TCGA数据库生物信息

1.从TCGA下载相应的癌症数据,包括正常样品和癌症样品。
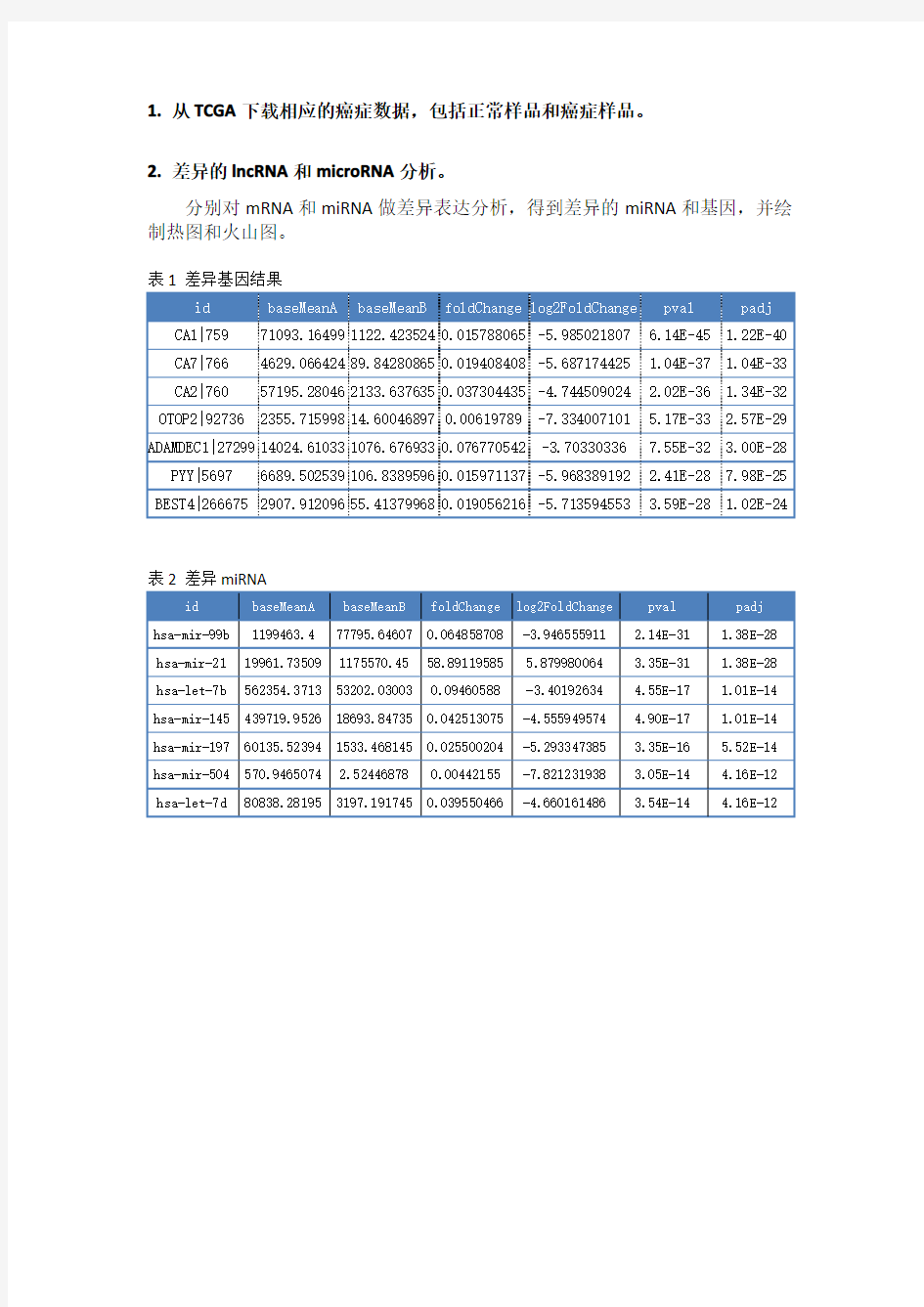
2.差异的lncRNA和microRNA分析。
分别对mRNA和miRNA做差异表达分析,得到差异的miRNA和基因,并绘制热图和火山图。
表差异
图1差异基因火山图
图2热图
3.共表达网络
基因和miRNA的共表达网络。
图3miRNA和mRNA共表达网络4.蛋白互作网络
对差异基因进行蛋白互作网络分析。
图4差异基因PPI网络
5.生存分析
分析基因高低表达与生存时间之间是否具有显著相关性,并且绘制生存曲线。当然,也可以分析临床信息与生存的关系,比如临床分期与生存时间的关系,癌症大小与生存时间的关系,用药与生存时间的关系,等等。
图5目标基因生存分析
6.基因表达与临床的关系
分析基因与临床数据的关系,如基因的表达和癌症转移的关系,基因表达和临床分期的关系,基因表达和其它临床信息的关系。
图6MARCH1表达与肺转移的关系
7.其它个性化分析
根据客户提供分析案例或者文献,做相应的生物信息分析。
有疑问请联系作者邮箱:602316645@https://www.360docs.net/doc/3017574114.html,
生物信息学简介范文
1、简介 生物信息学(Bioinformatics)是在生命科学的研究中,以计算机为工具对生物信息进行储存、检索和分析的科学。它是当今生命科学和自然科学的重大前沿领域之一,同时也将是21世纪自然科学的核心领域之一。其研究重点主要体现在基因组学(Genomics)和蛋白质组学(Proteomics)两方面,具体说就是从核酸和蛋白质序列出发,分析序列中表达的结构功能的生物信息。 具体而言,生物信息学作为一门新的学科领域,它是把基因组DNA序列信息分析作为源头,在获得蛋白质编码区的信息后进行蛋白质空间结构模拟和预测,然后依据特定蛋白质的功能进行必要的药物设计。基因组信息学,蛋白质空间结构模拟以及药物设计构成了生物信息学的3个重要组成部分。从生物信息学研究的具体内容上看,生物信息学应包括这3个主要部分:(1)新算法和统计学方法研究;(2)各类数据的分析和解释;(3)研制有效利用和管理数据新工具。 生物信息学是一门利用计算机技术研究生物系统之规律的学科。 目前的生物信息学基本上只是分子生物学与信息技术(尤其是因特网技术)的结合体。生物信息学的研究材料和结果就是各种各样的生物学数据,其研究工具是计算机,研究方法包括对生物学数据的搜索(收集和筛选)、处理(编辑、整理、管理和显示)及利用(计算、模拟)。 1990年代以来,伴随着各种基因组测序计划的展开和分子结构测定技术的突破和Internet的普及,数以百计的生物学数据库如雨后春笋般迅速出现和成长。对生物信息学工作者提出了严峻的挑战:数以亿计的ACGT序列中包涵着什么信息?基因组中的这些信息怎样控制有机体的发育?基因组本身又是怎样进化的? 生物信息学的另一个挑战是从蛋白质的氨基酸序列预测蛋白质结构。这个难题已困扰理论生物学家达半个多世纪,如今找到问题答案要求正变得日益迫切。诺贝尔奖获得者W. Gilbert在1991年曾经指出:“传统生物学解决问题的方式是实验的。现在,基于全部基因都将知晓,并以电子可操作的方式驻留在数据库中,新的生物学研究模式的出发点应是理论的。一个科学家将从理论推测出发,然后再回到实验中去,追踪或验证这些理论假设”。 生物信息学的主要研究方向:基因组学- 蛋白质组学- 系统生物学- 比较基因组学,1989年在美国举办生物化学系统论与生物数学的计算机模型国际会议,生物信息学发展到了计算生物学、计算系统生物学的时代。 姑且不去引用生物信息学冗长的定义,以通俗的语言阐述其核心应用即是:随着包括人类基因组计划在内的生物基因组测序工程的里程碑式的进展,由此产生的包括生物体生老病死的生物数据以前所未有的速度递增,目前已达到每14个月翻一番的速度。同时随着互联网的普及,数以百计的生物学数据库如雨后春笋般迅速出现和成长。然而这些仅仅是原始生物信息的获取,是生物信息学产业发展的初组阶段,这一阶段的生物信息学企业大都以出售生物数据库为生。以人类基因组测序而闻名的塞莱拉公司即是这一阶段的成功代表。 原始的生物信息资源挖掘出来后,生命科学工作者面临着严峻的挑战:数以亿计的ACGT序列中包涵着什么信息?基因组中的这些信息怎样控制有机体的发育?基因组本身又是怎样进化的?生物信息学产业的高级阶段体现于此,人类从此进入了以生物信息学为中心的后基因组时代。结合生物信息学的新药创新工程即是这一阶段的典型应用。 2、发展简介 生物信息学是建立在分子生物学的基础上的,因此,要了解生物信息学,就必须先对分子生物学的发展有一个简单的了解。研究生物细胞的生物大分子的结构与功能很早就已经开始,1866年孟德尔从实验上提出了假设:基因是以生物成分存在,1871年Miescher从死的白细胞核中分离出脱氧核糖核酸(DNA),在Avery和McCarty于1944年证明了DNA是生命器官的遗传物质以前,人们仍然认为染色体蛋白质携带基因,而DNA是一个次要的角色。1944年Chargaff发现了著名的Chargaff规律,即DNA中鸟嘌呤的量与胞嘧定的量总是相等,腺嘌呤与胸腺嘧啶的量相等。与此同时,Wilkins与Franklin用X射线衍射技术测
