Linux下设计一个简单的线程池
Linux下设计一个简单的线程池
定义
什么是线程池?简单点说,线程池就是有一堆已经创建好了的线程,初始它们都处于空闲等待状态,当有新的任务需要处理的时候,就从这个池子里面取一个空闲等待的线程来处理该任务,当处理完成了就再次把该线程放回池中,以供后面的任务使用。当池子里的线程全都处理忙碌状态时,线程池中没有可用的空闲等待线程,此时,根据需要选择创建一个新的线程并置入池中,或者通知任务线程池忙,稍后再试。
为什么要用线程池?
我们说,线程的创建和销毁比之进程的创建和销毁是轻量级的,但是当我们的任务需要大量进行大量线程的创建和销毁操作时,这个消耗就会变成的相当大。比如,当你设计一个压力性能测试框架的时候,需要连续产生大量的并发操作,这个是时候,线程池就可以很好的帮上你的忙。线程池的好处就在于线程复用,一个任务处理完成后,当前线程可以直接处理下一个任务,而不是销毁后再创建,非常适用于连续产生大量并发任务的场合。
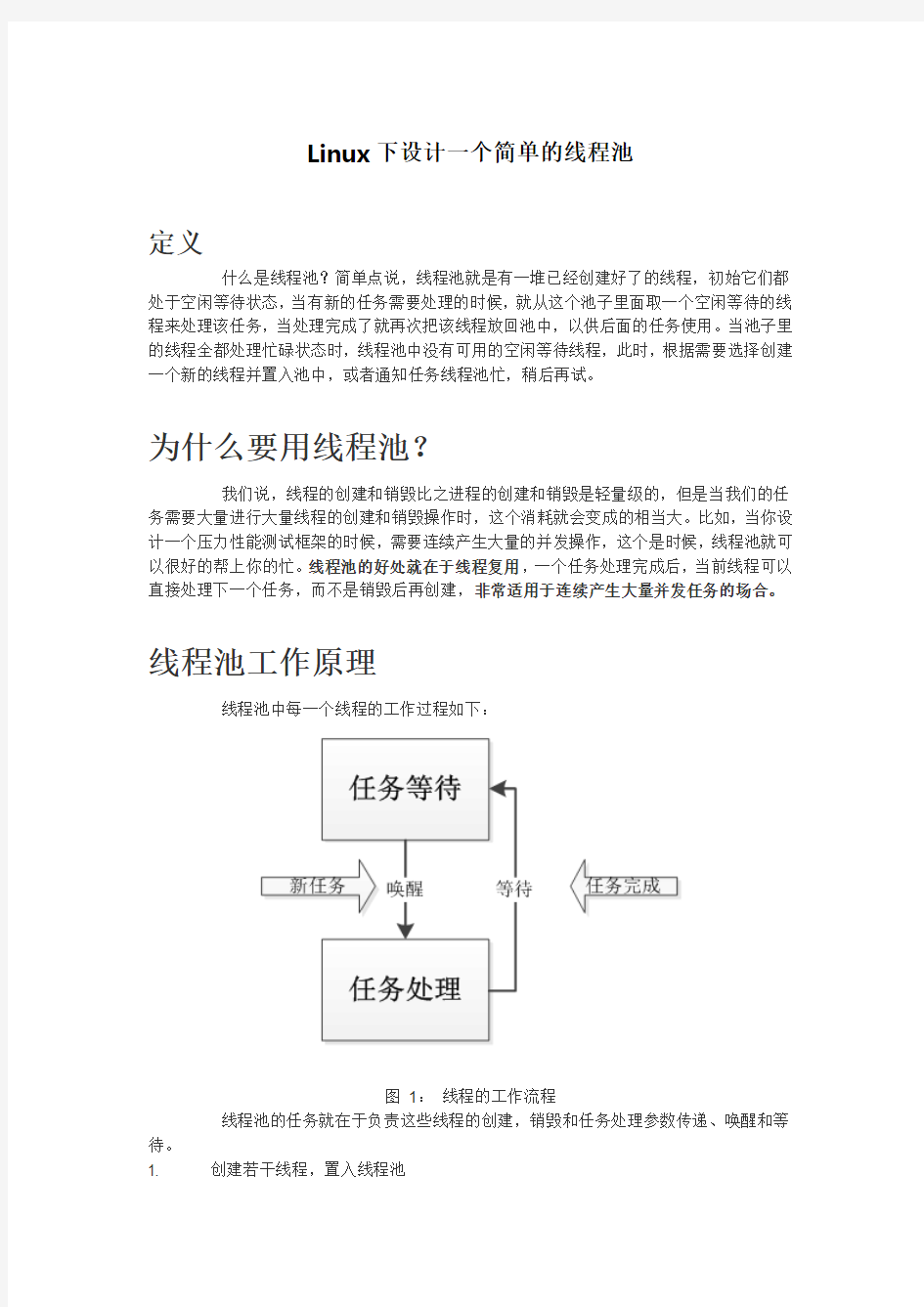
线程池工作原理
线程池中每一个线程的工作过程如下:
图1:线程的工作流程
线程池的任务就在于负责这些线程的创建,销毁和任务处理参数传递、唤醒和等待。
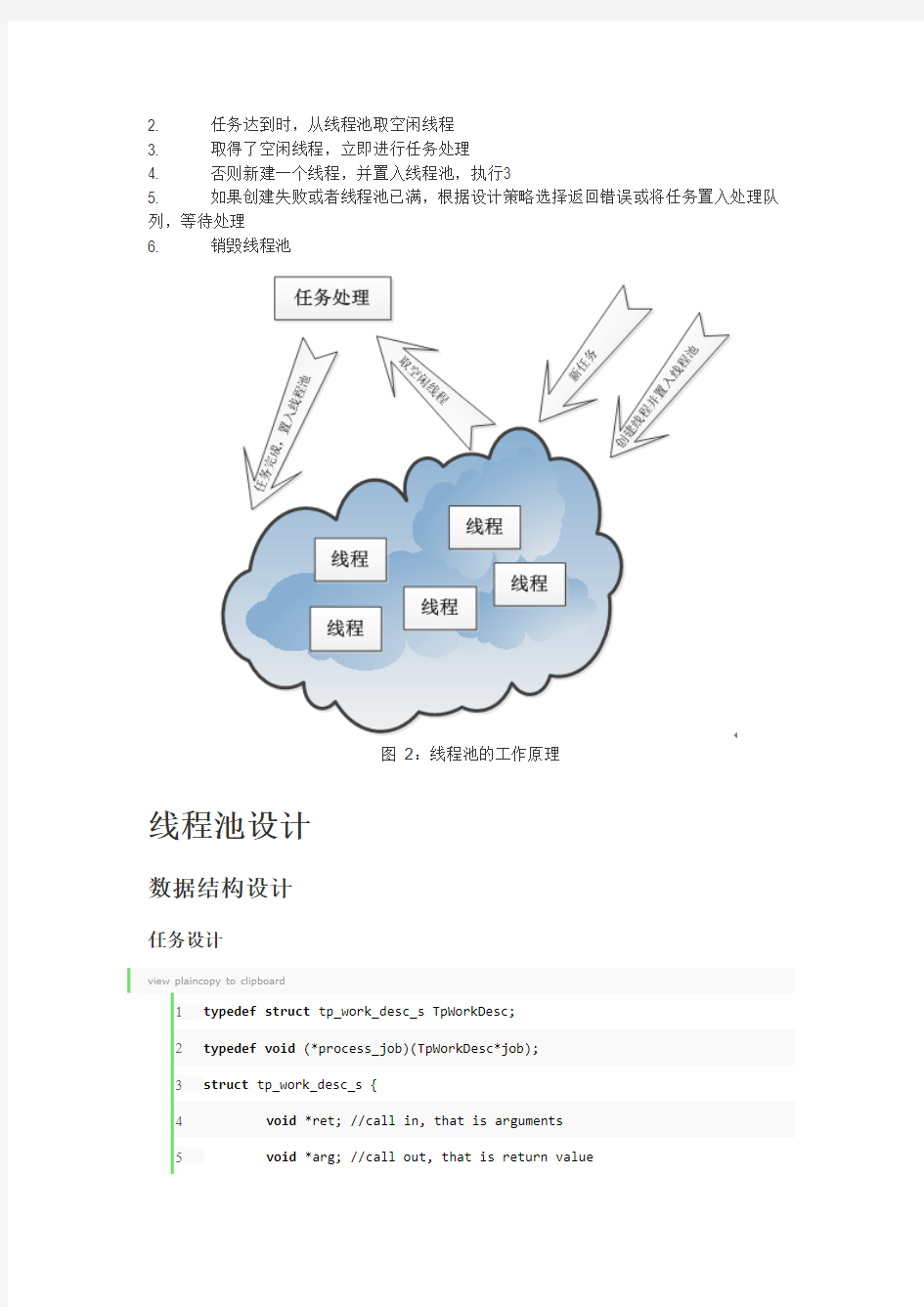
1. 创建若干线程,置入线程池
2. 任务达到时,从线程池取空闲线程
3. 取得了空闲线程,立即进行任务处理
4. 否则新建一个线程,并置入线程池,执行3
5. 如果创建失败或者线程池已满,根据设计策略选择返回错误或将任务置入处理队列,等待处理
6. 销毁线程池
图2:线程池的工作原理
线程池设计
数据结构设计
任务设计
view plaincopy to clipboard
1typedef struct tp_work_desc_s TpWorkDesc;
2typedef void (*process_job)(TpWorkDesc*job);
3struct tp_work_desc_s {
4void *ret; //call in, that is arguments
5void *arg; //call out, that is return value
6};
其中,TpWorkDesc是任务参数描述,arg是传递给任务的参数,ret则是任务处理完成后的返回值;
process_job函数是任务处理函数原型,每个任务处理函数都应该这样定义,然后将它作为参数传给线程池处理,线程池将会选择一个空闲线程通过调用该函数来进行任务处理;
线程设计
view plaincopy to clipboard
7typedef struct tp_thread_info_s TpThreadInfo;
8struct tp_thread_info_s {
9 pthread_t thread_id; //thread id num
10 TPBOOL is_busy; //thread status:true-busy;flase-idle
11 pthread_cond_t thread_cond;
12 pthread_mutex_t thread_lock;
13 process_job proc_fun;
14 TpWorkDesc* th_job;
15 TpThreadPool* tp_pool;
16};
TpThreadInfo是对一个线程的描述。
thread_id是该线程的ID;
is_busy用于标识该线程是否正处理忙碌状态;
thread_cond用于任务处理时的唤醒和等待;
thread_lock,用于任务加锁(此处保留);
proc_fun是当前任务的回调函数地址;
th_job是任务的参数信息;
tp_pool是所在线程池的指针;
线程池设计
view plaincopy to clipboard
17typedef struct tp_thread_pool_s TpThreadPool;
18struct tp_thread_pool_s {
19 unsigned min_th_num; //min thread number in the pool
20 unsigned cur_th_num; //current thread number in the pool
21 unsigned max_th_num; //max thread number in the pool
22 pthread_mutex_t tp_lock;
23 pthread_t manage_thread_id; //manage thread id num
24 TpThreadInfo* thread_info;
25 Queue idle_q;
26 TPBOOL stop_flag;
27};
TpThreadPool是对线程池的描述。
min_th_num是线程池中至少存在的线程数,线程池初始化的过程中会创建min_th_num数量的线程;
cur_th_num是线程池当前存在的线程数量;
max_th_num则是线程池最多可以存在的线程数量;
tp_lock用于线程池管理时的互斥;
manage_thread_id是线程池的管理线程ID;
thread_info则是指向线程池数据,这里使用一个数组来存储线程池中线程的信息,该数组的大小为max_th_num;
idle_q是存储线程池空闲线程指针的队列,用于从线程池快速取得空闲线程;
stop_flag用于线程池的销毁,当stop_flag为FALSE时,表明当前线程池需要销毁,所有忙碌线程在处理完当前任务后会退出;
算法设计
线程池的创建和初始化
线程创建
创建伊始,线程池线程容量大小上限为max_th_num,初始容量为min_th_num;
view plaincopy to clipboard
28TpThreadPool *tp_create(unsigned min_num, unsigned max_num) {
29 TpThreadPool *pTp;
30 pTp = (TpThreadPool*) malloc(sizeof(TpThreadPool));
