数学建模报告公司的销售额预测
公司的销售额预测
一、问题重述
某公司想用全行业的销售额作为自变量来预测公司的销售量,下表给出了1977—1981年公司的销售额和行业销售额的分季度数据(单位:百万元)
(1)画出数据的散点图,观察用线性回归模型拟合是否合适.
(2)建立公司销售额对全行业的回归模型,并用DW检验诊断随机误差项的自相关性.
(3)建立消除了随机误差项自相关性之后的回归模型.
二、问题分析与假设
销售收入预测的方法主要有时间序列法、因果分析法和本量利分析法等.
时间序列法,是按照时间的顺序,通过对过去几期实际数据的计算分析,确定预测期产品销售收入的预测值.
表1 的数据是以时间顺序为序列的,称为时间序列.由于公司销售额和行业销售额等经济变量均有一定的滞后性,因此,在这样的时间序列数据中,同一变量的顺序观测值之间出现相关现象是很自然的.然而,一旦数据中存在这种自相关序列,如果仍采用普通的回归
模型直接处理,将会出现不良后果,其观测也会失去意义,为此,我们必须先来检验数据是否存在自相关,一旦存在,就要考虑自相关关系,建立新的模型.
定义与符号说明
三、模型建立与求解
一、基本统计回归模型建立
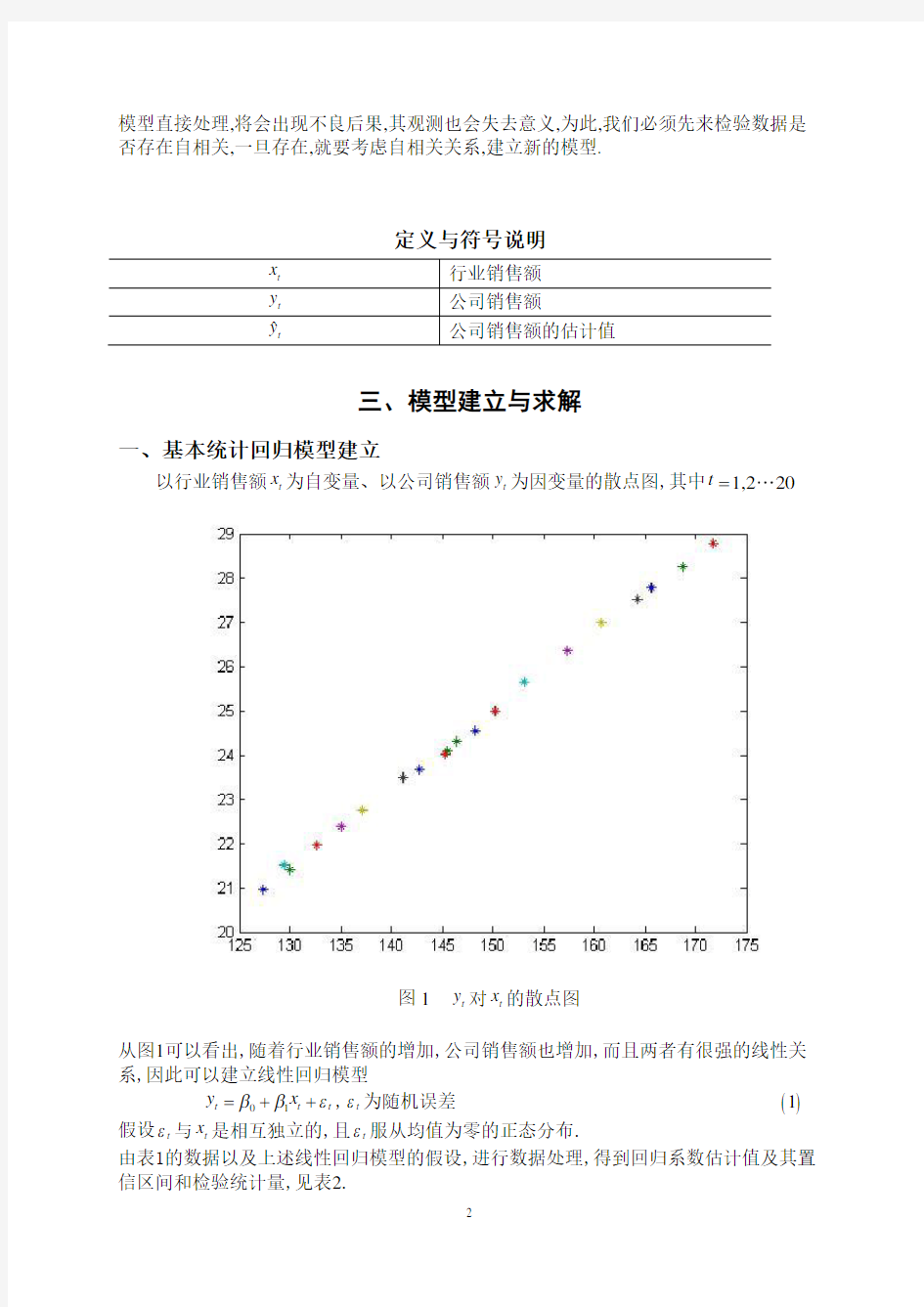
以行业销售额t x 为自变量、以公司销售额t y 为因变量的散点图,其中1,2
20t =
图1 t y 对t x 的散点图
从图1可以看出,随着行业销售额的增加,公司销售额也增加,而且两者有很强的线性关系,因此可以建立线性回归模型
01t t t y x ββε=++,t ε为随机误差 ()1 假设t ε与t x 是相互独立的,且t ε服从均值为零的正态分布.
由表1的数据以及上述线性回归模型的假设,进行数据处理,得到回归系数估计值及其置信区间和检验统计量,见表2.
表2 模型1的计算结果
将参数估计值代入()1得到,
? 1.454750.176283t t y x =-+ ()2
由表2知21R =,t y 几乎处处可由()2确定.用Matlab 作出其交互式画面,由此可以给出不同水平下的预测值及其置信区间,通过左方的Export 下拉式菜单,可以输出模型的统计
结果,见图2.
图2 回归分析中的交互式画面
二、自相关性的判别
我们可以看到模型()2的拟合度很高(21R =),即可认为t y 可由模型确定.但此模型并未考虑到我们的数据是一个时间序列.在对时间序列数据做回归分析时,模型的随机误差项可能存在相关性,违背于模型对t 独立的基本假设.现在我们考虑如下模型:
011t t t
t t t y x u ββεερε-=++=+ ()3
其中ρ是自相关系数,1ρ≤,t u 相互独立且服从均值为0的正态分布.
模型()3中,若0ρ=,则退化为普通的回归模型;若0ρ>,则随机误差t ε存在正的自相关;若0ρ<,则随机误差t ε存在负的自相关.大多数与经济有关的时间序列数据,在经济规律作用下,一般随着时间的推移有一种向上或向下的变动趋势,其随机误差表现出正相关性.
D W -检验是一种常用的诊断自相关现象的统计方法.首先根据模型()2得到的残差,计算DW 统计量如下:
2
1
2
2
1
()n
t
t t n
t
t e e
DW e
-==-=
∑∑ ()4
其中n 是观察值个数,残差?t t t e y y
=-为随机误差项的估计值.当n 较大时, 122121n
t t t n
t t e e DW e -==??
??
??≈-??????
∑∑
()5
而()5式的右端
1
2
2
1
n
t t t n
t
t e e
e
-==∑∑正是自相关系数ρ的估计值?ρ
,于是 ?2(1)DW ρ
≈- ()6 由于?11ρ
-≤≤,所以04DW ≤≤,并且若?ρ在0附近时,则DW 在2附近,t ε的自相关性很弱(或不存在自相关性);若?ρ
在1±附近时,则DW 在0或4附近,t ε的自相关性很强. 要根据DW 的具体数值来确定是否存在自相关性,应该在给定的检验水平下依照样
本容量和回归变量数目,查D W -分布表,得到检验的临界L d 和U d ,然后由表3中DW 所
三、加入自相关后的模型
根据()4式可计算出0.73465DW =,对于显著性水平0.01,20,1n q α===,查D W -分布表,得到检验的临界值0.95L d =和 1.15U d =,现在L DW d <,由表3可以认为随机误
差存在正自相关,且ρ的估计值可由()6式得?0.63268ρ
=. 作变换,
'1t t t y y y ρ-=-,'1t t t x x x ρ-=-, ()7 则模型()3化为
''''01t t t y x u ββ=++,其中()'001ββρ=-,'11ββ= ()8
以ρ的估计值代入()7式作变换,利用变换后的数据't y 、't x 估计模型()8的参数,得到
对模型()8也做一次自相关检验,即诊断随机误差t u 是否还存在自相关,从模型()8的残差
可计算出 1.65199DW =,对于显著性水平0.01,1q α==以及19n =时,检验的临界值为0.93, 1.13L U d d ==,故4U U d DW d <<-,所以可以认为随机误差不存在自相关.因此经变换()7得到的回归模型()8是适用的.
