unity3d内存管理

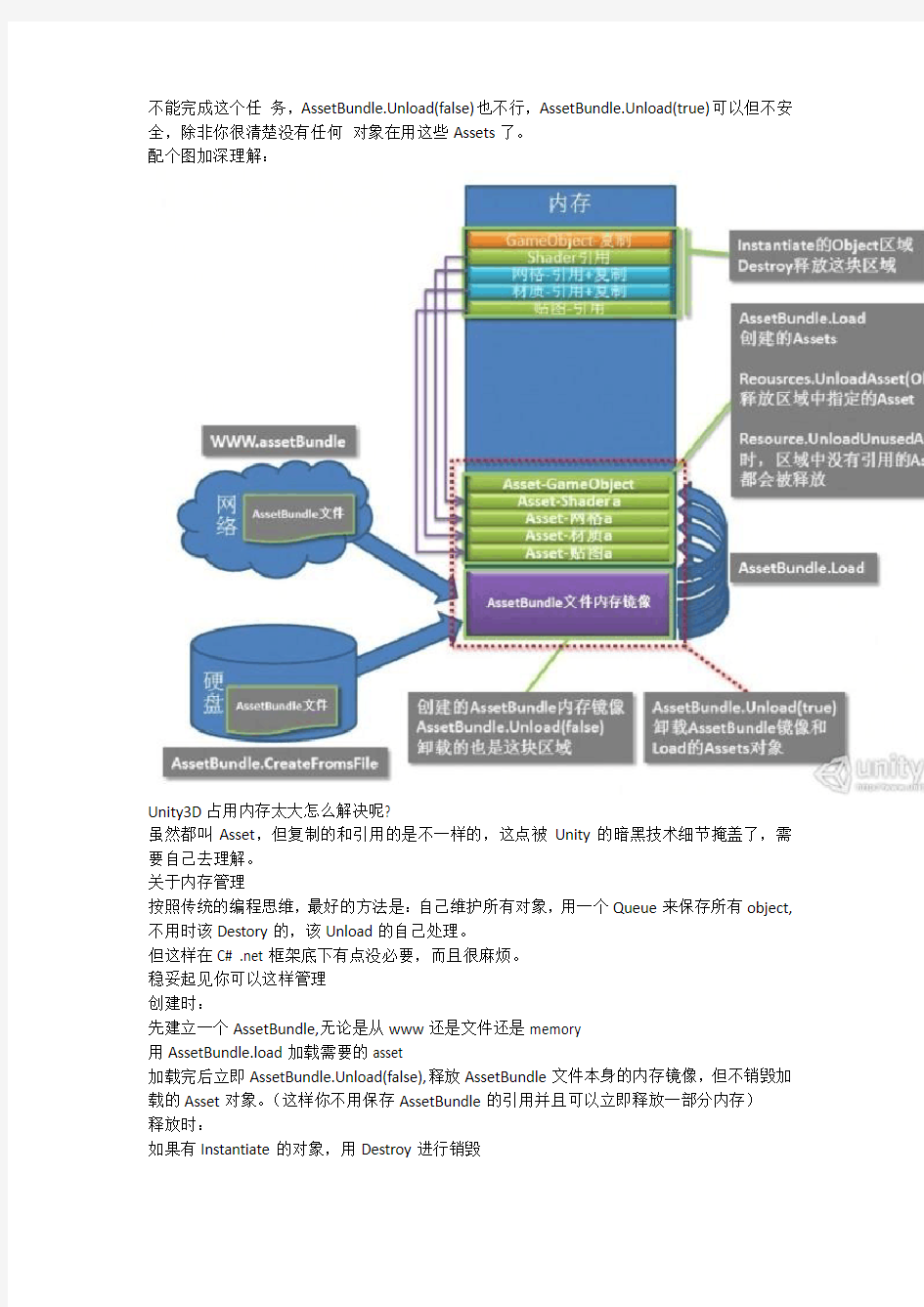
Unity3D 里有两种动态加载机制:一个是Resources.Load,另外一个通过AssetBundle,其实两者区别不大。 Resources.Load就是从一个缺省打进程序包里的AssetBundle里加载资源,而一般AssetBundle文件需要你自己创建,运行时动态加载,可以指定路径和来源的。
其实场景里所有静态的对象也有这么一个加载过程,只是Unity3D后台替你自动完成了。
详细说一下细节概念:
AssetBundle运行时加载:
来自文件就用CreateFromFile(注意这种方法只能用于standalone程序)这是最快的加载方法也可以来自Memory,用CreateFromMemory(byte[]),这个byte[]可以来自文件读取的缓冲,www的下载或者其他可能的方式。
其实WWW的assetBundle就是内部数据读取完后自动创建了一个assetBundle而已
Create完以后,等于把硬盘或者网络的一个文件读到内存一个区域,这时候只是个AssetBundle内存镜像数据块,还没有Assets的概念。
Assets加载:
用AssetBundle.Load(同Resources.Load) 这才会从AssetBundle的内存镜像里读取并创建一个Asset对象,创建Asset对象同时也会分配相应内存用于存放(反序列化)
异步读取用AssetBundle.LoadAsync
也可以一次读取多个用AssetBundle.LoadAll
AssetBundle的释放:
AssetBundle.Unload(flase)是释放AssetBundle文件的内存镜像,不包含Load创建的Asset内存对象。
AssetBundle.Unload(true)是释放那个AssetBundle文件内存镜像和并销毁所有用Load创建的Asset内存对象。
一个Prefab从assetBundle里Load出来里面可能包括:Gameobject transform mesh texture material shader script和各种其他Assets。
你 Instaniate一个Prefab,是一个对Assets进行Clone(复制)+引用结合的过程,GameObject transform 是Clone是新生成的。其他mesh / texture / material / shader 等,这其中些是纯引用的关系的,包括:Texture和TerrainData,还有引用和复制同时存在的,包括:Mesh/material /PhysicMaterial。引用的Asset对象不会被复制,只是一个简单的指针指向已经Load的Asset 对象。这种含糊的引用加克隆的混合,大概是搞糊涂大多数人的主要原因。
专门要提一下的是一个特殊的东西:Script Asset,看起来很奇怪,Unity里每个Script都是一个封闭的Class定义而已,并没有写调用代码,光Class的定义脚本是不会工作的。其实Unity 引擎就是那个调用代码,Clone一个script asset等于new一个class实例,实例才会完成工作。把他挂到Unity主线程的调用链里去,Class实例里的OnUpdate OnStart等才会被执行。多个物体挂同一个脚本,其实就是在多个物体上挂了那个脚本类的多个实例而已,这样就好理解了。在new class这个过程中,数据区是复制的,代码区是共享的,算是一种特殊的复制+引用关系。
你可以再Instaniate一个同样的Prefab,还是这套mesh/texture/material/shader...,这时候会有新的GameObject等,但是不会创建新的引用对象比如Texture.
所以你Load出来的Assets其实就是个数据源,用于生成新对象或者被引用,生成的过程可能是复制(clone)也可能是引用(指针)
当你Destroy一个实例时,只是释放那些Clone对象,并不会释放引用对象和Clone的数据源对象,Destroy并不知道是否还有别的object在引用那些对象。
等到没有任何游戏场景物体在用这些Assets以后,这些assets就成了没有引用的游离数据块了,是UnusedAssets了,这时候就可以通过 Resources.UnloadUnusedAssets来释放,Destroy
不能完成这个任务,AssetBundle.Unload(false)也不行,AssetBundle.Unload(true)可以但不安全,除非你很清楚没有任何对象在用这些Assets了。
配个图加深理解:
Unity3D占用内存太大怎么解决呢?
虽然都叫Asset,但复制的和引用的是不一样的,这点被Unity的暗黑技术细节掩盖了,需要自己去理解。
关于内存管理
按照传统的编程思维,最好的方法是:自己维护所有对象,用一个Queue来保存所有object,不用时该Destory的,该Unload的自己处理。
但这样在C# .net框架底下有点没必要,而且很麻烦。
稳妥起见你可以这样管理
创建时:
先建立一个AssetBundle,无论是从www还是文件还是memory
用AssetBundle.load加载需要的asset
加载完后立即AssetBundle.Unload(false),释放AssetBundle文件本身的内存镜像,但不销毁加载的Asset对象。(这样你不用保存AssetBundle的引用并且可以立即释放一部分内存)
释放时:
如果有Instantiate的对象,用Destroy进行销毁
在合适的地方调用Resources.UnloadUnusedAssets,释放已经没有引用的Asset.
