Disruptor:一种高性能的、在并发线程间数据交换领域用于替换有界限队列的方案

Disruptor:一种高性能的、在并发线程间数据交换领域用于替换有界限队列的方案
作者:Martin Thompson
Dave Farley
Micheal Barker
Patricia Gee
Andrew Stewart
1 摘要
LMAX公司被创建去构建一种高性能的金融交易平台。作为我们为达到这样的目标所做的工作的一部分,我们论证了一些设计这个系统的方案。但是随着我们的测试,我们发现传统方案的一些根本的局限性。
许多应用使用队列来实现在其线程间的数据交互。通过测试我们发现,非常戏剧性的——使用队列造成的延迟与磁盘IO操作(RAID、SSD磁盘)造成的延迟同样的多!如果在一个端对端操作中使用多个队列,这将会增加数百毫秒的总延迟。显然,这是一个需要优化的领域。
进一步的研究和专注于计算机科学的学习使我们认识到,传统方案固有的合并特点导致了在多线程实现中出现了争用现象,这意味着或许应该有更好的解决办法。
考虑下现代CPU的工作原理,有一种我们称之为“硬件机制共鸣”的编程优化方法,使用优化设计方案、专注于分离问题我们最后创建了一套数据结构和对应的设计模式,我们称之为Disruptor。
测试表明,使用Disruptor的三个线程管道的平均延迟要比相当的使用队列的方案低得多,而且在同样的配置下,Disruptor的吞吐量大约为队列的8倍。
这些性能上的提高,使我们开始重新思考并发编程的方式。Disruptor,这个全新的模式对于任何需要高吞吐低延迟特性的异步事件驱动架构来说都是一个理想的借鉴基础。
在LMAX公司,我们在Disruptor模式基础上构建了次序匹配引擎、实时风险管理系统、高可用性内存事务处理系统,这些项目都获得了巨大的成功。这些系统的性能都为业界设置了新的标杆——在我们看来、在目前一段可以预期的时间内不会被超越!(译者注:好狂妄的老外)
Disruptor并不是只能应用于金融业的解决方案,它是一种通用的机制,以简单的实现来最大程度的提高性能,用来解决并发编程中的复杂问题。尽管Disruptor中的一些概念似乎不大主流,但是以我们的成功经验证明,使用这种模式构建系统要比使用同类机制实现起来简单得多。
Disruptor框架显著的减少了写的争用、具有更低的系统开销和比之同类其他机制更好的缓存(译者注:这里指CPU的缓存)友好特性,所有这些优点使Disruptor具有更加强大的吞吐性能和平稳的低延迟处理能力。使用中等的时钟频率的处理器,我们测试得到了每秒2500万消息发送,上述延迟低于50纳秒(译者注:1纳秒=一秒的10亿分之一,神乎其技啊~~!)。这样的性能相对于我们见过的任何其他的实现方案来说都是显著的提高。这已经非常接近现代CPU处理器在核心之间交换数据的理论极限了。(译者注:再次惊叹,神乎其技啊!)
2 概述
Disruptor是我们在LMAX公司构建世界上最快的高性能金融交易平台过程中的研究成果。早期,我们的设计是基于SEDA派生和Actors模式的,使用管道来提供吞吐量。在评测了各种不同的实现之后,事实证明在各个管道的事件排队是主要的系统消耗来源。我们也发现队列产生相当的延迟和较高的时间偏差。我们花费了大量的精力去实现更高性能的队列,但是,事实证明队列作为一种基础的数据结构带有它的局限性——在生产者、消费者、
以及它们的数据存储之间的合并设计问题。Disruptor就是我们在构建这样一种能够清晰地分割这些关注问题的数据结构过程中所诞生的成果。
3 并发的复杂性
在我们这一段里我们来讨论并发。在计算机科学中,并发的意思是两个或两个以上的任务同时并行的执行,但是也要通过争抢来接入资源。争抢的资源可能是数据库、文件系统、套接字、甚至或者说内存中的一块区域。
并发的执行代码包括两个方面:互斥性和改变的可见性。互斥性是指线程对资源进行争用状态的改变的管理(译者注:从后面看出,这里的争用状态主要是指写的操作要保持互斥性),而改变可见性是指控制何时这种改变对其他线程可见。很明显,如果能消除争用就能够避免互斥性管理——如果有某种算法,能够确保任何给定的资源同一时刻只被一个线程修改,那么互斥性就不是必要的了。读和写操作需要所有改变对其他线程都是可见的,但是只有争用写操作需要保持互斥性。
在任何并发的环境中,争用写操作是花费最大代价的。为了支持多个并发的线程对同一块资源进行写操作是需要花费复杂而昂贵的代价来进行协调的。最典型的解决这种协调的方法是引入某种锁的策略。
3.1 锁的代价
锁提供了互斥性并且确保改变对其他线程的可见性以一种命令式的方式发生。锁的代价消耗是难以置信的大——因为它们当遇到争用时需要进行仲裁。这种仲裁是通过一种上下文切换到操作系统的内核,挂起线程等待锁的释放。在这样的上下文切换过程中,也会交还控制权给操作系统——操作系统此时可能同时决定去做其他一些请理性的工作,这样正在执行中的上下文对象将会丢失之前预读的缓存中的数据和指令(译者注:这里的缓存指的是CPU 缓存)。对现代CPU而言,这将会造成一系列的性能上的坏的影响。可以使用快速的用户模式的锁,但是这也仅当没有争用的时候能够带来真正的益处。
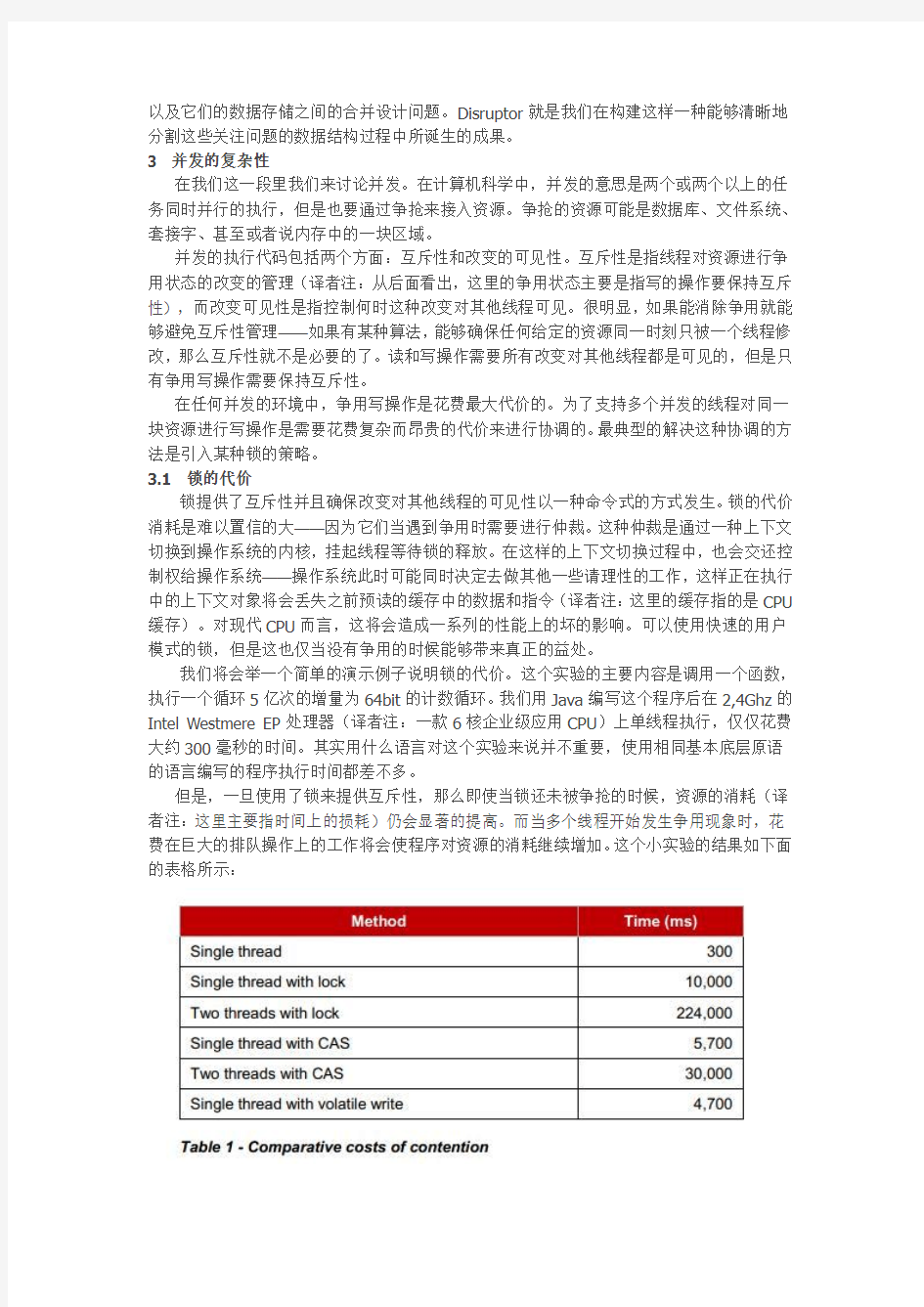
我们将会举一个简单的演示例子说明锁的代价。这个实验的主要内容是调用一个函数,执行一个循环5亿次的增量为64bit的计数循环。我们用Java编写这个程序后在2,4Ghz的Intel Westmere EP处理器(译者注:一款6核企业级应用CPU)上单线程执行,仅仅花费大约300毫秒的时间。其实用什么语言对这个实验来说并不重要,使用相同基本底层原语的语言编写的程序执行时间都差不多。
但是,一旦使用了锁来提供互斥性,那么即使当锁还未被争抢的时候,资源的消耗(译者注:这里主要指时间上的损耗)仍会显著的提高。而当多个线程开始发生争用现象时,花费在巨大的排队操作上的工作将会使程序对资源的消耗继续增加。这个小实验的结果如下面的表格所示:
3.2 CAS
在需要修改的内存数据仅为一个字长时,有些更有效的方案可以用来替代锁来进行内存修改。这些替代方案是基于原子性、互锁性的现代CPU实现的指令的。这些指令通常被称为“CAS”(Compare And Swap)操作,例如x86处理器上的"lock cmpxchg"。CAS操作是一种特殊的机器码指令,它在一定条件下可以允许对内存中一个字长的操作成为原子操作。在上一小节的计数器小实验中,每个线程轮流在一个循环中读取计算器并尝试在同一个原子指令中将计算器累加为新的值。累加后的新值和累加前的旧值一起作为该指令的参数,如果指令执行后计数器的值与指令的新值参数相同,则指令执行成功,将计数器的值置为新值;否则,如果计数器此时与指令的新值参数不同,则该CAS操作失败,此时回到线程重新读取计数器增量加到原来的新值参数上作为新的新值参数(译者注:即设指令为f,新值参数为B,旧值参数为A,计数增量为k:由f(A,B)改为f(B,B+k)重新执行指令),重复上述过程,直到指令执行成功。CAS方法比锁要有效得多,因为它不需要切换上下文到操作系统内核去仲裁。但是,CAS操作也并不是没有资源消耗的,处理器必须锁定它的指令通道去确保原子性,并且要创建一个内存栅栏(memory barrier)来使得状态的变化对其他线程可见。具体到实际的编程实现上,CAS操作在Java开发中,可以使用java.util.concurrent.Atomic.*包中的类来实现。
