管理统计学描述统计实验
实验一SPSS基本操作与描述统计
实验目的:
1. 掌握SPSS数据文件的建立
2. 掌握描述性特征量的计算
3. 掌握频数分布图的制作
4.根据已存在的变量建立新变量以及对记录进行排序
5. 对观测值进行摘要分析
实验内容:
一SPSS数据文件的建立
SPSS对数据的处理是以变量为前提的,因此下面先介绍定义变量。
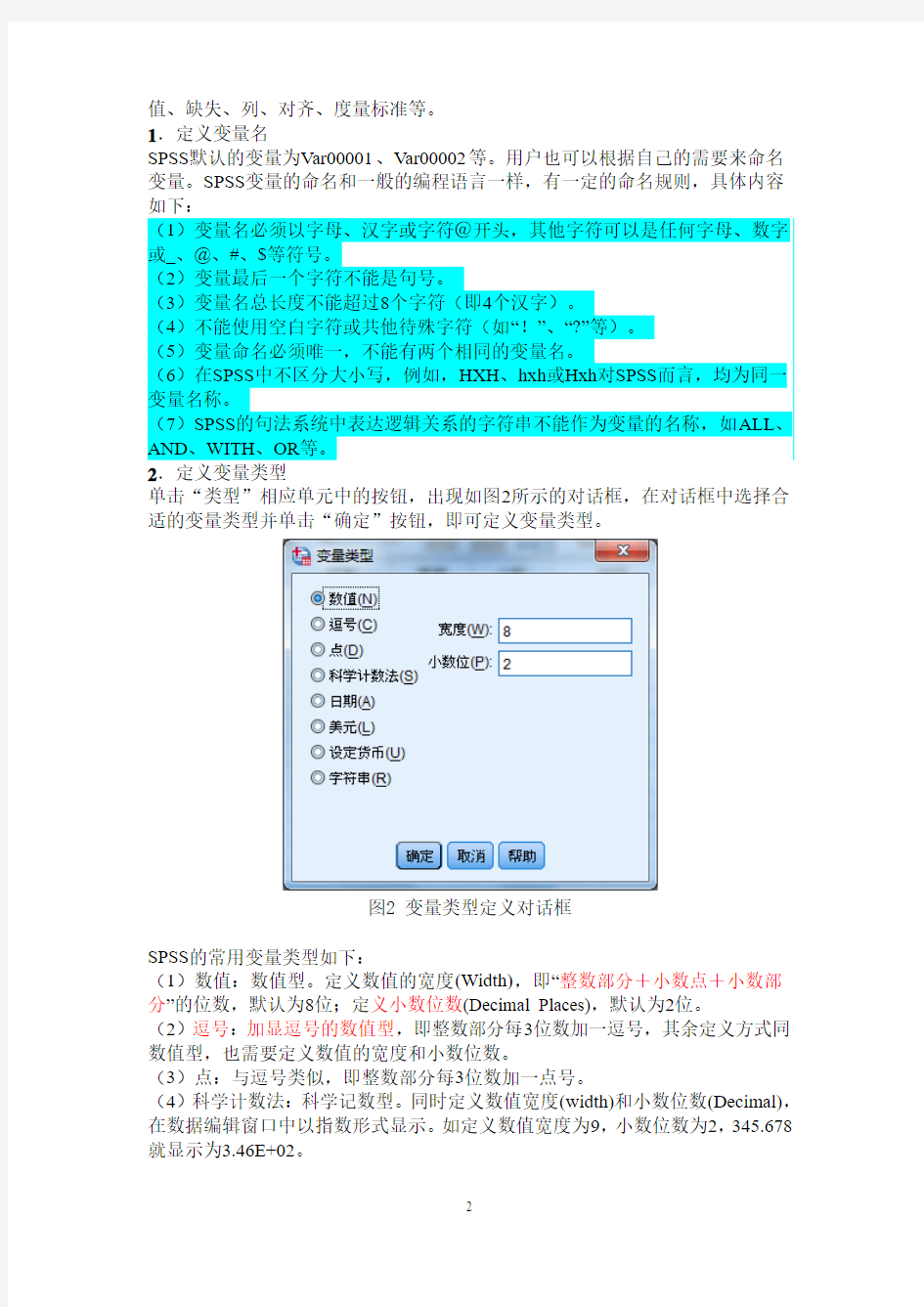
启动SPSS后,出现如图1所示数据编辑窗口。由于还没有输入数据,因此显示的是一个空文件。
输入数据前首先要定义变量。定义变量即要定义变量名、变量类型、变量长度(小数位数)、变量标签(或值标签)和变量的格式。
单击数据编辑窗口左下方的“Variable View”标签或双击列的题头(变量),进入如图1所示的变量定义窗口,在此窗口中即可定义变量。
图1 SPSS数据变量定义窗口
变量的定义信息
该窗口的每一行代表一个变量的定义信息,包括名称、类型、宽度、小数、标签、
值、缺失、列、对齐、度量标准等。
1.定义变量名
SPSS默认的变量为Var00001、Var00002等。用户也可以根据自己的需要来命名变量。SPSS变量的命名和一般的编程语言一样,有一定的命名规则,具体内容如下:
(1)变量名必须以字母、汉字或字符@开头,其他字符可以是任何字母、数字或_、@、#、$等符号。
(2)变量最后一个字符不能是句号。
(3)变量名总长度不能超过8个字符(即4个汉字)。
(4)不能使用空白字符或共他待殊字符(如“!”、“?”等)。
(5)变量命名必须唯一,不能有两个相同的变量名。
(6)在SPSS中不区分大小写,例如,HXH、hxh或Hxh对SPSS而言,均为同一变量名称。
(7)SPSS的句法系统中表达逻辑关系的字符串不能作为变量的名称,如ALL、AND、WITH、OR等。
2.定义变量类型
单击“类型”相应单元中的按钮,出现如图2所示的对话框,在对话框中选择合适的变量类型并单击“确定”按钮,即可定义变量类型。
图2 变量类型定义对话框
SPSS的常用变量类型如下:
(1)数值:数值型。定义数值的宽度(Width),即“整数部分+小数点+小数部分”的位数,默认为8位;定义小数位数(Decimal Places),默认为2位。
(2)逗号:加显逗号的数值型,即整数部分每3位数加一逗号,其余定义方式同数值型,也需要定义数值的宽度和小数位数。
(3)点:与逗号类似,即整数部分每3位数加一点号。
(4)科学计数法:科学记数型。同时定义数值宽度(width)和小数位数(Decimal),在数据编辑窗口中以指数形式显示。如定义数值宽度为9,小数位数为2,345.678就显示为3.46E+02。
(5)日期。
(6)美元。
(7)设定货币。
(8)字符串:字符型,用户可定义字符长度(Characters)以便输入字符。3.变量长度Width
设置变量的长度,当变量为日期型时无效。
4.变量小数点位数Decimal
设置变量的小数点位数,当变量为日期型时无效。
5.变量标签Label
变量标签是对变量名的进一步说明或注释,变量只能由不超过8个字符组成,而8个字符经常不足以说清楚变量的含义。而变量标签可长达120个字符、可显示大小写,需要时可借此对变量名的含义加以较为清晰地解释。
6.变量值标签Values Labels
变量值标签是对变量的每一个可能取值的进一步描述。当变量是定类变量或定序变量时,这是非常有用的。例如,在统计中经常用不同的数字代表被试的性别是男或女;被试的职业是教师、警察、……,还是公务员;被试的教育程度是高中以下、本科、硕士、博士等信息。为避免以后对数字所代表的类别发生遗忘,就可以使用变量值标签加以说明和记录。比如用1代表“male”(男)、2代表“female”(女),其设置方法为:单击values相应单元,出现如图3所示的对话框;在第一个Value文本框内输入l,在第二个Value文本框内输入“male”;单击Add按钮;再重复这一过程完成变量值2的标签,就完成了该变量所有可能取值的标签的添加。
图3 变量值标签定义对话框
7.变量的显示宽度Columns
输入变量的显示宽度,默认为8。
8.变量的测量尺度Measure
前一章已经介绍,变量按测量水平可被划分定类变量、定序变量、定距变量和定比变量几种。这里可根据测量量表的不同水平设置对应的变量测量尺度,设置方式为:定类变量选择Nominal,定序变量选择Ordinal,定距变量和定比变量均选择Scale。
二描述性特征量的计算
1、描述统计
利用SPSS软件,对一组数据进行描述性统计量或特征量的计算是一个很简单的过程,众多的特征量几乎可以通过一个对话框就可完成。具体操作是选择“分析”菜单中的“描述统计”,然后单击“描述”(如图4所示),打开如图4的描述性统计分析的主对话框。从对话框左边的变量列表中选择一个或多个要进行分析的变量。
接着,单击对话框上的“选项”按钮打开如图5所示的对话框。对话框上有一系列描述性统计特征量的选择框,其中均值(mean)、标准差(Std. deviation)的默认状态就是被勾选的,用户可以根据计算的需要勾选。一般,在描述性统计分析中,常常需要计算的特征量是平均数、总和(Sum)、标准差、方差(Variance)、全距(Range)、最小值(Minimum)和最大值(Maximum)。
图4 描述统计选项主对话框
图5 描述统计选项
2、频率
上述描述性统计量的计算大部分还可以通过“频率”命令来完成,其过程与“描述”过程相似。具体操作是选择“分析”菜单中的“描述统计”,然后单击“频率”打开频率的主对话框,如图6所示。从对话框左边的变量列表中选择一个或多个要进行分析的变量。如果要计算各个变量值在数据列中出现的次数,则需要勾选对话框左下角的“显示频率表”命令,系统会输出一个变量值的频数分布表。接着单击对话框上的“统计量”按钮,就可以打开如图7所示的对话框。
如果需要,利用这一对话框,也可以得到平均数、总和、标准差、方差、全距、最大值和最小值的计算结果,同时还可以获得众数(Mode)、中位数(Median)、四分位数(选中Quartiles)等的计算结果。
如果需要计算其他的百分位数,则可以在“百分位数”命令前的方框中打勾,激活其后面的方框,在其中填入所需要计算的百分位数对应的百分等级,然后单击“添加”将其加载到方框中,该方框可以加载许多个百分等级数。然后单击“继续”返回上一层次的对话框,再单击“确认”即可得到所需要的描述性特征量和要求其计算的百分位数。
图6 频率分析的主对话框