最后,将模型()8中的't y 和't x 还原为原始变量t y 和t x ,得到结果为:
11?0.391410.632680.173740.10992t t t t y
y x x --=-++- ()9 四、结果分析与预测
从机理上看,对于带滞后性的经济规律作用下的时间序列数据,加入自相关的模型
()9更为合理,而且在本例中,衡量与实际数据拟合程序的指标——剩余标准差从模型()2的0.081减少到0.0671.当用模型()9对公司的销售额t y 作预测时,先估计未来的全行业销
售额t x ,比如,设t=21时,t x =174.1,容易由模型()9得到?t y
=29.1860.
四 、模型的评价
一、模型的优点
经D W -检验认为普通回归模型()1的随机误差存在自相关,由()4,()7式估计出自
相关系数ρ后,采用变换()8的方法得到模型()9,成称为广义差分法.这种方法消除了原模型随机误差的自相关性,得到的()9式是一阶自相关模型.
二、模型的缺点
D W -检验和广义差分法在经济数据建模中有着广泛的应用,但是也存在着明显的不足:若DW 的数值落在无法确定自相关性的区间,则只能设法增加数据量,或选用其他方法;如果原始数据序列存在高阶自相关性,则需要反复使用D W -检验和广义差分,直至判定不存在自相关为止.另外,D W -分布表中数据容量n 的下限是15.
参考文献
[1] 徐金明,张孟喜,丁涛,《MATLAB 实用教程》,北京:清华大学出版社;北京交通大学出版社,2005.7(2007.8重印).
[2]. 姜启源,谢金星、叶俊,《数学模型(第四版)》,北京:高等教育出版社,20011.1(2012.5重印).
附录
1.散点图的程序
clear;
x=[127.3 130.0 132.7 129.4 135.0 137.1 141.2 142.8 145.5 145.3 148.3 146.4 150.2 153.1 157.3 160.7 164.2 165.6 168.7 171.7]’;
y=[20.96 21.40 21.96 21.52 22.39 22.76 23.48 23.66 24.10 24.01
24.54 24.30 25.00 25.64 26.36 26.98 27.52 27.78 28.24 28.78]’;
plot(x,y,'*')
2.模型(1)的计算程序
clear;
x=[127.3 130.0 132.7 129.4 135.0 137.1 141.2 142.8 145.5 145.3
148.3 146.4 150.2 153.1 157.3 160.7 164.2 165.6 168.7 171.7]’;
y=[20.96 21.40 21.96 21.52 22.39 22.76 23.48 23.66 24.10 24.01
24.54 24.30 25.00 25.64 26.36 26.98 27.52 27.78 28.24 28.78]’;
x=[ones(20,1),x];
[b,bint,r,rint,stats]=regress(y,x)
输出结果:
b =
-1.45475004139634
0.176282811457384
bint =
-1.90465420468789 -1.00484587810479
0.173247525367995 0.179318097546773
r =
-0.0260518571286674
-0.0620154480636046
0.0220209610014628
0.163754238810824
0.046570494649476
0.0463765905889701
0.043617063613695
-0.058435434718124
-0.0943990256530576
-0.149142463361581
-0.147990897733738
-0.0530535559647056
-0.0229282395027646
0.105851607270822
0.0854637991498031
0.106102240194701
0.0291124000938581
0.0423164640535205
-0.0441602514643726
-0.0330086858365206
rint =
-0.195385871759251 0.143282157501916
-0.231871886037631 0.107840989910421
-0.152853753861225 0.19689567586415
0.0131634673388031 0.314345010282846
-0.128820728276878 0.22196171757583
-0.130374632908482 0.223127814086423
-0.135221944162416 0.222456071389806
-0.236666572408848 0.119795702972601
-0.26910531130757 0.0803072600014548
-0.313617420748614 0.0153324940254506
-0.31288219186159 0.0169003963941133
-0.232314787682902 0.126207675753491
-0.203701178032592 0.157844699027063
-0.0664228030147936 0.278126017556437
-0.0879446576592735 0.25887225595888
-0.0620923905849254 0.274296870974328
-0.144034956949209 0.202259757136925
-0.128748679311955 0.213381607418996
-0.211614739705066 0.123294236776321
-0.197152337494454 0.131134965821413
stats =
Columns 1 through 3
0.998792444207198 14888.1435565111 1.01315527327091e-027
Column 4
0.00740568340707954
3. 散点图的交互式程序
clear;
x=[127.3 130.0 132.7 129.4 135.0 137.1 141.2 142.8 145.5 145.3 148.3 146.4 150.2 153.1 157.3 160.7 164.2 165.6 168.7 171.7]’;
y=[20.96 21.40 21.96 21.52 22.39 22.76 23.48 23.66 24.10 24.01
24.54 24.30 25.00 25.64 26.36 26.98 27.52 27.78 28.24 28.78]’;
rstool(x,y,'linear')
4.模型(2)的残差
x=[127.3 130.0 132.7 129.4 135.0 137.1 141.2 142.8 145.5 145.3 148.3 146.4 150.2 153.1 157.3 160.7 164.2 165.6 168.7 171.7]’;
y=[20.96 21.40 21.96 21.52 22.39 22.76 23.48 23.66 24.10 24.01
24.54 24.30 25.00 25.64 26.36 26.98 27.52 27.78 28.24 28.78]’;
for i=1:1:20
z(i)=-1.45475+0.17628*x(i);
e(i)=y(i)-z(i);
end
z
e
输出结果:
z =
Columns 1 through 3
20.985694 21.46165 21.937606
Columns 4 through 6
21.355882 22.34305 22.713238
Columns 7 through 9
23.435986 23.718034 24.19399
Columns 10 through 12
24.158734 24.687574 24.352642
Columns 13 through 15
25.022506 25.533718 26.274094
Columns 16 through 18
26.873446 27.490426 27.737218
Columns 19 through 20
28.283686 28.812526
e =
Columns 1 through 3
-0.0256939999999979 -0.0616500000000002 0.0223940000000056 Columns 4 through 6
0.164118000000002 0.0469500000000025 0.0467620000000046 Columns 7 through 9
0.0440140000000042 -0.0580339999999993 -0.093989999999998 Columns 10 through 12
-0.148733999999997 -0.147574000000002 -0.0526419999999987 Columns 13 through 15