如果程序的关键部分要比我们上面举的计数器例子复杂,这就需要更加复杂的使用多个CAS操作的机器指令来协调线程间的争用。用锁来编写并发程序很难;用CAS操作和内存栅栏开发无锁算法来编写并发程序有时候更难!而且这样的程序更加难以测试,难以确保其正确性!(译者注:好绝望啊orz)
理想的算法应该是仅仅使用一个单线程来处理所有的对一个资源的写操作,而有多个线程执行读取处理结果的操作。在一个多处理器或多核处理器环境下处理对资源的读操作需要内存栅栏来确保一个线程状态改变对其他处理器上运行的线程可见。
3.3 内存栅栏
现代的处理器为了提高效率,采用无序的方式执行其指令、在内存和对应的执行单元间加载和存储数据。处理器仅仅需要确保程序逻辑执行出正确的结果而不去关心其执行顺序。这不是单线程程序的特性。但是当线程间彼此共享状态时为了确保数据交换的成功处理,在需要的时点,内存的改变能够按次序发生就是很重要的了。内存栅栏是处理器用来指出代码块在哪里修改内存是需要有序的进行的。它们是硬件排序和线程间保持彼此改变可见性的重要手段。编译器会在适当的位置设置合适的软件栅栏来确保代码按照正确的顺序编译,处理器本身也会使用这样的软件栅栏作为硬件栅栏的一种补充。
现代的处理器要比同代的内存快得多的多。为了填补这样一个速度差距的鸿沟,CPU使用了复杂的缓存系统——非常快的通过硬件实现的无链哈希表。这些缓存系统通过消息传递协议与其他处理器CPU的缓存系统保持协调一致。另外作为补充,处理器的“存储缓冲”可以将写操作从上述缓冲上卸载下来,在一个写操作将要发生的时候,缓存协调协议通过这样的一个“失效队列”快速的通知失效消息。
这些对于数据来说意味着,当某个数据值的最后一个版本刚刚被写操作执行之后,将会被存储登记给一个存储缓冲——可能是CPU的某一层缓存、或者是一块内存区域。如果线程想要共享这一数据,那么它需要以一种有序的方式轮流对其他线程可见,这是通过处理器协调消息的协调来实现的。这些及时的协调消息的生成,是又内存栅栏来控制的。
读操作内存栅栏对CPU的加载指令进行排序,通过失效队列来得知当前缓存的改变。这使得读操作内存栅栏对其之前的已排序的写操作有了一个持久化的视界。
写操作内存栅栏对CPU的存储指令进行排序,通过存储缓冲执行,因此,通过对应的CPU缓存来刷新写输出。写操作内存栅栏提供了一个在其之前的存储操作如何发生的、有序的视界。
一个完整的内存栅栏即对加载排序也对存储排序,但这只针对执行该栅栏的CPU。
一些CPU还有上述三种元件的变体,但是介绍这三种元件已经足够来理解相关的复杂联系了。在Java的内存模型中,对一个volatile类型成员变量的域的读和写,分别实现了读内存栅栏和写内存栅栏。(译者注:对volatile类型的成员变量虚拟机不采用优化策略,即不在每个线程中保存其副本,每次读取和修改都将到共享的内存域中进行)这在关于Java 内存模型的一篇文章中已经有很详细的描述
(https://www.360docs.net/doc/8615393634.html,/developerworks/library/j-jtp02244/index.html),上述这种特性已经随着Java 5一起发布。
3.4 缓存行
(译者注:这里缓存行实际上是单词cache line的拙劣翻译-_-! 意思是CPU缓存与物理内存间交互时所一次发生的数据,一般为64个字节)
现代处理器使用缓存的方式对成功的高性能操作而言具有重要的意义。这种处理器架构在数据搅动和指令存储方面有极大作用,反之,如果缓存出现丢失的话将对系能造成极大的影响。
我们的硬件在移动内存数据的时候不是以字节和字长为单位的,为了更加有效的工作,缓存被组织成缓存行的形式,每个缓存行为32-256个字节大小,一般是64字节。这是缓存协调协议操作的粒度层级。这意味着如果两个变量在同一个缓存行内,并且它们是被两个不同的线程写入的话,它们将会呈现出相同的写争用问题,就好像它们是一个变量一样!这就是“伪共享”概念。所以为了提高性能,应该确保独立的且并发的写操作、并且写操作的变量不在同一个缓存行内,可以使争用最小化。
当访问内存时,一个具有预读功能的CPU会通过预读的方式来减少访问时花费的延迟——CPU会预读有可能下次需要访问的数据、并在后台将其提取到缓存中。这种机制仅仅在处理器侦测到某种访问上的模式是时候启动,就好像是本来一步一步走路的内存访问突然来了个“跳跃”一样。比如,在对一个数组中的内容进行遍历的时候,上述的预读跳跃是会启动的,所以相应的内存数据会被提前提取到CPU缓存中,最大可能的提高了访问效率。上述跳跃一般来讲是不大于2048个字节的,或者说CPU能够预测到的字节也不大于这个数字。但是,像链表或树集这种由分散在内存空间不同位置的节点组成的数据结构,是没有办法启动预读跳跃的。这种在内存中没有规律的存储限制了系统预读内存行,会导致内存的访问效率下降两个数量级。
3.5 队列所带来的问题
一般来说队列是使用链表或者数组来作为其中元素的基本存储的。如果一个内存中的队列没有被限制大小成为无界队列时,在很多种类的问题当中它可能会没有被校验的增长——直到灾难性的出现内存耗尽为止,这种情况发生在生产者“跑”的比消费者快的时候。无界的队列在生产者确保不会跑的比消费者快的并且内存资源比较稀缺的系统中比较有用,但是如果这种假设不成立队列变得无限制的增长的话总会有一定的风险的。为了避免这种灾难发生,队列一般会被限制大小成为有界队列,方法是要么使用数组来实现队列、要么实时的去跟踪队列的大小。
队列的实现可能会在队首、队尾和记录队列大小的变量上发生写操作争用。在使用过程中,由于生产者和消费中跑的快慢不同,队列总是处于将满或者将空状态,而很少处于一种生产者快慢相当的平衡的中间状态。这种大部分时间处于将满或将空状态的倾向导致了大量的争用和昂贵的缓存协调代价。而且问题还在于即使用不同的并发对象(比如锁或CAS变
量)来分别实现头尾机制,它们通常会占用同一块缓存行。(译者注:发生伪共享,导致并行失败)
使用单个大粒度的带锁队列,生产者声明队首、消费者声明队尾、中间的存储节点用来设计并发,这样的实现管理起来非常复杂。队列上为了put和take操作的大粒度的锁实现起来很简单,但是会导致吞吐量上很大的瓶颈问题。如果只使用队列自有的语义模型来消除并发矛盾的话,那么除了单生产者单消费者这种情况之外,其他情况实现起来相当复杂。
在Java中使用队列还有另外一个问题,队列是很容易产生垃圾的结构。首先对象会被分配并置放在队列中,其次如果是使用链表实现的队列,那么对象需要被分配去实现链表中的节点。当不再被引用的时候,所有这些为支持队列实现所分配的对象需要被重新声明。(译者注:实际上是说在Java中,队列的垃圾回收代价很大,特别是对链表式队列而言)