31
32 memset(pTp, 0, sizeof(TpThreadPool));
33
34 //init member var
35 pTp->min_th_num = min_num;
36 pTp->cur_th_num = min_num;
37 pTp->max_th_num = max_num;
38 pthread_mutex_init(&pTp->tp_lock, NULL);
39
40 //malloc mem for num thread info struct
41if (NULL != pTp->thread_info)
42 free(pTp->thread_info);
43 pTp->thread_info = (TpThreadInfo*) malloc(sizeof(TpThreadInfo) *
pTp->max_th_num);
44 memset(pTp->thread_info, 0, sizeof(TpThreadInfo) * pTp->max_th_num);
45
46return pTp;
47}
线程初始化
view plaincopy to clipboard
48TPBOOL tp_init(TpThreadPool *pTp) {
49int i;
50int err;
51 TpThreadInfo *pThi;
52
53 initQueue(&pTp->idle_q);
54 pTp->stop_flag = FALSE;
55
56 //create work thread and init work thread info
57for (i = 0; i < pTp->min_th_num; i++) {
58 pThi = pTp->thread_info +i;
59 pThi->tp_pool = pTp;
60 pThi->is_busy = FALSE;
61 pthread_cond_init(&pThi->thread_cond, NULL);
62 pthread_mutex_init(&pThi->thread_lock, NULL);
63 pThi->proc_fun = def_proc_fun;
64 pThi->th_job = NULL;
65 enQueue(&pTp->idle_q, pThi);
66
67 err = pthread_create(&pThi->thread_id, NULL, tp_work_thread, pThi);
68if (0 != err) {
69 perror("tp_init: create work thread failed.");
70 clearQueue(&pTp->idle_q);
71return FALSE;
72 }
73 }
74
75 //create manage thread
76 err = pthread_create(&pTp->manage_thread_id, NULL, tp_manage_thread, pTp); 77if (0 != err) {
78 clearQueue(&pTp->idle_q);
79 printf("tp_init: creat manage thread failed\n");
80return FALSE;
81 }
82
83return TRUE;
84}
初始线程池中线程数量为min_th_num,对这些线程一一进行初始化;
将这些初始化的空闲线程一一置入空闲队列;
创建管理线程,用于监控线程池的状态,并适当回收多余的线程资源;
线程池的关闭和销毁
view plaincopy to clipboard
85void tp_close(TpThreadPool *pTp, TPBOOL wait) {
86 unsigned i;
87
88 pTp->stop_flag = TRUE;
89if (wait) {
90for (i = 0; i < pTp->cur_th_num; i++) {
91 pthread_cond_signal(&pTp->thread_info[i].thread_cond);
92 }
93for (i = 0; i < pTp->cur_th_num; i++) {
94 pthread_join(pTp->thread_info[i].thread_id, NULL);
95 pthread_mutex_destroy(&pTp->thread_info[i].thread_lock);
96 pthread_cond_destroy(&pTp->thread_info[i].thread_cond);
97 }
98 } else {
99 //close work thread
100for (i = 0; i < pTp->cur_th_num; i++) {
101 kill((pid_t)pTp->thread_info[i].thread_id, SIGKILL);
102 pthread_mutex_destroy(&pTp->thread_info[i].thread_lock);
103 pthread_cond_destroy(&pTp->thread_info[i].thread_cond);
104 }
105 }
106 //close manage thread
107 kill((pid_t)pTp->manage_thread_id, SIGKILL);
108 pthread_mutex_destroy(&pTp->tp_lock);
109
110 //free thread struct
111 free(pTp->thread_info);
112 pTp->thread_info = NULL;
113}
线程池关闭的过程中,可以选择是否对正在处理的任务进行等待,如果是,则会唤醒所有任务,然后等待所有任务执行完成,然后返回;如果不是,则将立即杀死所有线程,然后返回,注意:这可能会导致任务的处理中断而产生错误!
