the oracle export utility executable must be specified解决方法
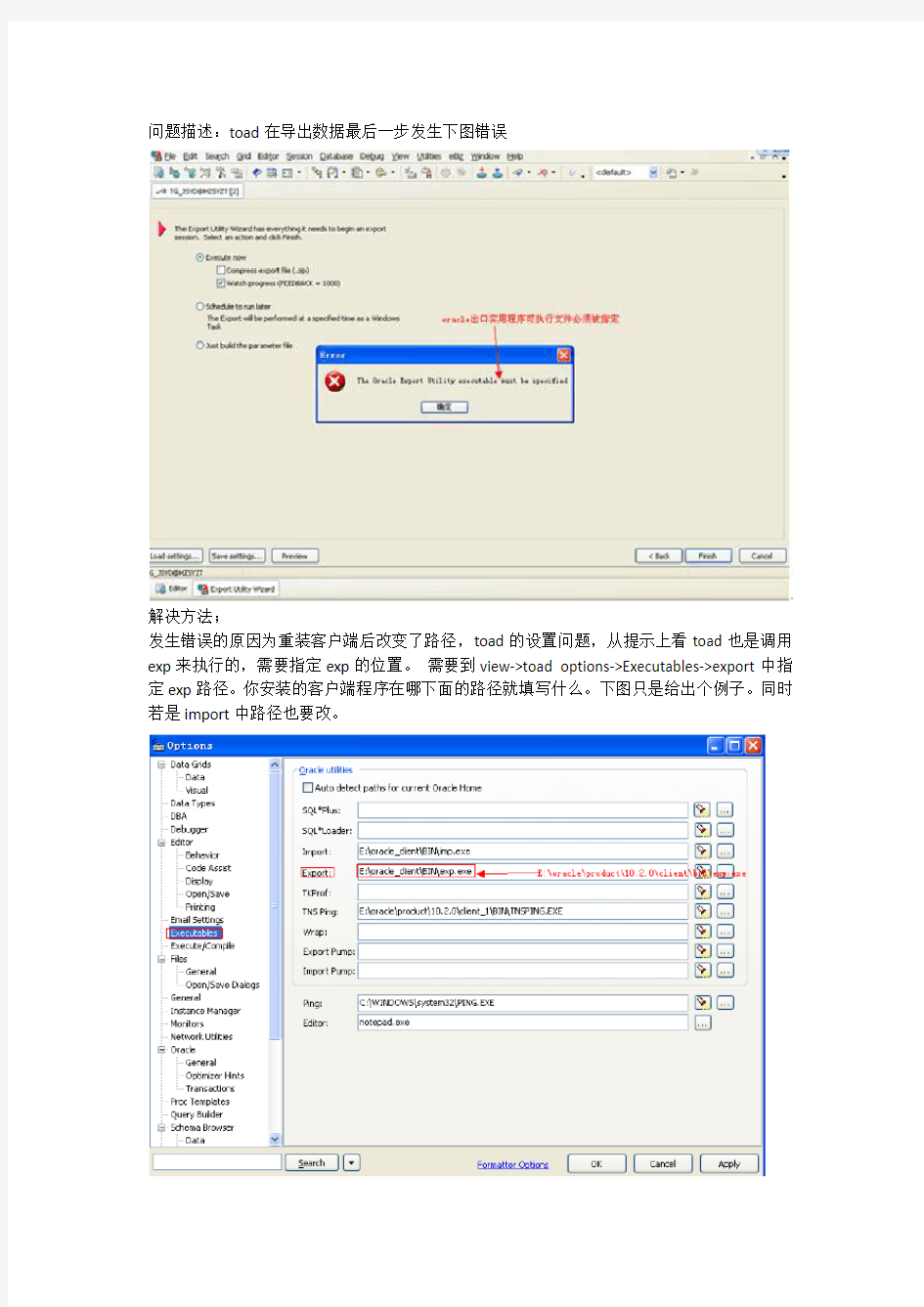
问题描述:toad在导出数据最后一步发生下图错误
解决方法;
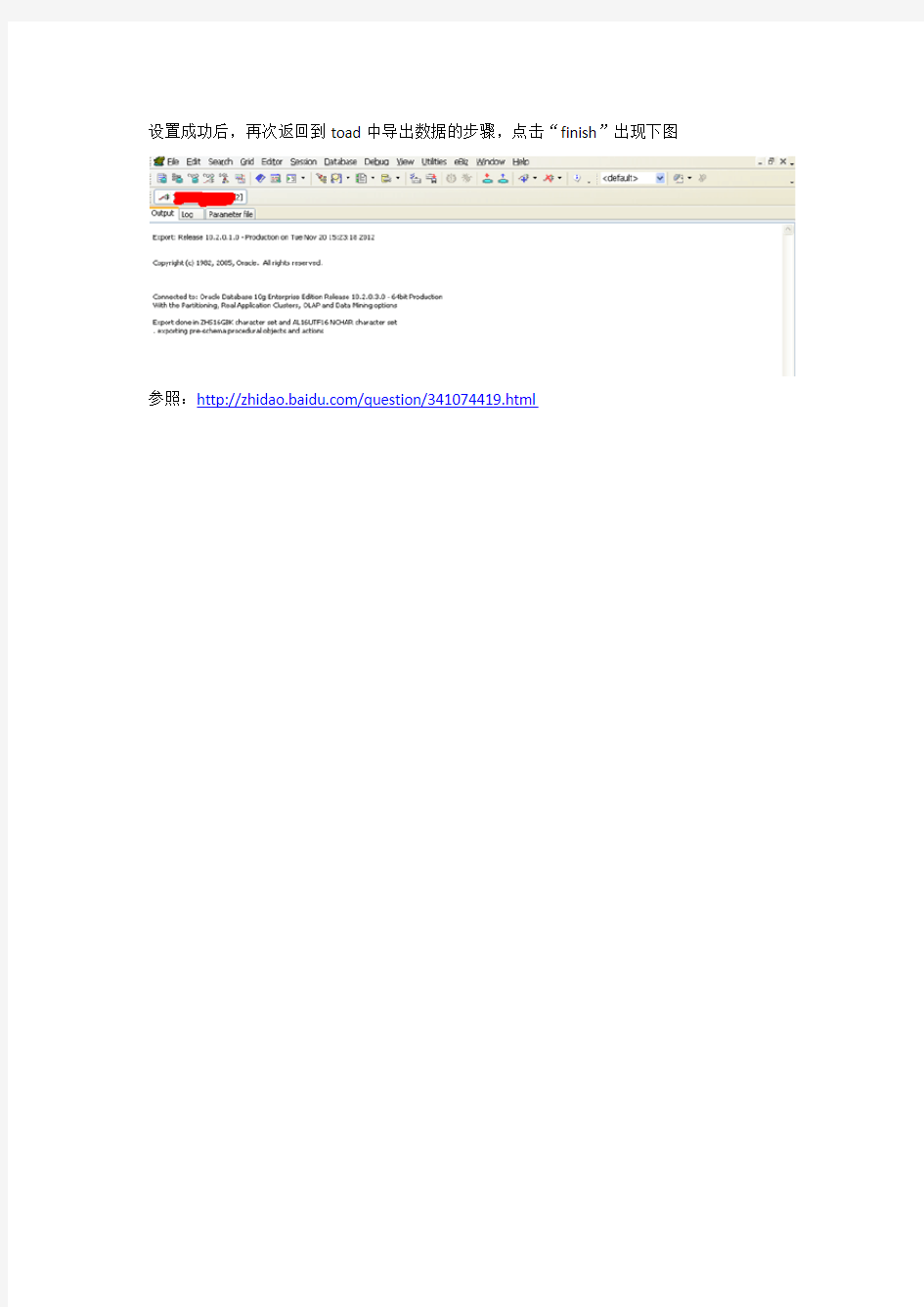
发生错误的原因为重装客户端后改变了路径,toad的设置问题,从提示上看toad也是调用exp来执行的,需要指定exp的位置。需要到view->toad options->Executables->export中指定exp路径。你安装的客户端程序在哪下面的路径就填写什么。下图只是给出个例子。同时若是import中路径也要改。
设置成功后,再次返回到toad中导出数据的步骤,点击“finish”出现下图
参照:https://www.360docs.net/doc/9611122265.html,/question/341074419.html
基于java实现访问oracle数据库的方法
基于java实现访问oracle数据库的方法 【摘要】随着Java Web的迅速发展,数据库连接已成为应用程序开发中的主要问题之一,连接数据库的效率也成为直接影响应用程序执行效率的因素。本文以Oracle数据库系统为例,详细介绍了在Java程序中访问数据库的传统数据库的连接方法和数据库连接池技术,并对此进行了分析和比较。 【关键词】Java;数据库;JDBC;连接池 1.引言 随着Java Web技术和计算机网络的迅速发展,人们对网络资源的共享提出了更高的要求。在网络环境中,对于数据的访问往往都是非常频繁的。在Java Web 的应用程序开发中使用Java访问数据库,是整个应用程序开发过程中的主要问题之一。下面就将以Oracle数据库系统为例,阐述在Java程序中访问数据库的传统的数据库连接方法和数据库连接池技术。 2.传统的数据库连接方法 2.1 JDBC简介 JDBC是用java连接数据库最为传统的方法,下面详细阐述在java程序中它具体是怎么实现的。 2.1.1 JDBC概念 JDBC的全称是Java Database Connectivity,即Java数据库连接。JDBC是标准的Java访问数据库的API。JDBC定义了数据库的连接、SQL语句的执行以及查询结果集的遍历等。它由一组用Java编程语言编写的类和接口组成,位于包java.sql下面,如java.sql.Connection,java.sql.Statement,java.sql.ResultSet等。JDBC提供给Java程序使用的,它将各种数据库的差异对Java程序屏蔽了起来,Java程序可以使用同样的可移植的接口访问数据库,使Java的应用程序屏蔽了数据库领域,同时保持了Java语言的“一次编写,各处运行”的优点。 2.1.2 JDBC的结构 JDBC主要有两类接口:面向程序开发人员的JDBC API和面向JDBC驱动程序的JDBC DRIVER API。前者是开发人员用来编写前端应用程序的,后者是由数据库厂商开发的。 (1)JDBC API由两个部分组成,一个是核心的API,其类包路径为javax.sql,这是J2EE的一部分,它具有可滚动的结果集、批量更新的实现类。另一个是扩展的API,其类包的路径为javax.sql,这是J2EE的一部分,它具有访问JNDI
深入学习分区表及分区索引(详解oracle分区)
下载的,写的非常好,给大家分享下。 什么时候使用分区: 1、大数据量的表,比如大于2GB。一方面2GB文件对于32位os是一个上限,另外备份时间长。 2、包括历史数据的表,比如最新的数据放入到最新的分区中。典型的例子:历史表,只有当前月份的数据可以被修改,而其他月份只能read-only ORACLE只支持以下分区:tables, indexes on tables, materialized views, and indexes on materialized views 分区对SQL和DML是透明的(应用程序不必知道已经作了分区),但是DDL 可以对不同的分区进行管理。 不同的分区之间必须有相同的逻辑属性,比如共同的表名,列名,数据类型,约束; 但是可以有不同的物理属性,比如pctfree, pctused, and tablespaces. 分区独立性:即使某些分区不可用,其他分区仍然可用。 最多可以分成64000个分区,但是具有LONG or LONG RAW列的表不可以,但是有CLOB or BLOB列的表可以。 可以不用to_date函数,比如: alter session set nls_date_format='mm/dd/yyyy'; CREATE TABLE sales_range (salesman_id NUMBER(5), salesman_name VARCHAR2(30), sales_amount NUMBER(10), sales_date DATE) PARTITION BY RANGE(sales_date) ( PARTITION sales_jan2000 VALUES LESS THAN('02/01/2000'),
