模式识别课程上机实验要求

模式识别课程上机实验要求
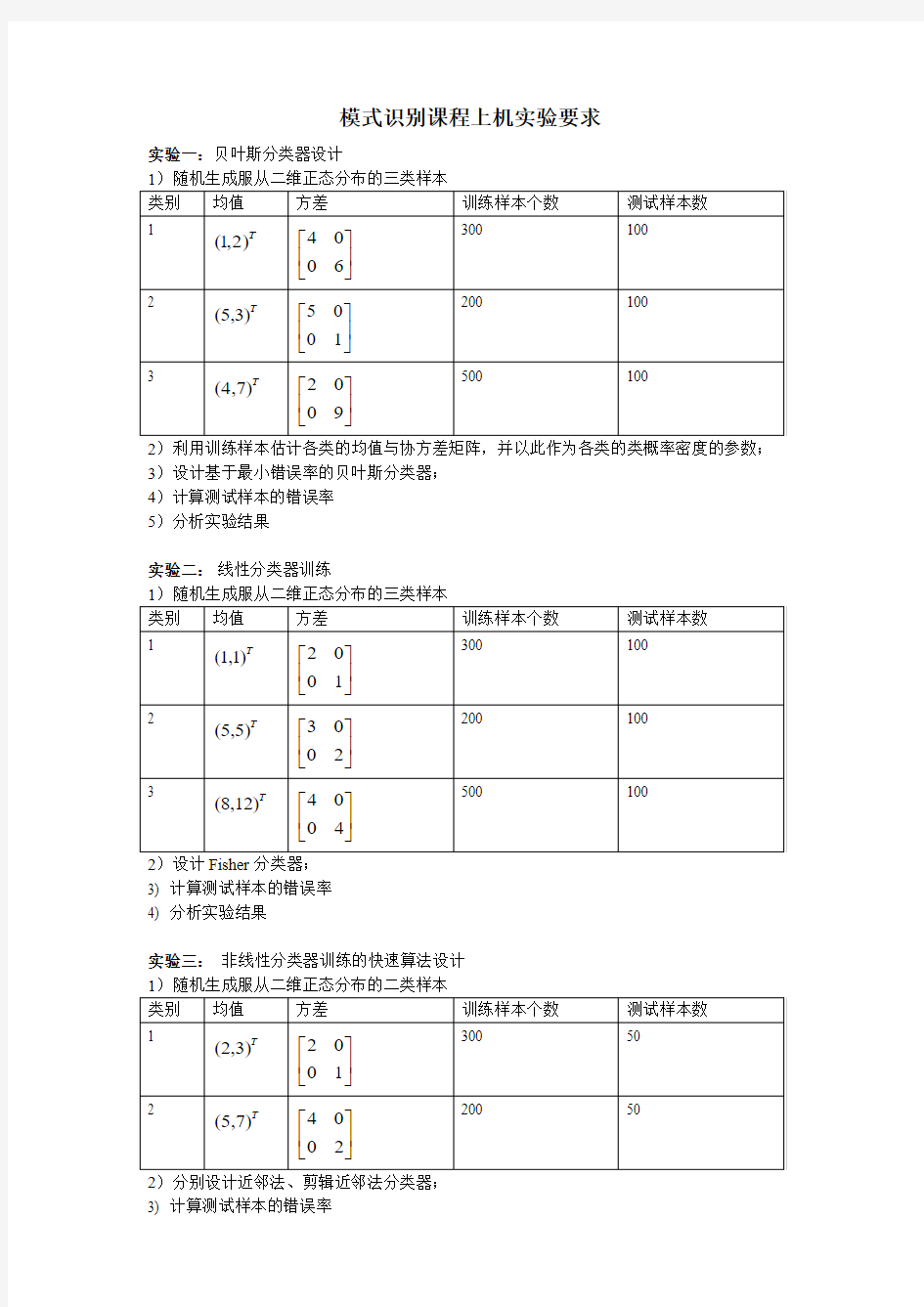
实验一:贝叶斯分类器设计
2)利用训练样本估计各类的均值与协方差矩阵,并以此作为各类的类概率密度的参数;3)设计基于最小错误率的贝叶斯分类器;
4)计算测试样本的错误率
5)分析实验结果
实验二:线性分类器训练
3) 计算测试样本的错误率
4) 分析实验结果
实验三:非线性分类器训练的快速算法设计
3) 计算测试样本的错误率
4) 分析实验对比结果
实验四:特征选择与变换的算法实现
测得四个变量的20个样本,
1)试用原数据以及标准化后的数据分别做主成分分析
2)计算累积贡献率;若要求累积贡献率至少达到90%,需几个主成分?3)比较两种方法的差别
注意事项:
1、实验报告手写;程序的电子文档上交。文件打包压缩,文件名称
班级_姓名_实验编号
2、注意实验结果的图表表示方法,程序流程图。
3、实验报告及程序雷同者记零分
wanwanyuan@https://www.360docs.net/doc/304729946.html,
模式识别课matlab数字识别程序
名称:模式识别 题目:数字‘3’和‘4’的识别
实验目的与要求: 利用已知的数字样本(3和4),提取样本特征,并确定分类准则,在用测试样本对分类确定准则的错误率进行分析。进一步加深对模式识别方法的理解,强化利用计算机实现模式识别。 实验原理: 1.特征提取原理: 利用MATLAN 软件把图片变为一个二维矩阵,然后对该矩阵进行二值化处理。由于“3”的下半部分在横轴上的投影比“4”的下半部分在横轴上的投影宽,所以可以统计‘3’‘4’在横轴上投影的‘1’的个数作为一个特征。又由于‘4’中间纵向比‘3’的中间‘1’的个数多,所以可以统计‘4’和‘3’中间区域‘1’的个数作为另外一个特征,又考虑‘4’的纵向可能会有点偏,所以在统计一的个数的时候,取的范围稍微大点,但不能太大。 2.分类准则原理: 利用最近邻对测试样本进行分类 实验步骤 1.利用MATLAN 软件把前30个图片变为一个二维矩阵,然后对该矩阵进行二值化处理。 2.利用上述矩阵生成特征向量 3.利用MATLAN 软件把后5个图片变为一个二维矩阵,然后对该矩阵进行二值化处理。 4.对测试样本进行分类,用F矩阵表示结果,如果是‘1’表示分类正确,‘0’表示分类错误。 5.对分类错误率分析 实验原始程序: f=zeros(5,2) w=zeros(35,2) q=zeros(35,2) for i=1:35 filename_1='D:\MATLAB6p5\toolbox\images\imdemos\3\' filename_2='.bmp' a= num2str (i) b=strcat(filename_1,a) c=strcat(b,filename_2) d=imread(c) e=im2bw(d) n=0 for u=1:20 m=0 for t=32:36 if(e(t,u)==0) m=m+1 end end if(m<5) n=n+1 end end
模式识别实验指导书
类别1234 样本x 1x 2x 1x 2x 1x 2x 1x 2 10.1 1.17.1 4.2-3.0-2.9-2.0-8.4 2 6.87.1-1.4-4.30.58.7-8.90.23-3.5-4.1 4.50.0 2.9 2.1-4.2-7.74 2.0 2.7 6. 3 1.6-0.1 5.2-8.5-3.25 4.1 2.8 4.2 1.9-4.0 2.2-6.7-4.06 3.1 5.0 1.4-3.2-1.3 3.7-0.5-9.27-0.8-1.3 2.4-4.0-3. 4 6.2-5.3-6.7 80.9 1.2 2.5-6.1-4.1 3.4-8.7-6.4 9 5.0 6.48.4 3.7-5.1 1.6-7.1-9.7 10 3.9 4.0 4.1-2.2 1.9 5.1-8.0-6.3 实验一 感知器准则算法实验 一、实验目的: 贝叶斯分类方法是基于后验概率的大小进行分类的方法,有时需要进行概率密度函数的估计,而概率密度函数的估计通常需要大量样本才能进行,随着特征空间维数的增加,这种估计所需要的样本数急剧增加,使计算量大增。 在实际问题中,人们可以不去估计概率密度,而直接通过与样本和类别标号有关的判别函数来直接将未知样本进行分类。这种思路就是判别函数法,最简单的判别函数是线性判别函数。采用判别函数法的关键在于利用样本找到判别函数的系数,模式识别课程中的感知器算法是一种求解判别函数系数的有效方法。本实验的目的是通过编制程序,实现感知器准则算法,并实现线性可分样本的分类。 二、实验内容: 实验所用样本数据如表2-1给出(其中每个样本空间(数据)为两维,x 1表示第一维的值、x 2表示第二维的值),编制程序实现1、 2类2、 3类的分类。分析分类器算法的性能。 2-1 感知器算法实验数据 具体要求 1、复习 感知器算法;2、写出实现批处理感 知器算法的程序1)从a=0开 始,将你的程序应用在和的训练数据上。记下收敛的步数。2)将你的程序应用在和类上,同样记下收敛的步数。3)试解释它们收敛步数的差别。 3、提高部分:和的前5个点不是线性可分的,请手工构造非线性映射,使这些点在映射后的特征空间中是线性可分的,并对它们训练一个感知
北邮模式识别课堂作业答案(参考)
