Java Web 高性能开发,第 1 部分_ 前端的高性能
Java Web 高性能开发,第 1 部分: 前端的高性能
魏 强, 研究生, 东北大学
简介: Web 发展的速度让许多人叹为观止,层出不穷的组件、技术,只需要合理的组合、恰当的设置,就可以
让 Web 程序性能不断飞跃。所有 Web 的思想都是通用的,它们也可以运用到 Java Web。这一系列的文章,
将从各个角度,包括前端高性能、反向代理、数据库高性能、负载均衡等等,以 Java Web 为背景进行讲述,同时用实际的工具、实际的数据来对比被优化前后的 Java Web 程序。第一部分 , 主要讲解网页前端的性能优化,这一部分是最直接与用户接触的。事实证明,与其消耗大量时间在服务器端,在前端进行的优化更易获得用户的肯定。
发布日期: 2011 年 10 月 24 日
级别: 中级
访问情况 : 17642 次浏览
评论: 10 (查看 | 添加评论 - 登录)
平均分 (92个评分)
为本文评分
引言
前端的高性能部分,主要是指减少请求数、减少传输的数据以及提高用户体验,在这个部分,图片的优化显得至关重要。许多网站的美化,都是靠绚丽的图片达到的,图片恰恰是占用带宽的元凶。每个 img 标签,浏览器都会试图发起一个下载请求。本文就详细介绍了图片优化的几种方式,介绍了使用的工具以及优化后的结果。
图片压缩
减少图片的大小,可以明显的提高性能,而对于已有图片,要想减少图片的大小,只能改变图片的格式,这里推荐的是 PNG8 的格式,它可以在基本保持清晰度的情况下,减少图片的大小。知道这个原理以后,可以用 Windows 的画图工具、以及 PhotoShop 工具逐个的改变。但是这样做的缺点是单张处理,效率太慢。本文推荐一个在线转换工具 Smush.it,可以批量的进行压缩与转换。它的地址是:https://www.360docs.net/doc/7810238140.html,/ysmush.it。打开后效果如下图所示。
图 1. Yahoo 提供的在线压缩工具
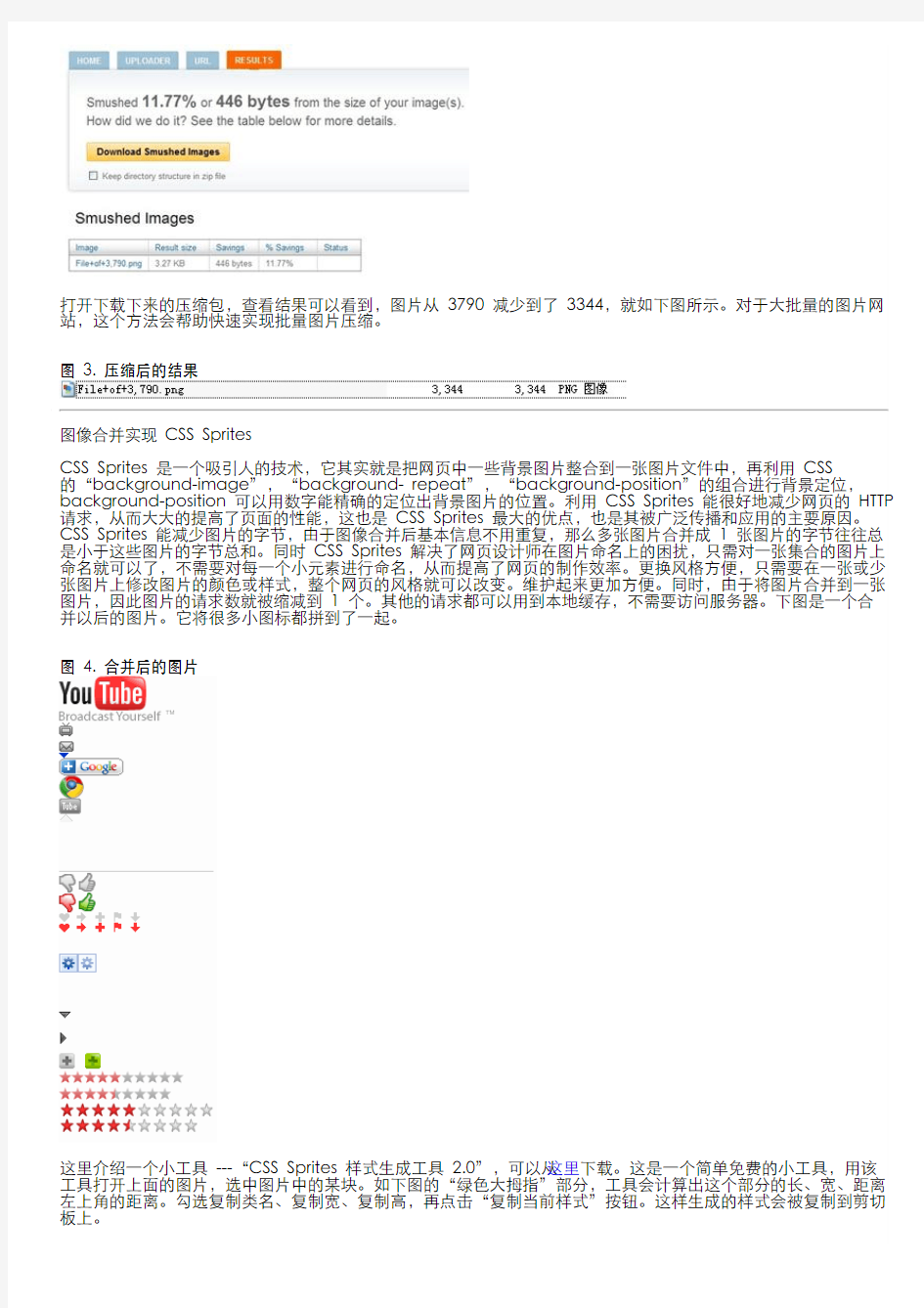
我们上传了一张大小为 3790K 的图片,待在线程序处理完毕后,点击 Download Smushed Images 下载查看结果。下载界面如下图所示。
图 2. 压缩后的结果
打开下载下来的压缩包,查看结果可以看到,图片从 3790 减少到了 3344,就如下图所示。对于大批量的图片网
站,这个方法会帮助快速实现批量图片压缩。
图 3. 压缩后的结果
图像合并实现 CSS Sprites
CSS Sprites 是一个吸引人的技术,它其实就是把网页中一些背景图片整合到一张图片文件中,再利用 CSS
的“background-image”,“background- repeat”,“background-position”的组合进行背景定位,
background-position 可以用数字能精确的定位出背景图片的位置。利用 CSS Sprites 能很好地减少网页的 HTTP 请求,从而大大的提高了页面的性能,这也是 CSS Sprites 最大的优点,也是其被广泛传播和应用的主要原因。
CSS Sprites 能减少图片的字节,由于图像合并后基本信息不用重复,那么多张图片合并成 1 张图片的字节往往总是小于这些图片的字节总和。同时 CSS Sprites 解决了网页设计师在图片命名上的困扰,只需对一张集合的图片上命名就可以了,不需要对每一个小元素进行命名,从而提高了网页的制作效率。更换风格方便,只需要在一张或少张图片上修改图片的颜色或样式,整个网页的风格就可以改变。维护起来更加方便。同时,由于将图片合并到一张图片,因此图片的请求数就被缩减到 1 个。其他的请求都可以用到本地缓存,不需要访问服务器。下图是一个合并以后的图片。它将很多小图标都拼到了一起。
图 4. 合并后的图片
这里介绍一个小工具 ---“CSS Sprites 样式生成工具 2.0”,可以从 这里下载。这是一个简单免费的小工具,用该工具打开上面的图片,选中图片中的某块。如下图的“绿色大拇指”部分,工具会计算出这个部分的长、宽、距离左上角的距离。勾选复制类名、复制宽、复制高,再点击“复制当前样式”按钮。这样生成的样式会被复制到剪切板上。
图 5. 小工具的使用
生成的 CSS 代码如清单 1 所示。
清单 1. 小工具生成的 CSS 代码
.d i v_6148{w i d t h:18p x;h e i g h t:20p x;b a c k g r o u n d-p o s i t i o n:-17p x-209p x;}
将这段代码运用在网页上,它的代码如下清单所示。
清单 2. 测试 CSS Sprites 代码
.d i v_6148
{
w i d t h:18p x;
h e i g h t:20p x;
b a
c k g r o u n d-i m a g e:u r l(c s s-s p r i t e s-s o u r c e.g i f);
b a
c k g r o u n d-p o s i t i o n:-17p x-209p x;
}
打开测试网页显示结果如下图所示。
图 6. 测试网页效果
可以看到,网页只显示工具选择的“绿色大拇指”部分,这样的代码可以运用在网页的多个部分,而图片只需要下载一次,这就是该技术的最大优势,减少了因为小图片引起的多个请求。
多域名请求
有时候,图片数据太多,一些公司的解决方法是将图片数据分到多个域名的服务器上,这在一方面是将服务器的请求压力分到多个硬件服务器上。另一方面,是利用了浏览器的特性。一般来说,浏览器对于相同域名的图片,最多用 2-4 个线程并行下载。不同浏览器的并发下载数,都是不同的,并发数如下清单所示。
清单 3. 各浏览器的并发下载数
B r o w s e r s H T T P/1.1H T T P/1.0
I E6,724
I E866
F i r e F o x228
F i r e F o x366
S a f a r i3,444
C h r o m e1,26?
