数据分析试题
大数据试题答案与解析_最全
1、当前大数据技术的基础是由( C)首先提出的。(单选题,本题2分) A:微软 B:百度 C:谷歌 D:阿里巴巴 2、大数据的起源是(C )。(单选题,本题2分) A:金融 B:电信 C:互联网 D:公共管理 3、根据不同的业务需求来建立数据模型,抽取最有意义的向量,决定选取哪种方法的数据分析角色人员是 ( C)。(单选题,本题2分) A:数据管理人员 B:数据分析员 C:研究科学家 D:软件开发工程师 4、(D )反映数据的精细化程度,越细化的数据,价值越高。(单选题,本题2分) A:规模 B:活性 C:关联度 D:颗粒度 5、数据清洗的方法不包括( D)。(单,本题2分)
A:缺失值处理 B:噪声数据清除 C:一致性检查 D:重复数据记录处理 6、智能健康手环的应用开发,体现了( D)的数据采集技术的应用。(单选题,本题2分) A:统计报表 B:网络爬虫 C:API接口 D:传感器 7、下列关于数据重组的说法中,错误的是( A)。(单选题,本题2分) A:数据重组是数据的重新生产和重新采集 B:数据重组能够使数据焕发新的光芒 C:数据重组实现的关键在于多源数据融合和数据集成 D:数据重组有利于实现新颖的数据模式创新 8、智慧城市的构建,不包含( C)。(单选题,本题2分) A:数字城市 B:物联网 C:联网监控 D:云计算 大数据的最显著特征是( A)。(单选题,本题2分) A:数据规模大 B:数据类型多样
C:数据处理速度快 D:数据价值密度高 10、美国海军军官莫里通过对前人航海日志的分析,绘制了新的航海路线图,标明了大风与洋流可能发生的地 点。这体现了大数据分析理念中的(B )。(单选题,本题2分) A:在数据基础上倾向于全体数据而不是抽样数据 B:在分析方法上更注重相关分析而不是因果分析 C:在分析效果上更追究效率而不是绝对精确 D:在数据规模上强调相对数据而不是绝对数据 11、下列关于舍恩伯格对大数据特点的说法中,错误的是(D )。(单选题,本题2分) A:数据规模大 B:数据类型多样 C:数据处理速度快 D:数据价值密度高 12、当前社会中,最为突出的大数据环境是(A )。(单选题,本题2分) A:互联网 B:物联网 C:综合国力 D:自然资源 13、在数据生命周期管理实践中,( B)是(单选题,本题2分) A:数据存储和备份规 B:数据管理和维护 C:数据价值发觉和利用
《数据分析》练习题
《数据分析》练习题 1.一个地区某月前两周从星期一到星期五各天的最低气温依次是(单位:℃):x 1, x 2, x 3, x 4, x 5和x 1+1, x 2+2, x 3+3, x 4+4, x 5+5,若第一周这五天的平均最低气温为7℃,则第二周这五天的平均最低气温为 。 2.有10个数据的平均数为12,另有20个数据的平均数为15,那么所有这30个数据的平均数是( ) A .12 B. 15 C. 1 3.5 D. 14 3.一组数据8,8,x ,6的众数与平均数相同,那么这组数据的中位数是 ( ) A. 6 B. 8 C.7 D. 10 4.某校在一次考试中,甲乙两班学生的数学成绩统计如下: 请根据表格提供的信息回答下列问题: (1)甲班众数为 分,乙班众数为 分,从众数看成绩较好的是 班; (2)甲班的中位数是 分,乙班的中位数是 分; (3)若成绩在80分以上为优秀,则成绩较好的是 班;、 (4)甲班的平均成绩是 分,乙班的平均成绩是 分,从平均分看成绩较好的是 班. 5.在方差的计算公式 ()()()222 21210120202010 s x x x ??= -+-+???+-??中, 数字10和20分别表示的意义可以是( ) A .数据的个数和方差 B .平均数和数据的个数 C .数据的个数和平均数 D .数据组的方差和平均数 6..如果将所给定的数据组中的每个数都减去一个非零常数,那么该数组的 ( ) A.平均数改变,方差不变 B.平均数改变,方差改变 C.平均输不变,方差改变 D.平均数不变,方差不变 7..已知7,4,3,,321x x x 的平均数是6,则_____________321=++x x x . 8..已知一组数据-3,-2,1,3,6,x 的中位数为1,则其方差为 . 9..已知一组数据x 1,x 2,x 3,x 4,x 5的平均数是2,方差是 3 1 ,那么另一组数据3x 1-2,3x 2-2,3x 3-2, 3x 4-2,3x 5-2的平均数是和方差分别是 . 10..关于一组数据的平均数、中位数、众数,下列说法中正确的是( ) A.平均数一定是这组数中的某个数 B. 中位数一定是这组数中的某个数 C.众数一定是这组数中的某个数 D.以上说法都不对 分数 50 60 70 80 90 100 人数 甲 1 6 12 11 15 5 乙 3 5 15 3 13 11
科研常用的实验数据分析与处理方法