第一次课堂作业 1.人在识别事物时是否可以避免错识 2.如果错识不可避免,那么你是否怀疑你所看到的、听到的、嗅 到的到底是真是的,还是虚假的 3.如果不是,那么你依靠的是什么呢用学术语言该如何表示。 4.我们是以统计学为基础分析模式识别问题,采用的是错误概率 评价分类器性能。如果不采用统计学,你是否能想到还有什么合理地分类 器性能评价指标来替代错误率 1.知觉的特性为选择性、整体性、理解性、恒常性。错觉是错误的知觉,是在特定条件下产生的对客观事物歪曲的知觉。认知是一个过程,需要大脑的参与.人的认知并不神秘,也符合一定的规律,也会产生错误 2.不是 3.辨别事物的最基本方法是计算 . 从不同事物所具有的不同属性为出发点认识事物. 一种是对事物的属性进行度量,属于定量的表示方法(向量表示法 )。另一种则是对事务所包含的成分进行分析,称为定性的描述(结构性描述方法)。 4.风险 第二次课堂作业 作为学生,你需要判断今天的课是否点名。结合该问题(或者其它你熟悉的识别问题,如”天气预报”),说明: 先验概率、后验概率和类条件概率 按照最小错误率如何决策 按照最小风险如何决策 ωi为老师点名的事件,x为判断老师点名的概率 1.先验概率: 指根据以往经验和分析得到的该老师点名的概率,即为先验概率 P(ωi ) 后验概率: 在收到某个消息之后,接收端所了解到的该消息发送的概率称为后验概率。 在上过课之后,了解到的老师点名的概率为后验概率P(ωi|x) 类条件概率:在老师点名这个事件发生的条件下,学生判断老师点名的概率p(x| ωi ) 2. 如果P(ω1|X)>P(ω2|X),则X归为ω1类别 如果P(ω1|X)≤P(ω2|X),则X归为ω2类别 3.1)计算出后验概率 已知P(ωi)和P(X|ωi),i=1,…,c,获得观测到的特征向量X 根据贝叶斯公式计算 j=1,…,x
模式识别第二次上机实验报告
北京科技大学计算机与通信工程学院 模式分类第二次上机实验报告 姓名:XXXXXX 学号:00000000 班级:电信11 时间:2014-04-16
一、实验目的 1.掌握支持向量机(SVM)的原理、核函数类型选择以及核参数选择原则等; 二、实验内容 2.准备好数据,首先要把数据转换成Libsvm软件包要求的数据格式为: label index1:value1 index2:value2 ... 其中对于分类来说label为类标识,指定数据的种类;对于回归来说label为目标值。(我主要要用到回归) Index是从1开始的自然数,value是每一维的特征值。 该过程可以自己使用excel或者编写程序来完成,也可以使用网络上的FormatDataLibsvm.xls来完成。FormatDataLibsvm.xls使用说明: 先将数据按照下列格式存放(注意label放最后面): value1 value2 label value1 value2 label 然后将以上数据粘贴到FormatDataLibsvm.xls中的最左上角单元格,接着工具->宏执行行FormatDataToLibsvm宏。就可以得到libsvm要求的数据格式。将该数据存放到文本文件中进行下一步的处理。 3.对数据进行归一化。 该过程要用到libsvm软件包中的svm-scale.exe Svm-scale用法: 用法:svmscale [-l lower] [-u upper] [-y y_lower y_upper] [-s save_filename] [-r restore_filename] filename (缺省值:lower = -1,upper = 1,没有对y进行缩放)其中,-l:数据下限标记;lower:缩放后数据下限;-u:数据上限标记;upper:缩放后数据上限;-y:是否对目标值同时进行缩放;y_lower为下限值,y_upper为上限值;(回归需要对目标进行缩放,因此该参数可以设定为–y -1 1 )-s save_filename:表示将缩放的规则保存为文件save_filename;-r restore_filename:表示将缩放规则文件restore_filename载入后按此缩放;filename:待缩放的数据文件(要求满足前面所述的格式)。缩放规则文件可以用文本浏览器打开,看到其格式为: y lower upper min max x lower upper index1 min1 max1 index2 min2 max2 其中的lower 与upper 与使用时所设置的lower 与upper 含义相同;index 表示特征序号;min 转换前该特征的最小值;max 转换前该特征的最大值。数据集的缩放结果在此情况下通过DOS窗口输出,当然也可以通过DOS的文件重定向符号“>”将结果另存为指定的文件。该文件中的参数可用于最后面对目标值的反归一化。反归一化的公式为: (Value-lower)*(max-min)/(upper - lower)+lower 其中value为归一化后的值,其他参数与前面介绍的相同。 建议将训练数据集与测试数据集放在同一个文本文件中一起归一化,然后再将归一化结果分成训练集和测试集。 4.训练数据,生成模型。 用法:svmtrain [options] training_set_file [model_file] 其中,options(操作参数):可用的选项即表示的涵义如下所示-s svm类型:设置SVM 类型,默
DX3004模式识别与人工智能--教学大纲概要
