WEKA数据分析实验

WEKA 数据分析实验
1.实验简介
借助工具Weka 3.6 ,对数据样本进行测试,分类测试方法包括:朴素贝叶斯、决策树、随机数三类,聚类测试方法包括:DBScan,K均值两种;
2.数据样本
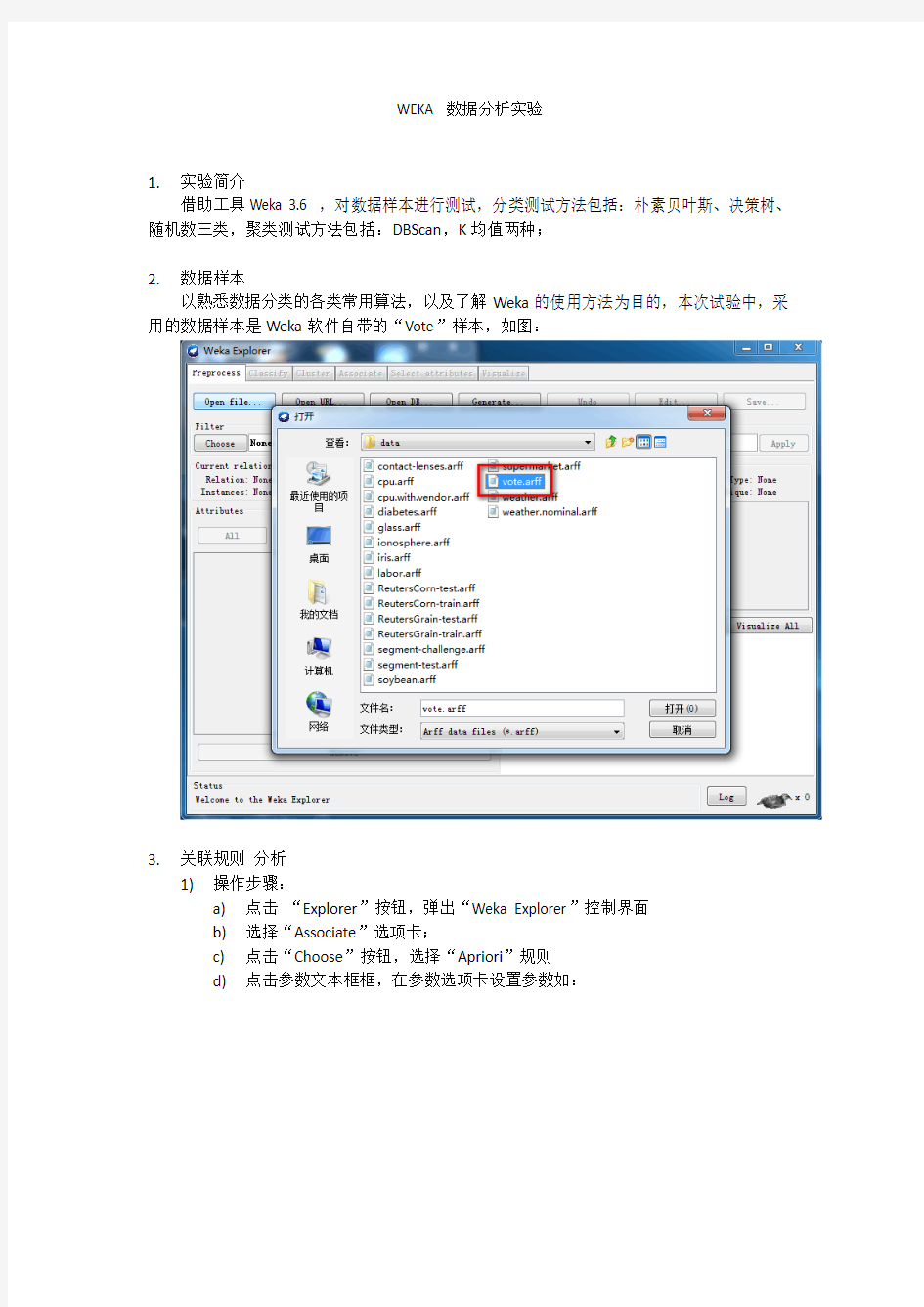
以熟悉数据分类的各类常用算法,以及了解Weka的使用方法为目的,本次试验中,采用的数据样本是Weka软件自带的“Vote”样本,如图:
3.关联规则分析
1)操作步骤:
a)点击“Explorer”按钮,弹出“Weka Explorer”控制界面
b)选择“Associate”选项卡;
c)点击“Choose”按钮,选择“Apriori”规则
d)点击参数文本框框,在参数选项卡设置参数如:
e)点击左侧“Start”按钮
2)执行结果:
=== Run information ===
Scheme: weka.associations.Apriori -I -N 10 -T 0 -C 0.9 -D 0.05 -U 1.0 -M 0.5 -S -1.0 -c -1 Relation: vote
Instances: 435
Attributes: 17
handicapped-infants
water-project-cost-sharing
adoption-of-the-budget-resolution
physician-fee-freeze
el-salvador-aid
religious-groups-in-schools
anti-satellite-test-ban
aid-to-nicaraguan-contras
mx-missile
immigration
synfuels-corporation-cutback
education-spending
superfund-right-to-sue
crime
duty-free-exports
export-administration-act-south-africa
Class
=== Associator model (full training set) ===
Apriori
=======
Minimum support: 0.5 (218 instances)
Minimum metric
Number of cycles performed: 10
Generated sets of large itemsets:
Size of set of large itemsets L(1): 12
Large Itemsets L(1):
handicapped-infants=n 236
adoption-of-the-budget-resolution=y 253
physician-fee-freeze=n 247
religious-groups-in-schools=y 272
anti-satellite-test-ban=y 239
aid-to-nicaraguan-contras=y 242
synfuels-corporation-cutback=n 264
education-spending=n 233
crime=y 248
duty-free-exports=n 233
export-administration-act-south-africa=y 269
Class=democrat 267
Size of set of large itemsets L(2): 4
Large Itemsets L(2):
adoption-of-the-budget-resolution=y physician-fee-freeze=n 219
adoption-of-the-budget-resolution=y Class=democrat 231
physician-fee-freeze=n Class=democrat 245
aid-to-nicaraguan-contras=y Class=democrat 218
Size of set of large itemsets L(3): 1
Large Itemsets L(3):
adoption-of-the-budget-resolution=y physician-fee-freeze=n Class=democrat 219
Best rules found:
1. adoption-of-the-budget-resolution=y physician-fee-freeze=n 219 ==> Class=democrat 219 conf:(1)
2. physician-fee-freeze=n 247 ==> Class=democrat 245 conf:(0.99)
3. adoption-of-the-budget-resolution=y Class=democrat 231 ==> physician-fee-freeze=n 219 conf:(0.95)
4. Class=democrat 267 ==> physician-fee-freeze=n 245 conf:(0.92)
5. adoption-of-the-budget-resolution=y 253 ==> Class=democrat 231 conf:(0.91)
6. aid-to-nicaraguan-contras=y 242 ==> Class=democrat 218 conf:(0.9)
3)结果分析:
a)该样本数据,数据记录数435个,17个属性,进行了10轮测试
b)最小支持度为0.5,即至少需要218个实例;
c)最小置信度为0.9;
d)进行了10轮搜索,频繁1项集12个,频繁2项集4个,频繁3项集1个;
4.分类算法-随机树分析
1)操作步骤:
a)点击“Explorer”按钮,弹出“Weka Explorer”控制界面
b)选择“Classify ”选项卡;
c)点击“Choose”按钮,选择“trees” “RandomTree”规则
d)设置Cross-validation 为10次
e)点击左侧“Start”按钮
2)执行结果:
=== Run information ===
Scheme:weka.classifiers.trees.RandomTree -K 0 -M 1.0 -S 1
Relation: vote
Instances:435
Attributes:17
handicapped-infants
water-project-cost-sharing
adoption-of-the-budget-resolution
physician-fee-freeze
el-salvador-aid
religious-groups-in-schools
anti-satellite-test-ban
aid-to-nicaraguan-contras
mx-missile
immigration
synfuels-corporation-cutback
education-spending
superfund-right-to-sue
crime
duty-free-exports
export-administration-act-south-africa
Class
Test mode:10-fold cross-validation
=== Classifier model (full training set) ===
RandomTree
==========
el-salvador-aid = n
| physician-fee-freeze = n
| | duty-free-exports = n
| | | anti-satellite-test-ban = n
| | | | synfuels-corporation-cutback = n
| | | | | crime = n : republican (0.96/0)
| | | | | crime = y
| | | | | | handicapped-infants = n : democrat (2.02/0.01) | | | | | | handicapped-infants = y : democrat (0.05/0)
| | | | synfuels-corporation-cutback = y
| | | | | handicapped-infants = n : democrat (0.79/0.01)
| | | | | handicapped-infants = y : democrat (2.12/0)
| | | anti-satellite-test-ban = y
| | | | adoption-of-the-budget-resolution = n
| | | | | handicapped-infants = n : democrat (1.26/0.01)
| | | | | handicapped-infants = y : republican (1.25/0.25)
| | | | adoption-of-the-budget-resolution = y
| | | | | handicapped-infants = n
| | | | | | crime = n : democrat (5.94/0.01)
| | | | | | crime = y : democrat (5.15/0.12)
| | | | | handicapped-infants = y : democrat (36.99/0.09)
| | duty-free-exports = y
| | | crime = n : democrat (124.23/0.29)
| | | crime = y
| | | | handicapped-infants = n : democrat (16.9/0.38)
| | | | handicapped-infants = y : democrat (8.99/0.02)
| physician-fee-freeze = y
| | immigration = n
| | | education-spending = n
