基于IBM SPSS Modeler 14.2的数据挖掘
基于IBM SPSS Modeler14.2的数据挖掘
对某公司销售记录进行分析。该公司在2012.7.13-2010.8.17进行了发放优惠劵活动,产生了1291条记录,9个字段,每个字段的意义如表1所示。数据可以到下面地址下载:http://61.129.34.202/BIweb/eBay_business_case_v3.0.xlsx。
表1 记录中字段的意义
字段名字段类型字段意义
Cmpgn_name 标志活动名,均为Coupon campaign name
Control_yn 标志购买者类型: 控制:'c', 测试:'t'
Redeemer_YN 标志是否为重复购买者: 是:'y', 否:'n'
USER_ID 连续购买者ID
Gender 名义购买者性别: 女:'F',男:'M', 未知:'U'
sge 连续购买者年龄, age=-99 意味着信息丢失
CK_DATE 连续购买日期
BUY_QTY 连续购买商品数量
GMB 连续购买金额(美元)
下面利用IBM SPSS Modeler 14.2进行决策树、聚类分析、关联分析和回归分析。
(1)决策树分析
启动IBM SPSS Modeler 14.2,导入文件。在工作平台上,添加一个Excel源节点。双击该节点,文件类型设为“Excel 2007,2010(*.xlsx)”,导入文件为源Excel文件的路径,按名称DATA选择工作表,其他默认设置,如图15.87所示。
图15.87 导入文件
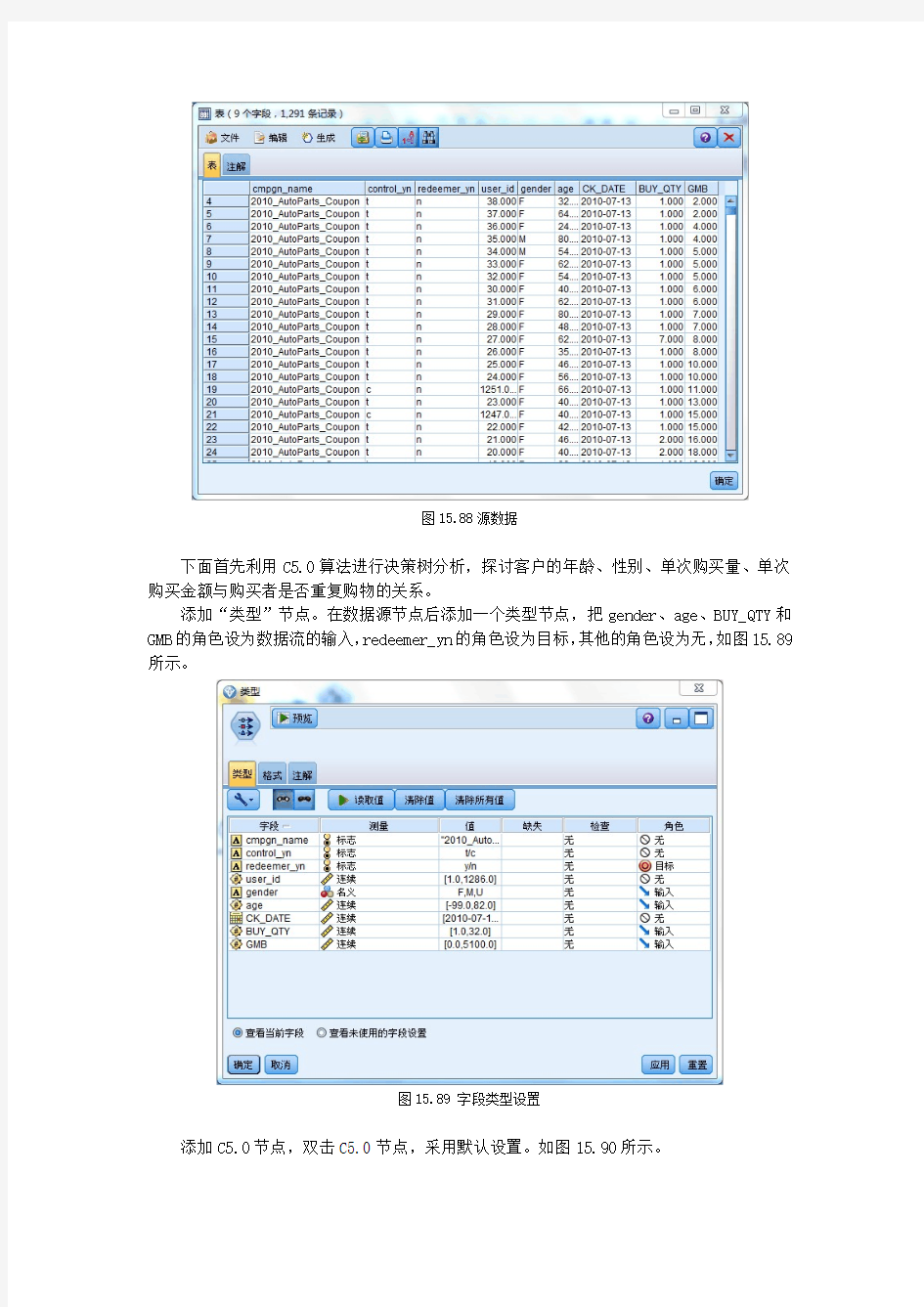
查看源数据。添加一个“表”节点,运行该表节点。如图15.88所示,共有9个字段,1291条记录。
图15.88源数据
下面首先利用C5.0算法进行决策树分析,探讨客户的年龄、性别、单次购买量、单次购买金额与购买者是否重复购物的关系。
添加“类型”节点。在数据源节点后添加一个类型节点,把gender、age、BUY_QTY和GMB的角色设为数据流的输入,redeemer_yn的角色设为目标,其他的角色设为无,如图15.89所示。
图15.89 字段类型设置
添加C5.0节点,双击C5.0节点,采用默认设置。如图15.90所示。
图15.90 C5.0节点设置
点击图15.90中的“运行”按钮,生成C5.0模型,右键浏览,如图15.91所示。可以看到生成的决策树,从中可以转化为一些规则,例如当GMB<=19时,购买者不是重复购买者。但是从业务角度来讲,更加关注哪些客户是重新购买者。可以看出,当每次购买金额GMB
超过19,且年龄在61且性别为男或未知时,顾客为重复购买者。
图15.91 C5.0决策树
预测变量重要性的情况如图15.92所示,可以看到年龄、GMB、gender、BUY_QTY对建
模的影响是逐渐降低的。
图15.92 预测变量重要性
在生成模型之后添加一个分析节点,运行可以得到图15.93所示的结果。可以看出,决策树的正确率为95.35%。
图15.93 分析决策树模型的质量
(2)聚类分析
下面再利用两步聚类算法对源数据进行分析,选择购买者的年龄、性别、单次购买量、购买金额、是否为重复购买者等字段作为聚类的属性。
在数据源节点后添加一个类型节点,把redeemer_yn、gender、age、BUY_QTY和GMB 的角色设置为输入,其他字段的角色设为无,如图15.94所示。
图15.94 类型节点设置
在类型节点后添加一个“两步”节点,双击该节点,如图15.95所示,采用默认设置。
图15.95 两步节点设置
点击图15.9中的“运行”按钮,生成两步模型,右键浏览该模型。两步模型的概要和聚类质量如图15.96所示,聚类质量比较好(值为0.7)。
图15.96 模型概要和聚类质量
两步聚类算法得到的4个聚类所占总记录的百分比为44.0%、43.0%、9.3%和3.7%,最大聚类与最小聚类的比值为11.83,如图15.97所示。
图15.97 两步模型聚类大小
两步模型各个字段的重要性如图15.98所示,其中每个字段重要性如下:Redeemer(1.0)、gender(0.96)、BUY_QTY(0.54)、GMB(0.09)和age(0.02)。
图 15.98 预测变量重要性
图15.99显示了聚类结果的详细信息,不仅可以看到每个聚类的大小,也能够看到每个字段对聚类的作用。
图15.99 聚类结果
(3)关联分析
下面利用Apriori算法对购买者的年龄、性别以及是否为重复购买者进行关联分析。
在数据源节点之后,添加一个“类型”节点,把redeemer_yn、gender和age的角色设置为两者,其他字段设为无,如图15.100所示。
图15.100 字段类型角色设置
在源数据中,存在着性别不确定的记录,对gender取值不确定的记录进行清除。在字段节点后添加一个“选择”节点,双击该节点,选择模式为“丢弃”,条件设置为gender=‘U’,如图15.101所示。
图15.101 选择节点设置
添加一个Apriori节点,双击该节点,设置最低支持度为5.0最小规则置信度为10.0,最大前项数为5,其他采用默认设置,如图15.102。
图15.102 Apriori节点设置
点击图15.102中的“运行”按钮,生成Apriori模型,右键浏览,如图15.103所示。可以看到,当redeemer_yn为‘y‘时,gender=M的支持度为9.373,置信度为63.636。当redeemer_yn为‘y’时,gender=F的支持度为9.373,置信度为36.364。当gender=M时,redeemer_yn为‘y’的支持度为51.278,置信度为11.631。
图15.103 生成关联规则
(4)回归分析
回归分析使用的数据为某企业销售数据,共1168个记录,包含BUY_QTY_Sum、BUY_QTY_Mean、GMB_Sum、GMB_Mean、Record_Count、redeemer_yn、gender、age等字段,分别表示客户购买商品总数量、客户单次购买商品平均数量、客户购买商品总金额、客户单次购买商品平均金额、客户购买次数、客户是否为重复购买者、客户性别和客户年龄。
下面利用IBM SPSS Modeler14.2分别进行线性回归和Logistic回归分析。回归分析主要
挖掘客户相关数据与GMB_Sum(客户购买商品总金额)之间的关系。客户相关数据包括age (客户的年龄)、gender (性别)、BUY_QTY_Sum (客户购买商品总数量)、BUY_QTY_Mean (客户单次购买商品平均数量)、GMB_Mean(客户单次购买商品平均金额),如图15.104所示。
图15.104 回归分析字段角色设置
预处理后的数据可到http://61.129.34.202/BIweb/syjj.htm下载,回归分析的数据流如图15.105所示。
图15.105 回归分析的数据流
