windows下配置mpi

MPICH并行程序设计环境简介
安竹林
(合肥工业大学 计算机与信息学院 可视化与协同计算研究室)
anzhulin@https://www.360docs.net/doc/3f15800575.html,
[摘要] MPI(Message Passing Interface)是目前一种比较著名的应用于并行环境的消息传
递标准。MPICH是MPI1.2标准的一个完全实现,也是应用范围最广的一种并行及分布式环境。
MPICH除包含MPI函数库之外,还包含了一套程序设计以及运行环境。本文将简要介绍如何
应用MPICH的Windows版本,建立一个基于Windows的并行程序设计及运行环境。并给出一
个C+MPI程序设计实例。
1MPICH for Microsoft Windows的安装与配置
1.1系统要求
安装MPICH for Microsoft Windows对系统有如下要求:
y Windows NT4/2000/XP 的Professional 或Server版(不支持Windows 95/98)
y所有主机必须能够建立TCP/IP连接
MPICH支持的编译器有:MS VC++ 6.x,MS VC++.NET,Compaq Visual Fortran 6.x,Intel Fortran,gcc,以及g77。安装MPICH,必须以管理员的身份登录。
1.2下载
MPICH的下载地址是:https://www.360docs.net/doc/3f15800575.html,/mpi/mpich/download.html Windows 版本的mpich.nt.1.2.5.exe的下载地址是:https://www.360docs.net/doc/3f15800575.html,/~ashton/mpich.nt/
1.3安装
以管理员的身份登录每台主机,在所有主机上建立一个同样的账户(当然也可以每个机器使用不同的用户名和账户,然后建立一个配置文件,使用命令行的方式运行程序),然后,运行下载的安装文件,将MPICH安装到每台主机上。
打开“任务管理器”中的“进程”选项卡,查看是否有一个mpd.exe的进程。如果有的话说明安装成功。以后每次启动系统,该进程将自动运行。
1.4注册与配置
安装好MPICH之后还必须对每台计算机进行注册和配置才能使用。其中注册必须每台计算机都要进行,配置只要在主控的计算机执行就行了。
注册的目的是,将先前在每台计算机上申请的账号与密码注册到MPICH中去,这样MPICH才能在网络环境中访问每台主机。配置方法:运行“mpich\mpd\bin\MPIRegister.exe”首先会提示输入用户账号,然后会提示输入两边密码,之后会问你是否保持上面的设定。如
图一 MPIRegister
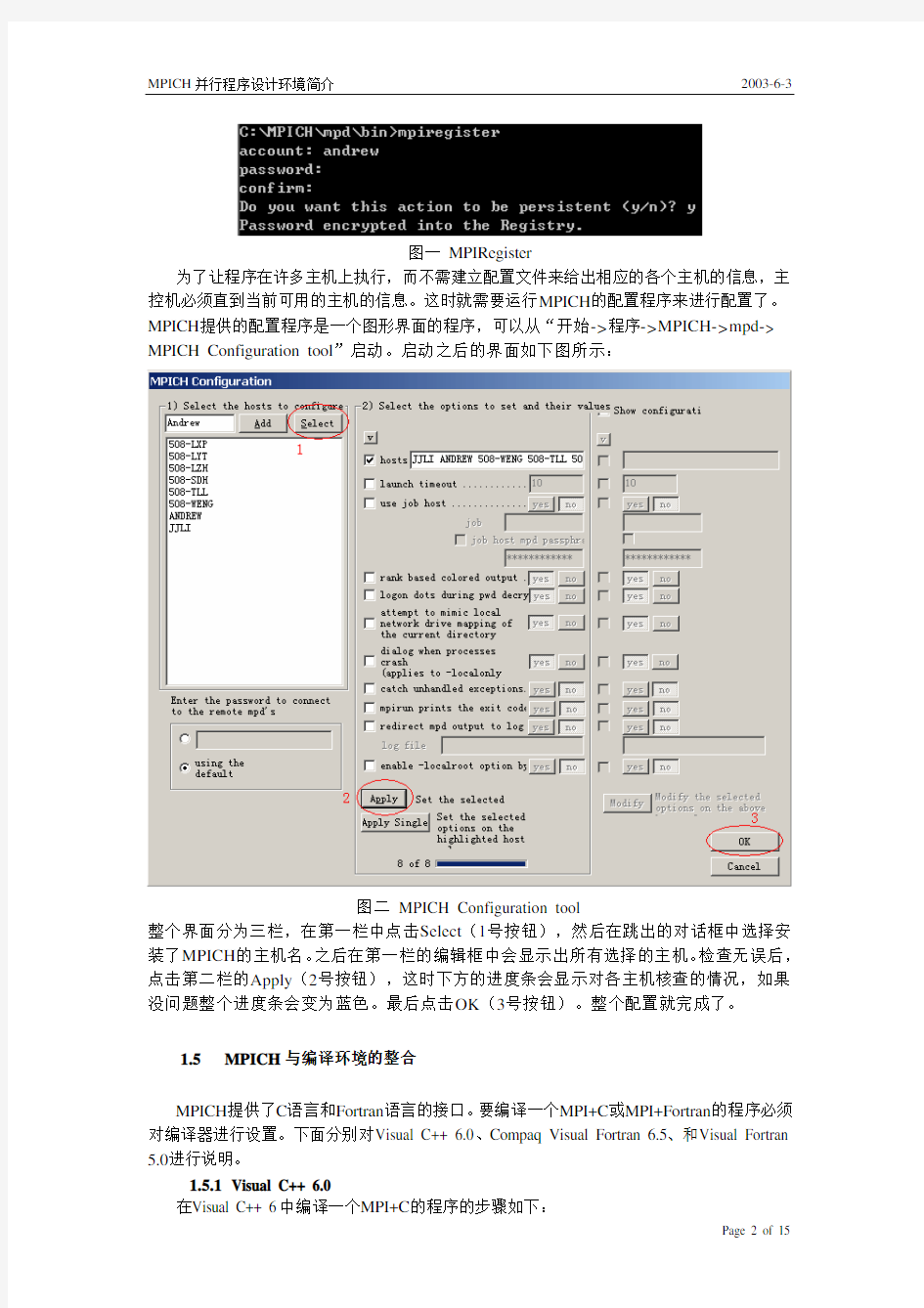
为了让程序在许多主机上执行,而不需建立配置文件来给出相应的各个主机的信息,主控机必须直到当前可用的主机的信息。这时就需要运行MPICH的配置程序来进行配置了。MPICH提供的配置程序是一个图形界面的程序,可以从“开始->程序->MPICH->mpd-> MPICH Configuration tool”启动。启动之后的界面如下图所示:
图二MPICH Configuration tool
整个界面分为三栏,在第一栏中点击Select(1号按钮),然后在跳出的对话框中选择安装了MPICH的主机名。之后在第一栏的编辑框中会显示出所有选择的主机。检查无误后,点击第二栏的Apply(2号按钮),这时下方的进度条会显示对各主机核查的情况,如果没问题整个进度条会变为蓝色。最后点击OK(3号按钮)。整个配置就完成了。