C h r o m e344
O p e r a9.63,10.00a l p h a44
而相同域名的其他图片,则要等到其他图片下载完后才会开始下载。 这里我做了一个测试,选择了多个相同域名的图片在同一网页上。代码如清单 5 所示。
清单 4. 单域名的多图片下载
接下来,使用 FireFox 的 Firebug 插件监控网络。结果如下图所示。
图 7. 单域名多图片的监控效果
可以看到,相同域名的多张图片,它们下载的起始点是存在延迟的。它们并不是并行下载。当我们将其中的 3 张图片换成别的域名图片。如清单 6 所示。
清单 5. 多域名多图片下载
再次查看网络监控,可以看到,这些图片是并行下载的。
图 8. 多域名多图片测试结果
多域名的下载固然很好,但是太多域名并不太好,一般在 2-3 个域名下载就差不多。
图像的 BASE64 编码
不管如何,图片的下载始终都要向服务器发出请求,要是图片的下载不用向服务器发出请求,而可以随着 HTML 的下载同时下载到本地那就太好了。而目前,浏览器已经支持了该特性,我们可以将图片数据编码成 BASE64 的字符串,使用该字符串代替图像地址。假设用 S代表这个 BASE64 字符串,那么就可以使用 src="data:image/png;base64,S"> 来显示这个图像。可以看出,图像的数据包含在了 HTML 代码里,无需再次访问服务器。那么图像要如何编码成 BASE64 字符串呢?可以使用 在线的工具---“Base64 Online”,这个工具可以上传图片将图片转换为 BASE64 字符串。当然,如果读者有兴趣,完全可以自己实现一个 BASE64 编码工具,比如使用 Java 开发,它的代码就如清单 7 所示。 清单 6. BASE64 的 Java 代码 p u b l i c s t a t i c S t r i n g g e t P i c B A S E64(S t r i n g p i c P a t h){ S t r i n g c o n t e n t=n u l l; t r y{ F i l e I n p u t S t r e a m f i s=n e w F i l e I n p u t S t r e a m(p i c P a t h); b y t e[]b y t e s=n e w b y t e[f i s.a v a i l a b l e()]; f i s.r e a d(b y t e s); c o n t e n t=n e w s u n.m i s c.B A S E64E n c o d e r().e n c o d e(b y t e s);//具体的编码方法 f i s.c l o s e(); }c a t c h(E x c e p t i o n e){ e.p r i n t S t a c k T r a c e(); } r e t u r n c o n t e n t; } 本文编码了一个图像,并且将编码获得的 BASE64 字符串,写到了 HTML 之中,如下清单 8 所示。 清单 7. 嵌入 BASE64 的测试 HTML 代码 由于图片数据包含在了 BASE64 字符串中,因此无需向服务器请求图像数据,结果显示如下图所示。 图 9. BASE64 显示图像 然而这种策略并不能滥用,它适用的情况是浏览器连接服务器的时间 > 图片下载时间,也就是发起连接的代价要大于图片下载,那么这个时候将图片编码为 BASE64 字符串,就可以避免连接的建立,提高效率。如果图片较大的话,使用 BASE64 编码虽然可以避免连接建立,但是相对于图像下载,请求的建立只占很小的比例,如果用BASE64,对于动态网页来说图像缓存就会失效(静态网页可以缓存),而且 BASE64 字符串的总大小要大于纯图片的大小,这样一算就非常不合适了。因此,如果你的页面已经静态化,图像又不是非常大,可以尝试 BASE64 编 码,客户端会将网页内容和图片的 BASE64 编码一起缓存;而如果你的页面是动态页面,图像还较大,每次都要下载 BASE64 字符串,那么就不能用 BASE64 编码图像,而正常引用图像,从而使用到浏览器的图像缓存,提高下载速度。从现实我们接触的角度看,如一些在线 HTML 编辑器,里面的小图标,如笑脸等,都使用到了 BASE64 编码,因为它们非常小,数量多,BASE64 可以帮助网页减少图标的请求数,提高效率。 GZIP 压缩 为了减少传输的数据,压缩是一个不错的选择,而 HTTP 协议支持 GZIP 的压缩格式,服务器响应的报头包含Content-Encoding: gzip,它告诉浏览器,这个响应的返回数据,已经压缩成 GZIP 格式,浏览器获得数据后要进行解压缩操作。这在一定程度可以减少服务器传输的数据,提高系统性能。那么如何给服务器响应添加 Content-Encoding: gzip 报头,同时压缩响应数据呢?如果你用的是 Tomcat 服务器,打开 $tomcat_home$/conf/server.xml 文件,对 Connector 进行配置,配置如清单 9 所示。 清单 8. TOMCAT 配置清单 m a x T h r e a d s="150"m i n S p a r e T h r e a d s="25"m a x S p a r e T h r e a d s="75" e n a b l e L o o k u p s=" f a l s e"r e d i r e c t P o r t="8443"a c c e p t C o u n t="100" c o n n e c t i o n T i m e o u t="20000" d i s a b l e U p l o a d T i m e o u t="t r u e"U R I E n c o d i n g="u t f-8" c o m p r e s s i o n="o n" c o m p r e s s i o n M i n S i z e="2048" n o C o m p r e s s i o n U s e r A g e n t s="g o z i l l a,t r a v i a t a" c o m p r e s s a b l e M i m e T y p e="t e x t/h t m l,t e x t/x m l"/> 我们为 Connector 添加了如下几个属性,他们意义分别是: compression="on" 打开压缩功能 compressionMinSize="2048" 启用压缩的输出内容大小,这里面默认为 2KB noCompressionUserAgents="gozilla, traviata" 对于以下的浏览器,不启用压缩 compressableMimeType="text/html,text/xml, image/png" 压缩类型 有时候,我们无法配置 server.xml,比如如果我们只是租用了别人的空间,但是它并没有启用 GZIP,那么我们就要使用程序启用 GZIP 功能。我们将需要压缩的文件,放到指定的文件夹,使用一个过滤器,过滤对这个文件夹里文件的请求。 清单 9. 