(整理)字符串处理.

五、字符串编辑距离
给定一个源字符串和目标字符串,能够对源串进行如下操作:
1.在给定位置上插入一个字符
2.替换任意字符
3.删除任意字符
求通过以上操作使得源字符串和目标字符串一致的最小操作步数。
简单描述一下解该题的思想,源字符串和目标字符串分别为str_a、str_b,二者的长度分别为la、lb,定义f[i,j]为子串str_a[0...i]和str_b[0...j]的最小编辑距离,简单分析可知求得的str_a[0...i]和str_b[0...j]的最小编辑距离有一下三种可能:
(1)去掉str_a[0...i]的最后一个字符跟str_b[0...j]匹配,则f[i, j]的值等于f[i-1, j]+1;(2)去掉str_b[0...j]的最后一个字符跟str_a[0...i]匹配,则f[i, j]的值等于f[i, j-1]+1;(3)去掉str_a[0...i]和str_b[0...j]的最后一个字符,让二者匹配求得f[i-1, j-1],计算f[i, j]时要考虑当前字符是否相等,如果str_a[i]==str_b[j]说明该字符不用编辑,所以f[i, j]的值等于f[i-1, j-1],如果str_a[i]!=str_b[j]说明该字符需要编辑一次(任意修改str_a[i]或者str_b[j]即可),所以f[i, j]的值等于f[i-1, j-1]+1。
因为题目要求的是最小的编辑距离,所以去上面上中情况中的最小值即可,因此可以得到递推公式:
f[i, j] = Min ( f[i-1, j]+1, f[i, j-1]+1, f[i-1, j-1]+(str_a[i]==str_b[j] ? 0 : 1) )
维基百科中的描述如下:
1)递归方法(用到动态规划)
由上述的递归公式可以有以下代码:
[cpp]view plaincopy
1.//求两个字符串的编辑距离问题
2.//递归版本,备忘录C[i,j]表示strA[i]...strA[size_A-1]与strB[j]...strB[size_B-1]
的编辑距离
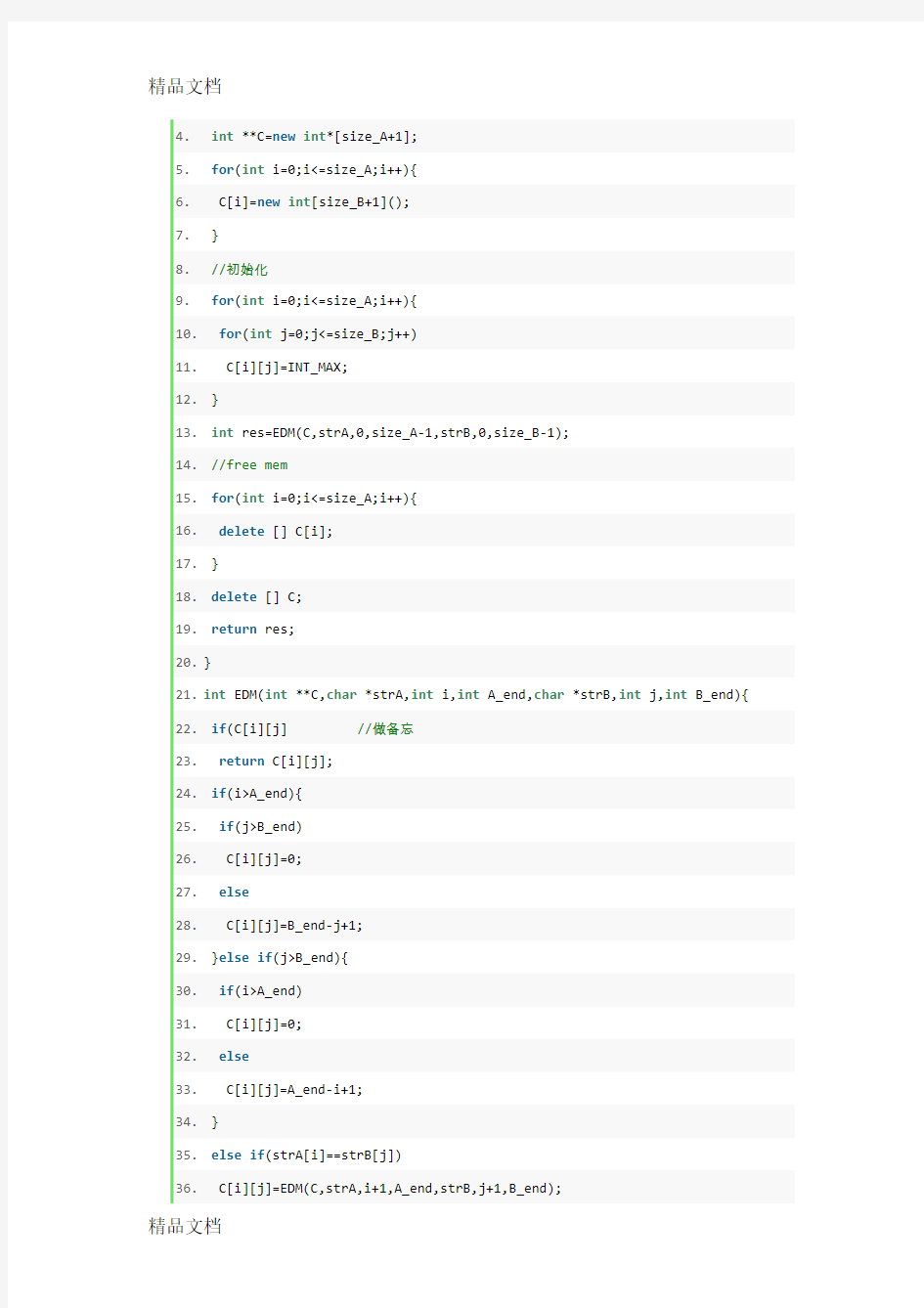
3.int editDistance_mem(char *strA,int size_A,char *strB,int size_B){
4.int **C=new int*[size_A+1];
5.for(int i=0;i<=size_A;i++){
6. C[i]=new int[size_B+1]();
7. }
8.//初始化
9.for(int i=0;i<=size_A;i++){
10.for(int j=0;j<=size_B;j++)
11. C[i][j]=INT_MAX;
12. }
13.int res=EDM(C,strA,0,size_A-1,strB,0,size_B-1);
14.//free mem
15.for(int i=0;i<=size_A;i++){
16.delete [] C[i];
17. }
18.delete [] C;
19.return res;
20.}
21.int EDM(int **C,char *strA,int i,int A_end,char *strB,int j,int B_end){
22.if(C[i][j] 23.return C[i][j]; 24.if(i>A_end){ 25.if(j>B_end) 26. C[i][j]=0; 27.else 28. C[i][j]=B_end-j+1; 29. }else if(j>B_end){ 30.if(i>A_end) 31. C[i][j]=0; 32.else 33. C[i][j]=A_end-i+1; 34. } 35.else if(strA[i]==strB[j]) 36. C[i][j]=EDM(C,strA,i+1,A_end,strB,j+1,B_end); 37.else{ 38.int a=EDM(C,strA,i+1,A_end,strB,j+1,B_end); 39.int b=EDM(C,strA,i,A_end,strB,j+1,B_end); 40.int c=EDM(C,strA,i+1,A_end,strB,j,B_end); 41. C[i][j]=min(a,b,c)+1; 42. } 43.return C[i][j]; 44.} 2)矩阵标记法 递推方法(也可称为矩阵标记法),通过分析可知可以将f[i, j]的计算在一个二维矩阵中进行,上面的递推式实际上可以看做是矩阵单元的计算递推式,只要把矩阵填满了,f[la-1, lb-1]的值就是要求得最小编辑距离。代码如下: [cpp]view plaincopy 1.//求两个字符串的编辑距离问题 2.//递推版本 C[i,j]表示strA[i]...strA[size_A-1]与strB[j]...strB[size_B-1]的编辑 距离 3.int editDistance_iter(char *strA,int size_A,char *strB,int size_B){ 4.int **C=new int*[size_A+1]; 5.for(int i=0;i<=size_A;i++){ 6. C[i]=new int[size_B+1](); 7. } 8.for(int i=size_A;i>=0;i--){ 9.for(int j=size_B;j>=0;j--){ 10.if(i>size_A-1){ 11.if(j>size_B-1) 12. C[i][j]=0; 13.else 14. C[i][j]=size_B-j; 15. }else if(j>size_B-1){ 16.if(i>size_A-1) 17. C[i][j]=0; 18.else 19. C[i][j]=size_A-i; 20. }else if(strA[i]==strB[j]) 21. C[i][j]=C[i+1][j+1]; 22.else 23. C[i][j]=min(C[i+1][j+1],C[i+1][j],C[i][j+1])+1; 24. } 25. } 26.int res=C[0][0]; 27.//free mem 28.for(int i=0;i<=size_A;i++){ 29.delete [] C[i]; 30. } 31.delete [] C; 32.return res; 33.} 六、最长不重复子串 很好理解,即求一个串内最长的不重复子串。 1)使用Hash 要求子串中的字符不能重复,判重问题首先想到的就是hash,寻找满足要求的子串,最直接的方法就是遍历每个字符起始的子串,辅助hash,寻求最长的不重复子串,由于要遍历每个子串故复杂度为O(n^2),n为字符串的长度,辅助的空间为常数hash[256]。代码如下: [cpp]view plaincopy 1./* 最长不重复子串我们记为 LNRS */ 2.int maxlen; 3.int maxindex; 4.void output(char * arr); 5./* LNRS 基本算法 hash */ 6.char visit[256]; 7.void LNRS_hash(char * arr, int size) 8.