数据流向图
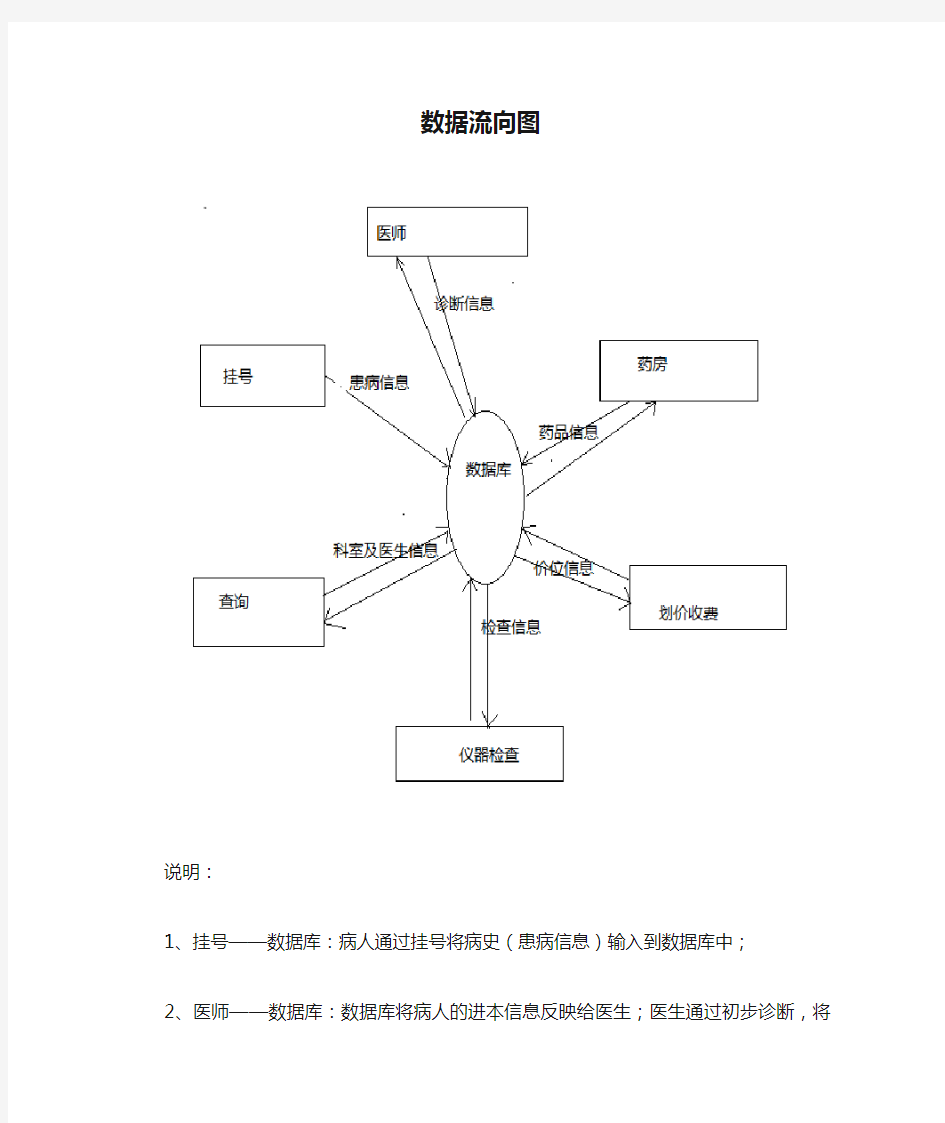

数据流向图
说明:
1、挂号——数据库:病人通过挂号将病史(患病信息)输入到数据库中;
2、医师——数据库:数据库将病人的进本信息反映给医生;医
生通过初步诊断,将结果送入到数据库,并给病人合理的建议;
3、划价——数据库:通过数据库将处方进行划价;并把结果送到数据库;
4、药房——数据库:通过数据库药房拿到病人的处方,开出相应的药品(针剂);并把信息返回数据库;
5、仪器——数据库:通过数据库将所要进行的检查送到医检室,给病人做出相应的检查;并把检查结果送回到数据库;
6、查询——数据库:从数据库查询相关医生的就诊情况以及仪器设备情况;将查询的结果返回到数据库;
数据结构课程设计图的遍历和生成树求解
数学与计算机学院 课程设计说明书 课程名称: 数据结构与算法课程设计 课程代码: 6014389 题目: 图的遍历和生成树求解实现 年级/专业/班: 学生姓名: 学号: 开始时间: 2012 年 12 月 09 日 完成时间: 2012 年 12 月 26 日 课程设计成绩: 指导教师签名:年月日
目录 摘要 (3) 引言 (4) 1 需求分析 (5) 1.1任务与分析 (5) 1.2测试数据 (5) 2 概要设计 (5) 2.1 ADT描述 (5) 2.2程序模块结构 (7) 软件结构设计: (7) 2.3各功能模块 (7) 3 详细设计 (8) 3.1结构体定义 (19) 3.2 初始化 (22) 3.3 插入操作(四号黑体) (22) 4 调试分析 (22) 5 用户使用说明 (23) 6 测试结果 (24) 结论 (26)
摘要 《数据结构》课程主要介绍最常用的数据结构,阐明各种数据结构内在的逻辑关系,讨论其在计算机中的存储表示,以及在其上进行各种运算时的实现算法,并对算法的效率进行简单的分析和讨论。进行数据结构课程设计要达到以下目的: ?了解并掌握数据结构与算法的设计方法,具备初步的独立分析和设计能力; ?初步掌握软件开发过程的问题分析、系统设计、程序编码、测试等基本方法和技能; ?提高综合运用所学的理论知识和方法独立分析和解决问题的能力; 训练用系统的观点和软件开发一般规范进行软件开发,培养软件工作者所应具备的科学的工作方法和作风。 这次课程设计我们主要是应用以前学习的数据结构与面向对象程序设计知识,结合起来才完成了这个程序。 因为图是一种较线形表和树更为复杂的数据结构。在线形表中,数据元素之间仅有线性关系,每个元素只有一个直接前驱和一个直接后继,并且在图形结构中,节点之间的关系可以是任意的,图中任意两个数据元素之间都可能相关。因此,本程序是采用邻接矩阵、邻接表、十字链表等多种结构存储来实现对图的存储。采用邻接矩阵即为数组表示法,邻接表和十字链表都是图的一种链式存储结构。对图的遍历分别采用了广度优先遍历和深度优先遍历。 关键词:计算机;图;算法。
数据流图复习及解题技巧.docx
