描述性数据的分布和度量实验报告

重庆科技学院学生实验报告
,其中
数据的收集整理与描述知识点归纳
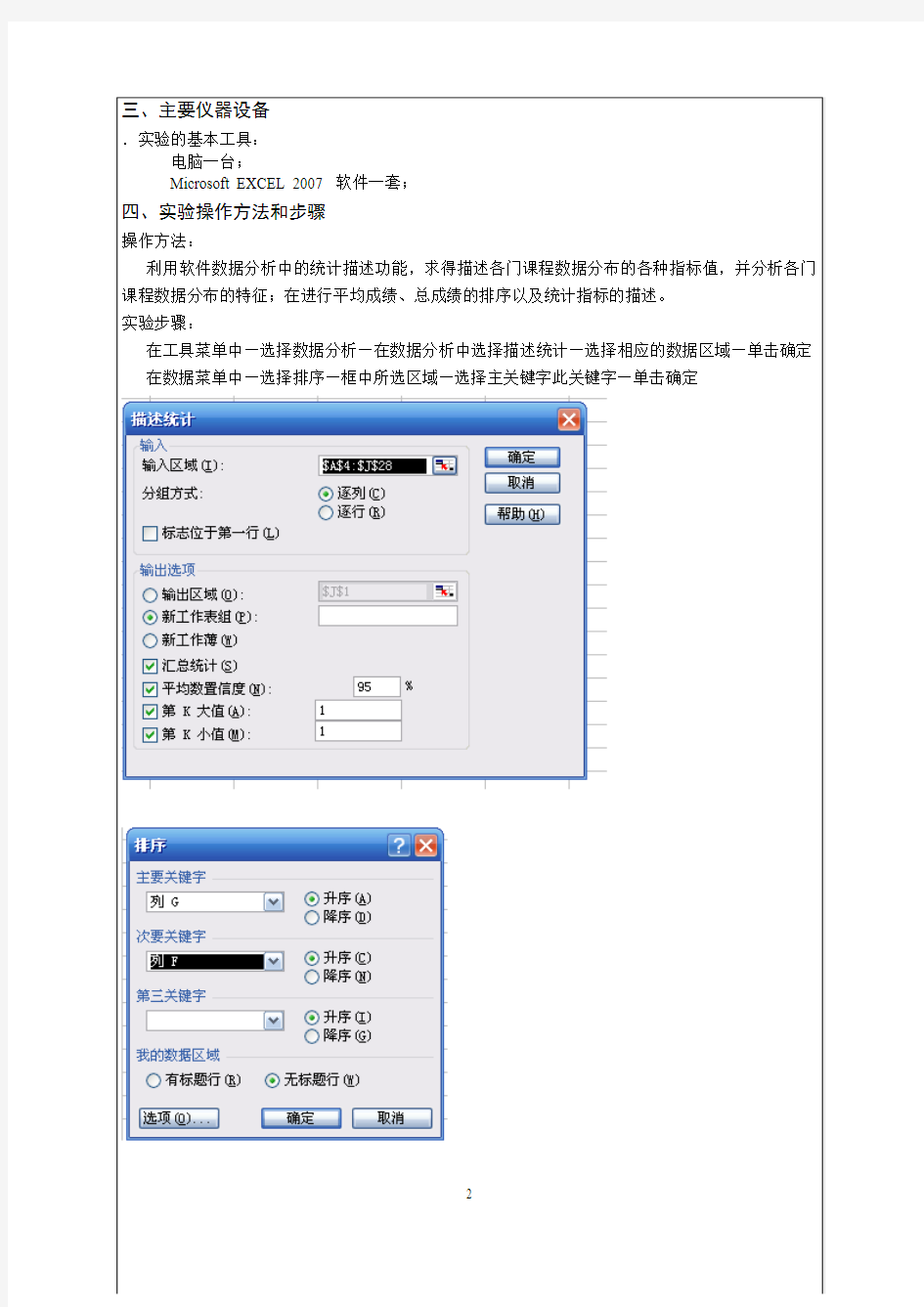
一、目标与要求 1.了解全面调查的概念;会设计简单的调查问卷,收集数据;掌握划记法,会用表格整理数据;会画扇形统计图,能用统计图描述数据;经历统计调查的一般过程,体验统计与生活的关系。 2.经历数据的收集、整理和分析的模拟过程,了解抽样调查、样本、个体与总体等统计概念;学会从样本中分析、归纳出较为正确的结论,增强用统计方法解决问题的意识。 3.理解频数、频数分布的意义,学会制作频数分布表;学会画频数分布直方图和频数折线图。 二、重点 学会画频数分布直方图; 分层抽样的方法和样本的分析、归纳; 抽样调查、样本、总体等概念以及用样本估计总体的思想; 全面调查的过程(数据的收集、整理、描述)。 三、难点 绘制扇形统计图; 样本的抽取; 分层抽样方案的制定; 确定组距和组数。 四、知识框架 五、知识概念 1.数据的整理:我们利用划记法整理数据,如下图所示,
2.数据的描述:为了更直观地看出上表中的信息,我们还可以用条形统计图和扇形统计图来描述数据。如下图所示: 3.全面调查:考察全体对象的调查方式叫做全面调查。 4.抽样调查:抽样调查是,一种非全面调查,它是从全部调查研究对象中,抽选一部分单位进行调查,并据以对全部调查研究对象作出估计和推断的一种调查方法。显然,抽样调查虽然是非全面调查,但它的目的却在于取得反映总体情况的信息资料,因而,也可起到全面调查的作用。 5.抽样调查分类:根据抽选样本的方法,抽样调查可以分为概率抽样和非概率抽样两类。 概率抽样是按照概率论和数理统计的原理从调查研究的总体中,根据随机原则来抽选样本,并从数量上对总体的某些特征作出估计推断,对推断出可能出现的误差可以从概率意义上加以控制。习惯上将概率抽样称为抽样调查。 6.总体:要考察的全体对象称为总体。 7.个体:组成总体的每一个考察对象称为个体。 8.样本:被抽取的所有个体组成一个样本。为了使样本能够正确反映总体情况,对总体要有明确的规定;总体内所有观察单位必须是同质的;在抽取样本的过程中,必须遵守随机化原则;样本的观察单位还要有足够的数量。又称“子样”。按照一定的抽样规则从总体中取出的一部分个体。 10% 25% 20% 45% 新闻 体育 动画 娱乐 15 5 人数 10 20 新闻 动画 0 节目类别 体育 娱乐 4 10 8 18
数据分析实验报告
数据分析实验报告 文稿归稿存档编号:[KKUY-KKIO69-OTM243-OLUI129-G00I-FDQS58-
第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出: 统计量 全国居民 农村居民 城镇居民 N 有效 22 22 22 缺失 均值 1116.82 747.86 2336.41 中值 727.50 530.50 1499.50 方差 1031026.918 399673.838 4536136.444 百分位数 25 304.25 239.75 596.25 50 727.50 530.50 1499.50 75 1893.50 1197.00 4136.75 3画直方图,茎叶图,QQ 图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民 Stem-and-Leaf Plot Frequency Stem & Leaf 5.00 0 . 56788 数据分析实验报告 【最新资料,WORD 文档,可编辑修改】
2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689 1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下:(1)K—S检验
结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。 (2 )W 检验 结果:在Shapiro-Wilk 检验结果972.00 w ,p=0.174大于0.05 接受原假设,即数据来自正太总体。 习题1.5 5 多维正态数据的统计量 数据:
SAS数据的描述性统计分析答案
实验一数据的描述性统计分析 一、选择题 1、以下( B )语句对变量进行分组,在使用前需按分组变量进行排序? 以下( C )语句可对变量进行分类,在使用前不必按分类变量进行排序? 用( A )语句可以选择输入数据集的一个行子集来进行分析? (A)WHERE语句(B)BY语句(C)CLASS语句(D)FREQ语句2、排序过程步中必须用什么语句对变量进行排序?( A ) (A)BY语句(B)CLASS语句(C)WHERE语句 3、如果要对数据集中的数据进行正态性检验,需要使用哪个过程?( B )(A)MEANS (B)UNIV ARIATE (C)FREQ 4、用UNIV ARIATE过程进行数据分析,要求此过程输出茎叶图、正态概率图等,应在语句中加上什么选项?(plot ) 5、用UNIV ARIATE过程进行数据分析,在输出结果中哪个统计量是对样本均值 为零的T检验的概率值?( A ) (A)T: Mean (B)Prob>|S| (C)Sgn Rank (D)Prob>|T| 二、假设某校100名女生的血清总蛋白含量(g/L)服从均值为75,标准差为3的正态分布,试产生样本数据,并利用SAS软件解决下面问题: 1、计算样本均值、方差、标准差、极差、四分位极差、变异系数、偏度、峰度; 2、画出直方图(垂直条形图); 3、画出茎叶图、盒形图和正态概率图; 4、试进行正态性检验。 Data N; DO i=1to100; x=75+3*normal(12345); output; end; proc print; run; proc univariate data=N; var x; run; proc gchart data=N; block x; run; proc univariate data=N plot; var x;
