ARMA模型时间序列预测GDP

题目:分析美国国民生产总值的季度数据
摘要:国民经济的发展关系着民生福祉,GNP作为衡量一国经济总量的重要指标。对GNP科学精确的预测能够使得政策的制定更趋于完善。本文选取1947第一季度到1996第三季度的美国GNP数据,首先对数据进行图像化,发现有明显的指数上升趋势,故对数据进行线性变换,然后利用SAS软件做ARMA模型拟合,并预测其后两年每季度美国的GNP数据。预测结果表明ARMA模型的预测结果较其它方法更精确。
关键词:GNP 预测SAS软件ARMA模型
实验内容:
1.对数据进行图形化并做一些简单处理,确定适当的的拟合模型;
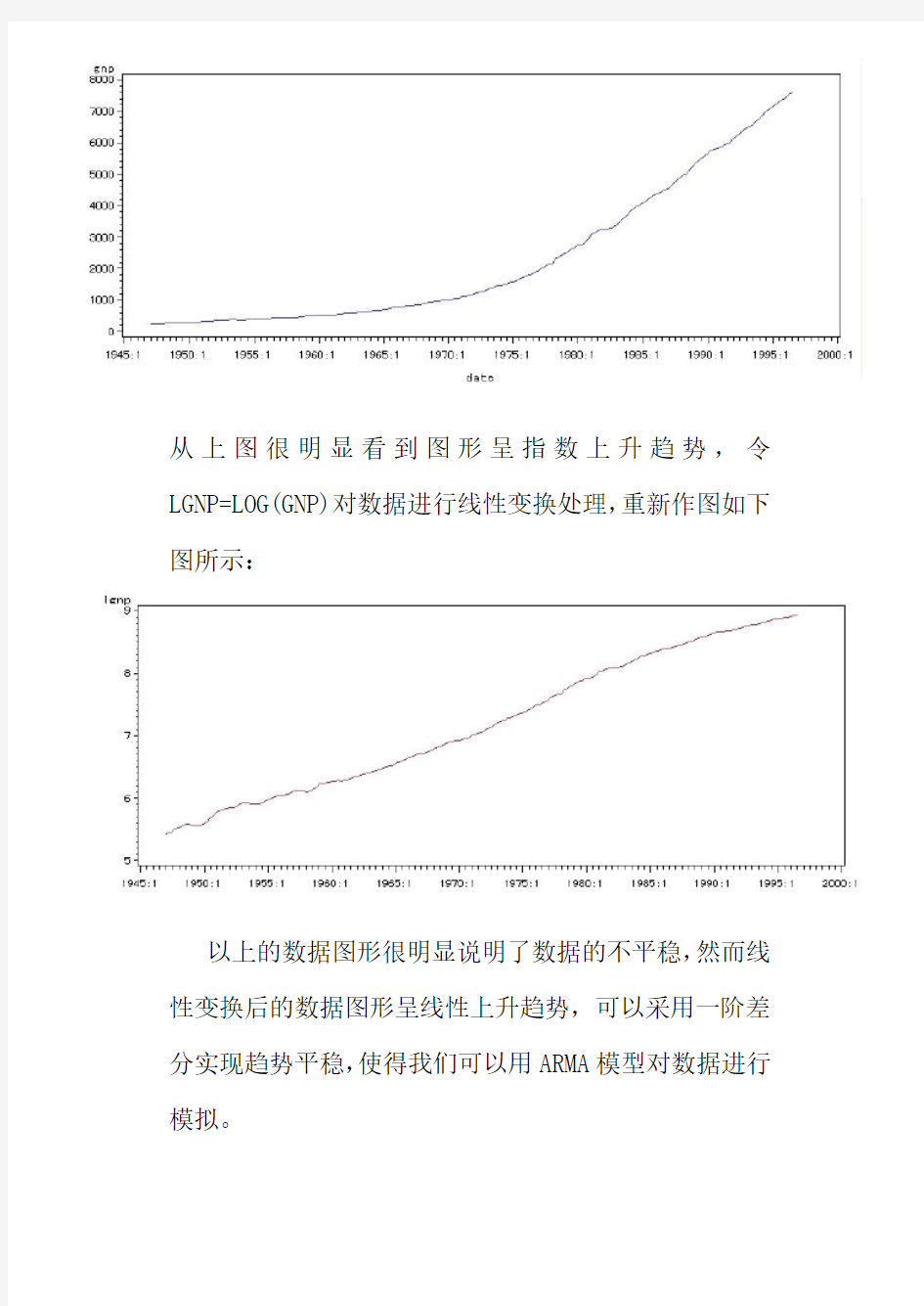
打开SAS软件对数据进行图形处理做时序GNP图,结果如下图所示:
从上图很明显看到图形呈指数上升趋势,令LGNP=LOG(GNP)对数据进行线性变换处理,重新作图如下图所示:
以上的数据图形很明显说明了数据的不平稳,然而线性变换后的数据图形呈线性上升趋势,可以采用一阶差分实现趋势平稳,使得我们可以用ARMA模型对数据进行模拟。
2.模型口径的确定,模型和参数的检验;
为了避免经验的不足导致的模型识别问题,我们采用MINIC 命令进行自行判断,得出在自相关延迟阶数和移动平均延迟阶数均小于等于8的所有ARMA(p,q)模型中,BIC 信息量相对最小的是ARMA(0,5)模型,即MA (5)模型。
使用最大似然估计法,确定MA(5)模型的口径为:
t
52).30001B 0-B 107153.0.0.467401(0.01766(gnp)log ε+++=B 其中0.0010954=t ε。 模型的检验:
残差白噪声检验显示延迟6阶、12阶、18阶LB 检验统计量的P 值均显著大于0.05,所以该MA(5)模型显著有效。
参数显著性检:
估计方法
均值的检验
1
θ的检验
2
θ的检验
3
θ的检验t统计量P值t统计量P值t统计量P值t统计量P值
条件最小二乘16.12 <
0.001
-7.07
<
0.001
-4.66
<
0.001
4.87
<
0.001
验结果显示三参数t统计量的P值均小于0.05,即
三参数均显著。
因此MA(5)模型是该序列的有效拟合模型。
3.预测结果:
1996-1 1996-2 1996-3 1996-4 1997-1 1997-2 1997-3 1997-4 7452.40 7537.52 7678.53 7694.56 7825.47 7974.43 8117.77 8291.31
4.使用不同模型进行拟合并比较:
尝试初步根据个人经验以自相关系数和偏自相关系
数图判断拟合模型,可以认为自相关系数5阶以后拖尾,
尝试模拟AR(5)模型;
模型口径:
5
216988.00.12497B -0.46024B -1012637.0(gnp)log B t
++
=ε
模型检验:
残差白噪声检验显示拟合模型有效。 参数检验:
估计方法
均值的检验 1θ的检验 2θ的检验 3θ的检验 t 统计量 P 值
t 统计量 P 值
t 统计量 P 值
t 统计量 P 值
条件最小二乘 16.65
<
0.001 5.90
<
0.001 1.61