(1)预测变量重要性。回归分析模型预测变量的重要性如图15.106所示,其中GMB_Mean重要性的值为0.86,BUY_QTY_Sum重要性值为0.14,其余变量对GMB_Sum 影响不大。
图15.106 预测变量重要性
(2)回归方程如图15.107所示。
图15.107 回归方程
(3)模型概要。从图15.108中可以看出,R方检验值为0.845,调整后的R方检验值为0.845,标准误差为101.426689。回归分析建立的模型质量可以接受。
图15.108 模型概要
(4)系数分析。图15.109为模型的系数分析,根据显著性可以知道,除age变量没通过显著性检验外,其他自变量均符合要求,且age变量对模型重要性较低。因此,可以得到回归分析得到的模型质量是较好的。
图15.109 模型系数分析
(5)回归模型分析。利用分析节点对回归模型分析的结果如图15.110所示。可以看出,线性相关度为0.919。本次分析的数据量较大,误差值域为[-678.294,2817.485])也是可以接受的。
图15.110 回归模型分析
Logistic回归分析主要分析客户是否重复购买redeemer_yn与客户相关数据的关系。客户的相关数据包括gender、age、BUY_QTY_Sum和GMB_Sum,如图15.111所示。
图15.111 Logistic回归分析变量角色设置
Logistics回归分析的数据流与回归分析相似,如图15.112所示。
图15.112 Logistics回归分析数据流程
Logistic回归分析预测变量重要性如图15.113所示。变量的重要性由BUY_QTY_Sum、GMB_Sum、gender和age逐渐递减,重要性的值为分别为0.56、0.17、0.16和0.11。
图15.113 预测变量重要性
得到的Logistic回归方程如图15.114所示。
图15.114 Logistic回归方程
图15.115为Logistic回归模型的记录处理汇总信息。可以看到,记录中的重复购买者数量为11,占总数的9%,非重复购买者数量为1157,男客户数量为585,占总数50.1%等信息。
图15.115 记录处理汇总
从图15.116所示的模型拟合信息可见,模型的显著性值为0.000<0.005,通过显著性检验。
图15.116 模型拟合信息
准判定系数是因变量变异的比例,Cox and Snell、Nagelkerke和Mcfadden等参数分别为0.078、0.775、0.765,如图15.117所示。可见除Cox and Snell外,其他两个参数值是较大的,即Logistic回归分析的模型质量较好。
图15.117准判定系数
参数分析主要分析各个参数的质量,如图15.118。其中B是指回归系数β的假设检验,
Std.Error是各个字段的标准差,Wald是参数的Wald检验值,主要是检验方程显著性水平,Sig为显著性水平。可以看到,常量(Intercept)、BUY_QTY_Sum和GMB_Sum的显著性值均小于0.05,age的显著性值为0.170,[gender=F]显著性值为0.358。尽管以上两个参数的显著性大于0.05,但是根据预测变量重要性可以,这两个参数在模型建模中较为不重要。因此, Logistic回归模型模拟质量是可以接受的。
图15.118 参数分析
利用分析节点对模型分析得到的结果如图15.119。可以看出,Logistic回归分析模型与能够准确预测1163条记录,预测错误的记录有5条,准确率达99.57%。
图15.119 模型分析
最后,再利用RFM模型分析用户购买的情况,为目标营销提供决策支持。
RFM模型是一种根据顾客在某段时间内购买情况,确定顾客价值的方法。其中R(recency)表示顾客最近一次购买的时间(距某个时间点),F(frequency)表示顾客在最近一段时间内购物的频率,M (monetary)表示顾客在最近一段时间内购物的金额。下面采用IBM SPSS Modeler 14.2中的RFM模型,对顾客数据(下载地址http://61.129.34.202/BIweb/eBay_business_case_v3.0.xlsx)进行分析,找出目标营销顾客。在此基础上,采用k-means方法进行聚类,分析每类顾客的特点。
首先读入数据,选择用户标签(user_id)、购买日期(CK_DATE)和购买额(GMB)作为分析字段。转换日期格式,添加一个填充节点,把CK_DATE字段转为data类型,如图15.120所示。
图15.120 转换日期类型
添加一个RFM汇总节点,如图15.121所示进行设置。
在RFM汇总节点后添加一个表节点,如图15.122所示。
图15.122 查看RFM汇总信息
选择RFM分析节点。本次分析的数据时间间隔较短,这里把频数、顾客的消费金额的权
重设置大些:近因、频数和货币的权重分别设置为10.0,40.0和20.0,如图15.123所示。
图15.123 RFM分析设置
在RFM节点后添加一个表节点,结果如图15.124所示,得到每一个顾客的近因、频数和货币得分,计算加权求和得到RFM得分。根据近因、频数和货币得分的情况,可以看出当客户在分析时间范围内重复购买时,顾客的频数得分较高;近因得分和货币得分与顾客最近一次购买时间和购买金额相关。根据RFM得分情况,可以把得分比较高的一些顾客作为目标
营销的对象。
图15.124 RFM分析结果
进一步地,把顾客的基本信息(年龄、性别等)以及由RFM分析得到的近因得分、频数得分、货币得分等作为k-means聚类算法的输入,如图15.125所示。
图15.125 设置k-means聚类角色
k-means聚类的结果如图15.126所示。可以看出,对于聚类1,货币得分为5、性别为男(M)、频数得分为1和近因得分为5,分别占该聚类总数的61.3%、100%、77.9%和35.7%,年龄均值为44.21。其他类别也可以进行类似的分析。可以对不同类别的顾客进行不同的促
销活动。
图15.126 k-means聚类分析上述数据挖掘的数据流如图15.127所示。
图15.127 数据流
数据挖掘研究现状及发展趋势