图7 频率分布分析的特征量选项对话框
三频数分布分析方法
单击图6所示对话框上的“图表”按钮打开频数分布制作设置对话框,利用这些对话框可以对频数分布图的类型和变量性质进行设置。
图形类型(Chart type)各选项:
(1)无:不显示图形,它是系统默认选项。
(2)条形图:适用于离散型随机变量。当选择“条形图”或“饼图”时,“图表值”栏才被激活。如果选择“条形图”,在“图表值”栏里选择频数”,图的纵坐标代表频数;选择“频率”,纵坐标将代表频率,即百分数。
(3)直方图。适用于连续型随机变量。选择此项时还可以确定是否选择“在直方图上显示正态曲线”,如果选择,则在显示的直方图中附带正态曲线,有助于判断数据是否呈正态分布。
(4)饼图。
各选项确定后,单击“继续”按钮返回主对话框,单击“确认”,生成的频数分布图就会在输出窗口中显示出来。
【例】利用SPSS系统制作频数分布表和频数分布图。表1所示是某初中二年级1班在2007~2008年度第一学期部分课程期末考试成绩,试针对这些数据制作学生在3门课程上的频数分布表和频数分布图。
表1 某初中二年级1班学生2007~2008学年第一学期部分课程考试成绩
学号性别语文数学英语
02001 女87 89 98
02002 男65 83 92
02003 男60 85 89
02004 女85 93 89
02005 女70 60 95
02006 女75 87 90
02007 女89 83 100
02008 男67 95 98
02009 女80 86 98
02010 男84 88 78
02011 男77 86 82
02012 女95 83 87
02013 男90 90 85
02014 女70 86 70
02015 男84 96 73
02016 男80 80 65
02017 男82 90 90
02018 女73 75 95
02019 女100 93 98
02020 男78 85 85
02021 女83 88 82
02022 女89 85 91
02023 女75 93 70
02024 女78 83 79
02025 男87 92 68
02026 男89 81 70
02027 男86 90 89
02028 男75 82 82
02029 男65 92 83
02030 女85 85 82
步骤1:建立数据文件
启动SPSS系统,进入默认的启动界面——数据编辑器。按照前面所介绍的方法建立SPSS数据文件。如果欲将表1中的信息全部记录在该数据文件中,则需要定义五个变量,即:学号(id)、性别(gender)、语文(chinese)、数学(math)和英语(english)。其中性别变量的变量值类型可以设置成字符型(string),以便直接输入学生性别的“男”或“女”,也可以是数字型(numeric),可分别用1和2代表不同的性别。其他变量值类型均由系统默认为数字型。变量定义好之后,可以使用文档的复制(copy)和粘贴(paste)功能直接将表1中的数据输入到SPSS 数据编辑窗中。一个变量占一列、一个学生占一行,所以该数据文件的数据区由30行5列组成。
步骤2:对话框操作
(1)选择“分析”下的“描述统计”菜单,单击“频率”命令,弹出“频率”对话框。在对话框左侧的变量列表中选择“chinese”、“math”、“English”变量,单击添加按钮将这三个变量名添加到“Variable”框中。
(2)选中对话框左下角的“显示频率表格”复选框,以便系统输出三门课程成绩的频数分布表。
(3)如果想同时获取三门课程成绩的平均数、标准差、最小值、最大值、中位数等统计量,可单击对话框上的“统计”按钮,选中相应的项目后点击“继续”返回主对话框。
(4)单击对话框上的“图表”按钮,打开频数分布图制作对话框。因为三门课程考试成绩均为连续变量,所以选择输出“直方图”,并选择“在直方图上显示正态曲线”以便在直方图上附带正态曲线。单击“继续”返回主对话框。
(5)单击“确认”按钮,完成对话框操作。系统就会输出所需要的上述结果。
步骤3:结果读取、选择与编辑
根据题目要求和上述对话框操作,输出结果主要包括三个部分:频数分布表、数据样本的主要统计量和频数分布直方图。
四、根据已存在的变量建立新变量以及对记录进行排序
1.选择[转换]=>[计算变量],打开如图8所示的[计算变量]对话框。在对话框中的[目标变量]下框中输入符合变量命名规则的变量名,目标变量可以是现存变量或新变量。对话框中[数值表达式]下的文本框用于输入计算目标变量值的表达式。表达式能够使用左下框列出的现存变量名、计算器板列出的算术运算符和常数和[函数]列表框显示的各种函数等。可以在文本框中直接输入和编辑表达式,也可以使用变量列表、计算器板和函数列表将元素粘贴到文本框中。如图8所示,计算每位同学的总分。
图8 计算变量对话框
2.对记录进行排序
在数据文件中,可根据一个或多个排序变量的值重排观测的顺序。选择[数据]=>[排
序个案],打开[排序个案]对话框,如图9所示,对总分列进行排序。
图9 观测值排序对话框
五对观测值进行摘要分析
例:对30位学生的总分进行观测值摘要分析。
Step1:按分析-报告-个案汇总的顺序单击,打开摘要个案主对话框
Step2: 将变量“总分”选入变量框中作为摘要分析的变量,将“性别”选入框中作为分组变量。如图10所示。
Step3:清除显示个案复选框。
Step4: 单击统计量按钮,选中需要输出的统计量。
图10 摘要个案对话框
例:某市2008年110名7岁男童身高数据如下:
114.4 119.2 124.7 125.0 115.0 112.8 120.2 110.2 120.9 120.1 125.5 120.3 122.3 118.2 116.7 121.7 116.8 121.6 115.2 122.0 121.7 118.8 121.8 124.5 121.7 122.7 116.3 124.0 119.0 124.5 121.8 124.9 130.0 123.5 128.1 119.7 126.1 131.3 123.8 114.7 122.2 122.8 128.6 122.0 132.5 122.0 123.5 116.3 126.1 119.2 126.4 118.4 121.0 119.1 116.9 131.1 120.4 115.2 118.0 122.4 114.3 116.9 126.4 114.2 127.2 118.3 127.8 123.0 117.4 123.0 119.9 122.1 120.4 124.8 122.1 114.4 120.5 115.0 122.8 116.8 125.8 120.1 124.8 122.7 119.4 128.2 124.1 127.2 120.0 122.7 118.3 127.1 122.5 116.3 125.1 124.4 112.3 121.3 127.0 113.5 118.8 127.6 125.2 121.5 122.5 129.1 122.6 134.5 118.3 132.8
