老黎石墨建模工具-Graphite Modeling Tools-Align教程

石墨建模工具-Graphite Modeling Tools 教程
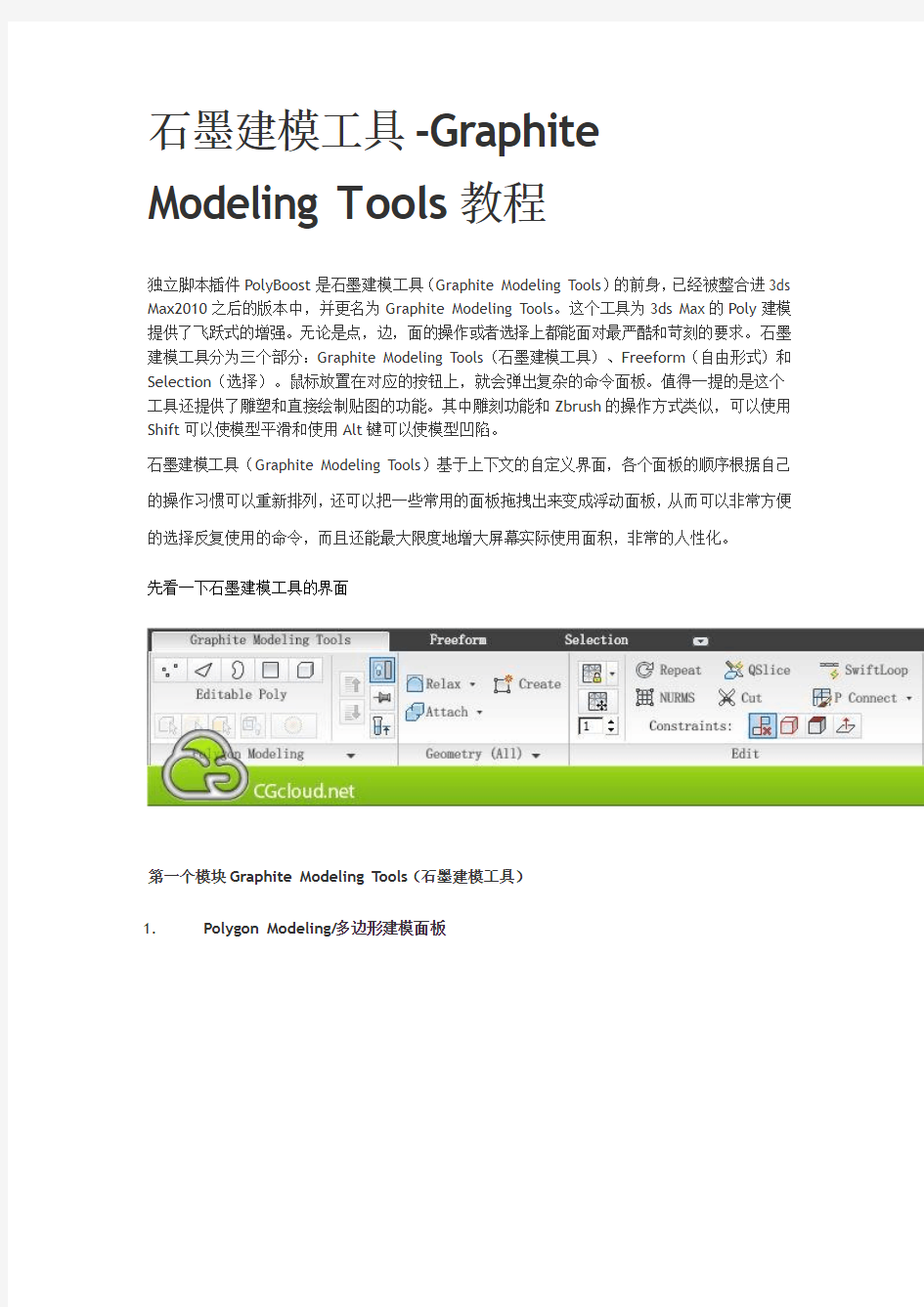
独立脚本插件 PolyBoost 是石墨建模工具 (Graphite Modeling Tools) 的前身, 已经被整合进 3ds Max2010 之后的版本中,并更名为 Graphite Modeling Tools。这个工具为 3ds Max 的 Poly 建模 提供了飞跃式的增强。无论是点,边,面的操作或者选择上都能面对最严酷和苛刻的要求。石墨 建模工具分为三个部分:Graphite Modeling Tools(石墨建模工具)、Freeform(自由形式)和 Selection(选择)。鼠标放置在对应的按钮上,就会弹出复杂的命令面板。值得一提的是这个 工具还提供了雕塑和直接绘制贴图的功能。其中雕刻功能和 Zbrush 的操作方式类似,可以使用 Shift 可以使模型平滑和使用 Alt 键可以使模型凹陷。 石墨建模工具(Graphite Modeling Tools)基于上下文的自定义界面,各个面板的顺序根据自己 的操作习惯可以重新排列, 还可以把一些常用的面板拖拽出来变成浮动面板, 从而可以非常方便 的选择反复使用的命令,而且还能最大限度地增大屏幕实际使用面积,非常的人性化。 先看一下石墨建模工具的界面
第一个模块 Graphite Modeling Tools(石墨建模工具) 1. Polygon Modeling/多边形建模面板
?
| 顶点子物体层级/Vertex
与 MAX 自身修改命令面板上的顶点子对象按钮的选择转化和功能是一样的,相互关联。
?
| 边子物体层级/Edge
与 MAX 自身修改命令面板上的边子物体按钮的选择转化和功能是一样的,相互关联。边与边界 子物体层级兼容,所以可在二者之间切换,将保留所有现有选择。
?
| 边界子物体层级/Border
与 MAX 自身修改命令面板上的边界子物体按钮的选择转化和功能是一样的,相互关联。边与边 界子物体层级兼容,所以可在二者之间切换,将保留所有现有选择。
?
| 多边形子物体层级/Polygon
与 MAX 自身修改命令面板上的多边形子对象按钮的选择转化和功能是一样的,相互关联。多边 形与元素子物体层级兼容,所以可在二者之间切换,将保留所有现有选择。
?
| 元素子对象层级/Element
与 MAX 自身修改命令面板上的元素子对象按钮的选择转化和功能是一样的,相互关联。多边形 与元素子物体层级兼容,所以可在二者之间切换,将保留所有现有选择。
?
| Editable poly
这个只不过起到一个显示作用, 显示当前选中模型所激活的修改器名称。 没有选中任何多边形模 型时,这栏不会显示在面板上。
?
| 预览关闭/Preview Off
在物体层级, 没有选择任何子物体层级时此按钮无效, 只有选中多边形模型的某个子物体层级时 有效。关闭所有子物体层级所选的内容。
?
| 预览子对象/Preview SubObject
在物体层级, 没有选择任何子物体层级时此按钮无效, 只有选中多边形模型的某个子物体层级时 有效。可预览当前子物体层级上一次所选择的内容,比如在顶点子物体层级上选中一些顶点,点 此按钮可以被显示出来。但我觉得此按钮是多余的,MAX 自身的子物体层级切换也会自动显示 出来。
?
| 预览多个/Preview Multi
在物体层级, 没有选择任何子物体层级时此按钮无效, 只有选中多边形模型的某个子物体层级时 有效。可预览所有子物体层级上一次所选择的内容。比如在顶点子物体层级上选中一些顶点,再 在边子物体层级上选中一些边,再在多边形子物体层级上选中一些面,MAX 会自动保存这次所 选的点边面,点此按钮可以显示刚选中的点边面。
?
| 忽略背面/Ignore Backfacing
与 MAX 自身的 Ignore Backfacing 是一样的,相互关联。启用后,选中某个子物体层级时,只能 选中你能看得到的那些点边面。
?
| 使用软选择/Use Soft Selection
开启后,石墨工具上的软选择命令面板被显示出来。关于这个命令面板的介绍在下面。与 MAX 自身的软选择功能相关联。
?
| 下一个修改器/Next Modifier
上移堆栈,当选中的多边形模型没有修改器或激活在最上端的修改器时,此按钮失效。相当于在 修改器堆栈中单击当前修改器的上一个修改器。
?
| 上一个修改器/Previous Modifier
下移堆栈,当选中的多边形模型没有修改器或激活在最下端的修改器时,此按钮失效。相当于在 修改器堆栈中单击当前修改器的下一个修改器。
?
| 切换命令面板/Toggle Command Panel
命令面板的可见性的开关。
?
| 锁定堆栈/Pin Stack
与 MAX 自身的 Pin Stack 是一样的,相互关联。将堆栈中的某个修改器锁定,以后再选这个物体 时,在堆栈中的修改器还是保持在刚才选中的状态。
?
| 显示最终结果(关闭/打开)/Show End Result
显示在堆栈中所有修改完毕后出现的选定对象,与您当前在堆栈中的位置无关。禁用此切换时, 对象将显示为对堆栈中的当前修改器所做的最新修改。与 MAX 自身的相关联。
?
| 塌陷堆栈/Collapse Stack
与 MAX 自身的 Collapse All(塌陷全部)是一样的,将选定对象的整个堆栈塌陷到当前编辑模式, 并保留累加修改后的最终效果。比如选中的模型是网格编辑(Editable Mesh)模式,那塌陷后 结果也是网络编辑模式。
?
| 转换到多边形/Convert to Poly
与塌陷堆栈差不多,区别在于不论哪种编辑模式都将选定模型的整个堆栈塌陷到多边形编辑 (Editable Poly)模式,并保留累加修改后的最终效果。比如选中的模型是网格编辑(Editable Mesh)模式,那塌陷后结果是多边形编辑(Editable Poly)模式。
?
| 应用编辑多边形模式/Apply Edit Poly Mod
在选中的多边形模型所激活的修改器上方增加一个多边形编辑(Edit Poly)修改器。
?
| 生成拓扑/Genetate Topology
使用生成拓扑会弹出对话框,有 20 种预设和 1 种自定义碎化的拓扑类型,快速更改选中多边形 模型的布线排列。
01
墙/Wall:生成的布线有大小不同的方形砖块排列结构。可以连续使用此工具。
02
拼贴/Tiles1:生成的布线有大小相对均匀的砖块排列结构。可以连续使用此工具。
03
砖块/Bricks:生成的布线类似砖块状的排列结构。使用此按钮必需选择一条边, 横向的还是纵向的,这样才可以确定砖块结构的方向。不可以连续使用此工具。
04
蜂窝/Hive:生成的布线类似蜂巢状的排列结构。使用此按钮必需选择一条边,横 向的还是纵向的,这样才可以确定蜂窝状结构的方向。不可以连续使用此工具。
05
拼贴/Tiles2:生成的布线有大小相对均匀的砖块排列结构。可以连续使用此工具。
06
马赛克/Mosaic:生成的布线包含不同大小的随机砖石类似马赛克的排列结构。
07
地板/Floor1:生成的布线类似木地板的排列结构。
08
地板/Floor2:生成的布线类似木地板的排列结构。
09
蒙皮/Skin:生成的布线也象是马赛克又象是两栖类动物皮肤。可以连续使用此工 具。
10
孔洞/Holer:生成的布线有大小不同的孔洞。可以连续使用此工具。
11
菱形/Diamond:生成的布线方向为规则的对角线排列结构。可以连续使用此工具。
12
简化/Simplify:生成的布线通过移除随机部位某些边的区域保留不动,而达到简 化的布线。可以连续使用此工具。
13
混乱/Chaos:生成的布线完全混乱不规则的排列结构。可以连续使用此工具。
14
四边形/Fours:生成的布线有大小不同的四边形排列结构。可以连续使用此工具。
15
星形/Stars:生成的布线类似平滑后星形的排列结构。可以连续使用此工具。
16
交叉/Cross:生成的布线像是十字交叉的排列结构。可以连续使用此工具。
17
板/Planks1:生成的布线有大小不同的板类排列结构。可以连续使用此工具。
18
板/Planks2:生成的布线较宽的板类排列结构。可以连续使用此工具。
19
板/Planks3:生成的布线比较均匀的板类排列结构。可以连续使用此工具。
20
板/Planks4:生成的布线比较长的板类排列结构。可以连续使用此工具。
碎化/Tatter:生成的布线有大小不同的多边形分隔的孔洞。大小/Size:确定生 成孔的总体大小;迭代次数/Iterations:确定生成孔时使用多少种不同的大小。 平滑/Smooth:确定生成孔的圆形度。参数调完后,再点下碎化图标就可以产生 效果了。 扔弃顶点/ScrapVerts:移除多边形模型中其延伸出 2 条边的所有顶点。 Plane:创建一个多边形编辑(Editable Poly)模式的平面物体,可以快速的测 试这个“生成拓扑”工具里面的不同工具。“S”参数的值确定将要创建平面物体中 片段数量。
? … ?
| 对称工具/Sysmmetry Tools
完全交互/Full Interactivity
这里的完全交互的意思是实时更新,当你修改参数设置时,效果一直会显示最终结果。
Polygon Modeling/多边形建模面板这里讲完了,有什么问题希望 CG 爱好者踊跃提出,我会修 改完善。 下一篇讲几何体(全部)/Geometry(All)
石墨建模工具-Graphite Modeling Tools-Geometry(All) 教程
2.几何体(全部)/Geometry(All)
先看一下界面
这个命令面板对选择子物体层级的不同而有所变化,我觉得这个命令面板最重要的是四边化命 令,其它命令 MAX 自身都有,而且相互关联。
?
| 松驰/Relax
对选中多边形模型上相邻的顶点之间进行平均位移。 当制作的模型不平滑或布线不均匀时, 可以 使用此命令,使模型更加平滑,但简模或没有边界的模型不太使用这个松驰命令,会改变模型的 外轮廓。这个命令对所有的子物体层级都有效,而且支持针对局部选中的内容(顶点、边、边界、 多边形、元素)进行计算。与 MAX 自身的 Relax 命令是完全一样的。按住 Shfit+鼠标左键点中 松驰命令或点中松驰命令旁边的小三角形下拉的 Relax settings(松驰设置)命令弹出对话框, 如图:
数量/Amount:控制当前选中多边形模型将要移动每次迭代次数的顶点程度。也就是说顶点的 原始位置到相邻顶点之间的距离进行平均化的百分比值。默认为 0.5,0.5=50×100%。 迭代次数/Iterations:设置顶点与顶点之间距离的平均化位置的次数。对于每一次迭代来说都需 要重新计算顶点的平均位置, 重新将要松弛的值应用到当前选中多边形模型上的每一个顶点。 默 认值为 1。 保留边界点/Hold Boundary Points:开启这个命令对当前选中多边形模型边界上的顶点不参加 计算。默认设置是启用。去掉前面的勾,则计算当前选中多边形模型上的所有顶点,会较大程度 的改变你的模型轮廓。 保留外部点/Hold Outer Points:启用此选项后,保留距离对象中心最远的顶点的原始位置。 下面是几不同参数所显示的不同结果
原始模型
默认值
数量:0.5;迭代次数:4 留边界点
数量:0.5;迭代次数:4;禁用保
数量:0.5;迭代次数:4;启用保留外部点
?
| 结合/Attach
将场景中其他物体结合到当前选中的多边形物体中,变成一个物体。使用此命令后,单击一个其 他物体可将其结合到选当前选中的多边形物体中。 结合完毕后此命令还处于激活状态, 退出此命 令按鼠标右键或 ESC 键或再点一个此命令。此命令可以结合样条线、片面物体和 NURBS 曲面。 与 MAX 自身的 Attach 功能是完全一样的。 结合物体时,两个对象的材质可以采用以下几种方式进行组合: 1.如果正要被结合进来的物体没有分配材质, 那么这个物体的材质会继承当前选中的多边形的材 质。 2.如果当前选中的物体没有分配材质,正要被结合进来的模型也没有分配材质的话,也会继承当 前选中物体没有分配材质的状态。 3.如果两个物体有各自不同的材质,会生成一个新的多维/子物体材质。这时会显示结合选项的 对话框,其中提供了三种组合物体材质和材质 ID 的方法。如图:
匹配材质 ID 到材质/Match Material IDs to Material:修改结合物体材质的 ID 数量,使得它们 不大于指定到这些对象上的子材质的数目。例如,如果只为一个长方体指定了两个子材质,并且 将该长方体附加到另一个对象上,那么长方体就只有两个材质 ID,而不是在创建时所指定的六 个。 匹配材质到材质 ID/Match Material to Material IDs:通过调整所获得的多维/子对象材质的子 材质数目,来保持附加对象的原始 ID 指定不变。例如,如果附加两个长方体,它们都只指定了 一个材质,但是它们的默认指定为 6 个材质 ID,这样就产生了含有 12 个子对象的多维/子对
象材质(六个含有一个长方体材质的实例,六个含有另一个长方体材质的实例)。当保持几何体 中的原始材质 ID 非常重要时,请使用此选项。 不修改材质 ID 或材质/Do Not Modify Mat IDs or Material:不调整所得子对象材质的子材质数 目。请注意,如果一个对象上的材质 ID 数目大于其多维/子对象材质的子材质数目,那么在附 加后所得到的面材质指定可能会不一样。 精简材质和 ID/Condense Material and IDs:这个选项只针对”匹配材质 ID 到材质/Match Material IDs to Material“,对其他二个选项不起作用。影响“匹配材质 ID 到材质”选项。启用该 选项后, 在对象上不使用的复制子材质或子材质将从附加操作所得到的多维/子对象材质上移除。 默认设置为启用。
当要结合很多物体时,一个个结合进来比较麻烦,把要结合的物体全部选中,按 Alt+Tab 键隔离 显示, 再按 Shfit+鼠标左键点中这个结合命令或点中结合命令旁边的小三角形下拉的 Attach List (结合列表)命令弹出对话框,在列表中全选所有物体就可以了。
?
| 分离/Detach
将当前选中多边形模型的子对象(顶点、边、边界、多边形、元素)进行单独物体和元 素分离的处理。 当要做分离处理的时候会弹出一个分离选项对话框,如图:
分离到元素/Detach To Element:启用此项时,选择物体上某些面进行分离时,这些选 择的面与其它面断开,形成第二个元素。 克隆分离/Detach As Clone:启用此项时,在当前选中的子物体克隆一个位置相同的单 独新物体,当前选中的模型不任何修改。当子物体层级选的是顶点、边或边界时,克隆 出来的单独新物体是根据该相连到整个面进行分离。
?
| 创建/Create
这个命令最主要创建新的多边形物体,创建出来的多边形模型会成为当前选中多边形模 型的子物体。使用的方式取决于激活哪一个物体层级。 物体级别、多边形层级和元素层级允许在活动视口中添加多边形。启用“创建”之后,在 任意位置(包括物体上的顶点)单击鼠标三次或更多次数,以定义新的多边形形状。要 结束,单击右键。
?
| 塌陷/Collapse
通过将其顶点与选择中心的顶点焊接,使连续选定子对象的组产生塌陷。此命令支持所 有子物体层级。
选择不相连的区域顶点,以各自的区域塌陷到中心点上
选择不相连的区域面,以各自的区域塌陷到中心点上。
选择一个方向的一组圈线,塌陷到以这组圈线的各个中心点上,连成一条中心线。
?
| 封口多边形/Cap Poly
这个命令最主要用来补洞的,类似 MAX 自带的修改器 Edit Poly 边界子物体层级里面的 Cap 命令和 Bridge 命令, 只不过这个命令还支持顶点子物体层级和边子物体层级下操作, 不支持多边形子物体层级和元素子物体下操作。
数据库建模经验总结
数据库如何建模 笔者从98年进入数据库及数据仓库领域工作至今已经有近八年的时间,对数据建模工作接触的比较多,创新性不敢谈,本文只是将工作中的经验总结出来,供大家一同探讨和指正。 提起数据建模来,有一点是首先要强调的,数据建模师和DBA有着较大的不同,对数据建模师来说,对业务的深刻理解是第一位的,不同的建模方法和技巧是为业务需求来服务的。而本文则暂时抛开业务不谈,主要关注于建模方法和技巧的经验总结。 从目前的数据库及数据仓库建模方法来说,主要分为四类。 第一类是大家最为熟悉的关系数据库的三范式建模,通常我们将三范式建模方法用于建立各种操作型数据库系统。 第二类是Inmon提倡的三范式数据仓库建模,它和操作型数据库系统的三范式建模在侧重点上有些不同。Inmon的数据仓库建模方法分为三层,第一层是实体关系层,也即企业的业务数据模型层,在这一层上和企业的操作型数据库系统建模方法是相同的;第二层是数据项集层,在这一层的建模方法根据数据的产生频率及访问频率等因素与企业的操作型数据库系统的建模方法产生了不同;第三层物理层是第二层的具体实现。 第三类是Kimball提倡的数据仓库的维度建模,我们一般也称之为星型结构建模,有时也加入一些雪花模型在里面。维度建模是一种面向用户需求的、容易理解的、访问效率高的建模方法,也是笔者比较喜欢的一种建模方式。 第四类是更为灵活的一种建模方式,通常用于后台的数据准备区,建模的方式不拘一格,以能满足需要为目的,建好的表不对用户提供接口,多为临时表。
下面简单谈谈第四类建模方法的一些的经验。 数据准备区有一个最大的特点,就是不会直接面对用户,所以对数据准备区中的表进行操作的人只有ETL工程师。ETL工程师可以自己来决定表中数据的范围和数据的生命周期。下面举两个例子: 1)数据范围小的临时表 当需要整合或清洗的数据量过大时,我们可以建立同样结构的临时表,在临时表中只保留我们需要处理的部分数据。这样,不论是更新还是对表中某些项的计算都会效率提高很多。处理好的数据发送入准备加载到数据仓库中的表中,最后一次性加载入数据仓库。 2)带有冗余字段的临时表 由于数据准备区中的表只有自己使用,所以建立冗余字段可以起到很好的作用而不用承担风险。 举例来说,笔者在项目中曾遇到这样的需求,客户表{客户ID,客户净扣值},债项表{债项ID,客户ID,债项余额,债项净扣值},即客户和债项是一对多的关系。其中,客户净扣值和债项余额已知,需要计算债项净扣值。计算的规则是按债项余额的比例分配客户的净扣值。这时,我们可以给两个表增加几个冗余字段,如客户表{客户ID,客户净扣值,客户余额},债项表{债项ID,客户ID,债项余额,债项净扣值,客户余额,客户净扣值}。这样通过三条SQL就可以直接完成整个计算过程。将债项余额汇总到客户余额,将客户余额和客户净扣值冗余到债项表中,在债项表中通过(债项余额×客户净扣值/客户余额)公式即可直接计算处债项净扣值。
数学建模常用软件
数学建模常用软件有哪些哈 MatlabMathematicalingoSAS详细介绍:数学建模软件介绍一般来说学习数学建模,常用的软件有四种,分别是:matlab、lingo、Mathematica和SAS下面简单介绍一下这四种。 1.MA TLAB的概况MA TLAB是矩阵实验室(Matrix Laboratory)之意。除具备卓越的数值计算能力外,它还提供了专业水平的符号计算,文字处理,可视化建模仿真和实时控制等功能。MATLAB的基本数据单位是矩阵,它的指令表达式与数学,工程中常用的形式十分相似,故用MATLAB来解算问题要比用C,FORTRAN等语言完相同的事情简捷得多. 当前流行的MA TLAB 5.3/Simulink 3.0包括拥有数百个内部函数的主包和三十几种工具包(Toolbox).工具包又可以分为功能性工具包和学科工具包.功能工具包用来扩充MATLAB的符号计算,可视化建模仿真,文字处理及实时控制等功能.学科工具包是专业性比较强的工具包,控制工具包,信号处理工具包,通信工具包等都属于此类. 开放性使MATLAB广受用户欢迎.除内部函数外,所有MA TLAB主包文件和各种工具包都是可读可修改的文件,用户通过对源程序的修改或加入自己编写程序构造新的专用工具包. 2.Mathematica的概况Wolfram Research 是高科技计算机运算( Technical computing )的先趋,由复杂理论的发明者Stephen Wolfram 成立于1987年,在1988年推出高科技计算机运算软件Mathematica,是一个足以媲美诺贝尔奖的天才产品。Mathematica 是一套整合数字以及符号运算的数学工具软件,提供了全球超过百万的研究人员,工程师,物理学家,分析师以及其它技术专业人员容易使用的顶级科学运算环境。目前已在学术界、电机、机械、化学、土木、信息工程、财务金融、医学、物理、统计、教育出版、OEM 等领域广泛使用。Mathematica 的特色·具有高阶的演算方法和丰富的数学函数库和庞大的数学知识库,让Mathematica 5 在线性代数方面的数值运算,例如特征向量、反矩阵等,皆比Matlab R13做得更快更好,提供业界最精确的数值运算结果。·Mathematica不但可以做数值计算,还提供最优秀的可设计的符号运算。·丰富的数学函数库,可以快速的解答微积分、线性代数、微分方程、复变函数、数值分析、机率统计等等问题。·Mathematica可以绘制各专业领域专业函数图形,提供丰富的图形表示方法,结果呈现可视化。·Mathematica可编排专业的科学论文期刊,让运算与排版在同一环境下完成,提供高品质可编辑的排版公式与表格,屏幕与打印的自动最佳化排版,组织由初始概念到最后报告的计划,并且对txt、html、pdf 等格式的输出提供了最好的兼容性。·可与C、C++ 、Fortran、Perl、Visual Basic、以及Java 结合,提供强大高级语言接口功能,使得程序开发更方便。·Mathematica本身就是一个方便学习的程序语言。Mathematica提供互动且丰富的帮助功能,让使用者现学现卖。强大的功能,简单的操作,非常容易学习特点,可以最有效的缩短研发时间。 3.lingo的概况LINGO则用于求解非线性规划(NLP—NON—LINEAR PROGRAMMING)和二次规则(QP—QUARATIC PROGRAMING)其中LINGO 6.0学生版最多可版最多达300个变量和150个约束的规则问题,其标准版的求解能力亦再10^4量级以上。虽然LINDO和LINGO不能直接求解目标规划问题,但用序贯式算法可分解成一个个LINDO和LINGO能解决的规划问题。模型建立语言和求解引擎的整合LINGO是使建立和求解线性、非线性和整数最佳化模型更快更简单更有效率的综合工具。LINGO提供强大的语言和快速的求解引擎来阐述和求解最佳化模型。■简单的模型表示LINGO可以将线性、非线性和整数问题迅速得予以公式表示,并且容易阅读、了解和修改。■方便的数据输入和输出选择LINGO建立的模型可以直接从数据库或工作表获取资料。同样地,LINGO可以将求解结果直接输出到数据库或工作表。■强大的求解引擎LINGO内建的求解引擎有线性、非线性(convex and nonconvex)、二次、二次
Powerdesigner数据库建模--概念模型--ER图
目标: 本文主要介绍PowerDesigner中概念数据模型CDM的基本概念。 一、概念数据模型概述 数据模型是现实世界中数据特征的抽象。数据模型应该满足三个方面的要求:1)能够比较真实地模拟现实世界 2)容易为人所理解 3)便于计算机实现 概念数据模型也称信息模型,它以实体-联系(Entity-RelationShip,简称E-R)理论为基础,并对这一理论进行了扩充。它从用户的观点出发对信息进行建模,主要用于数据库的概念级设计。 通常人们先将现实世界抽象为概念世界,然后再将概念世界转为机器世界。换句话说,就是先将现实世界中的客观对象抽象为实体(Entity)和联系(Relationship),它并不依赖于具体的计算机系统或某个DBMS系统,这种模型就是我们所说的CDM;然后再将CDM转换为计算机上某个DBMS所支持的数据模型,这样的模型就是物理数据模型,即PDM。 CDM是一组严格定义的模型元素的集合,这些模型元素精确地描述了系统的静态特性、动态特性以及完整性约束条件等,其中包括了数据结构、数据操作和完整性约束三部分。 1)数据结构表达为实体和属性; 2)数据操作表达为实体中的记录的插入、删除、修改、查询等操作; 3)完整性约束表达为数据的自身完整性约束(如数据类型、检查、规则等)和数据间的参照完整性约束(如联系、继承联系等); 二、实体、属性及标识符的定义 实体(Entity),也称为实例,对应现实世界中可区别于其他对象的“事件”或“事物”。例如,学校中的每个学生,医院中的每个手术。 每个实体都有用来描述实体特征的一组性质,称之为属性,一个实体由若干个属性来描述。如学生实体可由学号、姓名、性别、出生年月、所在系别、入学年份等属性组成。 实体集(Entity Set)是具体相同类型及相同性质实体的集合。例如学校所有学生的集合可定义为“学生”实体集,“学生”实体集中的每个实体均具有学号、姓名、性别、出生年月、所在系别、入学年份等性质。 实体类型(Entity Type)是实体集中每个实体所具有的共同性质的集合,例如“患者”实体类型为:患者{门诊号,姓名,性别,年龄,身份证号.............}。实体是实体类型的一个实例,在含义明确的情况下,实体、实体类型通常互换使用。
建模工具用户手册
明源建模工具操作手册目录 第一章如何使用建模工具 1 1.1 建模工具环境要求 1 1.2 建模工具使用概述 1 第二章表 4 2.1 新建表 4 2.2 设计表 7 2.3 预览数据 8 2.4 删除表 10 第三章查询 11 3.1 新建查询 11 3.2 修改查询 23 3.3 删除查询 23 第四章实体 23 4.1 新建实体 23 4.2 修改实体 28
4.3 删除实体 29 第五章高级管理 30 5.1 对象浏览器 30 5.2 导入导出 31 5.3 日志浏览器 35 第六章其它 36 6.1 快捷键 36 6.2 附录 37 本书使用的符号解释: “”大项说明——用于无先后顺序的明细条目的说明。 “”小项说明——用于在大项下无先后次序的小项说明 “ ” 提示——这个图标提醒您,如果您想把事情做的好些,就要牢记这些信息。 “ ”警告——如果您想避免不必要的损失,就要牢记这些信息
第一章如何使用建模工具 该工具用于CRM的数据建模需要,实现数据层的业务对象定义。支持用户或项目实施人员对实体对象的维护。 1.1 建模工具环境要求 目前建模工具支持CRM管理系统。对系统配置要求如下: 1.2 建模工具使用概述 打开建模工具,弹出数据库配置,如图: 图1-1
【窗口说明】 ● 服务器地址:建模工具连接的服务器地址,服务器地址可以是IP地址或者机器名 ● 数据库:服务器中需要维护的数据库名称 ● 登录名:服务器SQL Server名称 ● 密码:服务器SQL Server登录密码 输入数据库配置信息后,点击登录;打开建模工具操作窗口,如图: 图1-2 【菜单】 图1-3 ● 文件:点击文件,如图:
数据建模目前有两种比较通用的方式
数据建模目前有两种比较通用的方式1983年,数学建模作为一门独立的课程进入我国高等学校,在清华大学首次开设。1987年高等教育出版社出版了国内第一本《数学模型》教材。20多年来,数学建模工作发展的非常快,许多高校相继开设了数学建模课程,我国从1989年起参加美国数学建模竞赛,1992年国家教委高教司提出在全国普通高等学校开展数学建模竞赛,旨在“培养学生解决实际问题的能力和创新精神,全面提高学生的综合素质”。近年来,数学模型和数学建模这两个术语使用的频率越来越高,而数学模型和数学建模也被广泛地应用于其他学科和社会的各个领域。本文主要介绍了数学建模中常用的方法。 一、数学建模的相关概念 原型就是人们在社会实践中所关心和研究的现实世界中的事物或对象。模型是指为了某个特定目的将原型所具有的本质属性的某一部分信息经过简化、提炼而构造的原型替代物。一个原型,为了不同的目的可以有多种不同的模型。数学模型是指对于现实世界的某一特定对象,为了某个特定目的,进行一些必要的抽象、简化和假设,借助数学语言,运用数学工具建立起来的一个数学结构。 数学建模是指对特定的客观对象建立数学模型的过程,是现实的现象通过心智活动构造出能抓住其重要且有用的特征的表示,常常是形象化的或符号的表示,是构造刻画客观事物原型的数学模型并用以分析、研究和解决实际问题的一种科学方法。 二、教学模型的分类 数学模型从不同的角度可以分成不同的类型,从数学的角度,按建立模型的数学方法主要分为以下几种模型:几何模型、代数模型、规划模型、优化模型、微分方程模型、统计模型、概率模型、图论模型、决策模型等。 三、数学建模的常用方法 1.类比法 数学建模的过程就是把实际问题经过分析、抽象、概括后,用数学语言、数学概念和数学符号表述成数学问题,而表述成什么样的问题取决于思考者解决问题的意图。类比法建模一般在具体分析该实际问题的各个因素的基础上,通过联想、归纳对各因素进行分析,并且与已知模型比较,把未知关系化为已知关系,
实验一 数据库建模工具的使用
《数据库原理》实验报告 一、实验目的: 1、使用Powderdesigner建模工具完成本实验。 2、完成下列表中所描述数据库的概念数据模型设计,对关键字、空值、域完整性等做出必要的描 述,根据实际情况确定联系的类型。 3、依据所涉及的概念数据模型(CDM)生成相应的物理数据模型(PDM),可以对生成的物理数据模 型作必要的修改。 4、生成建立数据库的目标代码。 二、实验使用环境: SQL server 2012、Powerdesigne:16.5 三、实验内容与完成情况: 1.创建概念模型 客户与订购单是一对多的关系:一个客户可以有多个订购单,但是一个订购单只能属于一个客户订购单与产品是多对多的关系:一个产品可以有多个订购单,一个订购单也可以包括多个产品内容 2.属性数据类型 客户表:
产品表: 订购单表: 3.概念模型转换为物理模型 由于客户与订购单是一对多的关系,所以客户的主键(客户号)存在于订购单中做外键,加入订单日期由于订购单与产品是多对多的关系,所以订购单的主键(订单号)和产品的主键(产品号)存在于两者的关系订单明细中作为主键和外键,另外加入序号和数量作为
4.约束条件 客户号:前两个字符为字母 客户名称:不允许为空值: 邮政编码:6位数字字符 电话:数字字符 电子邮箱:包含@字符
产品号:前两个字符为字母 产品名称:值唯一 单价:>0 客户号:不允许空值
订购日期:默认是系统时间 序号:自增1,初值1 5.生成数据库脚本 得到商店.sql 脚本,见附件 新建数据库
测试结果: 连接数据源 导入数据库:
数据分析和数据建模
数据分析和数据建模 大数据应用有几个方面,一个是效率提升,帮助企业提升数据处理效率,降低数据存储成本。另外一个是对业务作出指导,例如精准营销,反欺诈,风险管理以及业务提升。过去企业都是通过线下渠道接触客户,客户数据不全,只能利用财务数据进行业务运营分析,缺少围绕客户的个人数据,数据分析应用的领域集中在企业内部经营和财务分析。 大数据应用有几个方面,一个是效率提升,帮助企业提升数据处理效率,降低数据存储成本。另外一个是对业务作出指导,例如精准营销,反欺诈,风险管理以及业务提升。过去企业都是通过线下渠道接触客户,客户数据不全,只能利用财务数据进行业务运营分析,缺少围绕客户的个人数据,数据分析应用的领域集中在企业内部经营和财务分析。 数字时代到来之后,企业经营的各个阶段都可以被记录下来,产品销售的各个环节也被记录下来,客户的消费行为和网上行为都被采集下来。企业拥有了多维度的数据,包括产品销售数据、客户消费数据、客户行为数据、企业运营数据等。拥有数据之后,数据分析成为可能,企业成立了数据分析团队整理数据和建立模型,找到商品和客户之间的关联关系,商品之间关联关系,另外也找到了收入和客户之间的关联关系。典型的数据分析案例如沃尔玛啤酒和尿布、蛋挞和手电筒,Target的判断16岁少女怀孕都是这种关联关系的体现。
关联分析是统计学应用最早的领域,早在1846年伦敦第二次霍乱期间,约翰医生利用霍乱地图找到了霍乱的传播途径,平息了伦敦霍乱,打败了霍乱源于空气污染说的精英,拯救了几万人的生命。伦敦霍乱平息过程中,约翰医生利用了频数分布分析,建立了霍乱地图,从死亡案例分布的密集程度上归纳出病人分布同水井的关系,从而推断出污染的水源是霍乱的主要传播途径,建议移除水井手柄,降低了霍乱发生的概率。 另外一个典型案例是第二次世界大战期间,统计分析学家改造轰炸机。英美联盟从1943年开始对德国的工业城市进行轰炸,但在1943年年底,轰炸机的损失率达到了英美联盟不能承受的程度。轰炸军司令部请来了统计学家,希望利用数据分析来改造轰炸机的结构,降低阵亡率,提高士兵生还率。统计学家利用大尺寸的飞机模型,详细记录了返航轰炸机的损伤情况。统计学家在飞机模型上将轰炸机受到攻击的部位用黑笔标注出来,两个月后,这些标注布满了机身,有的地方标注明显多于其他地方,例如机身和侧翼。有的地方的标注明显少于其他地方,例如驾驶室和发动机。统计学家让军火商来看这个模型,军火商认为应该加固受到更多攻击的地方,但是统计学家建议对标注少的地方进行加固,标注少的原因不是这些地方不容易被击中,而是被击中的这些地方的飞机,很多都没有返航。这些标注少的地方被击中是飞机坠毁的一个主要原因。军火商按照统计学家的建议进行了飞机加固,大大提高了轰炸机返航的比率。以二战著名的B-17轰炸机为例,其阵亡率由26%降到了7%,帮助美军节约了几亿美金,大大提高了士兵的生还率。 一数据分析中的角色和职责 数据分析团队应该在科技部门内部还在业务部门内部一直存在争议。在业务部门内部,对数据场景比较了解,容易找到数据变现的场景,数据分析对业务提升帮助较大,容易出成绩。但是弊端是仅仅对自己部门的业务数据了解,分析只是局限独立的业务单元之内,在数据获取的效率上,数据维度和数据视角方面缺乏全局观,数据的商业视野不大,对公司整体业务的推动发展有限。业务部门的数据分析团队缺少数据技术能力,无法利用最新的大数据计算和分析技术,来实现数
28款经典数据库管理工具
1、MySQL Workbench MySQL Workbench是一款专为MySQL设计的ER/数据库建模工具。它是著名的数据库设计工具DBDesigner4的继任者。你可以用MySQL Workbench 设计和创建新的数据库图示,建立数据库文档,以及进行复杂的MySQL迁移MySQL Workbench是下一代的可视化数据库设计、管理的工具,它同时有开源和商业化的两个版本。该软件支持Windows和Linux系统,下面是一些该软件运行的界面截图:
2、数据库管理工具Navicat Lite Navicat TM是一套快速、可靠并价格相宜的资料库管理工具,大可使用来简化资料库的管理及降低系统管理成本。它的设计符合资料库管理员、开发人员及中小企业的需求。Navicat是以直觉化的使用者图形介面所而建的,让你可以以安全且简单的方式建立、组织、存取并共用资讯。 界面如下图所示:
Navicat提供商业版Navicat Premium和免费的版本Navicat Lite。免费版本的功能已经足够强大了。 Navicat支持的数据库包括MySQL、Oracle、SQLite、PostgreSQL和SQL Server等。
3、开源ETL工具Kettle Kettle是一款国外开源的etl工具,纯java编写,绿色无需安装,数据抽取高效稳定(数据迁移工具)。Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
?授权协议:LGPL ?开发语言:Java ?操作系统:跨平台 4、Eclipse SQL Explorer SQLExplorer是Eclipse集成开发环境的一种插件,它可以被用来从Eclipse 连接到一个数据库。 SQLExplorer插件提供了一个使用SQL语句访问数据库的图形用户接口(GUI)。通过使用SQLExplorer,你能够显示表格、表格结构和表格中的数据,以及提取、添加、更新或删除表格数据。 SQLExplorer同样能够生成SQL脚本来创建和查询表格。所以,与命令行客户端相比,使用SQLExplorer可能是更优越的选择,下图是运行中的界面,很好很强大。
数据库概念设计及数据建模(一)有答案
数据库概念设计及数据建模(一) 一、选择题 1. 数据库概念设计需要对一个企业或组织的应用所涉及的数据进行分析和组织。现有下列设计内容 Ⅰ.分析数据,确定实体集 Ⅰ.分析数据,确定实体集之间的联系 Ⅰ.分析数据,确定每个实体集的存储方式 Ⅰ.分析数据,确定实体集之间联系的基数 Ⅰ.分析数据,确定每个实体集的数据量 Ⅰ.分析数据,确定每个实体集包含的属性 以上内容不属于数据库概念设计的是______。 A.仅Ⅰ、Ⅰ和Ⅰ B.仅Ⅰ和Ⅰ C.仅Ⅰ、Ⅰ和Ⅰ D.仅Ⅰ和Ⅰ 答案:D [解答] 数据库概念设计主要是理解和获取引用领域中的数据需求,分析,抽取,描述和表示清楚目标系统需要储存和管理什么数据,这些数据共有什么样的属性特征以及组成格式,数据之间存在什么样的依赖关系,同时也要说明数据的完整性与安全性。而数据的储存方式和数据量不是概念设计阶段所考虑的。 2. 关于数据库概念设计阶段的工作目标,下列说法错误的是______。 A.定义和描述应用系统设计的信息结构和范围
B.定义和描述应用系统中数据的属性特征和数据之间的联系 C.描述应用系统的数据需求 D.描述需要存储的记录及其数量 答案:D [解答] 数据库概念设计阶段的工作目标包括定义和描述应用领域涉及的数据范围;获取应用领域或问题域的信息模型;描述清楚数据的属性特征;描述清楚数据之间的关系;定义和描述数据的约束;说明数据的安全性要求;支持用户的各种数据处理需求;保证信息模型方便地转换成数据库的逻辑结构(数据库模式),同时也便于用户理解。 3. 需求分析阶段的文档不包括______。 A.需求说明书 B.功能模型 C.各类报表 D.可行性分析报告 答案:D [解答] 数据库概念设计的依据是需求分析阶段的文档;包括需求说明书、功能模型(数据流程图或IDEF0图)以及在需求分析阶段收集到的应用领域或问题域中的各类报表等,因此本题答案为D。 4. 数据库概念设计的依据不包括______。
免费的数据库建模工具
免费的数据库建模工具 对于数据模型的建模,最有名的要数ERWin和PowerDesigner,基本上,PowerDesigner 是在中国软件公司中他是非常有名的,其易用性、功能、对流行技术框架的支持、以及它的模型库的管理理念,都深受设计师们喜欢。PowerDesigner是我一直以来非常喜欢的一个设计工具,对于它,我可以用两个字来形容,那就是我能驾驭这个工具! 现在所在的公司自上市以来,对软件版权问题看得非常重,公司从上市以后,对软件的版权做了一些相应的规定,不允许使用破解的软件,软件只能使用开源的、免费的、或者共享的软件!所用软件必须公司注册的!没办法,我也只能放弃我多年的喜好,转向开源、免费的领域! 数据库物理建模是在软件设计当中必不可少的环节,数据库建得怎么样,关系到以后整个系统的扩展、性能方面的优化以及后期的维护。使用一个数据建模工具是非常必须的。那在开源或免费的领域,有没有比较好的工具呢?其实是有很多的,只是开源这一块,功能上、易用性上没有商业软件那么好用! 现在介绍几个相对比较好用的工具: 第一个:ERDesigner NG 官方网址是:https://www.360docs.net/doc/2c12344520.html,/?Welcome:ERDesigner_NG 属于sourceforge的一个开源产品,目前版本为1.4 以下是官方所描述的: 程序代码 The Mogwai ERDesigner is a entity relation modeling tool such as ERWin and co. The only difference is that it is Open Source and does not cost anything. It was designed to make database modeling as easy as it can be and to support the developer in the whole development process, from database design to schema and code generation. This tool was also designed to support a flexible plug in architecture, to extend the system simply by installing a new plug in. This way, everybody can implement new featur es and tools to make ERDesigner fit the requirements.
数据库建模工具2
二、实体、属性及标识符的定义 实体(Entity),也称为实例,对应现实世界中可区别于其他对象的“事件”或“事物”。例如,学校中的每个学生,医院中的每个手术。 每个实体都有用来描述实体特征的一组性质,称之为属性,一个实体由若干个属性来描述。如学生实体可由学号、姓名、性别、出生年月、所在系别、入学年份等属性组成。 实体集(Entity Set)是具体相同类型及相同性质实体的集合。例如学校所有学生的集合可定义为“学生”实体集,“学生”实体集中的每个实体均具有学号、姓名、性别、出生年月、所在系别、入学年份等性质。 实体类型(Entity Type)是实体集中每个实体所具有的共同性质的集合,例如“患者”实体类型为:患者{门诊号,姓名,性别,年龄,身份证号.............}。实体是实体类型的一个实例,在含义明确的情况下,实体、实体类型通常互换使用。 实体类型中的每个实体包含唯一标识它的一个或一组属性,这些属性称为实体类型的标识符(Identifier),如“学号”是学生实体类型的标识符,“姓名”、“出生日期”、“信址”共同组成“公民”实体类型的标识符。 有些实体类型可以有几组属性充当标识符,选定其中一组属性作为实体类型的主标识符,其他的作为次标识符。 目标: 本文主要介绍PowerDesigner中概念数据模型 CDM的基本概念。 一、概念数据模型概述 数据模型是现实世界中数据特征的抽象。数据模型应该满足三个方面的要求:1)能够比较真实地模拟现实世界 2)容易为人所理解 3)便于计算机实现 概念数据模型也称信息模型,它以实体-联系(Entity-RelationShip,简称E-R)理论为基础,并对这一理论进行了扩充。它从用户的观点出发对信息进行建模,主要用于数据库的概念级设计。 通常人们先将现实世界抽象为概念世界,然后再将概念世界转为机器世界。换句话说,就是先将现实世界中的客观对象抽象为实体(Entity)和联系(Relationship),它并不依赖于具体的计算机系统或某个DBMS系统,这种模型就是我们所说的CDM;然后再将CDM转换为计算机上某个DBMS所支持的数据模型,这样的模型就是物理数据模型,即PDM。 CDM是一组严格定义的模型元素的集合,这些模型元素精确地描述了系统的静态
数据建模总结
仓库管理系统总结 姓名:闫军 学号:1115115327
目录 引言 (3) 一、项目背景。 (3) 二、编写目的和意义。 (3) 三、软件定义。 (4) 四、数据字典 (5) 1.数据流 (5) 2.数据项 (5) 3.数据文件 (6) 五、仓库管理系统CDM模型 (8) 六、仓库管理系统LDM模型 (9) 七、仓库管理系统PDM模型 (10) 八、总结 (10)
引言 随着社会经济的迅速发展和科学技术的全面进步,计算机事业的飞速发展,以计算机及与通信技术为基础的信息系统正处于蓬勃发展的时期。各种仓库管理的方法也是日新月异。以前全是由人力管理的方法存在很多缺点,仓库的管理问题也就提上了日程。随着这种企事业单位产品和材料的大量增加,起管理难度也越来越大,如何优化仓库夫人日常管理也就成为了一个重要的课题。 在计算机飞速发展的今天,将计算机这一信息处理利器应用于仓库。的日常管理已经是势在必行,而且这也将为仓库管理带来前所未有的改变,它可以带来意想不到的效益,同时也会为企业飞速发展提供无限制的潜力。采用计算机管理信息系统已经成为仓库管理科学化和现代化的重要标志,它给企业带来了明显的经济效益和社会效益。主要体现在:极大的提高了仓库管理人员的工作效率,大大减少了以往入、出、存流程繁琐杂乱周期长的弊端。基于仓库管理的全面自动化,可以减少入库管理、出库管理和库存管理的漏洞。可以节约不少管理开支,增加企业收入。仓库管理的操作自动化和信息的电子化,全面提高了仓库的管理水平。 随着我国改革开放的不断深入,经济的飞速发展,企业要想生存发展,要想在激烈的市场竞争中立于不败之地,没有现代化的管理是万万不行的,仓库管理的全面自动化,信息化则是其中及其重要的部分。为了加快产库管理的自动化步伐,提高仓库管理业务的处理小效率,建立仓库管理系统已经变得十分必要。 一、项目背景。 企业的仓库物资管理往往是很复杂、很繁琐的。由于所掌握的物资种类众多,订货、管理、发放的渠道各有差异,各个企业之间的管理体制不尽相同,各类统计报表繁多,因此仓库的仓库管理必须编制一套仓库管理信息系统,实现计算机化操作,而且必须根据企业的具体情况制定相应的方案。 传统的商品由进货到发货,要经过若干环节,多次账面转抄,由于物品繁多,规格型号的标识繁多,加之业务人员素质的因素,易造成仓库供应效率低下,影响生产.;由于库房与管理部门之间存在信息难以交流。供应业务员、仓库保管员、计划员和有关领导相互之间信息流通困难,使得仓库供应效率低下,造成库存积压。使库存储备很大,影响资金周转。另外,使得仓库的管理数据的汇总,以及信息的传递困难;手抄的,手工作业容易造成失误,同时每月向上级单位所报报表需耗费相当大的人力资源进行大量数据计算,这将影响数据的准确率和效率,从而造成不必要的损失和浪费。 根据当前的企业管理体制,一般的仓库管理系统,总是根据所掌握的物资类别,相应分成几个科室来进行物资的计划,订货,核销托收,验收入库,根据企业各个部门的需求来发送物资设备,并随时按期进行仓库盘点,作台帐,根据企业领导和自身管理的需要按月、季度、年度进行统计分析,产生相应报表。为了加强关键物资、设备的管理,要定期掌握其储备,消耗情况,根据计划定额和实际纤毫定额的比较,进行定额管理,使得资金使用合理,物资设备的储备最佳。 仓库的仓库管理是整个物资供应管理系统的核心。因此有必要开发一套独立的仓库管理系统来提高企业工作效率,。而所使用的这套仓库管理系统是企业生产经营管理活动中的核心,此系统必须可以用来控制合理的仓库费用、适时适量的仓库数量,使企业生产活动效率最大化。通过对这些情况的仔细调查,我开发了下面的仓库仓库管理系统。 二、编写目的和意义。 项目开发目的:大多数仓库管理理论认为,库存是物理上和逻辑上库房库位的所有有形和无形物料
数据库建模
软件工程环境 综合实践结业论文—数据建模
1.1数据建模的基本概念 在设计数据库时,对现实世界进行分析、抽象、并从中找出内在联系,进而确定数据库的结构,这一过程就称为数据库建模。 数据建模中的三种模型的简介 a)概念模型 把现实世界中的客观对象抽象为某一种信息结构,这种信息结构并不依赖于具体的计算机系统,不是某一个数据库管理系统(DBMS)支持的数据模型,而是概念级的模型,成为概念模型。 b)逻辑模型 逻辑模型是对概念模型的扩展。不仅定义了描述概念模型中对象的相关属性,而且定义了对象之间的逻辑关系,比如:聚合、扩展。在数据仓库中,它关联着逻辑模型和物理模型两方。目前最流行就是关系模型也就是对应的关系数据库。常见的实体联系有:一对一联系,一对多联系,多对多联系。 c)物理模型 物理模型定义了数据的物理存储方式。通常是我们定义的一种数据库。如关系数据库中的一些对象为表、视图、字段、数据类型、长度、主键、外键、索引、约束、是否可为空、默认值。 1.2 MDA转化
模型驱动架构(MDA)的模型转换提供了一个完全可配置的方式将一个模型中的元素和模型片段从一个域转换到另一个域。这通常涉及到平台无关模型(PIM)元素转换成指定平台的模型(PSM)的元素。从单一的、平台独立的元素到可以负责创建跨多个域的多个平台相关的元素。也就是说从概念模型可以转化成任何语言的逻辑模型,没有平台的限制,例如:java、c++、c#等等,数据库建模的时候我们可以给它转化成具体的数据库管理系统。 a)定义配置转换 EA中提供了MDA转换模板,打开EA工具下的Tools目录下的MDA Transformation Templates,得到下图: 本文讲的是数据建模,因此我们选择DDL语言,在DDL转换中主要是将逻辑图中的类转化为物理存储系统中的表: 将类中Attribute转换为表的列:
最常用的数据模型
1.2.3 最常用的数据模型 最常用的数据模型包括四种: 注1:非关系模型在20世纪70-80年代很流行,现在逐步被关系模型取代。 注2:下面讲的数据模型都是指逻辑上的数据模型,即用户眼中看到的数据围。 一、层次模型 定义: ①有只有一个结点没有双亲结点,这个结点称为根结点; ②根以外的其他结点有且只有一个双亲结点。 代表产品:IBM公司的IMS(Information Management System)数据库管理系统。 1. 数据结构 基本结构 ①用树形结构来表示各类实体以及实体间的联系。 ②每个结点表示一个记录类型(实体),结点之间的连线表示记录类型间一对多的父子联系,这种联系只能是父子联系。 ③每个记录类型可包含若干个字段(属性)。 图1.12 教员学生层次数据库模型
图1.13 教员学生层次数据库的一个值 多对多联系在层次模型中的表示 ①必须首先将其分解成一对多联系。 ②分解方法有两种:冗余结点法和虚拟结点法。 图1.14(a) 一个学生选课的多对多联系 图1.14(b) 冗余结点法将多对多联系转化为一对多联系 图1.14(c) 虚拟结点法将多对多联系转化为一对多联系
2. 数据操作与完整性约束 数据操作:查询、插入、删除和修改。 完整性约束: ①插入:如果没有相应的双亲结点值就不能插入子女结点值。如:图1.13中,若新调入一名教师,在未分配到某个教研室以前,不能将新教员插入到数据库。 ②删除:如果删除双亲结点值,则相应的子女结点值也被同时删除。如:图1.9中,若删除网络教研室,需要首先删除属于网络教研室的所有教师的数据。 ③修改:应修改所有相应记录,以保证数据的一致性。如:图1.14(b)中,若一个学生要改,则两处学生记录值均要修改。 3. 存储结构 存储容:数据本身;数据之间的联系。 两种方法:邻接法;法。 图 1.15(a) 数据模型 图1.15(b) 数据值 图1.15(c) 邻接法存储
数据库常用名词解释大全
数据库常用名词解释 ◆DB:数据库(Database), DB是统一管理的相关数据的集合。DB能为各种用户共享,具有最小冗 余度,数据间联系密切,而又有较高的数据独立性。 ◆超键:在关系中能唯一标识元组的属性集称为关系模式的超键。(注意,超键是一个属性集) ◆候选键:不含有多余属性的超键称为候选键。 ◆主键:用户选作元组标识的一个候选键为主键。 ◆外键:某个关系的主键相应的属性在另一关系中出现,此时该主键在就是另一关系的外键,如 有两个关系S和SC,其中S#是关系S的主键,相应的属性S#在关系SC中也出现,此时S#就是关 系SC的外键。 ◆实体完整性规则:这条规则要求关系中元组在组成主键的属性上不能有空值。如果出现空值, 那么主键值就起不了唯一标识元组的作用。 ◆参照完整性规则:这条规则要求“不引用不存在的实体”。其形式定义如下:如果属性集K是 关系模式R1的主键,K也是关系模式R2的外键,那么R2的关系中,K的取值只允许有两种可能,或者为空值,或者等于R1关系中某个主键值。 这条规则在使用时有三点应注意: 1) 外键和相应的主键可以不同名,只要定义在相同值域上即可。 2) R1和R2也可以是同一个关系模式,表示了属性之间的联系。 3) 外键值是否允许空应视具体问题而定。 ◆过程性语言:在编程时必须给出获得结果的操作步骤,即“干什么”和“怎么干”。如Pascal 和C语言等。 ◆非过程性语言:编程时只须指出需要什么信息,不必组出具体的操作步骤的语言,各种关系查 询语言均属于非过程性语言。 ◆无限关系:当一个关系中存在无穷多个元组时,此关系为无限关系。如元组表达式{t|┐R(t)}表 示所有不在关系R中的元组的集合,这是一个无限关系。 ◆无穷验证:在验证公式时需对无穷多个元组进行验证就是无穷验证。如验证公式(∨u)(P(u))的真 假时需对所有的元组u进行验证,这是一个无穷验证的问题。
SAP BW数据建模分析
数据建模分析 1.建立模型前应该想到的问题。 1.1数据仓库的数据组织是面向主题的,而不是报表。 操作型数据库的数据组织结构面向事物处理任务,各个业务系统之间各自分离,而数据仓库中的数据是按照一定的主题进行组织的。主题是一个抽象的概念,是指用户使用的数据仓库进行决策时所关心的重点方面,一个主题通常与多个操作型信息系统相关。 这和软件编程中的面向对象的概念类似,在项目中要面向一个功能模块的实现,不是面向一个方法的实现。在我们建模中,也是面向一个分析点的方面。 可以参照以下主题,来判断如何划分主题: !顾客的购买行为 !产品销售情况 !企业生产事物 !原料采购 !合作伙伴关系 !会计科目余额 但是现在的数据仓库实施中,很多数据仓库需求都是来自业务部门的出具的报表的需求,这样数据仓库的数据模型结构往往来源于报表的数据需求。 基于报表的需求要比没有明确的需求要好,所以现在大多数业务部门更多的是采用报表的需求方式来进行开发的,这样需求方和实施方都会拥有一个比较明确的界限和口径。 但是面向报表的开发不是最好的,而且有很多缺点。所以我们正确的做法是,要对现有的报表需求进行细致的分类,分析和调整,不能为了实现单个报表而进行大量的建模工作。要根据分析的不同内容和主题对报表进行分类,明确报表中每个数据的定义,统计口径及不同数据之间的关系,建立在
行归集,从而形成面向主题的数据类型。 例如:我们的利润表报表,当业务部门发我们一个利润表的报表,作为需求时,我们应该进行细致的分析,最终我们确定我们面向的主题不是利润表,而是比利润表更大的一个层次的所有科目业务量的主题,这样我们在做别的报表,例如资产负债表,现金流量表等报表时,就不用重复建模的工作了,做到了软件工程中的可重用规则。 1.2数据仓库要实现对数据的集成与数据的同构性。 面向事物处理的操作型数据库通常与某些特定的应用相关,数据库之间相互独立并且往往是异构的。而数据仓库中的数据是在对原有分散的数据库数据抽取,清理的基础上经过系统加工,汇总和整理得到的,必须消除源数据的不一致性,以保证数据仓库内的信息是关于整个企业的一致的全局信息。 例如:在总公司和分公司之间,某个部门id或公司id名字不一样,不是同构的,比如一个人家人叫他张三别人叫他小张,这种情况在数据库中一定会被认为是两个人,所以我们要建立统一的数据字典,来统一数据。 要实现数据的同构性,是一件复杂的工作,涉及到大量的数据转换工作和调研工作。在数据的获取阶段,要确保所有的数据来源是一致的,或者经过一定的处理后是一致的。如果数据来源不一样的,那么我们就有必要把数据来源信息也包含在数据仓库中,以便在后续的数据转换中对不同来源数据进行分析。 综上所述,我们在项目开始之前,要对现有数据建立统一的数据字典,交付品应该有一个《XXX数据字典》的文件。 1.3明确数据库历史数据和即时数据 操作型数据库主要关心当前某一个时间段的数据,而数据仓库中的数据通常包含历史信息,系统记录了企业从过去某一点到目前各个阶段的信息。通过这些信息,可以对企业的发展历程和未来趋势作出定量分析和预测。 但是数据仓库中还包括即时的数据分析需求,所以我们要安排好历史数据和即时数据以及明细数据之间的不同存储方式,采用不同的处理方法。根据业务分析需要进行数据存储划分,对不同的分析要求提供不同明细级别的数据基础。此外,还要对数据或信息的生命周期有良好的管理,安排好旧的归档工作。 2.sap bi项目流程和分析方法 2.1收集客户需求 用户的需求工作是一个非常关键的环节,因为用户的需求可能详细可能不明确,也可能会经常变动,所以建模之前要收集足够的信息,要对客户的需求进行深度挖掘。 2.1.1组织架构 这一方面不仅仅是报表本身需要的数据,还涉及到系统权限和报表发布等工作的需求。要了解各个部门的基本业务,业务流程,考核指标,担负职责。了解各个业务部门对内或对外的主要产品和服务。了解客户的以业务流程,明确bi应该展示的分析内容是正确建立模型的需要。一般情况下,客户都不能用技术术语去表达他们的需求,所以有时候需要在技术应用方面的
常用数据库建模工具
常用数据库建模工具 导语: 事实上,数据库建模是在软件设计当中必不可少的环节,数据库建得怎么样,关系到以后整个系统的扩展、性能方面的优化以及后期的维护。因此我们要学习如何设计数据库建模。这其中,可以使用专业的工具来设计制作。 免费获取免费数据库设计软件:https://www.360docs.net/doc/2c12344520.html,/software-diagram-tool/databasediagram/ 常用的数据库建模工具有哪些? 数据库建模工具可能你听得较多的是Visio,但其实国内有一款数据库建模工具也十分不错。亿图图示专家是一款非常实用的绘制实体关系图、Chen-ERD 图、ORM图、数据库模型图、Express-G图以及Martin ERD图的工具。亿图软件内置了大量的标准实体关系符号及各种工具,可以更加快速的创建ER模型图,在功能上可以媲美微软的Visio。
配置需求: Windows 7, 8, 10, XP, Vista, Citrix Mac OSX 10.10+ Linux Debian, Ubuntu, Fedora, CentOS, OpenSUSE, Mint, Knoppix, RedHat, Gentoo及更多 用亿图图示设计数据库E-R图有哪些优势? 1、亿图软件内置了大量的模型图符号和模型图模板,以及更多的在线模板,可快速创建实体关系模型图即ER模型图。 2、通过拖拽就能简单的说明实体关系图,操作十分简单、智能化。 3、连接线可自动吸附到图形上,让绘图更加的轻松、快捷。 4、内置丰富的模板和实例,以及更多的网页在线模板,可免费下载使用。 5、可以通过浮动按钮,快速对文字、图形属性进行修改,比如:字体、大小、颜色、边框类型、图层位置、对齐方式等等。 6、在不删除原有图形的基础上,只需选中该图形,然后点击浮动按钮的替换图形即可。