心统集中量数、差异量数总结
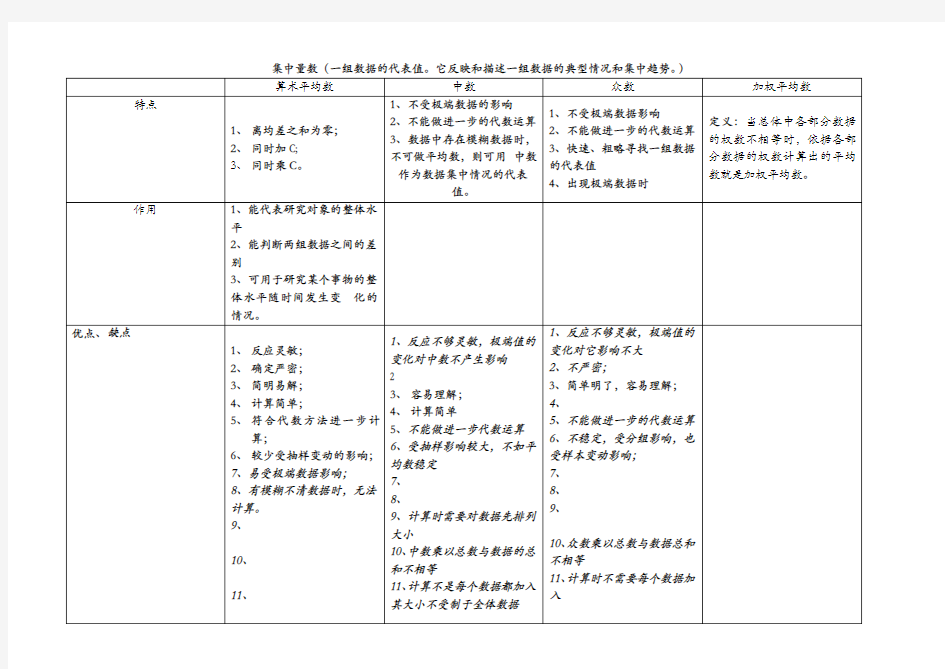

集中量数(一组数据的代表值。它反映和描述一组数据的典型情况和集中趋势。)
差异量数
1、同一团体不同观测值离散程度的比较
2、对于水平相差较大,但进行的是同一观测的各种团体离散程
度的比较。
使用时注意的问题:1、测量的数据要保证具有等距尺度。
2、观测工具要具有绝对零
3、差异系数只能用于一般的相对差异量的描述,至今尚无有效的假设检验的方法,因此对差异系数不能进行统计推论。标准分数:标准分数又称为基分数或Z分数,是以标准差为单位表示一个分数在团体中所处位置的相对位置量数。
性质:1、无实际单位,是以平均数为参照点,以标准差为单位的一个相对量;
2、一组原始分数转换得到的Z分数可以是正值,也可以是负值;
3、一组数据中,各个Z分数的标准差是1;
4、若原始数据呈正态分布,则转换得到的所有Z分数值的均值为0,标准差为1的标准正态分布。
优点:1、可比性
2、可加性
3、明确性
4、稳定性
?应用:1、用于比较几个分属性质不同的观测值在各自数据分布中相对位置的高低, 标准分数值越大,说明所处位置越高(前)。
2、计算不同质的观测值的总和或平均值,以表示在团体中的相对位置
3、表示标准测验分数
统计学名词解释超级大全
统计学名词解释超级大全第一章导论 统计学:一门阐明如何去采集、整理、显示、描述、分析数据和由数据得出结论的一系列概念、原理、原则、方法和技术的科学,是一门独立的、实用性很强的通用方法论科学。 教育统计学:专门研究如何搜集、整理、分析在心理和教育方面对实验或调查所获得的数字资料,如何根据这些资料所传递的信息,进行数学推论,找出客观规律的一门科学。 描述统计:对实验或调查所获得的数据加以整理(如制表、绘图),并计算其各种代表量数(如集中量数、差异量数、相关量数等),其基本思想是平均,如在集中量数中将原始数据进行平均,在差异量数中将离均差进行平均,在相关量数中将积差进行平均等等。 推断统计:又称抽样统计。它是根据对部分个体进行观测所得到的信息,通过概括性的分析、论证,在一定可靠程度上去推测相应团体。换言之,就是根据已知的情况推测未知情况。 实验设计:研究如何更加合理、有效地获得观测资料,如何更正确、更经济、更有效地达到实验目的,以揭示试验中各种变量关系的实验计划。 统计常态法则:从总体中随机抽取一部分个体所组成的样本,差不多可以保持总体的特征。这种样本特性保持着总体特性的现象叫做统计常态法则。 小数永存法则:第一个样本中所表现出的特性,在其他样本中也会存在,这就是小数永存法则。此处“小数”是指小数量的意思。 大量惰性原则:某一事物的某一性质或状态,在反复观察或试验中是保持不变的。
有效数字:指能影响测量准确性的数字。 变量:又称随机变量。具有变异性的数据。三个特性,离散型,变异性,规律性。 数据:某个数值一旦被取定了,则称这个数值为随机变量的一个观察值。即数据。 总体:性质相同的一类事物的全体。 个体:构成总体的每一基本单位或单元。 样本:总体抽出的部分个体。 参数:表示总体特征的量数。 统计量:直接从样本计算出的量数,代表样本的特征。 名称变量:指一事物与其他事物在属性、类别上不同。 顺序变量:事物的某一属性的多少或大小按顺序排列起来的变量。既无相等的单位又无绝对的零点的变量。 等距变量:只具有相等的单位,而没有绝对的零点的变量。 比率变量:既有相等的单位,又有绝对的零点的变量。 连续变量:指取值可以是某区间内任一数值的随机变量,它是指测量单位之间可以划分成无限多个细小单位,其数字形式多取小数。 离散变量:指测量单位之间不能再细分的数字资料,其数字形式常取整数。 计数数据:计算人或物的个数所获得的数据。 度量数据:用一定的测量工具或测量标准测量时所获得的数据。 指标:表明总体数量特征的概念和具体数值,又称统计指标,它是把各个个体的特征加总起来的综合结果。
