Finance Journal Rankings List

43
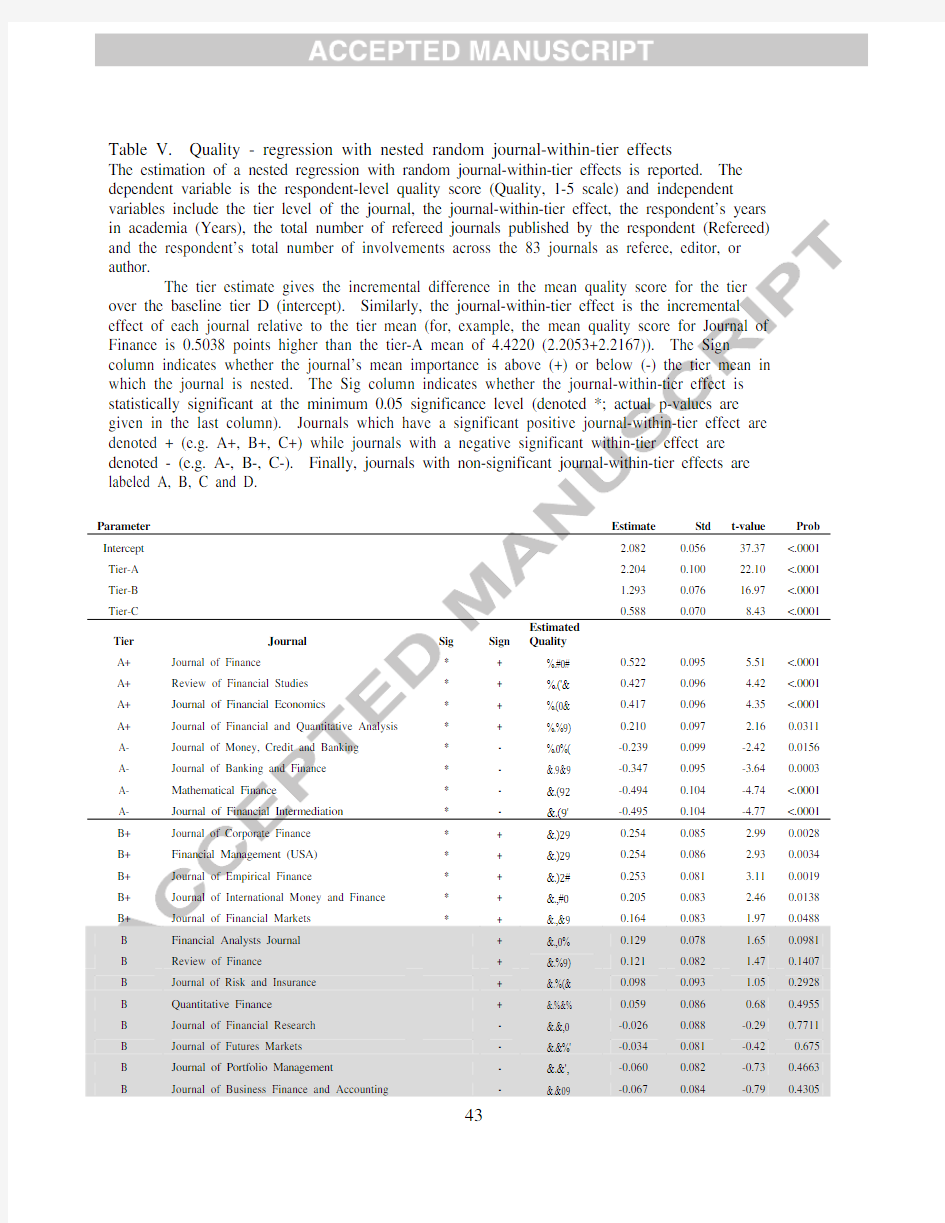
Table V. Quality - regression with nested random journal-within-tier effects
The estimation of a nested regression with random journal-within-tier effects is reported. The dependent variable is the respondent-level quality score (Quality, 1-5 scale) and independent variables include the tier level of the journal, the journal-within-tier effect, the respondent’s years in academia (Years), the total number of refereed journals published by the respondent (Refereed) and the respondent’s total number of involvements across the 83 journals as referee, editor, or author.
The tier estimate gives the incremental difference in the mean quality score for the tier
over the baseline tier D (intercept). Similarly, the journal-within-tier effect is the incremental effect of each journal relative to the tier mean (for, example, the mean quality score for Journal of Finance is 0.5038 points higher than the tier-A mean of 4.4220 (2.2053+2.2167)). The Sign
column indicates whether the journal’s mean importance is above (+) or below (-) the tier mean in which the journal is nested. The Sig column indicates whether the journal-within-tier effect is statistically significant at the minimum 0.05 significance level (denoted *; actual p-values are given in the last column). Journals which have a significant positive journal-within-tier effect are denoted + (e.g. A+, B+, C+) while journals with a negative significant within-tier effect are denoted - (e.g. A-, B-, C-). Finally, journals with non-significant journal-within-tier effects are labeled A, B, C and D.
