Self-Similar Hot Accretion Flow onto a Rotating Neutron Star Structure and Stability

a r X i v :a s t r o -p h /0105185v 1 10 M a y 2001
Self-Similar Hot Accretion Flow onto a Rotating Neutron Star:Structure and
Stability
Mikhail V.Medvedev 1and Ramesh Narayan 2
1
CITA,University of Toronto,Toronto,Ontario,M5S 3H8,Canada
2
Harvard-Smithsonian Center for Astrophysics,60Garden Street,Cambridge,MA 02138
Abstract.We present analytical and numerical solutions which describe a hot,vis-cous,two-temperature accretion ?ow onto a rotating neutron star or any other rotating compact star with a surface.We assume Coulomb coupling between the protons and electrons,and free-free cooling from the electrons.Outside a thin boundary layer,where the accretion ?ow meets the star,we show that there is an extended settling region which is well-described by two self-similar solutions:(i)a two-temperature so-lution which is valid in an inner zone r ≤102.5(r is in Schwarzchild units),and (ii)a one-temperature solution at larger radii.In both zones,ρ∝r ?2,?∝r ?3/2,v ∝r 0,T p ∝r ?1;in the two-temperature zone,T e ∝r ?1/2.The luminosity of the settling zone arises from the rotational energy of the star as the star is braked by viscosity.Hence the luminosity and the ?ow parameters (density,temperature,angular velocity)
are independent of ˙M
.The settling solution described here is not advection-dominated,and is thus di?erent from the self-similar ADAF found around black holes.When the spin of the star is small enough,however,the present solution transforms smoothly to a (settling)ADAF.
We carried out a stability analysis of the settling ?ow.The ?ow is convectively and viscously stable and is unlikely to have strong winds or out?ows.Unlike another cooling-dominated system —the SLE disk,—the settling ?ow is thermally stable provided that thermal conduction is taken into account.This strong saturated-like thermoconduction does not change the structure of the ?ow.
THE SETTLING FLOW
At small mass accretion rates,<~
10?2of the Eddington rate,black holes (BHs)accrete via an ADAF —a hot,two-temperature,radiatively ine?cient,geometri-cally thick,advection-dominated accretion ?ow [1,2].In contrast,accretion onto compact stars,e.g.,a neutron star (NS)may occur via either an ADAF of a settling solution [3].The latter corresponds to strongly rotating stars only.In the settling ?ow the rotational energy is extracted from the star via viscous torques in the boundary layer where the ?ow meets the star surface.The extracted energy heats
the ?ow and ultimately escapes from the ?ow as free-free radiation.In addition,viscosity extracts angular momentum from the star as well.In the stationary ?ow,this angular momentum must be transported though the ?ow to the outermost radii,where it goes into the ambient medium.It is this huge angular momen-tum ?ux ˙J which modi?es the entire structure of the accretion ?ow and makes it drastically di?erent from an ADAF.Note that no angular momentum may be extracted from a BH horizon by viscosity.Thus a viscous settling ?ow may exist in NS systems and not in BH systems.
The structure of the steady,rotating,axisymmetric,quasi-spherical,two-temperature settling ?ow has been found analytically and con?rmed numerically [3].We use the height-integrated form of the viscous hydrodynamic equations with the Shakura-Sunyaev-type viscosity parametrized by dimensionless α.We assume vis-cous heating of protons,Bremsstrahlung cooling of electrons and Coulomb energy transfer from the protons to the electrons;we neglect Comptonization but include thermal conduction in the form discussed in the next section.In the inner zone
1
2
34
5
6
Log R
-8
-6
-4
-2
L o g ?/?k ,N S
1
2
34
5
6
Log R
-9
-8
-7-6-5
-4-3L o g v /c
1
2
34
5
6
Log R
-16
-14-12
-10-8-6
-4-2
L o g ρ
1
2
34
5
6
Log R
6
7
8
91011
12
L o g T p ,T e
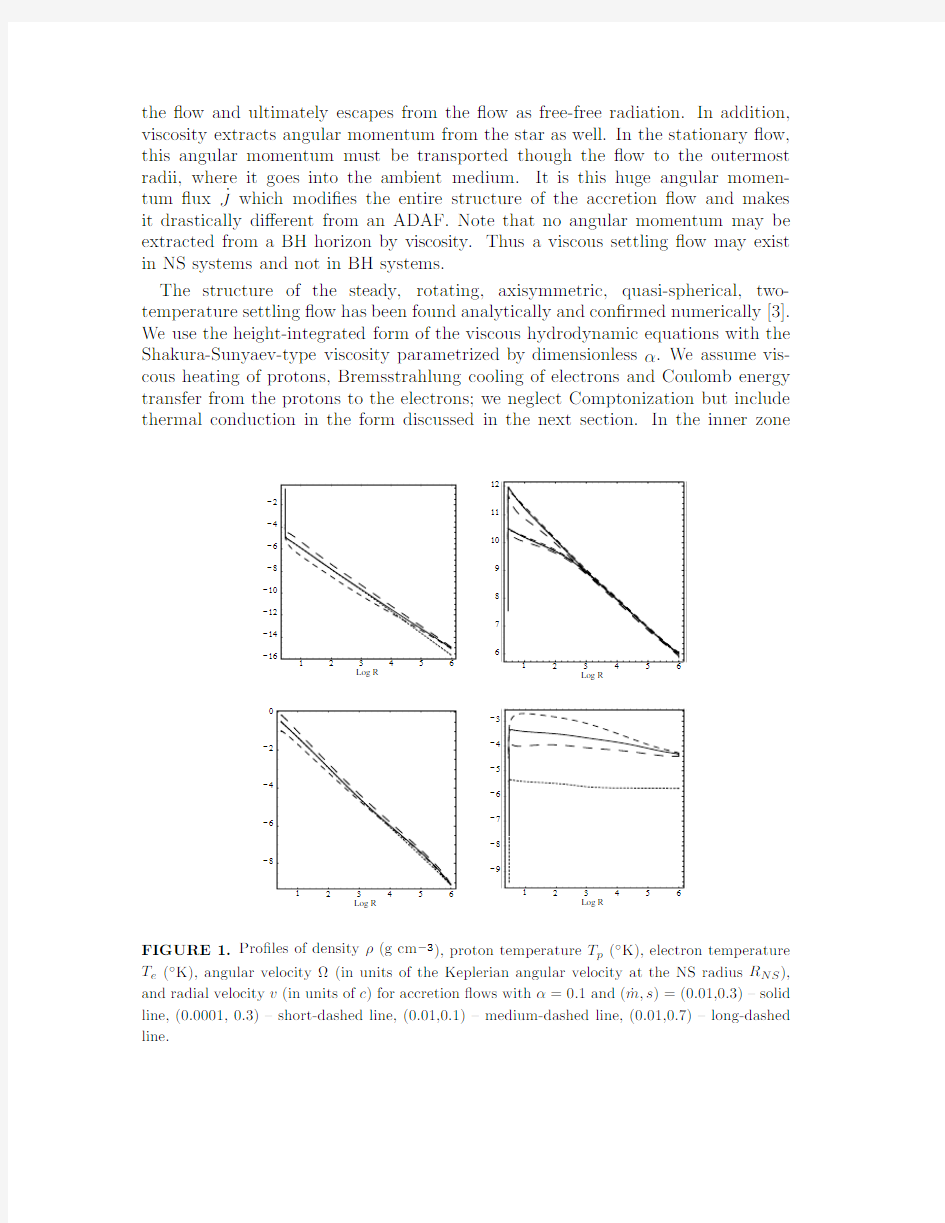
FIGURE 1.Pro?les of density ρ(g cm ?3),proton temperature T p (?K),electron temperature T e (?K),angular velocity ?(in units of the Keplerian angular velocity at the NS radius R NS ),and radial velocity v (in units of c )for accretion ?ows with α=0.1and (˙m,s )=(0.01,0.3)–solid line,(0.0001,0.3)–short-dashed line,(0.01,0.1)–medium-dashed line,(0.01,0.7)–long-dashed line.