3.6 管线和图
在许多种类的问题中把几个阶段处理捆绑为一个管线是个好办法,这些管线一般具有并行的路径,组成一种图状的拓扑结构。每个阶段之间的链接一般使用队列来实现,每个阶段具有其自己的线程。
这种方案的代价可不便宜——在每个阶段我们不得不花费工作单元进队和出队的开销。当有多个目标其路径分叉时会加倍这种开销,并且当上述分叉路径必须合并时也会遭受无法避免的争用的代价。
如果处理图状依赖拓扑结构时,能够避免在各阶段之间使用队列的开销的话,那将是非常理想的。
4 LMAX Disruptor的独特设计
在试着定位上面几段中描述的那些个问题的时候,一个通过严格剔除像队列导致的一系列问题为目标的设计浮现出来了。这个方案关注确保任何一块数据同一时刻只被一个线程执行写操作,因此便消除了写争用,这便是“Disruptor”框架。之所以叫这个名字,是因为它在处理依赖性拓扑结构的时候与Java 7中支持分叉合并的"Phasers"(译者注:Java7中引入的一种新的并发特性,属于一种新型并发barrier)有着相似的地方。
LMAX公司的Disruptor框架的设计被定位于上述问题,通过尝试最大化内存分配的效率、以缓存友好的工作方式优化在现代硬件上的性能。
处于Disruptor机制中心脏地位的是一个预先分配的有界数据结构形式——环状缓冲。数据通过一个或多个生产者添加到环状缓冲中,并通过一个或多个消费者从其中取出处理。
4.1 内存分配
环状缓冲(ring buffer)的所有内存空间是在启动的时候预先分配好的。环状缓冲既可以存储一整个数组的指向实体的指针、或者是代表实体本身的数据结构。由于Java语言本身的限制意味着实体是以对象的引用的形式存放在环状缓冲中的。每一个实体一般并不是直接存放的,而是放在一个容器里,而把容器放在缓冲中。这种实体存放空间的预分配的形式终结了支持垃圾回收机制的语言所带来的问题,因为实体会被重复使用并在Disruptor实例的生命周期中一致存在。这些实体的内存空间是在同一时刻分配好的,并且一般来说是在内存中连续的一块地址,因此支持缓存跳跃(译者注:即前文中提到的预读跳跃)。John Rose 有一篇关于Java语言的建议,介绍什么样的值类型允许Java的数组能够像其他语言、例如C 语言中那样确保分配给其的内存是连续的,从而避免使用指针寻址。
在一个像Java这样被管理的运行时环境中开发低延迟系统时,垃圾回收可能会是个问题。分配的内存越多,垃圾收集器的负担就越大。当对象的生命周期都极短或者对象永不销毁的情况下,垃圾收集器可以达到最佳性能(译者注:实际上是最小的负担)。环状缓冲中的实体内存是预先分配好的,意味着它在垃圾回收器工作的时候是永不销毁的,所以只带来很少的负担。
由于基于队列的系统在高负载时会导致执行率降低、并且导致分配的对象释放其所在空间上的延迟,所以一代又一代的垃圾收集器都在这一点上进行不断优化。这有两层意思:第一,对象不得不在每一代之间进行复制,这导致了不定的延迟。第二,这些对象可能会从旧代中收集,这可能会是更加消耗性的操作,可能增加“世界停止”一般的暂停,这发生在零碎的内存空间被重新压实的时候。在大内存堆中这会导致每GB数秒的暂停。
4.2 梳理影响因素
4.3 使用序列号
4.4 批量效应
当消费者等待环状缓冲中最新可用的游标序列号时会有一定几率发生一个在队列中不会发生的有趣的现象:如果消费者发现与它上次检查的时候相比,环状缓冲的游标已经向前走了许多步的话,它可以直接处理到那个最新的序列号而不必纠缠于并发机制。这样的结果是本来落后的生产者会重新赢得与之前突然爆发的生产者的赛跑比赛,重新平衡了系统。这种批量效应增加了处理吞吐量并减少和平稳了延迟。根据我们的观察,在内存子系统饱和之前,不管负载多大,这种效应的延迟始终接近一个时间常量,对应的变化曲线是线性的并遵循利特尔法则,这与我们使用队列时在负载不断增加时延迟呈指数级增长得到的J形曲线是截然不同的。
4.5 依赖关系
队列代表着一个生产者与消费者之间的简单单步管线依赖。如果消费者之间形成了某种链状或图状依赖关系的话,在图状依赖的每个阶段就都需要一个队列。在图的各个依赖阶段之间导致大量的队列固定时间消耗。在我们设计LMAX公司的金融交易平台的时候,我们的研究表明,基于队列的方案在事务处理中的执行延迟大量是花费在排队上了(译者注:大量花费在排队上而不是事务本身的处理逻辑)。
因为使用Disruptor模式分离了生产者与消费者矛盾,使得我们可以仅仅使用核心的环状缓冲来表示复杂的多个消费者之间的依赖关系。这减少了大量的执行上的固定消耗,并增加了吞吐处理能力、减少了延迟。
一个环状缓冲可以用来存储表示一整个工作流的复杂数据结构的实体。在设计这样的数据结构的时候必须注意,在被独立的不同消费者写入的时候要避免导致缓存行的伪共享。
4.6 Disruptor的类结构图
下面的类图描述了Disruptor框架的核心关系。如图中所示,易于使用的类可以简化编程模型。在建立了依赖关系之后,编程模式变得很简单。生产者通过ProducerBarrier使用序列号声明实体,在声明好的实体中写入改变,然后通过ProducerBarrier将实体提交回来并使其可以被消费者使用。而消费者仅仅需要提供一个BatchHandler的实现即可,该实现负责接收当一个新的实体可用时的回调请求。这种结果驱动编程模型是基于事件的,与Actor 模型有很多相似的地方。
在分离了使用队列实现所带来的问题之后,便可以实现更灵活的设计。Disruptor模式的核心——RingBuffer,可以提供存储使得数据的交换在不发生争用的情况下进行。经由生产者、消费者与RingBuffer的交互中分离出了传统并发所带来的问题。ProducerBarrier负责管理所有在环状缓冲中声明序列位置的并发问题,并跟踪各个消费者以确保这个环不会缠绕。(译者注:在RingBuffer这个环状的跑道上,最快的生产者超过了最慢的消费者,即为环的缠绕。)ConsumerBarrier用来提醒消费者是否有新的实体可用,这样消费者便可以构造图状的依赖关系用来表示一个处理关系中多个阶段。
4.7 代码示例
下面的代码是一个单生产者单消费者的例子,使用了方便的BatchHandler接口来实现消费者。消费者使用单独的线程来接收那些可用的实体。
//Callback handler which can be implemented by consumers
finalBatchHandler
{
public void onAvailable(final ValueEntryentry) throws Exception
{
// process a new entry as it becomesavailable.
}
public void onEndOfBatch() throws Exception
{
// useful for flushing results to an IOdevice if necessary.
