Linux内核源代码分析与移植

Linux内核源代码分析与移植
Linux提供三个不同的命令进行Linux的配置,效果完全一样:
make config 控制台命令行方式配置命令
make menuconfig 文本菜单方式配置命令
make xconfig X窗口图形界面方式配置命令
其他部分命令:
Make mrproper 命令清除所有的旧的配置和旧的编译目标文件等。
Make dep 命令搜索Linux编译输出与源代码之间的依赖关系、并生成依赖文件。
Make clean 清除以前构造内核时生成的所有目标文件、模块文件和临时文件。
Linux内核的两种启动过程:
(1)Flash本地运行方式:内核的未经压缩的可执行映像固化在Flash,系统启动时内核在Flash中开始逐句执行。
(2)压缩内核加载方式:内核的压缩映像固化在Flash上,系统启动时由附加在压缩映像前的解压复制程序读取压缩映像,在内存中解压后执行,这种方式相对复杂,但是运行速度更快。
Linux操作系统的移植涉及很多方面:开发环境的构建,引导加载程序(Boot Loader)的移植,内核(Kernel)的移植,根文件系统(Root File System)的制作和测试等几个方面。
构建开发环境
BootLoader的移植
Linux内核的移植
建立根文件系统
YAFFS的移植
测试
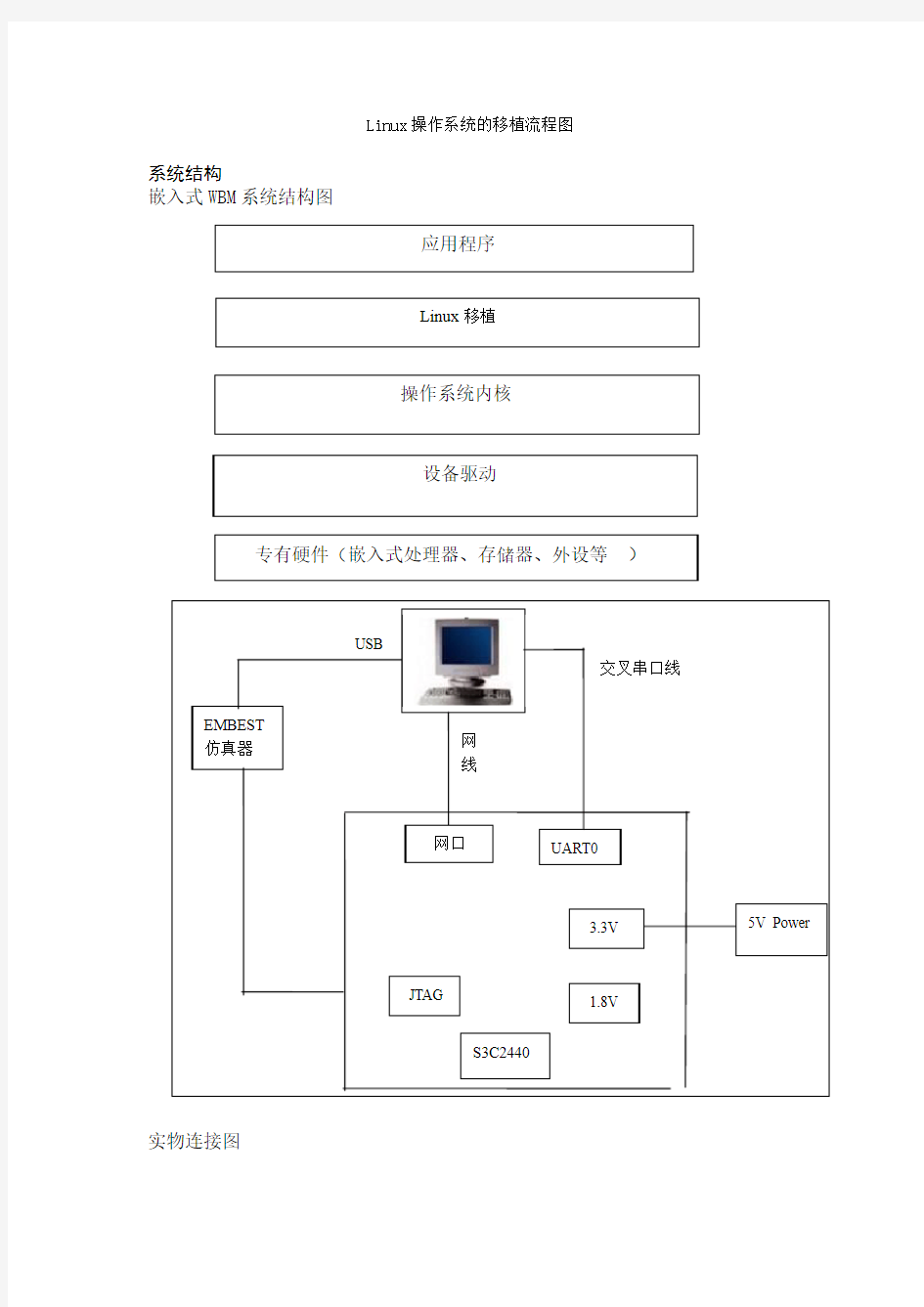
Linux操作系统的移植流程图
系统结构
嵌入式WBM系统结构图
实物连接图
应用程序
操作系统内核
设备驱动
专有硬件(嵌入式处理器、存储器、外设等)
Linux移植
USB
交叉串口线
网
线
EMBEST
仿真器
网口
JTAG
S3C2440
3.3V
1.8V
5V Power UART0
嵌入式WEB服务器的实现
初始化
侦听客户请求
解析客户请求字符串
文本
带参数的命令
脚本引擎文件
输出命令执行模块
毕业设计论文
摘要
论文主要介绍了基于ARM的嵌入式web服务器boa的软、硬件设计及其实现,其中硬件部分的核心是三星的S3C2410X为处理器。最后成果形式为可以远程访问的webserver嵌入式服务器。Boa是一款单任务的HTTP服务器。与其他传统的Web服务器不同的是当有连接请求到来时,它并不为每个连接单独创建进程, 也不通过复制自身进程来处理多链接。而是通过建立HTTP请求列表来处理多路HTTP连接请求。同时它只为CGI程序创建新的进程,这样就在最大程度上节省了系统资源,这对嵌入式系统来说至关重要。同时它还具有自动生成目录、自动解压文件等功能。因此, Bo a在嵌入式系统中具有很高的应用价值。
关键词:ARM;嵌入式web服务器;CGI
毕业设计论文
- 2 -
Abstract
this paper has mainly developed the software hardware design and realization of the embedded Web server Boa based on ARM. And The core o f the Hardware part is S3C2410X microprocessor produced by Samsung . The final achievement is the embedded webserver which can remote visit. Boa i s a single-tasking Http server. That means that unlike traditional webservers, it does not fork for each incoming connection, nor does it fork many copies of itself t o handle multiple connections. I t internally multiplexes all of the ongoing http connections. And forks only for CGI programs, this is very important to embedded system. At the same time, it also has the function of automatic directory generation、automatic file gunzipping and so on. So Boa is of highly value in the embedded system application.