-0.0225059999999964 0.106282000000004 0.0859059999999978 Columns 16 through 18
0.106554000000003 0.0295740000000038 0.0427820000000025 Columns 19 through 20
-0.0436859999999974 -0.0325259999999936
5.计算DW和
e =[-0.0256939999999979
-0.0616500000000002
0.0223940000000056
0.164118000000002
0.0469500000000025
0.0467620000000046
0.0440140000000042
-0.0580339999999993
-0.093989999999998
-0.148733999999997
-0.147574000000002
-0.0526419999999987
-0.0225059999999964
0.106282000000004
0.0859059999999978
0.106554000000003
0.0295740000000038
0.0427820000000025
-0.0436859999999974
-0.0325259999999936];
s=0;
for t=2:1:20
s=s+(e(t)-e(t-1))^2;
end
m=0;
for i=1:1:20
m=m+e(i)^2;
end
DW=s/m
p=1-1/2*DW
输出结果:
DW =
0.734645539224993
p =
0.632677230387503
6.模型(3)中的数据变换
x=[127.3 130.0 132.7 129.4 135.0 137.1 141.2 142.8 145.5 145.3 148.3 146.4 150.2 153.1 157.3 160.7 164.2 165.6 168.7 171.7]’;
y=[20.96 21.40 21.96 21.52 22.39 22.76 23.48 23.66 24.10 24.01
24.54 24.30 25.00 25.64 26.36 26.98 27.52 27.78 28.24 28.78]’;
p=0.63268
for t=1:1:19
y1(t)=y(t+1)-p*y(t);
x1(t)=x(t+1)-p*x(t);
end
y1
x1
输出结果:
p =
0.63268
y1 =
Columns 1 through 3
8.1390272 8.420648 7.6263472
Columns 4 through 6
8.7747264 8.5942948 9.0802032
Columns 7 through 9
8.8046736 9.1307912 8.762412
Columns 10 through 12
9.3493532 8.7740328 9.625876 Columns 13 through 15
9.823 10.1380848 10.3025552 Columns 16 through 18
10.4502936 10.3686464 10.6641496 Column 19
10.9131168
x1 =
Columns 1 through 3
49.459836 50.4516 45.443364 Columns 4 through 6
53.131208 51.6882 54.459572 Columns 7 through 9
53.465584 55.153296 53.24506 Columns 10 through 12
56.371596 52.573556 57.575648 Columns 13 through 15
58.071464 60.436692 61.179436 Columns 16 through 18
62.528324 61.713944 63.928192 Column 19
64.966884
7.模型(3)的计算结果
y1 =[8.1390272
8.420648
7.6263472
8.7747264
8.5942948
9.0802032
8.8046736
9.1307912
8.762412
9.3493532
8.7740328
9.625876
9.823
10.1380848
10.3025552
10.4502936
10.3686464
10.6641496
10.9131168];
x1 =[49.459836
50.4516
45.443364
53.131208
51.6882
54.459572
53.465584
55.153296
53.24506
56.371596
52.573556
57.575648
58.071464
60.436692
61.179436
62.528324
61.713944
63.928192
64.966884];
x2=[ones(19,1),x1];
[b,bint,r,rint,stats]=regress(y1,x2)
输出结果:
b =
-0.391413728791626
0.173739484728835
bint =
-0.743959505289538 -0.0388679522937137 0.167481672152938 0.179997297304732 r =
-0.0626854926210676
0.0466267410463246
0.122454283086727
-0.0648485721489394
0.00542729423064792
0.00983895095872533
-0.0929956860946302
-0.060100299345299
-0.0969435599642878
-0.0532051135904403
0.0313439989890654
0.0141263123428352
0.125107495982524
0.0292588019963098
0.0646852421508761
-0.0219314639260322
0.0379112976474367
-0.0512878089344184
0.0172175781936197
-0.194112737017012 0.0687417517748767
-0.0885336593085636 0.181787141401213
0.0161292648746043 0.228779301298849
-0.201462271956211 0.0717651276583323
-0.133792997199822 0.144647585661118
-0.131797031575754 0.151474933493204
-0.225302669864897 0.0393112976756366
-0.1985101568317 0.0783095581411017
-0.228268383451548 0.0343812635229727
-0.192519727444524 0.0861095002636433
-0.107973506382257 0.170661504360388
-0.127481451736758 0.155734076422428
-0.000122557504840748 0.250337549469889
-0.109224013348295 0.167741617340915
-0.0693312030770827 0.198701687378835
-0.157373208239308 0.113510280387243
-0.0980543981169386 0.173876993411812
-0.181348373667138 0.0787727557983009
-0.112564188002673 0.146999344389912
stats =
Columns 1 through 3
0.995069834050953 3431.159******** 4.68398711682588e-021 Column 4
0.00450814925050438
8.模型(3)的残量
clear;
y1 =[8.1390272
8.420648
7.6263472
8.7747264
8.5942948
9.0802032
8.8046736
9.1307912
8.762412
9.3493532
8.7740328
9.625876
9.823
10.1380848
10.3025552
10.4502936
10.3686464
10.6641496
10.9131168];
x1 =[49.459836
50.4516
45.443364
53.131208
51.6882
54.459572
53.465584
55.153296
56.371596
52.573556
57.575648
58.071464
60.436692
61.179436
62.528324
61.713944
63.928192
64.966884];
for i=1:1:19
