URL编码表 Base64编码表 HTTP消息含义===
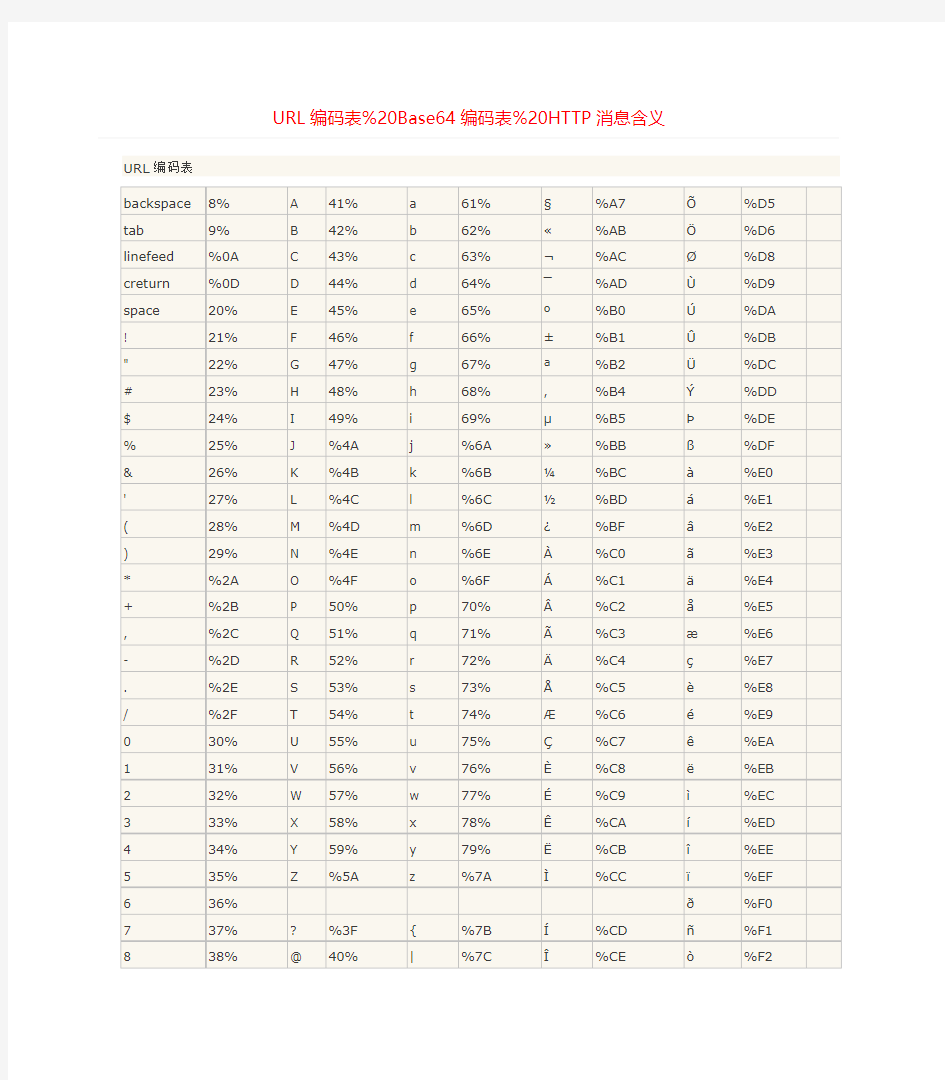
URL编码表
backspace 8% A 41% a 61% §%A7 ?%D5 tab 9% B 42% b 62% ?%AB ?%D6 linefeed %0A C 43% c 63% ?%AC ?%D8 creturn %0D D 44% d 64% ˉ%AD ù%D9 space 20% E 45% e 65% o%B0 ú%DA ! 21% F 46% f 66% ±%B1 ?%DB " 22% G 47% g 67% a%B2 ü%DC # 23% H 48% h 68% , %B4 Y%DD $ 24% I 49% i 69% μ%B5 T%DE % 25% J %4A j %6A ?%BB ?%DF & 26% K %4B k %6B ? %BC à%E0 ' 27% L %4C l %6C ? %BD á%E1 ( 28% M %4D m %6D ?%BF a%E2 ) 29% N %4E n %6E à%C0 ?%E3 * %2A O %4F o %6F á%C1 ?%E4 + %2B P 50% p 70% ?%C2 ?%E5 , %2C Q 51% q 71% ?%C3 ? %E6 - %2D R 52% r 72% ?%C4 ?%E7 . %2E S 53% s 73% ?%C5 è%E8 / %2F T 54% t 74% ? %C6 é%E9
0 30% U 55% u 75% ?%C7 ê%EA
1 31% V 56% v 76% è%C8 ?%EB
2 32% W 57% w 77% é%C9 ì%EC
3 33% X 58% x 78% ê%CA í%ED
4 34% Y 59% y 79% ?%CB ?%EE
5 35% Z %5A z %7A ì%CC ?%EF
6 36% e%F0
7 37% ? %3F { %7B í%CD ?%F1
8 38% @ 40% | %7C ?%CE ò%F2
9 39% [ %5B } %7D ?%CF ó%F3 : %3A \ %5C ~ %7E D%D0 ?%F4 ; %3B ] %5D ¢%A2 ?%D1 ?%F5 < %3C ^ %5E £%A3 ò%D2 ?%F6 = %3D _ %5F ¥%A5 ó%D3 ÷%F7 > %3E ` 60% | %A6 ?%D4 ?%F8
ù%F9
java中图片与base64位编码互转
JAVA CODE import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.io.OutputStream; import sun.misc.BASE64Decoder; import sun.misc.BASE64Encoder; public class Test64Bit { public static void main(String[] args) { // 测试从Base64编码转换为图片文件 String strImg = "这里放64位编码"; GenerateImage(strImg, "D:\wangyc.jpg"); // 测试从图片文件转换为Base64编码 System.out.println(GetImageStr("d:\wangyc.jpg")); } public static String GetImageStr(String imgFilePath) {// 将图片文件转化为字节数组字符串,并对其进行Base64编码处理 byte[] data = null; // 读取图片字节数组
try { InputStream in = new FileInputStream(imgFilePath); data = new byte[in.available()]; in.read(data); in.close(); } catch (IOException e) { e.printStackTrace(); } // 对字节数组Base64编码 BASE64Encoder encoder = new BASE64Encoder(); return encoder.encode(data);// 返回Base64编码过的字节数组字符串 } public static boolean GenerateImage(String imgStr, String imgFi lePath) {// 对字节数组字符串进行Base64解码并生成图片 if (imgStr == null) // 图像数据为空 return false; BASE64Decoder decoder = new BASE64Decoder(); try { // Base64解码 byte[] bytes = decoder.decodeBuffer(imgStr); for (int i = 0; i < bytes.length; ++i) { if (bytes[i] < 0) {// 调整异常数据 bytes[i] += 256; } }
HTTP状态码查询
