jqGrid连接数据库

JqGrid学习笔记
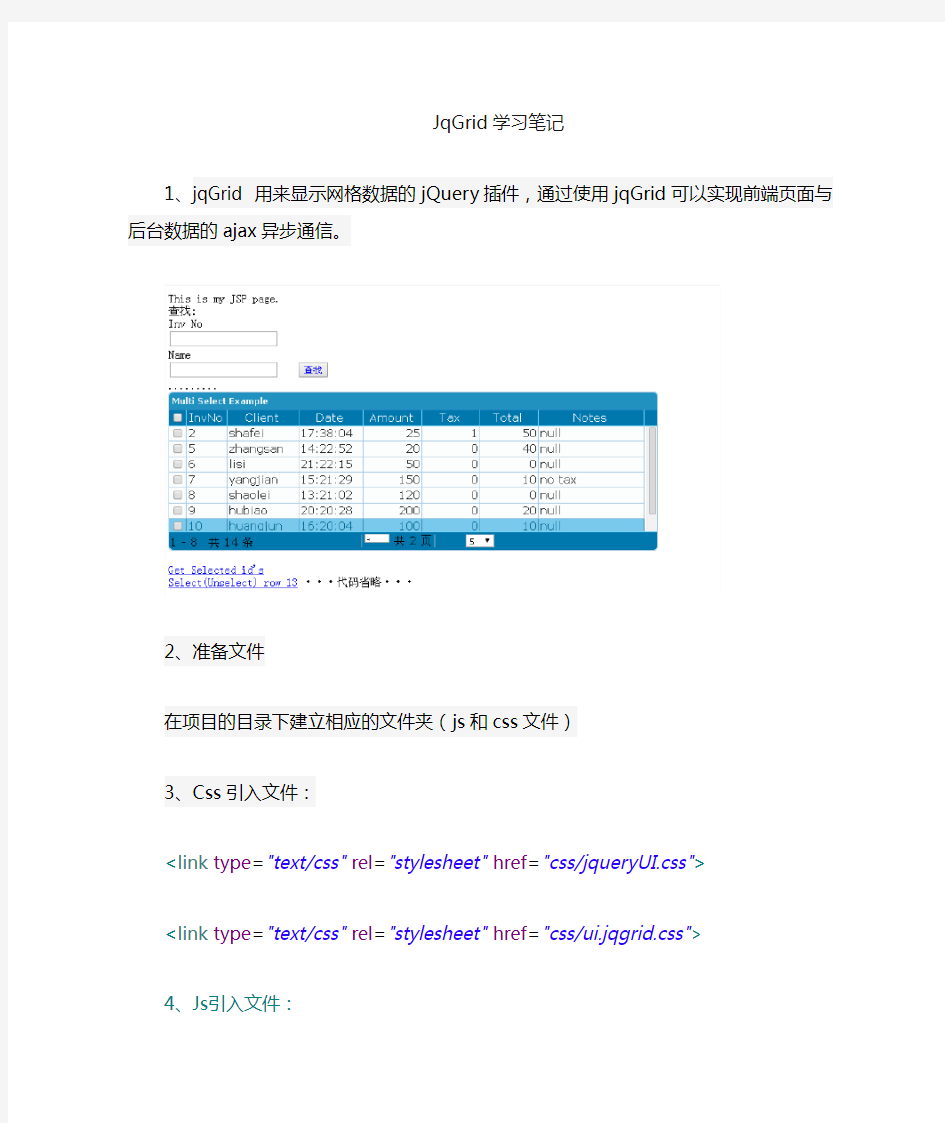
1、jqGrid 用来显示网格数据的jQuery插件,通过使用jqGrid可以实现前端页面与后台数据的ajax异步通信。
2、准备文件
在项目的目录下建立相应的文件夹(js和css文件)
3、Css引入文件:
href="css/jqueryUI.css">
href="css/ui.jqgrid.css">
4、Js引入文件:
5、js和body中的代码:
This is my JSP page.
Inv No
Name
/>
.........
id's
···代码省略···
6、连接数据库并且经过sql语句过滤进行分页查询后台代码:
package web;
import java.io.IOException;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* Servlet implementation class JSONData
*/
public class JSONData extends HttpServlet {
private static final long serialVersionUID = 1L;
/**
* @see HttpServlet#HttpServlet()
*/
public JSONData() {
super();
}
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
doPost(req,resp);
}
/**
* @see HttpServlet#doPost(HttpServletRequest request, HttpServletResponse response)
*/
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String page=request.getParameter("page");//当前页数
String rows=request.getParameter("rows");//取得每页显示的行数
String cd_mask = request.getParameter("cd_mask") ;
String nm_mask = request.getParameter("nm_mask") ;
String driver="com.mysql.jdbc.Driver";
String url="jdbc:mysql://localhost:3306/jd1109db2";
String user="root";
String password="root";
String sql=null;
String sql2=null;
Connection conn=null;
Statement statement=null;
ResultSet rs=null;
ResultSet rs2=null;
System.out.println(cd_mask+"__"+nm_mask);
try
{
int sum=0;
Class.forName(driver);
conn = DriverManager.getConnection(url,
user,password);
statement = conn.createStatement();
int pages = Integer.parseInt(page);
int rows2 = Integer.parseInt(rows);
int k=(pages-1)*rows2;
if(cd_mask!=null && !"".equals(cd_mask) && nm_mask!=null && !"".equals(nm_mask)){
sql = "select * from shafei2 where InvNo='" +
cd_mask +
"' and Client='" +
nm_mask +
"' limit "+k+"," +rows2;
sql2="select count(*) as sum from shafei2 where InvNo='" +
cd_mask +
"' and Client='" +
nm_mask +
"' limit "+k+"," +rows2;
}else if(cd_mask!=null && !"".equals(cd_mask))
{
sql="select * from shafei2 where InvNo='"+cd_mask+"' limit "+k+"," +rows2;
sql2="select count(*) as sum from shafei2 where InvNo='"+cd_mask+"' limit "+k+"," +rows2;
}else if(nm_mask!=null && !"".equals(nm_mask))
{
sql="select * from shafei2 where Client='"+nm_mask+"' limit "+k+"," +rows2;
sql2="select count(*) as sum from shafei2 where Client='"+nm_mask+"' limit "+k+"," +rows2;
}else
{
sql = "select * from shafei2 limit "+k+"," +rows2;
sql2="select count(*) as sum from shafei2 limit "+k+"," +rows2;
}
System.out.println(sql);
rs=statement.executeQuery(sql);
if(!conn.isClosed())
{
System.out.println("Succeeded connecting to the Database!");
}
String InvNo=null;
String Date=null;
String Client=null;
String Amount=null;
String Total=null;
String Notes=null;
String tax=null;
Statement stmt =
conn.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE,ResultSet.CONC
UR_UPDATABLE);
ResultSet rset=stmt.executeQuery(sql2);
int totalRecord=0;
while(rset.next())
{
totalRecord=rset.getInt("sum");
}
System.out.println("一共有"+totalRecord+"条记录,"+"每页显示"+rows+"行!");
int totalPage = totalRecord%Integer.parseInt(rows) == 0 ?