科研常用的实验数据分析与处理方法 对于每个科研工作者而言,对实验数据进行处理是在开始论文写作之前十分常见的工作之一。但是,常见的数据分析方法有哪些呢?常用的数据分析方法有:聚类分析、因子分析、相关分析、对应分析、回归分析、方差分析。 1、聚类分析(Cluster Analysis) 聚类分析指将物理或抽象对象的集合分组成为由类似的对象组成的多个类的分析过程。聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。聚类分析所使用方法的不同,常常会得到不同的结论。不同研究者对于同一组数据进行聚类分析,所得到的聚类数未必一致。 2、因子分析(Factor Analysis) 因子分析是指研究从变量群中提取共性因子的统计技术。因子分析就是从大量的数据中寻找内在的联系,减少决策的困难。因子分析的方法约有10多种,如重心法、影像分析法,最大似然解、最小平方法、阿尔发抽因法、拉奥典型抽因法等等。这些方法本质上大都属近似方法,是以相关系数矩阵为基础的,所不同的是相关系数矩阵对角线上的值,采用不同的共同性□2估值。在社会学研究中,因子分析常采用以主成分分析为基础的反覆法。
3、相关分析(Correlation Analysis) 相关分析(correlation analysis),相关分析是研究现象之间是否存在某种依存关系,并对具体有依存关系的现象探讨其相关方向以及相关程度。相关关系是一种非确定性的关系,例如,以X和Y 分别记一个人的身高和体重,或分别记每公顷施肥量与每公顷小麦产量,则X与Y显然有关系,而又没有确切到可由其中的一个去精确地决定另一个的程度,这就是相关关系。 4、对应分析(Correspondence Analysis) 对应分析(Correspondence analysis)也称关联分析、R-Q 型因子分析,通过分析由定性变量构成的交互汇总表来揭示变量间的联系。可以揭示同一变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系。对应分析的基本思想是将一个联列表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来。 5、回归分析 研究一个随机变量Y对另一个(X)或一组(X1,X2,…,Xk)变量的相依关系的统计分析方法。回归分析(regression analysis)是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法。运用十分广泛,回归分析按照涉及的自变量的多少,可分为一
数据分析师常见的7道笔试题目及答案
数据分析师常见的7道笔试题目及答案 导读:探索性数据分析侧重于在数据之中发现新的特征,而验证性数据分析则侧 重于已有假设的证实或证伪。以下是由小编J.L为您整理推荐的实用的应聘笔试题目和经验,欢迎参考阅读。 1、海量日志数据,提取出某日访问百度次数最多的那个IP。 首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有个2^32个IP。同样可以采用映射的方法,比如模1000,把 整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用 hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000 个最大的IP中,找出那个频率最大的IP,即为所求。 或者如下阐述: 算法思想:分而治之+Hash 1.IP地址最多有2^32=4G种取值情况,所以不能完全加载到内存中处理; 2.可以考虑采用“分而治之”的思想,按照IP地址的Hash(IP)24值,把海量IP日 志分别存储到1024个小文件中。这样,每个小文件最多包含4MB个IP地址; 3.对于每一个小文件,可以构建一个IP为key,出现次数为value的Hash map,同时记录当前出现次数最多的那个IP地址; 4.可以得到1024个小文件中的出现次数最多的IP,再依据常规的排序算法得到总体上出现次数最多的IP; 2、搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。 假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也 就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。 典型的Top K算法,还是在这篇文章里头有所阐述, 文中,给出的最终算法是: 第一步、先对这批海量数据预处理,在O(N)的时间内用Hash表完成统计(之前写成了排序,特此订正。July、2011.04.27); 第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。 即,借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一 个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比所以,我们最终的时间复杂度是:O(N) + N’*O(logK),(N为1000万,N’为300万)。ok,更多,详情,请参考原文。 或者:采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10 个元素的最小推来对出现频率进行排序。 3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。 方案:顺序读文件中,对于每个词x,取hash(x)P00,然后按照该值存到5000 个小文件(记为x0,x1,…x4999)中。这样每个文件大概是200k左右。 如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到 分解得到的小文件的大小都不超过1M。 对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树 /hash_map等),并取出出现频率最大的100个词(可以用含100 个结点的最小堆),并把
