CF代码解析之(vcap-java)

Vcap-java概述
Vcap-java 是cloud foundry为了在java中更好的使用CF做的封装包。
源代码下载路径:https://https://www.360docs.net/doc/1612763875.html,/cloudfoundry/vcap-java
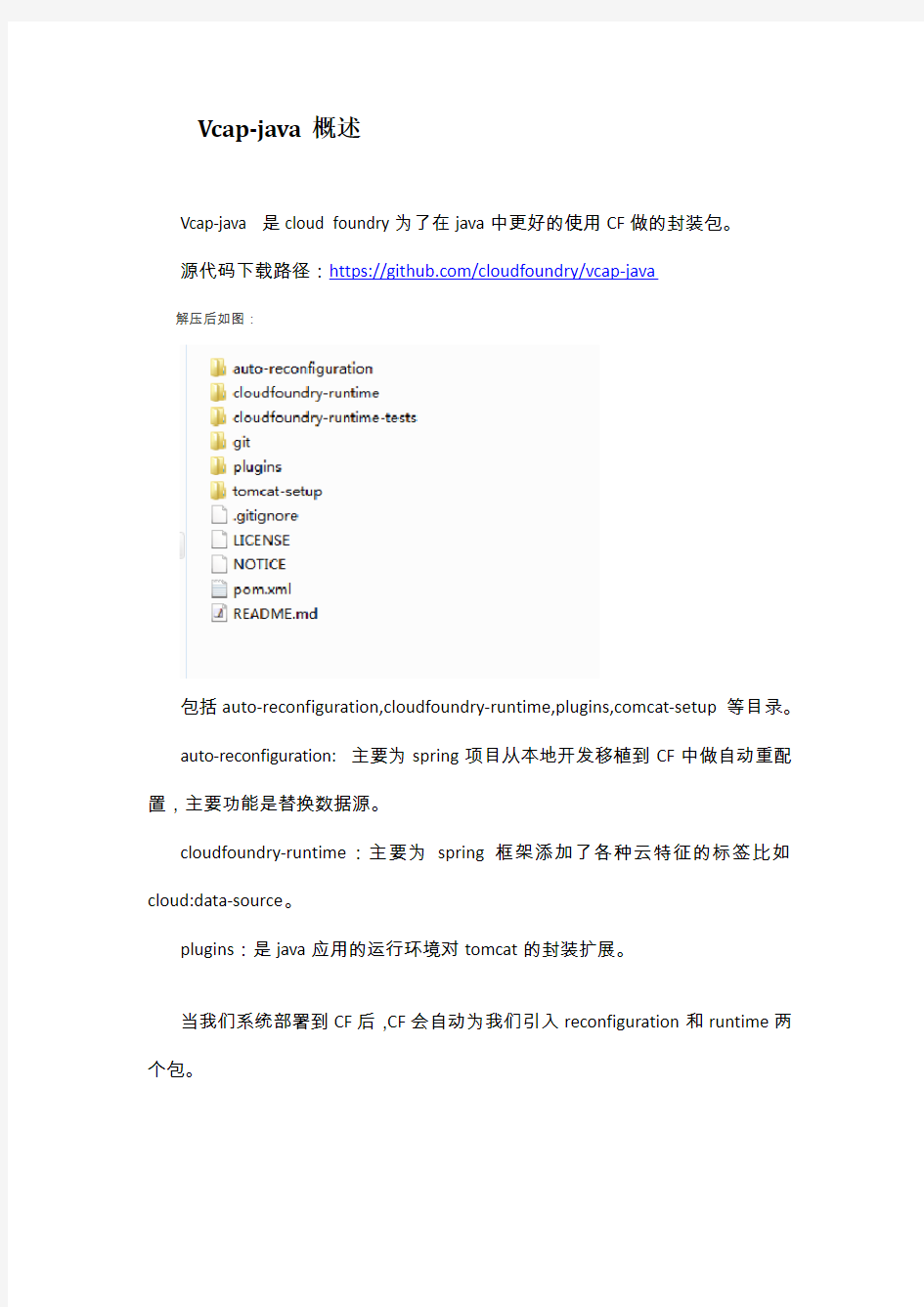
解压后如图:
包括auto-reconfiguration,cloudfoundry-runtime,plugins,comcat-setup等目录。
auto-reconfiguration: 主要为spring项目从本地开发移植到CF中做自动重配置,主要功能是替换数据源。
cloudfoundry-runtime:主要为spring框架添加了各种云特征的标签比如cloud:data-source。
plugins:是java应用的运行环境对tomcat的封装扩展。
当我们系统部署到CF后,CF会自动为我们引入reconfiguration和runtime两个包。
备注:如果我们的java工程未使用到spring,那么这个包基本作废。
代码解析
Cloudfoundry-runtime
解读runtime需对spring的自定义标签有一定了解,其实runtime包就是一个spring为支持CF所做的新标签包。
我们来看src下的resource目录
如上图
查看spring.schemas
http\://https://www.360docs.net/doc/1612763875.html,/spring/cloudfoundry-spring-0.8.xs d
=org/cloudfoundry/runtime/service/config/xml/cloudfoundry-spring. xsd
http\://https://www.360docs.net/doc/1612763875.html,/spring/cloudfoundry-spring.xsd
=org/cloudfoundry/runtime/service/config/xml/cloudfoundry-spring. xsd
新标签的schema文件为cloudfoundry-spring.xsd ,具体内容请看附件。
重要几个标签,如下图:
Cloud标签
data-source
data-source标签是CF上关系型数据库的数据源标签,属性包括id,name,元素包括connection,pool。
目前CF上关系型数据库包括:mysql,PostgreSQL
rabbit-connection-factory
是rabbitMQ的连接池,rabbitMQ是消息中间件。
redis-connection-factory
是redis连接池配置。redis是一个key-value存储系统。和Memcached 类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)和zset(有序集合)。这些数据类型都支持push/pop、add/remove 及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
mongo-db-factory
指mongoDB连接池配置。MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,是类似json的bjson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
properties
读取CF上的环境变量信息,支持在配置文件中使用占位符
service-scan
与spring原先的
完成解析工作,会用到NamespaceHandler和BeanDefinitionParser这两个概念。具体说来NamespaceHandler会根据schema和节点名找到某个BeanDefinitionParser,然后由BeanDefinitionParser完成具体的解析工作。Spring 提供了默认实现类NamespaceHandlerSupport和AbstractSingleBeanDefinitionParser,runtime就是使用了这种扩展机制。
CF 标签的实现类,在spring.handlers中配置,配置信息如下:
如上所示,CloudNamespaceHandler是具体的实现类
命名空间Handler(CloudNamespaceHandler)
org.cloudfoundry.runtime.service.keyvalue.CloudRedisConnectionFactory Bean;
import
org.cloudfoundry.runtime.service.messaging.CloudRabbitConnectionFacto ryBean;
import
org.cloudfoundry.runtime.service.relational.CloudDataSourceFactory; import
org.springframework.beans.factory.xml.AbstractSimpleBeanDefinitionPar ser;
import https://www.360docs.net/doc/1612763875.html,spaceHandlerSupport; import org.w3c.dom.Element;
/**
* Handler for the 'cloud' namespace
*
* @author Mark Fisher
* @author Costin Leau
* @author Ramnivas Laddad
* @author Scott Andrews
* @author Thomas Risberg
*
*/
publicclass CloudNamespaceHandler extends NamespaceHandlerSupport {
@Override
publicvoid init() {
this.registerBeanDefinitionParser("rabbit-connection-factory", new
CloudRabbitConnectionFactoryParser(CloudRabbitConnectionFactoryBean.c lass, RabbitServiceInfo.class));
this.registerBeanDefinitionParser("redis-connection-factory", new
CloudRedisConnectionFactoryParser(CloudRedisConnectionFactoryBean.cla ss, RedisServiceInfo.class));
this.registerBeanDefinitionParser("mongo-db-factory",
new
CloudMongoDbFactoryParser(CloudMongoDbFactoryBean.class, MongoServiceInfo.class));
this.registerBeanDefinitionParser("data-source",
new
CloudDataSourceFactoryParser(CloudDataSourceFactory.class, RdbmsServiceInfo.class));
this.registerBeanDefinitionParser("properties", new AbstractSimpleBeanDefinitionParser() {
@Override
protected Class getBeanClass(Element element) {
return CloudPropertiesFactoryBean.class;
}
});
this.registerBeanDefinitionParser("service-scan", new AbstractSimpleBeanDefinitionParser() {
@Override
protected Class getBeanClass(Element element) {
return CloudServicesScanner.class;
}
@Override
protectedboolean shouldGenerateId() {
returntrue;
}
});
}
}
我们看到在init方法中定义了各种标签的实现类(registerBeanDefinitionParser方法就是把节点名和解析类联系起来)
解析类
这些bean定义解析类之间的关系如下:
