sas数据集例题

试
验目的本实验主要练习数据集的导入和导出,建立、删除和保留变量、数据集的合并与拆分,排序、转置等操作。
掌握从已有数据文件建立数据集以及在已有数据集的基础上建立、删除变量;
掌握sas的程序控制的三种基本控制流;
掌握数据数据修正、排序、转置和标准化的过程或语句。
实验内容完成下列各题
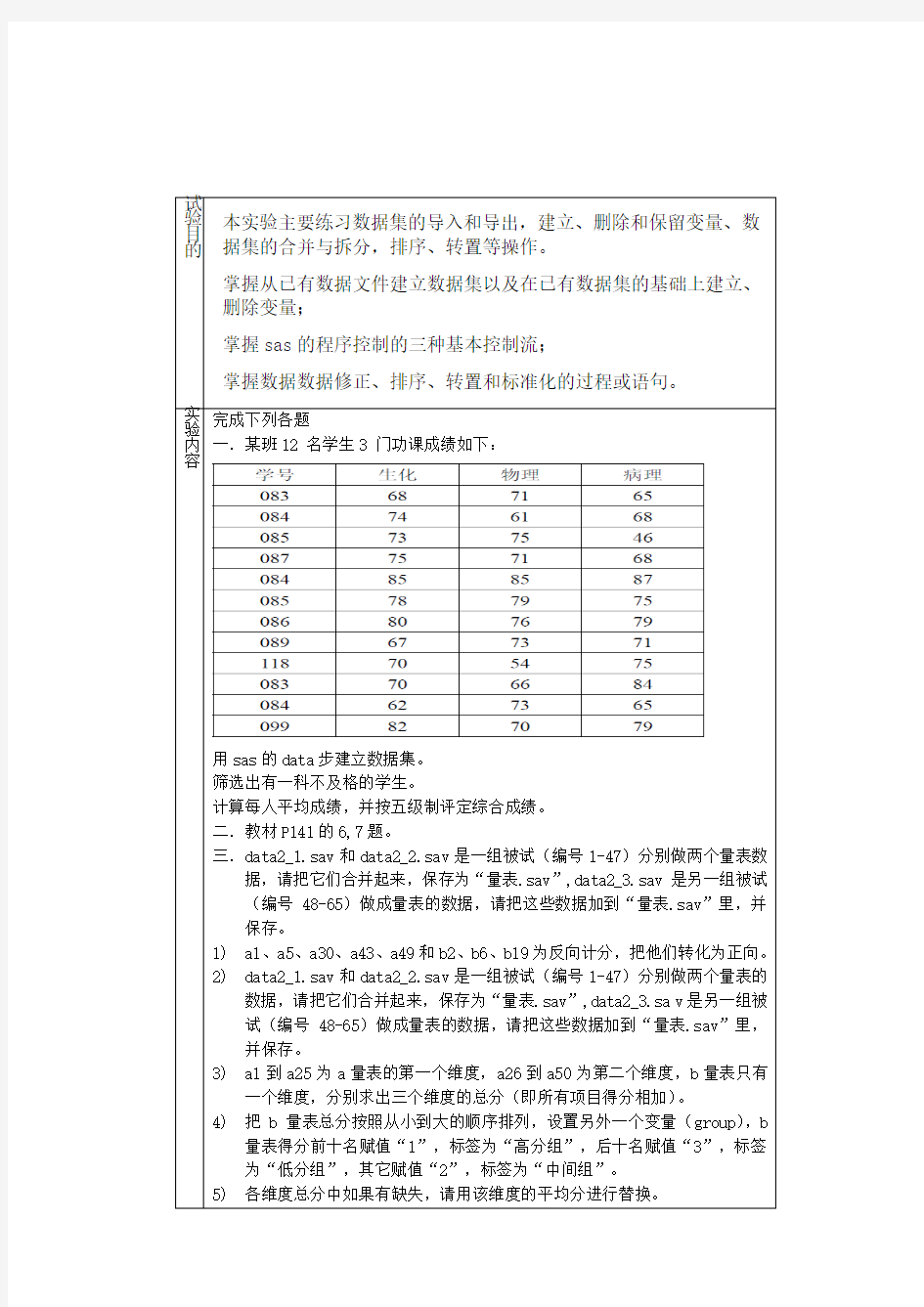
一.某班12 名学生3 门功课成绩如下:
用sas的data步建立数据集。
筛选出有一科不及格的学生。
计算每人平均成绩,并按五级制评定综合成绩。
二.教材P141的6,7题。
三.data2_1.sav和data2_2.sav是一组被试(编号1-47)分别做两个量表数据,请把它们合并起来,保存为“量表.sav”,data2_3.sav是另一组被试(编号48-65)做成量表的数据,请把这些数据加到“量表.sav”里,并保存。
1)a1、a5、a30、a43、a49和b2、b6、b19为反向计分,把他们转化为正向。
2)data2_1.sav和data2_2.sav是一组被试(编号1-47)分别做两个量表的
数据,请把它们合并起来,保存为“量表.sav”,data2_3.sa v是另一组被试(编号48-65)做成量表的数据,请把这些数据加到“量表.sav”里,并保存。
3)a1到a25为a量表的第一个维度,a26到a50为第二个维度,b量表只有
一个维度,分别求出三个维度的总分(即所有项目得分相加)。
4)把b量表总分按照从小到大的顺序排列,设置另外一个变量(group),b
量表得分前十名赋值“1”,标签为“高分组”,后十名赋值“3”,标签为“低分组”,其它赋值“2”,标签为“中间组”。
5)各维度总分中如果有缺失,请用该维度的平均分进行替换。
结果分析一、
(1)
data class;
input id biochemistry$physical pathology;
label id='学号' biochemistry='生化' physical='物理' pathology='病理';
cards;
083 68 71 65
084 74 61 68
085 73 75 46
087 75 71 68
084 85 85 87
085 78 79 75
086 80 76 79
089 67 73 71
118 70 54 75
083 70 66 84
084 62 73 65
099 82 70 79
;
run;
proc print data=class label;
run;
(2)
(3)
data class;
input id biochemistry $ physical $ pathology $ ave $ @@; label id='学号' biochemistry='生化' physical='物理' pathology='病理';
ave=mean(biochemistry,physical,pathology);
if ave<60then ave='E';
if60<=ave<70then ave='D';
if70<=ave<=79then ave='C';
if80<=ave<=89then ave='B';
if90<=ave<=100then ave='A';
return;
cards;
083 68 71 65
084 74 61 68
085 73 75 46
087 75 71 68
084 85 85 87
085 78 79 75
086 80 76 79
089 67 73 71
118 70 54 75
083 70 66 84
084 62 73 65
099 82 70 79
;
proc print;
run;
二.