<
0.001
-2.38
0.0184
参数显著性检验结果显示几个参数几乎均显著。 因此可以认为AR (5)模型也是该序列的有效拟合模型。 预测结果:
1996-1
1996-2
1996-3
1996-4
1997-1
1997-2
1997-3
1997-4
7450.29 7540.84 7675.67 7704.91 7839.16 7991.06 8145.93 8318.31
5.模型的优化
利用AIC和SBC信息准则进行模型优;
利用AIC准则和SBC准则评判本文中的两个模型的相对
优劣。
检验结果:
模型AIC SBC
MA(5) -1240.3 -1227.15
AR(5) -1230.68 -1210.95
最小信息量检验显示无论是使用AIC准侧还是SBC
准则,MA(5)模型都要优于AR(5)模型,所以本文中MA(5)
模型是相对优化模型。
总结:
本实验源于实际经济数据,客观实用使得笔者的时间
序列分析能力有大幅提高。合理的模型拟合能够实现精
确的预测,所以模型的选择至关重要。除此之外笔者发
现:理论基础欠缺,实践操作不足导致试验时间的冗长
和实验内容的不尽人意。以后应该强化相关理论的推理
演绎,多久实际问题进行实战分析,积累相关专业经验;SAS软件应用不熟,看图吃力,以后应该多和老师同学交流弥补硬性不足。
参考文献:
1.王燕等著.应用时间序列分析.北京:中国人大学出版社,2002
2.高慧璇等编译.SAS软件使用手册.北京:中国统计出版社,1998
时间序列预测模型
时间序列预测模型时间序列是指把某一变量在不同时间上的数值按时间先后顺序排列起来所形成的序列,它的时间单位可以是分、时、日、周、旬、月、季、年等。时间序列模型就是利用时间序列建立的数学模型,它主要被用来对未来进行短期预测,属于趋势预测法。一、简单一次移动平均预测法例1.某企业1月~11月的销售收入时间序列如下表所示.取n 4,试用简单一次移动平均法预测第12月的销售收入,并计算预测的标准误差. 二、加权一次移动平均预测法简单一次移动平均预测法,是把参与平均的数据在预测中所起的作用同等对待,但参与平均的各期数据所起的作用往往是不同的。为此,需要采用加权移动平均法进行预测,加权一次移动平均预测法是其中比较简单的一种。三、指数平滑预测法 1、一次指数平滑预测法一元线性回归模型 * 项数n的数值,要根据时间序列的特点而定,不宜过大或过小.n过大会降低移动平均数的敏感性,影响预测的准确性;n过小,移动平均数易受随机变动的影响,难以反映实际趋势.一般取n的大小能包含季节变动和周期变动的时期为好,这样可消除它们的影响.对于没有季节变动和周期变动的时间序列,项数n的取值可取较大的数;如果历史数据的类型呈上升或下降型的发展趋势,则项数n的数值应取较小的数,这样能取得较好的预测效果. 1102.7 1015.1 963.9 892.7 816.4 772.0 705.1 649.8 606.9 574.6 533.8 销售收入 11 10 9 8 7 6 5 4 3 2 1 月份 t 158542.7 993.6 12 12950.4 19016.4 17662.4 24617.6 27989.3
时间序列作业ARMA模型--.