数据分析期末试题及答案
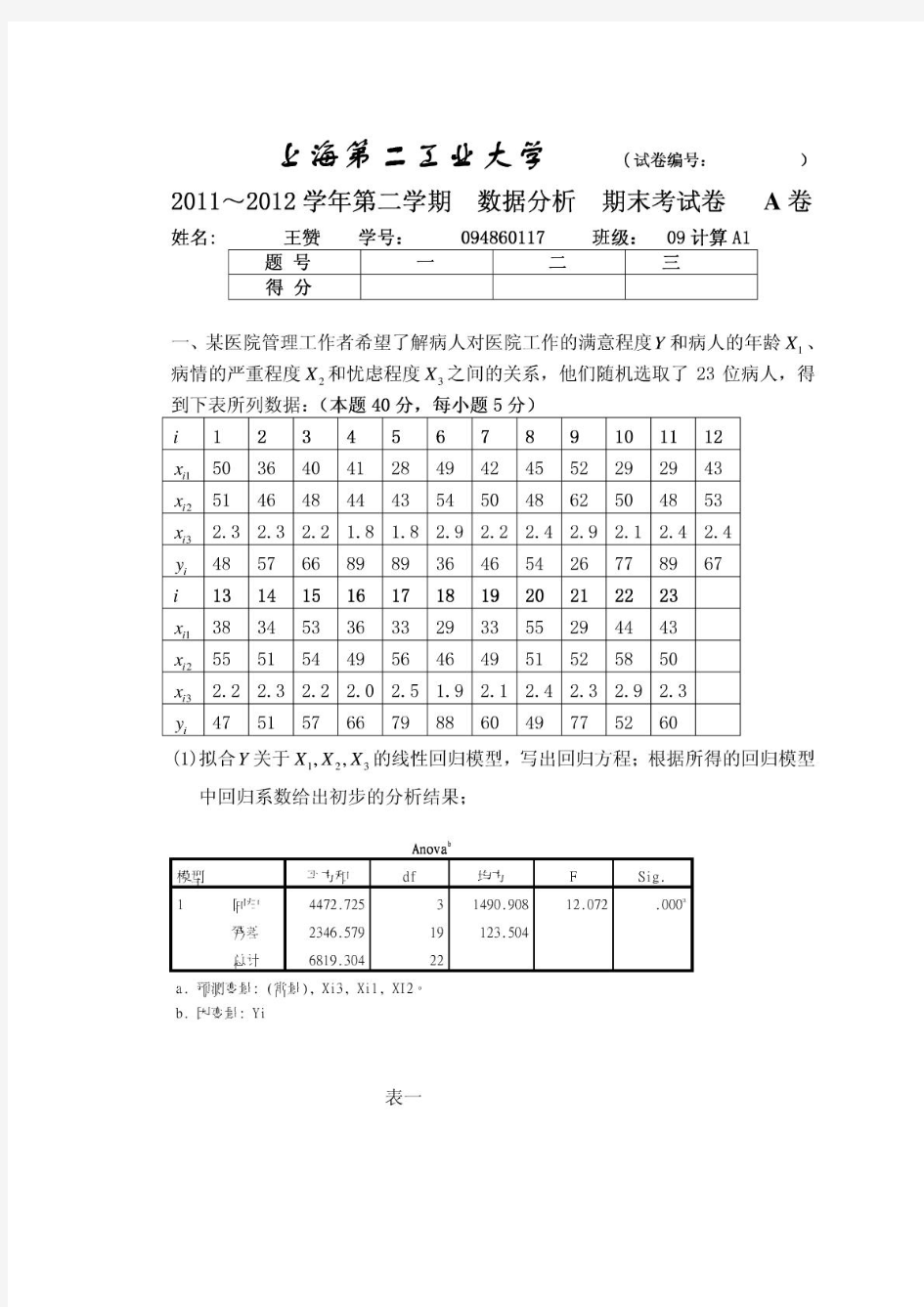
数据分析期末试题及答案 一、人口现状.sav数据中是1992年亚洲各国家和地区平均寿命(y)、按购买力计算的人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)的数据,试用多元回归分析的方法分析各国家和地区平均寿命与人均GDP、成人识字率、一岁儿童疫苗接种率的关系。(25分) 解: 1.通过分别绘制地区平均寿命(y)、按购买力计算的人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)之间散点图初步分析他们之间的关系 上图是以人均GDP(x1)为横轴,地区平均寿命(y)为纵轴的散点图,由图可知,他们之间没有呈线性关系。尝试多种模型后采用曲线估计,得出 表示地区平均寿命(y)与人均GDP(x1)的对数有线性关系
上图是以成人识字率(x2)为横轴,地区平均寿命(y)为纵轴的散点图,由图可知,他们之间基本呈正线性关系。 上图是以疫苗接种率(x3)为横轴,地区平均寿命(y)为纵轴的散点图,由图可知,他们之间没有呈线性关系 。 x)为横轴,地区平均寿命(y)为纵轴的散点图,上图是以疫苗接种率(x3)的三次方(3 3 由图可知,他们之间呈正线性关系 所以可以采用如下的线性回归方法分析。
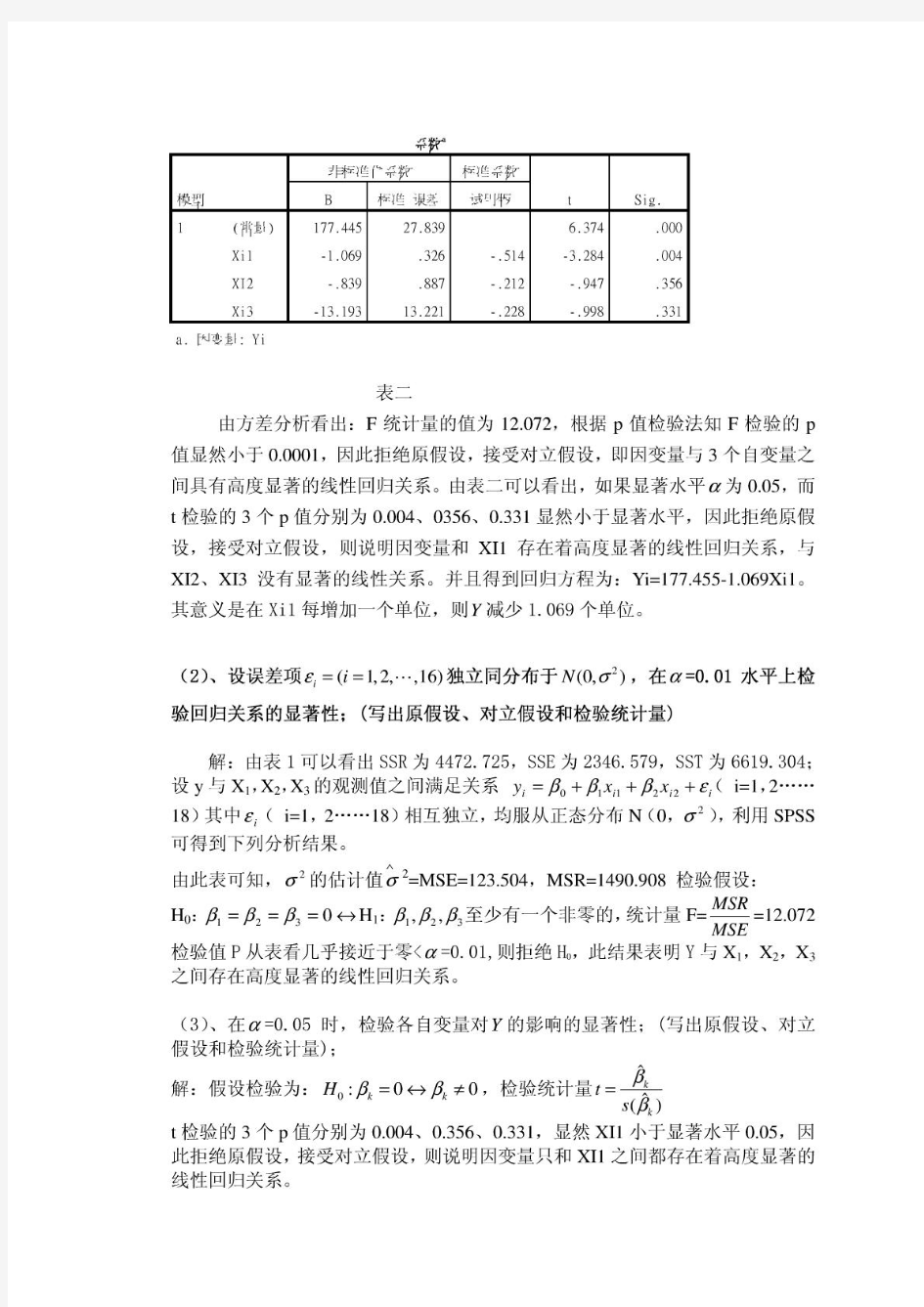
2.线性回归 先用强行进入的方式建立如下线性方程 设Y=β0+β1*(Xi1)+β2*Xi2+β3* X+εi i=1.2 (24) 3i 其中εi(i=1.2……22)相互独立,都服从正态分布N(0,σ^2)且假设其等于方差 R值为0.952,大于0.8,表示两变量间有较强的线性关系。且表示平均寿命(y)的95.2%的信息能由人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)一起表示出来。 建立总体性的假设检验 提出假设检验H0:β1=β2=β3=0,H1,:其中至少有一个非零 得如下方差分析表 上表是方差分析SAS输出结果。由表知,采用的是F分布,F=58.190,对应的检验概率P值是0.000.,小于显著性水平0.05,拒绝原假设,表示总体性假设检验通过了,平均寿命(y)与人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)之间有高度显著的的线性回归关系。
数据分析笔试题
数据分析笔试题 一、编程题(每小题20分)(四道题任意选择其中三道) 有一个计费表表名jifei 字段如下:phone(8位的电话号码),month(月份),expenses (月消费,费用为0表明该月没有产生费用) 下面是该表的一条记录:64262631,201011,30.6 这条记录的含义就是64262631的号码在2010年11月份产生了30.6元的话费。 按照要求写出满足下列条件的sql语句: 1、查找2010年6、7、8月有话费产生但9、10月没有使用并(6、7、8月话费均在51-100 元之间的用户。 2、查找2010年以来(截止到10月31日)所有后四位尾数符合AABB或者ABAB或者AAAA 的电话号码。(A、B 分别代表1—9中任意的一个数字) 3、删除jifei表中所有10月份出现的两条相同记录中的其中一条记录。
4、查询所有9月份、10月份月均使用金额在30元以上的用户号码(结果不能出现重复) 二、逻辑思维题(每小题10分)须写出简要计算过程和结果。 1、某人卖掉了两张面值为60元的电话卡,均是60元的价格成交的。其中一张赚了20%, 另一张赔了20%,问他总体是盈利还是亏损,盈/亏多少? 2、有个农场主雇了两个小工为他种小麦,其中A是一个耕地能手,但不擅长播种;而B 耕地很不熟练,但却是播种的能手。农场主决定种10亩地的小麦,让他俩各包一半,于是A从东头开始耕地,B从西头开始耕。A耕地一亩用20分钟,B却用40分钟,可是B播种的速度却比A快3倍。耕播结束后,庄园主根据他们的工作量给了他俩600元工钱。他俩怎样分才合理呢? 3、1 11 21 1211 111221 下一行是什么? 4、烧一根不均匀的绳,从头烧到尾总共需要1个小时。现在有若干条材质相同的绳子,问如何用烧绳的方法来计时一个小时十五分钟呢?(绳子分别为A 、B、C、D、E、F 。。。。。来代替)
16种常用的大数据分析报告方法汇总情况