6.
data student;
infile'c:\sasdt\student.txt';
length id $18;
length name $16;
input id $ name $ English conputer; age= 2015-input(substr(id,7,4),4.); if mod(substr(compress(id),17,1),2) then sex='1';
else sex='2';
drop id;
run;
data sas7bdat.mstu;
set student;
if sex=1;
keep name age sex English computer; data sas7bdat.fstu;
set student;
if sex=2;
keep name age sex English computer; run;
proc print;
run;
7.
data student;
infile'c:\sasdt\student.txt';
length id $18;
length name $16;
input id $ name $ English conputer; age= 2015-input(substr(id,7,4),4.); if mod(substr(compress(id),17,1),2) then sex='1';
else sex='2';
drop id;
run;
data sas7bdat.stu90;
set student;
where English>90 and conputer>90; run;
proc print;
run;
三.
首先导入数据集
data liangbiao;
MERGE D1 D2;
data lb;
set liangbiao D3;
proc export data=lb outfile="d:\cym\SAS作业\量表.sav"
REPLACE ;
data lb;
array lb[72] a1-a50 b1-b22;
set lb;
lb(1)=6-lb(1);lb(5)=6-lb(5);lb(30)=6-lb(30);lb(43)=6-lb(43);
lb(49)=6-lb(49);lb(52)=6-lb(52);lb(56)=6-lb(56);lb(69)=6-lb(69);
sum1=sum(of a1-a25);
sum2=sum(of a26-a50);
sum3=sum(of b1-b22);
data lb;
set lb;
proc standard data=lb out=lb replace;
var sum1 sum2 sum3;
run;
proc sort data=lb;
by sum3;
data cheng;
input group @@;
datalines;
1 1 1 1 1 1 1 1 1 1
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
3 3 3 3 3 3 3 3 3 3
run;
data lg;
MERGE lb cheng;
run;
data lg;
set lg;
if (group = 1) then sum='高分组';
if (group = 2) then sum='中间组';
if (group = 3) then sum='低分组';
run;
结果如下:
成
绩教师签名
数据库课后练习题
ORACLE数据库课程习题 1 通过SQL*PLUS等数据库访问工具登录数据库服务器时, 所需的数据库连接串是在以下哪个文件中定义的( )A (A) tnsnames.ora (B) sqlnet.ora (C) listener.ora (D) init.ora (E) 以上所述都不正确 2 以下关于数据库连接串的叙述正确的是( )E (A) 数据库连接串必须与数据库名一致 (B) 数据库连接串必须与全局数据库名一致 (C) 数据库连接串必须与数据库的实例名(INSTANCE)一致 (D) 数据库连接串必须与数据库的SID一致 (E) 以上所述都不正确 3 关于SQL*PLUS的叙述正确的是( )A (A) SQL*PLUS是ORACLE数据库的专用访问工具 (B) SQL*PLUS是标准的SQL访问工具,可以访问各类关系型数据库 (C) SQL*PLUS是所有ORACLE应用程序的底层API (D) SQL*PLUS是访问ORACLE数据库的唯一对外接口 (E) 以上所述都不正确 4 SQL*PLUS在ORACLE数据库系统中的作用,以下叙述正确的是( )C (A) 是ORACLE数据库服务器的主要组成部分,是服务器运行的基础构件. (B) 是ORACLE数据库系统底层网络通信协议,为所有的ORACLE应用程序提供一个公共的通信平台 (C) 是ORACLE客户端访问服务器的一个工具,通过它可以向服务器发送SQL命令 (D) 是ORACLE客户端到客户端的点对点的通信工具,用来传递各个客户端的数据 (E) 以上所述都不正确 5 命令sqlplus /nolog的作用是( )C (A) 仅创建一个ORACLE实例,但并不打开数据库. (B) 仅创建一个ORACLE实例,但并不登录数据库. (C) 启动sqlplus,但并不登录数据库 (D) 以nolog用户身份启动sqlplus (E) 以上所述都不正确
(完整版)数据库课后习题及答案
第一章数据库系统概述 选择题 1实体-联系模型中,属性是指(C) A.客观存在的事物 B.事物的具体描述 C.事物的某一特征 D.某一具体事件 2对于现实世界中事物的特征,在E-R模型中使用(A) A属性描述B关键字描述C二维表格描述D实体描述 3假设一个书店用这样一组属性描述图书(书号,书名,作者,出版社,出版日期),可以作为“键”的属性是(A) A书号B书名C作者D出版社 4一名作家与他所出版过的书籍之间的联系类型是(B) A一对一B一对多C多对多D都不是 5若无法确定哪个属性为某实体的键,则(A) A该实体没有键B必须增加一个属性作为该实体的键C取一个外关键字作为实体的键D该实体的所有属性构成键 填空题 1对于现实世界中事物的特征在E-R模型中使用属性进行描述 2确定属性的两条基本原则是不可分和无关联 3在描述实体集的所有属性中,可以唯一的标识每个实体的属性称为键 4实体集之间联系的三种类型分别是1:1 、1:n 、和m:n 5数据的完整性是指数据的正确性、有效性、相容性、和一致性 简答题 一、简述数据库的设计步骤 答:1需求分析:对需要使用数据库系统来进行管理的现实世界中对象的业务流程、业务规则和所涉及的数据进行调查、分析和研究,充分理解现实世界中的实际问题和需求。 