软件设计师考试的下午题的笫一道题,数据库系统工程师考试的下午题的笫一道题都是数据流图题,而能够将这道题全部做对的考生是非常少的。根据本人儿年的辅导和阅卷经验, 发现很多考生不是因为这方面的解题能力不够,而是缺乏解这种题的方法与技巧。本章介绍一些解这种类型题的方法和技巧,希望起来抛砖引玉的效果。 一?解题当中考生表现岀的特点 由于这是下午考试的第一道题,所以很多考生从考前的紧张氛围当中逐渐平静下来开始答题,头脑还比较清醒,阅读起来比较流畅,速度还可以,自我感觉不错。可偏偏这道题有很多人不能全取15分,纠其原因有以下一些特点: 1.拿卷就做,不全面了解试卷,做到心中有数。这样会导致在解题过程当中缺少一种整体概念,不能明确自己在哪些题上必需拿分(多花时间),哪些题上自己拿不了分(少花时间)。这样,在解题时目标就会明确很多。 2.速度快,读一遍题就开始动手做。 3.速度慢,用手指逐个字的去看,心想看一遍就能做出题来。 4.在阅读题目时,不打记,不前后联系起來思考。 5.边做边怀疑边修改,浪费时间。 6.缺少的数据流找不准,可去掉的文件找不出来。 7.由于缺少项目开发经验,对一些事务分析不知如何去思考。 8.盲目乐观,却忽略了答题格式,丢了不应该丢的分。 二?解题的方法与技巧 1?首先要懂得数据流图设计要略。 有时为了增加数据流图的清晰性,防止数据流的箭头线太长,减少交叉绘制数据流条数, 一般在一张图上可以重复同名的数据源点、终点与数据存储文件。如某个外部实体既是数据源点又是数据汇点,可以在数据流图的不同的地方重复绘制。在绘制时应该注意以下要点: (1)自外向内,自顶向下,逐层细化,完善求精。
统计思维导图
第十一章 统计与概率 第一节 统 计 统计 知识梳理 学法指导 总结升华 统计的相关概念 数据的收集与整理 分析数据 平均数 中位数 学习误区 1.认真理解各个基本概念的实质,找出区别与联系. 知能提升 理解各个统计量的作用,使分析数据更具有方向性. 样本估计总体的方法 画统计图 即通过从总体中抽取一个样本,根据样本的情况去估计总体的相应情况,常用于设计实际应用题. 画频率分布直方图的步骤 画频数分布折线图的方法 取直方图中每个矩形上边的中点,把这些点用线段依次连接起来即可. 平均数、众数和中位数的区别 极差、方差与标准差 利用统计量解决实际问题 数形结合法 总体 个体 样本 样本容量 统计图表 调查的方式 众数 极差 方差 标准差 总体、样本的概念混乱. 分不清集中趋势和离散趋势. 弄不清三种统计图的表达意义的侧重点. 3.注意题目的侧重点来选取合适的知识解题. 1.收集数据;(放到统计图内) 7.写出统计图的名称和数据来源. 常见的命题形式 (1)观察分析各类统计图表,解决相关问题. (2)根据已知条件,绘制或补全各类统计图. 1.比赛成绩的评估. 2.植物长势的判断. 3.对事件提出合理化的建议. 他们都是衡量一组数据波动大小的量.这三个量越小,这组数据的波动越小,也越稳定;反之亦然. 平均数的大小与每一个数据有关,任一数据的变动都会引起平均数的变动. 众数的大小只与数据中的部分数据有关. 中位数只与数据的排列位置有关,某些数据的变动对它没有影响. 2.计算数据中的最大值与最小值的极差; 3.确定组距与组数; 4.确定分点; 5.列频率分布表; 6.画直方图; 在统计中,所有考察对象的全体. 在统计中,组成总体的每一个考察对象. 在统计中,实际观测或调查的那部分个体. 在统计中,所提取的样本个数. 扇形统计图. 条形统计图. 折线统计图. 频率分布图 直方图 普查 抽样调查 为了一定的目的,对考察对象进行全面的调查. 从总体中,抽取部分个体进行调查的方式. 算数平均数 加权平均数 n 个数据按大小顺序排列,处于中间位置的一个数据(或中间两个数据的平均数). 一组数据中,出现次数最多的那个数(注:有时会有多个). 一组数据中,最大与最小数据的差.