z(i)=-0.39141+0.17374*x1(i);
e(i)=y1(i)-z(i);
end
z
e
输出结果:
z =
Columns 1 through 3
8.20174190664 8.374050984 7.50392006136
Columns 4 through 6
8.83960607792 8.588897868 9.07039603928
Columns 7 through 9
8.89770056416 9.19092364704 8.8593867244
Columns 10 through 12
9.40259108904 8.74271961944 9.61178308352
Columns 13 through 15
9.69792615536 10.10886086808 10.23790521064
Columns 16 through 18
10.47226101176 10.33077063056 10.71547407808
Column 19
10.89593642616
e =
Columns 1 through 3
-0.0627147066400013 0.0465970159999998 0.122427138639998 Columns 4 through 6
-0.0648796779199987 0.00539693200000002 0.00980716071999943 Columns 7 through 9
-0.0930269641599999 -0.0601324470399991 -0.0969747244000008 Columns 10 through 12
-0.0532******* 0.0313131805599998 0.0140929164799992 Columns 13 through 15
0.125073844640001 0.0292239319199989 0.0646499893599994 Columns 16 through 18
-0.0219674117599986 0.0378757694399994 -0.0513244780799997 Column 19
0.0171803738400005
9.求模型(3)的DW值
e =[-0.0627147066400013
0.0465970159999998
0.122427138639998
-0.0648796779199987
0.00539693200000002
0.00980716071999943
-0.0930269641599999
-0.0601324470399991
-0.0969747244000008
-0.0532*******
0.0313131805599998
0.0140929164799992
0.125073844640001
0.0292239319199989
0.0646499893599994
-0.0219674117599986
0.0378757694399994
-0.0513244780799997
0.0171803738400005];
s=0;
for t=2:1:19
s=s+(e(t)-e(t-1))^2;
end
m=0;
for i=1:1:19
m=m+e(i)^2;
end
DW=s/m
输出结果:
DW =
1.6519922652328
excel预测与决策分析实验报告
《EXCEL预测与决策分析》 实验报告册 2014- 2015 学年第学期 班级: 学号: 姓名: 授课教师:实验教师: 实验学时:实验组号: 信息管理系
目录 实验一网上书店数据库的创建及其查询 (3) 实验二贸易公司销售数据的分类汇总分析 (7) 实验三餐饮公司经营数据时间序列预测 (9) 实验四住房建筑许可证数量的回归分析 (12) 实验五电信公司宽带上网资费与电缆订货决策 (15) 实验六奶制品厂生产/销售的最优化决策 (17) 实验七运动鞋公司经营投资决策 (19)
实验一网上书店数据库的创建及其查询 【实验环境】 ?Microsoft Office Access 2003; ?Microsoft Office Query 2003。 【实验目的】 1.实验1-1: ?理解数据库的概念; ?理解关系(二维表)的概念以及关系数据库中数据的组织方式; ?了解数据库创建方法。 2.实验1-2: ?理解DOBC的概念; ?掌握利用Microsoft Query进行数据查询的方法。 3.实验1-3: ?掌握复杂的数据查询方法:多表查询、计算字段和汇总查询。 【实验步骤】 实验1-1 一、表的创建和联系的建立 步骤1:创建空数据库“xddbookstore”。 步骤2:数据库中表结构的定义。 步骤3:保存数据表。 步骤4:定义“响当当”数据库的其他表。 步骤5:“响当当”数据库中表之间联系的建立。 二、付款方式表的数据输入 步骤1:选中需要输入数据的表(如付款方式表)。 步骤2:输入数据。 三、订单表的数据导入 在本书配套磁盘提供的xddbookstore.xls文件中,包含了响当当数据库所有表的数据。可以利用该文件将订单表数据导入到“xddbookstore.mdb”数据库中。 步骤1:选择要导入的文件。 步骤2:规定要导入的数据表。 步骤3:指明在要导入的数据中是否包含列标题。 步骤4:规定数据应导入到哪个表中,可以是新表或现有的表。 步骤5:完成数据导入工作。 实验1-2 一、建立odbc数据源 在利用 microsoft office query对“响当当”网上书店进行数据查询之前,必须先建立一个用于连接该数据库的odbc数据源“bookstore”,具体步骤如下: 步骤1:启动microsoft office query应用程序。 步骤2:进入“创建新数据源”对话框。
销售分析报告10篇
《销售分析报告》 销售分析报告(一): 小家电行业销售分析报告 随着我国经济的发展和人们生活水平的提高,人们对品质生活有了更高要求,小家电产品开始跟随彩电、空调、冰箱等大家电之后,成为每个家庭的追求产品。小编近期精心准备了一份小家电行业销售分析报告,大家如果有需要了解的话,能够阅读一下。 一、行业分析 1、市场总量及增长 近几年小家电市场每年以15%左右的增长速度快速发展,2007年,中国小家电生产规模到达14.4亿台,同比增长12.7%,全国小家电销售额到达971.9亿元(在各小家电品类中,厨卫类小家电占据最大的份额,占整体小家电市场销售额的78%,家居类小家电紧随其后)。2008年销售规模到达1109亿元人民币,同比预计增长14.1%,预计2010年会突破1500亿元,市场潜力巨大。从市场需求量上看,欧洲平均每家有30多种小家电,而在中国平均每家仅有3~4种小家电。随着人们经济水平的提高,小家电快速进入消费者家庭,在大家电市场日趋饱和、受人民币升值以及经济发展带来的收入增长、国家鼓励消费政策的出台等环境下,业内人士指出,今后25年仍将是我国小家电发展的黄金时期,年需求量增幅在30%以上。 另据中怡康数据显示,2010年前三季度厨卫、小家电行业整体销售额到达1094亿元,同比增长16%,预计全年将到达1500亿元的市场规模。应对如此巨大的市场机遇,雅乐思、爱庭、浪木等小家电品牌开始借助三四级市场高速成长从而快速崛起。 2、家电行业整体状况 最新统计数据显示,在发布2010年度业绩预报的28家家电行业上市公司中,预增的有21家,续盈2家,扭亏1家,首亏2家,预减2家。整体而言,报喜的上市公司到达24家,占比高达85%,整体大面积盈利,意味着行业景气度持续高涨。但是分析发布业绩预告的公司数据,却能够发现一个事实:主营冰箱、洗衣机、空调的青岛海尔(29.06,0.44,1.54%)、美的电器(18.73,-0.22,-1.16%)、格力电器(19.00,-0.27,-1.40%)等主流大家电公司尽管营收规模都在四百亿元以上,但是业绩增幅都较大,可谓是大象起舞。而构成鲜明比较的是,近年来持续登陆资本市场的厨卫类小家电上市公司,尽管营收规模多在二三十亿元,其增幅却明显缓慢。 3、渠道竞争 2010年中国网购家电突破800亿元,其中小家电占比超过50%,成为销售增长最快和最有潜力的销售渠道。美的日电集团CEO黄健表示,到2015年中国人口预计将到达15亿,加速发展的城镇化,将使城镇人口第一次超过农村人口,国内市场消费潜力十分巨大。美的到2015年,日电中国营销总部的美的小家电专卖店将到达15000家,销售网点将到达10万家,其中增长最多的就是在三四级市场。 雅乐思电器销售公司总经理付英杰介绍说,在去年电磁炉全行业委缩30%的状况下,企业获得了15%的增长,这在很大程度上受益于三四级市场的高速增长。爱庭电器有限公司办公室主任秦满棋表示,随着城镇化建设速度的加快,中国三四级市场家庭对电磁炉和
数学建模实验报告
数学建模实验报告