《模式识别与人工智能》课程教学大纲 一、课程基本信息 课程代码:DX3004 课程名称:模式识别与人工智能 课程性质:选修课 课程类别:专业与专业方向课程 适用专业:电气信息类专业 总学时: 64 学时 总学分: 4 学分 先修课程:MATLAB程序设计;数据结构;数字信号处理;概率论与数理统计 后续课程:语音处理技术;数字图像处理 课程简介: 模式识别与人工智能是60年代迅速发展起来的一门学科,属于信息,控制和系统科学的范畴。模式识别就是利用计算机对某些物理现象进行分类,在错误概率最小的条件下,使识别的结果尽量与事物相符。模式识别技术主要分为两大类:基于决策理论的统计模式识别和基于形式语言理论的句法模式识别。模式识别的原理和方法在医学、军事等众多领域应用十分广泛。本课程着重讲述模式识别的基本概念,基本方法和算法原理,注重理论与实践紧密结合,通过大量实例讲述如何将所学知识运用到实际应用之中去,避免引用过多的、繁琐的数学推导。这门课的教学目的是让学生掌握统计模式识别基本原理和方法,使学生具有初步综合利用数学知识深入研究有关信息领域问题的能力。 选用教材: 《模式识别》第二版,边肇祺,张学工等编著[M],北京:清华大学出版社,1999; 参考书目: [1] 《模式识别导论》,齐敏,李大健,郝重阳编著[M]. 北京:清华大学出版社,2009; [2] 《人工智能基础》,蔡自兴,蒙祖强[M]. 北京:高等教育出版社,2005; [3] 《模式识别》,汪增福编著[M]. 安徽:中国科学技术大学出版社,2010; 二、课程总目标 本课程为计算机应用技术专业本科生的专业选修课。通过本课程的学习,要求重点掌握统计模式识别的基本理论和应用。掌握统计模式识别方法中的特征提取和分类决策。掌握特征提取和选择的准则和算法,掌握监督学习的原理以及分类器的设计方法。基本掌握非监督模式识别方法。了解应用人工神经网络和模糊理论的模式识别方法。了解模式识别的应用和系统设计。要求学生掌握本课程的基本理论和方法并能在解决实际问题时得到有效地运用,同时为开发研究新的模式识别的理论和方法打下基础。 三、课程教学内容与基本要求 1、教学内容: (1)模式识别与人工智能基本知识; (2)贝叶斯决策理论; (3)概率密度函数的估计; (4)线性判别函数; (5)非线性胖别函数;
模式识别实验指导书
实验一、基于感知函数准则线性分类器设计 1.1 实验类型: 设计型:线性分类器设计(感知函数准则) 1.2 实验目的: 本实验旨在让同学理解感知准则函数的原理,通过软件编程模拟线性分类器,理解感知函数准则的确定过程,掌握梯度下降算法求增广权向量,进一步深刻认识线性分类器。 1.3 实验条件: matlab 软件 1.4 实验原理: 感知准则函数是五十年代由Rosenblatt 提出的一种自学习判别函数生成方法,由于Rosenblatt 企图将其用于脑模型感知器,因此被称为感知准则函数。其特点是随意确定的判别函数初始值,在对样本分类训练过程中逐步修正直至最终确定。 感知准则函数利用梯度下降算法求增广权向量的做法,可简单叙述为: 任意给定一向量初始值)1(a ,第k+1次迭代时的权向量)1(+k a 等于第k 次的权向量)(k a 加上被错分类的所有样本之和与k ρ的乘积。可以证明,对于线性可分的样本集,经过有限次修正,一定可以找到一个解向量a ,即算法能在有限步内收敛。其收敛速度的快慢取决于初始权向量)1(a 和系数k ρ。 1.5 实验内容 已知有两个样本空间w1和w2,这些点对应的横纵坐标的分布情况是: x1=[1,2,4,1,5];y1=[2,1,-1,-3,-3]; x2=[-2.5,-2.5,-1.5,-4,-5,-3];y2=[1,-1,5,1,-4,0]; 在二维空间样本分布图形如下所示:(plot(x1,y1,x2,y2))
-6-4-20246 -6-4 -2 2 4 6w1 w2 1.6 实验任务: 1、 用matlab 完成感知准则函数确定程序的设计。 2、 请确定sample=[(0,-3),(1,3),(-1,5),(-1,1),(0.5,6),(-3,-1),(2,-1),(0,1), (1,1),(-0.5,-0.5),( 0.5,-0.5)];属于哪个样本空间,根据数据画出分类的结果。 3、 请分析一下k ρ和)1(a 对于感知函数准则确定的影响,并确定当k ρ=1/2/3时,相应 的k 的值,以及)1(a 不同时,k 值得变化情况。 4、 根据实验结果请说明感知准则函数是否是唯一的,为什么?
贝叶斯决策理论-模式识别课程作业
研究生课程作业 贝叶斯决策理论 课程名称模式识别 姓名xx 学号xxxxxxxxx 专业软件工程 任课教师xxxx 提交时间2019.xxx 课程论文提交时间:2019 年3月19 日
需附上习题题目 1. 试简述先验概率,类条件概率密度函数和后验概率等概念间的关系: 先验概率 针对M 个事件出现的可能性而言,不考虑其他任何条件 类条件概率密度函数 是指在已知某类别的特征空间中,出现特 征值X 的概率密度,指第 类样品其属性X 是如何分布的。 后验概率是指通过调查或其它方式获取新的附加信息,利用贝叶斯公式对先验概率进行修正,而后得到的概率。贝叶斯公式可以计算出该样品分属各类别的概率,叫做后验概率;看X 属于那个类的可能性最大,就把X 归于可能性最大的那个类,后验概率作为识别对象归属的依据。贝叶斯公式为 类别的状态是一个随机变量.而某种状态出现的概率是可以估计的。贝叶斯公式体现了先验概率、类条件概率密度函数、后验概率三者关系的式子。 2. 试写出利用先验概率和分布密度函数计算后验概率的公式 3. 写出最小错误率和最小风险决策规则相应的判别函数(两类问题)。 最小错误率 如果12(|)(|)P x P x ωω>,则x 属于1ω 如果12(|)(|)P x P x ωω<,则x 属于2ω 最小风险决策规则 If 12(|) (|) P x P x ωλω< then 1x ω∈ If 12(|) (|) P x P x ωλω> then 2x ω∈