分析的策略:自下而上——静态需求、自上而下——动态需求 2数据库概念设计:数据库概念设计是在需求分析的基础上,建立概念数据模型,用概念模型描述实际问题所涉及的数据及数据之间的联系。 3数据库逻辑设计:数据库逻辑设计是根据概念数据模型建立逻辑数据模型,逻辑数据模型是一种面向数据库系统的数据模型。 4数据库实现:依据关系模型,在数据库管理系统环境中建立数据库。 二、数据库的功能 答:1提供数据定义语言,允许使用者建立新的数据库并建立数据的逻辑结构 2提供数据查询语言 3提供数据操纵语言 4支持大量数据存储 5控制并发访问 三、数据库的特点 答:1数据结构化。2数据高度共享、低冗余度、易扩充3数据独立4数据由数据库管理系统统一管理和控制:(1)数据安全性(2)数据完整性(3)并发控制(4)数据库恢复 第二章关系模型和关系数据库 选择题 1把E-R模型转换为关系模型时,A实体(“一”方)和B实体(“多”方)之间一对多联系在关系模型中是通过(A)来实现的
SAS软件对数据集一些简单操作
SAS软件对数据集一些简单操作Libname AA 'd:\SAS'; Data AA.feng; Input a b c; cards; 3 4 56 64 43 34 累加 DATA A; INPUT X Y @@; S+X; CARDS; 3 5 7 9 20 21 ; PROC PRINT; RUN; ; run; DATA D1; INFILE ‘C:FIT.TXT' INPUT NUM $ 1-4 SEX $ 5 H 6-9 W 10-11; RUN; 建立数据集求均值 data a; input name$sex$math chinese@@; cards; 张三男82 96 刘四女81 98 王五男90 92 黄六女92 92 ; proc print data=a; proc means data=a mean; var math chinese; run; 保留列 data b; set a; keep name math; run; 丢弃列 data b; set b;
drop name; run; 条件选择 data c; set a; if math>90 and chinese>90; run; 把超过九十分改为90分data aa; set a; if chinese>90 then chinese=90; run; 筛选行 data aaa ; set a(firstobs=2 obs=3); run; 拆分男女 data a1 a2; set a; select(sex); when('男')output a1; when('女')output a2; otherwise put sex='wrong'; end; drop sex; run; 合并 data new; set a1(in=male) a2(in=female); if male=1 then sex=''; if female=1 then sex=''; run; 纵向合并Set 横向合并merge 重命名rename 改标志label 排序语句 proc sort data=a out=b; by sex;
《SAS数据分析范例》(SAS数据集)
《SAS数据分析范例》数据集 目录 表1 sas.bd1 (3) 表2 sas.bd3 (4) 表3 sas.bd4 (5) 表4 sas.belts (6) 表5 sas.c1d2 (7) 表6 sas.c7d31 (8) 表7 sas.dead0 (9) 表8 sas.dqgy (10) 表9 sas.dqjyjf (11) 表10 sas.dqnlmy3 (12) 表11 sas.dqnlmy (13) 表12 sas.dqrjsr (14) 表13 sas.dqrk (15) 表14 sas.gjxuexiao0 (16) 表15 sas.gnsczzgc (17) 表16 sas.gnsczzs (18) 表17 sas.gr08n01 (19) 表18 sas.iris (20) 表19 sas.jmcxck0 (21) 表20 sas.jmjt052 (22) 表21 sas.jmjt053 (23) 表22 sas.jmjt054 (24) 表23 sas.jmjt055 (25) 表24 sas.jmxfsps (26) 表25 sas.jmxfspzs0 (27) 表26 sas.jmxfzss (28) 表27 sas.jmxfzst (29) 表28 sas.kscj2 (30) 表29 sas.modeclu4 (31) 表30 sas.ms8d1 (32) 表31 sas.nlmyzzs (33) 表32 sas.plates (34) 表33 sas.poverty (35) 表34 sas.rjnycpcl0 (36) 表35 sas.rjsrs (37) 表36 sas.sanmao (38) 表37 sas.sczz1 (39) 表38 sas.sczz06s (40) 表39 sas.sczz (41) 表40 sas.sczzgc1 (42)
数据库sql课后练习题及答案解析
数据库sql课后练习题及答案解析 (borrow 表) (reader表)1) 找出姓李的读者姓名(NAME)和所在单位(COMPANY)。2) 列出图书库中所有藏书的书名(BOOK_NAME)及出版单位(OUTPUT)。3) 查找“高等教育出版社”的所有图书名称(BOOK_NAME)及单价(PRICE),结果按单价降序排 序。4) 查找价格介于10元和20元之间的图书种类(SORT),结果按出版单位(OUTPUT)和单价(PRICE)升序排序。5) 查找书名以”计算机”开头的所有图书和作者(WRITER)。6) 检索同时借阅了总编号(BOOK_ID)为112266和449901两本书的借书证号(READER_ID)。##7)* 查找所有借了书的读者的姓名(NAME)及所在单位(COMPANY)。8)* 找出李某所借所有图书的书名及借书日期(BORROW_DATE)。9)* 无重复地查询xx年10月以后借书的读者借书证号(READER_ID)、姓名和单位。##10)* 找出借阅了