}
public void onCompletion()
{
// do any necessary clean up beforeshutdown
}
};
RingBuffer
newRingBuffer
ClaimStrategy.Option.SINGLE_THREADED,
WaitStrategy.Option.YIELDING);
ConsumerBarrier
ringBuffer.createConsumerBarrier();
BatchConsumer
newBatchConsumer
ringBuffer.createProducerBarrier(batchConsumer);
//Each consumer can run on a separate thread
EXECUTOR.submit(batchConsumer);
//Producers claim entries in sequence
ValueEntryentry = producerBarrier.nextEntry();
//copy data into the entry container
//make the entry available to consumers
https://www.360docs.net/doc/8615393634.html,mit(entry);
5 吞吐量性能测试
作为对比,我们选取了Doug Lea的优秀数据结构
java.util.concurrent.ArrayBlockingQueue来作为参照,这种队列在我们测试中在所有的有界队列中是性能最好的。这些测试设置成一个阻塞的编程用来匹配Disruptor。这些个测试的详细代码已经包含在Disruptor的开源项目里了。注意:想运行这些测试的话需要能够并行运行四个线程能力的硬件环境。(译者注:恩,没错,这个Disruptor是个白富美框架,想护到她的,实力低于i5双核4线程的就赶紧去升级CPU吧。。。)
在上面的配置中,每条数据流的弧是用ArrayBlockingQueue来实现的,与之对比Disruptor 使用的是一种内存栅栏。下面的表格列出了每秒操作数的性能测试的结果,使用Java 1.6.0_25 64-bit Sun JVM,Windows 7,Intel Core i7 860 @2.8GHz 不带超线程,另一组使用Intel Core i7-2720QM,Ubuntu 11.04,取3组处理5亿次消息测试中最好的一组作为测试成绩。测试在不同的JVM上执行都得到类似的结果,并且如下数据上的差距并不是我们测试观察中最大的。
6 延迟性能测试
为了测量延迟,我们准备了一个三个阶段的管线,并生成少于饱和的事件量。这通过在注入一个事件后等待1毫秒然后在注入另一个事件来实现,上述动作执行5千万次。要做到这如此精密的情况下计时,有必要使用CPU的时间戳计数器了。我们选择带有不变TSC 值的CPU,因为旧型号的CPU为了节省电源休眠状态通常切换比较频繁,Intel Nehalem和其之后的处理器使用了不变的TSC,可以在Ubuntu 11.04上用最新的Oracle JVM访问。这个测试没有使用CPU绑定。
为了对比,我们再一次使用了ArrayBlockingQueue,我们本可以用ConcurrentLinkedQueue的,这样可能会得到更好的测试成绩,但是想使用一种有界队列的实现来避免产生更多后台压力使生产者比消费者跑得快。下面的结果是基于2.2GHz Core i7-2720QM,Java 1.6.0_25 64-bit,Ubuntu 11.04。
每次循环的平均延迟,Disruptor为52纳秒,ArrayBlockingQueue是32757纳秒。研究表明,锁和通过条件变量传递信号是ArrayBlockingQueue主要的延迟来源。
7 结论
Disruptor在一个许多应用都要考虑的重要方面,迈出了重要一步,——即如何在一个可预估的延迟范围内,提高并发执行的上下文吞吐量和减少延迟。我们的测试表明它是具有出色性能的进程间数据交互方案。我们相信对这种数据交互来说,Disruptor是最高性能的机制。通过专注于准确的分离线程间数据交互带来的问题、通过避免写争用和最少化的读争用、通过保证程序代码能够适应现代处理器的缓存模式,我们创造了一种高效的在应用的线程间交换数据的机制。
Disruptor特有的批量效应允许多个消费者在没有任何争用抢占的情况下、在一个确定的起始点下处理输入,这为高性能系统引入了一个新的特性。对于大多数的系统来说,随着负载的不断加大、争用抢占的情况不断增多,系统的延迟会呈指数级增加——典型的“J”形曲线(译者注:以负载为x轴,延迟为y轴,由压测数据制作的曲线)。而对于Disruptor,随着负载的增加,延迟在系统的内存饱和之前几乎是保持平稳的,一条几乎水平的曲线。
我们相信,Disruptor为高性能计算建立了一个新的基准,也(译者注:在Java应用代码层面)为更有效的利用现代处理器和计算机结构提供了新的参考意义。
解决多线程中11个常见问题
并发危险 解决多线程代码中的11 个常见的问题 Joe Duffy 本文将介绍以下内容:?基本并发概念 ?并发问题和抑制措施 ?实现安全性的模式?横切概念本文使用了以下技术: 多线程、.NET Framework 目录 数据争用 忘记同步 粒度错误 读写撕裂 无锁定重新排序 重新进入 死锁 锁保护 戳记 两步舞曲 优先级反转 实现安全性的模式 不变性 纯度 隔离 并发现象无处不在。服务器端程序长久以来都必须负责处理基本并发编程模型,而随着多核处理器的日益普及,客户端程序也将需要执行一些任务。随着并发操作的不断增加,有关确保安全的问题也浮现出来。也就是说,在面对大量逻辑并发操作和不断变化的物理硬件并行性程度时,程序必须继续保持同样级别的稳定性和可靠性。 与对应的顺序代码相比,正确设计的并发代码还必须遵循一些额外的规则。对内存的读写以及对共享资源的访问必须使用同步机制进行管制,以防发生冲突。另外,通常有必要对线程进行协调以协同完成某项工作。 这些附加要求所产生的直接结果是,可以从根本上确保线程始终保持一致并且保证其顺利向前推进。同步和协调对时间的依赖性很强,这就导致了它们具有不确定性,难于进行预测和测试。 这些属性之所以让人觉得有些困难,只是因为人们的思路还未转变过来。没有可供学习的专门API,也没有可进行复制和粘贴的代码段。实际上的确有一组基础概念需要您学习和适应。很可能随着时间的推移某些语言和库会隐藏一些概念,但如果您现在就开始执行并发操作,则不会遇到这种情况。本
文将介绍需要注意的一些较为常见的挑战,并针对您在软件中如何运用它们给出一些建议。 首先我将讨论在并发程序中经常会出错的一类问题。我把它们称为“安全隐患”,因为它们很容易发现并且后果通常比较严重。这些危险会导致您的程序因崩溃或内存问题而中断。 当从多个线程并发访问数据时会发生数据争用(或竞争条件)。特别是,在一个或多个线程写入一段数据的同时,如果有一个或多个线程也在读取这段数据,则会发生这种情况。之所以会出现这种问题,是因为Windows 程序(如C++ 和Microsoft .NET Framework 之类的程序)基本上都基于共享内存概念,进程中的所有线程均可访问驻留在同一虚拟地址空间中的数据。静态变量和堆分配可用于共享。请考虑下面这个典型的例子: static class Counter { internal static int s_curr = 0; internal static int GetNext() { return s_curr++; } } Counter 的目标可能是想为GetNext 的每个调用分发一个新的唯一数字。但是,如果程序中的两个线程同时调用GetNext,则这两个线程可能被赋予相同的数字。原因是s_curr++ 编译包括三个独立的步骤: 1.将当前值从共享的s_curr 变量读入处理器寄存器。 2.递增该寄存器。 3.将寄存器值重新写入共享s_curr 变量。 按照这种顺序执行的两个线程可能会在本地从s_curr 读取了相同的值(比如42)并将其递增到某个值(比如43),然后发布相同的结果值。这样一来,GetNext 将为这两个线程返回相同的数字,导致算法中断。虽然简单语句s_curr++ 看似不可分割,但实际却并非如此。 忘记同步 这是最简单的一种数据争用情况:同步被完全遗忘。这种争用很少有良性的情况,也就是说虽然它们是正确的,但大部分都是因为这种正确性的根基存在问题。 这种问题通常不是很明显。例如,某个对象可能是某个大型复杂对象图表的一部分,而该图表恰好可使用静态变量访问,或在创建新线程或将工作排入线程池时通过将某个对象作为闭包的一部分进行传递可变为共享图表。 当对象(图表)从私有变为共享时,一定要多加注意。这称为发布,在后面的隔离上下文中会对此加以讨论。反之称为私有化,即对象(图表)再次从共享变为私有。 对这种问题的解决方案是添加正确的同步。在计数器示例中,我可以使用简单的联锁: static class Counter { internal static volatile int s_curr = 0; internal static int GetNext() { return Interlocked.Increment(ref s_curr);
java多线程面试题