将上述数据录入SPSS,并进行描述统计。
实验报告内容:
完成教材P71案例2.2和案例2.3
管理统计学试题及答案
、单项选择题(每小题 2分,共40分) 1要了解某市工业企业生产设备情况,则统计总体是 A.该市工业企业的全部生产设备 B.该市每一个工业企业 C.该市工业企业的某一台设备 D.该市全部工业企业 2 ?若甲单位的平均数比乙单位的平均数小,但甲单位的标准差比乙单位的标准差大, 则 (B ) A.甲单位的平均数代表性比较大 B. 甲单位的平均数代表性比较小 C.两单位的平均数一样大 D. 无法判断 3.—个统计总体 (C ) A.只能有一个标志 B.只能有一个指标 C.可以有多个标志 D.可以有多个指标 4.品质标志的表现形式是 (D ) A.绝对数 B.相对数 C.平均数 D.文字 5.统计工作的各项任务归纳起来就是两条 ( A ) A.统计调查和统计分析 B.统计设计和统计研究 C.统计预测和统计 D.统计服务和 统计监督 6.对上海港等十多个沿海大港口进行调查, 以了解全国的港口吞吐量情况,则这种调查方 式是(B ) A.普查 B. 重点调查 C.典型调查 D.抽样调查 7.某连续变量分为五组:第一组为 40? 50;第二组为 50?60;第三组为 60?70;第四组 为70?80;第五组为80以上。依习惯上规定 (C ) A. 50在第一组,70在第四组 B. 60在第二组,80在第五组 C. 70在第四组, 80在第五组 D. 80在第四组,50在第二组 &某城市为了解决轻工业生产情况,要进行一次典型调查,在选送调查单位时,应选择生 产情况()的企业。 (D ) 该组的分组标志是 A.性别 C.文化程度 10?变量数列中各组频率的总和应该 A.小于1 C.大于1 A.较好 B.中等 C.较差 D.好、中、差 9 ?某厂的职工工人人数构成如下表所示 (A )
管理统计学试验指导书和答案
.= 《管理统计学》实验指导书及 实验报告 王金玉编著 沈阳航空工业学院经济管理学院 班级 学号 姓名 成绩
实验一用Excel对数据的图表描述 实验目的:掌握用EXCEL进行数据的搜集整理和显示 实验步骤: 用Excel进行数据的统计分组描述,可以获得相应数据分组的频数、频率以及向上向下累计频数、频率的情况,并能做出相应的直方图、折线图等描述数据分布特征的统计图形。我们举例介绍一下数据的Excel图表描述的操作方法。 【例1-1】为了确定灯泡的使用寿命(小时),在一批灯泡中随机抽取100只进行测试,所得结果如下,数据进行适当的 分组,编制频数分布表;(2)制作合适的统计图反映分布特征。 700 716 728 719 685 709 691 684 705 718 706 715 712 722 691 708 690 692 707 701 708 729 694 681 695 685 706 661 735 665 668 710 693 697 674 658 698 666 696 698 706 692 691 747 699 682 698 700 710 722 694 690 736 689 696 651 673 749 708 727 688 689 683 685 702 741 698 713 676 702 701 671 718 707 683 717 733 712 683 692 693 697 664 681 721 720 677 679 695 691 713 699 725 726 704 729 703 696 717 688 一、编制分布数列 在Excel中有两类方法可以实现分布数列的编制:一是使用相关的函数,如Frequency函数;二是使用分析工具中的【直方图】工具。本例中我们采用函数方法。具体步骤如下: 第一步:将表1-1中的数据输入或导入到Excel电子表格中,并输入相应的分组数据。如图1-1所示。 图1-1 图1-1中,C、J列均为原始输入数据,寿命数据在A2:A101(图中未完全显示出来),J列的接受区域的各个数据(各组的上限值)是使用Frequency函数或【直方图】分析工具编制分布数列所必需的数据。 第二步:选定D5:D14,输入公式“=Frequency(A2:A101,J5:J14)”,然后按Ctrl+Shift+Enter组合键,即可计算出各组的频数。该函数的第一个参数指定用于编制数列的原始数据,第二个参数指定每一组的上限。在D15中输入公式“=sum (D5:D14)”计算出频数的合计。 第三步:计算频率。在E5中输入公式“=D5/D$15*100”,然后将该公式复制到E6:E14即可。D15存放的是频数的合计数。 第四步:计算向上累计频数。在F5单元格中输入“=D5”,在F6单元格中输入公式“=D6+F5”,再将公式复制到F7:F14。
管理统计学--实验二-spss
《管理统计学》 实验二假设检验与方差分析 实验项目名称 案例4.1 谷类食品生产商的投资问题 案例4.2 数控机床的选购问题 案例5.1 运动员团体成绩预测问题 案例5.2 手机电池通话时间测试 案例5.3 月份与CPI的关系 目录
一、实验目的 (3) 二、实验原理 (3) 三、设备 (3) 四、实验内容和实验步骤 (3) 1、案例4.1 谷类食品生产商的投资问题 (3) 2、案例4.2 数控机床的选购问题 (6) 3、案例5.1 运动员团体成绩预测问题 (11) 4、案例5.2 手机电池通话时间测试 (17) 5、案例5.3 月份与CPI的关系整理 (22) 五、实验总结 (29)
一、实验目的 1. 掌握SPSS数据文件的建立 2. 掌握SPSS统计分析中的均值比较和T检验方法 3. 掌握单因素方差分析和多因素方差分析的原理与步骤 4. 学习并将管理统计学课程所学的知识用于解决实际问题 二、实验原理 SPSS软件有数据整理、分析数据的功能,其中包括假设检验及方差分析实验可以用到的工具,如均值比较、参数分析、建立线性模型等。 三、设备 SPSS软件(英文名称Statistical Package for the Social Science) 四、实验内容和实验步骤 1、案例4.1 谷类食品生产商的投资问题 1)启动SPSS,在变量视图里面输入案例变量“食用者类型(字符串)”和“热量摄取量(数值,小数设为0位)” 2)在数据输入窗口输入数据
