第八讲 有序分类资料的统计分析Stata实现

第十二章有序分类资料的统计分析的 Stata 实现
本章使用的 STATA 命令: 列变量有序时的分类资料 CMH 卡方分析 双向有序时的 Spearman 相关 opartchi 行变量 [weight], by(列变量) (见 Stata7 附加程序) spearman 变量 1 变量 2
例 12-2
某研究欲观察人参的镇静作用,选取 32 只同批次的小白鼠,将其
中 20 只随机分配到人参组:以 5%人参浸液对其做腹腔注射,12 只分配到对照 组:以等量蒸馏水对其做同样注射。实验结果如表 12-2 所示。能否说明人参有 镇静作用? 表 12-2
镇静等级 ± + ++ +++
人参镇静作用的实验结果
对照组 11 0 1 0 0
人参组 4 1 2 1 12
1.建立检验假设,确定检验水准。
H 0 :人参没有镇静作用(样本来自两个相同总体)
H 1 :人参有镇静作用(样本来自两个不同总体)
? ? 0.05
Stata 数据为:
a 1 1 1 1 1 2 2 2 2 2
Stata 命令为:
b 1 2 3 4 5 1 2 3 4 5
x
4 1 2 1 12 11 0 1 0 0
opartchi b [weight=x],by(a) 结果为: Chi-square tests df Chi-square P-value Independence 4 16.64 0.0023 ------------------------------------------------------Components of independence test Location 1 15.29 0.0001 Dispersion 1 .3496 0.5543
在 ? ? 0.05 的水平上,拒绝 H 0 ,接受 H1,认为两总体之间的差别有统计学 意义, 可以认为人参组和对照组镇静等级的差别有统计学意义, 人参有镇静作用。
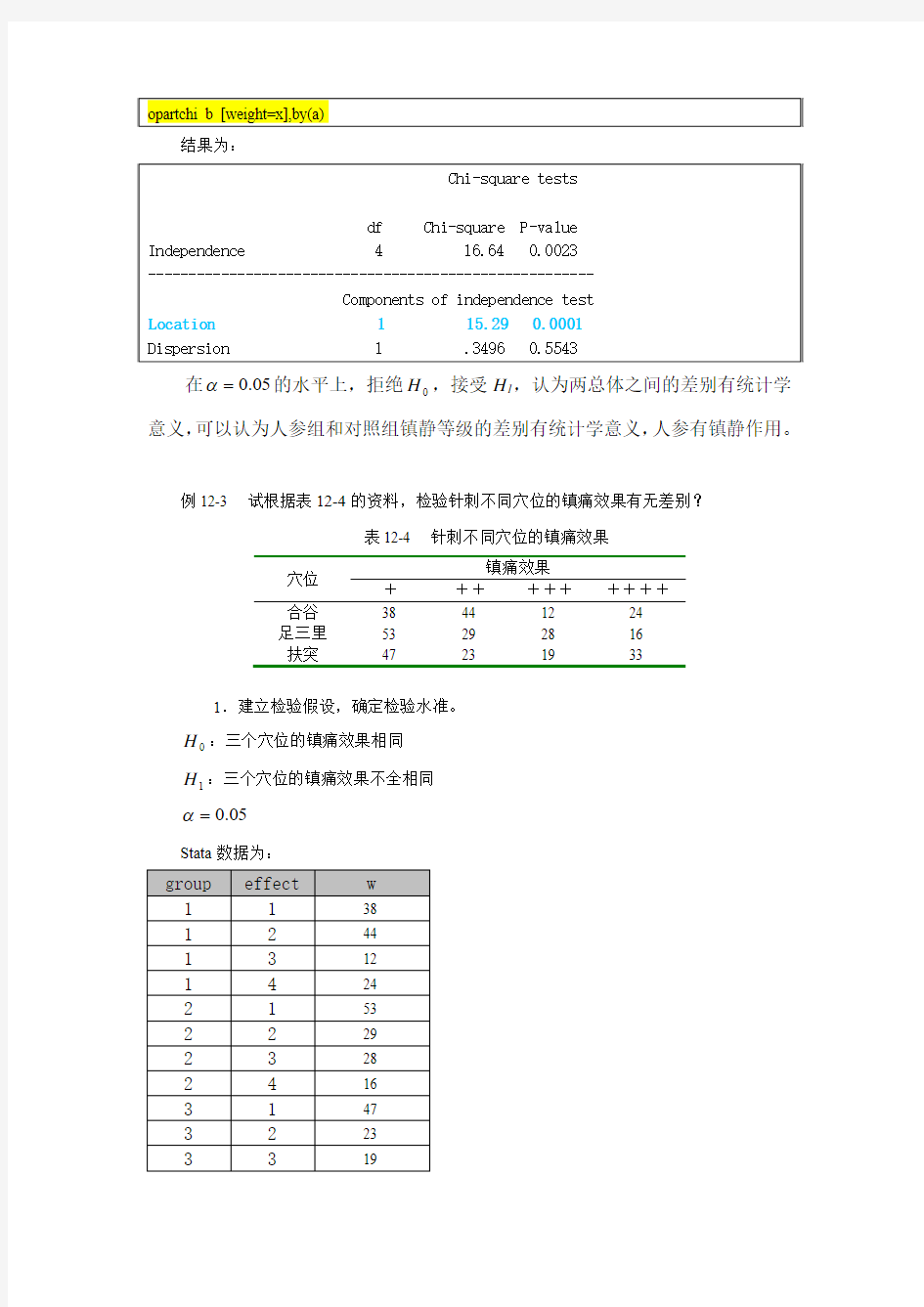
例 12-3
试根据表 12-4 的资料,检验针刺不同穴位的镇痛效果有无差别? 表 12-4 穴位 合谷 足三里 扶突 + 38 53 47 针刺不同穴位的镇痛效果 镇痛效果 ++ +++ 44 12 29 28 23 19 ++++ 24 16 33
1.建立检验假设,确定检验水准。
H 0 :三个穴位的镇痛效果相同
H 1 :三个穴位的镇痛效果不全相同
? ? 0.05
Stata 数据为:
group 1 1 1 1 2 2 2 2 3 3 3
effect 1 2 3 4 1 2 3 4 1 2 3
w
38 44 12 24 53 29 28 16 47 23 19
3
4
33
Stata 命令为: opartchi effect [weight=w],by(group) 结果为: Chi-square tests df Chi-square P-value Independence 6 22.07 0.0012 ------------------------------------------------------Components of independence test Location 2 3.118 0.2103 Dispersion 2 5.914 0.0520
有 P ? 0.05 。 ? ? 0.05 的水平上尚不能拒绝 H 0 ,即根据本例资料尚不能认 在 为针刺不同穴位的镇痛效果差别有统计学意义。
例 12-4
两名放射科医师对 13 张肺部 X 线片各自做出评定,评定方法是将
X 线片按病情严重程度给出等级,结果如表 12-6 所示。问他们的评定结果是否 相关。 表12-6
X片编号 甲医师X 乙医师Y 1 + ? 2 ++ ++ 3 - +
两名放射科医师对13张肺部X片的评定结果
4 ? + 5 - - 6 + ++ 7 ++ +++ 8 +++ ++ 9 ++ +++ 10 +++ +++ 11 - ? 12 ++ ++ 13 + ++
1.建立检验假设,确定检验水准。
H 0 : ? s =0(两名医师的等级评定结果不相关)
H 1 : ? s ? 0 (两名医师的等级评定结果相关)
? ? 0.05
Stata 数据为: i
1 2 3 4 5
x 2 3 0 1 0
y 1 3 2 2 0
6 7 8 9 10 11 12 13
2 3 4 3 4 0 3 2
3 4 3 4 4 1 3 3
Stata 命令为:
spearman y x
结果为:
Number of obs = Spearman's rho = 13 0.8082
Test of Ho: y and x are independent Prob > |t| = 0.0008
P<0.05。在 ? ? 0.05 水平上,拒绝 H0,接受 H1,认为两名射科医师对肺部 X 片的等级评定结果有正相关关系。
例12-5
300名抑郁症患者按其抑郁程度和自杀意向的轻重程度的分类数据
如表12-8所示。 问自杀意向的轻重程度和抑郁程度之间是否存在线性变化趋势? 表12-8
自杀意向(X) 无 想要自杀 曾自杀过 合计 (X=1) (X=2) (X=3)
300名抑郁症患者的分类数据
抑郁程度(Y) 中等 (Y=2) 73 9 23 105 严重 (Y=3) 14 10 23 47 合计 222 24 54 300
轻度 (Y=1) 135 5 8 148
1、建立检验假设,确定检验水准。
H 0 :自杀意向与抑郁症之间不存在线性变化趋势
H 1 :自杀意向与抑郁症之间存在线性变化趋势
? ? 0.05
Stata 数据为: y x w
1 1 1 2 2 2 3 3 3
1 2 3 1 2 3 1 2 3
135 5 8 73 9 23 14 10 23
Stata 命令和结果为*: . corr y x [fw=w] (obs=300) | y x -------------+-----------------y | 1.0000 x | 0.4642 1.0000 . return list scalars: r(N) = 300 r(rho) = .4641844307421609 . display (r(N)-1)*r(rho)^2 64.424689
在 ? ? 0.05 水平上,拒绝 H0,接受 H1,可以推断自杀意向的轻重程度与抑 郁症之间存在线性变化趋势。
*参考文献:
Does Stata provide a test for trend?
