下面给出Matlab中下标及希腊字母的使用方法
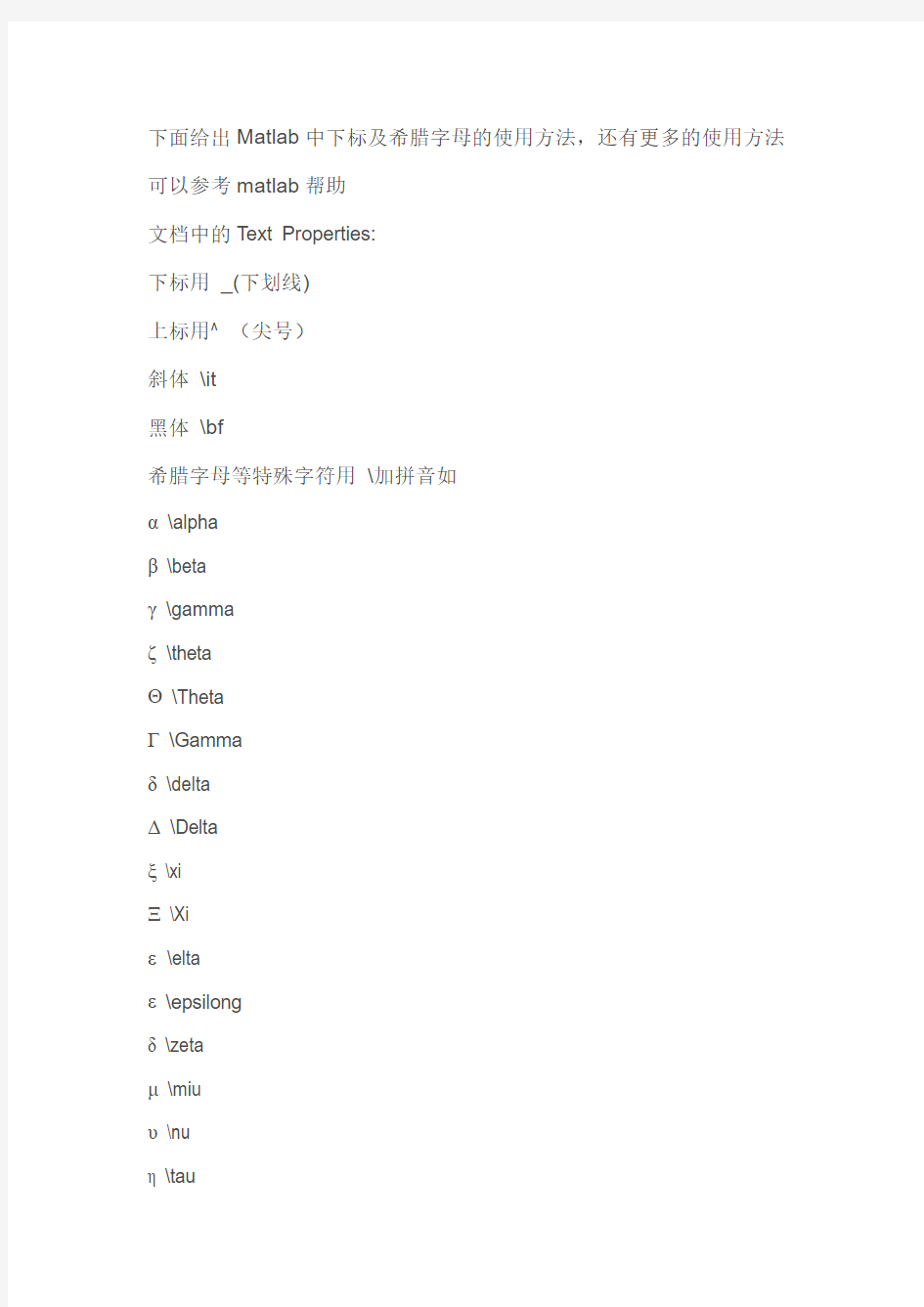
下面给出Matlab中下标及希腊字母的使用方法,还有更多的使用方法可以参考matlab帮助
文档中的Text Properties:
下标用_(下划线)
上标用^ (尖号)
斜体\it
黑体\bf
希腊字母等特殊字符用\加拼音如
α \alpha
β \beta
γ \gamma
ζ \theta
Θ \Theta
Г \Gamma
δ \delta
Δ \Delta
ξ \xi
Ξ \Xi
ε \elta
ε \epsilong
δ \zeta
μ \miu
υ \nu
η \tau
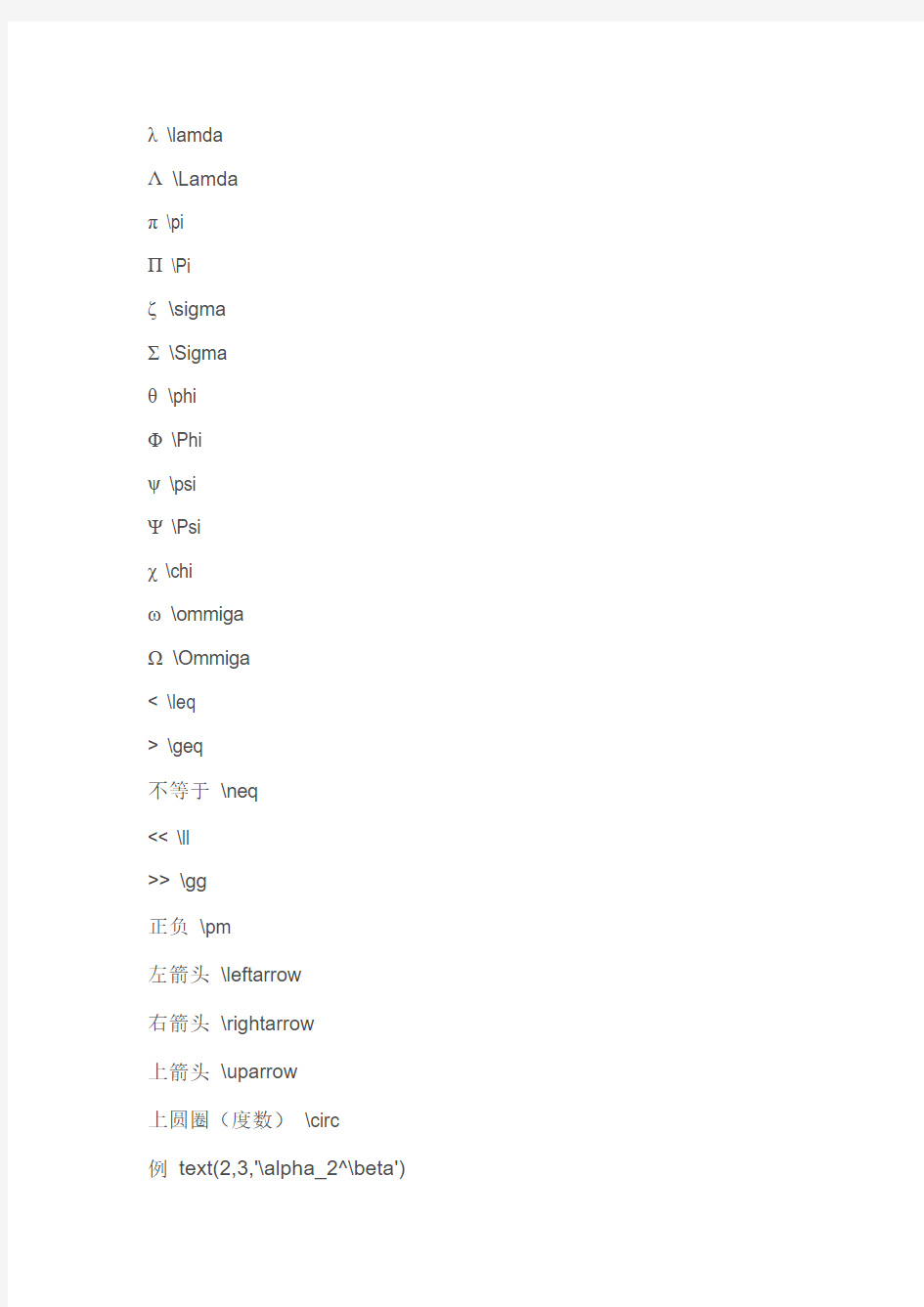
λ \lamda
Λ \Lamda
π \pi
Π \Pi
ζ \sigma
Σ \Sigma
θ \phi
Φ \Phi
ψ \psi
Ψ \Psi
χ \chi
ω \ommiga
Ω \Ommiga
< \leq
> \geq
不等于\neq
<< \ll
>> \gg
正负\pm
左箭头\leftarrow
右箭头\rightarrow
上箭头\uparrow
上圆圈(度数)\circ
例text(2,3,'\alpha_2^\beta')
注:可用{}把须放在一起的括起来
希腊字母
n x x x x 321 = 希腊字母 希腊字母 类型 全音素文字 语言 希腊语,在其他许多语言中亦有不同的修订 使用时期 约公元前800年到现在 母书写系统 圣书体 ? 原始迦南字母 ? 腓尼基字母 ? 希腊字母 子书写系统 哥德字母 格拉哥里字母 西里尔字母 科普特字母 古意大利字母 拉丁字母 亚美尼亚字母(争议) ISO 15924 Greek Unicode 范围 U+0370–U+03FF 希腊字母 和科普特字母 U+1F00–U+1FFF 扩展希腊字母 注意:本页可能包含Unicode 的国际音标。 [显示] 字母历史 希腊字母源自腓尼基字母。腓尼基字母只有辅音,从右向左写。希腊语的元音发达,希腊人增添了元音字母。因为希腊人的书写工具是蜡板,有时前一行从右向左写完后顺势就从左向右写,变成所谓“耕地”式书写,后来逐渐演变成全部从左向右写。字母的方向也颠倒了。罗马人引进希腊字母,略微改变变为拉丁字母,在世界广为流行。希腊字母广泛应用到学术领域,如数学等。 目录 [隐藏] ? 1 简述
?2 字母表 ?2.1 经典的字母 ?2.2 已停用字母 ?2.3 新补充字母 ?3 二合字母和双元音 ?4 字形 ?5 计算机编码与输入 ?5.1 ISO 8859-7编码 ?5.2 Unicode编码 ?5.3 在MS Word中输入希腊字母 ?6 参看 ?7 注释与引用 ?8 参考文献 ?9 外部链接 简述[编辑] 希腊字母是希腊语所使用的字母,是世界上最早的有元音的字母,也广泛使用于数学、物理、生物、天文等学科。俄语等使用的西里尔字母也是由希腊字母演变而成。希腊字母进入了许多语言的词汇中,英语单字“alphabet”(字母表),源自拉丁语“alphabetum”,源自希腊语“αιθαβεηνλ”,即为前两个希腊字母α(“Alpha”)及β(“Beta”)所合成,三角洲(“Delta”)这个词就来自希腊字母Γ,因为Γ是三角形。 希腊字母在对希腊文明乃至西方文化影响深远。《新约》里,神说:“我是阿拉法、我是俄梅戛、我是首先的、我是末后的、我是初、我是终。”[1]在希腊字母表里,第一个字母是“Α,α”(阿尔法),代表开始;最后一个字母是“Χ,ω” (欧米茄),代表终了。这正是《新约》用希腊语写作的痕迹。 字母表[编辑] 在黑彩陶器上的字母表,现藏于雅典国家考古博物馆
基于matlab的图像识别与匹配
基于matlab的图像识别与匹配 摘要 图像的识别与匹配是立体视觉的一个重要分支,该项技术被广泛应用在航空测绘,星球探测机器人导航以及三维重建等领域。 本文意在熟练运用图像的识别与匹配的方法,为此本文使用一个包装袋并对上面的数字进行识别与匹配。首先在包装袋上提取出来要用的数字,然后提取出该数字与包装袋上的特征点,用SIFT方法对两幅图进行识别与匹配,最终得到对应匹配数字的匹配点。仿真结果表明,该方法能够把给定数字与包装袋上的相同数字进行识别与匹配,得到了良好的实验结果,基本完成了识别与匹配的任务。
1 研究内容 图像识别中的模式识别是一种从大量信息和数据出发,利用计算机和数学推理的方法对形状、模式、曲线、数字、字符格式和图形自动完成识别、评价的过程。 图形辨别是图像识别技术的一个重要分支,图形辨别指通过对图形的图像采用特定算法,从而辨别图形或者数字,通过特征点检测,精确定位特征点,通过将模板与图形或数字匹配,根据匹配结果进行辨别。 2 研究意义 数字图像处理在各个领域都有着非常重要的应用,随着数字时代的到来,视频领域的数字化也必将到来,视频图像处理技术也将会发生日新月异的变化。在多媒体技术的各个领域中,视频处理技术占有非常重要的地位,被广泛的使用于农业,智能交通,汽车电子,网络多媒体通信,实时监控系统等诸多方面。因此,现今对技术领域的研究已日趋活跃和繁荣。而图像识别也同样有着更重要的作用。 3 设计原理 3.1 算法选择 Harris 角点检测器对于图像尺度变化非常敏感,这在很大程度上限制了它的应用范围。对于仅存在平移、旋转以及很小尺度变换的图像,基于Harris 特征点的方法都可以得到准确的配准结果,但是对于存在大尺度变换的图像,这一类方法将无法保证正确的配准和拼接。