生物信息数据库
生物信息数据库 1生物信息数据库产生背景 上个世纪60年代以来,随着核酸序列测定、蛋白质序列测定以及基因克隆和PCR技术的不断发展与完善,全世界各研究机构获得了大量的生物信息原始数据。面对这些以指数方式增长的数据资源,传统的研究方式已经来不及迅速消化,因此有必要采用有效的方法将它们进行适当的储存、管理和维护,以便进一步分析、处理和利用,这就需要建立数据库即生物信息数据库[1]。生物信息数据库是一切生物信息学工作的基础。 2生物信息数据库的特点 2.1数据库种类的多样性。生物信息学各类数据库几乎覆盖了生命科学的各个领域,如核酸序列数据库,蛋白质序列数据库,蛋白质、核酸、多糖的三维结构数据库,基因组数据库,文献数据库和其他各类达数百种。 2.2数据库的更新和增长快。数据库的更新周期越来越短,有些数据库每天更新。数据的规模以指数形式增长。 2.3数据库的复杂性增加、层次加深。许多数据库具有相关的内容和信息,数据库之间相互引用,如PDB就与文献库、酶学数据库、蛋白质二级数据库、蛋白质结构分类数据库、蛋白折叠库等十几种数据库交叉索引。 2.4数据库使用高度计算机化和网络化。越来越多的生物信息学数据库与因特网联结,从而为分子生物学家利用这些信息资源提供了前所未有的机遇[2]。 2.5面向应用。首先各个数据库除了提供数据之外,还提供许多分析工具,如核酸数据库提供的序列搜索、基因识别程序等。此外,还在原始数据库的基础上开发了许多面向特殊应用的二级数据库,如蛋白质二级结构数据库等[3]。 3生物信息数据库的分类 生物信息数据库种类繁多,归纳起来,大体可以分为5个大类:核酸序列数据库、基因组数据库、蛋白质序列数据库、生物大分子(主要是蛋白质)结构数据库以及以这4类数据库和文献资料为基础构建的二次数据库。其中主要类型是序列数据库[4]。来自基因组作图的基因组数据库、来自序列测定的序列数据库以及来自X-衍射和核磁共振结构测定的结构数据库是分子生物信息学的基本数据资源,通常称为基本数据库或初始数据库,也称一次数据库。根据生命科学不同研究领域的实际需要,在一次数据库、实验数据和理论分析的基础上进行整理、归纳和注释,构建具有特殊生物学意义和专门用途的数据库即二次数据库, 也称专门数据库、专业数据库或专用数据库[2, 3, 5]。 3.1核酸序列数据库 EMBL、GenBank和DDBJ是国际上三大主要核酸序列数据库。EMBL是德国海德堡市的欧洲分子生物学实验室(European Molecular Biology Laboratory)1980年创建的,其名称也由此而来。美国国家健康研究院(National Institurte of Health,简称NIH)也于1982年委托洛斯阿拉莫斯(Los Alamos)国家实验室建立GenBank,后移交给美国国立卫生研究院国家生物技术中心(National Center for Bio-technology Information—NCBI)。DDBJ是日本静冈市的日本国立遗传学研究所于1986年创建的日本DNA数据库(DNA Database of Japan—DDBJ)。1988年,EMBL、GenBank与DDBJ共同成立了国际核酸序列联合数据库中心,建立了合作关系。根据协议,这三个数据库分别收集所在区域的有关实验室和测序机构所发布的核酸序列信息,并共享收集到的数据,每天交换各自数据库新建立的序列记录,以保证这三个数据库序列信息
生物信息学数据库或软件
一、搜索生物信息学数据库或者软件 数据库是生物信息学的主要内容,各种数据库几乎覆盖了生命科学的各个领域。 核酸序列数据库有GenBank,EMBL,DDB等,核酸序列是了解生物体结构、功能、发育和进化的出发点。国际上权威的核酸序列数据库有三个,分别是美国生物技术信息中心(NCBI)的GenBank ,欧洲分子生物学实验室的EMBL-Bank(简称EMBL),日本遗传研究所的DDBJ 蛋白质序列数据库有SWISS-PROT,PIR,OWL,NRL3D,TrEMBL等, 蛋白质片段数据库有PROSITE,BLOCKS,PRINTS等, 三维结构数据库有PDB,NDB,BioMagResBank,CCSD等, 与蛋白质结构有关的数据库还有SCOP,CATH,FSSP,3D-ALI,DSSP等, 与基因组有关的数据库还有ESTdb,OMIM,GDB,GSDB等, 文献数据库有Medline,Uncover等。 另外一些公司还开发了商业数据库,如MDL等。