任务处理
view plaincopy to clipboard
114TPBOOL tp_process_job(TpThreadPool *pTp, process_job proc_fun, TpWorkDesc *job) {
115 TpThreadInfo *pThi ;
116 //fill pTp->thread_info's relative work key
117 //pthread_mutex_lock(&pTp->tp_lock);
118 pThi = (TpThreadInfo *) deQueue(&pTp->idle_q);
119 //pthread_mutex_unlock(&pTp->tp_lock);
120if(pThi){
121 pThi->is_busy =TRUE;
122 pThi->proc_fun = proc_fun;
123 pThi->th_job = job;
124 pthread_cond_signal(&pThi->thread_cond);
125 DEBUG("Fetch a thread from pool.\n");
126return TRUE;
127 }
128 //if all current thread are busy, new thread is created here
129 pthread_mutex_lock(&pTp->tp_lock);
130 pThi = tp_add_thread(pTp);
131 pthread_mutex_unlock(&pTp->tp_lock);
132
133if(!pThi){
134 DEBUG("The thread pool is full, no more thread available.\n");
135return FALSE;
136 }
137 DEBUG("No more idle thread, created a new one.\n");
138 pThi->proc_fun = proc_fun;
139 pThi->th_job = job;
140
141 //send cond to work thread
142 pthread_cond_signal(&pThi->thread_cond);
143return TRUE;
144}
当一个新任务到达是,线程池首先会检查是否有可用的空闲线程,如果是,则采用才空闲线程进行任务处理并返回TRUE,如果不是,则尝试新建一个线程,并使用该线程对任务进行处理,如果失败则返回FALSE,说明线程池忙碌或者出错。
view plaincopy to clipboard
145static void *tp_work_thread(void *arg) {
146 pthread_t curid;//current thread id
147 TpThreadInfo *pTinfo = (TpThreadInfo *) arg;
148
149 //wait cond for processing real job.
150while (!(pTinfo->tp_pool->stop_flag)) {
151 //pthread_mutex_lock(&pTinfo->thread_lock);
152 pthread_cond_wait(&pTinfo->thread_cond, &pTinfo->thread_lock);
153 //pthread_mutex_unlock(&pTinfo->thread_lock);
155 //process
156 pTinfo->proc_fun(pTinfo->th_job);
157
158 //thread state be set idle after work
159 //pthread_mutex_lock(&pTinfo->thread_lock);
160 pTinfo->is_busy = FALSE;
161 enQueue(&pTinfo->tp_pool->idle_q, pTinfo);
162 //pthread_mutex_unlock(&pTinfo->thread_lock);
163 DEBUG("Job done, I am idle now.\n");
164 }
165}
上面这个函数是任务处理函数,该函数将始终处理等待唤醒状态,直到新任务到达或者线程销毁时被唤醒,然后调用任务处理回调函数对任务进行处理;当任务处理完成时,则将自己置入空闲队列中,以供下一个任务处理。
view plaincopy to clipboard
166TpThreadInfo *tp_add_thread(TpThreadPool *pTp) {
167int err;
168 TpThreadInfo *new_thread;
169
170if (pTp->max_th_num <= pTp->cur_th_num)
171return NULL;
172
173 //malloc new thread info struct
174 new_thread = pTp->thread_info + pTp->cur_th_num;
175
176 new_thread->tp_pool = pTp;
177 //init new thread's cond & mutex
178 pthread_cond_init(&new_thread->thread_cond, NULL);
179 pthread_mutex_init(&new_thread->thread_lock, NULL);
181 //init status is busy, only new process job will call this function
182 new_thread->is_busy = TRUE;
183 err = pthread_create(&new_thread->thread_id, NULL, tp_work_thread,
new_thread);
184if (0 != err) {
185 free(new_thread);
186return NULL;
187 }
188 //add current thread number in the pool.
189 pTp->cur_th_num++;
190
191return new_thread;
192}
上面这个函数用于向线程池中添加新的线程,该函数将会在当线程池没有空闲线程可用时被调用。
函数将会新建一个线程,并设置自己的状态为busy(立即就要被用于执行任务)。
线程池管理
线程池的管理主要是监控线程池的整体忙碌状态,当线程池大部分线程处于空闲状态时,管理线程将适当的销毁一定数量的空闲线程,以便减少线程池对系统资源的消耗。
这里设计认为,当空闲线程的数量超过线程池线程数量的1/2时,线程池总体处理空闲状态,可以适当销毁部分线程池的线程,以减少线程池对系统资源的开销。
线程池状态计算
这里的BUSY_THRESHOLD的值是0.5,也即是当空闲线程数量超过一半时,返回0,说明线程池整体状态为闲,否则返回1,说明为忙。
view plaincopy to clipboard
193int tp_get_tp_status(TpThreadPool *pTp) {
194float busy_num = 0.0;
195int i;
197 //get busy thread number
198 busy_num = pTp->cur_th_num - pTp->idle_q.count;
199
200 DEBUG("Current thread pool status, current num: %u, busy num: %u, idle num: %u\n", pTp->cur_th_num, (unsigned)busy_num, pTp->idle_q.count);
201 //0.2? or other num?
202if (busy_num / (pTp->cur_th_num) < BUSY_THRESHOLD)
203return 0;//idle status
204else
205return 1;//busy or normal status
206}
线程的销毁算法
1. 从空闲队列中dequeue一个空闲线程指针,该指针指向线程信息数组的某项,例如这里是p;
2. 销毁该线程
3. 把线程信息数组的最后一项拷贝至位置p
4. 线程池数量减少一,即cur_th_num--
图3:线程销毁
view plaincopy to clipboard
207TPBOOL tp_delete_thread(TpThreadPool *pTp) {
208 unsigned idx;
209 TpThreadInfo *pThi;
210 TpThreadInfo tT;
211
212 //current thread num can't < min thread num
213if (pTp->cur_th_num <= pTp->min_th_num)
214return FALSE;
215 //pthread_mutex_lock(&pTp->tp_lock);
216 pThi = deQueue(&pTp->idle_q);
217 //pthread_mutex_unlock(&pTp->tp_lock);
218if(!pThi)
219return FALSE;
220
221 //after deleting idle thread, current thread num -1
222 pTp->cur_th_num--;
223 memcpy(&tT, pThi, sizeof(TpThreadInfo));
224 memcpy(pThi, pTp->thread_info + pTp->cur_th_num, sizeof(TpThreadInfo));
225
226 //kill the idle thread and free info struct
227 kill((pid_t)tT.thread_id, SIGKILL);
228 pthread_mutex_destroy(&tT.thread_lock);
229 pthread_cond_destroy(&tT.thread_cond);
230
231return TRUE;
232}
线程池监控
线程池通过一个管理线程来进行监控,管理线程将会每隔一段时间对线程池的状态进行计算,根据线程池的状态适当的销毁部分线程,减少对系统资源的消耗。
view plaincopy to clipboard
233static void *tp_manage_thread(void *arg) {
234 TpThreadPool *pTp = (TpThreadPool*) arg;//main thread pool struct instance 235
236 //1?
237 sleep(MANAGE_INTERVAL);
238
239do {
240if (tp_get_tp_status(pTp) == 0) {
241do {
242if (!tp_delete_thread(pTp))
243break;
244 } while (TRUE);
245 }//end for if
246
247 //1?
