决策树案例及答案
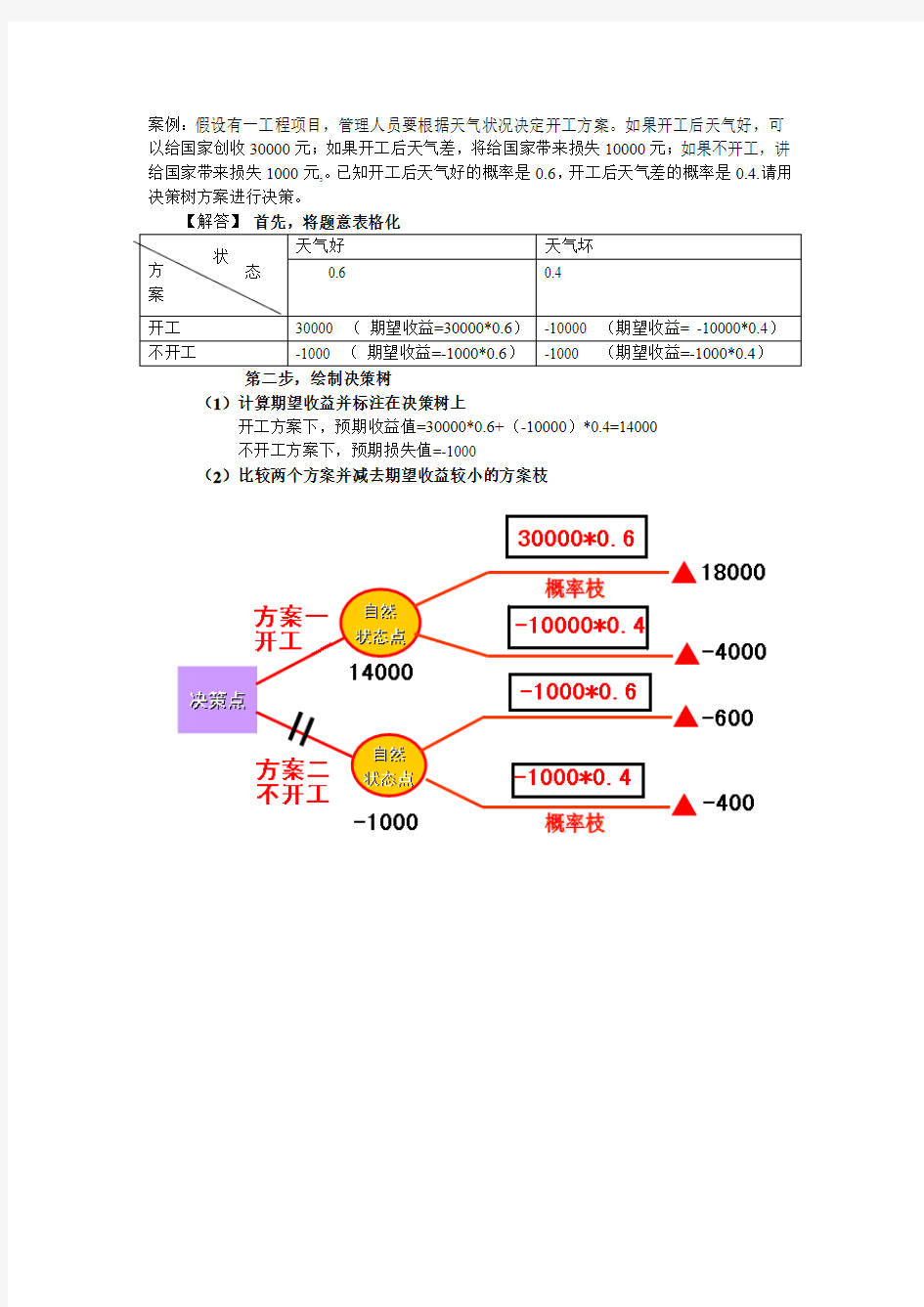
案例:假设有一工程项目,管理人员要根据天气状况决定开工方案。如果开工后天气好,可以给国家创收30000元;如果开工后天气差,将给国家带来损失10000元;如果不开工,讲给国家带来损失1000元,。已知开工后天气好的概率是0.6,开工后天气差的概率是0.4.请用决策树方案进行决策。 【解答】 首先,将题意表格化
方
案
天气好 天气坏 0.6 0.4 开工
30000 ( 期望收益=30000*0.6) -10000 (期望收益= -10000*0.4) 不开工 -1000 ( 期望收益=-1000*0.6) -1000 (期望收益=-1000*0.4)
第二步,绘制决策树
(1)计算期望收益并标注在决策树上
开工方案下,预期收益值=30000*0.6+(-10000)*0.4=14000
不开工方案下,预期损失值=-1000
(2)比较两个方案并减去期望收益较小的方案枝
状 态
R语言-决策树算法知识讲解
R语言-决策树算法
决策树算法 决策树定义 首先,我们来谈谈什么是决策树。我们还是以鸢尾花为例子来说明这个问题。 观察上图,我们判决鸢尾花的思考过程可以这么来描述:花瓣的长度小于 2.4cm的是setosa(图中绿色的分类),长度大于1cm的呢?我们通过宽度来判别,宽度小于1.8cm的是versicolor(图中红色的分类),其余的就是 virginica(图中黑色的分类) 我们用图形来形象的展示我们的思考过程便得到了这么一棵决策树: 这种从数据产生决策树的机器学习技术叫做决策树学习, 通俗点说就是决策树,说白了,这是一种依托于分类、训练上的预测树,根据已知预测、归类未来。 前面我们介绍的k-近邻算法也可以完成很多分类任务,但是他的缺点就是含义不清,说不清数据的内在逻辑,而决策树则很好地解决了这个问题,他十分好理解。从存储的角度来说,决策树解放了存储训练集的空间,毕竟与一棵树的存储空间相比,训练集的存储需求空间太大了。 决策树的构建 一、KD3的想法与实现 下面我们就要来解决一个很重要的问题:如何构造一棵决策树?这涉及十分有趣的细节。 先说说构造的基本步骤,一般来说,决策树的构造主要由两个阶段组成:第一阶段,生成树阶段。选取部分受训数据建立决策树,决策树是按广度优先建立直到每个叶节点包括相同的类标记为止。第二阶段,决策树修剪阶段。用剩余数据检验决策树,如果所建立的决策树不能正确回答所研究的问题,我们要对决策树进行修剪直到建立一棵正确的决策树。这样在决策树每个内部节点处进行属性值的比较,在叶节点得到结论。从根节点到叶节点的一条路径就对应着一条规则,整棵决策树就对应着一组表达式规则。 问题:我们如何确定起决定作用的划分变量。 我还是用鸢尾花的例子来说这个问题思考的必要性。使用不同的思考方式,我们不难发现下面的决策树也是可以把鸢尾花分成3类的。 为了找到决定性特征,划分出最佳结果,我们必须认真评估每个特征。通常划分的办法为信息增益和基尼不纯指数,对应的算法为C4.5和CART。 关于信息增益和熵的定义烦请参阅百度百科,这里不再赘述。 直接给出计算熵与信息增益的R代码:
决策树示例
决策树示例 %************************************************************** %* mex interface to Andy Liaw et al.'s C code (used in R package randomForest) %* Added by Abhishek Jaiantilal ( abhishek.jaiantilal@https://www.360docs.net/doc/1312713407.html, ) %* License: GPLv2 %* Version: 0.02 % % Calls Regression Random Forest % A wrapper matlab file that calls the mex file % This does training given the data and labels % Documentation copied from R-packages pdf % https://www.360docs.net/doc/1312713407.html,/web/packages/randomForest/randomForest.pdf % Tutorial on getting this working in tutorial_ClassRF.m %%************************************************************** % function model = classRF_train(X,Y,ntree,mtry, extra_options) % %___Options % requires 2 arguments and the rest 3 are optional % X: data matrix % Y: target values % ntree (optional): number of trees (default is 500). also if set to 0 % will default to 500 % mtry (default is