{ 9.for(int i = 0; i < size; ++i) 10. { 11. memset(visit,0,sizeof(visit)); 12. visit[arr[i]] = 1; 13.for(int j = i+1; j < size; ++j) 14. { 15.if(visit[arr[j]] == 0) 16. { 17. visit[arr[j]] = 1; 18. } 19.else 20. { 21.if(j-i > maxlen) 22. { 23. maxlen = j - i; 24. maxindex = i; 25. } 26.break; 27. } 28. } 29. } 30. output(arr); 31.} 2)动态规划法 字符串的问题,很多都可以用动态规划处理,比如这里求解最长不重复子串,和前面讨论过的最长递增子序列问题就有些类似,在LIS(最长递增子序列)问题中,对于当前的元素,要么是与前面的LIS构成新的最长递增子序列,要么就是与前面稍短的子序列构成新的子序列或单独构成新子序列。 这里我们采用类似的思路:某个当前的字符,如果它与前面的最长不重复子串中的字符没有重复,那么就可以以它为结尾构成新的最长子串;如果有重复,那么就与某个稍短的子串构成新的子串或者单独成一个新子串。 我们来看看下面两个例子: 1)字符串“abcdeab”,第二个a之前的最长不重复子串是“abcde”,a与最长子串中的字符有重复,但是它与稍短的“bcde”串没有重复,于是它可以与其构成一个新的子串,之前的最长不重复子串“abcde”结束; 2)字符串“abcb”,跟前面类似,最长串“abc”结束,第二个字符b与稍短的串“c”构成新的串; 我们貌似可以总结出一些东西:当一个最长子串结束时(即遇到重复的字符),新的子串的长度是与(第一个重复的字符)的下标有关的。 于是类似LIS,对于每个当前的元素,我们“回头”去查询是否有与之重复的,如没有,则最长不重复子串长度+1,如有,则是与第一个重复的字符之后的串构成新的最长不重复子串,新串的长度便是当前元素下标与重复元素下标之差。 可以看出这里的动态规划方法时间复杂度为O(N^2),我们可以与最长递增子序列的动态规划方案进行对比,是一个道理的。代码如下: [cpp]view plaincopy 1./* LNRS 动态规划求解 */ 2.int dp[100]; 3.void LNRS_dp(char * arr, int size) 4.{ 5.int i, j; 6. maxlen = maxindex = 0; 7. dp[0] = 1; 8.for(i = 1; i < size; ++i) 9. { 10.for(j = i-1; j >= 0; --j) 11. { 12.if(arr[j] == arr[i]) 13. { 14. dp[i] = i - j; 15.break; 16. } 17. } 18.if(j == -1) 19. { 20. dp[i] = dp[i-1] + 1; 21. } 22.if(dp[i] > maxlen) 23. { 24. maxlen = dp[i]; 25. maxindex = i + 1 - maxlen; 26. } 27. } 28. output(arr); 29.} 3)动态规划和hash结合 我们发现在动态规划方法中,每次都要“回头”去寻找重复元素的位置,所以时间复杂度徒增到O(n^2),结合方法1)中的Hash思路,我们可以用hash记录元素是否出现过,我们当然也可以用hash记录元素出现过的下标,,这样就不必“回头”了,而时间复杂度必然降为O(N),只不过需要一个辅助的常数空间visit[256],这也是之前我另外一篇文章找工作笔试面试那些事儿(15)---互联网公司面试的零零种种和多家经验提到的的空间换时间思路,不过一般我们的面试里面优先考虑时间复杂度,所以这是可取的方法。 [cpp]view plaincopy 1./* LNRS 动态规划 + hash 记录下标 */ 2.void LNRS_dp_hash(char * arr, int size) 3.{ 4. memset(visit, -1, sizeof visit); //visit数组是-1的时候代表这个字符没有在集 合中 5. memset(dp, 0, sizeof dp); 6. maxlen = maxindex = 0; 7. dp[0] = 1; 8. visit[arr[0]] = 0; 9.for(int i = 1; i < size; ++i) 10. { 11.if(visit[arr[i]] == -1) //表示arr[i]这个字符以前不存在 12. { 13. dp[i] = dp[i-1] + 1; 14. visit[arr[i]] = i; /* 记录字符下标 */ 15. }else 16. { 17. dp[i] = i - visit[arr[i]]; 18. visit[arr[i]] = i; /* 更新字符下标 */ 19. } 20.if(dp[i] > maxlen) 21. { 22. maxlen = dp[i]; 23. maxindex = i + 1 - maxlen; 24. } 25. } 26. output(arr); 27.} 4)空间再优化 上面的方法3)已经将时间复杂度降到了O(n),可是这时面试官又发言了,说你用的辅助空间多了,还有优化方法吗,我们仔细观察动态规划最优子问题解的更新方程: dp[i] = dp[i-1] + 1; dp[i-1]不就是更新dp[i]当前的最优解么?这又与之前提到的最大子数组和问题的优化几乎同出一辙,我们不需要O(n)的辅助空间去存储子问题的最优解,而只需O(1)的空间就可以了,至此,我们找到了时间复杂度O(N),辅助空间为O(1)(一个额外变量与256大小的散列表)的算法,代码如下: [cpp]view plaincopy 1./* LNRS 动态规划+hash,时间复杂度O(n) 空间复杂度O(1)算法*/ 2.void LNRS_dp_hash_ultimate(char * arr, int size) 3.{ 4. memset(visit, -1, sizeof visit); 5. maxlen = maxindex = 0; 6. visit[arr[0]] = 0; 7.int curlen = 1; 8.for(int i = 1; i < size; ++i) 9. { 10.if(visit[arr[i]] == -1) 11. { 12. ++curlen; 13. visit[arr[i]] = i; /* 记录字符下标 */ 14. } 15.else 16. { 17. curlen = i - visit[arr[i]]; 18. visit[arr[i]] = i; /* 更新字符下标 */ 19. } 20.if(curlen > maxlen) 21. { 22. maxlen = curlen; 23. maxindex = i + 1 - maxlen; 24. } 25. } 26. output(arr); 27.