| | | | crime = n : democrat (1.09/0)
| | | | crime = y : democrat (1.01/0.01)
| | | education-spending = y : republican (1.06/0.02)
| | immigration = y
| | | synfuels-corporation-cutback = n
| | | | religious-groups-in-schools = n : republican (3.02/0.01)
| | | | religious-groups-in-schools = y : republican (1.54/0.04)
| | | synfuels-corporation-cutback = y : republican (1.06/0.05)
el-salvador-aid = y
| synfuels-corporation-cutback = n
| | physician-fee-freeze = n
| | | handicapped-infants = n
| | | | superfund-right-to-sue = n
| | | | | crime = n : democrat (1.36/0)
| | | | | crime = y
| | | | | | mx-missile = n : republican (1.01/0)
| | | | | | mx-missile = y : democrat (1.01/0.01)
| | | | superfund-right-to-sue = y : democrat (4.83/0.03)
| | | handicapped-infants = y : democrat (8.42/0.02)
| | physician-fee-freeze = y
| | | adoption-of-the-budget-resolution = n
| | | | export-administration-act-south-africa = n
| | | | | mx-missile = n : republican (49.03/0)
| | | | | mx-missile = y : democrat (0.11/0)
| | | | export-administration-act-south-africa = y
| | | | | duty-free-exports = n
| | | | | | mx-missile = n : republican (60.67/0)
| | | | | | mx-missile = y : republican (6.21/0.15)
| | | | | duty-free-exports = y
| | | | | | aid-to-nicaraguan-contras = n
| | | | | | | water-project-cost-sharing = n
| | | | | | | | mx-missile = n : republican (3.12/0)
| | | | | | | | mx-missile = y : democrat (0.01/0)
| | | | | | | water-project-cost-sharing = y : democrat (1.15/0.14) | | | | | | aid-to-nicaraguan-contras = y : republican (0.16/0)
| | | adoption-of-the-budget-resolution = y
| | | | anti-satellite-test-ban = n
| | | | | immigration = n : democrat (2.01/0.01)
| | | | | immigration = y
| | | | | | water-project-cost-sharing = n
| | | | | | | mx-missile = n : republican (1.63/0)
| | | | | | | mx-missile = y : republican (1.01/0.01)
| | | | | | water-project-cost-sharing = y
| | | | | | | superfund-right-to-sue = n : republican (0.45/0)
| | | | | | | superfund-right-to-sue = y : republican (1.71/0.64) | | | | anti-satellite-test-ban = y
| | | | | mx-missile = n : republican (7.74/0)
| | | | | mx-missile = y : republican (4.05/0.03)
| synfuels-corporation-cutback = y
| | adoption-of-the-budget-resolution = n
| | | superfund-right-to-sue = n
| | | | anti-satellite-test-ban = n
| | | | | physician-fee-freeze = n : democrat (1.39/0.01)
| | | | | physician-fee-freeze = y
| | | | | | water-project-cost-sharing = n : republican (1.01/0)
| | | | | | water-project-cost-sharing = y : democrat (1.05/0.05)
| | | | anti-satellite-test-ban = y : democrat (1.13/0.01)
| | | superfund-right-to-sue = y
| | | | education-spending = n
| | | | | physician-fee-freeze = n
| | | | | | crime = n : democrat (0.09/0)
| | | | | | crime = y
| | | | | | | handicapped-infants = n : democrat (1.01/0.01)
| | | | | | | handicapped-infants = y : democrat (1/0)
| | | | | physician-fee-freeze = y
| | | | | | immigration = n
| | | | | | | export-administration-act-south-africa = n : democrat
(0.34/0.11)
| | | | | | | export-administration-act-south-africa = y
| | | | | | | | crime = n : democrat (0.16/0)
| | | | | | | | crime = y
| | | | | | | | | mx-missile = n
| | | | | | | | | | handicapped-infants = n : republican (0.29/0) | | | | | | | | | | handicapped-infants = y : republican (1.88/0.87) | | | | | | | | | mx-missile = y : democrat (0.01/0)
| | | | | | immigration = y : republican (1.01/0)
| | | | education-spending = y
| | | | | physician-fee-freeze = n
| | | | | | handicapped-infants = n : democrat (1.51/0.01)
| | | | | | handicapped-infants = y : democrat (2.01/0)
| | | | | physician-fee-freeze = y
| | | | | | crime = n : republican (1.02/0)
| | | | | | crime = y
| | | | | | | export-administration-act-south-africa = n
| | | | | | | | handicapped-infants = n
| | | | | | | | | immigration = n
| | | | | | | | | | mx-missile = n
| | | | | | | | | | | water-project-cost-sharing = n : democrat (1.01/0.01)
| | | | | | | | | | | water-project-cost-sharing = y : republican (1.81/0)
| | | | | | | | | | mx-missile = y : democrat (0.01/0)
| | | | | | | | | immigration = y
| | | | | | | | | | mx-missile = n : republican (2.78/0)
| | | | | | | | | | mx-missile = y : democrat (0.01/0)
| | | | | | | | handicapped-infants = y
| | | | | | | | | mx-missile = n : republican (2/0)
| | | | | | | | | mx-missile = y : democrat (0.4/0)
| | | | | | | export-administration-act-south-africa = y