Oracle 分区的概念
Oracle 分区的概念 分区是指将巨型的表或索引分割成相对较小的、可独立管理的部分,这些独立的部分称为原来表或索引的分区。分区后的表与未分区的表在执行查询语句或其他DML语句时没有任何区别,一旦进行分区之后,还可以使用DDL语句对每个单独的分区进行操作。因此,对巨型表或者索引进行分区后,能够简化对它们的管理和维护操作,而且分区对于最终用户和应用程序是完全透明的。 在对表进行分区后,每一个分区都具有相同的逻辑属性。例如,各个分区都具有相同的字段名、数据类型和约束等。但是各个分区的物理属性可以不同,例如,各个分区可以具有不同的存储参数,或者位于不同的表空间中。 如果对表进行了分区,表中的每一条记录都必须明确地属于某一个分区。记录应当属于哪一个分区是记录中分区字段的值决定的。分区字段可以是表中的一个字段或多个字段的组合,这时在在创建分区表时确定。在对分区表执行插入、删除或更新等操作时,Oracle会自动根据分区字段的值来选择所操用的分区。分区字段由1~16个字段以某种顺序组成,但不能包含ROWID等伪列,也不能包含全为NULL值的字段。 图10-1显示了一个典型的分区表。通常在对表进行分区时也会将地对应的索引进行分区,但是未分区的表可以具有分区的索引,而分区的表也可以具有未分区的索引。 索引索引 索引 索引 5月6月7月 未分区的表(分区的索引) 分区的表(分区的索引) 图10-1 分区表与分区索引 一个表可以被分割成任意数目的分区,但如果在表中包含有LONG或LONG RAW类型的字段,则不能对表分区。对于索引组织表而言,虽然也可以分区,但是有如下一些限制: ●索引组织表仅支持范围和散列分区,不能以列表或复合方式对索引组织表进行分 区。 ●分区字段必须是主键字段的一个子集。 ●如果在索引组织表中使用了OVERFLOW子句,溢出存储段将随表的分区进行相 同的分割。 下面给出了应当考虑对表进行分区的一些常见情况: ●如果一个表的大小超过了2GB,通常会对它进行分区。 ●如果要对一表进行并行DML操作,则必须对它进行分区。 ●如果为了平衡硬盘I/O操作,需要将一个表分散存储在不同的表空间中,这时就必 须对表进行分区。 ●如果需要将表的一部分置为只读,而另一部分为可更新的,则必须以它进行分区。
oracle 分区技术总结
Oracle分区技术总结 电信事业部 张雷
一.分区概述: 为了简化数据库大数据量的管理,ORACLE推出了分区选项。分区将表或索引分离在若干不同的表空间上,用分而治之的方法来支撑无限膨胀的大表和索引,从而提高大表和索引在物理一级的可管理性。将它们分割成较小的分区可以改善表和分区的维护、备份、恢复、事务及查询性能。 二.分区的特点: ◆所有的分区的逻辑属性是相同的,但他们的物理属性可以不同。 ◆分区的剪枝(Partition Pruning) Oracle server 可以自动识别分区,根据select 语句所指定的选择条件,只查询 有用的分区。如果语句的条件中对分区字段使用了函数,优化器则不能进行分区剪 枝,但to_date函数除外。 ◆分区的优点 (1) 高可用性:如果表的一个分区由于系统故障而不能使用,表的其余好的分区仍 然可以使用; (2) 减少关闭时间:如果系统故障只影响表的一部分分区,那么只有这部分分区需 要修复,故能比整个大表修复花的时间更少; (3) 维护轻松:对于大型的历史数据表,将其分区,分别管理和方便地添加和删除。; (4) 均衡I/O:可以把表的不同分区分配到不同的磁盘来平衡I/O改善性能; (5) 改善性能:对大表的查询、增加、修改等操作可以分解到表的不同分区来并行 执行,可使运行速度更快; (6) 基于分区的 join 操作,会提高查询性能 (7) 分区对用户透明,最终用户感觉不到分区的存在。 三.分区的方法: ◆Range Partitioning (范围分区)
范围分区就是对数据表中的某个值的范围进行分区,根据某个值的范围,决定将该数据存储在哪个分区上。如根据城市分区,根据时间进行分区等。实现方法就是在CREATE TABLE命令中增加PARTITION BY RANGE子句。 例如:CREATE TABLE UNITELE.BB_ACCOUNT_INFO_T ( ACCOUNT_ID NUMBER(10), CITY_CODE V ARCHAR2(8 BYTE) NOT NULL, CUSTOMER_ID NUMBER(10) NOT NULL, MAIL_SERVICE NUMBER(4), UNIT_COUNT NUMBER(8) DEFAULT 0, REMARK V ARCHAR2(256 BYTE), IF_VALID NUMBER(2) DEFAULT 1, ACCOUNT_FA VOUR_ID NUMBER(8) DEFAULT 0 NOT NULL ) TABLESPACE TS_TAB_BASE PARTITION BY RANGE (CITY_CODE) ( PARTITION PART840 V ALUES LESS THAN ('841'), PARTITION PART_OTHER V ALUES LESS THAN (MAXV ALUE) ); 分区的字段可以是一个列,也可以是多个列。 ★范围分区的特点 a、Range分区特别适合于按时间周期进行数据的存储。日、周、月、年等。 b、数据管理能力强,可以进行数据迁移,数据备份以及数据交换的操作。 c、范围分区的数据可能分布不均匀。 d、范围分区与记录值相关,实施难度和可维护性相对较差。有可能出现一个表分 成上万个分区,还可能出现后期拆分分区,增加分区的操作。 Hash Partitioning(散列分区);
