基于聚类挖掘的移动资费体系研究与设计

第26卷第6期贵州大学学报(自然科学版)Vol.26No.6 2009年 12月Journal of Guizhou University(Natural Sciences)Dec.2009文章编号 1000-5269(2009)06-0104-04
基于聚类挖掘的移动资费体系研究与设计
王显明1,23
(1.贵州大学计算机科学与信息学院,贵州贵阳550025;2.中国移动贵州公司,贵州贵阳550002)
摘 要:资费套餐体系是电信运营商核心竞争力之一,首先分析移动运营商现行资费套餐存在的问题,然后运用数据挖掘中的聚类分析方法,通过对移动经营分析系统中真实的客户通信数据的挖掘,建立客户消费需求细分模型,最后结合资费设计原则和移动运营策略,研究分析提出了一整套全新的移动资费体系,提高了客户满意度、移动运营商的竞争力和经营效益。
关键词:数据挖掘;聚类;客户细分;资费体系
中图分类号:T N915.5 文献标识码:B
当前通信企业之间的竞争日趋激烈,国内、国际电信业的竞争,对电信运营企业的服务意识、服务内容、服务方式、服务质量以及经营管理水平等均提出了严峻的挑战。资费套餐作为新的竞争方式,已经成为运营商核心竞争力之一。电信市场的快速发展,用户需求逐渐表现出细分化、多元化的特征。
需求之间存在一定的差距,套餐设计存在诸多的问题。一方面套餐设计单一化,没有将用户的需求、消费习惯以及用户的特征结合起来,形成以用户需求为出发点的量身定做的套餐;另一方面没有有效区分用户群,使得各个套餐的目标用户之间存在重叠和交叉,导致用户在选择套餐时茫然无措。
目前,国内学者关于移动资费套餐的设计问题的研究还比较少。本文的研究建立在某个已运营的移动经营分析系统(BASS,BusinessAnalysis Sup2 porting Syste m)用户的真实数据基础上,通过建立聚类客户细分模型,结合数据挖掘方法[1]及资费套餐设计原则进行移动资费套餐的研究,设计出完整的新资费体系,为移动运营企业进行套餐设计提供了科学的方法支撑,同时对其他行业的资费套餐设计也有一定的借鉴意义。
1 基于聚类挖掘的移动客户细分本文以客户需求细分为挖掘主题,选择采用行业标准的数据挖掘过程———CR I SP2DM模型[2]实施挖掘过程,利用S AS的E M模块来分析建立客户细分模型。1.1 商业理解和宽表设计
商业理解和宽表设计过程完成客户需求的理解,展开相关的客户细分变量的设计工作。宽表设计阶段主要根据挖掘目标理解,数据的可获取性,研究和确定需要采用的变量。本文使用的是某省移动用户的消费记录数据,共500000条,变量包括客户属性、通信属性、消费行为和衍生变量等。1.2 数据理解准备
在数据理解准备阶段,主要完成在数据统计口径的理解和样本数据的提取。客户数据,均源于经营分析系统中,数据口径的定义取自BASS系统的元数据管理系统,有明确的业务含义描述。样本提取遵守随机抽样原则,保证样本用户能够准确反映全省用户的消费需求。
1.3 数据探索和预处理
数据质量问题是影响数据挖掘结果的重要因素,因此客户数据预处理过程在整个细分过程中相当重要。利用各类统计分析方法对数据进行探索性分析,例如交叉表、结构分布等,删除可能影响分群效果的数据。数据预处理包含对缺失值的处理和对异常值的处理。
1.4 客户聚类建模
客户聚类过程是细分的核心过程,为保证聚类效果与模型可解释性,在本文的研究过程中结合业务经验,采取多步聚类方式进行聚类,同时由于K2 Means算法具有结果容易理解,建模时间快等特
收稿日期:2009-10-15
作者简介:王显明(1970-),男,贵州遵义人,工程师,从事通信工作,Email:wangxina m ing@gz.china https://www.360docs.net/doc/9d13403661.html,. 3通讯作者:王显明,Email:wangxina m ing@gz.china https://www.360docs.net/doc/9d13403661.html,.
