二叉树-后序遍历java
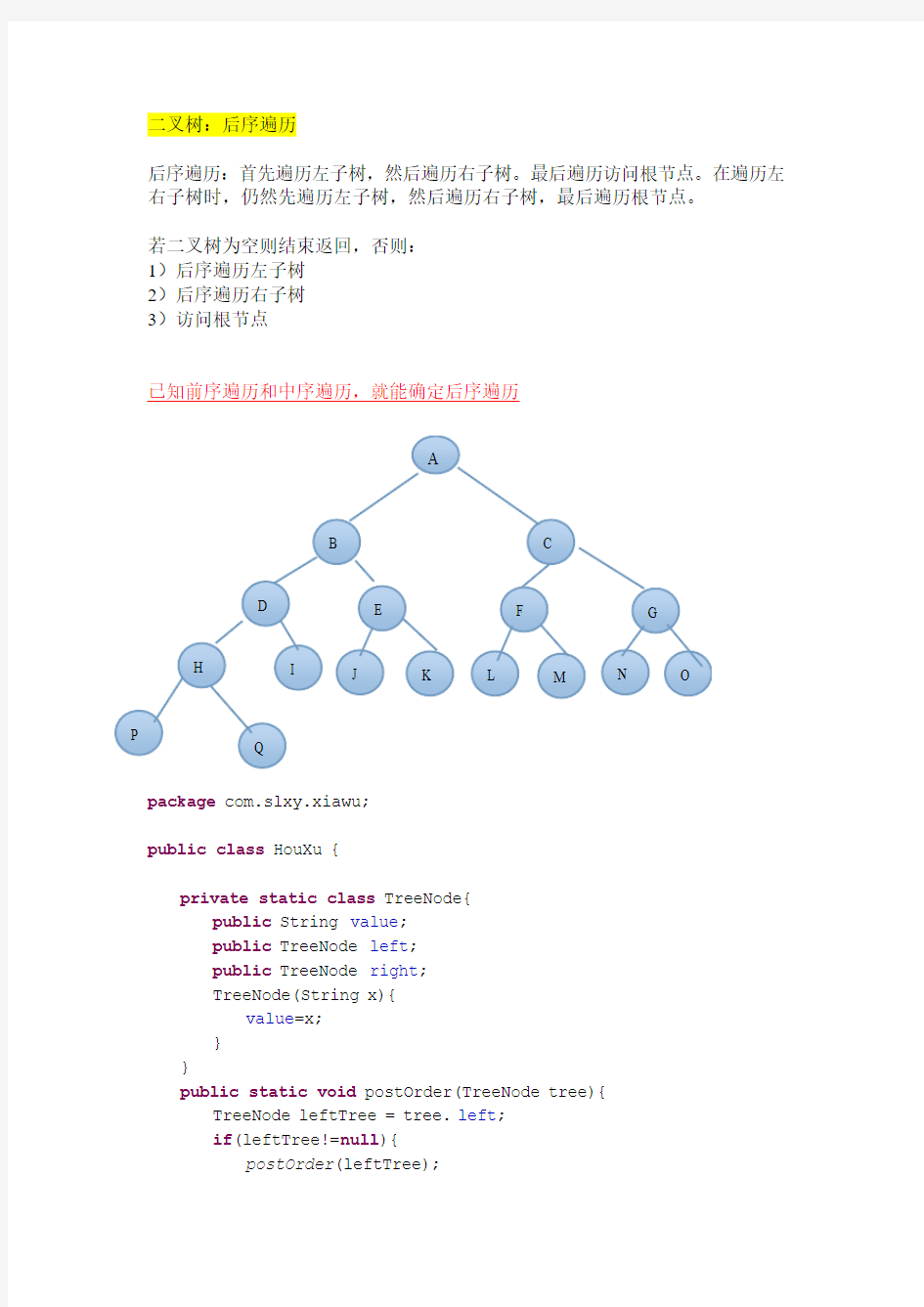

二叉树:后序遍历
后序遍历:首先遍历左子树,然后遍历右子树。最后遍历访问根节点。在遍历左右子树时,仍然先遍历左子树,然后遍历右子树,最后遍历根节点。
若二叉树为空则结束返回,否则:
1)后序遍历左子树
2)后序遍历右子树
3)访问根节点
已知前序遍历和中序遍历,就能确定后序遍历
package com.slxy.xiawu;
public class HouXu {
private static class TreeNode{
public String value ;
public TreeNode left ;
public TreeNode right ;
TreeNode(String x){
value =x;
}
}
public static void postOrder(TreeNode tree){
TreeNode leftTree = tree.left ;
if (leftTree!=null ){
postOrder (leftTree);
L A B J F G
E C M K Q P O N I D H
}
TreeNode rightTree = tree.right;
if(rightTree!=null){
postOrder(rightTree);
}
System.out.print(tree.value+" ");
}
public static void main(String[] args) {
TreeNode tree = new TreeNode("A");
tree.left=new TreeNode("B");
tree.right=new TreeNode("C");
tree.left.left=new TreeNode("D");
tree.left.right=new TreeNode("E");
tree.right.left=new TreeNode("F");
tree.right.right=new TreeNode("G");
tree.left.left.left=new TreeNode("H");
tree.left.left.right=new TreeNode("I");
tree.left.right.left=new TreeNode("J");
tree.left.right.right=new TreeNode("K");
tree.right.left.left= new TreeNode("L");
tree.right.left.right=new TreeNode("M");
tree.right.right.left=new TreeNode("N");
tree.right.right.right=new TreeNode("O");
tree.left.left.left.left=new TreeNode("P");
tree.left.left.left.right=new TreeNode("Q");
postOrder(tree);
}
}
来源:https://www.360docs.net/doc/883307815.html,/link?url=WfoPkxek7JCuP3ASgSbMmOCDXjqYaB42lpszSOe 7mZHlo6Rs7UAQuV_saOEpQDpgejkqSryrJ8mjHayYBzU1w_
https://www.360docs.net/doc/883307815.html,/link?url=GjNDaFchjW_ftjXVmGmHb4scxl7XOUrUEgl17q_ xZ4mN-XRcEoSU0fBeW7gONTV-O0N_B1LgS7js48Z32QP41q
https://www.360docs.net/doc/883307815.html,/link?url=yhiasxb4SsuNgQZi_OaLnkjvYeL_gF1LnhI-B4Yj8pk OdVkN2CFkx_TW0Qbjygab8uyrDHa7i4MkJPC0kJbm1q
创建一个二叉树并输出三种遍历结果
实验报告 课程名称数据结构 实验项目实验三--创建一个二叉树并输出三种遍历结果 系别■计算机学院 _________________ 专业_______________ 班级/学号_____________ 学生姓名___________ 实验日期— 成绩______________________________ 指导 教师