HTTP 1xx - 信息提示 这些状态代码表示临时的响应。客户端在收到常规响应之前,应准备接收一个或多个 1xx 响应。 ?100 - 继续。 ?101 - 切换协议。 2xx - 成功 这类状态代码表明服务器成功地接受了客户端请求。 ?200 - 确定。客户端请求已成功。 ?201 - 已创建。 ?202 - 已接受。 ?203 - 非权威性信息。 ?204 - 无内容。 ?205 - 重置内容。 ?206 - 部分内容。 ?207 - 多状态 (WebDAV)。 3xx - 重定向 客户端浏览器必须采取更多操作来实现请求。例如,浏览器可能不得不请求服务器上的不同的页面,或通过代理服务器重复该请求。 ?301 - 已永久移动 ?302 - 对象已移动。 ?304 - 未修改。 ?307 - 临时重定向。 4xx - 客户端错误 发生错误,客户端似乎有问题。例如,客户端请求不存在的页面,客户端未提供有效的身份验证信息。 ?400 - 错误的请求。 ?401 - 访问被拒绝。IIS 定义了几个不同的 401 错误,用于指示更为具体的错误原因。这些具体的错误代码在浏览器中显示,但不在 IIS 日志中显示: o401.1 - 登录失败。 o401.2 - 服务器配置导致登录失败。 o401.3 - 由于 ACL 对资源的限制而未获得授权。 o401.4 - 筛选器授权失败。 o401.5 - ISAPI/CGI 应用程序授权失败。 o401.7 –由 Web 服务器上的 URL 验证策略拒绝访问。这个错误代码为IIS 6.0 所专用。 ?403 - 禁止访问:IIS 定义了几个不同的 403 错误,用于指示更为具体的错误原因:o403.1 - 执行访问被禁止。 o403.2 - 读访问被禁止。 o403.3 - 写访问被禁止。
HTTP返回值状态码
HTTP 状态码知道哪些? 1. 临时响应 100——客户必须继续发出请求 101——客户要求服务器根据请求转换HTTP 协议版本 2. 成功 200——服务器成功返回网页 201——提示知道新文件的URL 202——接受和处理、但处理未完成。 203——返回信息不确定或不完整 204——请求收到,但返回信息为空。 205——服务器完成了请求,用户代理必须复位当前已经浏览过的文件。206——服务器已经完成了部分用户的GET 请求 3. 重定向 300——请求的资源可在多处得到 301——删除请求数据 302——在其他地址发现了请求数据 303——建议客户访问其他URL 或访问方式 304——客户端已经执行了GET,但文件未变化。 305——请求的资源必须从服务器指定的地址得到 306——前一版本HTTP 中使用的代码,现行版本中不再使用。307——申明请求的资源临时性删除 4. 客户端错误 400——错误请求,如语法错误 401——请求授权失败 402——保留有效ChargeTo 头响应 403——请求不允许 404——请求的网页不存在 405——用户在Request-Line 字段定义的方法不允许 406——根据用户发送的Accept 拖,请求资源不可访问。407——类似401,用户必须首先在代理服务器上得到授权。 408——客户端没有在用户指定的饿时间内完成请求 409——对当前资源状态,请求不能完成。 410——服务器上不再有此资源且无进一步的参考地址 411——服务器拒绝用户定义的Content-Length 属性请求 412——一个或多个请求头字段在当前请求中错误 413——请求的资源大于服务器允许的大小 414——请求的资源URL 长于服务器允许的长度 415——请求资源不支持请求项目格式 416——请求中包含Range 请求头字段,在当前请求资源范围内没有range 指示值,请求也不包含If-Range 请求头字段。 417——服务器不满足请求Expect 头字段指定的期望值,如果是代理服务器,可能是下一级服务器不能满足请求。 5. 服务器错误 500——服务器产生内部错误 501——服务器不支持请求的函数 502——服务器暂时不可用,有时是为了防止发生系统过载。 503——服务器超时过载或暂停维修 504——关口过载,服务器使用另一个关口或服务来响应用户,等待时间设定值较长。505——服务器不支持或拒绝支请求头中指定的HTTP 版本
Base64编解码
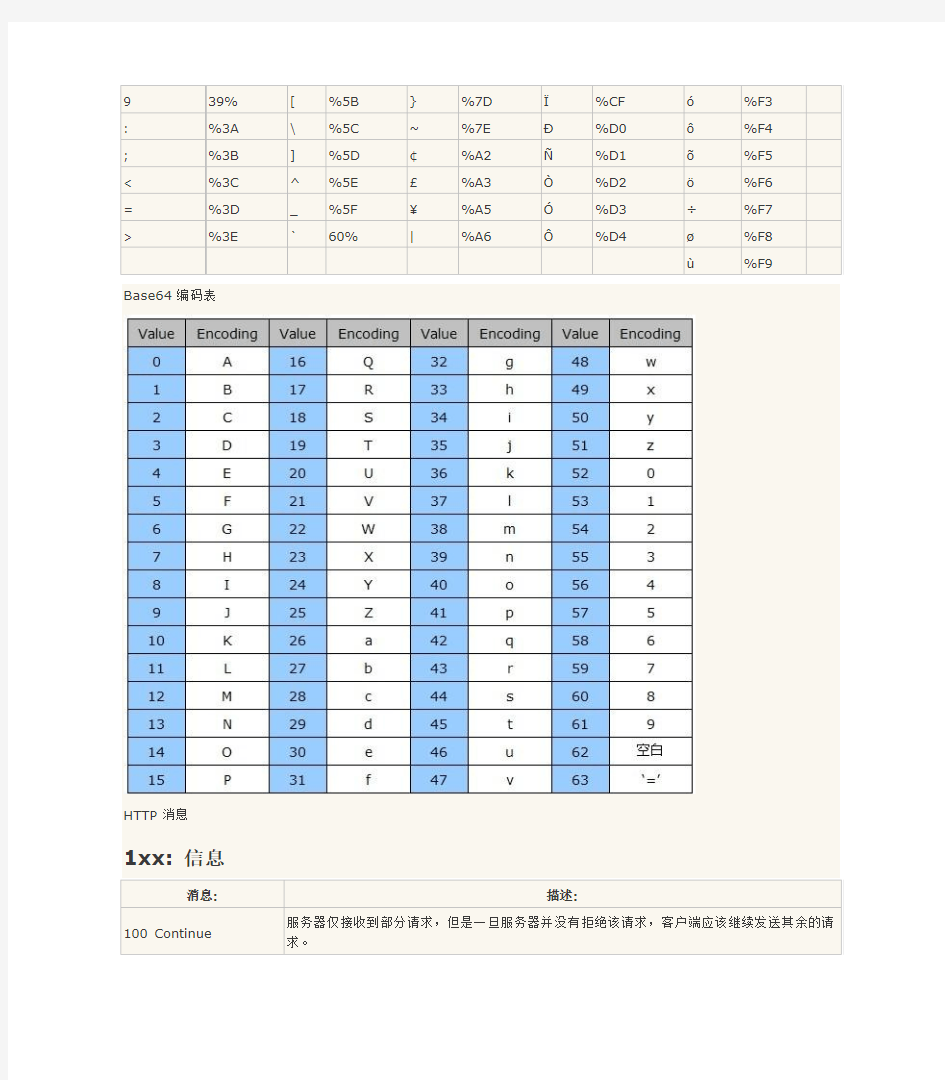
Base64编解码 一、编码原理 Base64是一种基于64个可打印字符来表示二进制数据的表示方法。由于2的6次方等于64,所以每6个比特为一个单元,对应某个可打印字符。三个字节有24个比特,对应于4个Base64单元,即3个字节需要用4个可打印字符来表示。编码后的数据比原来的数据略长,是原来的4/3倍。它可用来作为电子邮件的传输编码。在Base64中的可打印字符包括字母A-Z、a-z、数字0-9 ,这样共有62个字符,此外两个可打印符号在不同的系统中而不同(Base64de 编码表如下所示)。Base64常用于在通常处理文本数据的场合,表示、传输、存储一些二进制数据。包括MIME的email,email via MIME, 在XML中存储复杂数据. Base64编码表
二、编码流程 步骤1:将要编码的所有字符都转化成对应的ASCII码。 步骤2:将所有的ASCII码转换成对应的8位长的二进制数。 步骤3:将所得的二进制数从高位到低位开始分成6位一组,最后一组不足六的则补充0 步骤4:将每组二进制数转换成十进制数,然后对照base64的编码表查找得到相应的编码。 注意:1、要求被编码字符是8bit的,所以须在ASCII编码范围内,\u0000-\u00ff,中文就不行。 2、如果被编码的字符串中字符的个数为3的倍数,按照上面的步骤即可得到正确的base64编码。但是如果不是3的倍数则要分情况讨论。如果是3的倍数余1,则要在编好的码字后面加上两个“=”,如果是3的倍数余2,这要在编好的码字后面加上一个“=”。(例如w的base64编码为dw==,w1的base64编码为dzE=) 下面我们来对具体的字符串进行编码举例,以便更好的理解编码流程: 编码「Man」 在此例中,Base64算法将三个字符编码为4个字符 特殊情况
VB Base64编码与解码函数