自定义 Filter 压缩 GZIP //监视对g z i p C a t e g o r y文件夹的请求 @W e b F i l t e r(u r l P a t t e r n s={"/g z i p C a t e g o r y/*"}) p u b l i c c l a s s G Z I P F i l t e r i m p l e m e n t s F i l t e r{ @O v e r r i d e p u b l i c v o i d d o F i l t e r(S e r v l e t R e q u e s t r e q u e s t,S e r v l e t R e s p o n s e r e s p o n s e, F i l t e r C h a i n c h a i n)t h r o w s I O E x c e p t i o n,S e r v l e t E x c e p t i o n{ S t r i n g p a r a m e t e r=r e q u e s t.g e t P a r a m e t e r("g z i p"); //判断是否包含了A c c e p t-E n c o d i n g请求头部 H t t p S e r v l e t R e q u e s t s=(H t t p S e r v l e t R e q u e s t)r e q u e s t; S t r i n g h e a d e r=s.g e t H e a d e r("A c c e p t-E n c o d i n g"); //"1".e q u a l s(p a r a m e t e r)只是为了控制,如果传入g z i p=1,才执行压缩,目的是测试用 i f("1".e q u a l s(p a r a m e t e r)&&h e a d e r!=n u l l&&h e a d e r.t o L o w e r C a s e().c o n t a i n s("g z i p")){ H t t p S e r v l e t R e s p o n s e r e s p=(H t t p S e r v l e t R e s p o n s e)r e s p o n s e; f i n a l B y t e A r r a y O u t p u t S t r e a m b u f f e r=n e w B y t e A r r a y O u t p u t S t r e a m(); H t t p S e r v l e t R e s p o n s e W r a p p e r h s r w=n e w H t t p S e r v l e t R e s p o n s e W r a p p e r( r e s p){ @O v e r r i d e p u b l i c P r i n t W r i t e r g e t W r i t e r()t h r o w s I O E x c e p t i o n{ r e t u r n n e w P r i n t W r i t e r(n e w O u t p u t S t r e a m W r i t e r(b u f f e r, g e t C h a r a c t e r E n c o d i n g())); } @O v e r r i d e p u b l i c S e r v l e t O u t p u t S t r e a m g e t O u t p u t S t r e a m()t h r o w s I O E x c e p t i o n{ r e t u r n n e w S e r v l e t O u t p u t S t r e a m(){ @O v e r r i d e p u b l i c v o i d w r i t e(i n t b)t h r o w s I O E x c e p t i o n{ b u f f e r.w r i t e(b); } }; } }; c h a i n. d o F i l t e r(r e q u e s t,h s r w); b y t e[]g z i p D a t a=g z i p(b u f f e r.t o B y t e A r r a y()); r e s p.a d d H e a d e r("C o n t e n t-E n c o d i n g","g z i p"); r e s p.s e t C o n t e n t L e n g t h(g z i p D a t a.l e n g t h); S e r v l e t O u t p u t S t r e a m o u t p u t=r e s p o n s e.g e t O u t p u t S t r e a m(); o u t p u t.w r i t e(g z i p D a t a); o u t p u t.f l u s h(); }e l s e{ c h a i n. d o F i l t e r(r e q u e s t,r e s p o n s e); } } //用G Z I P压缩字节数组 p r i v a t e b y t e[]g z i p(b y t e[]d a t a){ B y t e A r r a y O u t p u t S t r e a m b y t e O u t p u t=n e w B y t e A r r a y O u t p u t S t r e a m(10240); G Z I P O u t p u t S t r e a m o u t p u t=n u l l; t r y{ o u t p u t=n e w G Z I P O u t p u t S t r e a m(b y t e O u t p u t); o u t p u t.w r i t e(d a t a); }c a t c h(I O E x c e p t i o n e){ }f i n a l l y{ t r y{ o u t p u t.c l o s e(); }c a t c h(I O E x c e p t i o n e){ } } r e t u r n b y t e O u t p u t.t o B y t e A r r a y(); } …… } 该程序的主体思想,是在响应流写回之前,对响应的字节数据进行 GZIP 压缩,因为并不是所有的浏览器都支持GZIP 解压缩,如果浏览器支持 GZIP 解压缩,会在请求报头的 Accept-Encoding 里包含 gzip。这是告诉服务器浏览器支持 GZIP 解压缩,因此如果用程序控制压缩,为了保险起见,还需要判断浏览器是否发送 accept-encoding: gzip 报头,如果包含了该报头,才执行压缩。为了验证压缩前后的情况,使用 Firebug 监控请求和响应报头。 清单 10. 压缩前请求 G E T/t e s t P r o j e c t/g z i p C a t e g o r y/t e s t.h t m l H T T P/1.1 A c c e p t:*/* A c c e p t-L a n g u a g e:z h-c n A c c e p t-E n c o d i n g:g z i p,d e f l a t e U s e r-A g e n t:M o z i l l a/4.0(c o m p a t i b l e;M S I E6.0;W i n d o w s N T5.1;S V1) H o s t:l o c a l h o s t:9090 C o n n e c t i o n:K e e p-A l i v e 清单 11. 不压缩的响应 H T T P/1.1200O K S e r v e r:A p a c h e-C o y o t e/1.1 E T a g:W/"5060-1242444154000" L a s t-M o d i f i e d:S a t,16M a y200903:22:34G M T C o n t e n t-T y p e:t e x t/h t m l C o n t e n t-L e n g t h:5060 D a t e:M o n,18M a y200912:29:49G M T 清单 12. 