4. 分别写出以下两种情况下,最小错误率贝叶斯决策规则: (1)两类情况,且12(|)(|)P X P X ωω= (2)两类情况,且12()()P P ωω= 最小错误率贝叶斯决策规则为: If 1...,(|)()max (|)i i j j c p x P P x ωωω==, then i x ω∈ 两类情况: 若1122(|)()(|)()p X P p X P ωωωω>,则1X ω∈ 若1122(|)()(|)()p X P p X P ωωωω<,则2X ω∈ (1) 12(|)(|)P X P X ωω=, 若12()()P P ωω>,则1X ω∈ 若12()()P P ωω<,则2X ω∈ (2) 12()()P P ωω=,若12(|)(|)p X p X ωω>,则1X ω∈ 若12(|)(|)p X p X ωω<,则2X ω∈ 5. 对两类问题,证明最小风险贝叶斯决策规则可表示为, 若 112222221111(|)()() (|)()() P x P P x P ωλλωωλλω->- 则1x ω∈,反之则2x ω∈ 计算条件风险 2 111111221(|)(|)(|)(|)j j j R x p x P x P x αλωλωλω===+∑ 2 222112221 (|)(|)(|)(|)j j j R x p x P x P x αλωλωλω===+∑ 如果 111122(|)(|)P x P x λωλω+<211222(|)(|)P x P x λωλω+ 2111112222()(|)()(|)P x P x λλωλλω->- 211111122222()()(|)()()(|)P p x P p x λλωωλλωω->-
模式识别实验报告
模式识别实验报告
————————————————————————————————作者:————————————————————————————————日期:
实验报告 实验课程名称:模式识别 姓名:王宇班级: 20110813 学号: 2011081325 实验名称规范程度原理叙述实验过程实验结果实验成绩 图像的贝叶斯分类 K均值聚类算法 神经网络模式识别 平均成绩 折合成绩 注:1、每个实验中各项成绩按照5分制评定,实验成绩为各项总和 2、平均成绩取各项实验平均成绩 3、折合成绩按照教学大纲要求的百分比进行折合 2014年 6月
实验一、 图像的贝叶斯分类 一、实验目的 将模式识别方法与图像处理技术相结合,掌握利用最小错分概率贝叶斯分类器进行图像分类的基本方法,通过实验加深对基本概念的理解。 二、实验仪器设备及软件 HP D538、MATLAB 三、实验原理 概念: 阈值化分割算法是计算机视觉中的常用算法,对灰度图象的阈值分割就是先确定一个处于图像灰度取值范围内的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。 最常用的模型可描述如下:假设图像由具有单峰灰度分布的目标和背景组成,处于目标和背景内部相邻像素间的灰度值是高度相关的,但处于目标和背景交界处两边的像素灰度值有较大差别,此时,图像的灰度直方图基本上可看作是由分别对应于目标和背景的两个单峰直方图混合构成。而且这两个分布应大小接近,且均值足够远,方差足够小,这种情况下直方图呈现较明显的双峰。类似地,如果图像中包含多个单峰灰度目标,则直方图可能呈现较明显的多峰。 上述图像模型只是理想情况,有时图像中目标和背景的灰度值有部分交错。这时如用全局阈值进行分割必然会产生一定的误差。分割误差包括将目标分为背景和将背景分为目标两大类。实际应用中应尽量减小错误分割的概率,常用的一种方法为选取最优阈值。这里所谓的最优阈值,就是指能使误分割概率最小的分割阈值。图像的直方图可以看成是对灰度值概率分布密度函数的一种近似。如一幅图像中只包含目标和背景两类灰度区域,那么直方图所代表的灰度值概率密度函数可以表示为目标和背景两类灰度值概率密度函数的加权和。如果概率密度函数形式已知,就有可能计算出使目标和背景两类误分割概率最小的最优阈值。 假设目标与背景两类像素值均服从正态分布且混有加性高斯噪声,上述分类问题可以使用模式识别中的最小错分概率贝叶斯分类器来解决。以1p 与2p 分别表示目标与背景的灰度分布概率密度函数,1P 与2P 分别表示两类的先验概率,则图像的混合概率密度函数可用下式表示为
2014春《文献检索》实验指导书-机械类六个专业-(需要发送电子稿给学课件
《文献检索》实验指导书 刘军安编写 适用专业:机械类各专业 总学时:24~32学时 实验学时:6~14 机械设计与制造教研室 2014. 3