VB Base64编码与解码函数 ' Module1.bas Option Explicit Private Const cstBase64 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/" Private arrBase64() As String Public Function Base64Encode(strSource As String) As String'编码 On Error Resume Next If UBound(arrBase64) = -1 Then arrBase64 = Split(StrConv(cstBase64, vbUnicode), vbNullChar) End If Dim arrB() As Byte, bTmp(2) As Byte, bT As Byte Dim I As Long, J As Long arrB = StrConv(strSource, vbFromUnicode) J = UBound(arrB) For I = 0 To J Step 3 Erase bTmp bTmp(0) = arrB(I + 0) bTmp(1) = arrB(I + 1) bTmp(2) = arrB(I + 2) bT = (bTmp(0) And 252) / 4 Base64Encode = Base64Encode & arrBase64(bT) bT = (bTmp(0) And 3) * 16 bT = bT + bTmp(1) \ 16 Base64Encode = Base64Encode & arrBase64(bT) bT = (bTmp(1) And 15) * 4 bT = bT + bTmp(2) \ 64 If I + 1 <= J Then Base64Encode = Base64Encode & arrBase64(bT) Else Base64Encode = Base64Encode & "=" End If bT = bTmp(2) And 63 If I + 2 <= J Then Base64Encode = Base64Encode & arrBase64(bT) Else
BASE64编码规则
(一)、BA SE64编码规则及JAVA中的使用 1、编码规则: Base64编码要求把3个8位字节(3*8=24)转化为4个6位的字节(4*6=24),之后在6位的前面补两个0,形成8位一个字节的形式。 例如字符串“张3” : 11010101 11000101 00110011 转换后: 00110101 00011100 00010100 00110011 用十进制表示即为:53 34 20 51 这个并不是最终的结果,还需要根据Base64的编码表查询出转换后的值。下面就是BASE64编码表: Table 1: The Base64 Alphabet Value Encoding Value Encoding Value Encoding Value Encoding 0 A 17 R 34 i 51 z 1 B 18 S 35 j 5 2 0 2 C 19 T 36 k 5 3 1 3 D 20 U 37 l 5 4 2 4 E 21 V 38 m 5 5 3 5 F 22 W 39 n 5 6 4 6 G 23 X 40 o 5 7 5 7 H 24 Y 41 p 58 6 8 I 25 Z 42 q 59 7 9 J 26 a 43 r 60 8 10 K 27 b 44 s 61 9 11 L 28 c 45 t 62 + 12 M 29 d 46 u 63 / 13 N 30 e 47 v (pad) = 14 O 31 f 48 w 15 P 32 g 49 x 16 Q 33 h 50 y 以上一共是64个编码,这也是Base64名称的由来,编码的编号对应的是得出的新字节的十进制值。因此,上例中字符串“张3”经过编码后就成了字符串“1iUz”了。 当代码量不是3的整数倍时,代码量/3的余数自然就是2或者1。转换的时候,结果不够6位的用0来补上相应的位置,之后再在6位的前面补两个0。转换完空出的结果就用就用“=”来补位。譬如结果若最后余下的为2个字节的“张”: 字符串“张” 11010101 HEX:D5 11000101 HEX:C5 00110101 00011100 00010100 十进制53 十进制34 十进制20 pad 字符’1’ 字符’i’ 字符’U’ 字符’=’
Base64编码及其作用
Base64编码的作用:由于某些系统中只能使用ASCII字符。Base64就是用来将非ASCII 字符的数据转换成ASCII字符的一种方法。它使用下面表中所使用的字符与编码。 而且base64特别适合在http,mime协议下快速传输数据。 base64其实不是安全领域下的加密解密算法。虽然有时候经常看到所谓的base64加密解密。其实base64只能算是一个编码算法,对数据内容进行编码来适合传输。虽然base64编码过后原文也变成不能看到的字符格式,但是这种方式很初级,很简单。 Base64编码方法要求把每三个8Bit的字节转换为四个6Bit的字节,其中,转换之后的这四个字节中每6个有效bit为是有效数据,空余的那两个bit用0补上成为一个字节。因此Base64所造成数据冗余不是很严重,Base64是当今比较流行的编码方法,因为它编起来速度快而且简单 举个例子,有三个字节的原始数据:aaaaaabb bbbbccccc ccdddddd(这里每个字母表示一个bit位) 那么编码之后会变成:00aaaaaa00bbbbbb00cccccc 00dddddd 所以可以看出base64编码简单,虽然编码后不是明文,看不出原文,但是解码也很简单 一、编码规则 Base64编码的思想是是采用64个基本的ASCII码字符对数据进行重新编码。它将需要编码的数据拆分成字节数组。以3个字节为一组。按顺序排列24 位数据,再把这24位数据分成4组,即每组6位。