Eviews软件数据分析例文

小学期作业
影响财政收入的主要因素
学院:经济学院
班级:统计学班
姓名:梁语丝
学号:2011407036
影响财政收入的主要因素
摘要:
财政收入是一国政府实现政府职能的基本保障,主要有资源配置、收入再分配和宏观经济调控三大职能。财政收入的增长情况关系着一个国家经济的发展和社会的进步。我国财政收入主要受国民经济发展、预算外资金收入、税收收入等因素的影响。本文针对我国财政收入影响因素建立了计量经济模型,并利用Eviews软件对收集到的数据进行相关回归分析,排除简单多元回归模型存在的严重多重共线性等问题,建立财政收入影响因素更精确的模型,分析了影响财政收入主要因素及其影响程度,预测我国财政收入增长趋势。
二、模型设定
研究财政收入的影响因素离不开一些基本的经济变量。大多数相关的研究文献中都把总税收、国内生产总值这两个指标作为影响财政收入的基本因素,还有一些文献中也提出了其他一些变量, 比如其他收入、经济发展水平等。影响财政收入的因素众多复杂, 但是通过研究经济理论对财政收入的解释以及对实践的观察, 对财政收入影响的因素主要是税收收入。下面我们就以税收收入、能源消费总量、和预算外资金收入作为影响财政收入的主要研究因素。
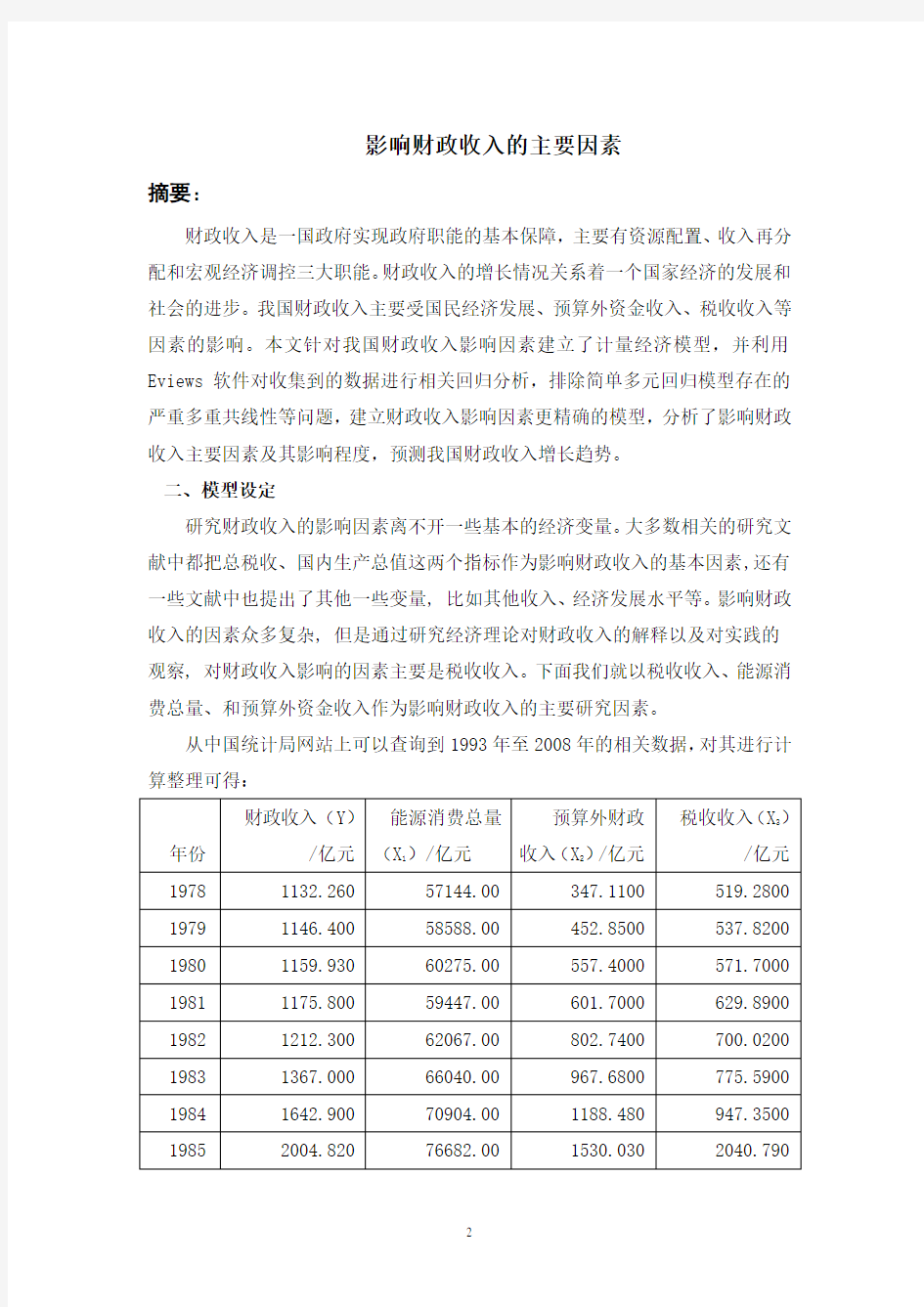
从中国统计局网站上可以查询到1993年至2008年的相关数据,对其进行计算整理可得:
年份财政收入(Y)
/亿元
能源消费总量
(X
1
)/亿元
预算外财政
收入(X
2
)/亿元
税收收入(X
3
)
/亿元
1978 1132.260 57144.00 347.1100 519.2800 1979 1146.400 58588.00 452.8500 537.8200 1980 1159.930 60275.00 557.4000 571.7000 1981 1175.800 59447.00 601.7000 629.8900 1982 1212.300 62067.00 802.7400 700.0200 1983 1367.000 66040.00 967.6800 775.5900 1984 1642.900 70904.00 1188.480 947.3500 1985 2004.820 76682.00 1530.030 2040.790
1986 2122.000 80850.00 1737.310 2090.730 1987 2199.400 86632.00 2028.800 2140.360 1988 2357.200 92997.00 2360.770 2390.470 1989 2664.900 96934.00 2658.830 2727.400 1990 2937.100 98703.00 2708.640 2821.860 1991 3149.480 103783.0 3243.300 2990.170 1992 3483.370 109170.0 3854.920 3296.910 1993 4348.950 115993.0 1432.540 4255.300 1994 5218.100 122737.0 1862.530 5126.880 1995 6242.200 131176.0 2406.500 6038.040 1996 7407.990 138948.0 3893.340 6909.820 1997 8651.140 137798.0 2826.000 8234.040 1998 9875.950 132214.0 3082.290 9262.800 1999 11444.08 133831.0 3385.170 10682.58 2000 13395.23 138553.0 3826.430 12581.51 2001 16386.04 143199.0 4300.000 15301.38 2002 18903.64 151797.0 4479.000 17636.45 2003 21715.25 174990.0 4566.800 20017.31 2004 26396.47 203227.0 4699.180 24165.68 2005 31649.29 224682.0 5544.160 28778.54 2006 38760.20 246270.0 6407.880 34804.35 2007 51321.78 265583.0 6820.320 45621.97 2008 61330.35 285000.0 7039.720 54219.62
4.、模型的建立
根据1978—2008年每年的财政收入Y( 亿元) , 能源消费总量X1( 亿元),预算外资金收入X2( 亿元) ,税收收入X3( 亿元) 的统计数据,由E-views软件得到y,x1,x2,x3的线性图,如下:
由图可知,y,x1, x3都是逐年增长的,但增长速率有所变动,而x2呈现水平波动,说明变量间不一定是线性关系,可探索将模型设定为以下形式:
lnY=β
0+β
1
lnX1+β
2
X2+β
3
lnX3+U
三,模型估计与调整
利用Eviews软件对模型进行最小二乘法全回归,结果如下:
第一步,进行模型的检验。
(一),进行多重共线性的检验
方程的修正后的R平方值很高,说明变量对因变量的拟合程度很好,但是应该注意到c,lnx1,x2三者的t值很低(在此选择置信度为0.05),未通过检
验,因此怀疑其中存在变量之间的多重共线问题。
检测自变量lny,lnx1,x2,lnx3之间的相关系数,判断多重共线性的可能如下图:
观察得知:各个解释变量之间的相关系数比较高,进一步怀疑其存在多重共线,需进行进一步修正。
(二),进行异方差的检验
1,图形法检验
通过生成残差平方序列绘制散点图如下:
由图可以看出,残差平方对解释变量的散点图主要集中分布在图形的下方,判断模型可能存在异方差。但是否确实存在异方差还需进行进一步的检验。
2,White检验:
根据估计结果,得到White检验的结果如下:
由图可知,nR2=17.7399,由White检验知,在置信度为0.05下,得临界值
为18.3070> nR2=17.7399,表明模型不存在异方差。
(三),进行自相关检验
由原模型的回归结果得,修正后的R2= 0.9765,F = 416.1494,df=31,DW =0.1915,该回归方程可决系数较高,回归系数均显著。对样本量为31,、三个解释变量的模型、5%显著水平,查DW 统计表可知,dL=1.229,dU=1.650,模型中DW 由图可发现残差波动比较大,连续为正和连续为负,并且由回归结果可知残差项存在一阶自相关问题,需采取补救措施。 第二步,通过以上分析,对该模型进行修正,如下: 1,进行多重共线性的修正, 通过对相关系数观察得知,利用逐步回归法对原模型进行修正,以lnx3为因变量对其他解释变量进行逐步回归,可得如下分析结果, 经分析可知,当加入lnx1时,可决系数有所改善,但t检验不显著,且参数为负值不合理,从相关系数也可以看出,lnx1与其他变量高度相关。而加入x2时,t检验显著,且可决系数改善也较大。这说明主要是lnx1引起了多重共线性,予以剔除。 2,对修正后的模型再次进行自相关检验 由修正后模型的回归结果得,修正后的R2= 0.9765,F = 623.8471,df=31,DW =0.2599,该回归方程可决系数较高,回归系数均显著。对样本量为31,、二个解释变量的模型、5%显著水平,查DW 统计表可知,dL=1.297,dU=1.570,模型中DW 由图可发现残差波动比较大,连续为正和连续为负,并且由回归结果可知残差项存在一阶自相关问题,需采取补救措施。 3,进行自相关的修正 为解决自相关问题,选用广义差分法。对残差进行回归分析,得到e的残差序 列,对其进行滞后一期的自回归,可得回归方程如下:e t=0.8290e t-1 对该模型进行广义差分,得到下图: 由于使用了广义差分数据,样本容量减少了1个,为30个。由图得,DW=1.4672,查1%显著水平的DW 统计表可知dL= 1.070,dU = 1.339,模型中DW=1.4672>dU,说明广义差分模型中已无自相关。同时,修正后的可决系数R2、t、F 统计量均达到理想水平。由此可见,财政收入与税收收入和预算外收入成正相关,这与理论分析和经验判断相一致,通过了经济学意义的检验。 由此,我们得到最终的财政收入模型为: lnY=3.1655+(9.22E-06)X2+ 0.6197lnX3 经上述论证,财政收入(Y)主要与税收(x3)成正相关关系。而且,从经济意义上面分析,虽然财政收入一般与预算外收入的关系也不是很大,但还是有一定关系的,且经过计量经济分析通过了检验,所以同样予以保留。 EViews 6.0 beta在面板数据模型估计中的应用 来自免费的minixi 1、进入工作目录cd d:\nklx3,在指定的路径下工作是一个良好的习惯 2、建立面板数据工作文件workfile (1)最好不要选择EViews默认的blanaced panel 类型 Moren_panel (2)按照要求建立简单的满足时期周期和长度要求的时期型工作文件 3、建立pool对象 (1)新建对象 (2)选择新建对象类型并命名 (3)为新建pool对象设置截面单元的表示名称,在此提示下(Cross Section Identifiers: (Enter identifiers below this line )输入截面单元名称。,建议采用汉语拼音,例如29个省市区的汉语拼音,建议在拼音名前加一个下划线“_”,如图 关闭建立的pool对象,它就出现在当前工作文件中。 