floor(sqrt(size(X,2))) D=number of features in X). also if set to 0 % will default to 500 % % % Note: TRUE = 1 and FALSE = 0 below % extra_options represent a structure containing various misc. options to % control the RF % extra_options.replace = 0 or 1 (default is 1) sampling with or without % replacement % extra_options.strata = (not Implemented) % extra_options.sampsize = Size(s) of sample to draw. For classification, % if sampsize is a vector of the length the number of strata, then sampling is stratified by strata, % and the elements of sampsize indicate the numbers to be drawn from the strata. I don't yet know how this works. % extra_options.nodesize = Minimum size of terminal nodes. Setting this number larger causes
决策树算法研究及应用概要
决策树算法研究及应用? 王桂芹黄道 华东理工大学实验十五楼206室 摘要:信息论是数据挖掘技术的重要指导理论之一,是决策树算法实现的理论依据。决 策树算法是一种逼近离散值目标函数的方法,其实质是在学习的基础上,得到分类规则。本文简要介绍了信息论的基本原理,重点阐述基于信息论的决策树算法,分析了它们目前 主要的代表理论以及存在的问题,并用具体的事例来验证。 关键词:决策树算法分类应用 Study and Application in Decision Tree Algorithm WANG Guiqin HUANG Dao College of Information Science and Engineering, East China University of Science and Technology Abstract:The information theory is one of the basic theories of Data Mining,and also is the theoretical foundation of the Decision Tree Algorithm.Decision Tree Algorithm is a method to approach the discrete-valued objective function.The essential of the method is to obtain a clas-sification rule on the basis of example-based learning.An example is used to sustain the theory. Keywords:Decision Tree; Algorithm; Classification; Application 1 引言 决策树分类算法起源于概念学习系统CLS(Concept Learning System,然后发展 到ID3
决策树练习题
决策树作业题 公司拟建一预制构件厂,一个方案就是建大厂,需投资300万元,建成后如销路好每年可获利100 万元,如销路差,每年要亏损20万元,该方案的使用期均为10年;另一个方案就是建小厂,需投资170 万元,建成后如销路好,每年可获利40万元,如销路差每年可获利30万元;若建小厂,则考虑在销路好的情况下三年以后再扩建,扩建投资130万元,可使用七年,每年盈利85万元。假设前3年销路好的概率就是0、7,销路差的概率就是0、3,后7年的销路情况完全取决于前3年;为了适应市场的变化,投资者又提出了第三个方案,即先小规模投资160万元,生产3年后,如果销路差,则不再投资,继续生产7年;如果销路好,则再作决策就是否再投资140万元扩建至大规模(总投资300万元),生产7年。前3 年与后7年销售状态的概率见表16,大小规模投资的年损益值同习题58。试用决策树法选择最优方案。 表16 销售概率表 项目前3年销售状态概率后7年销售状态概率好差好差 销路差0、7 0、3 0、9 0、1 决策树例题 1.某投资者预投资兴建一工厂,建设方案有两种:①大规模投资300万元;②小规模投资160万元。两个 方案的生产期均为10年,其每年的损益值及销售状态的规律见下表。试用决策树法选择最优方案。 (2)计算各状态点的期望收益值 节点②:[100*0、7+(-20)*0、3]*10-300=340;