Title Author Date A comparison of different tests for trend William Sribney, StataCorp March 1996
Let me make a bunch of comments comparing SAS PROC FREQ, Pearson’s correlation, Patrick Royston’s ptrend command, linear regression, logit/probit regression, Stata’s vwls command, and Stata’s nptrend command.
Tests for trend in 2 x r tables
Let me use Les Kalish’s example:
Outcome ---------------------------group | y_i | Good | Better | a_1=1| a_2=2 | Best a_3=3
------+--------+--------+--------| y_1=0| | | y_2=1| | | 1 19 | | 31 | | 67 n_13
n_11 | | |
n_12 | | 5 |
21 n_23
n_21 | |
n_22 | |
------+--------+--------+--------20 n_+1 36 n_+2 88 n_+3
PROC FREQ
When I used SAS in grad school to analyze these data, we used
PR0C FREQ DATA=... TABLES GROUP*OUTCOME / CHISQ CMH SCORES=TABLE
The test statistic was shown on the output as
DF --Mantel-Haenszel Chi-Square 1
Value ----4.515
Prob ----0.034
The test statistic is not a Mantel–Haenszel—at least not according to what I learned a Mantel–Haenszel statistic is (from Gary Koch at UNC—note that any errors here, I should add, are those of this student, not of this great researcher/teacher).
Dr. Koch called this chi-squared statistic Qs, where s stands for score.
Chi-squared statistic for trend Qs
Let me express Qs in terms of a simpler statistic, T:
T = (sum over group i)(sum over outcome j) nij * aj * yi
The aj are scores; here 1, 2, 3, but there can be other choices for the scores (I’ll get to this later).
Under the null hypothesis there is no association between group and outcome, so we can consider the permutation (i.e., randomization) distribution of T. That is, we fix the margins of the table, just as we do for Fisher’s exact test, and then consider all the possible permutations that give these same marginal counts.
Under this null hypothesis permutation distribution, it is easy to see that the mean of T is
E(T) = N * a_bar * y_bar
where a_bar is the weighted average of aj (using the marginal counts n+j):
a_bar = (sum over j) n+j * aj / N
Similarly, y_bar is a weighted average of yi.
The variance of T, under the permutation distribution, is (exactly)
V(T) = (N - 1) * Sa2 * Sy2
where Sa2 is the standard deviation squared for aj:
Sa2 = (1/(N-1)) * (sum over j) n+j * (aj - a_bar)2
We can compute a chi-squared statistic:
Qs = (T - E(T))2 / V(T)
If you look at the formula for Qs, you see something interesting. It is simply
Qs = (N - 1) * ray2
where ray is Pearson’s correlation coefficient for a and y.
Just Pearson’s correlation
This ―test of trend‖ is nothing more than Pearson’s correlation coefficient. Let’s try this.
. list
+----------------+ | y a weight |
|----------------| 1. | 0 2. | 0 3. | 0 4. | 1 5. | 1 1 2 3 1 2 19 | 31 | 67 | 1 | 5 |
|----------------| 6. | 1 3 21 |
+----------------+
. corr y a [fw=weight] (obs=144)
|
y
a
-------------+-----------------y | 1.0000 a | 0.1777 1.0000
. return list
scalars: r(N) = r(rho) = 144 .1776868721791401
. display (r(N)-1)*r(rho)^2 4.5148853
PROC FREQ gave chi-squared = 4.515.
Royston’s ptrend and the Cochran–Armitage test
Let’s now use Patrick Royston’s ptrend command [note: Patrick posted his ptrend command on Statalist]. The data must look like the following for this command:
. list
+-------------+ | a n1 n2 |
|-------------| 1. | 1 2. | 2 3. | 3 19 31 67 1 | 5 | 21 |
+-------------+
. ptrend n1 n2 a
n1 1. 2. 3. 19 31 67
n2 1 5 21
_prop 0.950 0.861 0.761
a 1 2 3
Trend analysis for proportions
Regression of p = n1/(n1+n2) on a: Slope = -.09553, std. error = .0448, Z = 2.132
Overall chi2(2) = Chi2(1) for trend = Chi2(1) for departure =
4.551, 4.546, 0.004,
pr>chi2 = 0.1027 pr>chi2 = 0.0330 pr>chi2 = 0.9467
The ―Chi2(1) for trend‖ is slightly different. It’s 4.546 rather than 4.515. Well, ptrend is just using N rather than N ? 1 in the formula:
Qtrend = Chi2(1) for trend = N * ray2
Let’s go back to data arranged for the corr computation and show this.
. quietly corr y a [fw=weight]
. display r(N)*r(rho)^2 4.5464579
Qtrend is just Pearson’s correlation again. A regression is performed here to compute the slope, and the test of slope = 0 is given by the Qtrend statistic. Well, we all know the relationship between Pearson’s correlation and regression—this is all this is. Qdeparture (="Chi2(1) for departure" as Royston’s output nicely labels it) is the statistic for the Cochran–Armitage test. But Qtrend and Qdeparture are usually performed at the same time, so lumping them together under the name ―Cochran–Armitage‖ is sometimes loosely done. The null hypothesis for the Cochran–Armitage test is that the trend is linear, and the test is for ―departures‖ from linearity; i.e., it’s simply a goodness-of-fit test for the linear model. Qs (or equivalently Qtrend) tests the null hypothesis of no association. Since it’s just a Pearson’s correlation, we know that it’s powerful against alternative hypotheses of monotonic trend, but it’s not at all powerful against curvilinear (or other) associations with a 0 linear component.