再在每组的的最高位前补两个0凑足一个字节。这样就把一个3字节为一组的数据重新编码成了4个字节。当所要编码的数据的字节数不是3的整倍数,也就是说在分组时最后一组不够3个字节。这时在最后一组填充1到2个0字节。并在最后编码完成后在结尾添加1到2个“=”。 例:将对ABC进行BASE64编码: 1、首先取ABC对应的ASCII码值。A(65)B(66)C(67); 2、再取二进制值A(01000001)B(01000010)C(01000011); 3、然后把这三个字节的二进制码接起来(010000010100001001000011); 4、再以6位为单位分成4个数据块,并在最高位填充两个0后形成4个字节的编码后的值,(00010000)(00010100)(00001001)(00000011),其中蓝色部分为真实数据; 5、再把这四个字节数据转化成10进制数得(16)(20)(9)(3); 6、最后根据BASE64给出的64个基本字符表,查出对应的ASCII码字符(Q)(U)(J)(D),这里的值实际就是数据在字符表中的索引。 注:BASE64字符表:ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
http状态码定义(1)
附录1 状态码定义 表1HTTP协议定义状态码
表2WAPGW扩展状态码
1001---正常 1002---终端错误1003---服务端错误
HTTP 400 - 请求无效 HTTP 401.1 - 未授权:登录失败 HTTP 401.2 - 未授权:服务器配置问题导致登录失败 HTTP 401.3 - ACL 禁止访问资源 HTTP 401.4 - 未授权:授权被筛选器拒绝 HTTP 401.5 - 未授权:ISAPI 或CGI 授权失败 HTTP 403 - 禁止访问 HTTP 403 - 对Internet 服务管理器的访问仅限于Localhost HTTP 403.1 禁止访问:禁止可执行访问 HTTP 403.2 - 禁止访问:禁止读访问 HTTP 403.3 - 禁止访问:禁止写访问 HTTP 403.4 - 禁止访问:要求SSL HTTP 403.5 - 禁止访问:要求SSL 128 HTTP 403.6 - 禁止访问:IP 地址被拒绝 HTTP 403.7 - 禁止访问:要求客户证书 HTTP 403.8 - 禁止访问:禁止站点访问 HTTP 403.9 - 禁止访问:连接的用户过多 HTTP 403.10 - 禁止访问:配置无效 HTTP 403.11 - 禁止访问:密码更改 HTTP 403.12 - 禁止访问:映射器拒绝访问 HTTP 403.13 - 禁止访问:客户证书已被吊销 HTTP 403.15 - 禁止访问:客户访问许可过多 HTTP 403.16 - 禁止访问:客户证书不可信或者无效 HTTP 403.17 - 禁止访问:客户证书已经到期或者尚未生效HTTP 404.1 - 无法找到Web 站点 HTTP 404- 无法找到文件 HTTP 405 - 资源被禁止 HTTP 406 - 无法接受 HTTP 407 - 要求代理身份验证 HTTP 410 - 永远不可用 HTTP 412 - 先决条件失败 HTTP 414 - 请求- URI 太长 HTTP 500 - 内部服务器错误 HTTP 500.100 - 内部服务器错误- ASP 错误 HTTP 500-11 服务器关闭 HTTP 500-12 应用程序重新启动 HTTP 500-13 - 服务器太忙 HTTP 500-14 - 应用程序无效 HTTP 500-15 - 不允许请求global.asa Error 501 - 未实现 HTTP 502 - 网关错误
HTTP代码大全
不知道大家上网是是否碰到过打开网页后报303,403等错误,让侯IE会给出一大堆的提示告诉你如何处理这些事,但是最后还是不能打开网页,有的人都认为是自己网络问题,其实不然,有时候网页的服务器负载也会出现这类的现象,所以大家就要好好了解下,到底代码所代表的意思了,HTTP状态码(HTTP Status Code)是用以表示网页服务器HTTP响应状态的3位数字代码。它由RFC 2616 规范定义的,并得到RFC 2518、RFC 2817、RFC 2295、RFC 2774、RFC 4918等规范扩展。 1xx(临时响应) 表示临时响应并需要请求者继续执行操作的状态代码。 代码说明 100 (继续)请求者应当继续提出请求。服务器返回此代码表示已收到请求的第一部分,正在等待其余部分。 101 (切换协议)请求者已要求服务器切换协议,服务器已确认并准备切换。 2xx (成功) 表示成功处理了请求的状态代码。 代码说明 200 (成功)服务器已成功处理了请求。通常,这表示服务器提供了请求的网页。 201 (已创建)请求成功并且服务器创建了新的资源。 202 (已接受)服务器已接受请求,但尚未处理。 203 (非授权信息)服务器已成功处理了请求,但返回的信息可能来自另一来源。 204 (无内容)服务器成功处理了请求,但没有返回任何内容。 205 (重置内容)服务器成功处理了请求,但没有返回任何内容。 206 (部分内容)服务器成功处理了部分GET 请求。 3xx (重定向) 表示要完成请求,需要进一步操作。通常,这些状态代码用来重定向。 代码说明 300 (多种选择)针对请求,服务器可执行多种操作。服务器可根据请求者(user agen t) 选择一项操作,或提供操作列表供请求者选择。 301 (永久移动)请求的网页已永久移动到新位置。服务器返回此响应(对GET 或H EAD 请求的响应)时,会自动将请求者转到新位置。 302 (临时移动)服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。 303 (查看其他位置)请求者应当对不同的位置使用单独的GET 请求来检索响应时,服务器返回此代码。 304 (未修改)自从上次请求后,请求的网页未修改过。服务器返回此响应时,不会返回网页内容。 305 (使用代理)请求者只能使用代理访问请求的网页。如果服务器返回此响应,还表示请求者应使用代理。 307 (临时重定向)服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