一案例分析的目的 本案例选取2001年1月,到2013年我国铁路运输客运量月度数据来构建ARMA模型,并利用该模型进行外推预测分析。 二、实验数据 数据来自中经网统计数据库
数据来源:中经网数据库 三、ARMA 模型的平稳性 首先绘制出N 的折线图,如图 从图中可以看出,N 序列具有较强的非线性趋势性,因此从图形可以初步判断该序列是非平
稳的。此外,N在每年同期出现相同的变动方式,表明N还存在季节性特征。下面对N 的平稳性和季节季节性进行进一步检验。 四、单位根检验 为了减少N 的变动趋势以及异方差性,先对N进行对数处理,记为LN其曲线图如下:GENR LN = LOG(N) 对数后的N趋势性也很强。下面观察N 的自相关表,选择滞后期数为36,如下: 从上图可以看出,LN的PACF只在滞后一期是显著的ACF随着阶数的增加慢慢衰减至0,因此从偏/自相关系数可以看出该序列表现一定的平稳性。进一步进行单位根检验,打开LN选择存在趋势性的形式,并根据AIC自动选择滞后阶数,单位根检验结果如下:
T统计值的值小于临界值,且相伴概率为0.0001,因此该序列不存在单位根,即该序列是平稳序列。 五、季节性分析 趋势性往往会掩盖季节性特征,从LN的图形可以看出,该序列具有较强的趋势性,为了分析季节性,可以对LN进行差分处理来分析季节性: Genr = DLN = LN – LN (-1) 观察DLN的自相关表,如下:
DLN在之后期为6、12、18、24、30、36处的自相关系数均显著异于0,因此,该序列是以周期6呈现季节性,而且季节自相关系数并没有衰减至0,因此,为了考虑这种季节性,进行季节性差分: GENR SDLN = DLN – DLN(-6) 再做关于SDLN的自相关表,如下: SDLN在滞后期36之后的季节ACF和PACF已经衰减至0,下面对SDLN建立SARMA模型。 六、滞后阶数的初步确定 观察SDLN的自相关、偏自相关图,ACF 和PACF在滞后期1和滞后期6还有滞后期12异于0,其余均与0无异,因此,SARMA(p,q)(k,m)s 中p和q均不超过1,k和m均不超过2.6考虑到高洁移动平均模型估计较为困难,而且自回归模型的检验可以表示无穷的移动平均过程,因此q尽可能取较小的取值。本例拟选择SARMA(1,0)(1,0)6、SARMA(1,0)(1,1)6、SARMA(1,0)(1,2)6、SARMA(1,0)(2,1)6、SARMA(1,1)(1,0)6、SARMA(1,1)(1,1)6、SARMA(1,1)(1,2)6、SARMA(1,1)(0,1)6八个模型来拟合SDLN。
时间序列分析基于R——习题答案
第一章习题答案 略 第二章习题答案 2.1 (1)非平稳 (2)0.0173 0.700 0.412 0.148 -0.079 -0.258 -0.376 (3)典型的具有单调趋势的时间序列样本自相关图 2.2 (1)非平稳,时序图如下 (2)-(3)样本自相关系数及自相关图如下:典型的同时具有周期和趋势序列的样本自相关图
2.3 (1)自相关系数为:0.2023 0.013 0.042 -0.043 -0.179 -0.251 -0.094 0.0248 -0.068 -0.072 0.014 0.109 0.217 0.316 0.0070 -0.025 0.075 -0.141 -0.204 -0.245 0.066 0.0062 -0.139 -0.034 0.206 -0.010 0.080 0.118 (2)平稳序列 (3)白噪声序列 2.4 ,序列LB=4.83,LB统计量对应的分位点为0.9634,P值为0.0363。显著性水平=0.05 不能视为纯随机序列。 2.5 (1)时序图与样本自相关图如下
(2) 非平稳 (3)非纯随机 2.6 (1)平稳,非纯随机序列(拟合模型参考:ARMA(1,2)) (2)差分序列平稳,非纯随机 第三章习题答案 3.1 ()0t E x =,2 1 () 1.9610.7 t Var x ==-,220.70.49ρ==,220φ= 3.2 1715φ=,2115 φ= 3.3 ()0t E x =,10.15 () 1.98(10.15)(10.80.15)(10.80.15) t Var x += =--+++ 10.8 0.7010.15 ρ= =+,210.80.150.41ρρ=-=,3210.80.150.22ρρρ=-= 1110.70φρ==,2220.15φφ==-,330φ= 3.4 10c -<<, 1121,1,2 k k k c c k ρρρρ--?=? -??=+≥? 3.5 证明: 该序列的特征方程为:32 --c 0c λλλ+=,解该特征方程得三个特征根: 11λ=,2c λ=3c λ=-
时间序列分析基于R——习题答案
第一章习题答案 第二章习题答案 2.1 (1)非平稳 (2)0.0173 0.700 0.412 0.148 -0.079 -0.258 -0.376 (3)典型的具有单调趋势的时间序列样本自相关图 Au+ocorreliil. i ons Correlation -1 M 7 6 5 4 3 2 1 0 I ; 3 4 5 6 7 9 9 1 1.00000■Hi ■ K. B H,J B ik L L1■* J.1 jA1-.IM L L* rn^rp ■ i>i?iTwin H'iTiii M[lrp i,*nfr 'TirjlvTilT'1 iBrp O.7QOO0■ill. Ii ill ■ _.ill?L■ ill iL si ill .la11 ■ fall■ 1 ■ rpTirp Tp和阳申■丽轉■晒?|?卉(ft 0.41212■强:料榊<牌■ 0.14343'■讯榊* -.07078■ -.25758, WWHOHHf ■ -.375761 marks two 总t and&rd errors 2.2 (1) 非平稳,时序图如下 (2) - ( 3)样本自相关系数及自相关图如下:典型的同时具有周期和趋势序列的样本自相关图