2.1 嵌入式系统简介
嵌入式系统被定义为:以应用为中心、以计算机技术为基础、软件硬件可裁剪、适应应用系统对功能、可靠性、成本、体积、功耗严格要求的专用计算机系统。在制造工业、过程控制、通讯、仪器、仪表、汽车、船舶、航空、航天、军事装备、消费类产品等方面均是嵌入式计算机的应用领域。嵌入式系统是将先进的计算机技术、半导体技术和电子技术和各个行业的具体应用相结合后的产物,这一点就决定了它必然是一个技术密集、资金密集、高度分散、不断创新的知识集成系统。
2.2 嵌入式系统和Linux
随着微处理器的产生,价格低廉、结构小巧的CPU和外设连接提供了稳定可靠的硬件架构,那么限制嵌入式系统发展的瓶颈就突出表现在了软件方面。尽管从八十年代末开始,陆续出现了一些嵌入式操作系统,比较著名的有Vxwork、pSOS、Nucleus和Windows CE。但这些专用操作系统都是商业化产品,其高昂的价格使许多生产低端产品的小公司望而却步;而且源代码封闭性也大大限制了开发者的积极性。另外结合国内实情,当前国家对自主操作系统的大力支持,也为源码开放的Linux的推广提供的广阔的发展前景。还有,对上层应用开发者而言,嵌入式系统需要的是一套高度简练、界面友善、质量可靠、应用广泛、易开发、多任务,并且价格低廉的操作系统。在不久的将来,从冰箱到收音机都会内置处理器。因为Linux的开放性,许多人认为Linux非常适合多数Internet设备。他们认为Linux可以支持不同的设备,支持不同的配置。Linux对厂商不偏不倚而且成本极低,能够很快成为用于各种设备的操作系统。如今,业界已经达成共识:即嵌入式Linux是大势所趋,其巨大的市场潜力与酝酿的无限商机必然会吸引众多的厂商进入这一领域。 Linux为嵌入操作系统提供了一个极有吸引力的选择,它是个和Unix相似、以核心为基础的、完全内存保护、多任务多进程的操作系统。支持广泛的计算机硬件,包括
X86,Alpha,Sparc,MIPS,PPC,ARM,NEC,MOTOROLA等现有的大部分芯片。程式源码全部公开,任何人可以修改并在GNU通用公共许可证
(GNU General Public License)下发行,这样,开发人员可以对操作系统进行定制,再也不必担心像MS windows操作系统中"后门"的威胁。同时由于有GPL的控制,大家开发的东西大都相互兼容,不会走向分裂之路。Linux用户遇到问题
时可以通过Internet向网上成千上万的Linux开发者请教,这使最困难的问题也有办法解决。Linux带有Unix用户熟悉的完善的开发工具,几乎所有的Unix系统的应用软件都已移植到了Linux上。Linux还提供了强大的网络功能,有多种可选择窗口管理器(X windows)。其强大的语言编译器gcc、g++等也可以很容易得到。不但成熟完善、而且使用方便选择Linux的原因:
1.可应用于多种硬件平台。Linux已经被移植到多种硬件平台,这对受开销、时间限制的研究与开发项目是很有吸引力的。原型可以在标准平台上开发然后移植到具体的硬件上,加快了软件与硬件的开发过程。
2.Linux可以随意地配置不需要任何的许可证或商家的合作关系。
3.它是免费的,源代码可以得到。这是最吸引人的。毫无疑问,这会节省大量的开发费用。
4.它本身内置网络支持。
5.Linux的高度模块化使添加部件非常容易。
6.Linux在台式机上的成功,使大家看到了Linux在嵌入式系统中的辉煌前景。
2.3 ARM9硬件平台
2.3.1 ARM简介
广义地讲,凡是带有微处理器的专用软硬件系统都可以称为嵌入式系统。它是嵌入到对象体系中的专用计算机系统,以应用为中心,以计算机技术为基础,软硬件可裁剪,适应应用系统对功能、可靠性、成本、体积、功耗等严格要求的专用计算机系统。ARM作为嵌入式系统得核心,既可以认为是一个公司的名字,也可以认为是对一类微处理器的通称,还可以认为是一种技术的名字,目前非常流行的ARM内核有ARM7TDM1、StrongARM、ARM720T、ARM9TDM1、ARM920T、ARM940T、ARM946T、ARM966T、ARM10TDM1等。本文所讨论的目标板的CPU为ARM920T内核的三星S3C2410芯片。下面介绍该微处理器的特点。
实验四Linux内核移植实验
合肥学院 嵌入式系统设计实验报告 (2013- 2014第二学期) 专业: 实验项目:实验四 Linux内核移植实验 实验时间: 2014 年 5 月 12 实验成员: _____ 指导老师:干开峰 电子信息与电气工程系 2014年4月制
一、实验目的 1、熟悉嵌入式Linux的内核相关代码分布情况。 2、掌握Linux内核移植过程。 3、学会编译和测试Linux内核。 二、实验内容 本实验了解Linux2.6.32代码结构,基于S3C2440处理器,完成Linux2.6.32内核移植,并完成编译和在目标开发板上测试通过。 三、实验步骤 1、使用光盘自带源码默认配置Linux内核 ⑴在光盘linux文件夹中找到linux-2.6.32.2-mini2440.tar.gz源码文件。 输入命令:#tar –jxvf linux-2.6.32.2-mini2440-20110413.tar对其进行解压。 ⑵执行以下命令来使用缺省配置文件config_x35 输入命令#cp config_mini2440_x35 .config;(注意:x35后面有个空格,然后有个“.”开头的 config ) 然后执行“make menuconfig”命令,但是会出现出现缺少ncurses libraries的错误,如下图所示: 解决办法:输入sudo apt-get install libncurses5-dev 命令进行在线安装ncurses libraries服务。
安装好之后在make menuconfig一下就会出现如下图所示。 ⑶配置内核界面,不用做任何更改,在主菜单里选择
嵌入式Linux内核移植详解(顶嵌)