一、描述统计 描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:剔除法、均值法、最小邻居法、比率回归法、决策树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A 单样本t检验:推断该样本来自的总体均数μ与已知的某一总体均数μ0 (常为理论值或标准值)有无差别; B 配对样本t检验:当总体均数未知时,且两个样本可以配对,同对中的两者在可能会影响处理效果的各种条件方面扱为相似;
C 两独立样本t检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验 非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。 A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析 检査测量的可信度,例如调查问卷的真实性。 分类: 1、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度 2、在信度;每个量表是否测量到单一的概念,同时组成两表的在体项一致性如何,常用方法分半信度。 四、列联表分析 用于分析离散变量或定型变量之间是否存在相关。
数据分析经典语录汇总
数据分析经典语录汇总 【数据分析三字经】①学习:先了解,后深入;先记录,后记忆;先理论,后实践;先模仿,后创新;②方法:先思路,后方法;先框架,后细化;先方法,后工具;先思考,后动手; ③分析:先业务,后数据;先假设,后验证;先总体,后局部;先总结,后建议; 做数据分析首先是熟悉业务及行业知识,其次是分析思路清晰,再次才是方法与工具,切勿为了方法而方法,为工具而工具。 【数据分析的3点要求】第一,熟悉业务,不熟业务,分析的结果将脱离实际,业无从指导;第二,多思考,只有经常发问为什么是这样的?为什么不是那样的?只有这样才有突破点;第三,多动手,不动手,靠脑袋想是不够的,不要怕错,大不了错了重来。 数据分析不仅是个工具,而且是门艺术,优秀的数据分析师不光要懂业务、懂管理,懂分析、还要懂创意、懂设计、懂生活,所以数据分析师也是个艺术家。 【数据分析流程】首先明确分析目的,然后搭建分析体系,确定各个分析内容,进行数据搜集、数据处理、数据分析、数据展现逐步完成,最后检验是否达到分析目的! 【数据挖掘流程】①业务理解:清晰定义业务问题;②数据理解:有什么数据,数据质量心中有数;③数据准备:数据抽样、转换、缺失值处理等;③建模:选择和应用不同的模型技术,调整模型参数;④评估:对前面步骤进行评估;⑤部署:把数据挖掘成果送到相应人手中,并进行日常监测和维护、更新。 【以终为始的分析原则】我做这个数据分析的目的是什么?然后,再根据这个目标倒推应该从哪几个角度、指标进行分析。
【数据分析5步走】1、锁定分析目标,梳理思路,叫纸上谈兵;2、把杂乱的数据整理出图表报表,用数据探业务,叫自问数答;3、锁定核心抓重点,设定最终算法,叫挟天子以令诸侯;4、梳理重点发现,准备剧本开拍,接受PK,叫才辨无双;5、效果梳理,总结经验,叫内视反听。 【数据分析框架的重要性】问题的高效解决开始于将待解决问题的结构化,然后进行系统的假设和验证。分析框架可以帮助我们:1、以完整的逻辑形式结构化问题;2、把问题分解成相关联的部分并显示它们之间的关系;3、理顺思路、系统描述情形/业务;4、然后洞察什么是造成我们正在解决的问题的原因。 数据分析如果一开始数据分析方向就错了,所有努力都是徒劳,后果不堪设想。亲们,数据分析前先明确目的,再根据分析目的确定分析框架与内容,以及所采用的数据分析方法。【常用数据分析方法】:趋势分析:查看一段时间某一数据或者某一组的变动趋势,得出某一个业务上升、下降、平稳、波动等趋势信息;对比分析:自己和自己比,找趋势、规律;自己和别人比,找差异、问题。结构分析:拆字诀,子类目、属性值、新老会员、各个运营节点,都可拆。 【数据分析注意点】1、要注意每种统计分析方法的适用范围;2、使用不同的数据分析方法对同一问题进行解释,来互相验证结论的真伪,多次尝试;3、结果要使用通俗易懂的语言或图表进行描述;4、需要耐心和细致,不能出现任何疏漏,别一个老鼠害一锅汤;5、高级数据分析不一定是最好的,简单有效才是最好的。 【如何用数据看透问题】1、确定指标,看数值;2、问题还不够明确?将指标层层分解;3、只看数值还不能确定问题?多周期看趋势;4、问题初步明确了,找不到原因或者发力点?将统计对象分类,拆解为不同角度来观察;5、参考行业对比数据,如果有的话...而每一步具体怎么走,全靠业务理解!
数据分析笔试题全解