压缩后的响应 H T T P/1.1200O K S e r v e r:A p a c h e-C o y o t e/1.1 E T a g:W/"5060-1242444154000" L a s t-M o d i f i e d:S a t,16M a y200903:22:34G M T C o n t e n t-E n c o d i n g:g z i p C o n t e n t-T y p e:t e x t/h t m l C o n t e n t-L e n g t h:837 D a t e:M o n,18M a y200912:27:33G M T 可以看到,压缩后的数据比压缩前数据小了很多。压缩后的响应报头包含 Content-Encoding: gzip。同时Content-Length 包含了返回数据的大小。GZIP 压缩是一个重要的功能,前面提到的是对单一服务器的压缩优化,在高并发的情况,多个 Tomcat 服务器之前,需要采用反向代理的技术,提高并发度,而目前比较火的反向 代理是 Nginx(这在后续的文章会进行详细的介绍)。对 Nginx 的 HTTP 配置部分里增加如下配置。 清单 13. Nginx 的 GZIP 配置 g z i p o n; g z i p_m i n_l e n g t h1000; g z i p_b u f f e r s48k; g z i p_t y p e s t e x t/p l a i n a p p l i c a t i o n/x-j a v a s c r i p t t e x t/c s s t e x t/h t m l a p p l i c a t i o n/x m l; 由于 Nginx 具有更高的性能,利用该配置可以更好的提高性能。在高性能服务器上该配置将非常有用。 懒加载与预加载 预加载和懒加载,是一种改善用户体验的策略,它实际上并不能提高程序性能,但是却可以明显改善用户体验或减 轻服务器压力。 预加载原理是在用户查看一张图片时,就将下一张图片先下载到本地,而当用户真正访问下一张图片时,由于本地 缓存的原因,无需从服务器端下载,从而达到提高用户体验的目的。为了实现预加载,我们可以实现如下的一个函数。 清单 14. 预加载函数 f u n c t i o n p r e l o a d(c a l l b a c k){ v a r i m a g e O b j=n e w I m a g e(); i m a g e s=n e w A r r a y(); i m a g e s[0]="p r e_i m a g e1.j p g"; i m a g e s[1]="p r e_i m a g e2.j p g"; i m a g e s[2]="p r e_i m a g e3.j p g"; f o r(v a r i=0;i<=2;i++){ i m a g e O b j.s r c=i m a g e s[i]; i f(i m a g e O b j.c o m p l e t e){//如果图片已经存在于浏览器缓存,直接调用回调函数 c a l l b a c k.c a l l(i m a g e O b j); }e l s e{ i m a g e O b j.o n l o a d=f u n c t i o n(){//图片下载完毕时异步调用c a l l b a c k函数 c a l l b a c k.c a l l(i m a g e O b j);//将回调函数的t h i s替换为I m a g e对象 }; } } } f u n c t i o n c a l l b a c k() { a l e r t(t h i s.s r c+“已经加载完毕,可以在这里继续预加载下一组图片”); } 上面的代码,首先定义了 Image 对象,并且声明了需要预加载的图像数组,然后逐一的开始加载 (.src=images[i])。如果已经在缓存里,则不做其他处理;如果不在缓存,监听 onload 事件,它会在图片加载完毕时调用。 软件开发的几种模式 2015-05-27彭波模模搭 模模搭开发日志057软件开发的几种模式归类 1.边做边改模型(Build-and-Fix Model) 好吧,其实现在许多产品实际都是使用的“边做边改”模型来开发的,特别是很多小公司产品周期压缩的太短。在这种模型中,既没有规格说明,也没有经过设计,软件随着客户的需要一次又一次地不断被修改。 在这个模型中,开发人员拿到项目立即根据需求编写程序,调试通过后生成软件的第一个版本。在提供给用户使用后,如果程序出现错误,或者用户提出新的要求,开发人员重新修改代码,直到用户和测试等等满意为止。 这是一种类似作坊的开发方式,边做边改模型的优点毫无疑问就是前期出成效快。 对编写逻辑不需要太严谨的小程序来说还可以对付得过去,但这种方法对任何规模的开发来说都是不能令人满意的,其主要问题在于: 1)缺少规划和设计环节,软件的结构随着不断的修改越来越糟,导致无法继续修改; 2)忽略需求环节,给软件开发带来很大的风险; 3)没有考虑测试和程序的可维护性,也没有任何文档,软件的维护十分困难。 2. 瀑布模型(Waterfall Model) 瀑布模型是一种比较老旧的软件开发模型,1970年温斯顿·罗伊斯提出了著名的“瀑布模型”,直到80年代都还是一直被广泛采用的模型。 瀑布模型将软件生命周期划分为制定计划、需求分析、软件设计、程序编写、软件测试和运行维护等六个基本活动,并且规定了它们自上而下、相互衔接的固定次序,如同瀑布流水,逐级下落。 在瀑布模型中,软件开发的各项活动严格按照线性方式进行,当前活动接受上一项活动的工作结果,实施完成所需的工作内容。当前活动的工作结果需要进行验证,如验证通过,则该结果作为下一项活动的输入,继续进行下一项活动,否则返回修改。 瀑布模型优点是严格遵循预先计划的步骤顺序进行,一切按部就班比较严谨。 瀑布模型强调文档的作用,并要求每个阶段都要仔细验证。但是,这种模型的线性过程太理想化,已不再适合现代的软件开发模式,其主要问题在于: 1)各个阶段的划分完全固定,阶段之间产生大量的文档,极大地增加了工作量; 2)由于开发模型是线性的,用户只有等到整个过程的末期才能见到开发成果,从而增加了开发的风险; 3)早期的错误可能要等到开发后期的测试阶段才能发现,进而带来严重的后果。 4)各个软件生命周期衔接花费时间较长,团队人员交流成本大。 5)瀑布式方法在需求不明并且在项目进行过程中可能变化的情况下基本是不可行的。 3. 迭代模型(stagewise model)(也被称作迭代增量式开发或迭代进化式开发) 是一种与传统的瀑布式开发相反的软件开发过程,它弥补了传统开发方式中的一些弱点,具有更高的成功率和生产率。 在迭代式开发方法中,整个开发工作被组织为一系列的短小的、固定长度(如3周)的小项目,被称为一系列的迭代。每一次迭代都包括了需求分析、设计、实现与测试。采用这种方法,开发工作可以在需求被完整地确定之前启动,并在一次迭代中完成系统的一部分功能或业务逻辑的开发工作。再通过客户的反馈来细化需求,并开始新一轮的迭代。 软件开发管理新模式 传统的软件开发模式是以技术为主、以管理为辅,项目经理多数来自于技术开发人员,既要负责整个项目的推进,又要负责技术研发工作。尽管他是项目组中的技术权威,但他的管理能力不一定行,这样往往会使项目在管理方面陷入泥潭。 在实践了多个软件开发项目后,我们采用了一种新的软件项目开发管理模式—在项目组同时设立了项目经理和技术经理。 项目经理负责总控,管理项目日常事务,包括客户需求调研、项目组内部(公司部门之间)的组织与协调、人员管理、项目计划、风险管理、文档管理及评审等。 技术经理(也有的称之为构架设计师)则专职负责技术研发的管理和指导,包括需求分析、设计、编码和测试等工作。 采用这种模式,软件项目组按照既定的规范进行开发,不仅确保了产品的技术质量,还保证了项目组文档的完整性。 本篇文章将展示一个软件开发的部分流程,并通过这一流程,说明项目经理和技术经理如何在项目开发过程中相互配合。该流程是一个比较通用和规范的开发流程。 