| | | | | | | | mx-missile = n : republican (8.77/0)
| | | | | | | | mx-missile = y : democrat (0.02/0)
| | adoption-of-the-budget-resolution = y
| | | anti-satellite-test-ban = n
| | | | handicapped-infants = n
| | | | | crime = n : democrat (2.52/0.01)
| | | | | crime = y : democrat (7.65/0.07)
| | | | handicapped-infants = y : democrat (10.83/0.02)
| | | anti-satellite-test-ban = y
| | | | physician-fee-freeze = n
| | | | | handicapped-infants = n
| | | | | | crime = n : democrat (2.42/0.01)
| | | | | | crime = y : democrat (2.28/0.03)
| | | | | handicapped-infants = y : democrat (4.17/0.01)
| | | | physician-fee-freeze = y
| | | | | mx-missile = n : republican (2.3/0)
| | | | | mx-missile = y : democrat (0.01/0)
Size of the tree : 143
Time taken to build model: 0.01seconds
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 407 93.5632 %
Incorrectly Classified Instances 28 6.4368 %
Kappa statistic 0.8636
Mean absolute error 0.0699
Root mean squared error 0.2379
Relative absolute error 14.7341 %
Root relative squared error 48.8605 %
Total Number of Instances 435
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure ROC Area Class
0.955 0.095 0.941 0.955 0.948 0.966 democrat
0.905 0.045 0.927 0.905 0.916 0.967 republican
Weighted Avg. 0.936 0.076 0.936 0.936 0.935 0.966 === Confusion Matrix ===
a b <-- classified as
255 12 | a = democrat
16 152 | b = republican
3)结果分析:
a)该样本数据,数据记录数435个,17个属性,进行了10轮交叉验证
b)随机树长143
c)正确分类共407个,正确率达93.5632 %
d)错误分类28个,错误率6.4368 %
e)测试数据的正确率较好
5.分类算法-随机树分析
1)操作步骤:
a)点击“Explorer”按钮,弹出“Weka Explorer”控制界面
b)选择“Classify ”选项卡;
c)点击“Choose”按钮,选择“trees” “J48”规则
d)设置Cross-validation 为10次
e)点击左侧“Start”按钮
2)执行结果:
=== Run information ===
Scheme:weka.classifiers.trees.J48 -C 0.25 -M 2
Relation: vote
Instances:435
Attributes:17
handicapped-infants
water-project-cost-sharing
adoption-of-the-budget-resolution
physician-fee-freeze
el-salvador-aid
religious-groups-in-schools
anti-satellite-test-ban
aid-to-nicaraguan-contras
mx-missile
immigration
synfuels-corporation-cutback
education-spending
superfund-right-to-sue
crime
duty-free-exports
export-administration-act-south-africa
Class
Test mode:10-fold cross-validation
=== Classifier model (full training set) ===
J48 pruned tree
------------------
physician-fee-freeze = n: democrat (253.41/3.75)
physician-fee-freeze = y
| synfuels-corporation-cutback = n: republican (145.71/4.0)
| synfuels-corporation-cutback = y
| | mx-missile = n
| | | adoption-of-the-budget-resolution = n: republican (22.61/3.32) | | | adoption-of-the-budget-resolution = y
| | | | anti-satellite-test-ban = n: democrat (5.04/0.02)
| | | | anti-satellite-test-ban = y: republican (2.21)
| | mx-missile = y: democrat (6.03/1.03)
Number of Leaves : 6
Size of the tree : 11
Time taken to build model: 0.06seconds
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 419 96.3218 % Incorrectly Classified Instances 16 3.6782 % Kappa statistic 0.9224
Mean absolute error 0.0611
Root mean squared error 0.1748
Relative absolute error 12.887 %
Root relative squared error 35.9085 %
Total Number of Instances 435
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure ROC Area Class
0.97 0.048 0.97 0.97 0.97 0.971 democrat
0.952 0.03 0.952 0.952 0.952 0.971 republican
Weighted Avg. 0.963 0.041 0.963 0.963 0.963 0.971
=== Confusion Matrix ===
a b <-- classified as
259 8 | a = democrat
8 160 | b = republican
3)结果分析:
a)该样本数据,数据记录数435个,17个属性,进行了10轮交叉验证
b)决策树分6级,长度11
c)正确分类共419个,正确率达96.3218 %
d)错误分类16个,错误率3.6782 %
e)测试结果接近随机数,正确率较高
6.分类算法-朴素贝叶斯分析
1)操作步骤:
a)点击“Explorer”按钮,弹出“Weka Explorer”控制界面
b)选择“Classify ”选项卡;
c)点击“Choose”按钮,选择“bayes” “Naive Bayes”规则
d)设置Cross-validation 为10次
e)点击左侧“Start”按钮
2)执行结果:
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 392 90.1149 %
Incorrectly Classified Instances 43 9.8851 %
Kappa statistic 0.7949
Mean absolute error 0.0995
Root mean squared error 0.2977
Relative absolute error 20.9815 %
Root relative squared error 61.1406 %
Total Number of Instances 435
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure ROC Area Class
0.891 0.083 0.944 0.891 0.917 0.973
democrat
0.917 0.109 0.842 0.917 0.877 0.973
republican
Weighted Avg. 0.901 0.093 0.905 0.901 0.902 0.973 === Confusion Matrix ===
a b <-- classified as
238 29 | a = democrat
14 154 | b = republican
3)结果分析
a)该样本数据,数据记录数435个,17个属性,进行了10轮交叉验证
b)正确分类共392个,正确率达90.1149 %
c)错误分类43个,错误率9.8851 %
d)测试正确率较高
7.
根据以上对比结果,三类分类算法对样板数据Vote测试准确率类似;
8.