} 七、最长回文子串 给出一个字符串S,找到一个最长的连续回文串。例如串babcbabcbaccba 最长回文 是:abcbabcba 1)自中心向两端寻找 回文是一种特殊的字符串,我们可以以源字符串的每个字符为中心,依次寻找出最长回文子串P0, P1,...,Pn。这些最长回文子串中的最长串Pi = max(P1, P2,...,Pn)即为所求。核心代码如下: [cpp]view plaincopy 1.string find_lps_method1(const string &str) 2.{ 3.int center = 0, max_len = 0; 4.for(int i = 1; i < str.length()-1; ++i) 5. { 6.int j = 1; 7.//以str[i]为中心,依次向两边扩展,寻找最长回文Pi 8.while(i+j < str.length() && i-j >= 0 && str[i+j] == str[i-j]) 9. ++j; 10. --j; 11.if(j > 1 && j > max_len) 12. { 13. center = i; 14. max_len = j; 15. } 16. } 17.return str.substr(center-max_len, (max_len << 1) + 1); 18.} 2)利用最长公共字串的方法 这里用到了一个我们观察出来的结论:对于串S, 假设它反转后得到的串是S', 那么S 的最长回文串是S和S'的最长公共字串。 例如S = babcbabcbaccba, S' = abccabcbabcbab,S和S'的最长公共字串 是abcbabcba也是S的最长回文字串。 代码这个地方就不写了,用首指针++,尾指针--很容易实现串的翻转,再结合前面写过的最长公共子串代码可得到最后结果。 3)利用栈的性质 这是一个不成熟的想法,博主只是觉得比较好的想法需要拿出来分享一下,对于长度为偶数的最长回文,可以采用这样一种思路求得: 将字符串中的字符从左至右逐个入栈,出现情况:1)若栈顶字符和要入栈的字符相同,则该字符不入栈且栈pop出栈顶字符,回文长度加一。2)若栈顶字符与要入栈的字符不相同,直接入栈。则依次入栈出栈,求最长连续出栈序列即可。 因为对于奇数长度的字符串,博主没有想到时间复杂度低的类似处理方法,所以这里就不写代码了,大家有好的解法或者思路欢迎留言。 4)著名的Manacher’s Algorithm算法 算法首先将输入字符串S,转换成一个特殊字符串T,转换的原则就是将S的开头结尾以及每两个相邻的字符之间加入一个特殊的字符,例如# 例如: S = “abaaba”, T = “#a#b#a#a#b#a#”. 为了找到最长的回文字串,例如我们当前考虑以Ti为回文串中间的元素,如果要找到最长回文字串,我们要从当前的Ti扩展使得Ti-d … Ti+d 组成最长回文字串. 这里d其实和以Ti为中心的回文串长度是一样的. 进一步解释就是说,因为我们这里插入了# 符号, 对于一个长度为偶数的回文串,他应该是以#做为中心的,然后向两边扩,对于长度是奇数的回文串,它应该是以一个普通字符作为中心的。通过使用#,我们将无论是奇数还是偶数的回文串,都变成了一个以Ti为中心,d为半径两个方向扩展的问题。并且d就是回文串的长度。 例如#a#b#a#, P = 0103010, 对于b而言P的值是3,是最左边的#,也是延伸的最左边。这个值和当前的回文串是一致的。 如果我们求出所有的P值,那么显然我们要的回文串,就是以最大P值为中心的回文串。 T = # a # b # a # a # b # a # P = 0 1 0 3 0 1 6 1 0 3 0 1 0 例如上面的例子,最长回文是“abaaba”, P6 = 6. 根据观察发现,如果我们在一个位置例如abaaba的中间位置,用一个竖线分开,两侧的P值是对称的。当然这个性质不是在任何时候都会成立,接下来就是分析如何利用这个性质,使得我们可以少算很多P的值。 下面的例子S = “babcbabcbaccba”存在更多的折叠回文字串。 C表示当前的回文中心,L和R处的线表示以C为中心可以到达的最左和最右位置,如果知道这些,我们如何可以更好的计算C后面的P[i]. 假设我们当前计算的是i = 13, 根据对称性,我们知道对称的那个下标i' = 9. 根据C对称的原则,我们很容易得到如下数 据P[ 12 ] = P[ 10 ] = 0, P[ 13 ] = P[ 9 ] = 1, P[ 14 ] = P[ 8 ] = 0). 当时当i = 15的时候,却只能得到回文“a#b#c#b#a”,长度是5,而对称i ' = 7 的长度是7. 如上图所示,如果以i, i' 为中心,画出对称的区域如图,其中以i‘ = 7 对称的区域是实心绿色+ 虚绿色和左侧,虚绿色表示当前的对称长度已经超过之前的对称中心C。而之前的P对称性质成立的原因是i 右侧剩余的长度R - i 正好比以i‘为中心的回文小。 这个性质可以这样归纳,对于i 而言,因为根据C对称的最右是R,所以i的右侧有R - i 个元素是保证是i' 左侧是对称的。而对于i' 而言他的P值,也就是回文串的长度,可能会比R-i 要大。如果大于R - i, 对于i而言,我们只能暂时的先填 写P[i] = R - i, 然后依据回文的属性来扩充P[i] 的值;如果P[i '] 小于R-i,那么说明在对称区间C内,i的回文串长度和i' 是一样长的。例如我们的例子中i = 15, 因为R = 20,所以i右侧在对称区间剩余的是R - 15 = 5, 而i’ = 7 的长度是7. 说明i' 的回文长度已经超出对称区间。我们只能使得P[i] 赋值为5,然后尝试扩充P[i]. if P[ i' ] ≤R –i, then P[ i ] ←P[ i' ] else P[ i ] ≥R –i. (这里下一步操作是扩充P[ i ]. 扩充P[i] 之后,我们还要做一件事情是更新R 和C,如果当前对称中心的最右延伸大于R,我们就更新C和R。在迭代的过程中,我们试探i的时候,如果P[i'] <= R - i, 那么只要做一件事情。如果不成立我们对当前P[i] 做扩展,因为最大长度是n,扩展最多就做n次,所以最多做2*n。所以最后算法复杂度是O(n) 具体实现的代码如下: [cpp]view plaincopy 1.// 转换S 到 T. 2.// 例如, S = "abba", T = "^#a#b#b#a#$". 3.// ^ 和 $ 作为哨兵标记加到两端以避免边界检查 4.string preProcess(string s) { 5.int n = s.length(); 6.if (n == 0) return"^$"; 7. string ret = "^"; 8.for (int i = 0; i < n; i++) 9. ret += "#" + s.substr(i, 1); 10. 