上机实验1、数据资料的整理与描述
上机实验1、数据资料的整理与描述 班级:12食品转本学号:12110517 姓名:颜廷珍 一、实验目的: 熟悉SPSS、Excel软件环境,掌握应用SPSS、Excel软件对原始数据资料进行整理、作表、作图、 描述性统计分析。 二、实验内容: (一)数据的描述统计。 1、描述性分析(学生体检数据.sav):对某校3个班级 16名学生的体检数据进行描述性分析,以班级为单位列 表计算年龄、体重和身高的统计量,包括极差、最小值、 最大值、均值、标准差和方差。 2、探索性分析(height.sav):对60个12岁小孩的身高 数据进行探索性分析。输出箱图、直方图、茎叶图、Q-Q 图。 Q-Q图是一种散点图,对应于正态分布的Q-Q图,就是由标准正态分布的分位数为横坐 标,样本值为纵坐标的散点图. 要利用Q-Q图鉴别样本数据是否近似于正态分布,只需看 Q-Q图上的点是否近似地在一条直线附近,而且该直线的斜率为标准差,截距为均值. 第一四分位数(Q1),又称“较小四分位数”,等于该样本中所有数值由小到大排列 后第25%的数字。第二四分位数(Q2),又称“中位数”,等于该样本中所有数值由小到 大排列后第50%的数字。第三四分位数(Q3),又称“较大四分位数”,等于该样本中所 有数值由小到大排列后第75%的数字。第三四分位数与第一四分位数的差距又称四分位距(InterQuartile Range, IQR)。 (二)《食品试验设计与统计分析基础》P38 习题14中的数据整理与描述。 1、将数据资料做成依次表,求极差与中数。 2、按照P21表2-3的格式,制作次数分布三线表。 3、对数据进行描述性统计分析,包括:均值、中数、众数、方差、标准差、变异系数、均值标准误。 4、绘次数分布直方图和折线图,显示正态分布曲线。 (三)数据资料的图表描述。 1、将数据资料制成三线表和柱形图。 单位脱水量耗电 真空处理冻干全过程 A组 1.3 6.2 4.7 B组0.7 5.9 5.1 C组0 5.6 6 2、按将数据资料制成折线图。 三、实验 结果 (一)数据 的描述性 分析。
数据分析实验报告
《数据分析》实验报告 班级:07信计0班学号:姓名:实验日期2010-3-11 实验地点:实验楼505 实验名称:样本数据的特征分析使用软件名称:MATLAB 实验目的1.熟练掌握利用Matlab软件计算均值、方差、协方差、相关系数、标准差与变异系数、偏度与峰度,中位数、分位数、三均值、四分位极差与极差; 2.熟练掌握jbtest与lillietest关于一元数据的正态性检验; 3.掌握统计作图方法; 4.掌握多元数据的数字特征与相关矩阵的处理方法; 实验内容安徽省1990-2004年万元工业GDP废气排放量、废水排放量、固体废物排放量以及用于污染治理的投入经费比重见表6.1.1,解决以下问题:表6.1.1废气、废水、固体废物排放量及污染治理的投入经费占GDP比重 年份 万元工业GDP 废气排放量 万元工业GDP 固体物排放量 万元工业GDP废 水排放量 环境污染治理投 资占GDP比重 (立方米)(千克)(吨)(%)1990 104254.40 519.48 441.65 0.18 1991 94415.00 476.97 398.19 0.26 1992 89317.41 119.45 332.14 0.23 1993 63012.42 67.93 203.91 0.20 1994 45435.04 7.86 128.20 0.17 1995 46383.42 12.45 113.39 0.22 1996 39874.19 13.24 87.12 0.15 1997 38412.85 37.97 76.98 0.21 1998 35270.79 45.36 59.68 0.11 1999 35200.76 34.93 60.82 0.15 2000 35848.97 1.82 57.35 0.19 2001 40348.43 1.17 53.06 0.11 2002 40392.96 0.16 50.96 0.12 2003 37237.13 0.05 43.94 0.15 2004 34176.27 0.06 36.90 0.13 1.计算各指标的均值、方差、标准差、变异系数以及相关系数矩阵; 2.计算各指标的偏度、峰度、三均值以及极差; 3.做出各指标数据直方图并检验该数据是否服从正态分布?若不服从正态分布,利用boxcox变换以后给出该数据的密度函数; 4.上网查找1990-2004江苏省万元工业GDP废气排放量,安徽省与江苏省是 否服从同样的分布?
数据的收集、整理与描述知识点教学文案