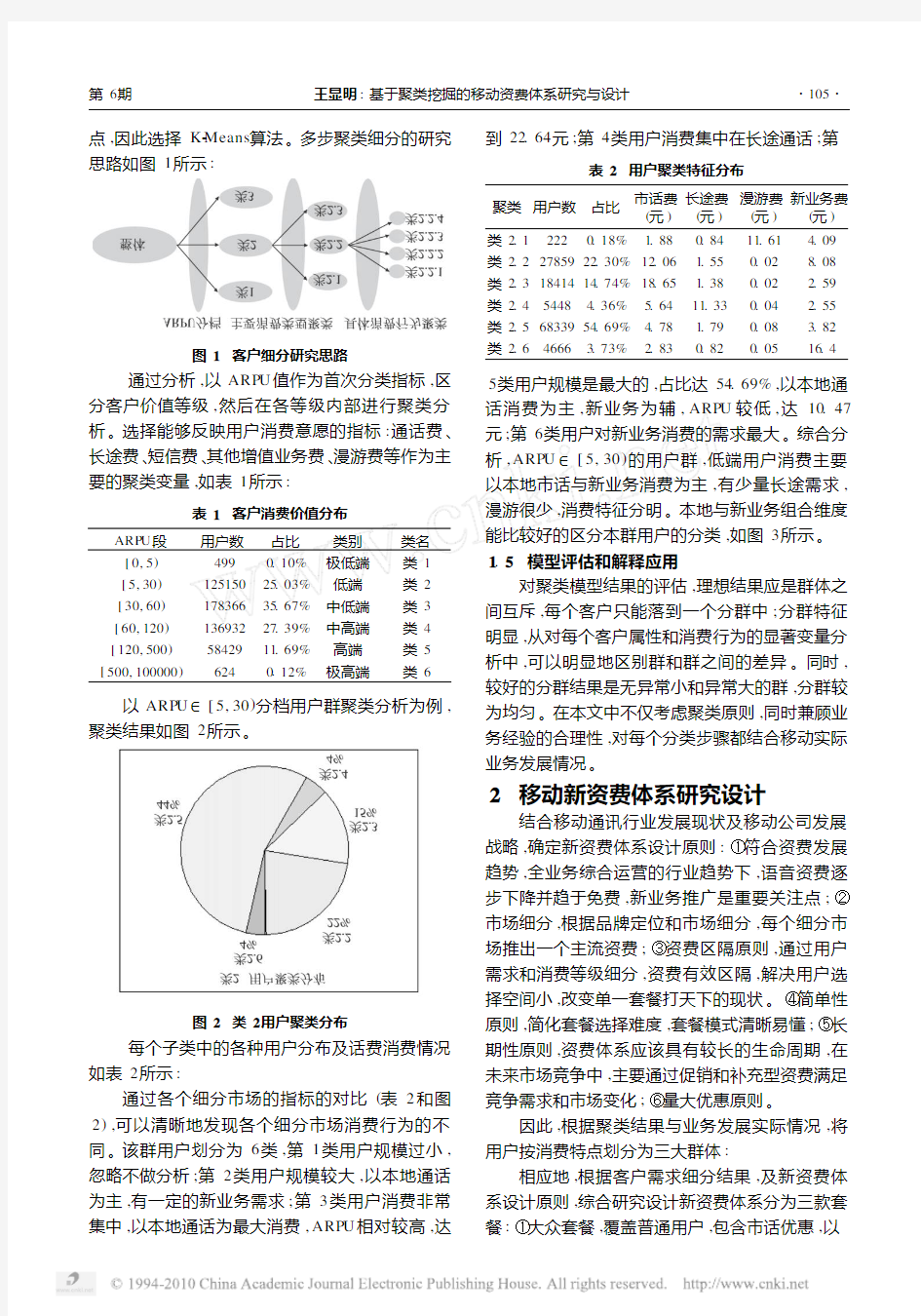
点,因此选择K 2Means 算法。多步聚类细分的研究思路如图1所示
:
图1 客户细分研究思路
通过分析,以ARP U 值作为首次分类指标,区
分客户价值等级,然后在各等级内部进行聚类分析。选择能够反映用户消费意愿的指标:通话费、长途费、短信费、其他增值业务费、漫游费等作为主要的聚类变量,如表1所示:
表1 客户消费价值分布
ARP U 段
用户数占比类别类名[0,5)499
0.10%
极低端类1[5,30)12515025.03%低端类2[30,60)17836635.67%中低端类3[60,120)27.39%中高端类4[120,
500)5842911.69%高端类
5
[500,100000)
624
0.12%
极高端
类6
以ARP U ∈[5,30)分档用户群聚类分析为例,聚类结果如图2所示。
图2 类2用户聚类分布
每个子类中的各种用户分布及话费消费情况如表2所示:
通过各个细分市场的指标的对比(表2和图2),可以清晰地发现各个细分市场消费行为的不
同。该群用户划分为6类,第1类用户规模过小,忽略不做分析;第2类用户规模较大,以本地通话为主,有一定的新业务需求;第3类用户消费非常集中,以本地通话为最大消费,ARP U 相对较高,达
到22.64元;第4类用户消费集中在长途通话;第
表2 用户聚类特征分布
聚类用户数
占比
市话费(元)长途费(元)漫游费(元)新业务费
(元)
类2.12220.18%1.88
0.8411.614.09类2.22785922.30%12.061.550.028.08类2.31841414.74%18.651.380.022.59类2.454484.36%5.6411.330.042.55类2.56833954.69%