totalRecord/Integer.parseInt(rows) : totalRecord/Integer.parseInt(rows)+1; // 计算总页数
String json1 = "{\"total\":"+totalPage+",\"page\": "+page+", \"records\": "+totalRecord+",\"rows\": [";
String json="";
int i=1;
while(rs.next())
{
InvNo = rs.getString("InvNo");
Date = rs.getString("Date");
Client = rs.getString("Client");
Amount = rs.getString("Amount");
tax = rs.getString("tax");
Total = rs.getString("Total");
Notes = rs.getString("Notes");
try {
int index = (Integer.parseInt(page)-1)*Integer.parseInt(rows); //开始记录数
int pageSize = Integer.parseInt(rows);
//System.out.println(json);
if(i!=1){
json
+=",{\"InvNo\":\""+InvNo+"\",\"Date\":\""+Date+"\",\"Client\":\""+Cli
ent+"\",\"Amount\":\""+Amount+"\",\"tax\":\""+tax+"\",\"Total\":\""+T otal+"\",\"Notes\":\""+Notes+"\"}";
}else{
json
="{\"InvNo\":\""+InvNo+"\",\"Date\":\""+Date+"\",\"Client\":\""+Clien t+"\",\"Amount\":\""+Amount+"\",\"tax\":\""+tax+"\",\"Total\":\""+Tot al+"\",\"Notes\":\""+Notes+"\"}";
}
i++;
}//tr y结束
catch (Exception ex)
{
System.out.println("Exception In getWriter:"+ex.getMessage());
}
}//while(rs.next());
json1 =json1+json+"]}";
//System.out.println("第一页:");
System.out.println(json1);
response.getWriter().write(json1); // 将JSON数据返回页面
}//try结束
catch(Exception ex)
{
System.out.println("Exception In Do Post:"+ex.getMessage());
}
}
}
关于DBCP数据库连接池配置整理
1.简介 DBCP(DataBase Connection Pool),数据库连接池。是 apache 上的一个 java 连接池项目,也是tomcat 使用的连接池组件。单独使用dbcp需要3个包:common-dbcp.jar,common-pool.jar,common-collections.jar由于建立数据库连接是一个非常耗时耗资源的行为,所以通过连接池预先同数据库建立一些连接,放在内存中,应用程序需要建立数据库连接时直接到连接池中申请一个就行,用完后再放回去。 dbcp提供了数据库连接池可以在spring,iBatis,hibernate中调用dbcp完成数据库连接,框架一般都提供了dbcp连接的方法; tomcat中也提供了dbcp的jndi设置方法,也可以不在框架中使用dbcp,单独使用dbcp 需要3个包:common-dbcp.jar,common-pool.jar,common-collections.jar 2.参数说明 翻译自https://www.360docs.net/doc/519199321.html,
这里可以开启PreparedStatements池. 当开启时, 将为每个连接创建一个statement 池,并且被下面方法创建的PreparedStatements将被缓存起来: ●public PreparedStatement prepareStatement(String sql) ●public PreparedStatement prepareStatement(String sql, int resultSetType, int resultSetConcurrency) 如果容许则可以使用下面的方式来获取底层连接: Connection conn = ds.getConnection(); Connection dconn = ((DelegatingConnection) conn).getInnermostDelegate(); ... conn.close() 默认false不开启, 这是一个有潜在危险的功能, 不适当的编码会造成伤害.(关闭底层 连接或者在守护连接已经关闭的情况下继续使用它).请谨慎使用,并且仅当需要直接访问驱动的特定功能时使用. 注意: 不要关闭底层连接, 只能关闭前面的那个 如果开启"removeAbandoned",那么连接在被认为泄露时可能被池回收. 这个机制在(getNumIdle() < 2) and (getNumActive() > getMaxActive() - 3)时被触发。 举例当maxActive=20, 活动连接为18,空闲连接为1时可以触发"removeAbandoned".但是活动连接只有在没有被使用的时间超过"removeAbandonedTimeout"时才被删除,默认300秒.在resultset中游历不被计算为被使用。 3.使用注意点
空间数据库的建立和维护