数据挖掘研究现状及发展趋势摘要:从数据挖掘的定义出发,介绍了数据挖掘的神经网络法、决策树法、遗传算法、粗糙集法、模糊集法和关联规则法等概念及其各自的优缺点;详细总结了国内外数据挖掘的研究现状及研究热点,指出了数据挖掘的发展趋势。 关键词:数据挖掘;挖掘算法;神经网络;决策树;粗糙集;模糊集;研究现状;发展趋势 Abstract:From the definition of data mining,the paper introduced concepts and advantages and disadvantages of neural network algorithm,decision tree algorithm,genetic algorithm,rough set method,fuzzy set method and association rule method of data mining,summarized domestic and international research situation and focus of data mining in details,and pointed out the development trend of data mining. Key words:data mining,algorithm of data mining,neural network,decision tree,rough set,fuzzy set,research situation,development tendency 1引言 随着信息技术的迅猛发展,许多行业如商业、企业、科研机构和政府部门等都积累了海量的、不同形式存储的数据资料[1]。这些海量数据中往往隐含着各种各样有用的信息,仅仅依靠数据库的查询检索机制和统计学方法很难获得这些信息,迫切需要能自动地、智能地将待处理的数据转化为有价值的信息,从而达到为决策服务的目的。在这种情况下,一个新的技术———数据挖掘(Data Mining,DM)技术应运而生[2]。 数据挖掘是一个多学科领域,它融合了数据库技术、人工智能、机器学习、统计学、知识工程、信息检索等最新技术的研究成果,其应用非常广泛。只要是有分析价值的数据库,都可以利用数据挖掘工具来挖掘有用的信息。数据挖掘典型的应用领域包括市场、工业生产、金融、医学、科学研究、工程诊断等。本文主要介绍数据挖掘的主要算法及其各自的优缺点,并对国内外的研究现状及研究热点进行了详细的总结,最后指出其发展趋势及问题所在。 江西理工大学
大数据挖掘商业案例
1.前言 随着中国加入WTO,国金融市场正在逐步对外开放,外资金融企业的进入在带来先进经营理念的同时,无疑也加剧了中国金融市场的竞争。金融业正在快速发生变化。合并、收购和相关法规的变化带来了空前的机会,也为金融用户提供了更多的选择。节约资金、更完善的服务诱使客户转投到竞争对手那里。即便是网上银行也面临着吸引客户的问题,最有价值的客户可能正离您而去,而您甚至还没有觉察。在这样一种复杂、激烈的竞争环境下,如何才能吸引、增加并保持最好的客户呢? 数据挖掘、模式(Patterns>等形式。用统计分析和数据挖掘解决商务问题。 金融业分析方案可以帮助银行和保险业客户进行交叉销售来增加销售收入、对客户进行细分和细致的行为描述来有效挽留有价值客户、提高市场活动的响应效果、降低市场推广成本、达到有效增加客户数量的目的等。 客户细分―使客户收益最大化的同时最大程度降低风险 市场全球化和购并浪潮使市场竞争日趋激烈,新的管理需求迫切要求金融机构实现业务革新。为在激烈的竞争中脱颖而出,业界领先的金融服务机构正纷纷采用成熟的统计分析和数据挖掘技术,来获取有价值的客户,提高利润率。他们在分析客户特征和产品特征的同时,实现客户细分和市场细分。 数据挖掘实现客户价值的最大化和风险最小化。SPSS预测分析技术能够适应用于各种金融服务,采用实时的预测分析技术,分析来自各种不同数据源-来自ATM、交易、呼叫中心以及相关分支机构的客户数据。采用各种分析技术,发现数据中的潜在价值,使营销活动更具有针对性,提高营销活动的市场回应率,使营销费用优化配置。 客户流失―挽留有价值的客户 在银行业和保险业,客户流失也是一个很大的问题。例如,抵押放款公司希望知道,自己的哪些客户会因为竞争对手采用低息和较宽松条款的手段而流失;保险公司则希望知道如何才能减少取消保单的情况,降低承包成本。 为了留住最有价值的客户,您需要开展有效的保留活动。然而,首先您需要找出最有价值的客户,理解他们的行为。可以在整个客户群的很小一部分中尽可能多地找出潜在的流失者,从而进行有效的保留活动并降低成本。接着按照客户的价值和流失倾向给客户排序,找出最有价值的客户。 交叉销售 在客户关系管理中,交叉销售是一种有助于形成客户对企业忠诚关系的重要工具,有助于企业避开“挤奶式”的饱和竞争市场。由于客户从企业那里获得更多的产品和服务,客户与企业的接触点也就越多,企业就越有机会更深入地了解客户的偏好和购买行为,因此,企业提高满足客户需求的能力就比竞争对手更有效。 研究表明,银行客户关系的年限与其使用的服务数目、银行每个账户的利润率之间,存在着较强的正相关性。企业通过对现有客户进行交叉销售,客户使用企业的服务数目就会增多,客户使用银行服务的年限就会增大,每个客户的利润率也随着增大。 从客户的交易数据和客户的自然属性中寻找、选择最有可能捆绑在一起销售的产品和服务,发现有价值的产品和服务组合,从而有效地向客户提供额外的服务,提高活期收入并提升客户的收益率。
数据挖掘商业案例
金融行业应用 1.前言 随着中国加入WTO,国内金融市场正在逐步对外开放,外资金融企业的进入在带来先进经营理念的同时,无疑也加剧了中国金融市场的竞争。金融业正在快速发生变化。合并、收购和相关法规的变化带来了空前的机会,也为金融用户提供了更多的选择。节约资金、更完善的服务诱使客户转投到竞争对手那里。即便是网上银行也面临着吸引客户的问题,最有价值的客户可能正离您而去,而您甚至还没有觉察。在这样一种复杂、激烈的竞争环境下,如何才能吸引、增加并保持最好的客户呢? 数据挖掘(Data Mining,DM)是指从大量不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、有用的信息和知识的过程。其表现形式为概念(Concepts)、规则(Rules)、模式(Patterns)等形式。用统计分析和数据挖掘解决商务问题。 金融业分析方案可以帮助银行和保险业客户进行交叉销售来增加销售收入、对客户进行细分和细致的行为描述来有效挽留有价值客户、提高市场活动的响应效果、降低市场推广成本、达到有效增加客户数量的目的等。 客户细分―使客户收益最大化的同时最大程度降低风险 市场全球化和购并浪潮使市场竞争日趋激烈,新的管理需求迫切要求金融机构实现业务革新。为在激烈的竞争中脱颖而出,业界领先的金融服务机构正纷纷采用成熟的统计分析和数据挖掘技术,来获取有价值的客户,提高利润率。他们在分析客户特征和产品特征的同时,实现客户细分和市场细分。 数据挖掘实现客户价值的最大化和风险最小化。SPSS预测分析技术能够适应用于各种金融服务,采用实时的预测分析技术,分析来自各种不同数据源-来自ATM、交易网站、呼叫中心以及相关分支机构的客户数据。采用各种分析技术,发现数据中的潜在价值,使营销活动更具有针对性,提高营销活动的市场回应率,使营销费用优化配置。 客户流失―挽留有价值的客户 在银行业和保险业,客户流失也是一个很大的问题。例如,抵押放款公司希望知道,自己的哪些客户会因为竞争对手采用低息和较宽松条款的手段而流失;保险公司则希望知道如何才能减少取消保单的情况,降低承包成本。 为了留住最有价值的客户,您需要开展有效的保留活动。然而,首先您需要找出最有价值的客户,理解他们的行为。可以在整个客户群的很小一部分中尽可能多地找出潜在的流失者,从而进行有效的保留活动并降低成本。接着按照客户的价值和流失倾向给客户排序,找出最有价值的客户。 交叉销售 在客户关系管理中,交叉销售是一种有助于形成客户对企业忠诚关系的重要工具,有助于企业避开“挤奶式”的饱和竞争市场。由于客户从企业那里获得更多的产品和服务,客户与企业的接触点也就越多,企业就越有机会更深入地了解客户的偏好和购买行为,因此,企业提高满足客户需求的能力就比竞争对手更有效。 研究表明,银行客户关系的年限与其使用的服务数目、银行每个账户的利润率之间,存在着较强的正相关性。企业通过对现有客户进行交叉销售,客户使用企业的服务数目就会增多,客户使用银行服务的年限就会增大,每个客户的利润率也随着增大。