1.5MPICH与编译环境的整合
MPICH提供了C语言和Fortran语言的接口。要编译一个MPI+C或MPI+Fortran的程序必须对编译器进行设置。下面分别对Visual C++ 6.0、Compaq Visual Fortran 6.5、和Visual Fortran 5.0进行说明。
1.5.1Visual C++ 6.0
1.打开Visual C++ 6的Develop Studio。
2.新建一个工程,通常为Win32 Console Application。
3.在新的工程的编辑界面下,按Alt+F7打开工程设置对话框。
图三 Visual C++设置(1)
图四 Visual C++设置(2)
4.切换到C/C++选项卡。(如图三)首先选择“Win32 Debug”(①的下拉框),再选择“Code Generation”(②的下拉框),再选择“Debug Multithreaded”(③的下拉框)。
Release”(①的下拉框)重复上述步骤。(图四)
5.在C/C++选项卡中,选择“All Configurations”。(①的下拉框)选择“Preprocessor”
(②的下拉框),在“Additional include directories”的文本框中输入MPICH所附带的头文件的目录。(如图五)
图五 Visual C++设置(3)
6.在Link选项卡中,选择“All Configurations”。(①的下拉框)然后再选择“Input”
(②的下拉框),在“Additional library path”的文本框中输入MPICH所附带的库文件的目录。(如图六)
(②的下拉框),然后在“Object/library modules”(③)的文本框中添加“ws2_32.lib”。
点击“OK”。这时在“Common Options”(④)中会出现“ws2_32.lib”。(如图七)
图七 Visual C++设置(5)
8.在Link选项卡中,选择“Win32 Debug”。(①的下拉框)然后再选择“General”(②的下拉框),然后在“Object/library modules”(③)的文本框中添加“mpichd.lib”。
点击“OK”。这时在“Project Options”(④)中会出现“mpichd.lib”。(如图八)
的下拉框),然后在“Object/library modules”(③)的文本框中添加“mpich.lib”。
点击“OK”。这时在“Project Options”(④)中会出现“mpich.lib”。(如图九)
图九 Visual C++设置(7)
10.关闭工程设置对话框。
1.5.2Compaq Visual Fortran 6.5
Compaq Visual Fortran 6.5的Develop Studio跟Visual C++ 6.0基本一致,所以设置方法也大致相同,在这里不再重复了。
1.5.3Visual Fortran 5.0
MPICH手册中并没有提到支持Visual Fortran 5.0。这时因为Visual Fortran 5.0所附带的Link.exe是Microsoft Develop Studio 97里的版本(5.00.7022),如果在Visual Fortran 5.0中直接编译MPI程序会提示如下错误:
--------------------Configuration: testran - Win32 Debug--------------------
Compiling Fortran...
C:\Program Files\DevStudio\MyProjects\testran\test.for
Linking...