节点③:[60*0、7+20*0、3]*10-160=320; 将各状态点的期望收益值标在圆圈上方。 (3)决策 比较节点②与节点③的期望收益值可知,大规模投资方案优于小规模投资方案,故应选择大规模投资方案,用符号“//”在决策树上“剪去”被淘汰的方案。 2.某项目有两个备选方案A与B,两个方案的寿命期均为10年,生产的产品也完全相同,但投资额及年 净收益均不相同。A方案的投资额度为500万元,其年净收益在产品销售好时为150万元,销售差时为50万元;B方案的投资额度为300万元,其年净收益在产品销售好时为100万元,销售差时为10万元,根据市场预测,在项目寿命期内,产品销路好时的可能性为70%,销路差的可能性为30%,试根据以上资料对方案进行比较。 3、公司拟建一预制构件厂,一个方案就是建大厂,需投资300万元,建成后如销路好每年可获利100万元,如销路差,每年要亏损20万元,该方案的使用期均为10年;另一个方案就是建小厂,需投资170万元,建成后如销路好,每年可获利40万元,如销路差每年可获利30万元;若建小厂,则考虑在销路好的情况下三年以后再扩建,扩建投资130万元,可使用七年,每年盈利85万元。假设前3年销路好的概率就是0、7,销路差的概率就是0、3,后7年的销路情况完全取决于前3年;试用决策树法选择方案。 解:这个问题可以分前3年与后7年两期考虑,属于多级决策类型,如图所示。
Clementine决策树CHAID算法
CHAID算法(Chi-Square Automatic Interaction Detection) CHAID提供了一种在多个自变量中自动搜索能产生最大差异的变量方案。 不同于C&R树和QUEST节点,CHAID分析可以生成非二进制树,即有些分割有两个以上的分支。 CHAID模型需要一个单一的目标和一个或多个输入字段。还可以指定重量和频率领域。 CHAID分析,卡方自动交互检测,是一种用卡方统计,以确定最佳的分割,建立决策树的分类方法。 1.CHAID方法(卡方自动交叉检验) CHAID根据细分变量区分群体差异的显著性程度(卡方值)的大小顺序,将消费者分为不同的细分群体,最终的细分群体是由多个变量属性共同描述的,因此属于多变量分析。 在形式上,CHAID非常直观,它输出的是一个树状的图形。 1.它以因变量为根结点,对每个自变量(只能是分类或有序变量,也就是离散性的,如果是连续 变量,如年龄,收入要定义成分类或有序变量)进行分类,计算分类的卡方值(Chi-Square-Test)。如果 几个变量的分类均显著,则比较这些分类的显著程度(P值的大小),然后选择最显著的分类法作为子节点。 2.CHIAD可以自动归并自变量中类别,使之显著性达到最大。 3.最后的每个叶结点就是一个细分市场 CHAID 自动地把数据分成互斥的、无遗漏的组群,但只适用于类别型资料。 当预测变量较多且都是分类变量时,CHAID分类最适宜。 2.CHAID分层的标准:卡方值最显著的变量 3.CHAID过程:建立细分模型,根据卡方值最显著的细分变量将群体分出两个或多个群体,对 于这些群体再根据其它的卡方值相对最显著的细分变量继续分出子群体,直到没有统计意义上显著的细分变量可以将这些子群体再继续分开为止。 4.CHAID的一般步骤 -属性变量的预处理 -确定当前分支变量和分隔值 属性变量的预处理: -对定类的属性变量,在其多个分类水平中找到对目标变量取值影响不显著的分类,并合并它们; -对定距型属性变量,先按分位点分组,然后再合并具有同质性的组; -如果目标变量是定类变量,则采用卡方检验 -如果目标变量为定距变量,则采用F检验 (统计学依据数据的计量尺度将数据划分为三大类,即定距型数据(Scale)、定序型数据(Ordinal)和定类型数据(Nominal)。定距型数据通常指诸如身高、体重、血压等 的连续性数据,也包括诸如人数、商品件数等离散型数据;定序型数据具有内在固有大 小或高低顺序,但它又不同于定距型数据,一般可以数值或字符表示。如职称变量可以 有低级、中级和高级三个取值,可以分别用1、2、3等表示,年龄段变量可以有老、中、青三个取值,分别用A、B、C表示等。这里无论是数值型的1、2、3还是字符型的A、B、C,都是有大小或高低顺序的,但数据之间却是不等距的。因为低级和中级职称之间的差距与中级和高级职称之间的差距是不相等的;定类型数据是指没有内在固定大小或高低 顺序,一般以数值或字符表示的分类数据。) F检验:比较两组数据的方差2s, 2 2 s F s 大 小 ,假设检验两组数据没有显著差异,F
决策树算法介绍(DOC)
3.1 分类与决策树概述 3.1.1 分类与预测 分类是一种应用非常广泛的数据挖掘技术,应用的例子也很多。例如,根据信用卡支付历史记录,来判断具备哪些特征的用户往往具有良好的信用;根据某种病症的诊断记录,来分析哪些药物组合可以带来良好的治疗效果。这些过程的一个共同特点是:根据数据的某些属性,来估计一个特定属性的值。例如在信用分析案例中,根据用户的“年龄”、“性别”、“收入水平”、“职业”等属性的值,来估计该用户“信用度”属性的值应该取“好”还是“差”,在这个例子中,所研究的属性“信用度”是一个离散属性,它的取值是一个类别值,这种问题在数据挖掘中被称为分类。 还有一种问题,例如根据股市交易的历史数据估计下一个交易日的大盘指数,这里所研究的属性“大盘指数”是一个连续属性,它的取值是一个实数。那么这种问题在数据挖掘中被称为预测。 总之,当估计的属性值是离散值时,这就是分类;当估计的属性值是连续值时,这就是预测。 3.1.2 决策树的基本原理 1.构建决策树 通过一个实际的例子,来了解一些与决策树有关的基本概念。 表3-1是一个数据库表,记载着某银行的客户信用记录,属性包括“姓名”、“年龄”、“职业”、“月薪”、......