一、课程总实验目的与任务 《文献检索》课程实验是机械学院机械类专业的选修课的实验。通过实验内容与过程,主要培养学生在信息数字化、网络化存储环境下信息组织与检索的原理、技术和方法,以及在数字图书馆系统和数字信息服务系统中检索专业知识的能力,辅助提高21世纪大学生人文素质。通过实验,使学生对信息检索的概念及发展、检索语言、检索策略、检索方法、检索算法、信息检索技术、网络信息检索原理、搜索引擎、信息检索系统的结构、信息检索系统的使用、信息检索系统评价以及所检索信息的分析等技术有一个全面熟悉和掌握。本实验主要培养和考核学生对信息检索基本原理、方法、技术的掌握和知识创新过程中对知识的检索与融合能力。实验主要侧重于培养学生对本专业技术原理和前言知识的信息检索能力,引导学生应理论联系实际,同时要了解本专业科技信息的最新进展和研究动态与走向。 二、实验内容 通过课程的学习,结合老师给出的检索主题,学生应该完成以下内容的实验: 实验一:图书馆专业图书检索(印刷版图书) 实验二:中文科技期刊信息检索 实验三:科技文献数据库信息检索 实验四:网络科技信息检索(含报纸和网络) 文献检索参考主题: 1.工业工程方向: 工业工程;工业工程师的素质、精神、修养、气质与能力;工业工程的本质;企业文化与工业工程;战略工程管理;工程哲学;创新管理;生产管理;品质管理;优化管理或管理的优化;零库存;敏捷制造;敏捷管理;(优秀的、现代的、或未来的)管理哲学;生产管理七大工具;质量管理;设备管理;基础管理;现场管理;六西格玛管理;生产线平衡;工程经济;系统哲学;系统管理;柔性制造;看板管理;工程心理学;管理心理学;激励管理;管理中的真、善、美(或假、恶、丑);工程哲学;工业工程中的责任;安全管理;优化调度;系统工程;系统管理与过程控制;设计哲学;智能管理;工业工程中的数学;智能工业工程,或工业工程的智能化;生态工程管理;绿色工业工程,或绿色管理;协同学与协同管理;工业工程中的协同;概念工程与概念管理;工业工程与蝴蝶效应;管理中的蝴蝶效应,等等…… 2.机械电子工程方向: CAD;CAM;CAE;CAPP;PDM;EPR;CIMS;VD;VM;FMS;PLC;协同设计;协同制造;概念设计;自底向上;自顶向下;智能设计;智能制造;智能材料;特种加工(线切割、电火花、激光加工、电化学加工、超声波加工、光刻技术、快速成型、反求工程);微机械;精密加工;精密制造;机电一体化;自动化;控制论;线性控制;非线性控制;混沌控制;模糊控制;人工智能;神经网络;纳米技术;纳米制造;机器人;智能机器人;传感器;智能传感器;自动化生产线;机械手;智能机械手;自动检测;数据采集;信号处理;信息识别、模式识别等等……
《认知心理学》实验指导
概念形成 简介: 概念是人脑反映事物本质属性的思维形式。个体掌握一类事物本质属性的过程,就是概念形成的过程。实验室中为了研究概念形成的过程,常使用人工概念。 制造人工概念时先确定一个或几个属性作为分类标准,但并不告诉被试,只是将材料交给被试,请其分类。在此过程中,反馈给被试是对还是错。通过这种方法,被试可以发现主试的分类标准,从而学会正确分类,即掌握了这个人工概念。通过人工概念的研究,可以了解概念形成的过程。一般来讲,被试都是经过概括-假设-验证的循环来达到概念形成的。 叶克斯复杂选择器可用来制造人工概念。本实验模拟叶克斯复杂选择器来研究简单空间位置关系概念的形成。 方法与程序: 本实验共有4个人工概念,难度顺次增加,被试可以任选其中1个。 实验时,屏幕上会出现十二个圆键,有空心和实心两种。其中只有一个实心圆与声音相联系,此键出现的相对位置是有规律的,被试要去发现其中的规律(概念),找到这个键。被试用鼠标点击相应的实心圆,如果没有发生任何变化,表明选择错误;如果有声音呈现,同时该圆变为红色,则表明选择正确。只有选择正确,才能继续下一试次。当连续三次第一遍点击就找对了位置时,就认为被试已形成了该人工概念,实验即结束。如果被试在60个试次内不能形成正确概念,实验自动终止。 结果与讨论: 结果文件第一行是被试达到标准所用的遍数(不包括连续第一次就对的三遍)。其后的结果分三列印出:第一列是遍数;第二列为每遍中反应错的次数,如为0则表示这一遍第一次就做对了;第三列表示这一遍所用的时间,以毫秒为单位。 根据结果试说明被试概念形成的过程。 交叉参考:思维策略 参考文献: 杨博民主编心理实验纲要北京大学出版社 319-321页
北邮模式识别课堂作业答案(参考)
第一次课堂作业 ? 1.人在识别事物时是否可以避免错识? ? 2.如果错识不可避免,那么你是否怀疑你所看到的、听到的、嗅到的到底 是真是的,还是虚假的? ? 3.如果不是,那么你依靠的是什么呢?用学术语言该如何表示。 ? 4.我们是以统计学为基础分析模式识别问题,采用的是错误概率评价分类 器性能。如果不采用统计学,你是否能想到还有什么合理地分类器性能评价指标来替代错误率? 1.知觉的特性为选择性、整体性、理解性、恒常性。错觉是错误的知觉,是在特定条件下产生的对客观事物歪曲的知觉。认知是一个过程,需要大脑的参与.人的认知并不神秘,也符合一定的规律,也会产生错误 2.不是 3.辨别事物的最基本方法是计算.从不同事物所具有的不同属性为出发点认识事物.一种是对事物的属性进行度量,属于定量的表示方法(向量表示法)。另一种则是对事务所包含的成分进行分析,称为定性的描述(结构性描述方法)。 4.风险 第二次课堂作业 ?作为学生,你需要判断今天的课是否点名。结合该问题(或者其它你熟悉的识别问题, 如”天气预报”),说明: ?先验概率、后验概率和类条件概率? ?按照最小错误率如何决策? ?按照最小风险如何决策? ωi为老师点名的事件,x为判断老师点名的概率 1.先验概率:指根据以往经验和分析得到的该老师点名的概率,即为先验概率P(ωi ) 后验概率:在收到某个消息之后,接收端所了解到的该消息发送的概率称为后验概率。 在上过课之后,了解到的老师点名的概率为后验概率P(ωi|x) 类条件概率:在老师点名这个事件发生的条件下,学生判断老师点名的概率p(x| ωi ) 2. 如果P(ω1|X)>P(ω2|X),则X归为ω1类别 如果P(ω1|X)≤P(ω2|X),则X归为ω2类别 3.1)计算出后验概率 已知P(ωi)和P(X|ωi),i=1,…,c,获得观测到的特征向量X 根据贝叶斯公式计算 j=1,…,x 2)计算条件风险