实验题目:实验三创建一个二叉树并输出三种遍历结果 实验目的 1)掌握二叉树存储结构; 2)掌握并实现二叉树遍历的递归算法和非递归算法; 3)理解树及森林对二叉树的转换; 4)理解二叉树的应用一哈夫曼编码及WPL计算。 实验内容 1)以广义表或遍历序列形式创建一个二叉树,存储结构自选; 2)输出先序、中序、后序遍历序列; 3)二选一应用题:1)树和森林向二叉树转换;2)哈夫曼编码的应用问题。 题目可替换上述前两项实验内容) 设计与编码 1)程序结构基本设计框架 (提示:请根据所选定题目,描述程序的基本框架,可以用流程图、界面描述图、 框图等来表示) 2)本实验用到的理论知识遍历二叉树,递归和非递归的方法 (应用型
(提示:总结本实验用到的理论知识,实现理论与实践相结合。总结尽量简明扼要,并与本次实验密切相关,要求结合自己的题目并阐述自己的理解和想法) 3) 具体算法设计 1) 首先,定义二叉树的存储结构为二叉链表存储,每个元素的数 据类型Elemtype,定义一棵二叉树,只需定义其根指针。 2) 然后以递归的先序遍历方法创建二叉树,函数为CreateTree(),在输 入字符时要注意,当节点的左孩子或者右孩子为空的时候,应当输入一 个特殊的字符(本算法为“ #”),表示左孩子或者右孩子为空。 3) 下一步,创建利用递归方法先序遍历二叉树的函数,函数为 PreOrderTreeQ,创建非递归方法中序遍历二叉树的函数,函数为 InOrderTree(),中序遍历过程是:从二叉树的根节点开始,沿左子树 向下搜索,在搜索过程将所遇到的节点进栈;左子树遍历完毕后,从 栈顶退出栈中的节点并访问;然后再用上述过程遍历右子树,依次类 推,指导整棵二叉树全部访问完毕。创建递归方法后序遍历二叉树的 函数,函数为LaOrderTree()。 (提示:该部分主要是利用C、C++ 等完成数据结构定义、设计算法实现各种操作,可以用列表分步形式的自然语言描述,也可以利用流程图等描述) 4) 编码 #include
已知某二叉树的先序遍历和中序遍历的结果是先序遍历ABDEGCF
树与二叉树复习 一、填空 1、由二叉树的(中)序和(前、后)序遍历序列可以唯一确定一棵二叉树。 2、任意一棵二叉树,若度为0的结点个数为n0,度为2的结点个数为n2,则n0等于(n0=n2+1 )。 3、一棵二叉树的第i(i≥1)层最多有(2i-1 )个结点。 4、一棵有n个结点的二叉树,若它有n0个叶子结点,则该二叉树上度为1的结点个数n1=(n-2n0+1 )。 5、在一棵高度为5的完全二叉树中,最少含有( 16 )个结点。 6、 2.有一个有序表为{1,3,9,12,32,41,45,62,75,77,82,95,100},当折半查找值为82的结点时,( C )次比较后查找成功。 A. 11 B 5 C 4 D 8 7、在有n个叶结点的哈夫曼树中,总结点数( 2n-1 )。 8、若一个问题的求解既可以用递归算法,也可以用递推算法,则往往用(递推)算法,因为(递推算法效率高)。 9、设一棵完全二叉树有700个结点,则共有( 350 )叶子结点。 10、设一棵完全二叉树具有1000个结点,该树有(500)个叶子结点,有(499 )个度为2的结点,有( 1 )个结点只有非空左子树。 二、判断 1、( × )在哈夫曼树中,权值最小的结点离根结点最近。 2、( √ ) 完全二叉树中,若一个结点没有左孩子,则它必是叶子结点。 3、( √ )二叉树的前序遍历序列中,任意一个结点均处在其孩子结点的前面。 4、( × ) 若一搜索树(查找树)是一个有n个结点的完全二叉树,则该树的最大值一定在叶结点上。 5、( √ )若以二叉链表作为树和二叉树的存储结构,则给定任一棵树都可以找到唯一的一棵二叉树与之对应。 6、( √ )若一搜索树(查找树)是一个有n个结点的完全二叉树,则该树的最小
C语言实现二叉树的前序遍历(递归)
C语言实现二叉树的前序遍历算法实现一: #include
#include
二叉树前序或中序或后序遍历
数学与计算机学院计算机系实验报告 课程名称: 数据结构 年级:2010 实验成绩: 指导教师: 黄襄念 姓名: 实验教室:6A-413 实验名称:二叉树前序或中序或后序遍历 学号: 实验日期:2012/6/10 实验序号:实验3 实验时间:8:00—11:40 实验学时:4 一、实验目的 1. 熟悉的掌握树的创建,和树的前序、中序、后序遍历。 二、实验环境 1. 操作系统:Windows7 2. 开发软件:Microsoft Visual C++ 6.0 三、实验内容 ● 程序功能 本程序完成了以下功能: 1. 前序遍历 2. 中序遍历 3. 后序遍历 ● 数据结构 本程序中使用的数据结构(若有多个,逐个说明): 1. 它的优缺点 1) 可以快速的查找数据。 2) 让数据层次更加清晰。 2. 逻辑结构图 3. 存储结构图