生物信息学数据库覆盖面广,分布分散且格式不统一, 因此一些生物计算中心将多个数据库整合在一起提供综合服务,如EBI的SRS(Sequence Retrieval System)包含了核酸序列库、蛋白质序列库,三维结构库等30多个数据库及CLUSTALW、PROSITESEARCH等强有力的搜索工具,用户可以进行多个数据库的多种查询。 二、搜索生物信息学软件 生物信息学软件的主要功能有: 分析和处理实验数据和公共数据,加快研究进度,缩短科研时间; 提示、指导、替代实验操作,利用对实验数据的分析所得的结论设计下一阶段的实验;寻找、预测新基因及预测其结构、功能; 蛋白高级结构预测。 如:核酸序列分析软件BioEdit、DNAClub等;序列相似性搜索BLAST;多重系列比对软件Clustalx;系统进化树的构建软件Phylip、MEGA等;PCR 引物设计软件Primer premier6.0、oligo6.0等;蛋白质二级、三级结构预测及三维分子浏览工具等等。 NCBI的网址是:https://www.360docs.net/doc/3017574114.html,。 Entrez的网址是:https://www.360docs.net/doc/3017574114.html,/entrez/。 BankIt的网址是:https://www.360docs.net/doc/3017574114.html,/BankIt。 Sequin的相关网址是:https://www.360docs.net/doc/3017574114.html,/Sequin/。 数据库网址是:https://www.360docs.net/doc/3017574114.html,/embl/。
生物信息学复习的总结
生物信息期末总结 1.生物信息学(Bioinformatics)定义:(第一章)★ 生物信息学是一门交叉科学,它包含了生物信息的获取、加工、存储、分配、分析、解释等在内的所有方面,它综合运用数学、计算机科学和生物学的各种工具来阐明和理解大量数据所包含的生物学意义。 (或:) 生物信息学是运用计算机技术和信息技术开发新的算法和统计方法,对生物实验数据进行分析,确定数据所含的生物学意义,并开发新的数据分析工具以实现对各种信息的获取和管理的学科。(NSFC) 2. 科研机构及网络资源中心: NCBI:美国国立卫生研究院NIH下属国立生物技术信息中心; EMBnet:欧洲分子生物学网络; EMBL-EBI:欧洲分子生物学实验室下属欧洲生物信息学研究所; ExPASy:瑞士生物信息研究所SIB下属的蛋白质分析专家系统;(Expert Protein Analysis System) Bioinformatics Links Directory; PDB (Protein Data Bank); UniProt 数据库 3. 生物信息学的主要应用: 1.生物信息学数据库;2.序列分析;3.比较基因组学;4.表达分析;5.蛋白质结构预测;6.系统生物学;7.计算进化生物学与生物多样性。 4.什么是数据库:★1、定义:数据库是存储与管理数据的计算机文档、结构化记录形式的数据集合。(记录record、字段field、值value) 2、生物信息数据库应满足5个方面的主要需求: (1)时间性;(2)注释;(3)支撑数据;(4)数据质量;(5)集成性。 3、生物学数据库的类型:一级数据库和二级数据库。 (国际著名的一级核酸数据库有Genbank数据库、EMBL核酸库和DDBJ库等;
生物信息数据库大全
生物信息(bioinformation)数据库大全 摘要: [生物信息(bioinformation)数据库大全] http: smartli77 cctrblog net cmd html?do=blogs&id=548&uid=1511 生物信息(bioinformation)数据 库一.数据库目录2000年,出版《核酸研究》的牛津大学出版社设立了一个 数据库目录网页,这个网页把数据库分成18类在郝柏林、张淑誉编著的《生物 信息(bioin……[关键词:数据库序列基因基因组蛋白质蛋白质序列基因 图谱]…… 关键词:数据库序列基因基因组蛋白质蛋白质序列基因图谱 https://www.360docs.net/doc/3017574114.html,/cmd.html?do=blogs&id=548&uid=1511 生物信息(bioinformation)数据库 一.数据库目录 2000年,出版《核酸研究》的牛津大学出版社设立了一个数据库目录网页,这个网页把数据库分成18类在郝柏林、张淑誉编著的《生物信息(bioinformation)学手册》中,他们进行了合并,又把数据库目录、农林牧有关数据库、医学数据库和文献单独列出,分成以下16类: 1.数据库目录 2.综合数据库包括DNA序列阵:EMBL、GenBank、DDBJ、GSDB、TDB和UniGene 3.DNA序列数据库主要是与基因结构和认定有关的数据库,如密码子使用频度表、
真核生物启动子库、内含子和外显子库等 4.RNA序列和核糖体数据库 5.基因图谱数据库 6.人类基因组数据库 7.其他物种基因组数据库 8.基因表达数据库 9.基因突变、病理和免疫数据库 10.蛋白质序列数据库 11.蛋白质结构数据库 12.比较基因组学(comparative genomics)和蛋白质组学(Proteomics)数据库 13.代谢途径和细胞调控数据库 14.与农林牧有关数据库 15.医学数据库 16.其他数据库 二.综合数据库 INSD,国际核酸序列数据库(International Nucleotide Sequence Databank)
生物信息学常用核酸蛋白数据库