数据的收集、整理与描述单元复习与巩固 一、知识网络 知识点一:总体、样本的概念 1.总体:要考察的全体对象称为总体. 2.个体:组成总体的每一个考察对象称为个体. 3.样本:被抽取的那些个体组成一个样本. 4.样本容量:样本中个体的数目叫样本容量(不带单位). 注意:为了使样本能较好地反映总体的情况,除了要有合适的样本容量外,抽取时还要尽量使每一个个体都有同等的机会被抽到. 知识点二:全面调查与抽样调查 调查的方式有两种:全面调查和抽样调查: 1.全面调查:考察全面对象的调查叫全面调查. 全面调查也称作普查,调查的方法有:问卷调查、访问调查、电话调查等. 全面调查的步骤: (1)收集数据; (2)整理数据(划记法); (3)描述数据(条形图或扇形图等). 2.抽样调查:若调查时因考察对象牵扯面较广,调查范围大,不宜采用全面调查,因此,采用抽样调查. 抽样调查只抽取一部分对象进行调查,然后根据调查数据推断全体对象的情况. 抽样调查的意义: (1)减少统计的工作量; (2)抽样调查是实际工作中应用非常广泛的一种调查方式,它是总体中抽取样本进行调查,根据样本来估计总体的一种调查. 3.判断全面调查和抽样调查的方法在于: ①全面调查是对考察对象的全面调查,它要求对考察范围内所有个体进行一个不漏的逐个准确统计;而抽样调查则是对总体中的部分个体进行调查,以样本来估计总体的情况. ②注意区分“总体”和“部分”在表述上的差异. 在调查实际生活中的相关问题时,要灵活处理,既要考虑问题本身的需要,又要考虑实现的可能性和所付出代价的大小. 调查方法:问卷,观察,走访,试验,查阅资料。 知识点三:扇形统计图和条形统计图及其特点 1.生活中,我们会遇到许多关于数据的统计的表示方法,它们多是利用圆和扇形来表示整体和部分的关系,即用圆代表总体,圆中的各个扇形分别代表总体中的不同部分,扇形的大小反映部分占总体的百分比的大小,这样的统计图叫做扇形统计图. (1)扇形统计图的特点: ①用扇形面积表示部分占总体的百分比;
数据分析实验报告
数据分析实验报告 【最新资料,WORD文档,可编辑修改】 第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出:
方差1031026.918399673.8384536136.444百分位数25304.25239.75596.25 50727.50530.501499.50 751893.501197.004136.75 3画直方图,茎叶图,QQ图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民Stem-and-Leaf Plot Frequency Stem & Leaf 9.00 0 . 122223344 5.00 0 . 56788 2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689
1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下:(1)K—S检验 单样本Kolmogorov-Smirnov 检验 身高N60正态参数a,,b均值139.00
标准差7.064 最极端差别绝对值.089 正.045 负-.089 Kolmogorov-Smirnov Z.686 渐近显着性(双侧).735 a. 检验分布为正态分布。 b. 根据数据计算得到。 结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。(2)W检验
数据整理和数据描述
实验一数据整理和数据描述分析 一、实验目的和要求: 能熟练的进行统计数据的录入、分组、汇总及各种常用统计图表的绘制。 二、实验内容: 1、数据的排序 (1) 2、分类汇总 (1) 3、统计分组 (1) 4、数据透视分析 (10) 5、用Excel绘制统计图 (11) 6、描述性统计 (15) 三、实验步骤 1、数据的排序 ①打开“数据整理.xls” 工作簿,选定“等候时间”工作表。 ②利用鼠标选定单元格A1:B37区域 ③在菜单中选择“数据”中的“排序”选项,则弹出排序对话框。 ④在排序对话框窗口中,选择“主要关键字”列表中的“等候时间”作为排序关键字,并选择按“递增”排序。由于所选取数据中已经包含标题,所以在“当前数据清单”中选择“有标题行”,然后单击“确定”按钮,即可得到排序的结果。 2、分类汇总 先选择需要分类汇总的数据区域,然后选择“数据”菜单中的“分类汇总”选项,则打开“分类汇总”对话框。(分类汇总前最好先排序一下) 在“分类字段”的下拉式列表中选择要进行分类的列标题,在“汇总方式”的下拉式列表中选择行汇总的方式,在资料“电器销售量”中分别选择按“订货单位”和“电器种类”进行分类,选择按“求和”进行汇总,单击“确定”按钮,便得到分类汇总的结果。 3、统计分组 用Excel进行统计分组和编制频数分布表有两种方法,一是函数法;二是利用数据分析中的“直方图”工具。 ㈠函数法 在Excel中利用函数进行统计分组和编制频数分布表可利用COUNTIF()和FREQUENCY()等函数,但要根据变量值的类型不同而选择不同的函数。当分组标志是品质标志时应使用COUNTIF()函数;当分组标志是数量标志时应使用FREQUENCY()函数。 ⒈COUNTIF()函数 COUNTIF()函数的语法构成是:COUNTIF(区域,条件)。具体使用方法举例如下。