差异量数
差异量数 对于一组数据资料,如果只通过求其集中量数,了解它的集中趋势,这并不能准确反映该群体的全貌。因为平均数相同的不同群体,在很多情况下,可能存在着较大的差异。例如,我们现在给出甲、乙、丙三组数据资料,每组都是5个数据,并且具有相同的平均值。 甲:56,66,76,86,96平均值为76 乙:70,72,76,80,82平均值为76 丙:66,71,76,81,86平均值为76 观察上面三组数据,我们可以发现,尽管三组的集中量数相同,但它们的离散程度明显存在着差异。乙组最集中,丙组居中,甲组最分散。如果用“全距”这一最简单的描述差异情况的量数来做比较,可以看出: 甲组差异量数最大,说明各数据值分散范围广并且参差不齐。 乙组差异量数最小,说明各数据值最集中、整齐。 丙组差异量数居中。 由此可知,为了客观认识数据资料的全貌,做出科学的判断,在比较各组数据资料平均值的同时,还要考虑其差异情况,只有这样,才能更准确可靠地掌握数据资料的全貌。 差异量数是代表一组数据变异程度或离散程度的量数。它反映了数据分布的离中趋势,即分化的程度。差异量数大,表示各数值分散的范围甚广且参差不齐;差异量数小,表示各数值甚为集中、整齐,其变动的范围小。 要想了解集中量数的代表性如何,可通过差异量数来进行判断。差异量数愈大,则集中量数的代表性愈小;差异量数愈小,则集中量数的代表性愈大。集中量数在量尺上反映为一个点,差异量数在量尺上反映为一段距离。只有很好地发挥二者的功能,才能对数据分布的全貌有一个比较明晰的了解。 差异量数大致分为绝对差异量数、相对差异量数和相对位置量数三类。绝对差异量数是反映一组数据离中趋势并以数据单位为单位的统计量,具体包括全距、平均差和标准差等。相对差异量数是一个比率值,不以数据单位为单位,它通常被用于比较两种测量单位不同的数据资料的差
统计学名词解释
训言 1. 此刻打盹,你将做梦;而此刻学习,你将圆梦。 2. 我荒废的今日,正是昨日殒身之人祈求的明日。 3. 觉得为时已晚的时候,恰恰是最早的时候。 4. 勿将今日之事拖到明日。 5. 学习时的苦痛是暂时的,未学到的痛苦是终生的。 6. 学习这件事,不是缺乏时间,而是缺乏努力。 7. 幸福或许不排名次,但成功必排名次。 8. 学习并不是人生的全部。但,既然连人生的一部分学习也无法征服,还能做什么呢? 9. 请享受无法回避的痛苦。 10. 只有比别人更早、更勤奋地努力,才能尝到成功的滋味。 11. 谁也不能随随便便成功,它来自彻底的自我管理和毅力。 12. 时间在流逝。 13. 现在淌的口水,将成为明天的眼泪。 14. 狗一样地学,绅士一样地玩。 15. 今天不走,明天要跑。 16. 投资未来的人是忠于现实的人。 17. 教育程度代表收入。 18. 一天过完,不会再来。 19. 即使现在,对手也不停地翻动书页。 20. 没有艰辛,便无所获。
第一章导论 统计学:一门阐明如何去采集、整理、显示、描述、分析数据和由数据得出结论的一系列概念、原理、原则、方法和技术的科学,是一门独立的、实用性很强的通用方法论科学。 教育统计学:专门研究如何搜集、整理、分析在心理和教育方面对实验或调查所获得的数字资料,如何根据这些资料所传递的信息,进行数学推论,找出客观规律的一门科学。 描述统计:对实验或调查所获得的数据加以整理(如制表、绘图),并计算其各种代表量数(如集中量数、差异量数、相关量数等),其基本思想是平均,如在集中量数中将原始数据进行平均,在差异量数中将离均差进行平均,在相关量数中将积差进行平均等等。 推断统计:又称抽样统计。它是根据对部分个体进行观测所得到的信息,通过概括性的分析、论证,在一定可靠程度上去推测相应团体。