、、、、、、、、、、、、、、、、、、、、 4.存储结构的C/C++ 语言描述 typedef struct node { DataType data; struct node *lchild; struct node *rchild; } BiTNode, *BiTree; typedef BiTree type; ●算法描述 本程序中采用的算法 1.算法名称:递归 2.算法原理或思想 是通过访问结点的左右孩子来进行循环查找的方法,拿中序遍历来说明:先从头结点开始,再去访问头结点的右孩子如果为空就访问头结点的左孩子,依次进行访问当结点的左右孩子都为空时,就访问上一级,到了最后。 3.算法特点 它能将查找进行2分,体现出了更高效快捷的特点,并且层次很清晰。 ●程序说明 1. 2. 1)前序遍历模块:将树进行从头结点开始再左孩子再右孩子。 代码:void InOrder(BiTree root) { Stack S(100); initStack(S); BiTNode *p = root; do { while(p != NULL) { Push(S, p);
数据结构C语言实现二叉树三种遍历
实验课题一:将下图中得二叉树用二叉链表表示: 1用三种遍历算法遍历该二叉树,给出对应得输出结果; 2写一个函数对二叉树搜索,若给出一个结点,根据其就是否属于该树,输出true或者f alse。 3写函数完成习题4、31(C++版)或4、28(C版教科书)。 #include "stdio、h" #include”malloc、h" typedefstruct BiTNode { char data; structBiTNode *lchild,*rchild; }BiTNode,*BiTree; BiTree Create(BiTreeT) { char ch; ch=getchar(); if(ch=='#’) T=NULL; else { T=(BiTNode *)malloc(sizeof(BiTNode)); T-〉data=ch; T->lchild=Create(T—〉lchild); T—〉rchild=Create(T-〉rchild); } return T; } int node(BiTree T) { int sum1=0,a,b; ?if(T) { if(T!=NULL) ??sum1++;
?a=node(T->lchild); sum1+=a; b=node(T—>rchild); sum1+=b; ?} return sum1; } int mnode(BiTree T) { ?int sum2=0,e,f; if(T) { ?if((T->lchild!=NULL)&&(T-〉rchild!=NULL))?sum2++; ?e=mnode(T-〉lchild); sum2+=e; f=mnode(T-〉rchild); sum2+=f; ?} return sum2; } void Preorder(BiTree T) { if(T) { printf("%c”,T->data); Preorder(T—>lchild); Preorder(T-〉rchild); } } int Sumleaf(BiTree T) { int sum=0,m,n; if(T) { if((!T-〉lchild)&&(!T-〉rchild)) sum++; m=Sumleaf(T->lchild); sum+=m; n=Sumleaf(T—>rchild); sum+=n; } return sum; }
二叉树的遍历(先序、中序、后序)
实践三:树的应用 1.实验目的要求 通过本实验使学生深刻理解二叉树的性质和存储结构,熟练掌握二叉树的遍历算法。认识哈夫曼树、哈夫曼编码的作用和意义。 实验要求:建一个二叉树并按照前序、中序、后序三种方法遍历此二叉树,正确调试本程序。 能够建立一个哈夫曼树,并输出哈夫曼编码,正确调程序。写出实验报告。 2.实验主要内容 2.1 对二叉树进行先序、中序、后序递归遍历,中序非递归遍历。 2.2 根据已知的字符及其权值,建立哈夫曼树,并输出哈夫曼编码。 3.实验步骤 2.1实验步骤 ●输入p127二叉链表的定义 ●录入调试p131算法6.4,实现二叉树的构造函数 ●编写二叉树打印函数,可以通过递归算法将二叉树输出为广义表的 形式,以方便观察树的结构。 ●参考算法6.1,实现二叉树的前序、中序和后序的递归遍历算法。 为简化编程,可以将visit函数直接使用printf函数输出结点内容来 代替。 #include