Parameter
Estimate Std t-value Prob Intercept 2.082 0.056 37.37 <.0001 Tier-A 2.204 0.100 22.10 <.0001 Tier-B 1.293 0.076 16.97 <.0001 Tier-C 0.588 0.070 8.43
<.0001
Tier Journal
Sig Sign Estimated Quality A+ Journal of Finance * + % # # 0.522 0.095 5.51 <.0001 A+ Review of Financial Studies * + % ('& 0.427 0.096 4.42 <.0001 A+ Journal of Financial Economics
* + % ( & 0.417 0.096 4.35 <.0001 A+ Journal of Financial and Quantitative Analysis * + % % ) 0.210 0.097 2.16 0.0311 A- Journal of Money, Credit and Banking * - % %( -0.239 0.099 -2.42 0.0156 A- Journal of Banking and Finance * - & & -0.347 0.095 -3.64 0.0003 A- Mathematical Finance
* - & ( -0.494 0.104 -4.74 <.0001 A- Journal of Financial Intermediation * - & ( ' -0.495 0.104 -4.77 <.0001 B+ Journal of Corporate Finance * + & ) 0.254 0.085 2.99 0.0028 B+ Financial Management (USA) * + & ) 0.254 0.086 2.93 0.0034 B+ Journal of Empirical Finance
* + & ) # 0.253 0.081 3.11 0.0019 B+ Journal of International Money and Finance * + & ,# 0.205 0.083 2.46 0.0138 B+ Journal of Financial Markets * + & ,& 0.164 0.083 1.97 0.0488 B Financial Analysts Journal + & , % 0.129 0.078 1.65 0.0981 B Review of Finance
+ & % ) 0.121 0.082 1.47 0.1407 B Journal of Risk and Insurance + & %(& 0.098 0.093 1.05 0.2928 B Quantitative Finance + & %&% 0.059 0.086 0.68 0.4955 B Journal of Financial Research - & &, -0.026 0.088 -0.29 0.7711 B Journal of Futures Markets - & &%' -0.034 0.081 -0.42 0.675 B Journal of Portfolio Management
- & &', -0.060 0.082 -0.73 0.4663 B
Journal of Business Finance and Accounting
- & &
-0.067
0.084
-0.79
0.4305
44
B Finance and Stochastics - & )# -0.107 0.085 -1.26 0.2076 B Financial Review
- & ,( -0.118 0.099 -1.20 0.2308 B Journal of Derivatives
- & ' -0.154 0.089 -1.73 0.083 B Journal of Int. Financial Markets, Institutions and Money
- & # -0.167 0.100 -1.68 0.0933 B Journal of Real Estate Finance and Economics - & , -0.170 0.093 -1.83 0.0674 B- National Tax Journal * - & ' -0.183 0.087 -2.10 0.0356 B- European Finance Review * - & ',# -0.218 0.089 -2.44 0.0148 B- European Financial Management * - & '%% -0.231 0.095 -2.44 0.0146 C+ Pacific Basin Finance Journal
* + & &# 0.369 0.079 4.64 <.0001 C+ Review of Quantitative Finance and Accounting
* + & '% 0.344 0.097 3.56 0.0004 C+ Geneva Papers on Risk and Insurance Theory * + 0.322 0.086 3.74 0.0002 C+ Financial Management (UK) * + ) 0.290 0.087 3.35 0.0008 C+ Journal of Fixed Income * + ,( 0.287 0.084 3.41 0.0007 C+ European Journal of Finance * + ( 0.258 0.087 2.96 0.0031 C+ Journal of Applied Corporate Finance * + # % 0.225 0.082 2.74 0.0061 C+ Journal of Financial Services Research * + #%% 0.175 0.092 1.91 0.0564 C Financial Markets, Institutions and Instruments + # ' 0.151 0.091 1.67 0.0957 C Review of Futures Markets
+ (#, 0.116 0.087 1.32 0.1857 C Journal of Multinational Financial Management
+ (#% 0.115 0.101 1.14 0.256 C Applied Mathematical Finance
+ (&& 0.063 0.098 0.64 0.5193 C International Review of Finance
+ (', 0.046 0.093 0.49 0.624 C Geneva Papers on Risk and Insurance: Issues and Practice
+ )( 0.010 0.092 0.11 0.9158 C Review of Derivatives Research - ), -0.019 0.097 -0.20 0.8416 C Annals of Finance
- )%# -0.022 0.097 -0.23 0.8203 C International Review of Financial Analysis - )%( -0.023 0.099 -0.23 0.8162 C International Journal of Finance and Economics
- )&% -0.036 0.094 -0.38 0.7003 C Public Finance Review
- ) % -0.046 0.098 -0.47 0.6405 C Int. Journal of Theoretical and Applied Finance
- ) -0.050 0.097 -0.52 0.6055 C Journal of Asset Management - ) -0.060 0.096 -0.63 0.5312 C International Finance - , , -0.075 0.086 -0.87 0.383 C Applied Financial Economics - ,(( -0.093 0.099 -0.94 0.3459 C Journal of Investing
- , -0.161 0.092 -1.75 0.0797 C Multinational Finance Journal
- , # -0.161 0.108 -1.50 0.1347 C Journal of Int. Financial Management and Accounting