(1)GenBank https://www.360docs.net/doc/3017574114.html,/ (2)dbEST (Database of Expressed Sequence Tags) https://www.360docs.net/doc/3017574114.html,/dbEST/index.html (3)UniGene 数据库 https://www.360docs.net/doc/3017574114.html,/UniGene/ (4)dbSTS (Database of Sequence Tagged Sites) https://www.360docs.net/doc/3017574114.html,/dbSTS/index.html (5)dbGSS (Database of Genome Survey Sequences) https://www.360docs.net/doc/3017574114.html,/dbGSS/index.html (6)HTG (High-Throughput Genomic Sequences) https://www.360docs.net/doc/3017574114.html,/HTGS/ (7)基因组数据库 https://www.360docs.net/doc/3017574114.html,/sites/entrez?db=genome (8)dbSNP (Database of Single Nucleotide Polymorphisms) 单核苷酸多态性数据库https://www.360docs.net/doc/3017574114.html,/sites/entrez?db=snp (9)EMBL (European Molecular Biology Laboratory) https://www.360docs.net/doc/3017574114.html,/embl (10)DDBJ (DNA Data Bank of Japan) http://www.ddbj.nig.ac.jp/Welcome-e.html 启动子(11)EPD (Eukaryotic Promoter Database) http://www.epd.isb-sib.ch/ 2、蛋白质数据库 https://www.360docs.net/doc/3017574114.html,/swissprot (2)TrEMBL (Translation of EMBL) https://www.360docs.net/doc/3017574114.html,/swissprot/ (3)PIR (Protein Information Resource) https://www.360docs.net/doc/3017574114.html, (4)PRF (Protein Research Foundation) http://www.prf.or.jp/en/os.html (5)PDBSTR (Re-Organized Protein Data Bank) http://www.genome.ad.jp (6)Prosite https://www.360docs.net/doc/3017574114.html,/prosite 3、结构数据库 (1)PDB (Protein Data Bank) https://www.360docs.net/doc/3017574114.html, (2)NDB(Nucleic Acid Database) https://www.360docs.net/doc/3017574114.html,/ (3)DNA-Binding Protein Database https://www.360docs.net/doc/3017574114.html,/ (4)SWISS-3D IMAGE http://www.expasy.ch/sw3d/
生物信息学研究方向简介
生物信息学研究方向简介 核心提示: 生物信息学在短短十几年间,已经形成了多个研究方向,以下简要介绍一些主要的研究重点. 1,序列比对(Sequence Alignment) 序列比对的基本问题是比较两个或两个以上符号序列的相似性或不相似性.从生物学的初衷来看,这一问题包含了以下几个意义:从相互重叠的序列片断中重构DNA的完整序列.在各种试验条件下从探测数据(probe data)中决定物理和基因图存贮,遍历和比较数据库中的DNA序列比较两个或多个序列的相似性在数据库中搜索相关序列和子序列寻找核苷酸(nucleotides)的连续产生 生物信息学在短短十几年间,已经形成了多个研究方向,以下简要介绍一些主要的研究重点. 1,序列比对(Sequence Alignment) 序列比对的基本问题是比较两个或两个以上符号序列的相似性或不相似性.从生物学的初衷来看,这一问题包含了以下几个意义:从相互重叠的序列片断中重构DNA的完整序列.在各种试验条件下从探测数据(probe data)中决定物理和基因图存贮,遍历和比较数据库中的DNA序列比较两个或多个序列的相似性在数据库中搜索相关序列和子序列寻找核苷酸(nucleotides)的连续产生模式找出蛋白质和DNA序列中的信息成分序列比对考虑了DNA序列的生物学特性,如序列局部发生的插入,删除(前两种简称为indel)和替代,序列的目标函数获得序列之间突变集最小距离加权和或最大相似性和,对齐的方法包括全局对齐,局部对齐,代沟惩罚等.