如果需要立即释放内存加上GC.Collect(),否则内存未必会立即被释放,有时候可能导致内存占用过多而引发异常。
这样可以保证内存始终被及时释放,占用量最少。也不需要对每个加载的对象进行引用。当然这并不是唯一的方法,只要遵循加载和释放的原理,任何做法都是可以的。
系统在加载新场景时,所有的内存对象都会被自动销毁,包括你用AssetBundle.Load加载的对象和Instaniate克隆的。但是不包括AssetBundle文件自身的内存镜像,那个必须要用Unload来释放,用.net的术语,这种数据缓存是非托管的。
总结一下各种加载和初始化的用法:
AssetBundle.CreateFrom.....:创建一个AssetBundle内存镜像,注意同一个assetBundle文件在没有Unload之前不能再次被使用
WWW.AssetBundle:同上,当然要先new一个再yield return 然后才能使用AssetBundle.Load(name):从AssetBundle读取一个指定名称的Asset并生成Asset内存对象,如果多次Load同名对象,除第一次外都只会返回已经生成的Asset 对象,也就是说多次Load 一个Asset并不会生成多个副本(singleton)。
Resources.Load(path&name):同上,只是从默认的位置加载。
Instantiate(object):Clone 一个object的完整结构,包括其所有Component和子物体(详见官方文档),浅Copy,并不复制所有引用类型。有个特别用法,虽然很少这样用,其实可以用Instantiate来完整的拷贝一个引用类型的Asset,比如Texture等,要拷贝的Texture必须类型设置为Read/Write able。
总结一下各种释放
Destroy: 主要用于销毁克隆对象,也可以用于场景内的静态物体,不会自动释放该对象的所有引用。虽然也可以用于Asset,但是概念不一样要小心,如果用于销毁从文件加载的Asset 对象会销毁相应的资源文件!但是如果销毁的Asset是Copy的或者用脚本动态生成的,只会销毁内存对象。
AssetBundle.Unload(false):释放AssetBundle文件内存镜像
AssetBundle.Unload(true):释放AssetBundle文件内存镜像同时销毁所有已经Load的Assets内存对象
Reources.UnloadAsset(Object):显式的释放已加载的Asset对象,只能卸载磁盘文件加载的Asset对象
Resources.UnloadUnusedAssets:用于释放所有没有引用的Asset对象
GC.Collect()强制垃圾收集器立即释放内存Unity的GC功能不算好,没把握的时候就强制调用一下
在3.5.2之前好像Unity不能显式的释放Asset
举两个例子帮助理解
例子1:
一个常见的错误:你从某个AssetBundle里Load了一个prefab并克隆之:obj = Instaniate(AssetBundle1.Load('MyPrefab”);
这个prefab比如是个npc
然后你不需要他的时候你用了:Destroy(obj);你以为就释放干净了
其实这时候只是释放了Clone对象,通过Load加载的所有引用、非引用Assets对象全都静静静的躺在内存里。
这种情况应该在Destroy以后用:AssetBundle1.Unload(true),彻底释放干净。
如果这个AssetBundle1是要反复读取的不方便Unload,那可以在Destroy以后用:
Resources.UnloadUnusedAssets()把所有和这个npc有关的Asset都销毁。
当然如果这个NPC也是要频繁创建销毁的那就应该让那些Assets呆在内存里以加速游戏体验。
由此可以解释另一个之前有人提过的话题:为什么第一次Instaniate 一个Prefab的时候都会卡一下,因为在你第一次Instaniate之前,相应的Asset对象还没有被创建,要加载系统内置的AssetBundle并创建Assets,第一次以后你虽然Destroy了,但Prefab的Assets对象都还在内存里,所以就很快了。
顺便提一下几种加载方式的区别:
其实存在3种加载方式:
一是静态引用,建一个public的变量,在Inspector里把prefab拉上去,用的时候instantiate 二是Resource.Load,Load以后instantiate
三是AssetBundle.Load,Load以后instantiate
三种方式有细节差异,前两种方式,引用对象texture是在instantiate时加载,而assetBundle.Load会把perfab的全部assets 都加载,instantiate时只是生成Clone。所以前两种方式,除非你提前加载相关引用对象,否则第一次instantiate时会包含加载引用assets 的操作,导致第一次加载的lag。
例子2:
从磁盘读取一个1.unity3d文件到内存并建立一个AssetBundle1对象
AssetBundle AssetBundle1 = AssetBundle.CreateFromFile("1.unity3d");
从AssetBundle1里读取并创建一个Texture Asset,把obj1的主贴图指向它
obj1.renderer.material.mainTexture = AssetBundle1.Load("wall") as Texture;
把obj2的主贴图也指向同一个Texture Asset
obj2.renderer.material.mainTexture =obj1.renderer.material.mainTexture;
Texture是引用对象,永远不会有自动复制的情况出现(除非你真需要,用代码自己实现copy),只会是创建和添加引用
如果继续:
AssetBundle1.Unload(true) 那obj1和obj2都变成黑的了,因为指向的Texture Asset没了
如果:
AssetBundle1.Unload(false) 那obj1和obj2不变,只是AssetBundle1的内存镜像释放了
继续:
Destroy(obj1),//obj1被释放,但并不会释放刚才Load的Texture
如果这时候:
Resources.UnloadUnusedAssets();
不会有任何内存释放因为Texture asset还被obj2用着
如果
Destroy(obj2)
obj2被释放,但也不会释放刚才Load的Texture
继续
Resources.UnloadUnusedAssets();
这时候刚才load的Texture Asset释放了,因为没有任何引用了
最后CG.Collect();
强制立即释放内存
由此可以引申出论坛里另一个被提了几次的问题,如何加载一堆大图片轮流显示又不爆掉不考虑AssetBundle,直接用www读图片文件的话等于是直接创建了一个Texture Asset
假设文件保存在一个List里
TLlist
int n=0;
IEnumerator OnClick()
{
WWW image = new www(fileList[n++]);
yield return image;
obj.mainTexture = image.texture;
n = (n>=fileList.Length-1)?0:n;
Resources.UnloadUnusedAssets();
}
这样可以保证内存里始终只有一个巨型Texture Asset资源,也不用代码追踪上一个加载的Texture Asset,但是速度比较慢
或者:
IEnumerator OnClick()
{
WWW image = new www(fileList[n++]);
yield return image;
Texture tex = obj.mainTexture;
obj.mainTexture = image.texture;
n = (n>=fileList.Length-1)?0:n;
Resources.UnloadAsset(tex);
}
这样卸载比较快
Hog的评论引用:
感觉这是Unity内存管理暗黑和混乱的地方,特别是牵扯到Texture
我最近也一直在测试这些用AssetBundle加载的asset一样可以用Resources.UnloadUnusedAssets卸载,但必须先AssetBundle.Unload,才会被识别为无用的asset。比较保险的做法是
创建时:
先建立一个AssetBundle,无论是从www还是文件还是memory
用AssetBundle.load加载需要的asset
用完后立即AssetBundle.Unload(false),关闭AssetBundle但不摧毁创建的对象和引用
销毁时:
对Instantiate的对象进行Destroy
在合适的地方调用Resources.UnloadUnusedAssets,释放已经没有引用的Asset.
如果需要立即释放加上GC.Collect()
这样可以保证内存始终被及时释放
只要你Unload过的AssetBundle,那些创建的对象和引用都会在LoadLevel时被自动释放。
全面理解Unity加载和内存管理机制之二:进一步深入和细节
Unity几种动态加载Prefab方式的差异:
其实存在3种加载prefab的方式:
一是静态引用,建一个public的变量,在Inspector里把prefab拉上去,用的时候instantiate 二是Resource.Load,Load以后instantiate
三是AssetBundle.Load,Load以后instantiate
三种方式有细节差异,前两种方式,引用对象texture是在instantiate时加载,而assetBundle.Load会把perfab的全部assets都加载,instantiate时只是生成Clone。所以前两种方式,除非你提前加载相关引用对象,否则第一次instantiate时会包含加载引用类assets 的操作,导致第一次加载的lag。官方论坛有人说Resources.Load和静态引用是会把所有资源都预先加载的,反复测试的结果,静态引用和Resources.Load也是OnDemand的,用到时才会加载。
几种AssetBundle创建方式的差异:
CreateFromFile:这种方式不会把整个硬盘AssetBundle文件都加载到内存来,而是类似建立一个文件操作句柄和缓冲区,需要时才实时Load,所以这种加载方式是最节省资源的,基本上AssetBundle本身不占什么内存,只需要Asset对象的内存。可惜只能在PC/Mac Standalone程序中使用。
CreateFromMemory和www.assetBundle:这两种方式AssetBundle文件会整个镜像于内存中,理论上文件多大就需要多大的内存,之后Load时还要占用额外内存去生成Asset对象。
什么时候才是UnusedAssets?
看一个例子:
Object obj = Resources.Load("MyPrefab");
GameObject instance = Instantiate(obj) as GameObject;
.........