248 sleep(MANAGE_INTERVAL);
249 } while (!pTp->stop_flag);
250return NULL;
251}
程序测试
至此,我们的设计需要使用一个测试程序来进行验证。于是,我们写下这样一段代码。
view plaincopy to clipboard
252#include
253#include
254#include "thread_pool.h"
255
256#define THD_NUM 10
257void proc_fun(TpWorkDesc *job){
258int i;
259int idx=*(int *)job->arg;
260 printf("Begin: thread %d\n", idx);
261 sleep(3);
262 printf("End: thread %d\n", idx);
263}
264
265int main(int argc, char **argv){
266 TpThreadPool *pTp= tp_create(5,10);
267 TpWorkDesc pWd[THD_NUM];
268int i, *idx;
269
270 tp_init(pTp);
271for(i=0; i < THD_NUM; i++){
272 idx=(int *) malloc(sizeof(int));
273 *idx=i;
274 pWd[i].arg=idx;
275 tp_process_job(pTp, proc_fun, pWd+i); 276 usleep(400000);
277 }
278 //sleep(1);
279 tp_close(pTp, TRUE);
280 free(pTp);
281 printf("All jobs done!\n");
282return 0;
283}
执行结果:
源码下载
地址:https://https://www.360docs.net/doc/8613893182.html,/projects/thd-pool-linux/
备注
该线程池设计比较简单,尚存在不少BUG,欢迎各位提出改进意见。
2016Linux程序设计复习题
一、填空题 1、在Linux 系统中,以文件方式访问设备。 2、Linux 内核引导时,从文件/etc/fstab 中读取要加载的文件系统。 3、Linux 文件系统中每个文件用i 节点来标识。 4、全部磁盘块由四个部分组成,分别为引导块、专用块、i 节点表块和数据存储块。 5、链接分为:硬链接和符号链接。 6、超级块包含了i 节点表和空闲块表等重要的文件系统信息。 7、某文件的权限为:drw-r--r-- ,用数值形式表示该权限,则该八进制数为:644 ,该文件属性是目录。 8、前台起动的进程使用Ctrl+C 终止。 9、静态路由设定后,若网络拓扑结构发生变化,需由系统管理员修改路由的设置。 10、网络管理的重要任务是:控制和监控。 11、安装Linux 系统对硬盘分区时,必须有两种分区类型:文件系统分区和交换分区。 12、编写的Shell 程序运行前必须赋予该脚本文件执行权限。 13、系统管理的任务之一是能够在分布式环境中实现对程序和数据的安全 保护、备份、恢复和更新。 14、系统交换分区是作为系统虚拟存储器的一块区域。 15、内核分为进程管理系统、内存管理系统、I/O 管理系统和文件管理系统等四个子系统。 16、内核配置是系统管理员在改变系统配置硬件时要进行的重要操作。 17、在安装Linux 系统中,使用netconfig 程序对网络进行配置,该安装程序会一步步提示用 户输入主机名、域名、域名服务器、IP 地址、网关地址和子网掩码等必要信息。 18、唯一标识每一个用户的是用户ID 和用户名。 19、RIP 协议是最为普遍的一种内部协议,一般称为动态路由选择协议。 20、在Linux 系统中所有内容都被表示为文件,组织文件的各种方法称为文件系统。 21、DHCP可以实现动态IP 地址分配。 22、系统网络管理员的管理对象是服务器、用户和服务器的进程以及系统的各种资源。 23、网络管理通常由监测、传输和管理三部分组成,其中管理部分是整个网络管理的 中心。 24、当想删除本系统用不上的设备驱动程序时必须编译内核,当内核不支持系统上的 设备驱动程序时,必须对内核升级。 25、Ping 命令可以测试网络中本机系统是否能到达一台远程主机,所以常常用于测试网络 的连通性。 26、vi 编辑器具有三种工作模式:命令模式、底行模式和输入模式。 27、可以用ls –al 命令来观察文件的权限,每个文件的权限都用10 位表示,并分为四段, 其中第一段占 1 位,表示文件类型,第二段占 3 位,表示文件所有者对该文件的权限。 28、进程与程序的区别在于其动态性,动态的产生和终止,从产生到终止进程可以具有的基 本状态为:运行态、就绪态和等待态(阻塞态)。 29、DNS实际上是分布在internet 上的主机信息的数据库,其作用是实现IP地址和主
JAVA线程池原理333
在什么情况下使用线程池? 1.单个任务处理的时间比较短 2.将需处理的任务的数量大 使用线程池的好处: 1.减少在创建和销毁线程上所花的时间以及系统资源的开销 2.如不使用线程池,有可能造成系统创建大量线程而导致消耗完系统内存以及”过度切换”。 线程池工作原理:
线程池为线程生命周期开销问题和资源不足问题提供了解决方案。通过对多个任务重用线程,线程创建的开销被分摊到了多个任务上。其好处是,因为在请求到达时线程已经存在,所以无意中也消除了线程创建所带来的延迟。这样,就可以立即为请求服务,使应用程序响应更快。而且,通过适当地调整线程池中的线程数目,也就是当请求的数目超过某个阈值时,就强制其它任何新到的请求一直等待,直到获得一个线程来处理为止,从而可以防止资源不足。 线程池的替代方案 线程池远不是服务器应用程序内使用多线程的唯一方法。如同上面所提到的,有时,为每个新任务生成一个新线程是十分明智的。然而,如果任务创建过于频繁而任务的平均处理时间过短,那么为每个任务生成一个新线程将会导致性能问题。 另一个常见的线程模型是为某一类型的任务分配一个后台线程与任务队列。AWT 和 Swing 就使用这个模型,在这个模型中有一个 GUI 事件线程,导致用户界面发生变化的所有工作都必须在该线程中执行。然而,由于只有一个 AWT 线程,因此要在 AWT 线程中执行任务可能要花费相当长时间才能完成,这是不可取的。因此,Swing 应用程序经常需要额外的工作线程,用于运行时间很长的、同 UI 有关的任务。 每个任务对应一个线程方法和单个后台线程(single-background-thread)方法在某些情形下都工作得非常理想。每个任务一个线程方法在只有少量运行时间很长的任务时工作得十分好。而只要调度可预见性不是很重要,则单个后台线程方法就工作得十分好,如低优先级后台任务就是这种情况。然而,大多数服务器应用程序都是面向处理大量的短期任务或子任务,因此往往希望具有一种能够以低开销有效地处理这些任务的机制以及一些资源管理和定时可预见性的措施。线程池提供了这些优点。 工作队列 就线程池的实际实现方式而言,术语“线程池”有些使人误解,因为线程池“明显的”实现在大多数情形下并不一定产生我们希望的结果。术语“线程池”先于Java 平台出现,因此它可能是较少面向对象方法的产物。然而,该术语仍继续广泛应用着。 虽然我们可以轻易地实现一个线程池类,其中客户机类等待一个可用线程、将任务传递给该线程以便执行、然后在任务完成时将线程归还给池,但这种方法却存在几个潜在的负面影响。例如在池为空时,会发生什么呢?试图向池线程传递任务的调用者都会发现池为空,在调用者等待一个可用的池线程时,它的线程将阻塞。我们之所以要使用后台线程的原因之一常常是为了防止正在提交的线程被阻塞。完全堵住调用者,如在线程池的“明显的”实现的情况,可以杜绝我们试图解决的问题的发生。 我们通常想要的是同一组固定的工作线程相结合的工作队列,它使用 wait() 和
实验七:Linux多线程编程(实验分析报告)
实验七:Linux多线程编程(实验报告)
————————————————————————————————作者:————————————————————————————————日期:
实验七:Linux多线程编程(4课时) 实验目的:掌握线程的概念;熟悉Linux下线程程序编译的过程;掌握多线程程序编写方法。 实验原理:为什么有了进程的概念后,还要再引入线程呢?使用多线程到底有哪些好处?什么的系统应该选用多线程?我们首先必须回答这些问题。 1 多线程概念 使用多线程的理由之一是和进程相比,它是一种非常"节俭"的多任务操作方式。运行于一个进程中的多个线程,它们彼此之间使用相同的地址空间,共享大部分数据,启动一个线程所花费的空间远远小于启动一个进程所花费的空间。 使用多线程的理由之二是线程间方便的通信机制。同一进程下的线程之间共享数据空间,所以一个线程的数据可以直接为其它线程所用,这不仅快捷,而且方便。2多线程编程函数 Linux系统下的多线程遵循POSIX线程接口,称为pthread。编写Linux下的多线程程序,需要使用头文件pthread.h,连接时需要使用库libpthread.a。pthread_t在头文件/usr/include/bits/pthreadtypes.h中定义: typedef unsigned long int pthread_t; 它是一个线程的标识符。 函数pthread_create用来创建一个线程,它的原型为: extern int pthread_create((pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg)); 第一个参数为指向线程标识符的指针,第二个参数用来设置线程属性,第三个参数是线程运行函数的起始地址,最后一个参数是运行函数的参数。 函数pthread_join用来等待一个线程的结束。函数原型为: extern int pthread_join(pthread_t th, void **thread_return); 第一个参数为被等待的线程标识符,第二个参数为一个用户定义的指针,它可以用来存储被等待线程的返回值。 函数pthread_exit的函数原型为: extern void pthread_exit(void *retval); 唯一的参数是函数的返回代码,只要pthread_join中的第二个参数thread_return不是NULL,这个值将被传递给thread_return。 3 修改线程的属性 线程属性结构为pthread_attr_t,它在头文件/usr/include/pthread.h中定义。属性值不能直接设置,须使用相关函数进行操作,初始化的函数为pthread_attr_init,这个函数必须在pthread_create函数之前调用。 设置线程绑定状态的函数为pthread_attr_setscope,它有两个参数,第一个是指向属性结构的指针,第二个是绑定类型,它有两个取值:PTHREAD_SCOPE_SYSTEM(绑定的)和PTHREAD_SCOPE_PROCESS(非绑定的)。 另外一个可能常用的属性是线程的优先级,它存放在结构sched_param中。用函数pthread_attr_getschedparam和函数pthread_attr_setschedparam进行存放,一般说来,我们总是先取优先级,对取得的值修改后再存放回去。 4 线程的数据处理
解决多线程中11个常见问题
并发危险 解决多线程代码中的11 个常见的问题 Joe Duffy 本文将介绍以下内容:?基本并发概念 ?并发问题和抑制措施 ?实现安全性的模式?横切概念本文使用了以下技术: 多线程、.NET Framework 目录 数据争用 忘记同步 粒度错误 读写撕裂 无锁定重新排序 重新进入 死锁 锁保护 戳记 两步舞曲 优先级反转 实现安全性的模式 不变性 纯度 隔离 并发现象无处不在。服务器端程序长久以来都必须负责处理基本并发编程模型,而随着多核处理器的日益普及,客户端程序也将需要执行一些任务。随着并发操作的不断增加,有关确保安全的问题也浮现出来。也就是说,在面对大量逻辑并发操作和不断变化的物理硬件并行性程度时,程序必须继续保持同样级别的稳定性和可靠性。 与对应的顺序代码相比,正确设计的并发代码还必须遵循一些额外的规则。对内存的读写以及对共享资源的访问必须使用同步机制进行管制,以防发生冲突。另外,通常有必要对线程进行协调以协同完成某项工作。 这些附加要求所产生的直接结果是,可以从根本上确保线程始终保持一致并且保证其顺利向前推进。同步和协调对时间的依赖性很强,这就导致了它们具有不确定性,难于进行预测和测试。 这些属性之所以让人觉得有些困难,只是因为人们的思路还未转变过来。没有可供学习的专门API,也没有可进行复制和粘贴的代码段。实际上的确有一组基础概念需要您学习和适应。很可能随着时间的推移某些语言和库会隐藏一些概念,但如果您现在就开始执行并发操作,则不会遇到这种情况。本
文将介绍需要注意的一些较为常见的挑战,并针对您在软件中如何运用它们给出一些建议。 首先我将讨论在并发程序中经常会出错的一类问题。我把它们称为“安全隐患”,因为它们很容易发现并且后果通常比较严重。这些危险会导致您的程序因崩溃或内存问题而中断。 当从多个线程并发访问数据时会发生数据争用(或竞争条件)。特别是,在一个或多个线程写入一段数据的同时,如果有一个或多个线程也在读取这段数据,则会发生这种情况。之所以会出现这种问题,是因为Windows 程序(如C++ 和Microsoft .NET Framework 之类的程序)基本上都基于共享内存概念,进程中的所有线程均可访问驻留在同一虚拟地址空间中的数据。静态变量和堆分配可用于共享。请考虑下面这个典型的例子: static class Counter { internal static int s_curr = 0; internal static int GetNext() { return s_curr++; } } Counter 的目标可能是想为GetNext 的每个调用分发一个新的唯一数字。但是,如果程序中的两个线程同时调用GetNext,则这两个线程可能被赋予相同的数字。原因是s_curr++ 编译包括三个独立的步骤: 1.将当前值从共享的s_curr 变量读入处理器寄存器。 2.递增该寄存器。 3.将寄存器值重新写入共享s_curr 变量。 按照这种顺序执行的两个线程可能会在本地从s_curr 读取了相同的值(比如42)并将其递增到某个值(比如43),然后发布相同的结果值。这样一来,GetNext 将为这两个线程返回相同的数字,导致算法中断。虽然简单语句s_curr++ 看似不可分割,但实际却并非如此。 忘记同步 这是最简单的一种数据争用情况:同步被完全遗忘。这种争用很少有良性的情况,也就是说虽然它们是正确的,但大部分都是因为这种正确性的根基存在问题。 这种问题通常不是很明显。例如,某个对象可能是某个大型复杂对象图表的一部分,而该图表恰好可使用静态变量访问,或在创建新线程或将工作排入线程池时通过将某个对象作为闭包的一部分进行传递可变为共享图表。 当对象(图表)从私有变为共享时,一定要多加注意。这称为发布,在后面的隔离上下文中会对此加以讨论。反之称为私有化,即对象(图表)再次从共享变为私有。 对这种问题的解决方案是添加正确的同步。在计数器示例中,我可以使用简单的联锁: static class Counter { internal static volatile int s_curr = 0; internal static int GetNext() { return Interlocked.Increment(ref s_curr);
java深入理解线程池
深入研究线程池 一.什么是线程池? 线程池就是以一个或多个线程[循环执行]多个应用逻辑的线程集合. 注意这里用了线程集合的概念是我生造的,目的是为了区分执行一批应用逻辑的多个线程和 线程组的区别.关于线程组的概念请参阅基础部分. 一般而言,线程池有以下几个部分: 1.完成主要任务的一个或多个线程. 2.用于调度管理的管理线程. 3.要求执行的任务队列. 那么如果一个线程循环执行一段代码是否是线程池? 如果极端而言,应该算,但实际上循环代码应该算上一个逻辑单元.我们说最最弱化的线程池 应该是循环执行多个逻辑单元.也就是有一批要执行的任务,这些任务被独立为多个不同的执行单元.比如: int x = 0; while(true){ x ++; } 这就不能说循环中执行多个逻辑单元,因为它只是简单地对循环外部的初始变量执行++操作. 而如果已经有一个队列 ArrayList al = new ArrayList(); for(int i=0;i<10000;i++){ al.add(new AClass()); } 然后在一个线程中执行: while(al.size() != 0){ AClass a = (AClass)al.remove(0); a.businessMethod(); } 我们说这个线程就是循环执行多个逻辑单元.可以说这个线程是弱化的线程池.我们习惯上把这些相对独立的逻辑单元称为任务. 二.为什么要创建线程池? 线程池属于对象池.所有对象池都具有一个非常重要的共性,就是为了最大程度复用对象.那么 线程池的最重要的特征也就是最大程度利用线程. 从编程模型模型上说讲,在处理多任务时,每个任务一个线程是非常好的模型.如果确实可以这么做我们将可以使用编程模型更清楚,更优化.但是在实际应用中,每个任务一个线程会使用系统限入"过度切换"和"过度开销"的泥潭. 打个比方,如果可能,生活中每个人一辆房车,上面有休息,娱乐,餐饮等生活措施.而且道路交道永远不堵车,那是多么美好的梦中王国啊.可是残酷的现实告诉我们,那是不可能的.不仅每个人一辆车需要无数多的社会资源,而且地球上所能容纳的车辆总数是有限制的. 首先,创建线程本身需要额外(相对于执行任务而必须的资源)的开销.