四个标签解析类都继承自AbstractCloudServiceFactoryParser,父类就是spring提供的扩展类
AbstractSingleBeanDefinitionParser。AbstractCloudServiceFactoryParser重写了createInstance,代码如下:
此方法可以看出最后返回的bean实例是service,且都是通过抽象方法:protected abstract AbstractServiceCreator
获得ServiceCreator对象,然后调用ServiceCreator.createSingletonService返回具体的Service实例。
如上表所示:各种标签的解析类都实现了抽象方法getServiceCreator,返回了具体的服务创建者。
服务实例创建者
在看AbstractServiceCreator.createSingletonService方法
最后归结到AbstractServiceCreator.createService
抽象类AbstractServiceCreator定义了各种服务创建者必须实现的方法:public abstract S createService(SI serviceInfo);
分析四个服务创建者,最后创建服务后返回的bean,如下表:
标签使用例子
请看:
https://www.360docs.net/doc/1612763875.html,/frameworks/java/spring/spring.html
首先在spring的配置文件,头中要加入cloud标签的相关内容:
xmlns:xsi="https://www.360docs.net/doc/1612763875.html,/2001/XMLSchema-instance" xmlns:context="https://www.360docs.net/doc/1612763875.html,/schema/context" xmlns:cloud="https://www.360docs.net/doc/1612763875.html,/spring" xsi:schemaLocation="https://www.360docs.net/doc/1612763875.html,/schema/beans https://www.360docs.net/doc/1612763875.html,/schema/beans/spring-beans-3.1.xsd https://www.360docs.net/doc/1612763875.html,/schema/context https://www.360docs.net/doc/1612763875.html,/schema/context/spring-context-3.1.xsd https://www.360docs.net/doc/1612763875.html,/spring https://www.360docs.net/doc/1612763875.html,/spring/cloudfoundry-spring.xsd >
可用标签如下图:
建议使用spring3.1的新特征profile,可以在本地开发,发布到CF不用修改配置文件。发布到云上后,profile="cloud"的配置会生效,如果在本地profile="cloud"不会被加载。
配置例子:
destroy-method="close"> auto-reconfiguration 自动重新配置模块主要是为本地开发与发布到云做了更多智能化的事情,但是也有条件限制 1、各种服务类型的服务实例只能有一个 2、在spring中同种服务也只能有一个配置,比如关系型数据库只能有一个 datasource的配置 3、不使用CF的标签(可以使用properties标签) 如果符合这两个条件,auto-reconfiguration会自动将您本地的数据库配置修改为cloud为您的应用提供的数据库服务配置。 也就是说如果你的应用只用到一个数据库用户,那你直接在本地用spring开发,通过datasource来获得连接,那么你直接发布到CF上,可以直接运行(您的应用必须先绑定一个同类数据库的service)。 原理 当你发布Spring应用到CF,CF会将系统的各种参数(包括应用的参数、服务的参数等)设置到环境变量中,并会自动修改您应用中的web.xml ( 修改web.xm的过程请看CF源代码包: staging/lib/vcap/staging/plugin/java_web staging/lib/vcap/staging/plugin/spring 目录), 主要包括以下两个修改: 加入CloudApplicationContextInitializer Cf自动在web.xml加入: 备注:contextInitializerClasses配置项,必须在web.xml有配置listener才可生效 可以使用:org.springframework.web.context.ContextLoaderListener CloudApplicationContextInitializer代码如下: @Override publicfinalvoid initialize(ConfigurableApplicationContext applicationContext) { if (!cloudFoundryEnvironment.isCloudFoundry()) { https://www.360docs.net/doc/1612763875.html,("Not running on Cloud Foundry, skipping initialization"); return; } try { https://www.360docs.net/doc/1612763875.html,("Initializing Spring Environment for Cloud Foundry"); springEnvironment = applicationContext.getEnvironment(); addPropertySource(buildPropertySource()); addActiveProfile("cloud"); } catch (Throwable t) { logger.error("Unexpected exception on initialization: " + t.getMessage(), t); } } 在spring中ApplicationContextInitializer的initialize方法在加载配置文件前会被调用。 如initialize代码所示,CloudApplicationContextInitializer首先判断运行环境是否是云环境,如果是云环境,自动从环境变量VCAP_APPLICATION获得app信息,从VCAP_SERVICES获得services信息,都加载到参数中,并设置cloud标签为active 等。 加入bean配置文件 Cf会在web.xml的 这样spring在初始化是会加载: META-INF/cloud/cloudfoundry-auto-reconfiguration-context.xml中配置的类。 cloudfoundry-auto-reconfiguration-context.xml文件如下: xmlns:xsi="https://www.360docs.net/doc/1612763875.html,/2001/XMLSchema-instance" xmlns:util="https://www.360docs.net/doc/1612763875.html,/schema/util" xsi:schemaLocation="https://www.360docs.net/doc/1612763875.html,/schema/beans https://www.360docs.net/doc/1612763875.html,/schema/beans/spring-beans-2.5.xsd https://www.360docs.net/doc/1612763875.html,/schema/util https://www.360docs.net/doc/1612763875.html,/schema/util/spring-util-2.5.xsd"> deployment 如上,在cloudfoundry-auto-reconfiguration-context.xml中,CF预先定义了一个类: CloudAutoStagingBeanFactoryPostProcessor 而CloudAutoStagingBeanFactoryPostProcessor继承了BeanFactoryPostProcessor接 