§2.7 空间数据库的设计、建立和维护 二、空间数据库的建立和维护 1、空间数据库的建立 在完成空间数据库的设计之后,就可以建立空间数据库。建立空间数据库包括三项工作,即建立数据库结构、装入数据和试运行。 1)建立空间数据库结构 利用DBMS提供的数据描述语言描述逻辑设计和物理设计的结果,得到概念模式和外模式,编写功能软件,经编译、运行后形成目标模式,建立起实际的空间数据库结构。 2)数据装入 一般由编写的数据装入程序或DBMS提供的应用程序来完成。在装入数据之前要做许多准备工作,如对数据进行整理、分类、编码及格式转换(如专题数据库装入数据时,采用多关系异构数据库的模式转换、查询转换和数据转换)等。装入的数据要确保其准确性和一致性。最好是把数据装入和调试运行结合起来,先装入少量数据,待调试运行基本稳定了,再大批量装入数据。 3)调试运行 装入数据后,要对地理数据库的实际应用程序进行运行,执行各功能模块的操作,对地理数据库系统的功能和性能进行全面测试,包括需要完成的各功能模块的功能、系统运行的稳定性、系统的响应时间、系统的安全性与完整性等。经调试运行,若基本满足要求,则可投入实际运行。 由以上不难看出,建立一个实际的空间数据库是一项十分复杂的系统工程。
2、空间数据库的维护 建立一个空间数据库是一项耗费大量人力、物力和财力的工作,都希望能应用得好,生命周期长。而要做到这一点,就必须不断地对它进行维护,即进行调整、修改和扩充。空间数据库的重组织、重构造和系统的安全性与完整性控制等,就是重要的维护方法。 1)空间数据库的重组织 指在不改变空间数据库原来的逻辑结构和物理结构的前提下,改变数据的存储位置,将数据予以重新组织和存放。因为一个空间数据库在长期的运行过程中,经常需要对数据记录进行插入、修改和删除操作,这就会降低存储效率,浪费存储空间,从而影响空间数据库系统的性能。所以,在空间数据库运行过程中,要定期地对数据库中的数据重新进行组织。DBMS一般都提供了数据库重组的应用程序。由于空间数据库重组要占用系统资源,故重组工作不能频繁进行。 2)空间数据库的重构造 指局部改变空间数据库的逻辑结构和物理结构。这是因为系统的应用环境和用户需求的改变,需要对原来的系统进行修正和扩充,有必要部分地改变原来空间数据库的逻辑结构和物理结构,从而满足新的需要。数据库重构通过改写其概念模式(逻辑模式)的内模式(存储模式)进行。具体地说,对于关系型空间数据库系统,通过重新定义或修改表结构,或定义视图来完成重构;对非关系型空间数据库系统,改写后的逻辑模式和存储模式需重新编译,形成新的目标模式,原有数据要重新装入。空间数据库的重构,对延长应用系统的使用寿命非常重要,但只能对其逻辑结构和物理结构进行局部修改和扩充,如果修改和扩充的内容太多,那就要考虑开发新的应用系统。
数据库中的左连接
数据库中的左连接(left join)和右连接(right join)区别 Left Join / Right Join /inner join相关 关于左连接和右连接总结性的一句话: 左连接where只影向右表,右连接where只影响左表。 Left Join select * from tbl1 Left Join tbl2 where tbl1.ID = tbl2.ID 左连接后的检索结果是显示tbl1的所有数据和tbl2中满足where 条件的数据。 简言之Left Join影响到的是右边的表 Right Join select * from tbl1 Right Join tbl2 where tbl1.ID = tbl2.ID 检索结果是tbl2的所有数据和tbl1中满足where 条件的数据。 简言之Right Join影响到的是左边的表。 inner join select * FROM tbl1 INNER JOIN tbl2 ON tbl1.ID = tbl2.ID 功能和select * from tbl1,tbl2 where tbl1.id=tbl2.id相同。 其他相关资料 1 .WHERE子句中使用的连接语句,在数据库语言中,被称为隐性连接。INNER JOIN……ON子句产生的连接称为显性连接。(其他JOIN参数也是显性连接)WHERE 和INNER JOIN产生的连接关系,没有本质区别,结果也一样。但是!隐性连接随着数据库语言的规范和发展,已经逐渐被淘汰,比较新的数据库语言基本上已经抛弃了隐性连接,全部采用显性连接了。 2 .无论怎么连接,都可以用join子句,但是连接同一个表的时候,注意要定义别名,否则产生错误! a> inner join:理解为“有效连接”,两张表中都有的数据才会显示left join:理解为“有左显示”,比如on a.field=b.field,则显示a表中存在的全部数据及a\\b中都有的数据,A 中有、B没有的数据以null显示
数据库连接池的好处
数据库连接池的好处.txt-//自私,让我们只看见自己却容不下别人。如果发短信给你喜欢的人,他不回,不要再发。看着你的相片,我就特冲动的想P成黑白挂墙上!有时,不是世界太虚伪,只是,我们太天真。数据库连接池的好处 对于一个简单的数据库应用,由于对于数据库的访问不是很频繁。这时可以简单地在需要访问数据库时,就新创建一个连接,用完后就关闭它,这样做也不会带来什么明显的性能上的开销。但是对于一个复杂的数据库应用,情况就完全不同了。频繁的建立、关闭连接,会极大的减低系统的性能,因为对于连接的使用成了系统性能的瓶颈。 连接复用。通过建立一个数据库连接池以及一套连接使用管理策略,使得一个数据库连接可以得到高效、安全的复用,避免了数据库连接频繁建立、关闭的开销。 对于共享资源,有一个很著名的设计模式:资源池。该模式正是为了解决资源频繁分配、释放所造成的问题的。把该模式应用到数据库连接管理领域,就是建立一个数据库连接池,提供一套高效的连接分配、使用策略,最终目标是实现连接的高效、安全的复用。 数据库连接池的基本原理是在内部对象池中维护一定数量的数据库连接,并对外暴露数据库连接获取和返回方法。如: 外部使用者可通过getConnection 方法获取连接,使用完毕后再通过releaseConnection 方法将连接返回,注意此时连接并没有关闭,而是由连接池管理器回收,并为下一次使用做好准备。 数据库连接池技术带来的优势: 1.资源重用 由于数据库连接得到重用,避免了频繁创建、释放连接引起的大量性能开销。在减少系统消耗的基础上,另一方面也增进了系统运行环境的平稳性(减少内存碎片以及数据库临时进程/线程的数量)。 2.更快的系统响应速度 数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于池中备用。此时连接的初始化工作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了数据库连接初始化和释放过程的时间开销,从而缩减了系统整体响应时间。 3.新的资源分配手段 对于多应用共享同一数据库的系统而言,可在应用层通过数据库连接的配置,实现数据库连接池技术。某一应用最大可用数据库连接数的限制,避免某一应用独占所有数据库资源。