内核移植阶段 内核是操作系统最基本的部分。它是为众多应用程序提供对计算机硬件的安全访问的一部分软件,这种访问是有限的,并且内核决定一个程序在什么时候对某部分硬件操作多长时间。直接对硬件操作是非常复杂的,所以内核通常提供一种硬件抽象的方法来完成这些操作。硬件抽象隐藏了复杂性,为应用软件和硬件提供了一套简洁,统一的接口,使程序设计更为简单。 内核和用户界面共同为用户提供了操作计算机的方便方式。也就是我们在windows下看到的操作系统了。由于内核的源码提供了非常广泛的硬件支持,通用性很好,所以移植起来就方便了许多,我们需要做的就是针对我们要移植的对象,对内核源码进行相应的配置,如果出现内核源码中不支持的硬件这时就需要我们自己添加相应的驱动程序了。 一.移植准备 1. 目标板 我们还是选用之前bootloader移植选用的开发板参数请参考上文的地址: https://www.360docs.net/doc/833552246.html,/thread-80832-5-1.html。bootloader移植准备。 2. 内核源码 这里我们选用比较新的内核源码版本linux-2.6.25.8,他的下载地址是 ftp://https://www.360docs.net/doc/833552246.html,/pub/linux/kernel/v2.6/linux-2.6.25.8.tar.bz2。 3. 烧写工具 我们选用网口进行烧写这就需要内核在才裁剪的时候要对网卡进行支持 4. 知识储备 要进行内核裁剪不可缺少的是要对内核源码的目录结构有一定的了解这里进 行简单介绍。 (1)arch/: arch子目录包括了所有和体系结构相关的核心代码。它的每一个子 目录都代表一种支持的体系结构,例如i386就是关于intel cpu及与之相兼容体 系结构的子目录。PC机一般都基于此目录。 (2)block/:部分块设备驱动程序。 (3)crypto:常用加密和散列算法(如AES、SHA等),还有一些压缩和CRC校验 算法。 (4) documentation/:文档目录,没有内核代码,只是一套有用的文档。 (5) drivers/:放置系统所有的设备驱动程序;每种驱动程序又各占用一个子目 录:如,/block 下为块设备驱动程序,比如ide(ide.c)。 (6)fs/:所有的文件系统代码和各种类型的文件操作代码,它的每一个子目录支持 一个文件系统, 例如fat和ext2。
Linux操作系统源代码详细分析
linux源代码分析:Linux操作系统源代码详细分析 疯狂代码 https://www.360docs.net/doc/833552246.html,/ ?:http:/https://www.360docs.net/doc/833552246.html,/Linux/Article28378.html 内容介绍: Linux 拥有现代操作系统所有功能如真正抢先式多任务处理、支持多用户内存保护虚拟内存支持SMP、UP符合POSIX标准联网、图形用户接口和桌面环境具有快速性、稳定性等特点本书通过分析Linux内核源代码充分揭示了Linux作为操作系统内核是如何完成保证系统正常运行、协调多个并发进程、管理内存等工作现实中能让人自由获取系统源代码并不多通过本书学习将大大有助于读者编写自己新 第部分 Linux 内核源代码 arch/i386/kernel/entry.S 2 arch/i386/kernel/init_task.c 8 arch/i386/kernel/irq.c 8 arch/i386/kernel/irq.h 19 arch/i386/kernel/process.c 22 arch/i386/kernel/signal.c 30 arch/i386/kernel/smp.c 38 arch/i386/kernel/time.c 58 arch/i386/kernel/traps.c 65 arch/i386/lib/delay.c 73 arch/i386/mm/fault.c 74 arch/i386/mm/init.c 76 fs/binfmt-elf.c 82 fs/binfmt_java.c 96 fs/exec.c 98 /asm-generic/smplock.h 107 /asm-i386/atomic.h 108 /asm- i386/current.h 109 /asm-i386/dma.h 109 /asm-i386/elf.h 113 /asm-i386/hardirq.h 114 /asm- i386/page.h 114 /asm-i386/pgtable.h 115 /asm-i386/ptrace.h 122 /asm-i386/semaphore.h 123 /asm-i386/shmparam.h 124 /asm-i386/sigcontext.h 125 /asm-i386/siginfo.h 125 /asm-i386/signal.h 127 /asm-i386/smp.h 130 /asm-i386/softirq.h 132 /asm-i386/spinlock.h 133 /asm-i386/system.h 137 /asm-i386/uaccess.h 139 //binfmts.h 146 //capability.h 147 /linux/elf.h 150 /linux/elfcore.h 156 /linux/errupt.h 157 /linux/kernel.h 158 /linux/kernel_stat.h 159 /linux/limits.h 160 /linux/mm.h 160 /linux/module.h 164 /linux/msg.h 168 /linux/personality.h 169 /linux/reboot.h 169 /linux/resource.h 170 /linux/sched.h 171 /linux/sem.h 179 /linux/shm.h 180 /linux/signal.h 181 /linux/slab.h 184 /linux/smp.h 184 /linux/smp_lock.h 185 /linux/swap.h 185 /linux/swapctl.h 187 /linux/sysctl.h 188 /linux/tasks.h 194 /linux/time.h 194 /linux/timer.h 195 /linux/times.h 196 /linux/tqueue.h 196 /linux/wait.h 198 