11. ret += "#$"; 12.return ret; 13.} 14. 15.string longestPalindrome(string s) { 16. string T = preProcess(s); 17.int n = T.length(); 18.int *P = new int[n]; 19.int C = 0, R = 0; 20.for (int i = 1; i < n-1; i++) { 21.int i_mirror = 2*C-i; // equals to i' = C - (i-C) 22. 23. P[i] = (R > i) ? min(R-i, P[i_mirror]) : 0; 24. 25.// Attempt to expand palindrome centered at i 26.while (T[i + 1 + P[i]] == T[i - 1 - P[i]]) 27. P[i]++; 28. 29. 30. 31.// If palindrome centered at i expand past R, 32. 33.// adjust center based on expanded palindrome. 34.if (i + P[i] > R) { 35. C = i; 36. R = i + P[i]; 37. 38. } 39. } 40. 41.// Find the maximum element in P. 42. 43.int maxLen = 0; 44.int centerIndex = 0; 45. 46.for (int i = 1; i < n-1; i++) { 47.if (P[i] > maxLen) { 48. maxLen = P[i]; 49. 50. centerIndex = i; 51. 52. } 53. 54. } 55.delete[] P; 56. 57.return s.substr((centerIndex - 1 - maxLen)/2, maxLen); 58. 59.} 一、字符、字符串类型的使用 (一)字符类型 字符类型为由一个字符组成的字符常量或字符变量,字符常量定义: const 字符常量='字符'; 字符变量定义: Var 字符变量:char; 字符类型是一个有序类型, 字符的大小顺序按其ASCⅡ代码的大小而定,函数succ、pred、ord适用于字符类型,例如: 后继函数:succ('a')='b' 前继函数:pred('B')='A' 序号函数:ord('A')=65 【例1】按字母表顺序和逆序每隔一个字母打印,即打印出: a c e g I k m o q s u w y z x r v t p n l j h f d b 程序如下: program ex8_1; var letter:char; begin for letter:='a' to 'z' do if (ord(letter)-ord('a'))mod 2=0 then write(letter:3); writeln; for letter:='z' downto 'a' do if (ord(letter)-ord('z'))mod 2 =0 then write(letter:3); writeln; end. 分析:程序中,我们利用了字符类型是顺序类型这一特性,直接将字符类型变量作为循环变量,使程序处理起来比较直观。 (二)字符串类型 字符串是由字符组成的有穷序列,字符串类型定义: type <字符串类型标识符>=string[n]; var 字符串变量:字符串类型标识符; 其中:n是定义的字符串长度,必须是0~255之间的自然整数,第0号单元中存放串的实际长度,程序运行时由系统自动提供,第1~n号单元中存放串的字符,若将string[n]写成string,则默认n值为255。例如:type man=string[8]; line=string; var name:man; screenline:line; 另一种字符类型的定义方式为把类型说明的变量定义合并在一起。 例如:VAR name:STRING[8]; screenline:STRING; Turbo Pascal中,一个字符串中的字符可以通过其对应的下标灵活使用。 例如:var name:string; begin readln(nsme); for i:=1 to ord(name[0]) do writeln(name[i]); end. 语句writeln(name[i])输出name串中第i个字符。 【例2】求输入英文句子单词的平均长度 程序如下: program ex8_2; var 课程设计报告 课程设计题目:研究生初试录取 学生:俊 专业:计算机应用技术 班级: 1140302 指导教师:宋文琳 2012年 06 月 23日 目录 一)实验题目 (3) 二)实验目的 (3) 三)实验要求 (3) 四)实验思路 (4) 五)实验过程 (6) 六)实验调试和结果 (9) 七)实验小结 (13) 实验题目 字符串处理 (1)不使用系统库函数,编写多个函数实现; (2)定义字符数组存放字符串,从键盘输入; (3)调用不同的函数,实现字符串的连接、拷贝、比较、求字符串长度、对字符串字符进行排序、查找字符串中某个字符是否存在; (4)分别输出以上字符串处理的结果。 二)实验目的 本次课程设计的主要目的是综合运用所学的C语言知识解决一个比较实际的简单问题,侧重对数组、函数、指针、结构体等相关容的综合应用,使学生能进一步熟悉掌握C语言的基本语法,进一步提升编程能力并逐步培养编程思维,进而不断提高学生解决问题的能力,并为以后的语言学习打下良好的基础。三)实验要求 1. 学生独立完成课程设计的主要容; 2. 按照实验课表安排进行,不得无故旷课; 3.按照选题规则确定课程设计题目,不可随意更换,但可在完成规定的任务之后,根据 个人兴趣选做其它题目; 4.严格按照报告格式撰写课程设计报告; 5.程序实现方式可以自选,可采用指针、数组或其任意组合方式完成。 四)实验思路1)整体思路 五)实验过程 代码: #include strcpy(char destination[], const char source[]); strcpy:将字符串source拷贝到字符串destination中。 