typedef struct BiTNode{ TElemType data; struct BiTNode *lchild, *rchild; }BiTNode, *BiTree; // 构造栈的结构体 typedef BiTree SElemType; typedef struct{ SElemType *base; SElemType *top; int stacksize; }SqStack; Status InitStack(SqStack &S){ //构造一个空栈 S.base = (SElemType *)malloc(STACK_INIT_SIZE * sizeof(SElemType)); if(!S.base)exit(-2); S.top = S.base; S.stacksize = STACK_INIT_SIZE; return OK; } Status StackEmpty(SqStack S){ //若栈S为空栈,则返回TRUE,否则返回FALSE if(S.top==S.base) return 1; else return 0; }
C++二叉树的前序,中序,后序,层序遍历的递归算法55555
#include
二叉树前序、中序、后序遍历相互求法
二叉树前序、中序、后序遍历相互求法今天来总结下二叉树前序、中序、后序遍历相互求法,即如果知道两个的遍历,如何求第三种遍历方法,比较笨的方法是画出来二叉树,然后根据各种遍历不同的特性来求,也可以编程求出,下面我们分别说明。 首先,我们看看前序、中序、后序遍历的特性: 前序遍历: 1.访问根节点 2.前序遍历左子树 3.前序遍历右子树 中序遍历: 1.中序遍历左子树 2.访问根节点 3.中序遍历右子树 后序遍历: 1.后序遍历左子树 2.后序遍历右子树 3.访问根节点 一、已知前序、中序遍历,求后序遍历 例: 前序遍历: GDAFEMHZ 中序遍历: ADEFGHMZ 画树求法: 第一步,根据前序遍历的特点,我们知道根结点为G 第二步,观察中序遍历ADEFGHMZ。其中root节点G左侧的ADEF必然是root的左子树,G右侧的HMZ必然是root的右子树。 第三步,观察左子树ADEF,左子树的中的根节点必然是大树的root的leftchild。在前序遍历中,大树的root的leftchild位于root之后,所以左子树的根节点为D。 第四步,同样的道理,root的右子树节点HMZ中的根节点也可以通过前序遍历求得。在前序遍历中,一定是先把root和root的所有左子树节点遍历完之后才会遍历右子树,并且遍历的左子树的第一个节点就是左子树的根节点。同理,遍历的右子树的第一个节点就是右子树的根节点。 第五步,观察发现,上面的过程是递归的。先找到当前树的根节点,然后划分为左子树,右子树,然后进入左子树重复上面的过程,然后进入右子树重复上面的过程。最后就可以还原一棵树了。该步递归的过程可以简洁表达如下: 1 确定根,确定左子树,确定右子树。 2 在左子树中递归。
二叉树的建立及几种简单的遍历方法
#include "stdio.h" #include "stdlib.h" #define STACK_INIT_SIZE 100 //栈存储空间初始分配量 #define STACKINCREMENT 10 //存储空间分配增量 //------二叉树的存储结构表示------// typedef struct BiTNode{ int data; struct BiTNode *lchild,*rchild; }BiTNode,*BiTree; //-----顺序栈的存储结构表示------// typedef struct{ BiTree *top; BiTree *base; int stacksize; }SqStack; //*************************************************** //构造一个空栈s SqStack *InitStack(); //创建一颗二叉树 BiTree CreatBiTree(); //判断栈空 int StackEmpty(SqStack *S); //插入元素e为新的栈顶元素 void Push(SqStack *S,BiTree