、“信用等级”,每一行是一个客户样本,每一列是一个属性(字段)。这里把这个表记做数据集D。 银行需要解决的问题是,根据数据集D,建立一个信用等级分析模型,并根据这个模型,产生一系列规则。当银行在未来的某个时刻收到某个客户的贷款申请时,依据这些规则,可以根据该客户的年龄、职业、月薪等属性,来预测其信用等级,以确定是否提供贷款给该用户。这里的信用等级分析模型,就可以是一棵决策树。在这个案例中,研究的重点是“信用等级”这个属性。给定一个信用等级未知的客户,要根据他/她的其他属性来估计“信用等级”的值是“优”、“良”还是“差”,也就是说,要把这客户划分到信用等级为“优”、“良”、“差”这3个类别的某一类别中去。这里把“信用等级”这个属性称为“类标号属性”。数据集D中“信用等级”属性的全部取值就构成了类别集合:Class={“优”,
决策树习题练习(答案)
决策树习题练习答案 1.某投资者预投资兴建一工厂,建设方案有两种:①大规模投资300万元;②小规模投资160万元。两个方案的生产期均为10年,其每年的损益值及销售状态的规律见表15。试用决策树法选择最优方案。 【解】(1)绘制决策树,见图1; (2)计算各状态点的期望收益值 节点②:[] 10300340()???-=1000.7+(-20)0.3万元 节点③:[]10160320()???-=600.7+200.3万元 将各状态点的期望收益值标在圆圈上方。 (3)决策 比较节点②与节点③的期望收益值可知,大规模投资方案优于小规模投资方案,故应选择大规模投资方案,用符号“//”在决策树上“剪去”被淘汰的方案。 表1 各年损益值及销售状态
2.某项目有两个备选方案A和B,两个方案的寿命期均为10年,生产的产品也完全相同,但投资额及年净收益均不相同。A方案的投资额为500万元,其年净收益在产品销售好时为150万元,,销售差时为50万元;B方案的投资额为300万元,其年净收益在产品销路好时为100万元,销路差时为10万元,根据市场预测,在项目寿命期内,产品销路好时的可能性为70%,销路差的可能性为30%,试根据以上资料对方案进行比选。已知标准折现率i c=10%。 【解】(1)首先画出决策树 此题中有一个决策点,两个备用方案,每个方案又面临着两种状态,因此可以画出其决策树如图18。 (2)然后计算各个机会点的期望值 机会点②的期望值=150(P/A,10%,10)×0.7+(-50)(P/A,10%,10)×0.3=533(万元) 机会点③的期望值=100(P/A,10%,10)×0.7+10(P/A,10%,10)×0.3=448.5(万元) 最后计算各个备选方案净现值的期望值。 方案A的净现值的期望值=533-500=33(万元)方案B的净现值的期望值=448.5-300=148.5(万元)因此,应该优先选择方案B。 3.接习题1,为了适应市场的变化,投资者又提出了第三个方案,即先小规模投资160万元,生产3年后,如果销路差,则不再投资,继续生产7年;如果销路好,则再作决策是否再投资140万元扩建至大规模(总投资300万元),生产7年。前3年和后7年销售状态的概率见表16,大小规模投资的年损益值同习题58。试用决策树法选择最优方案。 表2 销售概率表
决策树算法的原理与应用
决策树算法的原理与应用 发表时间:2019-02-18T17:17:08.530Z 来源:《科技新时代》2018年12期作者:曹逸知[导读] 在以后,分类问题也是伴随我们生活的主要问题之一,决策树算法也会在更多的领域发挥作用。江苏省宜兴中学江苏宜兴 214200 摘要:在机器学习与大数据飞速发展的21世纪,各种不同的算法成为了推动发展的基石.而作为十大经典算法之一的决策树算法是机器学习中十分重要的一种算法。本文对决策树算法的原理,发展历程以及在现实生活中的基本应用进行介绍,并突出说明了决策树算法所涉及的几种核心技术和几种具有代表性的算法模式。 关键词:机器学习算法决策树 1.决策树算法介绍 1.1算法原理简介 决策树模型是一种用于对数据集进行分类的树形结构。决策树类似于数据结构中的树型结构,主要是有节点和连接节点的边两种结构组成。节点又分为内部节点和叶节点。内部节点表示一个特征或属性, 叶节点表示一个类. 决策树(Decision Tree),又称为判定树, 是一种以树结构(包括二叉树和多叉树)形式表达的预测分析模型,决策树算法被评为十大经典机器学习算法之一[1]。 1.2 发展历程 决策树方法产生于上世纪中旬,到了1975年由J Ross Quinlan提出了ID3算法,作为第一种分类算法模型,在很多数据集上有不错的表现。随着ID3算法的不断发展,1993年J Ross Quinlan提出C4.5算法,算法对于缺失值补充、树型结构剪枝等方面作了较大改进,使得算法能够更好的处理分类和回归问题。决策树算法的发展同时也离不开信息论研究的深入,香农提出的信息熵概念,为ID3算法的核心,信息增益奠定了基础。1984年,Breiman提出了分类回归树算法,使用Gini系数代替了信息熵,并且利用数据来对树模型不断进行优化[2]。2.决策树算法的核心 2.1数据增益 香农在信息论方面的研究,提出了以信息熵来表示事情的不确定性。在数据均匀分布的情况下,熵越大代表事物的越不确定。在ID3算法中,使用信息熵作为判断依据,在建树的过程中,选定某个特征对数据集进行分类后,数据集分类前后信息熵的变化就叫作信息增益,如果使用多个特征对数据集分别进行分类时,信息增益可以衡量特征是否有利于算法对数据集进行分类,从而选择最优的分类方式建树。如果一个随机变量X的可以取值为Xi(i=1…n),那么对于变量X来说,它的熵就是