Ctorrelat ion LOOOOO n.A'7F1 0.72171 0.51252 Q,34982 0.24600 0.20309 0.?1021 0.26429 0.36433 0.49472 0.58456 0.60198 0.51841 Q ?菲晡 日 0.20671 0.0013& -,03243 -.02710 Q.01124 0,08275 0.17011 Autocorrel at ions raarka two standard errors 2.3 (1) 自相关系数为: 0.2023 0.013 0.042 -0.043 -0.179 -0.251 -0.094 0.0248 -0.068 -0.072 0.014 0.109 0.217 0.316 0.0070 -0.025 0.075 -0.141 -0.204 -0.245 0.066 0.0062 -0.139 -0.034 0.206 -0.010 0.080 0.118 (2 )平稳序列 (3) 白噪声序列 2.4 LB=4.83 , LB 统计量对应的分位点为 0.9634 , P 值为0.0363。显著性水平 :-=0.05,序列 不能视为纯随机序列。 2.5 (1) 时序图与样本自相关图如下 AuEocorreI ati ons 弗卅制iti 电卅栅冷卅樹 側樹 榊 惟 1 ■ liihCidi iliihQriHi il>LljU_nll Hnlidiili Hialli iT ,, T^,, T^s ?T* iTijTirr ,^T 1 IT * -i> ■> - ■ ■ *畑** ? ■ ■ 耶曲邯 ? ■ ■ ■ >|{和怦I {册卅KHi 笊出恸 mrpmrp 山!rpEHi erp . 卑*寧* a 1 *
时间序列分析报告——ARMA模型实验
基于ARMA模型的社会融资规模增长分析 ————ARMA模型实验
第一部分实验分析目的及方法 一般说来,若时间序列满足平稳随机过程的性质,则可用经典的ARMA模型进行建模和预则。但是, 由于金融时间序列随机波动较大,很少满足ARMA模型的适用条件,无法直接采用该模型进行处理。通过对数化及差分处理后,将原本非平稳的序列处理为近似平稳的序列,可以采用ARMA模型进行建模和分析。 第二部分实验数据 2.1数据来源 数据来源于中经网统计数据库。具体数据见附录表5.1 。 2.2所选数据变量 社会融资规模指一定时期内(每月、每季或每年)实体经济从金融体系获得的全部资金总额,为一增量概念,即期末余额减去期初余额的差额,或当期发行或发生额扣除当期兑付或偿还额的差额。社会融资规模作为重要的宏观监测指标,由实体经济需求所决定,反映金融体系对实体经济的资金量支持。 本实验拟选取2005年11月到2014年9月我国以月为单位的社会融资规模的数据来构建ARMA模型,并利用该模型进行分析预测。 第三部分 ARMA模型构建 3.1判断序列的平稳性 首先绘制出M的折线图,结果如下图:
图3.1 社会融资规模M曲线图 从图中可以看出,社会融资规模M序列具有一定的趋势性,由此可以初步判断该序列是非平稳的。此外,m在每年同时期出现相同的变动趋势,表明m还存在季节特征。下面对m的平稳性和季节性·进行进一步检验。 为了减少m的变动趋势以及异方差性,先对m进行对数化处理,记为lm,其时序图如下: 图3.2 lm曲线图
对数化后的趋势性减弱,但仍存在一定的趋势性,下面观察lm的自相关图 表3.1 lm的自相关图 上表可以看出,该lm序列的PACF只在滞后一期、二期和三期是显著的,ACF随着滞后结束的增加慢慢衰减至0,由此可以看出该序列表现出一定的平稳性。进一步进行单位根检验,由于存在较弱的趋势性且均值不为零,选择存在趋势项的形式,并根据AIC自动选择之后结束,单位根检验结果如下: 表3.2 单位根输出结果 Null Hypothesis: LM has a unit root Exogenous: Constant, Linear Trend Lag Length: 0 (Automatic - based on SIC, maxlag=12) t-Statistic Prob.*
基于时间序列模型的中国GDP增长预测分析
第33卷 第178期2012年7月 财经理论与实践(双月刊) THE THEORY AND PRACTICE OF FINANCE AND ECONOMICS Vol.33 No.178 Jul. 2012 ·信息与统计· 基于时间序列模型的中国GDP增长预测分析 何新易 (南通大学商学院,江苏南通 226019)* 摘 要:作为度量一个国家或地区所有常住单位在一定时期之内所生产和所提供的最终产品或服务的重要总量指标,如果能够对GDP做出正确的预测,必然可以有效引导宏观经济健康发展,为高层管理部门提供决策依据。选用适合短期预测的ARIMA模型对中国1952~2010年的GDP进行计量建模分析,预测结果认为未来五年中国的经济增长仍将处于一个水平较高的上升通道。 关键词:时间序列模型;GDP;预测 中图分类号:F234 文献标识码: A 文章编号:1003-7217(2012)04-0096-04 一、引 言 作为度量一个国家或地区所有常住单位在一定时期之内所生产和所提供的最终产品或服务的重要总量指标,国内生产总值(Gross Domestic Product,GDP)对于判断经济态势运行、衡量经济综合实力、正确制定经济政策等诸多方面,以及在经济研究实际工作中,均起着不可替代的重要作用。 熊志斌(2011)深入分析了时间序列模型与神经网络(NN)模型的优势和劣势,按照两种模型的预测特性,在比较的基础之上,分别构建了ARIMA模型和NN模型,并根据一定算法对两种模型进行了集成。将GDP时间序列的数据结构,根据在非线性空间和线性空间的预测优势,进一步分解为线性非线性残差和自相关主体两部分,即首先用ARIMA分析技术构建线性主体模型,然后用NN模型估计非线性残差,再对序列的整个预测结果进行最终集成。仿真实证结果表明:与单一模型相比,集成模型的预测准确率显著提高,进行GDP预测当然使用集成模型更为有效[1]。桂文林和韩兆洲(2011)认为由于迄今为止,包括季度GDP在内的经季节调整之后的经济数据,中国政府尚未进行公布,不但无法进行国际之间的横向比较,也不利于监测中国宏观经济态势。本文运用1996年第1季度至2009年第4季度的中国实际GDP数据,构建了状态空间模型,使用卡尔曼滤波迭代算法对季节调整模型状态向量的 各分量,进行了最优平滑、预测和估计,并使用极大似然方法估计了超参数。经过对GDP的主要季节和趋势特征的分析,计算出了环比增长率指标来监测和分析经济走势,并与国际通用的TRAMO-SEATS季节调整模型进行了对比,以便鉴别趋势拐点,制定相关的经济政策[2]。高帆(2010)运用1952~2008年的上海GDP增长率数据,实证研究其内在变动机制,将GDP增长率分解为纯生产率效应、纯劳动投入效应、纯生产结构效应、纯劳动结构效应,并分析了这四种效应之间的交互影响。