数据结构实验报告-图的遍历
数据结构实验报告 实验:图的遍历 一、实验目的: 1、理解并掌握图的逻辑结构和物理结构——邻接矩阵、邻接表 2、掌握图的构造方法 3、掌握图的邻接矩阵、邻接表存储方式下基本操作的实现算法 4、掌握图的深度优先遍历和广度优先原理 二、实验内容: 1、输入顶点数、边数、每个顶点的值以及每一条边的信息,构造一个无向图G,并用邻接矩阵存储改图。 2、输入顶点数、边数、每个顶点的值以及每一条边的信息,构造一个无向图G,并用邻接表存储该图 3、深度优先遍历第一步中构造的图G,输出得到的节点序列 4、广度优先遍历第一部中构造的图G,输出得到的节点序列 三、实验要求: 1、无向图中的相关信息要从终端以正确的方式输入; 2、具体的输入和输出格式不限; 3、算法要具有较好的健壮性,对错误操作要做适当处理; 4、程序算法作简短的文字注释。 四、程序实现及结果: 1、邻接矩阵: #include
数据结构实验---图的储存与遍历
数据结构实验---图的储存与遍历
学号: 姓名: 实验日期: 2016.1.7 实验名称: 图的存贮与遍历 一、实验目的 掌握图这种复杂的非线性结构的邻接矩阵和邻接表的存储表示,以及在此两种常用存储方式下深度优先遍历(DFS)和广度优先遍历(BFS)操作的实现。 二、实验内容与实验步骤 题目1:对以邻接矩阵为存储结构的图进行DFS 和BFS 遍历 问题描述:以邻接矩阵为图的存储结构,实现图的DFS 和BFS 遍历。 基本要求:建立一个图的邻接矩阵表示,输出顶点的一种DFS 和BFS 序列。 测试数据:如图所示 题目2:对以邻接表为存储结构的图进行DFS 和BFS 遍历 问题描述:以邻接表为图的存储结构,实现图的DFS 和BFS 遍历。 基本要求:建立一个图的邻接表存贮,输出顶点的一种DFS 和BFS 序列。 测试数据:如图所示 V0 V1 V2 V3 V4 三、附录: 在此贴上调试好的程序。 #include
#define M 100 typedef struct node { char vex[M][2]; int edge[M ][ M ]; int n,e; }Graph; int visited[M]; Graph *Create_Graph() { Graph *GA; int i,j,k,w; GA=(Graph*)malloc(sizeof(Graph)); printf ("请输入矩阵的顶点数和边数(用逗号隔开):\n"); scanf("%d,%d",&GA->n,&GA->e); printf ("请输入矩阵顶点信息:\n"); for(i = 0;i
分层数据流图的设计方法
分层数据流图的设计方法 第一步,画子系统的输入输出 把整个系统视为一个大的加工,然后根据数据系统从哪些外部实体接收数据流,以及系统发送数据流到那些外部实体,就可以画出输入输出图。这张图称为顶层图(顶层加工名是软件项目名字)。 第二步,画子系统的内部 把顶层图的加工分解成若干个加工,并用数据流将这些加工连接起来,使得顶层图的输入数据经过若干加工处理后,变成顶层图的输出数据流。这张图称为0层图。从一个加工画出一张数据流图的过程就是对加工的分解。 可以用下述方法来确定加工: 在数据流的组成或值发生变化的地方应该画出一个加工,这个加工的功能就是实现这一变化,也可以根据系统的功能决定加工。 确定数据流的方法 用户把若干数据当作一个单位来处理(这些数据一起到达、一起处理)时,可以把这些数据看成一个数据流。 关于数据存储 对于一些以后某个时间要使用的数据,可以组织成为一个数据存储来表示。 第三步,画加工的内部 把每个加工看作一个小系统,把加工的输入输出数据流看成小系统的输入输出流。于是可以象画0层图一样画出每个小系统的加工的DFD图。 第四步,画子加工的分解图 对第三步分解出来的DFD图中的每个加工,重复第三步的分解过程,直到图中尚未分解的加工都是足够简单的(即不可再分解)。至此,得到了一套分层数据流图。 第五步,对数据流图和加工编号 对于一个软件系统,其数据流图可能有许多层,每一层又有许多张图。为了区分不同的加工和不同的DFD子图,应该对每张图进行编号,以便于管理。 ●顶层图只有一张,图中的加工也只有一个,所以不必为其编号。 ●0层图只有一张,图中的加工号分别是0.1、0.2、…,或者1,2 。 ●子图就是父图中被分解的加工号。 ●子图中的加工号是由图号、圆点和序号组成,如:1.12,1.3 等等。 应该注意的问题: 1.应适当的为数据流、加工、数据存储以及外部实体命名(尽量使用现实系统中已有的名字),名字应该反映该成分的实际含义,避免使用空洞的名字(如数据、信息)。 2.画数据流图,不是画控制流。 3.一个加工的输出数据流,不应与输入数据流同名,及时他们的组成完全相同。 4.允许一个加工有多条数据流流向另一个加工,也允许一个加工有两条相同的输出数据流流向不同的加工。 5.保持父图与子图的平衡。也就是说,父图中的某加工的输入输出流必须与他的子图的输入输出数据流在数量上和名字上相同。值得注意的是,如果父图中的一个输入(输出)数据流对应于子图中的几个输入(输出)数据流,而子图中组成这些数据流的数据项的全体正好是父图中的这一个数据流,那么他们仍然算是平衡的。 6.在自顶向下的分解过程中,若一个数据存储首次出现时,只与一个加工有关系,那么这个数据存储应作为这个加工的内部文件而不必画出。