数据库 内连接,左连,右连,全连的区别
数据库内连接,左连,右连,全连的区别 废话不说,直接上数据 create table AA(A_ID INT,A_NAME CHAR(8)) create table BB(B_ID INT,B_NAME CHAR(8)) 向AA,BB 分别添加 AA: BB 1. 内联语句: select * from AA INNER JOIN BB ON AA.A_ID=BB.B_ID 其实内联就相当于select * from AA ,BB where AA.A_ID=BB.B_ID 可以看到,这就是大家最普通用的语法结构。只有符合 AA.A_ID=BB.B_ID条件的才输出 2 左连语句 select * from AA LEFT JOIN BB ON AA.A_ID=BB.B_ID 大家可以看到,是以AA表为基础,不管BB表中,是否含有AA中的元素,AA都输入,但是BB中以NULL元素补充 3 右连语句
select * from AA RIGHT JOIN BB ON AA.A_ID=BB.B_ID 大家可以看到这种情况跟上边一样,只是是以BB表为基础,用AA补充。 大家猜想下如果 AA LEFT JOIN BB 和BBRIGHT JOIN AA结果一样吗?我为大家测试下 可以看到显示字段前后有所变化,其他都是完全一样的 4 全连接语句 select * from BB full JOIN AA ON AA.A_ID=BB.B_ID 大家可以看到这次表里,是AA BB 全都补充上是左连,右连的一个合集。 相信大家通过我这个小例子就可以清楚的学会这个知识点了。 呵呵一片飞羽,手打测试。。。希望大家转载注明百度“一片飞羽”不胜感激。。。
01关于数据库连接池和动态数据源的实现课案
关于数据库连接池和动态数据源的实现、使用 对于一个简单的数据库应用,由于数据库的访问不是很频繁。这时可以很简单地在需要访问数据库时,就新创建一个连接,用完后就关闭它,这样就不会带来更多的性能上的开销。但是对于复杂的数据库应用,情况就完全不同了。频繁的建立、关闭连接,会极大的减低系统的性能,因为对于连接的使用成了系统性能的瓶颈。这就意味我们需要去考虑怎样把一个连接多次使用。 连接复用,通过建立数据库的连接池以及一套连接使用的管理策略,使得一个数据库连接可以得到高效、安全的复用,避免了数据库连接频繁建立、关闭给系统带来的开销。外部使用者可以通过getConnection方法获取连接,使用完毕之后再通过releaseConnection 方法将连接返回,注意此时的连接并没有关闭,而是由连接池管理器回收,并为下一次使用做好准备。 一般的数据库连接池,是使用配置文件在项目启动的使用加载配置文件,根据文件中描述,生成对应的数据库连接池。连接池有许多的属性比如:连接池的初始化连接处、连接池的最大连接数、每次的自增连接数、最大空闲连接数等等 数据库连接池技术带来的优势: 1.资源重用 由于数据库连接得到重用,避免了频繁创建、释放连接引起的大量性能开销。在减 少系统消耗的基础上,另一方面也增进了系统运行环境的平稳性(减少内存碎片以 及数据库临时进程/线程的数量) 2.更快的系统响应速度 数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于池中备用,此 时连接的初始化工作均已完成,对于业务处理而言,直接利用现有的可以连接,避 免了数据库连接初始化和释放过程的时间开销,从而缩短了系统整体的响应时间。 3. 统一的连接管理,避免数据库连接泄露 在较为完备的数据库连接池实现中可以根据预先的连接占用超时设定,强制回收被 占用的连接。从而避免常规数据库连接操作中可能出现的资源泄露。 一个数据库连接池的实现 1.前言 数据库应用,在许多软件系统中经常用到,是开发中大型系统不可缺少的辅助。但如果对数据库资源没有很好地管理(如:没有及时回收数据库的游标(ResultSet)、Statement、连接(Connection)等资源),往往会直接导致系统的稳定。这类不稳定因素,不单单由数据库或者系统本身一方引起,只有系统正式使用后,随着流量、用户的增加,才会逐步显露。 在基于Java开发的系统中,JDBC是程序员和数据库打交道的主要途径,提供了完备的数据库操作方法接口。但考虑到规范的适用性,JDBC只提供了最直接的数据库操作规范,对数据库资源管理,如:对物理连接的管理及缓冲,期望第三方应用服务器(Application Server)的提供。下面以JDBC规范为基础,介绍相关的数据库连接池机制,并就如果以简单的方式,实现有效地管理数据库资源介绍相关实现技术。
实验一空间数据库的创建与数据导入
实验一空间数据库的创建与数据导入 一、实验目的 1.利用ArcCatalog管理地理空间数据库,熟悉ArcCatalog的操作。 2、理解Geodatabse空间数据库模型的相关概念,掌握创建个人地理数据库 的方法。 二、实验内容 1、拷贝实验数据 2、启动ArcCatalog,点击按钮(连接到文件夹). 建立到data 的连接 3、打开coverage、shapefile文件夹,查看下的要素及属性,理解两种数据模型。 4、打开montgomery.gdb 空间数据库查看并理解montgomery.gdb数据库中包含 的要素集、要素类等信息,在预览窗口预览要素类等几何特性。 4、查看属性信息 在此预览窗口的下方,“预览”下拉列表中,选择“表格”。可以看到属性表,查看它的属性字段信息。
5、向Geodatabase导入coverage数据 (1)在ArcCatalog中右击Water 数据集,指向Import,点击Feature Class(multiple) (2)单击Browse 按钮,定位到laterals coverage中的弧段要素类, 单击Add. (3)单击OK,此时laterals_arc 要素类加入到Water 数据集. (4)在arccatalog中将laterals_arc要素类重命名为laterals (5)右击Laterals 并单击Properties,为该要素类输入别名“Water laterals”(6)单击Fields 标签,单击OBJECTID 字段并为该字段输入别名“Feature identifier”. (7)单击Preview 标签察看其特征.