两个序列比对常采用动态规划算法,这种算法在序列长度较小时适用,然而对于海量基因序列(如人的DNA序列高达109bp),这一方法就不太适用,甚至采用算法复杂性为线性的也难以奏效.因此,启发式方法的引入势在必然,著名的BALST和FASTA算法及相应的改进方法均是从此前提出发的. 2, 蛋白质结构比对和预测 基本问题是比较两个或两个以上蛋白质分子空间结构的相似性或不相似性.蛋白质的结构与功能是密切相关的,一般认为,具有相似功能的蛋白质结构一般相似.蛋白质是由氨基酸组成的长链,长度从50到1000~3000AA(Amino Acids),蛋白质具有多种功能,如酶,物质的存贮和运输,信号传递,抗体等等.氨基酸的序列内在的决定了蛋白质的3维结构.一般认为,蛋白质有四级不同的结构.研究蛋白质结构和预测的理由是:医药上可以理解生物的功能,寻找dockingdrugs的目标,农业上获得更好的农作物的基因工程,工业上有利用酶的合成.直接对蛋白质结构进行比对的原因是由于蛋白质的3维结构比其一级结构在进化中更稳定的保留,同时也包含了较AA序列更多的信息.蛋白质3维结构研究的前提假设是内在的氨基酸序列与3维结构一一对应(不一定全真),物理上可用最小能量来解释.
生物分子信息数据库
第4章生物分子数据库 国际上已建立起许多公共生物分子数据库,包括基因组图谱数据库、核酸序列数据库、蛋白质序列数据库、生物大分子结构数据库等。这些数据库由专门的机构建立和维护,他们负责收集、组织、管理和发布生物分子数据,并提供数据检索和分析工具,向生物学研究人员提供大量有用的信息,最大限度地满足他们研究和应用的需要,为他们的研究服务。 4.1 引言 建立生物分子数据库的动因是由于生物分子数据的高速增长,而另一方面也是为了满足分子生物学及相关领域研究人员迅速获得最新实验数据的要求。生物分子信息分析已经成为分子生物学研究必备的一种方法。如果说理论分析和算法模拟是生物信息学实验方法的话,那么来自于具体实验的原始数据和来自于数据库的数据则是生物信息学的实验材料。数据库及其相关的分析软件是生物信息学研究和应用的重要基础,也是分子生物学研究必备的工具。 从数据库使用的角度来看,公共生物分子数据库应满足以下5个方面的主要需求: (1)时间性对于新发表的数据,应该能够在很短的时间内(几个小时至几天)通过国际互连网访问。 (2)注释对于每一个基本数据(如序列),应附加一致的、深层次的辅助说明信息。 (3)支撑数据在有些情况下,数据库使用者需要得到原始的实验数据,因而要提供访问原始数据的方法。数据库中应包含原始数据,或者能够通过交叉索引访问实验数据库中的原始数据。 (4)数据质量必须保证数据库中数据的质量,数据库管理机构应对数据来源进行检查,并且关注数据库用户和专家提出的意见。 (5)集成性三种基本生物分子数据库(核酸序列、蛋白质序列、蛋白质结构)的集成对于用户来说是非常重要的。对于数据库中的每一个数据对象,必须与其它数据库中的相关数据联系起来,这样可以从某些分子数据出发得到一系列的相关信息。例如,从某个核酸序列出发,通过交叉索引,可进一步得到对应的基因、蛋白质序列、蛋白质结构,甚至得到蛋白质功能的信息。 分子生物学研究领域虽各有重点,但是研究对象之间存在着密切的联系,比如DNA序列与蛋白质序列之间的联系,基因调控信息与基因表达数据之间的联系。因而实验数据之间就必然存在着关联,一个方面的相关数据可能会影响或促进另一个方面的研究工作。现有的各类数据库已经成为分子生物学各方面交叉研究的桥梁。 生物分子数据库目前的发展状况有几个明显的特征: (1)生物分子数据库最突出的特征就是数据库的更新速度不断加快,数据量呈指数增长趋势。例如,核酸序列数据的年增长幅度为100%。 (2)数据库使用频率增长更快。人们越来越感到生物分子数据的重要性,也认识到它们的价值,因此各种数据库的使用人员在不断增加。据统计,数据库的平均使用频率每年增长幅度接近于500%。 (3)数据库的复杂程度不断增加。数据库中除了基本数据之外,还包括大量的注释、链接、参考文献等信息,例如,在SWISS-PROT数据库中,注释项涉及蛋白质的功能、结构域和活性位点、二级结构、四级结构、翻译后修饰、与其他蛋白质的相似性、与该蛋白质关联的疾病、序列变化等。 (4)数据库网络化。几乎所有的数据库都可以在国际互联网上访问,并且公共数据库之间相互链接,使用户可以迅速得到大量的相关生物分子信息。有的系统则将多个生物分子数据库整合在一起,形成集成的数据库系统。 (5)面向应用。首先,各个数据库服务器除了提供数据之外,还提供许多分析工具,如核酸数据库提供的序列搜索、基因识别程序等,生物大分子结构数据库提供的结构比较程序、结构模拟程序等。此外,还在原始数据库的基础上开发了许多面向特殊应用的二级数据库,如蛋白质分类数据库、蛋白质二级结构数据库等。 (6)先进的软硬件配置。从计算机硬件方面来看,许多数据库服务器已从工作站升级到大型服务器,使数据库能够高效地管理数据和为用户服务,并在专门的硬件(如并行机)上运行服务
生物信息学数据库综述