Destroy(instance);
创建随后销毁了一个Prefab实例,这时候MyPrefab已经没有被实际的物体引用了,但如果这时:
Resources.UnloadUnusedAssets();
内存并没有被释放,原因:MyPrefab还被这个变量obj所引用
这时候:
obj = null;
Resources.UnloadUnusedAssets();
这样才能真正释放Assets对象
所以:UnusedAssets不但要没有被实际物体引用,也要没有被生命周期内的变量所引用,才可以理解为Unused(引用计数为0)
所以所以:如果你用个全局变量保存你Load的Assets,又没有显式的设为null,那在这个变量失效前你无论如何UnloadUnusedAssets也释放不了那些Assets的。如果你这些Assets 又不是从磁盘加载的,那除了UnloadUnusedAssets或者加载新场景以外没有其他方式可以卸载之。
一个复杂的例子,代码很丑陋实际也不可能这样做,只是为了加深理解
IEnumerator OnClick()
{
Resources.UnloadUnusedAssets();//清干净以免影响测试效果
yield return new WaitForSeconds(3);
float wait = 0.5f;
//用www读取一个assetBundle,里面是一个Unity基本球体和带一张大贴图的材质,是一个
Prefab
WWW aa = new WWW(@"file://SpherePrefab.unity3d");
yield return aa;
AssetBundle asset = aa.assetBundle;
yield return new WaitForSeconds(wait);//每步都等待0.5s以便于分析结果Texture tt = asset.Load("BallTexture") as Texture;//加载贴图
yield return new WaitForSeconds(wait);
GameObject ba = asset.Load("SpherePrefab") as GameObject;//加载Prefab yield return new WaitForSeconds(wait);
GameObject obj1 = Instantiate(ba) as GameObject;//生成实例
yield return new WaitForSeconds(wait);
Destroy(obj1);//销毁实例
yield return new WaitForSeconds(wait);
asset.Unload(false);//卸载Assetbundle
yield return new WaitForSeconds(wait);
Resources.UnloadUnusedAssets();//卸载无用资源
yield return new WaitForSeconds(wait);
ba = null;//将prefab引用置为空以后卸无用载资源
Resources.UnloadUnusedAssets();
yield return new WaitForSeconds(wait);
tt = null;//将texture引用置为空以后卸载无用资源
Resources.UnloadUnusedAssets();
}
这是测试结果的内存Profile曲线图
Unity3D占用内存太大怎么解决呢?
图片:p12.jpg
很经典的对称造型,用多少释放多少。
这是各阶段的内存和其他数据变化
说明:
1 初始状态
2 载入AssetBundle文件后,内存多了文件镜像,用量上升,Total Object和Assets增加1(AssetBundle也是object)
3 载入Texture后,内存继续上升,因为多了Texture Asset,Total Objects和Assets增加1
4 载入Prefab后,内存无明显变化,因为最占内存的Texture已经加载,Materials上升是因为多了Prefab的材质,Total Objects和Assets增加6,因为Perfab 包含很多Components
5 实例化Prefab以后,显存的Texture Memory、GameObjectTotal、Objects in Scene上升,都是因为实例化了一个可视的对象
6 销毁实例后,上一步的变化还原,很好理解
7 卸载AssetBundle文件后,AssetBundle文件镜像占用的内存被释放,相应的Assets和Total Objects Count也减1
8 直接Resources.UnloadUnusedAssets,没有任何变化,因为所有Assets引用并没有清空
9 把Prefab引用变量设为null以后,整个Prefab除了Texture外都没有任何引用了,所以被UnloadUnusedAssets销毁,Assets和Total Objects Count减6
10 再把Texture的引用变量设为null,之后也被UnloadUnusedAssets销毁,内存被释放,assets和Total Objects Count减1,基本还原到初始状态
从中也可以看出:
Texture加载以后是到内存,显示的时候才进入显存的Texture Memory。
所有的东西基础都是Object
Load的是Asset,Instantiate的是GameObject和Object in Scene
Load的Asset要Unload,new的或者Instantiate的object可以Destroy
Unity 3D中的内存管理
Unity3D在内存占用上一直被人诟病,特别是对于面向移动设备的游戏开发,动辄内存占用飙上一两百兆,导致内存资源耗尽,从而被系统强退造成极差的体验。类似这种情况并不少见,但是绝大部分都是可以避免的。虽然理论上Unity的内存管理系统应当为开发者分忧解难,让大家投身到更有意义的事情中去,但是对于Unity对内存的管理方式,官方文档中并没有太多的说明,基本需要依靠自己摸索。最近在接手的项目中存在严重的内存问题,在参照文档和Unity Answer众多猜测和证实之后,稍微总结了下Unity中的内存的分配和管理的基本方式,在此共享。
虽然Unity标榜自己的内存使用全都是“Managed Memory”,但是事实上你必须正确地使用内存,以保证回收机制正确运行。如果没有做应当做的事情,那么场景和代码很有可能造成很多非必要内存的占用,这也是很多Unity开发者抱怨内存占用太大的原因。接下来我会介绍Unity使用内存的种类,以及相应每个种类的优化和使用的技巧。遵循使用原则,可以让非必要资源尽快得到释放,从而降低内存占用。
Unity中的内存种类
实际上Unity游戏使用的内存一共有三种:程序代码、托管堆(Managed Heap)以及本机堆(Native Heap)。
程序代码包括了所有的Unity引擎,使用的库,以及你所写的所有的游戏代码。在编译后,得到的运行文件将会被加载到设备中执行,并占用一定内存。
这部分内存实际上是没有办法去“管理”的,它们将在内存中从一开始到最后一直存在。一个空的Unity默认场景,什么代码都不放,在iOS设备上占用内存应该在17MB左右,而加上一些自己的代码很容易就飙到20MB左右。想要减少这部分内存的使用,能做的就是减少使用的库,稍后再说。
托管堆是被Mono使用的一部分内存。Mono项目一个开源的.net框架的一种实现,对于Unity 开发,其实充当了基本类库的角色。
托管堆用来存放类的实例(比如用new生成的列表,实例中的各种声明的变量等)。“托管”的意思是Mono“应该”自动地改变堆的大小来适应你所需要的内存,
并且定时地使用垃圾回收(Garbage Collect)来释放已经不需要的内存。关键在于,有时候你会忘记清除对已经不需要再使用的内存的引用,
从而导致Mono认为这块内存一直有用,而无法回收。
最后,本机堆是Unity引擎进行申请和操作的地方,比如贴图,音效,关卡数据等。Unity
使用了自己的一套内存管理机制来使这块内存具有和托管堆类似的功能。
基本理念是,如果在这个关卡里需要某个资源,那么在需要时就加载,之后在没有任何引用时进行卸载。听起来很美好也和托管堆一样,
但是由于Unity有一套自动加载和卸载资源的机制,让两者变得差别很大。自动加载资源可以为开发者省不少事儿,
但是同时也意味着开发者失去了手动管理所有加载资源的权力,这非常容易导致大量的内存占用(贴图什么的你懂的),
也是Unity给人留下“吃内存”印象的罪魁祸首。
优化程序代码的内存占用
这部分的优化相对简单,因为能做的事情并不多:主要就是减少打包时的引用库,改一改build设置即可。
对于一个新项目来说不会有太大问题,但是如果是已经存在的项目,可能改变会导致原来所需要的库的缺失(虽说一般来说这种可能性不大),
因此有可能无法做到最优。
当使用Unity开发时,默认的Mono包含库可以说大部分用不上,在Player Setting(Edit->Project Setting->Player或者Shift+Ctrl(Command)+B里的Player Setting按钮)
面板里,将最下方的Optimization栏目中“Api Compatibility Level”选为.NET 2.0 Subset,表示你只会使用到部分的.NET 2.0 Subset,不需要Unity将全部.NET的Api包含进去。接下来的“Stripping Level”表示从build的库中剥离的力度,每一个剥离选项都将从打包好的库中去掉一部分内容。你需要保证你的代码没有用到这部分被剥离的功能,