..\..\..\..\MPICH\SDK\Lib\mpich.lib : fatal error LNK1106: invalid file or disk full: cannot seek to 0x3ea20b5c Error executing link.exe.
testran.exe - 1 error(s), 0 warning(s)
解决方法是:用新版的Link.exe来代替。如果有Visual C++ 6.0以上版本的话可以把新版的Link.exe复制到\DevStudio\VC\BIN中覆盖原来的Link.exe。如果没有Visual C++ 6.0,则可以到Microsoft的网站下载Windows DDK,其中所包含的Microsoft的免费汇编器MASM,其中的Link.exe也可以用来作代替。
修正了Link.exe的版本错误之后,就可以用Visual Fortran 5.0来编译MPI+Fortran程序了。由于
设置。由于对于Fortran程序来说,MPI可以看作一个库,所以只要建立一个工程,并把MPICH 所附带的头文件和库文件添加到工程就可以编译了。具体方法是:在菜单中选择
“Project->Add to project->Files…”然后在跳出的对话框选择MPI的头文件和库文件。(图十)
图十在Visual Fortran 5.0中添加头文件和库文件
1.6样例程序的运行
在“MPICH\SDK\Examples\nt\Basic”有一个简单的计算π的程序,在VC下编译成可执行程序就可应用来测试并行环境。
在MPICH中运行并行程序有两种方式:命令行方式和图形方式。命令行方式可以使用配置文件,功能比较强,但操作复杂易出错。图形方式简单明了,下面以图形方式说明如何运行一个测试程序来测试并行环境。
在运行一个程序之前,首先要做的事是将待运行的目标程序复制到所有的主机的相同目
图十一 MPIRun
MPI 环境。(如上图所示)首先,选择待运行的程序,点击右上角的“..”按钮,选择相应
的程序;然后选择需要用于计算的主机个数,指定参加运算的主机名;最后点击Run ,运行
程序。运行的结果会显示在文本框,不同主机的输出信息会以不同的颜色标出。
2 MPI 程序设计简介
使用MPI 进行程序设计的关键是灵活的使用MPI 所提供的各种函数。下面是常见的MPI
函数的说明。(这里提供的是C 版本, Fortran 版本与之类似)
2.1 MPI 初始化
功能:初始化MP I 环境
int MPI_Init(int *argc, char ***argv)
2.2 MPI 结束
功能:终止MPI 环境
int MPI_Finalize(void)
2.3 当前进程标识
功能:返回当前进程的标识。如果有n 个进程,则进程的标识号从0到1?n 。
int MPI_Comm_rank(MPI_Comm comm, int *rank)
[ IN Comm ]
该进程所在的通信域(句柄) [ OUT rank ]
调用进程在COMM 中的标识号(整型)
2.4 通信域包含的进程数 功能:返回指定通信域中的进程个数。
int MPI_Comm_size(MPI_Comm comm, int *SIZE)
[ IN comm ] 该进程所在的通信域(句柄)
[ OUT size ] 通信域COMM 内包含的进程数(整型)
2.5消息发送
功能:将首地址为buf的count个数据类型为datatype的数据由当前进程发送给dest进程。
int MPI_Send(void* buf, int count, MPI_Datatype Datatype,
int dest, int tag, MPI_Comm comm)
[ IN buf ] 发送缓冲区的起始地址(可选类型)
[ IN count ] 将发送的数据的个数(非负整型)
[ IN datatype ] 发送数据的数据类型(句柄)
[ IN dest ] 目的进程标识号(整型)
[ IN tag ] 消息标志(整形)
[ IN comm ] 通信域(句柄)
2.6消息接收
功能:从source进程接受count个数据类型为datatype的数据并保存到首地址为buf的内存空间中。
int MPI_Recv(void* buf, int count, MPI_Datatpye datatype,
int source, int tag, MPI_Comm comm,
*status)
MPI_Status
[ OUT buf ] 发送缓冲区的起始地址(可选类型)
[ IN count ] 将发送的数据的个数(非负整型)
[ IN datatype ] 发送数据的数据类型(句柄)
[ IN source ] 源进程标识号(整型)
[ IN tag ] 息标识,与发送操作的标识匹配(整型)
[ IN comm ] 通信域(句柄)
[ OUT status ] 返回状态(状态类型)
2.7消息广播
功能:将首地址为buf的count个数据类型为datatype的数据由root进程广播给指定通信域中所有进程。
int MPI_Bcast(void* buf, int count, MPI_Datatype datatype,
MPI_Comm
comm)
root,
int
[ IN/OUT buf ] 通信消息缓冲区的起始地址(可选类型)
[ IN count ] 将广播出去或接收的数据个数(非负整型)
[ IN datatype ] 广播/接收数据的数据类型(句柄)
[ IN root ] 广播数据的根进程的标识号(整型) [ IN comm ] 通信域(句柄)
2.8 收集
功能:将各个进程中的数据收集到根进程中。
int MPI_Gather(void* sendbuf, int sendcount,
MPI_Datatype sendtype, void* recvbuf, int recvcount,