口 并实现了postProcessBeanFactory方法,代码如下: 备注:BeanFactoryPostProcessor的类在spring实例化类前会调用方法postProcessBeanFactory publicvoid postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException { if (autoStagingOff(CLOUD_SERVICES_FILE,beanFactory)) { return; } DefaultListableBeanFactory defaultListableBeanFactory = (DefaultListableBeanFactory) beanFactory; // defaultListableBeanFactory.getBean(CloudEnvironment.class) will do, // but we go through a mechanism that will work for spring-2.5.x as well Map defaultListableBeanFactory.getBeansOfType(CloudEnvironment.class,true,false); CloudEnvironment cloudEnvironment; if (cloudEnvironmentBeans.size() > 1) { logger.log(https://www.360docs.net/doc/1612763875.html,, "Multiple (" + cloudEnvironmentBeans.size() + ") CloudEnvironmentBeans found; zero or 1 expected"); return; } elseif (cloudEnvironmentBeans.size() == 1) { cloudEnvironment = cloudEnvironmentBeans.entrySet().iterator().next().getValue(); } else { cloudEnvironment = new CloudEnvironment(); } New DataSourceConfigurer(cloudEnvironment).configure(defaultListableBeanFactory); new MongoConfigurer(cloudEnvironment).configure(defaultListableBeanFactory); new RedisConfigurer(cloudEnvironment).configure(defaultListableBeanFactory); new RabbitConfigurer(cloudEnvironment).configure(defaultListableBeanFactory); } 1、判断spring中是否已经包括CloudServicesScanner或者AbstractCloudServiceFactory的定义,如果包含则直接退出,如果不包含则进行重新配置的具体操作。代码如下: if (autoStagingOff(CLOUD_SERVICES_FILE,beanFactory)) { return; } boolean autoStagingOff(String cloudServiceFileLocations, ConfigurableListableBeanFactory beanFactory) { Resource[] resources; try { resources = applicationContext.getResources(cloudServiceFileLocations); } catch (IOException e) { logger.log(Level.WARNING, "Error scanning for cloud services files: " + cloudServiceFileLocations + ". Autostaging will be active.", e); returnfalse; } for (Resource resource : resources) { BufferedReader fileReader = null; try { fileReader = new BufferedReader(new InputStreamReader(resource.getInputStream())); for (String line = fileReader.readLine(); line != null; line = fileReader.readLine()) { String cloudServiceClassName = line.trim(); if (usingCloudService(beanFactory, cloudServiceClassName)) { returntrue; } } } catch (IOException e) { logger.log(Level.WARNING, "Error reading cloud service file: " + resource + ". File contents will not be evaluated for cloud services.", e); } finally { if (fileReader != null) { try { fileReader.close(); } catch (IOException e) { logger.log(Level.WARNING, "Error closing file: "+ fileReader, e); } } } } logger.log(https://www.360docs.net/doc/1612763875.html,, "Autostaging is active."); returnfalse; } privateboolean usingCloudService(ConfigurableListableBeanFactory beanFactory, String cloudServiceClassName) { Class cloudServiceFactoryClazz = loadClass(cloudServiceClassName); if(cloudServiceFactoryClazz == null || beanFactory.getBeanNamesForType(cloudServiceFactoryClazz,true,false). length == 0) { returnfalse; } logger.log(https://www.360docs.net/doc/1612763875.html,,"Found an instance of " + cloudServiceClassName + ". Autostaging will be skipped."); returntrue; } 为什么这么判断呢?在我们前面讲到cloud的标签的解析类中的四种数据源标签返回的bean类型都是AbstractCloudServiceFactory的实现类,而CloudServicesScanner 是标签cloud:service-scan的bean类型,唯独properties返回的bean类型是CloudPropertiesFactoryBean,那意味着如果我们已经使用了cloud:service-scan和另外四种数据源的标签则退出,不进行自动配置。 如果未配置,执行下面代码: 如上代码所示,CF会重新配置这四种数据源。 我们看四种Configurer类的关系,如下: 显然他们有相同的父类AbstractServiceConfigurer 那么configuer方法做了什么呢?