init/.c 198 init/version.c 212 ipc/msg.c 213 ipc/sem.c 218 ipc/shm.c 227 ipc/util.c 236 kernel/capability.c 237 kernel/dma.c 240 kernel/exec_do.c 241 kernel/exit.c 242 kernel/fork.c 248 kernel/info.c 255 kernel/itimer.c 255 kernel/kmod.c 257 kernel/module.c 259 kernel/panic.c 270 kernel/prk.c 271 kernel/sched.c 275 kernel/signal.c 295 kernel/softirq.c 307 kernel/sys.c 307 kernel/sysctl.c 318 kernel/time.c 330 mm/memory.c 335 mm/mlock.c 345 mm/mmap.c 348 mm/mprotect.c 358 mm/mremap.c 361 mm/page_alloc.c 363 mm/page_io.c 368 mm/slab.c 372 mm/swap.c 394 mm/swap_state.c 395 mm/swapfile.c 398 mm/vmalloc.c 406 mm/vmscan.c 409
02--基于ARM9的Linux2.6内核移植
基于ARM9的Linux2.6内核移植 姓名 系别、专业 导师姓名、职称 完成时间
目录 摘要................................................... I ABSTARCT................................................ II 1 绪论.. (1) 1.1课题研究的背景、目的和意义 (1) 1.2嵌入式系统现状及发展趋势 (1) 1.3论文的主要工作 (4) 2 嵌入式 Linux系统构成和软件开发环境 (5) 2.1嵌入式Linux系统的体系结构 (5) 2.2嵌入式Linux系统硬件平台 (5) 2.3嵌入式Linux开发软件平台建立 (7) 2.4本章小结 (11) 3 嵌入式Linux的引导BootLoader程序 (12) 3.1 BootLoader概述 (12) 3.2 NAND Flash和NOR Flash的区别 (13) 3.3本章小结 (19) 4 Linux内核的编译、移植 (20) 4.1 Linux2.6内核的新特性简介 (20) 4.2 Linux内核启动流程 (20) 4.3内核移植的实现 (21) 4.4 MTD内核分区 (23) 4.5配置、编译内核 (24) 4.6本章小结 (26) 5 文件系统制作 (27) 5.1 yaffs文件系统简介 (27) 5.2 内核支持YAFFS文件系统 (27) 5.3本章小结 (30) 6测试 (31) 6.1简单测试方法的介绍 (31) 6.2编写简单C程序测试移植的系统 (31) 6.3在开发板执行测试程序 (32)
linux内核IMQ源码实现分析
本文档的Copyleft归wwwlkk所有,使用GPL发布,可以自由拷贝、转载,转载时请保持文档的完整性,严禁用于任何商业用途。 E-mail: wwwlkk@https://www.360docs.net/doc/833552246.html, 来源: https://www.360docs.net/doc/833552246.html,/?business&aid=6&un=wwwlkk#7 linux2.6.35内核IMQ源码实现分析 (1)数据包截留并重新注入协议栈技术 (1) (2)及时处理数据包技术 (2) (3)IMQ设备数据包重新注入协议栈流程 (4) (4)IMQ截留数据包流程 (4) (5)IMQ在软中断中及时将数据包重新注入协议栈 (7) (6)结束语 (9) 前言:IMQ用于入口流量整形和全局的流量控制,IMQ的配置是很简单的,但很少人分析过IMQ的内核实现,网络上也没有IMQ的源码分析文档,为了搞清楚IMQ的性能,稳定性,以及借鉴IMQ的技术,本文分析了IMQ的内核实现机制。 首先揭示IMQ的核心技术: 1.如何从协议栈中截留数据包,并能把数据包重新注入协议栈。 2.如何做到及时的将数据包重新注入协议栈。 实际上linux的标准内核已经解决了以上2个技术难点,第1个技术可以在NF_QUEUE机制中看到,第二个技术可以在发包软中断中看到。下面先介绍这2个技术。 (1)数据包截留并重新注入协议栈技术
(2)及时处理数据包技术 QoS有个技术难点:将数据包入队,然后发送队列中合适的数据包,那么如何做到队列中的数
激活状态的队列是否能保证队列中的数据包被及时的发送吗?接下来看一下,激活状态的队列的 证了数据包会被及时的发送。 这是linux内核发送软中断的机制,IMQ就是利用了这个机制,不同点在于:正常的发送队列是将数据包发送给网卡驱动,而IMQ队列是将数据包发送给okfn函数。
读Linux内核源代码
Linux内核分析方法 Linux的最大的好处之一就是它的源码公开。同时,公开的核心源码也吸引着无数的电脑爱好者和程序员;他们把解读和分析Linux的核心源码作为自己的最大兴趣,把修改Linux源码和改造Linux系统作为自己对计算机技术追求的最大目标。 Linux内核源码是很具吸引力的,特别是当你弄懂了一个分析了好久都没搞懂的问题;或者是被你修改过了的内核,顺利通过编译,一切运行正常的时候。那种成就感真是油然而生!而且,对内核的分析,除了出自对技术的狂热追求之外,这种令人生畏的劳动所带来的回报也是非常令人着迷的,这也正是它拥有众多追随者的主要原因: ?首先,你可以从中学到很多的计算机的底层知识,如后面将讲到的系统的引导和硬件提供的中断机制等;其它,象虚拟存储的实现机制,多任务机制,系统保护机制等等,这些都是非都源码不能体会的。 ?同时,你还将从操作系统的整体结构中,体会整体设计在软件设计中的份量和作用,以及一些宏观设计的方法和技巧:Linux的内核为上层应用提供一个与具体硬件不相关的平台; 同时在内核内部,它又把代码分为与体系结构和硬件相关的部分,和可移植的部分;再例如,Linux虽然不是微内核的,但他把大部分的设备驱动处理成相对独立的内核模块,这样减小了内核运行的开销,增强了内核代码的模块独立性。 ?而且你还能从对内核源码的分析中,体会到它在解决某个具体细节问题时,方法的巧妙:如后面将分析到了的Linux通过Botoom_half机制来加快系统对中断的处理。 ?最重要的是:在源码的分析过程中,你将会被一点一点地、潜移默化地专业化。一个专业的程序员,总是把代码的清晰性,兼容性,可移植性放在很重要的位置。他们总是通过定义大量的宏,来增强代码的清晰度和可读性,而又不增加编译后的代码长度和代码的运行效率; 他们总是在编码的同时,就考虑到了以后的代码维护和升级。甚至,只要分析百分之一的代码后,你就会深刻地体会到,什么样的代码才是一个专业的程序员写的,什么样的代码是一个业余爱好者写的。而这一点是任何没有真正分析过标准代码的人都无法体会到的。 然而,由于内核代码的冗长,和内核体系结构的庞杂,所以分析内核也是一个很艰难,很需要毅力的事;在缺乏指导和交流的情况下,尤其如此。只有方法正确,才能事半功倍。正是基于这种考虑,作者希望通过此文能给大家一些借鉴和启迪。 由于本人所进行的分析都是基于2.2.5版本的内核;所以,如果没有特别说明,以下分析都是基于i386单处理器的2.2.5版本的Linux内核。所有源文件均是相对于目录/usr/src/linux的。 方法之一:从何入手 要分析Linux内核源码,首先必须找到各个模块的位置,也即要弄懂源码的文件组织形式。虽然对于有经验的高手而言,这个不是很难;但对于很多初级的Linux爱好者,和那些对源码分析很
Linux内核移植开发手册
江苏中科龙梦科技有限公司 Linux内核移植开发手册 修 订 记 录 项 次 修订日期 版 本修订內容修订者审 核 1 2009‐02‐04 0.1 初版发行陶宏亮, 胡洪兵 2 2009‐11‐20 0.2 删除一些 多余文字 陶宏亮, 胡洪兵
DISCLAIMER THIS DOCUMENTATION IS PROVIDED FOR USE WITH LEMOTE PRODUCTS. NO LICENSE TO LEMOTE PROPERTY RIGHTS IS GRANTED. LEMOTE ASSUMES NO LIABILITY, PROVIDES NO WARRANTY EITHER EXPRESSED OR IMPLIED RELATING TO THE USAGE, OR INTELLECTUAL PROPERTY RIGHT INFRINGEMENT EXCEPT AS PROVIDED FOR BY LEMOTE TERMS AND CONDITIONS OF SALE. LEMOTE PRODUCTS ARE NOT DESIGNED FOR AND SHOULD NOT BE USED IN ANY MEDICAL OR LIFE SUSTAINING OR SUPPORTING EQUIPMENT. ALL INFORMATION IN THIS DOCUMENT SHOULD BE TREATED AS PRELIMINARY. LEMOTE MAY MAKE CHANGES TO THIS DOCUMENT WITHOUT NOTICE. ANYONE RELYING ON THIS DOCUMENTATION SHOULD CONTACT LEMOTE FOR THE CURRENT DOCUMENTATION AND ERRATA. JIANGSU LEMOTE TECHNOLOGY CORPORATION LIMITED MENGLAN INDUSTRIAL PARK,YUSHAN,CHANGSHU CITY,JIANGSU PROVINCE,CHINA Tel: 0512‐52308661 Fax: 0512‐52308688 Http: //https://www.360docs.net/doc/833552246.html,
Linux内核源代码阅读与工具介绍
Linux的内核源代码可以从很多途径得到。一般来讲,在安装的linux系统下,/usr/src/linux 目录下的东西就是内核源代码。另外还可以从互连网上下载,解压缩后文件一般也都位于linux目录下。内核源代码有很多版本,目前最新的版本是2.2.14。 许多人对于阅读Linux内核有一种恐惧感,其实大可不必。当然,象Linux内核这样大而复杂的系统代码,阅读起来确实有很多困难,但是也不象想象的那么高不可攀。只要有恒心,困难都是可以克服的。任何事情做起来都需要有方法和工具。正确的方法可以指导工作,良好的工具可以事半功倍。对于Linux内核源代码的阅读也同样如此。下面我就把自己阅读内核源代码的一点经验介绍一下,最后介绍Window平台下的一种阅读工具。 对于源代码的阅读,要想比较顺利,事先最好对源代码的知识背景有一定的了解。对于linux内核源代码来讲,基本要求是:⑴操作系统的基本知识;⑵对C语言比较熟悉,最好要有汇编语言的知识和GNU C对标准C的扩展的知识的了解。另外在阅读之前,还应该知道Linux内核源代码的整体分布情况。我们知道现代的操作系统一般由进程管理、内存管理、文件系统、驱动程序、网络等组成。看一下Linux内核源代码就可看出,各个目录大致对应了这些方面。Linux内核源代码的组成如下(假设相对于linux目录): arch这个子目录包含了此核心源代码所支持的硬件体系结构相关的核心代码。如对于X86平台就是i386。 include这个目录包括了核心的大多数include文件。另外对于每种支持的体系结构分别有一个子目录。 init此目录包含核心启动代码。 mm此目录包含了所有的内存管理代码。与具体硬件体系结构相关的内存管理代码位于arch/*/mm目录下,如对应于X86的就是arch/i386/mm/fault.c。 drivers系统中所有的设备驱动都位于此目录中。它又进一步划分成几类设备驱动,每一种也有对应的子目录,如声卡的驱动对应于drivers/sound。 ipc此目录包含了核心的进程间通讯代码。 modules此目录包含已建好可动态加载的模块。 fs Linux支持的文件系统代码。不同的文件系统有不同的子目录对应,如ext2文件系统对应的就是ext2子目录。 kernel主要核心代码。同时与处理器结构相关代码都放在arch/*/kernel目录下。 net核心的网络部分代码。里面的每个子目录对应于网络的一个方面。 lib此目录包含了核心的库代码。与处理器结构相关库代码被放在arch/*/lib/目录下。