数据挖掘经典案例
数据挖掘经典案例 当前,市场竞争异常激烈,各商家企业为了能在竞争中占据优势,费劲心思。使用过OLAP技术的企业都知道,OLAP技术能给企业带来新的生机和活力。OLAP技术把企业大量的数据变成了客户需要的信息,把这些信息变成了价值,提高了企业的产值和效益,增强了客户自身的竞争实力。 “啤酒与尿布”的故事家喻户晓,在IT界里,几乎是数据挖掘的代名词,那么各商家企业受了多少启发,数据挖掘又给他们带来了多少价值呢? 客户需求 客户面对大量的信息,用OLAP进行多维分析。如:一个网上书店,用OLAP技术可以浏览到什么时间,那个类别的客户买了多少书等信息,如果想动态的获得深层次的信息,比如:哪些书籍可以打包推荐,哪些书籍可以在销售中关联推出等等,就要用到数据挖掘技术了。 当客户在使用OLAP技术进行数据的多维分析的时候,联想到“啤酒与尿布”的故事,客户不禁会有疑问,能不能通过数据挖掘来对数据进行深层次的分析呢,能不能将数据挖掘和OLAP结合起来进行分析呢? SQL Server 2005 数据挖掘: SQL Server 2005的Data Mining是SQL Server2005分析服务(Analysis Services)中的一部分。数据挖掘通常被称为“从大型数据库提取有效、可信和可行信息的过程”。换言之,数据挖掘派生数据中存在的模式和趋势。这些模式和趋势可以被收集在一起并定义为挖掘模型。挖掘模型可以应用于特定的业务方案,例如:预测销售额、向特定客户发送邮件、确定可能需要搭售的产品、查找客户将产品放入购物车的顺序序列。 Microsoft 决策树算法、Microsoft Naive Bayes 算法、Microsoft 聚类分析算法、Microsoft 神经网络算法 (SSAS),可以预测离散属性,例如,预测目标邮件活动的收件人是否会购买某个产品。 Microsoft 决策树算法、Microsoft 时序算法可以预测连续属性,预测连续属性,例如,预测下一年的销量。 Microsoft 顺序分析和聚类分析算法预测顺序,例如,执行公司网站的点击流分析。 Microsoft 关联算法、Microsoft 决策树算法查找交易中的常见项的组,例如,使用市场篮分析来建议客户购买其他产品。 Microsoft 聚类分析算法、Microsoft 顺序分析和聚类分析算法,查找相似项的组,例如,将人口统计数据分割为组以便更好地理解属性之间的关系。 巅峰之旅之案例一:网上书店关联销售 提出问题 网上书店现在有了很强的市场和比较固定的大量的客户。为了促进网上书店的销售量的增长,各网上书店采取了各种方式,给客户提供更多更丰富的书籍,提供更优质服务,等方式吸引更多的读者。
数据挖掘研究及发展现状
数据挖掘技术的研究现状及发展方向 摘要:数据挖掘技术是当前数据库和人工智能领域研究的热点。从数据挖掘的定义出发,介绍了数据挖掘的神经网络法、决策树法、遗传算法、粗糙集法、模糊集法和关联规则法等概念及其各自的优缺点;详细总结了国内外数据挖掘的研究现状及研究热点,指出了数据挖掘的发展方向。 关键词:数据挖掘;神经网络;决策树;粗糙集;模糊集;研究现状;发展方向 The present situation and future direction of the data mining technology research Abstract: Data mining technology is hot spot in the field of current database and artificial intelligence. From the definition of data mining, the paper introduced concepts and advantages and disadvantages of neural network algorithm, decision tree algorithm, genetic algorithm, rough set method, fuzzy set method and association rule method of data mining, summarized domestic and international research situation and focus of data mining in details, and pointed out the development trend of data mining. Key words: data mining, neural network, decision tree, rough set, fuzzy set, research situation, development direction 0 引言 随着信息技术的迅猛发展,许多行业如商业、企业、科研机构和政府部门等都积累了海量的、不同形式存储的数据资料[1]。这些海量数据中往往隐含着各种各样有用的信息,仅仅依靠数据库的查询检索机制和统计学方法很难获得这些信息,数据和信息之间的鸿沟要求系统地开发数据挖掘工具,将数据坟墓转换成知识金砖,从而达到为决策服务的目的。在这种情况下,一个新的技术——数据挖掘(Data Mining,DM)技术应运而生[2]。数据挖掘正是为了迎合这种需要而产生并迅速发展起来的、用于开发信息资源的、一种新的数据处理技术。 数据挖掘通常又称数据库中的知识发现(Knowledge Discovery in Databases),是一个多学科领域,它融合了数据库技术、人工智能、机器学习、统计学、知识工程、信息检索等最新技术的研究成果,其应用非常广泛。只要是有分析价值的数据库,都可以利用数据挖掘工具来挖掘有用的信息。数据挖掘典型的应用领域包括市场、工业生产、金融、医学、科学研究、工程诊断等。本文主要介绍数据挖掘的主要算法及其各自的优缺点,并对国内外的研究现状及研究热点进行了详细的总结,最后指出其发展趋势及问题所在。 1 数据挖掘算法 数据挖掘就是从大量的、有噪声的、不完全的、模糊的、随机的实际应用数据中提取有效的、新颖的、潜在有用的知识的非平凡过程[3]。所得到的信息应具有先前未知、有效和实用三个特征。数据挖掘过程如图1所示。这些数据的类型可以是结构化的、半结构化的、甚至是异构型的。发现知识的方法可以是数学的、非数学的、也可以是归纳的。最终被发现了的知识可以用于信息管理、查询优化、决策支持及数据自身的维护等[4]。 数据选择:确定发现任务的操作对象,即目标对象; 预处理:包括消除噪声、推导计算缺值数据、消除重复记录、完成数据类型转换等; 转换:消减数据维数或降维; 数据开采:确定开采的任务,如数据总结、分类、聚类、关联规则发现或序列模式发现等,并确定使用什么样的开采算法; 解释和评价:数据挖掘阶段发现的模式,经过用户和机器的评价,可能存在冗余或无关的模式,这时需要剔除,使用户更容易理解和应用。十大经典算法如图2: 目前,数据挖掘的算法主要包括神经网络法、决策树法、遗传算法、粗糙集法、模糊集法、关联规则法等。