数据分析与挖掘实验报告
数据分析与挖掘实验报告
《数据挖掘》实验报告 目录 1.关联规则的基本概念和方法 (1) 1.1数据挖掘 (1) 1.1.1数据挖掘的概念 (1) 1.1.2数据挖掘的方法与技术 (2) 1.2关联规则 (5) 1.2.1关联规则的概念 (5) 1.2.2关联规则的实现——Apriori算法 (7) 2.用Matlab实现关联规则 (12) 2.1Matlab概述 (12) 2.2基于Matlab的Apriori算法 (13) 3.用java实现关联规则 (19) 3.1java界面描述 (19) 3.2java关键代码描述 (23) 4、实验总结 (29) 4.1实验的不足和改进 (29) 4.2实验心得 (30)
1.关联规则的基本概念和方法 1.1数据挖掘 1.1.1数据挖掘的概念 计算机技术和通信技术的迅猛发展将人类社会带入到了信息时代。在最近十几年里,数据库中存储的数据急剧增大。数据挖掘就是信息技术自然进化的结果。数据挖掘可以从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的,人们事先不知道的但又是潜在有用的信息和知识的过程。 许多人将数据挖掘视为另一个流行词汇数据中的知识发现(KDD)的同义词,而另一些人只是把数据挖掘视为知识发现过程的一个基本步骤。知识发现过程如下: ·数据清理(消除噪声和删除不一致的数据)·数据集成(多种数据源可以组合在一起)·数据转换(从数据库中提取和分析任务相关的数据) ·数据变换(从汇总或聚集操作,把数据变换和统一成适合挖掘的形式) ·数据挖掘(基本步骤,使用智能方法提取数
据模式) ·模式评估(根据某种兴趣度度量,识别代表知识的真正有趣的模式) ·知识表示(使用可视化和知识表示技术,向用户提供挖掘的知识)。 1.1.2数据挖掘的方法与技术 数据挖掘吸纳了诸如数据库和数据仓库技术、统计学、机器学习、高性能计算、模式识别、神经网络、数据可视化、信息检索、图像和信号处理以及空间数据分析技术的集成等许多应用领域的大量技术。数据挖掘主要包括以下方法。神经网络方法:神经网络由于本身良好的鲁棒性、自组织自适应性、并行处理、分布存储和高度容错等特性非常适合解决数据挖掘的问题,因此近年来越来越受到人们的关注。典型的神经网络模型主要分3大类:以感知机、bp反向传播模型、函数型网络为代表的,用于分类、预测和模式识别的前馈式神经网络模型;以hopfield 的离散模型和连续模型为代表的,分别用于联想记忆和优化计算的反馈式神经网络模型;以art 模型、koholon模型为代表的,用于聚类的自组
利用Excel进行数据整理和描述性统计分析
实训一利用Excel进行数据整理和描述性统计分析 一、实训目的 目的有三:(1)掌握Excel中基本的数据处理方法;(2)学会使用Excel进行统计分组;(3)学会使用Excel计算各种描述性统计指标,能以此方式独立完成相关作业。 二、实训要求 1、已学习教材相关内容,理解数据整理中的统计计算问题;理解描述性统计指标中的统计计算问题;已阅读本次实训指导书,了解Excel中相关的计算工具。 2、准备好一个统计分组问题、准备好一个或几个描述性统计指标计算问题及相应数据(可用本实训所提供问题与数据)。 3、以Word文件形式(其中的统计表和统计图用Excel制作)提交实训报告(含:实训过程记录、疑难问题发现与解决记录(可选))。此条为所有实训所要求。 三、实训内容和操作步骤 (一)问题与数据 有顾客反映某家航空公司售票处售票的速度太慢。为此,航空公司收集了解100位顾客购票所花费时间的样本数据(单位:分钟),结果如下表。 航空公司认为,为一位顾客办理一次售票业务所需的时间在五分钟之内就是合理的。上面的数据是否支持航空公司的说法?顾客提出的意见是否合理?请你对上面的数据进行适当的分析,回答下列问题。
(1)对数据进行等距分组,整理成频数分布表,并绘制频数分布图(直方图、折线图、饼图)。 (2)根据分组后的数据,计算中位数、众数、算术平均数和标准差。 (3)分析顾客提出的意见是否合理?为什么? (4)使用哪一个平均指标来分析上述问题比较合理? 答:(1): 2:
从表中我们可以得到中位数为2.5众数为1平均数为3.17标准差为2.864 (3):合理,虽然他的平均数是3.17<5属于正常范围,但是依旧有将近20%的购票时间>5分钟属于超过正常范围,那就是速度太慢了。平均数不能代表一切。 所以顾客提出的理由是正确的,购票太慢的现象确实存在。 (4):平均数比较合理,它能较好的反映购票的大概时间。比较有代表性! 实训二用Excel数据分析功能进行统计整理 和计算描述性统计指标 一、实训目的 学会使用Excel数据分析功能进行统计整理和计算各种描述性统计指标,能以此方式独立完成相关作业。 二、实训要求 1、已学习教材相关内容,理解统计整理和描述性统计指标中的统计计算问题;已阅读本次实验导引,了解Excel中相关的计算工具。 2、准备好一个统计分组问题、准备好一个或几个数字特征计算问题及相应数据(可用本实验导引所提供问题与数据)。 3、以Word文件形式(其中的统计表和统计图用Excel制作)提交实训报告(含:实训过程记录、疑难问题发现与解决记录(可选))。此条为所有实训所要求。 三、实训内容和操作步骤 (一)问题与数据 在一家财产保险公司的董事会上,董事们就加入世界贸易组织后公司的发展战略问题展开了激烈讨论,其中一个引人关注的问题就是如何借鉴国外保险公司的先进管理经验,提高自身的管理水平。有的董事提出,2003年公司的各项业务与去年相比有太大增长,除经济环境和市场竟争等因素外,对家庭财产保险的业务开展得不够,公司在管理方式上也存在问题。他认为,中国的家庭财产保险市场潜力巨大,应加大扩展这在业务的力度,同时,对公司家庭财产推销员实行目标管理,并根据目标完成情况建立相应的奖惩制度。董