换言之,就是根据已知的情况推测未知情况。 实验设计:研究如何更加合理、有效地获得观测资料,如何更正确、更经济、更有效地达到实验目的,以揭示试验中各种变量关系的实验计划。 统计常态法则:从总体中随机抽取一部分个体所组成的样本,差不多可以保持总体的特征。这种样本特性保持着总体特性的现象叫做统计常态法则。 小数永存法则:第一个样本中所表现出的特性,在其他样本中也会存在,这就是小数永存法则。此处“小数”是指小数量的意思。 大量惰性原则:某一事物的某一性质或状态,在反复观察或试验中是保持不变的。 有效数字:指能影响测量准确性的数字。 变量:又称随机变量。具有变异性的数据。三个特性,离散型,变异性,规律性。 数据:某个数值一旦被取定了,则称这个数值为随机变量的一个观察值。即数据。 总体:性质相同的一类事物的全体。 个体:构成总体的每一基本单位或单元。 样本:总体抽出的部分个体。 参数:表示总体特征的量数。 统计量:直接从样本计算出的量数,代表样本的特征。 名称变量:指一事物与其他事物在属性、类别上不同。 顺序变量:事物的某一属性的多少或大小按顺序排列起来的变量。既无相等的单位又无绝对的零点的变量。 等距变量:只具有相等的单位,而没有绝对的零点的变量。 比率变量:既有相等的单位,又有绝对的零点的变量。 连续变量:指取值可以是某区间内任一数值的随机变量,它是指测量单位之间可以划分成无限多个细小单位,其数字形式多取小数。 离散变量:指测量单位之间不能再细分的数字资料,其数字形式常取整数。
第四章 差异量数
第四章差异量数 一、单选题 1.欲比较同一团体不同观测值的离散程度,最适合的指标是() A. 全距 B. 方差 C. 四分位距 D. 变异系数 2.在比较两组平均数相差较大的数据的分散程度时,宜用() A. 全距 B. 四分差 C. 离中系数 D. 相对标准差 3.已知平均数x= 4.0,s=1.2,当X=6.4时,其相应的标准分数为() A. 2.4 B. 2.0 C. 5.2 D. 1.3 4.求数据16,18,20,22,17的平均差() A. 18.6 B. 1.92 C. 2.41 D. 5 5.测得某班学生的物理成绩(平均78分)和英语成绩(平均70分),若要比较两者的离中趋势,应计算() A. 方差 B. 标准差 C. 四分差 D. 差异系数 6.某学生某次数学测验的标准分为2.58,这说明全班同学中成绩在他以下的人数百分比是(),如果是-2.58,则全班同学中成绩在他以上的人数百分比是() A. 99% ,99% B. 99%,1% C. 95%,99% D. 95%,95% 7.已知一组数据6,5,7,4,6,8的标准差是1.29,把这组中的每一个数据都加上5,然后再乘以2,那么得到的新数据组的标准差是() A. 1.29 B. 6.29 C. 2.58 D. 12.58 8.标准分数是以()为单位表示一个分数在团体中所处位置的相对位置量数。 A. 方差 B. 标准差 C. 百分位差 D. 平均差 9.在一组原始数据中,各个Z分数的标准差为() A. 1 B. 0 C. 根据具体数据而定 D. 无法确定 10.已知某小学一年级学生的平均体重为26kg,体重的标准差为3.2kg,平均身高110cm,标准差为6.0cm,问体重与身高的离散程度哪个大()? A. 体重离散程度大 B. 身高离散程度大 C. 离散程度一样 D. 无法比较 11.已知一组数据服从正态分布,平均数为80,标准差为10。Z值为-1.96的原始数据是() A. 99.6 B. 81.96 C. 60.4 D. 78.04 12.某次英语考试的标准差为5.1分,考虑到这次考试难度的题目不大,评分时给每位应试者都加上了10分,加分后成绩的标准差是() A.10 B. 15.1 C. 4.9 D. 5.1 13.某城市调查8岁儿童的身高情况,所用单位为厘米,根据这批数据计算得出的差异系数() A. 单位是厘米 B. 单位是米 C. 单位是平方厘米 D. 无单位