结果表明:在上海GDP增长率提高的四种效应之中,纯生产率效应起到了关键作用。上海GDP增长率自1978年改革开放之后,在整体上对纯生产率效应的依赖度趋于增强。在1978~1989年期间,纯劳动结构效应是GDP增长的主要因素,由于市场化改革的进一步加大,劳动力跨部门流转在很大程度上得以实现。在1990~2008年期间,纯生产率效应是GDP增长的主要因素,正是由于在此历史阶段,由于资本深化进一步加速,从而有效提高了部门劳动生产率。基于实证的研究结论,可以针对性地制定出今后上海市经济实现持续增长的若干宏观政策[3]。腾格尔和何跃(2010)利用中国季度GDP数据分别构建了ARIMA和ARCH模型,同时利用GMDH自组织方法尝试建模,经过Bon-ferroni-Dunn检验,表明与单一模型相比,组合模型的拟合能力更强。研究表明,基于GMDH组合的GDP模 *收稿日期: 2012-02-12 作者简介: 何新易(1966—),男,湖北武汉人,南通大学商学院副教授,经济学博士,研究方向:宏观国民经济问题、中国企业集团融资和投资。
平稳时间序列的模型
目录 摘要 (1) 第一章绪论 (2) 1.1 时间序列模型的发展及其作用 (2) 1.2 什么是时间序列模型 (2) 1.3 本文研究的主要方法和手段 (2) 1.4 本文主要研究思路及内容安排 (2) 第二章 ARMA模型 (4) 2.1 ARMA模型的基本原理 (4) 2.2 样本自协方差函数、自相关函数和偏相关函数 (4) 2.3 ARMA模型识别方法 (5) 2.4 模型参数估计 (6) 第三章实例分析 (7) 3.1 题目 (7) 3.2 问题分析 (7) 3.3 问题求解 (8) 3.3.1数据的观测 (8) 3.3.2数据处理 (8) 3.3.3求解自相关和偏相关函数 (8) 3.4 模型的识别及求解 (9) 3.5 结论 (11) 参考文献 (12) 附录 (12) 评阅书 (15)
《随机过程》课程设计任务书
摘要 ARMA模型是研究时间序列的重要方法,由自回归模型(简称AR模型)与滑动平均模型(简称MA模型)为基础“混合”构成。ARMA模型广泛应用在经济、工程等各个领域得益于其在具体预测方面的优势。在许多方面用该模型所作出的预测比其他传统经济计量方法更加精确。平稳时间序列模型主要有自回归模型(AR)、滑动平均模型(MA)和自回归滑动平均模型(ARMA)等,这些线性模型考虑因素较简单。自回归滑动平均模型(ARMA)计算简单,易于实时更新数据。 本文描述了ARMA模型的原理、自相关函数和偏相关函数的计算过程、模型的识别方法以及ARMA模型的计算过程。并给出一组平稳时间序列的数据,对数据进行分析和处理,求出自相关系数和偏相关,并利用MATLAB软件画出自相关系数和偏相关图形,有图可知它们都是拖尾的,因此可以确定是) ARMA模 p , (q 型。接下来就是确定) ARMA的阶数,本文采用了AIC准则确定模型的阶数, p , (q 在实际问题中,为使线性模型简单起见,通常p与q的数值被取得较小,却需都不为零。确定阶数后,就用我们学过的求解方法解出未知的参数,这样我们就得到了混合模型的表达式。 关键字:) ARMA模型,自相关函数,偏相关函数 p , (q
时间序列分析——ARMA模型实验
基于ARMA模型的社会融资规模增长分 析 ————ARMA模型实验
第一部分实验分析目的及方法 一般说来,若时间序列满足平稳随机过程的性质,则可用经典的ARMA模型进行建模和预则。但是, 由于金融时间序列随机波动较大,很少满足ARMA模型的适用条件,无法直接采用该模型进行处理。通过对数化及差分处理后,将原本非平稳的序列处理为近似平稳的序列,可以采用ARMA模型进行建模和分析。 第二部分实验数据 2.1数据来源 数据来源于中经网统计数据库。具体数据见附录表5.1 。 2.2所选数据变量 社会融资规模指一定时期(每月、每季或每年)实体经济从金融体系获得的全部资金总额,为一增量概念,即期末余额减去期初余额的差额,或当期发行或发生额扣除当期兑付或偿还额的差额。社会融资规模作为重要的宏观监测指标,由实体经济需求所决定,反映金融体系对实体经济的资金量支持。 本实验拟选取2005年11月到2014年9月我国以月为单位的社会融资规模的数据来构建ARMA模型,并利用该模型进行分析预测。 第三部分ARMA模型构建 3.1判断序列的平稳性 首先绘制出M的折线图,结果如下图:
图3.1 社会融资规模M曲线图 从图中可以看出,社会融资规模M序列具有一定的趋势性,由此可以初步判断该序列是非平稳的。此外,m在每年同时期出现相同的变动趋势,表明m还存在季节特征。下面对m的平稳性和季节性·进行进一步检验。 为了减少m的变动趋势以及异方差性,先对m进行对数化处理,记为lm,其时序图如下: 图3.2 lm曲线图
对数化后的趋势性减弱,但仍存在一定的趋势性,下面观察lm的自相关图 表3.1 lm的自相关图 上表可以看出,该lm序列的PACF只在滞后一期、二期和三期是显著的,ACF随着滞后结束的增加慢慢衰减至0,由此可以看出该序列表现出一定的平稳性。进一步进行单位根检验,由于存在较弱的趋势性且均值不为零,选择存在趋势项的形式,并根据AIC自动选择之后结束,单位根检验结果如下: 表3.2 单位根输出结果 Null Hypothesis: LM has a unit root Exogenous: Constant, Linear Trend Lag Length: 0 (Automatic - based on SIC, maxlag=12) t-Statistic Prob.*
基于时间序列序列分析优秀论文
梧州学院 论文题目基于时间序列分析梧州市财政 收入研究 系别数理系 专业信息与计算科学 班级 09信息与计算科学 学号 200901106034 学生姓名胡莲珍 指导老师覃桂江 完成时间
摘要 梧州市财政收入主要来源于基金收入,地方税收收入和非税收收入等几方面。近年来梧州市在自治区党委、自治区政府和市委的正确领导下,全市广大干部群众深入贯彻落实科学发展观,抢抓机遇,开拓进取,克难攻坚,使得全市经济连续几年快速发展,全市人民的生活水平也大幅度提高,但伴随着发展的同时也存在一些问题,本文主要通过研究分析梧州财政收入近几年的状况,根据采用时间序列分析中的一次简单滑动平均法研究分析梧州市财政收入和支出的情况,得到的结果是梧州市财政收入呈现下降状态,而财政支出却逐年上涨,这种状况将导致梧州市人民生活水平下降,影响梧州市各方面的发展。给予一些有益于梧州市财政发展的建议。本文首先介绍主要运用的时间序列分析的概念及其一次简单滑动平均法的方法,再用图表说明了梧州市财政近几年的财政收入和支出状况,然后建立模型,分析由时间序列分析方法得出的对2012年财政收入状况的预测结果,最后,鉴于提高梧州市财政收入的思想,给予了一些合理性建议,比如:积极实施工业强县战略,壮大工业主导财源;大力发展第三产业,强化地方财源建设;完善公共财政支出机制,着力构建和谐社会。 关键词:梧州市;财政收入;时间序列分析;建立模型;建议
