编译原算符优先分析实验报告

学号E10714103专业计算机科学与技术姓名万学进
实验日期2010-5-25教师签字成绩
实验报告
【实验名称】算符优先文法分析
【实验目的】
掌握算符优先分析法的原理,利用算符优先分析法将赋值语句进行语法分析,翻译成等价的四元式表示。
【实验内容】
1.算术表达式的文法可以是:
(1)S->#E# (2)E->E+T (3)E->T (4)T->T*F (5)T->F (6)F->P^F (7)F->P (8)P->(E) (9)P->i
2.根据算符优先分析法,将表达式进行语法分析,判断一个表达式是否正确。
【设计思想】
(1)定义部分:定义常量、变量、数据结构。
(2)初始化:设立算符优先关系表、初始化变量空间(包括堆栈、结构体、数组、临时变量等);
(3)控制部分:从键盘输入一个表达式符号串;
(4)利用算符优先文法分析算法进行表达式处理:根据优先关系表对表达式符号串进行堆栈(或其他)操作,输出分析结果,如果遇到错误则显示错误信息。
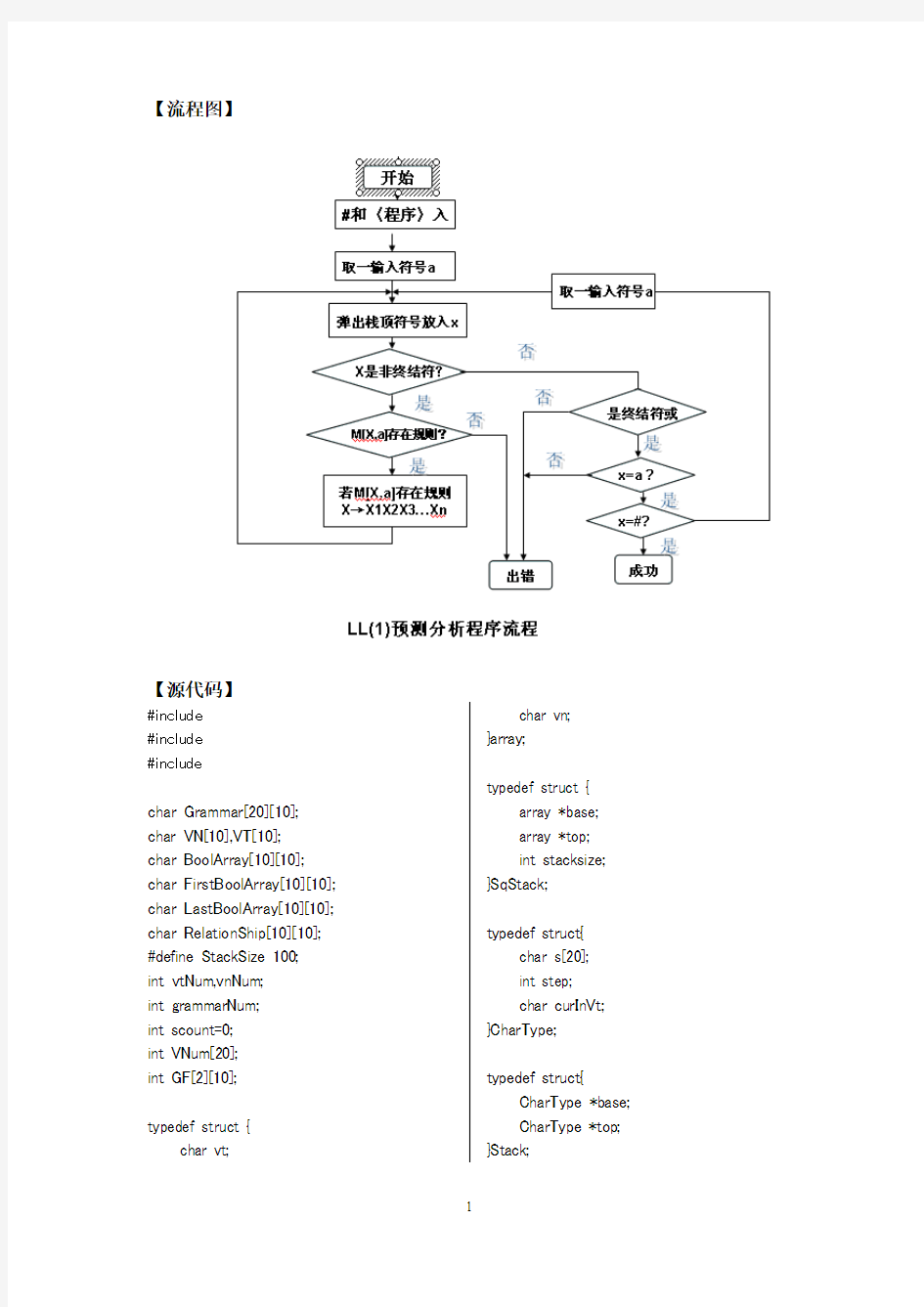
【流程图】
【源代码】
#include
#include
#include
char Grammar[20][10]; char VN[10],VT[10];
char BoolArray[10][10]; char FirstBoolArray[10][10]; char LastBoolArray[10][10]; char RelationShip[10][10]; #define StackSize 100;
int vtNum,vnNum;
int grammarNum;
int scount=0;
int VNum[20];
int GF[2][10];
typedef struct {
char vt;
char vn;
}array;
typedef struct {
array *base;
array *top;
int stacksize;
}SqStack;
typedef struct{
char s[20];
int step;
char curInVt;
}CharType;
typedef struct{
CharType *base;
CharType *top; }Stack;
typedef struct
{
int x;
int y;
}Position;
SqStack S;
Stack CS;
SqStack InitStack()
{
int i,j;
S.base=(array
*)malloc(100*sizeof(array));
if(!S.base)exit(1);
S.top=S.base;
S.stacksize=StackSize;
array temp;
printf("初始化栈:\n");
for(i=1;i<=vnNum;i++)
{
for(j=1;j<=vtNum;j++)
{
if(BoolArray[i][j]=='1')
{
temp.vt=BoolArray[0][j];
temp.vn=BoolArray[i][0];
*S.top=temp;
S.top++;
printf("%c,%c\n",temp.vn,temp.vt);
}
}
}
return S;
}
int vNumCount()
{
for(int i=0;i<=grammarNum;i++)
{
int j=1;
while(Grammar[i][j]!='\0')
{
j++;
}
VNum[i]=j;
printf("%d ",VNum[i]);
}
printf("\n");
return 0;
}
int ScanGrammar()
{
FILE *fp=fopen("算符优先文法.txt","r");
FILE *tp;
char singleChar,nextChar;
int i=0,j=0,k,count;
while(!feof(fp))
{
fscanf(fp,"%c",&singleChar);
if(singleChar=='?')