linux源代码分析实验报告格式
linux源代码分析实验报告格式
Linux的fork、exec、wait代码的分析 指导老师:景建笃 组员:王步月 张少恒 完成日期:2005-12-16
一、 设计目的 1.通过对Linux 的fork 、exec 、wait 代码的分析,了解一个操作系统进程的创建、 执行、等待、退出的过程,锻炼学生分析大型软件代码的能力; 2.通过与同组同学的合作,锻炼学生的合作能力。 二、准备知识 由于我们选的是题目二,所以为了明确分工,我们必须明白进程的定义。经过 查阅资料,我们得知进程必须具备以下四个要素: 1、有一段程序供其执行。这段程序不一定是进程专有,可以与其他进程共用。 2、有起码的“私有财产”,这就是进程专用的系统堆栈空间 3、有“户口”,这就是在内核中有一个task_struct 结构,操作系统称为“进程控制 块”。有了这个结构,进程才能成为内核调度的一个基本单位。同时,这个结构又 是进程的“财产登记卡”,记录着进程所占用的各项资源。 4、有独立的存储空间,意味着拥有专有的用户空间:进一步,还意味着除前述的 系统空间堆栈外,还有其专用的用户空间堆栈。系统为每个进程分配了一个 task_struct 结构,实际分配了两个连续的物理页面(共8192字节),其图如下: Struct task_struct (大约1K) 系统空间堆栈 (大约7KB )两个 连续 的物 理页 面 对这些基本的知识有了初步了解之后,我们按老师的建议,商量分工。如下: 四、 小组成员以及任务分配 1、王步月:分析进程的创建函数fork.c ,其中包含了get_pid 和do_fork get_pid, 写出代码分析结果,并画出流程图来表示相关函数之间的相互调用关系。所占工作 比例35%。 2、张少恒:分析进程的执行函数exec.c,其中包含了do_execve 。写出代码分析结 果,并画出流程图来表示相关函数之间的相互调用关系。所占工作比例35% 。 3、余波:分析进程的退出函数exit.c,其中包含了do_exit 、sys_wait4。写出代码 分析结果,并画出流程图来表示相关函数之间的相互调用关系。所占工作比例30% 。 五、各模块分析: 1、fork.c 一)、概述 进程大多数是由FORK 系统调用创建的.fork 能满足非常高效的生灭机制.除了 0进程等少数一,两个进程外,几乎所有的进程都是被另一个进程执行fork 系统调 用创建的.调用fork 的进程是父进程,由fork 创建的程是子进程.每个进程都有一
Linux源代码分析_存储管理
文章编号:1004-485X (2003)03-0030-04 收稿日期:2003-05-10 作者简介:王艳春,女(1964 ),副教授,主要从事操作系统、中文信息处理等方面的研究工作。 Linux 源代码分析 存储管理 王艳春 陈 毓 葛明霞 (长春理工大学计算机科学技术学院,吉林长春130022) 摘 要:本文剖析了Linux 操作系统的存储管理机制。给出了Linux 存储管理的特点、虚存的实现方法,以及主要数据结构之间的关系。 关键词:Linux 操作系统;存储管理;虚拟存储中图分类号:T P316 81 文献标识码:A Linux 操作系统是一种能运行于多种平台、源代码公开、免费、功能强大、与Unix 兼容的操作系统。自其诞生以来,发展非常迅速,在我国也受到政府、企业、科研单位、大专院校的重视。我们自2000年开始对Linux 源代码(版本号是Linux 2 2 16)进行分析,首先剖析了进程管理和存储管理部分,本文是有关存储管理的一部分。主要介绍了Linux 虚存管理所用到的数据结构及其相互间的关系,据此可以更好地理解其存储管理机制,也可以在此基础上对其进行改进或在此后的研究中提供借鉴作用。作为一种功能强大的操作系统,Linux 实现了以虚拟内存为主的内存管理机制。即能够克服物理内存的局限,使用户进程在透明方式下,拥有比实际物理内存大得多的内存。本文主要阐述了Linux 虚存管理的基本特点和主要实现技术,并分析了Linux 虚存管理的主要数据结构及其相互关系。 1 Lin ux 虚存管理概述 Linux 的内存管理采用虚拟页式管理,使用多级页表,动态地址变换。进程在运行过程中可以动态浮动和扩展,为用户提供了透明的、灵活有效的内存使用方式。 1)32 bit 虚拟地址 在Linux 中,进程的4GB 虚存需通过32 bit 地址进行寻址。Linux 中虚拟地址与线性地址为同一概念,虚拟地址被分成3个子位段,而大小为4k,如图1所示。 2)Linux 的多级页表结构 图1 32位虚拟地址 标准的Linux 的虚存页表为三级页表,依次为页目录(Pag e Directory PGD)、中间页目录(Pag e Middle Directory PMD )、页表(Page Table PT E )。在i386机器上Linux 的页表结构实际为两级,PGD 和PMD 页表是合二为一的。所有有关PMD 的操作关际上是对PGD 的操作。所以源代码中形如*_pgd _*()和*_pmd_*()函数实现的功能也是一样的。 页目录(PGD)是一个大小为4K 的表,每一个进程只有一个页目录,以4字节为一个表项,分成1024个表项(或称入口点),表项的索引即为32位虚拟地址的页目录,该表项的值为所指页表的起始地址。页表(PTE)的每一个入口点的值为此表项所指的一页框(page frame),页表项的索引即为32位虚拟地址中的页号。页框(page reame)并不是物理页,它指的是虚存的一个地址空间。 3) 页表项的格式 图2 Linux 中页目录项和页表项格式 4)动态地址映射 Linux 虚存采用动态地址映射方式,即进程的地址空间和存储空间的对应关系是在程序的执行过 第26卷第3期长春理工大学学报 Vol 26N o 32003年9月 Journal of Changchun University of Science and T echnology Sep.2003