光电效应实验报告数据处理 误差分析
表1-1:不同频率下的遏止电压表 λ(nm)365 404.7 435.8 546.1 577 v(10^14)8.219 7.413 6.884 5.493 5.199 |Ua|(v) 1.727 1.357 1.129 0.544 0.418 表1-2:λ=365(nm)时不同电压下对应的电流值 U/(v)-1.927 -1.827 -1.727 -1.627 -1.527 -1.427 -1.327 I/(10^-11)A-0.4 -0.2 0 0.9 3.9 8.2 14 -1.227 -1.127 -1.027 -0.927 -0.827 -0.727 -0.718 24.2 38.1 52 66 80 97.2 100 表1-3:λ=404.7(nm)时不同电压下对应的电流值 U/(v) -1.477 -1.417 -1.357 -1.297 -1.237 -1.177 -1.117 I/(10^-11)A -1 -0.4 0 1.8 4.1 10 16.2 -1.057 -0.997 -0.937 -0.877 -0.817 -0.757 -0.737 24.2 36.2 49.8 63.9 80 93.9 100 表1-4:λ=435.8(nm)时不同电压下对应的电流值 U/(v)-1.229 -1.179 -1.129 -1.079 -1.029 -0.979 -0.929 I/(10^-11)A-1.8 -0.4 0 2 4.2 10.2 17.9 -0.879 -0.829 -0.779 -0.729 -0.679 -0.629 -0.579 -0.575 24.8 36 47 59 71.6 83.8 98 100 表1-5:λ=546.1(nm)时不同电压下对应的电流值 U/(v)-0.604 -0.574 -0.544 -0.514 -0.484 -0.454 -0.424 I/(10^-11)A-4 -2 0 3.8 10 16.2 24 -0.394 -0.364 -0.334 -0.304 -0.274 -0.244 -0.242 34 46 56.2 72 84.2 98.2 100 表1-6:λ=577(nm)时不同电压下对应的电流值 U/(v)-0.478 -0.448 -0.418 -0.388 -0.358 -0.328 -0.298 I/(10^-11)A-3.1 -1.8 0 2 6 10.2 16.1 -0.268 -0.238 -0.208 -0.178 -0.148 -0.118 -0.088 -0.058 22.1 31.8 39.8 49 58 68.2 79.8 90.1 -0.04 100
多组和分类数据的描述性统计分析
§3.2多组和分类数据的描述性统计分析17 ?盒子图 盒子图能够直观简洁地展现数据分布的主要特征.我们在R 中使用boxplot()函数作盒子图.在盒子图中,上下四分位数分别确定中间箱体的顶部和底部,箱体中间的粗线是中位数所在的位置.由箱体向上下伸出的垂直部分为“触须”(whiskers),表示数据的散布范围,其为1.5倍四分位间距内距四分位点最远的数据点.超出此范围的点可看作为异常点(outlier). §3.2多组和分类数据的描述性统计分析 在对于多组数据的描述性统计量的计算和图形表示方面,前面所介绍的部分方法不能够有效地使用,例如许多函数都不能直接对数据框进行操作.这时我们需要一些其他的函数配合使用. 1.图形表示: ?散点图:前面介绍的plot,可直接对数据框操作.此时将绘出数据框中所对应的所有变量两两之间的散点图.所做图框中第一行的散点图是以第一个变量为纵坐标,分别以第二、三...个变量为横坐标的散点图.这里数据举例说明. library(DAAG);plot(hills) ?盒子图:前面介绍的boxplot,亦可直接对数据框操作,其在同一个作图区域内画出各组数的盒子图.但是注意,此时由于不同组数据的尺度可能差别很大,这样的盒子图很多时候表达出来不是很有意义.boxplot(faithful).因此这样做比较适合多组数据具有同样意义或近似尺度的情形.例如,我们想做某一数值变量在某个因子变量的不同水平下的盒子图.我们可采用类似如下的命令: boxplot(skullw ~age,data=possum),亦可加上参数horizontal=T,将该盒子图横向放置. boxplot(possum$skullw ~possum$sex,horizontal=T) ?条件散点图:当数据集中含有一个或多个因子变量时,我们可使用条件散点图函数coplot()作出因子变量不同水平下的多个散点图,当然该方法也适用于各种给定条件或限制情形下的作图.其调用格式为 coplot(formula,data)比如coplot(possum[[9]]~possum[[7]] possum[[4]]),或 coplot(skullw ~taill age,data=possum); coplot(skullw ~taill age+sex,data=possum)