模式识别课程设计
模式识别 课程设计 关于黄绿树叶的分类问题 成员:李家伟2015020907010 黄哲2015020907006 老师:程建 学生签字:
一、小组分工 黄哲:数据采集以及特征提取。 李家伟:算法编写设计,完成测试编写报告。 二、特征提取 选取黄、绿树叶各15片,用老师给出的识别算法进行特征提取 %Extract the feature of the leaf clear, close all I = imread('/Users/DrLee/Desktop/kmeans/1.jpg'); I = im2double(I); figure, imshow(I) n = input('Please input the number of the sample regions n:'); h = input('Please input the width of the sample region h:'); [Pos] = ginput(n); SamNum = size(Pos,1); Region = []; RegionFeatureCum = zeros((2*h+1)*(2*h+1)*3,1); RegionFeature = zeros((2*h+1)*(2*h+1)*3,1); for i = 1:SamNum P = round(Pos(i,:)); rectangle('Position', [P(1) P(2) 2*h+1 2*h+1]); hold on Region{i} = I(P(2)-h:P(2)+h,P(1)-h:P(1)+h,:); RegionFeatureCum = RegionFeatureCum + reshape(Region{i},[(2*h+1)*(2*h+1)*3,1]); end hold off RegionFeature = RegionFeatureCum / SamNum 1~15为绿色树叶特征,16~30为黄色树叶特征,取n=3;h=1,表示每片叶子取三个区域,每个区域的特征为3*3*3维的向量,然后变为27*1的列向量,表格如下。
华南理工大学《模式识别》大作业报告
华南理工大学《模式识别》大作业报告 题目:模式识别导论实验 学院计算机科学与工程 专业计算机科学与技术(全英创新班) 学生姓名黄炜杰 学生学号201230590051 指导教师吴斯 课程编号145143 课程学分2分 起始日期2015年5月18日
实验概述 【实验目的及要求】 Purpose: Develop classifiers,which take input features and predict the labels. Requirement: ?Include explanations about why you choose the specific approaches. ?If your classifier includes any parameter that can be adjusted,please report the effectiveness of the parameter on the final classification result. ?In evaluating the results of your classifiers,please compute the precision and recall values of your classifier. ?Partition the dataset into2folds and conduct a cross-validation procedure in measuring the performance. ?Make sure to use figures and tables to summarize your results and clarify your presentation. 【实验环境】 Operating system:window8(64bit) IDE:Matlab R2012b Programming language:Matlab
模式识别大作业02125128(修改版)
模式识别大作业 班级 021252 姓名 谭红光 学号 02125128 1.线性投影与Fisher 准则函数 各类在d 维特征空间里的样本均值向量: ∑∈= i k X x k i i x n M 1 ,2,1=i (1) 通过变换w 映射到一维特征空间后,各类的平均值为: ∑∈= i k Y y k i i y n m 1,2,1=i (2) 映射后,各类样本“类内离散度”定义为: 22 ()k i i k i y Y S y m ∈= -∑,2,1=i (3) 显然,我们希望在映射之后,两类的平均值之间的距离越大越好,而各类的样本类内离 散度越小越好。因此,定义Fisher 准则函数: 2 1222 12||()F m m J w s s -= + (4) 使F J 最大的解* w 就是最佳解向量,也就是Fisher 的线性判别式. 从 )(w J F 的表达式可知,它并非w 的显函数,必须进一步变换。 已知: ∑∈= i k Y y k i i y n m 1,2,1=i , 依次代入上两式,有: i T X x k i T k X x T i i M w x n w x w n m i k i k === ∑∑∈∈)1 (1 ,2,1=i (5) 所以:2 21221221||)(||||||||M M w M w M w m m T T T -=-=- w S w w M M M M w b T T T =--=))((2121 (6)
