SPSS—二元Logistic回归结果分析

SPSS—二元Logistic回归结果分析
2011-12-02 16:48
身心疲惫,睡意连连,头不断往下掉,拿出耳机,听下歌曲,缓解我这严重的睡意吧!今天来分析二元Logistic回归的结果
分析结果如下:
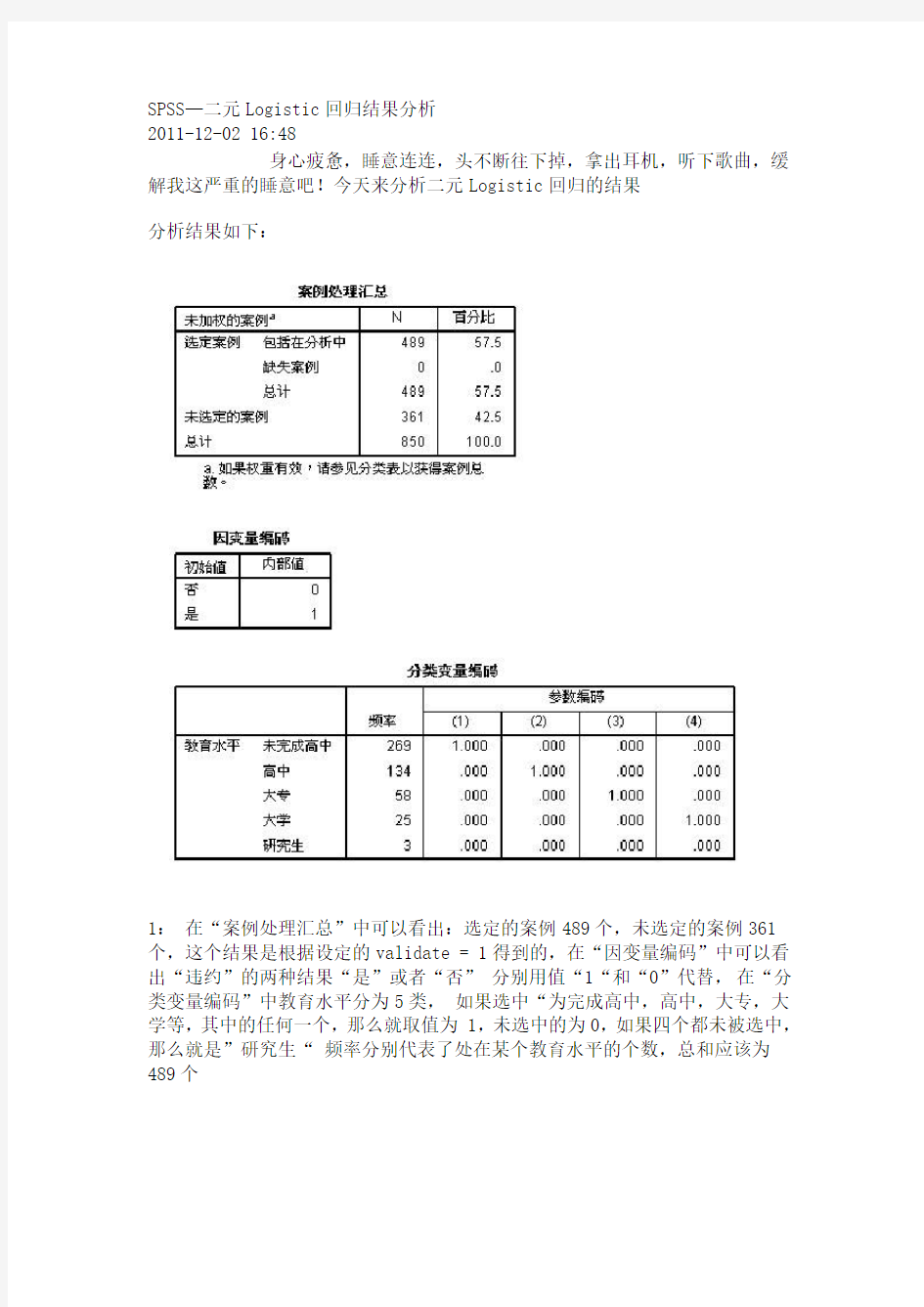
1:在“案例处理汇总”中可以看出:选定的案例489个,未选定的案例361个,这个结果是根据设定的validate = 1得到的,在“因变量编码”中可以看出“违约”的两种结果“是”或者“否” 分别用值“1“和“0”代替,在“分类变量编码”中教育水平分为5类,如果选中“为完成高中,高中,大专,大学等,其中的任何一个,那么就取值为 1,未选中的为0,如果四个都未被选中,那么就是”研究生“ 频率分别代表了处在某个教育水平的个数,总和应该为489个
1:在“分类表”中可以看出:预测有360个是“否”(未违约)有129个是“是”(违约)
2:在“方程中的变量”表中可以看出:最初是对“常数项”记性赋值,B为
-1.026,标准误差为:0.103
那么wald =( B/S.E)2=(-1.026/0.103)2 = 99.2248, 跟表中的“100.029几乎接近,是因为我对数据进行的向下舍入的关系,所以数据会稍微偏小,
B和Exp(B) 是对数关系,将B进行对数抓换后,可以得到:Exp(B) = e^-1.026 = 0.358, 其中自由度为1, sig为0.000,非常显著
1:从“不在方程中的变量”可以看出,最初模型,只有“常数项”被纳入了模型,其它变量都不在最初模型内
表中分别给出了,得分,df , Sig三个值, 而其中得分(Score)计算公式如下:
(公式中(Xi- Xˉ) 少了一个平方)
下面来举例说明这个计算过程:(“年龄”自变量的得分为例)
从“分类表”中可以看出:有129人违约,违约记为“1”则违约总和为129,选定案例总和为489