Linux多线程编程的基本的函数
Posix线程编程指南(一) 线程创建与取消 这是一个关于Posix线程编程的专栏。作者在阐明概念的基础上,将向您详细讲述Posix线程库API。本文是第一篇将向您讲述线程的创建与取消。 线程创建 1.1 线程与进程 相对进程而言,线程是一个更加接近于执行体的概念,它可以与同进程中的其他线程共享数据,但拥有自己的栈空间,拥有独立的执行序列。在串行程序基础上引入线程和进程是为了提高程序的并发度,从而提高程序运行效率和响应时间。 线程和进程在使用上各有优缺点:线程执行开销小,但不利于资源的管理和保护;而进程正相反。同时,线程适合于在SMP机器上运行,而进程则可以跨机器迁移。 1.2 创建线程 POSIX通过pthread_create()函数创建线程,API定义如下: 与fork()调用创建一个进程的方法不同,pthread_create()创建的线程并不具备与主线程(即调用pthread_create()的线程)同样的执行序列,而是使其运行 start_routine(arg)函数。thread返回创建的线程ID,而attr是创建线程时设置的线程属性(见下)。pthread_create()的返回值表示线程创建是否成功。尽管arg是void *类型的变量,但它同样可以作为任意类型的参数传给start_routine()函数;同时,start_routine()可以返回一个void *类型的返回值,而这个返回值也可以是其他类型,并由pthread_join()获取。 1.3 线程创建属性 pthread_create()中的attr参数是一个结构指针,结构中的元素分别对应着新线程的运行属性,主要包括以下几项: __detachstate,表示新线程是否与进程中其他线程脱离同步,如果置位则新线程不能用pthread_join()来同步,且在退出时自行释放所占用的资源。缺省为 PTHREAD_CREATE_JOINABLE状态。这个属性也可以在线程创建并运行以后用pthread_detach()来设置,而一旦设置为PTHREAD_CREATE_DETACH状态(不论是创建时设置还是运行时设置)则不能再恢复到PTHREAD_CREATE_JOINABLE状态。
Linux程序设计报告
Linux程序设计课程设计 Linux程序设计课程组 长春工业大学 2017-12-24
课程设计任务书
目录 第1章设计要求 (1) 2.1设计目的 (1) 2.2设计要求 (1) 第2章测试数据设计 (2) 第3章算法实现 (3) 第4章算法结果 (19) 第5章结果可视化 (21) 第6章性能分析 (21) 参考文献 (22) 心得 (22)
第1章设计要求 2.1设计目的 理解临界区和进程互斥的概念,掌握用信号量和PV操作实现进程互斥的方法。 2.2设计要求 在linux环境下编写应用程序,该程序运行时能创建N个线程,其中既有读者线程又有写者线程,它们按照事先设计好的测试数据进行读写操作。 读者/写者问题描述如下: 有一个被许多进程共享的数据区,这个数据区可以是一个文件,或者主存的一块空间,甚至可以是一组处理器寄存器。有一些只读取这个数据区的线程(reader)和一些只往数据区中写数据的线程(writer)。以下假设共享数据区是文件。这些读者和写者对数据区的操作必须满足以下条件:读—读允许;读—写互斥;写—写互斥。这些条件具体来说就是: (1)任意多的读线程可以同时读这个文件; (2)一次只允许一个写线程往文件中写; (3)如果一个写线程正在往文件中写,禁止任何读线程或写线程访问文件; (4)写线程执行写操作前,应让已有的写者或读者全部退出。这说明当有读者在读文件时不允许写者写文件。 对于读者-写者问题,有三种解决方法: 1、读者优先 除了上述四个规则外,还增加读者优先的规定,当有读者在读文件时,对随后到达的读者和写者,要首先满足读者,阻塞写者。这说明只要有一个读者活跃,那么随后而来的读者都将被允许访问文件,从而导致写者长时间等待,甚至有可能出现写者被饿死的情况。 2、写者优先 除了上述四个规则外,还增加写者优先的规定,即当有读者和写者同时等待时,首先满足写者。当一个写者声明想写文件时,不允许新的读者再访问文件。 3、无优先 除了上述四个规则外,不再规定读写的优先权,谁先等待谁就先使用文件。
完成端口加线程池技术实现
WinSock 异步I/O模型[5]---完成端口 - Completion Port ---------------------------------------------------------------------------- 如果你想在Windows平台上构建服务器应用,那么I/O模型是你必须考虑的。Windows操作系统提供了五种I/O模型,分别是: ■选择(select); ■异步选择(WSAAsyncSelect); ■事件选择(WSAEventSelect); ■重叠I/O(Overlapped I/O); ■完成端口(Completion Port) 。 每一种模型适用于一种特定的应用场景。程序员应该对自己的应用需求非常明确,综合考虑到程序的扩展性和可移植性等因素,作出自己的选择。 ============================================== █“完成端口”模型是迄今为止最复杂的一种 I/O 模型。但是,若一个应用程序同时需要管理很多的套接字, 那么采用这种模型,往往可以达到最佳的系统性能!但缺点是,该模型只适用于Windows NT 和 Windows 2000 以上版本的操作系统。 █因其设计的复杂性,只有在你的应用程序需要同时管理数百乃至上千个套接字的时候,而且希望随着系统内安装的CPU数量的增多, 应用程序的性能也可以线性提升,才应考虑采用“完成端口”模型。 █从本质上说,完成端口模型要求我们创建一个 Win32 完成端口对象,通过指定数量的线程, 对重叠 I/O 请求进行管理,以便为已经完成的重叠 I/O 请求提供服务。
浙江大学Linux程序设计实验报告
Linux程序设计实验报告1 ——操作系统基本命令使用 一、实验目的 1.通过对Emacs、vi、vim、gedit文本编辑器的使用,掌握在Linux环境下文本文件的编辑方法; 2.通过对常用命令mkdir、cp、cd、ls、mv、chmod、rm等文件命令的操作,掌握Linux操作系统中文件命令的用法。 二、实验任务与要求 1.emacs的使用,要求能新建、编辑、保存一个文本文件 2.vi或vim的使用,要求能新建、编辑、保存一个文本文件 3.gedit的使用,要求能新建、编辑、保存一个文本文件 4.掌握mkdir、cd命令的操作,要求能建立目录、进入与退出目录 5.掌握cp、ls、mv、chmod、rm命令的操作,要求能拷贝文件、新建文件、查看文件、文件重命名、删除文件等操作。 三、实验工具与准备 计算机PC机,Linux Redhat Fedora Core6操作系统 四、实验步骤与操作指导 任务1.学习emacs的使用,要求能新建、编辑、保存一个文本文件 (1)启动emacs (2)输入以下C程序 (3)保存文件为kk.c (4)用emacs打开文件kk.c (5)修改程序 (6)另存为文件aa.txt并退出。 任务2.vi或vim的使用,要求能新建、编辑、保存一个文本文件 (1)点击”应用程序”→ “附件”→“终端”,打开终端,在终端输入命令: [root@localhost root]#vi kk.c 按i键,进入插入状态。 (2)输入以下C程序 #include
printf(“Hello world!\n”); return 0; } 此时可以用Backspace、→、←、↑、↓键编辑文本。 (3)保存文件为kk.c 按Esc键,进入最后行状态,在最后行状态输入:wq保存文件,退出vi。 (4)用vi打开文件kk.c,输入命令: [root@localhost root]#vi kk.c (5)修改程序为: #include
linux下的多线程编程常用函数
Linux下pthread的实现是通过系统调用clone()来实现的。clone()是Linux所特 有的系统调用,他的使用方式类似fork. int pthread_create(pthread_t *restrict tidp,const pthread_attr_t *restrict attr, void *(*start_rtn)(void),void *restrict arg); 返回值:若是成功建立线程返回0,否则返回错误的编号 形式参数: pthread_t *restrict tidp 要创建的线程的线程id指针 const pthread_attr_t *restrict attr 创建线程时的线程属性 void* (start_rtn)(void) 返回值是void类型的指针函数 void *restrict arg start_rtn的行参 进行编译的时候要加上-lpthread 向线程传递参数。 例程2: 功能:向新的线程传递整形值 #include
使用 GPars 解决常见并发问题