spss相关分析实验报告
实验五相关分析实验报关费 一、实验目的: 学习利用spss对数据进行相关分析(积差相关、肯德尔等级相关)、偏相关分析。利用交叉表进行相关分析。 二、实验内容: 某班学生成绩表1如实验图表所示。 1.对该班物理成绩与数学成绩之间进行积差相关分析和肯德尔等级相关 分析。 2.在控制物理成绩不变的条件下,做数学成绩与英语成绩的相关分析(这 种情况下的相关分析称为偏相关分析)。 3.对该班物理成绩与数学成绩制作交叉表及进行其中的相关分析。 三、实验步骤: 1.选择分析→相关→双变量,弹出窗口,在对话框的变量列表中选变量 “数学成绩”、“物理成绩”,在相关系数列进行选择,本次实验选择 皮尔逊相关(积差相关)和肯德尔等级相关。单击选项,对描述统计 量进行选择,选择标准差和均值。单击确定,得出输出结果,对结果 进行分析解释。 2.选择分析→相关→偏相关,弹出窗口,在对话框的变量列表选变量“数 学成绩”、“英语成绩”,在控制列表选择要控制的变量“物理成绩” 以在控制物理成绩的影响下对变量数学成绩与英语成绩进行偏相关分 析;在“显著性检验”框中选双侧检验,单击确定,得出输出结果, 对结果进行分析解释。 3.选择分析→描述统计→交叉表,弹出窗口,对交叉表的行和列进行选 择,行选择为数学成绩,列选择为物理成绩。然后对统计量进行设置, 选择相关性,点击继续→确定,得出输出结果,对结果进行分析解释。 四、实验结果与分析:
表1
五、实验结果及其分析:
分析一:由实验结果可观察出,数学成绩与物理成绩的积差相关系数r=,肯德尔等级相关系数r=可知该班物理成绩和数学成绩之间存在显著相关。
统计分析实验报告
统计分析综合实验报告 学院: 专业: 姓名: 学号:
统计分析综合实验考题 一.样本数据特征分析: 要求收集国家统计局2011年全国人口普查与2000年全国人口普查相关数据,进行二者的比较,然后写出有说明解释的数据统计分析报告,具体要求如下: 1.报告必须包含所收集的公开数据表,至少包括总人口,流动人口,城乡、性别、年龄、民族构成,教育程度,家庭户人口八大指标; 2.报告中必须有针对某些指标的条形图,饼图,直方图,茎叶图以及累计频率条形图;(注:不同图形针对不同的指标)3.采用适当方式检验二次调查得到的人口年龄比例以及教育程度这两个指标是否有显著不同,写明检验过程及结论。 4.报告文字通顺,通过数据说明问题,重点突出。 二.线性回归模型分析: 自选某个实际问题通过建立线性回归模型进行研究,要求: 1.自行搜集问题所需的相关数据并且建立线性回归模型; 2.通过SPSS软件进行回归系数的计算和模型检验; 3.如果回归模型通过检验,对回归系数以及模型的意义进行 解释并且作出散点图
一、样本数据特征分析 2010年全国人口普查与2000年全国人口普查相关数据分析报告 2011年第六次全国人口普查数据显示,总人口数为1370536875,比2000年的第五次人口普查的1265825048人次,总人口数增加73899804人,增长5.84%,平均年增长率为0.57%。
做茎叶图分析: 描述 年份统计量标准误 人口数量2000年均值40084265.35 4698126.750 均值的 95% 置信区间 下限30489410.50 上限49679120.21 5% 修整均值39305445.50 中值35365072.00 方差 68424424372574 4.400 标准差26158062.691 极小值2616329
数据的描述性统计分析
统计分析往往是从了解数据的基本特征开始的。描述数据分布特征的统计量可分为两类:一类表示数量的中心位置,另一类表示数量的变异程度(或称离散程度)。两者相互补充,共同反映数据的全貌。 这些内容可以通过SPSS中的“Descriptive Statistics”菜单中的过程来完成。 1 频数分析 (Descriptive Statistics - Frequencies) 频数分布分析主要通过频数分布表、条形图和直方图,以及集中趋势和离散趋势的各 种统计量来描述数据的分布特征。 下面我们通过例子来学习单变量频数分析操作。 1) 输入分析数据 在数据编辑器窗口打开“data1-2.sav”数据文件。 2)调用分析过程 在主菜单栏单击“Analyze”,在出现的下拉菜单里移动鼠标至“Descriptive Statistics”项上,在出现的次菜单里单击“Frequencies”项,打开如图3-4所示的对话框。 图3-4 “Frequencies” 对话框 3)设置分析变量 从左则的源变量框里选择一个和多个变量进入“Variable(s):”框里。在这里我们选“三化 螟蚁螟[虫口数]”变量进入“Variable(s):”框。 4)输出频数分布表