- % & -0.177 0.105 -1.69 0.0904 C- Global Finance Journal
* - %( -0.199 0.090 -2.21 0.0271 C- International Journal of Managerial Finance * - %)# -0.202 0.104 -1.94 0.0525 C- Financial Accountability and Management * - %), -0.205 0.108 -1.90 0.0578 C- Journal of Risk Finance
* - %%) -0.224 0.084 -2.66 0.0078 C- Journal of Corporate Accounting and Finance * - %%' -0.229 0.093 -2.45 0.0142 C- Managerial Finance
* - % ' -0.249 0.102 -2.43 0.0152 C- Journal of Alternative Investments * - %' -0.258 0.113 -2.27 0.0231 C- Journal of Emerging Market Finance * - & -0.280 0.090 -3.11 0.0019 D
International Tax and Public Finance
+
)(
0.185
0.114
1.63
0.1035
45
D Financial Markets and Portfolio Management + & 0.148 0.109 1.35 0.1759 D British Tax Review + ' 0.138 0.116 1.20 0.2317 D Corporate Finance Review
+ 0.120 0.117 1.02 0.3065 D Journal of Pension Economics and Finance + '( 0.096 0.114 0.84 0.3983 D Advances in Taxation
+ ',, 0.073 0.111 0.65 0.5127 D Research in International Business and Finance + ',, 0.073 0.111 0.65 0.5127 D Journal of Wealth Management + '%& 0.060 0.114 0.53 0.595 D Journal of Financial Regulation and Compliance
+ ' ( 0.045 0.112 0.40 0.6899 D Public Budgeting and Finance
+ ''# 0.036 0.117 0.30 0.7605 D Investment Management and Financial Innovations - '' 0.028 0.114 0.24 0.8085 D Journal of Trading
- 0.010 0.111 0.09 0.9293 D Derivatives Use, Trading and Regulation - ( -0.012 0.119 -0.10 0.9212 D Cost Management
- &' -0.051 0.117 -0.43 0.6638 D Journal of Private Equity
- ' -0.063 0.116 -0.54 0.5869 D Journal of Finance and Management in Public Services
- ' , -0.087 0.116 -0.75 0.4515 D Intelligent Systems in Accounting, Finance and Management - ' ,) -0.126 0.120 -1.06 0.2911 D Australian Tax Forum - ' %) -0.137 0.117 -1.16 0.2447 D Journal of Structured Finance - ' # -0.154 0.113 -1.36 0.1734 D Finance and Development - ' % -0.158 0.116 -1.37 0.1712 D
Asia Pacific Journal of Taxation
-
' #)
-0.223
0.122
-1.83
0.0675
ZUC算法原理及实现过程
ZUC算法原理及实现过程 1.1 算法设计背景 ZUC算法,即祖冲之算法,是3GPP机密性算法EEA3和完整性算法EIA3的核心,为中国自主设计的流密码算法。2009年5月ZUC算法获得3GPP安全算法组SA立项,正式申请参加3GPPLT第三套机密性和完整性算法标准的竞选工作。历时两年多的时间,ZUC算法经过评估,于2011年9月正式被3GPPSA全会通过,成为3GPPLTE第三套加密标准核心算法。ZUC算法是中国第一个成为国际密码标准的密码算法。 1.2 算法原理 ZUC是一个面向字的流密码。它采用128位的初始密钥作为输入和一个128位的初始向量(IV),并输出关于字的密钥流(从而每32位被称为一个密钥字)。密钥流可用于对信息进行加密/解密 ZUC的执行分为两个阶段:初始化阶段和工作阶段。在第一阶段,密钥和初始向量进行初始化,即不产生输出。第二个阶段是工作阶段,在这个阶段,每一个时钟脉冲产生一个32比特的密钥输出。 (1)运算符说明 mod ? a|_b 3H 3L a 「:::::n k 整数模 整数比特异或 字符串a和b的连接 a二进制表示的最左16 位值 a二进制表示的最右16位值 a向左k比特的循环移位 a向右1比特的移位 l“a n —:匕山2,11|,5 a i值分配到对应b的值 (2)算法结构 ZUC有三个逻辑层,见下图。顶层为一个线性反馈移位寄存器(LFSR )的16个赛段,中间层是比特重组(BR),最下层为一个非线性函数F 。 图1 ZUC的整体结构图
(3)线性移位反馈寄存器(LFSR ) LFSR具有16个31比特的单元S0,S I,|||,S!5,每个单元S 0_i_15取值均在下面的集合中: 「123,川231-1? LFSR有两种模式的操作,即初始化模式和工作模式。在初始化模式中,LFSR接收一个31比特的输入u,u是删除非线性函数F的32位输出W最右边的位得到的。也就是说,可将初始化模式工作原理表示为:LFSRWithInitialisationMode ( u) { 〔、V=215S5 +217命+221S W +220S4 +(1 +28)s°mod(231—1 ); 31 2、s6=(V+u )mod(2 -1 ); 3、如果S!6 =0,则设$6 =231-1 ; 4(S,S2, |||,S6)T(S0,S1」II,S5 ) } 在工作模式中,LFSR不接收任何输入,它的工作原理表示为:LFSRWithWorkMode() { 仁S6 =215$5 +217S3 +221S W +220S4 +(1 + 28Js°mod(231—1 ); 2、如果% =0,则设36 =231 -1 ; 3、(s,S2,川,$6)T(S0,S1」II, S5 ); } (4)比特重组 ZUC算法的中间层是比特重组,从LFSR的单元中提取128比特的输出并形成4个32比特的字,前三个字将用于最底层的非线性F函数中,而最后一个字会在密钥流的产生中用到。 令S01S21S5,S71S91S111S14,S15是LFSR中的8个单元,则形成4个32比特字 X0.X1.X2.X3的比特重组过程如下:
Java中的常用容器的底层实现