重庆IT论坛https://www.360docs.net/doc/8613893182.html, 在并发性时代,带有4、6 和16 个处理器核心的芯片变得很普遍,而且在不久的将来,我们会看到带有上百甚至上千个核心的芯片。这种处理能力蕴含着巨大的可能性,但对于软件开发人员来说,它也带来了挑战。最大限度地利用这些闪耀新核的需求推动了对并发性、状态管理和为两者构建的编程语言的关注热潮。 Groovy、Scala 和Clojure 等JVM 语言满足了这些需求。这三种都是较新的语言,运行于高度优化的JVM 之上,可以使用Java 1.5 中新增的强大的Java 并发库。尽管每种语言基于其原理采用不同的方法,不过它们都积极支持并发编程。 在本文中,我们将使用GPars,一种基于Groovy 的并发库,来检查模型以便解决并发性问题,比如后台处理、并行处理、状态管理和线程协调。 为何选择Groovy ?为何选择GPars ? Groovy 是运行于JVM 之上的一种动态语言。基于Java 语言,Groovy 移除了Java 代码中的大量正式语法,并添加了来自其他编程语言的有用特性。Groovy 的强大特性之一是它允许编程人员轻松创建基于Groovy 的DSL。(一个DSL 或域特定语言是一种旨在解决特定编程问题的脚本语言。参阅参考资料了解有关DSL 的更多信息。) 获取代码和工具 参阅参考资料部分下载Groovy、GPars 和本文中用到的其他工具。您可以随时下载本文的可执行代码样例。 GPars 或Groovy Parallel Systems 是一种Groovy 并发库,捕捉并发性和协调模型作为DSL。GPars 的构思源自其他语言的一些最受欢迎的并发性和协调模型,包括:?来自Java 语言的executors 和fork/join ?来自Erlang 和Scala 的actors ?来自Clojure 的agents ?来自Oz 的数据流变量 Groovy 和GPars 的结合成为展示各种并发性方法的理想之选。甚至不熟悉Groovy 的Java 开发人员也能轻松关注相关讨论,因为Groovy 的语法以Java 语言为基础。本文中的示例基于Groovy 1.7 和GPars 0.10。 回页首 后台和并行处理 一个常见的性能难题是需要等待I/O。I/O 可能涉及到从一个磁盘、一个web 服务或甚至是一名用户读取数据。当一个线程在等待I/O 的过程中被阻止时,将等待中的线程与原始执行线程分离开来将会很有用,这将使它能继续工作。由于这种等待是在后台发生的,所以我们称这种技术为后台处理。 例如,假设我们需要这样一个程序,即调用Twitter API 来找到针对若干JVM 语言的最新tweets 并将它们打印出来。Groovy 能够使用Java 库twitter4j 很容易就编写出这样的程序,如清单1 所示: 清单1. 串行读取tweets (langTweets.groovy) import twitter4j.Twitter import twitter4j.Query
Linux程序设计模式(机制与策略)
Linux程序设计模式—机制与策略 什么是设计模式(Design pattern)? 设计模式(Design pattern)是一套被反复使用、多数人知晓的、经过分类编目的、软件设计经验的总结。使用设计模式是为了提高代码或模块的重用、让程序更容易被他人理解、提高代码可靠性和可维护性。同时,通过学习设计模式可以降低解决一般性问题的开发难度。 Linux程序设计模式的起源和发展 Linux程序的设计模式起源于Unix文化,是Unix哲学的重要组成部分,而Linux本身就是Unix的一个发展分支。Unix哲学说来不算是一种正规设计方法,它是自下而上的,而不是自上而下的。Unix哲学注重实效,立足于丰富的经验。你不会在正规方法学和标准中找到它,它更接近于隐性的半本能的知识,即Unix文化所传播的专业经验。它鼓励那种分清轻重缓急的感觉,以及怀疑一切的态度,并鼓励你以幽默达观的态度对待这些。 什么是Unix哲学? Unix管道的发明人、Unix传统的奠基人之一Doug McIlroy在[McIlroy78]中曾经说过: I. 让每个程序就做好一件事。如果有新任务,就重新开始,不要往原程序中加入新功能而搞得复杂。 II. 假定每个程序的输出都会成为另一个程序的输入,哪怕那个程序还是未知的。输出中不要有无关的信息干扰。避免使用严格的分栏格式和二进制格式输入。不要坚持使用交互式输入。 III. 尽可能早地将设计和编译的软件投入试用, 哪怕是操作系统也不例外,理想情况下, 应该是在几星期内。对拙劣的代码别犹豫,扔掉重写。 IV. 优先使用工具而不是拙劣的帮助来减轻编程任务的负担。工欲善其事,必先利其器。后来他这样总结道(引自《Unix的四分之一世纪》): Unix哲学是这样的:一个程序只做一件事,并做好。程序要能协作。程序要能处理文本流,因为这是最通用的接口。 从整体上来说,可以概括为以下几点: 01.模块原则:使用简洁的接口拼合简单的部件。 02.清晰原则:清晰胜于机巧。 03.组合原则:设计时考虑拼接组合。 04.分离原则:策略同机制分离,接口同引擎分离。 05.简洁原则:设计要简洁,复杂度能低则低。 06.吝啬原则:除非确无它法,不要编写庞大的程序。 07.透明性原则:设计要可见,以便审查和调试。 08.健壮原则:健壮源于透明与简洁。 09.表示原则:把知识叠入数据以求逻辑质朴而健壮。 10.通俗原则:接口设计避免标新立异。 11.缄默原则:如果一个程序没什么好说的,就沉默。 12.补救原则:出现异常时,马上退出并给出足够错误信息。 13.经济原则:宁花机器一分,不花程序员一秒。 14.生成原则:避免手工hack,尽量编写程序去生成程序。 15.优化原则:雕琢前先要有原型,跑之前先学会走。 16.多样原则:决不相信所谓“不二法门”的断言。 17.扩展原则:设计着眼未来,未来总比预想来得快。 给大家推荐一本书《UNIX 编程艺术》————这不是一本讲如何编程的书,而是一本讲UNIX设计哲学的书,当然也适应于Linux。这本书是我来威胜工作后,同事们推荐我读的第二
Tomcat线程池实现简介
Tomcat线程池实现简介 目前市场上常用的开源Java Web容器有Tomcat、Resin和Jetty。其中Resin从V3.0后需要购买才能用于商业目的,而其他两种则是纯开源的。可以分别从他们的网站上下载最新的二进制包和源代码。 作为Web容器,需要承受较高的访问量,能够同时响应不同用户的请求,能够在恶劣环境下保持较高的稳定性和健壮性。在HTTP服务器领域,Apache HTTPD的效率是最高的,也是最为稳定的,但它只能处理静态页面的请求,如果需要支持动态页面请求,则必须安装相应的插件,比如mod_perl可以处理Perl脚本,mod_python可以处理Python脚本。 上面介绍的三中Web容器,都是使用Java编写的HTTP服务器,当然他们都可以嵌到Apache 中使用,也可以独立使用。分析它们处理客户请求的方法有助于了解Java多线程和线程池的实现方法,为设计强大的多线程服务器打好基础。 Tomcat是使用最广的Java Web容器,功能强大,可扩展性强。最新版本的Tomcat(5.5.17)为了提高响应速度和效率,使用了Apache Portable Runtime(APR)作为最底层,使用了APR 中包含Socket、缓冲池等多种技术,性能也提高了。APR也是Apache HTTPD的最底层。可想而知,同属于ASF(Apache Software Foundation)中的成员,互补互用的情况还是很多的,虽然使用了不同的开发语言。 Tomcat 的线程池位于tomcat-util.jar文件中,包含了两种线程池方案。方案一:使用APR 的Pool技术,使用了JNI;方案二:使用Java实现的ThreadPool。这里介绍的是第二种。如果想了解APR的Pool技术,可以查看APR的源代码。 ThreadPool默认创建了5个线程,保存在一个200维的线程数组中,创建时就启动了这些线程,当然在没有请求时,它们都处理“等待”状态(其实就是一个while循环,不停的等待notify)。如果有请求时,空闲线程会被唤醒执行用户的请求。 具体的请求过程是:服务启动时,创建一个一维线程数组(maxThread=200个),并创建空闲线程(minSpareThreads=5个)随时等待用户请求。当有用户请求时,调用threadpool.runIt(ThreadPoolRunnable)方法,将一个需要执行的实例传给ThreadPool中。其中用户需要执行的实例必须实现ThreadPoolRunnable接口。ThreadPool 首先查找空闲的线程,如果有则用它运行要执行ThreadPoolRunnable;如果没有空闲线程并且没有超过maxThreads,就一次性创建minSpareThreads个空闲线程;如果已经超过了maxThreads了,就等待空闲线程了。总之,要找到空闲的线程,以便用它执行实例。找到后,将该线程从线程数组中移走。接着唤醒已经找到的空闲线程,用它运行执行实例(ThreadPoolRunnable)。运行完ThreadPoolRunnable后,就将该线程重新放到线程数组中,作为空闲线程供后续使用。 由此可以看出,Tomcat的线程池实现是比较简单的,ThreadPool.java也只有840行代码。用一个一维数组保存空闲的线程,每次以一个较小步伐(5个)创建空闲线程并放到线程池中。使用时从数组中移走空闲的线程,用完后,再“归还”给线程池。ThreadPool提供的仅仅是线程池的实现,而如何使用线程池也是有很大学问的。让我们看看Tomcat是如何使用ThreadPool的吧。 Tomcat有两种EndPoint,分别是AprEndpoint和PoolTcpEndpoint。前者自己实现了一套线