java多线程面试题 1.什么是多线程编程?什么时候使用? 多线程一般用于当一个程序需要同时做一个以上的任务。多线程通常用于GUI交互程序。一个新的线程被创建做一些耗时的工作,当主线程保持界面与用户的交互。 2.为什么wait(),notify()和notifyall()函数定义在Object类里面? 因为所有类都是继承于Object类,这样所有类就可以简单的进行多线程编程了。 3.wait()方法和sleep()方法有什么不同? sleep()方法执行后仍然拥有线程,只是延时。而wait方法放弃了线程控制,其它线程可以运行,想要再次运行是要重新开始。 4.Thread和Runnable有什么不同? JA V A线程控制着程序执行的主路径。当你用java命令调用JVM时,JVM创建了一个隐式线程来执行main方法。Thread类提供了主线程调用其它线程并行运行的机制。 Runnable接口定义了一个能被Thread运行的类。实现Runnable的类只需要实行run方法。可以很灵活的扩展现在的已经继承自其它父类的类。而thread则不可以,因为java 只允许继承一个父类。 Runnable可以共享数据,Thread是一个类,而Runnable是一个接口 5.我可以重载start()方法么? 可以重载,重载后还要重载run()方法, 9.编译运行下面的代码会发生什么? 1.public class Bground extends Thread{ 2.public static void main(String argv[]) 3.{ 4. Bground b = new Bground(); 5. b.run(); 6.} 7.public void start()
JAVA 面试题总览(书签完整版)
JAVA面试题总览 JAVA基础 1.JAVA中的几种基本数据类型是什么,各自占用多少字节。 2.String类能被继承吗,为什么。 3.String,Stringbuffer,StringBuilder的区别。 4.ArrayList和LinkedList有什么区别。 5.讲讲类的实例化顺序,比如父类静态数据,构造函数,字段,子类静态数据,构造函数, 字段,当new的时候,他们的执行顺序。 6.用过哪些Map类,都有什么区别,HashMap是线程安全的吗,并发下使用的Map是什么, 他们内部原理分别是什么,比如存储方式,hashcode,扩容,默认容量等。 7.JAVA8的ConcurrentHashMap为什么放弃了分段锁,有什么问题吗,如果你来设计, 你如何设计。 8.有没有有顺序的Map实现类,如果有,他们是怎么保证有序的。 9.抽象类和接口的区别,类可以继承多个类么,接口可以继承多个接口么,类可以实现多个接 口么。 10.继承和聚合的区别在哪。 11.IO模型有哪些,讲讲你理解的nio,他和bio,aio的区别是啥,谈谈reactor模型。 12.反射的原理,反射创建类实例的三种方式是什么。 13.反射中,Class.forName和ClassLoader区别。 14.描述动态代理的几种实现方式,分别说出相应的优缺点。 15.动态代理与cglib实现的区别。 16.为什么CGlib方式可以对接口实现代理。 17.final的用途。 18.写出三种单例模式实现。 19.如何在父类中为子类自动完成所有的hashcode和equals实现?这么做有何优劣。 20.请结合OO设计理念,谈谈访问修饰符public、private、protected、default在应 用设计中的作用。 21.深拷贝和浅拷贝区别。 22.数组和链表数据结构描述,各自的时间复杂度。 23.error和exception的区别,CheckedException,RuntimeException的区别。 24.请列出5个运行时异常。 25.在自己的代码中,如果创建一个https://www.360docs.net/doc/8615393634.html,ng.String类,这个类是否可以被类加载器加 载?为什么。
多线程常见面试题
1)现在有T1、T2、T3三个线程,你怎样保证T2在T1执行完后执行,T3在T2执行完 后执行? T1.start(); T1.join(); T2.start(); T2.join(); T3.start() 2)11) 为什么我们调用start()方法时会执行run()方法,为什么我们不能直接调用run() 方法? start()方法最本质的功能是从CPU中申请另一个线程空间来执行run()方法中的代码,它和当前的线程是两条线,在相对独立的线程空间运行 ,也就是说,如果你直接调用线程对象的run()方法,当然也会执行,但那是在当前线程中执行,run()方法执行完成后继续执行下面的代码.而调用start()方法后,run()方法的代码会和当前线程并发(单CPU)或并行(多CPU)执行。 调用线程对象的run方法不会产生一个新的线程 3)在java中wait和sleep方法的不同? sleep()睡眠时,保持对象锁,仍然占有该锁; 而wait()睡眠时,释放对象锁。 sleep()使当前线程进入停滞状态(阻塞当前线程),让出CUP的使用、目的是不让当前线程独自霸占该进程所获的CPU资源,以留一定时间给其他线程执行的机会; sleep()是Thread类的Static(静态)的方法;因此他不能改变对象的机锁,所以当在一个Synchronized块中调用Sleep()方法是,线程虽然休眠了,但是对象的机锁并木有被释放,其他线程无法访问这个对象(即使睡着也持有对象锁)。 在sleep()休眠时间期满后,该线程不一定会立即执行,这是因为其它线程可能正在运行而且没有被调度为放弃执行,除非此线程具有更高的优先级。 wait()方法是Object类里的方法;当一个线程执行到wait()方法时,它就进入到一个和该对象相关的等待池中,同时失去(释放)了对象的机锁(暂时失去机锁,wait(long timeout)超时时间到后还需要返还对象锁);其他线程可以访问; wait()使用notify或者notifyAlll或者指定睡眠时间来唤醒当前等待池中的线程。 wiat()必须放在synchronized block中,否则会在program runtime时扔出”https://www.360docs.net/doc/8615393634.html,ng.IllegalMonitorStateException“异常。 4)为什么wait, notify 和notifyAll这些方法不在thread类里面? 因为这些是关于锁的 而锁是针对对象的 锁用于线程的同步应用 决定当前对象的锁的方法就应该在对象中吧 我是这么理解的希望对你有帮助
JAVA多线程试题 答案
多线程 一.选择题 1.下列说法中错误的一项是(A) A.线程就是程序 B.线程是一个程序的单个执行流 B.多线程是指一个程序的多个执行流D.多线程用于实现并发 2.下列哪个一个操作不能使线程从等待阻塞状态进入对象阻塞状态(D) A.等待阴塞状态下的线程被notify()唤 B.等待阻塞状态下的纯种被interrput()中断 C.等待时间到 D.等待阻塞状态下的线程调用wait()方法 3.下列哪个方法可以使线程从运行状态进入其他阻塞状态(A) A.sleep B.wait C.yield D.start 4.下列说法中错误的一项是(D) A.一个线程是一个Thread类的实例 B.线程从传递给纯种的Runnable实例run()方法开始执行 C.线程操作的数据来自Runnable实例 D.新建的线程调用start()方法就能立即进入运行状态 5.下列关于Thread类提供的线程控制方法的说法中,错误的一项是(D) A.在线程A中执行线程B的join()方法,则线程A等待直到B执行完成 B.线程A通过调用interrupt()方法来中断其阻塞状态 C.若线程A调用方法isAlive()返回值为true,则说明A正在执行中 D.currentThread()方法返回当前线程的引用 6.下列说法中,错误的一项是() A.对象锁在synchronized()语句执行完之后由持有它的线程返还 B.对象锁在synchronized()语句中出现异常时由持有它的线程返还 C.当持有锁的线程调用了该对象的wait()方法时,线程将释放其持有的锁 D.当持有锁的线程调用了该对象的构造方法时,线程将释放其持有的锁 7.下面的哪一个关键字通常用来对对象的加锁,从而使得对对象的访问是排他的A A.sirialize B transient C synchronized D static 二.填空题 1.在操作系统中,被称做轻型的进程是线程 2.多线程程序设计的含义是可以将一个程序任务分成几个并行的任务 3.在Java程序中,run()方法的实现有两种方式:实现Runnable接口和继承Thread类 4.多个线程并发执行时,各个线程中语句的执行顺序是确定的,但是线程之间的相对执行顺序是不确定的 6.Java中的对象锁是一种独占的排他锁 7.程序中可能出现一种情况:多个线种互相等待对方持有的锁,而在得到对方的锁之前都不会释放自己的锁,这就是死锁 8.线程的优先级是在Thread类的常数MIN_PRIORITY和MAX_PRIORITY 之间的一个值 9.处于新建状态的线程可以使用的控制方法是start()和stop()。 10.一个进程可以包含多个线程
精选大厂java多线程面试题50题