一、实验目的 1、通过具体的题目实例,使学生理解数学建模的基本思想和方法,掌握 数学建模分析和解决的基本过程。 2、培养学生主动探索、努力进取的的学风,增强学生的应用意识和创新 能力,为今后从事科研工作打下初步的基础。 二、实验题目 (一)题目一 1、题目:电梯问题有r个人在一楼进入电梯,楼上有n层。设每个 乘客在任何一层楼出电梯的概率相同,试建立一个概率模型,求直 到电梯中的乘客下完时,电梯需停次数的数学期望。 2、问题分析 (1)由于每位乘客在任何一层楼出电梯的概率相同,且各种可能的情况众多且复杂,难于推导。所以选择采用计算机模拟的 方法,求得近似结果。 (2)通过增加试验次数,使近似解越来越接近真实情况。 3、模型建立 建立一个n*r的二维随机矩阵,该矩阵每列元素中只有一个为1,其余都为0,这代表每个乘客在对应的楼层下电梯(因为每 个乘客只会在某一层下,故没列只有一个1)。而每行中1的个数 代表在该楼层下的乘客的人数。 再建立一个有n个元素的一位数组,数组中只有0和1,其中1代表该层有人下,0代表该层没人下。 例如: 给定n=8;r=6(楼8层,乘了6个人),则建立的二维随机矩阵及与之相关的应建立的一维数组为: m = 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 0 0 c = 1 1 0 1 0 1 1 1 4、解决方法(MATLAB程序代码):
n=10;r=10;d=1000; a=0; for l=1:d m=full(sparse(randint(1,r,[1,n]),1:r,1,n,r)); c=zeros(n,1); for i=1:n for j=1:r if m(i,j)==1 c(j)=1; break; end continue; end end s=0; for x=1:n if c(x)==1 s=s+1; end continue; end a=a+s; end a/d 5、实验结果 ans = 6.5150 那么,当楼高11层,乘坐10人时,电梯需停次数的数学期望为6.5150。 (二)题目二 1、问题:某厂生产甲乙两种口味的饮料,每百箱甲饮料需用原料6 千克,工人10名,可获利10万元;每百箱乙饮料需用原料5千 克,工人20名,可获利9万元.今工厂共有原料60千克,工人 150名,又由于其他条件所限甲饮料产量不超过8百箱.问如何 安排生产计划,即两种饮料各生产多少使获利最大.进一步讨 论: 1)若投资0.8万元可增加原料1千克,问应否作这项投资. 2)若每百箱甲饮料获利可增加1万元,问应否改变生产计划. 2、问题分析 (1)题目中共有3个约束条件,分别来自原料量、工人数与甲饮料产量的限制。 (2)目标函数是求获利最大时的生产分配,应用MATLAB时要转换
数学建模 人口模型 人口预测
关于计划生育政策调整对人口数量、结构及其影响的研究 【摘要】 本文着重于讨论两个问题:1、从目前中国人口现状出发,对于中国未来人口数量进行预测。2、针对深圳市讨论单独二胎政策对未来人口数量、结构及其对教育、劳动力供给与就业、养老等方面的影响。 对于问题1从中国的实际情况和人口增长的特点出发,针对中国未来人口的老龄化、出生人口性别比以及乡村人口城镇化等,提出了 Logistic 、灰色预测、等方法进行建模预测。 首先,本文建立了 Logistic 阻滞增长模型,在最简单的假设下,依照中国人口的历 史数据,运用线形最小二乘法对其进行拟合, 对 2014 至 2040 年的人口数目进行了预测, 得出在 2040 年时,中国人口有 14.32 亿。在此模型中,由于并没有考虑人口的年龄、 出生人数男女比例等因素,只是粗略的进行了预测,所以只对中短期人口做了预测,理 论上很好,实用性不强,有一定的局限性。 然后, 为了减少人口的出生和死亡这些随机事件对预测的影响, 本文建立了 GM(1,1) 灰色预测模型,对 2014 至 2040 年的人口数目进行了预测,同时还用 2002 至 2013 年的 人口数据对模型进行了误差检验,结果表明,此模型的精度较高,适合中长期的预测, 得出 2040 年时,中国人口有 14.22 亿。与阻滞增长模型相同,本模型也没有考虑年龄 一类的因素,只是做出了人口总数的预测,没有进一步深入。 对于问题2针对深圳市人口结构中非户籍人口比重大,流动人口多这一特点,我们采用了灰色GM(1,1)模型,通过matlab 对深圳市自2001至2010年的数据进行拟合,发现其人口变化近似呈线性增长,线性相关系数高达0.99,我们就此认定其为线性相关并给出线性方程。同理,针对其非户籍人口,我们进行matlab 拟合发现,其为非线性相关,并得出相关函数。并做出了拟合函数 0.0419775(1)17255.816531.2t X t e ?+=?-。 对于新政策的实施,我们做出了两个假设。在假设只有出生率改变的情况,人口呈现一次函数线性增加。并拟合出一次函数0.032735617965.017372.5t Y e ?=?-;在假设人口增长率增长20%时,做出了预测如果单独二胎政策实施,到2021年,深圳市常住人口数将会到达1137.98千万人。 关键词:GM(1,1)灰色模型 Logistic 阻滞增长模型 线性拟合 非线性拟合
餐饮行业消费趋势与预测分析报告范文
餐饮行业消费趋势与预测分析报告-金六顺 2009年08月19日星期三 17:22 近年来,我国的餐饮业发展非常迅速,餐饮业营业额连续18年实现两位数高速增长,预计未来将保持17%以上速度发展,行业发展前景看好,可以说我国正迎来一个餐饮业大发展的时期,市场潜力巨大,前景非常广阔,长期发展趋势良好。2004年,全国实现餐饮业零售额7486亿元,比上年净增1330亿元,同比增长%,连续14年实现两位数的高增长,比同期社会消费品零售总额增长率高出个百分点,占社会消费品零售总额的%,对社会消费品零售总额的增长贡献率为21%,拉动社会消费品零售总额增长个百分点。2005年,中国餐饮业零售额实现亿元,同比增长%,比上年净增1336亿元,高出社会消费品零售总额增幅个百分点,占社会消费品零售总额的比重达到%,对社会消费品零售总额的增长贡献率和拉动率分别为%和%。全年实现营业税金亿元,同比增长%。2006年,中国餐饮消费全年零售额首次突破万亿元大关,达到亿元,同比增长%,比上年净增1458亿元,连续16年实现两位数高速增长,与改革开放初期的1978年相比增长了188倍。2007年全国餐饮企业营业零售额累计达12352亿元,同比增长%,占社会消费品零售总额的%,拉动社会消费品零售总额增长个百分点,对社会消费品零售总额的增长贡献率为%。其中快餐业和火锅业发展最快。与改革开放初期相比,2007年中国餐饮营业额是1978年的225倍,年平均增长率高达%。2008年零售额达15404亿元,比2007年增长%,连续18年保持两位数的速度。而在海外,中餐不断攻城掠地,2008年中餐首入奥运食谱,更进一步走向国际化,根据历年数据分析,预计到2010年,中国餐饮业零售额将达到20000亿元。餐饮业已经成为拉动消费、实现增长、扩大就业的重要因素之一。我国经济近年取得的快速发展,国内生产总值快速提高,是持续迅速带动国内消费需求增长的主因。08年人均国内生产总值(GDP)超过2000美元,居民消费能力增强,消费层次提高,中式正餐高端消费额比重将持续增长。从长远来看,随着对外开放的扩大和经济持续稳定快速增长,城乡居民收入增加,生活水平不断提高,我国的餐饮业发展非常迅速,近几年餐饮业的增长率都比其它行业高出十个百分点以上,可以说我国正迎来一个餐饮业大发展的时期,市场潜力巨大,前景非常广阔。行业政策分析目前,我国餐饮行业缺乏规划引导,法规建设滞后问题。在快速发展中有盲目、无序和低水平发展的现象。尚未建立适用于餐饮业的国家级法规,缺乏系统严格的市场准入制度和强制性标准,餐饮企业的标准参差不齐,内容不全面、技术知识含量低,缺乏全国统一性。我国餐饮业缺乏统一的行业执法,市场秩序不规范,餐饮环境不卫生,食品安全问题时有发生,市场管理和行业管理跟不上形势发展需要,市场秩序有待规范。但是,国家加快服务业发展战略将为餐饮业发展带来新机遇。目前我国服务业总量相对较小,2007服务业产值比重不到40%,与全球服务业产值平均比重60%(发达国家超过70%)相距甚远。党的十七大报告提出“加快发展现代服务业,提高服务业的比重和水平”。国务院《关于加快发展服务业的若干意见》及国务院办公厅《关于加快发展服务业若干政策措施的实施意见》,为服务业加快发展奠定了良好政策基础,为餐饮业发展带来难得的机遇。1、金融危机对中国餐饮行业影响简要分析自08年美国金融危机爆发波及全球,美国、日本、欧洲各国政府都忙着救市,目前来看效果还不明显,这次金融危机对于我国经济影响主要是外汇储备部分损失,出口困难,减缓经济增长,失业增加,消费者收入下降,对餐饮业影响主要有三
数学建模实验报告
数学建模实验报告 实验一计算课本251页A矩阵的最大特征根和最大特征向量 1 实验目的 通过Wolfram Mathematica软件计算下列A矩阵的最大特征根和最大特征向量。 2 实验过程 本实验运用了Wolfram Mathematica软件计算,计算的代码如下:
3 实验结果分析 从代码的运行结果,可以得到最大特征根为5.07293,最大特征向量为 {{0.262281},{0.474395},{0.0544921},{0.0985336},{0.110298}},实验结果 与标准答案符合。