3)分别对两种食用者类型的热量摄取量均值进行检验(α=0.05),按照”分析-比较均值-独立样本检验”,加入检验变量“热量摄取量”、加入分组变量“食用者类型”,设置组1、2分别为A、B组,点击选项,设置置信区间百分比为95%
应用统计学论文
应用统计学课程论文 经过这学期短暂的学习应用统计学,我对这门学科也有了一定认识。应用统计学是一门运用统计学的原理和方法,研究各个领域有关数据收集、整理、分析的科学是经济、管理类专业的一门重要专业基础课程。掌握统计学的基本理论和方法,具有较好的科学素养,能熟练地运用计算机分析数据,能从事统计调查、统计信息管理、数量分析、市场研究、质量控制等工作。在当前的社会发展中,是市场经济和信息经济的时代,社会各个方面的发展都需要对信息进行收集、分析和整理,所以学好应用统计对不久即将走向社会的我们是只有好处,没有坏处的。 绪论 一、应用统计学的发展: 从统计学的发展过程来看,可以把统计学大致分为古典统计学、近代统计学和现代统计学三个时期。 第一、古典统计学时期: 古典统计学时期是指17世纪初至18世纪末,这是统计学的创立时期,亦称古典统计学时期。在这时期出现了政治算术学派和德国的国势学派两个统计学派. 1、国势学派 国势学派又称记述学派,产生于17世纪的德国。由于该学派主要以文字记述国家的显著事项,故称记述学派。 2、政治算术学派 政治算术学派产生于19世纪中叶的英国,其创始人是威廉和约翰.“算术”是指统计方法。主要利用实际资料,运用数字、重量和尺度等统计方法对实际情况作了系统的数量对比分析,从而为统计学的形成和发展奠定了方法论基础。 第二、近代统计学时期: 近代统计学是指18世纪末到19世纪末这一百年的统计学,它是古典统计学的继续和发展,是古典统计学向现代统计学过渡的统计学。近代统计学的发端,不能不提到著名的统计学家阿道夫·凯特勒的卓越员献。他既继承了国势学和政治算术的传统,把统计学从作为管理国家行政的“政治医学”,扩展到作为研究社会内在矛盾及其规律性数量表现的科学认识方法,又积极地把古典概率引人统计学,以研究社会经济现象偶然变化中的规律性表现。 1、数理统计学派 指概率论引进统计学形成数理统计学,以概率作为理论基础,抽象掉统 计学的社会经济现象内涵,变成了抽象的数学分析和推断技术. 2、社会统计学派 指研究社会现象变动的原因和规律性的实质性科学。社会统计学在这里也称为社会经济统计学,包括政治统计.经济统计.人口统计.犯罪统计等多方面内容. 第三、现代统计学时期:
管理统计学试卷含答案
统计学试卷C(含答案及评分标准) 一、单项选择题 每小题1分共10分。(请将唯一正确答案序号写在括号内) 1.社会经济统计学的研究对象是( A ) A .社会经济现象的数量方面; B .统计工作; C .社会经济的内在规律; D .统计方法; 2.要考察全国居民的人均住房面积,其统计总体是( A ) A .全国所有居民户; B .全国的住宅 ; B .各省市自治区; D .某一居民户; 3.某市国内生产总值的平均增长速度:1999-2001年为13%,2002-2003年为9%,则这5年的平均增长速度为( D )。 A.52309.013.0? B. 109.013.0523-? C. 52309.113.1? D. 109.113.1523-? 4.总体中的组间方差表示( B ) A.组内各单位标志值的变异 B.组与组之间平均值的变异 C.总体各单位标志值的变异 D.组内方差的平均值 5.在其他条件相同的前提下:重复抽样误差( A ) A. 大于不重复抽样误差; B.小于不重复抽样误差 C. 等于不重复抽样误差; D.何者更大无法判定; 6.所谓显着水平是指 ( A )
A.原假设为真时将其接受的概率; B. 原假设不真时将其舍弃的概率; C. 原假设为真时将其舍弃的概率; D. 原假设不真时将其接受的概率; 7. 编制质量指标综合指数所采用的同度量因素是( B)。 A.质量指标; B.数量指标; C.综合指标; D.相对指标; 8.以下最适合用来反映多元线形回归模型拟合程度的指标是(C) A.相关系数; B.决定系数; C.修正自由度的决定系数; D.复相关系数; 9.以下方法属于综合评价中的客观赋权法( D )。 A.最大组中值法; B.统计平均法; C.层次分析法; D.变异系数法; 10.以下方法适合用来计算间隔相等的时点数列的序时平均数( D ) A. 移动平均; B.算术平均; C.几何平均; D.首尾折半法; 二、多项选择题每小题2分共10分(正确答案包含1至5项,请将正确答案的序号写在括号内,错选、漏选、多选均不得分) ADE)。 A.国内生产总值; B.商品库存额; C.人口数; D.出生人数; E.投资额;
管理统计学报告
《管理统计学》 综合性实验报告 题目:大学生消费情况综合分析 班级:____________姓名:____________学号:____________ 综合实验报告评分标准 评分项目比例得分 所有同学每月生活费的平均值,最大值和最小 10% 值 10% 男生、女生每月生活费的平均值,最大值和最 小值 所有同学每月生活费的茎叶图10% 频数分布表10% 方差分析部分40% 聚类分析部分10% 语言表达与排版10% 实验报告总评(用A,B,C,D和E表示) 1.通过综合性实验检验对SPSS的掌握情况,并作为期末的考核标准之一。 二、实验内容: 1.用SPSS分别计算农村学生的比例,女生比例 2.用SPSS计算出所有同学每月生活费的平均值,最大值和最小值。 3.用SPSS分别计算出男生、女生每月生活费的平均值,最大值和最小值。 4.作出所有同学每月生活费的茎叶图。 5.整理所有同学每月生活费数据,制作一个频数分布表(分成5组)。 6.从每个班中随机抽10人,这10人每月生活费可以看作本班的一个随机样本,试分析信 管1班,2班,3班,4班,工业工程1班,2班之间的每月生活费的方差是否齐性,判 断每个班同学的月均生活费是否有显著差异;分析户口所在地、性别对每月的生活费的 影响是否显著。(显著性水平为0.05)