Model it
Rich Goldstein recommended logistic regression. Regression is certainly a better context to understand what you are doing—rather than all these chi-squared tests that are simply Pearson’s correlations or goodness-of-fit
tests under another name. Since Pearson’s correlation is equivalent to a regression of y on ―a‖, why not just do the regression
. regress y a [fw=weight]
of obs =
Source | 144
SS
df
MS
Number F( 1,
-------------+-----------------------------142) = 4.63 Model | = 0.0331 142 .1496118 .692624451 1 .692624451
Prob > F
Residual | 21.2448755 R-squared = 0.0316
-------------+-----------------------------R-squared = 0.0248 MSE Total | = .3868 21.9375 143 .153409091
Adj Root
----------------------------------------------------------------------------y | Conf. Interval] -------------+--------------------------------------------------------------0.033 -.2748375 a | .0077618 .0955344 .183307 .0444011 .1144041 2.15 -0.43 0.671 Coef. Std. Err. t P>|t| [95%
_cons | -.0486823 .177473
----------------------------------------------------------------------------But recall that y is a 0/1 variable. Heck, wouldn’t you be laughed at by your colleagues if you presented this result? They’d say, ―Don’t ya know anything, you dummy, you should be using logit/probit for a 0/1 dependent variable!‖ But call these same results a ―chi-squared test for linear trend‖ and, oh wow, instant respectability.
Your colleagues walk away thinking how smart you are and jealous about all those special statistical tests you know. I guess it sounds as if I’m agreeing fully with Rich Goldstein’s recommendation for logit (or probit, which Rich didn’t mention). I’ll say some redeeming things about Pearson’s correlation (hey, let’s call it what it really is) below, but for now, let me give you another modeling alternative.
Try the vwls command
One can do a little better using the command vwls (variance-weighted least squares) in Stata rather than regress
. vwls y a [fw=weight]
Variance-weighted least-squares regression = 144 Goodness-of-fit chi2(1) = 7.79 Prob > chi2 = 0.0053 = = 0.01 0.9359
Number of obs Model chi2(1) Prob > chi2
----------------------------------------------------------------------------y | Conf. Interval] Coef. Std. Err. z P>|z| [95%
-------------+--------------------------------------------------------------0.005 a | .0944406 .0338345 .0281261 .160755 .0758028 2.79 -0.61 0.545
_cons | -.0459275 -.1944984 .1026433
----------------------------------------------------------------------------The ―test for linear trend‖ is again the test of the coefficient of a = 0. It also gives you a goodness-of-fit test. The linear model is the same as regress, but the weighting is a little different. The weights are 1/Var(y|a). Now
Var(y|aj) = pj * (1 - pj) / n+j
where pj = n2j / n+j (recall n2j = #(y=1) for outcome j).
Essentially, this means that you are downweighting (relative to regress) points aj that have pj close to 0 or 1. regress with weights nij puts too much weight on these points.
If you are determined to fit a linear model for y vs. aj, I believe that vwls is a better way to do it.
vwls can do more. y can be a continuous variable, too. The regressors x1, x2, x3, ... can be any variables as long as for each unique value of the combination of x1, x2, x3, ... there are enough points to reasonably estimate the variance of y. For example, Gary Koch had us using this to model y = # of colds versus x = 1 (drug) or 0 (placebo).
You can do the equivalent of vwls in SAS using PROC CATMOD with a RESPONSE MEAN option.
Using different scores aj: aj = average ranks
As I said above, the scores aj are simply a regressor variable, and we can use anything we want for them. Let’s revisit Les’s little dataset:
Outcome ---------------------------group | y_i | Good | Better | a_2=2 | Best a_3=3
a_1=1 |
------+--------+--------+--------| y_1=0 | | | y_2=1 | | | 1 19 | | 31 | | 67 n_13
n_11 | | |
n_12 | | 5 |
21 n_23
n_21 | |
n_22 | |
------+--------+--------+--------20 n_+1 36 n_+2 88 n_+3
ranks
1-20
21-56
57-144
sum of ranks 210 1386 8844
average rank 10.5 38.5 100.5
Let’s now use the average ranks instead of aj. Call these scores rj. Let’s compute Pearson’s coefficient for y and r j.
. list
+------------------------+ | y a weight r |
|------------------------| 1. | 0 2. | 0 3. | 0 4. | 1 5. | 1 1 2 3 1 2 19 31 67 1 5 10.5 | 38.5 | 100.5 | 10.5 | 38.5 |
|------------------------| 6. | 1 3 21 100.5 |
+------------------------+
. corr y r [fw=w] (obs=144)
|
y
r
-------------+-----------------y | r | 1.0000 0.1755 1.0000
. display (r(N)-1)*r(rho)^2 4.4063138
The above is our chi-squared test statistic for Pearson’s correlation coefficient, which Gary Koch called Qs. This is exactly what nptrend is doing. nptrend is again Pearson’s correlation coefficient by another name.
nptrend, unfortunately, does not allow weights, so we must expand the data:
. expand weight (138 observations created)
. nptrend a, by(y)
y 0 1
score 0 1
obs 117 27
sum of ranks 8126.5 2313.5
z
=
2.10 0.036
Prob > |z| =
. ret list
scalars: r(p) = r(z) = r(T) = r(N) = .0358061342131952 2.099122151413003 2313.5 144
. display r(z)^2
4.4063138
Voila, the same answer! nptrend takes the variable given after the command—here ―a‖—and computes the average ranks for it just as we did. It then correlates the average ranks with the values in y.
In SAS, if you specify SCORES=MODRIDIT, the scores used are the average ranks. PROC FREQ with SCORES=MODRIDIT should give exactly what nptrend produces.
More on nptrend: r x c tables
nptrend allows y to be anything. If y is 0, 1, 2, then we are doing Pearson’s correlation in 3 x 3 tables.
nptrend a, by(y) allows you to substitute different values (i.e., scores) for y: when you specify the score(scorevar) option on nptrend, it uses the values of scorevar in place of the values of y in computing the correlation coefficient. nptrend always uses averaged ranks for the scores for the ―a‖ variable.
This is a little confusing. Remember, we are simply computing corr y x. y can be anything, and x can be anything in theory. But nptrend is restrictive; it allows any values for y but only allows x to be averaged ranks. There are other ways to do r x c tables. We do not have to assume an ordering on r. If we don’t, guess what we get. ANCOVA! The scores for the outcome ―a‖ are the ―continuous‖ variable. We can model different slopes per block r. Test slopes = 0 with a chi-squared stat, give it a fancy name, and no one will know we are just doing ANCOVA!
Stratified 2 x c tables
Generalizing the above analysis to stratified 2 x c tables gives what I learned as the ―Extended Mantel–Haenszel‖ test. Rothman calls it the ―Mantel extension test‖ and then says that it can be done with or without strata. Yes, it can be done with or without strata, but in the terminology I know, it’s only called the Extended Mantel–Haenszel test only when there are strata. Thanks, Ken, for adding yet another name for unstratified 2 x c tables! Say, the test for stratified tables is NOT just Pearson’s correlation coefficient in disguise. First, define, as we did before, the statistic
Th = (sum over group i)(sum over outcome j) nhij * ahj * yhi
for each stratum h. Then form the statistic T by summing over strata. Sometimes the sum is weighted by stratum totals, sometimes strata are equally weighted. (I believe that SAS does the former; Rothman gives the
formula for the latter.) Since the strata are independent, the mean and variance of T are easy to compute from Th.
Distribution of Pearson’s correlation coefficient
I said that Qs = (N ? 1) * ray2 (where ray is Pearson’s correlation coefficient) had a chi-squared distribution. And one can use this to get a p-value for Pearson’s correlation coefficient. But this isn’t what pwcorr does. pwcorr is using a t distribution to get a p-value (which assumes normality of "a" and y). These are asymptotically equivalent procedures (under the null hypothesis).
Qs is a second-moment approximation for the permutation distribution for r ay. The permutation distribution for ray makes no assumptions about "a" and y.