实验二求解食饵-捕食者模型方程的数值解 1实验目的 通过Wolfram Mathematica或MATLAB软件求解下列习题。 一个生物系统中有食饵和捕食者两种种群,设食饵的数量为x(t),捕食者为y(t),它们满足的方程组为x’(t)=(r-ay)x,y’(t)=-(d-bx)y,称该系统为食饵-捕食者模型。当r=1,d=0.5,a=0.1,b=0.02时,求满足初始条件x(0)=25,y(0)=2的方程的数值解。 2 实验过程 实验的代码如下 Wolfram Mathematica源代码: Clear[x,y] sol=NDSolve[{x'[t] (1-0.1y[t])x[t],y'[t] 0.02x[t]y[t]-0.5y[t],x[0 ] 25,y[0] 2},{x[t],y[t]},{t,0,100}] x[t_]=x[t]/.sol y[t_]=y[t]/.sol g1=Plot[x[t],{t,0,20},PlotStyle->RGBColor[1,0,0],PlotRange->{0,11 0}] g2=Plot[y[t],{t,0,20},PlotStyle->RGBColor[0,1,0],PlotRange->{0,40 }] g3=Plot[{x[t],y[t]},{t,0,20},PlotStyle→{RGBColor[1,0,0],RGBColor[ 0,1,0]},PlotRange->{0,110}] matlab源代码 function [ t,x ]=f ts=0:0.1:15; x0=[25,2]; [t,x]=ode45('shier',ts,x0); End function xdot=shier(t,x)
技术经济效益预测分析报告
工业锅炉封闭循环相变供热系统 技术经济环境效益预测分析报告 一、技术开发效益分析 《工业锅炉封闭循环相变供热系统》节能产品技术的开发与应用,标志着蒸汽供热凝结水回收余热利用技术一次创新性大提高,彻底改变了中小企业锅炉供热采用开式回收系统,余热利用率低,浪费严重,节能技术水平差的窘状,为蒸汽供热余热利用节能技术的进步起到了积极有力的推进作用。 凝结水回收封闭系统技术的开发与应用,将回水率、利用率、汽水损失率、排污率、结垢速率和回收系统金属腐蚀速率降耗指标提升到很高的水平。循环相变技术的开发与应用,使锅炉给水温度大幅提升,取消锅炉额定补给水,缩短运行时间,降低能源消耗,提高热效率,有力促进了锅炉及供热系统节能降耗技术的发展。 技术先进、工艺合理、节能显著、应用广、投资少、见效快、效益可观是它的突出特点。与蒸汽供热凝结水回收开式系统相比,除在高效、节能、节水、环保等方面处于超越领先水平外,在投资和运行费用方面,尤其是技术经济效益还具有明显的优势。该“系统”既符合国家产业政策,又适用锅炉蒸汽供热余热节能市场需求,同时也降低了客户使用费用,技术经济效益十分明显,销售市场前景十分广阔。(一)、回收利用技术效益计算: 《工业锅炉封闭循环相变供热系统》产品节能技术所产生的效益主要表现在回收率、利用率、回收水温、汽水热损失、排污热损、结
垢速率、取消和降低辅机设备配置等几方面。 我们以凝结水开式回收系统作为效益对比条件,每蒸吨为对比单元,以燃煤锅炉为对比能源设备进行节能效益计算。 开式回收系统:凝结水回收率:65% 凝结水回收温度:60-70℃ 凝结水回收利用率:~80% 排污热损:2% 汽水热损失: 3--5% 结垢热损失:3—15% 疏水阀逃逸热损失:4—16% 封闭回收系统:凝结水回收率:99.6% 凝结水回收温度:140℃ 凝结水回收利用率:~100% 排污热损:0.4% 汽水热损失: ≤1% 结垢热损失:≤1% 疏水阀逃逸热损失:无 燃煤锅炉封闭系统节能效益汇总表
数学建模与数学实验报告
数学建模与数学实验报告 指导教师__郑克龙___ 成绩____________ 组员1:班级______________ 姓名______________ 学号_____________ 组员2:班级______________ 姓名______________ 学号______________ 实验1.(1)绘制函数cos(tan())y x π=的图像,将其程序及图形粘贴在此。 >> x=-pi:0.01:pi; >> y=cos(tan(pi*x)); >> plot(x,y) -4 -3 -2 -1 1 2 3 4 -1-0.8-0.6-0.4-0.200.20.40.60.8 1 (2)用surf,mesh 命令绘制曲面2 2 2z x y =+,将其程序及图形粘贴在此。(注:图形注意拖放,不要太大)(20分) >> [x,y]=meshgrid([-2:0.1:2]); >> z=2*x.^2+y.^2; >> surf(x,y,z)
-2 2 >> mesh(x,y,z) -2 2 实验2. 1、某校60名学生的一次考试成绩如下:
93 75 83 93 91 85 84 82 77 76 77 95 94 89 91 88 86 83 96 81 79 97 78 75 67 69 68 84 83 81 75 66 85 70 94 84 83 82 80 78 74 73 76 70 86 76 90 89 71 66 86 73 80 94 79 78 77 63 53 55 1)计算均值、标准差、极差、偏度、峰度,画出直方图;2)检验分布的正态性;3)若检验符合正态分布,估计正态分布的参数并检验参数. (20分) 1) >> a=[93 75 83 93 91 85 84 82 77 76 77 95 94 89 91 88 86 83 96 81 79 97 78 75 67 69 68 84 83 81 75 66 85 70 94 84 83 82 80 78 74 73 76 70 86 76 90 89 71 66 86 73 80 94 79 78 77 63 53 55]; >> pjz=mean(a) pjz = 80.1000 >> bzhc=std(a) bzhc = 9.7106 >> jc=max(a)-min(a) jc = 44 >> bar(a)
北京房地产大预测分析报告文案
2003年房地产大预测 1、2003年房地产市场将平稳发展,不会出现房地产过热和泡沫现象 2002年房地产市场开发势头强劲:1-9月份,房地产开发投资完成612.9亿元,比去年同期增长29.5%;全市新开工各类商品房1652万平方米,比去年同期增长7.4%。有观点认为,目前房地产开发过热,担心2003年会出现房地产泡沫,其根据主要来自对空置率和房价的分析,而我们分析后认为并非如此。 ●不能简单由空置率高得出过热结论 目前国际上普遍认为空置率在5-10%之间为合理区。根据市统计局公布的数据,2001年市商品房空置率为18.1%,商品住宅空置率为19.2%。同时,近几年的商品房空置率均高于5-10%这个区间,1999年空置率曾高达26.8%。表面看来这一指标的确高,但具体分析,可以发现商品房空置率高有其特殊原因,与国外指标也不具有可比性,因此不能简单得出过热结论。 首先,在市目前空置的商品房当中,有相当一部分属于政策性空置,在住房拆迁实物补偿时期,政府要求先建安置房,再进行拆迁工作,后政策发生变化,实物补偿变为货币补偿,使一些建好的安置房变成空置房。 其次,结构性空置也须引起注意,根据伟业顾问对市场的监测,在空置的商品房中,中高价位商品房占的比重较大,而4000元/平方米以下的低价位房销售状况良好,空置比重很小。 另外,我国商品房空置率统计口径与国外不同,在国外物业要空置超过一年才计入空置面积,但我国商品房在建成后而未出售便立即算入空置面积。截至2002年6月份,的商品房整体空置面积为710.1万平方米,其中,空置时间在一年以的有376万平方米,占全市空置面积的53%,主要是新竣工的商品房,而空置在3年以上的商品房面积则只有10%。 从商品房竣工、销售和空置面积走势图来看,竣工与销售面积基本上还是同步增长的。因此,尽管2000年以来的房地产开发、开复工面积、竣工面积都有了较大幅度的增长,但由于宏观经济、基础设施等各方面的利好因素,房地产开发主流呈现出销售旺盛趋势,空置面积有望得到控制。
数学建模实验报告
matlab 试验报告 姓名 学号 班级 问题:.(插值) 在某海域测得一些点(x,y)处的水深z 由下表给出,船的吃水深度为5英尺,在矩形区域(75,200)*(-50,150)里的哪些地方船要避免进入。 问题的分析和假设: 分析:本题利用插值法求出水深小于5英尺的区域,利用题中所给的数据,可以求出通过空间各点的三维曲面。随后,求出水深小于5英尺的范围。 基本假设:1表中的统计数据均真实可靠。 2矩形区域外的海域不对矩形海域造成影响。 符号规定:x ―――表示海域的横向位置 y ―――表示海域的纵向位置 z ―――表示海域的深度 建模: 1.输入插值基点数据。 2.在矩形区域(75,200)×(-50,150)作二维插值,运用三次插值法。 3.作海底曲面图。 4.作出水深小于5的海域范围,即z=5的等高线。 x y z 129 140 103.5 88 185.5 195 105 7.5 141.5 23 147 22.5 137.5 85.5 4 8 6 8 6 8 8 x y z 157.5 107.5 77 81 162 162 117.5 -6.5 -81 3 56.5 -66.5 84 -33.5 9 9 8 8 9 4 9