那么: yˉ = 129/489 = 0.2638036809816
xˉ = 16951 / 489 = 34.664621676892
所以:∑(Xi-xˉ)2 = 30074.9979
yˉ(1-yˉ)=0.2638036809816 *(1-0.2638036809816 )
=0.19421129888216
则:yˉ(1-yˉ)* ∑(Xi-xˉ)2 =0.19421129888216 * 30074.9979 = 5 840.9044060372
则:[∑Xi(yi - yˉ)]^2 = 43570.8
所以:
=43570.8 / 5 840.9044060372 = 7.4595982010876 = 7.46 (四舍五入)
计算过程采用的是在 EXCEL 里面计算出来的,截图如下所示:
从“不在方程的变量中”可以看出,年龄的“得分”为7.46,刚好跟计算结果吻合!!答案得到验证~!!!!
1:从“块1” 中可以看出:采用的是:向前步进的方法,在“模型系数的综合检验”表中可以看出:所有的SIG 几乎都为“0”而且随着模型的逐渐步进,卡方值越来越大,说明模型越来越显著,在第4步后,终止,
根据设定的显著性值和自由度,可以算出卡方临界值,公式为:
=CHIINV(显著性值,自由度) ,放入excel就可以得到结果
2:在“模型汇总“中可以看出:Cox&SnellR方和 Nagelkerke R方拟合效果都不太理想,最终理想模型也才:0.305 和 0.446,
最大似然平方的对数值都比较大,明显是显著的
似然数对数计算公式为:
计算过程太费时间了,我就不举例说明计算过程了
Cox&SnellR方的计算值是根据:
1:先拟合不包含待检验因素的Logistic模型,求对数似然函数值
INL0 (指只包含“常数项”的检验)
2:再拟合包含待检验因素的Logistic模型,求新的对数似然函数值
InLB (包含自变量的检验)
再根据公式:即可算出:Cox&SnellR方的值!