{
Grammar[i][j]='\0';
break;
}
if(singleChar=='\n')
{
Grammar[i][j]='\0';
i++;
j=0;
continue;
}
if(singleChar=='-')
{
tp=fp;
fscanf(tp,"%c",&nextChar);
if(nextChar=='>')
{
fp=tp;
continue;
}
}
if(singleChar=='|')
{
Grammar[i+1][0]=Grammar[i][0];
Grammar[i][j]='\0';
i++;
j=1;
continue;
}
Grammar[i][j]=singleChar;
if(singleChar>='A'&&singleChar<='Z')
{
count=0;
while(VN[count]!=singleChar&&VN[coun t]!='\0')
{
count++;
}
if(VN[count]=='\0')
{
VN[count]=singleChar;
vnNum=count+1;
}
}
else
{
count=0;
while(VT[count]!=singleChar&&VT[coun t]!='\0')
{
count++;
}
if(VT[count]=='\0')
{
VT[count]=singleChar;
vtNum=count+1;
}
}
j++;
}
printf("输入的文法:\n");
for(k=0;k<=i;k++)
{
j=0;
while(Grammar[k][j]!='\0')
{
if(j==1)
{
printf("->");
}
printf("%c",Grammar[k][j]);
j++;
}
printf("\n");
}
printf("vnNum:%d\n",vnNum);
printf("vtNum:%d\n",vtNum);
printf("%d\nVN:",i);
count=0;
while(VN[count]!='\0')
{
BoolArray[count+1][0]=VN[count];
LastBoolArray[count+1][0]=VN[count];
printf("%d%c
",count+1,BoolArray[count+1][0]);
count++;
}
printf("\nVT:");
count=0;
while(VT[count]!='\0')
{
BoolArray[0][count+1]=VT[count];
LastBoolArray[0][count+1]=VT[count];
printf("%d%c
",count+1,BoolArray[0][count+1]);
count++;
}
printf("\n");
fclose(fp);
return i;
}
int print()
{
for(int i=1;i<=vnNum;i++)
for(int j=1;j<=vtNum;j++)
{
if(BoolArray[i][j]=='1')
printf("%c %c\n",BoolArray[i][0],BoolArr ay[0][j]);
}
return 0;
}
int printlast()
{
for(int i=1;i<=vnNum;i++)
for(int j=1;j<=vtNum;j++)
{
if(LastBoolArray[i][j]=='1')
printf("%c %c\n",LastBoolArray[i][0],Las tBoolArray[0][j]);
}
return 0;
}
int BoolArrayInitial(char vn,char vt)
{
int row=1,column=1;
while(BoolArray[row][0]!=vn)
{
row++;
}
while(BoolArray[0][column]!=vt)
{
column++;
}
if(BoolArray[row][column]=='1')
{
return 0;
}
BoolArray[row][column]='1';
printf("%d %d\n",row,column);
return 0;
} int LastBoolArrayInitial(char vn,char vt) {
int row=1,column=1;
while(LastBoolArray[row][0]!=vn)
{
row++;
}
while(LastBoolArray[0][column]!=vt)
{
column++;
}
if(LastBoolArray[row][column]=='1')
{
return 0;
}
LastBoolArray[row][column]='1';
printf("%d %d\n",row,column);
return 0;
}
int FirstInitial(int grammarNum)
{
int i;
for(i=0;i<=grammarNum;i++)
{
if(Grammar[i][1]<'A'||Grammar[i][1]>'Z') {
BoolArrayInitial(Grammar[i][0],Grammar [i][1]);
continue;
}
if(Grammar[i][1]>='A'&&Grammar[i][1]<= 'Z'&&Grammar[i][2]!='\0')
{
if(Grammar[i][2]<'A'||Grammar[i][2]>'Z')
BoolArrayInitial(Grammar[i][0],Grammar [i][2]);
}
}
printf("文法表中各行文法字符数:");
vNumCount();
return 0;
}
int LastInitial(int grammarNum)
{
int i,count;
for(i=0;i<=grammarNum;i++)
{
count=VNum[i]-1;
if(Grammar[i][count]<'A'||Grammar[i][co unt]>'Z')
{
LastBoolArrayInitial(Grammar[i][0],Gra mmar[i][count]);
continue;
}
if(count<=1)continue;
if(Grammar[i][count]>='A'&&Grammar[i] [count]<='Z'&&Grammar[i][count-1]!='\0')
{
if(Grammar[i][count-1]<'A'||Grammar[i][ count-1]>'Z')
LastBoolArrayInitial(Grammar[i][0],Gra mmar[i][count-1]);
}
}
printlast();
return 0;
}
Position GetPos(array temp)
{
for(int i=1;i<=vnNum;i++)
{
if(BoolArray[i][0]==temp.vn)
break;
}
for(int j=1;j<=vtNum;j++)
{
if(BoolArray[0][j]==temp.vt)
break;
}
Position pos;
pos.x=i;
pos.y=j;
return pos;
}
int PrintStack()
{
array *p=S.top,scan;
scount++;
printf("scount %d:\n",scount);
while(p!=S.base)
{
scan=*p;
printf("%c %c\n",scan.vn,scan.vt);
p--;
}
return 0;
}
int Insert(array pushTemp)
{
Position pos;
array scan;
pos=GetPos(pushTemp);
if(BoolArray[pos.x][pos.y]=='\0')
{
BoolArray[pos.x][pos.y]='1';
array *p=S.base;
while(p!=S.top)
{
scan=*p;