4、在pool对象中建立面板数据序列 双击pool对象,打开pool对象窗口,在菜单view的下拉项中选择spreedsheet (展开表) 在打开的序列列表窗口中输入你要建立的序列名称,如果是面板数据序列必须在序列名后添加“?”。例如,输入GDP?,在GDP后的?的作用是各个截面单元的占位符,生成了29个省市区的GDP的序列名,即GDP后接截面单元名,再在接时期,就表示出面板数据的3维数据结构(1变量2截面单元3时期)了。 请看工作文件窗口中的序列名。展开表(类似excel)中等待你输入、贴入数据。 (1)打开编辑(edit)窗口 (2)贴入数据 (3)关闭pool窗口,赶快存盘见好就收6、在pool窗口对各个序列进行单位根检验 选择单位根检验 设置单位根检验 互联网营销与大数据分析大数据营销,依托大数据技术的基础大数据营销是基于多平台的大量数据行大数据营销衍 生于互联网上,应用于互联网广告行业的营销方式。依托多平台的大数据采集,以及大数据技业,又作用于互联网行业。给品牌企业带来更能够使广告更加精准有效,术的分析与预测能力,高的投资回报率。大数据营销的核心在于让网络广告在合适的时间,通过合适的载体,以合适的方式,投给合适的人。 大数据营销是指通过互联网采集大量的行为数据,首先帮助广告主找出目标受众,以此对广告投放的内容、时间、形式等进行预判与调配,并最终完成广告投放的营销过程。 大数据营销,随着数字生活空间的普及,全球的信息总量正呈现爆炸式增长。基于这个趋势之上的,是大数据、云计算等新概念和新范式的广泛兴起,它们无疑正引领着新一轮的互联网风潮。 多平台化数据采集:大数据的数据来源通常是多样化的,多平台化的数据采集能使对网民行为的刻画更加全面而准确。多平台采集可包含互联网、移动互联网、广电网、智能电视未来还有户外智能屏等[1]?。数据 [2]?:在网络时代,网民的消费行为和购买方式极易时效性强调在短的时间内发生变化。在网民需求点最高时及时进行营销非常重对此提出了时间营销策略,AdTime要。全球领先的大数据营销企业 它可通过技术手段充分了解网民的需求,并及时响应每一个网民当前 的需求,让他在决定购买的“黄金时间”内及时接收到商品广告。 个性化营销:在网络时代,广告主的营销理念已从“媒体导向”向“受众导向”转变。以往的营销活动须以媒体为导向,选择知名度高、浏览量大的媒体进行投放。如今,广告主完全以受众为导向进行广告营销,因为大数据技术可让他们知晓目标受众身处何方,关注着什么位置的什么屏幕。大数据技术可以做到当不同用户关注同一媒体的相同界面时,广告内容有所不同,大数据营销实现了对网民的个性化营销。性价比高:和传统广告“一半的广告费被浪费掉”相比,大数据营销在最大程度上,让广告主的投放做到有的放矢,并可根据实时性的效果反馈,及时对投放策略进行调整。 关联性:大数据营销的一个重要特点在于网民关注的广告与广告之间的关联性,由于大数据在采集过程中可快速得知目标受众关注的内容,以及可知晓网民身在何处,这些有价信息可让广告的投放过程产生前所未有的关联性。即网民所看到的上一条广告可与下一条广告进行深度互动。 大数据营销的实现过程: [3]?大数据营销并非是一个停留在概念上的名词,而是一个通过大量运算基础上的技术实现过程。虽然围绕着大数据进行的话题层出不穷,且在大多数人对大数据营销的过程不甚清晰。事实上,国内的全球领先的大很多以技术为驱动力的企业也在大数据领域深耕不辍。. 率先推出了大数据广告运营平台——云图。据AdTime数据营销平台 介绍,云图的云代表云计算,图代表可视化。云图的含义是将云计算 EViews 6.0在面板数据模型估计中的实验操作 1、进入工作目录cd d:\nklx3,在指定的路径下工作是一个良好的习惯 2、建立面板数据工作文件workfile (1)最好不要选择EViews默认的blanaced panel 类型 Moren_panel (2)按照要求建立简单的满足时期周期和长度要求的时期型工作文件 3、建立pool对象 (1)新建对象 (2)选择新建对象类型并命名 (3)为新建pool对象设置截面单元的表示名称,在此提示下(Cross Section Identifiers: (Enter identifiers below this line )输入截面单元名称。建议采用汉语拼音,例如29个省市区的汉语拼音,建议在拼音名前加一个下划线“_”,如图 关闭建立的pool对象,它就出现在当前工作文件中。 4、在pool对象中建立面板数据序列 双击pool对象,打开pool对象窗口,在菜单view的下拉项中选择spreedsheet (展开表) 在打开的序列列表窗口中输入你要建立的序列名称,如果是面板数据序列必须在序列名后添加“?”。例如,输入GDP?,在GDP后的?的作用是各个截面单元的占位符,生成了29个省市区的GDP的序列名,即GDP后接截面单元名,再在接时期,就表示出面板数据的3维数据结构(1变量2截面单元3时期)了。 请看工作文件窗口中的序列名。