提示:将Hosmer 和 Lemeshow 检验和“随机性表” 结合一起来分析
1:从 Hosmer 和 Lemeshow 检验表中,可以看出:经过4次迭代后,最终的卡方统计量为:11.919,而临界值为:CHINV(0.05,8) = 15.507
卡方统计量< 临界值,从SIG 角度来看: 0.155 > 0.05 , 说明模型能够很好的拟合整体,不存在显著的差异。
2:从Hosmer 和 Lemeshow 检验随即表中可以看出:”观测值“和”期望值“几乎是接近的,不存在很大差异,说明模型拟合效果比较理想,印证了“Hosmer 和 Lemeshow 检验”中的结果
而“Hosmer 和 Lemeshow 检验”表中的“卡方”统计量,是通过“Hosmer 和Lemeshow 检验随即表”中的数据得到的(即通过“观测值和”预测值“)得到的,计算公式如下所示:
x2(卡方统计量) = ∑(观测值频率- 预测值频率)^2 / 预测值的频率
举例说明一下计算过程:以计算 "步骤1的卡方统计量为例 "
1:将“Hosmer 和 Lemeshow 检验随即表”中“步骤1 ”的数据,复制到excel 中,得到如下所示结果:
从“Hosmer 和 Lemeshow 检验”表中可以看出,步骤1 的卡方统计量为:7.567,在上图中,通过excel计算得到,结果为 7.566569 ~~7.567 (四舍五入),结果是一致的,答案得到验证!!
1:从“分类表”—“步骤1” 中可以看出:选定的案例中,“是否曾今违约”总计:489个,其中没有违约的 360个,并且对360个“没有违约”的客户进行了预测,有 340个预测成功,20个预测失败,预测成功率为:340 / 360 =94.4%
其中“违约”的有189个,也对189个“违约”的客户进行了预测,有95个预测失败, 34个预测成功,预测成功率:34 / 129 = 26.4%
总计预测成功率:(340 + 34)/ 489 = 76.5%
步骤1 的总体预测成功率为:76.5%,在步骤4终止后,总体预测成功率为:83.4,预测准确率逐渐提升 76.5%—79.8%—81.4%—83.4。 83.4的预测准确率,不能够算太高,只能够说还行。
从“如果移去项则建模”表中可以看出:“在-2对数似然中的更改” 中的数值是不是很眼熟???,跟在“模型系数总和检验”表中“卡方统计量"量的值是一样的!!!
将“如果移去项则建模”和“方程中的变量”两个表结合一起来看
1:在“方程中的变量”表中可以看出:在步骤1中输入的变量为“负债率”,在”如果移去项则建模“表中可以看出,当移去“负债率”这个变量时,引起了74.052的数值更改,此时模型中只剩下“常数项”-282.152为常数项的对数似然值
在步骤2中,当移去“工龄”这个自变量时,引起了44.543的数值变化(简称:似然比统计量),在步骤2中,移去“工龄”这个自变量后,还剩下“负债率”和“常量”,此时对数似然值变成了:-245.126,此时我们可以通过公式算出“负债率”的似然比统计量:计算过程如下:
似然比统计量 = 2(-245.126+282.152)=74.052 答案得到验证!!!
2:在“如果移去项则建模”表中可以看出:不管移去那一个自变量,“更改的显著性”都非常小,几乎都小于0.05,所以这些自变量系数跟模型显著相关,不能够剔去!!
3:根据" 方程中的变量“这个表,我们可以得出 logistic 回归模型表达式:
= 1 / 1+ e^-(a+∑βI*Xi) 我们假设 Z = 那么可以得到简洁表达式:
P(Y) = 1 / 1+e^ (-z)
将”方程中的变量“ —步骤4中的参数代入模型表达式中,可以得
到 logistic回归模型如下所示:
P(Y) = 1 / 1 + e ^ -(-0.766+0.594*信用卡负债率+0.081*负债率-0.069*地址-0.249*功龄)
从”不在方程中的变量“表中可以看出:年龄,教育,收入,其它负债,都没有纳入模型中,其中:sig 值都大于 0.05,所以说明这些自变量跟模型显著不相关。
在”观察到的组和预测概率图”中可以看出:
1:the Cut Value is 0.5, 此处以 0.5 为切割值,预测概率大于0.5,表示客户“违约”的概率比较大,小于0.5表示客户“违约”概率比较小。
2:从上图中可以看出:预测分布的数值基本分布在“左右两端”在大于0.5的切割值中,大部分都是“1” 表示大部分都是“违约”客户,(大约230个违约客户)预测概率比较准,而在小于0.5的切割值中,大部分都是“0” 大部分都是“未违约”的客户,(大约500多个客户,未违约)预测也很准
在运行结束后,会自动生成多个自变量,如下所示:
1:从上图中可以看出,已经对客户“是否违约”做出了预测,上面用颜色标记的部分-PRE_1 表示预测概率,
上面的预测概率,可以通过前面的 Logistic 回归模型计算出来,计算过程不演示了
2:COOK_1 和 SRE_1 的值可以跟预测概率(PRE_1) 进行画图,来看 COOK_1 和SRE_1 对预测概率的影响程度,因为COOK值跟模型拟合度有一定的关联,发生奇异值,会影响分析结果。如果有太多奇异值,应该单独进行深入研究!