Based onThe Time Series Analysis of Wuzhou city Finance Income Studies Abstract Wuzhou city, fiscal revenue mainly comes from fund income, local tax revenue and the tax revenue etc. Wuzhou city in recent years in the autonomous region party committee, the government of the autonomous region and the municipal party committee under the correct leadership, the cadres and masses thoroughly apply the scientific outlook on development, catch every opportunity, pioneering and enterprising, g hard, make the crucial economic rapid development for several years, the people's living standard has also increased significantly, but with the development at the same time, there are also some problems, this paper mainly through the research and analysis the condition of wuzhou fiscal revenue in recent years, according to the time series analysis of a simple moving average method research and analysis of financial income and expenditure wuzhou city, the result obtained is wuzhou city, fiscal revenue decline present condition, and fiscal spending is rising year by year, the situation will lead to wuzhou city, the people's living standards decline, influence all aspects of wuzhou city development. Give some Suggestions on the development of the financial benefit wuzhou city. This paper first introduces the main use of the time series analysis of the concept and a simple moving average method method, reoccupy chart illustrates the wuzhou city, in recent years the financial revenue and expenditure situation, then set a model, analysis the time series analysis method to draw 2012 fiscal income condition prediction results, finally, in view of wuzhou city, improve the financial income thoughts, give some advice, for instance: rationality vigorously implement the strategy of industrial county, strengthen the industry leading financial sources, A vigorous development of the third industry, and to strengthen the construction of local revenue;
时间序列:ARIMA模型
实验:建立ARIMA模型(综合性实验) 实验题目:某城市连续14年的月度婴儿出生率数据如下表所示: 26.663 23.598 26.931 24.740 25.806 24.364 24.477 23.901 23.175 23.227 21.672 21.870 21.439 21.089 23.709 21.669 21.752 20.761 23.479 23.824 23.105 23.110 21.759 22.073 21.937 20.035 23.590 21.672 22.222 22.123 23.950 23.504 22.238 23.142 21.059 21.573 21.548 20.000 22.424 20.615 21.761 22.874 24.104 23.748 23.262 22.907 21.519 22.025 22.604 20.894 24.677 23.673 25.320 23.583 24.671 24.454 24.122 24.252 22.084 22.991 23.287 23.049 25.076 24.037 24.430 24.667 26.451 25.618 25.014 25.110 22.964 23.981 23.798 22.270 24.775 22.646 23.988 