Base64的编解码方法
Base64是一种很常用的编码方式,利用它可以将任何二进制的字符编码到可打印的64个字符之中,这样,不管是图片,中文文本等都可以编码成只有ASCII的纯文本。至于为什么要进行这个转换呢,最初主要使用在EMail领域,早期的一些邮件网关只识别ASCII,如果发现邮件里有其他字符,就会将它们过滤掉,这样中文的邮件,有图片附件的邮件在这些网关上就会发生问题,于是将中文和图片都使用base64编码然后传输,接受后再解码就客服了这个问题了。Base64除了可以使用在相似场合,还可以用作简单的加密等等。下面介绍下Base64的方法: 首先是Base64中可能出现的所有字符: 0 A 17 R 34 i 51 z 1 B 18 S 35 j 5 2 0 2 C 19 T 36 k 5 3 1 3 D 20 U 37 l 5 4 2 4 E 21 V 38 m 5 5 3 5 F 22 W 39 n 5 6 4 6 G 23 X 40 o 5 7 5 7 H 24 Y 41 p 58 6 8 I 25 Z 42 q 59 7 9 J 26 a 43 r 60 8 10 K 27 b 44 s 61 9 11 L 28 c 45 t 62 + 12 M 29 d 46 u 63 / 13 N 30 e 47 v 14 O 31 f 48 w (pad) = 15 P 32 g 49 x 16 Q 33 h 50 y 所有的字符就是'A'~'Z','a'~'z','0'~'9','+','/'共64个,以及末尾的填充字符'=' 编码的方法是: 从输入缓冲中依次取出字符,第一个字符的,从最高位开始取出6个bit,这6个bit的值的范围在0~63,将这个值作为索引,对应上面的表格,找到相应的字符,这便是第一个Base64后的字符,然后将第一个字符的低2位与第二个字符的高4位组成6个bit, 同样查表得到第二个Base64字符,以此类推,从左向右没凑足6个bit就转换成一个Base64字符,由于输入缓冲中每3个字符包含24个bit,这24个bit正好可以转成4个Base64字符,所以没3个字符能组成一个转换循环,如果输入缓冲中字符的个数是3 的整数倍,那么结果就是4的整数倍,两者的长度是3:4的关系,但是如果输入字符不是3的整数倍呢?这就涉及到了末尾填充问题。 输入缓冲的末尾可能余下一个字符,或两个字符: 如果余下一个字符,前6个bit转换成Base64,剩下的低2位要右边补0 ,凑成6bit,然后转
base64
base64 在URL中的应用 VB版的Base64编码函数定义 JS版的Base64编码函数定义 C#实现BASE64加密、解密算法 Base64-MIME 在URL中的应用 VB版的Base64编码函数定义 JS版的Base64编码函数定义 C#实现BASE64加密、解密算法 Base64-MIME Base64是网络上最常见的用于传输8Bit字节代码的编码方式之一,大家可以查看RFC2045~RFC2049,上面有MIME的详细规范。 Base64编码可用于在HTTP环境下传递较长的标识信息。例如,在Java Persi stence系统Hibernate中,就采用了Base64来将一个较长的唯一标识符(一般为1 28-bit的UUID)编码为一个字符串,用作HTTP表单和HTTP GET URL中的参数。在其他应用程序中,也常常需要把二进制数据编码为适合放在URL(包括隐藏表单域)中的形式。此时,采用Base64编码不仅比较简短,同时也具有不可读性,即所编码的数据不会被人用肉眼所直接看到。 然而,标准的Base64并不适合直接放在URL里传输,因为URL编码器会把标准Base64中的“/”和“+”字符变为形如“%XX”的形式,而这些“%”号在存入数据库时还需要再进行转换,因为ANSI SQL中已将“%”号用作通配符。 为解决此问题,可采用一种用于URL的改进Base64编码,它不在末尾填充'='号,并将标准Base64中的“+”和“/”分别改成了“*”和“-”,这样就免去了在URL编解码和数据库存储时所要作的转换,避免了编码信息长度在此过程中的增加,并统一了数据库、表单等处对象标识符的格式。 另有一种用于正则表达式的改进Base64变种,它将“+”和“/”改成了“!”和“-”,因为“+”,“*”以及前面在IRCu中用到的“[”和“]”在正则表达式中都可能具有特殊含义。 此外还有一些变种,它们将“+/”改为“_-”或“._”(用作编程语言中的标识符名称)或“.-”(用于XML中的Nmtoken)甚至“_:”(用于XML中的Name)。 Base64要求把每三个8Bit的字节转换为四个6Bit的字节(3*8 = 4*6 = 24),然后把6Bit再添两位高位0,组成四个8Bit的字节,也就是说,转换后的字符串理论上将要比原来的长1/3。 关于这个编码的规则: ①.把3个字符变成4个字符.. ②每76个字符加一个换行符..
HTTP状态码大全