MPI_Datatype Recvtype, int root, int comm)
[ IN sendbuf ] 发送消息缓冲区的起始地址(可选类型)
[ IN sendcount ] 发送消息缓冲区中的数据个数(非负整型)
[ IN sendtype ] 发送消息缓冲区中的数据类型(句柄)
[ OUT recvbuf ] 接收消息缓冲区的起始地址(可选类型)
[ IN recvcount ] 接收消息缓冲区中的数据个数(非负整型)
[ IN recvtype ] 接收消息缓冲区中的数据类型(句柄)
[ IN root ] 接收数据的根进程的标识号(整型)
[ IN comm ] 通信域(句柄)
3 基于MPI 的并行程序设计
并行的程序设计的核心问题是任务分配和通信,MPI 对通信提供了良好的支持,所以如
何分配任务成了我们主要关心的问题。这里通过对一个实例的分析和实现来简要的介绍一下
如何使用MPI 来构造一个对等模式的并行程序。
实例:求一个二维数组(Data )中所有元素之和。
3.1 分析
这个问题中的处理对象是一个二维数组(下标从1开始),即我们要把这个二维数组分
配到各个处理器上去。在每个处理器上分别求和,然后再将所有处理器计算出来的“部分和”
累加起来,就可以得出最后结果。如何分配呢?按行来分配是首先想到的方法,我们可以按
处理器的个数把二维数组按行分块,每个处理器一块。对于7行(7]0[=ArraySize ),3
个处理器(3=size )的情况下,分配方案如下图所示:
图十二 数组的分配
如何实现呢?假设首先,我们可以计算出每个处理器至少分配到的行数:
??size ArraySize eNumber AverageLin /]0[=
如果处理器个数不能整除行数,这样将有
size ArraySize ssorNumber HeavyProce mod ]0[=
个处理器分得1+eNumber AverageLin 行,我们规定编号小的处理器分得更多的行,这样
我们就可以得到编号为rank 的处理器分得的行数:
???≥<+=ssorNumber
HeavyProce rank eNumber AverageLin ssorNumber HeavyProce rank eNumber AverageLin er MyLineNumb 1 有了每个处理器分配的行数,就可以分配任务了。
在实际操作中会存在这样一个问题,MPI 的通信函数对传递的信息是这样组织的:给出
缓冲区起始地址和缓冲区的长度。而实际的程序中,一方面,二维数组是按行或按列存放的,
另一方面,数组中存放的元素一般不会达到数组的上界,就是说数组一般不会存满元素。这
样就造成了数组中的元素在内存中实际上是离散存放的。如果直接给出二维数组的首地址和
长度,并不能把我们预想的元素在处理器之间进行传递。解决办法是,用一维数组来存放二
维数组,由程序员完成地址的映射,这样就可以顺利的解决上面的问题了。在本问题的解决
中,采用了SendArray 来存储Data 中的元素来完成数据的传递和计算。
另外一个在实际操作中容易出错的地方是,发送缓冲区和接收缓冲区的长度的一致性问
题。由于基于MPI 的并行程序一般是由一个主控程序读取数据然后将任务分配,但是分配
任务的时候,被控程序并不知道主控程序发送的数据缓冲区的长度。对这个问题的一种解决
方法是,主控程序在发送数据前先发送数据缓冲区的长度;另一种方法是,由被控程序自己
计算缓冲区的长度。本着减少通信的原则,通常采取第二种方法解决上述问题。这个问题尽
管看起来很简单,但在实际操作中极容易被忽视,应该引起重视。
上面我们提到,在处理二维数组的时候,通常先把二维数组转换为一维数组进行传递。
实际中的许多问题,在被控程序计算完毕之后,可能要把结果返还给主控程序,而结果可能
是根据这个一维数组计算出来的一个数组,所以在被控程序的处理过程中,往往不把一维数
配任务的时候往往采取这样的方法,将一个处理其应分配的数据由二维数组转化为一维数组后马上把这个一维数组传递出去,然后在用这个一维数组存储应分配给下一个处理器的数据。这样,如果我们选择了0号处理器作为主控程序,就必须从后向前分配任务。因为如果我们以相反的顺序分配任务的话,0号处理器首先将自己应分配的数据转化为一维数组,但这个数组它应该自己保存,所以它必须另找地方保存这个一维数组,在分配好任务之后,再将这个数组转移回来,这就造成了程序控制和存储上的冗余。而如果采取从后向前的方法分配,主控程序在分配完受控程序的数据后,刚好得到了自己应得的数据。
3.2流程图
整个程序的大体思路是:由主控程序从文件中读出数组的信息,然后把数组的尺寸广播给所有处理器,以便每个处理器计算出自己应得的数据长度,做好接收准备。然后,主控程序分配任务,从处理器接收任务。接下来,各个处理器完成自己的计算任务。最后,主处理器将所有结果收集起来,完成最后的处理,并输出结果。流程图如图十三所示。
3.3源代码
MPI_Bcast(ArraySize,2,MPI_INT,0,MPI_COMM_WORLD);
//定义与任务分配有关的数据结构
AverageLineNumber,HeavyProcessorNumber,MyLineNumber;
int
CurrentLine,StartLine,SendSize;
int
SendArray[MAXX*MAXY];
float
//计算每个处理其应分得的矩阵行数
AverageLineNumber=ArraySize[0] / size;
HeavyProcessorNumber=ArraySize[0] % size;
if (rank < HeavyProcessorNumber)
MyLineNumber=AverageLineNumber+1;
else
MyLineNumber=AverageLineNumber;
//如果是0号处理器,进行任务分配
if (rank == 0)
{