if(scan.vn==pushTemp.vn && scan.vt==pushTemp.vt)
break;
p++;
}
if(p==S.top)
{
S.top++;
*S.top=pushTemp;
PrintStack();
}
}
return 1;
}
int PushPop()
{
int i;
array temp,pushTemp;
while(S.top!=S.base)
{
temp=*S.top;
S.top--;
for(i=0;i<=grammarNum;i++)
{
if(Grammar[i][1]==temp.vn)
{
pushTemp.vn=Grammar[i][0];
pushTemp.vt=temp.vt;
Insert(pushTemp);
}
}
}
print();
return 0;
}
int LastPushPop()
{
int i,count;
array temp,pushTemp;
while(S.top!=S.base)
{
temp=*S.top;
S.top--;
for(i=0;i<=grammarNum;i++)
{
count=VNum[i]-1;
if(Grammar[i][count]==temp.vn)
{
pushTemp.vn=Grammar[i][0];
pushTemp.vt=temp.vt;
Insert(pushTemp);
}
}
}
print();
return 0;
}
int ResetStack()
{
int i,j;
array temp;
while(S.top!=S.base)
{
S.top--;
}
printf("\n");
for(i=1;i<=vnNum;i++)
{
for(j=1;j<=vtNum;j++)
{
if(BoolArray[i][j]=='1')
{
temp.vt=BoolArray[0][j];
temp.vn=BoolArray[i][0];
*S.top=temp;
S.top++;
printf("%c,%c\n",temp.vn,temp.vt);
}
}
}
return 0;
}
int Judge(int i,int j)
{
if(Grammar[i][j+1]=='\0')return -1;
if(Grammar[i][j]>='A'&&Grammar[i][j]<=' Z'&&(Grammar[i][j+1]<'A'||Grammar[i][j+1]>'Z '))
return 0;
else return 1;
}
Position GetOpPos(char vni,char vnj)
{
for(int i=1;i<=vtNum;i++)
if(RelationShip[i][0]==vni)
break;
for(int j=1;j<=vtNum;j++)
{
if(RelationShip[0][j]==vnj)
break;
}
Position pos;
pos.x=i;
pos.y=j;
return pos;
}
int GetVtPos(char vt)
{
for(int i=1;i<=vtNum;i++)
if(LastBoolArray[i][0]==vt)
break;
return i;
}
int RelEqual()
{
Position pos;
int j;
for(int i=0;i<=grammarNum;i++)
{
j=1;
while(Grammar[i][j]!='\0')
{
if(Grammar[i][j+2]=='\0')break;
if((Grammar[i][j]<'A'||Grammar[i][j]>'Z')& &(Grammar[i][j+2]<'A'||Grammar[i][j+2]>'Z'))
{
pos=GetOpPos(Grammar[i][j],Grammar[i ][j+2]);
RelationShip[pos.x][pos.y]='=';//2表示=
}
j++;
}
}
return 0;
}
int RelShBlanket()
{
int row;
Position pos;
int i,j;
for(i=1;i<=vtNum;i++)
{
RelationShip[i][0]=BoolArray[0][i];
RelationShip[0][i]=BoolArray[0][i];
}
for(i=0;i<=grammarNum;i++)
{
j=1;
while(Grammar[i][j]!='\0')
{
if(Judge(i,j)==-1)break;
if(Judge(i,j)==0)
{
row=GetVtPos(Grammar[i][j]);
for(int ii=1;ii<=9;ii++)
{
if(LastBoolArray[row][ii]=='1')
{
pos=GetOpPos(LastBoolArray[0][ii],Gra mmar[i][j+1]);
RelationShip[pos.x][pos.y]='>';//3表示大于
}
}
}
if(Judge(i,j)==1)
{
row=GetVtPos(Grammar[i][j+1]);
for(int ii=1;ii<=9;ii++)
{
if(FirstBoolArray[row][ii]=='1')
{
pos=GetOpPos(Grammar[i][j],FirstBool Array[0][ii]);
RelationShip[pos.x][pos.y]='<';//1表示小于
}
}
}
j++;
}
}
RelEqual();
printf("表达式文法算符优先关系表:\n");
RelationShip[0][0]=' ';
for(i=0;i<=vtNum;i++)
{
for(int j=0;j<=vtNum;j++)
{
if(RelationShip[i][j]=='\0')
RelationShip[i][j]='0';
printf("%4c
",RelationShip[i][j]);
}
printf("\n");
}
return 0;
}
int ChangeValue()
{ int change=0;
int i,j;
for(i=1;i<=vtNum;i++)
for(j=1;j<=vtNum;j++)
{
if(RelationShip[i][j]=='>')
{
if(GF[0][i]<=GF[1][j])
{
GF[0][i]=GF[1][j]+1;
change=1;
}
}
if(RelationShip[i][j]=='<')
{
if(GF[0][i]>=GF[1][j])
{
GF[1][j]=GF[0][i]+1;
change=1;
}
}
if(RelationShip[i][j]=='=')
{
if(GF[0][i]!=GF[1][j])
{
if(GF[0][i]>GF[1][j])
{
GF[1][j]=GF[0][i];
change=1;
}