数据挖掘应用案例
网上书店关联销售 应用背景: 网上书店现在有了很强的市场和比较固定的大量的客户。为了促进网上书店的销售量的增长,各网上书店采取了各种方式,给客户提供更多更丰富的书籍,提供更优质服务,等方式吸引更多的读者。但是这样还不足够,给众多网上书店的商家们提供一种非常好的促进销售量增长,吸引读者的方法,就是关联销售分析。这种方法就是给客户提供其他的相关书籍,也就是在客户购买了一种书籍之后,推荐给客户其他的相关的书籍。这种措施的运用给他们带来了可观的效益。 这里介绍的关联销售并不是,根据网上书店的销售记录进行的比例统计,也区别于简单的概率分析统计,是用的关联规则算法。“啤酒和尿布”的故事足以证明了该算法的强大功能和产生的震撼效果。 那么,怎么来实现这样一个效果呢? 解决步骤: 首先,通过数据源,也就是销售记录。这里做数据挖掘模型,要用到两张表,一张表是会员,用会员ID号来代替;另一张表是那个会员买了什么书。应用SQL Server 2005的Data Mining工具,建立数据挖掘模型。 具体步骤如下: 第一步:定义数据源。选取的为网上书店的销售记录数据源(最主要的是User表和Sales表)。 第二步:定义数据源视图。在此建立好数据挖掘中事例表和嵌套表,并定义两者之间的关系,定义User为事例表(Case Table),Sales为嵌套表(Nested Table)。 第三步:选取Microsoft Association Rules(关联规则)算法,建立挖掘模型。 第四步:设置算法参数,部署挖掘模型。 第五步、浏览察看挖掘模型。对于关联规则算法来说,三个查看的选项卡。 A:项集:“项集”选项卡显示被模型识别为经常发现一起出现的项集的列表。在这里指的是经过关联规则算法处理后,发现关联在一起的书籍的集合。
文本数据挖掘及其应用
文本数据挖掘及其应用 摘要:随着Internet上文档信息的迅猛发展,文本分类成为处理和组织大量文档数据的关键技术。本文首先对文本挖掘进行了概述包括文本挖掘的研究现状、主要内容、相关技术以及热点难点进行了探讨,然后通过两个例子简单地说明了文本挖掘的应用问题。 关键词:文本挖掘研究现状相关技术应用 1 引言 随着科技的发展和网络的普及,人们可获得的数据量越来越多,这些数据多数是以文本形式存在的。而这些文本数据大多是比较繁杂的,这就导致了数据量大但信息却比较匮乏的状况。如何从这些繁杂的文本数据中获得有用的信息越来越受到人们的关注。“在文本文档中发现有意义或有用的模式的过程"n1的文本挖掘技术为解决这一问题提供了一个有效的途径。而文本分类技术是文本挖掘技术的一个重要分支,是有效处理和组织错综复杂的文本数据的关键技术,能够有效的帮助人们组织和分流信息。 2 文本挖掘概述 2.1文本挖掘介绍 数据挖掘技术本身就是当前数据技术发展的新领域,文本挖掘则发展历史更短。传统的信息检索技术对于海量数据的处理并不尽如人意,文本挖掘便日益重要起来,可见文本挖掘技术是从信息抽取以及相关技术领域中慢慢演化而成的。 1)文本挖掘的定义 文本挖掘作为数据挖掘的一个新主题引起了人们的极大兴趣,同时它也是一个富于争议的研究方向。目前其定义尚无统一的结论,需要国内外学者开展更多的研究以进行精确的定义,类似于我们熟知的数据挖掘定义。我们对文本挖掘作如下定义。 定义 2.1.1 文本挖掘是指从大量文本数据中抽取事先未知的可理解的最终可用的信息或知识的过程。直观地说,当数据挖掘的对象完全由文本这种数据类型组成时,这个过程就称为文本挖掘。 2 )文本挖掘的研究现状 国外对于文本挖掘的研究开展较早,50年代末,H.P.Luhn在这一领域进行了开创性的研究,提出了词频统计思想于自动分类。1960年,Maron发表了关于自动分类的第一篇论文,随后,众多学者在这一领域进行了卓有成效的研究工作。研究主要有围绕文本的挖掘模型、文本特征抽取与文本中间表示、文本挖掘算法(如关联规则抽取、语义关系挖掘、文本聚类与主题分析、趋势分析)、文本挖掘工具等,其中首次将KDD中的只是发现模型运用于KDT。 我国学术界正式引入文本挖掘的概念并开展针对中文的文本挖掘是从最近几年才开始的。从公开发表的有代表性的研究成果来看,目前我国文本挖掘研究还处于消化吸收国外相关的理论和技术与小规模实验阶段,还存在如下不足和问题: (1) 没有形成完整的适合中文信息处理的文本挖掘理论与技术框架。目前的中文文本挖掘研究只是在某些方面和某些狭窄的应用领域展开。在技术手段方面主要是借用国外针对英文语料的挖掘技术,没有针对汉语本身的特点,没有充分利用当前的中文信息处理与分析技术来构建针对中文文本的文本挖掘模型,限制了中文文本挖掘的进一步发展。 (2) 中文文本的特征提取与表示大多数采用“词袋”法,“词袋”法即提取文本高词频构成特征向量来表达文本特征。这样忽略了词在文本(句子)中担当的语法和语义角色,同样也忽略了词与词之间的顺序,致使大量有用信息丢失。而且用“词袋”法处理真实中文文本数据
数据挖掘中数据探索方法及应用
数据挖掘中数据探索方法及应用 摘要:随着科技的快速发展,大数据时代已经来临。面对大量的数据,为了从中提取到有用的信息,数据挖掘技术就应运而生。本文所要研究的数据探索,是数据挖掘过程中的重要组成部分,它既是数据预处理的前提,更是结论有效性的基础。本文借助spss软件,主要从数据质量分析和数据特征分析两个方面论述了数据探索的方法,并且通过实例演示了数据探索在解决实际数据问题中的作用。 关键词:数据挖掘;数据质量分析;数据特征分析;数据探索的应用 Abstract: With the rapid development of science and technology, the explosion of time data is ushered in. In order to extract useful information from a large number of data, data mining technology emerges. The data exploration we researched in this paper is an important part of data mining, which is the premise of data preprocessing and the basis of conclusion validity. With the help of SPSS software, we mainly from the two aspects of data quality analysis and data analysis discuss the data exploration methods. And we also demonstrate the role of data exploration in solving actual data problems. Key words:Data mining;Data quality analysis;Data analysis;Data exploration application