展开表(类似excel)中等待你输入、贴入数据。 (1)打开编辑(edit)窗口 (2)贴入数据 (3)关闭pool窗口,赶快存盘见好就收6、在pool窗口对各个序列进行单位根检验 选择单位根检验 设置单位根检验 互联网营销与大数据分析 大数据营销 大数据营销是基于多平台的大量数据,依托大数据技术的基础上,应用于互联网广告行业的营销方式。大数据营销衍生于互联网行业,又作用于互联网行业。依托多平台的大数据采集,以及大数据技术的分析与预测能力,能够使广告更加精准有效,给品牌企业带来更高的投资回报率。 大数据营销的核心在于让网络广告在合适的时间,通过合适的载体,以合适的方式,投给合适的人。 大数据营销是指通过互联网采集大量的行为数据,首先帮助广告主找出目标受众,以此对广告投放的内容、时间、形式等进行预判与调配,并最终完成广告投放的营销过程。 大数据营销,随着数字生活空间的普及,全球的信息总量正呈现爆炸式增长。基于这个趋势之上的,是大数据、云计算等新概念和新范式的广泛兴起,它们无疑正引领着新一轮的互联网风潮。 多平台化数据采集:大数据的数据来源通常是多样化的,多平台化的数据采集能使对网民行为的刻画更加全面而准确。多平台采集可包含互联网、移动互联网、广电网、智能电视未来还有户外智能屏等数据[1]。 强调时效性[2]:在网络时代,网民的消费行为和购买方式极易在短的时间内发生变化。在网民需求点最高时及时进行营销非常重要。全球领先的大数据营销企业AdTime对此提出了时间营销策略, 它可通过技术手段充分了解网民的需求,并及时响应每一个网民当前的需求,让他在决定购买的“黄金时间”内及时接收到商品广告。 个性化营销:在网络时代,广告主的营销理念已从“媒体导向”向“受众导向”转变。以往的营销活动须以媒体为导向,选择知名度高、浏览量大的媒体进行投放。如今,广告主完全以受众为导向进行广告营销,因为大数据技术可让他们知晓目标受众身处何方,关注着什么位置的什么屏幕。大数据技术可以做到当不同用户关注同一媒体的相同界面时,广告内容有所不同,大数据营销实现了对网民的个性化营销。 性价比高:和传统广告“一半的广告费被浪费掉”相比,大数据营销在最大程度上,让广告主的投放做到有的放矢,并可根据实时性的效果反馈,及时对投放策略进行调整。 关联性:大数据营销的一个重要特点在于网民关注的广告与广告之间的关联性,由于大数据在采集过程中可快速得知目标受众关注的内容,以及可知晓网民身在何处,这些有价信息可让广告的投放过程产生前所未有的关联性。即网民所看到的上一条广告可与下一条广告进行深度互动。 大数据营销的实现过程: 大数据营销[3]并非是一个停留在概念上的名词,而是一个通过大量运算基础上的技术实现过程。虽然围绕着大数据进行的话题层出不穷,且在大多数人对大数据营销的过程不甚清晰。事实上,国内的很多以技术为驱动力的企业也在大数据领域深耕不辍。全球领先的大 1.已知1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(cp,不变价格)和人均收入(ip,不变价格)居民,利用数据(1)建立面板 数据(panel data)工作文件;(2)定义序列名并输入数据;(3)估计选择面板模型;(4)面板单位根检验。 年人均消费(consume)和人均收入(income)数据以及消费者价格指数(p)分别见表9.1,9.2和9.3。 表9.1 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(元)数据人均消费1996 1997 1998 1999 2000 2001 2002 CONSUMEAH 3607.43 3693.55 3777.41 3901.81 4232.98 4517.65 4736.52 CONSUMEBJ 5729.52 6531.81 6970.83 7498.48 8493.49 8922.72 10284.6 CONSUMEFJ 4248.47 4935.95 5181.45 5266.69 5638.74 6015.11 6631.68 CONSUMEHB 3424.35 4003.71 3834.43 4026.3 4348.47 4479.75 5069.28 CONSUMEHLJ 3110.92 3213.42 3303.15 3481.74 3824.44 4192.36 4462.08 CONSUMEJL 3037.32 3408.03 3449.74 3661.68 4020.87 4337.22 4973.88 CONSUMEJS 4057.5 4533.57 4889.43 5010.91 5323.18 5532.74 6042.6 CONSUMEJX 2942.11 3199.61 3266.81 3482.33 3623.56 3894.51 4549.32 CONSUMELN 3493.02 3719.91 