p); //若栈不为空,则删除s栈顶的元素e,将e插入到链表L中void Pop(SqStack *S,BiTree *q); //非递归先序遍历二叉树 void PreOrderTraverse(BiTree L); //非递归中序遍历二叉树 void InOrderTraverse(BiTree L); //非递归后序遍历二叉树 void PostOrderTraverse(BiTree L); //递归后序遍历二叉树 void PostOrder(BiTree bt); //递归中序遍历二叉树 void InOrder(BiTree bt); //递归先序遍历二叉树 void PreOrder(BiTree bt); //***************************************************
二叉树遍历C语言(递归,非递归)六种算法
数据结构(双语) ——项目文档报告用两种方式实现表达式自动计算 专业: 班级: 指导教师: 姓名: 学号:
目录 一、设计思想 (01) 二、算法流程图 (02) 三、源代码 (04) 四、运行结果 (11) 五、遇到的问题及解决 (11) 六、心得体会 (12)
一、设计思想 二叉树的遍历分为三种方式,分别是先序遍历,中序遍历和后序遍历。先序遍历实现的顺序是:根左右,中序遍历实现的是:左根右,后续遍历实现的是:左右根。根据不同的算法分,又分为递归遍历和非递归遍历。 递归算法: 1.先序遍历:先序遍历就是首先判断根结点是否为空,为空则停止遍历,不为空则将左子作为新的根结点重新进行上述判断,左子遍历结束后,再将右子作为根结点判断,直至结束。到达每一个结点时,打印该结点数据,即得先序遍历结果。 2.中序遍历:中序遍历是首先判断该结点是否为空,为空则结束,不为空则将左子作为根结点再进行判断,打印左子,然后打印二叉树的根结点,最后再将右子作为参数进行判断,打印右子,直至结束。 3.后续遍历:指针到达一个结点时,判断该结点是否为空,为空则停止遍历,不为空则将左子作为新的结点参数进行判断,打印左子。左子判断完成后,将右子作为结点参数传入判断,打印右子。左右子判断完成后打印根结点。 非递归算法: 1.先序遍历:首先建立一个栈,当指针到达根结点时,打印根结点,判断根结点是否有左子和右子。有左子和右子的话就打印左子同时将右子入栈,将左子作为新的根结点进行判断,方法同上。若当前结点没有左子,则直接将右子打印,同时将右子作为新的根结点判断。若当前结点没有右子,则打印左子,同时将左子作为新的根结点判断。若当前结点既没有左子也没有右子,则当前结点为叶子结点,此时将从栈中出栈一个元素,作为当前的根结点,打印结点元素,同时将当前结点同样按上述方法判断,依次进行。直至当前结点的左右子都为空,且栈为空时,遍历结束。 2.中序遍历:首先建立一个栈,定义一个常量flag(flag为0或者1),用flag记录结点的左子是否去过,没有去过为0,去过为1,默认为0.首先将指针指向根结点,将根结点入栈,然后将指针指向左子,左子作为新的结点,将新结点入栈,然后再将指针指向当前结点的左子,直至左子为空,则指针返回,flag置1,出栈一个元素,作为当前结点,打印该结点,然后判断flag,flag为1则将指针指向当前结点右子,将右子作为新的结点,结点入栈,再次进行上面的判断,直至当前结点右子也为空,则再出栈一个元素作为当前结点,一直到结束,使得当前结点右子为空,且栈空,遍历结束。 3.后续遍历:首先建立两个栈,然后定义两个常量。第一个为status,取值为0,1,2.0代表左右子都没有去过,1代表去过左子,2,代表左右子都去过,默认为0。第二个常量为flag,取值为0或者1,0代表进左栈,1代表进右栈。初始时指针指向根结点,判断根结点是否有左子,有左子则,将根结点入左栈,status置0,flag置0,若没有左子则判断结点有没有右子,有右子就把结点入右栈,status置0,flag置1,若左右子都没有,则打印该结点,并将指针指向空,此时判断flag,若flag为0,则从左栈出栈一个元素作为当前结点,重新判断;若flag为1则从右栈出栈一个元素作为当前结点,重新判断左右子是否去过,若status 为1,则判断该结点有没有右子,若有右子,则将该结点入右栈,status置1,flag置1,若没有右子,则打印当前结点,并将指针置空,然后再次判断flag。若当前结点status为2,且栈为空,则遍历结束。若指针指向了左子,则将左子作为当前结点,判断其左右子情况,按上述方法处理,直至遍历结束。
遍历二叉树老师的程序(绝对正确,实现先序、中序、后序遍历)