我来说linux移植过程
我对linux移植过程的整体理解 首先,要开始移植一个操作系统,我们要明白为什么要移植。因为我们要在另外一个平台上用到操作系统,为什么要用操作系统,不用行不行?这个问题的答案不是行或不行来回答。单片机,ARM7都没有操作系统,我们直接对寄存器进行操作进而实现我们需要的功能也是可以。但是,一些大型的项目设计牵涉很多到工程的创建,单纯对裸机进行操作会显得杂乱庞大这时候需要一个操作系统。 操作系统的功能能。我们用到操作系统,一方面可以控制我们的硬件和维护我们的硬件,另一方面可以为我们得应用程序提供服务。呵呵,这样说还是很抽象,具体到项目中就可以感受到操作系统的好处。 Linux操作系统的移植说白了总共三大部分:一,内核的重新编译。二,bootloader的重新编译。三,文件系统的制作。在这里要解释这些名词也很不好说的明白,首先,一个完整的操作系统是包括这三大部分的,内核、Bootloader、文件系统。我们知道Linux有很多版本,不同的版本只是文件系统不一样而内核的本质都是一样的。 那么,我们开始进行移植。首先是内核。1.我们需要下载一个内核源码,这个在网上很好下载,下载后,保存下。2.把这个压缩包复制到ubuntu(我用的版本)里,一般复制到/home/dong/SoftEmbed(我的目录,呵呵),然后呢,我们需要对这个内核进行修改重新编译,为什么要这样做,因为我们要让内核为我们的ARM服务,所以需要修改一些东西的。至于具体如何修改,我已经写在另外一个文档里了。3.修改的内容主要是 Makefile(设置体系架构为arm,设置交叉编译器)、时钟频率(我们板子的频率)、内核配置(进入内核配置主要是设置一些选项以适合我们的开发板)。具体设置步骤我会另加说明。4.设置好后我们需要重新编译内核,用的是make zImage命令。编译后就生成了我们自己编译好的内核,呵呵。 接下来,进行文件系统的移植。我们需要一个Yaffs2文件系统压缩包。1.复制这个压缩包到/home/dong/SoftEmede(我自己在ubuntu里建的目录,呵呵),2.解压,会生成一个文件夹。3.给内核打补丁,通过执行 ./patsh-ker.sh c /内核目录。呵呵4.进入 make menuconfig中配置选项,要选择对yaffs2的支持,具体怎么设置我写在另一个文档。 接下来,我们进行根文件制作,需要一个制作工具 mkyaffs2image.taz.还是复制到我自己的目录下,解压,安装。接着,我们需要对Busybox的移植、配置,具体移植、配置步骤我另写,呵呵。最后是构建我们自己的文件系统,到此我们已经完成了内核移植和文件系统的制作。准备移植,呵呵。今天先写到这里,累了。
Linux内核源码分析方法
Linux内核源码分析方法 一、内核源码之我见 Linux内核代码的庞大令不少人“望而生畏”,也正因为如此,使得人们对Linux的了解仅处于泛泛的层次。如果想透析Linux,深入操作系统的本质,阅读内核源码是最有效的途径。我们都知道,想成为优秀的程序员,需要大量的实践和代码的编写。编程固然重要,但是往往只编程的人很容易把自己局限在自己的知识领域内。如果要扩展自己知识的广度,我们需要多接触其他人编写的代码,尤其是水平比我们更高的人编写的代码。通过这种途径,我们可以跳出自己知识圈的束缚,进入他人的知识圈,了解更多甚至我们一般短期内无法了解到的信息。Linux内核由无数开源社区的“大神们”精心维护,这些人都可以称得上一顶一的代码高手。透过阅读Linux 内核代码的方式,我们学习到的不光是内核相关的知识,在我看来更具价值的是学习和体会它们的编程技巧以及对计算机的理解。 我也是通过一个项目接触了Linux内核源码的分析,从源码的分析工作中,我受益颇多。除了获取相关的内核知识外,也改变了我对内核代码的过往认知: 1.内核源码的分析并非“高不可攀”。内核源码分析的难度不在于源码本身,而在于如何使用更合适的分析代码的方式和手段。内核的庞大致使我们不能按照分析一般的demo程序那样从主函数开始按部就班的分析,我们需要一种从中间介入的手段对内核源码“各个击破”。这种“按需索取”的方式使得我们可以把握源码的主线,而非过度纠结于具体的细节。 2.内核的设计是优美的。内核的地位的特殊性决定着内核的执行效率必须足够高才可以响应目前计算机应用的实时性要求,为此Linux内核使用C语言和汇编的混合编程。但是我们都 知道软件执行效率和软件的可维护性很多情况下是背道而驰的。如何在保证内核高效的前提下提高内核的可维护性,这需要依赖于内核中那些“优美”的设计。 3.神奇的编程技巧。在一般的应用软件设计领域,编码的地位可能不被过度的重视,因为开发者更注重软件的良好设计,而编码仅仅是实现手段问题——就像拿斧子劈柴一样,不用太多的思考。但是这在内核中并不成立,好的编码设计带来的不光是可维护性的提高,甚至是代码性能的提升。 每个人对内核的了理解都会有所不同,随着我们对内核理解的不断加深,对其设计和实现的思想会有更多的思考和体会。因此本文更期望于引导更多徘徊在Linux内核大门之外的人进入Linux的世界,去亲自体会内核的神奇与伟大。而我也并非内核源码方面的专家,这么做也只是希望分享我自己的分析源码的经验和心得,为那些需要的人提供参考和帮助,说的“冠冕堂皇”一点,也算是为计算机这个行业,尤其是在操作系统内核方面贡献自己的一份绵薄之力。闲话少叙(已经罗嗦了很多了,囧~),下面我就来分享一下自己的Linix内核源码分析方法。 二、内核源码难不难? 从本质上讲,分析Linux内核代码和看别人的代码没有什么两样,因为摆在你面前的一般都不是你自己写出来的代码。我们先举一个简单的例子,一个陌生人随便给你一个程序,并要你看完源码后讲解一下程序的功能的设计,我想很多自我感觉编程能力还可以的人肯定觉得这没什么,只要我耐心的把他的代码从头到尾看完,肯定能找到答案,并且事实确实是如此。那么现在换一个假设,如果这个人是Linus,给你的就是Linux内核的一个模块的代码,你还会觉得依然那么 轻松吗?不少人可能会有所犹豫。同样是陌生人(Linus要是认识你的话当然不算,呵呵~)给 你的代码,为什么给我们的感觉大相径庭呢?我觉得有以下原因:
基于ARM的嵌入式linux内核的裁剪与移植.