数据挖掘实验报告
《数据挖掘》Weka实验报告 姓名_学号_ 指导教师 开课学期2015 至2016 学年 2 学期完成日期2015年6月12日
1.实验目的 基于https://www.360docs.net/doc/506321914.html,/ml/datasets/Breast+Cancer+WiscOnsin+%28Ori- ginal%29的数据,使用数据挖掘中的分类算法,运用Weka平台的基本功能对数据集进行分类,对算法结果进行性能比较,画出性能比较图,另外针对不同数量的训练集进行对比实验,并画出性能比较图训练并测试。 2.实验环境 实验采用Weka平台,数据使用来自https://www.360docs.net/doc/506321914.html,/ml/Datasets/Br- east+Cancer+WiscOnsin+%28Original%29,主要使用其中的Breast Cancer Wisc- onsin (Original) Data Set数据。Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 3.实验步骤 3.1数据预处理 本实验是针对威斯康辛州(原始)的乳腺癌数据集进行分类,该表含有Sample code number(样本代码),Clump Thickness(丛厚度),Uniformity of Cell Size (均匀的细胞大小),Uniformity of Cell Shape (均匀的细胞形状),Marginal Adhesion(边际粘连),Single Epithelial Cell Size(单一的上皮细胞大小),Bare Nuclei(裸核),Bland Chromatin(平淡的染色质),Normal Nucleoli(正常的核仁),Mitoses(有丝分裂),Class(分类),其中第二项到第十项取值均为1-10,分类中2代表良性,4代表恶性。通过实验,希望能找出患乳腺癌客户各指标的分布情况。 该数据的数据属性如下: 1. Sample code number(numeric),样本代码; 2. Clump Thickness(numeric),丛厚度;
大数据挖掘weka大数据分类实验报告材料
一、实验目的 使用数据挖掘中的分类算法,对数据集进行分类训练并测试。应用不同的分类算法,比较他们之间的不同。与此同时了解Weka平台的基本功能与使用方法。 二、实验环境 实验采用Weka 平台,数据使用Weka安装目录下data文件夹下的默认数据集iris.arff。 Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java 写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 三、数据预处理 Weka平台支持ARFF格式和CSV格式的数据。由于本次使用平台自带的ARFF格式数据,所以不存在格式转换的过程。实验所用的ARFF格式数据集如图1所示 图1 ARFF格式数据集(iris.arff)
对于iris数据集,它包含了150个实例(每个分类包含50个实例),共有sepal length、sepal width、petal length、petal width和class五种属性。期中前四种属性为数值类型,class属性为分类属性,表示实例所对应的的类别。该数据集中的全部实例共可分为三类:Iris Setosa、Iris Versicolour和Iris Virginica。 实验数据集中所有的数据都是实验所需的,因此不存在属性筛选的问题。若所采用的数据集中存在大量的与实验无关的属性,则需要使用weka平台的Filter(过滤器)实现属性的筛选。 实验所需的训练集和测试集均为iris.arff。 四、实验过程及结果 应用iris数据集,分别采用LibSVM、C4.5决策树分类器和朴素贝叶斯分类器进行测试和评价,分别在训练数据上训练出分类模型,找出各个模型最优的参数值,并对三个模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。 1、LibSVM分类 Weka 平台内部没有集成libSVM分类器,要使用该分类器,需要下载libsvm.jar并导入到Weka中。 用“Explorer”打开数据集“iris.arff”,并在Explorer中将功能面板切换到“Classify”。点“Choose”按钮选择“functions(weka.classifiers.functions.LibSVM)”,选择LibSVM分类算法。 在Test Options 面板中选择Cross-Validatioin folds=10,即十折交叉验证。然后点击“start”按钮:
数据挖掘WEKA实验报告
数据挖掘-WEKA 实验报告一 姓名及学号:杨珍20131198 班级:卓越计科1301 指导老师:吴珏老师
一、实验内容 1、Weka 工具初步认识(掌握weka程序运行环境) 2、实验数据预处理。(掌握weka中数据预处理的使用) 对weka自带测试用例数据集weather.nominal.arrf文件,进行一下操作。 1)、加载数据,熟悉各按钮的功能。 2)、熟悉各过滤器的功能,使用过滤器Remove、Add对数据集进行操作。 3)、使用weka.unsupervised.instance.RemoveWithValue过滤器去除humidity 属性值为high的全部实例。 4)、使用离散化技术对数据集glass.arrf中的属性RI和Ba进行离散化(分别用等宽,等频进行离散化)。 (1)打开已经安装好的weka,界面如下,点击openfile即可打开weka自带测试用例数据集weather.nominal.arrf文件
(2)打开文件之后界面如下: (3)可对数据进行选择,可以全选,不选,反选等,还可以链接数据库,对数
据进行编辑,保存等。还可以对所有的属性进行可视化。如下图: (4)使用过滤器Remove、Add对数据集进行操作。
(5)点击此处可以增加属性。如上图,增加了一个未命名的属性unnamed.再点击下方的remove按钮即可删除该属性. (5)使用weka.unsupervised.instance.RemoveWithValue过滤器去除humidity属性值为high的全部实例。 没有去掉之前: (6)去掉其中一个属性之后:
基于weka的数据分类分析实验报告
基于weka的数据分类分析实验报告 1实验基本内容 本实验的基本内容是通过使用weka中的三种常见分类方法(朴素贝叶斯,KNN和决策树C4.5)分别在训练数据上训练出分类模型,并使用校验数据对各个模型进行测试和评价,找出各个模型最优的参数值,并对三个模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。 2数据的准备及预处理 2.1格式转换方法 原始数据是excel文件保存的xlsx格式数据,需要转换成Weka支持的arff文件格式或csv文件格式。由于Weka对arff格式的支持更好,这里我们选择arff格式作为分类器原始数据的保存格式。 转换方法:在excel中打开“movie_given.xlsx”,选择菜单文件->另存为,在弹出的对话框中,文件名输入“total_data”,保存类型选择“CSV(逗号分隔)”,保存,我们便可得到“total_data.csv”文件;然后,打开Weka的Exporler,点击Open file按钮,打开刚才得到的“total_data”文件,点击“save”按钮,在弹出的对话框中,文件名输入“total_data”,文件类型选择“Arff data files(*.arff)”,这样得到的数据文件为“total_data.arff”。 2.2如何建立数据训练集,校验集和测试集 数据的预处理过程中,为了在训练模型、评价模型和使用模型对数据进行预测能保证一致性和完整性,首先要把movie_given.xslx和test.xslx合并在一起,因为在生成arff文件的时候,可能会出现属性值不一样的情况,否则将为后来的测试过程带来麻烦。 通过统计数据信息,发现带有类标号的数据一共有100行,为了避免数据的过度拟合,必须把数据训练集和校验集分开,目前的拆分策略是各50行。类标号为‘female’的数据有21条,而类标号为‘male’的数据有79条,这样目前遇到的问题是,究竟如何处理仅有的21条female数据?为了能在训练分类模型时有更全面的信息,所以决定把包含21条female类标号数据和29条male类标号数据作为模型训练数据集,而剩下的另49条类标号类male的数据将全部用于校验数据集,这是因为在校验的时候,两种类标号的数据的作用区别不大,而在训练数据模型时,则更需要更全面的信息,特别是不同类标号的数据的合理比例对训练模型的质量有较大的影响。