if(GF[0][i] { GF[0][i]=GF[1][j]; change=1; } } } } if(change==1) { ChangeValue(); } return 0; } int PreFunction() { int change=0,j; for(int i=1;i<=vtNum;i++) { GF[0][i]=1; GF[1][i]=1; } ChangeValue(); printf("优先函数:\n"); for(i=0;i<=1;i++) { for(j=1;j<=vtNum;j++) { printf("%3d",GF[i][j]); } printf("\n"); } return 0; } int PrintCStack() { CharType *p=CS.top,scan; while(p!=CS.base) { scan=*p; printf("%d %c %s\n",scan.step,scan.curIn Vt,scan.s); p--; } return 0; } int JudgeVt(char a) { for(int j=1;j<=vtNum;j++) { if(a==BoolArray[0][j]) return 1; } return 0; } int JudgeRela(char a,char b)//判断优先关系 { int apos,bpos; for(int i=1;i<=vtNum;i++) { if(a==BoolArray[0][i])apos=i; if(b==BoolArray[0][i])bpos=i; } if(GF[0][apos]>GF[1][bpos])return 1; if(GF[0][apos] else return 0; } int Reduction() { int count=1,i=0,k=1,j,p,sign; char prerela; char operate[5]; char q; char S[100]={'\0'},Input[20]; S[0]=' '; scanf("%s",Input); S[k]='#'; printf("步骤栈优先关系当前符号剩余输入串移进或规约\n"); while(Input[i]!='\0') { if(JudgeVt(S[k])) j=k; else j=k-1; sign=JudgeRela(S[j],Input[i]); if(sign==1) { L: q=S[j]; if(JudgeVt(S[j-1]))j--; else j-=2; if(JudgeRela(S[j],q)==-1) { memcpy(operate,"归约",5*sizeof(char)); p=k; while(p!=j) { S[p]='\0'; p--; } k=j+1; S[k]='N'; } else goto L; } if(sign==0) { if(JudgeRela(S[j],'#')==0) { memcpy(operate,"接受",5*sizeof(char)); // break; } k++; S[k]=Input[i]; memcpy(operate,"移进",5*sizeof(char)); } if(sign==-1) { k++; S[k]=Input[i]; memcpy(operate,"移进",5*sizeof(char)); } if(sign==1)prerela='>'; if(sign==0)prerela='='; if(sign==-1)prerela='<'; printf("%d\t%s\t%c\t\t%c\t%s\t\t%s\n", count,S,prerela,Input[i],Input,operate); count++; i++; } printf("规约结束!"); return 0; } int main() { grammarNum=ScanGrammar(); FirstInitial(grammarNum); InitStack(); PushPop(); memcpy(FirstBoolArray,BoolArray,100* sizeof(char)); LastInitial(grammarNum); memcpy(BoolArray,LastBoolArray,100*s izeof(char)); scount=0; ResetStack(); LastPushPop(); memcpy(LastBoolArray,BoolArray,100*s izeof(char)); RelShBlanket(); PreFunction(); Reduction(); return 0; } 【运行结果】 编译原理实验报告 题目: 算符优先分析法分析器 学 院 计算机科学与技术 专 业 xxxxxxxxxxxxxxxx 学 号 xxxxxxxxxxxx 姓 名 宁剑 指导教师 xxxx 2015年xx 月xx 日 算符优先分析法分析器 装 订 线 一、实验目的 1.理解自底向上优先分析,比较和自顶向下优先分析的不同。 2.理解算符优先分析的特点,体会其和简单优先分析方法的不同。 3.加深对编译器语法分析的理解。 二、实验原理 1.自底向上优先分析方法,也称移进-归约分析,粗略地说它的思想是对输入符号串自左向右进行扫描,并将输入符号逐个移入一个后进先出栈,边移入边分析,一旦栈顶符号串形成某个句型的句柄或可归约串时,就将该产生式的左部非终极符代替相应的右边文法符号串。 2.算符优先分析法的基本思想 首先确定算符(确切地说是终结符)之间的优先关系和结合性质,然后借助这种关系,比较相邻算符之间的优先级来确定句型的可归约串,并进行归约。 注意:算符优先分析过程是自下而上的归约过程,但它的可归约串未必是句柄,也就是说,算符优先分析过程不是一种规归约。 3.终结符号间优先关系的确定,用FIRSTVT和LASTVT计算。 4.最左素短语 所谓素短语是指这样一个短语,它至少含有一个终结符,并且除它自身之外不再含有其它素短语。最左素短语是指处于句型最左边的那个素短语。最左素短语是算符优先分析算法的可归约串。 5.计算得到所给文法的算符优先矩阵 6.算符优先分析的基本过程 三、实验要求 使用算符优先分析算法分析下面的文法: E’→#E# E→E+T|T T→T*F|F F→P^F|P 编译原理课程设计报告_算符优先分析法 编译原理课程设计报告 选题名称: 算符优先分析法 系(院): 计算机工程学院 专业: 计算机科学与技术 班级: 姓名: 学号: 指导教师: 学年学期: 7>2012 ~ 2013 学年第 1 学期 2012年 12 月 04 日 设计任务书 课题名称算符优先分析法 设计 目的 通过一周的课程设计,对算符优先分析法有深刻的理解,达到巩固理论知识、锻炼实践能力、构建合理知识结构的目的。实验环境Windows2000以上操作系统,Visual C++6.0编译环境 任务要求 1.判断文法是否为算符优先文法,对相应文法字符串进行算符优先分析; 2.编写代码,实现算符优先文法判断和相应文法字符串的算符优先分析; 3.撰写课程设计报告; 4提交报告。工作进度计划序号起止日期工作内容 1 理论辅导,搜集资料 2 ~编写代码,上机调试 3 撰写课程设计报告 4 提交报告 指导教师(签章): 年月日 摘要: 编译原理是计算机专业重要的一门专业基础课程,内容庞大,涉及面广,知识点多。本次课程设计的目的正是基于此,力求为学生提供一个理论联系实际的机会,通过布置一定难度的课题,要求学生独立完成。我们这次课程设计的主要任务是编程实现对输入合法的算符优先文法的相应的字符串进行算符优先分析,并输出算符优先分析的过程。算符优先分析法特别有利于表达式的处理,宜于手工实现。算符优先分析过程是自下而上的归约过程,但这种归约未必是严格的规范归约。而在整个归约过程中,起决定作用的是相继连个终结符之间的优先关系。因此,所谓算符优先分析法就是定义算符之间的某种优先关系,并借助这种关系寻找句型的最左素短语进行归约。通过实践,建立系统设计的整体思想,锻炼编写程序、调试程序的能力,学习文档编写规范,培养独立学习、吸取他人经验、探索前言知识的习惯,树立团队协作精神。同时,课程设计可以充分弥补课堂教学及普通实验中知识深度与广度有限的缺陷。 关键字:编译原理;归约;算符优先分析;最左素短语; 目录 1 课题综述 1 1.1 课题来源 1 1.2课题意义 1 1.3 预期目标 1 1.4 面对的问题 1 2 系统分析 2 《数据结构与数据库》 实验报告 实验题目 算术表达式求值 学院:化学与材料科学学院 专业班级:09级材料科学与工程系PB0920603 姓名:李维谷 学号:PB09206285 邮箱:liwg@https://www.360docs.net/doc/878999684.html, 指导教师:贾伯琪 实验时间:2010年10月10日 一、需要分析 问题描述: 表达式计算是实现程序设计语言的基本问题之一,它的实现是栈的应用的一个典型例子。设计一个程序,演示通过将数学表达式字符串转化为后缀表达式,并通过后缀表达式结合栈的应用实现对算术表达式进行四则混合运算。 问题分析: 在计算机中,算术表达式由常量、变量、运算符和括号组成。由于不同的运算符具有不同的优先级,又要考虑括号,因此,算术表达式的求值不可能严格地从左到右进行。