SQL Server三种连接数据库(左连接,右连接,内链接)
SQL三种连接数据库 1.SQL join 用于根据两个或多个表中的列之间的关系,从这些表中查询数据。 Join 和 Key 连接分为三种:内连接、外连接、交叉连接 2. 3.内连接:INNER JOIN 4.分为三种:等值连接、自然连接、不等连接 5. 6.外连接: 7.分为三种:左外连接(LEFT OUTER JOIN或LEFT JOIN)、右外连接(RIGHT OUTER JOIN 或RIGHT JOIN)和全外连接(FULL OUTER JOIN或FULL JOIN)三种 8. 9.交叉连接(CROSS JOIN) 10.没有WHERE 子句,它返回连接表中所有数据行的笛卡尔积 有时为了得到完整的结果,我们需要从两个或更多的表中获取结果。我们就需要执行 join。 数据库中的表可通过键将彼此联系起来。主键(Primary Key)是一个列,在这个列中的每一行的值都是唯一的。在表中,每个主键的值都是唯一的。这样做的目的是在不重复每个表中的所有数据的情况下,把表间的数据交叉捆绑在一起。 请看 Persons 表: 请注意,"Id_P" 列是 Persons 表中的的主键。这意味着没有两行能够拥有相同的 Id_P。即使两个人的姓名完全相同,Id_P 也可以区分他们。 接下来请看 "Orders" 表:
请注意,"Id_O" 列是 Orders 表中的的主键,同时,"Orders" 表中的 "Id_P" 列用于引用"Persons" 表中的人,而无需使用他们的确切姓名。 请留意,"Id_P" 列把上面的两个表联系了起来。 不同的 SQL JOIN 下面列出了您可以使用的 JOIN 类型,以及它们之间的差异。 * JOIN: 如果表中有至少一个匹配,则返回行 * LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行 * RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行 * FULL JOIN: 只要其中一个表中存在匹配,就返回行 SQL INNER JOIN 关键字 在表中存在至少一个匹配时,INNER JOIN 关键字返回行。 INNER JOIN 关键字语法 Java代码 1.SELECT column_name(s) 2.FROM table_name1 3.INNER JOIN table_name2 4.ON table_name1.column_name=table_name2.column_name 注释:INNER JOIN 与 JOIN 是相同的。 现在,我们希望列出所有人的定购。 您可以使用下面的 SELECT 语句: Java代码 1.SELECT https://www.360docs.net/doc/519199321.html,stName, Persons.FirstName, Orders.OrderNo
数据库连接池原理
一、连接池的基本工作原理 1、基本概念及原理 数据库连接池的基本思想就是为数据库连接建立一个“缓冲池”。预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去。我们可以通过设定连接池最大连接数来防止系统无尽的与数据库连接。更为重要的是我们可以通过连接池的管理机制监视数据库的连接的数量和使用情况,为系统开发、测试及性能调整提供依据。 2、服务器自带的连接池 JDBC的API中没有提供连接池的方法。一些大型的WEB应用服务器如BEA的WebLogic 和IBM的WebSphere等提供了连接池的机制,但是必须有其第三方的专用类方法支持连接池的用法。 二、连接池关键问题分析 1、并发问题 为了使连接管理服务具有最大的通用性,必须考虑多线程环境,即并发问题。这个问题相对比较好解决,因为Java语言自身提供了对并发管理的支持,使用synchronized关键字即可确保线程是同步的。使用方法为直接在类方法前面加上synchronized关键字,如:public synchronized Connection getConnection () 2、多数据库服务器和多用户 对于大型的企业级应用,常常需要同时连接不同的数据库(如连接Oracle和Sybase)。如何连接不同的数据库呢?我们采用的策略是:设计一个符合单例模式的连接池管理类,在连接池管理类的唯一实例被创建时读取一个资源文件,其中资源文件中存放着多个数据库的地址、用户名、密码等信息。根据资源文件提供的信息,创建多个连接池类的实例,每一个实例都是一个特定数据库的连接池。连接池管理类实例为每个连接池实例取一个名字,通过不同的名字来管理不同的连接池。 对于同一个数据库有多个用户使用不同的名称和密码访问的情况,也可以通过资源文件处理,即在资源文件中设置多个具有相同url地址,但具有不同用户名和密码的数据库连接信息。 3、事务处理 我们知道,事务具有原子性,此时要求对数据库的操作符合“ALL-ALL-NOTHING”原则,即对于一组SQL语句要么全做,要么全不做。 在Java语言中,Connection类本身提供了对事务的支持,可以通过设置Connection的AutoCommit属性为false,然后显式的调用commit或rollback方法来实现。但要高效的进行Connection复用,就必须提供相应的事务支持机制。可采用每一个事务独占一个连接来实现,这种方法可以大大降低事务管理的复杂性。 4、连接池的分配与释放 连接池的分配与释放,对系统的性能有很大的影响。合理的分配与释放,可以提高连接的复用度,从而降低建立新连接的开销,同时还可以加快用户的访问速度。 对于连接的管理可使用空闲池。即把已经创建但尚未分配出去的连接按创建时间存放到一个空闲池中。每当用户请求一个连接时,系统首先检查空闲池内有没有空闲连接。如果有就把建立时间最长(通过容器的顺序存放实现)的那个连接分配给它(实际是先做连接是否有效的判断,如果可用就分配给用户,如果不可用就把这个连接从空闲池删掉,重新检测空闲池是否还有连接),如果没有则检查当前所开连接池是否达到连接池所允许的最大连接数(maxConn),如果没有达到,就新建一个连接,如果已经达到,就等待一定的时间(timeout)。如果在等待的时间内有连接被释放出来就可以把这个连接分配给等待的用户,如果等待时间
实验三 空间数据库的建立
《地理信息系统》实验报告 试验( 二 ) 题目:空间数据库的建立、运行 姓名: 班级:测绘工程10-2班 专业:测绘工程 时间:2013.10.9