数据挖掘开发及应用研究
数据挖掘开发及应用研究 摘要:数据挖掘在当今的数字时代、网络时代以及大数据时代发展尤为迅猛,属于多学科、多领域的交叉学科,它在较短的时间内取得了令人瞩目的研究成果,并在社会的各个领域获得应用,表现了出巨大的优势和潜能。本文对数据挖掘的过程和数据挖掘技术进行了较为详细的介绍,并探讨了其应用领域和前景,旨在为数据挖掘理论与实践提供一些借鉴和新的思路。 关键词:数据挖掘;大数据;网络 中图分类号:TP311 文献标识码:A DOI: 10.3969/j.issn.1003-6970.2015.05.017 0 引言 数据挖掘是从大量的(或海量的)、不完全的、模糊的、有噪声的以及具有随性的数据中,对隐含的、具有潜在作用和有意义(有时称作有趣的)知识进行提取的过程。其主要任务是从数据集中发现模式。通过数据挖掘发现的模式形式可以多样,根据功能可分为预测性模式和描述性模式两种。在实际运用中,则可根据其实际作用划分为分类模式、预测模式、相关性分析模式、序列模式、聚类模式以及数据可视化等。数据挖掘涉及多种学科、技术和领域,因此也会有一
些不同的挖掘方法和实现。根据挖掘对象的不同,可分为关系数据库、空间数据库、文本数据源、时态数据库、多媒体数据库、遗产数据库和万维网Web等的挖掘技术;根据挖掘任务的不同,可将其分为分类或预测模型发现、聚类、关联规则发掘、数据汇总、序列模式发现、依赖关系或依赖模型发现、异常和趋势发现等;同时还可以根据挖掘方法进行划分,大致分为统计学方法、机器学习方法、数据库方法和神经网络方法等。 1 数据挖掘过程 首先,目标定义与数据准备。目标定义即是定义出明确的数据挖掘目标,数据挖掘的成败受到目标定义是否适度的影响,因此在目标定义的过程中技术人员需要具备丰富的数据挖掘经验,并与相关专家、最终用户实现紧密协作来实现,在明确实际工作的数据挖掘要求的同时,进行各种学习算法的对比,最终确定有效科学的算法。整个数据挖掘过程中数据准备占有最大的比例,约60%左右。数据准备阶段具体过程分为三步,即数据选择,数据预处理和数据变换。(1)数据选择(DataSeleetion):数据选择即是从已有的数据库或数据仓库中进行相关数据的提取,并形成目标数据(TargetData)。(2)数据预处理(DataProcessing):对参与提取的数据进行处理,从而使数据能够符合数据挖掘的要求。(3)数据变换(Data Transformation):数据变换的目的
《数据挖掘:你必须知道的32个经典案例》
第五章 经典的机器学习案例 机器学习是一门成熟的学科,它所能解决的问题涵盖多种行业。本章介绍了四种经典的机器学习算法,它们所关心的重点在于机器学习是如何将统计学和数据挖掘连接起来的。通过学习本章,读者可以见识到机器学习的特殊魅力,并明白机器学习与其他学科的异同。使读者可以熟练地应用机器学习算法来解决实际问题是本章的目标。 5.1 机器学习综述 在正式开始了解机器学习之前,我们首先要搞清楚这样一个问题:世界上是不是所有的问题都可以使用一行一行清楚无误的代码解决?举个例子,倘若我们想让一个机器人完成出门去超市买菜并回家这一任务,我们能不能在程序里详详细细地把机器人所有可能遇到的情况以及对策都写下来,好让机器人一条一条按着执行? 答案是“很难”。机器人在路上可能遭遇塑料袋儿、石头、跑动的儿童等障碍物,在超市可能遇到菜卖完了、菜篮挪动了位置等问题,把这些问题全部罗列出来是不太可能的,因此我们就难以使用硬性的、固定的程序来命令机器人完成这件事,我们需要的是一种灵活的、可以变化的程序。就像你去买菜时不用你妈告诉你路上看见有人打架要躲开,你就知道要躲开一样(即便你以前从来没有遇见过这种情况),我们希望机器人也可以根据经验学习到正确的做法,而不是必须依赖程序员一条一条地输入“IF……THEN……”。 美国人塞缪尔设计的下棋程序是另一个的经典机器学习算法。塞缪尔设计了一个可以依靠经验积累概率知识的下棋程序,一开始这个程序毫无章法,但四年以后,它就能够打败塞缪尔了,又过了三年,它战胜了美国的围棋冠军。这个下棋程序进步的方式和人类学习下棋的过程非常类似,如何让机器像人类一样学习,正是机器学习关心的事情。 不难想象,机器学习是一门多领域交叉的学科,它主要依赖统计学、概率论、逼近论等数学学科,同时也依赖算法复杂度、编译原理等计算机学科。通俗的说,机器学习首先将统计学得到的统计理论拿来进一步研究,然后改造成适合编译成程序的机器学习算法,最终才会应用到实际中。但机器学习和统计学仍有不同的地方,这种差异主要在于统计学关心理论是否完美,而机器学习关心实际效果是否良好。同时,机器学习侧重于归纳和总结,而不是演绎。 机器学习将统计学的研究理论改造成能够移植在机器上的算法,数据挖掘将机器学习的成果直接拿来使用。从这一意义上来说,机器学习是统计学和数据挖掘之间的桥梁。机器学习也是人工智能的核心,机器学习算法普遍应用于人工智能的各个领域。此外,机器学习和模式识别具有并列的关系,它们一个注重模仿人类的学习方式,一个注重模仿人类认识世界的方式。因此机器学习、数据挖掘、人工智能和模式识别等本来就属于一个不可分的整体,离开其他学科的支持,任何学科都难以独立生存下去。 本章介绍了语义搜索、顺序分析、文本分析和协同过滤这四种经典的机器学习算法,它们不仅理论完善,同时也具有广泛的应用。通过本章的学习,读者将看到机器学习在各行各业中的神奇作用以及广阔前景,并学会如何使用机器学习算法来解决实际问题。
数据挖掘在Web中的应用案例分析