If you want to get fussy about getting p-values, then one should compute the permutation distribution or compute higher-moment terms for the permutation distribution for ray. For small N, Pearson’s correlation coefficient has an advantage over logistic regression. One can compute the permutation distribution of Pearson’s correlation coefficient exactly. For the exact distribution, true type I error is equal to nominal type I error. Such won’t be the case for logistic. Also, I bet that it’s more powerful than logistic for small N. One could do some simulations and look at this—it’s a good master’s paper project, perhaps. This is the case where, I believe, that Pearson’s correlation coefficient is a better choice than logistic regression or other regression modeling.
Tests for trend in Stata
Clearly, we need a command to do r x c tables, stratified and unstratified, with various choices of scores.
We plan to implement something in the future. But, in the meantime, for moderate to large N, there is logit/probit regression (and vwls). If you do want Qs for linear scores, it’s easy to use corr as I’ve done here. One can also use stmh, stmc, and tabodds. For average-rank scores, it’s not too difficult to compute the average ranks yourself and then use corr. For stratified tables, there’s nothing easy available that I know of.
16种常用的数据分析方法汇总
一、描述统计 描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:剔除法、均值法、最小邻居法、比率回归法、决策树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A 单样本t检验:推断该样本来自的总体均数μ与已知的某一总体均数μ0 (常为理论值或标准值)有无差别; B 配对样本t检验:当总体均数未知时,且两个样本可以配对,同对中的两者在可能会影响处理效果的各种条件方面扱为相似;
C 两独立样本t检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验 非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。 A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析 检査测量的可信度,例如调查问卷的真实性。 分类: 1、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度 2、内在信度;每个量表是否测量到单一的概念,同时组成两表的内在体项一致性如何,常用方法分半信度。 四、列联表分析 用于分析离散变量或定型变量之间是否存在相关。
第十一章 无序分类资料的统计分析
第十一章无序分类资料的统计分析的Stata实现 例11-1 根据某地区的血型普查结果可知,该地区人群中血型为O的占30%,血型为A的占25%,血型为B的占35%,血型为AB的占10%。研究者在邻近该地区的一个山区人群中进行一个血型的流行病调查,在该山区人群中随机抽样调查了200人,检测这些对象的血型,表11-1给出了血型检测的结果。问该山区人群与这个地区人群的血型分布是否一致? 表11-1 山区人群血型抽样调查结果 血型O A B AB 合计 人数50 70 50 30 200 例11-2 某研究小组为研究慢支口服液II号对慢性支气管炎治疗效果,以口服消咳喘为对照进行了临床试验,试验组120人、对照组117人(两组受试者病程、病情等均衡),疗程2周,疗效见表11-3。问慢支口服液II号与消咳喘治疗慢性支气管炎的疗效是否相同? 表11-3 试验组与对照组疗效 组别有效无效合计有效率(%)试验组116 4 120 96.67 对照组82 35 117 70.09 合计198 39 237 83.54
1.建立检验假设,确定检验水准 0H :21ππ=,即两种药物治疗慢性支气管炎的疗效相同 1H :21ππ≠,即两种药物治疗慢性支气管炎的疗效不同 05.0=α 结果: Pearson chi2(1) = 30.4463 Pr = 0.000,05.0
绝0H ,差别有统计学意义,可认为慢支口服液II 号治疗慢性支气管炎有效率高于消咳喘。 例11-3 为评价中西结合治疗抑郁发作的疗效。将187例患者随机分为2组,两组患者均选用阿咪替林西医综合治疗,中西医结合组在上述治疗的同时,再配合中医辨证治疗,根据中医辨证分型采用不同的方剂,治疗结果见表11-5,问两种治疗方案的疗效有无差别? 表11-5 试验组与对照组疗效 组别 有效 无效 合计 有效率(%) 中西医结合组 92(88.973) 2(5.027) 94 97.87 西医组 85(88.027) 8(4.973) 93 91.40 注 ;括号内为理论频数 例11-3 假设检验步骤 1.建立检验假设,确定检验水准 0H :21ππ=,即两种治疗方案疗效相同 1H :21ππ≠,即两种治疗方案疗效不同 05.0=α Stata 命令: 结果:
第十一章 分类资料的回归分析
第十一章分类资料的回归分析 ――Regression菜单详解(下) (医学统计之星:张文彤) 上次更新日期: 10.1 Linear过程 10.1.1 简单操作入门 10.1.1.1 界面详解 10.1.1.2 输出结果解释 10.1.2 复杂实例操作 10.1.2.1 分析实例 10.1.2.2 结果解释 10.2 Curve Estimation过程 10.2.1 界面详解 10.2.2 实例操作 10.3 Binary Logistic过程 10.3.1 界面详解与实例 10.3.2 结果解释 10.3.3 模型的进一步优化与简单诊断 10.3.3.1 模型的进一步优化 10.3.3.2 模型的简单诊断 在很久很久以前,地球上还是一个阴森恐怖的黑暗时代,大地上恐龙横行,我们的老祖先--类人猿惊恐的睁大了双眼,围坐在仅剩的火堆旁,担心着无边的黑暗中不知何时会出现的妖魔鬼怪,没有电视可看,没有网可上... 我是疯了,还是在说梦话?都不是,类人猿自然不会有机会和恐龙同时代,只不过是我开机准备写这一部分的时候,心里忽然想到,在10年前,国内的统计学应用上还是卡方检验横行,分层的M-H卡方简直就是超级武器,在流行病学中称王称霸,更有那些1:M的配对卡方,N:M的配对卡方,含失访数据的N:M 配对卡方之类的,简直象恐龙一般,搞得我头都大了。其实恐龙我还能讲出十多种来,可上面这些东西我现在还没彻底弄明白,好在社会进步迅速,没等这些恐龙完全统制地球,Logistic模型就已经飞速进化到了现代人的阶段,各种各样的Logistic模型不断地在蚕食着恐龙爷爷们的领地,也许还象贪吃的人类一样贪婪的享用着恐龙的身体。好,这是好事,这里不能讲动物保护,现在我们就远离那些恐龙,来看看现代白领的生活方式。 特别声明:我上面的话并非有贬低流行病学的意思,实际上我一直都在做流行病学,我这样写只是想说明近些年来统计方法的普及速度之快而已。