strcpy函数应用举例 原型:strcpy(char destination[], const char source[]); 功能:将字符串source拷贝到字符串destination中 例程: #include 华北科技学院计算机学院综合性实验 实验报告 课程名称___________ 《C++程序设计B》 ________ 实验学期2017 至2016学年第二学期 学生所在系部网络工程 ___________________ 年级2015 ___________ 专业班级网络B151 学生姓名_______________ 学号___________________ 任课教师_______________ 胡英___________________ 成绩评定: 1、类及类文件、函数文件设计:A( ),B( ),C( ),D( ),F() 2、程序结构合理,格式美观:A( ),B( ),C( ),D( ),F() 3、语法语义及算法准确:A( ),B( ),C( ),D( ),F() 4、实验结果正确,运行界面:A( ),B( ),C( ),D( ),F() 5、操作熟练,解析完整:A( ),B( ),C( ),D( ),F() 5、报告规范度:A( ),B( ),C( ),D( ),F() 实验成绩___________________________________________ 计算机学院制 《C++程序设计》课程综合性实验报告 开课实验室:基础实验室三2018年6月5日 } 五、实验结果(运行界面)及测试数据分析 MyString1("Z00")调用构造函数MyString::MyString(char *str),MyString2(MyStringl) 调用复制构造函数MyString::MyString(const MyString &str) ,MyString3 调用构造函数MyString()。使用运算符重载函数>>输入字符串对MyString3重新赋值为hello。MyString3调用成员函数int length()求得字符串MyString3的长度。使用运算符重载函数=把MyString1的值赋给MyString3。使用运算符重载函数+把字符串MyString1 和MyString3进行连接。使用运算符重载函数>和<对字符串MyString1和MyString3 进行判断。使用运算符重载函数==对字符串MyString1和MyString2进行判断。 MyString3调用函数UprString()把字符串小写转换为大写。MyString1调用函数LwrStri ng()把字符串大写转换为小写。 六、实验总结 通过本学期的课程学习使我对C++程序设计有了初步的认识,也让我对面向对象 有了一个更深刻的理解。本系统虽然仍然存在着不足之处,但对于题目要求实现的功能均已实现。 源代码: #in clude 实验三数组和字符串 一、实验目的 1.掌握Java中的数组定义、引用 2.掌握向量的基本概念和应用技术 3.掌握使用字符串String类处理字符串的方法 4.掌握使用字符串StringBuffer类处理字符串的方法 5.掌握Date类以及Calendar类的常用方法; 二、实验内容 1.使用https://www.360docs.net/doc/864303931.html,ng.Math类,生成100 个100~999 之间的随机整数,找出他们之中的最大的和最小的,并统计随机产生的大于300 的整数个数。 package exercise; publicclass shiyan3_1 { publicstaticvoid main(String [] args) { int count=0; int max=0; int min=Integer.MIN_VALUE; int num[]=newint[100];//声明并创建一个具有100 个元素的整型数组对象num int i; for(i=1;i<=100;i++) { num[i-1]=100+(int)(Math.random()*899); System.out.print(num[i-1]+"\t");//随机产生一个100~999 之间的随机整数 if(i % 10 == 0) System.out.println();//输出当前产生的随机数,并一行输出10 个数 if(num[i-1]>max) max=num[i-1]; if(num[i-1] 示例 1.字符串输出示例。 程序: #include int x,y; x=strlen(a); y=strlen("abc13"); printf("%d\n%d\n\n",x,y); } 结果: 4.字符串连接函数的使用。 程序: #include 实验三 MATLAB 矩阵分析与处理、字符串操作 一、实验目的 1.掌握生成特殊矩阵的方法 2.熟练掌握矩阵的特殊操作及一些特殊函数 3.熟练掌握MATLAB 的字符串操作 4.掌握MATLAB 矩阵的关系运算及逻辑运算法则 二、实验内容 1.特殊矩阵分析与处理操作 常用的产生通用特殊矩阵的函数有:zeros( );ones( );eye( );rand( );randn( ). 下面建立随机矩阵。 (1) 在区间[20,50]内均匀分布的5阶随机矩阵。 (2) 均值为0.6、方差为0.1的5阶随机矩阵。 说明:产生(0 ,1)区间均匀分布随机矩阵使用rand 函数,假设得到了一组满 足(0,1)区间均匀分布的随机数x i ,则若想得到任意[a,b]区间上均匀分布的随机数,只需要用i i x a b a y )(-+=计算即可。产生均值为0、方差为1的标准正态分布随机矩阵使用randn 函数,假设已经得到了一组标准正态分布随机数x i ,如果想要更一般地得到均值为i i x y ,、σμσμ+=可用的随机数方差为2计算出来。针对本例,命令如下: x=20+(50-20)*rand(5) y=0.6+sqrt(0.1)*randn(5) 建立对角阵。 diag( )函数除了可以提取矩阵的对角线元素以外,还可以用来建立对角矩阵。 设V 为具有m 个元素的向量,diag(V)将产生一个m*m 对角矩阵,其主对角线元素即为向量V 的元素。例如: diag([1,2,-1,4]) ans= 40000 10000 20000 1 diag(V)函数也有另一种形式diag(V ,k),其功能是产生一个n*n(n=m+|k|)的对角矩阵,其第k 条对角线的元素即为向量V 的元素。例如: diag(1:3,-1) ans=03000 0200 0010 000 矩阵的旋转 函数rot90(A,k)表示将矩阵A 以90度为单位对矩阵按逆时针方向进行k 倍的旋转。 rem 与mod 函数的区别 练习: 1> 写出完成下列操作的命令。 (1)建立3阶单位矩阵A 。eye(3) (2)建立5*6随机矩阵A ,其元素为[100,200]范围内的随机整数。 A=100+(200-100)*rand(5,6) (3)产生均值为1,方差为0.2的500个正态分布的随机数。 B=1+sqrt(0.2)*randn(50,10) (4)产生和A 同样大小的零矩阵。 zeros(size(A)) (5)将矩阵A 主对角线的元素加30。 B=eye(5,6)*30 A+B (6)从矩阵A 提取主对角线元素,并以这些元素构成对角阵。 B=diag(diag(A)’) 注:转置是把列向量转变成行向量。 2> 先建立5*5的矩阵A ,然后将A 的第一行元素乘以1,第二行元素乘以2,…,第五行乘以5。(提示:用一个对角矩阵左乘一个矩阵时,相当于用对角阵的 Windows字符串类型 C++主要使用的是C-Style字符串,而M$在Windows中又增加了很多C-Style字符串的变体。这个一多嘛,就容易乱~ 所谓字符串,就是由字符组合而成,所以我们先来将将字符类型。 首先,存在两种最基本的字符类型:char和wchar_t。