CurrentLine=ArraySize[0];
for (i=size-1; i >= 0; i--)
{
SendSize=0;
if
<
HeavyProcessorNumber)
(i
StartLine=CurrentLine-AverageLineNumber;
else
StartLine=CurrentLine-AverageLineNumber+1;
for (j=StartLine; j <= CurrentLine; j++)
for (k=1; k <= ArraySize[1]; k++)
SendArray[SendSize++]=Data[j][k];
0)
!=
if
(i
MPI_Send(SendArray,SendSize,
MPI_FLOAT,i,10,MPI_COMM_WORLD);
CurrentLine=StartLine-1;
}
}
//非0号处理其接收分配的矩阵
else
MPI_Recv(SendArray,MyLineNumber*ArraySize[1],
MPI_FLOAT,0,10,MPI_COMM_WORLD,&Status);
//定义每个处理器的“部分和”变量
*Sum=new(float);
float
//每个处理器,完成自己的计算任务
*Sum=0;
for (i=0; i < MyLineNumber*ArraySize[1]; i++)
*Sum+=SendArray[i];
float
AllSum[MAXPROCESSOR];
//将所有计算结果收集到0号处理器
MPI_Gather(Sum,1,MPI_FLOAT,AllSum,1,MPI_FLOAT,0,MPI_COMM_WORLD); //如果是0号处理器,则进行最后的计算,并输出结果
if (rank == 0)
{
*Sum=0;
for (i=0; i < size; i++)
*Sum+=AllSum[i];
cout<<"The Sum of the Array is:"<<*Sum< } //MPI终止 MPI_Finalize(); } 3.4如何使用MPI并行化一个已存在的串行程序 串行程序并行化的关键是:发掘串行程序中的并行成分,合理的分配任务。其程序结构跟上述的直接构造并行程序类似。构造方法大致为:在原来的程序中添加MPI初始化以及终止的调用;明晰串行部分和并行部分的接口关系,尽量简化接口的数据量;在两个接口部分分别编写任务分配和数据收集的代码;最后,寻找程序结构中可以进行优化的部分,提高程序运行的效率。 4FAQ y Q:MPICH有Windows和Linux的版本,那么可以同时在两个环境下运行一个程序吗? A:不行。同一个MPI程序可以分别在Windows和Linux环境下编译和运行,但却不能同时运行。这是因为MPICH确立和管理主机间的Socket连接的代码是不兼容的。 y Q:为什么得到错误信息“Unhandled exception caught in RedirectIOThread”? A:这是由于向标准输出(屏幕)打印了过多的信息而造成的。由于在运行MPIRun的时候,所有主机的信息全部输出在0号进程所在的主机的屏幕上,如果每个程序输出了过多的信息,这就会造成上述错误。解决方法是,减少不必要的调试信息的输出。 y Q:为什么得到错误信息“MPI_RECV : Message truncated”? A:这是由于MPI_RECV的接收缓冲区比对应的MPI_SEND的发送缓冲区小造成的,解决办法是,调整MPI_RECV的接收缓冲区尺寸,使其与发送缓冲区的尺寸一致。 y Q:为什么得到错误信息“Error 64 – GetQueuedCompletenessStatus failed”? A:通常这是由于MPI_RECV与MPI_SEND不匹配造成的。解决方法是,检查每个MPI_RECV是否都有相应的MPI_SEND与之匹配。如果都匹配,再查看是否有进程非正常终止。 y Q:为什么得到错误信息“Failed to launch the root process: c:\cpi.exe LaunchProcess Failed, 登陆失败:未知的用户名或错误的密码” A:这是由于某台运行程序的主机,没有运行MPIRegister进行注册,或者注册的用户名或密码不一致。 编辑推荐 ◆书中内容侧重于以MPI库为基础开发并行应用程序,对MP规范定义的各项功能和特征在阐述其特点基础上均配以实例加以说明和印证。 ◆书中所附实例尽量采用独立的功能划分,其中的代码片段可直接用于并行应用程序开发 ◆在讲述基本原理的同时,注重对各项消息传递和管理操作的功能及局限性、适用性进行分析从而使熟读此书的读者能够编写出适合应用特点,易维护、高效率的并行程序。 ◆与本书配套的电子教案可在清华大学出版社网站下载。 本书简介 本书旨在通过示例全面介绍MP1并行程序开发库的使用方法、程序设计技巧等方面的内容,力争完整讨论MP1规范所定义的各种特征。主要也括MPI环境下开发并行程序常用的方法、模式、技巧等 内容。在内容组织上力求全面综合地反映MPl-1和MPI-2规范。