实验内容: 建立数据库及要素集和要素类 实验要求: 根据ArcGIS参考教材,熟悉基本功能及操作,要求自主构建数据库,熟悉流程。实验过程及图示: 一:创建新 Shapefile (1)在 ArcCatalog 目录树中,右键单击需要创建 Shapefile 的文件夹,单击 New,再单击 Shapefile (2)打开 Create New Shapefile 对话框,设置文件名称和要素类型。要素类型可以通过下拉菜单选择 Polyline、 Polygon、 MultiPoint、 MultiPatch 等要素类型。 (3)单击编辑按钮,定义 Shapefile 的坐标系统,打开 Spatial Reference 对话框(4)单击 Select 按钮,可以选择一种预定义的坐标系统;单击 Import 按钮,可以选择想要复制其坐标系统的数据源;单击 New 按钮,可以定义一个新的、自定义的坐标系统。
(5)如果 Shapefile 要存储表示路线的折线,那么要复选 Coordinates will contain M Values,如果Shapefile 将存储三维要素,那么要复选Coordinates will contain Z Values。(6)单击 OK 按钮,新的 Shapefile 在文件夹中出现。 二、 Geodatabase 数据库创建 1、建立persornal database 在ArcCatalog的目录树中,定位到要创建数据库在磁盘上的位置,鼠标右键,选择
SQL 左外连接,右外连接,全连接,内连接 四种连接的差异
外联接。外联接可以是左向外联接、右向外联接或完整外部联接。 在FROM 子句中指定外联接时,可以由下列几组关键字中的一组指定: LEFT JOIN 或LEFT OUTER JOIN。 左向外联接的结果集包括LEFT OUTER 子句中指定的左表的所有行,而不仅仅是联接列所匹配的行。如果左表的某行在右表中没有匹配行,则在相关联的结果集行中右表的所有选择列表列均为空值。 RIGHT JOIN 或RIGHT OUTER JOIN。 右向外联接是左向外联接的反向联接。将返回右表的所有行。如果右表的某行在左表中没有匹配行,则将为左表返回空值。 FULL JOIN 或FULL OUTER JOIN。 完整外部联接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。 仅当至少有一个同属于两表的行符合联接条件时,内联接才返回行。内联接消除与另一个表中的任何行不匹配的行。而外联接会返回FROM 子句中提到的至少一个表或视图的所有行,只要这些行符合任何WHERE 或HAVING 搜索条件。将检索通过左向外联接引用的左表的所有行,以及通过右向外联接引用的右表的所有行。完整外部联接中两个表的所有行都将返回。 Microsoft? SQL Server?2000 对在FROM 子句中指定的外联接使用以下SQL-92 关键字: LEFT OUTER JOIN 或LEFT JOIN RIGHT OUTER JOIN 或RIGHT JOIN FULL OUTER JOIN 或FULL JOIN SQL Server 支持SQL-92 外联接语法,以及在WHERE 子句中使用*= 和=* 运算符指定外联接的旧式语法。由于SQL-92 语法不容易产生歧义,而旧式Transact-SQL 外联接有时会产生歧义,因此建议使用SQL-92 语法。 使用左向外联接 假设在city 列上联接authors 表和publishers 表。结果只显示在出版商所在城市居住的作者(本例中为Abraham Bennet 和Cheryl Carson)。 若要在结果中包括所有的作者,而不管出版商是否住在同一个城市,请使用SQL-92 左向外联接。下面是Transact-SQL 左向外联接的查询和结果:
连接池优缺点
数据库连接池的好处 对于一个简单的数据库应用,由于对于数据库的访问不是很频繁。这时可以简单地在需要访问数 据库时,就新创建一个连接,用完后就关闭它,这样做也不会带来什么明显的性能上的开销。但 是对于一个复杂的数据库应用,情况就完全不同了。频繁的建立、关闭连接,会极大的减低系统 的性能,因为对于连接的使用成了系统性能的瓶颈。 连接复用。通过建立一个数据库连接池以及一套连接使用管理策略,使得一个数据库连接可以 得到高效、安全的复用,避免了数据库连接频繁建立、关闭的开销。 对于共享资源,有一个很著名的设计模式:资源池。该模式正是为了解决资源频繁分配、释放 所造成的问题的。把该模式应用到数据库连接管理领域,就是建立一个数据库连接池,提供一套 高效的连接分配、使用策略,最终目标是实现连接的高效、安全的复用。 数据库连接池的基本原理是在内部对象池中维护一定数量的数据库连接,并对外暴露数据库连接 获取和返回方法。如: 外部使用者可通过getConnection方法获取连接,使用完毕后再通过releaseConnection方法将连接返回,注意此时连接并没有关闭,而是由连接池管理器回收,并为下一次使用做好准备。 数据库连接池技术带来的优势: 1.资源重用 由于数据库连接得到重用,避免了频繁创建、释放连接引起的大量性能开销。在减少系统消耗的 基础上,另一方面也增进了系统运行环境的平稳性(减少内存碎片以及数据库临时进程/线程的数量)。 2.更快的系统响应速度 数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于池中备用。此时连接的初始 化工作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了数据库连接初始化和 释放过程的时间开销,从而缩减了系统整体响应时间。 3.新的资源分配手段 对于多应用共享同一数据库的系统而言,可在应用层通过数据库连接的配置,实现数据库连接池 技术,几年钱也许还是个新鲜话题,对于目前的业务系统而言,如果设计中还没有考虑到连接池 的应用,那么…….快在设计文档中加上这部分的内容吧。某一应用最大可用数据库连接数的限制,避免某一应用独占所有数据库资源。 4.统一的连接管理,避免数据库连接泄漏 在较为完备的数据库连接池实现中,可根据预先的连接占用超时设定,强制收回被占用连接。从 而避免了常规数据库连接操作中可能出现的资源泄漏。一个最小化的数据库连接池实现: 连接池的优缺点 优点 使用连接池的最主要的优点是性能。创建一个新的数据库连接所耗费的时间主要取决于网络的速 度以及应用程序和数据库服务器的(网络)距离,而且这个过程通常是一个很耗时的过程。而采用 数据库连接池后,数据库连接请求可以直接通过连接池满足而不需要为该请求重新连接、认证到 数据库服务器,这样就节省了时间。 缺点 数据库连接池中可能存在着多个没有被使用的连接一直连接着数据库(这意味着资源的浪费)。
空间数据库毕业课程设计报告
空间数据库课程设计兼ARCSDE入门 手册 一.ArcSDE的配置 数据库的创建 数据库的配置 数据库的网络配置 数据库的控制和管理 ArcSDE的配置 二.数据库的设计 建立数据库连接 表的创建与设计 版本的注册与创建 成员角色与任务分配 三.问题与解决方案 软件本身的问题 多版本编辑的问题 四.总结 个人心得 各成员工作情况 一. ArcSDE的配置 1.数据库的创建:
打开Database Configuration Assistant工具 如图(1.1)所示 为初始界面 图(1.1) 按照向导对话框依次选择执行的操作创建数据库→选择一般用途的模→输入数据库名称和SID号(*注意SID号默认和数据库名相同)→管理选项(默认设置)→输入口令号(*可以根据不同的用户设置不同的口令)→存储选项(默认设置)→数据库文件所在位置(默认设置)→恢复配置(默认设置)→数据库内容(默认设置)→初始化参数(默认设置)→数据库存储(默认设置)→创建选项(如图1.2)→确定对话框→开始创建图1.2 2.数据库的配置 创建数据库成功之后需要进行数据库的配置,同上打开Database Configuration Assistant工具,点击下一步,选择配置数据库选项→选择需要配置的数据库→数据库内容(默认设置)→连接模式(*客户机较少时默认设置),点击完成开始配置数据库(如上图) 3.数据库的网络配置 配置数据库之后,打开Oracle Net Configuration Assistant 工具,如图(1.4)为初始界面 图1.4
按下一步进入监听程序配置→监听程序(*若需要添加新的监听程序,选择添加,这里选择已有的监听程序,选择重新配置如右图)→选择监听程序→选择协议(默认有TCP)→选择端口(*端口号默认为1521,若配置了多个监听程序,不应重复使用1521端口,否则后期的本地NET服务名配置会出错,如右图)→完成配置好监听程序后配置本地NET服务名配置→重新配置→选择Net服务名(根据新创建的数据库选择服务名)→服务名配置(输入新创建的数据库名)→选择协议(默认配置)→输入主机号和选择端口(主机号为计算机名)→选择测试→测试登录方式用户名填system,口令重新输入,如右图(若测试失败,可以试着重新配置数据库,注意配置端口号) 4.数据库的控制和管理 工具: OEM和SQL*PLUS 登录OEM方式:网页登陆。(下图) 网址可在安装目录oracle\product\10.2.0\db_1\install\readme.txt中得到,输入网址,并用sys用户登录,使用SYSDBA身份。 登录SQL*PLUS方式:对话框登录。 输入用户名:System, 输入口令: 输入主机字符串:数据库名 (右图)
Java实现数据库连接池的代码.
1 package com.kyo.connection; 2 3 import java.sql.Connection; 4 import java.sql.DatabaseMetaData; 5 import java.sql.Driver; 6 import java.sql.DriverManager; 7 import java.sql.SQLException; 8 import java.sql.Statement; 9 import java.util.Enumeration; 10 import java.util.Vector; 11 12 public class ConnectionPool { 13 14 private ConnectionParam param; 15 16 private String testTable = ""; // 测试连接是否可用的测试表名,默认没 有测试表 17 18 private Vector connections = null; // 存放连接池中数据库连接的向量 , 初始时为 19 // null,它中存放的对象为PooledConnection 型 20 21 public void setParam(ConnectionParam param { 22 this.param = param; 23 } 24 25 public ConnectionParam getParam( { 26 return param;
27 } 28 29 /** 30 * 构造函数 31 * 32 * @param param 33 */ 34 public ConnectionPool(ConnectionParam param { 35 this.param = param; 36 } 37 38 /** 39 * 40 * 获取测试数据库表的名字 41 * 42 * @return 测试数据库表的名字 43 */ 44 45 public String getTestTable( { 46 return this.testTable; 47 } 48 49 /** 50 * 51 * 设置测试表的名字 52 * 53 * @param testTable
SQL 左外连接,右外连接,全连接,内连接的区别和用法
SQL 左外连接,右外连接,全连接,内连接连接条件可在FROM或WHERE子句中指定,建议在FROM子句中指定连接条件。WHERE和HAVING子句也可以包含搜索条件,以进一步筛选连接条件所选的行。 连接可分为以下几类: 内连接。(典型的连接运算,使用像= 或<> 之类的比较运算符)。包括相等连接和自然连接。 内连接使用比较运算符根据每个表共有的列的值匹配两个表中的行。例如,检 索students 和courses 表中学生标识号相同的所有行。 外连接。外连接可以是左向外连接、右向外连接或完整外部连接。 在FROM子句中指定外连接时,可以由下列几组关键字中的一组指定: LEFT JOIN 或LEFT OUTER JOIN。 左向外连接的结果集包括LEFT OUTER子句中指定的左表的所有行,而不仅仅是连接列所匹配的行。如果左表的某行在右表中没有匹配行,则在相关联的结果集行中右表的所有选择列表列均为空值。 RIGHT JOIN 或 RIGHT OUTER JOIN。 右向外连接是左向外连接的反向连接。将返回右表的所有行。如果右表的某行在左表中没有匹配行,则将为左表返回空值。 FULL JOIN 或FULL OUTER JOIN。 完整外部连接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。 交叉连接。交叉连接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉连接也称作笛卡尔积。 例如,下面的内连接检索与某个出版商居住在相同州和城市的作者: USE pubs SELECT a.au_fname, a.au_lname, p.pub_name FROM authors AS a INNER JOIN publishers AS p ON a.city = p.city AND a.state = p.state ORDER BY a.au_lname ASC, a.au_fname ASC FROM 子句中的表或视图可通过内连接或完整外部连接按任意顺序指定;但是,用左或右向外连接指定表或视图时,表或视图的顺序很重要。有关使用左或右向外连接排列表的更多信息,请参见使用外连接。 例子:
数据库连接池配置的几种方法