#include
C语言实现二叉树的前序、中序、后续遍历(递归法)
二叉树的前序遍历、中序遍历、后续遍历 (递归法) 1、前序遍历(递归): 算法实现一: #include
算法实现二: #include
二叉树三种遍历算法代码_
二叉树三种遍历算法的源码 二叉树三种遍历算法的源码背诵版 本文给出二叉树先序、中序、后序三种遍历的非递归算法,此三个算法可视为标准算法,直接用于考研答题。 1.先序遍历非递归算法 #define maxsize 100 typedef struct { Bitree Elem[maxsize]; int top; }SqStack; void PreOrderUnrec(Bitree t) { SqStack s; StackInit(s); p=t; while (p!=null || !StackEmpty(s)) { while (p!=null) //遍历左子树 { visite(p->data); push(s,p); p=p->lchild; }//endwhile if (!StackEmpty(s)) //通过下一次循环中的内嵌while实现右子树遍历 { p=pop(s); p=p->rchild; }//endif }//endwhile }//PreOrderUnrec 2.中序遍历非递归算法 #define maxsize 100 typedef struct { Bitree Elem[maxsize];
int top; }SqStack; void InOrderUnrec(Bitree t) { SqStack s; StackInit(s); p=t; while (p!=null || !StackEmpty(s)) { while (p!=null) //遍历左子树 { push(s,p); p=p->lchild; }//endwhile if (!StackEmpty(s)) { p=pop(s); visite(p->data); //访问根结点 p=p->rchild; //通过下一次循环实现右子树遍历}//endif }//endwhile }//InOrderUnrec 3.后序遍历非递归算法 #define maxsize 100 typedef enum{L,R} tagtype; typedef struct { Bitree ptr; tagtype tag; }stacknode; typedef struct { stacknode Elem[maxsize]; int top; }SqStack; void PostOrderUnrec(Bitree t)
二叉树及其先序遍历
实验二叉树及其先序遍历 一、实验目的: 1.明确了解二叉树的链表存储结构。 2.熟练掌握二叉树的先序遍历算法。 一、实验内容: 1.树型结构是一种非常重要的非线性结构。树在客观世界是广泛存在的,在计算 机领域里也得到了广泛的应用。在编译程序里,也可用树来表示源程序的 语法结构,在数据库系统中,数形结构也是信息的重要组织形式。 2.节点的有限集合(N大于等于0)。在一棵非空数里:(1)、有且仅 有 一个特定的根节点;(2)、当N大于1时,其余结点可分为M(M大于0) 个互不相交的子集,其中每一个集合又是一棵树,并且称为根的子树。树 的定义是以递归形式给出的。 3.二叉树是另一种树形结构。它的特点是每个结点最多有两棵子树,并且,二叉 树的子树有左右之分,其次序不能颠倒。 4.二叉树的结点存储结果示意图如下: 二叉树的存储(以五个结点为例):
三、实验步骤 1.理解实验原理,读懂实验参考程序。 2. (1)在纸上画出一棵二叉树。 A B E C D G F (2) 输入各个结点的数据。 (3) 验证结果的正确性。 四、程序流程图 先序遍历
五、参考程序 # define bitreptr struct type1 /*二叉树及其先序边历*/ # define null 0 # define len sizeof(bitreptr) bitreptr *bt; int f,g; bitreptr /*二叉树结点类型说明*/ { char data; bitreptr *lchild,*rchild; }; preorder(bitreptr *bt) /*先序遍历二叉树*/ { if(g==1) printf("先序遍历序列为:\n"); g=g+1; if(bt) { printf("%6c",bt->data); preorder(bt->lchild); preorder(bt->rchild); } else if(g==2) printf("空树\n");