后来,研究人员相继提出了具有尺度不变性的特征点检测方法,具有仿射不变性的特征点检测方法,局部不变性的特征检测方法等大量的基于不变量技术的特征检测方法。 David.Lowe 于2004年在上述算法的基础上,总结了现有的基于不变量技术的特征检测方法,正式提出了一种基于尺度空间的,对图像平移、旋转、缩放、甚至仿射变换保持不变性的图像局部特征,以及基于该特征的描述符。并将这种方法命名为尺度不变特征变换(Scale Invariant Feature Transform),以下简称SIFT 算法。SIFT 算法首先在尺度空间进行特征检测,并确定特征点的位置和特征点所处的尺度,然后使用特征点邻域梯度的主方向作为该特征点的方向特征,以实现算子对尺度和方向的无关性。利用SIFT 算法从图像中提取出的特征可用于同一个物体或场景的可靠匹配,对图像尺度和旋转具有不变性,对光照变化、
希腊字母的正确读法是什么
希腊字母的正确读法是什么? 1 Αα alpha a:lf 阿尔法角度;系数 2 Β β beta bet 贝塔磁通系数;角度;系数 3 Γγ gamma ga:m 伽马电导系数(小写) 4Γδ delta delt 德尔塔变动;密度;屈光度 5 Δε epsilon ep`silon 伊普西龙对数之基数 6 Εδ zeta zat 截塔系数;方位角;阻抗;相对粘度;原子序数 7 Ζε eta eit 艾塔磁滞系数;效率(小写) 8 Θ ζthet ζit 西塔温度;相位角 9 Ηη iot aiot 约塔微小,一点儿 10 Κ θ kappa kap 卡帕介质常数 11∧ι lambda lambd 兰布达波长(小写);体积 12 Μκ mu mju 缪磁导系数;微(千分之一);放大因数(小写) 13 Νλ nu nju 纽磁阻系数 14 Ξμ xi ksi 克西 15 Ον omicron omik`ron 奥密克戎 16 ∏π pi pai 派圆周率=圆周÷直径=3.1416 17 Ρξ rho rou 肉电阻系数(小写) 18 ∑ζ sigma `sigma 西格马总和(大写),表面密度;跨导(小写) 19 Τη tau tau 套时间常数 20 Υυ upsilon jup`silon 宇普西龙位移 21 Φθ phi fai 佛爱磁通;角 22 Φχ chi phai 西
23 Χ ψ psi psai 普西角速;介质电通量(静电力线);角 24 Ψ ω omega o`miga 欧米伽欧姆(大写);角速(小写);角 希腊字母读法 Αα:阿尔法Alpha Ββ:贝塔Beta Γγ:伽玛Gamma Γδ:德尔塔Delte Δε:艾普西龙Epsilon δ :捷塔Zeta Εε:依塔Eta Θζ:西塔Theta Ηη:艾欧塔Iota Κθ:喀帕Kappa ∧ι:拉姆达Lambda Μκ:缪Mu Νλ:拗Nu Ξμ:克西Xi Ον:欧麦克轮Omicron ∏π:派Pi Ρξ:柔Rho ∑ζ:西格玛Sigma Τη:套Tau Υυ:宇普西龙Upsilon Φθ:fai Phi Φχ:器Chi Χψ:普赛Psi Ψω:欧米伽Omega 希腊字母怎么打希腊字母的正确读法是什么? 1 Α α alpha a:lf 阿尔法角度;系数 2 Β β beta bet 贝塔磁通系数;角度;系数 3 Γ γ gamma ga:m 伽马电导系数(小写) 4 Γ δ delta delt 德尔塔变动;密度;屈光度 5 Δ ε epsilon ep`silon 伊普西龙对数之基数 6 Ε δ zeta zat 截塔系数;方位角;阻抗;相对粘度;原子序数 7 Ζ ε eta eit 艾塔磁滞系数;效率(小写) 8 Θ ζ thet ζit 西塔温度;相位角 9 Η η iot aiot 约塔微小,一点儿 10 Κ θ kappa kap 卡帕介质常数 11 ∧ι lambda lambd 兰布达波长(小写);体积 12 Μ κ mu mju 缪磁导系数;微(千分之一);放大因数(小写) 13 Ν λ nu nju 纽磁阻系数 14 Ξ μ xi ksi 克西 15 Ο ν omicron omik`ron 奥密克戎
Matlab中下标,斜体,及希腊字母的使用方法(转)
下面是Matlab官方列出来的Tex代码列表,包含了绝大部分的希腊字母和数学
下面给出Matlab中下标及希腊字母的使用方法,还有更多的使用方法可以参考matlab帮助 文档中的Text Properties: 下标用_(下划线) 上标用^ (尖号) 斜体\it 黑体\bf << \ll >> \gg 正负\pm 左箭头\leftarrow 右箭头\rightarrow 上箭头\uparrow 上圆圈(度数)\circ 例text(2,3,'\alpha_2^\beta') it\w(x):mm,要求w(x)是斜体,而:mm不要求斜体 {it\w(x)}:mm 把要设置成斜体的用大括号放在一起 注:可用{}把须放在一起的括起来 特殊的数学符号 \approx ≈\oplus ≡\neq ≠\leq ≤\geq ≥\pm ±
\times× \div ÷\int ∫\exists∝\infty ∞\in ∈\sim ≌\forall ~\angle∠\perp⊥\cup ∪\cap ∩\vee ∨\wedge ∧\surd根号\otimes 叉乘符号\oplus? 箭头 \uparrow ↑\downarrow ↓\rightarrow →\leftarrow ← 在图形的坐标处书写文字注释 x=0:0.2:2*pi; y=sin(x); plot(x,y) text(2,sin(2),'wacs5'); MATLAB图形上的文字修饰 文字标注是图形修饰中的重要因素,它可以是用户在窗口上随意添加的字符说明,还可以是坐标轴对象中所用到的刻度标志等。字符对象的常用属性如下: ?Color属性:字符的颜色。该属性的属性值是一个1x3颜色向量。 ?FontAngle属性:字体倾斜形式。如正常'normal'和斜体'italic'等。 ?FontName属性:字体的名称。如'TimesNewRoman'与'Courier'等。 ?FontSize属性:字号大小。默认以pt为单位,属性值应该为实数。 ?FontWeight属性:字体是否加黑。可以选择'light'、'normal'(默认值)、'demi'和'bold'4个选项,其颜色逐渐变黑。 ?HorizontalAlignment属性:表示文字的水平对齐方式。可以有'left'(按左边对齐)、'center' (居中对齐)、'right'(按右边对齐)三种选择。类似地,对字符矩阵的位置还有VerticalAlignment属性。 ?FontUnits属性:字体大小的单位。如'points'(磅数,即pt)为默认的值,此外,还可以使用如下单位'inches'(英寸)、'centimeters'(厘米)、 'normalized'(归一值)与'pixels'(像素)等。 ?Rotation属性:字体旋转角度。可以为任何数值。 ?Editing属性:是否允许交互式修改。选项可以为'on'和'off'。 ?String属性:构成本字符对象的字符串。可以是字符串矩阵。 ?Interpreter属性:是否允许TeX格式。选项为'tex'(允许TeX格式)和'none'(不允许)两种,前者显示的效果好,而后者速度快。
基于MATLAB的图像处理字母识别
数字图像处理 报告名称:字母识别 学院:信息工程与自动化学院专业:物联网工程 学号:201310410149 学生姓名:廖成武 指导教师:王剑 日期:2015年12月28日 教务处制
目录 字母识别 1.---------------------测试图像预处理及连通区域提取 2.---------------------样本库的建立采集feature 3.---------------------选择算法输入测试图像进行测试 4.---------------------总结
字母识别 1.imgPreProcess(联通区域提取)目录下 conn.m:连通区域提取分割(在原图的基础上进行了膨胀、腐蚀、膨胀的操作使截取的图像更加接近字母) %%提取数字的边界,生成新的图 clear; clc; f=imread('5.jpg'); f=imadjust(f,[0 1],[1 0]); SE=strel('square',5); %%膨胀、腐蚀、膨胀 A2=imdilate(f,SE); SE=strel('disk',3) f=imerode(A2,SE) SE=strel('square',3); f=imdilate(f,SE); gray_level=graythresh(f); f=im2bw(f,gray_level); [l,n]=bwlabel(f,8) %%8连接的连接分量标注 imshow(f) hold on for k=1:n %%分割字符子句 [r,c]=find(l==k); rbar=mean(r); cbar=mean(c); plot(cbar,rbar,'Marker','o','MarkerEdgeColor','g','MarkerFaceColor',' y','MarkerSize',10); % plot(cbar,rbar,'Marker','*','MarkerEdgecolor','w'); row=max(r)-min(r) col=max(c)-min(c) for i=1:row for j=1:col seg(i,j)=1; end
希腊字母
希腊语 古代[1]现代[2]古代[1]现代[2]古代[1]现代[2] Alpha Alfa [a][a] (Aleph)a a Beta Vita [b][v] (Beth)b v Gamma Gama [g][?] (Gimel)g g, gh, j Delta Delta [d][e] (Daleth)d d, dh Epsilon Epsilon [e][e] (He)e e Zeta Zita [dz, zd][z] (Zayin)z z Eta Ita [??][i] (Heth)ēi Theta Thita [t h ][θ] (Teth)th th Iota Iota [i][i] (Yodh)i i Kappa Kapa [k][k] (Kaph)k k Lambda Lambda [l][l] (Lamedh)l l Mu Mi [m][m] (Mem)m m Nu Ni [n][n] (Nun)n n Xi Xi [ks][ks] (Samekh)x x Omicron Omikron [o] [o] (Ayin)o o Pi Pi [p][p] (Pe)p p Rho Ro [r][r] (Res)rh r Sigma Sigma [s][s] (Shin) s s Tau Taf [t][t] (Taw)t t Upsilon Ipsilon [u][i] (Waw) u y Phi Fi [p h ][f]- (来源有争议) ph f Chi Chi [k h ][x]ch ch Psi Psi [ps][ps]ps ps Omega Omega [o ?] [o] (Ayin)ō o 欲看其他细节或意译系统请看希腊语罗马字转写系统。在前古典时期或不用于雅典的方言时,一些字母有不同的发音。欲知详情,请看希腊字母的历史。
Matlab中给图形添加【希腊字母】
比如画一条蓝色的x号线 plot(x,y,'bg') 画图: 线形:-实线-. 点划线--长虚线:短虚线 符号颜色符号线形 b 蓝. 点 c 青。圈 g 绿××标记 k 黑-实线 m 紫红* 星号 r 红:点线 w 白-. 点划线 y 黄--虚线 上下标: ^{任意字符} _{任意字符} figure,title('\ite^{-t}sint'); %% \it表示斜体 figure,title('x~{\chi}_{\alpha}^{2}(3)'); Matlab中给图形添加希腊字母 \alpha \beta \gamma \delta \epsilon \zeta \eta \theta \iota \kappa \lambda \mu \nu \xi \omicron \pi \rho \sigma \tau \upsilon \phi \chi \psi \omega 大写小写英文注音国际音标注音中文注音 1 Ααalpha a:lf 阿尔法 2 Ββbeta bet 贝塔 3 Γγgamma ga:m 伽马 4 Γδdelta delt 德尔塔 5 Δεepsilon ep`silon 伊普西龙 6 Εδzeta zat 截塔 7 Ζεeta eit 艾塔 8 Θζtheta ζit 西塔 9 Ηηiota aiot 约塔 10 Κθkappa kap 卡帕 11 ∧ιlambda lambd 兰布达 12 Μκmu mju 缪 13 Νλnu nju 纽 14 Ξμxi ksi 克西 15 Ονomicron omik`ron 奥密克戎 16 ∏πpi pai 派 17 Ρξrho rou 肉 18 ∑ζsigma `sigma 西格马 19 Τηtau tau 套 20 Υυupsilon jup`silon 宇普西龙 21 Φθphi fai 佛爱 22 Φχchi phai 西 23 Χψpsi psai 普西
基于matlab的人脸识别算法(PCA)
3.基于matlab的人脸识别算法 3.1 问题描述 对于一幅图像可以看作一个由像素值组成的矩阵,也可以扩展开,看成一个矢量,如一幅 N*N 象素的图像可以视为长度为N2 的矢量,这样就认为这幅图像是位于N2 维空间中的一个点,这种图像的矢量表示就是原始的图像空间,但是这个空间仅是可以表示或者检测图像的许多个空间中的一个。不管子空间的具体形式如何,这种方法用于图像识别的基本思想都是一样的,首先选择一个合适的子空间,图像将被投影到这个子空间上,然后利用对图像的这种投影间的某种度量来确定图像间的相似度,最常见的就是各种距离度量。因此,本次试题采用PCA算法并利用GUI实现。 对同一个体进行多项观察时,必定涉及多个随机变量X1,X2,…,Xp,它们都是的相关性, 一时难以综合。这时就需要借助主成分分析来概括诸多信息的主要方面。我们希望有一个或几个较好的综合指标来概括信息,而且希望综合指标互相独立地各代表某一方面的性质。 任何一个度量指标的好坏除了可靠、真实之外,还必须能充分反映个体间的变异。如果有一项指标,不同个体的取值都大同小异,那么该指标不能用来区分不同的个体。由这一点来看,一项指标在个体间的变异越大越好。因此我们把“变异大”作为“好”的标准来寻求综合指标。3.1.1 主成分的一般定义 设有随机变量X1,X2,…,Xp,其样本均数记为,,…,,样本标准差记为S1,S2,…,Sp。首先作标准化变换,我们有如下的定义: (1) 若C1=a11x1+a12x2+ … +a1pxp,…,且使 Var(C1)最大,则称C1为第一主成分; (2) 若C2=a21x1+a22x2+…+a2pxp,…,(a21,a22,…,a2p)垂直于(a11,a12,…,a1p),且使Var(C2)最大,则称C2为第二主成分; (3) 类似地,可有第三、四、五…主成分,至多有p个。 3.1.2 主成分的性质 主成分C1,C2,…,Cp具有如下几个性质: (1) 主成分间互不相关,即对任意i和j,Ci 和Cj的相关系数 Corr(Ci,Cj)=0 i j (2) 组合系数(ai1,ai2,…,aip)构成的向量为单位向量, (3) 各主成分的方差是依次递减的,即 Var(C1)≥Var(C2)≥…≥Var(Cp)
输入希腊字母
如何在几何画板中输入希腊字母 方法一:复制+粘贴 这是一种最易想到的方法,但需要借助其他平台,虽然几何画板中直接输入比较困难,但在word中输入却非常容易,比如现在要将几何画板中一条线段的标签a 改为希腊字母“ε”: (1)打开word,选择菜单【插入】/【符号】,在打开的符号对话框中子集选择“基本希腊语”,找到“ε”插入word中,快捷键ctrl+c复制。(2)切换到几何画板界面,用直尺工具作一线段,用文本工具给线段添加标签a,双击标签打开对话框,标签a呈选中状态,按快捷键ctrl+v粘贴后字母a变为ε,单击确定完成。 方法二:修改标签样式 (1)再用直尺工具作一线段,用文本工具给线段加标签b,双击标签打开对话框,点击样式按钮,打开标签样式对话框,将默认字体arial修改为希腊字母样式即symbol,点击确定关闭对话框,恢复到上层对话框。 (2)选中原标签字母b,改为小写字母e,确定退出,此时你会发现点b的标签不是变为e,而是变成了希腊字母“ε”。这是因为我们已经将字体的样式改为“symbol”,所以此时键盘上的英文字母已经代表着相应的原希腊字母。几个常用的希腊字母所对应的英文字母:a-α、b-β、j-ψ、l-ι、m-κ、q-ζ、w-ω。 附:为方便起见,特把几何画板中可言直接输入的希纳字母列出如下: 1. αalpha; 2. βbeta ; 3. γgamma ; 4 . δ delta ; 5. ε epsilon ; 6 δzeta; 7.ε eta ; 8. ζ theta; 9.η iota; 10. θkappa ; 11. ιlambda; 12. κmu; 13. λnu; 14. μ xi; 15.πpi ; 16. ρrho ; 17. ζ sigma; 18.η tau 19.υupsilon; 20. θphi; 21. χ chi ; 22. ψ psi ; 23. ω omega. 输入格式为:{}
Matlab中常用希腊字母表查询
Matlab中常用希腊字母表查询
————————————————————————————————作者:————————————————————————————————日期:
Matlab中常用希腊字母表查询 Matlab的text中经常需要用到希腊字母表,我现在将所有的都总结了下 比如在坐标轴的[0.5 0.5]位置上要显示δ字符,那么可以直接输入text(0.5,0.5,'\delta') 如果需要显示大写希腊字符的话,那直接将首字母改为大写就可以了 注意必须使用“\”引导,如果需要显示“\”,那么必须输入“\\”;类似的在字符串组合的时候如果要输入“'”则必须如下输入“''” 另外text字符可以重叠显示,这样就可以构造出一些有趣的效果,比如将某个字符上添加一个斜杠或者画一个叉等 序号大 写 小 写 英文注 音 国际音标注 音 中文读 音 意义 1Ααalpha a:lf阿尔法角度;系数 2Ββbeta bet贝塔磁通系数;角度;系数3Γγgamma ga:m伽马电导系数 4Δδdelta delt德尔塔变动;密度;屈光度 5Εεepsilon ep`silon 伊普西 龙 对数之基数 6Ζζzeta zat截塔阻抗;相对粘度;原子序 数 7Ηηeta eit艾塔磁滞系数;效率 8Θθthetθit西塔温度;相位角 9Ιιiot aiot约塔微小,一点儿 10Κκkappa kap卡帕介质常数 11Λλlambda lambd兰布达波长;体积 12Μμmu mju缪磁导系数;放大因子13Ννnu nju纽磁阻系数 14Ξξxi ksi克西 15Οοomicron omik`ron 奥密克戎 16Ππpi pai派圆周率17Ρρrho rou肉电阻系数
基于MATLAB的人脸识别
基于MATLAB的人脸识别
————————————————————————————————作者: ————————————————————————————————日期:
图像识别 题目:基于MATLAB的人脸识别 院系:计算机科学与应用系 班级: 姓名: 学号: 日期:
设计题目基于MATLAB的人脸识别设 计技术参数 测试数据库图片10张训练数据库图片20张图片大小1024×768 特征向量提取阈值 1 设计要求综合运用本课程的理论知识,并利用MATLAB作为工具实现对人脸图片的预处理,运用PCA算法进行人脸特征提取,进而进行人脸匹配识别。 工作量 两周的课程设计时间,完成一份课程设计报告书,包括设计的任务书、基本原理、设计思路与设计的基本思想、设计体会以及相关的程序代码; 熟练掌握Matlab的使用。 工作计划第1-2天按要求查阅相关资料文献,确定人脸识别的总体设计思路; 第3-4天分析设计题目,理解人脸识别的原理同时寻求相关的实现算法;第5-8天编写程序代码,创建图片数据库,运用PCA算法进行特征提取并编写特征脸,上机进行调试; 第9-12天编写人脸识别程序,实现总体功能; 第13-14天整理思路,书写课程设计报告书。 参考资料1 黄文梅,熊佳林,杨勇编著.信号分析与处理——MATALB语言及应用.国防科技大学出版社,2000 2 钱同惠编著.数字信号处理.北京:机械工业出版社,2004 3 姚天任,江太辉编著.数字信号处理.第2版.武汉:武汉理工大学出版社,2000 4 谢平,林洪彬,王娜.信号处理原理及应用.机械工业出版社,2004 5刘敏,魏玲.Matlab.通信仿真与应用.国防工业出版社,2005 6 楼顺天.基于Matlab7.x 的系统分析与设计.西安电子科技大学,2002 7孙洪.数字信号处理.电子工业出版社,2001 目录 引言?错误!未定义书签。 1 人脸识别技术?错误!未定义书签。 1.1人脸识别的研究内容?错误!未定义书签。 1.1.1人脸检测(Face Detection)........... 错误!未定义书签。
如何在matlab中输入希腊字母
如何在matlab中输入希腊字母 matlab中用转义符来输入希腊字母的方法上标用^(指数) 下标用_(下划线) 希腊字母等特殊字符用\加拼音如 α \alpha β \beta γ \gamma ζ \theta Θ \Theta Г \Gamma δ \delta Δ \Delta ξ \xi Ξ \Xi ε \elta ε \epsilong δ \zeta μ \miu υ \nu η \tau
λ \lamda ∧\Lamda π \pi ∏ \Pi ζ \sigma ∑ \Sigma θ \phi Φ \Phi ψ \psi Ψ \Psi χ \chi ω \ommiga Ω \Ommiga < \leq > \geq 不等于\neq << \ll >> \gg 正负\pm 左箭头\leftarrow 右箭头\rightarrow
上箭头\uparrow 例text(2,3,'\alpha_2^\beta') 注:可用{}把须放在一起的括起来 Matlab图形中允许用TEX文件格式来显示字符。使用\bf,\it,\rm表示黑体,斜体,正体字符,特别注意大括号{ }的用法。 matlab 矩阵显示精度问题 我用了format long 计算结果是 ans = 1.0e+005 * 4.955607459688747 4.868345427502330 7.367964665393308 7.367964665393308 2.586881270077396 7.586119745859352 7.629750761952561 7.629750761952561 7.500000000000000 7.500000000000000 5.000000000000000 2.500000000000000 我不想让它显示成 1.0e+005 * 而是直接495560.7459688747,怎么办? format long g
基于matlab数字图像处理与识别系统含程序
目录 第一章绪论 (2) 1.1 研究背景 (2) 1.2 人脸图像识别的应用前景 (3) 1.3 本文研究的问题 (4) 1.4 识别系统构成 (4) 1.5 论文的内容及组织 (5) 第二章图像处理的Matlab实现 (6) 2.1 Matlab简介 (6) 2.2 数字图像处理及过程 (6) 2.2.1图像处理的基本操作 (6) 2.2.2图像类型的转换 (7) 2.2.3图像增强 (7) 2.2.4边缘检测 (8) 2.3图像处理功能的Matlab实现实例 (8) 2.4 本章小结 (11) 第三章人脸图像识别计算机系统 (11) 3.1 引言 (11) 3.2系统基本机构 (12) 3.3 人脸检测定位算法 (13) 3.4 人脸图像的预处理 (18) 3.4.1 仿真系统中实现的人脸图像预处理方法 (19) 第四章基于直方图的人脸识别实现 (21) 4.1识别理论 (21) 4.2 人脸识别的matlab实现 (21) 4.3 本章小结 (22) 第五章总结 (22) 致谢 (23) 参考文献 (24) 附录 (25)
第一章绪论 本章提出了本文的研究背景及应用前景。首先阐述了人脸图像识别意义;然后介绍了人脸图像识别研究中存在的问题;接着介绍了自动人脸识别系统的一般框架构成;最后简要地介绍了本文的主要工作和章节结构。 1.1 研究背景 自70年代以来.随着人工智能技术的兴起.以及人类视觉研究的进展.人们逐渐对人脸图像的机器识别投入很大的热情,并形成了一个人脸图像识别研究领域,.这一领域除了它的重大理论价值外,也极具实用价值。 在进行人工智能的研究中,人们一直想做的事情就是让机器具有像人类一样的思考能力,以及识别事物、处理事物的能力,因此从解剖学、心理学、行为感知学等各个角度来探求人类的思维机制、以及感知事物、处理事物的机制,并努力将这些机制用于实践,如各种智能机器人的研制。人脸图像的机器识别研究就是在这种背景下兴起的,因为人们发现许多对于人类而言可以轻易做到的事情,而让机器来实现却很难,如人脸图像的识别,语音识别,自然语言理解等。如果能够开发出具有像人类一样的机器识别机制,就能够逐步地了解人类是如何存储信息,并进行处理的,从而最终了解人类的思维机制。 同时,进行人脸图像识别研究也具有很大的使用价依。如同人的指纹一样,人脸也具有唯一性,也可用来鉴别一个人的身份。现在己有实用的计算机自动指纹识别系统面世,并在安检等部门得到应用,但还没有通用成熟的人脸自动识别系统出现。人脸图像的自动识别系统较之指纹识别系统、DNA鉴定等更具方便性,因为它取样方便,可以不接触目标就进行识别,从而开发研究的实际意义更大。并且与指纹图像不同的是,人脸图像受很多因素的干扰:人脸表情的多样性;以及外在的成像过程中的光照,图像尺寸,旋转,姿势变化等。使得同一个人,
希腊字母读音及手写
希腊字母 希腊字母在现代已经超越了希腊民族的局限而成为了国际性的符号(自然科 学的、社会科学的),尤其在土木工程,材料学、土力学、水力学及相应设计课程里作为科学符号多而杂,初学者很难对其读音和书写准确掌握,所以本文编辑了希腊字母有关历史和读音、书写,以便初学和自学者在掌握这些符号的基本读写后尽快能熟悉其在专业中的意义! 希腊语是印欧语系独立的一支,作为古希腊文明的载体,作为文学、哲学、科学、宗教等众多领域使用的语言,它的灿烂光辉举世罕见。古希腊语是极少数至今仍然在世界范围内被学习和使用的古典语言之一。“希腊”的中文名字不是来自英语Greece,而是来自Hellas这个诗歌语汇。此举与希腊这个艺术的国度是多么相称啊!讲希腊语的民族在大约4000年前从巴尔干半岛来到希腊半岛及附近地区。他们的语言分化为4种方言:伊奥里亚、爱奥尼亚、阿卡迪亚-塞浦路斯和多利安方言。著名的《荷马史诗》——《伊利亚特》和《奥德赛》是大约公元前9世纪的作品,使用的是爱奥尼亚方言。由爱奥尼亚方言发展为雅典语——古希腊语的主要形式和共同语Koine的基础。《圣经》的《旧约全书》在公元前3-公元前2世纪译为Koine;《新约全书》则是直接用Koine写作的。信仰东正教的人们现在还在使用这种古典语言的《圣经》。 现在使用希腊语的国家包括希腊、塞浦路斯、意大利、阿尔巴尼亚、土耳其等,以希腊语为母语的人有1500多万。