关于Java中的常用容器的底层实现 1.首先介绍Collection,包含有List、Set、Queue ----1.1 List ArrayList LinkedList ----1.2 Set 常用来去重 HashSet:其允许使用null元素,HashSet的底层是通过哈希表实现的,实际就是HashMap的key的一个集合,所以hashSet不能有从重复的元素;另外hashset.add()添加元素,因为底层是HashMap的key,所有其实实质就是hashmap.put(),于是首先判断key是否存在,key 若存在的话,则修改value值,如不存在则插入;value是一个static final Object对象标识;综上,所有的对HashSet的操作实质都是底层对HashMap的操作; LinkedHashSet:其有HashSet的特点,因为他是基于链接式的HashMap实现,所有他是有序的,因为具有链表的特点,按元素的插入顺序排序; TreeSet:其底层是基于树实现的,所以他是有序的,因为是按Comparator来指定树形集中的元素顺序,所以是按字典序的,也就是自然顺序; ----1.3 Queue 2.其次介绍Map,三大实现接口HashMap、LinkedHashMap、TreeMap ----2.1 HashMap 构成:允许使用null值和null键 老版本:数组+链表 1.8版本:数组+链表+红黑树(所谓红黑树,既是二叉查找树,但是在每个节点上增加一个存储位表示节点的颜色,可以是Red\Black) 原因:为什么最新版本中要加入红黑树呢? 因为红黑树的查找时间要比链表的查找时间快,特别是链表的长度比较大时,或者超过8时,那么红黑树的查找时间O(logN)明显优于链表查找时间O(N) 所以Hash值决定在数组中存储位置,那么相同Hash值所对应的值是通过链表存储,那么当相同Hash值的元素比较多时,那么这个链表查找时间就比较长了,所以该用红黑树存储。那么Hash值是如何算的,是有key进行计算而得。 线程不安全性:所以引入了了快速失败机制 从迭代器创建之后,若想修改HashMap的结构必须用迭代器自带的remove方法,否则便抛出ConcurrentModificationException。 Map m = Collections.synchronizedMap(new HashMap(...)); HashMap工作原理: HashMap是基于 Hashing原理,put(k,v)存放键值对,他的存储过程,首先调用键的hasCode方法,计算出键的哈希码,然后对应找到 bucket位置来对应存储Entry对象,那么当获取对象时如何获取的呢,首先声明当两个对象的hashCode相同,不能代表两个对象相同,因为两个对象的hashCode相同,所以他们的bucket位置相同,于是会发生碰撞,这个时候就体现出 HashMap链表数据结构的好处,将碰撞的Entry对象存储在链
Servlet底层原理
Servlet底层原理 从 Servlet 容器说起 要介绍 Servlet 必须要先把 Servlet 容器说清楚,Servlet 与 Servlet 容器的关系有点像枪和子弹的关系,枪是为子弹而生,而子弹又让枪有了杀伤力。虽然它们是彼此依存的,但是又相互独立发展,这一切都是为了适应工业化生产的结果。从技术角度来说是为了解耦,通过标准化接口来相互协作。既然接口是连接 Servlet 与 Servlet 容器的关键,那我们就从它们的接口说起。 前面说了 Servlet 容器作为一个独立发展的标准化产品,目前它的种类很多,但是它们都有自己的市场定位,很难说谁优谁劣,各有特点。例如现在比较流行的 Jetty,在定制化和移动领域有不错的发展,我们这里还是以大家最为熟悉 Tomcat 为例来介绍 Servlet 容器如何管理 Servlet。Tomcat 本身也很复杂,我们只从 Servlet 与 Servlet 容器的接口部分开始介绍,关于 Tomcat 的详细介绍可以参考我的另外一篇文章《 Tomcat 系统架构与模式设计分析》。 Tomcat 的容器等级中,Context 容器是直接管理 Servlet 在容器中的包装类 Wrapper,所以 Context 容器如何运行将直接影响 Servlet 的工作方式。 图 1 . Tomcat 容器模型 从上图可以看出 Tomcat 的容器分为四个等级,真正管理 Servlet 的容器是 Context 容器,一个 Context 对应一个 Web 工程,在 Tomcat 的配置文件中可以很容易发现这一点,如下: 清单 1 Context 配置参数
深入了解php-底层机制
深入了解php底层机制(-) 洪定坤 摘要 作为一门动态语言,php是如何实现的,其底层机制如何,具有什么样的特点,本文深入浅出介绍了包括php设计理念、整体结构、核心数据结构和变量在内的相关底层知识,对我们更好的开发php程序,优化性能等有一定的指导意义。 TAG Php 底层机制性能优化 目录 1、概述 (1) what is php? (1) 了解它底层实现的目的? (2) 2、php的设计理念及特点 (2) 3、Php的四层体系 (2) 4、Sapi (4) 5、Php的执行流程&opcode (6) 6、HashTable -- 核心数据结构 (7) 7、Php变量 (9) 概述 (9) Zval (10) 整数、浮点数类型变量 (11) 字符串变量 (11) 数组变量 (12) 资源类型变量 (12) Php变量的作用域 (13) 1、概述 what is php? 一种适用于web开发的动态语言。具体点说:就是一个用c语言实现包含大量组件的软件框架。更狭义点看,可以把它认为是一个强大的ui框架。
了解它底层实现的目的? 动态语言要像用好首先得了解它 内存管理、框架模型值得我们借鉴 通过扩展开发实现更多更强大的功能,优化我们程序的性能 2、php的设计理念及特点 多进程模型 由于php是多进程模型,不同请求间互不干涉,这样保证了一个请求挂掉不会对全盘服务造成影响,当然,随着时代发展,php也早已支持多线程模型。 弱类型语言 和c/c++、java、c#等语言不同,Php是一门弱类型语言:一个变量的类型并不是一开始就确定不变,运行中才会确定并可能发生隐式或显式的类型转换,这种机制的灵活性在web开发中非常方便、高效,具体会在后面php变量中详述。 引擎(Zend)+组件(ext)的模式降低内部耦合 中间层(sapi)隔绝web server和php 语法简单灵活,没有太多规范。(导致风格混杂) 再差的程序员也不会写出太离谱危害全局的程序。 3、Php的四层体系 Php的核心架构如下图
Hash底层实现原理
HashMap的底层实现原理 一、HashMap的数据结构 总述: 哈希的出现时因为传统数据结构如线性表(数组,链表等),树中,关键字与其它的存放位置不存在对应的关系。因此在查找关键字的时候需要逐个比对,虽然出现了二分查找等各种提高效率的的查找算法。但是这些并不足够,希望在查询关键字的时候不经过任何比较,一次存取便能得到所查记录。因此,我们必须在关键字和其对应的存储位置间建立对应的关系f。这种对应的关系f被称为哈希函数,按此思想建立的表为哈希表。关键在于哈希函数如何构造。 意思就是:关键字的存储位置是有关键字的内容决定的。 数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端。 数组: 数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难; 链表: 链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N)。链表的特点是:寻址困难,插入和删除容易。 哈希表: 那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表。哈希表((Hash table)既满足了数据的查找方便,同时不占用太多的内容空间,使用也十分方便。哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法——拉链法,我们可以理解为“链表的数组” 一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)&len-1获得,也就是元素的key的哈希值对数组长度取模得到。 HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。 首先HashMap里面实现一个静态内部类Entry,其重要的属性有key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。 Transient Entry[]table; 二、HashMap的存取实现: // 存储时: int hash = key.hashCode(); // 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值 int index = hash % Entry[].length; Entry[index] = value; // 取值时: int hash = key.hashCode(); int index = hash % Entry[].length; return Entry[index]; (1)Put
ZUC算法原理及实现过程