4.781.790.083.82类
2.64666
3.73%
2.83
0.82
0.05
16.4
5类用户规模是最大的,占比达54.69%,以本地通
话消费为主,新业务为辅,ARP U 较低,达10.47元;第6类用户对新业务消费的需求最大。综合分析,ARP U ∈[5,30)的用户群,低端用户消费主要以本地市话与新业务消费为主,有少量长途需求,漫游很少,消费特征分明。本地与新业务组合维度能比较好的区分本群用户的分类,如图3所示。1.5 模型评估和解释应用对聚类模型结果的评估,理想结果应是群体之间互斥,每个客户只能落到一个分群中;分群特征明显,从对每个客户属性和消费行为的显著变量分析中,可以明显地区别群和群之间的差异。同时,较好的分群结果是无异常小和异常大的群,分群较为均匀。在本文中不仅考虑聚类原则,同时兼顾业务经验的合理性,对每个分类步骤都结合移动实际业务发展情况。
2 移动新资费体系研究设计
结合移动通讯行业发展现状及移动公司发展战略,确定新资费体系设计原则:①符合资费发展趋势,全业务综合运营的行业趋势下,语音资费逐步下降并趋于免费,新业务推广是重要关注点;②市场细分,根据品牌定位和市场细分,每个细分市场推出一个主流资费;③资费区隔原则,通过用户需求和消费等级细分,资费有效区隔,解决用户选择空间小,改变单一套餐打天下的现状。④简单性原则,简化套餐选择难度,套餐模式清晰易懂;⑤长期性原则,资费体系应该具有较长的生命周期,在未来市场竞争中,主要通过促销和补充型资费满足竞争需求和市场变化;⑥量大优惠原则。
因此,根据聚类结果与业务发展实际情况,将用户按消费特点划分为三大群体:
相应地,根据客户需求细分结果,及新资费体系设计原则,综合研究设计新资费体系分为三款套餐:①大众套餐,覆盖普通用户,包含市话优惠,以
?