对MPI所定义的各种功能、特征分别 给出可验证和测试其工作细节的示例程序 目录 第1章 MPI并行环境及编程模型 1.1 MPICH2环境及安装和测试 1.1.1 编译及安装 1.1.2 配置及验汪 1.1.3 应用程序的编译、链接 1.1.4 运行及调试 1.1.5 MPD中的安全问题 1.2 MPI环境编程模型 1.2.1 并行系统介绍 1.2.2 并行编程模式 1.2.3 MPI程序工作模式 1.3 MPI消息传递通信的基本概念 1.3.1 消息 1.3.2 缓冲区 1.3.3 通信子 1.3.4 进样号和进程纰 1.3.5 通价胁议 1.3.6 隐形对象 第2章 点到点通信 2.1 阻糍通信 2.1.1 标准通信模式 2.1.2 缓冲通信模式 2.1.3 就绪通信模式 2.1.4 同步通信模式 2.1.5 小结 2.2 非阻塞通信 2.2.1 通信结束测试 2.2.2 非重复的非阻塞通信 2.2.3 可醺复的非阻塞通信 2.2.4 Probe和Cancel 2.3 组合发送接收 2.3.1 MPl_Send,MPI_RecvoMPl_Sendreev 2.3.2 MPI_Bsend←→MPl_Sendrecv 2.3.3 MPI_Rsend←→MPI_Sendrecv 2.3.4 MPl_Ssend←→MPl_Sendrecv 2.3.5 MPl_lsend←→MP1一Sendrecv 2.3.6 MPl_Ibsend←→MPI_Sendrecv 2.3.7 MPI_Irsend←→MPI_Sendrecv 2.3.8 MPl_Issend,MPI_Irecv←→MPI_Sendrecv 2.3.9 MPI Send_init←→MPl_Sendrecv 2.3.10 MPI一Bsendj init←→MPl_Sendrecv 2.3.11 MPI_Rsend_init←→MPI_Sendrecv 2.3.12 MPl_Ssend_init,MPl_Recv_init←→MPl_Sendrecv 2.4 点到点通信总结 第27卷 第3期河北理工学院学报Vol127 No13 2005年8月Journa l of Hebe i I n stitute of Technology Aug.2005 文章编号:100722829(2005)0320041203 MP I并行编程环境及程序设计 杨爱民1,陈一鸣2 (11河北理工大学理学院,河北唐山063009;21燕山大学理学院,河北秦皇岛066004)关键词:MP I;并行编程;消息传递 摘 要:通过对MP I原理和特点的研究,给出了并行MP I程序的基本设计思路和执行过程,并 实现了向量相加的并行计算。 中图分类号:TP316 文献标识码:A 0 引 言 近几十年来,大规模和超大规模的并行机取得了快速发展,由于各种原因,开发商对用户提供的必要支持,如它们各自专有的消息传递包NX、EU I、P VM等,虽然在特定平台上具有很优越的性能,但是从应用程序来看,可移植性差。1992年11月,在Supercomputi ong’92会议上,正式成立了一个旨在建立一个消息传递标准平台的MP I(Message Passing I nterface)论坛,该论坛不仅包括了许多P VM、Exp ress等的研制者及并行程序用户,还吸收了许多著名计算机厂商的代表。论坛于1994年5月,公布了MP I标准。MP I是一种为消息传递而开发的广泛使用的标准,它为消息传递建立了一个可移植的、高效、灵活的标准。 1 MP I的原理与特征 MP I是一个函数库,而不是一门语言,它是一种消息传递模型,它的最终目的是服务于进程间通信。MP I作为一个并行程序库的开发平台,为用户编写和运行程序提供了便利的条件。由于MP I是基于消息传递机制构建的系统,因此它在体系结构为分布存储的并行机中有很宽阔的应用空间,它可以应用在各种同构和异构的网络平台中。它的编程语言可以为Fortran77/90、C/C++。在Fortran77/90、C/C++语言中都可以对MP I的函数进行调用,它作为一种消息传递模式的并行编程环境,MP I并行程序要求将任务进行划分,同时启动多个进程并发的执行,而各个进程之间通过MP I的库函数来实现其中的消息传递。 MP I与其它并行编程环境相比,显著的特点有: (1)可移植性强,能同时支持同构和异构的并行计算; (2)可伸缩性强,允许并行结构中的节点任意增加或减少; (3)能很好的支持点对点通信和集体通信方式; (4)对C语言和Fortran语言的支持,使其能很好的满足各种大规模科学和工程计算的需要。 这样,以MP I作为公共消息传递接口的并行应用程序就可以不作任何改动的移植到不同种类和型号的并行机上,也能够正常运行,或者移到网络环境中也一样。 2 MP I的基本函数 MP I为消息传递和相关操作提供了功能强大的库函数,MPl-1中有128个,MP I-2中有287个库函数。但是从理论上来说,MP I的所有通信功能都可以用它的6个基本调用来完成,即使用这6个函数可以实现所有的消息传递并行程序。这六个函数分别为呼(Fortran77语言的调用格式来描述): (1)MP I初始化 MP I程序的初始化工作通过调用MPl l N I T(I ERROR)来实现,所有MP I程序的第一条可执行语句都是 收稿日期:2004210221 基金项目:河北省自然科学基金项目(E2004000245) 作者简介:杨爱民(19782),男,河北顺平人,河北理工大学理学院教师,硕士。 国家973项目高性能计算环境支持讲座 MPI与PETSc 莫则尧 (北京应用物理与计算数学研究所) 个人介绍 莫则尧,男,汉族,1971年7月生,副研究员:●1992年国防科技大学应用数学专业本科毕业; ●1997年国防科技大学计算机应用专业并行算法 方向博士毕业; ●1999年北京应用物理与计算数学数学博士后流 动站出站,并留所工作; ●主要从事大规模科学与工程并行计算研究。 消息传递并行编程环境MPI 一、进程与消息传递 二、MPI环境的应用现状 三、MPI并行程序设计入门(程序例1) 四、初步的MPI消息传递函数 五、作业一 六、先进的MPI函数 七、MPI并行程序示例2(求解- u=f); 八、MPI环境的发展 九、作业二 一、进程与消息传递 1.单个进程(process ) ● 同时包含它的执行环境(内存、寄存器、程序计数器等),是操作系统中独立存在的可执行的基本程序单位; ● 通俗理解:串行应用程序编译形成的可执行代码,分为“指令”和“数据”两个部分,并在程序执行时“独立地申请和占有”内存空间,且所有计算均局限于该内存空间。 2.