看下面代码: publicboolean configure(DefaultListableBeanFactory beanFactory) { //获得工厂中包括此类型的对象数量(类型由子类提供,是个抽象方法) String[] beanNames = getBeanNames(beanFactory); if (beanNames.length == 0) { logger.log(https://www.360docs.net/doc/1612763875.html,, "No beans of type " + getBeanClass() + " found in application context"); returnfalse; } elseif (beanNames.length> 1) { logger.log(https://www.360docs.net/doc/1612763875.html,, "More than 1 (" + beanNames.length + ") beans of type " + getBeanClass() + "found in application context. Skipping autostaging."); returnfalse; } List cloudEnvironment.getServiceInfos(serviceInfoClass); if (cloudServices.isEmpty()) { logger.log(https://www.360docs.net/doc/1612763875.html,, "No services found. Skipping autostaging"); returnfalse; } if (cloudServices.size() > 1) { logger.log(https://www.360docs.net/doc/1612763875.html,, "Error creating cloud service. LL(1)语法分析实验报告 一、实验题目 LL(1)语法分析 二、实验目的 通过设计、编制、调试一个典型的语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,检查语法错误,进一步掌握常用的语法分析方法。 三、实验内容 构造LL(1)语法分析程序,任意输入一个文法符号串,并判断它是否为文法的一个句子。程序要求为该文法构造预测分析表,并按照预测分析算法对输入串进行语法分析,判别程序是否符合已知的语法规则,如果不符合则输出错误信息。 消除递归前的文法消除递归和提取公因子后的等价文法 S →S ∨ a T | a T | ∨ a T S→aTS’ |vaTS’ T →∧ a T | ∧a S’→vaTS’ |ε T→∧ a T’ T’→∧ aT’ |ε 根据已建立的分析表,对下列输入串:a∧ a∧ a进行语法分析,判断其是否符合文法。 四、实验要求 1.根据已由的文法规则建立LL(1)分析表; 2.输出分析过程。 请输入待分析的字符串: a∧ a∧ a 符号栈输入串所用产生式 #S a∧ a∧ a# #S’Ta a∧ a∧ a# S→aTS’ #S’T ∧ a∧ a# # S’T’a∧∧ a∧ a# T→∧ a T’ # S’T’a a∧ a# # S’T’∧ a# # S’T’a∧∧ a# T’→∧ aT’ # S’ T’a a# # S’ T’# # S’ # T’→ε # # S’→ε 五、程序思路 模块结构: 1、定义部分:定义常量、变量、数据结构。 2、初始化:设立LL(1)分析表、初始化变量空间(包括堆栈、结构体等); 3、运行程序:让程序分析一个text文件,判断输入的字符串是否符合文法定义的规则; 4、利用LL(1)分析算法进行表达式处理:根据LL(1)分析表对表达式符号串进行堆栈(或其他)操作,输出分析结果,如果遇到错误则显示简单的错误提示。 六、程序源代码 /* 程序名称: LL(1)文法分析程序 */ /* S->S>aT|aT|>aT */ /* T-> Nginx源代码解析 1.Nginx代码的目录和结构 nginx的源码目录结构层次明确,从自动编译脚本到各级的源码,层次都很清晰,是一个大型服务端软件构建的一个范例。以下是源码目录结构说明: ├─auto 自动编译安装相关目录 │├─cc 针对各种编译器进行相应的编译配置目录,包括Gcc、Ccc等 │├─lib 程序依赖的各种库,包括md5,openssl,pcre等 │├─os 针对不同操作系统所做的编译配置目录 │└─types ├─conf 相关配置文件等目录,包括nginx的配置文件、fcgi相关的配置等 ├─contrib ├─html index.html └─src 源码目录 ├─core 核心源码目录,包括定义常用数据结构、体系结构实现等 ├─event 封装的事件系统源码目录 ├─http http服务器实现目录 ├─mail 邮件代码服务器实现目录 ├─misc 该目录当前版本只包含google perftools包 └─os nginx对各操作系统下的函数进行封装以及实现核心调用的目录。2.基本数据结构 2.1.简单的数据类型 在core/ngx_config.h 目录里面定义了基本的数据类型的映射,大部分都映射到c语言自身的数据类型。 typedef intptr_t ngx_int_t; typedef uintptr_t ngx_uint_t; typedef intptr_t ngx_flag_t; 其中ngx_int_t,nginx_flag_t,都映射为intptr_t;ngx_uint_t映射为uintptr_t。 这两个类型在/usr/include/stdint.h的定义为: /* Types for `void *' pointers. */ #if __WORDSIZE == 64 # ifndef __intptr_t_defined 黑莓手机错误代码详解 blackberry系统错误提示 希望国内的黑莓用户对黑莓手机出错提示有个很好的认识,从而来解决问题。 101 Previous startup failed 当jvm启动过程中,前一个启动的项目失败了,设备已经被重置。这个错误表明jvm 在启动时找到“启动进行中”这个标志位已经设置了,当前屏幕信息为:有意停止“系统继续重置”这个死循环,来纠正系统当前不正确的启动操作 102 Invalid code in filesystem 在文件系统中发现无效的代码。手持设备的系统检查.cod文件的变动时,在一些.cod 文件中检测到这个问题。他肯可能是表明生成过程中发生了错误,即在cod文件中存在一个有问题的签名。如果一些用户操作设备导致这个问题的发生,文件系统的代码被破坏,复位的周期将是连续循环的。唯一的恢复方法是擦去设备并且恢复一个新的系统。 103 Cannot find starting address 找不到启动的地址,用于启动系统的引导cod文件找不到。这个错误表明一个用于引导系统的cod文件没有安装到设备上,或者格式不正确。 104 Uncaught: 网众NXP错误代码解析 DDE(1)未知错误 DDE(2)磁盘快照打开模式错误 DDE(3)磁盘已经打开 DDE(4)磁盘文件没有找到 DDE(5)超级工作站文件已经存在 1)还原时发现超级工作站更新文件存在 2)转存时发现超级工作站更新文件存在 DDE(6)超级工作站文件不存在 DDE(7)还原点文件不存在 DDE(8)快照文件大小错误 DDE(9)超级工作站文件大小错误 DDE(10)还原点文件大小错误 DDE(11)错误的文件格式 DDE(12)分区备份文件大小错误 DDE(13)分区备份文件页面大小错误 DDE(14)快照文件索引没有找到,转存文件格式错误 DDE(15)错误的磁盘版本 快照版本和磁盘版本不匹配 1)普通工作站启动 这台工作站设定成了开机不删除工作站文件,然后做过超级工作站更新或者做过工作站转存 2)工作站转存 这台工作站启动过以后,做过超级工作站更新或者在其他工作站上做过工作站转存 3)还原 还原点的版本和磁盘版本不对应 /root/.xfetrash目录太大,占满了磁盘空间 xfe 文件管理器有个特性,可以指定删除文件时放到回收站里,也就是/root/.xfetrash目录, 关闭方法: 桌面-> 文件管理器-> Edit 菜单-> Preference -> Option 选项卡 第一项:Use trash can for file delete (safe delete) 把前面的打勾去掉 清空这个目录: 1)cd /root/.xfetrash rm -fr * 2)打开文件管理器,在Location中输入/root/.xfetrash,然后删除这个目录下面所有的文件 系统错误代码:Linux 0 = 成功 Windows常见错误代码解析 Windows常见非法操作详解 ■.停止错误编号:0x0000000A 说明文字RQL-NOT-LESS-OR-EQUAL 通常的原因:驱动程序使用了不正确的内存地址. 解决方法:如果无法登陆,则重新启动计算机.当出现可用的作系统列表时,按F8键.在Windows高级选项菜单屏幕上,选择"最后一次正确的配置",然后按回车键. 检查是否正确安装了所有的新硬件或软件.如果这是一次全新安装,请与硬件或软件的制造商联系,获得可能需要的任何Windows更新或驱动程序. 运行由计算机制造商提供的所有的系统诊断软件,尤其是内存检查. 禁用或卸掉新近安装的硬件(RAM,适配器,硬盘,调制解调器等等),驱动程序或软件. 确保硬件设备驱动程序和系统BIOS都是最新的版本. 