其中:T b M M M M S ))((2121--= (7) b S 是原d 维特征空间里的样本类内离散度矩阵,表示两类均值向量之间的离散度大 小,因此,b S 越大越容易区分。 将(4.5-6) i T i M w m =和(4.5-2) ∑∈= i k X x k i i x n M 1代入(4.5-4)2i S 式中: ∑∈-= i k X x i T k T i M w x w S 22)( ∑∈?--? =i k X x T i k i k T w M x M x w ))(( w S w i T = (8) 其中:T i X x k i k i M x M x S i k ))((--= ∑=,2,1=i (9) 因此:w S w w S S w S S w T T =+=+)(212221 (10) 显然: 21S S S w += (11) w S 称为原d 维特征空间里,样本“类内离散度”矩阵。 w S 是样本“类内总离散度”矩阵。 为了便于分类,显然 i S 越小越好,也就是 w S 越小越好。
温度控制系统曲线模式识别及仿真
锅炉温度定值控制系统模式识别及仿真专业:电气工程及其自动化姓名:郭光普指导教师:马安仁 摘要本文首先简要介绍了锅炉内胆温度控制系统的控制原理和参数辨识的概念及切线近似法模式识别的基本原理,然后对该系统的温控曲线进行模式识别,而后着重介绍了用串级控制和Smith预估器设计一个新的温度控制系统,并在MATLAB的Simulink中搭建仿真模型进行仿真。 关键词温度控制,模式识别,串级控制,Smith预测控制 ABSTRACT This article first briefly introduced in the boiler the gallbladder temperature control system's control principle and the parameter identification concept and the tangent approximate method pattern recognition basic principle, then controls the curve to this system to carry on the pattern recognition warm, then emphatically introduced designs a new temperature control system with the cascade control and the Smith estimator, and carries on the simulation in the Simulink of MATLAB build simulation model. Key Words:Temperature control, Pattern recognition, Cascade control, Smith predictive control
模式识别课程作业proj03-01
模式识别理论与方法 课程作业实验报告 实验名称:Maximum-Likelihood Parameter Estimation 实验编号:Proj03-01 姓 名: 学 号:规定提交日期:2012年3月27日 实际提交日期:2012年3月27日 摘 要: 参数估计问题是统计学中的经典问题,其中最常用的一种方法是最大似然估计法,最大似然估计是把待估计的参数看作是确定性的量,只是其取值未知。最佳估计就是使得产生已观测到的样本的概率为最大的那个值。 本实验研究的训练样本服从多元正态分布,比较了单变量和多维变量的最大似然估计情况,对样本的均值、方差、协方差做了最大似然估计。 实验结果对不同方式计算出的估计值做了比较分析,得出结论:对均值的最大似然估计 就是对全体样本取平均;协方差的最大似然估计则是N 个)'?x )(?x (u u k k --矩阵的算术平均,对方差2 σ的最大似然估计是有偏估计。 一、 技术论述
(1)高斯情况:∑和u 均未知 实际应用中,多元正态分布更典型的情况是:均值u 和协方差矩阵∑都未知。这样,参数向量θ就由这两个成分组成。 先考虑单变量的情况,其中参数向量θ的组成成分是:221,σθθ==u 。这样,对于单个训练样本的对数似然函数为: 2 12 2 )(212ln 21)(ln θθπθ θ-- - =k k x x p (1) 对上式关于变量θ对导: ???? ? ???????-+--=?=?2 2 2 12 12 2)(21 )(1 )(ln θθθθθθθθk k k x x x p l (2) 运用式l θ?=0,我们得到对于全体样本的对数似然函数的极值条件 0)?(?1 n 112=-∑=k k x θθ (3) 0?) (?11 2 2 2 112 =-+ -∑ ∑==n k k n k x θθθ (4) 其中1?θ,2?θ分别是对于1θ,2θ的最大似然估计。 把1?θ,2?θ用u ?,2?σ代替,并进行简单的整理,我们得到下述的对于均值和方差的最大似然估计结果 ∑==n k k x n u 1 1 ? (5) 2 1 2 )?(1 ?∑=-= n k k u x n σ (6) 当高斯函数为多元时,最大似然估计的过程也是非常类似的。对于多元高斯分布的均值u 和协方差矩阵∑的最大似然估计结果为: ∑=1 1 ?n k x n u (7) t k n k k u x u x )?()?(n 1 ?1 --=∑ ∑= (8) 二、 实验结果