数据流图与数据字典的一个经典例子
系统的数据流图与数据字典实例 作为示例,为简单起见,我们只考虑人机分工。此处的数据流图是计算机化的帐务处理系统中涉及到计算机部分的数据流图,人工完成的部分将不做反应。例如:计算机没有能力审核原始凭证、填制记账凭证,这些工作必须由人来完成,因此进入系统(系统的自动化部分)的应该是记账凭证而不是原始凭证。银行对帐单仍然是系统的输入数据流,原有的输出数据流系统也必须提供。 图1 系统的顶层数据流图 图2 系统的第一层分解图 记账凭证进入计算机系统需要进行输入操作,而且由于记账凭证本身可能出错,或输入过程中可能发生错误,因此系统必须提供对已输入的记账凭证的修改功能和审核功能,审核通过的记账凭证才能够记账。据此,对“凭证处理”分解得到第二层分解图,该分解图由凭证输入、凭证修改和凭证审核三个处理构成。如果记账凭证是由操作人员直接根据原始凭证
用计算机填制,则凭证处理还应该包含一个打印记账凭证的处理。 图3 系统第二层分解图之一(图1)在系统中,登帐处理由计算机完成,其分解的流程图与原来一致。 图4 系统第二层分解图之二(图2)
图5系统第二层分解图之三(图3) 图6 系统第二层分解图之四(图4) 8.1.3 数据字典 数据字典的作用是对数据流图中的各种成分进行详细说明,作为数据流图的细节补充,和数据流图一起构成完整的系统需求模型。数据字典一般应包括对数据项,数据结构、数据存储和数据处理的说明。以下列出本系统的主要数据字典条目。 1. 数据项条目 数据项编号:D01-001 数据项名称:凭证编号 别名:凭证流水号 符号名:PZBH 数据类型:数值型 长度:4 取值范围:1~9999 其余略。 2. 数据结构条目
数据结构图的遍历
#include"stdlib.h" #include"stdio.h" #include"malloc.h" #define INFINITY 32767 #define MAX_VERTEX_NUM 20 typedef enum{FALSE,TRUE}visited_hc; typedef enum{DG,DN,UDG,UDN}graphkind_hc; typedef struct arccell_hc {int adj; int*info; }arccell_hc,adjmatrix_hc[MAX_VERTEX_NUM][MAX_VERTEX_NUM]; typedef struct {char vexs[MAX_VERTEX_NUM]; adjmatrix_hc arcs; int vexnum,arcnum; graphkind_hc kind; }mgraph_hc; typedef struct arcnode_hc {int adjvex; struct arcnode_hc *nextarc; int*info; }arcnode_hc; typedef struct vnode_hc {char data; arcnode_hc *firstarc; }vnode_hc,adjlist_hc[MAX_VERTEX_NUM]; typedef struct {adjlist_hc vertices; int vexnum,arcnum; graphkind_hc kind; }algraph_hc; int locatevex_hc(mgraph_hc*g,char v) {int i,k=0; for(i=0;i
统计思维导图
统计思维导图应用 在统计学的教学工作中我们发现,学生普遍对统计方法的应用及创新存在困惑,究其根本的原因主要是对于知识的不理解,只是单纯地去记忆公式,违背了统计学的特点及规律。为了解决这个问题,在课堂中引入统计学思维导图,经实践证明,有利于学生掌握统计知识,提高学习效率,增强应用能力及创新能力。 统计学是一门收集、分析、表述和解释数据的学科,在市场营销中有着十分广泛的应用。首先,变异是社会中普遍存在的现象,采用统计方法,可以发现不确定现象背后隐藏的规律,从而对营销过程中提出的理论假设加以科学的验证。其次,结合统计学的知识,可以针对企业的特点,开展企业的市场营销管理工作,制定合理的营销策略,对产品的质量进行分析,对客户的需求进行定量化的描述,明确销售工作的重点和关键。因此,在我国目前的医药市场营销的相关专业中,普遍开设了统计类的课程,但是在教学过程中我们发现,学生在学习统计学时经常不知从何入手,教学内容主要以记忆为主,违背了统计学科应用性的特点,不利于学生对知识的掌握和对方法的创新。为了让学生更好的理解统计学,应用统计学,我们将思维导图应用于日常的教学工作中,取得了一定的经验效果。 1 统计思维导图 统计学思维导图是表达发散性思维的有效的图形工具,是一种革命性的思维工具。思维导图采用图文并重的方法,将各级各层的主题关系用相互隶属的