确保制造商可帮助你是否具有最新版本,也可帮助你获得这些硬件. 禁用 BIOS内存选项,例如cache或shadow. ■.停止错误编号:0x0000001E 说明文字:KMODE-EXPTION-NOT-HANDLED 通常的原因:内核模式进程试图执行一个非法或未知的处理器指令. 解决方法:确保有足够的空间,尤其是在执行一次新安装的时候. 如果停止错误消息指出了某个特定的驱动程序,那么禁用他.如果无法启动计算机.应试着用安全模式启动,以便删除或禁用该驱动程序. 如果有非 Microsoft支持的视频驱动程序,尽量切换到标准的VGA驱动程序或Windows提 供的适当驱动程序. 禁用所有新近安装的驱动程序. 确保有最新版本的系统BIOS.硬件制造商可帮助确定你是否具有最新版本,也可 以帮助你获得他. BIOS内存选项,例如cache,shadow. ■.停止错误编号:0x00000023或0x00000024 说明文字:FAT-FILE-SYSTEM或MTFS-FILE-SYSTEM 通常原因:问题出现在Ntfs.sys(允许系统读写NTFS驱动器的驱动程序文件)内. 解决方法:运行由计算机制造商提供的系统诊断软件,尤其是硬件诊断软件. 禁用或卸载所有的反病毒软件,磁盘碎片整理程序或备份程序. 通过在命令提示符下运行Chkdsk /f命令检查硬盘驱动器是否损坏,然后重新启动计算机. ■.停止编号:0x0000002E 说明文字ATA-BUS-ERROR 通常的原因:系统内存奇偶校验出错,通常由硬件问题导致. 解决方法:卸掉所有新近安装的硬件(RAM.适配器.硬盘.调制解调器等等). 运行由计算机制造商提供的系统诊断软件,尤其是硬件诊断软件. 确保硬件设备驱动程序和系统BIOS都是最新版本. 使用硬件供应商提供的系统诊断,运行内存检查来查找故障或不匹配的内存. 禁用BIOS内存选项,例如cache或shadow. 在启动后出现可用作系统列表时,按F8.在Windows高级选项菜单屏幕上,选择" 启动VGA模式:.然后按回车键.如果这样做还不能解决问题,可能需要更换不同 的视频适配器列表,有关支持的视频适配器列表,请参阅硬件兼容性列表. ■.停止编号:0x0000003F 目录 一、源代码结构 (2) 第一层次目录 (2) bionic目录 (3) bootloader目录 (5) build目录 (7) dalvik目录 (9) development目录 (9) external目录 (13) frameworks目录 (19) Hardware (20) Out (22) Kernel (22) packages目录 (22) prebuilt目录 (27) SDK (28) system目录 (28) Vendor (32) 一、源代码结构 第一层次目录 Google提供的Android包含了原始Android的目标机代码,主机编译工具、仿真环境,代码包经过解压缩后,第一级别的目录和文件如下所示: . |-- Makefile (全局的Makefile) |-- bionic (Bionic含义为仿生,这里面是一些基础的库的源代码) |-- bootloader (引导加载器),我们的是bootable, |-- build (build目录中的内容不是目标所用的代码,而是编译和配置所需要的脚本和工具) |-- dalvik (JAVA虚拟机) |-- development (程序开发所需要的模板和工具) |-- external (目标机器使用的一些库) |-- frameworks (应用程序的框架层) |-- hardware (与硬件相关的库) |-- kernel (Linux2.6的源代码) |-- packages (Android的各种应用程序) |-- prebuilt (Android在各种平台下编译的预置脚本) |-- recovery (与目标的恢复功能相关) `-- system (Android的底层的一些库) linux源代码分析:Linux操作系统源代码详细分析 疯狂代码 https://www.360docs.net/doc/1612763875.html,/ ?:http:/https://www.360docs.net/doc/1612763875.html,/Linux/Article28378.html 内容介绍: Linux 拥有现代操作系统所有功能如真正抢先式多任务处理、支持多用户内存保护虚拟内存支持SMP、UP符合POSIX标准联网、图形用户接口和桌面环境具有快速性、稳定性等特点本书通过分析Linux内核源代码充分揭示了Linux作为操作系统内核是如何完成保证系统正常运行、协调多个并发进程、管理内存等工作现实中能让人自由获取系统源代码并不多通过本书学习将大大有助于读者编写自己新 第部分 Linux 内核源代码 arch/i386/kernel/entry.S 2 arch/i386/kernel/init_task.c 8 arch/i386/kernel/irq.c 8 arch/i386/kernel/irq.h 19 arch/i386/kernel/process.c 22 arch/i386/kernel/signal.c 30 arch/i386/kernel/smp.c 38 arch/i386/kernel/time.c 58 arch/i386/kernel/traps.c 65 arch/i386/lib/delay.c 73 arch/i386/mm/fault.c 74 arch/i386/mm/init.c 76 fs/binfmt-elf.c 82 fs/binfmt_java.c 96 fs/exec.c 98 /asm-generic/smplock.h 107 /asm-i386/atomic.h 108 /asm- i386/current.h 109 /asm-i386/dma.h 109 /asm-i386/elf.h 113 /asm-i386/hardirq.h 114 /asm- i386/page.h 114 /asm-i386/pgtable.h 115 /asm-i386/ptrace.h 122 /asm-i386/semaphore.h 123 /asm-i386/shmparam.h 124 /asm-i386/sigcontext.h 125 /asm-i386/siginfo.h 125 /asm-i386/signal.h 127 /asm-i386/smp.h 130 /asm-i386/softirq.h 132 /asm-i386/spinlock.h 133 /asm-i386/system.h 137 /asm-i386/uaccess.h 139 //binfmts.h 146 //capability.h 147 /linux/elf.h 150 /linux/elfcore.h 156 /linux/errupt.h 157 /linux/kernel.h 158 /linux/kernel_stat.h 159 /linux/limits.h 160 /linux/mm.h 160 /linux/module.h 164 /linux/msg.h 168 /linux/personality.h 169 /linux/reboot.h 169 /linux/resource.h 170 /linux/sched.h 171 /linux/sem.h 179 /linux/shm.h 180 /linux/signal.h 181 /linux/slab.h 184 /linux/smp.h 184 /linux/smp_lock.h 185 /linux/swap.h 185 /linux/swapctl.h 187 /linux/sysctl.h 188 /linux/tasks.h 194 /linux/time.h 194 /linux/timer.h 195 /linux/times.h 196 /linux/tqueue.h 196 /linux/wait.h 198 init/.c 198 init/version.c 212 ipc/msg.c 213 ipc/sem.c 218 ipc/shm.c 227 ipc/util.c 236 kernel/capability.c 237 kernel/dma.c 240 kernel/exec_do.c 241 kernel/exit.c 242 kernel/fork.c 248 kernel/info.c 255 kernel/itimer.c 255 kernel/kmod.c 257 kernel/module.c 259 kernel/panic.c 270 kernel/prk.c 271 kernel/sched.c 275 kernel/signal.c 295 kernel/softirq.c 307 kernel/sys.c 307 kernel/sysctl.c 318 kernel/time.c 330 mm/memory.c 335 mm/mlock.c 345 mm/mmap.c 348 mm/mprotect.c 358 mm/mremap.c 361 mm/page_alloc.c 363 mm/page_io.c 368 mm/slab.c 372 mm/swap.c 394 mm/swap_state.c 395 mm/swapfile.c 398 mm/vmalloc.c 406 mm/vmscan.c 409 10004—WSAEINTR 函数调用中断。