char大家都很熟悉了,我就跳过。至于wchar_t,是应用于UNICODE的宽字符,即一个字符2Bytes,16Bits。事实上,Windows 中利用 typedef unsigned short wchar_t 定义wchar_t 然后为了书写方便(MS我也没觉得有多大差别),M$又把那两个基本字符类型重新的给他typedef了一遍,即: typedef char CHAR typedef wchar_t WCHAR 为了使得兼容性更加,M$又定义了TCHAR数据类型: #ifdef UNIOCDE typedef WCHAR TCHAR #else typedef CHAR TCHAR #endif 这样,你不用关心是要使用ANSI字符串还是Unicode,编译器会自动根据你的OS来选择。 然后,M$又利用上面的几种基本数据类型,定义了一些字符串指针类型。 LPSTR和LPCSTR:LPSTR是指向以0结尾的ANSI字符串的指针,后者是const指针typedef CHAR* LPSTR typedef const CHAR* LPCSTR LPWSTR和LPCWSTR:LPWSTR是指向以0结尾的UNICODE字符串的指针,后者是const 指针 typedef WCHAR* LPWSTR typedef const WCHAR* LPCWSTR 同样,为了摆脱对ANSI还是UNICODE的选择麻烦,M$也增加了LPTSTR和LPCTSTR两个字符串指针类型。他们被如下定义: typedef TCHAR* LPTSTR #ifdef UNICODE typedef LPWSTR LPTSTR #else typedef LPSTR LPTSTR #endif ///////////////////////////////////// VB常用字符串操作函数2009/11/25 18:321. ASC(X,Chr(X:转换字符字符码[格式]: P=Asc(X 返回字符串X的第一个字符的字符码 P=Chr(X 返回字符码等于X的字符 [范例]:(1P=Chr(65 ‘ 输出字符A,因为A的ASCII码等于65 (2P=Asc(“A” ‘ 输出65 2. Len(X:计算字符串X的长度 [格式]: P=Len(X [说明]:空字符串长度为0,空格符也算一个字符,一个中文字虽然占用2 Bytes,但也算 一个字符。 [范例]: (1 令X=”” (空字符串 Len(X 输出结果为0 (2 令X=”abcd” Len(X 输出结果为4 (3 令X=”VB教程” Len(X 输出结果为4 3. Mid(X函数:读取字符串X中间的字符 [格式]: P=Mid(X,n 由X的第n个字符读起,读取后面的所有字符。 P=Mid(X,n,m 由X的第n个字符读起,读取后面的m个字符。 [范例]: (1 X=”abcdefg” P=Mid(X,5 结果为:P=”efg” (2 X=”abcdefg” P=Mid(X,2,4 结果为 P=”bcde” 4. R eplace: 将字符串中的某些特定字符串替换为其他字符串 [格式]: P=Replace(X,S,R [说明]:将字符串X中的字符串S替换为字符串R,然后返回。[范例]:X=”VB is very good” P=Replace(X,good,nice 输出结果为:P=”VB is very nice” 5. StrReverse:反转字符串 [格式]: P=StrReverse(X [说明]:返回X参数反转后的字符串 [范例]:(1)X=”abc” P=StrReverse(X 输出结果:P=”cba” 6. Ucase(X,Lcase(X:转换英文字母的大小写 [格式]:P=Lcase(X ‘ 将X字符串中的大写字母转换成小写P=Ucase(X ‘ 将X字符串中的小写字母转换成大写 [说明]:除了英文字母外,其他字符或中文字都不会受到影响。 [范例]:(1)令X=”VB and VC” 则Lcase(X的结果为”vb and vc”,Ucase(X的结果为”VB AND VC” 7. InStr函数:寻找字符串 [格式]: P=InStr(X,Y 从X第一个字符起找出Y出现的位置 P=InStr(n,X,Y 从X第n个字符起找出Y出现的位置 [说明]:(1)若在X中找到Y,则返回值是Y第一个字符出现在X中的位置。(2) InStr(X,Y相当于 InStr(1,X,Y。(3)若字符串长度,或X为空字符串,或在X中找不到Y,则都 返回0。(4)若Y为空字符串,则返回0。 ---------------------------------------------------------------------------------------------- mid(字符串,从第几个开始,长度 ByRef 在[字符串]中[从第几个开始]取出[长度个字符串] 例如 mid("小欣无敌",1,3 则返回 "小欣无" instr(从第几个开始,字符串1,字符串2 ByVal 从规定的位置开始查找,返回字符 字符串类数据列类型 字符串可以用来表示任何一种值,所以它是最基本的类型之一。我们可以用字符串类型来存储图象或声音之类的二进制数据,也可存储用gzip压缩的数据。下表介绍了各种字符串类型:Table 1.3. 字符串类数据列类型 类型长度占用存储空间CHAR[(M)]M字节M字节VARCHAR[(M)]M字节L+1字节TINYBLOD,TINYTEXT2^8-1字节L+1字节BLOB,TEXT2^16-1字节L+2MEDIUMBLOB,MEDIUMTEXT2^24-1字节L+3LONGBLOB,LONGTEXT2^32-1字节L+4ENUM('value1','value2',...)65535个成员1或2字节SET('value1','value2',...)64个成员1,2,3,4或8字节 L+1、L+2是表示数据列是可变长度的,它占用的空间会根据数据行的增减面则改变。数据行的总长度取决于存放在这些数据列里的数据值的长度。L+1或L+2里多出来的字节是用来保存数据值的长度的。在对长度可变的数据进行处理时,MySQL要把数据内容和数据长度都保存起来。 如果把超出字符串长度的数据放到字符类数据列中,MySQL会自动进行截短处理。 ENUM和SET类型的数据列定义里有一个列表,列表里的元素就是该数据列的合法取值。如果试图把一个没有在列表里的值放到数据列里,它会被转换为空字符串(“”)。 字符串类型的值被保存为一组连续的字节序列,并会根据它们容纳的是二进制字符串还是非二进制字符而被区别对待为字节或者字符: 二进制字符串被视为一个连续的字节序列,与字符集无关。MySQL把BLOB数据列和带BINARY属性的CHAR和VARCHAR数据列里的数据当作二进制值。 非二进制字符串被视为一个连续排列的字符序列。与字符集有关。MySQL把TEXT列与不带BINARY属性的CHAR和VARCHAR数据列里的数据当作二进制值对待。 在MySQL4.1以后的版本中,不同的数据列可以使用不同的字符集。在MySQL4.1版本以前,MySQL用服务器的字符集作为默认字符集。 