501?第6期王显明:基于聚类挖掘的移动资费体系研究与设计
图3 类2
用户聚类结果维度区隔
图4 用户总体分群
及部分新业务,套餐内市话单价逐档降低;②商旅套餐,覆盖中高端商旅用户,即长途+漫游话务占全部话务50%以上的用户,长市漫一口价;③时尚套餐,覆盖新业务消费用户,即新业务费/(新业务费+通话费)>50%的用户,包短信与部分新业务,包内短信单价逐档降低,通话单价不变。
新资费体系基本模式为:基本套餐+可选包模式,采用“X 元打Y 分钟”的计费模式。针对家庭市场,设计新家庭共享策略:一个套餐可供家庭共享,达到消费共享、积分共享、服务共享,提升客户黏性。发展新业务的新模式:①购买新业务赠送语音业务,转变客户消费观念;②“新业务超市”+“菜篮子”模式,转变新业务固定捆绑模式,赠送客户定额价值,客户可自行选择新业务,如图5所示。
3 新资费体系的优势
新资费体系满足了各个客户细分市场的通信需求,给客户带来优惠的同时,也提高了运营收入,并在新的竞争环境中,继续引领市场。新资费体系体现了三点优势:
(1)提出资费套餐新模式,即基本套餐+可选包模式,基本套餐只设三类,简化体系结构,套餐结
图5 “新业务超市”+“菜篮子”模式
构直观明晰,套餐内细分消费档次,满足不同价值用户对于语音与新业务的共性需求。基本套餐均
采用“X 元打Y 分钟”模式,计费简单,理解清晰。可选业务包,包含独特的语音业务包和新业务包等,满足用户的个性化需求,满足竞争和营销的需要,在未来的竞争中可以不断更新可选包,灵活、多变、高效。
(2)提出新业务新发展模式,即“购买新业务送语音”和“超市菜篮子”模式。“购买新业务赠送语音业务”的新模式,改变现在“购买语音业务赠送新业务”的现状,是对新业务发展策略的新探索,将改变市场对新业务的惯性认识。“新业务超市”+“菜篮子”的新模式,转变新业务固定捆绑模式,给予客户定额的新业务价值,客户根据自身喜好需求,定制新业务。不仅能够促进新业务健康发展,而且充分体现客户消费的个性化。
(3)提出家庭共享新策略,由现在实行的个体消费、个体积分提升为套餐消费共享、积分共享、服务共享。这种创新的消费模式,将给以家庭为单位的客户提供很大优惠,不仅节省了套餐消费支出,而且可以享受家庭共同消费带来的积分反馈和服务。
?601?贵州大学学报(自然科学版)第26卷
4 结语
本文从通信行业的发展现状出发,研究如何科学地使用客户细分挖掘和资费设计原则来设计资费体系,制定针对不同客户群的资费套餐,以中国移动某省分公司真实客户消费记录为研究基础,进行了客户需求细分和新资费体系设计,最后,提出了一套移动新资费体系,该体系能够提供共性化和个性化的业务需求解决方案,通过设计不同的资费套餐刺激客户的需求和消费,提高客户的满意度和忠诚度。参考文献:
[1]Jia wei Han,M icheline Ka mber .Data M ining:Concep ts and Tech 2
niques,2nd editi on[M ].San Francisco:Morgan Kauf mann,2006.[2]SPSS .CR I SP -DM:Step -by -step Data M ining Guide [EB /
OL ].H tt p://www .cris p https://www.360docs.net/doc/9d13403661.html,/CR I SP W P -O8OO.pdf .2000-08-15.
[3]吕廷杰,尹涛,王琦.客户关系管理与主题分析[M ].北京:人
民邮电出版社,2002.
[4]张光建,黄贤英.基于最小聚类单元的聚类算法研究及其在
CRM 中的应用[J ].计算机科学,2006,33(7):188-190.[5]Hung S Y,Yen Dc,W ang H Y .App lying data m ining t o telecom
churn manage ment[J ].Expert Syste m s with App licati ons,2006,31(3):515-524.
[6]Kalf ma Il L,Rousseeuw P J.Finding Gr oup s in Data:An I ntr oduc 2
ti on t o Cluster Analysis[M ].New York:John W iley&Sons .1990.[7]范英,张忠健,凌君邀.聚类方法在通信行业客户细分中的应
用[J ].计算机工程,2004(12):23-25.