该错误表明由于对WSACancelBlockingCall的调用,造成了一次调用被强行中断。 10009—WSAEBADF 文件句柄错误。该错误表明提供的文件句柄无效。在MicrosoftWindowsCE下,socket函数可能返回这个错误,表明共享串口处于“忙”状态。 10013—WSAEACCES 权限被拒。尝试对套接字进行操作,但被禁止。若试图在sendto或WSASendTo中使用一个广播地址,但是尚未用setsockopt和SO_BROADCAST这两个选项设置广播权限,便会产生这类错误。 10014—WSAEFAULT 地址无效。传给Winsock函数的指针地址无效。若指定的缓冲区太小,也会产生这个错误。10022—WSAEINV AL 参数无效。指定了一个无效参数。例如,假如为WSAIoctl调用指定了一个无效控制代码,便会产生这个错误。另外,它也可能表明套接字当前的状态有错,例如在一个目前没有监听的套接字上调用accept或WSAAccept。 10024—WSAEMFILE 打开文件过多。提示打开的套接字太多了。通常,Microsoft提供者只受到系统内可用资源数量的限制。 10035—WSAEWOULDBLOCK 资源暂时不可用。对非锁定套接字来说,如果请求操作不能立即执行的话,通常会返回这个错误。比如说,在一个非暂停套接字上调用connect,就会返回这个错误。因为连接请求不能立即执行。 10036—WSAEINPROGRESS 操作正在进行中。当前正在执行非锁定操作。一般来说不会出现这个错误,除非正在开发16位Winsock应用程序。 10037—WSAEALREADY 操作已完成。一般来说,在非锁定套接字上尝试已处于进程中的操作时,会产生这个错误。比如,在一个已处于连接进程的非锁定套接字上,再一次调用connect或WSAConnect。另外,服务提供者处于执行回调函数(针对支持回调例程的Winsock函数)的进程中时,也会出现这个错误。 10038—WSAENOTSOCK 无效套接字上的套接字操作。任何一个把SOCKET句柄当作参数的Winsock函数都会返回这个错误。它表明提供的套接字句柄无效。 10039—WSAEDESTADDRREQ 需要目标地址。这个错误表明没有提供具体地址。比方说,假如在调用sendto时,将目标地址设为INADDR_ANY(任意地址),便会返回这个错误。 10040—WSAEMSGSIZE 消息过长。这个错误的含义很多。如果在一个数据报套接字上发送一条消息,这条消息对内部缓冲区而言太大的话,就会产生这个错误。再比如,由于网络本身的限制,使一条消息过长,也会产生这个错误。最后,如果收到数据报之后,缓冲区太小,不能接收消息时,也会产生这个错误。 10041—WSAEPROTOTYPE 套接字协议类型有误。在socket或WSASocket调用中指定的协议不支持指定的套接字类型。 Mysql源代码分析系列(2): 源代码结构 Mysql源代码主要包括客户端程序代码,服务器端代码,测试工具和一些库构成,下面我们对比较重要的目录做些介绍。 BUILD 这个目录在本系列的上篇文章中我们仔细看过,内含各种平台的编译脚本,这里就不仔细说了。 client 这个目录下有如下比较让人眼熟的文件: , , , ,等等,如果你编译一下就会发现那些眼熟的程序也出现了,比如mysql。明白了吧,这个目录就是那些客户端程序所在的目录。这个目录的内容也比较少,而且也不是我们阅读的重点。 Docs 这个目录包含了文档。 storage 这个目录包含了所谓的Mysql存储引擎(storage engine)。存储引擎是数据库系统的核心,封装了数据库文件的操作,是数据库系统是否强大最重要的因素。Mysql实现了一个抽象接口层,叫做handler(sql/,其中定义了接口函数,比如:ha_open, ha_index_end, ha_create等等,存储引擎需要实现这些接口才能被系统使用。这个接口定义超级复杂,有900多行:-(,不过我们暂时知道它是干什么的就好了,没必要深究每行代码。对于具体每种引擎的特点,我推荐大家去看mysql的在线文档: 应该能看到如下的目录: * innobase, innodb的目录,当前最流行的存储引擎 * myisam, 最早的Mysql存储引擎,一直到innodb出现以前,使用最广的引擎。 * heap, 基于内存的存储引擎 * federated, 一个比较新的存储引擎 * example, csv,这几个大家可以作为自己写存储引擎时的参考实现,比较容易读懂 mysys 包含了对于系统调用的封装,用以方便实现跨平台。大家看看文件名就大概知道是什么情况了。 sql 这个目录是另外一个大块头,你应该会看到,没错,这里就是数据库主程序mysqld所在的地方。大部分的系统流程都发生在这里。你还能看到, , ,等等,分别实现了对应的SQL命令。后面我们还要经常提到这个目录下的文件。 大概有如下及部分: SQL解析器代码: , , , 等,实现了对SQL语句的解析操作。 Runtime错误解释分析 Runtime是运行时的意思,Runtime Error就是运行时错误,就是在运行期间出现的错误。 An error that occurs during the execution of a program. In contrast, compile-time errors occur while a program is being compiled. Runtime errors indicate bugs in the program or problems that the designers had anticipated but could do nothing about. For example, running out of memory will often cause a runtime error.(运行时错误是程序执行期间发生的错误,它不同于编译期间发生的错误.运行时错误可能是程序中的毛病引起的,也可能程序并无错误,例如机器存储器不够引起) Note that runtime errors differ from bombs or crashes in that you can often recover gracefully from a runtime error.(运行时错误不同于炸弹或系统垮掉,运行时错误一般不影响操作系统运行) 具体的运行错误,要参照错误信息,分析后,想办法解决. RUNTIME ERROR SSS AT III:MMM 其中,SSS是运行错误代码,III是错误发生的程序段,MMM是错误地址。 DOS 错误代码: 1 无效DoS功能号 2 文件末找到 3 路径未找到 4 打开文件过多 5 禁止文件存取 6 无效文件句柄 12 无效文件存取代码 15 无效驱动器号 如何看懂源代码--(分析源代码方法) 4 推 荐 由于今日计划着要看Struts 开源框架的源代码 昨天看了一个小时稍微有点头绪,可是这个速度本人表示非常不满意,先去找了下资 料, 觉得不错... 摘自(繁体中文 Traditional Chinese):http://203.208.39.132/translate_c?hl=zh-CN&sl=en&tl=zh-CN&u=http://ww https://www.360docs.net/doc/1612763875.html,/itadm/article.php%3Fc%3D47717&prev=hp&rurl=https://www.360docs.net/doc/1612763875.html,&usg=AL kJrhh4NPO-l6S3OZZlc5hOcEQGQ0nwKA 下文为经过Google翻译过的简体中文版: 我们在写程式时,有不少时间都是在看别人的代码。 例如看小组的代码,看小组整合的守则,若一开始没规划怎么看,就会“噜看噜苦(台语)”不管是参考也好,从开源抓下来研究也好,为了了解箇中含意,在有限的时间下,不免会对庞大的源代码解读感到压力。网路上有一篇关于分析看代码的方法,做为程式设计师的您,不妨参考看看,换个角度来分析。也能更有效率的解读你想要的程式码片段。 六个章节: ( 1 )读懂程式码,使心法皆为我所用。