Display frequency tables,选中显示。 5)设置输出的统计量 单击“Statistics”按钮,打开图3-5所示的对话框,该对话框用于选择统计量: 图3-5 “Statistics”对话框 ①选择百分位显示“Percentiles Values”栏: Quartiles:四分位数,显示25%、50%和75%的百分位数。 Cut points for 10 equal groups:将数据平分为输入的10个等份。 Percentile(s)::用户自定义百分位数,输入值0—100之间。选中此项后,可以利用“Add”、“Change”和 “Remove”按钮设置多个百分位数。 ②选择变异程度的统计量“Dispersion”:(离散趋势) Std.deviation标准差 Minimum 最小值 Variance 方差 Maximum 最大值 Range 极差 S.E.mean均值标准误 ③选择表示数据中心位置的统计量“Central Tendency”:(集中趋势) Mean 均值 Median 中位数 Mode 众数 Sum 算术和
数据分析实验报告p
第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出: 3画直方图,茎叶图,QQ 图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民 Stem-and-Leaf Plot Frequency Stem & Leaf 5.00 0 . 56788 2.00 1 . 03 数据分析实验报告 【最新资料,WORD 文档,可编辑修改】
1.00 1 . 7 1.00 2 . 3 3.00 2 . 689 1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验 数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下: (1)K—S检验 单样本 Kolmogorov-Smirnov 检验 身高 N 60 正态参数a,,b均值139.00 标准差7.064 最极端差别绝对值.089 正.045 负-.089 Kolmogorov-Smirnov Z .686 渐近显着性(双侧) .735 a. 检验分布为正态分布。 b. 根据数据计算得到。 结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。(2)W检验 正态性检验
结果:在Shapiro-Wilk 检验结果972.00=w ,p=0.174大于0.05 接受原假设,即数据来自正太总体。 习题1.5 5多维正态数据的统计量 均值向量为:)767.33,505.4,836.27,219.18(=- X
数据的收集、整理、描述与分析报告
数据的收集、整理与描述——备课人:发 【问题】统计调查的一般过程是什么?统计调查对我们有什么帮助?统计调查一般包括收集数据、整理数据、描述数据和分析数据等过程;可以帮助我们更好地了解周围世界,对未知的事物作出合理的推断和预测. 一、数据处理的一般程序 二、回顾与思考 Ⅰ、数据的收集 1、收集数据的方法(在收集数据时,为了方便统计,可以用字母表示调查的各种类型。) ①问卷调查法:为了获得某个总体的信息,找出与该信息有关的因素,而编制的一些带有问题的问卷调查。 ②媒体调查法:如利用报纸、、电视、网络等媒体进行调查。 ③民意调查法:如投票选举。 ④实地调查法:如现场进行观察、收集和统计数据。 例1、调查下列问题,选择哪种方法比较恰当。 ①班里谁最适合当班长()②正在播出的某电视节目收视率() ③本班同学早上的起床时间()④黄河某段水域的水污染情况() 2、收集数据的一般步骤: ①明确调查的问题;——谁当班长最合适 ②确定调查对象;——全班同学 ③选择调查方法;——采用推荐的调查方法 ④展开调查;——每位同学将自己心目中认为最合适的写在纸上,投入推荐箱 ⑤统计整理调查结果;——由一位同学唱票,另一位同学记票(划正字),第三位同学在旁边监督。 ⑥分析数据的记录结果,作出合理的判断和决策; 3、收集数据的调查方式 (1)全面调查 定义:考察全体对象的调查叫做全面调查。 全面调查的常见方法:①问卷调查法;②访问调查法;③调查法; 特点:收集到的数据全面、准确,但花费多、耗时长、而且某些具有破坏性的调查不宜用全面调查; (2)抽样调查 定义:只抽取一部分对象进行调查,然后根据调查数据来推断全体对象的情况,这种方法是抽样调查。 总体:要考察的全体对象叫做总体; 个体:组成总体的每一个考察对象叫做个体; 样本:从总体中抽取的那一部分个体叫做样本。 样本容量:样本中个体的数目叫做样本容量(样本容量没有单位); 特点:省时省钱,调查对象涉及面广,容易受客观条件的限制,结果往往不如全面调查准确,且样本选取不当,会增大估计总体的误差。 性质:具有代表性与广泛性,即样本的选取要恰当,样本容量越大,越能较好地反映总体的情况。(代表性:
数据图表展示、概括性度量
实验1 数据的收集、整理和图表展示 一、实验目的: 了解数据的收集方法,掌握在EXCEL、SPSS中如何进行数据的整理和图表展示。 二、实验环境: Microsoft EXCEL;加载EXCEL 宏:数据分析工具;SPSS分析软件 三、实验内容: 1、为评价家电行业售后服务的质量,随机抽取了由100个家庭构成的一个样本。服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。调查结果见1.1。 (1)指出上面的数据属于什么类型? (2)用Excel制作一张频数分布表; (3)绘制一张条形图,反映评价等级的分布。 2、为了确定灯泡的使用寿命(单位:h),在一批灯泡中随机抽取100只进行测试,所得结果见1.2。 (1)利用计算机对上面的数据进行排序; (2)以组距为10进行等距分组,整理成频数分布表; (3)根据分组数据绘制直方图,说明数据分布的特点。 (4)制作茎叶图,并与直方图作比较。 3、甲乙两个班各有40名学生,期末统计学考试成绩的分布见1.3。 (1)根据上面的数据,画出两个班考试成绩的复合柱形图、环形图和图饼图。 (2)比较两个班考试成绩分布的特点。 (3)画出雷达图,比较两个班考试成绩的分布是否相似。 4、1997年我国几个主要城市各月份的平均相对湿度数据见1.4,试绘制箱线图,并分析各城市平均相对湿度的分布特征。