Research and Desi gn of M obile Tari ff Syste m
Based on Cluster i n g M i n i n g
WANG Xian 2m ing
1,2
(1.College of Computer Science and I nf or mati on,Guizhou University,Guiyang 550025,China;
2.China Mobile Communicati on Gr oup,Guizhou Co .L td,Guiyang 550002,China )
Abstract:The p r oble m s in the existing tariff packages were firstly analyzed .Then Data M ining Cluster Analysis method was used,byMobile Business Analysis Supporting Syste m in real cust o mer communicati ons data m ining,t o build cust omer subdivisi on model of consumer de mand .Finally in combinati on with tariff design p rinci p les and mobile operat or strategy,thr ough research and analysis,a set of brand ne w mobile tariff syste m was p r oposed .It will i m p r ove cust omer satisfacti on,mobile operat ors,the competitiveness and operating efficiency .Key words:data m ining;clustering;cust omer subdivisi on;tariff syste m
?
701?第6期王显明:基于聚类挖掘的移动资费体系研究与设计
数据挖掘考试题目聚类
数据挖掘考试题目——聚类 一、填空题 1、密度的基于中心的方法使得我们可以将点分类为:__________、________ 、_________。 2、DBSCAN算法在最坏的情况下,时间复杂度是__________、空间复杂度是__________。 3、DBSCAN算法的优点是_______、__________________________。 4、DBSCAN算法的缺点是处理_________________、_____________的数据效果不好。 5、DBSCAN算法的参数有:___________、____________。 6、簇的有效性的非监督度量常常可以分为两类:__________、__________,它常采用的指标为__________。 7、簇的有效性的监督度量通常称为___________,它度量簇标号与外部提供的标号的匹配程度主要借助____________。 8、在相似度矩阵评价的聚类中,如果有明显分离的簇,则相似度矩阵应当粗略地是__________。 9、DBSCAN算法的参数确定的基本方法是观察____________________的特性。 10、不引用附加的信息,评估聚类分析结果对数据拟合情况属于__________技术。 答案: 1、核心点边界点噪声点 2、O(n2) O(n) 3、耐噪声能够处理任意大小和形状的簇 4、高维数据变密度的 5、EPS MinPts 6、簇的凝聚性簇的分离性均方差(SSE) 7、外部指标监督指标的熵 8、块对角的 9、点到它的第K个最近邻的距离(K-距离) 10、非监督 二、选择题 1、DBSCAN算法的过程是(B)。 ①删除噪声点。 ②每组连通的核心点形成一个簇。 ③将所有点标记为核心点、边界点和噪声点。 ④将每个边界点指派到一个与之关联的核心点的簇中。 ⑤为距离在Eps之内的所有核心点之间赋予一条边。 A:①②④⑤③ B:③①⑤②④ C:③①②④⑤ D:①④⑤②③ 2、如果有m个点,DBSCAN在最坏的情况下的时间复杂度度为(C)。 A O(m) B O(mlogm) C O(m2) D O(logm) 3、在基本DBSCAN的参数选择方法中,点到它的K个最近邻的距离中的K选作为哪一个参数(B)。 A Eps B MinPts C 质心 D 边界
毕业论文管理系统分析与设计说明
毕业论文管理系统分析与设计 班级:信息管理与信息系统 1102 指导教师:黄立明 学号: 0811110206 姓名:高萍