层级图形表现出来,把关键词和图形、图像、颜色等建立记忆链接。 思维导图充分利用人脑的机能,利用记忆、思维等规律,协助人们对问题进行学习和理解,可以将其广泛地应用于统计学的教学工作中。 2 统计学思维导图在教学中的应用 随着多媒体技术的普及,很多高等医学院校都采用了PPT 进行教学,这种教学方法比较直观,能通过生动的图像、声音等方法,调动学生的情绪,提高学习效率。但是,由于其同样具有大信息量、大容量性的特点,使得学生在学习时感觉吃力,跟不上授课的进度。而且,多数幻灯片对于学习内容的排列方式是线式的,不符合人脑的发散性思维模式,不利于学生对知识的掌握和理解。 统计学与一般的理科学科有所不同,它的知识自成体系,有逻辑,有层 次,在授课过程中,可以通过统计思维导图来帮助学生加深理解,并在此基础上进行应用及创新。 2.1 思维导图在统计描述中的应用统计描述是统计学中最基本的内容,也是统计分析中重要的一部分。在统计学中,经常用统计指标和统计图表来揭示和反映原始资料的数量特征和信息。在药学营销问题中,如果需要对理论问题加以验证,最常用的方法是通过实验数据来说明。经过严谨的统计设计,将实验中收集的数据进行筛查或转换,然后就可以通过统计描述的方法来总结这组数据的一些重要的特征,使得实验得到的数据表达清晰,便于做进一步的分析。 在统计学中,对数据的描述可以是直观的图表,也可以是客观定量的计 算,无论是何种方式,都需要根据数据的类型及分布的类型等因素进行适当的选
数据结构课程设计之图的遍历和生成树求解
##大学 数据结构课程设计报告题目:图的遍历和生成树求解 院(系):计算机工程学院 学生: 班级:学号: 起迄日期: 2011.6.20 指导教师:
2010—2011年度第 2 学期 一、需求分析 1.问题描述: 图的遍历和生成树求解实现 图是一种较线性表和树更为复杂的数据结构。在线性表中,数据元素之间仅有线性关系,每个数据元素只有一个直接前驱和一个直接后继;在树形结构中,数据元素之间有着明显的层次关系,并且每一层上的数据元素可能和下一层中多个元素(及其孩子结点)相关但只能和上一层中一个元素(即双亲结点)相关;而在图形结构中,节点之间的关系可以是任意的,图中任意两个数据元素之间都可能相关。 生成树求解主要利用普利姆和克雷斯特算法求解最小生成树,只有强连通图才有生成树。 2.基本功能 1) 先任意创建一个图; 2) 图的DFS,BFS的递归和非递归算法的实现 3) 最小生成树(两个算法)的实现,求连通分量的实现 4) 要求用邻接矩阵、邻接表等多种结构存储实现 3.输入输出
输入数据类型为整型和字符型,输出为整型和字符 二、概要设计 1.设计思路: a.图的邻接矩阵存储:根据所建无向图的结点数n,建立n*n的矩阵,其中元素全是无穷大(int_max),再将边的信息存到数组中。其中无权图的边用1表示,无边用0表示;有全图的边为权值表示,无边用∞表示。 b.图的邻接表存储:将信息通过邻接矩阵转换到邻接表中,即将邻接矩阵的每一行都转成链表的形式将有边的结点进行存储。 c.图的广度优先遍历:假设从图中的某个顶点v出发,在访问了v之后依次访问v的各个未曾访问过的邻接点,然后再访问此邻接点的未被访问的邻接点,并使“先被访问的顶点的邻接点”先于“后被访问的顶点的邻接点”被访问,直至图中所有已被访问的顶点的邻接点都被访问到。若此时图中还有未被访问的,则另选未被访问的重复以上步骤,是一个非递归过程。 d.图的深度优先遍历:假设从图中某顶点v出发,依依次访问v的邻接顶点,然后再继续访问这个邻接点的系一个邻接点,如此重复,直至所有的点都被访问,这是个递归的过程。 e.图的连通分量:这是对一个非强连通图的遍历,从多个结点出发进行搜索,而每一次从一个新的起始点出发进行搜索过程中得到的顶点访问序列恰为其连通分量的顶点集。本程序利用的图的深度优先遍历算法。 2.数据结构设计: ADT Queue{ 数据对象:D={a i | a i ∈ElemSet,i=1,2,3……,n,n≥0} 数据关系:R1={| a i-1 ,a i ∈D,i=1,2,3,……,n} 基本操作: InitQueue(&Q) 操作结果:构造一个空队列Q。 QueueEmpty(Q) 初始条件:Q为非空队列。 操作结果:若Q为空队列,则返回真,否则为假。 EnQueue(&Q,e) 初始条件:Q为非空队列。 操作结果:插入元素e为Q的新的队尾元素。 DeQueue(&Q,e) 初始条件:Q为非空队列。 操作结果:删除Q的队头元素,并用e返回其值。}ADT Queue
数据流图(DFD)专题讲解
软件设计师考试的下午题的第一道题,数据库系统工程师考试的下午题的第一道题都是数据流图题,而能够将这道题全部做对的考生是非常少的。根据历年的辅导和阅卷经验,发现很多考生不是因为这方面的解题能力不够,而是缺乏解这种题的方法与技巧。本文介绍一些解这种类型题的方法和技巧,希望起来抛砖引玉的效果。 一.解题当中考生表现出的特点 由于这是下午考试的第一道题,所以很多考生从考前的紧张氛围当中逐渐平静下来开始答题,头脑还比较清醒,阅读起来比较流畅,速度还可以,自我感觉不错。可偏偏这道题有很多人不能全取15分,纠其原因有以下一些特点: 1.拿卷就做,不全面了解试卷,做到心中有数。这样会导致在解题过程当中缺少一种整体概念,不能明确自己在哪些题上必需拿分(多花时间),哪些题上自己拿不了分(少花时间)。这样,在解题时目标就会明确很多。 2.速度快,读一遍题就开始动手做。 3.速度慢,用手指逐个字的去看,心想看一遍就能做出题来。 4.在阅读题目时,不打记,不前后联系起来思考。 5.边做边怀疑边修改,浪费时间。