Java Web应用与Oracle连接问题一例
Java Web应用与Oracle连接问题 1.概况 刚安装的Java Web应用连接不到数据库,初步判断是数据库连接字符串没有正确配置。通常在Tomcat中可以通过配置WEB-INF下的web.xml或者applicationContext.xml文件来修改数据库连接字符串。 后询问高手,在Tomcat自身路径下也有配置文件: %TOMCAT%\conf\Catalina\localhost\%APPNAME%.xml 修改数据库连接字符串中的IP和SID
oracle 表分区 partition技术
oracle 表分区 partition技术(转) 2009年06月12日星期五 11:23 一下内容转至:https://www.360docs.net/doc/9611122265.html,/blog/166078 一、Oracle分区简介 ORACLE的分区是一种处理超大型表、索引等的技术。分区是一种“分而治之”的技术,通过将大表和索引分成可以管理的小块,从而避免了对每个表作为一个大的、单独的对象进行管理,为大量数据提供了可伸缩的性能。分区通过将操作分配给更小的存储单元,减少了需要进行管理操作的时间,并通过增强的并行处理提高了性能,通过屏蔽故障数据的分区,还增加了可用性。 二、Oracle分区优缺点 优点:λ 增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用; 维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能; 改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。缺点:λ 分区表相关:已经存在的表没有方法可以直接转化为分区表。不过 Oracle 提供了在线重定义表的功能。 三、Oracle分区方法 范围分区:λ 范围分区就是对数据表中的某个值的范围进行分区,根据某个值的范围,决定将该数据存储在哪个分区上。如根据序号分区,根据业务记录的创建日期进行分区等。 Hash分区(散列分区):λ 散列分区为通过指定分区编号来均匀分布数据的一种分区类型,因为通过在I/O 设备上进行散列分区,使得这些分区大小一致。 λ List分区(列表分区): 当你需要明确地控制如何将行映射到分区时,就使用列表分区方法。与范围分区和散列分区所不同,列表分区不支持多列分区。如果要将表按列分区,那么分区键就只能由表的一个单独的列组成,然而可以用范围分区或散列分区方法进行分区的所有的列,都可以用列表分区方法进行分区。 范围-散列分区(复合分区):λ 有时候我们需要根据范围分区后,每个分区内的数据再散列地分布在几个表空间中,这样我们就要使用复合分区。复合分区是先使用范围分区,然后在每个分区内再使用散列分区的一种分区方法(注意:先一定要进行范围分区) 范围-列表分区(复合分区):λ 范围和列表技术的组合,首先对表进行范围分区,然后用列表技术对每个范围分区再次分区。与组合范围-散列分区不同的是,每个子分区的所有内容表示数据的逻辑子集,由适当的范围和列表分区设置来描述。(注意:先一定要进行范围分区) 四、Oracle表分区表操作 --Partitioning 是否为true select * from v$option s order by s.PARAMETER desc
ORACLE 数据库管理系统介绍
ORACLE 数据库管理系统介绍 1.ORACLE的特点: 可移植性ORACLE采用C语言开发而成,故产品与硬件和操作系统具有很强的独立性。从大型机到微机上都可运行ORACLE的产品。可在UNIX、DOS、Windows等操作系统上运行。可兼容性由于采用了国际标准的数据查询语言SQL,与IBM的SQL/DS、DB2等均兼容。并提供读取其它数据库文件的间接方法。 可联结性对于不同通信协议,不同机型及不同操作系统组成的网络也可以运行ORAˉCLE数据库产品。 2.ORACLE的总体结构 (1)ORACLE的文件结构一个ORACLE数据库系统包括以下5类文件:ORACLE RDBMS的代码文件。 数据文件一个数据库可有一个或多个数据文件,每个数据文件可以存有一个或多个表、视图、索引等信息。 日志文件须有两个或两个以上,用来记录所有数据库的变化,用于数据库的恢复。控制文件可以有备份,采用多个备份控制文件是为了防止控制文件的损坏。参数文件含有数据库例程起时所需的配置参数。 (2)ORACLE的内存结构一个ORACLE例程拥有一个系统全程区(SGA)和一组程序全程区(PGA)。 SGA(System Global Area)包括数据库缓冲区、日志缓冲区及共