决策树算法介绍
3.1分类与决策树概述 3.1.1分类与预测 分类是一种应用非常广泛的数据挖掘技术,应用的例子也很多。例如,根据信用卡支付历史记录,来判断具备哪些特征的用户往往具有良好的信用;根据某种病 症的诊断记录,来分析哪些药物组合可以带来良好的治疗效果。这些过程的一个共同特点是:根据数据的某些属性,来估计一个特定属性的值。例如在信用分析案例中,根据用户的“年龄”、“性别”、“收入水平”、“职业”等属性的值,来估计该用户“信用度”属性的值应该取“好”还是“差”,在这个例子中,所研究的属性“信用度”是E—个离散属性,它的取值是一个类别值,这种问题在数 据挖掘中被称为分类。 还有一种问题,例如根据股市交易的历史数据估计下一个交易日的大盘指数,这 里所研究的属性“大盘指数”是一个连续属性,它的取值是一个实数。那么这种 问题在数据挖掘中被称为预测。 总之,当估计的属性值是离散值时,这就是分类;当估计的属性值是连续值时,这就是预测。 3.1.2决策树的基本原理 1. 构建决策树 通过一个实际的例子,来了解一些与决策树有关的基本概念。 表3-1是一个数据库表,记载着某银行的客户信用记录,属性包括“姓名”、“年龄”、“职业”、“月薪”、......、“信用等级”,每一行是一个客户样本,每一列是一个属性(字段)。这里把这个表记做数据集D。 银行需要解决的问题是,根据数据集D,建立一个信用等级分析模型,并根据这个模型,产生一系列规则。当银行在未来的某个时刻收到某个客户的贷款申请时,依据这些规则,可以根据该客户的年龄、职业、月薪等属性,来预测其信用等级,以确定是否提供贷款给该用户。这里的信用等级分析模型,就可以是一棵决策树。在这个案例中,研究的重点是“信用等级”这个属性。给定一个信用等级未知的客户,要根据他/她的其他属性来估计“信用等级”的值是“优”、“良”还是 “差”,也就是说,要把这客户划分到信用等级为“优”、“良”、“差”这3 个类别的某一类别中去。这里把“信用等级”这个属性称为“类标号属性”。数据集D中“信用等级”属性的全部取值就构成了类别集合:Class={ “优”,
决策树练习题计算题
计算题 1.为生产甲产品,小行星公司设计了两个基本方案:一是建大工厂,二是建小工厂。如果销路好,3年以后考虑扩建。建大工厂需投资300万元,建小工厂需投资160万元,3年后扩建另需投资140万元。扩建后可使用7年,其年度损益值与大工厂相同。每种自然状态的预测概率及年度损益值如下表: 前 3 年 后 7 年
根据上述资料试用决策树法做出决策。 2、计算题(15分)
答:建大厂收益=581-300=281 建小厂收益=447-160=287 所以应选择建小厂方案。 3.山姆公司的生产设备已经落后,需要马上更新。公司有人认为,目前产品销路增长,应在更新设备的同时扩大再生产的规模。但也有人认为,市场形势尚难判断,不如先更新设备,3年后再根据形势变化考虑扩大再生产的规模问题。这样,该公司就面临着两个决策方案。决策分析的有关资料如下: A、现在更新设备,需投资35万元, 3年后扩大生产规模,另需投资40万元。 B、现在更新设备的同时扩大再生产的规模,需投资60万元。 C、现在只更新设备,在销售情况良好时,每年可获利6万元;在销售情况不好时,每年可获利4、5万元。 D、如果现在更新与扩产同时进行,若销售情况好,
前3年每年可获利12万元;后7年每年可获利15万元;若销售情况不好,每年只获利3万元。 E、每种自然状态的预测概率如下表 前 3 年 后 7 年 根据上述资料试用决策树法做出决策。
答案:
结点7收益值=0、85×7 × 15+0、15 ×7 ×3=92、4(万元) 结点8收益值=0、85×7 ×6+0、15 ×7 ×4、5=40、4(万元) 结点9收益值=0、1×7 × 15+0、9 ×7 ×3=29、4(万元) 结点10收益值=0、1×7 × 6+0、9 ×7 ×4、5=32、6(万元) 结点1收益值=0、7×[52、4+(3 × 6)]+0、3 ×[32、6+(3 × 4、5)]=63、1(万元) 结点2收益值=0、7×[92、4+(3 × 12)]+0、3 ×[29、4+(3 × 3)]=101、4(万元) 答:用决策树法进行决策应选择更新扩产方案,可获得收益41、4万元。 4. 某厂准备生产Y种新产品,对未来的销售前景预测不准,可能出现高需求、中需求、低需求三种自然状态。组织有三个方案可供选择:新建一个车间;扩建原有车间; 对原有车间的生产线进行局部改造。三个方案在5年内的经济效益见下表(单位:万元): 0 1 请分别用悲观决策法、乐观决策法、最
决策树分类算法与应用
机器学习算法day04_决策树分类算法及应用课程大纲 决策树分类算法原理决策树算法概述 决策树算法思想 决策树构造 算法要点 决策树分类算法案例案例需求 Python实现 决策树的持久化保存 课程目标: 1、理解决策树算法的核心思想 2、理解决策树算法的代码实现 3、掌握决策树算法的应用步骤:数据处理、建模、运算和结果判定