6.缺少的数据流找不准,可去掉的文件找不出来。 7.由于缺少项目开发经验,对一些事务分析不知如何去思考。 8.盲目乐观,却忽略了答题格式,丢了不应该丢的分。 二.解题的方法与技巧 1.首先要懂得数据流图设计要略。 有时为了增加数据流图的清晰性,防止数据流的箭头线太长,减少交叉绘制数据流条数,一般在一张图上可以重复同名的数据源点、终点与数据存储文件。如某个外部实体既是数据源点又是数据汇点,可以在数据流图的不同的地方重复绘制。在绘制时应该注意以下要点: (1)自外向内,自顶向下,逐层细化,完善求精。 (2)保持父图与子图的平衡。 为了表达较为复杂问题的数据处理过程,用一个数据流图往往不够。一般按问题的层次结构进行逐步分解,并以分层的数据流图反映这种结构关系。根据层次关系一般将数据流图分为顶层数据流图、中间数据流图和底层数据流图,除顶层图外,其余分层数据流图从0开始编号。对任何一层数据流图来说,称它的上层数据流图为父图,在它的下一层的数据流图为子图。
大数据时代思维导图
大数据时代大数据时代的思维变革不是样本而是全部小数据时代的随机取样全数据模式,样本=总体谷歌流感趋势预测分析美国整个互联网检索记录,可以推测到某个城市的流感状况L y tro 相机 记录整个光场里的所有光,具体生成的照片可以根据需要决定乔布斯癌症治疗对乔布斯DNA 、肿瘤DNA 全测序,根据其特定基因组成按需用药不是精确性而是混杂性谷歌翻译虽然搜集的有错误翻译,但巨大的语料库优势完全压倒了缺点,使其好于布朗、微软的班科和布里尔、IBM 的C a ndide F a c e bo o k 等社交网站 由用户随意贴标签分类照片象棋残局1 w o rd 语法检查 1 更混杂的数据量而不是更精确的算法大数据不只是优于少量数据那么简单,而是能创造更好的结果不是因果关系而是相关关系亚马逊推荐系统根据产品间的联系推荐,增加100倍销售量沃尔玛飓风来临前,将蛋挞与飓风用品摆在一起可增加销量基于相关关系的预测是大数据的核心塔吉特与怀孕预测美国折扣零售商通过对女性消费记录分析,可以发现她是否怀孕,从而在相应阶段寄送相应的折扣券U PS 与汽车修理预测U PS 国际快递公司通过监测车辆的各个部位,提早更换需 要更换的零件早产儿病情诊断实时监测病人信息,提早预测感染知道是什么就够了,没必要知道为什么 大数据时代的管理变革风险--让数据主宰一切的隐忧无处不在的第三只眼亚马逊监视着我们的购物习惯谷歌监视着我们的网页浏览习惯微博窃听到了我们心中的TA f a c e bo o k 似乎什么都知道,包括我们的社交关系网 隐私被二次利用大数据时代,不管是告知与许可、模糊化还是匿名化的隐私保护策略都失效预测与惩罚预测犯罪并提前制止;老年人需要交更多保险费;这否定了人的自由权利、公平,无法独立选择和自由意识数据独裁过于信任、依赖数据掌控--责任与自由并举的信息管理个人隐私保护让使用者承担责任公司负有特定时间之后删除个人数据的义务保护个人动因反数据垄断大亨程序员监控大数据并保持透明度大数据时代的商业变革一切皆可量化坐姿转化成数据孕育出一些服务和一个产业汽车防盗系统能识别是否是车主,不是需要输入密码,错误则自动熄火识别盗贼通过收集到的数据识别盗贼提醒疲劳驾驶坐姿与行驶安全关系通过分析事故发生前的坐姿变化情况地板数据化适时的开灯、开门根据体重、站姿、走路方式确认他的身份监控商店人流量文字变为数据谷歌数据图书馆谷歌翻译沟通变成数据微博情绪数据化来自世界不同文化的人每天、每周的心情都遵循着相似的模式-2011.s c ie nc e 监听新微博发布频率预测电影成败分析微博数据文本,作为股市投资信号位置数据化G PS 通过手机预测交通情况处理来自手机的数据预测人类行为流感时期:通过分析每个人去了哪里见了谁,知道应该隔离谁,怎么找到他数据创新数据的价值不只是漂浮着... 数据再利用网页流量测量揭示用户喜好-Hitw is e 公司数据重组整合手机用户信息与癌症患者信息揭示手机是否增加致癌率-无关扩展数据利用零售店监控摄像头零售店监控摄像头除了安全保卫,还可以跟踪客流及客户停留的位置从而设计店面最佳布局、判断营销的有效性;最终变纯粹的成本为可增收的投资数据折旧及时剔除失去基本用途的数据,如亚马逊推荐系统一般不用用10年前客户买的书来进行推荐数据废气利用谷歌根据用户点击的搜索结果所在的位置来更正排名,将更相关的提前谷歌拼写检查反馈系统通过用户自行更正的搜索词、或点击显示正确拼写的页面来完善相比微软创建维护词典库更先进,变碎屑为金粉开放数据开 放政府数据的倡议响彻全球;私营部门社会对数据的利用更具创新性;数据的价值不只是浮在水面的冰山一角;数据、技术、思维三足鼎立数据拥有者数据拥有者可以选择将数据授权给其他公司,如ITA S o ftw a re ;可以自行开发分析,如M a s te rCa rd ; 大数据技术公司微软Am a lga 系统,减少病人再度入院、大数据思维公司与个人20岁的克罗斯与四个朋友创办了F lightCa s te r 预测航班晚 点数据中间商 结语大数据给我们提供的不是最终答案,而是参考答案,人类的作用依然无法完全被替代。世界不是贫乏规整的惨象,而是纷繁复杂的,天地间存在的事物也远远多于系统想象 大数据时代思维导图