书的最高价格、最低价格和总册数。#16) 分别找出各单位当前借阅图书的读者人数及所在单位。17)* 找出当前至少借阅了2本图书(大于等于2本)的读者姓名及其所在单位。18) 分别找出借书人次数多于1人次的单位及人次数。19) 找出藏书中各个出版单位的名称、每个出版社的书籍的总册数(每种可能有多册)、书的价值总额。20) 查询经济系是否还清所有图书。如果已经还清,显示该系所有读者的姓名、所在单位和职称。附录:建表语句创建图书管理库的图书、读者和借阅三个基本表的表结构:创建BOOK:(图书表)CREATE TABLE BOOK ( BOOK_ID int, SORT VARCHAR(10), BOOK_NAME VARCHAR(50), WRITER VARCHAR(10), OUTPUT VARCHAR(50), PRICE int); 创建READER:(读者表)CREATE TABLE READER (READER_ID int,COMPANY VARCHAR(10),NAME VARCHAR(10),SEX VARCHAR(2),GRADE VARCHAR(10),ADDR VARCHAR(50)); 创建BORROW:(借阅表)CREATE TABLE BORROW ( READER_ID int, BOOK_ID int, BORROW_DATE datetime)插入数据:BOOK表:insert into BOOK values(445501,'TP3/12','数据库导论','王强','科学出版社', 17、90);insert into BOOK values(445502,'TP3/12','数据库导论','王强','科学出版社', 17、90);insert into BOOK values(445503,'TP3/12','数据库导论','王强','科学出版社',
第三课SAS数据集
第三课SAS数据集 一.SAS数据集的结构 SAS数据集是关系型的,它通常分为两部分: ●描述部分——包含了一些关于数据属性的信息 ●数据部分——包括数据值 SAS的数据值被安排在一个矩阵式的表状结构中,见图3-1所示。 ●表的列称之为变量(Variable),变量类似于其它文件类型的域或字段(Field); ●表的行称之为观察(Observation),观察相当于记录(Record)。 变量1 变量2 变量3 变量4 Name Test1 Test2 Test3 观察1 Xiaoer 90 86 88 观察2 Zhangsan 100 98 89 观察3 Lisi 79 76 70 观察4 Wangwu 68 71 64 观察5 Zhaoliu 100 89 99 图3-1 一个SAS数据文件 二.SAS数据集形式 SAS系统中共有两种类型的数据集: ●SAS 数据文件(SAS data files) ●SAS 数据视窗(SAS data views) SAS 数据文件不仅包括描述部分,而且包括数据部分。SAS 数据视窗只有描述部分,没有数据部分,只包含了与其它数据文件或者其它软件数据的映射关系,能使SAS的所有过程可访问到,实际上并不包含SAS 数据视窗内的数据值。 自始自终,在SAS语言中,“SAS数据集”与这二种形式中之一有关。在下面的例子中,PRINT过程用相同方法处理数据集aaa.abc,而忽略它的形式: PROC PRINT DATA=aaa.abc 三.SAS数据集的名字 SAS数据集名字包括三个部分,格式如下: Libref.data-set-name.membertype ●Libref(库标记)──这是SAS数据库的逻辑名字 ●data-set-name(数据集名字)──这是SAS数据集的名字 ●membertype(成员类型)──SAS数据集名字的这一部分用户使用时不必给出。 SAS 数据文件的成员类型是DATA;SAS 数据视窗的成员类型是VIEW 例如上面例子中的aaa.abc这个SAS数据集名字,aaa是库标记,abc是数据集名字,成
数据库课后习题答案
第1章绪论 1 .试述数据、数据库、数据库系统、数据库管理系统的概念。 答: ( l )数据(Data ) :描述事物的符号记录称为数据。数据的种类有数字、文字、图形、图像、声音、正文等。数据与其语义是不可分的。解析在现代计算机系统中数据的概念是广义的。早期的计算机系统主要用于科学计算,处理的数据是整数、实数、浮点数等传统数学中的数据。现代计算机能存储和处理的对象十分广泛,表示这些对象的数据也越来越复杂。数据与其语义是不可分的。500 这个数字可以表示一件物品的价格是500 元,也可以表示一个学术会议参加的人数有500 人,还可以表示一袋奶粉重500 克。 ( 2 )数据库(DataBase ,简称DB ) :数据库是长期储存在计算机内的、有组织的、可共享的数据集合。数据库中的数据按一定的数据模型组织、描述和储存,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种用户共享。 ( 3 )数据库系统(DataBas 。Sytem ,简称DBS ) :数据库系统是指在计算机系统中引入数据库后的系统构成,一般由数据库、数据库管理系统(及其开发工具)、应用系统、数据库管理员构成。解析数据库系统和数据库是两个概念。数据库系统是一个人一机系统,数据库是数据库系统的一个组成部分。但是在日常工作中人们常常把数据库系统简称为数据库。希望读者能够从人们讲话或文章的上下文中区分“数据库系统”和“数据库”,不要引起混淆。 ( 4 )数据库管理系统(DataBase Management sytem ,简称DBMs ) :数据库管理系统是位于用户与操作系统之间的一层数据管理软件,用于科学地组织和存储数据、高效地
SAS数据集操作
目录 SAS 数据集操作 2014年03月28日 1.合并 2.删选,修改 3.查询 PPT 模板下载:https://www.360docs.net/doc/1c7068229.html,/moban/
1 数据集的合并: (1)纵向合并:添加或合并样本变量 (2)横向合并:添加或合并(指标)变量
(1)数据集纵向合并:可以添加或合并样本变量 形式: data 合并后数据名; set 数据名1 数据名2 ; run; 例:将名为male、female 的两个数据集纵向合并成一个名为total 的数据集data total; set male female; proc print data=total; run; /*若male 与female 变量名不同则total 的变量名为两者之并,数据值以缺失值形式出现*/