3890.74 3989.93 4356.06 4654.42 5342.64 CONSUMENMG 2767.84 3032.3 3105.74 3468.99 3927.75 4195.62 4859.88 CONSUMESD 3770.99 4040.63 4143.96 4515.05 5022 5252.41 5596.32 CONSUMESH 6763.12 6819.94 6866.41 8247.69 8868.19 9336.1 10464 CONSUMESX 3035.59 3228.71 3267.7 3492.98 3941.87 4123.01 4710.96 CONSUMETJ 4679.61 5204.15 5471.01 5851.53 6121.04 6987.22 7191.96 CONSUMEZJ 5764.27 6170.14 6217.93 6521.54 7020.22 7952.39 8713.08 表9.2 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均收入(元)数据人均收入1996 1997 1998 1999 2000 2001 2002 INCOMEAH 4512.77 4599.27 4770.47 5064.6 5293.55 5668.8 6032.4 INCOMEBJ 7332.01 7813.16 8471.98 9182.76 10349.69 11577.78 12463.92 INCOMEFJ 5172.93 6143.64 6485.63 6859.81 7432.26 8313.08 9189.36 INCOMEHB 4442.81 4958.67 5084.64 5365.03 5661.16 5984.82 6679.68 INCOMEHLJ 3768.31 4090.72 4268.5 4595.14 4912.88 5425.87 6100.56 INCOMEJL 3805.53 4190.58 4206.64 4480.01 4810 5340.46 6260.16 INCOMEJS 5185.79 5765.2 6017.85 6538.2 6800.23 7375.1 8177.64 INCOMEJX 3780.2 4071.32 4251.42 4720.58 5103.58 5506.02 6335.64 INCOMELN 4207.23 4518.1 4617.24 4898.61 5357.79 5797.01 6524.52 INCOMENMG 3431.81 3944.67 4353.02 4770.53 5129.05 5535.89 6051 INCOMESD 4890.28 5190.79 5380.08 5808.96 6489.97 7101.08 7614.36 INCOMESH 8178.48 8438.89 8773.1 10931.64 11718.01 12883.46 13249.8 INCOMESX 3702.69 3989.92 4098.73 4342.61 4724.11 5391.05 6234.36 INCOMETJ 5967.71 6608.39 7110.54 7649.83 8140.5 8958.7 9337.56 INCOMEZJ 6955.79 7358.72 7836.76 8427.95 9279.16 10464.67 11715.6 表9.3 1996—2002年中国东北、华北、华东15个省级地区的消费者物价指数 物价指数1996 1997 1998 1999 2000 2001 2002 PAH 109.9 101.3 100 97.8 100.7 100.5 99 毕业论文(设计) 题目基于互联网APP行业的用户行为数据分析与挖掘系信息工程系 专业、年级计算机网络12级 学生姓名赵伯韬 指导教师康健职称副教授 论文字数9956 完成日期2015 年 4 月30 日 唐山职业技术学院毕业设计任务书 信息工程系计算机网络专业一班学生姓名:赵伯韬学号:121120101 一、毕业设计(论文)题目:基于互联网APP行业的用户行为数据分析与挖掘 任务进行的日期:2014 年 12 月 10 日起至 2015 年 4 月 30 日 三、任务书的内容:基于互联网APP行业的用户行为数据分析与挖掘 (一)选题的目的和意义: 随着近年来国内互联网APP的强势发展与三网融合的态势进展,互联网APP行业的市场竞争愈发激烈,各运营商基于用户习惯产品的竞争将是服务的竞争。由于互联网APP业务的多样性,国内运营商逐步从“产品独立运营”向以“客户为中心”的融合运营模式转变,新的商业模式和日趋激烈的竞争环境对电信增值业务运营管理提出了新的要求和挑战。 (二)设计内容: 首先探讨了用户行为分析及其方法,深入学习各种数据挖掘的算法与软件的基础上构建用户行为分析与业务匹配模型。然后在对移动互联网的数据分析理解之后进行数据收集,对于获取到的数据,按照ETL (Extraction-Transformation-Loading)对七千万条数据进行清理、整合,构建数据库。通过数据挖掘的相关工具对用户行为分别在热点时间、用户兴趣、匹配业务等角度采用聚类、文本挖掘、关联分析等方法进行知识挖掘,从统计数据中发现现有营销策略的问题,给运营商提供新的思路并为精准营销提供数据支撑。(三)主要参考资料: [1] 王禹媚,田俊维移动互联网产业发展国际论坛会议纪要2013中国国际工业博览会论坛上海2014年11月10日 [2] 宴宗明基于用户行为分析的移动通信增值业务市场策略研究长沙:2013 [3] 杰斌.数据挖掘与OLAP理论与务实.北京:清华大学出版社,20013 (四)时间进度要求: 2013年12月-2014年3月毕业设计调查 2014年4月—2014年8月毕业设计初步设计 2014年9月—2015年1月毕业设计详细设计 2015年2月—2015年5月准备毕业答辩 指导教师签名: 2015年 5月 16 日 教研室主任签名:年月日 学生签名:年月日 1.已知1996—2002 年中国东北、华北、华东15 个省级地区的居民家庭人均消费(cp ,不变价格)和人均收入(ip ,不变价格)居民,利用数据(1)建立面板数据(panel data)工作文件;(2)定义序列名并输入数据;(3)估计选择面板模型;(4)面板单位根检验。 年人均消费(consume)和人均收入(income)数据以及消费者价格指数(p)分别见表9.1,9.2 和9.3。 表9.1 1996—2002 年中国东北、华北、华东15 个省级地区的居民家庭人均消费(元)数据人均消费1996 1997 1998 1999 2000 2001 2002 CONSUMEAH 3607.43 3693.55 3777.41 3901.81 4232.98 4517.65 4736.52 CONSUMEBJ 5729.52 6531.81 6970.83 7498.48 8493.49 8922.72 10284.6 CONSUMEFJ 4248.47 4935.95 5181.45 5266.69 5638.74 6015.11 6631.68 CONSUMEHB 3424.35 4003.71 3834.43 4026.3 4348.47 4479.75 5069.28 CONSUMEHLJ 3110.92 3213.42 3303.15 3481.74 3824.44 4192.36 4462.08 CONSUMEJL 3037.32 3408.03 3449.74 3661.68 4020.87 4337.22 4973.88 CONSUMEJS 4057.5 4533.57 4889.43 5010.91 5323.18 5532.74 6042.6 CONSUMEJX 2942.11 3199.61 3266.81 3482.33 3623.56 3894.51 4549.32 CONSUMELN 3493.02 3719.91 3890.74 3989.93 4356.06 4654.42 5342.64 CONSUMENMG 2767.84 3032.3 3105.74 3468.99 3927.75 4195.62 4859.88 CONSUMESD 3770.99 4040.63 4143.96 4515.05 5022 5252.41 5596.32 CONSUMESH 6763.12 6819.94 6866.41 8247.69 8868.19 9336.1 10464 CONSUMESX 3035.59 3228.71 3267.7 3492.98 3941.87 4123.01 4710.96 CONSUMETJ 4679.61 5204.15 5471.01 5851.53 6121.04 6987.22 7191.96 CONSUMEZJ 5764.27 6170.14 6217.93 6521.54 7020.22 7952.39 8713.08 表9.2 1996—2002 年中国东北、华北、华东15 个省级地区的居民家庭人均收入(元)数据人均收入1996 1997 1998 1999 2000 2001 2002 INCOMEAH 4512.77 4599.27 4770.47 5064.6 5293.55 5668.8 6032.4 INCOMEBJ 7332.01 7813.16 8471.98 9182.76 10349.69 11577.78 12463.92 INCOMEFJ 5172.93 6143.64 6485.63 6859.81 7432.26 8313.08 9189.36 