非二进制字符串,即我们通常所说的字符串,是按字符在字符集中先后次序进行比较和排序的。而二进制字符串因为与字符集无关,所以不以字符顺序排序,而是以字节的二进制值作为比较和排序的依据。下面介绍两种字符串的比较方式: 二进制字符串的比较方式是一个字节一个字节进行的,比较的依据是两个字节的二进制值。也就是说它是区分大小写的,因为同一个字母的大小写的数值编码是不一样的。 非二进制字符串的比较方式是一个字符一个字符进行的,比较的依据是两个字符在字符集中的先后顺序。在大多数字符集中,同一个字母的大小写往往有着相同的先后顺序,所以它不区分大小写。 二进制字符串与字符集无关,所以无论按字符计算还是按字节计算,二进制字符串的长度都是一样的。所以VARCHAR(20)并不表示它最多能容纳20个字符,而是表示它最多只能容纳可以用20个字节表示出来的字符。对于单字节字符集,每个字符只占用一个字节,所以这两者的长度是一样的,但对于多字节字符集,它能容纳的字符个数肯定少于20个。 1.2.2.1. CHAR和VARCHAR CHAR和VARCHAR是最常用的两种字符串类型,它们之间的区别是: CHAR是固定长度的,每个值占用相同的字节,不够的位数MySQL会在它的右边用空格字符补足。 VARCHAR是一种可变长度的类型,每个值占用其刚好的字节数再加上一个用来记录其长度的字节即L+1字节。 CHAR(0)和VARCHAR(0)都是合法的。VARCHAR(0)是从MySQL4.0.2版开始的。它们的作用是作为占位符或用来表示各种on/off开关值。 字符数组与字符串类型 字符型变量:VAR CH :CHAR ; 一、字符数组:数组基类型(元素的类型为字符型。 VAR A:ARRAY [ 1. . N ] OF CHAR ; 输入、输出也与普通数组一样,只能用循环结构,逐个元素地给它赋值,即: FOR I:= 1 TO N DO READ(A[ I ] ; 或者: A[I]:=‘ X ’ ; 不能用:A :=‘ IT IS A PEN ’ ; 例一:判断从键盘输入的字符串是否为回文(从左到右和从右到左读一串字符的值是一样的, 如 ABCDCBA , 1234321, 11, 1 ,串长 < 100 ,且以点号‘. ’结束。 2000年竞赛题:判断一个数是否为回文数。 VAR LETTER:ARRAY [ 1. . 100 ] OF CHAR ; I, J :0. . 100 ; CH:CHAR ; BEGIN WRITELN(‘ INPUT A STRING :’ ; I := O ; READ (CH ; WHILE CH < > ‘. ’ DO BEGIN I:=I+1 ; LETTER[ I ] := CH ; READ (CH ; END ; J :=1 ; { I 指向数组的尾部, J 指向数组的头部 ,逐个比较 } WHILE (J < I AND (LETTER[ J ]= LETTER[ I ] DO BEGIN I:= I – 1 ; J :=J + 1 END ; IF J > = I THEN WRITELN(‘ YES ’ ELSE WRITELN(‘ NO ’ ; END . 二、字符串类型:针对 TURBO PASCAL 1、字符串常量:CONST STR=‘ THIS IS A BOOK。’ ; 我们经常在 WRITE 语句中用到字符串,也可以 WRITE (STR ;语句输出 STR 的值。 2、字符串类型:也是一种构造类型。 定义形式:TYPE 字符串类型名 = STRING[ N ]; 实验四数组及其字符串的处理 1.输入一串英文字母,统计每个字母(不区分大小写)出现的次数。(输 出统计结果时一律显示为小写字母) 如输入:Good 则输出:字母d有1个 字母g有1个 字母o有2个 请根据提示填空,使程序实现相应功能。 #include 3.求裴波那契数列(1 1 2 3 5 8 13 21 34……)的前18项。 4.求字符串长度(实现strlen 函数的功能) 提示:可参考第1题。 5.输入一个5*5的矩阵(#define N 5),求 (1)所有元素的和 (2)主对角线元素之和 (3)最大值及最小值所在位置 #include C语言基本类型:字符型(char)用法介绍 1.字符型(char)简介 字符型(char)用于储存字符(character),如英文字母或标点。严格来说,char 其实也是整数类型(integer type),因为char 类型储存的实际上是整数,而不是字符。计算机使用特定的整数编码来表示特定的字符。美国普遍使用的编码是ASCII(American Standard Code for Information Interchange 美国信息交换标准编码)。例如:ASCII 使用65 来代表大写字母A,因此存储字母A 实际上存储的是整数65。注意:许多IBM大型机使用另一种编码——EBCDIC(Extended Binary-Coded Decimal Interchange Code 扩充的二进制编码的十进制交换码);不同国家的计算机使用的编码可能完全不同。 ASCII 的范围是0 到127,故而7 位(bit)就足以表示全部ASCII。char 一般占用8 位内存单元,表示ASCII绰绰有余。许多系统都提供扩展ASCII(Extended ASCII),并且所需空间仍然在8 位以内。注意,不同的系统提供的扩展ASCII 的编码方式可能有所不同! 许多字符集超出了8 位所能表示的范围(例如汉字字符集),使用这种字符集作为基本字符集的系统中,char 可能是16 位的,甚至可能是32 位的。总之,C 保证char 占用空间的大小足以储存系统所用的基本字符集的编码。C 语言定义一个字节(byte)的位数为char 的位数,所以一个字节可能是16 位,也可能是32 位,而不仅仅限于8 位。 2. 声明字符型变量 字符型变量的声明方式和其它类型变量的声明方式一样: char good; char better, best; 以上代码声明了三个字符型变量:good、better,和best。 3. 字符常量与初始化 我们可以使用以下语句来初始化字符型变量: char ch = 'A'; 这个语句把ch 的值初始化为 A 的编码值。在这个语句中,'A' 是字符常量。C 语言中,使用单引号把字符引起来就构成字符常量。我们来看另外一个例子: char fail; /* 声明一个字符型变量*/ fail = 'F'; /* 正确*/ fail = "F"; /* 错!"F" 是字符串字面量*/ sstrstr与strchar用法 原型:extern char *strstr(char *haystack, char *needle); 用法:#include 博客网站设定了校验密码的规则,编写方法检验一个字符串是否是合法的密码。