24.737 26.276 25.816 25.210 25.199 23.162 24.707 24.364 22.644 25.565 24.062 25.431 24.635 27.009 26.606 26.268 26.462 25.246 25.180 24.657 23.304 26.982 26.199 27.210 26.122 26.706 26.878 26.152 26.379 24.712 25.688 24.990 24.239 26.721 23.475 24.767 26.219 28.361 28.599 27.914 27.784 25.693 26.881 26.217 24.218 27.914 26.975 28.527 27.139 28.982 28.169 28.056 29.136 26.291 26.987 26.589 24.848 27.543 26.896 28.878 27.390 28.065 28.141 29.048 28.484 26.634 27.735 27.132 24.924 28.963 26.589 27.931 28.009 29.229 28.759 28.405 27.945 25.912 26.619 26.076 25.286 27.660 25.951 26.398 25.565 28.865 30.000 29.261 29.012 26.992 27.897 (1)选择适当模型拟和该序列的发展 (2)使用拟合模型预测下一年度该城市月度婴儿出生率 实验内容: 给出实际问题的非平稳时间序列,要求学生利用R统计软件,对该序列进行分析,通过平稳性检验、差分运算、白噪声检验、拟合ARMA模型,建立ARIMA模型,在此基础上进行预测。 实验要求: 处理数据,掌握非平稳时间序列的ARIMA建模方法,并根据具体的实验题目要求完成实验报告,并及时上传到给定的FTP和课程网站。 实验步骤: 第一步:编程建立R数据集; 第二步:调用plot.ts程序对数据绘制时序图。 第三步:从时序图中利用平稳时间序列的定义判断是否平稳? 第四步:若不满足平稳性,则可利用差分运算是否能使序列平稳?重复第三步步骤第五步:根据Box.test纯随机检验结果,利用LB统计量和白噪声特性检验最后处理的
基于时间序列模型与线性回归模型的历史数据预测
基于时间序列模型与线性回归模型的历史数据预测 摘要:本文通过具体案例,简要说明根据时间序列数据建立和相应经济理论建立线性回归模型的简要步骤及基本原则,并着重介绍了在模型建立和模型有效性检验过程中需要注意的三个主要问题,最后简单介绍了进行模型修正的相应方法。 一、引言 多元线性回归模型的一般形式为: Y=β0+β1X1+β2X2+…+βkXk+μi(k,i=1,2,…,n) 其中k为解释变量的数目,βk(k=1,2,…,n)称为回归系数,上式也被称为总体回归函数的随机表达式。 从统计意义上说,所谓时间序列模型就是将某一个指标在不同时间上的不同数值,按照时间的先后顺序排列而成的数列。这种数列由于受到各种偶然因素的影响,往往表现出某种随机性,彼此之间存在着统计上的依赖关系。从数学意义上说,如果我们对某一过程中的某一个变量或一组变量X(t)进行观察测量,在一系列时刻t1,t2,…,tn(t为自变量,且t1 7 平稳时间序列预测法 7.1 概述 7.2 时间序列的自相关分析 7.3 单位根检验和协整检验 7.4 ARMA模型的建模 回总目录 7.1 概述 时间序列取自某一个随机过程,则称: 一、平稳时间序列 过程是平稳的――随机过程的随机特征不随时间变化而变化过程是非平稳的――随机过程的随机特征随时间变化而变化回总目录 回本章目录 宽平稳时间序列的定义: 设时间序列 ,对于任意的t,k和m,满足: 则称宽平稳。 回总目录 回本章目录 Box-Jenkins方法是一种理论较为完善的统计预测方法。 他们的工作为实际工作者提供了对时间序列进行分析、预测,以及对ARMA模型识别、估计和诊断的系统方 法。使ARMA模型的建立有了一套完整、正规、结构 化的建模方法,并且具有统计上的完善性和牢固的理 论基础。 ARMA模型是描述平稳随机序列的最常用的一种模型; 回总目录 回本章目录 ARMA模型三种基本形式: 自回归模型(AR:Auto-regressive); 移动平均模型(MA:Moving-Average); 混合模型(ARMA:Auto-regressive Moving-Average)。回总目录 回本章目录 如果时间序列满足 其中是独立同分布的随机变量序列,且满足: 则称时间序列服从p阶自回归模型。 二、自回归模型 回总目录 回本章目录 自回归模型的平稳条件: 滞后算子多项式 的根均在单位圆外,即 的根大于1。 回总目录 回本章目录 如果时间序列满足 则称时间序列服从q阶移动平均模型。或者记为。 平稳条件:任何条件下都平稳。 三、移动平均模型MA(q) 回总目录 回本章目录 四、ARMA(p,q)模型 如果时间序列 满足: 则称时间序列服从(p,q)阶自回归移动平均模型。 或者记为: 回总目录 回本章目录 q=0,模型即为AR(p); p=0,模型即为MA(q)。 ARMA(p,q)模型特殊情况: 回总目录 回本章目录 例题分析 设 ,其中A与B 为两个独立的零均值随机变量,方差为1; 第六节时间序列模型的建立与预测 ARIMA过程y t用 Φ (L) (Δd y t)= α+Θ(L) u t 表示,其中Φ (L)和Θ (L)分别是p, q阶的以L为变数的多项式,它们的根都在单位圆之外。α为Δd y t过程的漂移项,Δd y t表示对y t 进行d次差分之后可以表达为一个平稳的可逆的ARMA 过程。这是随机过程的一般表达式。它既包括了AR,MA 和ARMA过程,也包括了单整的AR,MA和ARMA过程。 可取 图建立时间序列模型程序图 建立时间序列模型通常包括三个步骤。(1)模型的识别,(2)模型参数的估计,(3)诊断与检验。 模型的识别就是通过对相关图的分析,初步确定适合于给定样本的ARIMA模型形式,即确定d, p, q的取值。 模型参数估计就是待初步确定模型形式后对模型参数进行估计。样本容量应该50以上。 诊断与检验就是以样本为基础检验拟合的模型,以求发现某些不妥之处。如果模型的某些参数估计值不能通过显著性检验,或者残差序列不能近似为一个白噪声过程,应返回第一步再次对模型进行识别。如果上述两个问题都不存在,就可接受所建立的模型。建摸过程用上图表示。下面对建摸过程做详细论述。 