一个基本的软件开发流程,通常包括项目立项、计划、需求获取与分系、概要设计、详细设计、编码、测试、软件发布和软件维护阶段,如图所示。 在实际开发过程中,许多活动是并行或迭代的,在某一个时间段可能同时进行多项活动,或者是某一活动可能会要求返回到上一个阶段再次进行(精化)。 基于以上流程,项目经理和技术经理在各个开发阶段的具体活动(本过程覆盖大多数而非全部的软件生命周期,且不包括维护阶段)的职责各有不同,需要相互协调和相互补充。 1、项目立项 此阶段工作以项目经理为主,技术经理为辅。 项目经理:全面规划项目工作的内容,确定目标市场、技术指标和应用要求,划定项目工作范围和交付成果,明确项目实现的总体设想和实施方案;明确项目需要用到的各种资源,与技术经理共同预估项目的工作量和成本;提交《项目任务书》,报公司上级领导审批,进行立项评审。 技术经理:负责确定项目中的新技术的可行性;协助项目经理明确项目需要用到的各种资源,协助预估项目的工作量和成本。 2、项目计划 立项通过的项目才能进入正式的开发工作,此阶段工作同样以项目经理为主,技术经理为辅。 项目经理:召集关键技术人员(可以是其他项目组的成员),详细估算项目的工作量和成本;明确各阶段的活动内容,以及各阶段需要完成的软件工作产品,制定《工作拆分表(WBS)》,作为项目开展工作和详细计划的基础;对项目进行一系列的风险评估,进行详细进度计划安排,落实时间进度、资源(人员、设备)、技术、资金等,完成《软件开发计划》及进度表;组织项目组成员和高层对此阶段完成的文档进行评审。 技术经理:参与详细估算项目的工作量和成本;协助项目经理完成《软件开发计划》及《进度表》;参与评审本阶段提交的文档。 3、需求获取与分析 从这一阶段开始,项目开发管理的重心开始转移,一直到测试任务完成以前,项目开发的工作都是以技术经理为主导,项目经理只是辅助监督技术经理按照流程的标准和要求完成任务。 需求的获取是一个不断反复、不断深化的过程,可能需要多次,并一直到软件开发活动结束为止。为使需求调研更有效果、针对性更强,此阶段开始前,建议由项目经理和技术经理共同准备一份《需求调研问卷》,将需要调研的问题详细罗列在问卷中,并根据问卷展开调研。问卷中的问题最初以客户的高层需求为主,随着设计与开发的深入,问题逐渐细化为系统实现的技术细节。 技术经理:与项目经理共同准备《需求调研问卷》,审核问卷中的问题;参与需求调研;调研结束后,根据项目需求报告界定的工作范围和应用方案的设计思路,进一步深入细化应用方案,描述将要开发的系统中包含的业务流程、约定、数据源、报表格式等,整理成《软件需求规格说明书》或《软件用例说明书》;指导测试组完成《系统测试用例》;参与评审本阶段提交的需求文档。 项目经理:参与准备《需求调研问卷》,审核问卷中的问题;参与需求调研;协助技术经理整理《软件需求规格说明书》;指导测试组完成《软件测试计划》;组织项目组成员对完 几种常用软件开发工具比较(2008-10-27 10:11:59) 标签:职场it [转]近日和公司的系统分析员探讨了几种开发工具的特性,由其总结了下面的内容。 文章客观评价了各种开发工具的优缺点,本人把文章拿来和大家一起讨论一下,欢迎专业人事补充和指正。 一、跨平台特性 VB:无★ PB:WINDOWS家族, Solaris,Macintosh ★★★ C++ Builder/Dephi:WINDOWS家族,Linux ★★★ VC:无★ JAVA:所有能够运行JAVA虚拟机的操作系统★★★★ 二、组件技术支持 VB:COM,ActiveX ★★★ PB:COM,JavaBean,Jaguar,UserObject使用:CORBA+Acti veX ★★★ C++ Builder/Dephi:COM, ActiveX CORBA(本身自带CORBA中间件VisiBroker,有丰富向导)★★★★★ VC:COM,ActiveX,CORBA(没有任何IDE支持,是所有C编译器的功能,需要CORBA中间件支持) ★★★ JAVA:JavaBean,CORBA;ActiveX ★★★★ 三、数据库支持级别 数据访问对象: VB:DAO,ADO,RDO功能相仿;★ PB:Transaction,DwControl,可绑定任何SQL语句和存储过程,数据访问具有无与比拟的灵活性★★★★ C++ Builder/Dephi:具有包括DataSource,Table,Query,Midas,ADO在内的二十多个组件和类完成数据访问★★★ VC:同VB,但有不少类库可供使用,但极不方便,开发效率很低★★ JAVA:JAVA JDBC API,不同的IDE具有不同的组件★★ 数据表现对象: VB:DBGriD,与数据库相关的数据表现控件只有此一种,只能表现简单表格数据,表现手段单一★ PB:DataWindow对象(功能异常强大,其资源描述语句构成类似HTML的另外一种语言,可在其中插入任何对象,具有包括DBGrid在内的数百种数据表现方法),只此一项功能就注定了PB在数据库的功能从诞生的那 一天起就远远超过了某些开发工具今天的水平★★★★★ C++ Builder/Dephi:具有包括DBGrid,DBNavigator,DBEdit,DBLookupListBox在内的15 个数据感知组件,DecisionCube,DecisionQuery在内的6个数据仓库组件和包括QRChart, QRExpr在内的20多个报表组建,可灵活表现数据★★★ 软件开发模式有哪些? 快速原型模型:(需要迅速造一个可以运行的软件原型,以便理解和澄清问题) 快速原型模型允许在需求分析阶段对软件的需求进行初步的非完全的分析和定义,快速设计开发出软件系统的原型(展示待开发软件的全部或部分功能和性能 (过程:用户对该原型进行测试评定,给出具体改善的意见以及丰富的细化软件需求,开发人员进行修改完善) 优点: 克服瀑布模型的缺点,减少由于软件需求不明确带来的开发风险 缺点: A、所选用的开发技术和工具不一定符合主流的发展 B、快速建立起来的系统加上连续的修改可能会造成产品质量底下 增量模型:(采用随着日程时间的进展而交错的线性序列,每一个线性徐磊产生软件的一个可发布的“增量”,第一个增量往往就是核心的产品) 与其他模型共同之处:它与原型实现模型和其他演化方法一样,本质都是迭代 与原型实现模型不同之处:它强调每一个增量均发布一个可操作产品,(它不需要等到所有需求都出来,只要摸个需求的增量包出来即可进行开发) 优点: 1、人员分配灵活,一开始不需要投入大量人力资源 2、当配备人员不能在限定的时间内完成产品时,它可以提供一种先推出核心产品的途径,可现发布部分功能给用户(对用户起镇静作用) 3、增量能够有计划的管理技术风险 缺点: 1、如果增量包之间存在相交的情况且未很好处理,则必须做全盘系统分析 注: 这种模型将功能细化后分别开发的方法较适应于需求经常改变的软件开发过程 原型模型:(样品模型,采用逐步求精的方法完善原型) 主要思想: 先借用已有系统作为原型模型,通过“样品”不断改进,使得最后的产品就是用户所需要的。原型模型通过向用户提供原型获取用户的反馈,使开发出的软件能够真正反映用户的需求, 采用方法: 原型模型采用逐步求精的方法完善原型,使得原型能够“快速”开发,避免了像瀑布模型一样在冗长的开发过程中难以对用户的反馈作出快速的响应 优点: 项目类别开发策略项目开发模式 别墅历经大起大落,如今又渐渐引起发展商的注意。广州碧桂园的别墅在几天内被抢购一空,许多收入丰厚者抱怨买不到好别墅。在中国现阶段开发别墅极具挑战性,很多国际常理不通行,比如某知名楼盘的别墅被称作农民房,却仍然供不应求。该讲深入调查别墅市场的盈利模型,为我们提出了现实指南。 第1 操作环节:别墅项目开发前期战略分析 分析A:别墅项目特性剖析 别墅的词义出自“别业”是指本宅门外供游玩休养的园林房屋,《宋书.谢灵运传》中有“修营别业,傍水依山,尽幽居之美。”改革开放前,别墅数量少,仅仅出现在一些风景胜地供度假租用,或由少数特殊人拥有,比如广州的华侨新村。八十年代后,随着房地产的发展,别墅的含义也逐渐扩大了,在中高档有花园的小住宅都被称做“别墅”,甚至高层公寓顶层复式单元也被冠名“空中别墅”,功能上不仅是游憩之处,还有居住、办公、投资等多种用途。 