因而在程序设计时,借助栈实现。 设置运算符栈(字符型)和运算数栈(浮点型)辅助分析算符优先关系。在读入表达式的字符序列的同时完成运算符和运算数的识别处理,然后进行运算数的数值转换在进行四则运算。 在运算之后输出正确运算结果,输入表达式后演示在求值中运算数栈内的栈顶数据变化过程,最后得到运算结果。 算法规定: 输入形式:一个算术表达式,由常量、变量、运算符和括号组成(以字符串形式输入)。为使实验更完善,允许操作数为实数,操作符为(、)、.(表示小数点)、+、-、*、/、^(表示乘方),用#表示结束。 输出形式:演示表达式运算的中间结果和整个表达式的最终结果,以浮点型输出。 程序功能:对实数内的加减乘除乘方运算能正确的运算出结果,并能正确对错误输入和无定义的运算报错,能连续测试多组数据。 测试数据:正确输入:12*(3.6/3+4^2-1)# 输出结果:194.4 实验名称: 实验任务: 对下述描述算符表达式的算符优先文法G[E],给出算符优先分析的实验结果。 实验容: 有上下无关文法如下: E->E+T|E-T|T T->T*F|T/F|F F->(E)|i 说明:优先关系矩阵的构造过程: (1) = 关系由产生式 F->(E) 知‘(’=‘)’ FIRSTVT集及LASTVT集 FIRSTVT(E)={ +,-,*,/,(,i } FIRSTVT(F)={ (,i } FIRSTVT(T)={ *,/,(,i } LASTVT(E)={ +,-,*,/,),i } LASTVT(F)={ ),i } LASTVT(T)={ *,/,),i } (2) < 关系 +T 则有:+ < FIRSTVT(T) -T 则有:- < FIRSTVT(T) *F 则有:* < FIRSTVT(F) /F 则有:/ < FIRSTVT(F) (E 则有:( < FIRSTVT(E) (3) > 关系 E+ 则有: LASTVT(E) > + E- 则有: LASTVT(E) > - T* 则有: LASTVT(T) > * T/ 则有: LASTVT(T) > / E) 则有: LASTVT(E) > ) (4)请大家画出优先关系矩阵 终结符之间的优先关系是唯一的,所以该文法是算符优先文法。程序的功能描述:程序由文件读入字符串(以#结束),然后进行算符优先分析,分析过程中如有错误,则终止程序并报告错误位置,最终向屏幕输出移近——规约过程。 (5)依据文法和求出的相应FirstVT和 LastVT 集生成算符优先分析表。算法描述如下: for 每个形如 P->X1X2…Xn的产生式 do for i =1 to n-1 do begin if Xi和Xi+1都是终结符 then Xi = Xi+1 if i<= n-2, Xi和Xi+2 是终结符, 但Xi+1 为非终结符 then Xi = Xi+2 if Xi为终结符, Xi+1为非终结符 then for FirstVT 中的每个元素 a do Xi < a if Xi为非终结符, Xi+1为终结符 then for LastVT 中的每个元素 a do a > Xi+1 end (6)构造总控程序 算法描述如下: stack S; k = 1; //符号栈S的使用深度 编译原理实验代码: 对于任意给定的文法,判断其是否是算符优先文法。 代码如下: #include //判断(A,a)栈是否为空 bool ifEmpty(stack S) { if(S.top==S.bottom) return true; //如果栈为空,则返回true else return false; //否则不为空,返回false } //插入栈顶(A,a)元素 void Insert(stack &S,StackElement e) { if(S.top-S.bottom>=S.stacksize) cout<<"栈已满,无法插入!"< 编译原理实验3 算符优先分析 一、实验目的 通过设计编制调试构造FIRSTVT集、LASTVT集和构造算符优先表、对给定符号串进行分析的程序,了解构造算符优先分析表的步骤,对文法的要求,生成算符优先关系表的算法,对给定的符号串进行分析的方法。 二、实验内容 1. 给定一文法G,输出G的每个非终结符的FIRSTVT集和LASTVT集。 2. 构造算符优先表。 3. 对给定的符号串进行分析,包含符号栈,符号栈栈顶符号和输入串当前符号的优先级,最左素短语和使用的产生式和采取的动作。 三、程序思路 在文法框内输入待判断文法产生式,格式E->a|S,注意左部和右部之间是“->”,每个产生式一行,ENTER键换行。文法结束再输入一行G->#E# 1. 先做文法判断,即可判断文法情况。 2. 若是算符优先文法,则在优先表栏显示优先表。 3. 写入要分析的句子,按回车即可。 4. 在分析过程栏,可以看到整个归约过程情况 四、实验结果 FunctorFirst.h #include #define rightlength 20 #define product_num 20 // 产生式最多个数 #define num_noterminal 26 // 非终结符最多个数 #define num_terminal 26 // 终结符最多个数 struct Production { char Left; char Right[rightlength]; int num; }; struct VT { bool vt[num_noterminal][num_terminal]; }; struct Stack { char P; char a; }; class CMyDlg { public:CMyDlg(); void InputRule(); CString showLastVT(); CString showFirstVT(); CString shownoTerminal(char G[]); CString showTerminal(char g[]); CString showLeftS(char S[], int j, int k); void InitAll(); CString showSentence(CString sen, int start); CString showStack(char S[], int n); void Initarry(char arry[], int n); CString ProdtoCStr(Production prod); int selectProd(int i, int j, char S[]); void preFunctor(CString sen); void insertFirstVT(Stack S[], int&sp, char P, char a); void insertLastVT(Stack S[], int&sp, char P, char a); void ShowPreTable(); void createPreTable(); 实验5 语法分析程序的设计(2) 一、实验目的 通过设计、编制、调试一个典型的语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,进一步掌握常用的语法分析中算法优先分析方法。 二、实验内容 设计一个文法的算法优先分析程序,判断特定表达式的正确性。 三、实验要求 1、给出文法如下: G[E] E->T|E+T; T->F|T*F; F->i|(E); + * ( ) i + * ( ) i 2、计算机中表示上述优先关系,优先关系的机内存放方式有两种1)直接存放,2)为 优先关系建立优先函数,这里由学生自己选择一种方式; 1、给出算符优先分析算法如下: k:=1; S[k]:=‘#’; REPEAT 把下一个输入符号读进a中; IF S[k]∈V T THEN j:=k ELSE j:=k-1; WHILE S[j] a DO BEGIN REPEAT Q:=S[j]; IF S[j-1]∈V T THEN j:=j-1 ELSE j:=j-2 UNTIL S[j] Q 把S[j+1]…S[k]归约为某个N; k:=j+1; S[k]:=N; END OF WHILE; IF S[j] a OR S[j] a THEN BEGIN k:=k+1;S[k]:=a END ELSE ERROR UNTIL a=‘#’ 1、 根据给出算法,利用适当的数据结构实现算符优先分析程序; 2、 利用算符优先分析程序完成下列功能: 1) 手工将测试的表达式写入文本文件,每个表达式写一行,用“;”表示结束; 2) 读入文本文件中的表达式; 3) 调用实验2中的词法分析程序搜索单词; 4) 把单词送入算法优先分析程序,判断表达式是否正确(是否是给出文法的语 言),若错误,应给出错误信息; 5) 完成上述功能,有余力的同学可以对正确的表达式计算出结果。 