r<102.5(r is in Schwarzchild units,R S=2GM/c2),the?ow is two-temperature with the density,proton and electron temperatures,angular and radial velocities scalings as
ρ=ρ0r?2,T p=T p0r?1,T e=T e0r?1/2,?=?0r?3/2,v=v0r0,(1) whereρ0,T p0,T e0,?0,v0are functions of M,αand the star spin s=??/?K(R?), and?K(R)=(GM/R3)1/2is the Keplerian angular velocity.In the outer zone r> 102.5,we have T e=T p∝r?1and the same other scalings.This self-similar solution is valid for the part of the?ow below the radius r s related to the mass accretion rate˙m(in Eddington units,˙M Edd=1.4×1018m g/s,and here m=M/M⊙):
,(2)
˙m<2.2×10?3α20.1s20.3r?1/2
s,3
where r s,3=r s/103,α0.1=α/0.1,etc..The numerical solution of the hydrodynamic equations with appropriate inner and outer boundary conditions is represented in Figure1.It is in excellent agreement with the self-similar solition(1).
There is a remarkable property of the settling?ow:all quantities,e.g.,ρ,T p,etc., except v,are independent of the mass accretion rate˙M.This happens because the gravitational energy of the accreting gas is much smaller than the energy extracted from the rotating star.It is this energy which dominates the?ow luminosity.We should also remark that the settling?ow is more similar to a steady,radiative cooling-dominated“atmosphere”rather than to a rapidly infalling?ow:the radial infall velocity is constant and is much less then the free-fall velocity v/v?∝r1/2→0 as r→0.The structure of the settling is very sensitive to the rotation rate of the central star.As the angular velocity decreases below few percents of the Keplerian value,the settling?ow smoothly transforms into a conventional ADAF solution,as represented in Figure2.
It was shown that the settling?ow is(i)convectively stable and(ii)may not have strong winds and out?ows(the Bernoulli number is negative)if the adiabatic index satis?es
3(1?s2/2)
γ>
V 0(x )=2A x ?y ,(4)
where 2A =d V 0/dx is the shear frequency,x,y,z are the radial,azimuthal,
and vertical coordinates,and “hat”denotes a unit vector.We assume that there is a Coriolis acceleration due to ?=??z .The vorticity and epicyclic frequency
are then 2B =2A +2?,κ2
epi =4?B .For a Keplerian-type ?ow,?∝R ?3/2,which is the case for both the settling and SLE solutions considered below,one has 2A =?(3/2)?and 2B =?/2.We assume that perturbations have only s -component,which corresponds to axisymmetric perturbations.We ignore motions in z direction.We use hydrodynamic equations with thermoconductive ?ux.
The settling ?ow is hot (sub-virial),so that the mean-free-path (of both electrons and protons)is larger than the size of the system.Hence the conventional Spitzer theory fails.Without collisions but in the presence of magnetic ?elds electrons stream freely along the ?eld lines,therefore the parallel heat ?ux remains large.In contrast,transverse heat ?ux is greatly reduced in a magnetic ?eld because electrons are tied to the ?eld lines on the scale of the Larmor orbit and cannot move across the ?eld lines too far.In a tangled ?eld,however,electrons can jump
1
2
345
6
Log R
-8
-6
-4
-2L o g ?/?k ,N S
R -3/2
1
2
3456
Log R
-7
-6
-5-4-3-2-1
L o g v /c
R -1/2
R 0
1
2
345
6
Log R
-14
-12-10-8-6-4
-2L o g ρ
R -2
R -3/2
1
2
345
6
Log R
6
7
891011
12
L o g T p ,T e
R -1
FIGURE 2.Same as in Fig.1for γ=4/3and s =0.3(solid curve)and s =0.01(dotted curve).The self-similar slopes for an ADAF ?ow and a settling ?ow are shown for comparison.The long-dashed curves represent the same solution as the solid curve,but with ten times higher temperature at R out .
from one?eld line to another and thus transfer heat across the?eld[7].The average thermal conductivity in tangled?elds is
κB?nk B v T l B??10?2nk B v T Rξ?1??1,(5) where l B=ξR is the correlation scale of the magnetic?elds set by?ow turbulence and?<1takes in to account that only a fraction of all particles may pass though the magnetic barriers.The rest of them will remain trapped in magnetic wells and, hence,will not transport energy to large distances?l B.The thermoconductive ?ux is
q cond=?αc ρc2s
dx
,whereαc?
R
γ?1+
i(n?1)
τcond ω2?κ2epi?k2c2s ?ω
ω+i(2B/A?1)
(9αs2+2αc)
??1K?