(2)数据集横向合并:添加或合并(指标)变量 形式: data 合并后数据名; merge 数据名1 数据名2 ; by 共有变量名; run; 例:将名为dataONE 和data TWO 的两个数据集按共有变量pid 横向合并成数据集total2 (以下程序以data total2 名义保存)
data one; input pid sex$ age; cards; 101 m 54 105 w 36 102 m 43 104 w 45 ; data two; input pid weight height; cards; 105 54 163 102 63 174 103 57 173 104 45 156 ;
proc sort data=one;/*必须先对共有变量(本例中pid)分别排序才能横向合并*/ by pid; /* 排序语句proc sort data=被排序变量所在数据集名; by 被排序变量名;排序时默认数值由小到大字母由先而后*/ proc sort data=two; /*必须先对共有变量(本例中pid)分别排序才能横向合并*/ by pid; /*以下为合并过程*/ data total2; /*合并后数据名*/ merge one two; /*形式: merge 被合并数据集名1 被合并数据集名2; */ 注意输出结果中的缺省值,输入数据时若有缺省分量一定要以. 表示,否则SAS 会将该行数据自行删除*/ by pid; proc print data=total2; run;
sas数据集例题
试 验目的本实验主要练习数据集的导入和导出,建立、删除和保留变量、数据集的合并与拆分,排序、转置等操作。 掌握从已有数据文件建立数据集以及在已有数据集的基础上建立、删除变量; 掌握sas的程序控制的三种基本控制流; 掌握数据数据修正、排序、转置和标准化的过程或语句。 实验内容完成下列各题 一.某班12 名学生3 门功课成绩如下: 用sas的data步建立数据集。 筛选出有一科不及格的学生。 计算每人平均成绩,并按五级制评定综合成绩。 二.教材P141的6,7题。 三.data2_1.sav和data2_2.sav是一组被试(编号1-47)分别做两个量表数据,请把它们合并起来,保存为“量表.sav”,data2_3.sav是另一组被试(编号48-65)做成量表的数据,请把这些数据加到“量表.sav”里,并保存。 1)a1、a5、a30、a43、a49和b2、b6、b19为反向计分,把他们转化为正向。 2)data2_1.sav和data2_2.sav是一组被试(编号1-47)分别做两个量表的 数据,请把它们合并起来,保存为“量表.sav”,data2_3.sa v是另一组被试(编号48-65)做成量表的数据,请把这些数据加到“量表.sav”里,并保存。 3)a1到a25为a量表的第一个维度,a26到a50为第二个维度,b量表只有 一个维度,分别求出三个维度的总分(即所有项目得分相加)。 4)把b量表总分按照从小到大的顺序排列,设置另外一个变量(group),b 量表得分前十名赋值“1”,标签为“高分组”,后十名赋值“3”,标签为“低分组”,其它赋值“2”,标签为“中间组”。 5)各维度总分中如果有缺失,请用该维度的平均分进行替换。
SAS介绍和SAS数据集
SAS系统
SAS系统介绍
SAS系统是用于数据分析与决策支持的大
邓 伟 2013.11 wdeng@https://www.360docs.net/doc/1c7068229.html,
型集成式模块化软件包。 其早期的名称Statistical Analysis Software 统计分析软件→大型集成应用系统 商业智能(BI)和分析挖掘(DM)
1
2
SAS系统是用于决策支持 的大型集成信息系统
SAS系统主要完成以数据为中心的四大任务: 数据访问 数据管理 数据呈现 数据分析
SAS历史
SAS成立于1976年,是全球最大的私人软件公司(预 打包软件),全球十大独立软件供应商之一 1966年 美国北卡州立大学 Jim Barr and Jim
Goodnight
1972年 推出SAS72供大学使用 1976年 创立公司
SAS软件研究所(SAS Institute Inc.) 举办第一个SUGI (SAS Users Group International) 会议 Base SAS 软件上市 与IBM建立合作伙伴关系
3 4
SAS历史
1985 第一个PC DOS SAS System 版本(Base SAS 和SAS/RTERM 软件)取得成功 1986面向个人计算机的SAS/IML 和SAS/STAT 软 件上市 1992
决策支持功能扩展到以下领域:指导性数据分析、临床 试验分析和报告、财务电子表格和英语查询 SAS第一个垂直市场软件:制药行业的临床审查系统上 市
SAS历史
1995 SAS 成为真正的端到端数据仓库解决 方案唯一的供应商,推出Rapid Warehousing Program 1999 美国食品和药品管理局选择SAS开发的 技术,作为接收和归档电子数据的标准
5
6
1
SAS EG数据统计分析题库
《SAS EG数据统计分析题库》 单选题 1、分析教师和会计师之间收入的差异,选择什么分析方法最合适? A、卡方分析 B、方差分析 C、两样本T检验 D、相关系数 答案C 2、分析购买不同产品的频次时,使用以下哪个任务? A、列表数据 B、汇总表 C、汇总统计量 D、单因子频数 答案D 3、以下哪个语句可以将字符型数值date(示例:“2001-02-19”)转换为数值类型? A、INPUT(date,YYMMDD10.) B、PUT(date,YYMMDD10) C、INPUT(date,YYMMDD10.) D、PUT(date,YYMMDD10)
答案A 4、来自于总体的样本最主要的属性是什么? A、随机 B、有代表性 C、正态分布 D、连续分布 答案B 5、D—W统计量用于检验? A、异方差 B、自相关 C、解释变量线性相关 D、扰动项不服从正态分布 答案B 6、什么统计量用于检验解释变量之间线性相关 A、标准化的残差 B、D—W统计量
C、Cook's D D、膨胀系数 答案D 7、连续变量右偏的情况下,中位数在均值的? A、左边 B、右边 C、相等 D、无法判断 答案A 8、代表变量离散程度的指标是? A、均值 B、标准差 C、最大值 D、中位数 答案B 9、解释变量是多分类变量,被解释变量是连续变量,使用什么分析方法?