生物信息学数据库综述 摘要本文对生物信息学常见的数据库进行了汇总。常见数据库分为三类:核酸序列数据库、蛋白质序列数据库、三维分子结构数据库。并分别对其中常见数据库进行了介绍。对于生物信息学数据库的现存问题也进行了论述。 关键词数据库;核酸序列数据库;蛋白质序列数据库;三维分子结构数据库; 随着生物信息的发展,生物信息学数据库的数量在不断的递增,内部结构也不断的复杂化,功能也越来越细化。根据数据的类型可以将数据库分为核酸序列数据库、蛋白质序列数据库三维分子结构数据库。本文将比较常见的数据进行了汇总。 1 核酸序列数据库 常用的核酸序列数据库有GenBank核酸序列数据库、EMBL核酸数据库、DDBJ数据库、GDBD等。 1.1GenBank Genbank库包含了所有已知的核酸序列和蛋白质序列,以及与它们相关的文献著作和生物学注释。它是由美国国立生物技术信息中心(N CBI)建立和维护的。Genbank每天都会与欧洲分子生物学实验室(EM BL)的数据库,和日本的DNA 数据库(DDBJ)交换数据,使这三个数据库的数据同步。Genbank的数据可以从N CBI的FrP服务器上免费下载完整的库,或下载积累的新数据。N CBI还提供广泛的数据查询、序列相似性搜索以及其它分析服务,用户可以从N CBI的主页上找到这些服务。Gel~ bank 库里的所有数据记录被划分在若干个文件里,如细菌类、病毒类、灵长类、啮齿类,以及EST数据、基因组测序数据、大规模基因组序列数据等16类,其中EST数据等又被各自分成若干个文件 1.2 EM BL核酸序列数据库 EM BL 核酸序列数据库由欧洲生物信息学研究所(EBI)维护的核酸序列数据构成,由于与Genbank和DDBJ的数据合作交换,它也是一个全面的核酸序列数据库。该数据库由Oracal数据库系统管理维护,查询检索可以通过因特网上的序列提取系统(SRS)N务完成l 6J。向E M BL核酸序列数据库提交序列可以通过基于W eb的WEBI N工具,也可以用Sequi n 软件来完成。 1.3 DD BJ 数据库 D D BJ数据库创建于1984 年,由日本国立遗传学研究所遗传信息中心维护。它首先反映日本所产生的DNA数据,同时与Genbank、EMBL合作互通有无,同步更新,每年四版。日本DNA数据仓库(DDBJ)也是一个全面的核酸序列数据库。可以使用其主页上提供的SAS工具进行数据检索和分析。可以用Sequin 软件向该数据库提交序列。 1 .4 G D B 人类基因组数据库(GD B)是人类基因图谱和疾病的数据库。GDB的目标是构建关于人类基因组图谱和测序。目前GDB中有:人类基因组区域(包括基因、克隆、amplimersPCR标记、断点breakpoint细胞遗传标记cytogenetic markers、
生物信息学数据库大全
综合数据库 ★INSD,国际核酸序列数据库(International Nucleotide Sequence Databank)。由日本的DDBJ、欧洲的EMBL和美国的GenBank三家各自建立和共同维护。 ★EMBL库,欧洲分子生物学实验室的DNA和RNA 序列库。https://www.360docs.net/doc/3017574114.html,/embl.html ★GenBank ,美国国家生物技术信息中心(NCBI)所维护的供公众自由读取的、带注释的DNA序列的总数据库。https://www.360docs.net/doc/3017574114.html,/Web/Genbank/ ★DNA Databank of Japan (DDBJ) ,日本核酸数据库。http://www.ddbj.nig.ac.jp/ ★GSDB是由美国国家基因组资源中心(NCGR)维护的DNA序列关系数据库(Genome Sequence DataBase)。https://www.360docs.net/doc/3017574114.html,/gsdb/ ★TIGR DATAbase,是世界上最大的cDNA数据库,还有大量的EST序列和人类基因索引(HGI)。https://www.360docs.net/doc/3017574114.html,/tdb/hcd/overview.html DNA序列数据库 包括与DNA的复制、转录、修复等有密切关系的蛋白质因子。 ★BioSino是中国自主开发的核酸序列公共数据库。 https://www.360docs.net/doc/3017574114.html,/ ★CUTG,MM子使用频度表。 http://www.dna.affrc.go.jp/~nakamura/CUTG.html http://www.kazusa.or.jp/codon/ http://www.dna.affrc.go.jp/~nakamura/CUTG.html ★EPD,真核生物启动子数据库(Eukaryotic Promotor Database)。 http://www.epd.isb-sib.ch/ ★TRANSFAC,真核生物基因表达调控因子的数据库。 http://transfac.gbf.de/TRANSFAC ★TRRD.真核生物基因组转录调控区数据库。 http://www.mgs.bionet.nsc.ru/mgs/dbases/trrd4/ ★OOTFD,转录因子和基因表达数据库。 https://www.360docs.net/doc/3017574114.html,/ ★RepBase,真核生物DNA中重复序列数据库。 