享区域。 PGA(Program Global Area)是每一个Server进程有一个。一个Server进程起动时,就为其分配一个PGA区,以存放数据及控制信息。 (3)ORACLE的进程结构ORACLE包括三类进程: ①用户进程用来执行用户应用程序的。 ②服务进程处理与之相连的一组用户进程的请求。 ③后台进程ORACLE为每一个数据库例程创建一组后台进程,它为所有的用户进程服务,其中包括: DBWR(Database Writer)进程,负责把已修改的数据块从数据库缓冲区写到数据库中。LGWR(Log Writer)进程,负责把日志从SGA中的缓冲区中写到日志文件中。 SMON(System Moniter)进程,该进程有规律地扫描SAG进程信息,注销失败的数据库例程,回收不再使用的内存空间。PMON (Process Moniter)进程,当一用户进程异常结束时,该进程负责恢复未完成的事务,注销失败的用户进程,释放用户进程占用的资源。 ARCH(ARCHIVER)进程。每当联机日志文件写满时,该进程将其拷贝到归档存储设备上。另外还包括分布式DB中事务恢复进程RECO和对服务进程与用户进程进行匹配的Dnnn进程等。 3.ORACLE的逻辑结构 构成ORACLE的数据库的逻辑结构包括: (1)表空间
oracle表分区的几种方法以及维护
表分区有以下优点: 1、数据查询:数据被存储到多个文件上,减少了I/O负载,查询速度提高。 2、数据修剪:保存历史数据非常的理想。 3、备份:将大表的数据分成多个文件,方便备份和恢复。 4、并行性:可以同时向表中进行DML操作,并行性性能提高。 当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),这样查询数据时,不至于每次都扫描整张表。 Oracle中提供了以下几种表分区: 一、范围分区:这种类型的分区是使用列的一组值,通常将该列成为分区键。示例1:假设有一个CUSTOMER表,表中有数据200000行,我们将此表通过CUSTOMER_ID进行分区,每个分区存储100000行,我们将每个分区保存到单独的表空间中,这样数据文件就可以跨越多个物理磁盘。下面是创建表和分区的代码,如下: CREATE TABLE CUSTOMER ( CUSTOMER_ID NUMBER NOT NULL PRIMARY KEY, FIRST_NAME VARCHAR2(30) NOT NULL, LAST_NAME VARCHAR2(30) NOT NULL, PHONE VARCHAR2(15) NOT NULL, EMAIL VARCHAR2(80), STATUS CHAR(1) ) PARTITION BY RANGE (CUSTOMER_ID) ( PARTITION CUS_PART1 VALUES LESS THAN (100000) TABLESPACE CUS_TS01, PARTITION CUS_PART2 VALUES LESS THAN (200000) TABLESPACE CUS_TS02 ) 在创建表进行分区时,表空间必须先存在,而且建议将不同的分区放入不同的表空间中。 示例2:假设有ORDER_ACTIVITIES表,每6个月对订单进行清理,我们可以按月份对表进行分区,分区代码如下: CREATE TABLE ORDER_ACTIVITIES ( ORDER_ID NUMBER(7) NOT NULL, ORDER_DATE DATE, TOTAL_AMOUNT NUMBER, CUSTOTMER_ID NUMBER(7), PAID CHAR(1) ) PARTITION BY RANGE (ORDER_DATE) ( PARTITION ORD_ACT_PART01 VALUES LESS THAN
Java连接各种数据库写法
随笔- 6 文章- 0 评论- 1 Java连接各种数据库写法 # 示例配置参考,涵盖几乎所有的主流数据库 ############# Oracle数据库######################## # 数据库驱动名 driver=oracle.jdbc.driver.OracleDriver # 数据库URL(包括端口) dburl=jdbc:oracle:thin:@127.0.0.1:1521:zvfdb # 数据库用户名 user=root # 用户密码
password=zvfims ############# DB2数据库######################## # 数据库驱动名 driver=com.ibm.db2.jcc.DB2Driver # 数据库URL(包括端口) dburl=jdbc:db2://127.0.0.1:50000/zvfdb # 数据库用户名 user=root # 用户密码 password=zvfims ############# MySQL数据库######################## # 数据库驱动名