( 2 )摸清架构,便可轻松掌握全貌。( 3 )优质工具在手,读懂程式非难事。( 4 )望文生义,进而推敲组件的作用。( 5 )找到程式入口,再由上而下抽丝剥茧。( 6 )阅读的乐趣,透过程式码认识作者。 程式码是别人写的,只有原作者才真的了解程式码的用途及涵义。许多程式人心里都有一种不自觉的恐惧感,深怕被迫去碰触其他人所写的程式码。但是,与其抗拒接收别人的程式码,不如彻底了解相关的语言和惯例,当成是培养自我实力的基石。 对大多数的程式人来说,撰写程式码或许是令人开心的一件事情,但我相信,有更多人视阅读他人所写成的程式码为畏途。许多人宁可自己重新写过一遍程式码,也不愿意接收别人的程式码,进而修正错误,维护它们,甚至加强功能。 这其中的关键究竟在何处呢?若是一语道破,其实也很简单,程式码是别人写的,只有原作者才真的了解程式码的用途及涵义。许多程式人心里都有一种不自觉的恐惧感,深怕被迫去碰触其他人所写的程式码。这是来自于人类内心深处对于陌生事物的原始恐惧。 读懂别人写的程式码,让你收获满满 不过,基于许多现实的原因,程式人时常受迫要去接收别人的程式码。例如,同事离职了,必须接手他遗留下来的工作,也有可能你是刚进部门的菜鸟,而同事经验值够了,升级了,风水轮流转,一代菜鸟换菜鸟。甚至,你的公司所承接的专案,必须接手或是整合客户前一个厂商所遗留下来的系统,你们手上只有那套系统的原始码(运气好时,还有数量不等的文件)。 诸如此类的故事,其实时常在程式人身边或身上持续上演着。许多程式人都将接手他人的程式码,当做一件悲惨的事情。每个人都不想接手别人所撰写的程式码,因为不想花时间去探索,宁可将生产力花在产生新的程式码,而不是耗费在了解这些程式码上。 系统错误提示代码解析: 0 0x0000 操作成功完成。 1 0x0001 函数不正确。 2 0x0002 系统找不到指定的文件。 3 0x0003 系统找不到指定的路径。 4 0x0004 系统无法打开文件。 5 0x0005 拒绝访问。 6 0x0006 句柄无效。 7 0x0007 存储控制块被损坏。 8 0x0008 存储空间不足,无法处理此命令。 9 0x0009 存储控制块地址无效。 10 0x000A 环境不正确。 11 0x000B 试图加载格式不正确的程序。 12 0x000C 访问码无效。 13 0x000D 数据无效。 14 0x000E 存储空间不足,无法完成此操作。 15 0x000F 系统找不到指定的驱动器。 16 0x0010 无法删除目录。 17 0x0011 系统无法将文件移到不同的驱动器。 18 0x0012 没有更多文件。 19 0x0013 媒体受写入保护。 20 0x0014 系统找不到指定的设备。 21 0x0015 设备未就绪。 22 0x0016 设备不识别此命令。 23 0x0017 数据错误(循环冗余检查)。 24 0x0018 程序发出命令,但命令长度不正确。 25 0x0019 驱动器找不到磁盘上特定区域或磁道。 26 0x001A 无法访问指定的磁盘或软盘。 27 0x001B 驱动器找不到请求的扇区。 28 0x001C 打印机缺纸。 29 0x001D 系统无法写入指定的设备。 30 0x001E 系统无法从指定的设备上读取。 31 0x001F 连到系统上的设备没有发挥作用。 32 0x0020 另一个程序正在使用此文件,进程无法访问。 33 0x0021 另一个程序已锁定文件的一部分,进程无法访问。 34 0x0022 驱动器中的软盘不对。将%2 插入(卷序列号: %3)驱动器%1。 36 0x0024 用来共享的打开文件过多。 38 0x0026 已到文件结尾。 39 0x0027 磁盘已满。 50 0x0032 不支持请求。 51 0x0033 Windows 无法找到网络路径。请确认网络路径正确并且目标计算机不忙或已关闭。如果Windows 仍然无法找到网络路径,请与网络管理员联系。 52 0x0034 由于网络上有重名,没有连接。请到“控制面板”中的“系统”更改计算机名, 常见错误代码及解决方法 在用户申报宽带故障时,拨号错误通常有个数字提示出错。通常,6开头错误一般都是与服务器之间通讯有问题,这个很麻烦也很不好解决,691/619除外这个是账号问题,7开头错误一般都是网卡问题,这个好解决,718/738除外这个是PPPOE服务器故障,尤其是769错误,是网卡禁用。如果出现其他7开头错误。可以查看网卡工作状态以及协议是否齐全 错误代码解决方式 678 工作人员上门 1.个别用户:需询问用户几台电脑如果用户是多台电脑使用路由器连接请用户将主网线连接一台电脑查看错误代码 2.大面积用户:如果小区或者楼道设备箱停电会出现大面积678的现象 691 客服电话解决 1.宽带连接用户名和密码输入错误请用户重新输入用户名和密码或者重新建立宽带连接重新输入 2.此用户账号欠费停机可以在开户系统查询该账号状态 769客服电话解决 本地网卡问题网上邻居右键属性里本地连接是禁用状态才显示769 双击本地连接启用即可如果没有本地连接显示是网卡驱动掉了或者是网卡坏了这是用户电脑问题与宽带公司无关 738 PPPOE服务器不能分配IP地址服务器故障,用户太多超过服务器所能提供的IP地址 815 工作人员上门 Vista系统中显示该错误代码与678操作一致 651 工作人员上门 W7系统中显示该错误代码与678操作一致 619 客服电话解决 宽带连接服务器超时请用户电脑重启或者重新连接宽带如果真有网络问题会显示678 实在连接不上再派工作人员上门 718 问题:验证用户名时远程计算机超时没有响应,断开连接 PPPOE 服务器故障 备注说明 619 734 720 此类错误代码出现时,如果是个别用户,则请用户重新启动电脑重新连接宽带即可。如果是大面积用户反映此代码,一般多为网络问题,需与公司网管及时联系,查看服务器 宽带连接建立方法:XP系统创建拨号连接方法 1网上邻居右键属性///或者--开始菜单—控制面板---左键单击:网络邻居 2.点击页面左上角“创建一个新的连接” 开始菜单-----选择:控制面板 Redis源代码分析 一直有打算写篇关于redis源代码分析的文章,一直很忙,还好最近公司终于闲了一点,总算有点时间学习了,于是终于可以兑现承诺了,废话就到此吧,开始我们的源代码分析,在文章的开头我们把所有服务端文件列出来,并且标示出其作用: adlist.c //双向链表 ae.c //事件驱动 ae_epoll.c //epoll接口, linux用 ae_kqueue.c //kqueue接口, freebsd用 ae_select.c //select接口, windows用 anet.c //网络处理 aof.c //处理AOF文件 config.c //配置文件解析 db.c //DB处理 dict.c //hash表 intset.c //转换为数字类型数据 multi.c //事务,多条命令一起打包处理 networking.c //读取、解析和处理客户端命令 object.c //各种对像的创建与销毁,string、list、set、zset、hash rdb.c //redis数据文件处理 redis.c //程序主要文件 replication.c //数据同步master-slave sds.c //字符串处理 sort.c //用于list、set、zset排序 t_hash.c //hash类型处理 t_list.c //list类型处理 t_set.c //set类型处理 t_string.c //string类型处理 t_zset.c //zset类型处理 ziplist.c //节省内存方式的list处理 zipmap.c //节省内存方式的hash处理 zmalloc.c //内存管理 上面基本是redis最主要的处理文件,部分没有列出来,如VM之类的,就不在这里讲了。 首先我们来回顾一下redis的一些基本知识: 1、redis有N个DB(默认为16个DB),并且每个db有一个hash表负责存放key,同一个DB不能有相同的KEY,但是不同的DB可以相同的KEY; 常见错误代码及解决办法 错误 691,客户名密码错,错误提示如图所示: 1)输入的上网帐号(上网客户名)或密码填写错误导致,首先请找出客户的客户名和密码,核对一下,重新再输入一次。依然不行,在电脑右下角找到本地连接的图标-右击,在最下面一排会出现打开网络连接等类似字样(VISTA WIN7也一样,可能文字描述会有一点点不同而 已),打开后的界面里同样会有一个移动宽带连接的图标,双击打开如下图: 按照上图设置完成后,检查帐号是否正确,然后重新输入密码连接。 如果仍然连接不上,且错误代码仍为691,可能是用户宽带欠费(江大移动网基本都是手机帐号,如果手机欠费,宽带也等同于欠费),请续费后再试。