7.以每月平均生活费、伙食费所占比例、生活费来源中家庭给予所占比例为观测变量,对 本专业学生进行聚类分析。 三、实验详细过程与结果 问题1解:采用频率分布表解答。将户口与性别放入变量中,得到户口与性别的频率统计 答:由上面得到的第二个表格得出农村学生的比例为48.8,女生的比例为37.7。 问题2解:采用频率分布表解答。在统计量选项中勾中均值、最大值和最小值。
统计学方面课程论文
统计学方面课程论文 统计学是一门具有边缘学科和交叉学科性质的科学,现代统计学始终坚持将概率论等一系列数学理论作为指导,不断扩展和加深对统计学的研究。下文是为大家搜集整理的关于统计学方面课程论文的内容,欢迎大家阅读参考! 统计学方面课程论文篇1浅谈改革职高统计学教学的策略 统计学作为职业高中会计电算化专业的核心课程,是学生认识问题和解决问题必不可少的工具。然而,学生普遍的感受是统计学概念抽象、公式多而复杂、不好掌握,学生的学习主动性不足。 其次,学生对统计学这门核心课程,缺乏认识,未能深刻了解统计学的作用,往往以满足于通过考试或者取得相应的学分为目的。 第三,职业高中学生本身素质就差,相当一部分学生看到公式就头疼,对统计学有着本能式的排斥,缺乏学好统计学的自信心。针对以上现状,作为一名统计学教师,就必须在教学改革上有所突破,以教学改革带动、促进学生对统计学的学习。 一、改革考试模式,引导学生学习 考试虽不是教学的目的,但考试的形式和内容却是学生学习的指挥棒,也是检验学生学习情况,评估教学质量的重要手段。传统的统计学考试,通常采用闭卷笔试的方式。常用的题型包括单项选择、多项选择、判断、简答和计算,考试的内容以客观题为主。这种考试方
式对于保证教学质量,维持正常的教学秩序起到了一定的作用,但也存在着缺陷,这种客观题的最大特点是,标准答案具有唯一性,学生答题不必具备较强的分析能力,也无须发挥自己的想象力,只需死记硬背书本中的概念、公式和习题就可以了,导致了学生在学习《统计学》课程的过程中,为应付考试搞题海战术,把精力过多的花在了概念、公式的死记硬背上。这与统计学的教学目的,即培养学生掌握统计基本理论并能运用统计方法分析解决实际问题的能力相差甚远。 改革考试模式,可以大胆地加入调查报告、专题论文、案例分析等考试形式。学生成绩的测评应根据学生参与教学活动的程度、学习过程中提交的报告或论文、上机操作和卷面考试成绩等综合评定。采用这样的考试模式,必将极大地提高学生学习的主动性和自觉性,充分调动学生的求知欲和创造性,变被动学习为主动学习,从而提高学习效率。在考试内容上,应侧重检查学生运用知识的能力,而知识标准化的客观题不宜过多的作为统计学考试的内容,最好使用结合实际经济生活而设计的主观应用题,注重学生各种能力的考查。 二、改革教学的形式和手段,调动学生的学习积极性 首先要变灌输式教学为启发式教学和双向互动式教学。针对学生的实际情况,应尽可能减少公式的推导,手工的运算过程。要启发学生分析统计数字、统计技术背后的含意。课堂上要加强与学生的沟通,开拓学生的发散思维,变灌输式教育为启发式教育,启发式教学有利于激活学生的潜能,引领学生对所学问题进行思考和探究。教师在运用启发式教学时,对所提出的问题的设置要注意讲求质量和层次,要
管理统计学试题及答案
一、单项选择题(每小题2分,共40分) 1.要了解某市工业企业生产设备情况,则统计总体就是(A) A、该市工业企业的全部生产设备 B、该市每一个工业企业 C、该市工业企业的某一台设备 D、该市全部工业企业 2.若甲单位的平均数比乙单位的平均数小,但甲单位的标准差比乙单位的标准差大,则(B) A、甲单位的平均数代表性比较大 B、甲单位的平均数代表性比较小 C、两单位的平均数一样大 D、无法判断 3.一个统计总体(C) A、只能有一个标志 B、只能有一个指标 C、可以有多个标志 D、可以有多个指标 4.品质标志的表现形式就是(D) A、绝对数 B、相对数 C、平均数 D、文字 5.统计工作的各项任务归纳起来就就是两条(A) A、统计调查与统计分析 B、统计设计与统计研究 C、统计预测与统计 D、统计服务与统计监督 6.对上海港等十多个沿海大港口进行调查,以了解全国的港口吞吐量情况,则这种调查方式就是(B) A、普查 B、重点调查 C、典型调查 D、抽样调查 7.某连续变量分为五组:第一组为40~50;第二组为50~60;第三组为60~70;第四组为70~80;第五组为80以上。依习惯上规定(C) A、50在第一组,70在第四组 B、60在第二组,80在第五组 C、70在第四组,80在第五组 D、80在第四组,50在第二组 8.某城市为了解决轻工业生产情况,要进行一次典型调查,在选送调查单位时,应选择生产情况( )的企业。(D) A、较好 B、中等 C、较差 D、好、中、差 该组的分组标志就是(A) A、性别 B、男、女 C、文化程度 D、性别与文化程度 10.变量数列中各组频率的总与应该(B) A、小于1 B、等于1 C、大于1 D、不等于1 11.已知变量X与Y之间的关系如下图所示,则其相关系数可能为(C)
统计学实验报告
河南工业大学管理学院 课程设计(实验)报告书题目统计学实验 专业电子商务 班级1204班 学生姓名伍琴 学号201217050430 指导教师任明利 时间:2012 年 4 月 6 日
实验一:数据整理 一、项目名称:数据整理 二、实验目的 (1)掌握Excel中基本的数据处理方法; (2)学会使用Excel进行统计分组,能以此方式独立完成相关作业。 三、实验要求 1、已学习教材相关内容,理解数据整理中的统计计算问题;已阅读本次实验导引,了解Excel中相关的计算工具。 2、准备好一个统计分组问题及相应数据(可用本实验导引所提供问题与数据)。 3、以Excel文件形式提交实验报告(包括实验过程记录、疑难问题发现与解决记录)。 四、实验内容和操作步骤 (一)问题与数据 某百货公司连续40天的商品销售额如下(单位:万元): 41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42 36 37 37 49 39 42 32 36 35 根据上面的数据进行适当分组,编制频数分布表,并绘制直方图. (二)操作步骤: 1、在单元区域A1:E9中输入原始数据,如图:
2、并计算原始数据的最大值(在单元格B10中)与最小值(在单元格D10中)。 3、根据经验公式计算经验组距和经验组数。 4、根据步骤3的计算结果,计算并确定各组上限、下限(在单元区域F1:G6),如图所示: 5、绘制频数分布表框架,如图所示: 6、计算各组频数: (1)选定B19:B23作为存放计算结果的区域。 (2)从“公式”菜单中选择“插入函数”项。 (3)在弹出的“插入函数”对话框中选择“统计”函数FREQUENCY.