2
αc
??1K.(7)
In the large-k limit,(7)yields the growth rate of the thermal mode.The stability criterion Imω<0is(forαs2<~αc)
kR> τcond A 1/2= 26αc13
BP神经网络实验——【机器学习与算法分析 精品资源池】
实验算法BP神经网络实验 【实验名称】 BP神经网络实验 【实验要求】 掌握BP神经网络模型应用过程,根据模型要求进行数据预处理,建模,评价与应用; 【背景描述】 神经网络:是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型。BP神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络,是目前应用最广泛的神经网络。其基本组成单元是感知器神经元。 【知识准备】 了解BP神经网络模型的使用场景,数据标准。掌握Python/TensorFlow数据处理一般方法。了解keras神经网络模型搭建,训练以及应用方法 【实验设备】 Windows或Linux操作系统的计算机。部署TensorFlow,Python。本实验提供centos6.8环境。 【实验说明】 采用UCI机器学习库中的wine数据集作为算法数据,把数据集随机划分为训练集和测试集,分别对模型进行训练和测试。 【实验环境】 Pyrhon3.X,实验在命令行python中进行,或者把代码写在py脚本,由于本次为实验,以学习模型为主,所以在命令行中逐步执行代码,以便更加清晰地了解整个建模流程。 【实验步骤】 第一步:启动python: 1
命令行中键入python。 第二步:导入用到的包,并读取数据: (1).导入所需第三方包 import pandas as pd import numpy as np from keras.models import Sequential from https://www.360docs.net/doc/519682196.html,yers import Dense import keras (2).导入数据源,数据源地址:/opt/algorithm/BPNet/wine.txt df_wine = pd.read_csv("/opt/algorithm/BPNet/wine.txt", header=None).sample(frac=1) (3).查看数据 df_wine.head() 1
数据挖掘常用资源及工具
资源Github,kaggle Python工具库:Numpy,Pandas,Matplotlib,Scikit-Learn,tensorflow Numpy支持大量维度数组与矩阵运算,也针对数组提供大量的数学函数库 Numpy : 1.aaa = Numpy.genfromtxt(“文件路径”,delimiter = “,”,dtype = str)delimiter以指定字符分割,dtype 指定类型该函数能读取文件所以内容 aaa.dtype 返回aaa的类型 2.aaa = numpy.array([5,6,7,8]) 创建一个一维数组里面的东西都是同一个类型的 bbb = numpy.array([[1,2,3,4,5],[6,7,8,9,0],[11,22,33,44,55]]) 创建一个二维数组aaa.shape 返回数组的维度print(bbb[:,2]) 输出第二列 3.bbb = aaa.astype(int) 类型转换 4.aaa.min() 返回最小值 5.常见函数 aaa = numpy.arange(20) bbb = aaa.reshape(4,5)
numpy.arange(20) 生成0到19 aaa.reshape(4,5) 把数组转换成矩阵aaa.reshape(4,-1)自动计算列用-1 aaa.ravel()把矩阵转化成数组 bbb.ndim 返回bbb的维度 bbb.size 返回里面有多少元素 aaa = numpy.zeros((5,5)) 初始化一个全为0 的矩阵需要传进一个元组的格式默认是float aaa = numpy.ones((3,3,3),dtype = numpy.int) 需要指定dtype 为numpy.int aaa = np 随机函数aaa = numpy.random.random((3,3)) 生成三行三列 linspace 等差数列创建函数linspace(起始值,终止值,数量) 矩阵乘法: aaa = numpy.array([[1,2],[3,4]]) bbb = numpy.array([[5,6],[7,8]]) print(aaa*bbb) *是对应位置相乘 print(aaa.dot(bbb)) .dot是矩阵乘法行乘以列 print(numpy.dot(aaa,bbb)) 同上 6.矩阵常见操作
题库深度学习面试题型介绍及解析--第7期
1.简述激活函数的作用 使用激活函数的目的是为了向网络中加入非线性因素;加强网络的表示能力,解决线性模型无法解决的问题 2.那为什么要使用非线性激活函数? 为什么加入非线性因素能够加强网络的表示能力?——神经网络的万能近似定理 ?神经网络的万能近似定理认为主要神经网络具有至少一个非线性隐藏层,那么只要给予网络足够数量的隐藏单元,它就可以以任意的精度来近似任何从一个有限维空间到另一个有限维空间的函数。 ?如果不使用非线性激活函数,那么每一层输出都是上层输入的线性组合;此时无论网络有多少层,其整体也将是线性的,这会导致失去万能近似的性质 ?但仅部分层是纯线性是可以接受的,这有助于减少网络中的参数。3.如何解决训练样本少的问题? 1.利用预训练模型进行迁移微调(fine-tuning),预训练模型通常在特征上拥有很好的语义表达。此时,只需将模型在小数据集上进行微调就能取得不错的效果。CV 有 ImageNet,NLP 有 BERT 等。 2.数据集进行下采样操作,使得符合数据同分布。
3.数据集增强、正则或者半监督学习等方式来解决小样本数据集的训练问题。 4.如何提升模型的稳定性? 1.正则化(L2, L1, dropout):模型方差大,很可能来自于过拟合。正则化能有效的降低模型的复杂度,增加对更多分布的适应性。 2.前停止训练:提前停止是指模型在验证集上取得不错的性能时停止训练。这种方式本质和正则化是一个道理,能减少方差的同时增加的偏差。目的为了平衡训练集和未知数据之间在模型的表现差异。 3.扩充训练集:正则化通过控制模型复杂度,来增加更多样本的适应性。 4.特征选择:过高的特征维度会使模型过拟合,减少特征维度和正则一样可能会处理好方差问题,但是同时会增大偏差。 5.你有哪些改善模型的思路? 1.数据角度 增强数据集。无论是有监督还是无监督学习,数据永远是最重要的驱动力。更多的类型数据对良好的模型能带来更好的稳定性和对未知数据的可预见性。对模型来说,“看到过的总比没看到的更具有判别的信心”。 2.模型角度
VFP常用函数大全整理