1. 决策树分类算法原理 1.1 概述 决策树(decision tree)——是一种被广泛使用的分类算法。 相比贝叶斯算法,决策树的优势在于构造过程不需要任何领域知识或参数设置 在实际应用中,对于探测式的知识发现,决策树更加适用 1.2 算法思想 通俗来说,决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话: 女儿:多大年纪了? 母亲:26。 女儿:长的帅不帅? 母亲:挺帅的。 女儿:收入高不? 母亲:不算很高,中等情况。 女儿:是公务员不? 母亲:是,在税务局上班呢。 女儿:那好,我去见见。 这个女孩的决策过程就是典型的分类树决策。 实质:通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见 假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么这个可以用下图表示女孩的决策逻辑
上图完整表达了这个女孩决定是否见一个约会对象的策略,其中: ◆绿色节点表示判断条件 ◆橙色节点表示决策结果 ◆箭头表示在一个判断条件在不同情况下的决策路径 图中红色箭头表示了上面例子中女孩的决策过程。 这幅图基本可以算是一颗决策树,说它“基本可以算”是因为图中的判定条件没有量化,如收入高中低等等,还不能算是严格意义上的决策树,如果将所有条件量化,则就变成真正的决策树了。 决策树分类算法的关键就是根据“先验数据”构造一棵最佳的决策树,用以预测未知数据的类别 决策树:是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
企业CRM系统中决策树算法的应用
企业CRM系统中决策树算法的应用 河北金融学院郭佳许明 保定市科技局《基于数据挖掘的客户关系管理系统应用研究》09ZG009 摘要:客户资源决定企业的核心竞争力,更多的关心自己的销售群体,并与之建立良好的、长期的客户关系,提升客户价值,对全面提升企业竞争能力和盈利能力具有重要作用。本文以某企业销售业绩为对象,利用决策树分类算法,得到支持决策,从而挖掘出理想客户。 关键字:客户关系管理;数据挖掘;分类算法 决策树分类是一种从无规则、无序的训练样本集合中推理出决策树表示形式的分类规则的方法。该方法采用自顶向下的比较方式,在决策树的内部结点进行属性值的比较,然后根据不同的属性值判断从该结点向下的分支,在决策树的叶结点得到结论。 本文主要研究决策树分类算法中ID3算法在企业CRM系统中的应用情况。 1.ID3算法原理 ID3算法是一种自顶向下的决策树生成算法,是一种根据熵减理论选择最优的描述属性的方法。该算法从树的根节点处的训练样本开始,选择一个属性来区分样本。对属性的每一个值产生一个分支。分支属性的样本子集被移到新生成的子节点上。这个算法递归地应用于每个子节点,直到一个节点上的所有样本都分区到某个类中。 2.用于分类的训练数据源组 数据挖掘的成功在很大程度上取决于数据的数量和质量。我们应从大量的企业客户数据中找到与分析问题有关的,具有代表性的样本数据子集。然后,进行数据预处理、分析,按问题要求对数据进行组合或增删生成新的变量,从而对问题状态进行有效描述。 在本文研究的企业数据中,是将客户的年龄概化为“小于等于30”、“30到50之间”和“大于50”三个年龄段,分别代表青年、中年和老年客户,将产品价格分为高、中、低三档等,详见表1,将企业CRM系统数据库中销售及客户信息汇总为4个属性2个类别。4个属性是客户年龄段、文化程度、销售地区、产品档次,类别是销售业绩,分为好和差两类。
管理学决策树习题及答案
注意答卷要求: 1.统一代号:P 为利润,C 为成本,Q 为收入,EP 为期望利润 2.画决策树时一定按照标准的决策树图形画,不要自创图形 3.决策点和状态点做好数字编号 4.决策树上要标出损益值 某企业似开发新产品,现在有两个可行性方案需要决策。 I 开发新产品A ,需要追加投资180万元,经营期限为5年。此间,产品销路好可获利170万元;销路一般可获利90万元;销路差可获利-6万元。三种情况的概率分别为30%,50%,20%。 II.开发新产品B ,需要追加投资60万元,经营期限为4年。此间,产品销路好可获利100万元;销路一般可获利50万元;销路差可获利20万元。三种情况的概率分别为60%,30%,10%。 (1)画出决策树 销路好 0.3 170 90 -6 100 50 20
(2)计算各点的期望值,并做出最优决策 求出各方案的期望值: 方案A=170×0.3×5+90×0.5×5+(-6)×0.2×5=770(万元) 方案B=100×0.6×4+50×0.3×4+20×0.1×4=308(万元) 求出各方案的净收益值: 方案A=770-180=590(万元) 方案B=308-60=248(万元) 因为590大于248大于0 所以方案A最优。 某企业为提高其产品在市场上的竞争力,现拟定三种改革方案:(1)公司组织技术人员逐渐改进技术,使用期是10年;(2)购买先进技术,这样前期投入相对较大,使用期是10年;(3)前四年先组织技术人员逐渐改进,四年后再决定是否需要购买先进技术,四年后买入技术相对第一年便宜一些,收益与前四年一样。预计该种产品前四年畅销的概率为0.7,滞销的概率为0.3。如果前四年畅销,后六年畅销的概率为0.9;若前四年滞销,后六年滞销的概率为0.1。相关的收益数据如表所示。 (1)画出决策树 (2)计算各点的期望值,并做出最优决策 投资收益 表单位:万元 解(1)画出决策树,R为总决策,R1为二级决策。
完整word版,决策树算法总结
决策树研发二部