今天遇到了关于数据源连接池配置的问题,发现有很多种方式可以配置,现总结如下,希望对大家有所帮助:(以Mysql数据库为例) 一,Tomcat配置数据源: 方式一:在WebRoot下面建文件夹META-INF,里面建一个文件context.xml,内容如下: A表(a1,b1,c1) B表(a2,b2) a1 b1 c1 a2 b2 01 数学 95 01 张三 02 语文 90 02 李四 03 英语 80 04 王五 select A.*,B.* from A left outer join B on(A.a1=B.a2) 结果是: a1 b1 c1 a2 b2 01 数学 95 01 张三 02 语文 90 02 李四 03 英语 80 NULL NULL select A.*,B.* from A right outer join B on(A.a1=B.a2) 结果是: a1 b1 c1 a2 b2 01 数学 95 01 张三 02 语文 90 02 李四 NULL NULL NULL 04 王五 数据库中的左连接(left join)和右连接(right join)区别Left Join / Right Join /inner join相关 关于左连接和右连接总结性的一句话: 左连接where只影向右表,右连接where只影响左表。 Left Join select * from tbl1 Left Join tbl2 where tbl1.ID = tbl2.ID 左连接后的检索结果是显示tbl1的所有数据和tbl2中满足where 条件的数据。 简言之 Left Join影响到的是右边的表 Right Join select * from tbl1 Right Join tbl2 where tbl1.ID = tbl2.ID 检索结果是tbl2的所有数据和tbl1中满足where 条件的数据。 简言之 Right Join影响到的是左边的表。 inner join select * FROM tbl1 INNER JOIN tbl2 ON tbl1.ID = tbl2.ID 功能和 select * from tbl1,tbl2 where tbl1.id=tbl2.id相同。 其他相关资料 1 .WHERE子句中使用的连接语句,在数据库语言中,被称为隐性连接。INNER JOIN……ON子句产生的连接称为显性连接。(其他JOIN 参数也是显性连接)WHERE 和INNER JOIN产生的连接关系,没有本质区别,结果也一样。但是!隐性连接随着数据库语言的规范和发展,已经逐渐被淘汰,比较新的数据库语言基本上已经抛弃了隐性连接,全部采用显性连接了。 2 .无论怎么连接,都可以用join子句,但是连接同一个表的时候,注意要定义别名,否则产生错误! 数据库连接池技术研究和实现 唐满英 (永州市职业技术学院,湖南永州 425100) 摘要数据库和数据库连接池技术已经得到了广泛的应用,数据库连接池建立的例子也很多。本文先简要介绍了数据库连接池的概念,然后分析了连接池的管理,即:连接池建立、连接池管理和连接池关闭。随后介绍了如何在基于Java的基础上建立连接池:定义连接池类、创建管理类、管理类与主程序的接口。最后简要分析了数据库连接池的优化架构,优化的主要目标是能动态调整连接池的容量,避免资源浪费。 关键词数据库;连接池;技术实现 1 数据库连接池简介 数据库连接池是一个存储数据库连接的缓冲池。在实际应用中,同一个数据库可能有多个用户反复连接和断开数据库,这会消耗数据库的很多资源,造成浪费。在具体操作上,连接池会选择性地保留程序释放的数据库连接,以便用户以后使用。当用户在连接上调用Open时,池进程就会检查池中是否有可用的连接,如果某个池连接可用,会将该连接返回给调用者,而不是打开新连接,以此节约连接资源,提高数据库的使用效率。同理,应用程序在该连接上调用Close时,池进程会将连接返回到活动连接池中,而不是真正关闭连接。连接返回到池中之后,即可供其它用户在下一个Open调用中使用。图1表示了连接池遇到新连接时的工作过程[1]: 图1 数据库连接池的工作机制 图1解释了数据库连接池的机制,即当用户申数据库连接时,在数据库池内连接匹配的情况下,便会从数据库连接池中直接获得一个一直被保持的连接。 2 连接池管理 连接池管理主要由三部分组成:连接池的建立、连接的使用管理、连接池的关闭。通过这三部分,连接池成为众多连接对象的“缓冲存储池”,也就是连接对象的集合体,它提供一种管理机制来控制连接池内部连接对象的数目,对应用程序提供获取、释放连接的接口。 2.1 连接池的建立 应用程序中要建立一个在系统初始化时就已分配好连接数目的静态连接池,且这些连接不能随意关闭。这些连接对象作为系统可分配的自由连接,以后所使用的连接都从连接池获取,这样可避免随意建立、释放连接所带来的开销。 2.2 连接的使用管理 连接的使用管理是连接池管理机制的核心。有了连接池,所有用户申请连接时直接向连接池申请,而非数据库。同理,所有用户释放连接时,是向连接池释放连接而非关闭数据库连接。连接池分配释放策略是[2]:连接池先检查有否未被分配的空闲连接,若有则把空闲连接分配给用户;反之要检查连接个数是否达到了连接上限。如果没有达到上限可以建立一个新连接分配给用户,否则需要等待,直到有别的用户释放连接时再把释放后的连接分配给该用户。由此可知:连接池技术能够保证数据库连接的有效复用,避免频繁地建立、释放连接所带来的系统资源开销。 2.3 连接池的关闭 用户退出程序时,与连接池的建立是一个相反的过程,即把在连接池建立时向数据库申请的连接对象统一归还给数据库连接池,以便连接池分配给其它用户。 3 基于java的连接池类的设计 主要要分为三个步骤:定义连接池类;创建管理类;管理类与主程序的接口。 3.1 定义连接池类 数据库连接池设计的方法很多,但是连接池的构建首先都要确定类,本方法构建如下五个类[3]:①GetProperty类,该类的功能用于从文件poolfile中读取数据库连接池的一般属性,如连接用户名,密码等验证信息。采用该方法的好处就是连接池不用关心操作的是什么类型的数据库,以及数据库的属性。当数据库的类型或属性发生改变时,管理员只要修改文件PropFile即可。②ConnectionFactory类,该类为连接池的工厂类,其中定义一些参数如:正在使用的连接池参数use、空闲连接池参数idle、最大连接数maxactive、最小连接数minactive、当前连接数active和管理策略参数等。③FactoryMangeThreadl类,该类的功能是实现静态管理和动态管理两种策略,并设置了最大限制和恒定的连接数,它将连接池又细分为两级小连接池,一个空闲连接池,一个使用池。④FactoryParam类,该类是连接池工厂的参数类,定义了最大连接数和最小连接数,并定义了回收策略,提供良好的用户接口等。⑤Substituteconnection类,该类定义了数据库连接和监控连接创建的语句,数据库上一次访问的时间和数据库的状态是否为忙,要接管的函数的名字等参数。它通过触发java.1ang.reflect包中invocationHandler的invoke方法,运用动态代理机制接管接口的方法接管,并实现了连接池的名字与其对象之间的映射。数据库左连接与右连接
数据库连接池