Java多线程50题 1)什么是线程? 线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。程序员可以通过它进行多处理器编程,你可以使用多线程对运算密集型任务提速。比如,如果一个线程完成一个任务要100毫秒,那么用十个线程完成改任务只需10毫秒。 2)线程和进程有什么区别? 线程是进程的子集,一个进程可以有很多线程,每条线程并行执行不同的任务。不同的进程使用不同的内存空间,而所有的线程共享一片相同的内存空间。别把它和栈内存搞混,每个线程都拥有单独的栈内存用来存储本地数据。更多详细信息请点击这里。 3)如何在Java中实现线程? https://www.360docs.net/doc/8615393634.html,ng.Thread类的实例就是一个线程但是它需要调用https://www.360docs.net/doc/8615393634.html,ng.Runnable接口来执行,由于线程类本身就是调用的 Runnable接口所以你可以继承https://www.360docs.net/doc/8615393634.html,ng.Thread类或者直接调用Runnable接口来重写run()方法实现线程。 4)Thread类中的start()和run()方法有什么区别? 这个问题经常被问到,但还是能从此区分出面试者对Java线程模型的理解程度。start()方法被用来启动新创建的线程,而且start()内部调用了run()方法,这和直接调用run()方法的效果不一样。当你
调用run()方法的时候,只会是在原来的线程中调用,没有新的线程启动,start()方法才会启动新线程。 5)Java中Runnable和Callable有什么不同? Runnable和Callable都代表那些要在不同的线程中执行的任务。Runnable从JDK1.0开始就有了,Callable是在JDK1.5增加的。它们的主要区别是Callable的call()方法可以返回值和抛出异常,而Runnable的run()方法没有这些功能。Callable可以返回装载有计算结果的Future对象。 6)Java内存模型是什么? Java内存模型规定和指引Java程序在不同的内存架构、CPU 和操作系统间有确定性地行为。它在多线程的情况下尤其重要。 Java内存模型对一个线程所做的变动能被其它线程可见提供了保证,它们之间是先行发生关系。 ●线程内的代码能够按先后顺序执行,这被称为程序次序 规则。 ●对于同一个锁,一个解锁操作一定要发生在时间上后发 生的另一个锁定操作之前,也叫做管程锁定规则。 ●前一个对Volatile的写操作在后一个volatile的读操作之 前,也叫volatile变量规则。 ●一个线程内的任何操作必需在这个线程的start()调用之 后,也叫作线程启动规则。 ●一个线程的所有操作都会在线程终止之前,线程终止规
15个Java多线程面试题及答案
15个Java多线程面试题及答案 1)现在有T1、T2、T3三个线程,你怎样保证T2在T1执行完后执行,T3在T2执行完后执行? 这个线程问题通常会在第一轮或电话面试阶段被问到,目的是检测你对”join”方法是否熟悉。这个多线程问题比较简单,可以用join方法实现。 2)在Java中Lock接口比synchronized块的优势是什么?你需要实现一个高效的缓存,它允许多个用户读,但只允许一个用户写,以此来保持它的完整性,你会怎样去实现它? lock接口在多线程和并发编程中最大的优势是它们为读和写分别提 供了锁,它能满足你写像ConcurrentHashMap这样的高性能数据结构和有条件的阻塞。Java线程面试的问题越来越会根据面试者的回答来提问。芯学苑老师强烈建议在你在面试之前认真读一下Locks,因为当前其大量用于构建电子交易终统的客户端缓存和交易连接空间。 3)在java中wait和sleep方法的不同?
通常会在电话面试中经常被问到的Java线程面试问题。最大的不同是在等待时wait会释放锁,而sleep一直持有锁。Wait通常被用于线程间交互,sleep通常被用于暂停执行。 4)用Java实现阻塞队列。 这是一个相对艰难的多线程面试问题,它能达到很多的目的。第一,它可以检测侯选者是否能实际的用Java线程写程序;第二,可以检测侯选者对并发场景的理解,并且你可以根据这个问很多问题。如果他用wait()和notify()方法来实现阻塞队列,你可以要求他用最新的Java 5中的并发类来再写一次。 5)用Java写代码来解决生产者——消费者问题。 与上面的问题很类似,但这个问题更经典,有些时候面试都会问下面的问题。在Java中怎么解决生产者——消费者问题,当然有很多解决方法,我已经分享了一种用阻塞队列实现的方法。有些时候他们甚至会问怎么实现哲学家进餐问题。 6)用Java编程一个会导致死锁的程序,你将怎么解决?
windows 并发的多线程的应用
(1)苹果香蕉问题 #include 多线程与并发面试题 JAVA多线程和并发基础面试问答 原文链接译文连接作者:Pankaj 译者:郑旭东校对:方腾飞 多线程和并发问题是Java技术面试中面试官比较喜欢问的问题之一。在这里,从面试的角度列出了大部分重要的问题,可是你依然应该牢固的掌握Java多线程基础知识来对应日后碰到的问题。(校对注:非常赞同这个观点) Java多线程面试问题 1. 进程和线程之间有什么不同? 一个进程是一个独立(self contained)的运行环境,它能够被看作一个程序或者一个应用。而线程是在进程中执行的一个任务。Java运行环境是一个包含了不同的类和程序的单一进程。线程能够被称为轻量级进程。线程需要较少的资源来创立和驻留在进程中,而且能够共享进程中的资源。 2. 多线程编程的好处是什么? 在多线程程序中,多个线程被并发的执行以提高程序的效率,CPU不会因为某个线程需要等待资源而进入空闲状态。多个线程共享堆内存(heap memory),因此创立多个线程去执行一些任务会比创立多个进程更好。举个例子,Servlets比CGI更好,是因为Servlets支持多线程而CGI不支持。 3. 用户线程和守护线程有什么区别? 当我们在Java程序中创立一个线程,它就被称为用户线程。一个守护线程是在后台执行而且不会阻止JVM终止的线程。当没有用户线程在运行的时候,JVM关闭程序而且退出。一个守护线程创立的子线程依然是守护线程。 4. 我们如何创立一个线程? 有两种创立线程的方法:一是实现Runnable接口,然后将它传递给Thread的构造函数,创立一个Thread对象;二是直接继承Thread类。若想了解更多能够阅读这篇关于如何在Java中创立线程的文章。 5. 有哪些不同的线程生命周期? ava最新常见面试题+ 答案汇总 1、面试题模块汇总 面试题包括以下十九个模块:Java 基础、容器、多线程、反射、对象拷贝、Java Web 模块、异常、网络、设计模式、Spring/Spring MVC、Spring Boot/Spring Cloud、Hibernate、Mybatis、RabbitMQ、Kafka、Zookeeper、MySql、Redis、JVM 。如下图所示: 可能对于初学者不需要后面的框架和JVM 模块的知识,读者朋友们可根据自己的情况,选择对应的模块进行阅读。 适宜阅读人群 需要面试的初/中/高级java 程序员 想要查漏补缺的人 想要不断完善和扩充自己java 技术栈的人 java 面试官 具体面试题 下面一起来看208 道面试题,具体的内容。 一、Java 基础 1.JDK 和JRE 有什么区别? 2.== 和equals 的区别是什么? 3.两个对象的hashCode()相同,则equals()也一定为true,对吗? 4.final 在java 中有什么作用? 5.java 中的Math.round(-1.5) 等于多少? 6.String 属于基础的数据类型吗? 7.java 中操作字符串都有哪些类?它们之间有什么区别? 8.String str="i"与String str=new String(“i”)一样吗? 9.如何将字符串反转? 10.String 类的常用方法都有那些? 11.抽象类必须要有抽象方法吗? 12.普通类和抽象类有哪些区别? 13.抽象类能使用final 修饰吗? 14.接口和抽象类有什么区别? 15.java 中IO 流分为几种? 16.BIO、NIO、AIO 有什么区别? 17.Files的常用方法都有哪些? 二、容器 18.java 容器都有哪些? 19.Collection 和Collections 有什么区别? 20.List、Set、Map 之间的区别是什么? 21.HashMap 和Hashtable 有什么区别? 22.如何决定使用HashMap 还是TreeMap? 23.说一下HashMap 的实现原理? 24.说一下HashSet 的实现原理? 25.ArrayList 和LinkedList 的区别是什么? 26.如何实现数组和List 之间的转换? 27.ArrayList 和Vector 的区别是什么? 28.Array 和ArrayList 有何区别? 29.在Queue 中poll()和remove()有什么区别? 30.哪些集合类是线程安全的? 31.迭代器Iterator 是什么? 32.Iterator 怎么使用?有什么特点? 33.Iterator 和ListIterator 有什么区别? 34.怎么确保一个集合不能被修改? 多线程 一、单项选择题(从下列各题四个备选答案中选出一个正确答案,并将其代号写在答题纸相应位置处。答案错选或未选者,该题不得分。)50 1.下述哪个选项为真?( ) A.Error类是一个RoutimeException异常 B.任何抛出一个RoutimeException异常的语句必须包含在try块之内 C.任何抛出一个Error对象的语句必须包含在try块之内 D. 任何抛出一个Exception异常的语句必须包含在try块之内 2.下列关于Java线程的说法哪些是正确的?( ) A.每一个Java线程可以看成由代码、一个真实的CPU以及数据3部分组成 B.创建线程的两种方法,从Thread类中继承的创建方式可以防止出现多父类问题 C.Thread类属于java.util程序包 D.