实验7相关及回归分析SPSS应用
实验7 相关与回归分析 7.1实验目的 熟练掌握一元线性回归分析的SPSS应用技能,掌握一元非线性回归分析的SPSS应用技能,对实验结果做出解释。 7.2相关知识(略) 7.3实验内容 7.3.1一元线性回归分析的SPSS实验 7.3.2一元非线性回归分析的SPSS实验 7.4实验要求 7.4.1准备实验数据 1.线性回归分析数据 (The Wall 美国各航空公司业绩的统计数据公布在《华尔街日报1999年年鉴》 Street Journal Almanac 1999)上。航班正点到达的比率和每10万名乘客投诉 的次数的数据,见表7-1所示。 表7-1 美国航空公司航空正点率与乘客投诉次数资料 2.非线性回归分析数据 1992~2013年某国保费收入与国内生产总值的数据,试研究保费收入与国内生产
总值的关系的数据,见表7-2所示。 表7-2 1992~2013年某国保费收入与国内生产总值数据 单位:万元 7.4.2完成一元线性回归分析的SPSS 实验,对实验结果作出简要分析。 7.4.3完成一元非线性回归分析的SPSS 实验,对实验结果作出简要分析。 7.5实验步骤 7.5.1 完成一元线性回归分析的SPSS 实验步骤 1.运用SPSS 绘制散点图散点图。 第一步:在excel 中输入数据 图7-1 第二步:将excel 数据导入spss 单击打开数据文档按钮(或选择菜单文件→打开)→选择文件航空公司航班
正点率与投诉率.xls 图7-2 第三步:选择菜单图形→旧对话框→散点/点状,在散点图/点图对话框中, 选择简单分布按钮 图7-3 第三步:在简单散点图对话框中,将候选变量框中的投诉率添加到Y轴,航班正点率添加到X轴,点击确定:
相关分析与回归分析SPSS实现
相关分析与回归分析 一、试验目标与要求 本试验项目的目的是学习并使用SPSS 软件进行相关分析和回归分析,具体包括: (1) 皮尔逊pearson 简单相关系数的计算与分析 (2) 学会在SPSS 上实现一元及多元回归模型的计算与检验。 (3) 学会回归模型的散点图与样本方程图形。 (4) 学会对所计算结果进行统计分析说明。 (5) 要求试验前,了解回归分析的如下内容。 ? 参数α、β的估计 ? 回归模型的检验方法:回归系数β的显著性检验(t -检验);回归 方程显著性检验(F -检验)。 二、试验原理 1.相关分析的统计学原理 相关分析使用某个指标来表明现象之间相互依存关系的密切程度。用来测度简单线性相关关系的系数是Pearson 简单相关系数。 2.回归分析的统计学原理 相关关系不等于因果关系,要明确因果关系必须借助于回归分析。回归分析是研究两个变量或多个变量之间因果关系的统计方法。其基本思想是,在相关分析的基础上,对具有相关关系的两个或多个变量之间数量变化的一般关系进行测定,确立一个合适的数据模型,以便从一个已知量推断另一个未知量。回归分析的主要任务就是根据样本数据估计参数,建立回归模型,对参数和模型进行检验和判断,并进行预测等。 线性回归数学模型如下: i ik k i i i x x x y εββββ+++++= 22110 在模型中,回归系数是未知的,可以在已有样本的基础上,使用最小二乘法对回归系数进行估计,得到如下的样本回归函数: i ik k i i i e x x x y +++++=ββββ????22110 回归模型中的参数估计出来之后,还必须对其进行检验。如果通过检验发现模型有缺陷,则必须回到模型的设定阶段或参数估计阶段,重新选择被解释变量
SPSS软件应用于相关分析与回归分析
实验五 SPSS软件应用于 相关分析与回归分析 学院:动物科技学院 班级:动科101 姓名:李貌 学号:2010020407