我们对希腊字母并不陌生,数学、物理、生物、天文学等学科都广泛使用希腊字母。读过初中的人对“阿尔法”、“贝塔”、“伽玛”……早已耳熟能详。《新约》里神说:“我是阿拉法,我是俄梅嘎。我是始,我是终。”在希腊字母表里,第一个字母是“阿尔法”(阿拉法),代表开始;最后一个字母是“欧美噶”(俄梅嘎),代表终了。这正是《新约》用希腊语写作的痕迹。罗马帝国时代,希腊语是继拉丁语之后的第二语言。它在教育领域的地位至今仍然在欧美国家的大学里延续。 希腊字母并不神秘,就像阿拉伯文、俄文字母一样,只是符号不同,标音的性质是一样的。阿拉伯文没有元音字母。希腊字母是世界上最早的有元音的字母。俄文、新蒙文等使用的基里尔字母和格鲁吉亚语字母都是由希腊字母发展而来,学过俄文的人使用希腊字母会觉得似曾相识。希腊字母进入了许多语言的词汇中,如delta(三角洲)这个国际语汇就来自希腊字母Δ,因为Δ是三角形。希腊字母原来有26个,大约在荷马时代减少了2个,雅典人的字母本来没有Η和Ω,是公元前403年增加的。那时定型的字母表一直使用到现在。全世界这么稳定而且悠久的文字是极少的。希腊文最早是从右向左横写,与阿拉伯文一致。之后有过向左与向右并存的情形,从右写到左,下一行有时不是从右端开始,而是从左端开始。玛雅铭文中这种行款很常见,甲骨文里也有这样的行款。最后,希腊文只使用从左到右一种行款,这是西方文字的书写习惯。
MATLAB指令详解
2011-04-11 23:59 MATLAB view 函数使用教程 三维做图中,我们可以使用plot3将坐标点置于任何地方,可以轻松实现定位。画图完毕后,为了达到更好的视觉效果,大都要进行图形的旋转调整。 调整视角主要有两种方法: 1. 使用绘图区域上方的工具按钮”Rotate 3D“; 2. 使用view命令定位视角。 view命令有两种格式,view(x,y,z)和view(az,el)。前者是在笛卡尔坐标系中设定视角的位置,该格式比较直观,不做讨论。后者的两个参数分别是视角的方位角和俯视角,用起来可能会带来困惑,下面图解之。 上图是指令view(30,30)所得。 这是一个很简单的3D视图,图中红色实线是X轴,蓝色实线是Y轴,黑色实线是Z轴,蓝色虚线是Y轴的负半轴。 现规定,逆时针方向为正,顺时针方向为负。 MATLAB提供了设置视点的函数view。其调用格式为:view(az,el) az是azimuth(方位角)的缩写,el是elevation(仰角)的缩写。它们均以度为单位。系统缺省的视点定义为方位角-37.5°,仰角30°。当x轴平行观察者身体,y轴垂直于观察者身体时,
az=0;以此点为起点,绕着z轴顺时针运动,az为正,逆时针为负。(az和el分别是方位角和俯视角,单位为角度。Y轴的负半轴到观测点与原点的连线在X-Y平面投影线的角为az,el是X-Y平面投影线到观测点与原点连线的角). el 为观察者眼睛与xy平面形成的角度。当观察者的眼睛在xy平面上时,el=0; 向上el为正,向下为负; AZ = -37.5, EL = 30 是默认的三维视角. AZ = 0, EL = 90 是2维视角,从图形正上方向下看,显示的是xy平面. AZ = EL = 0 看到的是xz平面. AZ = 180,EL=0 是从背面看到的xz平面. VIEW(2) 设置默认的二维视角, AZ = 0, EL = 90. VIEW(3) 设置默认的三维视角, AZ = -37.5, EL = 30. VIEW([X Y Z]) 设置Cartesian坐标系的视角,[X Y Z]向量的长度大小被忽略. [AZ,EL] = VIEW 返回当前的方位角和仰角. 下面是一些例子: 例1:从不同视点绘制多峰函数曲面 subplot(2,2,1);mesh(peaks); view(-37.5,30); %指定子图1的视点 title('azimuth=-37.5,elevation=30') subplot(2,2,2);mesh(peaks); view(0,90); %指定子图2的视点 title('azimuth=0,elevation=90') subplot(2,2,3);mesh(peaks); view(90,0); %指定子图3的视点 title('azimuth=90,elevation=0') subplot(2,2,4);mesh(peaks); view(-7,-10); %指定子图4的视点 title('azimuth=-7,elevation=-10') 例2:旋转观察多峰函数曲面 mesh(peaks); %绘制多峰函数 el=30; %设置仰角为30度。
基于MATLAB数字图像处理杂草识别
基于MATLAB数字图像处理杂草识别
基于数字图像处理的杂草识别 班级:信息5班 组员:李辉李少杰李港深胡欣阳 学号:04141394 04141395 04141393 0414139 指导教师:蔡利梅 组员分工: 李辉:部分程序,查找资料 李少杰:实验报告,PPT,演讲 李港深:部分程序,实验报告 胡欣阳:部分程序,实验报告