四、实验环境 PC 微机 DOS 操作系统或 Windows 操作系统 Turbo C 程序集成环境或 Visual C++ 程序集成环境 五、实验步骤 1、 分析文法中终结符号的优先关系; 2、 存放优先关系或构造优先函数; 3、利用算符优先分析的算法编写分析程序; 4、写测试程序,包括表达式的读入和结果的输出; 5、程序运行效果,测试数据可以参考下列给出的数据。 六、测试数据 输入数据: 编辑一个文本文文件expression.txt ,在文件中输入 如下内容: 正确 结果: (1)10; 输出:正确 (2)1+2; 输出:正确 (3)(1+2)*3+(5+6*7); 输出:正确 (4)((1+2)*3+4 10; 1+2; (1+2)*3+(5+6*7); ((1+2)*3+4; 1+2+3+(*4+5); (a+b)*(c+d); ((ab3+de4)**5)+1; 一、实验目的与任务 算术表达式和赋值语句的文法可以是(你可以根据需要适当改变): S→i=E E→E+E|E-E|E*E|E/E|(E)|i 根据算符优先分析法,将赋值语句进行语法分析,翻译成等价的一组基本操作,每一基本操作用四元式表示。 二、实验涉及的相关知识点 算符的优先顺序。 三、实验内容与过程 如参考C语言的运算符。输入如下表达式(以分号为结束):(1)a = 10; (2)b = a + 20; 注:此例可以进行优化后输出(不作要求):(+,b,a,20) (3)c=(1+2)/3+4-(5+6/7); 四、实验结果及分析 (1)输出:(=, a,10,-) (2)输出:(=,r1,20,-) (+,r2,a,r1) (=,b,r2,-) (3)输出:(+,r1,1,2) (/,r2,r1,3) (/,r3,6,7) (+,r4,5,r3,) (+,r5,r2,4) (-,r6,r5,r4) (=,c,r6,-) 五、实验有关附件(如程序、附图、参考资料,等) ... ... h == '#') o][Peek(n0).No]; if(r == '<') h == 'E'&& Peek(1).ch == '#' && Token[ipToken].ch == '#') return TRUE; else return FALSE; } h) { k = TRUE; h == 'E') { n ++; } return n; } 词结束(遇到“#”号),无法移进,需要规约,返回:1 词没有结束,需判断是否可以移进 栈单词<=单词:移进后返回:2 栈单词>单词:不能移进,需要规约,返回:1 单词没有优先关系:出错,返回:-1 int MoveIn() { SToken s,t; h = '#'; 学生学号0120810680316 实验课成绩 武汉理工大学 学生实验报告书 实验课程名称《编译原理》 开课学院计算机科学与技术学院 指导老师姓名何九周 学生姓名刘洋 学生专业班级软件工程0803 2010 —2011 学年第二学期 实验课程名称:编译原理 实验项目名称单词的词法分析程序设计实验成绩实验者刘洋专业班级软件0803 组别 同组者实验日期 2011 年 5 月 17日 第一部分:实验分析与设计(可加页) 一、实验内容描述(问题域描述) 实验目的: 设计,编制并调试一个词法分析程序,加深对词法分析原理的理解。 实验要求: 在上机前应认真做好各种准备工作,熟悉机器的操作系统和语言的集成环境,独立完成算法编制和程序代码的编写;上机时应随带有关的高级语言教材或参考书;要学会程序调试与纠错;每次实验后要交实验报告。 实验题目: 对于给定的源程序(如C语言或Pascal等),要求从组成源程序的字符行中寻找出单词,并给出它们的种别和属性——输出二元组序列。以便提供给语法分析的时候使用。要求能识别所有的关键字,标志符等,并且能够对出先的一些词法规则的错误进行必要的处理。 二、实验基本原理与设计(包括实验方案设计,实验手段的确定,试验步骤等,用硬件逻辑或 者算法描述) 实验原理: 由于这是一个用高级语言编写一个词法分析器,使之能识别输入串,并把分析结果(单词符号,标识符,关键字等等)输出.输入源程序,输入单词符号,本词法分析器可以辨别关键字,标识符,常数,运算符号和某些界符,运用了文件读入来获取源程序代码,再对该源程序代码进行词法分析,这就是词法分析器的基本功能.当词法分析器调用预处理子程序处理出一串输入字符放进扫描缓冲区之后,分析器就从此缓冲区中逐一识别单词符号.当缓冲区里的字符串被处理完之后,它又调用预处理子程序来处理新串. 编写的时候,使用了文件的输入和输出,以便于词法分析的通用型,同时在文件输出时,并保存在输出文件output文件中。 从左到右扫描程序,通过初始化:1为关键字;2为标志符; 3为常数;4为运算符或界符。 三、主要仪器设备及耗材 计算机 实验三算符优先分析算法的设计与实现 (8学时) 一、实验目的 根据算符优先分析法,对表达式进行语法分析,使其能够判断一个表达式是否正确。通过算符优先分析方法的实现,加深对自下而上语法分析方法的理解。 二、实验要求 1、输入文法。可以是如下算术表达式的文法(你可以根据需要适当改变): E→E+T|E-T|T T→T*F|T/F|F F→(E)|i 2、对给定表达式进行分析,输出表达式正确与否的判断。 程序输入/输出示例: 输入:1+2; 输出:正确 输入:(1+2)/3+4-(5+6/7); 输出:正确 输入:((1-2)/3+4 输出:错误 输入:1+2-3+(*4/5) 输出:错误 三、实验步骤 1、参考数据结构 char *VN=0,*VT=0;//非终结符和终结符数组 char firstvt[N][N],lastvt[N][N],table[N][N]; typedef struct //符号对(P,a) { char Vn; char Vt; } VN_VT; typedef struct //栈 { VN_VT *top; VN_VT *bollow; int size; }stack; 2、根据文法求FIRSTVT集和LASTVT集 给定一个上下文无关文法,根据算法设计一个程序,求文法中每个非终结符的FirstVT 集和LastVT 集。 算符描述如下: /*求 FirstVT 集的算法*/ PROCEDURE insert(P,a); IF not F[P,a] then begin F[P,a] = true; //(P,a)进栈 end; Procedure FirstVT; Begin for 对每个非终结符 P和终结符 a do F[P,a] = false for 对每个形如 P a…或 P→Qa…的产生式 do Insert(P,a) while stack 非空 begin 栈顶项出栈,记为(Q,a) for 对每条形如 P→Q…的产生式 do insert(P,a) end; end. 同理,可构造计算LASTVT的算法。 3、构造算符优先分析表 依据文法和求出的相应FirstVT和 LastVT 集生成算符优先分析表。 算法描述如下: for 每个形如 P->X1X2…X n的产生式 do for i =1 to n-1 do begin if X i和X i+1都是终结符 then X i = X i+1 if i<= n-2, X i和X i+2 是终结符, 但X i+1 为非终结符 then X i = X i+2 if X i为终结符, X i+1为非终结符 then for FirstVT 中的每个元素 a do X i < a ; if X i为非终结符, X i+1为终结符 then for LastVT 中的每个元素 a do a > X i+1 ; end 4、构造总控程序 算法描述如下: stack S; k = 1; //符号栈S的使用深度 S[k] = ‘#’ REPEAT 第五章语法分析—自下而上分析 本章要点 1. 