(完整版)统计学名词解释
统计学名词解释 第一章绪论 1.随机变量:在统计学上,把取值之间不能预料到什么值的变量。 2.总体:又称母全体、全域,指具有某种特征的一类事物的全体。 3.个体:构成总体的每个基本单元称为个体。 4.样本:从总体中抽取的一部分个体,称为总体的一个样本。 5.次数:指某一事件在某一类别中出现的数目,又称为频数。 6.频率:又称相对次数,即某一事件发生的次数被总的事件数目除,亦即某一数据出现的次数被这一组数据总个数去除。 7.概率:某一事物或某一情在某一总体中出现的比率。 8.观测值:一旦确定了某个值。就称这个值为某一变量的观测值。 9.参数:又称为总体参数,是描述一个总体情况的统计指标。 10.统计量:样本的那些特征值叫做统计量,又称特征值。 第二章统计图表 1.统计表:是由纵横交叉的线条绘制,并将数据按照一定的要求整理、归类、排列、填写在内的一种表格形式。一般由表号、名称、标目、数字、表注组成。 2.统计图:一般采用直角坐标系,通常横轴表示事物的组别或自变量x,称为分类轴。纵轴表示事物出现的次数或因变量,称为数值轴。一般由图号及图题、图目、图尺、图形、图例、图组成。 3.简单次数分布表:依据每一个分数值在一列数据中出现的次数或总计数资料编制成的统计表,适合数据个数和分布范围比较小的时候用。 4.分组次数分布表:数据量很大时,应该把所有的数据先划分在若干区间,然后将数据按其数值大小划归到相应区域的组别内,分别统计各个组别中包括的数据个数,再用列表的形式呈现出来,适合数据个数和分布范围比较大的时候用。 5.分组次数分布表的编制步骤: (1)求全距 (2)定组距和组数 (3)列出分组组距 (4)登记次数 (5)计算次数 6.分组次数分布的意义: (1)优点:A.可将杂乱无章数据排列成序,以发现各数据的出现次数及分布状况。B.可显示一组数据的集中情况和差异情况等。 (2)缺点:原始数据不见了,从而依据这样的统计表算出的平均值会与用原始数据算出的值有出入,出现误差,即归组效应。 7.相对次数分布表:用频数比率或百分数来表示次数 8.累加次数分布表:把各组的次数由下而上,或由上而下加在一起。最后一组的累加次数等于总次数。 9.双列次数分布表:对有联系的两列变量用同一个表表示其次数分布。
集中量数
集中量数 统计资料经过分组归类的初步整理和列表绘图之后,已经能够简化繁冗的数量而窥其分布的大概面貌。但如果要对数据资料进行深入的了解和研究,仅有图表是不够的,还必须计算出描述数据分布状况的特征量,包括集中量数、差异量数和相关量数等。本节的主要内容是介绍有关集中量数的计算。 在将数据资料进行初步整理所编制的次数分布表或图上,我们可以看出各组数据分布的次数虽然各有不同,但大部分数据都趋向于某点,这种向某点集中的现象,称为集中趋势。而代表数据的集中趋势的统计量被称为集中量数。例如,如果要分析两个班某个学科的考试分数,我们很难做到将两个班学生的分数加以一一对应的比较,因为学生的考试分数大多是不相同的,而且两个班的学生人数也不一定相等。在这种情况下,可以利用两班的平均分数进行比较,因为大多数的学生分数都分布在平均分数的附近,这里的平均分数就代表了某班某科的学生成绩的集中趋势。 常用的集中量数有算术平均数、中数、众数和几何平均数。 一. 算术平均数 (一)算术平均数的概念与性质 1.概念 算术平均数通常称为平均数、均值或均数。它是各变量值的总和除以变量总次数所得之商。因为“平均数”一词的英文是Mean ,所以一般用字母M 来表示。如果想表明平均数M 是由哪个变量计算得来的(或称某个变量的平均值),可以在该变量字母上面加一杠“—”来表示。如: 表示变量X 的平均数,表示变量Y 的平均数。 算术平均数是统计学中最常用的一种集中量数。算术平均数的基本运算公式为 简写为N X X ∑= (公式10—1) 式中:∑为希腊字母(读做Sigma ,西格玛),X 为算术平均数,N 为总次数,n X X X X 321为各变量值。 N X X X X X n ++++= 321