weka实验报告
基于w e k a的数据分类分析实验报告1 实验目的 (1)了解决策树和朴素贝叶斯等算法的基本原理。 (2)熟练使用weka实现上述两种数据挖掘算法,并对训练出的模型进行测试和评价。 2 实验基本内容 本实验的基本内容是通过基于weka实现两种常见的数据挖掘算法(决策树和朴素贝叶斯),分别在训练数据上训练出分类模型,并使用校验数据对各个模型进行测试和评价,找出各个模型最优的参数值,并对模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。 3 算法基本原理 (1)决策树 是一系列用在机器学习和数据挖掘的分类问题中的算法。它的目标是监督学习:给定一个数据集,其中的每一个元组都能用一组属性值来描述,每一个元组属于一个互斥的类别中的某一类。的目标是通过学习,找到一个从属性值到类别的映射关系,并且这个映射能用于对新的类别未知的实体进行分类。由 Quinlan在ID3的基础上提出的。ID3算法用来构造决策树。决策树是一种类似流程图的树结构,其中每个内部节点(非树叶节点)表示在一个属性上的测试,每个分枝代表一个测试输出,而每个树叶节点存放一个类标号。一旦建立好了决策树,对于一个未给定类标号的元组,跟踪一条有根节点到叶节点的路径,该叶节点就存放着该元组的预测。决策树的优势在于不需要任何领域知识或参数设置,适合于探测性的知识发现。 从ID3算法中衍生出了和CART两种算法,这两种算法在数据挖掘中都非常重要。 属性选择度量又称分裂规则,因为它们决定给定节点上的元组如何分裂。属性选择度量提供了每个属性描述给定训练元组的秩评定,具有最好度量得分的属性被选作给定元组的分裂属性。目前比较流行的属性选择度量有--信息增益、增益率和Gini指标。
基于weka的数据分类分析实验报告
基于weka的数据分类分析实验报告 姓名:陈诺言学号:0483 1实验基本内容 本实验的基本内容是通过使用weka中的三种常见分类方法(朴素贝叶斯,KNN和决策树)分别在训练数据上训练出分类模型,并使用校验数据对各个模型进行测试和评价,找出各个模型最优的参数值,并对三个模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。 2数据的准备及预处理 格式转换方法 原始数据是excel文件保存的xlsx格式数据,需要转换成Weka支持的arff文件格式或csv文件格式。由于Weka对arff格式的支持更好,这里我们选择arff格式作为分类器原始数据的保存格式。 转换方法:在excel中打开“”,选择菜单文件->另存为,在弹出的对话框中,文件名输入“total_data”,保存类型选择“CSV(逗号分隔)”,保存,我们便可得到“”文件;然后,打开Weka的Exporler,点击Open file按钮,打开刚才得到的“total_data”文件,点击“save”按钮,在弹出的对话框中,文件名输入“total_data”,文件类型选择“Arff data files (*.arff)”,这样得到的数据文件为“”。 如何建立数据训练集,校验集和测试集 数据的预处理过程中,为了在训练模型、评价模型和使用模型对数据进行预测能保证
一致性和完整性,首先要把和合并在一起,因为在生成arff文件的时候,可能会出现属性值不一样的情况,否则将为后来的测试过程带来麻烦。 通过统计数据信息,发现带有类标号的数据一共有100行,为了避免数据的过度拟合,必须把数据训练集和校验集分开,目前的拆分策略是各50行。类标号为‘female’的数据有21条,而类标号为‘male’的数据有79条,这样目前遇到的问题是,究竟如何处理仅有的21条female数据?为了能在训练分类模型时有更全面的信息,所以决定把包含21条female类标号数据和29条male类标号数据作为模型训练数据集,而剩下的另49条类标号类male的数据将全部用于校验数据集,这是因为在校验的时候,两种类标号的数据的作用区别不大,而在训练数据模型时,则更需要更全面的信息,特别是不同类标号的数据的合理比例对训练模型的质量有较大的影响。 预处理具体步骤 第一步:合并和,保存为; 第二步:在中删除多余的ID列信息; 第三步:在excel中打开“”,选择菜单文件->另存为,在弹出的对话框中,文件名输入“total_data”,保存类型选择“CSV(逗号分隔)”; 第四步:使用UltraEdit工具把中的数据缺失部分补上全局常量‘?’; 第五步:打开Weka的Exporler,点击Open file按钮,打开刚才得到的“”文件,点击“save”按钮,在弹出的对话框中,文件名输入“total_data”,文件类型选择“Arff data files (*.arff)”,这样得到的数据文件为“”。 第六步:从文件里面剪切所有没有分类标号的数据作为预测数据集(),共26项。 第七步:把剩下含有类标号数据的文件复制一份,作为总的训练数据集。文件名称为。 第八步:从文件中剩下的数据里面选取所有分类标号为male的49行数据作为校验数据集()。 第九步:从把剩下的文件改名为。 3. 实验过程及结果截图 决策树分类 用“Explorer”打开刚才得到的“”,并切换到“Class”。点“Choose”按钮选择“tree (,这是WEKA中实现的决策树算法。
数据仓库与数据挖掘实验报告-焦永赞
《数据仓库与数据挖掘》 实验报告册 2013- 2014学年第一学期 班级: T1153-8 学号: 20110530816 姓名:焦永赞 授课教师:杨丽华实验教师:杨丽华 实验学时: 16 实验组号: 1 信息管理系
目录 实验一 Microsoft SQL Server Analysis Services的使用.. 3 实验二使用WEKA进行分类与预测 (114) 实验三使用WEKA进行关联规则与聚类分析 (22) 实验四数据挖掘算法的程序实现 (28)
实验一 Microsoft SQL Server Analysis Services的使用 实验类型:验证性实验学时:4 实验目的: 学习并掌握Analysis Services的操作,加深理解数据仓库中涉及的一些概念,如多维数据集,事实表,维表,星型模型,雪花模型,联机分析处理等。 实验内容: 在实验之前,先通读自学SQL SERVER自带的Analysis Manager概念与教程。按照自学教程的步骤,完成对FoodMart数据源的联机分析。建立、编辑多维数据集,进行OLAP操作,看懂OLAP的分析数据。 实验步骤(写主要步骤,可以打印): 1、启动联机分析管理器:开始->程序->Microsoft SQL Server->Analysis Manager。 2、按照Analysis Service的自学教程完成对FoodMart数据源的联机分析。 3、在开始-设置-控制面板-管理工具-数据源(ODBC),数据源管理器中设置和源数据的 连接,“数据源名”为你的班级+学号+姓名,如T3730101张雨。 (1)打开管理工具中的数据源: (2)选择系统DNS
数据挖掘实验报告-实验1-Weka基础操作
数据挖掘实验报告-实验1-W e k a基础操作
学生实验报告 学院:信息管理学院 课程名称:数据挖掘 教学班级: B01 姓名: 学号:
实验报告 课程名称数据挖掘教学班级B01 指导老师 学号姓名行政班级 实验项目实验一: Weka的基本操作 组员名单独立完成 实验类型■操作性实验□验证性实验□综合性实验实验地点H535 实验日期2016.09.28 1. 实验目的和要求: (1)Explorer界面的各项功能; 注意不能与课件上的截图相同,可采用打开不同的数据文件以示区别。 (2)Weka的两种数据表格编辑文件方式下的功能介绍; ①Explorer-Preprocess-edit,弹出Viewer对话框; ②Weka GUI选择器窗口-Tools | ArffViewer,打开ARFF-Viewer窗口。(3)ARFF文件组成。 2.实验过程(记录实验步骤、分析实验结果) 2.1 Explorer界面的各项功能 2.1.1 初始界面示意