模式识别实验报告(一二)
信息与通信工程学院 模式识别实验报告 班级: 姓名: 学号: 日期:2011年12月
实验一、Bayes 分类器设计 一、实验目的: 1.对模式识别有一个初步的理解 2.能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识 3.理解二类分类器的设计原理 二、实验条件: matlab 软件 三、实验原理: 最小风险贝叶斯决策可按下列步骤进行: 1)在已知 ) (i P ω, ) (i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计 算出后验概率: ∑== c j i i i i i P X P P X P X P 1 ) ()() ()()(ωωωωω j=1,…,x 2)利用计算出的后验概率及决策表,按下面的公式计算出采取i a ,i=1,…,a 的条件风险 ∑== c j j j i i X P a X a R 1 )(),()(ωω λ,i=1,2,…,a 3)对(2)中得到的a 个条件风险值) (X a R i ,i=1,…,a 进行比较,找出使其条件风险最小的 决策k a ,即()() 1,min k i i a R a x R a x == 则 k a 就是最小风险贝叶斯决策。 四、实验内容 假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为 正常状态:P (1ω)=; 异常状态:P (2ω)=。 现有一系列待观察的细胞,其观察值为x : 已知先验概率是的曲线如下图:
)|(1ωx p )|(2ωx p 类条件概率分布正态分布分别为(-2,)(2,4)试对观察的结果 进行分类。 五、实验步骤: 1.用matlab 完成分类器的设计,说明文字程序相应语句,子程序有调用过程。 2.根据例子画出后验概率的分布曲线以及分类的结果示意图。 3.最小风险贝叶斯决策,决策表如下: 结果,并比较两个结果。 六、实验代码 1.最小错误率贝叶斯决策 x=[ ] pw1=; pw2=; e1=-2; a1=; e2=2;a2=2; m=numel(x); %得到待测细胞个数 pw1_x=zeros(1,m); %存放对w1的后验概率矩阵 pw2_x=zeros(1,m); %存放对w2的后验概率矩阵
《模式识别基础》课程标准
《模式识别基础》课程标准 (执笔人:刘雨审阅学院:电子科学与工程学院)课程编号:08113 英文名称:Pattern Recognition 预修课程:高等数学,线性代数,概率论与数理统计,程序设计 学时安排:40学时,其中讲授32学时,实践8学时。 学分:2 一、课程概述 (一)课程性质地位 模式识别课基础程是军事指挥类本科生信息工程专业的专业基础课,通信工程专业的选修课。在知识结构中处于承上启下的重要位置,对于巩固已学知识、开展专业课学习及未来工作具有重要意义。课程特点是理论与实践联系密切,是培养学生理论素养、实践技能和创新能力的重要环节。是以后工作中理解、使用信息战中涉及的众多信息处理技术的重要知识储备。 本课程主要介绍统计模式识别的基本理论和方法,包括聚类分析,判别域代数界面方程法,统计判决、训练学习与错误率估计,最近邻方法以及特征提取与选择。 模式识别是研究信息分类识别理论和方法的学科,综合性、交叉性强。从内涵讲,模式识别是一门数据处理、信息分析的学科,从应用讲,属于人工智能、机器学习范畴。理论上它涉及的数学知识较多,如代数学、矩阵论、函数论、概率统计、最优化方法、图论等,用到信号处理、控制论、计算机技术、生理物理学等知识。典型应用有文字、语音、图像、视频机器识别,雷达、红外、声纳、遥感目标识别,可用于军事、侦探、生物、天文、地质、经济、医学等众多领域。 (二)课程基本理念 以学生为主体,教师为主导,精讲多练,以用促学,学以致用。使学生理解模式识别的本质,掌握利用机器进行信息识别分类的基本原理和方法,在思、学、用、思、学、用的循环中,达到培养理论素养,锻炼实践技能,激发创新能力的目的。 (三)课程设计思路 围绕培养科技底蕴厚实、创新能力突出的高素质人才的目标,本课程的培养目标是:使学生掌握统计模式识别的基本原理和方法,了解其应用领域和发展动态,达到夯实理论基础、锻炼理论素养及实践技能、激发创新能力的目的。 模式识别是研究分类识别理论和方法的学科,综合性、交叉性强,涉及的数学知识多,应用广。针对其特点,教学设计的思路是:以模式可分性为核心,模式特征提取、学习、分类为主线,理论上分层次、抓重点,方法上重比较、突出应用适应性。除了讲授传统的、经典的重要内容之外,结合科研成果,介绍不断出现的新理论、新方法,新技术、新应用,开拓学生视野,激发学习兴趣,培养创新能力。 教学设计以章为单元,用实际科研例子为引导,围绕基本原理展开。选择两个以上基本方法,辅以实验,最后进行对比分析、归纳总结。使学生在课程学习中达到一个思、学、用、