摘要 杂草同农田作物争夺阳光和养分,严重影响了农作物的生长。为了达到除草的目的,人们开始喷洒大量的除草剂来进行除草。可是却忽略了除草剂的不当使用给人、畜以及环境造成的危害。本文从实际应用出发,设计了一个基于数字图像处理的杂草图像特征提取及识别设计方案。运行在参考了前人研究成果的基础上,不断将算法改进,找出适合于MATLAB杂草识别的可行性方法。本文对杂草图像的处理和识别方法进行研究。采集来的图像经常会有模糊现象的发生,对模糊图像的恢复处理做了大量的研究试验,得出维纳滤波具有较好的恢复效果;绿色植物和土壤背景的分割试验中,提出了一种基于彩色图像的二值化方法,可以不经过彩色图像灰度化就能够直接把绿色植物与土壤背景分割开,和以往的分割方法相比处理速度快,分割效果好,更加满足实时性;杂草和作物的分割主要研究了行间杂草和作物的分割,参考国内外资料,并进行研究试验,表明运用位置特征识别法有很好的分割效果,寻找作物中心行采用了简单快速的像素位置直方图法,采用了区域生长,和其他方法相比减少了重复操作,节省了时间,满足实时处理的要求;分割后的图像为只含有杂草的二值图像,通常会有一些残余的叶片和颗粒的噪声,通过形态学滤波或中值滤波去除噪声。 1、研究目的及意义 杂草是生态系统中的一员,农田杂草是农业生态系统中的
基于matlab的形状识别
1、设计目的 基于Maltab或者C语言对图像进行识别。编写摄像头采集图像程序,对采集的图像进行预处理,如图像增强、图像分割等处理,对于处理的图像进行特征提取,根据特征进行模式识别,如对三角形、正方形与圆形的识别。 2、设计正文 2.1设计分析 1)编写摄像头采集图像程序 2)对采集的图像进行预处理 3)对于处理的图像进行特征提取 4)进行模式识别,区分各种形状 2.2设计原理 2.2.1图像预处理 彩色图像包含着大量的颜色信息,不但在存储上开销很大,而且在处理上也会降低系统的执行速度,因此在对图像进行识别等处理中经常将彩色图像转变为灰度图像,以加快处理速度。由彩色转换为灰度的过程叫做灰度化处理。选择的标准是经过灰度变换彩色图像包含着大量的颜色信息,不但在存储上开销很大,而且在处理上也会降低系统的执行速度,因此在对图像进行识别
等处理中经常将彩色图像转变为灰度图像,以加快处理速度。由彩色转换为灰度的过程叫做灰度化处理。选择的标准是经过灰度变换。 2.2.2对于处理的图像进行特征值提取 二值图像是指整幅图像画面内仅黑、白二值的图像。在实际的车牌处理系统中,进行图像二值变换的关键是要确定合适的阀值,使得字符与背景能够分割开来,二值变换的结果图像必须要具备良好的保形性,不丢掉有用的形状信息,不会产生额外的空缺等等。车牌识别系统要求处理的速度高、成本低、信息量大,采用二值图像进行处理,能大大地提高处理效率。阈值处理的操作过程是先由用户指定或通过算法生成一个阈值,如果图像中某中像素的灰度值小于该阈值,则将该像素的灰度值设置为0或255,否则灰度值设置为255或0。 两个具有不同灰度值的相邻区域之间总存在边缘,边缘就是灰度值不连续的结果,是图像分割、纹理特征提取和形状特征提取等图像分析的基础。为了对有意义的边缘点进行分类,与这个点相联系的灰度级必须比在这一点的背景上变换更有效,我们通过门限方法来决定一个值是否有效。所以,如果一个点的二维一阶导数比指定的门限大,我们就定义图像中的次点是一个边缘点,一组这样的依据事先定好的连接准则相连的边缘点就定义为一条边缘。经过一阶的导数的边缘检测,所求的一阶导数高于某个阈
基于Matlab的车牌识别(完整版)
基于Matlab的车牌识别 摘要:车牌识别技术是智能交通系统的重要组成部分,在近年来得到了很大的发展。本文从预处理、边缘检测、车牌定位、字符分割、字符识别五个方面,具体介绍了车牌自动识别的原理。并用MATLAB软件编程来实现每一个部分,最后识别出汽车车牌。 一、设计原理 车辆车牌识别系统的基本工作原理为:将摄像头拍摄到的包含车辆车牌的图像通过视频卡输入到计算机中进行预处理,再由检索模块对车牌进行搜索、检测、定位,并分割出包含车牌字符的矩形区域,然后对车牌字符进行二值化并将其分割为单个字符,然后输入JPEG或BMP格式的数字,输出则为车牌号码的数字。车牌自动识别是一项利用车辆的动态视频或静态图像进行车牌号码、车牌颜色自动识别的模式识别技术。其硬件基础一般包括触发设备、摄像设备、照明设备、图像采集设备、识别车牌号码的处理机等,其软件核心包括车牌定位算法、车牌字符分割算法和光学字符识别算法等。某些车牌识别系统还具有通过视频图像判断车辆驶入视野的功能称之为视频车辆检测。一个完整的车牌识别系统应包括车辆检测、图像采集、车牌识别等几部分。当车辆检测部分检测到车辆到达时触发图像采集单元,采集当前的视频图像。车牌识别单元对图像进行处理,定位出车牌位置,再将车牌中的字符分割出来进行识别,然后组成车牌号码输出。 二、设计步骤 总体步骤为: 车辆→图像采集→图像预处理→车牌定位
→字符分割→字符定位→输出结果 基本的步骤: a.车牌定位,定位图片中的车牌位置; b.车牌字符分割,把车牌中的字符分割出来; c.车牌字符识别,把分割好的字符进行识别,最终组成车牌号码。 车牌识别过程中,车牌颜色的识别依据算法不同,可能在上述不同步骤实现,通常与车牌识别互相配合、互相验证。 (1)车牌定位: 自然环境下,汽车图像背景复杂、光照不均匀,如何在自然背景中准确地确定车牌区域是整个识别过程的关键。首先对采集到的视频图像进行大范围相关搜索,找到符合汽车车牌特征的若干区域作为候选区,然后对这些侯选区域做进一步分析、评判,最后选定一个最佳的区域作为车牌区域,并将其从图象中分割出来。 流程图: (2)车牌字符分割 : 完成车牌区域的定位后,再将车牌区域分割成单个字符,然后进行识别。字符分割一般采用垂直投影法。由于字符在垂直方向上的投影必然在字符间或字符内的间隙处取得局部最小值的附近,并且这个位置应满足车牌的字符书写格式、字符、尺寸限制和一些其他条件。利用垂直投影法对复杂环境下的汽车图像中的字符分割有较好的效果。 导入原始图像 图像预处理增强效果图像 边缘提取 车牌定位 对图像开闭运算