二叉树遍历课程设计心得【模版】
目录 一.选题背景 (1) 二.问题描述 (1) 三.概要设计 (2) 3.1.创建二叉树 (2) 3.2.二叉树的非递归前序遍历示意图 (2) 3.3.二叉树的非递归中序遍历示意图 (2) 3.4.二叉树的后序非递归遍历示意图 (3) 四.详细设计 (3) 4.1创建二叉树 (3) 4.2二叉树的非递归前序遍历算法 (3) 4.3二叉树的非递归中序遍历算法 (4) 4.4二叉树的非递归后序遍历算法 (5) 五.测试数据与分析 (6) 六.源代码 (6) 总结 (10) 参考文献: (11)
一.选题背景 二叉树的链式存储结构是用指针建立二叉树中结点之间的关系。二叉链存储结构的每个结点包含三个域,分别是数据域,左孩子指针域,右孩子指针域。因此每个结点为 由二叉树的定义知可把其遍历设计成递归算法。共有前序遍历、中序遍历、后序遍历。可先用这三种遍历输出二叉树的结点。 然而所有递归算法都可以借助堆栈转换成为非递归算法。以前序遍历为例,它要求首先要访问根节点,然后前序遍历左子树和前序遍历右子树。特点在于所有未被访问的节点中,最后访问结点的左子树的根结点将最先被访问,这与堆栈的特点相吻合。因此可借助堆栈实现二叉树的非递归遍历。将输出结果与递归结果比较来检验正确性。。 二.问题描述 对任意给定的二叉树(顶点数自定)建立它的二叉链表存贮结构,并利用栈的五种基本运算(置空栈、进栈、出栈、取栈顶元素、判栈空)实现二叉树的先序、中序、后序三种遍历,输出三种遍历的结果。画出搜索顺序示意图。
三.概要设计 3.1.创建二叉树 3.2.二叉树的非递归前序遍历示意图 图3.2二叉树前序遍历示意图3.3.二叉树的非递归中序遍历示意图 图3.3二叉树中序遍历示意图
习题6 树和二叉树
习题6 树和二叉树 说明: 本文档中,凡红色字标出的题请提交纸质作业,只写题号和答案即可。 6.1 单项选择题 1.由于二叉树中每个结点的度最大为2,所以二叉树是一种特殊的树,这种说法__B__。 A. 正确 B. 错误 2. 假定在一棵二叉树中,双分支结点数为15,单分支结点数为30个,则叶子结点数为B 个。 A .15 B .16 C .17 D .47 3. 按照二叉树的定义,具有3个结点的不同形状的二叉树有__C__种。 A. 3 B. 4 C. 5 D. 6 4. 按照二叉树的定义,具有3个不同数据结点的不同的二叉树有__C__种。 A. 5 B. 6 C. 30 D. 32 5. 深度为5的二叉树至多有__C__个结点。 A. 16 B. 32 C. 31 D. 10 6. 设高度为h 的二叉树上只有度为0和度为2的结点,则此类二叉树中所包含的结点数至少为_B ___。 A. 2h B. 2h-1 C. 2h+1 D. h+1 7. 对一个满二叉树,m 个树叶,n 个结点,深度为h ,则__A__ 。 A. n=h+m B. h+m=2n C. m=h-1 D. n=2 h -1 8. 任何一棵二叉树的叶结点在先序、中序和后序遍历序列中的相对次序__A__。 A.不发生改变 B.发生改变 C.不能确定 D.以上都不对 9. 如果某二叉树的前根次序遍历结果为stuwv ,中序遍历为uwtvs ,那么该二叉树的后序为__C__。 A. uwvts B. vwuts C. wuvts D. wutsv 10. 二叉树的前序遍历序列中,任意一个结点均处在其子女结点的前面,这种说法__A__。 A. 正确 B. 错误 11. 某二叉树的前序遍历结点访问顺序是abdgcefh ,中序遍历的结点访问顺序是dgbaechf ,则其后序遍历的结点访问顺序是__D__。 A. bdgcefha B. gdbecfha C. bdgaechf D. gdbehfca 12. 在一非空二叉树的中序遍历序列中,根结点的右边__A__。 A. 只有右子树上的所有结点 B. 只有右子树上的部分结点 C. 只有左子树上的部分结点 D. 只有左子树上的所有结点 13.如图6.1所示二叉树的中序遍历序列是__B__。 A. abcdgef B. dfebagc C. dbaefcg D. defbagc 图 6.1 14. 一棵二叉树如图6.2所示,其中序遍历的序列为__B__。 A. abdgcefh B. dgbaechf C. gdbehfca D. abcdefgh 15.设a,b 为一棵二叉树上的两个结点,在中序遍历时,a 在b 前的条件是B 。 图6.2
二叉树的层次遍历算法