第三章 集中量数答案
第三章集中量数 一、单选题 1.一位教授计算了全班20个同学考试成绩的均值、中数和众数,发现大部分同学的考试成绩集中于高分段。下面哪句话不可能是正确的?() A. 全班65%的同学的考试成绩高于均值 B. 全班65%的同学的考试成绩高于中数 C. 全班65%的同学的考试成绩高于众数 D. 全班同学的考试成绩是负正态分布 2.一个N=10的总体,SS=200.其离差的和∑(X –μ)是() A. 14.14 B. 200 C. 数据不足,无法计算 D. 以上都不对 3.中数在一个分布中的百分等级是() A. 50 B. 75 C. 25 D. 50~51 4.平均数是一组数据的() A. 平均差 B. 平均误 C. 平均次数 D. 平均值 5.六名考生在作文题上的得分为12,8,9,10,13,15,其中数为() A. 12 B. 11 C. 10 D. 9 6.下列描述数据集中情况的统计量是() A. M M d μ B. Mo M d S C.S M Wσ D. M M d M g 7.对于下列实验数据:1,108,11,8,5,6,8,8,7,11,描述其趋势用()最为适宜,其值是() A. 平均数,14.4 B. 中数,8.5 C. 众数,8 D. 众数,11 8.一个n=10的样本其均值是21,在这个样本中增添了一个分数。得到的新样本均值是25,这个增添的分数值是() A. 40 B. 65 C. 25 D. 21 9.有一组数据其均值是20,对其中的每一个数据都加上10,那么得到的这组数据的均值是() A. 20 B. 10 C. 15 D. 30 10. 有一组数据其均值是25,对其中的每一个数据都乘以2,那么得到的这组数据的均值是() A. 25 B. 50 C. 27 D. 2 11.一个有10个数据的样本,它们中的每一个分别与20相减后所得的差相加是100,那么这组数据的均值是() A. 20 B. 10 C. 30 D. 50
第四章-差异量数
第一节 全距、百分位差、四分位差、平均差 一、全距 全距是一列数据中最大数与最小数的差距,又称极差,用符号Rg (Range )表示,其公式为 min max X X Rg -= 全距是说明数据离散程度最简单的统计量。 全距的局限:该统计量只依据分布中的两个极端值,未利用到分布的大部分信息。它不能反映观察值的整个变异度,样本的例数越多,全距越大,不够稳定。 二、百分位差 百分位差表示某两个百分位数之间差异程度的指标。常用的百分位差如793P P -, 1090P P -。 百分位数是指量尺上的一个点,在此点以下,包括数据分布中全部数据个数的一定百分比,符号为Pp 。其计算公式为: 例4-1:用下面的次数分布表计算该分布的百分位差P 90- P 10。 组别 f d 65~ 1 157 60~ 4 156 55~ 6 152 50~ 8 146 45~ 16 138 40~ 24 122 35~ 34 98 30~ 21 64 25~ 16 43 20~ 11 27 15~ 9 16 20~ 7 7 ∑ 100 — 解:先计算P 90 和P 10 第1步:确定P 百分位数对应的位置, ,i f F N p L P b b p ?-?+=1003.14110090157=?7 .15100 10 157=?