[数据挖掘在Web中的应用] 在竞争日益激烈的网络经济中,只有赢得用户才能最终赢得竞争的优势。作为一个网站,你知道用户都在你的网站上干什么吗?你知道你的网站哪些部分最为用户喜爱、哪些让用户感到厌烦?什么地方出了安全漏洞?什么样的改动带来了显著的用户满意度提高、什么样的改动反而丢失了用户?你怎样评价你的网站广告条的效率、你知道什么样的广告条点击率最高吗?“知己知彼,才能百战不殆”,你真的了解自己吗?挑战的背后机会仍存,所有客户行为的电子化(Click Stream),使得大量收集每个用户的每一个行为数据、深入研究客户行为成为可能。如何利用这个机会,从这些“无意义”的繁琐数据中得到大家都看得懂的、有价值的信息和知识是我们面临的问题。 [问题]: 1.根据你所学的知识,思考从网站中所获取的大量数据中,我们能做哪些有意义的数据分 析? 基于WEB 使用的挖掘,也称为WEB 日志挖掘(Web Log Mining)。与前两种挖掘方式以网上的原始数据为挖掘对象不同,基于WEB 使用的挖掘面对的是在用户和网络交互的过程中抽取出来的第二手数据。这些数据包括:网络服务器访问记录、代理服务器日志记录、用户注册信息以及用户访问网站时的行为动作等等。WEB 使用挖掘将这些数据一一纪录到日志文件中,然后对积累起来的日志文件进行挖掘,从而了解用户的网络行为数据所具有的意义。我们前面所举的例子正属于这一种类型。 基于WEB 内容的挖掘:非结构化半结构化\文本文档超文本文档\Bag of words n-grams 词短语概念或实体关系型数据\TFIDF 和变体机器学习统计学(包括自然语言处理)\归类聚类发掘抽取规则发掘文本模式建立模式. 基于WEB 结构的挖掘:半结构化数据库形式的网站链接结构\超文本文档链接\边界标志图OEM 关系型数据图形\Proprietary 算法ILP (修改后)的关联规则\发掘高频的子结构发掘网站体系结构归类聚类. 基于WEB 使用的挖掘:交互形式\服务器日志记录浏览器日志记录\关系型表图形\Proprietary 算法机器学习统计学(修改后的)关联规则\站点建设改进与管理销建立用户模式. 2.根据你所学的数据挖掘知识,谈谈哪些数据挖掘技术可以应用于Web中,以这些数据挖 掘技术可以完成哪些功能? Web Mining 技术已经应用于解决多方面的问题,比如基于WEB 内容和结构的挖掘极大的帮助了我们从浩瀚的网络资源中更加快速而准确的获取所需要的资料,而基于使用的数据挖掘之威力,更是在商业运作上发挥的淋漓尽致,具体表现在: (1)对网站的修改能有目的有依据稳步的提高用户满意度 发现系统性能瓶颈,找到安全漏洞,查看网站流量模式,找到网站最重要的部分,发现用户的需要和兴趣,对需求强烈的地方提供优化,根据用户访问模式修改网页之间的连接,把用户想要的东西以更快且有效的方式提供给用户,在正确的地方正确的时间把正确的信息提供给正确的人。 (2)测定投资回报率 测定广告和促销计划的成功度 找到最有价值的ISP 和搜索引擎 测定合作和结盟网站对自身的价值
网络游戏运营中的数据挖掘技术及相关案例分析
网络游戏运营中的数据挖掘技术及相关案例分析 摘要 数据挖掘技术在网络游戏客户关系管理中的应用现今,数据挖掘技术已经在各个领域得以应用,并有了相当的发展。许多学者对数据挖掘的研究及其在客户关系管理中的应用上获得了相当的突破,很多行业因此获益匪浅。在我国,网络游戏作为一个新兴不久的行业,拥有着巨大的市场和庞大的潜力,但随之而来的是愈发激烈的市场竞争,一些主流的游戏运营商已经把目光投向了在传统行业中取得了巨大成功的客户关系管理体制。但是,不同于其他行业,网络游戏是建立在网络信息交流平台之上,它所搜集到的客户数据更为庞大和繁杂,那么怎样从如此庞大的数据中找到有效资料呢?这就需要应用到数据挖掘技术。本文简要介绍了网络游戏客户关系管理的模式和内容以及几种主要的数据挖掘技术;着重利用决策树玩家进行了分类、利用神经网络对玩家流失进行了分析、利用粗糙集对玩家信息进行了挖掘。通过上述分析论证了数据挖掘技术在网络游戏客户关系管理中应用的可行性和有效性。 关键词:网络游戏;客户关系管理;数据挖掘;应用 1 综述 “网络游戏”也被成为“在线游戏”(Online Games),是通过互联网进行、可以多人同时参与的电脑游戏,是通过人与人之间的互动以达到交流、娱乐和休闲的目的。网络游戏不同于其他行业,它建立在网络信息交流平台之上,因此,它所搜集到的客户数据更为庞大和繁杂,那么如何从如此庞大的数据中找到有效资料,又如何应用于客户关系管理之上,这便是我们需要去研究的问题。在我国,网络游戏是一个新兴的行业,对其研究多集中于法律的虚拟财产案件上,网络游戏客户关系管理方面的研究寥寥无几。虽然如此,但我们仍旧可以通过数据挖掘技术在其他行业上的客户关系管理中的应用里进行参考,进而对数据挖掘技术在网络游戏客户关系管理中的应用的可行性,有效性进行探讨。哈尔滨工程大学的鞠伟平,邓忆瑞所刊登的《基于决策树的数据挖掘方法在C R M 中的应用研究》中指出:“客户关系管理是一种旨在加强企业与客户之间关系的新的管理机制。其如何利用数据挖掘技术对客户数据进行深层分析,保留高价值客户、发掘潜力客户,实现在恰当的时间,为客户提供合适产品和服务是现在客户关系管理中的研究重点。本文将数据挖掘中的ID3 分类算法应用于CRM 系统中,不仅可以使企业更好地发现客户群特征,掌握市场动态,同时也将有助于企业的管理全面走向信息化。[3]” 山东财政学院的董宁所刊登的《数据挖掘技术在CRM 中的应用》中指出:“数据挖掘技术帮助企业管理客户生命周期的各个阶段,包括客户的识别、获取新的客户、让已有的客户创造更多的利润、保持住有价值的客户等。它能够帮助企业确定客户的特点,使企业能够为客户提供有针对性的服务……客户识别的关键问题是确定对企业有意义客户的标准……数据挖掘技术应用在对营销的反映情况的预测上。根据历史数据运用数据挖掘技术建立“客户行为反应”预测模型,对客户的未来行为进行预测……解决客户流失问题,可以使用数据挖掘方法对已经流失客户进行分类,并对每类流失客户的特征进行描述。然后,使用关联、近邻等挖掘技术和方法对现有客户消费行为进行分析,以确定每类客户流失的可能性,其中着重于发现那些流失可能性大的优质客户。[4]” 华中师范大学经济学院的曹萍刊登的《利用数据挖掘技术(DM)提升客户关系
大数据挖掘在媒体领域的应用教学文案
大数据挖掘在媒体领 域的应用
大数据挖掘在媒体领域的应用 背景 随着社会的进步和信息通信技术的发展,信息产生的数量越来越多,产生速度也越来越快。在这种情况下我们每天都接收着来自四面八方的信息,这些信息带给了我们极大的便利并改变着我们的生活。但是我们享受着海量的信息的同时也陷入了困顿,如今困扰我们的不是信息太少而是太多,多到让你不知如何选择,也无从辨别。那么,究竟如何从海量信息中准确提取出有价值的信息呢?这就涉及到一项核心技术——数据挖掘。 什么是数据挖掘? 数据挖掘(英语:Data mining),又称资料探勘、数据采矿。一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统和模式识别等诸多方法来实现上述目标。简单来说,数据挖掘就是从未经处理过的数据中提取信息的过程,重点是找到相关性和模式分析。
