面本文以采集今日头条为例,介绍网络文字抓取工具的使用方法。 采集网站: 使用功能点: ●Ajax滚动加载设置 ●列表内容提取 步骤1:创建采集任务
https://www.360docs.net/doc/114388624.html, 1)进入主界面选择,选择“自定义模式” 今日头条网络文字抓取工具使用步骤1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/114388624.html, 今日头条网络文字抓取工具使用步骤2 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容,即为今日头条最新发布的热点新闻。
https://www.360docs.net/doc/114388624.html, 今日头条网络文字抓取工具使用步骤3 步骤2:设置ajax页面加载时间 ●设置打开网页步骤的ajax滚动加载时间 ●找到翻页按钮,设置翻页循环 ●设置翻页步骤ajax下拉加载时间
https://www.360docs.net/doc/114388624.html, 1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定 今日头条网络文字抓取工具使用步骤4 注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量。
https://www.360docs.net/doc/114388624.html, 今日头条网络文字抓取工具使用步骤5 步骤3:采集新闻内容 创建数据提取列表 1)如图,移动鼠标选中评论列表的方框,右键点击,方框底色会变成绿色
python抓取网页数据的常见方法
https://www.360docs.net/doc/114388624.html, python抓取网页数据的常见方法 很多时候爬虫去抓取数据,其实更多是模拟的人操作,只不过面向网页,我们看到的是html在CSS样式辅助下呈现的样子,但爬虫面对的是带着各类标签的html。下面介绍python抓取网页数据的常见方法。 一、Urllib抓取网页数据 Urllib是python内置的HTTP请求库 包括以下模块:urllib.request 请求模块、urllib.error 异常处理模块、urllib.parse url解析模块、urllib.robotparser robots.txt解析模块urlopen 关于urllib.request.urlopen参数的介绍: urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None) url参数的使用 先写一个简单的例子:
https://www.360docs.net/doc/114388624.html, import urllib.request response = urllib.request.urlopen(' print(response.read().decode('utf-8')) urlopen一般常用的有三个参数,它的参数如下: urllib.requeset.urlopen(url,data,timeout) response.read()可以获取到网页的内容,如果没有read(),将返回如下内容 data参数的使用 上述的例子是通过请求百度的get请求获得百度,下面使用urllib的post请求 这里通过https://www.360docs.net/doc/114388624.html,/post网站演示(该网站可以作为练习使用urllib的一个站点使用,可以 模拟各种请求操作)。 import urllib.parse import urllib.request data = bytes(urllib.parse.urlencode({'word': 'hello'}), encoding='utf8')
网页内容如何批量提取
https://www.360docs.net/doc/114388624.html, 网页内容如何批量提取 网站上有许多优质的内容或者是文章,我们想批量采集下来慢慢研究,但内容太多,分布在不同的网站,这时如何才能高效、快速地把这些有价值的内容收集到一起呢? 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集】,以【新浪博客】为例,教大家如何使用八爪鱼采集软件采集新浪博客文章内容的方法。 采集网站: https://www.360docs.net/doc/114388624.html,/s/articlelist_1406314195_0_1.html 采集的内容包括:博客文章正文,标题,标签,分类,日期。 步骤1:创建新浪博客文章采集任务 1)进入主界面,选择“自定义采集”
https://www.360docs.net/doc/114388624.html, 2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/114388624.html, 步骤2:创建翻页循环
https://www.360docs.net/doc/114388624.html, 1)打开网页之后,打开右上角的流程按钮,使制作的流程可见状态。点击页面下方的“下一页”,如图,选择“循环点击单个链接”,翻页循环创建完成。(可在左上角流程中手动点击“循环翻页”和“点击翻页”几次,测试是否正常翻页。) 2)由于进入详情页时网页加载很慢,网址一直在转圈状态,无法立即执行下一个步骤,因此在“循环翻页”的高级选项里设置“ajax加载数据”,超时时间设置为5秒,点击“确定”。
https://www.360docs.net/doc/114388624.html, 步骤3:创建列表循环 1)鼠标点击列表目录中第一个博文,选择操作提示框中的“选中全部”。 2)鼠标点击“循环点击每个链接”,列表循环就创建完成,并进入到第一个循环项的详情页面。
微信文章抓取工具详细使用方法
https://www.360docs.net/doc/114388624.html, 微信文章抓取工具详细使用方法 如今越来越多的优质内容发布在微信公众号中,面对这些内容,有些朋友就有采集下来的需求,下面为大家介绍使用八爪鱼抓取工具去抓取采集微信文章信息。 抓取的内容包括:微信文章标题、微信文章关键词、微信文章部分内容展示、微信所属公众号、微信文章发布时间、微信文章URL等字段数据。 采集网站:https://www.360docs.net/doc/114388624.html,/ 步骤1:创建采集任务 1)进入主界面,选择“自定义模式”
https://www.360docs.net/doc/114388624.html, 微信文章抓取工具详细使用步骤1 2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/114388624.html, 微信文章抓取工具详细使用步骤2 步骤2:创建翻页循环 1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。点击页面中的文章搜索框,在右侧的操作提示框中,选择“输入文字”
https://www.360docs.net/doc/114388624.html, 微信文章抓取工具详细使用步骤3 2)输入要搜索的文章信息,这里以搜索“八爪鱼大数据”为例,输入完成后,点击“确定”按钮 微信文章抓取工具详细使用步骤4
https://www.360docs.net/doc/114388624.html, 3)“八爪鱼大数据”会自动填充到搜索框,点击“搜文章”按钮,在操作提示框中,选择“点击该按钮” 微信文章抓取工具详细使用步骤5 4)页面中出现了 “八爪鱼大数据”的文章搜索结果。将结果页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”
https://www.360docs.net/doc/114388624.html, 微信文章抓取工具详细使用步骤6 步骤3:创建列表循环并提取数据 1)移动鼠标,选中页面里第一篇文章的区块。系统会识别此区块中的子元素,在操作提示框中,选择“选中子元素”
百度贴吧内容抓取工具-让你的网站一夜之间内容丰富
百度贴吧内容抓取工具-让你的网站一夜之间内容丰富 [hide]
var $getreplytime=1; var $showimg=1; var $showcon=1; var $showauthor=1; var $showreplytime=1; var $showsn=0; var $showhr=0; var $replylista=array(); var $pat_reply="<\/a>(.+?)
<\/td>\r\n<\/tr><\/table>"; var $pat_pagecount="尾页<\/font><\/a>"; var $pat_title="(.+?)<\/font>"; var $pat_replycon="<\/td>\r\n \r\n