别墅面积标准从100-1000 平方米均有,可满足不同经济水平的需求。在组合上可以独立,也有并联和多联体,横向干扰少,没有竖向干扰。占地由几十平方到一百,庭院可以满足观景、娱乐、停车等要求。结构简单、工期短,不论坡地、水池均可建造,造型和空间可以随业主兴趣、基地条件而千变万化,因此受到广泛欢迎。但由于占地和市政投资不经济,因而售价高,政府从节约土地资源出发,也有一定限制。 未来的别墅发展,有几个值得关注的方向: (1)生态型。着重节约能源,改善地域气候,最大限度表现和利用自然环境。 2)智能化。重在运用最高技术设备,提高生活工作的效率和舒适度。 (3)个性化。极力体现业主或建筑师的个人风格,营造出独特的基地环境和室内空间。 (4)社区化。创造一定的群体氛围,方便信息交换和商务活动,丰富社区文 BT、BOT、PPP模式的含义 BT模式的含义 1. BT是英文Build(建设)和Transfer(移交)缩写形式,意即“建设--移交”,是政府利用非政府资金来进行基础非经营性设施建设项目的一种融资模式。 2. BT模式是BOT模式的一种变换形式,指一个项目的运作通过项目公司总承包,融资、建设验收合格后移交给业主,业主向投资方支付项目总投资加上合理回报的过程。 3. 目前采用BT模式筹集建设资金成了项目融资的一种新模式。 BOT模式的含义 BOT(build—operate—transfer)即建设—经营—转让,是指政府通过契约授予私营企业(包括外国企业)以一定期限的特许专营权,许可其融资建设和经营特定的公用基础设施,并准许其通过向用户收取费用或出售产品以清偿贷款,回收投资并赚取利润;特许权期限届满时,该基础设施无偿移交给政府。 BOT是英文建设——运营——移交的缩写。在国际融资领域 BOT不仅仅包含了建设、运营和移交的过程,更主要的是项目融资的一种方式,具有有限追索的特性。所谓项目融资是指以项目本身信用为基础的融资,项目融资是与企业融资相对应的。通过项目融资方式融资时,银行只能依靠项目资产或项目的收入回收贷款本金和利息。在这种融资方式中,银行承担的风险较企业融资大得多,如果项目失败了银行可能无法收回贷款本息,因此项目结果往往比较复杂。为了实现这种复杂的结构,需要做大量前期工作,前期费用较高。上述所说的只能依靠项目资产或项目收入回收本金和利息就是无追索权的概念。在实际BOT项目运作过程中,政府或项目公司的股东都或多或少地为项目提供一定程度的支持,银行对政府或项目公司股东的追索只限于这种支持的程度,而不能无限的追索,因此项目融资经常是有限追索权的融资。由于BOT项目具有有限追索的特性,BOT项目的债务不计入项目公司股东的资产负债表,这样项目公司股东可以为更多项目筹集建设资金,所以受到了股本投标人的欢迎而被广泛应用。 PPP模式的含义 PPP是指政府与民营机构(或更广义点,任何国营/民营/外商法人机构,下同)签订长期合作协议,授权民营机构代替 文档编号:____________ 保密级别: ____________ 软件产品开发模式Development Mode of Software Products Develop Department, WanHe Communication Tech. Integration Co. Ltd 目录 1.引言 (3) 2.6个最佳实践的有效部署 (6) 3.开发阶段 (7) 3.1初始阶段 (7) 3.1.1里程碑:生命周期的目标里程碑 (8) 3.1.2文档标准 (9) 3.1.3补充说明 (10) 3.2细化阶段 (11) 3.2.1里程碑:生命周期的结构里程碑 (12) 3.2.2文档标准 (12) 3.2.3补充说明 (14) 3.3构建阶段 (15) 3.3.1里程碑:初始功能里程碑 (16) 3.3.2产品状态 (16) 3.3.3补充说明 (17) 3.4交付阶段 (17) 3.4.1里程碑:产品发布 (18) 3.4.2交付的产品及其状态 (19) 1.引言 软件开发在整个的软件生产过程中处于一个非常重要的阶段。一个失败的软件项目不仅导致项目的投入资金的损失,同时更重要的是企业失去了抢占项目的市场的时间。这对于企业可能是最大的损失,尤其对于规模相对较小的企业来说,更是冲击很大。因此,提高项目开发的成功率,不仅降低了项目的风险,同时对项目以后的拓展也是非常重要的。 首先,在这里根据目前业届的实际情况和失败的项目案例,分析一下导致软件项目失败的原因。 软件的开发的管理与控制包括两方面的内容:一是软件开发的技术(软件工程),其次是软件的开发管理。软件工程是从技术的角度来规范软件开发的管理和控制。对于软件的项目的技术实现取决于技术人员的素质以及项目的合理化分析等方面。目前利用强大的可利用资源,在软件项目的方案上基本可以达到要求。 软件开发项目中经常会出现两种极端的情况:一种是创造了新的生产率和质量的纪录;一种则完全是一场灾难,不是软件项目被取消就是拖延了很长的时间。根据现在行业中的一些实例和专家的总结,首先我们看一下什么情况下为一个失败的软件项目: 1、由于费用超支或计划执行超时而终止。 2、完成计划的时间或费用超过了原计划的50%。 3、由于质量或性能的原因引起客户的纠纷。 为何在软件项目的开发中会出现的以上的结果,下面按照影响程度得到小顺序着重指明了5种错误的实践方式。 1、有软件开发的历史数据 缺乏软件开发的历史数据时大多数软件项目失败的关键所在,这样的结论也许是很多人感到吃惊,但事实就是如此。没有一个可靠的软件开发的历史数据会使项目经理、程序员、客户对于软件开发的过程缺少清醒的认识。 假设现在有一个软件项目,而这个项目还没有一个软件公司在30个月内完成。一个负责的经理作了一个比较细致和保守的估计,然后告诉的客户和的手下他认为这个项目需要30-32个月的时间完成。然而常常有这样的情况发生:客户和程序员要求把实践压缩到20个月。客户一方面希望软件尽可能的造投入使用而产生经济效益,一方面也像压缩项目实践作为一个讨价还价的筹码;而程序员方面可能过于自信,一方面尽早的结束项目也能使他们多赚点钱。而此时由于手上没有此软件项目开发的历史数据,在客户和程序员的压力下同意了20个月的软件开发计划。在项目的开始阶段发现计划被拖延了,于是开始向程序员们施加压力,要求他们加快进度,程序员为了追求进度而不得部把其他指标放在一边,这些为题不断的积累下来而项目经理却蒙在鼓里。到了项目的中后期这些质量问题会不断的暴露出来,而且是互相关联并且难于解决,甚至有些是系统设计的问题,这时才发现好多模块要推倒重来,20个月的开发计划变成了天方夜谭。 软件开发的历史数据是反映软件开发队伍的能力的标尺,没有了这个标尺,就无法对软件的开发过程有一个清醒的认识。 2、忽视使用软件费用估值软件和计划工具软件 软件开发模式简介 1. 边做边改模型(Build-and-Fix Model) 好吧,其实现在许多产品实际都是使用的“边做边改”模型来开发的,特别是很多小公司产品周期压缩的太短。在这种模型中,既没有规格说明,也没有经过设计,软件随着客户的需要一次又一次地不断被修改。 在这个模型中,开发人员拿到项目立即根据需求编写程序,调试通过后生成软件的第一个版本。在提供给用户使用后,如果程序出现错误,或者用户提出新的要求,开发人员重新修改代码,直到用户和测试等等满意为止。 这是一种类似作坊的开发方式,边做边改模型的优点毫无疑问就是前期出成效快。 对编写逻辑不需要太严谨的小程序来说还可以对付得过去,但这种方法对任何规模的开发来说都是不能令人满意的,其主要问题在于: 1)缺少规划和设计环节,软件的结构随着不断的修改越来越糟,导致无法继续修改; 2)忽略需求环节,给软件开发带来很大的风险; 3)没有考虑测试和程序的可维护性,也没有任何文档,软件的维护十分困难。 2. 瀑布模型(Waterfall Model) 瀑布模型是一种比较老旧的软件开发模型,1970年温斯顿·罗伊斯提出了著名的“瀑布模型”,直到80年代都还是一直被广泛采用的模型。 瀑布模型将软件生命周期划分为制定计划、需求分析、软件设计、程序编写、软件测试和运行维护等六个基本活动,并且规定了它们自上而下、相互衔接的固定次序,如同瀑布流水,逐级下落。 