ZUC 算法原理及实现过程 1.1 算法设计背景 ZUC 算法,即祖冲之算法,是3GPP 机密性算法EEA3和完整性算法EIA3的核心,为中国自主设计的流密码算法。2009年5月ZUC 算法获得3GPP 安全算法组SA 立项,正式申请参加3GPPLTE 第三套机密性和完整性算法标准的竞选工作。历时两年多的时间,ZUC 算法经过评估,于2011年9月正式被3GPPSA 全会通过,成为3GPPLTE 第三套加密标准核心算法。ZUC 算法是中国第一个成为国际密码标准的密码算法。 1.2 算法原理 ZUC 是一个面向字的流密码。它采用128位的初始密钥作为输入和一个128位的初始向量(IV ),并输出关于字的密钥流(从而每32位被称为一个密钥字)。密钥流可用于对信息进行加密/解密。 ZUC 的执行分为两个阶段:初始化阶段和工作阶段。在第一阶段,密钥和初始向量进行初始化,即不产生输出。第二个阶段是工作阶段,在这个阶段,每一个时钟脉冲产生一个32比特的密钥输出。 (1)运算符说明 mod 整数模 ⊕ 整数比特异或 a b 字符串a 和b 的连接 H a a 二进制表示的最左16位值 L a a 二进制表示的最右16位值 n a k <<< a 向左k 比特的循环移位 1a >> a 向右1比特的移位 ()()1212,,,,,,n n a a a b b b → i a 值分配到对应i b 的值 (2)算法结构 ZUC 有三个逻辑层,见下图。顶层为一个线性反馈移位寄存器(LFSR )的16个赛段,中间层是比特重组(BR ),最下层为一个非线性函数F 。 图1 ZUC 的整体结构图
第9章底层开发
第9章底层开发 很多程序往往需要实现和硬件打交道的功能,这种功能特别是对于那些不能开发驱动程序的语言来说,显得特别重要。这时可以采用C或者汇编语言开发一个驱动程序,通过这些程序和驱动程序通信,实现硬件的驱动。 9.1 基于WindowsNT操作系统的端口直接读写 WindowsNT/2000是一个非常出色的操作系统,凭借其安全性、可靠性、稳定性以及良好的人机交互界面,在商业高端操作系统中占据一席之地,成为工业控制计算机首选的操作系统。然而,Windows NT并不是一个实时的操作系统,出于安全稳定性考虑,它禁止用户态的应用程序直接操纵硬件,所有涉及物理内存、磁盘、中断、端口读写的操作,必须通过一个内核态的WDM驱动程序完成,否则就会出现一个特权指令异常的消息,系统提示用户要么终止、要么调试这个出现异常的应用程序。即便用户在WindowsNT的控制台窗口进行端口读写,IO操作要么被忽略,要么被一个叫做VDD 的虚拟设备驱动程序实现,尽管没有出现任何例外,但是用户并没有获得真正的IO口直接读写。通过编写WDM驱动程序,用户态应用程序可以借助与WDM程序的通信(利用CreateFile、CloseHandle、DeviceIOControl),实现IO读写,直接存取硬件。然而,一个CPUIO指令大约只需要30多个指令周期,然而调用驱动程序再要花费6000到12000个时钟周期,这将使系统的实时性和灵敏度大打折扣。端口指令允许所有的80X86CPU与系统中的其他硬件设备通信,从而实现对硬件设备的直接低层次控制。在C语言中提供了类似于汇编语言的端口操作指令,允许用户实现端口的读写。然而在WindowsNT/2000环境下,直接运行这些操作函数,将导致特权指令异常,并给出终止或者调试出错应用程序的选择。如果在WindowsNT/2000控制台窗口中运行16位的DOS应用程序进行端口操作,这时这些IO操作要么被忽略,要么通过WindowsNT/2000虚拟设备驱动程序仿真实现。尽管没有任何异常,但是用户得不到真正的IO操作。这是因为WindowsNT/2000的安全机制不允许用户态的应用程序直接访问硬件,从而摧毁和搞垮WindowsNT/2000无懈可击的稳定性。WindowsNT/2000规定用户态程序所有的IO操作必须借助于DeviceIOControl函数和内核驱动程序进行通信实现,然而和内核的通信势必会造成大量的时钟周期浪费和开销。 WindowsNT/2000只允许内核态的应用程序存取所有端口,对于用户态的程序,它通过设置IOPL实现了对IO操作的屏蔽。为了实现在用户态的直接IO操作,用户必须通过编写驱动程序去掉对读写端口的屏蔽。我们知道WindowsNT实现IO读写保护是有原因的,一方面它使系统异常的稳定,用户再也不必为Windows9x下的蓝屏和异常而苦恼了。用户可以放心大胆地调试应用程序,即便程序出现死锁,系统也会干脆利落地把它杀死,而不会波及到整个系统。IO读写保护与Windows98保护8253定时器端口是一样道理,它的目的就是防止用户使用简单的in/out指令,从而把系统搞垮。但是,对于大量的信号采集的系统而言,应用程序开发人员会更关心系统的实时性,更习惯于在程序中直接使用in/out指令实现信号采集。因此必须打破WindowsNT环境下的IO瓶颈,使得用户态的应用程序拥有IO读写权限,实现实时控制。 弄清楚如何把IO存取权授权给用户态的应用程序,用户必须了解WindowsNT环境下IO保护是如何实现的。WindowsNT本身并不能实现IO保护,由于CPU能够捕捉尝试的IO存取,WindowsNT利用了80x86这一特征。80x86采用了特权级别系统,它总共定义了0、1、2、3四个级别,即我们所说的Ring环。出于对ALPHA平台的兼容性,80x86仅使用了权限最高的Ring0和最低的ring3,CPU的当前运行权限级(CPL)保存在CS代码段寄存器的两位中。IO权限并不是由CPU静态定义的。CPU在处理器的标志寄存器Eflags的某两位定义了当前的IO权限级别(IOPL),通过比较当前的IO权限级和CPU的当前运行权限级,来决定IO指令能否自由使用。由于当前的IO权限级总是大于等于0,因此运行在Ring0环的内核模式的设备驱动程序,总是可以直接对IO端口进行存取。而运行在用户态的应用程序,工作在Ring3环,WindowsNT 把当前的IO权限级设置为0,因此,用户态的程序尝试端口存取时,必须经过保护机制。判断CPL>IOPL,仅仅是保护机制的第一步,I/O保护要么全有,要么全无。处理器采用了更为灵活的机制,使得操作系统能够根据任务的不同,对端口的任何子集进行授权。CPU是采用了一个位屏蔽矩阵(IOPM)实现这一步的。这个矩阵由0,1组成,每一个二进制位对应一个输入输出端口。这样,65536个端口共需要8192个字节,如果某一二进制位值为0,那么程序对该端口的读写就会不加阻拦。当然用户不能对一个只读端口进行写操作,只能对端口进行读操作。位屏蔽矩阵(IOPM)保存在主存的任务状态段结构中,我们可以通过NTOSKRNL库提供的一些内核模式设备驱动例程,实现对该位屏蔽矩阵进行读写,以便对某些端口进行授权。注意这些服务例程,在DDK帮助文档中并没有说明,并不能保证下个版本是否支持。我们可以通过VisualStudio提供的ViewDependcy工具打开windows/system32/driver/videoprt.sys,发现它调用了ntoskrnl.exe中的几个未见文档的服务例程。尽管没有说明,但顾名思义,我们也可以看出这些函数要干什么。 extern"C"{ void Ke386SetIoAccessMap(int,NTPORT*);//复制位图影像到NTPORT结构指针中 //int:1复制缓冲区,0用0xff填充 voidKe386QueryIoAccessMap(int,NTPORT*);//查询当前IOPM void Ke386IoSetAccessProcess(PEPROCESS,int);}}//int:1允许I/O,0禁止I/O PsGetCurrentProcess() //获得当前进程 设备驱动程序的加载是一个非常麻烦的事情。对于一个不是硬件的虚拟设备,用户不得不创建一个安装程序,或者编写一个.inf文件,利用控制面板中的添加新硬件功能,加入一个其它设备,或者直接编辑注册编辑表,把驱动程序复制到WINNT系统目录的Drivers32子目录中,有时还需要用户重新启动计算机。而用户需要的功能仅仅是一次(也许是最后一次)辅助驱动用户的小程序。正因为这个原因,本程序提供了一个设备驱动程序加载工具,实现设备驱动程序的动态加载,用户不用做任何添加新硬件的操作,也不用编辑注册表和重新启动计算机。驱动程序不一定位于系统目录中,但要求和程序提供的NTPORT.dll文件位于同一目录。本程序参考了NumegaDriveStudio提供的loaddrv例子程序。 下面简要介绍一下程序调用的有关API函数。 (1)首先使用OpenSCManager函数与指定服务控制管理器建立联系,打开指定的服务控制管理数据库。 schSCManager=OpenSCManager(NULL,NULL,SC_MANAGER_ALL_ACCESS); (2)利用CreateService函数创建一个服务对象,并把它加入到指定的服务控制管理数据库中。 SC_HANDLEschService=CreateService(SchSCManager,DriverName,DriverName,SERVICE_ALL_ACCESS, SERVICE_KERNEL_DRIVER,SERVICE_DEMAND_START,SERVICE_ERROR_NORMAL,ServiceExe,NULL,NULL,NULL,NULL,NULL); 具体参数请参考MSDN。 (3)用函数StartService启动一个服务,启动前用OpenService打开服务。
(整理)C底层机制.