从互联网巨头数据挖掘类招聘笔试题目看我们还差多少知识 1 从阿里数据分析师笔试看职业要求 以下试题是来自阿里巴巴招募实习生的一次笔试题,从笔试题的几个要求我们一起来看看数据分析的职业要求。 一、异常值是指什么?请列举1种识别连续型变量异常值的方法? 异常值(Outlier)是指样本中的个别值,其数值明显偏离所属样本的其余观测值。在数理统计里一般是指一组观测值中与平均值的偏差超过两倍标准差的测定值。 Grubbs’ test(是以Frank E. Grubbs命名的),又叫maximum normed residual test,是一种用于单变量数据集异常值识别的统计检测,它假定数据集来自正态分布的总体。 未知总体标准差σ,在五种检验法中,优劣次序为:t检验法、格拉布斯检验法、峰度检验法、狄克逊检验法、偏度检验法。 点评:考察的内容是统计学基础功底。 二、什么是聚类分析?聚类算法有哪几种?请选择一种详细描述其计算原理和步骤。 聚类分析(cluster analysis)是一组将研究对象分为相对同质的群组(clusters)的统计分析技术。聚类分析也叫分类分析(classification analysis)或数值分类(numerical taxonomy)。聚类与分类的不同在于,聚类所要求划分的类是未知的。 聚类分析计算方法主要有:层次的方法(hierarchical method)、划分方法(partitioning method)、基于密度的方法(density-based method)、基于网格的方法(grid-based method)、基于模型的方法(model-based method)等。其中,前两种算法是利用统计学定义的距离进行度量。 k-means 算法的工作过程说明如下:首先从n个数据对象任意选择 k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用均方差(标准差)作为标准测度
数据分析软件和工具
以下是我在近三年做各类计量和统计分析过程中感受最深的东西,或能对大家有所帮助。当然,它不是ABC的教程,也不是细致的数据分析方法介绍,它只是“总结”和“体会”。由于我所学所做均甚杂,我也不是学统计、数学出身的,故本文没有主线,只有碎片,且文中内容仅为个人观点,许多论断没有数学证明,望统计、计量大牛轻拍。 于我个人而言,所用的数据分析软件包括EXCEL、SPSS、STATA、EVIEWS。在分析前期可以使用EXCEL进行数据清洗、数据结构调整、复杂的新变量计算(包括逻辑计算);在后期呈现美观的图表时,它的制图制表功能更是无可取代的利器;但需要说明的是,EXCEL毕竟只是办公软件,它的作用大多局限在对数据本身进行的操作,而非复杂的统计和计量分析,而且,当样本量达到“万”以上级别时,EXCEL的运行速度有时会让人抓狂。 SPSS是擅长于处理截面数据的傻瓜统计软件。首先,它是专业的统计软件,对“万”甚至“十万”样本量级别的数据集都能应付自如;其次,它是统计软件而非专业的计量软件,因此它的强项在于数据清洗、描述统计、假设检验(T、F、卡方、方差齐性、正态性、信效度等检验)、多元统计分析(因子、聚类、判别、偏相关等)和一些常用的计量分析(初、中级计量教科书里提到的计量分析基本都能实现),对于复杂的、前沿的计量分析无能为力;第三,SPSS主要用于分析截面数据,在时序和面板数据处理方面功能了了;最后,SPSS兼容菜单化和编程化操作,是名副其实的傻瓜软件。 STATA与EVIEWS都是我偏好的计量软件。前者完全编程化操作,后者兼容菜单化和编程化操作;虽然两款软件都能做简单的描述统计,但是较之 SPSS差了许多;STATA与EVIEWS都是计量软件,高级的计量分析能够在这两个软件里得到实现;STATA的扩展性较好,我们可以上网找自己需要的命令文件(.ado文件),不断扩展其应用,但EVIEWS 就只能等着软件升级了;另外,对于时序数据的处理,EVIEWS较强。 综上,各款软件有自己的强项和弱项,用什么软件取决于数据本身的属性及分析方法。EXCEL适用于处理小样本数据,SPSS、 STATA、EVIEWS可以处理较大的样本;EXCEL、SPSS适合做数据清洗、新变量计算等分析前准备性工作,而STATA、EVIEWS在这方面较差;制图制表用EXCEL;对截面数据进行统计分析用SPSS,简单的计量分析SPSS、STATA、EVIEWS可以实现,高级的计量分析用 STATA、EVIEWS,时序分析用EVIEWS。 关于因果性 做统计或计量,我认为最难也最头疼的就是进行因果性判断。假如你有A、B两个变量的数据,你怎么知道哪个变量是因(自变量),哪个变量是果(因变量)? 早期,人们通过观察原因和结果之间的表面联系进行因果推论,比如恒常会合、时间顺序。但是,人们渐渐认识到多次的共同出现和共同缺失可能是因果关系,也可能是由共同的原因或其他因素造成的。从归纳法的角度来说,如果在有A的情形下出现B,没有A的情形下就没有B,那么A很可能是B的原因,但也可能是其他未能预料到的因素在起作用,所以,在进行因果判断时应对大量的事例进行比较,以便提高判断的可靠性。 有两种解决因果问题的方案:统计的解决方案和科学的解决方案。统计的解决方案主要指运用统计和计量回归的方法对微观数据进行分析,比较受干预样本与未接受干预样本在效果指标(因变量)上的差异。需要强调的是,利用截面数据进行统计分析,不论是进行均值比较、频数分析,还是方差分析、相关分析,其结果只是干预与影响效果之间因果关系成立的必要条件而非充分条件。类似的,利用截面数据进行计量回归,所能得到的最多也只是变量间的数量关系;计量模型中哪个变量为因变量哪个变量为自变量,完全出于分析者根据其他考虑进行的预设,与计量分析结果没有关系。总之,回归并不意味着因果关系的成立,因果关系的判定或推断必须依据经过实践检验的相关理论。虽然利用截面数据进行因果判断显得勉强,但如果研究者掌握了时间序列数据,因果判断仍有可为,其