选为“Use micro mscorlib”的话将使用最小的库(一般来说也没啥问题,不行的话可以试试之前的两个)。库剥离可以极大地降低打包后的程序的尺寸以及程序代码的内存占用,唯一的缺点是这个功能只支持Pro版的Unity。
这部分优化的力度需要根据代码所用到的.NET的功能来进行调整,有可能不能使用Subset 或者最大的剥离力度。
如果超出了限度,很可能会在需要该功能时因为找不到相应的库而crash掉(iOS的话很可能在Xcode编译时就报错了)。
比较好地解决方案是仍然用最强的剥离,并辅以较小的第三方的类库来完成所需功能。
一个最常见问题是最大剥离时Sysytem.Xml是不被Subset和micro支持的,如果只是为了xml,完全可以导入一个轻量级的xml库来解决依赖(Unity官方推荐这个)。
关于每个设定对应支持的库的详细列表,可以在这里找到。关于每个剥离级别到底做了什么,Unity的文档也有说明。
实际上,在游戏开发中绝大多数被剥离的功能使用不上的,因此不管如何,库剥离的优化方法都值得一试。
托管堆优化
Unity有一篇不错的关于托管堆代码如何写比较好的说明,在此基础上我个人有一些补充。首先需要明确,托管堆中存储的是你在你的代码中申请的内存(不论是用js,C#还是Boo 写的)。
一般来说,无非是new或者Instantiate两种生成object的方法(事实上Instantiate中也是调
用了new)。
在接收到alloc请求后,托管堆在其上为要新生成的对象实例以及其实例变量分配内存,如果可用空间不足,则向系统申请更多空间。
当你使用完一个实例对象之后,通常来说在脚本中就不会再有对该对象的引用了(这包括将变量设置为null或其他引用,超出了变量的作用域,
或者对Unity对象发送Destory())。在每隔一段时间,Mono的垃圾回收机制将检测内存,将没有再被引用的内存释放回收。总的来说,
你要做的就是在尽可能早的时间将不需要的引用去除掉,这样回收机制才能正确地把不需要的内存清理出来。但是需要注意在内存清理时有可能造成游戏的短时间卡顿,
这将会很影响游戏体验,因此如果有大量的内存回收工作要进行的话,需要尽量选择合适的时间。
如果在你的游戏里,有特别多的类似实例,并需要对它们经常发送Destroy()的话,游戏性能上会相当难看。比如小熊推金币中的金币实例,按理说每枚金币落下台子后
都需要对其Destory(),然后新的金币进入台子时又需要Instantiate,这对性能是极大的浪费。一种通常的做法是在不需要时,不摧毁这个GameObject,而只是隐藏它,
并将其放入一个重用数组中。之后需要时,再从重用数组中找到可用的实例并显示。这将极大地改善游戏的性能,相应的代价是消耗部分内存,一般来说这是可以接受的。
关于对象重用,可以参考Unity关于内存方面的文档中Reusable Object Pools部分,或者Prime31有一个是用Linq来建立重用池的视频教程(Youtube,需要翻墙,上,下)。
如果不是必要,应该在游戏进行的过程中尽量减少对GameObject的Instantiate()和Destroy()调用,因为对计算资源会有很大消耗。在便携设备上短时间大量生成和摧毁物体的
话,很容易造成瞬时卡顿。如果内存没有问题的话,尽量选择先将他们收集起来,然后在合适的时候(比如按暂停键或者是关卡切换),将它们批量地销毁并且回收内存。Mono的内存回收会在后台自动进行,系统会选择合适的时间进行垃圾回收。在合适的时候,也可以手动地调用System.GC.Collect()来建议系统进行一次垃圾回收。
要注意的是这里的调用真的仅仅只是建议,可能系统会在一段时间后在进行回收,也可能完全不理会这条请求,不过在大部分时间里,这个调用还是靠谱的。
本机堆的优化
当你加载完成一个Unity的scene的时候,scene中的所有用到的asset(包括Hierarchy中所有GameObject上以及脚本中赋值了的的材质,贴图,动画,声音等素材),
都会被自动加载(这正是Unity的智能之处)。也就是说,当关卡呈现在用户面前的时候,所有Unity编辑器能认识的本关卡的资源都已经被预先加入内存了,这样在本关卡中,用户将有良好的体验,不论是更换贴图,声音,还是播放动画时,都不会有额外的加载,这样的代价是内存占用将变多。Unity最初的设计目的还是面向台式机,
几乎无限的内存和虚拟内存使得这样的占用似乎不是问题,但是这样的内存策略在之后移动平台的兴起和大量移动设备游戏的制作中出现了弊端,因为移动设备能使用的资源始终非常有限。因此在面向移动设备游戏的制作时,尽量减少在Hierarchy对资源的直接引用,而是使用Resource.Load的方法,在需要的时候从硬盘中读取资源,
在使用后用Resource.UnloadAsset()和Resources.UnloadUnusedAssets()尽快将其卸载掉。总之,这里是一个处理时间和占用内存空间的trade off,
如何达到最好的效果没有标准答案,需要自己权衡。
在关卡结束的时候,这个关卡中所使用的所有资源将会被卸载掉(除非被标记了
DontDestroyOnLoad)的资源。注意不仅是DontDestroyOnLoad的资源本身,
其相关的所有资源在关卡切换时都不会被卸载。DontDestroyOnLoad一般被用来在关卡之间保存一些玩家的状态,比如分数,级别等偏向文本的信息。如果DontDestroyOnLoad了一个包含很多资源(比如大量贴图或者声音等大内存占用的东西)的话,这部分资源在场景切换时无法卸载,将一直占用内存,
这种情况应该尽量避免。
另外一种需要注意的情况是脚本中对资源的引用。大部分脚本将在场景转换时随之失效并被回收,但是,在场景之间被保持的脚本不在此列(通常情况是被附着在DontDestroyOnLoad 的GameObject上了)。而这些脚本很可能含有对其他物体的Component或者资源的引用,这样相关的资源就都得不到释放,
这绝对是不想要的情况。另外,static的单例(singleton)在场景切换时也不会被摧毁,同样地,如果这种单例含有大量的对资源的引用,也会成为大问题。
因此,尽量减少代码的耦合和对其他脚本的依赖是十分有必要的。如果确实无法避免这种情况,那应当手动地对这些不再使用的引用对象调用Destroy()
或者将其设置为null。这样在垃圾回收的时候,这些内存将被认为已经无用而被回收。
需要注意的是,Unity在一个场景开始时,根据场景构成和引用关系所自动读取的资源,只有在读取一个新的场景或者reset当前场景时,才会得到清理。
因此这部分内存占用是不可避免的。在小内存环境中,这部分初始内存的占用十分重要,因为它决定了你的关卡是否能够被正常加载。因此在计算资源充足
或是关卡开始之后还有机会进行加载时,尽量减少Hierarchy中的引用,变为手动用Resource.Load,将大大减少内存占用。在Resource.UnloadAsset()和Resources.UnloadUnusedAssets()时,只有那些真正没有任何引用指向的资源会被回收,因此请确保在资源不再使用时,将所有对该资源的引用设置为null或者Destroy。
同样需要注意,这两个Unload方法仅仅对Resource.Load拿到的资源有效,而不能回收任何场景开始时自动加载的资源。与此类似的还有AssetBundle的Load和Unload方法,灵活使用这些手动自愿加载和卸载的方法,是优化Unity内存占用的不二法则~
总之这些就是关于Unity3d优化细节,具体还是查看Unity3D的技术手册,以便实现最大的优化.
操作系统内存管理复习过程
操作系统内存管理
操作系统内存管理 1. 内存管理方法 内存管理主要包括虚地址、地址变换、内存分配和回收、内存扩充、内存共享和保护等功能。 2. 连续分配存储管理方式 连续分配是指为一个用户程序分配连续的内存空间。连续分配有单一连续存储管理和分区式储管理两种方式。 2.1 单一连续存储管理 在这种管理方式中,内存被分为两个区域:系统区和用户区。应用程序装入到用户区,可使用用户区全部空间。其特点是,最简单,适用于单用户、单任务的操作系统。CP/M和 DOS 2.0以下就是采用此种方式。这种方式的最大优点就是易于管理。但也存在着一些问题和不足之处,例如对要求内
存空间少的程序,造成内存浪费;程序全部装入,使得很少使用的程序部分也占用—定数量的内存。 2.2 分区式存储管理 为了支持多道程序系统和分时系统,支持多个程序并发执行,引入了分区式存储管理。分区式存储管理是把内存分为一些大小相等或不等的分区,操作系统占用其中一个分区,其余的分区由应用程序使用,每个应用程序占用一个或几个分区。分区式存储管理虽然可以支持并发,但难以进行内存分区的共享。 分区式存储管理引人了两个新的问题:内碎片和外碎片。 内碎片是占用分区内未被利用的空间,外碎片是占用分区之间难以利用的空闲分区(通常是小空闲分区)。 为实现分区式存储管理,操作系统应维护的数据结构为分区表或分区链表。表中各表项一般包括每个分区的起始地址、大小及状态(是否已分配)。