目录 1. 算法介绍 (1) 1.1.分支节点选取 (1) 1.2.构建树 (3) 1.3.剪枝 (10) 2. sk-learn中的使用 (12) 3. sk-learn中源码分析 (13)
1.算法介绍 决策树算法是机器学习中的经典算法之一,既可以作为分类算法,也可以作为回归算法。决策树算法又被发展出很多不同的版本,按照时间上分,目前主要包括,ID3、C4.5和CART版本算法。其中ID3版本的决策树算法是最早出现的,可以用来做分类算法。C4.5是针对ID3的不足出现的优化版本,也用来做分类。CART也是针对ID3优化出现的,既可以做分类,可以做回归。 决策树算法的本质其实很类似我们的if-elseif-else语句,通过条件作为分支依据,最终的数学模型就是一颗树。不过在决策树算法中我们需要重点考虑选取分支条件的理由,以及谁先判断谁后判断,包括最后对过拟合的处理,也就是剪枝。这是我们之前写if语句时不会考虑的问题。 决策树算法主要分为以下3个步骤: 1.分支节点选取 2.构建树 3.剪枝 1.1.分支节点选取 分支节点选取,也就是寻找分支节点的最优解。既然要寻找最优,那么必须要有一个衡量标准,也就是需要量化这个优劣性。常用的衡量指标有熵和基尼系数。 熵:熵用来表示信息的混乱程度,值越大表示越混乱,包含的信息量也就越多。比如,A班有10个男生1个女生,B班有5个男生5个女生,那么B班的熵值就比A班大,也就是B班信息越混乱。 基尼系数:同上,也可以作为信息混乱程度的衡量指标。
有了量化指标后,就可以衡量使用某个分支条件前后,信息混乱程度的收敛效果了。使用分支前的混乱程度,减去分支后的混乱程度,结果越大,表示效果越好。 #计算熵值 def entropy(dataSet): tNum = len(dataSet) print(tNum) #用来保存标签对应的个数的,比如,男:6,女:5 labels = {} for node in dataSet: curL = node[-1] #获取标签 if curL not in labels.keys(): labels[curL] = 0 #如果没有记录过该种标签,就记录并初始化为0 labels[curL] += 1 #将标签记录个数加1 #此时labels中保存了所有标签和对应的个数 res = 0 #计算公式为-p*logp,p为标签出现概率 for node in labels: p = float(labels[node]) / tNum res -= p * log(p, 2) return res #计算基尼系数 def gini(dataSet): tNum = len(dataSet) print(tNum) # 用来保存标签对应的个数的,比如,男:6,女:5 labels = {} for node in dataSet: curL = node[-1] # 获取标签 if curL not in labels.keys(): labels[curL] = 0 # 如果没有记录过该种标签,就记录并初始化为0 labels[curL] += 1 # 将标签记录个数加1 # 此时labels中保存了所有标签和对应的个数 res = 1
决策树分类算法
决策树分类算法 决策树是一种用来表示人们为了做出某个决策而进行的一系列判断过程的树形图。决策树方法的基本思想是:利用训练集数据自动地构造决策树,然后根据这个决策树对任意实例进行判定。 1.决策树的组成 决策树的基本组成部分有:决策节点、分支和叶,树中每个内部节点表示一个属性上的测试,每个叶节点代表一个类。图1就是一棵典型的决策树。 图1 决策树 决策树的每个节点的子节点的个数与决策树所使用的算法有关。例如,CART算法得到的决策树每个节点有两个分支,这种树称为二叉树。允许节点含有多于两个子节点的树称为多叉树。 下面介绍一个具体的构造决策树的过程,该方法
是以信息论原理为基础,利用信息论中信息增益寻找数据库中具有最大信息量的字段,建立决策树的一个节点,然后再根据字段的不同取值建立树的分支,在每个分支中重复建立树的下层节点和分支。 ID3算法的特点就是在对当前例子集中对象进行分类时,利用求最大熵的方法,找出例子集中信息量(熵)最大的对象属性,用该属性实现对节点的划分,从而构成一棵判定树。 首先,假设训练集C 中含有P 类对象的数量为p ,N 类对象的数量为n ,则利用判定树分类训练集中的对象后,任何对象属于类P 的概率为p/(p+n),属于类N 的概率为n/(p+n)。 当用判定树进行分类时,作为消息源“P ”或“N ”有关的判定树,产生这些消息所需的期望信息为: n p n log n p n n p p log n p p )n ,p (I 22++-++- = 如果判定树根的属性A 具有m 个值{A 1, A 2, …, A m },它将训练集C 划分成{C 1, C 2, …, C m },其中A i 包括C 中属性A 的值为A i 的那些对象。设C i 包括p i 个类P 对象和n i 个类N 对象,子树C i 所需的期望信息是I(p i , n i )。以属性A 作为树根所要求的期望信息可以通过加权平均得到
决策树算法总结
决策树决策树研发二部
目录 1. 算法介绍 (1) 1.1. 分支节点选取 (1) 1.2. 构建树 (3) 1.3. 剪枝 (10) 2. sk-learn 中的使用 (12) 3. sk-learn中源码分析 (13)