在瀑布模型中,软件开发的各项活动严格按照线性方式进行,当前活动接受上一项活动的工作结果,实施完成所需的工作内容。当前活动的工作结果需要进行验证,如验证通过,则该结果作为下一项活动的输入,继续进行下一项活动,否则返回修改。 瀑布模型优点是严格遵循预先计划的步骤顺序进行,一切按部就班比较严谨。 瀑布模型强调文档的作用,并要求每个阶段都要仔细验证。但是,这种模型的线性过程太理想化,已不再适合现代的软件开发模式,几乎被业界抛弃,其主要问题在于: 1)各个阶段的划分完全固定,阶段之间产生大量的文档,极大地增加了工作量; 2)由于开发模型是线性的,用户只有等到整个过程的末期才能见到开发成果,从而增加了开发的风险; 3)早期的错误可能要等到开发后期的测试阶段才能发现,进而带来严重的后果。 4)各个软件生命周期衔接花费时间较长,团队人员交流成本大。 5)瀑布式方法在需求不明并且在项目进行过程中可能变化的情况下基本是不可行的。 3. 迭代模型(stagewise model)(也被称作迭代增量式开发或迭代进化式开发) ,是一种与传统的瀑布式开发相反的软件开发过程,它弥补了传统开发方式中的一些弱点,具有更高的成功率和生产率。 在迭代式开发方法中,整个开发工作被组织为一系列的短小的、固定长度(如3周)的小项目,被称为一系列的迭代。每一次迭代都包括了需求分析、设计、实现与测试。采用这种方法,开发工作可以在需求被完整地确定之前启动,并在一次迭代中完成系统的一部分功能或业务逻辑的开发工作。再通过客户的反馈来细化需求,并开始新一轮的迭代。 教学中,对迭代和版本的区别,可理解如下:迭代一般指某版本的生产过程,包括从需求分析到测试完成;版本一般指某阶段软件开发的结果,一个可交付使用的产品。 与传统的瀑布模型相比较,迭代过程具有以下优点: 1)降低了在一个增量上的开支风险。如果开发人员重复某个迭代,那么损失只是这一个开发有误的迭代的花费。 2)降低了产品无法按照既定进度进入市场的风险。通过在开发早期就确定风险,可以尽早来解决而不至于在开发后期匆匆忙忙。 3)加快了整个开发工作的进度。因为开发人员清楚问题的焦点所在,他们的工作会更有效率。 4)由于用户的需求并不能在一开始就作出完全的界定,它们通常是在后续阶段中不断细化的。因此,迭代过程这种模式使适应需求的变化会更容易些。因此复用性更高 4. 快速原型模型(Rapid Prototype Model) 快速原型模型的第一步是建造一个快速原型,实现客户或未来的用户与系统的交互,用户或客户对原型进行评价,进一步细化待开发软件的需求。通过逐步调整原型使其满足客户的要求,开发人员可以确定客户的真正需求是什么;第二步则在第一步的基础上开发客户满意的软件产品。 显然,快速原型方法可以克服瀑布模型的缺点,减少由于软件需求不明确带来的开发风险,具有显著的效果。 快速原型的关键在于尽可能快速地建造出软件原型,一旦确定了客户的真正需求,所建造的原型将被丢弃。因此,原型系统的内部结构并不重要,重要的是必须迅速建立原型,随之迅速修改原型,以反映客户的需求。 快速原型模型有点整合“边做边改”与“瀑布模型”优点的意味。 5、增量模型(Incremental Model) 与建造大厦相同,软件也是一步一步建造起来的。在增量模型中,软件被作为一系列的增量构件来设计、实现、集成和测试,每一个构件是由多种相互作用的模块所形成的提供特定功能的代码片段构成。 增量模型在各个阶段并不交付一个可运行的完整产品,而是交付满足客户需求的一个子集的可运行产品。整个产品被分解成若干个构件,开发人员逐个构件地交付产品,这样做的好处是软件开发可以较好地适应变化,客户可以不断地看到所开发的软件,从而降低开发风险。但是,增量模型也存在以下缺陷: 1)由于各个构件是逐渐并入已有的软件体系结构中的,所以加入构件必须不破坏已构造好的系统部分,这需要软件具备开放式的体系结构。 2)在开发过程中,需求的变化是不可避免的。增量模型的灵活性可以使其适应这种变化的能力大大优于瀑布模型和快速原型模型,但也很容易退化为边做边改模型,从而是软件过程的控制失去整体性。 在使用增量模型时,第一个增量往往是实现基本需求的核心产品。核心产品交付用户使用后,经过评价形成下一个增量的开发计划,它包括对核心产品的修改和一些新功能的发布。这个过程在每个增量发布后不断重复,直到产生最终的完善产品。 例如,使用增量模型开发字处理软件。可以考虑,第一个增量发布基本的文件管理、编辑和文档生成功能,第二个增量发布更加完善的编辑和文档生成功能,第三个增量实现拼写和文法检查功能,第四个增量完成高级的页面布局功能。 6. 螺旋模型(Spiral Model) APP(应用程序)开发方式 一、名词介绍 1.Native APP Native APP 指的是原生程序,一般依托于操作系统,有很强的交互,是一个完整的App,可拓展性强,需要用户下载安装使用。(简单来说,原生应用是特别为某种操作系统开发的,比如iOS、Android、黑莓等等,它们是在各自的移动设备上运行的) 该模式通常是由“云服务器数据+APP应用客户端”两部份构成,APP应用所有的UI元素、数据内容、逻辑框架均安装在手机终端上。 原生应用程序是某一个移动平台(比如iOS或安卓)所特有的,使用相应平台支持的开发工具和语言(比如iOS平台支持Xcode和Objective-C,安卓平台支持Eclipse和Java)。原生应用程序看起来(外观)和运行起来(性能)是最佳的。 2.Web APP Web App 指采用HTML5语言写出的App,不需要下载安装。类似于现在所说的轻应用。生存在浏览器中的应用,基本上可以说是触屏版的网页应用。(Web 应用本质上是为移动浏览器设计的基于Web的应用,它们是用普通Web开发语言开发的,可以在各种智能手机浏览器上运行) Web App开发即是一种框架型APP开发模式(Html5 APP 框架开发模式),该开发具有跨平台的优势,该模式通常由“HTML5云网站+APP应用客户端”两部份构成,APP应用客户端只需安装应用的框架部份,而应用的数据则是每次打开APP的时候,去云端取数据呈现给手机用户。 HTML5应用程序使用标准的Web技术,通常是HTML5、JavaScript和CSS。这种只编写一次、可到处运行的移动开发方法构建的跨平台移动应用程序可以在多个设备上运行。虽然开发人员单单使用HTML5和JavaScript就能构建功能复杂的应用程序,但仍然存在一些重大的局限性,具体包括会话管理、安全离线存储以及访问原生设备功能(摄像头、日历和地理位置等)。 3.Hybrid APP 软件开发模式有哪些 ? 快速原型模型:(需要迅速造一个可以运行的软件原型,以便理解和澄清问题) 快速原型模型允许在需求分析阶段对软件的需求进行初步的非完全的分析和定义,快速设计开发出软件系统的原型(展示待开发软件的全部或部分功能和性能 (过程:用户对该原型进行测试评定,给出具体改善的意见以及丰富的细化软件需求,开发人员进行修改完善) 优点: 克服瀑布模型的缺点,减少由于软件需求不明确带来的开发风险 缺点: A、所选用的开发技术和工具不一定符合主流的发展 B、快速建立起来的系统加上连续的修改可能会造成产品质量底下 增量模型:(采用随着日程时间的进展而交错的线性序列,每一个线性徐磊产生软件的一个可发布的“增量”,第一个增量往往就是核心的产品) 与其他模型共同之处:它与原型实现模型和其他演化方法一样,本质都是迭代 与原型实现模型不同之处:它强调每一个增量均发布一个可操作产品,(它不需要等到所有需求都出来,只要摸个需求的增量包出来即可进行开发) 优点: 1、人员分配灵活,一开始不需要投入大量人力资源 2、当配备人员不能在限定的时间内完成产品时,它可以提供一种先推出核心产品的途径,可现发布部分功能给用户(对用户起镇静作用) 3、增量能够有计划的管理技术风险 缺点: 1、如果增量包之间存在相交的情况且未很好处理,则必须做全盘系统分析 注: 这种模型将功能细化后分别开发的方法较适应于需求经常改变的软件开发过程 原型模型:(样品模型,采用逐步求精的方法完善原型) 主要思想: 先借用已有系统作为原型模型,通过“样品”不断改进,使得最后的产品就是用户所需要的。