分区式存储管理常采用的一项技术就是内存紧缩(compaction)。 2.2.1 固定分区(nxedpartitioning)。 固定式分区的特点是把内存划分为若干个固定大小的连续分区。分区大小可以相等:这种作法只适合于多个相同程序的并发执行(处理多个类型相同的对象)。分区大小也可以不等:有多个小分区、适量的中等分区以及少量的大分区。根据程序的大小,分配当前空闲的、适当大小的分区。 优点:易于实现,开销小。 缺点主要有两个:内碎片造成浪费;分区总数固定,限制了并发执行的程序数目。 2.2.2动态分区(dynamic partitioning)。 动态分区的特点是动态创建分区:在装入程序时按其初始要求分配,或在其执行过程中通过系统调用进行分配或改变分区大小。与固定分区相比较其优点是:没有内碎
内存管理模型的设计与实现
操作系统课程实验报告 学生姓名:尹朋 班学号:111131 指导教师:袁国斌 中国地质大学信息工程学院 2015年1月4日
实习题目:内存管理模型的设计与实现 【需求规格说明】 对内存的可变分区申请采用链表法管理进行模拟实现。要求: 1.对于给定的一个存储空间自己设计数据结构进行管理,可以使用单个链 表,也可以使用多个链表,自己负责存储空间的所有管理组织,要求采用分页方式(指定单元大小为页,如4K,2K,进程申请以页为单位)来组织基本内容; 2.当进程对内存进行空间申请操作时,模型采用一定的策略(如:首先利用 可用的内存进行分配,如果空间不够时,进行内存紧缩或其他方案进行处理)对进程给予指定的内存分配; 3.从系统开始启动到多个进程参与申请和运行时,进程最少要有3个以上, 每个执行申请的时候都要能够对系统当前的内存情况进行查看的接口; 4.对内存的申请进行内存分配,对使用过的空间进行回收,对给定的某种页 面调度进行合理的页面分配。 5.利用不同的颜色代表不同的进程对内存的占用情况,动态更新这些信息。 【算法设计】 (1)设计思想: 通过建立一个链表,来描述已分配和空闲的内存分区。对于每一个分区,它可能存放了某个进程,也可能是两个进程间的空闲区。链表中的每一个结点,分别描述了一个内存分区,包括它的起始地址、长度、指向下一个结点的指针以及分区的当前状态。 在基于链表的存储管理中,当一个新的进程到来时,需要为它分配内存空间,即为它寻找某个空闲分区,该分区的大小必须大于或等于进程的大小. 最先匹配法:假设新进程的大小为M,那么从链表的首节点开始,将每一个空闲节点的大小与M相比较,直到找到合适的节点.这种算法查找的节点很少,因而速度很快. 最佳匹配算法:搜索整个链表,将能够装得下该进程的最小空闲区分配出去. 最坏匹配法:在每次分配的时候,总是将最大的那个空闲区切去一部分,分配给请求者.它的依据是当一个很大的空闲区被切割成一部分后,可能仍然是一个比较大的空闲区,从而避免了空闲区越分越小的问题. (2)设计表示: 分区结点设计: template
操作系统课程设计--连续动态分区内存管理模拟实现
(操作系统课程设计) 连续动态分区内存 管理模拟实现
目录 《操作系统》课程设计 (1) 引言 (3) 课程设计目的和内容 (3) 需求分析 (3) 概要设计 (3) 开发环境 (4) 系统分析设计 (4) 有关了解内存管理的相关理论 (4) 内存管理概念 (4) 内存管理的必要性 (4) 内存的物理组织 (4) 什么是虚拟内存 (5) 连续动态分区内存管理方式 (5) 单一连续分配(单个分区) (5) 固定分区存储管理 (5) 可变分区存储管理(动态分区) (5) 可重定位分区存储管理 (5) 问题描述和分析 (6) 程序流程图 (6) 数据结构体分析 (8) 主要程序代码分析 (9) 分析并实现四种内存分配算法 (11) 最先适应算 (11) 下次适应分配算法 (13) 最优适应算法 (16)
最坏适应算法......................................................... (18) 回收内存算法 (20) 调试与操作说明 (22) 初始界面 (22) 模拟内存分配 (23) 已分配分区说明表面 (24) 空闲区说明表界面 (24) 回收内存界面 (25) 重新申请内存界面..........................................................26. 总结与体会 (28) 参考文献 (28) 引言 操作系统是最重要的系统软件,同时也是最活跃的学科之一。我们通过操作系统可以理解计算机系统的资源如何组织,操作系统如何有效地管理这些系统资源,用户如何通过操作系统与计算机系统打交道。 存储器是计算机系统的重要组成部分,近年来,存储器容量虽然一直在不断扩大,但仍不能满足现代软件发展的需要,因此,存储器仍然是一种宝贵而又紧俏的资源。如何对它加以有效的管理,不仅直接影响到存储器的利用率,而且还对系统性能有重大影响。而动态分区分配属于连续分配的一种方式,它至今仍在内存分配方式中占有一席之地。 课程设计目的和内容: 理解内存管理的相关理论,掌握连续动态分区内存管理的理论;通过对实际问题的编程实现,获得实际应用和编程能力。
动态内存管理知识总结
1.标准链接库提供四个函数实现动态内存管理: (1)分配新的内存区域: void * malloc(size_t size); void *calloc(size_t count , size_t size); (2)调整以前分配的内存区域: void *realloc(void *ptr , size_t size); (3)释放以前分配的内存区域: void free(void *ptr); 2.void * malloc(size_t size); 该函数分配连续的内存空间,空间大小不小于size 个字节。但分配的空间中的内容是未知的。该函数空间分配失败则返回NULL。 3.void *calloc(size_t count , size_t size); 该函数也可以分配连续的内存空间,分配不少于count*size个字节的内存空间。即可以为一个数组分配空间,该数组有count个元素,每个元素占size个字节。而且该函数会将分配来的内存空间中的内容全部初始化为0 。该函数空间分配失败则返回NULL。 4. 以上两个分配内存空间的函数都返回void * (空类型指针或无类型指针)返回的指针值是“分配的内存区域中”第一个字节的地址。当存取分配的内存位置时,你所使用的指针类型决定如何翻译该位置的数据。以上两种分配内存空间的方法相比较,calloc()函数的效果更好。原因是它将分配得来的内存空间按位全部置0 。 5. 若使用上述两种分配内存的函数分配一个空间大小为0 的内存,函数会返回一个空指针或返回一个没有定义的不寻常指针。因此绝不可以使用“指向0 字节区域”的指针。 6. void *realloc(void *ptr , size_t size); 该函数释放ptr所指向的内存区域,并分配一个大小为size字节的内存区域,并返回该区域的地址。新的内存区域可以和旧的内存区域一样,开始于相同的地址。且此函数也会保留原始内存内容。如果新的内存区域没有从原始区域的地址开始,那么此函数会将原始的内容复制到新的内存区域。如果新的内存区域比较大,那么多出来部分的值是没有意义的。 7. 可以把空指针传给realloc()函数,这样的话此函数类似于malloc()函数,并得到一块内存空间。如果内存空间不足以满足内存区域分配的请求,那么realloc()函数返回一个空指针,这种情况下,不会释放原始的内存区域,也不会改变它的内容。 8. void free(void *ptr); 该函数释放动态分配的内存区域,开始地址是ptr,ptr的值可以是空指针。若在调用此函数时传入空指针,则此函数不起任何作用。 9. 传入free() 和realloc()函数的指针(若不为空指针时)必须是“尚未被释放的动态分配内存区域的起始地址”。否则函数的行为未定义。Realloc()函数也可以释放内存空间,例如:Char *Ptr = (char *)malloc(20); 如只需要10个字节的内存空间,且保留前十个字节的内容,则可以使用realloc()函数。 Ptr = Realloc(ptr,10); // 后十个字节的内存空间便被释放
基于可重定位分区分配算法的内存管理的设计与实现
组号成绩 计算机操作系统 课程设计报告 题目基于可重定位分区分配算法的内存管理的设计与实现 专业:计算机科学与技术 班级: 学号+: 指导教师: 2016年12月23 日
一.设计目的 掌握内存的连续分配方式的各种分配算法 二.设计内容 基于可重定位分区分配算法的内存管理的设计与实现。本系统模拟操作系统内存分配算法的实现,实现可重定位分区分配算法,采用PCB定义结构体来表示一个进程,定义了进程的名称和大小,进程内存起始地址和进程状态。内存分区表采用空闲分区表的形式来模拟实现。要求定义与算法相关的数据结构,如PCB、空闲分区;在使用可重定位分区分配算法时必须实现紧凑。 三.设计原理 可重定位分区分配算法与动态分区分配算法基本上相同,差别仅在于:在这种分配算法中,增加了紧凑功能。通常,该算法不能找到一个足够大的空闲分区以满足用户需求时,如果所有的小的空闲分区的容量总和大于用户的要求,这是便须对内存进行“紧凑”,将经过“紧凑”后所得到的大空闲分区分配给用户。如果所有的小空闲分区的容量总和仍小于用户的要求,则返回分配失败信息 四.详细设计及编码 1.模块分析 (1)分配模块 这里采用首次适应(FF)算法。设用户请求的分区大小为u.size,内存中空闲分区大小为m.size,规定的不再切割的剩余空间大小为size。