数据结构 图的存储、遍历与应用 源代码
实验四图的存储、遍历与应用姓名:班级: 学号:日期:一、实验目的: 二、实验内容: 三、基本思想,原理和算法描述:
四、源程序: (1)邻接矩阵的存储: #include
数据结构 图的遍历(初始化图)
实践四:图及图的应用 1.实验目的要求 理解图的基本概念,两种主要的存储结构。掌握在邻接链表存储结构下的图的深度优先递归遍历、广度优先遍历。通过选做题"最短路径问题"认识图及其算法具有广泛的应用意义。 实验要求:正确调试程序。写出实验报告。 2.实验主要内容 2.1 在邻接矩阵存储结构下的图的深度优先递归遍历、广度优先遍历。 2.1.1 要完成图的两种遍历算法,首先需要进行图的数据初始化。为把时间主要花在遍历算法的实现上,图的初始化采用结构体声明时初始化的方法。示例代码如下: #include "stdio.h" typedef int Arcell; typedef int AdjMatrix[5][5]; typedef struct { char vexs[5]; AdjMatrix arcs; int vexnum,arcnum; }MGraph; void main(){ MGraph g={ {'a','b','c','d','e'}, {{0,1,0,1,0}, {1,0,0,0,1}, {1,0,0,1,0}, {0,1,0,0,1}, {1,0,0,0,0}} ,5,9}; } 2.1.2 深度优先遍历算法7.5中FirstAdjVex方法和NextAdjVex方法需要自己实现。 2.2 拓扑排序,求图的拓扑序列 2.3 "最短路径问题",以校园导游图为实际背景进行设计。(选做) 程序代码如下: #include
#include
数据结构_图遍历的演示
实习报告 题目:图遍历的演示 编译环 境: Microsoft Visual Studio 2010 功能实现: 以邻接表为存储结构,演示在连通无向图上访冋全部节点的操作; 实现连通无向图的深度优先遍历和广度优先遍历; 建立深度优先生成树和广度优先生成树,按凹入表或树形打印生成树。 1.以邻接表为存储结构,演示在连通无向图上访问全部节点的操作。 该无向图为 一个交通网络,共25个节点,30条边,遍历时需要以用户指定的节点为起点, 建立深度优先生成树和广度优先生成树,再按凹入表或树形打印生成树。 2.程序的测试数据:graph.txt 文件所表示的无向交通图。 //边表结点 //邻接点域,即邻接点在顶点表中的下标 //顶点表结点 //数据域 struct TNode // 树结点 { stri ng data; struct TNode *fristchild, * nextchild; }; 2.邻接表类设计: class GraphTraverse { public: 需求分析 二、概要设计 1.主要数据结构设计: struct ArcNode { int vex In dex; ArcNode* n ext; }; struct VertexNode { stri ng vertex; ArcNode* firstArc; };
三、详细设计 1. 主要操作函数的实现: (1) 建立深度优先生成树函数: TNode* GraphTraverse::DFSForest(i nt v) { int i,j; TNode *p,*q,*DT; j=v; for(i=O;i
八年级下册数据分析思维导图
八年级下册数据分析思维导图 第一单元数据收集一、教材简析本单元是在学生已经学习了比较、分类等知识的基础上学习统计的基本知识的。 为了让学生能了解学习统计的必要性,教材选择了与学生生活有密切联系的生活场景,通过参与风趣的调查活动,使学生经历收集信息、处理信息的过程,了解调查的方法,学习收集、、描述和分析数据,认识统计的意义和作用。二、目标导向1、使学生体验数据的收集、、描述和分析的过程,了解统计的意义,会用简单的方法收集和数据。 2、使学生初步认识统计图(一格代表五个单位)和简单的复式统计表,能根据统计图表中的数据提出并回答简单的问题,并能够进行简单的分析。 3、通过对周围现实生活中有关事例的调查,激发学生的学习兴趣,培养学生的合作意识和创新精神。三、课时安排本单元建议用3课时进行教学。第1课时课时内容数据收集(一)课型新授课个性修改一课时目标1.知识目标:初步体验数据收集、、描述的过程,会用分类数数的方法将数据成简单的统计表;2.能力目标:初步认识统计表,能正确填写统计表,能从中获得简单统计的结果; 3.情感目标:通过对学生身边风趣事例的调查活动,激发学生学习的兴趣,培养学生的合作意识和能力。课时重难点重点:经历收集和数据的过程,初步认识统计表。难点:感受、经历数据的过程,能正确填写统计表。师生活动一、创设情境,导入新知、(1)你们喜爱运动吗?你们都喜欢哪些运动呢?(学生回答)(2)这么喜欢运动,现在的天气又这么好,来组织个比赛好吗?可是这么多运动项目,你想组织什么比赛呢?(学生解放发表意见,意见不一致)(3)意见不一致,这该这么办呢?(学生解放发表意见,老师适时导入)(4)收集一下数据,收集什么数据呢?(学生:最喜欢的运动)(5)引入新知:数据收集。 二、揭示目标本节课的学习目标是什么呢?请看:(出示投影,生齐读)。