统计学教案习题06分类资料的统计描述
第六章 分类资料的统计描述 一、教学大纲要求 (一)掌握内容 1. 绝对数。 2. 相对数常用指标:率、构成比、比。 3. 应用相对数的注意事项。 4. 率的标准化和动态数列常用指标:标准化率、标准化法、时点动态数列、时期动态数列、绝对增长量、发展速度、增长速度、定基比、环比、平均发展速度和平均增长速度。 (二)熟悉内容 1. 标准化率的计算。 2. 动态数列及其分析指标。 二、教学内容精要 (一) 绝对数 绝对数是各分类结果的合计频数,反映总量和规模。如某地的人口数、发病人数、死亡人数等。绝对数通常不能相互比较,如两地人口数不等时,不能比较两地的发病人数,而应比较两地的发病率。 (二)常用相对数的意义及计算 相对数是两个有联系的指标之比,是分类变量常用的描述性统计指标,常用两个分类的绝对数之比表示相对数大小,如率、构成比、比等。 常用相对数的意义及计算见表6-1。 表6-1 常用相对数的意义及计算 常用相对数 概念 表示方式 计算公式 举例 率 (rate ) 又称频率指标,说明一定时期内某现象发生的频率或强度 百分率(%)、千分率 (‰)等 单位时间内的发病率、患病 率,如年(季)发病率、时 点患病率等 构成比 (proportion ) 又称构成指标,说明某一事物内部各组成 部分所占的比重或分布 百分数 疾病或死亡的顺位、位次或所占比重 比 (ratio ) 又称相对比,是A 、B 两个有关指标之 比,说明A 是B 的若干倍或百分之几 倍数或分数 ①对比指标,如男:女 =106.04:100 ②关系指标,如医护人员:病床数=1.64 ③计划完成指标,如完成计划的130.5% (三) 应用相对数时应注意的问题 1. 计算相对数的分母一般不宜过小。 2. 分析时不能以构成比代替率 容易产生的错误有 (1)指标的选择错误如住院病人只能计算某病的病死率,不能认为是某病的死亡率; (2)若用构成指标下频率指标的结论将导致错误结论,如 某部队医院收治胃炎的门诊人数中军人的构成比最高,但不一定军人的胃炎发病率最高。 %100?=单位总数 可能发生某现象的观察数 发生某现象的观察单位率%100?= 观察单位总数 同一事物各组成部分的位数某一组成部分的观察单构成比B A = 比
分类资料的Logistic回归分析SPSS
S PSS 10.0高级教程十三:分类资料的Logistic回归分析 (2009-02-05 15:32:54) 转载▼ 所谓Logistic模型,或者说Logistic回归模型,就是人们想为两分类的应变量作一个回归方程出来,可概率的取值在0~1之间,回归方程的应变量取值可是在实数集中,直接做会出现0~1范围之外的不可能结果,因此就有人耍小聪明,将率做了一个Logit变换,这样取值区间就变成了整个实数集,作出来的结果就不会有问题了,从而该方法就被叫做了Logistic回归。 随着模型的发展,Logistic家族也变得人丁兴旺起来,除了最早的两分类Logistic外,还有配对Logistic模型,多分类Logistic模型、随机效应的Logistic模型等。由于SPSS的能力所限,对话框只能完成其中的两分类和多分类模型,下面我们就介绍一下最重要和最基本的两分类模型。 10.3.1 界面详解与实例 例11.1 某研究人员在探讨肾细胞癌转移的有关临床病理因素研究中,收集了一批行根治性肾切除术患者的肾癌标本资料,现从中抽取26例资料作为示例进行logistic回归分析(本例来自《卫生统计学》第四版第11章)。 ?i:标本序号 ?x1:确诊时患者的年龄(岁) ?x2:肾细胞癌血管内皮生长因子(VEGF),其阳性表述由低到高共3个等级 ?x3:肾细胞癌组织内微血管数(MVC) ?x4:肾癌细胞核组织学分级,由低到高共4级 ?x5:肾细胞癌分期,由低到高共4期 ?y:肾细胞癌转移情况(有转移y=1; 无转移y=0)。 i x1 x2 x3 x4 x5 y 1 59 2 43.4 2 1 0 2 36 1 57.2 1 1 0 3 61 2 190 2 1 0 4 58 3 128 4 3 1 5 55 3 80 3 4 1 6 61 1 94.4 2 1 0 7 38 1 76 1 1 0 8 42 1 240 3 2 0 9 50 1 74 1 1 0 10 58 3 68.6 2 2 0 11 68 3 132.8 4 2 0 12 25 2 94.6 4 3 1 13 52 1 56 1 1 0 14 31 1 47.8 2 1 0 15 36 3 31.6 3 1 1
分类资料的统计分析(doc 24页)
第十章分类资料的统计分析 A型选择题 1、下列指标不属于相对数的是() A、率 B、构成比 C、相对比 D、百分位数 E、比 2、表示某现象发生的频率或强度用 A 构成比 B 观察单位 C 相对比 D 率 E 百分比 3、下列哪种说法是错误的() A、计算相对数尤其是率时应有足够数量的观察单位数或观察次数 B、分析大样本数据时可以构在比代替率 C、应分别将分子和分母合计求合计率或平均率 D、相对数的比较应注意其可比性 E、样本率或构成比的比较应作假设检验 4、以下哪项指标不属于相对数指标( ) A.出生率 B.某病发病率 C.某病潜伏期的百分位数 D.死因构成比 E.女婴与男婴的性别比 5、计算麻疹疫苗接种后血清检查的阳转率,分母为( ). A.麻疹易感人群 B.麻疹患者数 C.麻疹疫苗接种人数 D.麻疹疫苗接种后的阳转人数 E.年均人口数 6、某病患者120人,其中男性114人,女性6人,分别占95%与5%,则结论为( ).
A.该病男性易得 B.该病女性易得 C.该病男性、女性易患率相等 D.尚不能得出结论 E.以上均不对 7、某地区某重疾病在某年的发病人数为0α,以后历年为1α,2α,…,n α,则该疾病发病人数的年平均增长速度为( )。 A.1...10+++n n ααα B. 110+??n n ααα C.n n 0 α α D.n n 0 α α -1 E. 10 -a a n 8、按目前实际应用的计算公式,婴儿死亡率属于( )。 A. 相对比(比,ratio ) B. 构成比(比例,proportion ) C. 标准化率(standardized rate ) D. 率(rate ) E 、以上都不对 9、某年某地乙肝发病人数占同年传染病人数的9.8%,这种指标是 A .集中趋势 B .时点患病率 C .发病率 D .构成比 E .相对比 10、构成比: A.反映事物发生的强度 B 、反映了某一事物内部各部分与全部构成的比重 C 、既反映A 也反映B D 、表示两个同类指标的比 E 、表示某一事物在时间顺序上的排列
第七讲 无序分类资料的统计分析
无序分类资料的统计分析 分类资料又称为定性资料,其取值是定性的,表现为互不相容的类别或属性。按类别间的关系,又分为有序分类资料(即等级资料)和无序分类资料。 Stata用于处理分类资料的命令为: tabulate var1 var2 [fw=频数变量] [,选择项] 其中,var1,var2分别表示行变量和列变量 [fw=频数变量]只在变量以频数形式存放时选用 选择项常用的有: chi2 /*(Pearson) x2检验 lrchi2 /*似然比x2检验 exact /*Fisher的确切概率 cell /*打印每个格子的频数占总频数的百分比 column /*打印每个格子的频数占相应列合计的百分比 row /*打印每个格子的频数占相应行合计的百分比 nofreq /*不打印频数 以上命令可以同时选用。 分类资料的一个特点是重复数较多,一般将数据整理成频数表,但收集数据时都是未整理的原始形式,stata对这两种形式的资料都可以进行分析,所得结果相同,只是命令稍有区别。 一、两独立样本四格表资料 (一)X2检验(n>=40且各个格子的理论数T>=5) 例11-2 某研究小组为研究慢支口服液II号对慢性支气管炎治疗 效果,以口服消咳喘为对照进行了临床试验,试验组120人、对照组 117人(两组受试者病程、病情等均衡),疗程2周,疗效见表11-3。问慢支口服液II号与消咳喘治疗慢性支气管炎的疗效是否相同? 表11-3 试验组与对照组疗效 组别有效无效合计有效率(%)试验组116 4 120 96.67 对照组82 35 117 70.09 合计198 39 237 83.54
(整理)多项分类Logistic回归分析的功能与意义1.