空闲分区按地址递增的顺序排列;在分配内存时,从空闲分区表第一个表目开始顺序查找,如果m.size≥u.size且m.size-u.size≤size,说明多余部分太小,不再分割,将整个分区分配给请求者;如果m.size≥u.size且 m.size-u.size>size,就从该空闲分区中按请求的大小划分出一块内存空间分配给用户,剩余的部分仍留在空闲分区表中;如果m.size 学生学号 实验课成绩 武汉理工大学 学生实验报告书 实验课程名称 计算机操作系统 开 课 学 院 计算机科学与技术学院 指导老师姓名 学 生 姓 名 学生专业班级 2016 — 2017 学年第一学期 实验三 内存管理 一、设计目的、功能与要求 1、实验目的 掌握内存管理的相关内容,对内存的分配和回收有深入的理解。 2、实现功能 模拟实现内存管理机制 3、具体要求 任选一种计算机高级语言编程实现 选择一种内存管理方案:动态分区式、请求页式、段式、段页式等 能够输入给定的内存大小,进程的个数,每个进程所需内存空间的大小等 能够选择分配、回收操作 内购显示进程在内存的储存地址、大小等 显示每次完成内存分配或回收后内存空间的使用情况 二、问题描述 所谓分区,是把内存分为一些大小相等或不等的分区,除操作系统占用一个分区外,其余分区用来存放进程的程序和数据。本次实验中才用动态分区法,也就是在作业的处理过程中划分内存的区域,根据需要确定大小。 动态分区的分配算法:首先从可用表/自由链中找到一个足以容纳该作业的可用空白区,如果这个空白区比需求大,则将它分为两个部分,一部分成为已分配区,剩下部分仍为空白区。最后修改可用表或自由链,并回送一个所分配区的序号或该分区的起始地址。 最先适应法:按分区的起始地址的递增次序,从头查找,找到符合要求的第一个分区。 最佳适应法:按照分区大小的递增次序,查找,找到符合要求的第一个分区。 最坏适应法:按分区大小的递减次序,从头查找,找到符合要求的第一个分区。 三、数据结构及功能设计 1、数据结构 定义空闲分区结构体,用来保存内存中空闲分区的情况。其中size属性表示空闲分区的大小,start_addr表示空闲分区首地址,next指针指向下一个空闲分区。 //空闲分区 typedef struct Free_Block { int size; int start_addr; struct Free_Block *next; } Free_Block; Free_Block *free_block; 定义已分配的内存空间的结构体,用来保存已经被进程占用了内存空间的情况。其中pid作为该被分配分区的编号,用于在释放该内存空间时便于查找。size表示分区的大小,start_addr表示分区的起始地址,process_name存放进程名称,next指针指向下一个分区。 //已分配分区的结构体 typedef struct Allocate_Block { int pid; int size; int start_addr; char process_name[PROCESS_NAME_LEN]; struct Allocate_Block *next; } Allocate_Block; 2、模块说明 2.1 初始化模块 对内存空间进行初始化,初始情况内存空间为空,但是要设置内存的最大容量,该内存空间的首地址,以便之后新建进程的过程中使用。当空闲分区初始化 第八章内存管理 1.地址捆绑 输入队列:在磁盘上等待调入内存以便执行的进程形成了输入队列 捆绑是从一个地址到另一个地址的映射。 编译时:如果在编译时就知道进程将在内存中的驻留地址,那么就可生成绝对代码 加载时:如果在编译时并不知到进程将驻留在何处,那么编译器就必须生成可重定位代码执行时:如果进程在执行时可以从一个内存段转移到另一个内存段,那么捆绑必须延迟到执行时才进行 2.逻辑地址(相对地址,虚拟地址):CPU所生成的地址or 用户程序中使用的地址 物理地址(内存地址,绝对地址):内存单元所看到的地址 编译时和加载时的地址捆绑生成相同的逻辑地址和物理地址运行时不同 重定位寄存器(relocation register)即基址寄存器(base register) 内存管理单元(MMU):运行时实现从虚拟地址到物理地址的映射(map)的硬件设备 3.动态加载 ①所有的子程序只有在调用时才被加载 ②提高内存空间使用率,不用的子程序绝不会被装入内存 ③如果大多数代码需要处理异常情况时是非常有用的。 ④不需要操作系统的特别支持,通过程序设计实现。操作系统可能会为程序员提供实现动态装入的库函数。 4.动态链接库 ①动态链接直到执行时才进行链接。 ②利用动态链接,在映象中为每个库函数引用(library-routine reference)包含一个占位程序(stub)。占位程序是一小段代码,它指明了怎样定位驻留在内存中的库函数或函数不在内存中时怎样装入库。占位程序执行时,它检查所需的函数(routine)是否已经在内存中。如果没有,就把函数装入内存。或者以另外一种方式,占位程序用函数地址取代自身并执行这个函数。这样,下一次到达这段代码时,可以直接执行库函数(library routine)而无需动态 内存管理模拟 实验目标: 本实验的目的是从不同侧面了解Windows 2000/XP 对用户进程的虚拟内存空间的管理、分配方法。同时需要了解跟踪程序的编写方法(与被跟踪程序保持同步,使用Windows提供的信号量)。对Windows分配虚拟内存、改变内存状态,以及对物理内存(physical memory)和页面文件(pagefile)状态查询的API 函数的功能、参数限制、使用规则要进一步了解。 默认情况下,32 位Windows 2000/XP 上每个用户进程可以占有2GB 的私有地址空间,操作系统占有剩下的2GB。Windows 2000/XP 在X86 体系结构上利用二级页表结构来实现虚拟地址向物理地址的变换。一个32 位虚拟地址被解释为三个独立的分量——页目录索引、页表索引和字节索引——它们用于找出描述页面映射结构的索引。页面大小及页表项的宽度决定了页目录和页表索引的宽度。 实验要求: 使用Windows 2000/XP 的API 函数,编写一个包含两个线程的进程,一个线程用于模拟内存分配活动,一个线程用于跟踪第一个线程的内存行为,而且要求两个线程之间通过信号量实现同步。模拟内存活动的线程可以从一个文件中读出要进行的内存操作,每个内存操作包括如下内容: 时间:操作等待时间。 块数:分配内存的粒度。 操作:包括保留(reserve)一个区域、提交(commit)一个区域、释放(release)一个区域、回收(decommit)一个区域和加锁(lock)与解锁(unlock)一个区域,可以将这些操作编号存放于文件。保留是指保留进程的虚拟地址空间,而不分配物理 存储空间。提交在内存中分配物理存储空间。回收是指释放物理内存空间,但在虚拟地址空间仍然保留,它与提交相对应,即可以回收已经提交的内存块。释放是指将物理存储和虚拟地址空间全部释放,它与保留(reserve)相对应,即可以释放已经保留的内存块。 大小:块的大小。 访问权限:共五种,分别为PAGE_READONLY,PAGE_READWRITE ,PAGE_EXECUTE,PAGE_EXECUTE_READ 和PAGE EXETUTE_READWRITE。可以将这些权限编号存放于文件中跟踪线程将页面大小、已使用的地址范围、物理内存总量,以及虚拟内存总量等信息显示出来。 第四章存储管理 1. C存储管理支持多道程序设计,算法简单,但存储碎片多。 A. 段式 B. 页式 C. 固定分区 D. 段页式 2.虚拟存储技术是 B 。 A. 补充内存物理空间的技术 B. 补充相对地址空间的技术 C. 扩充外存空间的技术 D. 扩充输入输出缓冲区的技术 3.虚拟内存的容量只受 D 的限制。 A. 物理内存的大小 B. 磁盘空间的大小 C. 数据存放的实际地址 D. 计算机地址位数 4.动态页式管理中的 C 是:当内存中没有空闲页时,如何将已占据的页释放。 A. 调入策略 B. 地址变换 C. 替换策略 D. 调度算法 5.多重分区管理要求对每一个作业都分配 B 的内存单元。 A. 地址连续 B. 若干地址不连续 C. 若干连续的帧 D. 若干不连续的帧 6.段页式管理每取一数据,要访问 C 次内存。 A. 1 B. 2 C. 3 D. 4 7.分段管理提供 B 维的地址结构。 A. 1 B. 2 C. 3 D. 4 8.系统抖动是指 B。 A. 使用计算机时,屏幕闪烁的现象 B. 刚被调出内存的页又立刻被调入所形成的频繁调入调出的现象 C. 系统盘不干净,操作系统不稳定的现象 D. 由于内存分配不当,造成内存不够的现象 9.在 A中,不可能产生系统抖动现象。 A. 静态分区管理 B. 请求分页式管理 C. 段式存储管理 D. 段页式存储管理 10.在分段管理中 A 。 A. 以段为单元分配,每段是一个连续存储区 B. 段与段之间必定不连续 C. 段与段之间必定连续 D. 每段是等长的 11.请求分页式管理常用的替换策略之一有 A 。 A. LRU B. BF C. SCBF D. FPF 12.可由CPU调用执行的程序所对应的地址空间为 D 。 A. 名称空间 B. 虚拟地址空间 C. 相对地址空间 D. 物理地址空间 13. C 存储管理方式提供二维地址结构。 A. 固定分区 B. 分页 两种常见的内存管理方法:堆和内存池 本文导读 在程序运行过程中,可能产生一些数据,例如,串口接收的数据,ADC采集的数据。若需将数据存储在内存中,以便进一步运算、处理,则应为其分配合适的内存空间,数据处理完毕后,再释放相应的内存空间。为了便于内存的分配和释放,AWorks提供了两种内存管理工具:堆和内存池。 本文为《面向AWorks框架和接口的编程(上)》第三部分软件篇——第9章内存管理——第1~2小节:堆管理器和内存池。 