HTTP状态码大全 HTTP 1.1中的状态码。这些状态码被分为五大类: 100-199 用于指定客户端应相应的某些动作。 200-299 用于表示请求成功。 300-399 用于已经移动的文件并且常被包含在定位头信息中指定新的地址信息。 400-499 用于指出客户端的错误。(自己电脑这边的问题) 500-599 用于支持服务器错误。(对方的问题) HttpServletResponse中的常量代表关联不同标准消息的状态码。在servlet程序中,你会更多地用到这些常量的标识来使用状态码。例如:你一般会使用response.setStatus(response.SC_NO_CONTENT)而不是response.setStatus(204),因为后者不易理解而且容易导致错误。但是,你应当注意到服务器允许对消息轻微的改变,而客户端只注意状态码的数字值。所以服务器可能只返回HTTP/1.1 200 而不是HTTP/1.1 200 OK。 100 (Continue/继续) 如果服务器收到头信息中带有100-continue的请求,这是指客户端询问是否可以在后续的请求中发送附件。在这种情况下,服务器用100(SC_CONTINUE)允许客户端继续或用417 (Expectation Failed)告诉客户端不同意接受附件。这个状态码是HTTP 1.1中新加入的。 101 (Switching Protocols/转换协议) 101 (SC_SWITCHING_PROTOCOLS)状态码是指服务器将按照其上的头信息变为一个不同的协议。这是HTTP 1.1中新加入的。 200 (OK/正常) 200 (SC_OK)的意思是一切正常。一般用于相应GET和POST请求。这个状态码对servlet是缺省的;如果没有调用setStatus方法的话,就会得到200。 201 (Created/已创建) 201 (SC_CREA TED)表示服务器在请求的响应中建立了新文档;应在定位头信息中给出它的URL。 202 (Accepted/接受) 202 (SC_ACCEPTED)告诉客户端请求正在被执行,但还没有处理完。 203 (Non-Authoritative Information/非官方信息) 状态码203 (SC_NON_AUTHORITA TIVE_INFORMA TION)是表示文档被正常的返回,但是由于正在使用的是文档副本所以某些响应头信息可能不正确。这是HTTP 1.1中新加入的。 204 (No Content/无内容) 在并没有新文档的情况下,204 (SC_NO_CONTENT)确保浏览器继续显示先前的文档。这各状态码对于用户周期性的重载某一页非常有用,并且你可以确定先前的页面是否已经更新。例如,某个servlet可能作如下操作: int pageVersion =Integer.parseInt(request.getParameter("pageVersion"));
HTTP协议的状态码
对于Web编程人员来说,熟悉了解HTTP协议的状态码是很有必要的,很多时侯可能根据HTTP协议的状态码很快就能定位到错误信息!今天整理了一下所有HTTP状态码。 HTTP状态码(HTTP Status Code)是用来表示网页服务器HTTP 响应状态的3位数字代码。它由RFC 2616规范定义的,并得到RFC 2518、RFC 2817、RFC 2295、RFC 2774、RFC 4918等规范扩展。所有状态码的第一个数字代表了响应的五种状态之一。 HTTP/1.1定义的状态码值和对应的原因短语(Reason-Phrase)的例子。 1XX表示:消息 这一类型的状态码,代表请求已被接受,需要继续处理。这类响应是临时响应,只包含状态行和某些可选的响应头信息,并以空行结束。由于HTTP/1.0协议中没有定义任何1xx 状态码,所以除非在某些试验条件下,服务器禁止向此类客户端发送1xx响应。这些状态码代表的响应都是信息性的,标示客户应该采取的其他行动。 “100″ : Continue客户端应当继续发送请求。这个临时响应是用来通知客户端它的部分请求已经被服务器接收,且仍未被拒绝。客户端应当继续发送请求的剩余部分. “101″ : witching Protocols 服务器已经理解了客户端的请求,并将通过Upgrade 消息头通知客户端采用不同的协议来完成这个请求。在发送完这个响应最后的空行后,服务器将会切换到在Upgrade消息头中定义的那些协议。: 只有在切换新的协议更有好处的时候才应该采取类似措施. “102″: Processing由WebDAV(RFC 2518)扩展的状态码,代表处理将被继续执行。 2XX表示:成功 这一类型的状态码,代表请求已成功被服务器接收、理解、并接受。
Base64编码原理教学文案
B a s e64编码原理
一. Base64编码由来 为什么会有Base64编码呢?因为有些网络传送渠道并不支持所有的字节,例如传统的邮件只支持可见字符的传送,像ASCII码的控制字符就不能通过邮件传送。这样用途就受到了很大的限制,比如图片二进制流的每个字节不可能全部是可见字符,所以就传送不了。最好的方法就是在不改变传统协议的情况下,做一种扩展方案来支持二进制文件的传送。把不可打印的字符也能用可打印字符来表示,问题就解决了。Base64编码应运而生,Base64就是一种基于64个可打印字符来表示二进制数据的表示方法。 二. Base64编码原理 看一下Base64的索引表,字符选用了"A-Z、a-z、0-9、+、/" 64个可打印字符。数值代表字符的索引,这个是标准Base64协议规定的,不能更改。64个字符用6个bit位就可以全部表示,一个字节有8个bit位,剩下两个bit就浪费掉了,这样就不得不牺牲一部分空间了。这里需要弄明白的就是一个Base64字符是8个bit,但是有效部分只有右边的6个bit,左边两个永远是0。