多项分类Logistic回归分析的功能与意义 我们经常会遇到因变量有多个取值而且无大小顺序的情况,比如职业、婚姻情况等等,这时一般的线性回归分析无法准确地刻画变量之间的因果关系,需要用其它回归分析方法来进行拟合模型。SPSS的多项分类Logistic回归便是一种简便的处理该类因变量问题的分析方法。 例子:下表给出了对山东省某中学20名视力低下学生视力监测的结果数据。试用多项分类Logistic回归分析方法分析视力低下程度(由轻到重共3级)与年龄、性别(1代表男性,2代表女性)之间的关系。
“年龄”使之进入“协变量”列表框。
还是以教程“blankloan.sav"数据为例,研究银行客户贷款是否违约(拖欠)的问题,数据如下所示: 上面的数据是大约700个申请贷款的客户,我们需要进行随机抽样,来进行二元Logistic 回归分析,上图中的“0”表示没有拖欠贷款,“1”表示拖欠贷款,接下来,步骤如下: 1:设置随机抽样的随机种子,如下图所示:
选择“设置起点”选择“固定值”即可,本人感觉200万的容量已经足够了,就采用的默认值,点击确定,返回原界面、 2:进行“转换”—计算变量“生成一个变量(validate),进入如下界面: 在数字表达式中,输入公式:rv.bernoulli(0.7),这个表达式的意思为:返回概率为0.7的bernoulli分布随机值 如果在0.7的概率下能够成功,那么就为1,失败的话,就为"0" 为了保持数据分析的有效性,对于样本中“违约”变量取缺失值的部分,validate变量也取缺失值,所以,需要设置一个“选择条件” 点击“如果”按钮,进入如下界面:
Stata统计分析命令
Stata统计分析常用命令汇总 一、winsorize极端值处理 范围:一般在1%和99%分位做极端值处理,对于小于1%的数用1%的值赋值,对于大于99%的数用99%的值赋值。 1、Stata中的单变量极端值处理: stata 11.0,在命令窗口输入“findit winsor”后,系统弹出一个窗口,安装winsor模块 安装好模块之后,就可以调用winsor命令,命令格式:winsor var1, gen(new var) p(0.01) 或者在命令窗口中输入:ssc install winsor安装winsor命令。winsor命令不能进行批量处理。 2、批量进行winsorize极端值处理: 打开链接:https://www.360docs.net/doc/826579755.html,/judson.caskey/data.html,找到winsorizeJ,点击右键,另存为到stata中的ado/plus/目录下即可。命令格式:winsorizeJ var1var2var3,suffix(w)即可,这样会生成三个新变量,var1w var2w var3w,而且默认的是上下1%winsorize。如果要修改分位点,则写成如下格式:winsorizeJ var 1 var2 var3,suffix(w) cuts(5 95)。 3、Excel中的极端值处理:(略) winsor2 命令使用说明 简介:winsor2 winsorize or trim (if trim option is specified) the variables in varlist at particular percentiles specified by option cuts(# #). In defult, new variables will be generated with a suffix "_w" or "_tr", which can be changed by specifying suffix() option. The replace option replaces the variables with their winsorized or trimmed ones. 相比于winsor命令的改进: (1) 可以批量处理多个变量; (2) 不仅可以winsor,也可以trimming; (3) 附加了by() 选项,可以分组winsor 或trimming; (4) 增加了replace 选项,可以不必生成新变量,直接替换原变量。 范例: *- winsor at (p1 p99), get new variable "wage_w" . sysuse nlsw88, clear . winsor2 wage *- left-trimming at 2th percentile . winsor2 wage, cuts(2 100) trim *- winsor variables by (industry south), overwrite the old variables . winsor2 wage hours, replace by(industry south) 使用方法: 1. 请将winsor 2.ado 和winsor2.sthlp 放置于stata12\ado\base\w 文件夹下; 2. 输入help winsor2 可以查看帮助文件;
分层回归分析
分层回归分析 2007-12-08 14:55:16| 分类:专业补充| 标签:|字号大中小订阅 Hierarchical Regression Analysis In a hierarchical multiple regression, the researcher decides not only how many predictors to enter but also the order in which they enter. Usually, the order of entry is based on logical or theoretical considerations. There are three predictor variables and one criterion variable in the following data set. A researcher decided the order of entry is X1, X2, and X3. SPSS for Windows 1. Enter Data. 2. Choose Analyze / Regression / Linear. Dependent: Select "y" and move it to the Dependent variable list. First, click on the variable y. Next, click on the right arrow. Block 1 of 1 Independent(s): Choose the first predictor variable x1 and move it to the Independent(s) box. Next, click the Next button as shown below. Block 2 of 2 Click the predictor variable x2 and move it to the Independent(s) box. Next, click the Next button as shown below. Block 3 of 3 Click the predictor variable x3 and move it to the Independent(s) box. 3. Click the Statistics button. Check R squared change. Click Continue and OK. SPSS Output 1. R square Change R Square and R Square Change Order of Entry Model 1 : Enter X1
STATA统计分析入门
STATA统计分析入门 STATA统计软件包是目前世界上最著名的统计软件之一,与SAS、SPSS一起被并称为三大权威软件。它广泛的应用于经济、教育、人口、政治学、社会学、医学、药学、工矿、农林等学科领域,同时具有数据管理软件、统计分析软件、绘图软件、矩阵计算软件和程序语言的特点,几乎可以完成全部复杂的统计分析工作。其功能非常强大且操作简单、使用灵活、易学易用、运行速度极快,在许多方面别具一格。 STATA最为突出的特点是短小精悍、功能强大,整个系统一般在200M左右,但是已经包含了全部的统计分析。数据管理和绘图等功能,尤其是它的统计分析功能极为全面,比起1G以上大小的SAS系统也毫不逊色。而且STATA在分析时是将数据全部读入内存,在计算全部完成后才和磁盘交换数据,因此运算速度极快。STATA的命令语句也极为简洁明快,而且在统计分析命令的设置上又非常有条理,它将相同类型的统计模型均归在同一个命令族下,而不同命令族又可以使用相同功能的选项,这使得用户学习时极易上手。STATA语句在简洁的同时又拥有着极高的灵活性,用户可以充分发挥自己的聪明才智,熟练应用各种技巧,真正做到随心所欲。 STATA的另一个特点是他的许多高级统计模块均是编程人员用宏语言写成的程 序文件(ADO文件),这些文件可以自行修改、添加和下载。用户可随时到STATA 网站寻找并下载最新的升级文件。 课程简介: 该课程主要是为大家介绍STATA的基本用法和简单的统计分析。 课程大纲: 第一课:STATA简介 介绍STATA基本情况(统计编程及作图功能),软件窗口界面及基本数据处理的操作方法。 第二课:STATA中的图形制作 介绍图形制作的基本命令和一些基本图形的绘制(直方图、散点图、箱线图、饼图等) 第三课:假设检验与方差分析ANOVA STATA下单双因素方差分析的操作,及假设检验 第四课:简单与多元回归 介绍大小样本下的最小二乘法与多元线性回归,介绍如何用STATA做回归诊断 课程基础: 简单的英文基础,因为STATA是英文版的