VFP常用函数大全整理 一.字符及字符串处理函数:字符及字符串处理函数的处理对象均为字符型数据,但其返回值类型各异. 1.取子串函数: 格式:substr(c,n1,n2) 功能:取字符串C第n1个字符起的n2个字符.返回值类型是字符型. 例:取姓名字符串中的姓. store \"王小风\" to xm ?substr(xm,1,2) 结果为:王 2.删除空格函数:以下3个函数可以删除字符串中的多余空格,3个函数的返回值均为字符型. trim(字符串):删除字符串的尾部空格 alltrim(字符串):删除字符串的前后空格 ltrim(字符串):删除字符串的前面的空格 例:去掉第一个字符串的尾空格后与第二个字符串连接 store \"abcd \" to x store \"efg\" to y ?trim(x)+y abcdefg 3.空格函数: 格式:space(n) 说明:该函数的功能是产生指定个数的空格字符串(n用于指定空格个数). 例:定义一个变量dh,其初值为8个空格 store space(8) to dh 4.取左子串函数: 格式:left(c,n) 功能:取字符串C左边n个字符. 5.取右子串函数: 格式:right(c,n) 功能:取字符串c右边的n个字符 例:a=\"我是中国人\" ?right(a,4) 国人 ?left(a,2) 我 6.empty(c):用于测试字符串C是否为空格. 7.求子串位置函数: 格式:At(字符串1,字符串2) 功能:返回字符串1在字符串2的位置 例:?At(\"教授\",\"副教授\") 2
8.大小写转换函数: 格式: lower(字符串) upper(字符串) 功能:lower()将字符串中的字母一律变小写;upper()将字符串中的字母一律变大写 例: bl=\"FoxBASE\" ?lower(bl)+space(2)+upper(bl) foxbase FOXBASE 9.求字符串长度函数: 格式:len(字符串) 功能:求指定字符串的长度 例:a=\"中国人\" ?len(a) 6 二.数学运算函数: 1.取整函数: 格式:int(数值) 功能:取指定数值的整数部分. 例:取整并显示结果 ?int(25.69) 25 2.四舍五入函数: 格式:round(数值表达式,小数位数) 功能:根据给出的四舍五入小数位数,对数值表达式的计算结果做四舍五入处理 例:对下面给出的数四舍五入并显示其结果 ?round(3.14159,4),round(2048.9962,0),round(2048.9962,-3) 3.1416 2049 2000 3.求平方根函数: 格式:sqrt(数值) 功能:求指定数值的算术平方根 例:?sqrt(100) 10 4.最大值、最小值函数: 格式: Max(数值表达式1,数值表达式2) Min(数值表达式1,数值表达式2) 功能:返回两个数值表达式中的最大值和最小值 例:
人工智能实践:Tensorflow笔记 北京大学 7 第七讲卷积网络基础 (7.3.1) 助教的Tenso
Tensorflow笔记:第七讲 卷积神经网络 本节目标:学会使用CNN实现对手写数字的识别。 7.1 √全连接NN:每个神经元与前后相邻层的每一个神经元都有连接关系,输入是特征,输出为预测的结果。 参数个数:∑(前层×后层+后层) 一张分辨率仅仅是28x28的黑白图像,就有近40万个待优化的参数。现实生活中高分辨率的彩色图像,像素点更多,且为红绿蓝三通道信息。 待优化的参数过多,容易导致模型过拟合。为避免这种现象,实际应用中一般不会将原始图片直接喂入全连接网络。 √在实际应用中,会先对原始图像进行特征提取,把提取到的特征喂给全连接网络,再让全连接网络计算出分类评估值。
例:先将此图进行多次特征提取,再把提取后的计算机可读特征喂给全连接网络。 √卷积Convolutional 卷积是一种有效提取图片特征的方法。一般用一个正方形卷积核,遍历图片上的每一个像素点。图片与卷积核重合区域内相对应的每一个像素值乘卷积核内相对应点的权重,然后求和,再加上偏置后,最后得到输出图片中的一个像素值。 例:上面是5x5x1的灰度图片,1表示单通道,5x5表示分辨率,共有5行5列个灰度值。若用一个3x3x1的卷积核对此5x5x1的灰度图片进行卷积,偏置项
b=1,则求卷积的计算是:(-1)x1+0x0+1x2+(-1)x5+0x4+1x2+(-1)x3+0x4+1x5+1=1(注意不要忘记加偏置1)。 输出图片边长=(输入图片边长–卷积核长+1)/步长,此图为:(5 – 3 + 1)/ 1 = 3,输出图片是3x3的分辨率,用了1个卷积核,输出深度是1,最后输出的是3x3x1的图片。 √全零填充Padding 有时会在输入图片周围进行全零填充,这样可以保证输出图片的尺寸和输入图片一致。 例:在前面5x5x1的图片周围进行全零填充,可使输出图片仍保持5x5x1的维度。这个全零填充的过程叫做padding。 输出数据体的尺寸=(W?F+2P)/S+1 W:输入数据体尺寸,F:卷积层中神经元感知域,S:步长,P:零填充的数量。 例:输入是7×7,滤波器是3×3,步长为1,填充为0,那么就能得到一个5×5的输出。如果步长为2,输出就是3×3。 如果输入量是32x32x3,核是5x5x3,不用全零填充,输出是(32-5+1)/1=28,如果要让输出量保持在32x32x3,可以对该层加一个大小为2的零填充。可以根据需求计算出需要填充几层零。32=(32-5+2P)/1 +1,计算出P=2,即需填充2
常用函数 类参考
全局函数1、common.func.php 公用函数 获得当前的脚本网址 function GetCurUrl() 返回格林威治标准时间 function MyDate($format='Y-m-d H:i:s',$timest=0) 把全角数字转为半角 function GetAlabNum($fnum) 把含HTML的内容转为纯text function Html2Text($str,$r=0) 把文本转HTML function Text2Html($txt) 输出Ajax头 function AjaxHead() 中文截取2,单字节截取模式 function cn_substr($str,$slen,$startdd=0) 把标准时间转为Unix时间戳 function GetMkTime($dtime) 获得一个0000-00-00 00:00:00 标准格式的时间 function GetDateTimeMk($mktime) 获得一个0000-00-00 标准格式的日期 function GetDateMk($mktime) 获得用户IP function GetIP() 获取拼音以gbk编码为准 function GetPinyin($str,$ishead=0,$isclose=1)
dedecms通用消息提示框 function ShowMsg($msg,$gourl,$onlymsg=0,$limittime=0) 保存一个cookie function PutCookie($key,$value,$kptime=0,$pa="/") 删除一个cookie function DropCookie($key) 获取cookie function GetCookie($key) 获取验证码 function GetCkVdValue() 过滤前台用户输入的文本内容 // $rptype = 0 表示仅替换html标记 // $rptype = 1 表示替换html标记同时去除连续空白字符// $rptype = 2 表示替换html标记同时去除所有空白字符// $rptype = -1 表示仅替换html危险的标记 function HtmlReplace($str,$rptype=0) 获得某文档的所有tag function GetTags($aid) 过滤用于搜索的字符串 function FilterSearch($keyword) 处理禁用HTML但允许换行的内容 function TrimMsg($msg) 获取单篇文档信息 function GetOneArchive($aid)