这是一篇介绍C语言中的函数调用是如何用实现的文章。写给那些对C语言各种行为的底层实现感兴趣人的入门级文章。如果你是C语言或者汇编、底层技术的老鸟或是对这个问题不感兴趣,那么这篇文章只会耽误您的时间,您大可不必阅读他。当然如果前辈们愿意为我指出不足,我将十分感谢您的指导,并对耽误您宝 贵的时间致歉。 好了,废话少说!要研究这个问题,让我们先打开VC++吧。最好是6.0的,:-P。(什么你没有VC++,倒!....赶快装一个!@#$,要快!) 首先,让我们在VC++里建立一个Win32 Console Application项目,并建立主文件fun.c。并输入以下内容。 int fun(int a, int b) { a = 0x4455; b = 0x6677; return a + b; } int main() { fun(0x8899,0x1100); return 0; } 之 后,最关键的是在项目设置里关闭优化功能。也就是把 Project->Setting->C/C++->Optimizations选 为Disabled。编译器的优化在分析底层实现时大多数情况不太受欢迎。按键盘上的F10键,进入单步调试模式(Step Over)。看到你的main函数左侧有个黄色的小箭头了吗?那个就是程序即将执行的语句。按Alt + 8。打开反编译窗口,看到汇编语句了吗?是不是想这个样子 ==> 00401078 push 1100h 0040107D push 8899h 00401082 call @ILT+5(fun) (0040100a) 00401087 add esp,8 看 到两个PUSH指令了吗?再看看后面的数字,不正是我们要传递的参数吗。奇怪阿?我们明明是先传递的0x8899怎么反倒先push 1100h呢?呵呵,这个现象就叫Calling conversion。究竟是何方神圣,我在后面会详细的给你解释的。先别着急。随后的Call指令的作用就是开始调用函数了。 接下来关掉反汇编窗口,在源代码窗口按F11(Step
接口技术实现方式
现在管理软件项目中接口需求很多,很多项目接口实现得并不理想,原因就在于接口协议质量不高,而接口协议是和接口调研紧密相关的。一般接口调研和其它调研方法是一样的,但要做好接口调研就必须具备一定的专业知识,这可能是能否做好接口调研的关键。 接口协议除一般性协议要素外,应该包括如下内容: 接口技术实现方式 接口方式最高级一种是主动式。 即通过直接对其它软件的数据库进行操作。这种方式因为涉及到对用户数据读写操作,对于对方软件而言,安全性是最大的问题,验证的复杂程度也最高。主动式基本有两种方式: 1)DATA方式,通过数据库语言对数据库进行直接读写。这种情况要求对对方数据有详细认识。需要对方的人员可以提供数据库的详细资料。为了保障数据的安全,要界定对读写要求。一般和用户自行开发的系统会比较多出现此类要求,商品化ERP很少提出这种方式。 2)利用其它软件提供的工具。除了直接对数据进行读写外,有些软件也提供了一些工具(可能是控件,函数,脚本等)。可以通过这些工具对数据库进行操作。例如现在神州数码易飞ERP就全部采用控件方式接口。 这种情况下要提供这些工具的详细使用说明。 接口方式相对主动式的就是被动式开放。 同主动式对应,即开放软件商自己的数据库或开发接口给其它供应商读取数据。这种方式涉及到软件商提供的数据或开发程序。对方要我们的哪些数据,将成为了解需求的重点。按提供方式的不同可以分为以下四种。
1)DATA方式。即开方我们的文件或数据库格式给对方。由对方软件直接读取数据。这样的情况一般在企业有开发能力,而且只需要信息提取(不是写入)时才使用。这种情况很少。 2)脚本方式。早期的脚本语言,多是一种专用高级编程语言。实现了基本的程序流程语句,简单的数据结构,在此基础上,提供访问软件内部数据的语句。通过这类专用语言,用户可以对程序进行界面配置,实现简单的功能扩展,给用户提供了一定的灵活性。而只需用户懂一点程序设计知识即可。这类语言的缺点是没有通用性,功能有限,由于解释执行,速度受到很大限制,并且应用软件开发商实现专用编程语言及调试环境有较大难度。对于应用程序,需实现三个要求,就可拥有脚本语言编程接口: A)应用程序的对象模型 B)适合应用程序对象模型的对象 C)脚本语言编程引擎 前面两个方面,需要应用程序用组件对象模型的方式构造。采用组件方式,是软件开发的发展方向,提供对象模型是一件很自然的事情。第三个方面,有通用脚本语言编程引擎供选择,微软的ActiveX脚本编程引擎可以免费使用,VBA 脚本引擎需要购买。ActiveX脚本引擎实现了基本功能,没有调试环境。VBA是一种通用编程语言,其核心就是应用广泛的VB,拥有大量函数支持,窗口编辑能力,强大的调试环境。很明显,微软希望VBA成为应用软件二次开发的通用语言。例如CAPP和国外PDM的接口就属于这种开放方式。
ZUC算法原理及实现过程
Z U C 算法原理及实现过程 1.1算法设计背景 ZUC 算法,即祖冲之算法,是3GPP 机密性算法EEA3和完整性算法EIA3的核心,为中国自主设计的流密码算法。2009年5月ZUC 算法获得3GPP 安全算法组SA 立项,正式申请参加3GPPLTE 第三套机密性和完整性算法标准的竞选工作。历时两年多的时间,ZUC 算法经过评估,于2011年9月正式被3GPPSA 全会通过,成为3GPPLTE 第三套加密标准核心算法。ZUC 算法是中国第一个成为国际密码标准的密码算法。 1.2算法原理 ZUC 是一个面向字的流密码。它采用128位的初始密钥作为输入和一个128位的初始向量(IV ),并输出关于字的密钥流(从而每32位被称为一个密钥字)。密钥流可用于对信息进行加密/解密。 ZUC 的执行分为两个阶段:初始化阶段和工作阶段。在第一阶段,密钥和初始向量进行初始化,即不产生输出。第二个阶段是工作阶段,在这个阶段,每一个时钟脉冲产生一个32比特的密钥输出。 (1)运算符说明 mod 整数模 ⊕ 整数比特异或 a b 字符串a 和b 的连接 H a a 二进制表示的最左16位值 L a a 二进制表示的最右16位值 n a k <<< a 向左k 比特的循环移位 1a >> a 向右1比特的移位 ()()1212,,,,,,n n a a a b b b →i a 值分配到对应i b 的值 (2)算法结构 ZUC 有三个逻辑层,见下图。顶层为一个线性反馈移位寄存器(LFSR )的16个赛段,中间层是比特重组(BR ),最下层为一个非线性函数F 。 图1ZUC 的整体结构图 (3)线性移位反馈寄存器(LFSR ) LFSR 具有16个31比特的单元()0115,, ,s s s ,每个单元()015i s i ≤≤取值均在下面 的集合中: LFSR 有两种模式的操作,即初始化模式和工作模式。在初始化模式中,LFSR 接收一个31比特的输入u ,u 是删除非线性函数F 的32位输出W 最右边的位得到的。也就是说,可将初始化模式工作原理表示为: LFSRWithInitialisationMode (u ) {