管理统计学选择
1、指出下列品质标志(C ) A、产品产量 B、工人工资 C、教师职称 D、工人工龄 2、指出下列连续变量(D) A、设备数B、学生数C、空调产量D、粮食产量 3、某三个学生的统计学考试成绩分别为:75分、80分、90分,则这三个数字是(D ) A、指标 B、标志 C、变量 D、变量值 4、指出下列数量指标(B) A、劳动生产率 B、国内生产总值 C、人均钢产量 D、人口密度 5、数量指标表现形式是(A ) A、绝对数 B、相对数 C、平均数 6、变量是(B ) A、可变的数量指标 B、可变的数量标志 C、可变的品质标志 1、人口普查的调查单位是(C) A、每一户 B、所有的户 C、每一个人 D、所有的人 2、对一批商品进行质量检验,最适宜采用的调查方法是(B) A、全面调查 B、抽样调查 C、典型调查 D、重点调查 3、下列调查中,调查单位与填报单位一致的是(D) A、企业设备调查 B、人口普查 C、农村耕畜调查 D、工业企业现状调查 4、调查大庆、胜利等几个主要油田来了解我国石油生产的基本情况,这种调查方式为(D) A、普查 B、抽样调查 C、典型调查 D、重点调查 5、对某市全部商业企业职工的生活状况进行调查,调查对象是(B) A、该市全部商业企业 B、该市全部商业企业的职工 C、该市每一个商业企业 D、该市商业企业的每一个职工 6、某市规定2010年工业经济活动成果年报呈报时间为2011年1月31日,则调查期限为(A) A、一个月 B、一天 C、一年 D、一年零一个月 1、统计分组的关键在于(A) A、分组标志的选择 B、分组形式的选择 C、按品质标志分组 D、按数量标志分组 2、在全距一定的条件下,组距大小与组数多少(B) A、成正比例关系 B、成反比例关系 C、不成比例关系 3、某企业生产计划完成百分比采用如下分组,正确的是(D) A、80—89% B、85%以下 C、90%以下 90—99% 85—95% 90—100% 100—109% 95—105% 100—110% 110%以上105—115% 110%以上 4、在进行组距式分组时,凡遇到某单位的标志值刚好等于相邻两组上下限的数值时,一般是( B ) A、将此值归入上限所在组 B、将此值归入下限所在组 C、将此值归入上限所在组或下限所在组均可 1、某企业劳动生产率计划要求提高5%,实际提高了10%,则劳动生产率计划完成程度为(A) A、104.76% B、95.45% C、200% D、50% 2、直接反映总体规模大小的指标是(C) A、平均指标 B、相对指标 C、总量指标 D、变异指标
管理统计学
管理学院实验报告 学号201305169063 姓名朱可欣 专业班级市场营销1302班 指导老师李洪斌 实验日期2015.11.05 课程名称管理统计学 实验名称管理统计学上机实验 实验成绩 实验报告具体内容一般应包括:一、实验目的和要求; 二、主要仪器设备(软件); 三、实验内容及实验数据记录; 四、实验体会
实验项目一:假设检验的Excel实现 实验时间:_____2015-11-5____________ 1. 实验目的和要求 巩固熟悉假设检验的相关原理及方法,掌握Excel中进行假设检验的相关计算过程。 2. 实验原理 假设检验的相关原理及方法。 3. 主要仪器设备(软件) 1)硬件配置: 使用综合实验室中现有配置的计算机,无特殊要求。 2)软件环境: Windows XP或以上的操作系统,Excel软件。 4. 实验内容及步骤 假设检验中关于T检验、F检验的相关内容选作2-3个计算实例。 5.实验数据记录 t-检验:双样本等方差假设 某家禽研究所各选8只粤黄鸡进行两种饲料饲养对比试验,试验时间为60天,增重结果如下,假设鸡的增重服从正态分布且两种饲料喂养的鸡增重方差相等,请问两种饲料对粤黄鸡的增重效果有无显著差异?(α=0.05) 饲料A 720 710 735 680 690 705 700 705 饲料B 680 695 700 715 708 685 698 688 解:饲料A和饲料B饲养的粤黄鸡平均增重分别用u 1和u 2 表示,检验无特定方 向,所以为双侧检验。这是两个正态总体,小样本抽样且总体方差未知的情形,采用合并方差的t检验。故: 本检验的假设为: H 0:u 1 -u 2 ≠0, H 1 :u 1 -u 2 =0
论文撰写中常见的统计学问题及其处理
论文撰写中常见的统计学问题及其处理 绝大多数的论文撰写,均需通过一定数量临床病例(或资料)的观察,研究事物间的相互关系,以探讨客观存在的新规律。如确定新诊断、新治疗等措施是否优于原沿用的方法,就需进行两种方法比较,这就涉及统计处理;统计设计又是整个课题研究设计中一个重要的组成部分。显然,经正确统计处理的结果可信度高,论文的质量也高。 据不完全统计,在难以发表的、已凝聚着作者心血并花费较长时间与较大财力撰写的研究论文中,约半数以上是由于统计错误致其结果与原文主要结论相违背。如一文采用某新药引产,96例足月孕妇的产后出血与新生儿低Apgar评分率均为2.1%(各2例),明显低于应用原药引产的19例,其产后出血与新生儿低Apgar评分发生率均为15.8%(各3例,χ2=7.164,P0.06),这样上述的主要结论就欠可靠而难以发表,否则论文可起误导作用。类似问题文稿中还常有出现。现就文稿中常见的统计问题及其相应的处理方法简述如下。 一、常用的统计术语 统计学中常用的概念有总体与样本、随机化与概率、计量与计数、等级资料及正态与偏态分布资料、标准差与标准误等。如某研究采用经会阴途径测定宫颈长度,以探讨不同宫颈长度与临产时间的关系。结果显示35例宫颈长度为25~34mm者与32例宫颈长为15~24mm者临产时间的均值±标准差(x±s)各为57.6±58.1与47.3±49.1小时。该计量资料,经t检验显示t=0.780,P>0.06,并未提示不同宫颈长度的临产时间差异有显著意义;从标准差大于均值,显示各变量值离散程度大,呈偏态分布,故不能采用x±s这一算术均数法计算均数。经偏态转换成近似正态分布资料后结果是:35例与32例的临产时间各为34.5±4.1与26.7±4.1小时,(t=7.778,P<0.005),两组差异有极显著意义。可认为随着宫颈长度的缩短、临产时间也缩短。此外,当两组资料单位不同时,其S单位也不同;即使两组单位相同的变量值,若其均数差异较大,也都应以变异系数替代s来比较两组值的离散度的大小。 二、正常值范围及异常阈值的确定 如何选择研究对象,至少需多少例,正确统计处理和参考一定数量的病例数据,是确定正常值范围及异常阈值的四个重要因素。 1.研究对象:应为"完全健康者",可包括患有不影响待测指标疾病的患者。如"正常妊娠"的条件:孕前月经周期规则、单胎、妊娠过程顺利、无产科并发症及其它有关合并症,
管理统计学1(选择)