广达电脑铝镁合金压铸模流道设计参考2010版
工作说明书版次 A 壓鑄模流道設計標準作業規範 页数 壓鑄模 流道設計 標準作業規範 发行日期修订日期原发行单位核准审查拟稿
工作说明书版次 A 壓鑄模流道設計標準作業規範 页数1 目 錄 前言 一、 模具流道設計基本流程 二、 模具流道設計前相關資料 2.1、說明 2.2、設計時产品3D电子档确认及檢討 2.3、壓鑄機車壁圖設計確認及要求事由 2.4、产品外观面及特殊要求确认方能設計流道 2.5、产品流道設計及模流分析 三、 模具流道設計分析 3.1、模具流道设计要点 3.2、流道分析与检讨 四、 流道設計(鎂鋁鋅流道設計) 4.1、鎂合金壓鑄模設計標準化 4.1.1 鎂合金流道設計(125t)(灌口置下) 4.1.2 鎂合金流道設計(150t)(灌口置下) 4.1.3 鎂合金流道設計(200t)(灌口置下) 4.1.4 鎂合金流道設計(125t)(灌口置中) 4.1.5 鎂合金流道設計(150t)(灌口置中) 4.1.6 鎂合金流道設計(200t)(灌口置中) 4.1.7 鎂合金流道設計(350t)(灌口置中) 4.1.8 鎂合金流道設計(500t)(灌口置中)
X X科技(y y)有限公司 作业办法/规定(续页)编号 工作说明书版次 A 壓鑄模流道設計標準作業規範 页数2 4.1.9 鎂合金流道設計(650t)(灌口置中) 4.1.10鎂合金流道設計(350t)(灌口置下) 4.1.11鎂合金流道設計(500t)(灌口置下) 4.1.12鎂合金流道設計(650t)(灌口置下) 4.2、鋁合金壓鑄模設計標準化 4.2.1鋁合金流道設計(125t)(灌口置下) 4.2.2鋁合金流道設計(250t)(灌口置下) 4.3、鋅合金壓鑄模設計標準化 4.3.1 鋅合金流道設計(75t)(灌口置中) 4.3.2 鋅合金流道設計(100t)(灌口置中) 4.3.3 鋅合金流道設計(75t)(灌口置下) 4.3.4 鋅合金流道設計(100t)(灌口置下) 五、產品豎流道長度限制規範標準化 5.1、鎂合金豎流道長度設計標準化 5.1.1 鎂合金豎流道長度設計限制(125t,150t,200t) 5.1.2 鎂合金豎流道長度設計限制(350t,500t,650t)(12”,13.4”,15”) (產品尺寸) 5.1.3 鎂合金豎流道長度設計限制(500t.650t)(17”,19”)(產品尺寸) 5.2、鋅合金豎流道長度設計標準化 5.2.1 鋅合金豎流道長度設計限制(75t,100t) 5.3、鋁合金豎流道長度設計標準化 5.3.1 鋁合金豎流道長度設計限制(125t,250t) 六、模具結構設計規範標準化 6.1鎂合金(125T,150T,200T),鋅合金(75T,100T),鋁合金(125T,250T)模具結構 設計規範標準化。 6.1.1鎂合金(125T,150T,200T),鋅合金(75T,100T),鋁合金(125T,250T)模 具結構設計規範標準化(模具無滑結構)。 6.1.2合金(125T,150T,200T),鋅合金(75T,100T),鋁合金(125T,250T)模
压铸模具设计开题汇报.doc
压铸模具设计开题报告 压铸是一种金属铸造工艺,其特点是利用模具内腔对融化的金属施加高压。模具通常是用强度更高的合金加工而成的,这个过程有些类似注塑成型。 一、选题的目的、意义和研究现状 根据对螺杆套压铸模的设计,了解和熟悉压力铸造的工艺设计过程和模具的设计过程。对压力铸造过程,模具的设计过程中以及实际应用过程中出现的缺陷问题,根据压铸模具工艺设计的理论与实践的结合,在外套的工艺结构不影响其性能和使用的情况下进行相应合理的设计,从而达到避免缺陷,提高外套工作性能的目的社会需要是促进科学技术发展的主要原因。当一种生产工艺不能满足社会需要时,就会有新的更好的工艺产生,压铸技术的出现就是如此。压铸最早用来铸造印刷用的铅字,当时需要生产大量清晰光洁以及可互换的铸造铅字,压铸法随之产生。根瑟勒Mergenthaler)发明了铅字压铸机。最初压铸的合金是常见的铅和锡合金。随着对压铸件需求量的增加,要求采用压铸发生产熔点和强度都更高的合金零件,这样,相应的压铸技术,压铸模具和压铸设备就不断地改进发展。Doehler)研究成功用于工业生产的压铸机,压铸锌,锡,铅合金铸件。agner)首先制成启动活塞压铸机,用于生产铝合金铸件。约瑟夫。波拉克Joset Polak)设计了冷压室压铸机,克服了热压室压铸机的不足之处,从而使压铸生产技术前进了一大步,铝,镁,锌,铜等合金零件开始广泛采用压铸工艺进行生产。压铸生产是所有压铸工艺中生产速度最快的一种,也是最富有竞争力的工艺之一,使得它在短短的年里的时间内发展成为航空航天,交通运输,仪器仪表,通
信等领域内有色金属铸件的重要生产工艺。 铸工艺与设备逐步完善的时期。而代到现在,则是电子技术和计算机技术加速用于压铸工艺与设备的大发展阶段。数控压铸机,计算机控制压铸柔性单元及系统和压铸工艺与设备计算机辅助设计的出现,标志着压铸生产开始从经验操作转变到科学控制新阶段,从而使压铸件的质量,自动化程度及劳动生产旅都得到了极大的提高。 在压铸生产中,正确采用各种压铸工艺参数是获得优质压铸件的重要措施,而金属压铸模则是提供正确选择和调整有关工艺参数的基础。所以说,能否顺利进行压铸生产,压铸件质量的优劣,压铸成型效率以及综合成本等,在很大程度上取决于金属压铸模结构的合理性和技术的先进性以及模具的制造质量。由于金属压铸成型有着不可比拟的突出优点,在工业技术快速发展的年代,必将得到越来越广泛的应用。特别是在大批量的生产中,虽然模具成本高一些,但总的说来,其生产的综合成本得到大幅度降低。在这个讲求微利的竞争时代,采用金属压铸成型技术,更有其积极和明显的经济价值。 近年来,汽车工业的飞速发展给压铸成型的生产带来了机遇。由于可持续发展和环境保护的需要,汽车轻量化是实现环保,节能,节才,告诉的最佳途径。因此,用压铸合金件代替传统的铸铁件,可使汽车质量减轻,压铸合金件还有一个显著地特点是传导性能良好,热量散失快,提高了汽车行车安全性。因此,金属压铸行业正面临着发展的机遇,其应用前景十分广阔。中国的压铸业经历了,已经成为具有相当规模的产业,并以每年速度增长,但是由于企业综合素质还有待提高,技术开发滞后于生产规模的扩大,经营方式滞后于市场竞争的需要。从总体看,我国
人工智能实践:Tensorflow笔记 北京大学 4 第四讲神经网络优化 (4.6.1) 助教的Tenso