A、卡方分析 B、方差分析 C、两样本T检验 D、相关系数 答案B 10、如果在方差分析中有20个观察值,你要计算残差。那么以下哪个值会是残差和? A、-20 B、0 C、400 D、从已知信息中无法推断 答案B 11、要进行一项研究,比较男女月均信用卡支出。可能使用哪一种统计方法? A、单样本T检验 B、双样本T检验 C、单因素方差分析 D、双因素方差分析 答案、C
数据库课本例题
Use basetest 【例1】查询全体学生的记录 【例2】查询全体学生的姓名和性别。 【例3】查询全体学生的姓名和出生年份。 【例4】在例3的基础上,将字段名替换成中文名显示。 【例5】显示学生表student中前5行数据。 【例6】查询学生课程表sc中选修了课程的学生学号。 【例7】查询SC表中选修了课程的学生学号、姓名、院系、课程号和成绩。 【例8】以student为主表查询例7。 【例9】查询表student中年龄大于20岁的学生姓名性别和各自的年龄大小。 【例10】查询年龄在21岁到23岁(包括21和23岁)之间的学生信息。 【例11】查询所有姓黄的学生的姓名、性别、年龄、院系 【例12】查询数学系(MA)学生的姓名、性别和年龄。 【例13】查询没有选修课(cpni)的课程名和学分。 【例14】查询cs系中男生的学号和姓名。 【例15】查询在sc表中选课了的女生的学号和姓名。 【例16】按学生年龄的降序对学生进行排序。 【例17】按院系、学号等对学生情况进行分组。 【例18】按院系、学号等对女学生情况进行分组。 【例19】按院系、性别查看学生的平均年龄。 【例20】在例19的基础上使用WITH CUBE关键字。 【例21】在例19的基础上使用WITH ROLLUP关键字。 【例22】求sc表中选修了课程的学生的总成绩。 【例23】计算选修了课程学生的平均成绩。 【例24】查询选修了课程的学生选修课程的数目 【例25】查询CS系中年龄最大的学生的姓名以及年龄 【例26】查询学号为05007的学生的选修课程的平均成绩和最高成绩 【例27】查询选修了课程5的学生信息,并计算平均成绩和最高成绩,以成绩高低排序。 查询所有系中年龄最大的学生的姓名以及年龄 【例28】查询选修了课程6的学生学号和姓名 【例29】查询选修了数据库的学生信息。 【例30】查询选修了课程6的学生学号、姓名和性别。 【例31】查询除了IS系的其他系中年龄不大于IS系中最小年龄学生的学生信息。 【例32】查询IS系的学生以及年龄大于20岁的学生。 【例33】对例32使用UNION ALL子句。
(完整版)数据库课后部分习题答案2015
习题1 5.实体之间联系有哪几种?分别举例说明? 答:1:1联系:如果实体集El中每个实体至多和实体集E2中的一个实体有联习,反之亦然,那么El和E2的联系称为“l:1联系”。例如:电影院的座位和观众实体之间的联系。 1:N联系:如果实体集El中每个实体可以与实体集E2中任意个(零个或多个)实体有联系,而E2中每个实体至多和El中一个实体有联系,那么El和E2的联系是“1:N联系”。例如:部门和职工两个实体集之间的联系。 M:N联系:如果实体集El中每个实体可以与实体集E2中任意个(零个或多个)实体有联系,反之亦然,那么El和E2的联系称为“M:N联系”。例如:工程项目和职工两个实体集之间的联系。 7.简述数据库系统的两级映像和数据独立性之间的关系。 答:为了能够在系统内部实现外部级、概念级和内部级3个抽象层次的联系和转换,数据库管理系统在这三级模式之间提供了两层映像: 外模式/模式映像定义通常包含在各自外模式的描述中,保证了数据与程序的逻辑独立性,简称数据的逻辑独立性,应用程序是依据外模式编写的; 模式/内模式映像包含在模式描述中,此映像是唯一的,它定义了数据全局逻辑结构与存储结构之间的对应关系,它保证了数据与程序的物理独立性,所以称为数据的物理独立性。 习题2 1.名词解释: 超键:能惟一标识元组的属性或属性集,称为关系的超键。 候选键:不含有多余属性的超键,称为候选键。 实体完整性规则:实体的主键值不允许是空值。 参照完整性规则:依赖关系中的外键值或者为空值,或者是相应参照关系中某个主键值。 函数依赖:设有关系模式R(U),X和Y是属性集U的子集,若对于R(U)的任意一个可能的关系r,r中不可能存在两个元组在X上的属性值相等,而在Y上的属性值不等,则称X函数确定Y或Y函数依赖(Functional Dependency,简记为FD)于X,记作X→Y。 无损分解:当对关系模式R进行分解时,R的元组将分别在相应属性集进行投影而产生新的关系。如果对新的关系进行自然连接得到的元组集合与原关系完全一致,则称该分解为无损分解。 2NF:如果关系模式R属于1NF,且它的每一个非主属性都完全函数依赖于R的候选键,则称R属于第二范式,简记为R∈2NF。 3NF:如果关系模式R属于1NF,且每个非主属性都不传递依赖于R的候选键,那么称R属于第三范式,简记为R∈3NF。 3.笛卡尔积、等值连接和自然连接三者之间有什么区别? 答:笛卡儿积是一个基本操作,而等值连接和自然连接是组合操作。 设关系R的元数为r,元组个数为m;关系S的元数为s。,元组个数为n。 那么,R×S的元数为r+s,元组个数为m×n; 的元数也是r+s,但元组个数小于等于m×n;
SAS例题及程序输出
地质勘探中,在A,B,C 三个地区采集了一些岩石,测量其部分化学成分,其 数据见表3.5。假定这三个地区掩饰的成分遵从()3,(1,2,3)(0.05)i i N i μα∑==() 。 (1)检验不全01231123:=:,,H H ∑=∑∑∑∑∑;不全等; (2)检验(1)(2)(1)(2)01::H H μμμμ=≠;; (3)检验(1)(2)(3)()()01::,i j H H i j μμμμμ==≠≠;存在使。 表3.5 岩石部分化学成分数据 解: (1)检验假设