自下而上语法分析法的基本概念: 2. 算符优先分析法; 3. LR分析法分析过程; 4. 语法分析器自动产生工具Y ACC; 5. LR分析过程中的出错处理。 本章目标 掌握和理解自下而上分析的基本问题、算符优先分析、LR分析法及语法分析器的自动产生工具YACC等内容。 本章重点 1.自下而上语法分析的基本概念:归约、句柄、最左素短语; 2.算符优先分析方法:FirstVT, LastVT集的计算,算符优先表的构造,工作原理;3.LR分析器: (1)LR(0)项目集族,LR(1)项目集簇; (2)LR(0)、SLR、LR(1)和LALR(1)分析表的构造; (3)LR分析的基本原理,分析过程; 4.LR方法如何用于二义文法; 本章难点 1. 句柄的概念; 2. 算符优先分析法; 3. LR分析器基本; 作业题 一、单项选择题: 1. LR语法分析栈中存放的状态是识别________的DFA状态。 a. 前缀; b. 可归前缀; c. 项目; d. 句柄; 2. 算符优先分析法每次都是对________进行归约: (a)句柄(b)最左素短语(c)素短语(d)简单短语 3. 有文法G=({S},{a},{S→SaS,S→ε},S),该文法是________。 a. LL(1)文法; b.二义性文法; c.算符优先文法; d.SLR(1)文法; 4. 在编译程序中,语法分析分为自顶向下分析和自底向上分析两类,和LL(1)分析法属于自顶向下分析; a. 深度分析法 b. 宽度优先分析法 c. 算符优先分析法 d. 递归下降子程序分析法 5. 自底向上语法分析采用分析法,常用的是自底向上语法分析有算符优先分析法和LR分析法。 a. 递归 b. 回溯 c. 枚举 d. 移进-归约 6. 一个LR(k)文法,无论k取多大,。 a. 都是无二义性的; b. 都是二义性的; c. 一部分是二义性的; d. 无法判定二义性; 7. 在编译程序中,语法分析分为自顶向下分析和自底向上分析两类,和LR分析法属于自底向上分析。 a. 深度分析法 b. 宽度优先分析法 c. 算符优先分析法 d. 递归下降子程序分析法 8. 在编译程序中,语法分析分为自顶向下分析和自底向上分析两类,自顶向下分析试图为输入符号串构造一个; a. 语法树 b. 有向无环图 c. 最左推导 d. 最右推导 9. 在编译程序中,语法分析分为自顶向下分析和自底向上分析两类,自底向上分析试图为输入符号串构造一个。 a. 语法树 b. 有向无环图 c. 最左推导 d. 最右推导 10. 采用自顶向下分析方法时,要求文法中不含有。 a. 右递归 b. 左递归 c. 直接右递归 d. 直接左递归 11. LR分析是寻找右句型的;而算符优先分析是寻找右句型的。 a. 短语; b. 素短语; c. 最左素短语; d. 句柄 12. LR分析法中分析能力最强的是;分析能力最弱的是。 a. SLR(1); b. LR(0); c. LR(1); d. LALR(1) 13. 设有文法G: T->T*F | F F->F↑P | P P->(T) | a 该文法句型T*P↑(T*F)的最左直接短语是下列符号串________。 a. (T*F), b. T*F, c. P, d. P↑(T*F) 14. 在通常的语法分析方法中,()特别适用于表达式的分析。 a.算符优先分析法b.LR分析法c.递归下降分析法d.LL(1)分析法 15. .运算符的优先数之间有几种关系。 a.3种 b. 2种 c. 4种 d. 1种 16. 算符优先法属于() a.自上而下分析法 b.LR分析法 c.SLR分析法 d.自下而上分析法 17. 在LR分析法中,分析栈中存放的状态是识别规范句型的DFA状态。 a.句柄 b. 前缀 c. 活前缀 d. LR(0)项目 一.答案: 1. b; 2. b; 3. b; 4. d; 5. d; 6. a; 7. c; 8. c; 9. d;10. b;11. d,c;12. c,b;13. a;14. a 15. a;16. d;17. c; 华北水利水电学院编译原理实验报告 一、实验题目:语法分析(算符优先分析程序) (1)选择最有代表性的语法分析方法算符优先法; (2)选择对各种常见程序语言都用的语法结构,如赋值语句(尤指表达式)作为分析对象,并且与所选语法分析方法要比较贴切。 二、实验内容 (1)根据给定文法,先求出FirstVt和LastVt集合,构造算符优先关系表(要求算符优先关系表输出到屏幕或者输出到文件); (2)根据算法和优先关系表分析给定表达式是否是该文法识别的正确的算术表达式(要求输出归约过程) (3)给定表达式文法为: G(E’): E’→#E# E→E+T | T T→T*F |F F→(E)|i (4) 分析的句子为: (i+i)*i和i+i)*i 三、程序源代 #include #include 第六章算符优先分析法 课前索引 【课前思考】 ◇什么是自下而上语法分析的策略? ◇什么是移进-归约分析? ◇移进-归约过程和自顶向下最右推导有何关系? ◇自下而上语法分析成功的标志是什么? ◇什么是可归约串? ◇移进-归约过程的关键问题是什么? ◇如何确定可归约串? ◇如何决定什么时候移进,什么时候归约? ◇什么是算符文法?什么是算符优先文法? ◇算符优先分析是如何识别可归约串的? ◇算符优先分析法的优缺点和局限性有哪些? 【学习目标】 算符优先分析法是自下而上(自底向上)语法分析的一种,尤其适应于表达式的语法分析,由于它的算法简单直观易于理解,因此,也是学习其它自下而上语法分析的基础。通过本章学习学员应掌握: ◇对给定的文法能够判断该文法是否是算符文法 ◇对给定的算符文法能够判断该文法是否是算符优先文法 ◇对给定的算符文法能构造算符优先关系表,并能利用算符优先关系表判断该文法是否是算符优先文法。 ◇能应用算符优先分析算法对给定的输入串进行移进-归约分析,在分析的每一步能确定当前应移进还是归约,并能判断所给的输入串是否是该文法的句子。 ◇了解算符优先分析法的优缺点和实际应用中的局限性。 【学习指南】 算符优先分析法是自下而上语法分析的一种,它的算法简单、直观、易于理解,所以通常作为学习其它自下而上语法分析的基础。为学好本章内容,学员应复习有关语法分析的知识,如:什么是语言、文法、句子、句型、短语、简单短语、句柄、最右推导、规范归约基本概念。 【难重点】 ◇通过本章学习后,学员应该能知道算符文法的形式。 ◇对一个给定的算符文法能构造算符优先关系分析表,并能判别所给文法是否为算符优先文法。 ◇分清规范句型的句柄和最左素短语的区别,进而分清算符优先归约和规范归约的区别。 ◇算符优先分析的可归约串是句型的最左素短语,在分析过程中如何寻找可归约串是算符优先分析的关键问题。对一个给定的输入串能应用算符优先关系分析表给出分析(归约)步骤,并最终判断所给输入串是否为该文法的句子。 ◇深入理解算符优先分析法的优缺点和实际应用中的局限性。 【知识点】 数学与计算机学院编译原理实验报告 年级专业学号姓名成绩 实验题目算符优先分析法分析器的设计实验日期 一、实验目的: 设计一个算符优先分析器,理解优先分析方法的原理。 二、实验要求: 设计一个算符优先分析器 三、实验内容: 使用算符优先分析算法分析下面的文法: E’→#E# E →E+T | T T →T*F | F F →P^F | P P →(E) | i 其中i可以看作是一个终结符,无需作词法分析。具体要求如下: 1、如果输入符号串为正确句子,显示分析步骤,包括分析栈中的内容、优先关系、输入符号串的变化情况; 2、如果输入符号串不是正确句子,则指示出错位置。 四、实验结果及主要代码: 1.