Tensorflow笔记:第四讲 神经网络优化 4.1 √神经元模型:用数学公式表示为:f(∑i x i w i+b),f为激活函数。神经网络是以神经元为基本单元构成的。 √激活函数:引入非线性激活因素,提高模型的表达力。 常用的激活函数有relu、sigmoid、tanh等。 ①激活函数relu: 在Tensorflow中,用tf.nn.relu()表示 r elu()数学表达式 relu()数学图形 ②激活函数sigmoid:在Tensorflow中,用tf.nn.sigmoid()表示 sigmoid ()数学表达式 sigmoid()数学图形 ③激活函数tanh:在Tensorflow中,用tf.nn.tanh()表示 tanh()数学表达式 tanh()数学图形 √神经网络的复杂度:可用神经网络的层数和神经网络中待优化参数个数表示 √神经网路的层数:一般不计入输入层,层数 = n个隐藏层 + 1个输出层
√神经网路待优化的参数:神经网络中所有参数w 的个数 + 所有参数b 的个数 例如: 输入层 隐藏层 输出层 在该神经网络中,包含1个输入层、1个隐藏层和1个输出层,该神经网络的层数为2层。 在该神经网络中,参数的个数是所有参数w 的个数加上所有参数b 的总数,第一层参数用三行四列的二阶张量表示(即12个线上的权重w )再加上4个偏置b ;第二层参数是四行两列的二阶张量()即8个线上的权重w )再加上2个偏置b 。总参数 = 3*4+4 + 4*2+2 = 26。 √损失函数(loss ):用来表示预测值(y )与已知答案(y_)的差距。在训练神经网络时,通过不断改变神经网络中所有参数,使损失函数不断减小,从而训练出更高准确率的神经网络模型。 √常用的损失函数有均方误差、自定义和交叉熵等。 √均方误差mse :n 个样本的预测值y 与已知答案y_之差的平方和,再求平均值。 MSE(y_, y) = ?i=1n (y?y_) 2n 在Tensorflow 中用loss_mse = tf.reduce_mean(tf.square(y_ - y)) 例如: 预测酸奶日销量y ,x1和x2是影响日销量的两个因素。 应提前采集的数据有:一段时间内,每日的x1因素、x2因素和销量y_。采集的数据尽量多。 在本例中用销量预测产量,最优的产量应该等于销量。由于目前没有数据集,所以拟造了一套数据集。利用Tensorflow 中函数随机生成 x1、 x2,制造标准答案y_ = x1 + x2,为了更真实,求和后还加了正负0.05的随机噪声。 我们把这套自制的数据集喂入神经网络,构建一个一层的神经网络,拟合预测酸奶日销量的函数。
转子体压铸工艺分析及模具设计-毕业论文
转子体压铸工艺分析及模具设计-毕业论文天津职业技术师范大学 Tianjin University of Technology and Education 专业:材料成型及控制工程 班级学号: 材料0711班-12号 学生姓名: 江艳平 指导教师: 段磊讲师 二〇一二年六月 天津职业技术师范大学本科生毕业设计 转子体压铸工艺分析及模具设计 Die-casting process analysis and die design of the rotor body 专业班级:材料0711班 学生姓名:江艳平 指导教师:段磊讲师 学院:机械工程学院 2012 年 6 月 摘要 压力铸造是目前成型有色金属铸件的重要成型工艺方法。压铸的工艺特点是铸件的强度和硬度较高,形状较为复杂且铸件壁较薄,而且生产率极高。压铸模具是压力铸造生产的关键,压铸模具的质量决定着压铸件的质量和精度,而模具设计直接影响着压铸模具的质量和寿命。因此,模具设计是模具技术进步的关键,也是模具发展的重要因素。
本文通过对转子体的分析,设计其压铸模具。对其铸件外形及其分析,得出一 模一腔的模具结构。根据铸件的特点,需要采用中心浇口,尽量避免铸件出现气孔、填不满、凝固不均等问题,由于大批量生产,采用二次分模,自动脱料的方案,并完成整体模具的设计,其中包括冷却水道的设计、浇注系统的设计、顶出系统的设计等,以及压铸机的选择与校核。此设计通过UG软件设计完成,在设计过 程中结合自身设计的结构选择标准件,来完成装配后的最终模具效果。在设计过程中,利用ProCast软件来分析压铸件的各项结果和从中发现问题,通过分析可以仿真出铝合金成型过程中的充填、流动、凝固等过程,准确预测铸件中可能存在的缺陷。利用模流分析技术,能预先分析模具设计的合理性,减少试模次数,加快产品研发,提高企业效率。 关键词:转子体;压铸;模流分析;模具设计 ABSTRACT Die-casting molding technology is playing a key role in non-ferrous metal structure forming processes. Die-casting process’s features are the strength and hardness of die casting on high, thin-walled castings with complex shape can be cast, and the production is efficient. The die-casting die is the key for the process of die casting, its quality decides the quality and accuracy of castings, and the design of the die-casting die affects its quality and operating life directly. Therefore, designing the die-casting die is the key to technological progress; it is also an important factor in the development of mold. In this paper,through analysis of the rotor body, design of its die-casting mold, through its shape and analysis, obtain the one mode of
压铸模具设计基本流程
压铸模具设计基本流程
一、模具设计之前 二、模具设计之中 三、模具设计审核 及图纸输出
客户资料审查 制品样板 3D产品设 计 结 果 回 馈 客 户 客 户 承 认 模 具 设 计 与 开 发 计 划 的 制 订 ﹑ 设 计 参 数 的 审 核 与 分 析 制 品 参 数 评 审 a﹑制品用在何处(外观要求)﹔怎样使用(力学性能要求)﹖ b﹑成型锌(铝)合金的收缩率多少﹖ 制品CAD 图面 3D产品设 计 c﹑制品是否要同其它零件进行配合(公差要求)﹖ d﹑制品结构脱模角分别是多少﹖ 制品3D档案3D审查 e﹑浇口位置﹑流线﹑结合线﹑顶出痕要求﹖ f﹑制品外观面有无特殊要求﹕喷砂﹑电镀...﹖ 制品3D档 与样板 图样比对 模 具 参 数 评 审 a﹑客户指定制品成型的材料特性如何﹖ b﹑预期将模具寿命多少件制品﹖ 制品CAD档 与样板 图样比对 c﹑预期的出模周期多长﹖ d﹑需要何种类型的流道及排气系统﹕单流道﹑多流道,渣 包排气、大排气,真空排气。 制品3D档 与CAD档 图图比对 e﹑模腔的布局﹖天地方向的选择﹖ f﹑制品出模方式的选择﹕手动拿出或自动落下﹔机械顶出 ﹑液压顶出 设计 规划设计日程的确定﹔该项目设计师指定﹑技术负责人指定 《模具设计之前》