管理统计学(选择+判断) A 1.按调查的范围不同。统计调查可以分为:B 全面调查和非全面调查 2.按数量标志将总体单位分组形成的分布数列是:A 变量数列;B 品质数列;C 变量分布数列;D 品质分布 数列;E 次数分布数列正确答案:ACE B 3.比较相对指标是用于:A 不同国家、地区和单位之间的比较;B 不同时间状态下的比较;C 先进地区水平 和后进地区水平的比较;D 不同空间条件下的比较正确答案:ACD 4.编制数量指标综合指数所采用的同度量因素是:A 质量指标 5.变量的具体表现称为变量值,只能用数值来表示。正确答案: 错 6.变量之间的关系按相关程度可分为:A 正相关;B 不相关; C 完全相关;D 不完全相关正确答案:BCD 7.标志变异指标的主要作用是:A 衡量平均数代表性的大小;B 反映统计数据的节奏性和均衡性;C 反映总 体单位的均匀性和稳定性;D 分析总体的变动趋势正确答案:ABC 8.不同总体之间的标准差不能直接对比是因为:A 平均数不一致; B 计量单位不一致 C 标准差不一致; D 总体单位数不一致正确答案:AB C 9.长期趋势是影响时间序列的根本性,决定性的因素。正确答案: 对 10.常见的离散型分布有:A 二点分布;B 二项分布; C 均匀分布; D 泊松分布正确答案:ABD 11.抽样调查和重点调查的主要区别有:A 抽选调查单位的多少不同;B 抽选调查单位的方式方法的不同;C 取 得资料的方法不同;D 原始资料的来源不同;E 在对调查资料使用时,所发挥的作用不同正确答案:BDE 12.抽样调查中的抽样误差是:A 随机误差;B 系统性误差;C 代表性误差;D 登记性误差正确答案:A 13.抽样平均误差反映了样本指标与总体指标之间的: D 平均误差程度 14.抽样实际误差是指某一次具体抽样中,样本指标值与总体真实值之间的偏差。答案: 对 15.抽样误差是由于破坏了随机原则而产生的系统性误差,也称偏差。正确答案: 错 16.抽样允许误差越大,抽样估计的精确度就:A 越高;B 越低;C 无法确定;D 两者之间没有关系正确答 案:B D 17.单位产品成本报告期比基期下降5%,产量增加6%,则生产费用:A 增加 18.单位成本与产品产量的相关关系,以及单位成本与单位产品原材料消耗量的相关关系,表述正确的是:B 前 者是负相关,后者是正相关 19.当我们冒5%的风险拒绝了本来为真的原假设时,则称5%为显著性水平。正确答案: 对 20.当需要对不同总体或样本数据的离散程度进行比较时,则应使用:D 离散系数 21.当总体单位不多,差异较小时,适宜采用简单随机抽样方式。正确答案: 对 22.点估计法一般不考虑抽样误差和可靠程度,计算简便、直观,是最常用的估计方法。正确答案: 错 23.调查时间是进行调查所需要的时间。正确答案: 错 24.定基发展速度与环比发展速度之间的关系表现为定基发展速度等于相应各环比发展速度:A 的连乘积 25.定序尺度可以:A 对事物分类;B 对事物排序;C 计算事物之间差距大小;D 计算事物数值之间的比值 正确答案:AB 26.对50名职工的工资收入情况进行调查,则总体单位是:C 每一名职工 27.对连续型变量值分为五组:第一组为40一50,第二组为50-60,第三组为60-70,第四组为70-80,第五
管理统计学综合训练二分析报告
管理统计学综合训练二统计分析报告(判断男生成绩与女生成绩是否有显著性差异) 专业班级:经济14-2班 指导教师: 王宏新 小组成员:宋佳玉林曼雪 潘香宇刘月 刘晓东刘子楗刘志强 时间:2016 年5月 分数:
一、训练要求与考查内容 1、训练要求:搜集某一个学期某个班级全部学生所学的全部学科的成绩,利用SPSS 软件进行处理,给出一个完整的统计分析报告。 2、考察内容:区间估计和假设检验知识单元 二、涉及的知识点回顾 (一)区间估计 1、两个总体均值差的区间估计 若随机变量)(~),(~2 2222 111σμσμ,,X X , (1)方差已知 经标准化后两个总体平均数之差服从标准正态分布,即 则两个总体平均数之差(μ1-μ2)在(1-α)置信水平下的双侧置信区间为 。 (2)方差未知(教材P 117,,不进行详细说明) ○1σ12=σ22,则两个总体平均数之差经标准化后服从自由度为(n 1+n 2-2)的t 分布; ○ 2σ12 ≠σ22,则两个总体平均数之差经标准化后近似服从自由度为v 的t 分布。 最终得到两个总体均值差的置信区间若是包含“0”,则认为两个总体之间不存在显著性差异,反之,若不包含“0”,则认为两个总体之间存在显著性差异。 2、两个总体方差比的区间估计 在总体均值μ1与μ2未知的情况下,)(~),(~2 2222 111σμσμ,,X X , 两个总体方差比服从 , 所以得到两个总体方差之比在1-α置信水平下的双侧置信区间为 ) 1,0(~) ()(2 2 2 1 2 1 2121N n n x x z σσμμ+ ---= 22 21212 21212221212 21)()()(n n z x x n n z x x σσμμσσαα ++-≤-≤+--)1,1(~//212 2 212 2 21--=n n F S S F σσ
[管理学]统计学实验报告
实验报告 ——(关于小麦品种对小麦产量显著性影响的分析研究) 班级:09工商2班组长:tjs学号:09513285成绩: 小组成员姓名: tjs 09513285 wdh 09513286 ww 09513287 wj 09513288 一、实验目的与意义 本文运用单因素方差分析的统计方法对小麦品种对小麦产量是否具有显著性影响进行实证研究,经过数据分析得出了不同小麦品种对小麦产量具有显著性影响的结论。 二、实验内容 1、为了研究不同的小麦品种对小麦的产量是否有显著性影响,我们选取三个小麦品种:品种1、品种 2、品种3并且对每个品种选取四个地块的产量作为观测值。设三个品种总体均值分别为μ1 μ2 μ3 提出假设:H0 :μ1 =μ2 =μ3 总体均值完全相等,自变量对因变量没有显著性影响。 H1 :μ1 μ2 μ3总体均值不完全相等,自变量对因变量有显著性影响 设置显著性水平为0.05 其数据结构如下: 2、运用spss软件进行数据处理,以下是具体操作过程 (1)选择[Analyze]=>[Compare Means]=>[One-Way ANOVA...],打开[One-Way ANOVA]主对 话框(如图所示)。
(2)从主对话框左侧的变量列表中选定小麦产量[var01],单击按钮使之进入[DependentList]框,再选定变量小麦品种[var02],单击按钮使之进入[Factor]框。单击[OK]按钮完成。 (3)生成统计结果如下:
3、结果分析 根据上面的计算结果,SS为离差平方和; df为自由度;MS为均方;F为检验的统计量;Sig=0.009 为P 值。我们直接运用计算出的P值与显著性水平α的进行比较,若P>α则不能拒绝原假设H0;若P<α则拒绝原 假设H0 ;在本题中,P=0.009<α=0.05 所以拒绝原假设H0 即小麦品种对产量有显著性影响。
统计学期末论文
国贸1242班娄丁山1220702204 国贸1241班王龙雨1220702109 关于用人单位对大学生培养质量的调查与研究 摘要:大学生素质不外乎文化素质、道德素质、身体素质、心理素质以及各种走向社会应具备的能力。我们都知道,管理者的工作质量是由他们所管理的人的工作质量来决定的,并且,企业的整个运作过程,除了一些核心技术之外,是没有多少秘密的,可以说企业是透明的,然而,一个企业能够成功,在市场上占据一席而立于不败之地,这关键在于对方法、措施的选择、运用、实施,而这关键也是人,可见,人在企业中的地位是不言而喻的,他对一个企业的成功与否,起着相当大的作用。而大学生作为现代社会的普遍群体,未来社会发展的主力军,其自身所有的就业能力素质,正是企业招聘人才的衡量标准之一。 关键词:培养环境毕业生优势综合素质工作态度 一、研究背景与研究目的 大学生素质不外乎文化素质、道德素质、身体素质、心理素质以及各种走向社会应具备的能力。首先,文化素质作为一个大学生来说应该是已经具备的最基本的素质。其次,道德素质对于一个大学生来说是至关重要的,当代的大学生虽然有较高的文化水平但走近我们的校园可以看到我们的大学生素质并不是想象中那么高的,食堂窗口拥挤不堪,剩菜剩饭一大片;宿舍物品失窃,发卡捡到不交更是比比皆是;自私自利唯我独尊也却有存在;甚至会发现有些大学生的素质不如那些没有受过教育的人。作为刚毕业的大学生要清楚的认识自己,正视自己你不比别人强多少,现在大学生很多见,不是什么稀罕物。对于公司来说更希望招到能够俯下身踏实工作的,富有团队意识的人。再次,良好的身体素质和心理素质是从业的必要和前提条件,很多公司在招人的时候都会进行体检,而心理素质则是一个人承受压力所必须的基本能力。最后,大学生走向社会要有强大的适应能力,耐力,知觉能力,思维能力,创新力,以及吃苦耐劳,勇于承担责任具有开拓精神的人。 大学生的就业问题早已成为社会问题中的重要一环。年复一年,大学毕业生都在为就业四处奔波,使出十八般武艺,据劳动保障部对全国114个城市劳动力