单机内多个进程: ● 多个进程可以同时存在于单机内同一操作系统:由操作系统负责调度分时共享处理机资源(CPU 、内存、存储、外设等); ● 进程间相互独立(内存空间不相交):在操作系统调度下各自独立地运行,例如多个串行应用程序在同一台计算机中运行; ● 进程间可以相互交换信息:例如数据交换、同步等待,内存 些信息在进程间的相互交换,是实现进程间通信的唯 一方式; ●最基本的消息传递操作:发送消息(send)、接受消 息(receive)、进程同步(barrier)、规约(reduction); ●消息传递的实现:共享内存或信号量,用户不必关心; 3.包含于通过网络联接的不同计算机的多个进程: ●进程独立存在:进程位于不同的计算机,由各自独立 的操作系统调度,享有独立的CPU和内存资源; ●进程间相互信息交换:消息传递; ●消息传递的实现:基于网络socket机制,用户不必关 心; 4.消息传递库函数: ●应用程序接口(API):提供给应用程序(FORTRAN、 C、C++语言)的可直接调用的完成进程间消息传递 MPI并行编程系列二快速排序 阅读:63评论:0作者:飞得更高发表于2010-04-06 09:00原文链接在上一篇中对枚举排序的MPI并行算法进行了详细的描述和实现,算法相对简单,采用了并行编程模式中的单程序多数据流的并行编程模式。在本篇中,将对快速排序进行并行化分析和实现。本篇代码用到了上篇中的几个公用方法,在本篇中将不再做说明。 在本篇中,我们首先对快速排序算法进行描述和实现,并在此基础上分析此算法的并行性,确定并行编程模式,最后给出该算法的MPI实现。 一、快速排序算法说明 快速排序时一种最基本的排序算法,效率相对较高。其基本思想是:在当前无序数组R[1,n]中选取一个记录作为比较的"基准",即作为排序中的"轴"。经过一趟排序后,当前无序数组R[1,n]就会以这个轴为核心划分为两个无序的子区r1[1,i-1],r2[i,n]。其中左边的无序子区都会比"轴"小,右边的无序子区都会比"轴"大。这样下一趟排序,我们就可以对这两个子区用同样的方法进行划分排序,知道所有的无序子区中的记录均排好为止。 根据算法的说明,快速排序时一个典型的递归算法,算法描述如下: 无序数组R[1],R[2],.,R[n] quick_sort(R,start,end) if(start end) r=partion(R,start,end) quick_sort(R,start,r-1) quick_sort(R,r+1,end) endif end quick_sort方法partion的作用就是选取"轴",并将数组分为两个无序子区,并将该"轴"的最终位置返回,在这里我们选择数组的第一个元素为"轴",其算法描述为: partion(R,start,end) r=R[start] while(start end) MPI 并行编程系列二快速排序 阅读:63 评论:0作者:飞得更高发表于2010-04-06 09 :00 原文链接 在上一篇中对枚举排序的MPI并行算法进行了详细的描述和实现,算法相对简单,采用了并行编程模式中的单程序多数据流的并行编程模式。在本篇中,将对快速排序进行并行化分析和实现。本篇代码用到了上篇中的几个公用方法,在本篇中将不再做说明。 在本篇中,我们首先对快速排序算法进行描述和实现,并在此基础上分析此 算法的并行性,确定并行编程模式,最后给出该算法的MPI实现。 一、快速排序算法说明 快速排序时一种最基本的排序算法,效率相对较高。其基本思想是:在当前 无序数组R[1,n] 中选取一个记录作为比较的"基准" ,即作为排序中的"轴" 。经过一趟排序后,当前无序数组R[1,n] 就会以这个轴为核心划分为两个无序的子区r1[1,i-1],r2[i,n] 。其中左边的无序子区都会比"轴"小,右边的无序子区都会比" 轴" 大。这样下一趟排序,我们就可以对这两个子区用同样的方法进行划分排序,知道所有的无序子区中的记录均排好为止。 根据算法的说明,快速排序时一个典型的递归算法,算法描述如下:无序数组R[1],R[2],.,R[n] quick_sort(R,start,end) if(start end) r=partion(R,start,end) quick_sort(R,start,r-1) quick_sort(R,r+1,end) endif end quick_sort 方法partion 的作用就是选取" 轴" ,并将数组分为两个 无序子区,并将该" 轴" 的最终位置返回,在这里我们选择数组的第一个元素为"轴" ,其算法描述为: partion(R,start,end) r=R[start] while(start end) while((R[end]=r)&&(start end)) end- end ehile R[start]=R[end] while((R[start]r)&&(start end)) start++ end wile R[end]=R[start] end while R[start]=r return start end partion 该排序算法的性能好坏主要取决于" 轴" 的选定,即无序数组的划分是否均衡。最好的情况下,无序数组每次都会被划为两个均等的无序子区,这是算法的负责度为o(nlogn) ;最坏的情况,无序数组每次划分都是左边n-1 个元素,右边0 个元素,这时算法的复杂度为 o(n A2)。在通常的情况下,该算法的复杂度会依然保持在o(nlogn) ,上只不过具有更高的常数因子。因此,选定一个有效地"轴",成为该算法的关键。一般情况下,会选定无序数组的第一个,中间或者是最后一个元素作为算法的"轴",我们可以对着三个元素进行比较,取大小居中的那个元素作为该算法的" 轴" 。 、快速排序算法的串行实现 确定在什么条件下终止递归操作。主函数代码如下: 1:void quick_sort_function(int*array,int start,int last){2 并行计算课程报告 题目:MPI并行编程环境概要指导老师:阮幼林教授 学院:信息工程学院 班级:信息研1001班 姓名:余华 学号:104972102820 时间:2011年01-10 摘要 随着科技的发展,新一代的计算机,无论计算能力和计算速度,都比旧的计算机优越。