手把手教你数据分析全流程
https://www.360docs.net/doc/1411980117.html,/ 手把手教你数据分析全流程 听到数据分析,很多竞价小编都会干到头很大有没有,正因为头大,所以我们才应该针对这方面去多种练习,一直练到什么时候拿到这个数据分析的任务感觉得心应手的时候正是我们成功的时候。 下图是某账户的营销数据。从你的角度看,你会觉得是哪里出了问题? 分析好之后,你便可以带着自己的答案看下去。 确定目的 一般情况下,我们进行数据分析是为了什么? 降低成本,增加对话、增加流量质量...等等。 但其实,最终我们都可以归结为一个目的:增加转化。
https://www.360docs.net/doc/1411980117.html,/ 那我们在分析时,便可以基于这个目的来出发。 发现问题 既然明确了目的,是增加转化,那便可先从结果出发。 从图中我们可以看出它的线索是逐步上升,但线索成本并没有下降。 那...从结果分析来看,我们的获客成本是较高的。 分析、确定问题 线索成本高,要么是因为我们的均价高,要么就是因为我们的对话率低。 但从对话率来看,它的数据我们可以接受,说明流量质量没问题;点击率略微下降,均价居高不下,所以导致对话成本也是处于一个较高的状态。 那,由此可以确定:对话成本高从而导致了一个线索成本的问题。 分解问题 确定了问题,我们就要分解问题。 建议像这种情况,我们可以在草稿或电脑上罗列出一个思维导图。 对话成本高,我们可以从两点来解决:
https://www.360docs.net/doc/1411980117.html,/ 1. 降低对话成本 2. 增加对话量 降低对话成本 降低对话成本,要么降低整体点击均价从而降低成本,要么提高对话率,以量取胜。 降低整体点击均价:我们可通过筛掉那些均价高、转化低的词来达到这一目的。 提高对话率:对话率往往和一个流量质量、转化引导有关系。那我们便可通过对以下四点进行分析,从而找到自身影响对话的一个薄弱之处。 抵达分析 承载分析 转化能力分析 流量质量分析 增加对话量 增加对话量,不过就是一个增加流量质量和流量数量的问题。 这就需要我们在增加流量数量的同时,筛选出垃圾流量。同样,我们可以通过分词来达到这一目的。 我们最初的目的是增加转化,那么便可先筛选出转化较好的词,然后进行分类。 均价高转化好:先加词,拓量之后优化创意,来控制流量。 均价低转化好:利用提价和放匹配相结合。 操作执行
软件设计师数据流图的设计(一)
[模拟] 软件设计师数据流图的设计(一) 填空题 阅读下列说明和数据流图,回答问题1至问题3,将解答填入对应栏内。 [说明] 某图书馆管理系统的主要功能是图书管理和信息查询。对于初次借书的读者,系统自动生成读者号,并与读者基本信息(姓名、单位、地址等)一起写入读者文件。 系统的图书管理功能分为4个方面:购入新书、读者借书、读者还书和图书注销。 (1)购入新书时需要为该书编制入库单。入库单内容包括图书分类目录号、书名、作者、价格、数量和购书日期,将这些信息写入图书目录文件并修改文件中的库存总量(表示到目前为止,购入此种图书的数量)。 (2)读者借书时需填写借书单。借书单内容包括读者号和所借图书分类目录号。系统首先检查该读者号是否有效,若无效,则拒绝借书;若有效,则进一步检查该读者已借图书是否超过最大限制数(假设每位读者能同时借阅的书不超过5本),若已达到最大限制数,则拒绝借书;否则允许借书,同时将图书分类目录号、读者号和借阅日期等信息写入借书文件中。 (3)读者还书时需填写还书单。系统根据读者号和图书分类目录号,从借书文件中读出与该图书相关的借阅记录,标明还书日期,再写回到借书文件中,若图书逾期,则处以相应的罚款。 (4)注销图书时,需填写注销单并修改图书目录文件中的库存总量。 系统的信息查询功能主要包括读者信息查询和图书信息查询。其中读者信息查询可得到读者的基本信息以及读者借阅图书的情况:图书信息查询可得到图书基本信息和图书的借出情况。 图书管理系统的顶层数据流图如图15-1所示,图书管理系统的第0层数据流图如图15-2所示,其中加工2的细化图如图15-3所示。 第1题: 数据流图15-2中有两条数据流是错误的,请指出这两条数据流的起点和终点。_________ 参考答案: (1)从“2处理查询请求”到“读者文件”的数据流; (2)从“读者文件”到“3登记读者信息”的数据流。 详细解答: