pET28a全序列
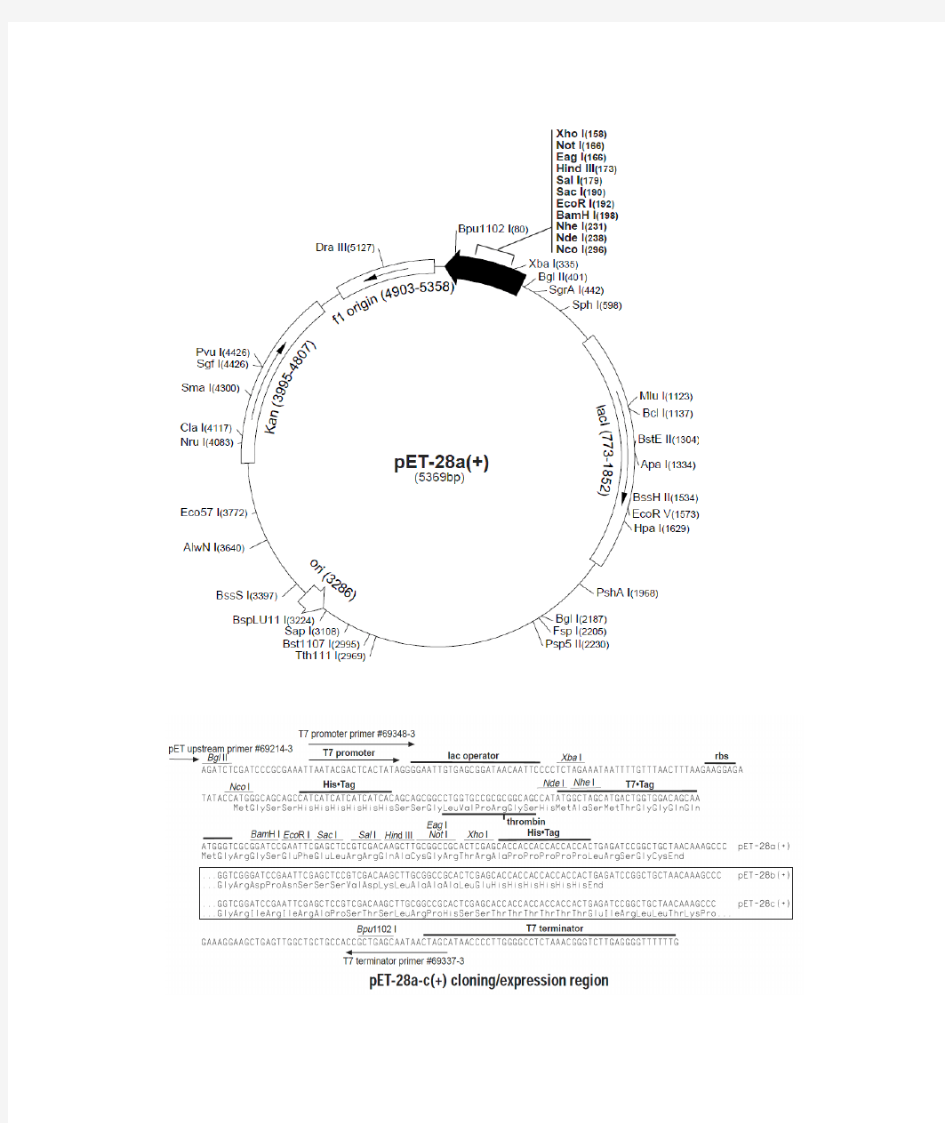

1 ATCCGGATAT AGTTCCTCCT TTCAGCAAAA AACCCCTCAA GACCCGTTTA
51 GAGGCCCCAA GGGGTTATGC TAGTTATTGC TCAGCGGTGG CAGCAGCCAA 101 CTCAGCTTCC TTTCGGGCTT TGTTAGCAGC CGGATCTCAG TGGTGGTGGT 151 GGTGGTGCTC GAGTGCGGCC GCAAGCTTGT CGACGGAGCT CGAATTCGGA 201 TCCGCGACCC ATTTGCTGTC CACCAGTCAT GCTAGCCATA TGGCTGCCGC 251 GCGGCACCAG GCCGCTGCTG TGATGATGAT GATGATGGCT GCTGCCCATG 301 GTATATCTCC TTCTTAAAGT TAAACAAAAT TATTTCTAGA GGGGAATTGT 351 TATCCGCTCA CAATTCCCCT ATAGTGAGTC GTATTAATTT CGCGGGATCG 401 AGATCTCGAT CCTCTACGCC GGACGCATCG TGGCCGGCAT CACCGGCGCC 451 ACAGGTGCGG TTGCTGGCGC CTATATCGCC GACATCACCG ATGGGGAAGA 501 TCGGGCTCGC CACTTCGGGC TCATGAGCGC TTGTTTCGGC GTGGGTATGG 551 TGGCAGGCCC CGTGGCCGGG GGACTGTTGG GCGCCATCTC CTTGCATGCA 601 CCATTCCTTG CGGCGGCGGT GCTCAACGGC CTCAACCTAC TACTGGGCTG 651 CTTCCTAATG CAGGAGTCGC ATAAGGGAGA GCGTCGAGAT CCCGGACACC 701 ATCGAATGGC GCAAAACCTT TCGCGGTATG GCATGATAGC GCCCGGAAGA 751 GAGTCAATTC AGGGTGGTGA ATGTGAAACC AGTAACGTTA TACGATGTCG 801 CAGAGTATGC CGGTGTCTCT TATCAGACCG TTTCCCGCGT GGTGAACCAG 851 GCCAGCCACG TTTCTGCGAA AACGCGGGAA AAAGTGGAAG CGGCGATGGC
901 GGAGCTGAAT TACATTCCCA ACCGCGTGGC ACAACAACTG GCGGGCAAAC 951 AGTCGTTGCT GATTGGCGTT GCCACCTCCA GTCTGGCCCT GCACGCGCCG 1001 TCGCAAATTG TCGCGGCGAT TAAATCTCGC GCCGATCAAC TGGGTGCCAG 1051 CGTGGTGGTG TCGATGGTAG AACGAAGCGG CGTCGAAGCC TGTAAAGCGG 1101 CGGTGCACAA TCTTCTCGCG CAACGCGTCA GTGGGCTGAT CATTAACTAT 1151 CCGCTGGATG ACCAGGATGC CATTGCTGTG GAAGCTGCCT GCACTAATGT 1201 TCCGGCGTTA TTTCTTGATG TCTCTGACCA GACACCCATC AACAGTATTA 1251 TTTTCTCCCA TGAAGACGGT ACGCGACTGG GCGTGGAGCA TCTGGTCGCA 1301 TTGGGTCACC AGCAAATCGC GCTGTTAGCG GGCCCATTAA GTTCTGTCTC 1351 GGCGCGTCTG CGTCTGGCTG GCTGGCATAA ATATCTCACT CGCAATCAAA 1401 TTCAGCCGAT AGCGGAACGG GAAGGCGACT GGAGTGCCAT GTCCGGTTTT 1451 CAACAAACCA TGCAAATGCT GAATGAGGGC ATCGTTCCCA CTGCGATGCT 1501 GGTTGCCAAC GATCAGATGG CGCTGGGCGC AATGCGCGCC ATTACCGAGT 1551 CCGGGCTGCG CGTTGGTGCG GATATCTCGG TAGTGGGATA CGACGATACC 1601 GAAGACAGCT CATGTTATAT CCCGCCGTTA ACCACCATCA AACAGGATTT 1651 TCGCCTGCTG GGGCAAACCA GCGTGGACCG CTTGCTGCAA CTCTCTCAGG 1701 GCCAGGCGGT GAAGGGCAAT CAGCTGTTGC CCGTCTCACT GGTGAAAAGA 1751 AAAACCACCC TGGCGCCCAA TACGCAAACC GCCTCTCCCC GCGCGTTGGC 1801 CGATTCATTA ATGCAGCTGG CACGACAGGT TTCCCGACTG GAAAGCGGGC 1851 AGTGAGCGCA ACGCAATTAA TGTAAGTTAG CTCACTCATT AGGCACCGGG 1901 ATCTCGACCG ATGCCCTTGA GAGCCTTCAA CCCAGTCAGC TCCTTCCGGT 1951 GGGCGCGGGG CATGACTATC GTCGCCGCAC TTATGACTGT CTTCTTTATC 2001 ATGCAACTCG TAGGACAGGT GCCGGCAGCG CTCTGGGTCA TTTTCGGCGA 2051 GGACCGCTTT CGCTGGAGCG CGACGATGAT CGGCCTGTCG CTTGCGGTAT 2101 TCGGAATCTT GCACGCCCTC GCTCAAGCCT TCGTCACTGG TCCCGCCACC 2151 AAACGTTTCG GCGAGAAGCA GGCCATTATC GCCGGCATGG CGGCCCCACG 2201 GGTGCGCATG ATCGTGCTCC TGTCGTTGAG GACCCGGCTA GGCTGGCGGG 2251 GTTGCCTTAC TGGTTAGCAG AATGAATCAC CGATACGCGA GCGAACGTGA 2301 AGCGACTGCT GCTGCAAAAC GTCTGCGACC TGAGCAACAA CATGAATGGT 2351 CTTCGGTTTC CGTGTTTCGT AAAGTCTGGA AACGCGGAAG TCAGCGCCCT 2401 GCACCATTAT GTTCCGGATC TGCATCGCAG GATGCTGCTG GCTACCCTGT 2451 GGAACACCTA CATCTGTATT AACGAAGCGC TGGCATTGAC CCTGAGTGAT 2501 TTTTCTCTGG TCCCGCCGCA TCCATACCGC CAGTTGTTTA CCCTCACAAC 2551 GTTCCAGTAA CCGGGCATGT TCATCATCAG TAACCCGTAT CGTGAGCATC 2601 CTCTCTCGTT TCATCGGTAT CATTACCCCC ATGAACAGAA ATCCCCCTTA 2651 CACGGAGGCA TCAGTGACCA AACAGGAAAA AACCGCCCTT AACATGGCCC 2701 GCTTTATCAG AAGCCAGACA TTAACGCTTC TGGAGAAACT CAACGAGCTG 2751 GACGCGGATG AACAGGCAGA CATCTGTGAA TCGCTTCACG ACCACGCTGA 2801 TGAGCTTTAC CGCAGCTGCC TCGCGCGTTT CGGTGATGAC GGTGAAAACC 2851 TCTGACACAT GCAGCTCCCG GAGACGGTCA CAGCTTGTCT GTAAGCGGAT 2901GCCGGGAGCAGACAAGCCCG TCAGGGCGCG TCAGCGGGTG TTGGCGGGTG 2951 TCGGGGCGCA GCCATGACCC AGTCACGTAG CGATAGCGGA GTGTATACTG 3001 GCTTAACTAT GCGGCATCAG AGCAGATTGT ACTGAGAGTG CACCATATAT 3051 GCGGTGTGAA ATACCGCACA GATGCGTAAG GAGAAAATAC CGCATCAGGC
3101 GCTCTTCCGC TTCCTCGCTC ACTGACTCGC TGCGCTCGGT CGTTCGGCTG 3151 CGGCGAGCGG TATCAGCTCA CTCAAAGGCG GTAATACGGT TATCCACAGA 3201 ATCAGGGGAT AACGCAGGAA AGAACATGTG AGCAAAAGGC CAGCAAAAGG 3251 CCAGGAACCG TAAAAAGGCC GCGTTGCTGG CGTTTTTCCA TAGGCTCCGC 3301 CCCCCTGACG AGCATCACAA AAATCGACGC TCAAGTCAGA GGTGGCGAAA 3351 CCCGACAGGA CTATAAAGAT ACCAGGCGTT TCCCCCTGGA AGCTCCCTCG 3401 TGCGCTCTCC TGTTCCGACC CTGCCGCTTA CCGGATACCT GTCCGCCTTT 3451 CTCCCTTCGG GAAGCGTGGC GCTTTCTCAT AGCTCACGCT GTAGGTATCT 3501 CAGTTCGGTG TAGGTCGTTC GCTCCAAGCT GGGCTGTGTG CACGAACCCC 3551 CCGTTCAGCC CGACCGCTGC GCCTTATCCG GTAACTATCG TCTTGAGTCC 3601 AACCCGGTAA GACACGACTT ATCGCCACTG GCAGCAGCCA CTGGTAACAG 3651 GATTAGCAGA GCGAGGTATG TAGGCGGTGC TACAGAGTTC TTGAAGTGGT 3701 GGCCTAACTA CGGCTACACT AGAAGGACAG TATTTGGTAT CTGCGCTCTG 3751 CTGAAGCCAG TTACCTTCGG AAAAAGAGTT GGTAGCTCTT GATCCGGCAA 3801 ACAAACCACC GCTGGTAGCG GTGGTTTTTT TGTTTGCAAG CAGCAGATTA 3851 CGCGCAGAAA AAAAGGATCT CAAGAAGATC CTTTGATCTT TTCTACGGGG 3901 TCTGACGCTC AGTGGAACGA AAACTCACGT TAAGGGATTT TGGTCATGAA 3951 CAATAAAACT GTCTGCTTAC ATAAACAGTA ATACAAGGGG TGTTATGAGC 4001 CATATTCAAC GGGAAACGTC TTGCTCTAGG CCGCGATTAA ATTCCAACAT 4051 GGATGCTGAT TTATATGGGT ATAAATGGGC TCGCGATAAT GTCGGGCAAT 4101 CAGGTGCGAC AATCTATCGA TTGTATGGGA AGCCCGATGC GCCAGAGTTG 4151 TTTCTGAAAC ATGGCAAAGG TAGCGTTGCC AATGATGTTA CAGATGAGAT 4201 GGTCAGACTA AACTGGCTGA CGGAATTTAT GCCTCTTCCG ACCATCAAGC 4251 ATTTTATCCG TACTCCTGAT GATGCATGGT TACTCACCAC TGCGATCCCC 4301 GGGAAAACAG CATTCCAGGT ATTAGAAGAA TATCCTGATT CAGGTGAAAA 4351 TATTGTTGAT GCGCTGGCAG TGTTCCTGCG CCGGTTGCAT TCGATTCCTG 4401 TTTGTAATTG TCCTTTTAAC AGCGATCGCG TATTTCGTCT CGCTCAGGCG 4451 CAATCACGAA TGAATAACGG TTTGGTTGAT GCGAGTGATT TTGATGACGA 4501 GCGTAATGGC TGGCCTGTTG AACAAGTCTG GAAAGAAATG CATAAACTTT 4551 TGCCATTCTC ACCGGATTCA GTCGTCACTC ATGGTGATTT CTCACTTGAT 4601 AACCTTATTT TTGACGAGGG GAAATTAATA GGTTGTATTG ATGTTGGACG 4651 AGTCGGAATC GCAGACCGAT ACCAGGATCT TGCCATCCTA TGGAACTGCC 4701 TCGGTGAGTT TTCTCCTTCA TTACAGAAAC GGCTTTTTCA AAAATATGGT 4751 ATTGATAATC CTGATATGAA TAAATTGCAG TTTCATTTGA TGCTCGATGA
4801 GTTTTTCTAA GAATTAATTC ATGAGCGGAT ACATATTTGA ATGTATTTAG
4851 AAAAATAAAC AAATAGGGGT TCCGCGCACA TTTCCCCGAA AAGTGCCACC 4901 TGAAATTGTA AACGTTAATA TTTTGTTAAA ATTCGCGTTA AATTTTTGTT
4951 AAATCAGCTC ATTTTTTAAC CAATAGGCCG AAATCGGCAA AATCCCTTAT
5001 AAATCAAAAG AATAGACCGA GATAGGGTTG AGTGTTGTTC CAGTTTGGAA 5051 CAAGAGTCCA CTATTAAAGA ACGTGGACTC CAACGTCAAA GGGCGAAAAA 5101 CCGTCTATCA GGGCGATGGC CCACTACGTG AACCATCACC CTAATCAAGT 5151 TTTTTGGGGT CGAGGTGCCG TAAAGCACTA AATCGGAACC CTAAAGGGAG 5201 CCCCCGATTT AGAGCTTGAC GGGGAAAGCC GGCGAACGTG GCGAGAAAGG 5251 AAGGGAAGAA AGCGAAAGGA GCGGGCGCTA GGGCGCTGGC AAGTGTAGCG
5301 GTCACGCTGC GCGTAACCAC CACACCCGCC GCGCTTAATG CGCCGCTACA 5351 GGGCGCGTCC CATTCGCCA
分子生物学 常用引物序列
日常备库引物序列(5'-3') 1492R GGTTACCTTGTTACGACTT 27F\8F AGAGTTTGATCCTGGCTCA 35S GACGCACAATCCCACTATCC 3'AD AGATGGTGCACGATGCACAG 3'AOX\AOX1rev GGCAAATGGCATTCTGACAT 3'BD TAAGAGTCACTTTAAAATTTGTATAC 5'AD\GAL4AD\P17110 TACCACTACAATGGATGATG 5'AOX\AOX1for GACTGGTTCCAATTGACAAGC 5'BD\GAL4-BD-Cfor TCATCGGAAGAGAGTAG 96gIII\M13-96 CCCTCATAGTTAGCGTAACG a-FACTOR\Alphafor TACTATTGCCAGCATTGCTGC BAC1 AACCATCTCGCAAATAAATA BAC2 ACGCACAGAATCTAGCGCTT BGH\pCDNA3.1R TAGAAGGCACAGTCGAGG CMV-24 TTAGGACAAGGCTGGTGG CMV-30 ATAACCCCGCCCCGTTG CMV-F\CMV-Profor CGCAAATGGGCGGTAGGCGTG\ATGGGCGGTAGGCGT G CMV-R TCGTTGGGCGGTCAGC DuetDOWN1 GATTATGCGGCCGTGTACAA DuetUP1 GATCTCGACGCTCTCCCT DuetUP2 TTGTACACGGCCGCATAATC EBVrev GTGGTTTGTCCAAACTCATC EGFP-Cfor AGCACCCAGTCCGCCCTGAGC EGFP-Nrev CGTCGCCGTCCAGCTC GAL1-Profor AACATTTTCGGTTTGTATTACTTC GLP1 TGTATCTTATGGTACTGTAACTG GLP2 CTTTATGTTTTTGGCGTCTTCCA
测序引物设计指南
测序引物设计指南 ?P CR引物设计方法: 1.引物最好在模板cDNA的保守区内设计。 DNA序列的保守区是通过物种间相似序列的比较确定的。在NCBI上搜索不同物种的同一基因,通过序列分析软件(比如DNAman)比对(Alignment),各基因相同的序列就是该基因的保守区。 2.引物长度一般在15~30碱基之间。 引物长度(primerlength)常用的是18-27bp,但不应大于38,因为过长会导致其延伸温度大于74℃,不适于TaqDNA 聚合酶进行反应。 3.引物GC含量在40%~60%之间,Tm值最好接近72℃。 GC含量(composition)过高或过低都不利于引发反应。上下游引物的GC含量不能相差太大。另外,上下游引物的Tm值(meltingtemperature)是寡核苷酸的解链温度,即在一定盐浓度条件下,50%寡核苷酸双链解链的温度。有效启动温度,一般高于Tm值5~10℃。若按公式Tm=4(G+C)+2(A+T)估计引物的Tm值,则有效引物的Tm为55~80℃,其Tm值最好接近72℃以使复性条件最佳。 4.引物3′端要避开密码子的第3位。 如扩增编码区域,引物3′端不要终止于密码子的第3位,因密码子的第3位易发生简并,会影响扩增的特异性与效率。 5.引物3′端不能选择A,最好选择T。 引物3′端错配时,不同碱基引发效率存在着很大的差异,当末位的碱基为A时,即使在错配的情况下,也能有引发链的合成,而当末位链为T时,错配的引发效率大大降低,G和C错配的引发效率介于A、T之间,所以3′端最好选择T。 6.碱基要随机分布。 引物序列在模板内应当没有相似性较高,尤其是3’端相似性较高的序列,否则容易导致错误引发(Falsepriming)。降低引物与模板相似性的一种方法是,引物中四种碱基的分布最好是随机的,不要有聚嘌呤或聚嘧啶的存在。尤其3′端不应超过3个连续的G或C,因这样会使引物在GC富集序列区错误引发。 7.引物自身及引物之间不应存在互补序列。 引物自身不应存在互补序列,否则引物自身会折叠成发夹结构(Hairpin)使引物本身复性。这种二级结构会因空间位阻而影响引物与模板的复性结合。引物自身不能有连续4个碱基的互补。 两引物之间也不应具有互补性,尤其应避免3′端的互补重叠以防止引物二聚体(Dimer与Crossdimer)的形成。引物之间不能有连续4个碱基的互补。 引物二聚体及发夹结构如果不可避免的话,应尽量使其△G值不要过高(应小于4.5kcal/mol)。否则易导致产生引物二聚体带,并且降低引物有效浓度而使P CR反应不能正常进行。
常用的β-actin 引物序列
human actin f ctc cat cct ggc ctc gct gt human actin r gct gtc acc ttc acc gtt cc product size:268 rabbit actin r agt gcg acg tgg aca tcc g rabbit actin f tgg ctc taa cag tcc gcc tag product size:295 mouse actin r cgt tga cat ccg taa aga cc mouse actin f aac agt ccg cct aga agc ac product size:281 rat actin f TCAGGTCATCACTATCGGCAAT rat actin r AAAGAAAGGGTGTAAAACGCA product size:432 human actin r gag cta cga gct gcc tga cg human actin f cct aga agc att tgc ggt gg product size:416 mouse actin f tca tca cta ttg gca acg agc mouse actin r aac agt ccg cct aga agc ac product size:399 rat actin f CCCATCTATGAGGGTTACGC rat actin r TTTAATGTCACGCACGATTTC product size:150 rabbit actin f tct tcc agc cct cct tcc tg rabbit actin r cgt ttc tgc gcc gtt agg t product size:409 内参基因名称引物引物最佳退火扩增 基因库序列号引物名称序列位置Tm 温度C 长度 Human actin beta F305 ctgggacgacatggagaaaa 305-324 52.3 BC002409 R868 aaggaaggctggaagagtgc 868-849 52.6 59.4 564 F1379 agcgagcatcccccaaagtt 1379-1398 57.3 R1663 gggcacgaaggctcatcatt 1663-1644 56.3 54 285 Rat actin beta F18 cacccgcgagtacaaccttc 18-37 54.5 NM_031144 R224 cccatacccaccatcacacc 224-205 54.4 60.4 207 F694 gagagggaaatcgtgcgtgac 694-714 54 R1146 catctgctggaaggtggaca 1146-1127 53.2 57.1 452 Mouse actin beta F91 atatcgctgcgctggtcgtc 91-110 57.5 NM_007393 R607 aggatggcgtgagggagagc 607-588 57.8 60.4 517 F1566 gtccctcaccctcccaaaag 1566-1585 54.5 F1831 gctgcctcaacacctcaaccc 1831-1811 54.4 55.7 266 human GAPDH F369 agaaggctggggctcatttg 369-388 55.6 BC004109 R626 aggggccatccacagtcttc 626-607 55.1 57.5 258
真菌检测鉴定通用引物-Fungal Primers
ITS1: 5’-CCGTAGGTGAACCTGCGG-3’ ITS4:5’-TCCTCCGCTTATTGATATGC-3’ Tm 55℃ NS17: CATGTCTAAGTTTAAGCAA NS3: GCAAGTCTGGTGCCAGCAGCC NS4: CTTCCGTCAATTCCTTTAAG NS22: AATTAAGCAGACAAATCACT NS24: AAACCTTgTTACgACTTTTA LR0R: 5’-GTACCCGCTGAACTTAAGC-3’ LR3: 5’-CCGTGTTTCAAGACGGG LR3R: 5’-GTCTTGAAACACGGACC (complementary to RLR3R: GGTCCGTGTTTCAAGAC) LR5: 5’-TTAAAAAGCTCGTAGTTGAAC-3’ LR7: 5’-TACTACCACCAAGATCT LR12: 5’-GACTTAGAGGCGTTCAG Lr0R/LR5: Tm 50-52℃ NL1: 5’-GCATATCAATAAGCGGAGGAAAAG NL1: 5′-TGCGTTGATTACGTCCCTGC (also called V9: TGCGTTGATTACGTCCCTGC) NL1: 5’-TGCTGGAGCCATGGATC-3 NL2: 5’-CTCTCTTTTCAAAGTTCTTTTCATCT NL2: 5’-AACGGCTTCGACAACAGC-3 NL2: 5’-CTTGTTCGCTATCGGTCTC (also NL2A: 5′-CTTGTTCGCTATCGGTCTC) NL2: 5’-TACTTGTTCGCTATCGGTCT-3' NL3: 5’-GAGACCGATAGCGAACAAG (also NL3A: 5’-GAGACCGATAGCGAACAAG) NL3: 5’-AGACCGATAGCGAACAAGTA NL3: 5’ NL4: 5’(similar to RLR3R:5′-GGTCCGTGTTTCAAGAC) NL4: 5’-TAGATACATGGCGCAGTC-3
实验室常用缓冲液 常用引物序列汇总
实验常用试剂、缓冲液的配制方法 Na2HPO4,2 mM KH2PO4 1 M Tris-HCl 、11M Tris-HCl □组份浓度 □配制量□配制量1L 1L (pH7.4,7.6,8.0) □配置方法1. 称量下列试剂,置于1L烧杯中。烧杯中。□配置方法1. 称量121.1gTris置于1L NaCl 加入约800mL的去离子水,充分搅拌溶解。 8 g 2. KCl 0.2g 3. 按下表量加入浓盐酸调节所需要的pH值。 Na2HPO4 1.42 g 浓值 HCl pH KH2PO4 0.27g 7.4 约70mL 2. 向烧杯中加入约800 mL的去离子水,充分搅拌溶解。 7.6 约60mL 3. 滴加HCl将pH42mL 8.0 约值调节至7.4,然后加入去离子水将溶液定容至1L。 4. 将溶解定容至1L。 4. 高温高压灭菌后,室温保存。 5. 高温高压灭菌后,室温保存。注意:上述PBS Buffer中无二价阳离子,如需要,可在配方中pH注意:应使溶液冷却至室温后再调定pH值,因为Tris溶液的补充1mM CaCl2和0.5 mM MgCl2。pH值随温度的变化差很大,温度每升高1℃,溶液的值大约降低 6、10 M醋酸铵0.03个单位。□组份浓度10 M醋酸铵 □配制量100mL 1.5 M Tris-HCl 2、1.5 M Tris-HCl □组份浓度□配置方法1. 称量77.1g醋酸铵置于100~配制量pH8.8 ()□1L 200 mL烧杯中,加入约30 mL的去离子水搅拌溶解。1L1. □配置方法称取181.7gTris置于烧杯中。 2. 加入约800mL2.加去离子水将溶液定容至100mL。的去离子水,充分搅拌溶解。 3.使用8.8pH3. 用浓盐酸调值至。0.22μm滤膜过滤除菌。 4.密封瓶口于室温保存。。1L 4. 将溶液定容至 5. 高温高压灭菌后,室温保存。注意:醋酸铵受热易分解,所以不能高温高压灭菌。 7、Tris- HCl平衡苯酚□溶液的注意:应使溶液冷却至室温后再调定pH值,因为Tris配置方法 1. 使用原料:大多数市售液化苯酚是清亮无色的,pH值大约无需重蒸馏℃,溶液的值随温度的变化差异很大,温度每升高pH1便可用于分子生物学实验。0.03降低个单位。但有些液化苯酚呈粉红色或黄色,应避免使用。同时也应避免使用结晶苯酚,结晶苯酚必须在160℃对其,□TE Buffer、310×组份浓度100 mM Tris-HCl10 mM EDTA
人全外显子组序列捕获及第二代测序
人全外显子组序列捕获及第二代测序 概述 外显子组是指全部外显子区域的集合,该区域包含合成蛋白质所需要的重要信息,涵盖了与个体表型相关的大部分功能性变异。外显子组序列捕获及第二代测序是一种新型的基因组分析技术:外显子序列捕获芯片(或溶液)可在同一张芯片上以高特异性和高覆盖率捕获研究者感兴趣的目标外显子区域,后续利用Solexa/SOLiD/Roche 454测序直接解析数据。 与全基因组重测序相比,外显子组测序只需针对外显子区域的DNA 即可,覆盖度更深、数据准确性更高,更加简便、经济、高效。可用于寻找复杂疾病(如:癌症、糖尿病、肥胖症等)的致病基因和易感基因等的研究。同时,基于大量的公共数据库提供的外显子数据,我们能够结合现有资源更好地解释我们的研究结果。 目前,SBC提供的外显子组序列捕获芯片是NimbleGen Sequence Capture 2.1M Human Exome Array及Agilent SureSelect Target Enrichment System(Human Exome)。 技术路线 以Nimblegen外显子捕获结合Solexa测序为例加以说明:基因组DNA首先被随机打断成500bp左右的片段,随后在DNA片段两端分别连接上接头。经过PCR库检合格后的DNA 片段与NimbleGen 2.1M Human Exome Array芯片进行杂交。去除未与芯片结合的背景DNA 后,将经过富集的外显子区域的DNA片段洗脱下来。这些DNA片段又随机连接成长DNA片段
后,再次被随机打断并在其两端加上测序接头,经过LM-PCR的线性扩增,在经qPCR质量检测合格后即可上机测序。 外显子组测序的实验流程示意图(https://www.360docs.net/doc/2812557302.html,) 生物信息学分析流程图 研究内容 1.外显子组捕获与测序 将基因组DNA随机打断成片段,通过与人全外显子捕获芯片杂交富集外显子区域,通过第二代测序技术对捕获的序列进行测序。 2.基本数据分析 数据产出统计:对测序结果进行图像识别(Base calling),去除污染及接头序列;统计结果包括:测定的序列(Reads)长度、Reads数量、数据产量。 3. 高级数据分析 高级数据分析内容包括: (1)Clean reads序列与参考基因组序列比对; (2)目标外显子区域测序深度分析; (3)目标外显子区域一致序列组装;
ISSR通用引物序列
ISSR通用引物序列
UBC Primer Set #9 (Microsatellite) 引物名称序列 801 ATA TAT ATA TAT ATA TT 802 ATA TAT ATA TAT ATA TG 803 ATA TAT ATA TAT ATA TC 804 TAT ATA TAT ATA TAT AA 805 TAT ATA TAT ATA TAT AC 806 TAT ATA TAT ATA TAT AG 807 AGA GAG AGA GAG AGA GT 808 AGA GAG AGA GAG AGA GC 809 AGA GAG AGA GAG AGA GG 810 GAG AGA GAG AGA GAG AT 811 GAG AGA GAG AGA GAG AC 812 GAG AGA GAG AGA GAG AA 813 CTC TCT CTC TCT CTC TT 814 CTC TCT CTC TCT CTC TA 815 CTC TCT CTC TCT CTC TG 816 CAC ACA CAC ACA CAC AT 817 CAC ACA CAC ACA CAC AA 818 CAC ACA CAC ACA CAC AG 819 GTG TGT GTG TGT GTG TA 820 GTG TGT GTG TGT GTG TC
821 GTG TGT GTG TGT GTG TT 822 TCT CTC TCT CTC TCT CA 823 TCT CTC TCT CTC TCT CC 824 TCT CTC TCT CTC TCT CG 825 ACA CAC ACA CAC ACA CT 826 ACA CAC ACA CAC ACA CC 827 ACA CAC ACA CAC ACA CG 828 TGT GTG TGT GTG TGT GA 829 TGT GTG TGT GTG TGT GC 830 TGT GTG TGT GTG TGT GG 831 ATA TAT ATA TAT ATA TYA 832 ATA TAT ATA TAT ATA TYC 833 ATA TAT ATA TAT ATA TYG 834 AGA GAG AGA GAG AGA GYT 835 AGA GAG AGA GAG AGA GYC 836 AGA GAG AGA GAG AGA GYA 837 TAT ATA TAT ATA TAT ART 838 TAT ATA TAT ATA TAT ARC 839 TAT ATA TAT ATA TAT ARG 840 GAG AGA GAG AGA GAG AYT 841 GAG AGA GAG AGA GAG AYC 842 GAG AGA GAG AGA GAG AYG
常见载体的测序引物
常见载体的测序引物: Primer of Vector: Vector:Primer(F);Primer(R) pACT T7 T3 pACT2 GAL4 AD pACT2-R pAS2-1 GAL4 BD pAS2-1.R pB42AD pB42ADF pB42ADR pBACPAK8 BAC1 BAC2 pBK-CMV T7 T3 PBS(SK/KS)/M13- M13F/T7 T3/M13R pBV220 PBV220F PBV220R pCAMBIA 1301(1300) P1 P2 pCAMBIA 2300 M13R(-48) M13F(-47) PCANTB5E S1/M13R S6 pCAT3-enhancer RVP3 此载体无反向引物pcDNA3.0 CMV-F/T7 SP6/BGH pcDNA3.1 T7 BGH pcDNA4 T7/CMV-F BGH pcDNA6 T7/CMV-F(J21025在T7前面)BGH pcDNAII T7 SP6 pCE2.1 M13F M13R pCEP4 pCEP-F EBV-R
pCF-T M13F M13R pCI T7(17Base)此载体无反向引物 pCI-neo T7(17Base)T3 pCMS-EGFP T7 T3 pCMV-3Tag-4A T3 /PFLAG-CMV-F T7 pCMV5 pCMV5F pCMV5R pCMV5-Flag pCMV5F pCMV5R pCMV-MYC/HA pCMV-F pCMV-R pCMV-Sport M13F/T7 SP6/M13R pCMV-Tag(KAN+) T3 T7 pCR2.1-TOPO M13F/T7 M13R pCR3.1 T7 BGH pCS2 SP6 T7 pDonar M13F M13R pDONR221 M13F M13R pDrive T7 SP6 pDRIveR(KAN+) T7 SP6 pDsRED1-C1 pDsRED-ex-C1-F pEGFP-N-3’(距离很近,一般不用) pDsRED2-C1(KAN+) pDsRED-ex-C1-F pEGFP-N-3’ pDSRED-N1(KAN+) pEGFP-N-5’ PDSRED-N-R pECFP-C pEGFP-C-5’ pECFP-C-3' pECFP-N1 pEGFP-N-5’ pEGFP-N-3’
Invitrogen中国测序通用引物序列
Invitrogen中国测序通用引物序列 引物名称序列(5'-3') M13R CAG GAA ACA GCT A TG ACC M13F TGT AAA ACG ACG GCC AGT M13F(-47) CGC CAG GGT TTT CCC AGT CAC GAC M13R(-48) AGC GGA TAA CAA TTT CAC ACA GGA M13(-96) CCC TCA TAG TTA GCG TAA CG SP6 A TT TAG GTG ACA CTA TAG T7 TAA TAC GAC TCA CTA TAG GG T7 terminator TGC TAG TTA TTG CTC AGC GG T3 A TT AAC CCT CAC TAA AGG GA pGEX-4T-5' GGG CTG GCA AGC CAC GTT TGG TG pGEX-4T-3' CCG GGA GCT GCA TGT GTC AGA GG GLp1 TGT A TC TTA TGG TAC TGT AAC TG GLp2 CTT TA T GTT TTT GGC GTC TTC CA RVp3 CTA GCA AAA TAG GCT GTC CC RVp4 GAC GA T AGT CA T GCC CCG CG pcDNA3.1R TAG AAG GCA CAG TCG AGG PinPoint primer CGT GAC GCG GTG CAG GGC G pCMV-F TCT AAA AGC TGC GGA A TT GT pCMV-R TCCAAACTCA TCAA TGTA TC pTRC99C-F: TTG CGC CGA CA T CA T AAC pTRC99C-R: CTGCGTTCTGA TTTAA TCTG pCEP-F: AGA GCT CGT TTA GTG AAC CG EBV-R : GTG GTT TGT CCA AAC TCA TC pIRES2-EGFP.P5’:GTA GGC GTG TAC GGT GGG AG pIRES2-EGFP.P3’: AAC GCA CAC CGG CCT TA T TC 3'AD: AGA TGG TGC ACG A TG CAC AG CMV -F CGC AAA TGG GCG GTA GGC GTG S1 CAA CGT GAA AAA A TT A TT A TT CGC S6 GTA AA T GAA TTT TCT GTA GTA GG 5`AOX1 GAC TGG TTC CAA TTG ACA AGC 3`AOX1 GCA AA T GGC A TT CTG ACA TCC α-Factor TAC TA T TGC CAG CA T TGC TGC GAL4 AD TAC CAC TAC AA T GGA TG pACT2-R GTGCACGA TGCACAGTTGAA pB42ADF: CCA GCC TCT TGC TGA GTG GAG A TG
常用的通用引物序列
常用之Universal Primer 序列 Primer Primer sequence Applicable vectors T7 TAATACGACTCACTATAGGG pGEM-T, pGEM-T-Easy, pCRII, pET, pBlueScript, pcDNA3.1, pT7Blue SP6 TATTTAGGTGACACTATAG pGEM-T, pGEM-T-Easy, pCRII T3 ATTAACCCTCACTAAAGGGA pBlueScript pUC/M13 Forward (-40) GTTTTCCCAGTCACGAC pUC, pGEM-T, pCRII, pBlueScript pUC/M13 Forward (-21) TGTAAAACGACGGCCAGT pUC, pCRII, pBlueScript pUC/M13 Reverse TCACACAGGAAACAGCTATGAC pUC, pGEM-T, pCRII, pBlueScript T7 Terminator GCTAGTTATTGCTCAGCGG pET pGEX 5’GGGCTGGCAAGCCACGTTTGGTG pGEX pGEX 3’CCGGGAGCTGCATGTGTCAGAGG pGEX pQEF GGCGTATCACGAGGCCCTTTCG pQE pQER CATTACTGGATCTATCAACAGG pQE polyhedrin F AAATGATAACCATCTCGCAA Stag GAACGCCAGCACATGGACAGC pET-4x BGH reverse TAGAAGGCACAGTCGAGG pcDNA3.1, pTracer-CMV 5’ AOX GACTGGTTCCAATTGACAAGC pPlCZα α-factor TATTGCCAGCATTGCTGC pPlCZα 3’ AOX GCAAATGGCATTCTGACATCC pPlCZα
RT-PCR常用引物序列
RT-PCR常用引物序列 RT-PCR引物序列基因来源引物序列产物大小(kb) β-actin 人有意义链CCTCG CCTTT GCCGA TCC 反义链GGA TC TTCAT GAGGT AGTCA GTC 0.62 kb β-actin* 大鼠有意义链TACAA CCTCC TTGCA GCTCC 反义链GGA TC TTCA T GAGGT AGTCA GTC 0.62kb β-actin 小鼠有意义链GTCGT ACCAC AGGCA TTGTG A TGG反义链GCAAT GCCTG GGTAC ATGGT GG 0.49 kb GAPDH 人有意义链GGTGA AGGTC GGAGT CAACG反义链CAAAG TTGTC ATGGA TGHACC 0.50kb GAPDH 大鼠有意义链GATGC TGGTG CTGAG TATGR CG反义链GTGGT GCAGG ATGCA TTGCT CTGA 0.20 kb Dynein 小鼠有意义链GCGGG CGCTG GAGGA GAA反义链GGA TC TTCA T GAGGT AGTCA GTC 12.3 kb Polymerase ε 人有意义链CGCCA AATTT CTCCC CTGAAA反义链CCGTA GTGCT GGGCA ATGTT C 6.8 kb Polymerase ε 人有意义链AAGGC TGGCG GATTA CTGCC反义链GA TGC TGCTG GTGAT GTACT C 3.5 kb Tuberous Sclerosis 人有意义链GGAGT TTATC ATCAC CGCGG AAATA CTGAG AG反义链TATTT CACTG ACAGG CAATA CCGTC CAAGG 5.3 kb 18S rRNA 大豆有意义链CTTTC GATGG TAGGA TAGTG GCCT反义链CAATG A TCCT TCCGC AGGTT CACCT AC 1.5 kb *引物不会扩增假基因 PCR引物序列基因来源引物序列产物大小(kb) HIV gag region 病毒SK 38ATTAAT CACTA TCCAG TAGGA GAAAT SK 39TTTGG TCCTG TCTTA TGTCC AGAAT GC 0.11kb β-globin 人(29923)GGTGT TCCCT TGATG TAGCA CA (34016)CCAGG ATTTT TGATG GGACA CG 4.1kb β-globin 人(31194)GCTGC TCTGT GCATC CGAGT GG (34016)CCAGG ATTTT TGATG GGACA CG 2.8kb
外显子捕获结题报告
外显子捕获结题报告2010-11-22
内容 1 项目信息 (1) 2 工作流程介绍 (2) 2.1 Agilent液相捕获平台 (2) 2.2 NimbleGen 液相捕获平台 (3) 2.3 生物信息分析流程 (4) 3 分析报告 (5) 结果 (5) 3.1 标准生物信息分析 (5) 3.1.1 数据产出统计 (5) 3.1.2 目标区域单碱基深度分布图 (6) 3.1.3外显子捕获测序的均一性 (7) 3.1.4一致序列组装和SNP检测 (7) 3.1.5 SNP注释 (8) 3.1.6插入/缺失(indels)检测 (9) 3.1.7插入/缺失(indels)注释 (9) 3.2个性化分析 (9) 3.2.1氨基酸替换预测 (9) 3.2.2群体SNP检测和等位基因频率估计 (12) 3.2.3孟德尔遗传病分析 (13) 3.2.4 NGS-GW AS 分析 (14) 3.2.5正向选择信号的检测 (14) 4 数据分析方法说明 (15) 4.1信息分析软件及常用参数介绍 (15) 4.2参考数据库 (16) 4.3数据文件格式 (17)
1 项目信息 PROJECT NAME CONTRACT NUMBER SAMPLE INFORMATION Species Information Genome Information Additional Information CUSTOMER INFORMATION PI Contact Person Company Name Contact Methods Name Tel E-mail Name Tel E-mail CONTACT INFORMATION (BGI) Sales Information Name Tel E-mail Name Tel E-mail Customer Service Name Tel E-mail Name Tel E-mail PROJECT DIRECTOR APPROVAL THE RESULTS HAVE BEEN APPROVED AND CAN BE SUBMITTED Signature: Date:
06-重测序、外显子组试卷答案.pdf
一、名词解释 1.比对将测序序列比对到参考基因组序列 2.单核苷酸多态性主要是指在基因组水平上由单个核苷酸的变异所引起的DNA序列多 态性 3.三体家系样本,父亲,母亲,和孩子家系外显子组中的一组家系样本 4.小的核苷酸的插入缺失 5.拷贝数变异是由基因组发生重排而导致的,一般指长度为1 kb以上的基因组大片段 的拷贝数增加或者减少,主要表现为亚显微水平的缺失和重复 二、填空题 1.bwa GATK 2.1% 3. 全基因组重测序全外显子组区域捕获测序 4. snp indel CNV SV 5. 5 50X 6. 1.5 3.5 7.0.1% 1% 8.液氮冻存-80冰箱冻存 9.血液 10.Agilent SureSelect All Exon V4 (+ UTR), NimbleGen SeqCap EZ Human Exome Library v3.0, Illumina TruSeq Exome Enrichment Kit 51M(71M), 64M, 62M 三、问答题 1. 建库:将基因组DNA经Covaris破碎仪随机打断成长度为180-280bp的片段,末端修复和加A 尾后在片段两端分别连接上接头制备 DNA 文库。 捕获:带有特异index的文库pooling后与多达543,872个生物素标记的探针进行液相杂交,再使用带链霉素的磁珠将20,965个基因的334,378个外显子捕获下来。 扩增及测序:经PCR线性扩增后进行文库质检,合格即可进行测序。 2. 人类85%的疾病位点位于编码区 域外显子组可以提供更深的测序 深度外显子组花费更低 3. 数据质控,比对到参考基因组,去重复重校正,预测个体snp和indel,预测体细胞突变,预测CNV和SV,候选位点注释 4. 常染色体显性遗传 常染色体隐形遗传 伴X 染色体显性遗传 伴X 染色体隐性遗传 伴Y 染色体遗传 找Denovo mutation,只在患病孩子有,不在健康父母里存在的位点 5.
常用引物信息列表
3’AOX5′-GGCAAATGGCATTCTGACAT-3‘ 3‘AD5′- AGA TGG TGC ACG ATG CAC AG-3‘ 3‘BD5′-TAA GAG TCA CTT TAA AAT TTG TAT C-3‘5’AOX5′-GACTGGTTCCAATTGACAAGC-3‘ A-FACTOR5′-TAC TAT TGC CAG CAT TGC TGC-3‘ CMV-F5′-CGCAAATGGGCGGTAGGCGTG-3‘ CMV-R5′-GTTCACGGTGCCCTCC-3‘ EGFP-Nrev5′-CGT CGC CGT CCA GCT C-3‘ GLP15′-TGT ATC TTA TGG TAC TGT AAC TG-3‘GLP25′-CTT TAT GTT TTT GGC GTC TTC CA-3‘ M13(-96)5′-CCCTCATAGTTAGCGTAACG-3‘ M13-205′-GTA AAA CGA CGG CCA GTG-3‘ M13F5′-TGTAAAACGACGGCCAGT-3‘ M13F(-47)5′-CGCCAGGGTTTTCCCAGTCACGAC-3‘ M13F-215′-TGT AAA ACG ACG GCC AGT-3‘ M13R5′-CAGGAAACAGCTATGACC-3‘ M13R(-48)5′-AGCGGATAACAATTTCACACAGGA-3‘ P125845′-TTTTCAGTATCTACGAT-3’ P171105′-TACCACTACAATGGATG-3’ pbd-gal4-f5′-GCCTCTAACATTGAGACAGC-3‘ pbd-gal4-r5′-AAGAGTTACTCAAGAACAAGAA-3‘ pbi-121(35s)5′-GACGCACAATCCCACTATCC-3‘ PBV220F5′-AAGAAGGGCAGCATTCAAAG-3‘ PBV220R5′-CTG CGT TCT GAT TTA ATC TG-3‘ PCDNA3.0-R25′-GGC AAC TAG AAG GCA CAG TC-3‘PCDNA3.1F5′-CTAGAGAACCCACTGCTTAC-3’ PCDNA3.1R5′-TAGAAGGCACAGTCGAGG-3’ PCMV-F5′-TCTAAAAGCTGCGGAATTGT-3‘ PCMV-5F5′-TTCCAAAATGTCGTAATAAC-3‘ PCMV-R5′-TCCAAACTCATCAATGTATC-3‘ PCMV-5R5′-ATTATAGAGGACACCTAGTC-3‘ PEGFP-C-3’5′-TATGGCTGATTATGATCAGT-3‘ PEGFP-C-5’5′-CATGGTCCTGCTGGAGTTCGTG-3‘ PEGFP-N-3’5′-CGTCGCCGTCCAGCTCGACCAG-3‘ PEGFP-N-5’5′-TGGGAGGTCTATATAAGCAGAG-3‘ PGEX-3’5′-CCGGGAGCTGCATGTGTCAGAGG-3‘ PGEX-5’5′-GGGCTGGCAAGCCACGTTTGGTG-3‘PIRES2-EGFP-F5′-GTA GGC GTG TAC GGT GGG AG-3‘PIRES3-EGFP-R5′-AAC GCA CAC CGG CCT TAT TC-3‘ pMAL-C2X-F5′-TGC GTA CTG CGG TGA TCA AC-3’ pMAL-C2X-R5′-CTG CAA GGC GAT TAA GTT GG-3’ PQE30F5′- TGA GCG GAT AAC AAT TTC AC-3‘ PQE30R5′- GTT CTG AGG TCA TTA CTG G-3‘ RVP35′-CTA GCA AAA TAG GCT GTC CC-3‘
引物设计常用序列
RT-PCR引物序列基因来源引物序列产物大小(kb) β-actin 人有意义链CCTCG CCTTT GCCGA TCC 反义链GGATC TTCAT GAGGT AGTCA GTC 0.62 kb β-actin* 大鼠有意义链TACAA CCTCC TTGCA GCTCC 反义链GGATC TTCAT GAGGT AGTCA GTC 0.62kb β-actin 小鼠有意义链GTCGT ACCAC AGGCA TTGTG ATGG反义链GCAAT GCCTG GGTAC ATGGT GG 0.49 kb GAPDH 人有意义链GGTGA AGGTC GGAGT CAACG反义链CAAAG TTGTC ATGGA TGHACC 0.50kb GAPDH 大鼠有意义链GATGC TGGTG CTGAG TATGR CG反义链GTGGT GCAGG ATGCA TTGCT CTGA 0.20 kb Dynein 小鼠有意义链GCGGG CGCTG GAGGA GAA反义链GGATC TTCAT GAGGT AGTCA GTC 12.3 kb Polymerase ε人有意义链CGCCA AATTT CTCCC CTGAAA反义链CCGTA GTGCT GGGCA ATGTT C 6.8 kb Polymerase ε 人有意义链AAGGC TGGCG GATTA CTGCC反义链GATGC TGCTG GTGAT GTACT C 3.5 kb Tuberous Sclerosis 人有意义链GGAGT TTATC ATCAC CGCGG AAATA CTGAG AG反义链TATTT CACTG ACAGG CAATA CCGTC CAAGG 5.3 kb 18S rRNA 大豆有意义链CTTTC GATGG TAGGA TAGTG GCCT反义链CAATG ATCCT TCCGC AGGTT CACCT AC 1.5 kb *引物不会扩增假基因 PCR引物序列基因来源引物序列产物大小(kb) HIV gag region 病毒SK 38ATTAAT CACTA TCCAG TAGGA GAAAT SK 39TTTGG TCCTG TCTTA TGTCC AGAAT GC 0.11kb β-globin 人(29923)GGTGT TCCCT TGATG TAGCA CA (34016)CCAGG ATTTT TGATG GGACA CG 4.1kb β-globin 人(31194)GCTGC TCTGT GCATC CGAGT GG (34016)CCAGG ATTTT TGATG GGACA CG 2.8kb 序列来源nvitrogen 公司
人外显子测序
人外显子测序 药明康德基因中心,陆桂1. 什么是外显子测序(whole exon sequencing)? 外显子组测序是指利用序列捕获技术将全基因组外显子区域DNA捕捉并富集后进行高通量测序的基因组分析方法。外显子测序相对于基因组重测序成本较低,对研究基因的SNP、Indel 等具有较大的优势,但无法研究基因组结构变异如染色体断裂重组等。 2. 外显子捕获试剂盒有哪些? 目前主要有Roche、Illumina和Agilent三家的外显子捕获试剂。Nimblegen和Illumina的捕获试剂盒中的探针是DNA探针,化学性质稳;Agilent的捕获试剂盒是RNA探针,有可能RNA 不是很稳定。 3. 外显子捕获效率是什么? 外显子测序过程中要用到杂交过程。在人的染色体上有许多与外显子有同源性的部分,这些有同源性的部分很可能在杂交过程中也被捕获下来。所以,测到的序列中,有一部分不是外显子序列。我们把测序得是外显子的部分占全部测序序列的比列称为捕获效率。 Nimblegen大约是70% Agilent大约是60% Illumina大约是50% 4. 外显子测序一般建议做多少倍的覆盖? 一般做100X或者150X。较高的覆盖倍数,对于测异质性的遗传变质,可以发现小比例的突变。另外,外显子测序的覆盖不是很均匀,这样较高的平均覆盖率有利于保证大部分的区域有足够的覆盖倍数。 5. 外显子测序能够测出多大的片段缺失? 大致能测出50bp的片段缺失。目前的测序主要还是用Hiseq 2000,单侧的测长就是100bp。由于外显子测序的覆盖很不平均,所以如果有大段的缺失,无法判断是因为杂交没有捕获到,还是因为缺失。目前能够测到的,就是在一个read中发现的缺失。一个read的长度也就是100bp,所以大到50bp以下的片段缺失可以从外显子测序中测出来。 6. 外显子捕获可以做CNV吗? 外显子测序因为有一个杂交捕获的过程,这样就会有一个杂交捕获效率的问题。各个外显子的杂交效率是不同的,其同源竞争的情况也不同,所以不同的外显子的覆盖率的差异就很大。所以一般情况下,外显子测序不能用于CNV的检测。但在癌症研究中,利用癌组织和癌旁组织对照,可以检测CNV。 现在我们有另外两种常规方法来检测CNV,一种是全基因组重测序,另外一种是用Affymetrix SNP6.0的芯片来测。其中Affymetrix SNP6.0的检测费用大约只有全基因测序费用的1/10,是一个相对经济的手段。 7. 外显子测序的优点是什么?
RT引物序列
-RT引物序列:AGGTCCACCACCCTGTTGCTGT 内参引物: GAPDH F: GTACGACTCACTATAGGGA AGGTCCACCACCCTGTTGCTGT GAPDH R: AGGTGACACTATAGAATA AACAGCGACACCCACTCCTCCA 通用引物: Universal F: GTACGACTCACTATAGGGA Universal R: AGGTGACACTATAGAATA I tube BV1 AGGTGACACTATAGAATA CTTGCACTCTGAACTAAACC BV2 AGGTGACACTATAGAATA TACCGTTCCCTGGACTTTC BV3 AGGTGACACTATAGAATA CAAAGTAACCCAGAGCTCG BV4 AGGTGACACTATAGAATA CCTGGACAGAGCCTGACA BV5 AGGTGACACTATAGAATA GAGWVRV ARAGGAAACTTCCCT II tube BV6 AGGTGACACTATAGAATA RMKCTCAGGTGTGATCCAA BV7a AGGTGACACTATAGAATA AACCTTCACCTACACGCCC BV7b AGGTGACACTATAGAATA TBCCTTCACCTACACACCC BV8 AGGTGACACTATAGAATA ATGCRRGGACTGGAGTTG BV9 AGGTGACACTATAGAATA AATGAAACAGTTCCAAATCGC III tube BV11 AGGTGACACTATAGAATA CGAGGAATGGAACTACACC BV12a AGGTGACACTATAGAATA TGAGATGTCACCAGACTGA BV12b AGGTGACACTATAGAATA TGACGTGTCACCAGACTTG