driver=com.mysql.jdbc.Driver # 数据库URL(包括端口) dburl=jdbc:mysql://127.0.0.1:3306/zvfdb # 数据库用户名 user=root # 用户密码 password=zvfims ############# PostgreSQL数据库数据库######################## # 数据库驱动名 driver=org.postgresql.Driver # 数据库URL(包括端口) dburl=jdbcostgresql://127.0.0.1/zvfdb
ORACLE数据库简介
1ORACLE数据库简介 一、概论 ORACLE 是以高级结构化查询语言(SQL)为基础的大型关系数据库,通俗地讲它是用方便逻辑管理的语言操纵大量有规律数据的集合。是目前最流行的客户/服务器(CLIENT/SERVER)体系结构的数据库之一。 二、特点 1、ORACLE7.X以来引入了共享SQL和多线索服务器体系结构。这减少了ORACLE 的资源占用,并增强了ORACLE的能力,使之在低档软硬件平台上用较少的资源就可以支持更多的用户,而在高档平台上可以支持成百上千个用户。 2、提供了基于角色(ROLE)分工的安全保密管理。在数据库管理功能、完整性检查、安全性、一致性方面都有良好的表现。 3、支持大量多媒体数据,如二进制图形、声音、动画以及多维数据结构等。 4、提供了与第三代高级语言的接口软件PRO*系列,能在C,C++等主语言中嵌入 SQL语句及过程化(PL/SQL)语句,对数据库中的数据进行操纵。加上它有许多优秀的前台开发工具如 POWER BUILD、SQL*FORMS、VISIA BASIC 等,可以快速开发生成基于客户端PC 平台的应用程序,并具有良好的移植性。 5、提供了新的分布式数据库能力。可通过网络较方便地读写远端数据库里的数据,并有对称复制的技术。 三、存储结构 1、物理结构 ORACLE数据库在物理上是存储于硬盘的各种文件。它是活动的,可扩充的,随着 数据的添加和应用程序的增大而变化。 下图为ORACLE数据库扩充前后在硬盘上存储结构的示意图:
2、逻辑结构 ORACLE数据库在逻辑上是由许多表空间构成。主要分为系统表空间和非系统 表空间。非系统表空间内存储着各项应用的数据、索引、程序等相关信息。我们准备上马一个较大的ORACLE应用系统时,应该创建它所独占的表空间,同时定义 物理文件的存放路径和所占硬盘的大小。 下图为ORACLE数据库逻辑结构与物理结构的对照关系: 四、分布式数据库管理介绍 1、原理 物理上存放于网络的多个ORACLE数据库,逻辑上可以看成一个单个的大数据库。 用户可以通过网络对异地数据库中的数据同时进行存取,而服务器之间的协同处理对于工作站用户及应用程序而言是完全透明的:开发人员无需关心网络的连接
ORACLE分区表、分区索引
深入学习Oracle分区表及分区索引 关于分区表和分区索引(About Partitioned Tables and Indexes)对于10gR2而言,基本上可以分成几类: ?Range(范围)分区 ?Hash(哈希)分区 ?List(列表)分区 ?以及组合分区:Range-Hash,Range-List。 对于表而言(常规意义上的堆组织表),上述分区形式都可以应用(甚至可以对某个分区指定compress属性),只不过分区依赖列不能是lob,long之类数据类型,每个表的分区或子分区数的总数不能超过1023个。 对于索引组织表,只能够支持普通分区方式,不支持组合分区,常规表的限制对于索引组织表同样有效,除此之外呢,还有一些其实的限制,比如要求索引组织表的分区依赖列必须是主键才可以等。 注:本篇所有示例仅针对常规表,即堆组织表! 对于索引,需要区分创建的是全局索引,或本地索引: l 全局索引(global index):即可以分区,也可以不分区。即可以建range分区,也可以建hash分区,即可建于分区表,又可创建于非分区表上,就是说,全局索引是完全独立的,因此它也需要我们更多的维护操作。 l 本地索引(local index):其分区形式与表的分区完全相同,依赖列相同,存储属性也相同。对于本地索引,其索引分区的维护自动进行,就是说你add/drop/split/truncate表的分区时,本地索引会自动维护其索引分区。 Oracle建议如果单个表超过2G就最好对其进行分区,对于大表创建分区的好处是显而易见的,这里不多论述why,而将重点放在when以及how。 ORACLE对于分区表方式其实就是将表分段存储,一般普通表格是一个段存储,而分区表会分成多个段,所以查找数据过程都是先定位根据查询条件定位分区范围,即数据在那个分区或那几个内部,然后在分区内部去查找数据,一个分区一般保证四十多万条数据就比较正常了,但是分区表并非乱建立,而其维护性也相对较为复杂一点,而索引的创建也是有点讲究的,这些以下尽量阐述详细即可。 range分区方式,也算是最常用的分区方式,其通过某字段或几个字段的组合的值,从小到大,按照指定的范围说明进行分区,我们在INSERT数据的时候就会存储到指定的分区中。 List分区方式,一般是在range基础上做的二级分区较多,是一种列举方式进行分区,一般讲某些地区、状态或指定规则的编码等进行划分。 Hash分区方式,它没有固定的规则,由ORACLE管理,只需要将值INSERT进去,ORACLE 会自动去根据一套HASH算法去划分分区,只需要告诉ORACLE要分几个区即可。 WHEN 一、When使用Range分区 Range分区呢是应用范围比较广的表分区方式,它是以列的值的范围来做为分区的划分条件,将记录存放到列值所在的range分区中,比如按照时间划分,2008年1季度的数据
详解ORACLE簇表、堆表、IOT表、分区表
详解ORACLE簇表、堆表、IOT表、分区表 簇和簇表 簇其实就是一组表,是一组共享相同数据块的多个表组成。将经常一起使用的表组合在一起成簇可以提高处理效率。 在一个簇中的表就叫做簇表。建立顺序是:簇→簇表→数据→簇索引 1、创建簇的格式 CREATE CLUSTER cluster_name (column date_type [,column datatype]...) [PCTUSED 40 | integer] [PCTFREE 10 | integer] [SIZE integer] [INITRANS 1 | integer] [MAXTRANS 255 | integer] [TABLESPACE tablespace] [STORAGE storage] SIZE:指定估计平均簇键,以及与其相关的行所需的字节数。 2、创建簇 create cluster my_clu (deptno number) pctused60 pctfree10 size1024 tablespace users storage( initial128k next128k minextents2 maxextents20
); 3、创建簇表 create table t1_dept( deptno number, dname varchar2(20) ) cluster my_clu(deptno); create table t1_emp( empno number, ename varchar2(20), birth_date date, deptno number ) cluster my_clu(deptno); 4、为簇创建索引 create index clu_index on cluster my_clu; 注:若不创建索引,则在插入数据时报错:ORA-02032: clustered tables cannot be used before the cluster index is built 管理簇 使用ALTER修改簇属性(必须拥有ALTER ANY CLUSTER的权限) 1、修改簇属性 可以修改的簇属性包括: * PCTFREE、PCTUSED、INITRANS、MAXTRANS、STORAGE * 为了存储簇键值所有行所需空间的平均值SIZE
在Oracle中调用Java
Oracle中的Java体系结构 目前,使用Java来扩展存储程序是一种很流行的方法。在使用Java类库处理数据的过程中,PL/SQL是必不可少的一环,这是因为PL/SQL 封装了Java类库的数据访问,即任何Java存储对象访问的数据都必须经过PL/SQL。 由于本章的所有内容只被最新的数据库版本所支持,因此它独立于本书的其他章节,以下是本章要介绍的内容: ●Oracle中的Java体系结构 ●Oracle JDBC的连接类型 ●客户端驱动器(Client-side driver),即JDBC瘦驱动(thin driver) ●Oracle调用接口驱动器,即中间层胖驱动(middle-tier thick driver) ●Oracle 服务器端内部驱动器(Oracle Server-Side Internal Driver),即 服务器级的胖驱动 ●在Oracle中创建Java类库 ●创建内部服务器的Java函数 ●创建内部服务器的Java过程 ●创建内部服务器的Java对象 ●创建、装载、删除、使用Java类库时的故障诊断 ●映射Oracle类型 本章将向您展示一张Oracle中巨大的Java组织结构图,在解释了Java的体系结构之后,您还会看到开发和扩展Java组件的方法。 使用Java扩展的原因: 我们将使用PL/SQL作为存储Java类库和其他PL/SQL存储程序或匿名块程序之间的接口。我们还会映射Oracle和Java之间的本地数据类型和用户自定义数据类型,以便能定义有效接口和支持JSP (Java Server Page,Java服务器页面)。
1 Oracle中的Java体系结构 Oracle 9i和10g版本的数据库为开发服务器端或内部Java程序组件提供了一个健壮的体系结构。Java组件采用OO (Object-Oriented,面向对象)的结构,这样的结构非常适合Oracle的对象-关系模型(Object-Relational model)。组件的体系结构实际上就是一个库栈,它包含: ●操作系统的平台依赖性,例如UNIX、LINUX、Microsoft Windows; ●依赖Oracle数据库的文件和库管理; ●独立于平台的JVM (Java Virtual Machine,Oracle Java虚拟机); ●Java内核类库,兼容不同的平台; ●Oracle支持的Java API (Application Programming Interfaces,应用程序接口),如SQLJ、JDBC和JNDI; ●Oracle的PL/SQL存储对象,为SQL和PL/SQL程序之间提供接口,就像服务器端J ava类库一样。 Oracle和Java库就和普通的文件系统一样来存储和管理应用程序,它们屏蔽了不同操作系统的结构差异和系统限制,从而建立起一个独立于平台的存储、检索和恢复文件的统一处理过程。同时,Java虚拟机为创建有大量文档支持的O O程序提供了一个标准环境。另外,Oracle PL/SQL也为其他PL/SQL存储对象以及SQL访问Java库提供了软件包。 下图5-1给出了Oracle JVM(Java虚拟机)的体系结构。 Oracle JVM使用两种格式的命名空间:长名称和短名称。长名称和Java中类的命名模式是一样的,我们可以用它本来的命名空间来调用存储Java程序。然而,本章中Java示例的名称都是短名称,并且程序也没有放进程序包中。当然,您完全可以将您的Java程序放进程序包中。Java存储代码的命名空间包括了程序包的整个层次。如果命名空间的长度超过30个字符,Oracle在数据字典视图中就使用哈希命名空间。使用DBMS_JAVA包和LONGNAME函数可以获得完整的命名空间,而如果要获取短名称可以使用DBMS_JAVA程序包和SHORTNAME函数。
Oracle数据库简介
oracle数据库是一种大型数据库系统,一般应用于商业,政府部门,它的功能很强大,能够处理大批量的数据,在网络方面也用的非常多。不过,一般的中小型企业都比较喜欢用SQL数据库系统,它的操作很简单,功能也非常齐全。只是比较oracle 数据库而言,在处理大量数据方面有些不如。 Oralce数据库的发展历程 Oralce数据库简介 Oracle简称甲骨文,是仅次于微软公司的世界第二大软件公司,该公司名称就叫Oracle。该公司成立于1979年,是加利福尼亚州的第一家在世界上推出以关系型数据管理系统(RDBMS)为中心的一家软件公司。 Oracle不仅在全球最先推出了RDBMS,并且事实上掌握着这个市场的大部分份额。现在,他们的RDBMS被广泛应用于各种操作环境:Windows NT、基于UNIX系统的小型机、IBM大型机以及一些专用硬件操作系统平台。 事实上,Oracle已经成为世界上最大的RDBMS供应商,并且是世界上最主要的信息处理软件供应商。由于Oracle公司的RDBMS都以Oracle为名,所以,在某种程度上Oracle己经成为了RDBMS的代名词。 Oracle数据库管理系统是一个以关系型和面向对象为中心管理数据的数据库管理软件系统,其在管理信息系统、企业数据处理、因特网及电子商务等领域有着非常广泛的应用。因其在数据安全性与数据完整性控制方面的优越性能,以及跨操作系统、跨硬件平台的数据互操作能力,使得越来越多的用户将Oracle作为其应用数据的处理系统。 Oracle数据库是基于“客户端/服务器”模式结构。客户端应用程序执行与用户进行交互的活动。其接收用户信息,并向“服务器端”发送请求。服务器系统负责管理数据信息和各种操作数据的活动。 Oracle数据库有如下几个强大的特性: 支持多用户、大事务量的事务处理 数据安全性和完整性的有效控制 支持分布式数据处理 可移植性很强 Oracle大体上分两大块,一块是应用开发,一块是系统管理。 开发主要是写存储过程、触发器什么的,还有就是用Oracle的Develop工具做form。有点类似于程序员,需要有较强的逻辑思维和创造能力。管理则需要对Oracle 数据库的原理有深刻的认识,有全局操纵的能力和紧密的思维,责任较大,因为一个小的失误就会丢失整个数据库,相对前者来说,后者更看重经验。 Oracle数据库服务器: Oracle数据库包括Oracle数据库服务器和客户端 Oracle Server是一个对象一关系数据库管理系统。它提供开放的、全面的、和集成的信息管理方法。每个Server由一个 Oracle DB和一个 Oracle Server实例组成。它具有场地自治性(Site Autonomy)和提供数据存储透明机制,以此可实现数据存储透明性。每个 Oracle数据库对应唯一的一个实例名SID,Oracle数据库服务器启动后,一般至少有以下几个用户:Internal,它不是一个真实的用户名,而是具有SYSDBA优
Oracle数据仓库-电信行业应用案例
转眼,从事电信行业BI/DW已经有三年时间了,一直想写点东西,给大家共同分享,感谢ERP 100给我了一个展示的平台! 连载时间:一周一篇 连载提纲: 第一篇数据仓库建设目标、系统规模及项目面临的技术挑战 第二篇选择数据仓库平台的考虑 第三篇选择Oracle产品的原因 第四篇系统现状分析、DW数据仓库建设原则及整体规划的实现 第五篇整体规划的实现、新增应用优先级的确定及螺旋式建设方法 第六篇数据仓库的效益、成本和风险控制 第七篇数据模型设计方法 第八篇构建闭环的信息流、数据模型-分层设计、DW中的数据功能划分 第九篇数据抽取策略、数据抽取过程管理、对脏数据的管理、数据去重及元数据管理及 第十篇典型的应用流程、主题分析及应用推广方法 (第一篇)数据仓库建设目标、系统规模及项目面临的技术挑战 1 数据仓库项目建设目标: 建立统一的数据信息平台,实现客户资料和生产数据的集中存储。利用先进的数据仓库技术和决策分析技术为市场营销和客户服务工作提供有效的支撑: 2 目前系统规模: 包含12个月的话单;数据库容量为65TB,其中原始数据为25TB;最大的表包含1800亿话单
3 项目面临的技术挑战: 数据存储-系统要求存储12-18个月的详单数据; 数据装载-按小时装载详单数据,要求每天在8小时内装载5亿条详单;高峰时一个小时装载6500万条详单;在8小时内同时完成1亿7000万个汇总操作 数据访问-支持680个并发用户,支持8000个系统用户;5%的预定义查询操作在5秒钟内完成;每秒钟23个查询操作 Sina微薄互动地址:https://www.360docs.net/doc/9611122265.html,/2186879022/zDx5x29Cw 感谢大家的参与和鼓励,pathwide的建议很好,下面列举出该连载的计划提纲,如下: 连载周期:一周一篇 连载提纲: 第一篇数据仓库建设目标、系统规模及项目面临的技术挑战 第二篇选择数据仓库平台的考虑 第三篇选择Oracle产品的原因 第四篇系统现状分析、DW数据仓库建设原则及整体规划的实现 第五篇整体规划的实现、新增应用优先级的确定及螺旋式建设方法 第六篇数据仓库的效益、成本和风险控制 第七篇数据模型设计方法 第八篇构建闭环的信息流、数据模型-分层设计、DW中的数据功能划分 第九篇数据抽取策略、数据抽取过程管理、对脏数据的管理、数据去重及元数据管理及 第十篇典型的应用流程、主题分析及应用推广方法 希望大家积极参与,共同分享BI/DW的项目经验,同时,有不到位的地方,还请大家多多指正,谢谢! 选择数据仓库平台时的考虑 4 选择数据仓库平台时的考虑 4.1 强大的ETL支持能力-支持按小时的数据装载 4.2 高效的数据访问-硬件的支持:多CPU 大内存并发处理 分区技术 索引技术 数据库内置分析能力 4.3 高可用性7 * 24小时不间断运行 4.4 数据访问每秒钟23到100个并发查询操作; 95%的查询在1秒内完成 4.5 数据表分区-混合分区 按地区建立列表分区; 按时间建立范围分区; 4.6 可传输的表空间 操作系统文件的直接复制;不需要数据的导入、导出
Java连接oracle数据库方法
Java连接oracle数据库 一、普通的连接数据库 1、注册驱动 Class.forName(“oracle.jdbc.driver.OracleDriver”); 2、获取连接 Connection conn=null; conn= DriverManager.getConnection(“jdbc:oracle:thin:@127.0.0.1:1521:XE”,user,pa ssword); 3、建立statement Statement stat=conn.createStatement(); 4、执行SQL语句 stat.execute(“SQL语句”); 5、处理结果集 ResultSet rs=null; rs=stat.executeQuery(“SQL语句”); While(rs.next()){ System.out.println(“id:”+rs.getInt(“id”)+”last_name”+getString(“l ast_name”)); } 6、关闭连接 Rs.close(); Stat.close(); Conn.close();
二、加载properties文件连接数据库并使用PreparedStatement --------------------首先准备xxx.properties文件---------------------user=xxxxx password=xxxxxx driver=oracle.jdbc.driver.DriverOracle url=jdbc:oracle:thin:@127.0.0.1:1521:XE -------------------------------------------------------------------------------- 1、创建properties实例对象 Properties prop=new Properties(); 2、加载xxx.properties文件 prop.load(new FileInputStream(“xxx.properties文件路径”)); 3、获取xxx.properties文件中的属性 Class.forName(prop.getString(“driver”)); conn=DriverManager.getConnetion(prop.getString(“url”,prop)); 4、创建PreparedStatement实例对象并执行语句 String sql=“select*from table_name where id=?And last_name=?”; PreparedStatement ps=conn.preparedStatement(sql); ps.setInt(1,4); ps.setString(2,”nihao”);