二叉树层次遍历算法实现 问题描述 对任意输入的表示某二叉树的字符序列,完成二叉树的层次遍历算法,并输出其遍历结果。 注:所需Queue ADT的实现见附录。 输入描述 从键盘上输入一串字符串,该字符串为二叉树的先序遍历结果,其中如果遍历到空树时用字符”#”代替。 输出描述 从显示器上输出二叉树的按层次遍历结果。 输入与输出示例 输入: +A##/*B##C##D## 输出: +A/*DBC 输入: ABD##GJ###CFH##I### 输出: ABCDGFJHI 附录(仅供参考): #include
//注:需要定义ElementType类型,如果是二叉树, // 则应定义为指向二叉树中结点的指针类型 //格式如: // typedef Tree ElementType; // 队列存储结构采用循环队列 struct QueueRecord; typedef struct QueueRecord *Queue; int IsEmpty(Queue Q); int IsFull(Queue Q); Queue CreateQueue(int MaxElements); void DisposeQueue(Queue Q); void MakeEmpty(Queue Q); int Enqueue(ElementType X, Queue Q); ElementType Front(Queue Q); int Dequeue(Queue Q, ElementType &X); #define MinQueueSize ( 5 ) struct QueueRecord { int Capacity; int Front; int Rear; ElementType *Array; }; int IsEmpty(Queue Q) { return ((Q->Rear + 1)% Q->Capacity == Q->Front); } int IsFull(Queue Q) { return ((Q->Rear + 2) % Q->Capacity == Q->Front); } Queue CreateQueue(int MaxElements) { Queue Q; if (MaxElements < MinQueueSize) return NULL; Q = (Queue)malloc(sizeof(struct QueueRecord));
根据二叉树的后序遍历和中序遍历还原二叉树解题方法
【题目】 假设一棵二叉树的后序遍历序列为DGJHEBIFCA ,中序遍历序列为DBGEHJACIF ,则其前序 遍历序列为( ) 。 A. ABCDEFGHIJ B. ABDEGHJCFI C. ABDEGHJFIC D. ABDEGJHCFI 由题,后序遍历的最后一个值为A,说明本二叉树以节点A为根节点(当然,答案中第一个节点都是A,也证明了这一点) 下面给出整个分析过程 【第一步】 由后序遍历的最后一个节点可知本树根节点为【A】 加上中序遍历的结果,得知以【A】为根节点时,中序遍历结果被【A】分为两部分【DBGEHJ】【A】【CIF】 于是作出第一幅图如下
【第二步】 将已经确定了的节点从后序遍历结果中分割出去 即【DGJHEBIFC】---【A】 此时,位于后序遍历结果中的最后一个值为【C】 说明节点【C】是某棵子树的根节点 又由于【第一步】中【C】处于右子树,因此得到,【C】是右子树的根节点 于是回到中序遍历结果【DBGEHJ】【A】【CIF】中来,在【CIF】中,由于【C】是根节点,所以【IF】都是这棵子树的右子树,【CIF】子树没有左子树,于是得到下图 【第三步】 将已经确定了的节点从后序遍历中分割出去 即【DGJHEBIF】---【CA】 此时,位于后序遍历结果中的最后一个值为【F】 说明节点【F】是某棵子树的根节点 又由于【第二步】中【F】处于右子树,因此得到,【F】是该右子树的根节点
于是回到中序遍历结果【DBGEHJ】【A】【C】【IF】中来,在【IF】中,由于【F】是根节点,所以【I】是【IF】这棵子树的左子树,于是得到下图 【第四步】 将已经确定了的节点从后序遍历中分割出去 即【DGJHEB】---【IFCA】 此时,位于后序遍历结果中的最后一个值为【B】 说明节点【B】是某棵子树的根节点 又由于【第一步】中【B】处于【A】的左子树,因此得到,【B】是该左子树的根节点 于是回到中序遍历结果【DBGEHJ】【A】【C】【F】【I】中来,根据【B】为根节点,可以将中序遍历再次划分为【D】【B】【GEHJ】【A】【C】【F】【I】,于是得到下图