多线程编程的详细说明完整版
VB .NET多线程编程的详细说明 作者:陶刚整理:https://www.360docs.net/doc/8613893182.html, 更新时间:2011-4-1 介绍 传统的Visual Basic开发人员已经建立了同步应用程序,在这些程序中事务按顺序执行。尽管由于多个事务多多少少地同时运行使多线程应用程序效率更高,但是使用先前版本的Visual Basic很难建立这类程序。 多线程程序是可行的,因为操作系统是多任务的,它有模拟同一时刻运行多个应用程序的能力。尽管多数个人计算机只有一个处理器,但是现在的操作系统还是通过在多个执行代码片断之间划分处理器时间提供了多任务。线程可能是整个应用程序,但通常是应用程序可以单独运行的一个部分。操作系统根据线程的优先级和离最近运行的时间长短给每一个线程分配处理时间。多线程对于时间密集型事务(例如文件输入输出)应用程序的性能有很大的提高。 但是也有必须细心的地方。尽管多线程能提高性能,但是每个线程还是需要用附加的内存来建立和处理器时间来运行,建立太多的线程可能降低应用程序的性能。当设计多线程应用程序时,应该比较性能与开销。 多任务成为操作系统的一部分已经很久了。但是直到最近Visual Basic程序员才能使用无文档记录特性(undocumented)或者间接使用COM组件或者操作系统的异步部分执行多线程事务。.NET框架组件为开发多线程应用程序,在System.Threading名字空间中提供了全面的支持。 本文讨论多线程的好处以及怎样使用Visual Basic .NET开发多线程应用程序。尽管Visual Basic .NET和.NET框架组件使开发多线程应用程序更容易,但是本文作了调整使其适合高级读者和希望从早期Visual Basic转移到Visual Basic .NET的开发人员。 多线程处理的优点 尽管同步应用程序易于开发,但是它们的性能通常比多线程应用程序低,因为一个新的事务必须等待前面的事务完成后才能开始。如果完成某个同步事务的时间比预想的要长,应用程序可能没有响应。多线程处理可以同时运行多个过程。例如,字处理程序能够在继续操作文档的同时执行拼写检查事务。因为多线程应用程序把程序分解为独立的事务,它们能通过下面的途径充分提高性能: l 多线程技术可以使程序更容易响应,因为在其它工作继续时用户界面可以保持激活。 l 当前不忙的事务可以把处理器时间让给其它事务。 l 花费大量处理时间的事务可以周期性的把时间让给其它的事务。 l 事务可以在任何时候停止。 l 可以通过把单独事务的优先级调高或调低来优化性能。 明确地建立多线程应用程序的决定依赖于几个因素。多线程最适合下面的情况:
11线程池的使用
第11章线程池的使用 第8章讲述了如何使用让线程保持用户方式的机制来实现线程同步的方法。用户方式的同步机制的出色之处在于它的同步速度很快。如果关心线程的运行速度,那么应该了解一下用户方式的同步机制是否适用。 到目前为止,已经知道创建多线程应用程序是非常困难的。需要会面临两个大问题。一个是要对线程的创建和撤消进行管理,另一个是要对线程对资源的访问实施同步。为了对资源访问实施同步,Wi n d o w s提供了许多基本要素来帮助进行操作,如事件、信标、互斥对象和关键代码段等。这些基本要素的使用都非常方便。为了使操作变得更加方便,唯一的方法是让系统能够自动保护共享资源。不幸的是,在Wi n d o w s提供一种让人满意的保护方法之前,我们已经有了一种这样的方法。 在如何对线程的创建和撤消进行管理的问题上,人人都有自己的好主意。近年来,我自己创建了若干不同的线程池实现代码,每个实现代码都进行了很好的调整,以便适应特定环境的需要。M i c r o s o f t公司的Windows 2000提供了一些新的线程池函数,使得线程的创建、撤消和基本管理变得更加容易。这个新的通用线程池并不完全适合每一种环境,但是它常常可以适合你的需要,并且能够节省大量的程序开发时间。 新的线程池函数使你能够执行下列操作: ? 异步调用函数。 ? 按照规定的时间间隔调用函数。 ? 当单个内核对象变为已通知状态时调用函数。 ? 当异步I / O请求完成时调用函数。 为了完成这些操作,线程池由4个独立的部分组成。表11 - 1显示了这些组件并描述了控制其行为特性的规则。 表11-1 线程池的组件及其行为特性
Step by Step:Linux C多线程编程入门(基本API及多线程的同步与互斥)
介绍:什么是线程,线程的优点是什么 线程在Unix系统下,通常被称为轻量级的进程,线程虽然不是进程,但却可以看作是Unix进程的表亲,同一进程中的多条线程将共享该进程中的全部系统资源,如虚拟地址空间,文件描述符和信号处理等等。但同一进程中的多个线程有各自的调用栈(call stack),自己的寄存器环境(register context),自己的线程本地存储(thread-local storage)。 一个进程可以有很多线程,每条线程并行执行不同的任务。 线程可以提高应用程序在多核环境下处理诸如文件I/O或者socket I/O等会产生堵塞的情况的表现性能。在Unix系统中,一个进程包含很多东西,包括可执行程序以及一大堆的诸如文件描述符地址空间等资源。在很多情况下,完成相关任务的不同代码间需要交换数据。如果采用多进程的方式,那么通信就需要在用户空间和内核空间进行频繁的切换,开销很大。但是如果使用多线程的方式,因为可以使用共享的全局变量,所以线程间的通信(数据交换)变得非常高效。 Hello World(线程创建、结束、等待) 创建线程 pthread_create 线程创建函数包含四个变量,分别为: 1. 一个线程变量名,被创建线程的标识 2. 线程的属性指针,缺省为NULL即可 3. 被创建线程的程序代码 4. 程序代码的参数 For example: - pthread_t thrd1? - pthread_attr_t attr? - void thread_function(void argument)? - char *some_argument? pthread_create(&thrd1, NULL, (void *)&thread_function, (void *) &some_argument); 结束线程 pthread_exit 线程结束调用实例:pthread_exit(void *retval); //retval用于存放线程结束的退出状态 线程等待 pthread_join pthread_create调用成功以后,新线程和老线程谁先执行,谁后执行用户是不知道的,这一块取决与操作系统对线程的调度,如果我们需要等待指定线程结束,需要使用pthread_join函数,这个函数实际上类似与多进程编程中的waitpid。 举个例子,以下假设 A 线程调用 pthread_join 试图去操作B线程,该函数将A线程阻塞,直到B线程退出,当B线程退出以后,A线程会收集B线程的返回码。 该函数包含两个参数:pthread_t th //th是要等待结束的线程的标识 void **thread_return //指针thread_return指向的位置存放的是终止线程的返回状态。 调用实例:pthread_join(thrd1, NULL); example1: 1 /************************************************************************* 2 > F i l e N a m e: t h r e a d_h e l l o_w o r l d.c 3 > A u t h o r: c o u l d t t(f y b y) 4 > M a i l: f u y u n b i y i@g m a i l.c o m 5 > C r e a t e d T i m e: 2013年12月14日 星期六 11时48分50秒 6 ************************************************************************/ 7 8 #i n c l u d e 9 #i n c l u d e 10 #i n c l u d e
11 12 v o i d p r i n t_m e s s a g e_f u n c t i o n (v o i d *p t r)? 13 14 i n t m a i n() 15 { 16 i n t t m p1, t m p2?