其中:explorer选项是数据挖掘梳理数据最常用界面,也是使用weka最简单的方法。 Experimenter:实验者选项,提供不同数值的比较,发现其中规律。 KnowledgeFlow:知识流,其中包含处理大型数据的方法,初学者应用较少。 Simple CLI :命令行窗口,有点像cmd 格式,非图形界面。 2.1.2 进入Explorer 界面功能介绍 (1)任务面板 Preprocess(数据预处理):选择和修改要处理的数据。 Classify(分类):训练和测试分类或回归模型。 Cluster(聚类):从数据中聚类。聚类分析时用的较多。 Associate(关联分析):从数据中学习关联规则。 Select Attributes(选择属性):选择数据中最相关的属性。 Visualize(可视化):查看数据的二维散布图。 (2)常用按钮
weka实验报告_
基于weka 的数据分类分析实验报告1实验目的 (1)了解决策树C4.5 和朴素贝叶斯等算法的基本原理。 (2)熟练使用weka 实现上述两种数据挖掘算法,并对训练出的模型进行测试和评价。 2实验基本内容 本实验的基本内容是通过基于weka 实现两种常见的数据挖掘算法(决策树C4.5 和朴素贝叶斯),分别在训练数据上训练出分类模型,并使用校验数据对各个模型进行测试和评价,找出各个模型最优的参数值,并对模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。 3算法基本原理 (1)决策树C4.5 C4.5 是一系列用在机器学习和数据挖掘的分类问题中的算法。它的目标是监督学习:给定一个数据集,其中的每一个元组都能用一组属性值来描述,每一个元组属于一个互斥的类别中的某一类。C4.5 的目标是通过学习,找到一个从属性值到类别的映射关系,并且这个映射能用于对新的类别未知的实体进行分类。C4.5 由J.Ross Quinlan 在ID3 的基础上提出的。ID3 算法用来构造决策树。决策树是一种类似流程图的树结构,其中每个内部节点(非树叶节点)表示在一个属性上的测试,每个分枝代表一个测试输出,而每个树叶节点存放一个类标号。一旦建立好了决策树,对于一个未给定类标号的元组,跟踪一条有根节点到叶节点的路径,该叶节点就存放着该元组的预测。决策树的优势在于不需要任何领域知识或参数设置,适合于探测性的知识发现。
从ID3 算法中衍生出了C4.5 和CART两种算法,这两种算法在数据挖掘中都非常重要。 属性选择度量又称分裂规则,因为它们决定给定节点上的元组如何分裂。属性选择度量提供了每个属性描述给定训练元组的秩评定,具有最好度量得分的属性被选作给定元组的分裂属性。目前比较流行的属性选择度量有-- 信息增益、增益率和Gini 指标。 (2)朴素贝叶斯 贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。 朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素,朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。通俗来说,就好比这么个道理,你在街上看到一个黑人,我问你你猜这哥们哪里来的,你十有八九猜非洲。为什么呢?因为黑人中非洲人的比率最高,当然人家也可能是美洲人或亚洲人,但在没有其它可用信息下,我们会选择条件概率最大的类别,这就是朴素贝叶斯的思想基础。 朴素贝叶斯分类的正式定义如下: 1)设x={a_1,a_2,...,a_m} 为一个待分类项,而每个a 为x 的一个特征属性。 2)有类别集合C={y_1,y_2,...,y_n} 。 3)计算 P(y_1|x),P(y_2|x),...,P(y_n|x) 。 4)如果 P(y_k|x)=max{P(y_1|x),P(y_2|x),...,P(y_n|x)} ,则x in y_k 。 那么现在的关键就是如何计算第3 步中的各个条件概率。我们可以这么做: 1)找到一个已知分类的待分类项集合,这个集合叫做训练样本集。
数据挖掘WEKA报告bezdekIris
第一部分概述 1.数据挖掘目的:根据已有的数据信息,寻找出鸢尾的属性之间存在怎样的关联规则。 2.数据源:UCI提供的150个实例,每个实例有5个属性。 3.数据集的属性信息: (1). sepal length in cm 萼片长度(单位:厘米)(数值型) (2). sepal width in cm 萼片宽度(单位:厘米)(数值型) (3). petal length in cm 花瓣长度(单位:厘米)(数值型) (4). petal width in cm 花瓣宽度(单位:厘米)(数值型) (5). class: 类型(分类型),取值如下 -- Iris Setosa 山鸢尾 -- Iris V ersicolor 变色鸢尾 -- Iris Virginica 维吉尼亚鸢尾 4.试验中我们采用bezdekIris.data数据集,对比UCI发布的iris.data数据集(08-Mar-1993)和bezdekIris.data数据集(14-Dec-1999),可知前者的第35个实例4.9,3.1,1.5,0.1,Iris-setosa和第38个实例4.9,3.1,1.5,0.1,Iris-setosa,后者相应的修改为:4.9,3.1,1.5,0.2,Iris-setosa和4.9,3.1,1.4,0.1,Iris-setosa。 第二部分将UCI提供的数据转化为标准的ARFF数据集 1. 将数据集处理为标准的数据集,对于原始数据,我们将其拷贝保存到TXT文档,采用UltraEdit工具打开,为其添加属性信息。如图: 2.(1)将bezdekIris.txt文件导入Microsoft Office Excel(导入时,文本类型选择文本文件),如图:
数据挖掘实验报告-实验1-Weka基础操作
学生实验报告 学院:信息管理学院 课程名称:数据挖掘 教学班级:B01 姓名: 学号: 页脚内容1
实验报告 1. 实验目的和要求: (1)Explorer界面的各项功能; 注意不能与课件上的截图相同,可采用打开不同的数据文件以示区别。(2)Weka的两种数据表格编辑文件方式下的功能介绍; ①Explorer-Preprocess-edit,弹出Viewer对话框; 页脚内容2
②Weka GUI选择器窗口-Tools | ArffViewer,打开ARFF-Viewer窗口。 (3)ARFF文件组成。 2.实验过程(记录实验步骤、分析实验结果) 2.1 Explorer界面的各项功能 2.1.1 初始界面示意 其中:explorer选项是数据挖掘梳理数据最常用界面,也是使用weka最简单的方法。 Experimenter:实验者选项,提供不同数值的比较,发现其中规律。 KnowledgeFlow:知识流,其中包含处理大型数据的方法,初学者应用较少。 Simple CLI :命令行窗口,有点像cmd 格式,非图形界面。 2.1.2 进入Explorer 界面功能介绍 (1)任务面板 页脚内容3
Preprocess(数据预处理):选择和修改要处理的数据。 Classify(分类):训练和测试分类或回归模型。 Cluster(聚类):从数据中聚类。聚类分析时用的较多。 Associate(关联分析):从数据中学习关联规则。 Select Attributes(选择属性):选择数据中最相关的属性。 Visualize(可视化):查看数据的二维散布图。 (2)常用按钮 页脚内容4
weka实验报告_
基于weka的数据分类分析实验报告 1 实验目的 (1)了解决策树C4.5和朴素贝叶斯等算法的基本原理。 (2)熟练使用weka实现上述两种数据挖掘算法,并对训练出的模型进行测试和评价。 2 实验基本内容 本实验的基本内容是通过基于weka实现两种常见的数据挖掘算法(决策树C4.5和朴素贝叶斯),分别在训练数据上训练出分类模型,并使用校验数据对各个模型进行测试和评价,找出各个模型最优的参数值,并对模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。 3 算法基本原理 (1)决策树C4.5 C4.5是一系列用在机器学习和数据挖掘的分类问题中的算法。它的目标是监督学习:给定一个数据集,其中的每一个元组都能用一组属性值来描述,每一个元组属于一个互斥的类别中的某一类。C4.5的目标是通过学习,找到一个从属性值到类别的映射关系,并且这个映射能用于对新的类别未知的实体进行分类。C4.5由J.Ross Quinlan在ID3的基础上提出的。ID3算法用来构造决策树。决策树是一种类似流程图的树结构,其中每个内部节点(非树叶节点)表示在一个属性上的测试,每个分枝代表一个测试输出,而每个树叶节点存放一个类标号。一旦建立好了决策树,对于一个未给定类标号的元组,跟踪一条有根节点到叶节点的路径,该叶节点就存放着该元组的预测。决策树的优势在于不需要任何领域知识或参数设置,适合于探测性的知识发现。