原型模型通过向用户提供原型获取用户的反馈,使开发出的软件能够真正反映用户的需求, 采用方法: 原型模型采用逐步求精的方法完善原型,使得原型能够“快速”开发,避免了像瀑布模型一样在冗长的开发过程中难以对用户的反馈作出快速的响应 优点: (1)开发人员和用户在“原型”上达成一致。这样一来,可以减少设计中的错误和开发中的风险,也减少了对用户培训的时间,而提高了系统的实用、正确性以及用户的满意程度。 (2)缩短了开发周期,加快了工程进度。 (3)降低成本。 缺点: 几种软件开发模式概述 瀑布模型(Waterfall Model)是由W.W.Royce在1970年最初提出的软件开发模型,在瀑布模型中,开发被认为是按照需求分析,设计,实现,测试 (确认),集成,和维护坚定地顺畅地进行。瀑布模型(Waterfall Model)最早强调系统开发应有完整之周期,且必须完整的经历周期之每一开发阶段,并系统化的考量分析与设计的技术、时间与资源之投入等,因此瀑布模型又可以称为‘系统发展生命周期’(System Development Life Cycle, SDLC)。由于该模式强调系统开发过程需有完整的规划、分析、设计、测试及文件等管理与控制,因此能有效的确保系统品质,它已经成为业界大多数软件开发的标准(Boehm, 1988)。 瀑布式的主要的问题是它的严格分级导致的自由度降低,项目早期即作出承诺导致对后期需求的变化难以调整,代价高昂。瀑布式方法在需求不明并且在项目进行过程中可能变化的情况下基本是不可行的。 迭代式开发也被称作迭代增量式开发或迭代进化式开发,是一种与传统的瀑布式开发相反的软件开发过程,它弥补了传统开发方式中的一些弱点,具有更高的成功率和生产率。在迭代式开发方法中,整个开发工作被组织为一系列的短小的、固定长度(如3周)的小项目,被称为一系列的迭代。每一次迭代都包括了需求分析、设计、实现与测试。采用这种方法,开发工作可以在需求被完整地确定之前启动,并在一次迭代中完成系统的一部分功能或业务逻辑的开发工作。再通过客户的反馈来细化需求,并开始新一轮的迭代。 螺旋模型是一种演化软件开发过程模型,它兼顾了快速原型的迭代的特征以及瀑布模型的系统化与严格监控。螺旋模型最大的特点在于引入了其他模型不具备的风险分析,使软件在无法排除重大风险时有机会停止,以减小损失。同时,在每个迭代阶段构建原型是螺旋模型用以减小风险的途径。螺旋模型更适合大型的昂贵的系统级的软件应用。 敏捷软件开发又称敏捷开发,是一种从1990年代开始逐渐引起广泛关注的一些新型软件开发方法,是一种应对快速变化的需求的一种软件开发能力。它们的具体名称、理念、过程、术语都不尽相同,相对于“非敏捷”,更强调程序员团队与业务专家之间的紧密协作、面对面的沟通(认为比书面的文档更有效)、频繁交付新的软件版本、紧凑而自我组织型的团队、能够很好地适应需求变化的代码编写和团队组织方法,也更注重做为软件开发中人的作用。 目前列入敏捷方法的有: 软件开发节奏,Software Development Rhythms 敏捷数据库技术,AD/Agile Database Techniques 敏捷建模,AM/Agile Modeling 自适应软件开发,ASD/Adaptive Software Development 水晶方法,Crystal 特性驱动开发,FDD/Feature Driven Development 动态系统开发方法,DSDM/Dynamic Systems Development Method APP的9种商业模式 模式一、单纯出售模式 图解:使用者支付金钱购买App, 开发者因而获利 这种应该就是最单纯的模式—开发者制作App,透过App Store或Market销售给使用者。在这种模式中,重点是让单价×销售量所得的销售额极大化,看起来似乎象是废话,但是值得思考的是—假如某个App对特定族群来说是很有用的,但对于大众来说也许不具吸引力,那么与其定$0.99但是也不会因此多卖几个,是否反而应该把价格定高一些,然后透过正确的宣传方式去让有需要的人得知此信息,虽然销售量有限,但是因为单价够高,整体销售额也许更有利。且因为单价高,之后还有打折促销的空间,进一步吸引价格敏感的消费者抢便宜。 模式二:广告模式 图解:使用者无需付费,广告主支付广告费给开发者,开发者因而获利。这也是相对单纯的模式,这张图在模式上有所简化,实际运作在广告主与开发者之间应该还有Apple或Google这两大“广告代理投放平台”才对。而此一模式的获利主要就是靠广告,因此要尽可能冲高App下载量,所以如果可以结合“使用者有需要”的服务例如信息或情报,一来需求已经存在,二来广告媒合效果也会更明显。 模式三:收入组合模式(「带路鸡」模式) 图解:使用者付费购买开发者所开发之多款App 这是「单纯出售模式」的延伸,意思是藉由其中一两项特别便宜的产品吸引消费者上门,再顺势同时卖其他的产品给他,就象是现实生活大卖场通常会有所谓的DM商品吸引消费者到卖场消费,同时有机会购买其他的东西提高营业额是相同的道理。而在App的领域,「带路鸡」甚至价格可以是$0(搭配「广告模式」一起运用) 模式四:持续推出更新附属功能模式 软件开发项目管理的模式概述 blueski推荐 [2006-6-22] 出处:CSDN 作者:不详 70年代基本上一个软件在项目规模上比较小,一两个人基本可以胜任一个软件的开发,这样的人被称为hero,认为是英雄主导着一个软件项目的进度,但随着业界对软件依赖的增加,软件在规模、复杂度上都有较大的增加,一两个人已经无法胜任工作的需要,而且,开发人员一旦离开公司,那么整个项目甚至整个公司可能会陷入瘫痪的地步。所以,在80年代初,软件公司开始重视软件开发的项目管理,把其他行业成功的项目管理经验开始引入软件开发领域。 美国PMI,Project Management Institute(项目管理研究所)在软件工程项目管理方面起到了很大的推动作用,每年发行一本PM book。微软在软件开发管理上也是基本参照传统的软件开发模式来做的。 除企业对软件开发项目管理的推动作用外,学术界也推出了有关的管理模式,如CMM(软件成熟度模型)。CMM在部分软件企业得到了推崇,但是并不是所有的软件企业都采用CMM,微软本身就没有采用。尽管如此,微软本身的管理方法与CMM也有异曲同工的地方。 业界也在推行自己的管理模式,RUP,Six Sigma,ISO,etc.关键是软件开发管理中的关键的部份要掌握好。 传统模式在美国很多公司都使用过,对这些开发模式不能盲目崇拜。 -------------------------------------------------------------------------------------------------- 传统的和其他的管理模式受到挑战 被认为太死板和官僚 效率高低受到质疑 太重规章制度项被认为是开发的枷锁 在执行起来太过于繁重 可能违背需要智力高度集中的软件开发工程管理的特性 因此这几年来开始有人唱反调 软件开发具有自己的特点 ********************************************************* 传统的项目管理模式 根据PMI观点,传统的项目管理通常具有几个固定的阶段: 第一项目启动阶段,第二计划阶段,项目的规模、项目的需求、项目的估算,第三阶段设计规范书(软件开发的蓝图),第四项目时间表(schedule)。样品的试开发。第五执行阶段,编程开发。同时fix bugs.第六控制阶段,对发现的错误进行回车重新开发。第七结束阶段。 启动、计划、执行、控制、结束 这五个阶段的传统的项目管理模式在业界使用的比较普遍。软件开发几种模式
软件开发管理模式
几种常用软件开发工具比较
软件开发模式有哪些
项目类别开发策略规划项目开发模式
几种模式知识讲解
软件产品开发模式
课题_软件开发模式简介
APP几种开发方式
软件开发模式有哪些
软件开发地几种的模式
最新APP的9种商业模式
软件开发项目管理的模式概述