第2步:确定百分位数所在的分组区间,P 90在“50~”这组,P 10在“15~”这 组 第3步:确定公式中的符号,5.49=b L ,5.14=b L ,138=b F ,7=b F ,5=i ,8=f , 9=f 第4步:代入公式计算P 90 ,P 10 第5步:计算P 90-P 10 23.3233.1956.511090=-=-P P 答:该分布的百分位差P 90-P 10是32.23。 百分等级:任意分数在整个分数分布中所处的百分位置,百分等级是一种相对位置量数。计算公式为: 三、四分位差 四分位差是百分位差的特例,用于分析75P (3Q )与25P (1Q )之差的一半,即 21 3Q Q Q -= 四、平均差 (一)概念及计算公式 平均差是一组数内各个数据之间与平均数的绝对离差的平均数。用 A.D.或者M.D.表示。 计算公式为: 分组数据计算平均差 ])([100i L X f F N P b b R -+?=离差 平均差--------------------A.D..A.D i i i X n X n X X ∑= ∑-= 表示平均差 :AD N x f AD ∑= 56 .5158 138 3.1415.4990=?-+=P 33.1959 7 7.155.1410=?-+=P
统计学 第三章 集中趋势的测量
第三章集中趋势的测量 表示数据集中趋势的指标叫做集中量数,它是一组数据的代表值。集中量数比起个别数据来,更能准确地反映所研究的事物和现象的真实情况,是真值最好的估计值。当要用一个数值代表全部数据时,或两组数据要进行比较时,就要用到集中量数。常用的集中量数有三种:平均数,中数,众数。 第一节平均数 平均数通常是指算术平均数, 只有在需要与其它平均数相区别时,才使用算术平均数这一名称。 图3-1 集中量数在不同分布中的位置 一、算术平均数 算术平均数(Mean)符号X。是集中趋势的重要指标。 如果数据的分布形态是正态分布,算术平均数的位置处于正态分布曲线的中间,位于对称轴上(图3-1上)。在偏态分布中总处于曲线偏斜的一端(图3-1下)。 只有当数据相对集中,并且数据中没有极端数值的时候,平均数才具有代表性,才适合使用平均数表示集中趋势。 1.未分组数据的计算
计算未分组数据的平均数,是用全部数据的和除以数据个数。所得的值为整组数据的代表。数据少时使用计算器较为方便。 平均数的计算公式: N X X ∑= (3.1) 式中,X :原始数据;Σ:求和符号(希腊字母,读:sigma ),表示将所有的数据都加起来;N :数据个数; 2.分组数据的计算 当数据较多,或需要了解数据的分布形态已将数据分组后,可利用已列好的次数分布表计算平均数。 N X f X '∑= (3.2) 式中,f :各小组的数据个数;X’:各小组中数;Σ:和号; N : 数据总个数。 例题3-2:一项心理测验成绩得出的次数分布表如下,请求出平均成绩。 表3-1 心理测验成绩 分数 X ’ F FX ’ 35-39 37 5 185 30-34 32 12 384 25-29 27 20 540 20-24 22 27 594 15-19 17 25 425 10-14 12 19 228 5 – 9 7 7 49 Σ / 115 2405 计算步骤: (1)在表中求出各组次数与各组中点的乘积列fX’列。 (2)累加各组次数f 列、得出总数115 (3)累加乘积fX’列、得出总数2405。 (4)用公式3.2求出 X 。 计算: 9.201152405 =='∑= N X f X 答:115人的成绩平均数为20.9分。 二、加权平均数