但人类对高性能计算的需求,也不断提高.除了增强处理器本身的计算能力外,并行处理是一种提高计算能力的有效手段.从前,并行处理要采用昂贵的专用计算机,随着个人计算机及网络成本下降,现已广泛用分布式网络计算机系统进行并行处理。在分布网络计算机系统中,采用消息传递方法实现进程间的通讯。当前流行基于消息传递的并行编程环境是MPI(Message Passing Interface)。 关键词:消息传递;消息传递接口;并行编程; Abstract Because of the development of technology, the new generation of computer should be better than the former ones in the power and speed of computing. But the people's demand of high performance of computing is increasing too. In addition to enhancing the computing power of the processor, parallel processing is also an efficient way to enhance the power of computing. In the past, the parallel processing can only run on the expensive and special computers. As the cost of personal computers and networks decreased, and now, it is popular to process the parallel processing on the distributed network computing systems. In the distributed network computing systems, message passing is used for the communication between processes. MPI (Message Passing Interface) are common development environments of parallel processing based on message passing. Keyword:Message passing; Message passing interface; Parallel programming; 中南大学 CENTRAL SOUTH UNIVERSITY 基于MPI的并行计算程序设计测试报告 学院:软件学院 专业:软件工程 学号: 姓名: 指导教师: 20**-**-** 基于MPI的并行计算程序设计测试报告 一.并行计算概述 1.采用并行计算的原因: ?串行程序速度提升缓慢。从串行程序的发展来讲,一方面,物理速度渐变发展,芯片速度每18个加快一倍,而内存传输率每年加快9%。另一方面,物理极限无法突破,芯片晶体管接近了原子极限,传输速度不可能超过光速。 ?可以加快速度。更短的时间内解决相同的问题,相同的时间内解决更多的复杂的问题。 ?可以加大规模。并行计算可以计算更大规模的问题。 2.并行计算简介 并行计算(Parallel Computing)是指同时使用多种计算资源解决计算问题的过程。为执行并行计算,计算资源应包括一台配有多处理机(并行处理)的计算机、一个与网络相连的计算机专有编号,或者两者结合使用。并行计算的主要目的是快速解决大型且复杂的计算问题。此外还包括:利用非本地资源,节约成本,使用多个“廉价”计算资源取代大型计算机,同时克服单个计算机上存在的存储器限制。为利用并行计算,通常计算问题表现为以下特征:1.将工作分离成离散部分,有助于同时解决;2.随时并及时地执行多个程序指令;3.多计算资源下解决问题的耗时要少于单个计算资源下的耗时。 对并行处理的需求极大的促进了并行技术的发展,因此许多大规模并行计算机系统相继问世,如PVP、SMP、MPP、DSM等。但传统的并行系统的高成本性、专用性、系统规模的不可伸缩性等使其难以推广到普通的商业应用和科学计算中。高性能集群系统因其性能价格比高、高可复用性、强可扩展性、用户编程方便等优点在科学研究中得到了广泛的应用。并行计算机系统的出现就需要对程序进行并行设计,这种需求使得各种不同的并行编程环境得到了很大发展。现行高性能计算机系统中使用的并行编程环境主要有两种:PVM(Parallel Virtual Machine)和MPI(Message Passing Interface)。PVM的开发始于1988年,由美国橡树岭国家实验室发起。目前很多人采用MPI作为并行开发环境。 3.并行计算的相关内容 ?存储方式。共享内存:ccNUMA,SMP;分布式内存:MPP,Cluster。 ?三种计算模式。Uniprocessor,shared memory,distribute memory. ?并行化分解方法。任务分解:多任务并行执行;功能分解:分解被执行的计算;区域分解:分解被执行的数据。 ?并行算法的分类。按运算的基本对象:分数值并行算法和非数值并行算法。按进程间的依赖关系:分同步并行算法,异步并行算法和纯并行算法。按并行计算的任务大小:分粗粒度并行算法,中粒度并行算法和细粒度并行算法。MPI并行程序设计实例教程
MPI并行编程环境及程序设计
消息传递并行编程环境MPI
MPI并行编程系列二快速排序
MPI并行编程系列二快速排序
基于MPI并行编程环境简述
基于MPI的并行计算程序设计测试报告