从ID3算法中衍生出了C4.5和CART两种算法,这两种算法在数据挖掘中都非常重要。 属性选择度量又称分裂规则,因为它们决定给定节点上的元组如何分裂。属性选择度量提供了每个属性描述给定训练元组的秩评定,具有最好度量得分的属性被选作给定元组的分裂属性。目前比较流行的属性选择度量有--信息增益、增益率和Gini指标。 (2)朴素贝叶斯 贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。 朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素,朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。通俗来说,就好比这么个道理,你在街上看到一个黑人,我问你你猜这哥们哪里来的,你十有八九猜非洲。为什么呢?因为黑人中非洲人的比率最高,当然人家也可能是美洲人或亚洲人,但在没有其它可用信息下,我们会选择条件概率最大的类别,这就是朴素贝叶斯的思想基础。 朴素贝叶斯分类的正式定义如下: 1)设x={a_1,a_2,...,a_m}为一个待分类项,而每个a为x的一个特征属性。 2)有类别集合C={y_1,y_2,...,y_n}。 3)计算P(y_1|x),P(y_2|x),...,P(y_n|x)。 4)如果P(y_k|x)=max{P(y_1|x),P(y_2|x),...,P(y_n|x)},则x in y_k。 那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做:1)找到一个已知分类的待分类项集合,这个集合叫做训练样本集。 2)统计得到在各类别下各个特征属性的条件概率估计。即 P(a_1|y_1),P(a_2|y_1),...,P(a_m|y_1);P(a_1|y_2),P(a_2|y_2),...,P(a_m| y_2);...;P(a_1|y_n),P(a_2|y_n),...,P(a_m|y_n)。 3)如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导: P(y_i|x)=frac{P(x|y_i)P(y_i)}{P(x)}
WEKA实验资料报告材料
基于weka的数据分类分析 学号:Z15030739 :丽丽专业:计算机技术 一、实验目的 1、使用数据挖掘中的分类算法,对数据集进行分类训练并测试; 2、应用不同的分类算法,比较他们之间的不同; 3、了解Weka平台的基本功能与使用方法。 二、实验环境 Windows7+weka 三、实验容与步骤 1、数据准备及预处理 2、三种分类方法分析 (1)、决策树分类; (2)、K最近邻算法分类; (3)、贝叶斯分类; 3、三类分类方法的校验结果比较 四、实验容与步骤 1、实验数据预处理 首先是格式处理,一般情况下,数据的储存格式是xlsx格式。使用weka进行数据分析时,需要将数据的格式利用格式转换工具转换成arff格式。比如先使用UltraEdit软件将xlsx转换成csv格式,然后再在weka中导入csv格式的数据,然后点击“save”,选择”.arff”格式。 本次实验选择的是“breast-cancer.arff”作为分析数据。所以无需格式转换处理。
其次是数据处理过程,用“Explorer”打开“breast-cancer.arff”。总共有286条数据。 第1步:从“breast-cancer.arff”中截取86条,另存储为“breast-data.arff”,作为校验数据。 第2步:把剩下的200条另存储为“breast-train.arff”,作为训练数据。 第3步:点击”undo”恢复原“breast-cancer.arff”。 2、实验过程及结果 2.1决策树分类 用“Explorer”打开“breast-train.arff”切换到classify面板,选择trees->J48分类器。选择默认参数。点击start按钮,启动实验。结果如下: 校验数据集决策树得出的结果:
基于Weka的数据分类分析实验报告
基于Weka的数据分类分析实验报告 基于Weka的数据分类分析实验报告 1 实验目的 使用数据挖掘中的分类算法,对数据集进行
分类训练并测试。应用不同的分类算法,比较他们之间的不同。与此同时了解Weka平 台的基本功能与使用方法。 2 实验环境 2.1 Weka介绍 Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java 写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可
结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。.
1 Weka图主界面系统包括处理标准数据挖掘问题的所Weka有方法:回归、分类、聚类、关联规则以及属性选择。分析要进行处理的数据是重要的一个环提供了很多用于数据可视化和 与处理节,Weka第一种是以输入数据可以有两种形式,的工具。格式为代表的文件;另一种是直接读取数ARFF 据库表。的方式主要有三种:第一种是将使用Weka学习方案应用于某个数据集,然后分析其输出,第二种是使用已经学从而更多地了解这些数据;第三种是使用多种习到的模型对新实例进 预测;然后根据其性能表现选择其中一种来进学习器,用户使用交互式界面菜单中选择一种学行预测。习方法,大部分学习方案都带有可调节的参数,然用户可通过属性列表或对象编辑器修改参数, 后通过同一个评估模块对学习方案的性能 进行评估。 2.2 数据和数据集 根据应用的不同,数据挖掘的对象可以是各
数据挖掘期末实验报告
数据挖掘技术期末报告 理学院 姓名: 学号: 联系电话: 专业班级: 评分:优□|良□|中□|及格□|不及格□
一、实验目的 基于从UCI公开数据库中下载的数据,使用数据挖掘中的分类算法,用Weka 平台的基本功能对数据集进行分类,对算法结果进行性能比较,画出性能比较图,另外针对不同数量的训练集进行对比实验,并画出性能比较图训练并测试。 二、实验环境 实验采用Weka平台,数据使用来自从UCI公开数据库中下载,主要使用其中的Breast Cancer Wisc-onsin (Original) Data Set数据。Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 三、实验步骤 3.1数据预处理 本实验是针对威斯康辛州(原始)的乳腺癌数据集进行分类,该表含有Sample code number(样本代码),Clump Thickness(丛厚度),Uniformity of Cell Size(均匀的细胞大小),Uniformity of Cell Shape (均匀的细胞形状),Marginal Adhesion (边际粘连),Single Epithelial Cell Size(单一的上皮细胞大小),Bare Nuclei(裸核),Bland Chromatin(平淡的染色质),Normal Nucleoli(正常的核仁),Mitoses (有丝分裂),Class(分类),其中第二项到第十项取值均为1-10,分类中2代表良性,4代表恶性。通过实验,希望能找出患乳腺癌客户各指标的分布情况。 该数据的数据属性如下: 1. Sample code number(numeric),样本代码; 2. Clump Thickness(numeric),丛厚度; 3.Uniformity of Cell Size(numeric)均匀的细胞大小; 4. Uniformity of Cell Shape(numeric),均匀的细胞形状; 5.Marginal Adhesion(numeric),边际粘连; 6.Single Epithelial Cell Size(numeric),单一的上皮细胞大小; 7.Bare Nuclei(numeric),裸核;
基于weka的数据分类和聚类分析实验报告