也可能是用户密码的确是错误了,这时候 用户可拨打10086进行重置密码,具体操作如下:拨打10086,根据语音提示拨通人工服务,接 通后跟客服人员说“我要重置(即初始化宽带密码)个人有线宽带的密码,帮我转接到宽带专 席(即宽带专家坐席)好么”,转接到宽带专席之后,跟宽带专席的客服人员说“我要重置个 人有线宽带的密码”……重置完了之后,跟客服人员说“再帮我把宽带帐号的端口刷新一下”, 说完就可以跟客服说声谢谢然后再见了。然后重新输入重置之后的密码(一般为123456,偶尔 会有123123),再进行连接。 错误800 1.关掉防火墙,杀毒软件等程序,再进行连接(可以关一个就连接一次,这样可以找出是哪个防火墙的问题) 2.检查本地连接以及IP和DNS设置:在电脑右下角找到本地连接的图标(找不到图标的话,XP系统:开始-控制面板(切换到经典模式)-网络连接;VISTA系统:开始-控制面板-网 络和INTERNET(没有这个选项的跳过这个直接往下看)-网络和共享中心-管理网络连接(在 界面的左侧);WIN7系统:开始-控制面板-网络和INTERNET(没有这个选项的跳过这个直 接往下看)-网络和共享中心-更改适配器设置(在界面的左侧))-右击,在最下面一排会 出现打开网络连接等类似字样(VISTA WIN7也一样,可能文字描述会有一点点不同而已), 在打开的界面里会有本地连接的图标,看本地连接的图标是否正常(正常的显示是:XP系 统会显示已连接上,VISTA和WIN7会显示网络或网络2、网络3……)。 a.正常的话右击本地连接,点击属性,在中间的位置会有一个小窗口,有很多列表,XP 系统找到“Internet选项TCP/IP协议”并双击打开,VISTA和WIN7找到一个含有“Ipv4” 的选项并双击打开,将其中IP和DNS都设置为自动获取。然后点击确定,然后点击此 界面里的移动宽带连接,按照“错误691”的解决方案设置好,然后重新输入密码并 连接。 b.本地连接不正常的话,查看本地连接上的文字提示。 1)本地连接上提示本地连接被停用的话,右击本地连接-启用,即可 2)本地连接上有个红色的叉叉,提示网络电缆被拔出。这说明你的网络线路有问题, 简单点说就是你的网线压根没插好,也有可能是接口坏掉了,可以把网线插拔试试, 红色叉叉消失了,就说明网线插好了。实在不行换跟网线或换个接口。 3)本地连接上有叹号,提示网络连接受限制或无连接。 ①XP系统:右击-修复 ②VISTA和WIN7系统:右击-诊断等待获取完网络地址。 没有叹号了的话,尝试进行连接 叹号仍然存在的话:右击本地连接-停用(禁用),然后再右击本地连接-启用, 等待获取完网络地址。没有叹号了的话,尝试进行连接 叹号仍然存在的话:右击本地连接-属性,中间有个小窗口有很多选项,取消所有 选项的前面的勾,点击确定。然后,右击本地连接-属性,中间有个小窗口有很多 选项,勾选所有选项的前面的勾,点击确定。等待获取完网络地址。 没有叹号了的话,尝试进行连接 叹号仍然存在的话,重复以上步骤,如果一直都有叹号,并且无法连接上移动宽 带,说明计算机本身驱动有存在问题,或网卡问题(此处驱动原因的可能性远远 大于网卡原因的可能性) 3.卸载已经安装的宽带连接软件,并重新安装,安装完成后要重新启动(必须),然后进行网络连接。 错误868(和错误800有些类似) 找到本地连接,点击开始,打开控制面板,XP系统:开始-控制面板(切换到经典模式)-网络连接;VISTA 系统:开始-控制面板-网络和INTERNET(没有这个选项的跳过这个直接往下看)-网络和共享中心-管理网络连接(在界面的左侧);WIN7系统:开始-控制面板-网络和INTERNET(没有这个选项的跳过这个直接往下看)-网络和共享中心-更改适配器设置(在界面的左侧)。 Java中的Exception 1异常相关概述 1.1 什么是异常 ?异常就是Java程序在运行过程中出现的错误。 ?前面接触过的空指针,数组越界,类型转换错误异常等 1.2 Throwable ?Throwable 类是Java 语言中所有错误或异常的超类。 ?只有当对象是此类(或其子类之一)的实例时,才能通过JVM 或者throw 语句抛出。 1.3异常的继承体系 1.3 JVM默认是如何处理异常的? ?jvm有一个默认的异常处理机制,就将该异常的名称、异常的信息、异常出现的位置打印在了控制台上,同时程序停止运行。 1.4 Java处理异常的两种方式 ?Java虚拟机处理 ?自己处理 1.5 为什么会有异常 因为你不知道未来会怎么样,需要做个准备(写代码也是,你需要对一些未知的东西做下处理),比如你去旅游,不知道会下雨还是出大太阳,你需要准备雨伞和帽子.如果下雨,我有雨伞可用,如果出大太阳,可以用帽子,也有可能天气刚刚好,雨伞和帽子都用不着,这叫白带。 1.6 回顾几个常见异常 2 try-catch 自己处理异常的两种方试 ?try…catch…finally ?throws 2.1 try-catch异常处理方式 2.2 try-catch-catch 多个catch处理方式 2.3 try-catch-catch 多个异常-另一种写法 2.4 多个异常处理的一个注意事项 ?catch中父类的Exception只能放在最后面 ?catch一个原则,先由子类处理异常,子类不能处理异常,再由父类处理try { //1.有可能出现数组越界异常 int[] arr = {1,2,3}; System.out.println(arr[1]); //2.算术异常 int a = 10 / 2; //3.空指针异常 int[] arr1 = null; //NullPointerException np; System.out.println(arr1[0]); }catch (ArrayIndexOutOfBoundsException e) { System.out.println("数组越界异常"); } catch (ArithmeticException e) { System.out.println("算术异常"); } catch (Exception e) { System.out.println("其它异常"); } 关键字: 分布式云计算 Google的核心竞争技术是它的计算平台。Google的大牛们用了下面5篇文章,介绍了它们的计算设施。 GoogleCluster: https://www.360docs.net/doc/1612763875.html,/archive/googlecluster.html Chubby:https://www.360docs.net/doc/1612763875.html,/papers/chubby.html GFS:https://www.360docs.net/doc/1612763875.html,/papers/gfs.html BigTable:https://www.360docs.net/doc/1612763875.html,/papers/bigtable.html MapReduce:https://www.360docs.net/doc/1612763875.html,/papers/mapreduce.html 很快,Apache上就出现了一个类似的解决方案,目前它们都属于Apache的Hadoop项目,对应的分别是: Chubby-->ZooKeeper GFS-->HDFS BigTable-->HBase MapReduce-->Hadoop 目前,基于类似思想的Open Source项目还很多,如Facebook用于用户分析的Hive。 HDFS作为一个分布式文件系统,是所有这些项目的基础。分析好HDFS,有利于了解其他系统。由于Hadoop的HDFS和MapReduce 是同一个项目,我们就把他们放在一块,进行分析。 下图是MapReduce整个项目的顶层包图和他们的依赖关系。Hadoop包之间的依赖关系比较复杂,原因是HDFS提供了一个分布式文件系统,该系统提供API,可以屏蔽本地文件系统和分布式文件系统,甚至象Amazon S3这样的在线存储系统。这就造成了分布式文件系统的实现,或者是分布式文件系统的底层的实现,依赖于某些貌似高层的功能。功能的相互引用,造成了蜘蛛网型的依赖关系。一个典型的例子就是包conf,conf用于读取系统配置,它依赖于fs,主要是读取配置文件的时候,需要使用文件系统,而部分的文件系统的功能,在包fs中被抽象了。 Hadoop的关键部分集中于图中蓝色部分,这也是我们考察的重点。语法分析程序实验报告及代码
Nginx源代码解析
黑莓手机错误代码详解 blackberry系统错误提示
网众NXP错误代码解析
Windows常见错误代码解析
Android源代码结构分析
Linux操作系统源代码详细分析
Socket编程协议错误代码解析
mysql源代码分析
Runtime错误解释分析
如何看懂源代码--(分析源代码方法)
系统错误提示代码解析
常见错误代码及解决方法
Redis源代码分析
常见错误代码及解决办法
java基础异常Exception代码讲解总结
Hadoop源代码分析(完整版)