以上说法无一正确 3.哪个关键字可以对对象加互斥锁?( ) A.transient B.synchronized C.serialize D.static 4.下列哪个方法可用于创建一个可运行的类?() A.public class X implements Runable { public void run() {……} } B. public class X implements Thread { public void run() {……} } C. public class X implements Thread { public int ru n() {……} } D.public class X implements Runable { protected void run() {……} } 5.下面哪个选项不会直接引起线程停止执行?( ) A.从一个同步语句块中退出来 B.调用一个对象的wait方法 C.调用一个输入流对象的read方法 D.调用一个线程对象的setPriority方法 6.使当前线程进入阻塞状态,直到被唤醒的方法是( ) A.resume()方法 B.wait()方法 C.suspend()方法 D.notify()方法 7.运行下列程序,会产生的结果是( ) public class X extends Thread implements Runnable { public void run(){ System.out.println(“this is run()”); } public static void main(String[] args) { Thread t=new Thread(new X()); t.start(); } 2019年Java并发面试题整理(答案) 1、多线程的价值? (1)发挥多核CPU 的优势 多线程,可以真正发挥出多核CPU 的优势来,达到充分利用CPU 的目的,采用多线程的方式去同时完成几件事情而不互相干扰。 (2)防止阻塞 从程序运行效率的角度来看,单核CPU 不但不会发挥出多线程的优势,反而会因为在单核CPU 上运行多线程导致线程上下文的切换,而降低程序整体的效率。但是单核CPU 我们还是要应用多线程,就是为了防止阻塞。试想,如果单核CPU 使用单线程,那么只要这个线程阻塞了,比方说远程读取某个数据吧,对端迟迟未返回又没有设置超时时间,那么你的整个程序在数据返回回来之前就停止运行了。多线程可以防止这个问题,多条线程同时运行,哪怕一条线程的代码执行读取数据阻塞,也不会影响其它任务的执行。 (3)便于建模 这是另外一个没有这么明显的优点了。假设有一个大的任务A,单线程编程,那么就要考虑很多,建立整个程序模型比较麻烦。但是如果把这个大的任务A 分解成几个小任务,任务B、任务C、任务D,分别建立程序模型,并通过多线程分别运行这几个任务,那就简单很多了。 2、实现可见性的方法有哪些? synchronized 或者Lock:保证同一个时刻只有一个线程获取锁执行代码,锁释放之前把最新的值刷新到主内存,实现可见性。 3、并发编程三要素? (1)原子性 原子性指的是一个或者多个操作,要么全部执行并且在执行的过程中不被其他操作打断,要么就全部都不执行。 (2)可见性 可见性指多个线程操作一个共享变量时,其中一个线程对变量进行修改后,其他线程可以立即看到修改的结果。 (3)有序性 有序性,即程序的执行顺序按照代码的先后顺序来执行。 java多线程并发面试题【java多线程和并 发基础面试题】 多线程和并发问题是Java技术面试中面试官比较喜欢问的问题之一。下面就由小编为大家介绍一下java多线程和并发基础面试题的文章,欢迎阅读。 java多线程和并发基础面试题篇1 1. 进程和线程之间有什么不同? 一个进程是一个独立(self contained)的运行环境,它可以被看作一个程序或者一个应用。而线程是在进程中执行的一个任务。Java运行环境是一个包含了不同的类和程序的单一进程。线程可以被称为轻量级进程。线程需要较少的来创建和驻留在进程中,并且可以共享进程中的。 2. 多线程编程的好处是什么? 在多线程程序中,多个线程被并发的执行以提高程序的效率,CPU不会因为某个线程需要等待而进入空闲状态。多个线程共享堆内存(heap memory),因此创建多个线程去执行一些任务会比创建多个进程更好。举个例子,Servlets比CGI更好,是因为Servlets支持多线程而CGI不支持。 3. 用户线程和守护线程有什么区别? 当我们在Java程序中创建一个线程,它就被称为用户线程。一个守护线程是在后台执行并且不会阻止JVM终止的 线程。当没有用户线程在运行的时候,JVM关闭程序并且退出。一个守护线程创建的子线程依然是守护线程。 4. 我们如何创建一个线程? 有两种创建线程的方法:一是实现Runnable接口,然后将它传递给Thread的构造函数,创建一个Thread对象;二是直接继承Thread类。 java多线程和并发基础面试题篇2 1. 有哪些不同的线程生命周期? 当我们在Java程序中新建一个线程时,它的状态是New。当我们调用线程的start()方法时,状态被改变为Runnable。线程调度器会为Runnable线程池中的线程分配CPU时间并且讲它们的状态改变为Running。其他的线程状态还有Waiting,Blocked 和Dead。 2. 可以直接调用Thread类的run()方法么? 当然可以,但是如果我们调用了Thread的run()方法,它的行为就会和普通的方法一样,为了在新的线程中执行我们的代码,必须使用Thread.start()方法。 3. 如何让正在运行的线程暂停一段时间? 我们可以使用Thread类的Sleep()方法让线程暂停一段时间。需要注意的是,这并不会让线程终止,一旦从休眠中唤醒线程,线程的状态将会被改变为Runnable,并且根据线程调度,它将得到执行。 26. 多线程(04) 本季讲解了线程通讯的经典案例,之后又讲解了Object类中对线程的支持,以及面试题目。 blog:[零基础学JAVA]Java SE应用部分-26.多线程(04) 2009-02-19 生产者和消费者问题(1) 生产者和消费者问题(2) class Person{ String name = "张三"; String sex = "男"; // 张三--> 男 // 李四--> 女 } class Pro implements Runnable{ //声明一个共享区域 Person per = null; public Pro(Person p){ this.per = p; } public void run(){ int i = 0; while(true){ if (i==0){ https://www.360docs.net/doc/8615393634.html, = "李四"; per.sex = "女"; i=1; }else{ https://www.360docs.net/doc/8615393634.html, = "张三"; per.sex = "男"; i =0; } } } } class Cus implements Runnable{ Person per = null; public Cus(Person p){ this.per = p; } public void run(){ while(true){ System.out.println(https://www.360docs.net/doc/8615393634.html,+" -->"+per.sex); } } } public class ThreadDemo01{ public static void main(String args[]){ Person per = new Person(); Pro p = new Pro(per); Cus c = new Cus(per); new Thread(p).start(); new Thread(c).start(); } } 看下效果: 并发危险:解决多线程代码中的11 个常见的问题 并发危险 解决多线程代码中的11 个常见的问题 Joe Duffy 目录 数据争用忘记同步粒度错误读写撕裂无锁定重新排序重新进入死锁锁保护戳记两步舞曲优先级反转实现安全性的模式不变性纯度隔离并发现象无处不在。服 务器端程序长久以来都必须负责处理基本并发编程模型,而随着多核处理器的日益普及,客户端程序也将需要执行一些任务。随着并发操作的不断增加,有关确保安 全的问题也浮现出来。也就是说,在面对大量逻辑并发操作和不断变化的物理硬件并行性程度时,程序必须继续保持同样级别的稳定性和可靠性。 与对应的顺序代码相比,正确设计的并发代码还必须遵循一些额外的规则。对内存的读写以及对共享资源的访问必须使用同步机制进行管制,以防发生冲突。另外,通常有必要对线程进行协调以协同完成某项工作。 这些附加要求所产生的直接结果是,可以从根本上确保线程始终保持一致并且保证其顺利向前推进。同步和协调对时间的依赖性很强,这就导致了它们具有不确定性,难于进行预测和测试。 这 些属性之所以让人觉得有些困难,只是因为人们的思路还未转变过来。没有可供学习的专门 API,也没有可进行复制和粘贴的代码段。实际上的确有一组基础概念需要您学习和适应。很可能随着时间的推移某些语言和库会隐藏一些概念,但如果您现在就 开始执行并发操作,则不会遇到这种情况。本文将介绍需要注意的一些较为常见的挑战,并针对您在软件中如何运用它们给出一些建议。 首先我将讨论在并发程序中经常会出错的一类问题。我把它们称为“安全隐患”,因为它们很容易发现并且后果通常比较严重。这些危险会导致您的程序因崩溃或内存问题而中断。