26 0 1 N 3.实验过程及结果截图 决策树分类 基 于 weka 的 数 据 分 类 分 析 实 验 报 告 1实验基本内容 本实验的基本内容是通过使用 分别在训练数据上训练岀分类模型, weka 中的三种常见分类和聚类方法(决策树 并使用校验数据对各个模型进行测试和评价,找岀各个模型最优的 J48、KNN 和 k-means ) 参数值,并对三个模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。 最后使用这些参数以及训练集和校验集数据一起构造岀一个最优分类器, 并利用该分类器对测试数据进 行预测。 2数据的准备及预处理 格式转换方法 (1)打开“”另存为CSV 类型,得到 ⑵在 WEKA 中提供了一个“ Arff Viewer 模块,打开一个“”进行浏览,然后另存为 ARFF 文件, 得到“”。 O dataOZ.arff (1)决策树分类 用“ Explorer ”打开数据“”,然后切换到 “ trees-J48 ",再在“ Test options ” 选择“ Cross-validation 始运行。 系统默认trees-J48 决策树算法中 ££ Classify "。点击"Choose ",选择算法 (Flods=10 )",点击"Start ",开 mi nNumObj=2,得到如下结果 ===Summary === Correctly Classified In sta nces In correctly Classified In sta nces Kappa statistic Mean absolute error Root mean squared error Relative absolute error 23 3 Root relative squared error Total Number of In sta nces ===Detailed Accuracy By Class === TP Rate FP Rate P recisio n Recall F-Measure ROC Area Class
weka实验报告
weka实验报告 数据挖掘实验报告 基于weka的数据分类分析实验报告 姓名: 学号: 1实验基本内容 本实验的基本内容是通过使用weka中的三种常见分类方法(朴素贝叶斯,KNN 和决策树C4.5)分别在训练数据上训练出分类模型,并使用校验数据对各个模型进行测试和评价,找出各个模型最优的参数值,并对三个模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。 2数据的准备及预处理 2.1格式转换方法 原始数据是老师直接给的arff文件,因此不用转换,可以直接导入。但如果原始数据是excel文件保存的xlsx格式数据,则需要转换成Weka支持的arff文件格式或csv文件格式。由于Weka对arff格式的支持更好,这里我们选择arff 格式作为分类器原始数据的保存格式。 转换方法:假如我们准备分析的文件为“breast-cancer.xlsx”,则在excel 中打开“breast-cancer.xlsx”,选择菜单文件->另存为,在弹出的对话框中,文件名输入“breast-cancer”,保存类型选择“CSV(逗号分隔)”,保存,我们便可得到“breast-cancer.csv”文件;然后,打开Weka的Exporler,点击Open file 按钮,打开刚才得到的“filename”文件,点击“save”按钮,在弹出的对话框
中,文件名输入“breast-cancer”,文件类型选择“Arff data files(*.arff)”,这样得到的数据文件为“breast-cancer.arff”。 1 数据挖掘实验报告 2.2如何建立数据训练集,校验集和测试集 通过统计数据信息,发现带有类标号的数据一共有286行,为了避免数据的过度拟合,必须把数据训练集和校验集分开,目前的拆分策略是训练集200行,校验集86行。类标号 01条,而类标号为‘recurrence-events’的数据有85为‘no-recurrence-events’的数据有2 条,为了能在训练分类模型时有更全面的信息,所以决定把包含115条no-recurrence-events 类标号数据和85条recurrence-events类标号数据作为模型训练数据集,而剩下的86条类标号类no-recurrence-events的数据将全部用于校验数据集,这是因为在校验的时候,两种类标号的数据的作用区别不大,而在训练数据模型时,则更需要更全面的信息,特别是不同类标号的数据的合理比例对训练模型的质量有较
weka数据挖掘实验3报告
数据挖掘实验报告 姓名:邢金雁 学号:091070106 专业:电子商务
实验三 一、实验名称: 基于聚类分析的信息获取 二、实验目的: 通过一个已有的训练数据集,观察训练集中的实例,进行聚类信息获取,更好地理解和掌握聚类分析算法基本原理,建立相应的预测模型,然后对新的未知实例进行预测,预测的准确程度来衡量所建立模型的好坏。 三、实验要求 1、熟悉Weka平台 2、掌握聚类分析算法 3、对数据进行预处理,利用Weka和不同参数设置进行聚类分析,对比结果, 得出结论,对问题进行总结。 四、实验平台 新西兰怀卡托大学研制的Weka系统
实验方法和步骤 过程 1.首先对于原始数据做预处理,步骤同实验二 2.用Weka打开bank-data.arff文件,进行相应设置后开始分析 图1——K=6,seed=10的结果 3.实验分析 (1)K=6,seed=50:Within cluster sum of squared errors: 1576.5199261033185 (2)K=6,seed=95:Within cluster sum of squared errors: 1546.8697861466735 (3)K=6,seed=100:Within cluster sum of squared errors:1555.6241507629218 (4)K=6,seed=105:Within cluster sum of squared errors:1529.4152722569527 (5)K=6,seed=110:Within cluster sum of squared
《数据挖掘实训》weka实验报告
《数据挖掘实训》课程论文(报告、案例分析) 院系信息学院 专业统计 班级 10级统计 3 班 学生姓名李健 学号 2010210453 任课教师刘洪伟 2013年 01月17日
课程论文评分表
《数据挖掘实训》课程论文 选题要求: 根据公开发表统计数据,请结合数据挖掘理论与方法,撰写一篇与数据挖掘领域相关的论文。 写作要求: (1)数据准确、有时效性,必须是最新的数据。 (2)文章必须有相应的统计方法,这些统计方法包括以前专业课中学到的任何统计方法,如参数估计、假设检验、相关与回归、多元统计等等。 (3)论文的内容必须是原创,有可靠的分析依据和明确的结论。 (4)论文按照规定的格式化撰写; (5)字数不少于2000字。
数据挖掘(WEKA软件)实验报告 统计学专业学生李健学号2010210453关键词:数据挖掘;游玩;因素;WEKA 本次实验指在熟练的运用软件weka进行数据处理,其中包括数据准备,关联规则等同时了解weka的基本用法。 一、软件介绍 1简介 数据挖掘、机器学习这些字眼,在一些人看来,是门槛很高的东西。诚然,如果做算法实现甚至算法优化,确实需要很多背景知识。但事实是,绝大多数数据挖掘工程师,不需要去做算法层面的东西。他们的精力,集中在特征提取,算法选择和参数调优上。那么,一个可以方便地提供这些功能的工具,便是十分必要的了。而weka,便是数据挖掘工具中的佼佼者。 WEKA的全名是怀卡托智能分析环境(Waikato Environment forKnowledge Analysis),是由新西兰怀卡托(Waikato)大学开发的机器学习软件,纯Java技术实现的开源软件,遵循于GNU General Public License,跨平台运行,集合了大量能承担数据挖掘任务的机器学习算法,分类器实现了常用ZeroR算法、Id3算法、J4.8算法等40多个算法,聚类器实现了EM算法、SimpleKMeans算法和Cobweb算法3种算法,能对数据进行预处理、分类、回归、聚类、关联规则以及在新的交互式界面上的可视化。2oo5年8月,在第11届ACM SIGKDD国际会议上,怀卡托大学的WEKA小组荣获了数据挖掘和知识探索领域的最高服务奖,WEKA系统得到了广泛的认可,被誉为数据挖掘和机器学习历史上的里程碑,是现今最完备的数据挖掘工具之一。WEKA使用的是一种叫做arff(Attribute—Relation File Format)的数据文件结构。这种arff文件是普通的ASCII文本文件,内部结构很简单,主要是测试算法使用的轻量级的数据文件结构。arff文件可以自己建立,也可通过JDBC从Oracle和Mysql等流行数据库中获得。整个arf文件可以分为两个部分。第一部分给出了头信息(Head information),包括关系声明(Relation Declaration)和属性声明(AttributeDeclarations)。第二部分给出了数据信息(Datainformation),即数据集中给出的数据。关系声明的定义格式为:@relation