Stata基本操作和数据分析入门第11章无序分类资料的统计分析Stata实现
第十一章 无序分类资料的统计分析 本章使用的STATA 的命令: 例11-1 根据某地区的血型普查结果可知,该地区人群中血型为O 的占30%,血型为A 的占25%,血型为B 的占35%,血型为AB 的占10%。研究者在邻近该地区的一个山区人群中进行一个血型的流行病调查,在该山区人群中随机抽样调查了200人,检测这些对象的血型,表11-1给出了血型检测的结果。问该山区人群与这个地区人群的血型分布是否一致? 表11-1 山区人群血型抽样调查结果 血型 O A B AB 合计 人数 50 70 50 30 200 例11-2 某研究小组为研究慢支口服液II 号对慢性支气管炎治疗效果,以口服消咳喘为对照进行了临床试验,试验组120人、对照组117人(两组受试者病程、病情等均衡),疗程2周,疗效见表11-3。问慢支口服液II 号与消咳喘治疗慢性支气管炎的疗效是否相同? 表11-3 试验组与对照组疗效 组别 有效 无效 合计 有效率(%) 试验组 116 4 120 96.67 对照组 82 35 117 70.09 合计 198 39 237 83.54 1.建立检验假设,确定检验水准 0H :21ππ=,即两种药物治疗慢性支气管炎的疗效相同
1H :21ππ≠,即两种药物治疗慢性支气管炎的疗效不同 05.0=α 解:STATA 数据如下: STA TA 命令: 结果: Pearson chi2(1) = 30.4463 Pr = 0.000,05.0
Stata教程:描述性统计命令与输出结果说明
本节STATA命令摘要 by 分组变量:]summarize变量名1变量名2… 变量名m[,detail] ci变量名1变量名2… 变量名m[,level(#)binomial poissonexposure(varname)by(分组变量)] cii 样本量 均数 标准差[,level(#)] tab1变量名[,generate(变量名)] · 资料特征描述(均数,中位数,离散程度) 例:某地测定克山病患者与克山病健康人的血磷测定值如下表(数据摘自四川医学院主编的卫生统计学,1978出版,p21): 患者 2.6 3.24 3.73 3.73 4.32 4.73 5.18 5.58 5.78 6.40 6.53 健康人 1.67 1.98 1.98 2.33 2.34 2.50 3.60 3.73 4.14 4.17 4.57 4.82 5.78 并假定这些数据已以STATA格式存入ex2.dta文件中,其中变量x1为患者的血磷测定值数据,变量x2为健康人的血磷测定值数据。上述数据也可以用变量x表示血磷测
定值,分组变量group=0表示患者组和group=1表示健康组(如:患者组中第一个数据为2.6,则x=2.6,group=0;又如:健康组中第三个数据为1.98,则x为1.98以及group为1),并假定这些数据已以STATA格式存入ex2a.dta文件中。 计算资料均数,标准差命令summarize,以述资料为例: useex2,clear summarizex1x2 结果: 变量 样本数 均数 标准差 最小值 最大值 Variable| Obs Mean Std.Dev. Min Max ---------+ x1| 11 4.710909 1.302977 2.6 6.53 x2| 13 3.354615 1.304368 1.67 5.78 即:本例中急性克山病患者组的样本数为11,血磷测定值均数为4.711(mg%),相应的标准差为1.303,最小值为2.6以及最大值为6.53;健康组的样本量为13,血磷测定值均数为3.3546,相应的标准差为1.3044,最小值为1.67以及最大值为5.78。 计算资料均数,标准差,中位数,低四分位数和高四分位数的命令summarize 以及子命令detail,仍以述资料为例: use ex2,clear summarizex1x2,detail 结果: x1 Percentiles Smallest(最小值) 1%
第八讲 有序分类资料的统计分析Stata实现
第十二章有序分类资料的统计分析的 Stata 实现
本章使用的 STATA 命令: 列变量有序时的分类资料 CMH 卡方分析 双向有序时的 Spearman 相关 opartchi 行变量 [weight], by(列变量) (见 Stata7 附加程序) spearman 变量 1 变量 2
例 12-2
某研究欲观察人参的镇静作用,选取 32 只同批次的小白鼠,将其
中 20 只随机分配到人参组:以 5%人参浸液对其做腹腔注射,12 只分配到对照 组:以等量蒸馏水对其做同样注射。实验结果如表 12-2 所示。能否说明人参有 镇静作用? 表 12-2
镇静等级 ± + ++ +++
人参镇静作用的实验结果
对照组 11 0 1 0 0
人参组 4 1 2 1 12
1.建立检验假设,确定检验水准。
H 0 :人参没有镇静作用(样本来自两个相同总体)
H 1 :人参有镇静作用(样本来自两个不同总体)
? ? 0.05
Stata 数据为:
a 1 1 1 1 1 2 2 2 2 2
Stata 命令为:
b 1 2 3 4 5 1 2 3 4 5
x
4 1 2 1 12 11 0 1 0 0
opartchi b [weight=x],by(a) 结果为: Chi-square tests df Chi-square P-value Independence 4 16.64 0.0023 ------------------------------------------------------Components of independence test Location 1 15.29 0.0001 Dispersion 1 .3496 0.5543
在 ? ? 0.05 的水平上,拒绝 H 0 ,接受 H1,认为两总体之间的差别有统计学 意义, 可以认为人参组和对照组镇静等级的差别有统计学意义, 人参有镇静作用。
例 12-3
试根据表 12-4 的资料,检验针刺不同穴位的镇痛效果有无差别? 表 12-4 穴位 合谷 足三里 扶突 + 38 53 47 针刺不同穴位的镇痛效果 镇痛效果 ++ +++ 44 12 29 28 23 19 ++++ 24 16 33
1.建立检验假设,确定检验水准。
H 0 :三个穴位的镇痛效果相同
H 1 :三个穴位的镇痛效果不全相同
? ? 0.05
Stata 数据为:
group 1 1 1 1 2 2 2 2 3 3 3
effect 1 2 3 4 1 2 3 4 1 2 3
w
38 44 12 24 53 29 28 16 47 23 19
应用潜在分类泊松回归模型及EM算法分析陈述偏好数据:
《统计计算》案例1,吕晓玲 应用潜在分类泊松回归模型及EM 算法分析陈述偏好数据: 以网络购物使用次数为例 1. 问题提出 随着网络的兴起,网上购物已经在人们的生活中发挥着越来越重要的作用。网上购物以其方便快捷等特点吸引了很多购物者,但是也有一些人质疑网上购物安全性、不可触摸性等问题。影响人们选择网上购物的因素有很多,不同的人对网上购物也有不同的态度。大学生是网络购物这个群体的很重要的一部分,什么因素影响大学生对网络购物的选择?大学生由于对网络购物的态度取向不同可分为多少潜在的类别?本文应用陈述偏好方法(stated preference method )收集大学生网上购物的数据,并应用潜在分类泊松回归模型(latent class Poisson regression model )及EM 算法分析数据,回答以上两个问题。 2. 数据收集 源于心理学的陈述偏好调查已经被市场营销中研究消费者行为广泛应用。虽然在进行每个具体研究时操作不尽相同,总的原则是事先设定几个重要因素,每个因素有若干水平,然后提出一些假想情景,每个情景是这些因素不同水平的组合。受访者按照他们的喜好给不同的情景打分或者排序。研究者应用模型分析数据,寻找各因素的重要性。 为了确定影响网络购物的重要因素,我们首先开展了预调查,针对购买商品的种类、价格、邮费、卖家信用度、介绍商品详细程度以及网上购物节省时间和到货时间等因素对大学生进行了调查,并应用简单统计分析得到了对网上购物次数影响比较显著的四个因素,分别是购买商品的种类、价格、卖家信誉度以及介绍商品的详细程度。具体因素和因素水平如下所示: 种类:服饰,化妆品,文体 价格:50元,100元,150元,200元,250元 卖家或网站的信誉度:1,2,3,4,5 介绍商品的详细程度:1,2,3,4,5 若每一种组合都进行调查则共有3555225???=组合,在这里运用了正交设计的方法进行试验设计,共进行75种不同的组合,将这75种组合分成25组,每组中包含3个场景(分别为3个不同的种类),每一个被调查者将被给定3个不同的场景。每个被调查者回答的问题是在特定的场景能够在十次购物中选择网上购物的可能次数。我们总共访问了197名在京大学生,得到了在588种场景下他们对网络购物的使用情况的有效回答。 3. 模型介绍 市场营销中常用的分析陈述偏好数据的方法是联合分析(conjoint analysis ),我们这里使用泊松回归模型,因为:(1)因变量不是受访者对场景的排序,而是使用网络购物的次数,它是一个取值为离散整数的变量,可以假设服从泊松分布;(2)可以对泊松回归模型进一步应用潜在分类模型分析受访者的异质性。我们首先介绍泊松回归模型和潜在分类模型,然后介绍如何应用最大似然法和EM 算法估计参数。 令ij Y 为第i (I i ,...,1=)个个体在面临第j (J j ,...,1=)种场景时的选择,服从参数为ij λ的泊松分布。因为从平均的意义上来讲,ij λ取值越大意味着受访者越倾向于多次使用