2016年数据分析面试常见问题
1、海量日志数据,提取出某日访问百度次数最多的那个IP。 首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有个2^32个IP。同样可以采用映射的方法,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即为所求。 或者如下阐述: 算法思想:分而治之+Hash 1.IP地址最多有2^32=4G种取值情况,所以不能完全加载到内存中处理; 2.可以考虑采用“分而治之”的思想,按照IP地址的Hash(IP)24值,把海量IP日志分别存储到1024个小文件中。这样,每个小文件最多包含4MB个IP地址; 3.对于每一个小文件,可以构建一个IP为key,出现次数为value的Hash map,同时记录当前出现次数最多的那个IP地址; 4.可以得到1024个小文件中的出现次数最多的IP,再依据常规的排序算法得到总体上出现次数最多的IP; 2、搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。 假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。 典型的Top K算法,还是在这篇文章里头有所阐述, 文中,给出的最终算法是:
第一步、先对这批海量数据预处理,在O(N)的时间内用Hash表完成统计(之前写成了排序,特此订正。July、2011.04.27); 第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。 即,借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比所以,我们最终的时间复杂度是:O(N)+ N’*O(logK),(N为1000万,N’为300万)。ok,更多,详情,请参考原文。 或者:采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。 3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。 方案:顺序读文件中,对于每个词x,取hash(x)P00,然后按照该值存到5000个小文件(记为x0,x1,…x4999)中。这样每个文件大概是200k左右。 如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。 对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map 等),并取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100个词及相应的频率存入文件,这样又得到了5000个文件。下一步就是把这5000个文件进行归并(类似与归并排序)的过程了。 4、有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个
数据分析岗面试题
数据分析岗面试题-标准化文件发布号:(9556-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII
数据分析岗面试题 1、表:table1(Id,class,score),用最高效最简单的SQL列出各班成绩最高的列 表,显示班级,成绩两个字段。 2、有一个表table1有两个字段FID,Fno,字都非空,写一个SQL语句列出 Fno的纪录。 3、有员工表empinfo 4、( 5、Fempno varchar2(10) not null pk, 6、Fempname varchar2(20) not null, 7、Fage number not null, 8、Fsalary number not null 9、); 10、假如数据量很大约1000万条;写一个你认为最高效的SQL,用一个SQL 计算以下四种人: 11、fsalary>9999 and fage > 35 12、fsalary>9999 and fage < 35 13、fsalary <9999 and fage > 35 14、fsalary <9999 and fage < 35 15、每种员工的数量; 4、
Sheet1: sheet2: Sheet1、sheet2是Excel中两个表,sheet2中 记录了各产品类别下面对应的产品编码,现 要在sheet1 C列中对应A列产品编码所对应 的产品类别,请写出公式。 5、某商品零售公司有100万客户资料数据(客户数据信息包括客户姓名、电话、地址、购买次数、购买时间、购买金额、购买产品种类等等),现要从中抽取10万客户,对这些客户发送目录手册,为了能使这批手册产生的利润最大,从已有的客户数据信息,我们应该如何挑选这10万个客户?
oltp数据分析方法
数据仓库与OLAP实践 清华大学出版社
第3章多维数据分析基础与方法 v3.1 多维数据分析基础 v3.2 多维数据分析方法 v3.3 维度表与事实表的连接v3.4 多维数据的存储方式 v3.5 小结