本章导读 在计算机系统中,数据一般存放在内存中,只有当数据需要参与运算时,才从内存中取出,交由CPU运算,运算结束再将结果存回内存中。这就需要系统为各类数据分配合适的内存空间。 一些数据需要的内存大小在编译前可以确定。主要有两类:一类是全局变量或静态变量,这部分数据在程序的整个生命周期均有效,在编译时就为这些数据分配了固定的内存空间,后续直接使用即可,无需额外的管理;一类是局部变量,这部分数据仅在当前作用域中有效(如函数中),它们需要的内存自动从栈中分配,也无需额外的管理,但需要注意的是,由于这一部分数据的内存从栈中分配,因此,需要确保应用程序有足够的栈空间,尽量避免定义内存占用较大的局部变量(比如:一个占用数K内存的数组),以避免栈溢出,栈溢出可能破坏系统关键数据,极有可能造成系统崩溃。 一些数据需要的内存大小需要在程序运行过程中根据实际情况确定,并不能在编译前确定。例如,可能临时需要1K内存空间用于存储远端通过串口发过来的数据。这就要求系统具有对内存空间进行动态管理的能力,在用户需要一段内存空间时,向系统申请,系统选择一段合适的内存空间分配给用户,用户使用完毕后,再释放回系统,以便系统将该段内存空间回收再利用。在AWorks中,提供了两种常见的内存管理方法:堆和内存池。9.1 堆管理器 实验五动态页式存储管理实现过程的模拟 一、实验目的与要求 在计算机系统中,为了提高主存利用率,往往把辅助存储器(如磁盘)作为主存储器的扩充,使多道运行的作业的全部逻辑地址空间总和可以超出主存的绝对地址空间。用这种办法扩充的主存储器称为虚拟存储器。通过本实验帮助学生理解在分页式存储管理中怎样实现虚拟存储器;掌握物理内存和虚拟内存的基本概念;掌握重定位的基本概念及其要点,理解逻辑地址与绝对地址;掌握动态页式存储管理的基本原理、地址变换和缺页中断、主存空间的分配及分配算法;掌握常用淘汰算法。 二、实验环境 VC++6.0集成开发环境或java程序开发环境。 三、实验内容 模拟分页式虚拟存储管理中硬件的地址转换和缺页中断,以及选择页面调度算法处理缺页中断。 四、实验原理 1、地址转换 (1)分页式虚拟存储系统是把作业信息的副本存放在磁盘上,当作业被选中时,可把作业的开始几页先装入主存且启动执行。为此,在为作业建立页表时,应说明哪些页已在主存,哪些页尚未装入主存,页表的格式如图10所示: 图10 页表格式 其中,标志----用来表示对应页是否已经装入主存,标志位=1,则表示该页已经在主存,标志位=0,则表示该页尚未装入主存。 主存块号----用来表示已经装入主存的页所占的块号。 在磁盘上的位置----用来指出作业副本的每一页被存放在磁盘上的位置。 (2)作业执行时,指令中的逻辑地址指出了参加运算的操作存放的页号和单元号,硬件的地址转换机构按页号查页表,若该页对应标志为“1”,则表示该页已在主存,这时根据关系式: 绝对地址=块号×块长+单元号 计算出欲访问的主存单元地址。如果块长为2的幂次,则可把块号作为高地址部分,把单元号作为低地址部分,两者拼接而成绝对地址。若访问的页对应标志为“0”,则表示该页不在主存,这时硬件发“缺页中断”信号,有操作系统按该页在磁盘上的位置,把该页信息从磁盘读出装入主存后再重新执行这条指令。 (3)设计一个“地址转换”程序来模拟硬件的地址转换工作。当访问的页在主存时,则形成绝对地址,但不去模拟指令的执行,而用输出转换后的地址来代替一条指令的执行。当访问的页不在主存时,则输出“* 该页页号”,表示产生了一次缺页中断。该模拟程序的算法如图11。 图11 地址转换模拟算法 2、用先进先出(FIFO)页面调度算法处理缺页中断。 第7章内存管理 复习题: 7.1.内存管理需要满足哪些需求? 答:重定位、保护、共享、逻辑组织和物理组织。 7.2.为什么需要重定位进程的能力? 答:通常情况下,并不能事先知道在某个程序执行期间会有哪个程序驻留在主存中。 此外还希望通过提供一个巨大的就绪进程池,能够把活动进程换入和换出主存,以便使处理器的利用率最大化。在这两种情况下,进程在主存中的确切位置是不可预知的。 7.3.为什么不可能在编译时实施内存保护? 答:由于程序在主存中的位置是不可预测的,因而在编译时不可能检查绝对地址来确保保护。并且,大多数程序设计语言允许在运行时进行地址的动态计算(例如,通过计算数组下标或数据结构中的指针)。因此,必须在运行时检查进程产生的所有存储器访问,以便确保它们只访问了分配给该进程的存储空间。 7.4.允许两个或多个进程访问进程的某一特定区域的原因是什么? 答:如果许多进程正在执行同一程序,则允许每个进程访问该程序的同一个副本要比让每个进程有自己单独的副本更有优势。同样,合作完成同一任务的进程可能需要共享访问同一个数据结构。 7.5.在固定分区方案中,使用大小不等的分区有什么好处? 答:通过使用大小不等的固定分区:1.可以在提供很多分区的同时提供一到两个非常大的分区。大的分区允许将很大的进程全部载入主存中。2.由于小的进程可以被放入小的分区中,从而减少了内部碎片。 7.6.内部碎片和外部碎片有什么区别? 答:内部碎片是指由于被装入的数据块小于分区大小而导致的分区内部所浪费的空间。外部碎片是与动态分区相关的一种现象,它是指在所有分区外的存储空间会变成越来越多的碎片的。 7.7.逻辑地址、相对地址和物理地址间有什么区别? 答:逻辑地址是指与当前数据在内存中的物理分配地址无关的访问地址,在执行对内存的访问之前必须把它转化成物理地址。相对地址是逻辑地址的一个特例,是相对于某些已知点(通常是程序的开始处)的存储单元。物理地址或绝对地址是数据在主存中的实际位置。 7.8.页和帧之间有什么区别? 答:在分页系统中,进程和磁盘上存储的数据被分成大小固定相等的小块,叫做页。 而主存被分成了同样大小的小块,叫做帧。一页恰好可以被装入一帧中。 7.9.页和段之间有什么区别? 答:分段是细分用户程序的另一种可选方案。采用分段技术,程序和相关的数据被划分成一组段。尽管有一个最大段长度,但并不需要所有的程序的所有段的长度都相等。习题: 7.1. 2.3节中列出了内存管理的5个目标,7.1节中列出了5中需求。请说明它们是一致 的。 答: 重定位≈支持模块化程序设计; 保护≈保护和访问控制以及进程隔离; 共享≈保护和访问控制; 逻辑组织≈支持模块化程序设计; 物理组织≈长期存储及自动分配和管理. 精心整理西安邮电大学 (计算机学院) 课内实验报告 1. (1 (2 (3 原因,写出实验报告。 2.实验要求: 1)掌握内存分配FF,BF,WF策略及实现的思路; 2)掌握内存回收过程及实现思路; 3)参考本程序思路,实现内存的申请、释放的管理程序,调试运行,总结程序设计中出现的问题并找出原因,写出实验报告。 3.实验过程: 创建进程: 删除其中几个进程:(默认以ff首次适应算法方式排列) Bf最佳适应算法排列方式: wf最差匹配算法排列方式: 4.实验心得: 明 实验中没有用到循环首次适应算法,但是对其他三种的描述还是很详细,总的来说,从实验中还是学到了很多。 5.程序源代码: #include #define PROCESS_NAME_LEN 32 //进程名长度 #define MIN_SLICE 10 //最小碎片的大小#define DEFAULT_MEM_SIZE 1024 //内存大小 #define DEFAULT_MEM_START 0 //起始位置 /*内存分配算法*/ #define MA_FF 1 #define MA_BF 2 #define MA_WF 3 /*描述每一个空闲块的数据结构*/ struct free_block_type { }; /* /* { }; /* /* void display_menu(); int set_mem_size(); void set_algorithm(); void rearrange(int algorithm); int rearrange_WF(); int rearrange_BF(); int rearrange_FF(); int new_process(); int allocate_mem(struct allocated_block *ab); 内存分段和请求式分页 在深入i386架构的技术细节之前,让我们先返回1978年,那一年Intel 发布了PC处理器之母:8086。我想将讨论限制到这个有重大意义的里程碑上。如果你打算知道更多,阅读Robert L.的80486程序员参考(Hummel 1992)将是一个很棒的开始。现在看来这有些过时了,因为它没有涵盖Pentium处理器家族的新特性;不过,该参考手册中仍保留了大量i386架构的基本信息。尽管8086能够访问1MB RAM的地址空间,但应用程序还是无法“看到”整个的物理地址空间,这是因为CPU寄存器的地址仅有16位。这就意味着应用程序可访问的连续线性地址空间仅有64KB,但是通过16位段寄存器的帮助,这个64KB大小的内存窗口就可以在整个物理空间中上下移动,64KB逻辑空间中的线性地址作为偏移量和基地址(由16位的段寄存器给处)相加,从而构成有效的20位地址。这种古老的内存模型仍然被最新的Pentium CPU支持,它被称为:实地址模式,通常叫做:实模式。 80286 CPU引入了另一种模式,称为:受保护的虚拟地址模式,或者简单的称之为:保护模式。该模式提供的内存模型中使用的物理地址不再是简单的将线性地址和段基址相加。为了保持与8086和80186的向后兼容,80286仍然使用段寄存器,但是在切换到保护模式后,它们将不再包含物理段的地址。替代的是,它们提供了一个选择器(selector),该选择器由一个描述符表的索引构成。