8.无序分类资料的统计推断—X2检验
8 无序分类资料的统计推断—— χ2检验 χ2检验(chi-square test )是一种用途较广的假设检验方法,这里仅介绍它在分类变量资料中的应用,检验两个或两个以上的样本率或构成比之间的差异是否有统计意义。 8.1 四格表资料的χ2检验 四格表即2 ? 2列联表,其自由度df =1,又分为一般与配对两种情形,本节介绍一般四格表的χ2检验,主要是用来推断两个总体率或构成比之间有无差别。一般四格表,①在总频数n ≥40且所有理论频数≥5时,用Pearson χ2统计量;②在总频数n ≥40且有理论频数<5但≥1时,用校正χ2统计量;③在总频数n <40或有理论频数<1时,用Fisher 精确概率法检验。计数资料的数据格式有两种,一种是频数表格式,如表8-1;一种是原始记录格式,如前面第4章统计描述中的表4-3,这两种格式在SPSS 操作时有所不同。 例8-1 欲研究内科治疗对某病急性期和慢性期的治疗效果有无不同,某医生收集了182例采用内科疗法的该病患者的资料,数据见表8-1。请分析不同病期的总体有效率有无差别? 表8-1 两种类型疾病的治疗效果 组别 有效 无效 合计 有效率(%) 急性期 69 37 106 65.1 慢性期 30 46 76 39.5 合计 99 83 182 54.4 解 这是一般四格表,012:H ππ=,即急性期和慢性期的总体有效率相同。建立3列4行的数据文件,如图8-1,其中行变量r 表示组别(值标签:1=“急性期”、2=“慢性期”),列变量c 表示疗效(值标签:1=“有效”、2=“无效”),freq 表示频数。 1.指定频数变量 选择菜单Data →Weight cases ,弹出Weight cases 对话框,见图8-2;选中Weight cases by ;在左边框中选中频数freq ,并将其送入Frequency 框中;单击OK 。 图8-1 例8.1数据文件 图8-2 Weight cases 对话框 2.进行χ2检验 选择菜单Analyze → Descriptive Statistics → Crosstabs (交叉表),弹出Crosstabs 主对话框;将组别r 送入行变量Row(s)框,将疗效c 送入列变量Column(s)框,如图8-3。
二分类Logistic回归的详细SPSS操作
SPSS操作:二分类Logistic回归 作者:张耀文 1、问题与数据 某呼吸内科医生拟探讨吸烟与肺癌发生之间的关系,开展了一项成组设计的病例对照研究。选择该科室内肺癌患者为病例组,选择医院内其它科室的非肺癌患者为对照组。通过查阅病历、问卷调查的方式收集了病例组和对照组的以下信息:性别、年龄、BMI、COPD病史和是否吸烟。变量的赋值和部分原始数据见表1和表2。该医生应该如何分析? 表1. 肺癌危险因素分析研究的变量与赋值 表2. 部分原始数据 ID gender age BMI COPD smoke cancer 1 0 34 0 1 1 0 2 1 32 0 1 0 1 3 0 27 0 1 1 1 4 1 28 0 1 1 0 5 1 29 0 1 0 0 6 0 60 0 2 0 0 7 1 29 0 0 1 1 8 1 29 1 1 1 1 9 1 37 0 1 0 0 10 0 17 0 0 0 0 11 0 20 0 0 1 1 12 1 35 0 0 0 0 13 0 17 1 0 1 1
………………… 2、对数据结构的分析 该设计中,因变量为二分类,自变量(病例对照研究中称为暴露因素)有二分类变量(性别、BMI和是否吸烟)、连续变量(年龄)和有序多分类变量(COPD 病史)。要探讨二分类因变量与自变量之间的关系,应采用二分类Logistic回归模型进行分析。 在进行二分类Logistic回归(包括其它Logistic回归)分析前,如果样本不多而变量较多,建议先通过单变量分析(t检验、卡方检验等)考察所有自变量与因变量之间的关系,筛掉一些可能无意义的变量,再进行多因素分析,这样可以保证结果更加可靠。即使样本足够大,也不建议直接把所有的变量放入方程直接分析,一定要先弄清楚各个变量之间的相互关系,确定自变量进入方程的形式,这样才能有效的进行分析。 本例中单变量分析的结果见表3(常作为研究报告或论文中的表1)。 表3. 病例组和对照组暴露因素的单因素比较 病例组(n=85)对照组(n=259) χ2 /t统计量P 性别,男(%)56 (65.9) 126 (48.6) 7.629 <0.01 年龄(岁),x± s40.3 ±14.0 38.6 ±12.4 1.081 0.28 BMI,n (%) 正常48 (56.5) 137 (52.9) 0.329 0.57 超重或肥胖37 (43.5) 122 (47.1) COPD病史,n (%) 无21 (24.7) 114 (44.0) 14.123 <0.01 轻中度24 (28.2) 75 (29.0) 重度40 (47.1) 70 (27.0) 是否吸烟,n(%) 否18 (21.2) 106 (40.9) 10.829 <0.01 是67 (78.8) 153 (59.1) 单因素分析中,病例组和对照组之间的差异有统计学意义的自变量包括:性别、COPD病史和是否吸烟。 此时,应当考虑应该将哪些自变量纳入Logistic回归模型。一般情况下,建议纳入的变量有:1)单因素分析差异有统计学意义的变量(此时,最好将P值放宽一些,比如0.1或0.15等,避免漏掉一些重要因素);2)单因素分析时,
Stata统计分析命令
S t a t a统计分析命令 Company number:【0089WT-8898YT-W8CCB-BUUT-202108】
Stata统计分析常用命令汇总 一、winsorize极端值处理 范围:一般在1%和99%分位做极端值处理,对于小于1%的数用1%的值赋值,对于大于99%的数用99%的值赋值。 1、Stata中的单变量极端值处理: stata ,在命令窗口输入“findit winsor”后,系统弹出一个窗口,安装winsor模块 安装好模块之后,就可以调用winsor命令,命令格式:winsor var1, gen(new var) p 或者在命令窗口中输入:ssc install winsor安装winsor命令。winsor命令不能进行批量处理。 2、批量进行winsorize极端值处理: 打开链接:,找到winsorizeJ,点击右键,另存为到stata中的ado/plus/目录下即可。命令格式:winsorizeJ var1var2var3,suffix(w)即可,这样会生成三个新变量,var1w var2w var3w,而且默认的是上下1%winsorize。如果要修改分位点,则写成如下格式:winsorizeJ var 1 var2 var3,suffix(w) cuts(5 95)。 3、Excel中的极端值处理:(略) winsor2 命令使用说明 简介:winsor2 winsorize or trim (if trim option is specified) the variables in varlist at particular percentiles specified by option cuts(# #). In defult, new variables will be generated with a suffix "_w" or "_tr", which can be changed by specifying suffix() option. The replace option replaces the variables with their winsorized or trimmed ones. 相比于winsor命令的改进: (1) 可以批量处理多个变量; (2) 不仅可以 winsor,也可以 trimming; (3) 附加了 by() 选项,可以分组 winsor 或 trimming;