INCOMEHB 4442.81 4958.67 5084.64 5365.03 5661.16 5984.82 6679.68 INCOMEHLJ 3768.31 4090.72 4268.5 4595.14 4912.88 5425.87 6100.56 INCOMEJL 3805.53 4190.58 4206.64 4480.01 4810 5340.46 6260.16 INCOMEJS 5185.79 5765.2 6017.85 6538.2 6800.23 7375.1 8177.64 INCOMEJX 3780.2 4071.32 4251.42 4720.58 5103.58 5506.02 6335.64 INCOMELN 4207.23 4518.1 4617.24 4898.61 5357.79 5797.01 6524.52 INCOMENMG 3431.81 3944.67 4353.02 4770.53 5129.05 5535.89 6051 INCOMESD 4890.28 5190.79 5380.08 5808.96 6489.97 7101.08 7614.36 INCOMESH 8178.48 8438.89 8773.1 10931.64 11718.01 12883.46 13249.8 INCOMESX 3702.69 3989.92 4098.73 4342.61 4724.11 5391.05 6234.36 INCOMETJ 5967.71 6608.39 7110.54 7649.83 8140.5 8958.7 9337.56 INCOMEZJ 6955.79 7358.72 7836.76 8427.95 9279.16 10464.67 11715.6 上海蓝草企业管理咨询有限公司 《大数据分析与互联网平台运营管理》 蓝草课程注意突出实战性、技能型领域的应用型课程;特别关注新技术、新渠道、新知识创新型知识课程。 蓝草咨询坚定认为,卓越的训练培训是获得知识的绝佳路径,但也应是学员快乐的旅程,蓝草企业的口号是:为快乐而培训为培训更快乐! 蓝草咨询为实现上述目标,为培训机构、培训学员提供了多种形式的优惠和增值快乐的政策和手段,可以提供开具培训费的增值税专用发票。 【课程背景】 如何了解线上客户的购买意愿和需求?如何进行网上消费行为的数据分析,从而指导各项运营工作的开展? 如何通过大数据分析,来对互联网平台的绩效分析,发现影响平台绩效的“罪魁祸首”,并进行运营优化和管理? 如何系统化地整体打造和改进互联网平台?从市场运营到产品创新,如何进行改进? 互联网平台如何有效的组织运营管理?日常的运营管理主要要做什么? 如何对互联网平台进行市场细分和定位,挖掘潜在目标客户?刺激潜在需求? 如何组织各种营销活动,对平台商品进行展示和包装,提升电商的销售转化率? 如何优化互联网平台的产品组合,优化品类?设计商品套装、解决方案? 如何通过消费者研究,开展产品的改进和创新?提升产品吸引力? 本课程将全方位提供专有技术对互联网平台进行全方位的设计和打造!包括以下内容: 上海蓝草企业管理咨询有限公司 基于我们对企业产品生产经营过程和工作模型的多年研究,本课程就是提供一个整体的方法论,拥有多项专有技术将网络平台的市场运营和规划设计,进行整体的打造! 自主研发三大专有技术模型,促进产品绩效提升!——评一个大数据分析课程的好坏,一定要看有没专业的分析模型才能落地!—— ——很多消费者研究分析技术分析的结果非常“碎片化”!不够精准!无法反应出影响消费者决策的各种因素和各种关联关系,只是进行“碎片式”的数据展示。该技术是自主研发的意向专有技术,专门研究影响消费购买之间的管理,建立了系统的逻辑关系,可更直观地用于运营管理,提升销售转化率! 大数据应用与案例分析 当下,”大数据”几乎是每个IT人都在谈论的一个词汇,不单单是时代发展的趋势,也是革命技术的创新。大数据对于行业的用户也越来越重要。掌握了核心数据,不单单可以进行智能化的决策,还可以在竞争激烈的行业当中脱颖而出,所以对于大数据的战略布局让越来越多的企业引起了重视,并重新定义了自己的在行业的核心竞争。 在当前的互联网领域,大数据的应用已十分广泛,尤其以企业为主,企业成为大数据应用的主体。大数据真能改变企业的运作方式吗?答案毋庸置疑是肯定的。随着企业开始利用大数据,我们每天都会看到大数据新的奇妙的应用,帮助人们真正从中获益。大数据的应用已广泛深入我们生活的方方面面,涵盖医疗、交通、金融、教育、体育、零售等各行各业。 大数据应用的关键,也是其必要条件,就在于"IT"与"经营"的融合,当然,这里的经营的内涵可以非常广泛,小至一个零售门店的经营,大至一个城市的经营。以下是关于各行各业,不同的组织机构在大数据方面的应用的案例,并在此基础上作简单的梳理和分类。 