基于ARM的嵌入式linux内核的裁剪与 移植 0引言微处理器的产生为价格低廉、结构小巧的CPU和外设的连接提供了稳定可靠的硬件架构,这样,限制嵌入式系统发展的瓶颈就突出表现在了软件方面。尽管从八十年代末开始,已经陆续出现了一些嵌入式操作系统(比较著名的有Vxwork、pSOS、Neculeus和WindowsCE)。但这些专用操作系统都是商业化产品,其高昂的价格使许多低端产品的小公司望而却步;而且,源代码封闭性也大大限制了开发者的积极性。而Linux的开放性,使得许多人都认为Linu 0 引言 微处理器的产生为价格低廉、结构小巧的CPU和外设的连接提供了稳定可靠的硬件架构,这样,限制嵌入式系统发展的瓶颈就突出表现在了软件方面。尽管从八十年代末开始,已经陆续出现了一些嵌入式操作系统(比较著名的有Vxwork、pSOS、Nec uleus和Windows CE)。但这些专用操作系统都是商业化产品,其高昂的价格使许多低端产品的小公司望而却步;而且,源代码封闭性也大大限制了开发者的积极性。而Linux的开放性,使得许多人都认为Linux 非常适合多数Intemet设备。Linux操作系统可以支持不同的设备和不同的配置。Linux对厂商不偏不倚,而且成本极低,因而很快成为用于各种设备的操作系统。嵌入式linux是大势所趋,其巨大的市场潜力与酝酿的无限商机必然会吸引众多的厂商进入这一领域。 1 嵌入式linux操作系统 Linux为嵌入操作系统提供了一个极有吸引力的选择,它是个和Unix 相似、以核心为基础、全内存保护、多任务、多进程的操作系统。可以支持广泛的计算机硬件,包括X86、Alpha、Sparc、MIPS、PPC、ARM、NEC、MOTOROLA 等现有的大部分芯片。Linux的程序源码全部公开,任何人都可以根据自己的需要裁剪内核,以适应自己的系统。文章以将linux移植到ARM920T内核的 s3c2410处理器芯片为例,介绍了嵌入式linux内核的裁剪以及移植过程,文中介绍的基本原理与方法技巧也可用于其它芯片。 2 内核移植过程 2.1 建立交叉编译环境 交叉编译的任务主要是在一个平台上生成可以在另一个平台上执行的程序代码。不同的CPU需要有不同的编译器,交叉编译如同翻译一样,它可以把相同的程序代码翻译成不同的CPU对应语言。 交叉编译器完整的安装涉及到多个软件安装,最重要的有binutils、gcc、glibc三个。其中,binutils主要用于生成一些辅助工具;gcc则用来生成交叉编译器,主要生成arm—linux—gcc交叉编译工具;glibc主要是提供用户程序所使用的一些基本的函数库。 自行搭建交叉编译环境通常比较复杂,而且很容易出错。本文使用的是
Linux内核源代码解读
Linux内核源代码解读!! 悬赏分:5 - 提问时间2007-1-24 16:28 问题为何被关闭 赵炯书中,Bootsect代码中有 mov ax , #BOOTSEG 等 我曾自学过80x86汇编,没有见过#的用法,在这为什么要用#? 另外, JMPI 的用法是什么?与JMP的区别是什么? 提问者: Linux探索者 - 一级 答复共 1 条 检举 系统初始化程序 boot.s 的分析 [转] 系统初始化程序 boot.s 的分析: 阚志刚,2000/03/20下午,在前人的基础之上进行整理完善 ******************************************************************************** ************** boot.s is loaded at 0x7c00 by the bios-startup routines, and moves itself out of the way to address 0x90000, and jumps there. 当PC 机启动时,Intel系列的CPU首先进入的是实模式,并开始执行位于地址0xFFF0处的代码,也就是ROM-BIOS起始位置的代码。BIOS先进行一系列的系统自检,然后初始化位于地址0的中断向量表。最后BIOS将启动盘的第一个扇区装入0x7C00(31K;0111,1100,0000,0000),并开始执行此处的代码。这就是对内核初始化过程的一个最简单的描述。 最初,Linux核心的最开始部分是用8086汇编语言编写的。当开始运行时,核心将自己装入到绝对地址0x90000(576K; 1001,0000,0000,0000,0000),再将其后的2k字节装入到地址0x90200(576.5k;1001,0000,0010,0000,0000)处,最后将核心的其余部分装入到0x10000(64k; 1,0000,0000,0000,0000). It then loads the system at 0x10000, using BIOS interrupts. Thereafter it disables all interrupts, moves the system down to 0x0000, changes to protected mode, and calls the start of system. System then must RE-initialize the protected mode in it's own tables, and enable interrupts as needed. 然后,关掉所有中断,把系统下移到0x0000(0k;0000,0000,0000,0000,0000)处,改变到保护模式,然后开始系统的运行.系统必须重新在保护模式下初始化自己的系统表格,并且打开所需的中断. NOTE 1! currently system is at most 8*65536(8*64k=512k; 1000,0000,0000,0000,0000) bytes long. This should be no problem, even in the future. I want to keep it simple. This 512 kB kernel size should be enough - in fact more would mean we'd have to move not just these start-up routines, but also do something about the cache-memory
Linux KVM虚拟化源代码分析文档
KVM虚拟机源代码分析 1,KVM结构及工作原理 1.1K VM结构 KVM基本结构有两部分组成。一个是KVM Driver ,已经成为Linux 内核的一个模块。负责虚拟机的创建,虚拟内存的分配,虚拟CPU寄存器的读写以及虚拟CPU的运行等。另外一个是稍微修改过的Qemu,用于模拟PC硬件的用户空间组件,提供I/O设备模型以及访问外设的途径。 图1 KVM基本结构 KVM基本结构如图1所示。其中KVM加入到标准的Linux内核中,被组织成Linux中标准的字符设备(/dev/kvm)。Qemu通KVM提供的LibKvm应用程序接口,通过ioctl系统调用创建和运行虚拟机。KVM Driver使得整个Linux成为一个虚拟机监控器。并且在原有的Linux两种执行模式(内核模式和用户模式)的基础上,新增加了客户模式,客户模式拥有自己的内核模式和用户模式。在虚拟机运行下,三种模式的分工如下: 客户模式:执行非I/O的客户代码。虚拟机运行在客户模式下。 内核模式:实现到客户模式的切换。处理因为I/O或者其它指令引起的从客户模式的退出。KVM Driver工作在这种模式下。 用户模式:代表客户执行I/O指令Qemu运行在这种模式下。
在KVM模型中,每一个Guest OS 都作为一个标准的Linux进程,可以使用Linux的进程管理指令管理。 在图1中./dev/kvm在内核中创建的标准字符设备,通过ioctl系统调用来访问内核虚拟机,进行虚拟机的创建和初始化;kvm_vm fd是创建的指向特定虚拟机实例的文件描述符,通过这个文件描述符对特定虚拟机进行访问控制;kvm_vcpu fd指向为虚拟机创建的虚拟处理器的文件描述符,通过该描述符使用ioctl系统调用设置和调度虚拟处理器的运行。 1.2K VM工作原理 KVM的基本工作原理:用户模式的Qemu利用接口libkvm通过ioctl系统调用进入内核模式。KVM Driver为虚拟机创建虚拟内存和虚拟CPU后执行VMLAUCH指令进入客户模式。装载Guest OS执行。如果Guest OS发生外部中断或者影子页表缺页之类的事件,暂停Guest OS的执行,退出客户模式进行一些必要的处理。然后重新进入客户模式,执行客户代码。如果发生I/O事件或者信号队列中有信号到达,就会进入用户模式处理。KVM采用全虚拟化技术。客户机不用修改就可以运行。 图2 KVM 工作基本原理