当 从多个线程并发访问数据时会发生数据争用(或竞争条件)。特别是,在一个或多个线程写入一段数据的同时,如果有一个或多个线程也在读取这段数据,则会发生 这种情况。之所以会出现这种问题,是因为Windows 程序(如C++ 和Microsoft .NET Framework 线程或者说多线程,是我们处理多任务的强大工具。线程和进程是不同的,每个进程都是一个独立运行 的程序,拥有自己的变量,且不同进程间的变量不能共享;而线程是运行在进程内部的,每个正在运行的进程至少有一个线程,而且不同的线程之间可以在进程范围内共享数据。也就是说进程有自己独立的存储 空间,而线程是和它所属的进程内的其他线程共享一个存储空间。线程的使用可以使我们能够并行地处理 一些事情。线程通过并行的处理给用户带来更好的使用体验,比如你使用的邮件系统(outlook、Thunderbird、foxmail等),你当然不希望它们在收取新邮件的时候,导致你连已经收下来的邮件都无法阅读,而只能等待收取邮件操作执行完毕。这正是线程的意义所在。 实现线程的方式 实现线程的方式有两种: 1.继承https://www.360docs.net/doc/8615393634.html,ng.Thread,并重写它的run()方法,将线程的执行主体放入其中。 2. 实现https://www.360docs.net/doc/8615393634.html,ng.Runnable接口,实现它的run()方法,并将线程的执行主体放入其中。 这是继承Thread类实现线程的示例: [java]view plaincopyprint? 1.public class ThreadTest extends Thread { 线程编程方面java笔试题 60、java中有几种方法可以实现一个线程?用什么关键字修饰同步方法? stop()和suspend()方法为何不推荐使用? 答:有两种实现方法,分别是继承Thread类与实现Runnable接口 用synchronized关键字修饰同步方法 反对使用stop(),是因为它不安全。它会解除由线程获取的所有锁定,而且如果对象处于一种不连贯状态,那么其他线程能在那种状态下检查和修改它们。结果很难检查出真正的问题所在。suspend()方法容易发生死锁。调用suspend()的时候,目标线程会停下来,但却仍然持有在这之前获得的锁定。此时,其他任何线程都不能访问锁定的资源,除非被"挂起"的线程恢复运行。对任何线程来说,如果它们想恢复目标线程,同时又试图使用任何一个锁定的资源,就会造成死锁。所以不应该使用suspend(),而应在自己的Thread类中置入一个标志,指出线程应该活动还是挂起。若标志指出线程应该挂起,便用wait()命其进入等待状态。若标志指出线程应当恢复,则用一个notify()重新启动线程。 61、sleep() 和 wait() 有什么区别? 答:sleep是线程类(Thread)的方法,导致此线程暂停执行指定时间,给执行机会给其他线程,但是监控状态依然保持,到时后会自动恢复。调用sleep不会释放对象锁。 wait是Object类的方法,对此对象调用wait方法导致本线程放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象发出notify方法(或notifyAll)后本线程才进入对象锁定池准备获得对象锁进入运行状态。 62、同步和异步有何异同,在什么情况下分别使用他们?举例说明。 答:如果数据将在线程间共享。例如正在写的数据以后可能被另一个线程读到,或者正在读的数据可能已经被另一个线程写过了,那么这些数据就是共享数据,必须进行同步存取。 当应用程序在对象上调用了一个需要花费很长时间来执行的方法,并且不希望让程序等待方法的返回时,就应该使用异步编程,在很多情况下采用异步途径往往更有效率。 63、启动一个线程是用run()还是start()? 答:启动一个线程是调用start()方法,使线程所代表的虚拟处理机处于可运行状态,这意味着它可以由JVM调度并执行。这并不意味着线程就会立即运行。run()方法可以产生必须退出的标志来停止一个线程。 64、当一个线程进入一个对象的一个synchronized方法后,其它线程是否可进入此对象的其它方法? 答:不能,一个对象的一个synchronized方法只能由一个线程访问。 65、请说出你所知道的线程同步的方法。 答:wait():使一个线程处于等待状态,并且释放所持有的对象的lock。 sleep():使一个正在运行的线程处于睡眠状态,是一个静态方法,调用此方法要捕捉Interrupt edException异常。 notify():唤醒一个处于等待状态的线程,注意的是在调用此方法的时候,并不能确切的唤醒某一个等待状态的线程,而是由JVM确定唤醒哪个线程,而且不是按优先级。 Allnotity():唤醒所有处入等待状态的线程,注意并不是给所有唤醒线程一个对象的锁,而是让它们竞争。 66、多线程有几种实现方法,都是什么?同步有几种实现方法,都是什么? 答:多线程有两种实现方法,分别是继承Thread类与实现Runnable接口 同步的实现方面有两种,分别是synchronized,wait与notify 一、你对MVC的理解,MVC有什么优缺点?结合Struts,说明在一个Web应用如何去使用? 答: MVC设计模式(应用观察者模式的框架模式) M: Model(Business process layer),模型,操作数据的业务处理层,并独立于表现层(Independent of presentation)。 V: View(Presentation layer),视图,通过客户端数据类型显示数据,并回显模型层的执行结果。 C: Controller(Control layer),控制器,也就是视图层和模型层桥梁,控制数据的流向,接受视图层发出的事件,并重绘视图 MVC框架的一种实现模型 模型二(Servlet-centric): JSP+Servlet+JavaBean,以控制为核心,JSP只负责显示和收集数据,Sevlet,连接视图和模型,将视图层数据,发送给模型层,JavaBean,分为业务类和数据实体,业务类处理业务数据,数据实体,承载数据,基本上大多数的项目都是使用这种MVC的实现模式。 StrutsMVC框架(Web application frameworks) Struts是使用MVC的实现模式二来实现的,也就是以控制器为核心。 Struts提供了一些组件使用MVC开发应用程序: Model:Struts没有提供model类。这个商业逻辑必须由Web应用程序的开发者以JavaBean或EJB的形式提供 View:Struts提供了action form创建form bean, 用于在controller和view 间传输数据。此外,Struts提供了自定义JSP标签库,辅助开发者用JSP创建交互式的以表单为基础的应用程序,应用程序资源文件保留了一些文本常量和错误消息,可转变为其它语言,可用于JSP中。 Controller:Struts提供了一个核心的控制器ActionServlet,通过这个核心的控制器来调用其他用户注册了的自定义的控制器Action,自定义Action需要符合Struts的自定义Action规范,还需要在struts-config.xml的特定配置文件中进行配置,接收JSP输入字段形成Action form,然后调用一个Action控制器。Action 控制器中提供了model的逻辑接口。 二、什么是WebService? 答: WebService是一个SOA(面向服务的编程)的架构,它是不依赖于语言,不依赖于平台,可以实现不同的语言间的相互调用,通过Internet进行基于Http协议的网络应用间的交互。 WebService实现不同语言间的调用,是依托于一个标准,webservice是需要遵守WSDL(web服务定义语言)/SOAP(简单请求协议)规范的。 WebService=WSDL+SOAP+UDDI(webservice的注册) Soap是由Soap的part和0个或多个附件组成,一般只有part,在part中有Envelope和Body。 Web Service是通过提供标准的协议和接口,可以让不同的程序集成的一种SOA 架构。 Web Service的优点 (1) 可以让异构的程序相互访问(跨平台)多线程与并发面试题
2019最新Java面试题,常见面试题及答案汇总
多线程练习题卷
Java并发编程面试题整理与答案
java多线程并发面试题【java多线程和并发基础面试题】
26. 多线程(04)-生产者和消费者问题、Object类中对线程的支持,以及面试题目
并发危险:解决多线程代码中的 11 个常见的问题
多线程面试题
public void run() {
// 在 这里编写线程执行的主体
// do something
}
} 这是实现Runnable接口实现多线程的示例: [java]view plaincopyprint? 1.public class RunnableTest implements Runnable {
public void run() {
// 在这里编写线程执行的主体
// do something
}
} 这两种实现方式的区别并不大。继承Thread类的方式实现起来较为简单,但是继承它的类就不能再继承 别的类了,因此也就不能继承别的类的有用的方法了。而使用是想Runnable接口的方式就不存在这个问 题了,而且这种实现方式将线程主体和线程对象本身分离开来,逻辑上也较为清晰,所以推荐大家更多地 采用这种方式。 如何启动线程线程编程方面笔试题
软件工程师面试题 含答案