01231123:=:,,H H ∑=∑∑∑∑∑;不全等, 在H 0成立时,取近似检验统计量为2()f χ 统计量: ()()*4=121ln d M d ξλ-=--。 由样本值计算三个总体的样本协方差阵: 1(1)(1)(1)(1) 11()() 11111110.243081=0.642649.2855240.014060.020520.00452n S A X X X X n n ααα='==----?? ?- ? ??? ∑()(), 1(2)(2)(2)(2) 23()() 12211116.30461= 4.756710.672230.05570.23880.006675n S A X X X X n n ααα='==----?? ?- ? ?-??∑()(), 1(3)(3)(3)(3) 33()()1 3311112.97141=0.63370.342140.00010.002950.001875n S A X X X X n n ααα='==----?? ? ? ?-?? ∑()()。 进一步计算可得 1231 0.0018318,0.0000942,0.0011851,0.0000417,10 S A S S S = ==== 24.52397,0.433333,12,M d f === (1)=13.896916d M ξ=-。 对给定显著性水平=0.05α,利用软件SAS9.3进行检验时,首先计算p 值: p =P {ξ≥13.896916}=0.3073394。 因为p 值=0.3073394>0.05,故接收0H ,即认为方差阵之间无显著性差异。 proc iml ; n1=5;n2=4;n3=4; n=n1+n2+n3;k=3;p=3; x1={47.22 5.06 0.1, 47.45 4.35 0.15,
数据库课后题E-R图
10 .试给出3个实际部门的E —R图,要求实体型之间具有一对一、一对多、多对多 各种不同的联系。 答: E 一R图,要求有三个实体型,而且3个实体型之间有多 3个实体型之间的多对多联系和三个实体型两两之间的三个多对多联系等价 吗 3个实体型之间的多对多联系和 它们拥有不同的语义。3个实体型两两之间的三个多对多联系如下图所示。 12.学校中有若干系,每个系有若干班级和教研室,每个教研室有若干教员,其中有的教授和副教授每 人各带若干研究生;每个班有若干学生,每个学生选修若干课程,每门课可由若干学生选修。请用E 一 R图画出此学校的概念模型。 答: 11 ?试给出一个实际部门的对 多联系。 为什么 答: 3个实体型两两之间的3个多对多联系是不等价,因为 祷
13.某工厂生产若干产品, 这些零件由不同的原材料制 成,不同零件所用的材料可以相同。这些零件按所属的不同产品分别放在仓库中,原材料按照类别放在若干仓库中。请用 E 一R图画出此工厂产品、 零件、材料、仓库的概念模型。 答: 14.试述层次模型的概念,举出三个层次模型的实例。 答: (I )教员学生层次数据库模型 每种产品由不同的零件组成,有的零件可用在不同的产品上。
I >?研穿爾勺I Itff畫拓I I学号]ft若]皓] It'til I 职工号I 甘吿I研樂疗时I (2 )行政机构层次数据库模型 18 .现有一局部应用,包括两个实体: 请读者 自己设计适当的属性,画出性名、码和完整性 约束条件)答: 罔为: 关系模型为:作者(作者号,姓名,年龄,性别,电话,地址)出版社(出版社号,名称, 地址,联系电 话)出版(作者号,出版社号,书的数量)出版关系的主码作者号,出版社号分别参照作者关系的主码作 者号和出版社关系的主码出版社号。 19 ?请设计一个图书馆数据库,此数据库中对每个借阅者保存读者记录,包括:读者号, 姓名,地址,性 别,年龄,单位。对每本书存有:书号,书名,作者,出版社。对每本被 辄办驚也也1 1斡空1 r 1 口咸HL 枸 I IKV ]堆再I哥凭丽「I “出版社”和“作者”,这两个实体是多对多的联系, E 一R图,再将其转换为关系模型(包括关系名、属 年站电 怖/:号 fl A
sas习题大全带程序编码资料
P265 1 今有某种型号的电池三批,它们分别是A、B、C三个工厂所生产的,为评比其质量,各随机抽取5只电池为样品,经试验得其寿命(h)如下: A B C 4042 4845 38 2628 3432 30 39 50 40 50 43 试在显著性水平0.05下检验电池的平均寿命有无显著的差异,若差异是显著的, 试求均差μ A -μ B ,μ A -μ C 和μ B -μ C 的置信水平为95%的置信区间。 代码: data l1; do b=1to5; do a=1to3; input x@@; output; end; end; cards; 40 26 39 42 28 50 48 34 40 45 32 50 38 30 43 proc anova; class a; model x=a; run; 结果输出: The SAS System 19:15 Friday, April 9, 2012 5 The ANOVA Procedure Class Level Information Class Levels Values a 3 1 2 3 Number of observations 15 The SAS System 19:15 Friday, April 9, 2012 6 The ANOVA Procedure Dependent Variable: x
Sum of Source DF Squares Mean Square F Value Pr > F Model 2 615.6000000 307.8000000 17.07 0.0003 Error 12 216.4000000 18.0333333 Corrected Total 14 832.0000000 R-Square Coeff Var Root MSE x Mean 0.739904 10.88863 4.246567 39.00000 Source DF Anova SS Mean Square F Value Pr > F a 2 615.6000000 307.8000000 17.07 0.0003 结论:结论:在显著水平为0.05下0.0003<0.05,所以各个总体均值间有显著差异。 代码: data l1;p265 1 (ua-ub) input lei n; do rep= 1to n; input x@@; output;end; cards; 1 5 40 42 48 45 38 2 5 26 28 34 32 30 ; proc ttest; class lei; var x; run;
数据库教材部分习题解答
1 n
习题1 题五。1
Ch2 题5: ⑴Пsno(σjno=j1 (spj)) ⑵Пsno(σjno=j1∧pno=p1 (spj)) ⑶Пsno(Пsno,pno(σjno=j1 (spj))∞Пpno(σ (p))) color=红色 ⑷Пjno(j)- Пjno(Пsno,pno(σcity=天津∧color=红色(s×p)) ∞spj) ⑸Пjno,pno(spj)÷Пpno(σsno=s1 (spj)) 4、