实验五SPSS软件应用于相关分析与回归分析 一、实验目的: 1、理解线性相关分析和回归分析的意义及应用并对有关数据进行分析。 2、熟悉SPSS软件应用于相关分析和回归分析的操作和步骤。 3、进一步掌握运用SPSS软件处理数据和分析数据的能力。 二、实验内容: 玉米在盐胁迫后的萎焉程度(R)与根中蛋白(R)、叶中蛋白(L)、脯氨酸(pro)之间关系如下,试进行变量间的相关分析、回归分析。 萎焉度(Y)/% 根中蛋白(R)/% 叶中蛋白(L)/% 脯氨酸(pro)/% 0.9300 0.79 0.98 0.093 0.9547 0.99 1.02 0.105 0.9661 0.91 1.58 0.119 0.9678 1.01 1.47 0.155 0.9725 1.14 1.89 0.234 0.9735 1.36 1.32 0.251 0.9856 1.36 1.76 0.217 1.0032 1.19 2.61 0.271 1.0045 1.21 2.33 0.227 1.0075 1.06 2.88 0.270 1.0186 1.58 2.40 0.282 1.0201 1.30 2.40 0.557 1.0245 1.81 2.37 0.650 1.0260 1.88 2.59 0.622 1.0283 1.46 3.10 0.611 1.0364 1.68 3.36 0.657 三、实验步骤: (一、线性回归分析) 1、启动SPSS,进行变量定义和数据录入,如(图1、2)。
相关分析和一元线性回归分析SPSS报告
用下面的数据做相关分析和一元线性回归分析: 选用普通高等学校毕业生数和高等学校发表科技论文数量做相关分析和一元线性回归分析。 一、相关分析 1.作散点图
普通高等学校毕业生数和高等学校发表科技论文数量的相关图 从散点图可以看出:普通高等学校毕业生数和高等学校发表科技论文数量的相关性很大。 2.求普通高等学校毕业生数和高等学校发表科技论文数量的相关系 数
把要求的两个相关变量移至变量中,因为都是定距数据,选择相关系数中的Pearson,点击确定,可以得到下面的结果:
Correlations 普通高等学校毕业生数(万人)高等学校发表科技论文数量(篇) 普通高等学校毕业生数(万人)Pearson Correlation1.998** Sig. (2-tailed).000 N1414 高等学校发表科技论文数量(篇)Pearson Correlation.998**1 Sig. (2-tailed).000 N1414 **. Correlation is significant at the 0.01 level (2-tailed). 两相关变量的Pearson相关系数=0.0998,表示呈高度正相关;相关系数检验对应的概率P值=0.000,小于显著性水平0.05,应拒绝原假设(两变量之间不具有相关性),即毕业生人数好发表科技论文数之间的相关性显著。 3.求两变量之间的相关性 选择相关系数中的全部,点击确定:
Correlations (万人)(篇) Kendall's tau_b(万人)Correlation Coefficient 1.000 1.000** Sig. (2-tailed).. N1414 (篇)Correlation Coefficient 1.000** 1.000 Sig. (2-tailed).. N1414 Spearman's rho(万人)Correlation Coefficient 1.000 1.000** Sig. (2-tailed).. N1414 (篇)Correlation Coefficient 1.000** 1.000 Sig. (2-tailed).. N1414 **. Correlation is significant at the 0.01 level (2-tailed). 注解:两相关变量(毕业生数和发表论文数)的Kendall相关系数=1.000,呈正相关;无相关系数检验对应的概率P值,应接受原假设(两变量之间不具有相关性),即毕业生数与发表论文数之间相关性不显著。 两相关变量(毕业生数和发表论文数)的Spearman相关系数=1.000,呈正相关;无相关系数检验对应的概率P值,应接受原假设(两变量之间不具有相关性),即毕业生数与发表论文数之间相关性不显著。 4.普通高等学校毕业生数和高等学校发表科技论文数量的相关系数