求解的Matlab程序代码: x=[129 140 103.5 88 185.5 195 105.5 157.5 107.5 77 81 162 162 117.5]; y=[7.5 141.5 23 147 22.5 137.5 85.5 -6.5 -81 3 56.5 -66.5 84 -33.5]; z=[-4 -8 -6 -8 -6 -8 -8 -9 -9 -8 -8 -9 -4 -9]; cx=75:0.5:200; cy=-50:0.5:150; cz=griddata(x,y,z,cx,cy','cubic'); meshz(cx,cy,cz),rotate3d xlabel('X'),ylabel('Y'),zlabel('Z') %pause figure(2),contour(cx,cy,cz,[-5 -5]);grid hold on plot(x,y,'+') xlabel('X'),ylabel('Y') 计算结果与问题分析讨论: 运行结果: Figure1:海底曲面图:
人口结构与经济发展预测=数学建模好论文
2011高教社杯全国大学生数学建模竞赛 承诺书 我们仔细阅读了中国大学生数学建模竞赛的竞赛规则. 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。 我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。 我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。如有违反竞赛规则的行为,我们将受到严肃处理。 我们参赛选择的题号是(从A/B/C/D中选择一项填写): B 我们的参赛报名号为(如果赛区设置报名号的话): j4228 所属学校(请填写完整的全名):**工程大学 参赛队员 (打印并签名) :1. 2. 3. 指导教师或指导教师组负责人 (打印并签名): 日期: 2012 年 9 月 10日
赛区评阅编号(由赛区组委会评阅前进行编号):
2011高教社杯全国大学生数学建模竞赛 编号专用页 赛区评阅编号(由赛区组委会评阅前进行编号): 赛区评阅记录(可供赛区评阅时使用): 全国统一编号(由赛区组委会送交全国前编号): 全国评阅编号(由全国组委会评阅前进行编号): 人口结构和经济发展预测模型 摘要 众所周知,人口结构和影响经济发展的因素是国家发展和制定政策的基础和依据。如果不能进行合理的预测,就会给政策制定带来困难甚至做出错误决策。因此,有必要对人口结构和影响经济发展的因素建立定量的数学模型。 问题一:首先建立了科布道格拉斯生产函数模型,计算出技术进步、固定资产投资、
销售额预测分析报告
销售额预测分析报告 一、模型选择 预测是重要的统计技术,对于领导层进行科学决策具有不可替代的支撑作用。 常用的预测方法包括定性预测法、传统时间序列预测(如移动平均预测、指数平滑预测)、现代时间序列预测(如ARIMA模型)、灰色预测(GM)、线性回归预测、非线性曲线预测、马尔可夫预测等方法。 综合考量方法简捷性、科学性原则,我选择ARIMA模型预测、GM(1,1)模型预测两种方法进行预测,并将结果相互比对,权衡取舍,从而选择最佳的预测结果。 二ARIMA模型预测 (一)预测软件选择----R软件 ARIMA模型预测,可实现的软件较多,如SPSS、SAS、Eviews、R等。使用R软件建模预测的优点是:第一,R是世最强大、最有前景的软件,已经成为美国的主流。第二,R是免费软件。而SPSS、SAS、Eviews正版软件极为昂贵,盗版存在侵权问题,可以引起法律纠纷。第三、R软件可以将程序保存为一个程序文件,略加修改便可用于其它数据的建模预测,便于方法的推广。 (二)指标和数据 指标是销售量(x),样本区间是1964-2013年,保存文本文件data.txt中。 (三)预测的具体步骤 1、准备工作 (1)下载安装R软件 目前最新版本是R3.1.2,发布日期是2014-10-31,下载地址是https://www.360docs.net/doc/565691882.html,/。我使用的是R3.1.1。 (2)把数据文件data.txt文件复制“我的文档”①。 (3)把data.txt文件读入R软件,并起个名字。具体操作是:打开R软件,输入(输入每一行后,回车): data=read.table("data.txt",header=T) data #查看数据② 回车表示执行。完成上面操作后,R窗口会显示: (4)把销售额(x)转化为时间序列格式 x=ts(x,start=1964) ①我的文档是默认的工作目录,也可以修改自定义工作目录。 ②#后的提示语句是给自己看的,并不影响R运行
白酒行业销售情况调查统计分析报告2016版
白酒行业销售情况调查统计分析报告2016版 《白酒行业销售情况调查统计分析报告2016版》采用定性和定量的数据分析方法,对白酒行业企业布局、行业内企业销售投入(销售费用、广告推广费、物流费、销售人员投入等)、行业内企业销售收入、细分区域和下游市场销售额以及主要产品销售价格等销售情况进行了详细的统计分析。
【需知:如果您想购买本报告或者获得更多报告信息,您可以通过页面上的网址、联系电话 以及QQ 联系我们,我们会在第一时间为您服务。】 点击购买报告 报告综述 中华产业网多年来一直致力于白酒行业销售和市场需求的研究分析,与行业内众多企业保持良好的合作关系,定期对其销售情况开展问卷调查工作。我们以跟踪调查所获得的一手资料为基础,结合工信部、统计局、工商局以及行业协会等权威部门发布的信息,精心整理编撰了《白酒行业销售情况调查统计分析报告2016版》。 报告采用定性和定量的数据分析方法,对白酒行业企业布局、行业销售投入(销售费用、广告推广费、物流费、销售人员投入等)、行业销售收入、细分区域和下游市场销售额以及主要产品销售价格等销售情况进行了详细的分析介绍。报告不仅对近3年行业整体以及分区域、分企业类型的销售情况进行了汇总分析,同时采用了描述性统计方法,对白酒行业细分企业的销售情况也进行了统计分析。因此通过该报告,客户不仅可以全面掌握行 业整体销售情况,还可以参照细分企业数据,将自己企业的销售情况与行业内企业进行对比分析,从而扬长避短,增强企业竞争力。
企业数量
二、白酒行业内企业销售投入状况统计分析 1、主要内容介绍 对白酒行业的销售中的费用投入情况以及人员投入情况进行了统计分析,详细内容见下图: 2、部分图表展示 2015年白酒行业销售费用占销售收入比重细分企业分析
关于中国人口预测模型的讨论模型-大学生数学建模竞赛优秀论文范文模板参考资料
承诺书 我们仔细阅读了中国大学生数学建模竞赛的竞赛规则. 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。 我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。 我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。如有违反竞赛规则的行为,我们将受到严肃处理。 我们参赛选择的题号是(从A/B/C/D中选择一项填写): A 我们的参赛报名号为(如果赛区设置报名号的话): 所属学校(请填写完整的全名):福州大学 参赛队员(打印并签名) :1. 李译(135********) 2. 李志坤(135********) 3. 殷婷 指导教师或指导教师组负责人(打印并签名): 日期: 2007 年 9 月 24 日赛区评阅编号(由赛区组委会评阅前进行编号):
编号专用页 赛区评阅编号(由赛区组委会评阅前进行编号): 全国统一编号(由赛区组委会送交全国前编号):全国评阅编号(由全国组委会评阅前进行编号):
中国人口增长预测 摘要: 针对题目所提要求,我们建立了两个中国人口预测模型,分别用于对中国人口的发展趋势做短期和中长期的预测。 为了对中国人口发展做短期的预测,考虑到题目所给的数据资料的不全面,我们由马尔萨斯的人口指数增长模型得到启发,针对中国人口发展的特点,把出生率和死亡率函数这两大对人口增长起主要作用的因素作为建模的关键参数,在附件中没有给出中国近年总人口数的情况下,建立了短期内预测中国人口增长的微分方程模型。在该模型中,为了得到出生率和死亡率函数这两个重要参数,我们通过分析题目所给数据,提取出有效信息,计算归纳出2001年到2005年的出生率和死亡率,并在此基础上引入灰色模型,用于对出生率和死亡率进行预测,得出了出生率和死亡率关于时间的函数。较准确的估计出了人口增长的关键参数,使得建立的人口增长短期预测模型不仅符合中国人口的发展特点,而且简单易用,能在未知总人口数的情况下预测人口的相对发展变化,这一优点使得可以方便且准确的用于预测中国人口短期内的发展趋势。 为了对中国人口发展做中长期的预测,考虑到短期模型在预测人口中长期发展中的局限性以及影响人口发展的众多因素的不确定性和它们之间关系的复杂性,我们利用灰色动态模型的特点,从《中国统计年鉴》中查到了中国近年的人口总数(见附表一),把人口数做为灰色量,对原始各年人口序列进行分段建模,对各分段模型进行定性分析比较,根据各阶段宏观指标的相关确定一组适当的权数,进行预测模型的最优组合,以确定最优预测模型,从而建立了中长期预测中国人口增长的灰色动态系统人口模型,对中国人口进行了中长期的预测。 在对中国总人口进行短期和中长期的总体预测后,我们从附件中提取出城、镇、乡三地人口、男女出生性别比、妇女生育率、老龄人口比率等相关数据,对中国未来城、镇、乡三地人口比例、男女出生性别比、妇女生育率、老龄人口比率等影响人口发展的主要因素做趋势预测,从而达到了对中国人口全方位的预测。 关键词:出生率、死亡率、指数增长模型、灰色动态模型、性别比、老龄化、生育率。