3.1 多维数据分析基础 v多维数据分析是以数据库或数据仓库为基础的,其最终数据来源与OLTP一样均来自底层的数据库系统,但两者面对的用户不同,数据的特点与处理也不同。 v多维数据分析与OLTP是两类不同的应用,OLTP面对的是操作人员和低层管理人员,多维数据分析面对的是决策人员和高层管理人员。 v OLTP是对基本数据的查询和增删改操作,它以数据库为基础,而多维数据分析更适合以数据仓库为基础的数据分析处理。
1. 多维数据集(Cube) v多维数据集由于其多维的特性通常被形象地称作立方体(Cube), v多维数据集是一个数据集合,通常从数据仓库的子集构造,并组织和汇总成一个由一组维度和度量值定义的多维结构。 v SQL Server 2000中一个多维数据集最多可包含128个维度和1024个度量值。
2. 度量值(Measure) v度量值是决策者所关心的具有实际意义的数值。v例如,销售量、库存量、银行贷款金额等。 v度量值所在的表称为事实数据表,事实数据表中存放的事实数据通常包含大量的数据行。 v事实数据表的主要特点是包含数值数据(事实),而这些数值数据可以统计汇总以提供有关单位运 作历史的信息。 v度量值是所分析的多维数据集的核心,它是最终用户浏览多维数据集时重点查看的数值数据。
3. 维度(Dimension) v维度(也简称为维)是人们观察数据的角度。v例如,企业常常关心产品销售数据随时间的变化情况,这是从时间的角度来观察产品的销售,因此时间就是一个维(时间维)。 v例如,银行会给不同经济性质的企业贷款,比如国有、集体等,若通过企业性质的角度来分析贷款数据,那么经济性质也就成为了一个维度。 v包含维度信息的表是维度表,维度表包含描述事实数据表中的事实记录的特性。
数据分析专员笔试题
XXX公司数据分析专员笔试试题 姓名:日期: 一、异常值是指什么?请列举1种识别连续型变量异常值的方法? 异常值(Outlier)是指样本中的个别值,其数值明显偏离所属样本的其余观测值。在数理统计里一般是指一组观测值中与平均值的偏差超过两倍标准差的测定值。 Grubbs’ test(是以Frank E. Grubbs命名的),又叫maximum normed residual test,是一种用于单变量数据集异常值识别的统计检测,它假定数据集来自正态分布的总体。 未知总体标准差σ,在五种检验法中,优劣次序为:t检验法、格拉布斯检验法、峰度检验法、狄克逊检验法、偏度检验法。 点评:考察的内容是统计学基础功底。 二、什么是聚类分析?聚类算法有哪几种?请选择一种详细描述其计算原理和步骤。 聚类分析(cluster analysis)是一组将研究对象分为相对同质的群组(clusters)的统计分析技术。聚类分析也叫分类分析(classification analysis)或数值分类(numerical taxonomy)。聚类与分类的不同在于,聚类所要求划分的类是未知的。 聚类分析计算方法主要有:层次的方法(hierarchical method)、划分方法(partitioning method)、基于密度的方法(density-based method)、基于网格的方法(grid-based method)、基于模型的方法(model-based method)等。其中,前两种算法是利用统计学定义的距离进行度量。 k-means 算法的工作过程说明如下:首先从n个数据对象任意选择 k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用均方差作为标准测度函数. k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。 其流程如下: (1)从 n个数据对象任意选择 k 个对象作为初始聚类中心; (2)根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分; (3)重新计算每个(有变化)聚类的均值(中心对象); (4)循环(2)、(3)直到每个聚类不再发生变化为止(标准测量函数收敛)。 优点:本算法确定的K 个划分到达平方误差最小。当聚类是密集的,且类与类之间区别明显时,效果较好。对于处理大数据集,这个算法是相对可伸缩和高效的,计算的复杂度为 O(NKt),其中N是数据对象的数目,t是迭代的次数。一般来说,K< https://www.360docs.net/doc/9b2933944.html, 如何做数据分析_数据分析方法汇总 如何做数据分析https://www.360docs.net/doc/9b2933944.html,_数据分析方法汇总。光环大数据认为,利用数据分析可以让公司管理者直接有效地进行数据分析,帮助他们更好地按照数据分析结果来作出商业决定。这些应用程序可以针对不同行业,也可以灵活机动地满足公司内部不同人群的需要:从市场部到财务部,从公司管理层到中层。那么如何做数据分析呢?光环大数据的数据分析师培训机构为大家汇总以下几种方法: 1、立体式分析 立体式分析也就是维度分析,产品数据的发掘不应该仅仅拘泥于产品,大环境下的娱乐产物必须综合产品、市场、用户进行不同切入点分析。 真正的数据分析不在于数据本身,而在于分析能力的概述;数据是参照物,是标杆,只有分析才是行为,是改变,那么如何分析,综合上面两个举例,已经可以很清晰的看到立体式分析。 