【React Native】实现原理详解(精选、)
React Native实现原理详解 前言 花了半个多月,把React Native源码看了一遍,大概的实现逻辑全看明白了,希望对想了解React Native实现原理的同学有所帮助,其实只要看懂文章的四幅图就明白它的原理了。 如果喜欢我的文章,可以关注我微博:袁峥Seemygo,也可以来小码哥,了解下我们的iOS培训课程。后续还会更新更多内容,有任何问题,欢迎简书留言袁峥Seemygo。。。 一、React Native背景 ?有没有朋友想过一个问题,为什么取名React Native?React是什么,Native又是什么? React ?React 是由Facebook推出的一个JavaScript框架,主要用于前段开发。 ?React 采用组件化方式简化Web开发 DOM:每个HTML界面可以看做一个DOM 原生的web开发方式,HTML一个文件,javaScript一个文件,文件分开,就会导致修改起来比较麻烦。 可以把一组相关的HTML标签和JavaScript单独封装到一个组件类中,便于复用,方便开发。 ?React 可以高效的绘制界面
原生的Web,刷新界面(DOM),需要把整个界面刷新. React只会刷新部分界面,不会整个界面刷新。 因为React独创了Virtual DOM机制。Virtual DOM是一个存在于内存中的JavaScript对象,它与DOM是一一对应的关系,当界面发送变化时,React会利用DOM Diff算法,把有变化的DOM进行刷新. ?React是采用JSX语法,一种JS语法糖,方便快速开发。 Native ?想要了解Native是什么,需要了解下开发App有哪些开发模式,卖了一个馆子,请继续往下看。 二、常见的五种App开发模式 ?常见的开发模式有5种(Native App,Web App,Hybrid App,Weex,React Native) Native App ?Native App:指使用原生API开发App,比如iOS用OC语言开发 ?优点:性能高 ?缺点:开发维护成本高,养一个原生开发工程师需要很多钱,最重要iOS版本更新也成问题。 Web App ?Web App:指使用Html开发的移动端网页App,类似微信小程序,整个App都是网页。 ?优点:用户不需要安装,不会占用手机内存 ?缺点:用户体验不好,不能离线,必须联网
【黑马程序员】Python字典底层实现原理
【黑马程序员】Python字典底层实现原理 在Python中,字典是通过散列表或说哈希表实现的。字典也被称为关联数组,还称为哈希数组等。也就是说,字典也是一个数组,但数组的索引是键经过哈希函数处理后得到的散列值。哈希函数的目的是使键均匀地分布在数组中,并且可以在内存中以O(1)的时间复杂度进行寻址,从而实现快速查找和修改。哈希表中哈希函数的设计困难在于将数据均匀分布在哈希表中,从而尽量减少哈希碰撞和冲突。由于不同的键可能具有相同的哈希值,即可能出现冲突,高级的哈希函数能够使冲突数目最小化。Python中并不包含这样高级的哈希函数,几个重要(用于处理字符串和整数)的哈希函数是常见的几个类型。通常情况下建立哈希表的具体过程如下: 数据添加:把key通过哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。 数据查询:再次使用哈希函数将key转换为对应的数组下标,并定位到数组的位置获取value。 哈希函数就是一个映射,因此哈希函数的设定很灵活,只要使得任何关键字由此所得的哈希函数值都落在表长允许的范围之内即可。本质上看哈希函数不可能做成一个一对一的映射关系,其本质是一个多对一的映射,这也就引出了下面一个概念–哈希冲突或者说哈希碰撞。哈希碰撞是不可避免的,但是一个好的哈希函数的设计需要尽量避免哈希碰撞。 Python2中使用使用开放地址法解决冲突。 CPython使用伪随机探测(pseudo-random probing)的散列表(hash table)
作为字典的底层数据结构。由于这个实现细节,只有可哈希的对象才能作为字典的键。字典的三个基本操作(添加元素,获取元素和删除元素)的平均事件复杂度为O(1)。 Python中所有不可变的内置类型都是可哈希的。 可变类型(如列表,字典和集合)就是不可哈希的,因此不能作为字典的键。 常见的哈希碰撞解决方法: 1 开放寻址法(open addressing) 开放寻址法中,所有的元素都存放在散列表里,当产生哈希冲突时,通过一个探测函数计算出下一个候选位置,如果下一个获选位置还是有冲突,那么不断通过探测函数往下找,直到找个一个空槽来存放待插入元素。 开放地址的意思是除了哈希函数得出的地址可用,当出现冲突的时候其他的地址也一样可用,常见的开放地址思想的方法有线性探测再散列,二次探测再散列等,这些方法都是在第一选择被占用的情况下的解决方法。 2 再哈希法 这个方法是按顺序规定多个哈希函数,每次查询的时候按顺序调用哈希函数,调用到第一个为空的时候返回不存在,调用到此键的时候返回其值。 3 链地址法 将所有关键字哈希值相同的记录都存在同一线性链表中,这样不需要占用其他的哈希地址,相同的哈希值在一条链表上,按顺序遍历就可以找到。 4 公共溢出区 其基本思想是:所有关键字和基本表中关键字为相同哈希值的记录,不管他们由哈希函数得到的哈希地址是什么,一旦发生冲突,都填入溢出表。
虚拟化技术实现原理(资料)
本文由zhenchengjin贡献 虚拟化技术实现原理 虚拟化概念很早就已出现。简单来说,虚拟化就是使用某些程序,并使其看起来类似于其他程序的过程。 将这个概念应用到计算机系统中可以让不同用户看到不同的单个系统(例如,一台计算机可以同时运行Linux 和 Microsoft? Windows?)。这通常称为全虚拟化(full virtualization)。虚拟化也可以使用更加复杂的格式,其中单个计算机看上去具有多个架构(对于一个用户来说,它是一个标准的 x86 平台;对于另外一个用户来说,它是 IBM Power PC? 平台)。这种虚拟化形式通常被称为硬件仿真。 最后,更加简单的一种虚拟化是操作系统虚拟化,其中一台计算机可以运行相同类型的多个操作系统。这种虚拟化可以将一个操作系统的多个服务器隔离开来(这意味着全都必须使用相同类型和版本的操作系统)。 虚拟化的工作原理 虚拟化解决方案的底部是要进行虚拟化的机器。这台机器可能直接支持虚拟化,也可能不会直接支持虚拟化;那么就需要系统管理程序层的支持。系统管理程序,或称为 VMM,可以看作是平台硬件和操作系统的抽象化。在某些情况中,这个系统管理程序就是一个操作系统;此时,它就称为主机操作系统. 系统管理程序之上是客户机操作系统,也称为虚拟机(VM)。