销售分析报告模板
报告 申请其它 撰稿人审核审批 日期:年月日 年月份销售分析报告 数据中心 报告评级: 报告评级标准:(月度销售分析报告首页须在审阅评级后于报告提交当月返回) 优 要点基本涵盖月度销售情况,80%或以上的要点分析全面、透彻,具有较强参考性和指导性;3条或以上有效建议; 良 要点基本涵盖月度销售情况,60%或以上的要点分析全面、透彻,具有一定的参考性和指导性;1条或以上有效建议; 中 要点基本涵盖月度销售情况,40%或以上要点分析全面、透彻; 可 要点基本涵盖月度销售情况,20%或以上要点分析全面、透彻; 差 作为月度销售分析报告,没有体现出月度销售情况和特点。 意见反馈:
第一节:总体销售情况 渠道 1月份 销售额 同比 增幅 环比 增幅 渠道 占比 去年同期 渠道占比 完成 年计划 15年1月份占全年之比 自营 加盟 总计 1月份市场销售仍呈现出向好景象,消费力与去年相比呈现良好上扬趋势,我品牌总体业绩再次突破 亿,自营店业绩也再次突破 亿,各因素增长比例见右表: 自营店经过15年第四季度销售高峰 期,本月销售有所放缓,相对上月销售呈下降趋势(较上月下降 %),但同比增长表现良好,仍保持15年第四季度增长势头,增长超过 %,增长主要有以下三方面原因: a 、国内宏观经济继续回升,衣着类消费品的市场需求仍保持稳定增长,我品牌1月份销量同比增长 %,销售额同比增长 %,总体商场排名 名,同比上升 名次,环比上升 名次。 1月份自营店日销售走势图: b 、去年1月24日后春节,即从25号即黄金周的第一天开始,业绩就大幅下滑,黄金周期间销售由 万缓慢增至 万,最低仅有 万,1.25-1.31销售 万只占当月自营店总销售业绩的 %;而今年春节在2月份,1月份处于春节前的销售 类型 数量 同比 增加额 增加额 占比 店均同比 增加额 加盟 原有店柜 新开 撤柜 临时 总计
2007年全国数学建模大赛A题中国人口增长预测与控制题目和论文赏析(1)(1)
中国人口增长预测与控制 摘要 近年来,中国人口最突出的特点是:老龄化加速、出生人口性别比持续增高和乡村人口城镇化。针对这些特点,建立各个影响因素的数学模型,最后建立中国人口的增长模型。 对于问题一,首先将人口增长的预测问题转化为对出生率、死亡率和城镇乡转移率的预测。通过原题附录3数据的分析研究,发现影响人口增长的主要因素可以归结为出生率、死亡率和城镇乡转移率,并依此建立了不同参数随时间变化的递推数学模型,讨论了各个参数对人口增长的影响。其次,分别拟合死亡率和生育率、城镇乡转移率对年龄的分布。建立了差分数学模型,将死亡率、生育率与城镇乡转移率的预测归结到总和死亡率、总和生育率与城镇乡总和转移率的预测,由于概率分布是相对稳定的,模型参数整体健壮。对中短期的预测而言,总和死亡率、生育率和转移率的变化是近似线性的;对长期的预测,采用SI和SIS模型来描述其非线性变化,其模型的控制参数变化体现了国家人口政策的控制力度,结果表明模型具有长期可控性。 对于问题二,采用所建模型对0—90岁人口做出中短期和长期预测。2006-2030年总人口逐年增加,2006年为13.062亿,2007年为13.109亿,2008年为13.158亿,2010年为13.3亿,2023年达到高峰期13.829亿,以后开始下降趋于平缓,到2030年为13.805;乡城转移率逐年增加,短期线性变化,2006年为0.454,2007年为0.471,2008年为0.490,2010年为0.526,长期由非线性模型描述,到2030年,城乡比例为0.901;整体老龄化程度增大,2006年为0.129,2007年为0.134,2008年为0.139,2010年为0.150,到2030年为0.325,在农村老龄化尤其严重,可以确定为地区间的迁移。同时在做长期预测时,不同的国家策略导致不同的人口状况(见图[26-30]),得到的结论可以作为国家制定人口方针的建议。 对于问题三,指出模型的优缺点。通过求解经典的Logistic模型和Leslie模型,并将所得结果与本文模型结果比较,发现本文模型具有易操作性、可控性、健壮性等优点;主要缺点是在短期预测时准确度稍差。 关键词:人口控制差分模型预测拟和Leslie模型Logistic方程 一、问题重述 中国是一个人口大国,人口问题始终是制约我国发展的关键因素之一。根据已有数据,运用数学建模的方法,对中国人口做出分析和预测是一个重要问题。近年来中国的人口发展出现了一些新的特点,例如,老龄化进程加速、出生人口性别比持续升高,以及乡村人口城镇化等因素,这些都影响着中国人口的增长。2007 年初发布的《国家人口发展战略研究报告》(附录1) 还做出了进一步的分析。关于中国人口问题已有多方面的研究,并积累了大量数据资料。附录2就是从《中国人口统计年鉴》上收集到的部分数据。试从中国的实际情况和人口
数学建模报告电子商务平台销售数据分析与预测
数模论文 论文题目:电子商务平台销售数据分析与预测题号 A 作者
电子商务平台销售数据分析与预测 摘要: 对电子商务平台销售数据分析与预测要建立在数据的基础上,但世界工厂分析认为,现在不是缺数据,而是数据太多。据统计,在今天的互联网上,每秒会产生几百万次的搜索、网络上会有几十万次的内容。稍大的电子商务公司,都会采集一些行为数据,这些数据中包含了大量对市场分析,预测有用的潜在信息,对这些信息进行深度分析,企业可以改进电子商务网站的质量并且可以提高电子商务的经营效率。论文以购买历史数据为预测客户行为的基础数据,采用神经网络,马尔可夫链方法为建模工具,对电子商务的客户访问行为、商品销售预测等问题进行了研究。本论文的主要工作如下: 1.分析每个店铺的销售特点(包括价格,服务态度,售后服务,产品质量,优惠,日常管理等店铺政策)和其销售量的关系,可用雷达图法进行分析,建立最大利润函数模型。 2.利用效用函数对所搜集到商品信息进行数学模型,但仅仅按照两种商品进行建立,需要进一步的扩展。3.利用MATLAB 统计中的命令regress求解。将回归系数的估计值带入模型中,即可预测未来两年的销售总额。
正文: 问题一:搜集同一款手机(三星note3)销量前20位的店铺相关信息,把这些信息与销售量进行相关性分析,并据此对店铺如何提高销售量提出建议。 分别到京东商城,国美,苏宁,亚马逊,淘宝等相关网站了解相关的店铺的信息得到销售量前20位的店铺。
分析每个店铺的销售特点(包括价格,服务态度,售后服务,产品质量,优惠,日常管理等店铺政策)和其销售量的关系。 分析用户的购买情况同等重要。(此雷达图摘自百度文库) 利用条形图进行不同的店铺之间的对比,饼状图同店铺不同要素之间的影响进行对比分析。 对每一个影响因素建立最大利润函数模型f(x)=ax2+bx+c,每一种因素分别对应x1,x2........。得到图形,利用图形对店铺进行销售建议。 问题二:针对某一种类的商品(比如女式凉鞋),搜集50组店铺对应的商品信息(至少涵盖销量、价格、用户评价、品牌、样式、材质等信息),并据此建立数
长安汽车销售预测分析报告文案
长安汽车销售预测分析报告 公司背景 重庆长安汽车股份有限公司,简称长安汽车或重庆长安,为中国长安汽车集团股份有限公司旗下的核心整车企业,1996年在深圳证券交易所上市,A股代码000625,B股代码200625。其悠久的历史可追溯到洋务运动时期,起源于1862年的上海洋炮局,曾开创了中国近代工业的先河。伴随中国改革开放大潮,上世纪八十年代初长安正式进入汽车领域。1996年注册并成为极具竞争力的上市公司,目前拥有2家上市公司、4支股票。多年来,长安汽车坚持以自强不息的精神,通过自我积累、滚动发展,旗下现有重庆、河北、江苏、江西4大国内产业基地,11个整车和2个发动机工厂;马来西亚、越南、美国、墨西哥、伊朗、埃及等6大海外产业基地;福特、铃木、马自达等多个国际战略合作伙伴;总资产526亿元,员工近5万人。 长安汽车始终坚持“科技创新,关爱永恒”的核心价值,以“美誉天下,创造价值”为品牌理念,致力于用科技创新引领汽车文明,努力为客户提供令人惊喜和感动的产品和服务。经过多年发展和不懈努力,现已形成微车、轿车、客车、卡车、SUV、MPV等低中高档、宽系列、多品种的产品谱系,拥有排量从0.8L到2.5L的发动机平台。2009年,长安汽车自主品牌排名世界第13位、中国第一,成为中国汽车行业最具价值品牌之一。 长安汽车始终坚持走自主创新之路,着力提升自主研发能力,建立了中国重庆、上海、北京、哈尔滨、江西、意大利都灵、日本横滨、英国诺丁汉、美国底特律“五国九地、各有侧重”的研发格局;拥有核心研发人员3000余人,优秀外籍专家70余人,国家“千人计划”7人,居中国汽车行业第一。2009年,长安汽车综合研发实力位居中国汽车行业第一。 长安汽车始终坚持战略前瞻,着眼长远,大力发展节能与新能源汽车。中国第一台氢内燃机在长安成功点火;中国第一辆产业化混合动力轿车杰勋下线并上市;成为国务院机关事务局唯一示范运行车;2009年,长安纯电动汽车奔奔mini下线……在新能源汽车的研发、产业化、示范运行方面,已走在全国前列。 其下属企业有:重庆长安汽车股份有限公司(本部),长安铃木汽车有限公司,长安福特马自达汽车有限公司,长安福特马自达南京公司,长安福特马自达发动机公司,南京长安汽车有限公司,河北长安汽车有限公司