模具结构设计1﹑制品能否从模腔中拉出﹖能否从模 芯上脱下﹖ 首先确定出模方向﹕首先根据制品Boss﹑倒勾等结构确定出模方向﹐若 无法正常成型和脱模则考虑设计内(外)滑块侧面抽芯。 2﹑确定分型面 以模具制造加工条件的要求为根据﹐满足制品外形要求来确定模具分型 面位置﹐便利简化磨削﹑铣削﹑CNC加工 3﹑设计合理的浇口位置﹑浇口形状以 及浇口数目 根据制品大小﹑流动性能﹑可能出现的料流结合线﹑模塑周期的长短﹔ 借用AnyCasting模流分析软件(公司尚未安装)等工具来确定浇口位置/大 小/型式(直胶口、内八字、外八字、反水口…)/数目。浇口的设计决定料 流结合线﹐而结合线的汇集将使内应力集中﹐这对于制品将是一个致命 的破坏因素 4﹑制品模穴排气渣包布局合理吗﹖ 针对制品模穴排气渣包问题﹐必须要排布在模穴的料流结合线处及料流 最易包气位置 5﹑镶件和成孔销的设计 针对一些精巧细小的部件采取模仁镶件的方法﹐如成形深而小的孔位﹔ 模仁成型面在工作过程中容易磨损破坏的结构﹔在分型面下方深处无法 加工或难以加工的结构. 6﹑排气结构设计 针对制品一些尖锐薄的位置﹐在压铸过程因排气不良而容易形成真空以 致压射压力损失大且粘料难以充饱产生射出制品缺料现象﹐我们需在该 处设置渣包及排气槽﹑开设镶件孔或将顶针设置于该处 7﹑顶出机构设计跟据产品类型确定合适的顶出方法(脱模板﹑顶杆﹑直推块) 8﹑冷却水路、油路设计 我们根据预期模塑量﹑模塑周期来确定冷却水路的有或没有﹕ a:对于较低模塑量的样件模﹐可以不设冷却水路﹔ b:对预期模塑量上万的模具我们精确的设计合理高效的冷却条件﹐避免 出现冷却不均匀甚至有些地方无法被冷却的现象。注意前后模水路要相 互配合﹑不能重垒平行﹐防止制品冷却不均匀,
数据库常用函数
数据库常用函数
一、基础 1、说明:创建数据库 CREATE DATABASE database-name 2、说明:删除数据库 drop database dbname 3、说明:备份和还原 备份:exp dsscount/sa@dsscount owner=dsscount file=C:\dsscount_data_backup\dsscount.dmp log=C:\dsscount_data_backup\outputa.log 还原:imp dsscount/sa@dsscount file=C:\dsscount_data_backup\dsscount.dmp full=y ignore=y log=C:\dsscount_data_backup\dsscount.log statistics=none 4、说明:创建新表 create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..) CREATE TABLE ceshi(id INT not null identity(1,1) PRIMARY KEY,NAME VARCHAR(50),age INT) id为主键,不为空,自增长 根据已有的表创建新表: A:create table tab_new like tab_old (使用旧表创建新表) B:create table tab_new as select col1,col2… from tab_old definition only 5、说明:删除新表 drop table tabname 6、说明:增加一个列 Alter table tabname add column col type 注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。 7、说明:添加主键: Alter table tabname add primary key(col) 说明:删除主键: Alter table tabname drop primary key(col) 8、说明:创建索引:create [unique] index idxname on tabname(col….) 删除索引:drop index idxname 注:索引是不可更改的,想更改必须删除重新建。 9、说明:创建视图:create view viewname as select statement 删除视图:drop view viewname 10、说明:几个简单的基本的sql语句 选择:select * from table1 where 范围 插入:insert into table1(field1,field2) values(value1,value2) 删除:delete from table1 where 范围 更新:update table1 set field1=value1 where 范围
压铸模具术语
压铸模具术语 1.压力铸造die casting 将熔融合金在高温、高压条件下填充模具型腔,并在高压下冷却凝固成型的铸造方法。 2.压铸模具die-casting die 压力铸造成型工艺中,用以成型铸件所用的模具。 3.定模fixed die 固定在压铸机定模安装板上的模具部分。前模,A 4.动模moving die 随压铸机动模安装板开合移动的模具部分。后模,B 5.型腔cavity 模具闭合后用以充填熔融合金,成型铸件的空腔。 6.分型面parting line 模具上为取出铸件和浇注系统凝料可分离的接触表面。 7.投影面积project area 模具型腔、浇注系统及溢流系统在垂直于锁模力方向上投影的面积总和。 8.收缩率shringkage 在室温下,模具型腔与铸件的对应线性尺寸之差和模具型腔对应线性尺寸之比。 9.锁模力locking force 在充型过程中,为使动、定模相互紧密闭合而施加在模具上的力。 10.压力中心pressure center 在平行于锁模力方向上,熔融合金传递给模具的压力合力的作用点。 11.充填速度filling velocity 熔融合金在压力作用下通过内浇口的速度。 12.压射速度injection speed 压射冲头运动的线速度。 13.压射比压injection pressure 冲型结束时压射冲头作用于熔融合金单位面积上的压力。 14.脱模斜度Draft 为使铸件顺利脱模,在模具型腔沿壁脱模或抽拔方向上设计的斜度。 15.闭合高度die shut height 模具处于闭合状态下的总高度。 16.最大开距maximum opening daylight 压铸机动模、定模安装板之间可分开的最大距离。 17.脱模距stripper distance 为取出铸件和浇注系统凝料,动、定模所需分开的距离。 18.浇注系统casting system 熔融合金在压力作用下充填模具型腔的通道,包括:直浇道,横浇道和内浇口。 19.直浇道sprue 从模具浇注系统入口至横浇道之间的通道。 20.横浇道runner 从模具浇注系统的直浇道末端至内浇口之间的通道。 21.内浇口gate 熔融合金进入模具型腔的入口。 22.溢流槽overflow well 在模具中用以排溢、容纳氧化物及冷污熔融合金或用以积聚熔融合金以提高模具局部温度的凹槽(渣包)。 23.排气槽air vent 为使压铸过程中型腔内的气体排出模具而设计的气流沟槽。 24.定模座板clamping plate of fixed half 安装定模于压铸机定模安装板上板件。 25.动模座板clamping plate of moving half 安装动模于压铸机动模安装板上的板件。