这些 VM 都是一些相互隔离的操作系统,将底层硬件平台视为自己所有。但是实际上,是系统管理程序为它们制造了这种假象。 目前使用虚拟化解决方案的问题是,并非所有硬件都可以很好地支持虚拟化。较老的 x86 处理器根据执行范围对特定指令会产生不同结果。这就产生了一个问题,因为系统管理程序应该只能在一个最受保护的范围中执行。由于这个原因,诸如 VMWare 之类的虚拟化解决方案会提前扫描要执行的代码,从而将这些指令替换为一些陷阱指令(trap instruction),这样系统管理程序就可以正确地处理它们。Xen 可以支持一种协作的虚拟化方法,它不需要任何修改,因为客户机知道自己正在进行虚拟化,并已经进行了修改。KVM 会简单地忽略这个问题,如果您希望进行虚拟化,就强制必须在更新的硬件上运行。 虚拟化的类型 实现虚拟化的方法不止一种。实际上,有几种方法都可以通过不同层次的抽象来实现相同的结果。本节将介绍 Linux 中常用的 3 种虚拟化方法,以及它们相应的优缺点。业界有时会使用不同的术语来描述相同的虚拟化方法。本文中使用的是最常用的术语,同时给出了其他术语以供参考。 硬件仿真 毫无疑问,最复杂的虚拟化实现技术就是硬件仿真。在这种方法中,可以在宿主系统上创建一个硬件 VM 来仿真所想要的硬件 正如您所能预见的一样,使用硬件仿真的主要问题是速度会非常慢。由于每条指令都必须在底层硬件上进行仿真,因此速度减慢 100 倍的情况也并不稀奇。若要实现高度保真的仿真,包括周期精度、所仿真的 CPU 管道以及缓存行为,实际速度差距甚至可能会达到 1000 倍之多。 硬件仿真也有自己的优点。例如,使用硬件仿真,您可以在一个 ARM 处理器主机上运行为PowerPC? 设计的操作系统,而不需要任何修改。您甚至可以运行多个虚拟机,每个虚拟器仿真一个不同的处理器。 完全虚拟化 完全虚拟化(full virtualization),也称为原始虚拟化,是另外一种虚拟化方法。这种模
java中HashMap底层实现原理和源码解析
java中HashMap底层实现原理 散列表(Hash table,也叫哈希表),是依据关键码值(Key value)而直接进行訪问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来訪问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。比如我们要存储八十八个数据,我们为他申请了100个元素的地址空间,80/100=0.88,这个数字叫做负载因子.我们之所以这样做是为了通过牺牲空间来换取时间,达到"高速存储"的目的.我们基于一种结果尽可能随机平均分布的固定函数H为每一个元素安排存储位置,这样就能够避免遍历性质的线性搜索,以达到高速存取。可是因为此随机性,也必定导致一个问题就是冲突。所谓冲突,即两个元素通过散列函数H得到的地址同样,那么这两个元素称为“同义词”。 解决冲突是一个复杂问题。冲突主要取决于: (1)散列函数,一个好的散列函数的值应尽可能平均分布。 (2)处理冲突方法。 (3)负载因子的大小。太大不一定就好,并且浪费空间严重,负载因子和散列函数是联动的。 解决冲突的办法: (1)线性探查法:冲突后,线性向前试探,找到近期的一个空位置。缺点是会出现堆积现象。存取时,可能不是同义词的词也位于探查序列,影响效率。 (2)双散列函数法:在位置d冲突后,再次使用还有一个散列函数产生一个与散列表桶容量m互质的数c,依次试探(d+n*c)%m,使探查序列跳跃式分布。 影响产生冲突多少有下面三个因素: 1.散列函数是否均匀; 2.处理冲突的方法; 3.散列表的装填因子。 散列表的装填因子定义为:α= 填入表中的元素个数/散列表的长度 α是散列表装满程度的标志因子。因为表长是定值,α与“填入表中的元素个数”成正比,所以,α越大,填入表中的元素较多,产生冲突的可能性就越大;α越小,填入表中的元素较少,产生冲突的可能性就越小。 HashMap数组(JDK8以前使用拉链法,JDK8以后使用红黑树)
底层机制突破
安卓面试突破专题课程 Android 基础与底层机制 1.数据库的操作类型有哪些,如何导入外部数据库? 读懂题目。如果碰到问题比较模糊的时候可以适当问问面试官。 配合面试官来面试:面试是一个相互了解的过程,要充分利用面试的题目和时间把自己的能力和技术展现出来,面试官能够看到你的真实技术。 1)使用数据库的方式有哪些? (1)openOrCreateDatabase(String path); (2)继承SqliteOpenHelper类对数据库及其版本进行管理(onCreate,onUpgrade) 当在程序当中调用这个类的方法getWritableDatabase()或者 getReadableDatabase();的时候才会打开数据库。如果当时没有数据库文件 的时候,系统就会自动生成一个数据库。 2)操作的类型:增删改查CRUD 直接操作SQL语句:SQliteDatabase.execSQL(sql); 面向对象的操作方式:SQLiteDatabase.insert(table, nullColumnHack, ContentValues); 如何导入外部数据库? 一般外部数据库文件可能放在SD卡或者res/raw或者assets目录下面。 写一个DBManager的类来管理,数据库文件搬家,先把数据库文件复制到”/data/data/包名/databases/”目录下面,然后通过db.openOrCreateDatabase(db文件),打开数据库使用。我上一个项目就是这么做的,由于app上架之前就有一些初始数据需要内置,也会碰到数据的升级等问题,我是这么做的……同时我碰到最有意思的问题就是关于数据库并发操作的问题,比如:多线程操作数据库的时候,我采取的是封装使用互斥锁来解决…… 2.是否使用过本地广播,和全局广播有什么差别? 引入本地广播的机制是为了解决安全性的问题: 1)正在发送的广播不会脱离应用程序,比用担心app的数据泄露; 2)其他的程序无法发送到我的应用程序内部,不担心安全漏洞。(比如:如何做一个杀不死的服务---监听火的app 比如微信、友盟、极光的广播,来启动自己。)3)发送本地广播比发送全局的广播高效。(全局广播要维护的广播集合表效率更低。 全局广播,意味着可以跨进程,就需要底层的支持。) 本地广播不能用静态注册。----静态注册:可以做到程序停止后还能监听。 使用: (1)注册 LocalBroadcastManager.getInstance(this).registerReceiver(new XXXBroadCastReceiver(), new IntentFilter(action)); (2)取消注册: LocalBroadcastManager.getInstance(this).unregisterReceiver(receiv er)