2、AARRR模型中的基本数据 接下来我们再综合AARRR模型分解一些较为常见的数据:Acquisition(获取)、Activation(活跃)、Retention(留存)、Revenue(收益)、Refer(传播)。 3、5W2H分析法 What(用户要什么?)Why(为什么要?)Where(从哪儿得到?)When(我们什么时候做?)Who(对谁做?)Howmuch(给多少?)How(怎么做?) https://www.360docs.net/doc/9b2933944.html, 4、SWOT分析模型 在战略规划报告里,SWOT分析算是一个众所周知的工具了。SWOT分析代表分析企业优势(strengths)、劣势(weakness)、机会(opportunity)和威胁(threats),因此,SWOT分析实际上是将对企业内外部条件各方面内容进行综合和概括,进而分析组织的优劣势、面临的机会和威胁的一种方法。 SWOT分析有四种不同类型的组合:优势——机会(SO)组合、弱点——机会(WO)组合、优势——威胁(ST)组合和弱点——威胁(WT)组合。 5、杜邦分析法 杜邦分析法(DuPontAnalysis)是利用几种主要的财务比率之间的关系来综合地分析企业的财务状况。具体来说,它是一种用来评价公司赢利能力和股东权益回报水平,从财务角度评价企业绩效的一种经典方法。 其基本思想是将企业净资产收益率逐级分解为多项财务比率乘积,这样有助于深入分析比较企业经营业绩,由于这种分析方法最早由美国杜邦公司使用,故名杜邦分析法。 数据分析培训,就选光环大数据! 为什么大家选择光环大数据! 大数据培训、人工智能培训、Python培训、大数据培训机构、大数据培训班、数据分析培训、大数据可视化培训,就选光环大数据!光环大数据,聘请专业的大数据领域知名讲师,确保教学的整体质量与教学水准。讲师团及时掌握时代潮流技术,将前沿技能融入教学中,确保学生所学知识顺应时代所需。通过深入浅出、通俗易懂的教学方式,指导学生更快 16种常用的数据分析方法汇总 2015-11-10分类:数据分析评论(0) 经常会有朋友问到一个朋友,数据分析常用的分析方法有哪些,我需要学习哪个等等之类的问题,今天数据分析精选给大家整理了十六种常用的数据分析方法,供大家参考学习。 一、描述统计 描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:易9除法、均值法、最小邻居法、比率回归法、决策树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前 需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W 检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A单样本t检验:推断该样本来自的总体均数卩与已知的某一总体均数卩0常为理论值或标准值)有无差别; B配对样本t检验:当总体均数未知时,且两个样本可以配对,同对中的两者在可能会影响处理效果的各种条件方面扱为相似; C两独立样本t检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验 非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。 适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的 A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10 以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析检査测量的可信度,例如调查问卷的真实性。 分类: 1、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度 2、内在信度;每个量表是否测量到单一的概念,同时组成两表的内在体项一致性如何,常用方法分半信度。 四、列联表分析 用于分析离散变量或定型变量之间是否存在相关。对于二维表,可进行卡方检验,对于三维表,可作Mentel-Hanszel 分层分析。 列联表分析还包括配对计数资料的卡方检验、行列均为顺序变量的相关检验。 五、相关分析 研究现象之间是否存在某种依存关系,对具体有依存关系的现象探讨相关方向及相关程度。 1、单相关:两个因素之间的相关关系叫单相关,即研究时只涉及一个自变量和一个因变量; 2、复相关:三个或三个以上因素的相关关系叫复相关,即研究时涉及两个或两个以上的自变量和因变量相关; 3、偏相关:在某一现象与多种现象相关的场合,当假定其他变量不变时,其中两个变量之间的相关关系称为偏相关。 六、方差分析 使用条件:各样本须是相互独立的随机样本;各样本来自正态分布总体;各总体方差相等。 分类1、单因素方差分析:一项试验只有一个影响因素,或者存在多个影响因素时, 只分析一个因素与响应变量的关系2、多因素有交互方差分析:一顼实验有多个影响如何做数据分析_数据分析方法汇总
16种统计分析方法-统计分析方法有多少种