主要代码 void operatorp() { char s[100]; char a,Q; int k,j,i,l; string input,temp; cin>>input; cout<<"步骤"<<'\t'<<"栈"<<'\t'<<"优先关系"<<'\t'<<"当前符号"<<'\t'<<"剩余输入串"<<'\t'<<"移进或归约"< for(l=1;l 淮阴工学院 编译原理课程设计报告 选题名称:算符优先分析法 系(院):计算机工程学院 专业:计算机科学与技术 班级:计算机1075 姓名:学号: 指导教师: 学年学期:2009 ~ 2010 学年第 2 学期2010 年 5 月17 日 设计任务书 指导教师(签章): 年月日 摘要: 编译原理是计算机系统的基本组成部分之一,而且多数据计算机系统都配有不止一个高级语言的编译程序,对有些高级语言甚至配置了几个不同性能的编译程序。从功能上看,一个编译程序就是一个语言翻译程序。算符优先分析法是一种简单直观、广为使用的自下而上分析法。这种方法特别有利于表达式分析,宜于手工实现。算符优先分析过程是自下而上的归约过程,但这种归约未必是严格的最左归约。也就是说,算符优先分析法不是一种规范归约法。所谓算符优先分析就是定义算符之间(确切地说,终结符之间)的某种优先关系,借助于这种优先关系寻找“可归约串”和进行归约。 关键词:编译原理;归约;算法;算符优先;编译 目录 1需求分析 (1) 2 概要设计 (1) 2.1算符优先分析法的思想及其原理 (1) 2.2算符优先分析算法 (4) 2.3 构建算符优先关系表 (6) 2.4 出错处理 (7) 3 详细设计 (7) 3.1 程序流程图 (7) 3.2 构建算符优先关系表 (8) 3.3 进栈优先函数 (8) 3.4 算符优先规约函数 (10) 3.5 弹出窗体 (12) 4 程序运行、调试及操作说明 (12) 总结 (15) 致谢 (16) 参考文献 (17) 1需求分析 本次课程设计的题目是算符优先分析法。算符优先分析法是一种简单直观、特别方便于表达式分析,易于手式实现的方法。算符优先法只考虑算符(广义为终结符号)之间的优先关系,它是一种自底向上的归约过程,但这种归约未必严格按照句柄归约。它是一种不规范归约法。 根据已知文法: E->E+T|E-T|T T->T*F|T/F|F F->(E)|i(E)|i|d(其中d表示0-9的数字,i表示字母,大小写均包括) 根据算符优先分析法,将表达式进行语法分析,判断一个表达式是否正确 (1)可以使用任何语言来完成,例如:Java、C++。 (2)构造此文法的分析过程 (3)输入测试字符串,输出测试结果 给出关键类类图、整个应用程序的结构描述文档、关键模块流程图、较详细的接口文档、所有源代码。对应用程序进行测试,对测试结果进行分析研究,进而对应用程序进行改进,对关键算法进行尽可能的优化,最终得到一个在windows运行的可以根据算符优先分析法,将表达式进行语法分析,判断一个表达式是否正确,输入测试字符串,输出测试结果的完整应用程序。 2 概要设计 2.1算符优先分析法的思想及其原理 算符优先分析算法算法原理: (1)初始化栈:k=1; S[k]=‘#’; (2)依次从输入串中读入符号a: ①当前单词若为标识符,则a值为i,若为常数则a值为d; 其它a直接取单词值。 ②若a大于等于栈顶第一个终结符的优先级,则a进栈; ③若a小于栈顶第一个终结符的优先级,则重复做: 软件技术基础实验报告 实验名称:表达式计算器 系别:通信工程 年级: 班级: 学生学号: 学生姓名: 1 《数据结构》课程设计报告 题目简易计算表达式的演示 【题目要求】 要求:实现基本表达式计算的功能 输入:数学表达式,表达式由整数和“+”、“-”、“×”、“/”、“(”、“)”组成 输出:表达式的值 基本操作:键入表达式,开始计算,计算过程和结果记录在文档中 难点:括号的处理、乘除的优先级高于加减 1.前言 在计算机中,算术表达式由常量、变量、运算符和括号组成。由于不同的运算符具有不同的优先级,又要考虑括号,因此,算术表达式的求值不可能严格地从左到右进行。因而在程序设计时,借助栈实现。 算法输入:一个算术表达式,由常量、变量、运算符和括号组成(以字符串形式输入)。为简化,规定操作数只能为正整数,操作符为+、-*、/、=,用#表示结束。 算法输出:表达式运算结果。 算法要点:设置运算符栈和运算数栈辅助分析算符优先关系。在读入表达式的字符序列 2 3 的同时,完成运算符和运算数的识别处理,以及相应运算。 2.概要设计 2.1 数据结构设计 任何一个表达式都是由操作符,运算符和界限符组成的。我们分别用顺序栈来寄存表达式的操作数和运算符。栈是限定于紧仅在表尾进行插入或删除操作的线性表。顺序栈的存储结构是利用一组连续的存储单元依次存放自栈底到栈顶的数据元素,同时附设指针top 指示栈顶元素在顺序栈中的位置,base 为栈底指针,在顺序栈中,它始终指向栈底,即top=base 可作为栈空的标记,每当插入新的栈顶元素时,指针top 增1,删除栈顶元素时,指针top 减1。 2.2 算法设计 为了实现算符优先算法。可以使用两个工作栈。一个称为OPTR ,用以寄存运算符,另一个称做OPND ,用以寄存操作数或运算结果。 1.首先置操作数栈为空栈,表达式起始符”#”为运算符栈的栈底元素; 2.依次读入表达式,若是操作符即进OPND 栈,若是运算符则和OPTR 栈的栈顶运算符比较优先权后作相应的操作,直至整个表达式求值完毕(即OPTR 栈的栈顶元素和当前读入的字符均为”#”)。 2.3 ADT 描述 ADT Stack{ 数据对象:D={i a |i a ∈ElemSet,i=1,2,…,n, n ≧0} 数据对象:R1={<1,-i i a a >|1-i a ,D a i ∈,i=2,…,n} 约定n a 端为栈顶,i a 端为栈底。 基本操作: InitStack(&S) 操作结果:构造一个空栈S 。 GetTop(S) 初始条件:栈S 已存在。 数学与计算机学院编译原理实验报告 年级09软工学号姓名成绩 专业软件工程实验地点主楼指导教师湛燕 实验项目算符优先关系算法实验日期2012.6.6 一、实验目的和要求 设计一个算符优先分析器,理解优先分析方法的原理。 重点和难点:本实验的重点是理解优先分析方法的原理;难点是如何构造算符优先关系。 二、实验内容 使用算符优先分析算法分析下面的文法: E’→ #E# E → E+T | T T → T*F | F F → P^F | P P → (E) | i 其中i可以看作是一个终结符,无需作词法分析。具体要求如下: 1、如果输入符号串为正确句子,显示分析步骤,包括分析栈中的内容、优先关系、输入符号串的变化情况; 2、如果输入符号串不是正确句子,则指示出错位置。 三、程序设计 全局变量有一下几个: static string input;//记录输入串 char s[20];//栈 int top=-1;//栈顶指针 有三个函数: int analyze(string input);//分析输入的串是否符合标准 void process();//进行归约的函数 int main() input是一个全局变量,记录输入串,用analyze(input)分析输入的是不是符合标准的字符串,(例如“i+i*i^(i+i)”)如果不符合标准,提示用户重新输入。 进行归约的函数主要思想是:先构造优先关系矩阵,有“<”,“>”,“=”和空格四种关系。Char a 记录栈中最高位的终结符,如果栈中是#E+E,则 a 的赋 值是“+”,如果形如“#E+”或“#E+i”则a 赋值“+”或“i”。charnowchar 记录当前的字符。a 与 nowchar 按照算符优先关系矩阵找出优先关系。如果优先关系是“<”,则进行移进;如果优先关系是“>”,则进行归约;如果是“=”,则去掉括号或分析成功。 五、代码和截图 自己编写代码如下: #include 算符优先分析器设计实验报告--宁剑
编译原理课程设计报告_算符优先分析法
数据结构实验二——算术表达式求值实验报告
实验4 算符优先分析法.
算符优先文法
编译原理 实验3 算符优先分析
编译原理实验报告5-语法分析程序的设计(2)
编译原理实验4算符优先算法
编译原理实验报告
实验三算符优先分析算法设计与实现
编译原理作业集-第五章-修订(精选.)
编译原理_实验报告实验二__语法分析(算符优先) 2
c语言实现算符优先语法分析
编译原理 六章 算符优先分析法
编译原理算符优先算法语法分析实验报告
算符优先分析法课程设计报告
数据结构算术表达式求值实验报告
算符优先分析算法