人工智能tensorflow实验报告
一、软件下载 为了更好的达到预期的效果,本次tensorflow开源框架实验在Linux环境下进行,所需的软件及相关下载信息如下: 1.CentOS 软件介绍: CentOS 是一个基于Red Hat Linux 提供的可自由使用源代码的企业级Linux 发行版本。每个版本的CentOS都会获得十年的支持(通过安全更新方式)。新版本的CentOS 大约每两年发行一次,而每个版本的CentOS 会定期(大概每六个月)更新一次,以便支持新的硬件。这样,建立一个安全、低维护、稳定、高预测性、高重复性的Linux 环境。CentOS是Community Enterprise Operating System的缩写。CentOS 是RHEL(Red Hat Enterprise Linux)源代码再编译的产物,而且在RHEL的基础上修正了不少已知的Bug ,相对于其他Linux 发行版,其稳定性值得信赖。 软件下载: 本次实验所用的CentOS版本为CentOS7,可在CentOS官网上直接下载DVD ISO镜像文件。 下载链接: https://www.360docs.net/doc/519682196.html,/centos/7/isos/x86_64/CentOS-7-x86_64-DVD-1611.i so. 2.Tensorflow 软件介绍: TensorFlow是谷歌基于DistBelief进行研发的第二代人工智能学习系统,其命名来源于本身的运行原理。Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算,TensorFlow为张量从流图的一端流动到另一端计算过程。TensorFlow是将复杂的数据结构传输至人工智能神经网中进行分析和处理过程的系统。TensorFlow可被用于语音识别或图像识别等多项机器深度学习领域,对2011年开发的深度学习基础架构DistBelief进行了各方面的改进,它可在小到一部智能手机、大到数千台数据中心服务器的各种设备上运行。TensorFlow将完全开源,任何人都可以用。
EXCEL常用分类函数
EXCEL常用分类函数 (注意有些函数只有加载“分析工具库”以后方能使用) 一、查找和引用函数 ROW 用途:返回给定引用的行号。 语法:ROW(reference)。 Reference为需要得到其行号的单元格或单元格区域。 实例:公式“=ROW(A6)”返回6,如果在C5单元格中输入公式“=ROW()”,其计算结果为5。 COLUMN 用途:返回给定引用的列标。 语法:COLUMN(reference)。 参数:Reference为需要得到其列标的单元格或单元格区域。如果省略reference,则假定函数COLUMN是对所在单元格的引用。如果reference为一个单元格区域,并且函数COLUMN作为水平数组输入,则COLUMN函数将reference中的列标以水平数组的形式返回。 实例:公式“=COLUMN(A3)”返回1,=COLUMN(B3:C5)返回2。 CELL 用途:返回某一引用区域的左上角单元格的格式、位置或内容等信息 IS类函数 用途:用来检验数值或引用类型的函数。它们可以检验数值的类型并根据参数的值返回TRUE或FALSE。ISBLANK(value)、ISNUMBER(value)、ISTEXT(value)和ISEVEN(number)、ISODD(number)。 ADDRESS 用途:以文字形式返回对工作簿中某一单元格的引用。 语法:ADDRESS(row_num,column_num,abs_num,a1,sheet_text) 参数:Row_num是单元格引用中使用的行号;Column_num是单元格引用中使用的列标;Abs_num指明返回的引用类型(1或省略为绝对引用,2绝对行号、相对列标,3相对行号、绝对列标,4是相对引用);A1是一个逻辑值,它用来指明是以A1或R1C1返回引用样式。如果A1为TRUE或省略,函数ADDRESS返回A1样式的引用;如果A1为FALSE,函数ADDRESS返回R1C1样式的引用。Sheet_text为一文本,指明作为外部引用的工作表的名称,如果省略sheet_text,则不使用任何工作表的名称。 实例:公式“=ADDRESS(1,4,4,1)”返回D1。 CHOOSE 用途:可以根据给定的索引值,从多达29个待选参数中选出相应的值或操作。 语法:CHOOSE(index_num,value1,value2,...)。
TensorFlow编程指南 嵌入
嵌入 本文档介绍了嵌入这一概念,并且举了一个简单的例子来说明如何在TensorFlow 中训练嵌入,此外还说明了如何使用TensorBoard Embedding Projector 查看嵌入(真实示例)。前两部分适合机器学习或TensorFlow 新手,而Embedding Projector 指南适合各个层次的用户。 有关这些概念的另一个教程,请参阅《机器学习速成课程》的“嵌入”部分。 嵌入是从离散对象(例如字词)到实数向量的映射。例如,英语字词的300 维嵌入可能包括: blue: (0.01359, 0.00075997, 0.24608, ..., -0.2524, 1.0048, 0.06259) blues: (0.01396, 0.11887, -0.48963, ..., 0.033483, -0.10007, 0.1158) orange: (-0.24776, -0.12359, 0.20986, ..., 0.079717, 0.23865, -0.014213) oranges: (-0.35609, 0.21854, 0.080944, ..., -0.35413, 0.38511, -0.070976) 这些向量中的各个维度通常没有固有含义,机器学习所利用的是向量的位置和相互之间的距离这些整体模式。 嵌入对于机器学习的输入非常重要。分类器(更笼统地说是神经网络)适用于实数向量。它们训练密集向量时效果最佳,其中所有值都有助于定义对象。不过,机器学习的很多重要输入(例如文本的字词)没有自然的向量表示。嵌入函数是将此类离散输入对象转换为有用连续向量的标准和有效方法。 嵌入作为机器学习的输出也很有价值。由于嵌入将对象映射到向量,因此应用可以将向量空间中的相似性(例如欧几里德距离或向量之间的角度)用作一项强大而灵活的标准来衡量对象相似性。一个常见用途是找到最近的邻点。例如,下面是采用与上述相同的字词嵌入后,每个字词的三个最近邻点和相应角度: blue: (red, 47.6°), (yellow, 51.9°), (purple, 52.4°) blues: (jazz, 53.3°), (folk, 59.1°), (bluegrass, 60.6°) orange: (yellow, 53.5°), (colored, 58.0°), (bright, 59.9°) oranges: (apples, 45.3°), (lemons, 48.3°), (mangoes, 50.4°) 这样应用就会知道,在某种程度上,苹果和橙子(相距45.3°)的相似度高于柠檬和橙子(相距48.3°)。