那么怎么用6个有效bit来表示传统字符的8个bit呢?8和6的最小公倍数是2 4,也就是说3个传统字节可以由4个Base64字符来表示,保证有效位数是一样的,这样就多了1/3的字节数来弥补Base64只有6个有效bit的不足。你也可以说用两个B ase64字符也能表示一个传统字符,但是采用最小公倍数的方案其实是最减少浪费的。结合下边的图比较容易理解。Man是三个字符,一共24个有效bit,只好用4个Base6 4字符来凑齐24个有效位。红框表示的是对应的Base64,6个有效位转化成相应的索引值再对应Base64字符表,查出"Man"对应的Base64字符是"TWFU"。说到这里有个原则不知道你发现了没有,要转换成Base64的最小单位就是三个字节,对一个字符串来说每次都是三个字节三个字节的转换,对应的是Base64的四个字节。这个搞清楚了其实就差不多了。
HTTP状态码大全
本部分余下的内容会详细地介绍 HTTP 1.1中的状态码。这些状态码被分为五大类: 100-199 用于指定客户端应相应的某些动作。 200-299 用于表示请求成功。 300-399 用于已经移动的文件并且常被包含在定位头信息中指定新的地址信息。400-499 用于指出客户端的错误。 500-599 用于支持服务器错误。 一些常见的状态代码为: 200 –服务器成功返回网页 404 –请求的网页不存在 503 –服务器暂时不可用 以下提供了 HTTP 状态代码的完整列表。 1xx(临时响应) 用于表示临时响应并需要请求者执行操作才能继续的状态代码。 100(继续|Continue)请求者应当继续提出请求。服务器返回此代码则意味着,服务器已收到了请求的第一部分,现正在等待接收其余部分。 101(切换协议|Switching Protocols)请求者已要求服务器切换协议,服务器已确认并准备进行切换。 2xx(成功) 用于表示服务器已成功处理了请求的状态代码。
200(成功|OK)服务器已成功处理了请求。通常,这表示服务器提供了请求的网页。如果您的 robots.txt 文件显示为此状态,那么,这表示Googlebot已成功检索到该文件。 201(已创建|Created)请求成功且服务器已创建了新的资源。 202(已接受|Accepted)服务器已接受了请求,但尚未对其进行处理。 203(非授权信息|Non-Authoritative Information)服务器已成功处理了请求,但返回了可能来自另一来源的信息。 204(无内容|No Content)服务器成功处理了请求,但未返回任何内容。 205(重置内容Reset Content)服务器成功处理了请求,但未返回任何内容。与 204 响应不同,此响应要求请求者重置文档视图(例如清除表单内容以输入新内容)。 206(部分内容|Partial Content)服务器成功处理了部分 GET 请求。 3xx(已重定向) 要完成请求,您需要进一步进行操作。通常,这些状态代码是永远重定向的。Google 建议您在每次请求时使用的重定向要少于 5 个。您可以使用网站管理员工具来查看Googlebot 在抓取您已重定向的网页时是否会遇到问题。诊断下的抓取错误页中列出了 Googlebot 由于重定向错误而无法抓取的网址。 300(多种选择|Multiple Choices)服务器根据请求可执行多种操作。服务器可根据请求者 (User agent) 来选择一项操作,或提供操作列表供请求者选择。 301(永久移动|Moved Permanently)请求的网页已被永久移动到新位置。服务器返回此响应(作为对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。您应使用此代码通知 Googlebot 某个网页或网站已被永久移动到新位置。 302(找到|Found)服务器目前正从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。此代码与响应 GET 和 HEAD 请求的 301 代码类似,会自动将请求者转到不同的位置。但由于 Googlebot 会继续抓取原有位置并将其编入索引,因此您不应使用此代码来通知 Googlebot 某个页面或网站已被移动。注意:在HTTP 1.0中,302表示消息是临时移动(Moved Temporarily)的而不是被找到。 303(参见其他信息|See Other)这个状态码和 301、302 相似,只是如果最初的请求是 POST,那么新文档(在定位头信息中给出)药用 GET 找回。这个状态码是新加入HTTP 1.1中的。
Microsoft Word - Base64编码原理doc - CHINAUNIX
Base64编码原理 Base64是网络上最常见的用于传输8Bit字节代码的编码方式之一,大家可以查看RFC2045~RFC2049,上面有MIME的详细规范。Base64要求把每三个8Bit的字节转换为四个6Bit的字节(3*8 = 4*6 = 24),然后把6Bit再添两位高位0,组成四个8Bit的字节,也就是说,转换后的字符串理论上将要比原来的长1/3。 这样说会不会太抽象了?不怕,我们来看一个例子: 转换前 aaaaaabb ccccdddd eeffffff 转换后 00aaaaaa 00bbcccc 00ddddee 00ffffff 应该很清楚了吧?上面的三个字节是原文,下面的四个字节是转换后的Base64编码,其前两位均为0。转换后,我们用一个码表来得到我们想要的字符串(也就是最终的Base64编码),这个表是这样的:(摘自RFC2045) Table 1: The Base64 Alphabet Value Encoding Value Encoding Value Encoding Value Encoding 0 A 17 R 34 i 51 z 1 B 18 S 35 j 5 2 0 2 C 19 T 36 k 5 3 1 3 D 20 U 37 l 5 4 2 4 E 21 V 38 m 5 5 3 5 F 22 W 39 n 5 6 4 6 G 23 X 40 o 5 7 5 7 H 24 Y 41 p 58 6 8 I 25 Z 42 q 59 7 9 J 26 a 43 r 60 8 10 K 27 b 44 s 61 9 11 L 28 c 45 t 62 + 12 M 29 d 46 u 63 / 13 N 30 e 47 v 14 O 31 f 48 w (pad) = 15 P 32 g 49 x 16 Q 33 h 50 y 让我们再来看一个实际的例子,加深印象! 