一、程序设计题 1.解: 2 S(学号,姓名,性别,专业,奖学金) C(课程号,课程名,学分) SC(学号,课程号,分数) 用关系代数表达式实现下列各题。 (1)检索“英语”专业学生所学课程的学号、姓名、课程名和分数。 解:1.П学号,姓名,课程名,分数(σ专业='英语'(学生∞学习∞课程)) (2)检索“数据库技术”课程成绩高于90分的所有学生的学号、姓名、专业和分数。 解:П学号,姓名,专业,分数(σ分数>90∧名称='数据库技术'(学生∞学习∞课程)) (3)检索选修课程号为C2和C5的学生学号。 解:除法 (4)检索不选修“C1”课程的学生学号,姓名和专业。 解:П学号,姓名,专业(学生)-П学号,姓名,专业(σ课程号='C1'(学生∞学习)) (5)检索没有任何一门课程成绩不及格的所有学生的学号、姓名和专业。 解:П学号,姓名,专业(学生)-П学号,姓名,专业(σ分数<60(学生∞学习))
①create table 借阅(借书证号 char(3), 总编号 char(6), 借书日期 datetime, primary key(借书证号, 总编号), FOREIGN KEY(借书证号) REFERENCES 读者(借书证号), FOREIGN KEY(总编号) REFERENCES图书(总编号)) ②alter table读者 add constraint c1 check(性别 in(‘男’,’女’)) ③ create unique index bookidx on 图书(总编号 desc) ④select * from 图书 where 出版单位=‘清华大学出版社’ order by 单价 desc ⑤select 图书* from 图书,借阅 where 图书. 总编号=借阅. 总编号 and 单价>17 ⑥select 总编号from 图书 where 单价>(select max(单价) from 图书 where 出版 单位=‘清华大学出版社’) ⑦select 出版单位,count(借书证号),sum(单价) from 图书 group by 出版单位 having count(借书证号)>5 ⑧ ⑨insert into 借阅 values(‘006’,‘010206’,’2000-12-16’) 10、 update 图书 set 单价=单价+5 where 出版单位=‘高等教育出版社’ 11、delete from 借阅 where ‘张三’= (select 作者from 图书WHERE 图书. 总 编号=借阅. 总编号) 12、create view dzview(借书证号,姓名,性别, 单位) as select 读者. 借书证号,姓名, 性别, 单位 from 图书,读者,借阅 where 读者. 借书证号=借阅. 借书证号and 图书. 总编号=借阅. 总编号 and 出版单位=‘清华大学出版社’and 单位=‘计算机系’ 13 grant select,update(借书日期) on 借阅 to 张军 3.4习题3* 二、 DC 三、 3.1 create trigger t1 on借阅 for delete as update读者 set 借阅册数=借阅册数-1 where 读者.书号=(select 书号 from deleted where 读者. 总编号= deleted . 总编号) 3.2 create procedure p1 @n char(3), @t dadatime as select * from借阅 where 借书证号=@n and 借书日期>=@t
SAS系统和数据分析SAS数据集的编辑
第十一课SAS数据集的编辑 通常从外部数据源转换得到SAS数据集后,并不是所有的数据集都满足统计数据要求,可立即调用统计过程进行统计分析。需要对数据集进行满足统计数据要求的编辑或生成新的数据集。 一、增加数据集一个新变量 SAS系统可通过赋值语句把包含操作符的表达式赋值给数据集所要创建的新变量。SAS 的表达式中还可以包含SAS函数,如一些常用的SAS函数见下表: 函数分类常用函数功能 数学运算函数ABS( ) 取绝对值 SQRT( ) 求平方根 INT( ) 取整数部分 EXP( ) 计数e的次幂 LOG( ) 求e为底的自然对数SIN( ) 计算正弦 LAGn( ) 求给定变量滞后为n的值 统计计算函数MAX( ) 求最大值 MIN( ) 求最小值 MEAN( ) 求平均值 SUM( ) 求和 DIFn( ) 求给定变量X的第n阶差STD( ) 求标准差 PROBNORM( ) 标准正态分布函数 日期时间处理函数DA TE( )/TODAY()取当日的日期值DAY( ) 计算某月的那一日HOUR( ) 计算小时 TIME( ) 取当日的时间YEAR( ) 取年值 字符函数INDEX( ) 搜寻字符串的位置LEFT( ) 字符串表达式左对齐SUBSTR( ) 抽取子字符串TRIM( ) 移走尾部空格LENGTH( ) 给出字符变量的长度UPCASE( ) 转换为大写 财政金融函数COMPOUND( ) 计算复利 IRR( ) 计算内部赢利率 NPV( ) 计算净现值 SA VING( ) 计算定期储蓄的本金和利息
例如,有一个学生成绩数据集中的数据来源写在CARDS语句后,但我们还需产生新的变量平均分和总分,数据步的程序如下: Data class2 ; Input id test1-test5 ; average=mean(test1,test2,test3,test4,test5); total=test1+test2+test3+test4+test5; Cards ; 980801 100 100 100 100 100 980802 90 100 90 100 90 980803 81 82 83 84 85 Proc print data=class2 ; Run ; 在OUTPUT窗口中显示的运行结果见图11.1所示。 图11.1 用赋值表达式创建数据集的新变量 二、选择数据集的变量和观测 数据库的三种基本操作是选择、投影和连接,如果我们把数据库看成是一张表格,选择和投影操作相当于从一张大的数据库表格中挑选所需的行和列形成一张小的数据库表格。连接操作相当于把两张或两张以上的数据库表格按某种规则合并成一张数据库表格。原始数据库表格可以是外部数据文件(用INFILE语句输入),或在作业流中(用CARDS语句输入),或来自其他SAS数据集(用SET语句输入)。 1.选择变量(即选择列) 使用DATA语句的DROP=和KEEP=选项可以控制从原始数据库中读出的变量是否被写入将要创建的数据集。