规则如下: 密码长度在8-16 之间 密码只能包含字母和数字 密码必须存在至少2 个数字如果用户输入的密码符合 2. import java.util.Scanner; 3. import java.util.regex.Pattern; 4. public class Check { 5. public static void main(String[] args) { 6. System.out.println("请输入密码:"); 7. Scanner sc = new Scanner(System.in); 8. String str = sc.next(); 9. Check ch = new Check(); 10. ch.checkup(str); 11. sc.close(); 12. } 13. 14. public void checkup(String str) { 15. String patternStr1 = "([0-9]|[a-zA-Z]){8,16}"; 16. String patternStr2 = ".*\\d.*\\d.*"; 17. boolean result1 = Pattern.matches(patternStr1, str); 18. boolean result2 = Pattern.matches(patternStr2, str); 19. if (result1 && result2) { 20. System.out.println(" valid password"); 21. } else { 22. System.out.println(" Invalid password "); 23. } 24. } 25. } 26. String patternStr2 = ".*\\d.*\\d.*"; 27. boolean result1 = Pattern.matches(patternStr1, str); 28. boolean result2 = Pattern.matches(patternStr2, str); 29. if (result1 && result2) { 30. System.out.println(" valid password"); 31. } else { 32. System.out.println(" Invalid password "); 33. } 34. } 35. } 要求从用户输入的多行文本中提取学生的姓名、学号及登录日期,并封装到Student 类中作为类的私有属性。创建一个Student 类型的对象数组,对学号进行升序排序并输出 /*从键盘输入多行文本,格式如下: 学生端名称,姓名,班级名称,学生ID,注册时间 姜涛,姜涛,,20092212232,2011-11-4 9:06:56 javascript字符串处理函数汇总 虽然JavaScript 有很多用处,但是处理字符串是其中最流行的一个。下面让我们深入地分析一下使用JavaScript 操作字符串。 在JavaScript 中,String 是对象。String 对象并不是以字符数组的方式存储的,所以我们必须使用内建函数来操纵它们的值。这些内建函数提供了不同的方法来访问字符串变量的内容。下面我们详细看一下这些函数。 操作字符串的值是一般的开发人员必须面临的家常便饭。操作字符串的具体方式有很多,比如说从一个字符串是提取出一部分内容来,或者确定一个字符串是否包含一个特定的字符。下面的JavaScript 函数为开发人员提供了他们所需要的所有功能: ? concat() –将两个或多个字符的文本组合起来,返回一个新的字符串。 ? indexOf() –返回字符串中一个子串第一处出现的索引。如果没有匹配项,返回-1 。 ? charA T() –返回指定位置的字符。 ? lastIndexOf() –返回字符串中一个子串最后一处出现的索引,如果没有匹配项,返回 -1 。 ? match() –检查一个字符串是否匹配一个正则表达式。 ? substring() –返回字符串的一个子串。传入参数是起始位置和结束位置。 ? replace() –用来查找匹配一个正则表达式的字符串,然后使用新字符串代替匹配的字符串。 ? search() –执行一个正则表达式匹配查找。如果查找成功,返回字符串中匹配的索引值。否则返回-1 。 ? slice() –提取字符串的一部分,并返回一个新字符串。 ? split() –通过将字符串划分成子串,将一个字符串做成一个字符串数组。 实验六字符串处理及基础类库 一、实验目的 1、理解并掌握String类、StringBuffer类; 2、理解并掌握StringTokenizer类 3、掌握字符串与其他数据类型的转换 4、掌握Math类的使用。 5、了解和掌握集合框架类。 6、掌握Java Application命令行参数的使用 二、实验内容与要求 1.,理解String类的使用 利用下面的关键代码编写一个完整的程序 String s=new String("This is an demo of the String method."); //String s="This is an demo of the String method."; System.out.println("Length: "+s.length()); System.out.println("SubString: "+s.substring(11,15)); public class theString { public static void main(String[] args){ String s=new String("This is an demo of the String method."); //String s="This is an demo of the String method."; System.out.println("Length: "+s.length()); System.out.println("SubString(int):"+s.substring(11)); System.out.println("SubString(int, int): "+s.substring(11,15)); } } 2.理解StringBuffer类的使用 利用下面的关键代码编写一个完整的程序 StringBuffer sb=new StringBuffer("Hello World!"); sb.append(" Hello Java!"); sb.insert(12," And"); System.out.println(sb); System.out.println(sb.charAt(0)); sb.setCharAt(0,''h''); System.out.println(sb.charAt(0)); System.out.println(sb);字符和字符串类型
C语言课程设计报告---字符串处理
C字符串处理函数全
字符串类设计
实验三 数组和字符串
各种字符串处理函数示例(基本)
实验3MATLAB矩阵分析与处理和字符串操作实...
windows中的字符串类型
VB常用字符串操作函数解读
字符串类数据列类型
20-字符数组与字符串类型.
实验四 数组及其字符串的处理
C语言基本类型字符型(char)用法介绍
acm常用字符串处理函数
实验5字符串的操作
javascript字符串处理函数汇总
实验六 字符串处理及基础类库