1、模型的识别 模型的识别主要依赖于对相关图与偏相关图的分析。在对经济时间序列进行分析之前,首先应对样本数据取对数,目的是消除数据中可能存在的异方差,然后分析其相关图。 识别的第1步是判断随机过程是否平稳。由前面知识可知,如果一个随机过程是平稳的,其特征方程的根都应在单位圆之外;如果 (L) = 0的根接近单位圆,自相关函数将衰减的很慢。所以在分析相关图时,如果发现其衰减很慢,即可认为该时间序列是非平稳的。这时应对该时间序列进行差分,同时分析差分序列的相关图以判断差分序列的平稳性,直至得到一个平稳的序列。对于经济时间序列,差分次数d通常只取0,1或2。 实际中也要防止过度差分。一般来说平稳序列差分得到的仍然是平稳序列,但当差分次数过多时存在两个缺点,(1)序列的样本容量减小;(2)方差变大;所以建模过程中要防止差分过度。对于一个序列,差分后若数据的极差变大,说明差分过度。 第2步是在平稳时间序列基础上识别ARMA模型阶数p, q。表1给出了不同ARMA模型的自相关函数和偏自相关函数。当然一个过程的自相关函数和偏自相关函数通常是未知的。用样本得到的只是估计的自相关函数和偏自相关函数,即相关图和偏相关图。建立ARMA模型,时间序列的相关图与偏相关图可为识别模型参数p, q提供信息。相关图和偏相关图(估计的自相关系数和偏自相关系数)通常比真实的自相关系数和偏自相关系数的方差要大,并表现为更高的自相关。实际中相关图,偏相关图的特征不会像自相关函数与偏自相关函数那样“规范”,所以应该善于从相关图,偏相关图中识别出模型的真实参数p, q。另外,估计的模型形式不是唯一的,所以在模型识别阶段应多选择几种模型形式,以供进一步选择。 摘要 在国民经济发展的过程中,国内生产总值(GDP)在一些程度上是衡量一个国家综合国力的重要参考指标。这个指标把国民经济经济活动的产出成果概括在一个极为简明的统计数字当中,为评价和衡量国家经济情况、经济增长趋势及社会财富的经济表现提供了一个较为综合的尺度,可以说,它是影响经济生活的重要指标之一,对其进行分析具有重要的理论与现实意义。 本文基于时间序列模型理论,以江苏省1996年至2016年地区生产总值为数据基础,建立ARIMA模型,并利用该模型对2017年江苏省GDP进行预测。 关键词:时间序列分析江苏省GDP ARIMA模型 Abstract In the process of national economic development, gross domestic product (GDP) is an important reference index to measure a country's overall national strength. The index of economic activities in the national economy output results summarized in a very simple statistics, which provides a more comprehensive scale for evaluating and measuring the economic situation of a country. It is one of the important indicators of influence of economy. To analyze it has important theoretical and practical significance. Based on the time series theory, this paper establishes a time series model based on the GDP of Jiangsu province from 1996 to 2016 and then uses the model to predict the future GDP of Jiangsu province. Key words:Time series analysis;Jiangsu GDP;ARIMA Model. ARMA模型及分析 本次试验主要是通过等时间间隔,连续读取70个某次化学反应的过程数据,构成一个时间序列。试对该时间序列进行ARMA模型拟合以及模型的优化,最后进行预测。以下本次试验的数据: 表1 连续读取70个化学反应数据 47 64 23 71 38 64 55 41 59 48 71 35 57 40 58 44 80 55 37 74 51 57 50 60 45 57 50 45 25 59 50 71 56 74 50 58 45 54 36 54 48 55 45 57 50 62 44 64 43 52 38 59 55 41 53 49 34 35 54 45 68 38 50 60 39 59 40 57 54 23 资料来源:O’Donovan, Consec. Readings Batch Chemical Proces, https://www.360docs.net/doc/391467557.html,ler et al. 下面的分析及检验、预测均是基于上述数据进行的,本次试验是在Eviews 6.0上完成的。 一、序列预处理 由于只有对平稳的时间序列才能建立ARMA模型,因此在建立模型之前,有必要对序列进行预处理,主要包括了平稳性检验和纯随机检验。 序列时序图显示此化学反应过程无明显趋势或周期,波动稳定。见图1。 图2 化学反应过程相关图和Q统计量 从图2的序列的相关分析结果:1. 可以看出自相关系数始终在0周围波动,判定该序列为平稳时间序列2.看Q统计量的P值:该统计量的原假设为X的1期,2期……k期的自相关系数均等于0,备择假设为自相关系数中至少有一个不等于0,因此如图知,该P值在滞后2、3、4期是都为0,所以拒接原假设,即序列是非纯随机序列,即非白噪声序列(因为序列值之间彼此之间存在关联,所以说过去的行为对将来的发展有一定的影响,因此为非纯随机序列,即非白噪声序列)。 二、模型识别 由于检验出时间序列是平稳的,且是非白噪声序列,因此可以建立模型,在建立模型之前需要识别模型阶数即确定阶数。阶数确定要借助于时间序列的相关图,即序列的自相关函数和偏自相关函数,并根据他们之间的理论模式进行阶数最后的确定。 下面给出自相关函数和偏自相关函数之间的理论模式:平稳时间序列预测法
时间序列模型的建立与预测
基于时间序列模型的xx省GDP统计分析
时间序列ARMA模型及分析