相关分析和回归分析SPSS实现
相关分析和回归分析 S P S S实现 TYYGROUP system office room 【TYYUA16H-TYY-TYYYUA8Q8-
相关分析与回归分析 一、试验目标与要求 本试验项目的目的是学习并使用SPSS软件进行相关分析与回归分析,具体包括: (1)皮尔逊pearson简单相关系数的计算与分析 (2)学会在SPSS上实现一元及多元回归模型的计算与检验。 (3)学会回归模型的散点图与样本方程图形。 (4)学会对所计算结果进行统计分析说明。 (5)要求试验前,了解回归分析的如下内容。 参数α、β的估计 回归模型的检验方法:回归系数β的显着性检验(t-检验);回归 方程显着性检验(F-检验)。 二、试验原理 1.相关分析的统计学原理 相关分析使用某个指标来表明现象之间相互依存关系的密切程度。用来测度简单线性相关关系的系数是Pearson简单相关系数。 2.回归分析的统计学原理 相关关系不等于因果关系,要明确因果关系必须借助于回归分析。回归分析是研究两个变量或多个变量之间因果关系的统计方法。其基本思想是,在相关分析的基础上,对具有相关关系的两个或多个变量之间数量变化的一般关系进行测定,确立一个合适的数据模型,以便从一个已知量推断另一个未知量。回归分析的主要任务就是根据样本数据估计参数,建立回归模型,对参数与模型进行检验与判断,并进行预测等。 线性回归数学模型如下: 在模型中,回归系数是未知的,可以在已有样本的基础上,使用最小二乘法对回归系数进行估计,得到如下的样本回归函数: 回归模型中的参数估计出来之后,还必须对其进行检验。如果通过检验发现模型有缺陷,则必须回到模型的设定阶段或参数估计阶段,重新选择被解释变量与解释变量及其函数形式,或者对数据进行加工整理之后再次估计参数。回归模型的检验包括一级检验与二级检验。一级检验又叫统计学检验,它是利用统计学的抽样理论来检验样本回归方程的可靠性,具体又可以分为拟与优度
第六章 spss相关分析和回归分析
第六章 SPSS相关分析与回归分析 6.1 相关分析和回归分析概述 客观事物之间的关系大致可归纳为两大类,即 ●函数关系:指两事物之间的一种一一对应的关系,如商品的销售额和销售量之间的 关系。 ●相关关系(统计关系):指两事物之间的一种非一一对应的关系,例如家庭收入和 支出、子女身高和父母身高之间的关系等。相关关系又分为线性相关和非线性相关。 相关分析和回归分析都是分析客观事物之间相关关系的数量分析方法。 6.2 相关分析 相关分析通过图形和数值两种方式,有效地揭示事物之间相关关系的强弱程度和形式。 6.2.1 散点图 它将数据以点的的形式画在直角坐标系上,通过观察散点图能够直观的发现变量间的相关关系及他们的强弱程度和方向。 6.2.2 相关系数 利用相关系数进行变量间线性关系的分析通常需要完成以下两个步骤: 第一,计算样本相关系数r; ●相关系数r的取值在-1~+1之间 ●R>0表示两变量存在正的线性相关关系;r<0表示两变量存在负的线性相关关 系 ●R=1表示两变量存在完全正相关;r=-1表示两变量存在完全负相关;r=0表 示两变量不相关 ●|r|>0.8表示两变量有较强的线性关系;|r|<0.3表示两变量之间的线性关系较 弱 第二,对样本来自的两总体是否存在显著的线性关系进行推断。 对不同类型的变量应采用不同的相关系数来度量,常用的相关系数主要有Pearson简单相关系数、Spearman等级相关系数和Kendall τ相关系数等。 6.2.2.1 Pearson简单相关系数(适用于两个变量都是数值型的数据) Pearson简单相关系数的检验统计量为: 6.2.2.2 Spearman等级相关系数 Spearman等级相关系数用来度量定序变量间的线性相关关系,设计思想与Pearson简 x y,而是利单相关系数相同,只是数据为非定距的,故计算时并不直接采用原始数据(,) i i