《管理统计学》习题及标准答案
《管理统计学》作业集习题集及答案 第一章导论 *1-1 对50名职工的工资收入情况进行调查,则总体单位是(单选)( 3 )(1)50名职工(2)50名职工的工资总额 (3)每一名职工(4)每一名职工的工资 *1-2 一个统计总体(单选)( 4 ) (1)只能有一个标志(2)只能有一个指标 (3)可以有多个标志(4)可以有多个指标 *1-3 某班学生数学考试成绩分别为65分、71分、80分和87分,这四个数字是(单选)( 4 ) (1)指标(2)标志(3)变量(4)标志值 第二章统计数据的调查与收集 *2-1 非全面调查包括(多项选择题)(12 4 ) (1)重点调查(2)抽样调查(3)快速普查 (4)典型调查(5)统计年报 *2-2 统计调查按搜集资料的方法不同,可以分为(多项选择题)( 12 3 ) (1)采访法(2)抽样调查法(3)直接观察法 (4)典型调查法(5)报告法 *2-3 某市进行工业企业生产设备状况普查,要求在7月1日至7月5日全部调查完毕。则规定的这一时间是(单项选择题)(2) (1) 调查时间(2) 调查期限(3) 标准时间(4) 登记期限 *2-4 某城市拟对占全市储蓄额五分之四的几个大储蓄所进行调查,以了解全市储蓄的一般情况,则这种调查方式是(单项选择题)(4) (1) 普查(2) 典型调查(3) 抽样调查(4) 重点调查 *2-5 下列判断中,不正确的有(多项选择题)(23 4 ) (1)重点调查是一种非全面调查,既可用于经常性调查,也可用于一次性调查; (2)抽样调查是非全面调查中最科学的方法,因此它适用于完成任何调查任务; (3)在非全面调查中,抽样调查最重要,重点调查次之,典型调查最不重要; (4)如果典型调查的目的是为了近似地估计总体的数值,则可以选择若干中等的典型单位进行调查; (5)普查是取得全面统计资料的主要调查方法。 *2-6 下列属于品质标志的是(单项选择题)( 2 ) (1)工人年龄(2)工人性别(3)工人体重(4)工人工资 *2-7 下列标志中,属于数量标志的有(多项选择题)(3) (1)性别(2)工种(3)工资(4)民族(5)年龄 *2-8 下列指标中属于质量指标的有(多项选择题)(13 4 ) (1)劳动生产率(2)废品量(3)单位产品成本 (1)资金利润率(5)上缴税利额 第三章统计数据的整理 *3-1 区分下列几组基本概念: (1)频数和频率;
管理统计学SPSS数据管理 实验报告
数据管理 一、实验目的与要求 1.掌握计算新变量、变量取值重编码的基本操作。 2.掌握记录排序、拆分、筛选、加权以及数据汇总的操作。 3.了解数据字典的定义和使用、数据文件的重新排列、转置、合并的操作。 二、实验内容提要 1.自行练习完成课本中涉及的对CCSS案例数据的数据管理操作 2.针对SPSS自带数据Employee data.sav进行以下练习。 (1)根据变量bdate生成一个新变量“年龄” (2)根据jobcat分组计算salary的秩次 (3)根据雇员的性别变量对salary的平均值进行汇总 (4)生成新变量grade,当salary<20000时取值为d,在20000~50000范围内时取值为c,在50000~100000范围内取值为b,大于等于100000时取值为a 三、实验步骤 1、针对CCSS案例数据的数据管理操作 1.1.计算变量,输入TS3到目标变量,在数字表达式中输入3,把任意年龄段分成三个组20-30设为1组,1-40设为2组41-50设为3组。图1, 图1 1.2.对已有变量的分组合并,在“名称”文本框中输入新变量名TS3单击“更改”按钮,原来的S3->?就会变为S3->TS3,单击“旧值和新值”按钮,系统打开“重新编码到其他变量:旧值和新值”,如下图2,
图2 图3 1.3.可视离散化,选择“转换”->“可视离散化”,打开的对话框要求用户选择希望进行离散化的变量,单击继续,如下图4,
图4 单击“生成分割点”,设定分割点数量为10,宽度为5,第一个分割点位置为18,单击“应用”,如下图, 图5 结果显示如下,
统计学实验报告7.统计指数分析.docx
实验报告 课程名称统计学学号 11学生姓名辅导教师 系别经济与管理系实验室名称实验时间 1.实验名称 统计指数分析 2.实验目的 掌握各项指数的计算及因素分析法的运用。 在 Excel 中完成各项指数及有关数值的计算,主要用到的是公式和公式复制 3.实验内容 甲乙丙三种商品基期和报告期各项数据如下: 价格(元) P销量 q 商品计量单位 基期 p0报告期 p1基期 q0报告期 q1 甲个302810001200 乙双202120001600 丙公斤232515001500 合计 1)计算三种商品的个体销售量指数和个体价格指数。 2)三种商品的销售额总指数。 3)三种商品的销售量总指数和价格总指数。 4)分析销售量变动和价格变动对销售额影响的绝对额。(这一问分析要手写完成) 4.实验原理 在 Excel 中实现综合指数及其相关数值的计算,主要用到的是公式和公式的复制功 能 5.实验过程及步骤 (1)在工作表中输入已知数据的名称和数值(包括商品名称,计量单位,基期价格,报告 期价格,基期销售量和报告期销售量) (2)计算综合指标的各个综合总量在单元格G4中输入公式“ =C4*E4”,在H4中输入“=D4*F4”, 在 I4 中输入“ =C4*F4”, 在 J4 中输入“ =D4*E4”, 公式复制 在 A7 中输入合计,在单元格中输入“=SuM(G4:G6),再将单元格 G7的公式向右复制到 J7 (3)分别计算各个综合指标及其分子分母之差额 在单元格 A10 中输入“销售额总额指数” ,在单元格 F10 中输入公式“ =H7/G7*100” , 在单元格 H10 中输入公式” =H7-G7”
统计学实验报告
重庆大学 学生实验报告 实验课程名称统计学 开课实验室DS1421 学院建管学院年级2011级 专业班级财管1班 学生姓名丁朝飞学号20110730 开课时间至学年第学期 总成绩 教师签名
建设管理及房地产学院制 《统计学》实验报告 开课实验室:年月日学院建管学院年级、专业、班11级财管01班姓名丁朝飞成绩 课程名称统计学 实验项目 名称 统计学实验 指导教 师 陈政辉 教师 评语教师签名: 年月日
一、实验目的: 通过对具体的搜集到的资料进行计算机操作、处理的训练,熟练掌握分组与分布数列编制的原则,并能根据实际资料设计出适当的统计表和统计图,通过对反映数据分布特征的重要指标的计算练习,使学生更加熟悉普及的Excel在统计学中的运用,切实感受到利用计算机实现资料的整理、计算和分析能够减轻在实践中进行资料处理的负担,进一步提高学生发现问题、分析问题、解决问题的能力。 二、实验内容: A 1. 要求筛选出(1)统计学成绩等于75分的学生;(2)数学成绩高的前3名学生;(3)4门课程成绩都大于70分的学生。 姓名统计学成绩数学成绩英语成绩经济学成绩 张已69 68 84 86 王翔91 75 95 94 田雨54 88 67 78 李华81 60 86 64 赵颖75 96 81 83 宋华83 72 66 71 袁方75 58 76 90 陈云87 76 92 77 刘文55 84 61 82 周克66 62 88 79 程前75 60 72 88 胡纳75 88 90 92 1.选中原始数据,点击“筛选”,出现下图所示窗口
2.统计学成绩等于75分的学生,点击“统计学成绩”上的,弹出下图所示对话框,在标识框 处输入“75” 单击“确定”按钮结果如下: 3.数学成绩高的前3名学生,点击“数学成绩”上的,选择“十个最大的值”,弹出如图所示