https://www.360docs.net/doc/3017574114.html,/~server/repbase.html ★MicroSatellite,微卫星重复序列数据库。 https://www.360docs.net/doc/3017574114.html,/gopher-menus/MicroSatelliteDatabase.html ★ALU数据库是人及其他灵长类代表性的Alu重复片段。 https://www.360docs.net/doc/3017574114.html,(/pub/jmc/alu/) ★Simple Repeats,简单重复序列库。 https://www.360docs.net/doc/3017574114.html, ★COMPEL,复合元件数据库。 ftp://ftp.gbf-braunschweig.de(/pub/compel/) ★MPDB,分子探针数据库。 http://www.biotech.ist.unige.it/interlab/mpdb.html ★HvrBase,灵长类mtDNA调控区序列库,主要是人的HVI和HVII两个高变异区的序列。http://monolith.eva.mpg.de/hvrbase/ ★PlantCARE,植物顺式作用(cis-acting)调控因子数据库。 http://sphinx.rug.ac.be:8080/PlantCare/
生物信息学数据库
数据库是生物信息学的主要内容,各种数据库几乎覆盖了生命科学的各个领域。核酸序列数据库有GenBank, EMBL, DDBJ等,蛋白质序列数据库有SWISS-PROT, PIR, OWL, NRL3D, TrEMBL等,蛋白质片段数据库有PROSITE, BLOCKS, PRINTS等,三维结构数据库有PDB, NDB, BioMagResBank, CCSD等,与蛋白质结构有关的数据库还有SCOP, CATH, FSSP, 3D-ALI, DSSP等,与基因组有关的数据库还有ESTdb, OMIM, GDB, GSDB等,文献数据库有Medline, Uncover等。另外一些公司还开发了商业数据库,如MDL等。生物信息学数据库覆盖面广,分布分散且格式不统一, 因此一些生物计算中心将多个数据库整合在一起提供综合服务,如EBI的SRS(Sequence Retrieval System)包含了核酸序列库、蛋白质序列库,三维结构库等30多个数据库及CLUSTALW、PROSITESEARCH等强有力的搜索工具,用户可以进行多个数据库的多种查询。 基因和基因组数据库 1. Genbank Genbank库包含了所有已知的核酸序列和蛋白质序列,以及与它们相关的文献著作和生物学注释。它是由美国国立生物技术信息中心(NCBI)建立和维护的。它的数据直接来源于测序工作者提交的序列;由测序中心提交的大量EST序列和其它测序数据;以及与其它数据机
构协作交换数据而来。Genbank每天都会与欧洲分子生物学实验室(EMBL)的数据库,和日本的DNA数据库(DDBJ)交换数据,使这三个数据库的数据同步。Genbank的数据可以从NCBI的FTP服务器上免费下载完整的库,或下载积累的新数据。NCBI还提供广泛的数据查询、序列相似性搜索以及其它分析服务,用户可
生物信息学数据库列表
生物信息学数据库列表 美国生物技术信息中心(NCBI)GenBank (https://www.360docs.net/doc/3017574114.html,/Web/Genbank/index.html) 欧洲分子生物学实验室(EMBL)EMBL-Bank(https://www.360docs.net/doc/3017574114.html,/embl/index.html) 日本遗传研究所DDBJ(http://www.ddbj.nig.ac.jp/) 基因组数据库: NCBI基因组数据库Entrez Genmous (https://www.360docs.net/doc/3017574114.html,/entrez/query.fcgi?db=Genome) 人类基因组计划图谱数据库:GDB(https://www.360docs.net/doc/3017574114.html,/) 酵母基因组数据库:SGD(https://www.360docs.net/doc/3017574114.html,/) 小鼠基因组信息学数据库:MGI(https://www.360docs.net/doc/3017574114.html,/) 果蝇基因组数据库:FlyBase(https://www.360docs.net/doc/3017574114.html,/) 线虫基因组数据库:WormBase(https://www.360docs.net/doc/3017574114.html,/) 综合基因组数据库:Ensembl(https://www.360docs.net/doc/3017574114.html,/) 表达序列标记数据库dbEST(https://www.360docs.net/doc/3017574114.html,/dbEST/) 