实验2 数据的概括性度量 一、实验目的: 为了全面掌握数据分布的特征,需要找到反映数据分析特征的各个代表只。掌握在EXCEL、SPSS中如何进行数据特征值的计算。 二、实验环境: Microsoft EXCEL;加载EXCEL 宏:数据分析工具;SPSS分析软件 三、实验内容: 1、在excel中运用函数和描述统计两种方法计算反映集中、离散及分布形态的特征值; 2、运用SPSS对表2.1进行探索分析,计算不同性别收入情况的描述统计量,绘制茎叶图、箱线图,并进行正态性检验。 3、结合2种方法的计算结果,分析收入与性别是否有关系? 四、实验内容: 课堂独立完成上述实验内容,并提交到数字大学城。
矢量及栅格数据分析实验报告
. 信息工程学院资源环境学院《GIS原理》实验报告 实验名称矢量及栅格数据分析 实验时间2015.4.22 实验地点资环楼229 姓名 学号 班级遥感科学与技术131
《GIS原理》实验报告 一、实验目的及要求 1)掌握矢量数据插值分析、栅格数据重分类、叠加分析的基本原理; 2)熟悉ArcGis 中离散点数据插值分析的基本方法; 3)熟悉ArcGis 中栅格数据重分类、栅格计算器的基本操作; 4)熟悉ArcGis 中栅格数据分区统计的基本方法; 5)了解ArcGis 中缓冲区分析、按掩膜提取的基本方法。 二、实验设备及软件平台 ArcCatalog 10、ArcMap 10.2 三、实验原理 1)数据插值分析 2)栅格数据重分类原理 3)叠加分析的基本原理 四、实验容与步骤 1 空间插值分析 1)打开ArcMap中,将数据框更名为“任务1”,加入省边界图层。
2)将2011 年02 月27 日08 时观测资料.xls、2011 年02 月27日14 时.xls 通过Add Xy Data 功能,生成点图层。导出数据,分别命名为Obs2708.shp 和Obs2714.shp。 3)对Obs2708.shp 中的属性“温度”在四川围进行插值分析。可以通过“Arctoolbox->Spatial Analyst(空间分析)工具中的Interpolate to Raster(插值)工具选择。(本实验采用反距离权重法IDW),点插值成栅格表面。
4)通过属性中的符号系统,修改显示样式。
2 多栅格局域运算 1)启动ArcMap,添加数据框,并更名为“任务2”,将温度栅格数据IDW2708、IDW2714 加入。 2)确认是否选择扩展模块的许可。“自定义菜单(Customize)”中的“扩展模块Extensions”功能对话框中的Spatial Analyst 均已打钩。
数据分析实验报告(主成分分析)
实验八主成分分析 一、实验目的和要求 能利用原始数据与相关矩阵、协主差矩阵作主成分分析,并能理解标准化变量主成分与原始数据主成分的联系与区别; 能根据SAS输出结果选出满足要求的几个主成分. 实验要求:编写程序,结果分析. 实验内容:书上4.5 4.6 4.5 data examp4_5; input id x1-x8; cards; 1 8.35 23.53 7.51 8.6 2 17.42 10.00 1.04 11.21 2 9.25 23.75 6.61 9.19 17.77 10.48 1.72 10.51 3 8.19 30.50 4.72 9.78 16.28 7.60 2.52 10.32 4 7.73 29.20 5.42 9.43 19.29 8.49 2.52 10.00 5 9.42 27.93 8.20 8.14 16.17 9.42 1.55 9.76 6 9.16 27.98 9.01 9.32 15.99 9.10 1.82 11.35
7 10.06 28.64 10.52 10.05 16.18 8.39 1.96 10.81 8 9.09 28.12 7.40 9.62 17.26 11.12 2.49 12.65 9 9.41 28.20 5.77 10.80 16.36 11.56 1.53 12.17 10 8.70 28.12 7.21 10.53 19.45 13.30 1.66 11.96 11 6.93 29.85 4.54 9.49 16.62 10.65 1.88 13.61 12 8.67 36.05 7.31 7.75 16.67 11.68 2.38 12.88 13 9.98 37.69 7.01 8.94 16.15 11.08 0.83 11.67 14 6.77 38.69 6.01 8.82 14.79 11.44 1.74 13.23 15 8.14 37.75 9.61 8.49 13.15 9.76 1.28 11.28 16 7.67 35.71 8.04 8.31 15.13 7.76 1.41 13.25 17 7.90 39.77 8.49 12.94 19.27 11.05 2.04 13.29