描述符表中的每一项都定义了一个24位的物理基址,允许访问16MB RAM,在当时这是一个很不可思议的数量。不过,80286仍然是16位CPU,因此线性地址空间仍然被限制在64KB。 1985年的80386 CPU突破了这一限制。该芯片最终砍断了16位寻址的锁链,将线性地址空间推到了4GB,并在引入32位线性地址的同时保留了基本的选择器/描述符架构。幸运的是,80286的描述符结构中还有一些剩余的位可以拿来使用。从16位迁移到32位地址后,CPU的数据寄存器的大小也相应的增加了两倍,并同时增加了一个新的强大的寻址模型。真正的32位的数据和地址为程序员带了实际的便利。事实上,在微软的Windows平台真正完全支持32位模型是在好几年之后。Windows NT的第一个版本在1993年7月26日发布,实现了真正意义上的Win32 API。但是Windows 3.x程序员仍然要处理由独立的代码和数据段构成的64KB内存片,Windows NT提供了平坦的4GB地址空间,在那儿可以使用简单的32位指针来寻址所有的代码和数据,而不需要分段。在内部,当然,分段仍然在起作用,就像我在前面提及的那样。不过管理段的所有责任都被移给了操作系统。 实验四内存管理模拟实验 模拟实现一个简单的固定(可变)分区存储管理系统 1.实验目的 通过本次课程设计,掌握了如何进行内存的分区管理,强化了对首次适应分配算法和分区回收算法的理解。 2.实验内容 (1)建立相关的数据结构,作业控制块、已分配分区及未分配分区 (2)实现一个分区分配算法,如最先适应算法、最优或最坏适应分配算法 (3)实现一个分区回收算法 (4)给定一个作业/进程,选择一个分配或回收算法,实现分区存储的模拟管理 图1.流程图 3.实验步骤 首先,初始化函数initial()将分区表初始化并创建空闲分区列表,空闲区第一块的长度是30,以后的每个块长度比前一个的长度长20。 frees[0].length=30 第二块的长度比第一块长20,第三块比第二块长20,以此类推。 frees[i].length=frees[i-1].length+20; 下一块空闲区的首地址是上一块空闲区的首地址与上一块空闲区长度的和。frees[i].front=frees[i-1].front+frees[i-1].length; 分配区的首地址和长度都初始化为零occupys[i].front=0;occupys[i].length=0; 显示函数show()是显示当前的空闲分区表和当前的已分配表的具体类容,分区的有起始地址、长度以及状态,利用for语句循环输出。有一定的格式,使得输出比较美观好看。 assign()函数是运用首次适应分配算法进行分区,从链首开始顺序查找,直至找到一个大小能满足要求的空闲分区为止;然后再按照作业的大小,从该分区中划出一块内存空间分配给请求者,余下的空闲分区仍留在空闲链中。若从链首直至链尾都不能找到一个能满足要求的分区,则此次内存分配失败,返回。这个算法倾向于优先利用内存中低址部分被的空闲分区,从而保留了高址部分的的大空闲区。着给为以后到达的大作业分配大的内存空间创造了条件。它的缺点是低地址部分不断被划分,会留下很多难以利用的、很小的空闲分区,而每次查找又都是从低址部分开始,这样无疑会增加查找可用空闲分区的开销。 分配内存,从空闲的分区表中找到所需大小的分区。设请求的分区的大小为job_length,表中每个空闲分区的大小可表示为free[i].length。如果frees[i].length>=job_length,即空闲空间I的长度大于等于作业的长度将空闲标志位设置为1,如果不满足这个条件则输出:“对不起,当前没有满足你申请长度的空闲内存,请稍后再试!”。如果frees[i].length>=job_length空闲区空间I的长度不大于作业长度,I的值加1判断下一个空闲区空间是否大于作业的长度。把未用的空闲空间的首地址付给已用空间的首地址,已用空间的长度为作业的长度,已用空间数量加1。如果(frees[i].length>job_length),空间的长度大于作业的长度,frees[i].front+=job_length; 空闲空间的起始首地址=原空闲区间的起始长度加作业长度frees[i].length-=job_length;空闲区间的长度=原空闲区间的长度-作业的长度。如果空间的长度与作业的长度相等,空闲区向前移一位,空闲区的数量也减一。这样判断所有情况并相应分配之后,内存空间分配成功。 第二个操作为:撤消相应作业。在这个操作中,进行了以下步骤: (1)按照系统提示输入将要撤消的作业名; (2)判断该作业是否存在 若不存在:输出“没有这个作业名,请重新输入作业名”; 若存在:则先分别用flag,start,len保存该作业在分配区表的位置i,内存空间的首地址以及长度。接着根据回收区的首地址,即该作业的首地址,从空闲区表中找到相应的插入点,将其加入空闲表,此时可能出现以下三种情况之一: 1 .回收区只与插入点前一个空闲分区F1相邻接即(frees[i].front+frees[i].length)==start),此时判断其是否与后一个空闲分区F2相邻接,又分两种情况: 若相邻接,则将三个分区合并,修改新的空闲分区的首地址和长度。新的首地址为F1的首地址,长度为三个分区长度之和,相应的代码为: 河南城建学院 《操作系统》课程设计说明书 设计题目:存储管理 专业:计算机科学与技术 指导教师:邵国金 班级:0814121 学号:081412112 姓名: 同组人: 计算机科学与工程学院 2015 年1 月9日 前言 本课程设计是编制页面置换算法FIFO、LRU、LFU、NUR和OPT的模拟程序,并模拟其在内存的分配过程。同时根据页面走向,分别采用FIFO、LRU、LFU、NUR和OPT算法进行页面置换,统计命中率;同时系统可以随意设置当前分配给作业的物理块数。 系统运行时,任意输入一个页面访问序列,可以设定不同的页面置换算法和物理块数,输出其页面淘汰的情况,计算其缺页次数和缺页率。系统结束后,比较同一个页面访问序列,可以得出在不同的页面置换算法和物理块数的情况下,其产生的缺页次数和缺页率。 使用FIFO算法,由于测试数据相同的页面比较少,所以采用FIFO算法时,需要置换的页面多,比较繁琐,没有优化效果,所以FIFO算法性能不好。使用LRU的算法,此组数据显示LRU的算法使用比较繁琐,总的来说,NUR、LFU、LRU 算法介于FIFO和OPT之间。通过系统模拟得出,OPT算法的性能高,LRU、NUR、LRU算法的性能次之,FIFO的算法性能最差,较少应用;由于OPT算法在实际上难于实现,所以实际应用一般用LRU算法。 本程序实现了操作系统中页式虚拟存储管理中缺页中断理想型淘汰算法,该算法在访问串中将来再也不出现的或是在离当前最远的位置上出现的页淘汰掉。这样,淘汰掉该页将不会造成因需要访问该页又立即把它调入的现象。该程序能按要求随机确定内存大小,随机产生页面数,进程数,每个进程的页数,给进程分配的页数等,然后运用理想型淘汰算法对每个进程进行计算缺页数,缺页率,被淘汰的序列等功能。 实验 4 内存管理 实验4内存管理 学校:FJUT 学号:3131903229 班级:计算机1302姓名:姜峰 注:其中LFU和NRU算法运行结果可能与其他人不同,只是实现方式不同,基本思路符合就可以。 .实验学时与类型 学时:2,课外学时:自定 实验类型:设计性实验二.实验目的 模拟实现请求页式存储管理中常用页面置换算法,理会操作系统对内存的 调度管理。 三?实验内容 要求:各算法要给出详细流程图以及执行结果截图。 假设有一程序某次运行访问的页面依次是: 0,124,3,4,5,1,2,5,1,2,3,4,5,6 ,请给出采用下列各页面置换算法时页面的换进换出情况,并计算各调度算法的命中率(命中率二非缺页次数/总访问次数),初始物理内存为空,物理内存可在4?20页中选择。 (1)FIFO :最先进入的页被淘汰; (2)LRU :最近最少使用的页被淘汰; (3)OPT :最不常用的页被淘汰;(选做) ⑷LFU :访问次数最少的页被淘汰(LFU)。(选做) 源代码: #i nclude 同组同学学号: 同组同学姓名: 实验日期:交报告日期: 实验(No. 4 )题目:编程与调试:内存管理 实验目的及要求: 实验目的: 操作系统的发展使得系统完成了大部分的内存管理工作,对于程序员而言,这些内存管理的过程是完全透明不可见的。因此,程序员开发时从不关心系统如何为自己分配内存,而且永远认为系统可以分配给程序所需的内存。在程序开发时,程序员真正需要做的就是:申请内存、使用内存、释放内存。其它一概无需过问。本章的3个实验程序帮助同学们更好地理解从程序员的角度应如何使用内存。 实验要求: 练习一:用vim编辑创建下列文件,用GCC编译工具,生成可调试的可执行文件,记录并分析执行结果,分析遇到的问题和解决方法。 练习二:用vim编辑创建下列文件,用GCC编译工具,生成可调试的可执行文件,记录并分析执行结果。 练习三:用vim编辑创建下列文件,用GCC编译工具,生成可调试的可执行文件,记录并分析执行结果。 改编实验中的程序,并运行出结果。 实验设备:多媒体电脑 实验内容以及步骤: 在虚拟机中编写好以下程序: #include 操作系统实验之内存管理实验报告
内存管理
操作系统课程设计内存管理
第四章 操作系统存储管理(练习题)
两种常见的内存管理方法:堆和内存池
实验五动态页式存储管理实现过程的模拟
操作系统第五版答案第7章内存管理
操作系统实验内存分配
操作系统内存管理原理
实验四 内存管理模拟实验
内存管理(操作系统)操作系统课程设计
实验4内存管理资料讲解
操作系统 内存管理实验报告