1. 算法介绍 决策树算法是机器学习中的经典算法之一,既可以作为分类算法,也可以作 为回归算法。决策树算法又被发展出很多不同的版本,按照时间上分,目前主要包括,ID3、C4.5和CART版本算法。其中ID3版本的决策树算法是最早出现的,可以用来做分类算法。C4.5是针对ID3的不足出现的优化版本,也用来做分类。CART也是针对 ID3优化出现的,既可以做分类,可以做回归。 决策树算法的本质其实很类似我们的if-elseif-else语句,通过条件作为分支依据,最终的数学模型就是一颗树。不过在决策树算法中我们需要重点考虑选取分支条件的理由,以及谁先判断谁后判断,包括最后对过拟合的处理,也就是剪枝。这是我们之前写if语句时不会考虑的问题。 决策树算法主要分为以下3个步骤: 1. 分支节点选取 2. 构建树 3. 剪枝 1.1. 分支节点选取 分支节点选取,也就是寻找分支节点的最优解。既然要寻找最优,那么必须要有一个衡量标准,也就是需要量化这个优劣性。常用的衡量指标有熵和基尼系数。 熵:熵用来表示信息的混乱程度,值越大表示越混乱,包含的信息量也就越多。比如,A班有10个男生1个女生,B班有5个男生5个女生,那么B班的熵值就比A班大,也就是B班信息越混乱。 Entropy = -V p ” 基尼系数:同上,也可以作为信息混乱程度的衡量指标。 Gini = 1 - p: l-L
决策树例题例题
决策树问题 问题类型:录音讲座 某房地产开发公司对某一地块有两种开发方案。 A方案:一次性开发多层住宅45000m2建筑面积,需投入总成本费用(包括前期开发成本、施工建造成本和销售成本,下同)9000万元,开发时间(包括建造、销售时间,下同)为18个月. B方案:将该地块分成东、西两区分两期开发。一期在东区先开发高层住宅36000m2,建筑面积,需投入总成本费用8100万元,开发时间为15个月。二期开发时,如果一期销路好,且预计二期销售率可达100%(售价和销量同一期),则在西区继续投入总成本费用8100万元开发高层住宅36000m2建筑面积;如果一期销路差,或暂停开发,或在西区改为开发多层住宅22000m2建筑面积,需投入总成本费用4600万元,开发时间为15个月。 两方案销路好和销路差时的售价和销量情况汇总于表2.1。 根据经验,多层住宅销路好的概率为0.7,高层住宅销路好的概率为0.6。暂停开发每季损失10万元。季利率为2%。 表2.1 表2.2 问题: 1.两方案销路好和销路差情况下分期计算季平均销售收入各为多少万元?(假定销售收入在开发时间内均摊) 2.绘制两级决策的决策树。 3.试决定采用哪个方案。 注:计算结果保留两位小数。 答案:
问题1 计算季平均销售收入: A方案开发多层住宅: 销路好:4.5x4800x100%÷6=3600(万元) 销路差:4.5x4300x80%÷6:2580(万元) B方案一期: 开发高层住宅:销路好:3.6x5500x100%÷5=3960(万元) 销路差:3.6x5000X70%÷5:2520(万元) B方案二期: 开发高层住宅:3.6~5500x100%÷5=3960(万元) 开发多层住宅:销路好:2.2x4800x100%÷5=2112(万元) 销路差:2.2x4300x80%÷5=1513.6(万元) [问题2]画两级决策树:
(完整word版)项目管理实战利器之八——决策树分析和EMV
项目管理实战利器之八——决策树分析和EMV 作者: 楼政 一、决策者的工具包 “决策就是从多种方案中选择一个行动方针的认知过程。每一个决策过程都会产生一个最终选择。”这是在维基百科所阐述的。但它没有说的是,有些决策必须为未来发生的结果而做出。有数种工具可以用来帮助做出复杂的决策,即决策树分析和预期货币价值。 二、预期货币价值(EMV,Expected Monetary Value) EMV是一种对概率和各种可能情景影响所做的平衡。以下两种方案,哪一种会提供更大的潜在收益呢? 方案1 最好的情景(Best case):盈利$180,000的概率为20%。 BC=20%*$180,000=$3 6,000 最坏的情景(Worst case):损失- $20,000的概率为 15%。 WC= 15%*(- $ 20,000)=-$3,000 最可能的情景(Most likely case):盈利$75,000元 的概率为65%。 MLC= 65%*$75,000 = $48,750 Total EMV = BC+WC+MLC = $36,000+(-$3,000)+$48,750=$81,750 方案2 最好的情景(Best case):盈利$200,000的概率为15%。BC=15%*$200,000=$30,00 最坏的情景(Worst case):盈利$15,000的概率为25%。WC= 25%*$15,000 = $ 3,750 最可能的情景(Most likely case):盈利$45,000元的概 率为60%。 MLC= 60%*$ 45,000 = $ 27,000 Total EMV = BC+WC+MLC = $30,000+$3,750+$27,000=$60,750 你选择哪种方案?当然选方案一,因为它具有更高的EMV为$81,750。 三、决策树分析(Decision Tree Analysis) 在决策树分析中,一个问题被描述为一个图表,这个图表显示了所有可能行动、事件和回报(成果),在一段时期内不同的时间点对上述内容必须作出的选择。 制造业的一个实例