转换前 10101101 10111010 01110110 转换后 00101011 00011011 00101001 00110110 十进制 43 27 41 54 对应码表中的值 r b p 2 所以上面的24位编码,编码后的Base64值为 rbp2 解码同理,把 rbq2 的二进制位连接上再重组得到三个8位值,得出原码。 (解码只是编码的逆过程,在此我就不多说了,另外有关MIME的RFC还是有很多的,如果需要详细情况请自行查找。) 用更接近于编程的思维来说,编码的过程是这样的: 第一个字符通过右移2位获得第一个目标字符的Base64表位置,根据这个数值取到表上相应的字符,就是第一个目标字符。 然后将第一个字符左移4位加上第二个字符右移4位,即获得第二个目标字符。 再将第二个字符左移2位加上第三个字符右移6位,获得第三个目标字符。 最后取第三个字符的右6位即获得第四个目标字符。
http协议(四)http状态码
http协议(四)http状态码 一:http状态码 表示客户端http请求的返回结果、标记服务器端的处理是否正常、通知出现的错误等工作状态码的类别如下: http状态码种类繁多,大概有60多种,实际上经常使用的只有14种,下面为一一介绍 1、2XX 成功:请求被正常处理 1.1 200 OK 表示从客户端发来的请求在服务器端被正常处理 1.2 204 No Content 表示服务器接收的请求以成功处理,但没有资源可返回,即:响应报文中不含实体的主体部分1.3 206 Partial Content 表示客户端进行了范围请求且服务器成功执行了这部分的GET请求,响应报文中包含由Content_Range指定范围的实体内容 “Content_Range为请求首部的一种类型,后面的随笔会讲到” 2、3XX 重定向:服务器需要执行某些特殊处理以正确处理请求(即URI地址或者资源的缓存的资源有效时间过期) 2.1 301 Moved Permanently 永久性重定向:表示请求的资源已被分配了新的URI,以后应使用资源现在的URI,如果已经保存了书签,这时候应该按照Location首部提示的URI重新保存 2.2 302 Found 临时性重定向:表示请求的资源已被分配到了新的URI,希望(本次)能使用新的URI访问2.3 303 See Other 表示请求对应的资源存在另一个URI,应该使用GET方法定向获取请求的资源 PS:当301、302、303响应状态码返回,几乎所有浏览器都会把POST改成GET,并删除请求报文内的主体,之后请求自动再次发送 301、302标准禁止将POST改为GET,但实际中都会允许这么做~~~GG 2.4 304 Not Modified 表示客户端发送得附带条件的请求时,服务器运行请求访问,但未满足条件的情况,304返回时,不包含任何响应的主体部分 附带条件:采用GET方法的请求报文中包含If-......条件的任一首部,后面的随笔中介绍2.5 307 Temporary Redirect 临时重定向:禁止将POST转换为GET,该状态码会严格遵守浏览器标准 3、客户端错误:4XX的响应结果表明客户端是发生错误的原因所在 3.1 400 Bad Ruquest
base64编码
RFC 3548 - The Base16, Base32, and Base64 Data Encodings RFC 3548 - The Base16, Base32, and Base64 Data Encodings Search the RFC Archives Or Display the document by number
[ RFC Index | Usenet FAQs | Web FAQs | Documents | Cities | Copyrights | Neighborhoods ] Network Working Group S. Josefsson, Ed. Request for Comments: 3548 July 2003 Category: Informational The Base16, Base32, and Base64 Data Encodings Status of this Memo This memo provides information for the Internet community. It does not specify an Internet standard of any kind. Distribution of this memo is unlimited. Copyright Notice Copyright (C) The Internet Society (2003). All Rights Reserved. Abstract This document describes the commonly used base 64, base 32, and base 16 encoding schemes. It also discusses the use of line-feeds in encoded data, use of padding in encoded data, use of non-alphabet characters in encoded data, and use of different encoding alphabets. Table of Contents