一、大数据应用案例之:医疗行业 Seton Healthcare是采用IBM最新沃森技术医疗保健内容分析预测的首个客户。该技术允许企业找到大量病人相关的临床医疗信息,通过大数据处理,更好地分析病人的信息。在加拿大多伦多的一家医院,针对早产婴儿,每秒钟有超过3000次的数据读取。通过这些数据分析,医院能够提前知道哪些早产儿出现问题并且有针对性地采取措施,避免早产婴儿夭折。 它让更多的创业者更方便地开发产品,比如通过社交网络来收集数据的健康类App。也许未来数年后,它们搜集的数据能让医生给你的诊断变得更为精确,比方说不是通用的成人每日三次一次一片,而是检测到你的血液中药剂已经代谢完成会自动提醒你再次服药。 二、大数据应用案例之:能源行业 智能电网现在欧洲已经做到了终端,也就是所谓的智能电表。在德国,为了鼓励利用太阳能,会在家庭安装太阳能,除了卖电给你,当你的太阳能有多余电的时候还可以买回来。通过电网收集每隔五分钟或十分钟收集一次数据,收集来的这些数据可以用来预测客户的用电习惯等,从而推断出在未来2~3个月时间里,整个电网大概需要多少电。有了这个预测后,就可以向发电或者供电企业购买一定数量的电。因为电有点像期货一样,如果提前买就会比较便宜,买现货就比较贵。通过这个预测后,可以降低采购成本。 互联网大数据文献综述 大数据分析的趋势 亮点 大数据分析中的当前的最先进技术的概述。 大数据分析的规模和应用前景趋势。 在硬件上的现况和未来的发展趋势,如何帮助我们解决大规模数据集。 讨论目前采用的软件技术和未来趋势,以解决大数据分析应用。 关键词: 大数据分析数据中心分布式系统 摘要: 大数据分析是并行的分布式系统未来的主要应用之一。数据仓库目前应用的规模已经超过EB级,并且其规模还在不断增长。当数据集和相关应用程序超出了他们的规模,给这些的构成要求和软件开发方法的考虑带来了重大挑战。数据集通常是分布式,它们的大小和安全考虑到分布式技术来得到保证。数据经常驻留在不同的平台上计算,对网络能力,容错性,安全性和访问控制的考虑是在许多应用中的关键。在其他应用程序中,分析任务的截止时间主要与数据质量有关。对于大多数新兴应用程序,数据驱动的模型和方法,能够大规模操作的方法,到目 前还未找到。即使知道可以缩放的方法,验证结果又是一个重大的问题。硬件平台的特性和软件堆栈从根本上影响数据分析。在这篇文章中,我们提供了一个概述的最先进的硬件和软件的趋势在大数据分析应用程序前景的应用。 引言 随着互联网关键的技术的发展,计算作为一个实用程序的设想在上世纪90年代中期开始形成。在网格计算时代的早期人们通常认为硬件作为主要资源。网格计算技术专注于分享、选择和聚合各种各样的地理上分布的资源。这些资源包括超级计算机、存储和其他设备,用来解决在科学、工程和商业的大规模计算密 集型问题。这些框架的一个关键特性是他们的支持透明跨域管理和资源管理能力。“数据即资源”的概念被普及在p2p系统。Napster、Gnutella,和Bit Torrent 允许节点共享多媒体数据内容通常直接彼此以分散的方式。这这些框架强调互操作性和动态性,降低成本,资源共享特定的沟通和协作,聚集。然而,在这些平台上,匿名,隐私问题和扩展性问题的考虑是次要的。 最近,云计算环境的可靠性、服务的健壮性被(通常的访问来自客户机的浏览器)来自于客户端,大规模生产的移动设备和通用计算机的访问检验。云计算的服务观念概述为“基础架构即服务”(云计算资源在云中可用),数据即服务(数据在云中可用)和软件即服务(访问程序在云中执行)。从服务提供者的角度来看这提供了相当大的好处(在硬件和管理的成本降低),整体资源的利用率,以及更好的客户端接口。云环境的计算底层通常依赖于高效和弹性的数据中心架构,基于虚拟化的计算和存储技术,高效利用商品硬件组件。目前的数据中心通常规模为成千上万的节点,计算在云计算中经常跨越多个数据节点。 新兴的基于云的环境与分布式数据中心托管的大型数据仓库,同时也为分析提供强力的处理有效的并行/分布式算法的需要。潜在的社会经济效益的大数据分析,与多样性的应用提出是很大的挑战,在本文的其他部分我们重点强调数据分析问题的规模和范围。我们描述了常用的硬件平台上执行分析应用的相关情况,并考虑存储,处理,网络和能量。然后,我们专注于应用程序,即虚拟化技术,运行时系统/执行环境和编程的软件基础模型。我们在多样性数据分析的应用中,对健康和人类福利进行计算机建模与模拟得出一个简短的结论。 1.1数据分析的规模和范围 最近保守的研究估计,在2008年世界上的企业服务器系统已经能处理了EViews面板数据模型估计教程
互联网营销与大数据分析
EViews6.0在面板数据模型估计中的操作
互联网营销与大数据分析
eviews面板数据模型详解
基于互联网APP行业的用户行为数据分析与挖掘[第二版]
eviews面板数据模型详解(可编辑修改word版)
《大数据分析与互联网平台运营管理》
大数据应用与案例分析
互联网大数据文献综述