序列标记位点数据库dbSTS(https://www.360docs.net/doc/3017574114.html,/dbSTS/) 蛋白质序列数据库 PIR(https://www.360docs.net/doc/3017574114.html,/pir/) SWISS-PROT(https://www.360docs.net/doc/3017574114.html,/swissprot/) TrEMBL(https://www.360docs.net/doc/3017574114.html,/trembl/index.html) 蛋白质数据仓库Uniprot(https://www.360docs.net/doc/3017574114.html,/uniprot.index.html) 生物大分子结构数据库 PDB(protein date bank)(https://www.360docs.net/doc/3017574114.html,/pdb/) MMDB(molecular modeling database) (https://www.360docs.net/doc/3017574114.html,/Structure/MMDB/mmdb.shtml) 单碱基多态性数据库dbSNP(https://www.360docs.net/doc/3017574114.html,/SNP/) 蛋白质结构分类数据库SCOP(https://www.360docs.net/doc/3017574114.html,/scop/) 蛋白质二级结构数据库DSSP(http://www.sander.embl-heidelberg.de/dssp/) 蛋白质同源序列比对数据库HSSP(http://www.sander.embl-heidelberg.de/hssp/) 序列模式数据库PROSITE(https://www.360docs.net/doc/3017574114.html,/prosite/) 蛋白质指纹数据库PRINTS(https://www.360docs.net/doc/3017574114.html,/dbbrowser/PRINTS/)
生物信息学数据库答案[1]
生物信息学(bioinformatics):是一门交叉学科,它包含了生物信息的获取,处理,存储,分发,分析和解释等在内的所以方面,它综合运用数学,计算机科学和生物学的各种工具,来阐明和理解大量数据所包含的生物学意义。 目的:揭示"基因组信息结构的复杂性及遗传语言的根本规律",解释生命的遗传语言。 方法:主要有创建一切适用于基因组信息分析的新方法,改进现有的理论分析方法,发展有效的能支持大尺度作图与测序需要的软件、数据库以及若干数据库工具等。 应用:生物信息的存储与获取,序列比对,测序与拼接,基因预测,生物进化与系统发育分析,蛋白质结构预测,RNA结构预测,分子设计与药物设计,代谢网络分析,基因芯片,DNA计算等。 1.1.3生物信息学的研究内容 1、序列比对(Alignment)。 2、结构比对。基本问题是比较两个或两个以上蛋白质分子空间结构的相似性或不相似性。已有一些算法。 3、蛋白质结构预测,包括2级和3级结构预测,是最重要的课题之一。 4、计算机辅助基因识别(仅指蛋白质编码基因)。 5、非编码区分析和DNA语言研究,是最重要的课题之一。 6、分子进化和比较基因组学,是最重要的课题之一。 7、序列重叠群(Contigs)装配。 8、遗传密码的起源。 9、基于结构的药物设计。10、其他。如基因表达浦分析,代谢网络分析;基因芯片设计和蛋白质组学数据分析等,逐渐成为生物信息学中新兴的重要研究领域。这里不再赘述。 3、开放式阅读框(ORF):是基因的起始密码子开始到终止密码子为止的一个连续编码的序列。 5、中心法则:包括DNA的自我复制,转录形成RNA并翻译成蛋白质,RNA的自我复制和逆转录的过程。 6序列比对(alignment):为确定两个或多个序列之间的相似性以至于同源性,而将它们按照一定的规律排列。 6、算法分析:评价一个算法的优劣,通过时间复杂度和空间复杂度来确定。 7、数据库管理系统:(database management system,DBMS)对DB进行管理的系统工程,提供DB的建立、查询、更新以及各种数据控制能。 8、数据库:统一管理的相关数据的集合。 9、搜索软件:对内容进行筛选,从中选择出符合用户的检索要求的内容同时进行分级排序,将结果显示出来。 10、人类基因组计划(HGP):是对人类24条染色体上的3X109个碱基对(base pair,bp)序列进行测定,完成图谱绘制、测序、基因识别,及信息系统的建立。 一、名词解释: 1.生物信息学:研究大量生物数据复杂关系的学科,其特征是多学科交叉,以互联网为媒介,数据库为载体。利用数学知识建立各种数学模型; 利用计算机为工具对实验所得大量生物学数据进行储存、检索、处理及分析,并以生物学知识对结果进行解释。 3一级数据库(一次数据库):基因组数据库来自基因组作图,序列数据库来自序列测定,结构数据库来自X射线衍射和核磁共振等结构测定。这些数据库是分子生物学的基本数据资源,通常称为基本数据库、初始数据库,也称一次数据库。 2.二级数据库:在一级数据库、实验数据和理论分析的基础上针对特定目标衍生而来,是对生物学知识和信息的进一步的整理。