大数据和数据挖掘之间有什么关系? 大数据是指无法在可承受的时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产;而数据挖掘则是从大数据海量信息资源中通过数据计算分析获取有效信息的过程。因此,大数据可以看作是进行数据挖掘的一个前提条件。 大数据挖掘具有数据量大,结构复杂,数据更新速度快等特征。由于互联网发展速度加快,全球的数据量正在不断膨胀,这给数据挖掘的实施提出了挑战。 大数据挖掘的价值 我们在说大数据挖掘价值之前,先来看一个经典案例,即尿布和啤酒的故事。说的是在一家超市把尿布和啤酒摆在一起出售。但是这个奇怪的举措却使尿布和啤酒的销量双双增加了。后来经过分析才发现原来,美国的妇女们经常会嘱咐她们的丈夫下班以后要为孩子买尿布,而丈夫在买完尿布之后又要顺手买回自己爱喝的啤酒,因此啤酒和尿布放在一起使得两种商品的销量都大大增加。之所以能发现尿布和啤酒的关系,则是因为对超市一年多原始交易数字进行详细分析的结果。
多种数据挖掘技术相结合的应用实例分析_张如
第35卷第2期 唐山师范学院学报 2013年3月 Vol.35 No.2 Journal of Tangshan Teachers College Mar. 2013 ────────── 收稿日期:2012-10-30 作者简介:张如(1975-),女,福建福州人,硕士,讲师,研究方向为数据库、多媒体、网络。 -47- 多种数据挖掘技术相结合的应用实例分析 张 如 (福州职业技术学院 计算机系,福建 福州 350108) 摘 要:利用限制性关联规则挖掘技术与粗糙集理论挖掘技术相结合,挖掘教学信息表,去除无关联属性后,最终得出影响教师教学效果的各因素及其各自的影响程度。 关键词:教学评价;数据挖掘;关联规则;粗糙集 中图分类号:TP311.13 文献标识码: A 文章编号:1009-9115(2013)02-0047-03 DOI :10.3969/j.issn.1009-9115.2013.02.016 Analysis of a Variety of Data Mining Technology Combined Application Instance ZHANG Ru (Department of Computer, Fuzhou V ocation Technology Institute, Fuzhou 350108, China) Abstract: The restrictive association rules and rough set theory was combined to analyze the teaching information table. After removing unrelated attributes, it eventually comes to the various factors affecting the effectiveness of teaching and their respective impact. Key Words: Teaching evaluation; Association rules; data mining; rough set 随着计算机相关技术的飞速发展和教育模式的改变,各高职院校纷纷采用了科技化的管理方式,而在各种管理工作中,教学管理无疑是重中之重。各高职院校都会有自身的初级数据管理系统,这些管理系统提供了大量数据的存储、查询和报表的统计功能。但面对如此丰富的数据,我们似乎只能基于表面的数据得到简单的结论,而不能从中得到更加有用的信息来促进教学管理的改革。 教师是教学工作的主要承接者,也是主导教学质量的最关键因素。能否运用教师的教学评价数据,通过数据挖掘技术找出教师的课堂教学效果与教师本人自身综合素质的关系。而通过所得到的挖掘信息,相关部门就可以得出相应的决策信息,在进行班级排课时充分考虑不同素质的教师在一个教学班级的配置情况。本课题正是基于数据挖掘技术挖掘教学管理系统中的数据,从而提取出有利的信息帮助管理决策层进行相应的教学管理改革。 1 问题的提出 随着高职院校信息化建设的逐步深入,传统教学与管理模式己经远远不能满足高职院校建设与发展需要,高职 教育的核心工作就是教学工作,而提高教学质量是促进院校进行改革与发展的关键,建立科学有效的教学质量评价体系是加强各院校教学管理和提高教学质量的重要举措。而利用数据挖掘技术为高职院校的教学管理与决策工作服务,是当今高职教学及管理改革的重要步骤。教学质量评价[1]是院校让学生共同参与教学管理监督的一种手段,让学生参与评价,能较公正地评价教师的教学能力。但学校对此评价结果的认识似乎还停留在评优评先的层面,这对于这些数据来说是大材小用了。学校的决策层远没有认识到其中隐藏的巨大的信息资源。 教师的教学效果与教师本身素质中哪些素质有关系?找出其中的规律,将有助于决策层在安排教学工作时能考虑到这些因素对于教师教学工作的影响,并促进教学安排工作事半功倍。研究教师教学效果与教师本身的综合素质中哪些素质有联系,联系程度又是如何,是本课题探讨的二个重要的问题。 2 解决方案的研究 2.1 解决思路的引入
数据挖掘应用案例集
数据挖掘应用案例集:NBA教练如何布阵以提升获胜机会 (2009-11-23 23:58:13) 转载 分类:技术 标签: 杂谈 数据挖掘应用目前在国内的基本结论是“大企业成功案例少,中小企业需求小”。但是对于市场来说,如果不是真的“没有人买”所以“没有人卖”,那一定是创新的机会所在。个人的判断是,一个数据库只要有几十万以上记录,就有数据挖掘的价值。 搜集以下案例,希望有一定的启发和学习价值。 1. 哪些商品放在一起比较好卖? 这是沃尔玛的经典案例:一般看来,啤酒和尿布是顾客群完全不同的商品。但是沃尔玛一年内数据挖掘的结果显示,在居民区中尿布卖得好的店面啤酒也卖得很好。原因其实很简单,一般太太让先生下楼买尿布的时候,先生们一般都会犒劳自己两听啤酒。因此啤酒和尿布一起购买的机会是最多的。这是一个现代商场智能化信息分析系统发现的秘密。这个故事被公认是商业领域数据挖掘的诞生。 另外,大家都知道在沃尔玛牙膏的旁边通常配备牙刷,在货价上这样放置,牙膏和牙刷才能都卖的很好。 2. 库存预测 过去零售商依靠供应链软件、内部分析软件甚至直觉来预测库存需求。随着竞争压力的一天天增大,很多零售商(从主要财务主管到库存管理员)都开始致力于找到一些更准确的方法来预测其连锁商店应保有的库存。预测分析是一种解决方案。它能够准确预测哪些商店位置应该保持哪些产品。 使用Microsoft(R) SQL Server(TM) 2005 中的Analysis Services 以及SQL Server 数据仓库,采用数据挖掘技术可以为产品存储决策提供准确及时的信息。SQL Server 2005 Analysis Services 获得的数据挖掘模型可以预测在未来一周内一本书是否将脱销,准确性为98.52%。平均来说,预测该书是否将在未来两周内脱销的准确性为86.45%。详情见https://https://www.360docs.net/doc/773603502.html,/china/technet/prodtechnol/sql/2005/ipmvssas.mspx