毕业论文管理系统 摘要 (3) 一.毕业论文管理系统的系统调研及规划 (3) 1.1 项目系统的背景分析 (3) 1.2毕业论文信息管理的基本需求 (3) 1.3 毕业论文管理信息系统的项目进程 (4) 1.4 毕业论文信息管理系统的系统分析 (4) 1.4.1系统规划任务 (4) 1.4.2系统规划原则 (4) 1.4.3采用企业系统规划法对毕业论文管理系统进行系统规划 (5) 1.4.3.1 准备工作 (5) 1.4.3.2定义企业过程 (5) 1.4.3.3定义数据类 (6) 1.4.3.4绘制UC矩阵图 (7) 二.毕业论文管理系统的可行性分析 (8) 2.1.学院毕业论文管理概况 (8) 2.1.1毕业论文管理的目标与战略 (8) 2.2拟建的信息系统 (8) 2.2.1简要说明 (8) 2.2.2对组织的意义和影响 (9) 2.3经济可行性 (9) 2.4技术可行性 (9) 2.5社会可行性分析 (9) 2.6可行性分析结果 (10) 三.毕业论文管理系统的结构化分析建模 (10) 3.1组织结构分析 (10) 3.2业务流程分析 (11) 3.3数据流程分析 (11) 四.毕业论文管理系统的系统设计 (13) 4.1毕业论文管理系统业务主要包括 (13) 4.2毕业论文管理系统功能结构图 (13) 4.3代码设计 (14) 4.4,输入输出界面设计 (15) 4.4.1输入设计 (15) 4.4.2输出设计 (15) 4.5 数据库设计 (15) 4.5.1需求分析 (15) 4.5.2数据库文件设计 (16) 4.5.2数据库概念结构设计 (17) 五.毕业论文管理系统的系统实施 (18) 5.1 开发环境 (18) 5.2 调试与测试过程 (19)
数据挖掘中的聚类分析方法
计算机工程应用技术本栏目责任编辑:贾薇薇 数据挖掘中的聚类分析方法 黄利文 (泉州师范学院理工学院,福建泉州362000) 摘要:聚类分析是多元统计分析的重要方法之一,该方法在许多领域都有广泛的应用。本文首先对聚类的分类做简要的介绍,然后给出了常用的聚类分析方法的基本思想和优缺点,并对常用的聚类方法作比较分析,以便人们根据实际的问题选择合适的聚类方法。 关键词:聚类分析;数据挖掘 中图分类号:TP311文献标识码:A文章编号:1009-3044(2008)12-20564-02 ClusterAnlaysisMethodsofDataMining HUANGLi-wen (SchoolofScience,QuanzhouNormalUniversity,Quanzhou362000,China) Abstract:Clusteranalysisisoneoftheimportantmethodsofmultivariatestatisticalanalysis,andthismethodhasawiderangeofapplica-tionsinmanyfields.Inthispaper,theclassificationoftheclusterisintroducedbriefly,andthengivessomecommonmethodsofclusteranalysisandtheadvantagesanddisadvantagesofthesemethods,andtheseclusteringmethodwerecomparedandanslyzedsothatpeoplecanchosesuitableclusteringmethodsaccordingtotheactualissues. Keywords:ClusterAnalysis;DataMining 1引言 聚类分析是数据挖掘中的重要方法之一,它把一个没有类别标记的样本集按某种准则划分成若干个子类,使相似的样品尽可能归为一类,而不相似的样品尽量划分到不同的类中。目前,该方法已经被广泛地应用于生物、气候学、经济学和遥感等许多领域,其目的在于区别不同事物并认识事物间的相似性。因此,聚类分析的研究具有重要的意义。 本文主要介绍常用的一些聚类方法,并从聚类的可伸缩性、类的形状识别、抗“噪声”能力、处理高维能力和算法效率五个方面对其进行比较分析,以便人们根据实际的问题选择合适的聚类方法。 2聚类的分类 聚类分析给人们提供了丰富多彩的分类方法,这些方法大致可归纳为以下几种[1,2,3,4]:划分方法、层次方法、基于密度的聚类方法、基于网格的聚类方法和基于模型的聚类方法。 2.1划分法(partitiongingmethods) 给定一个含有n个对象(或元组)的数据库,采用一个划分方法构建数据的k个划分,每个划分表示一个聚簇,且k≤n。在聚类的过程中,需预先给定划分的数目k,并初始化k个划分,然后采用迭代的方法进行改进划分,使得在同一类中的对象之间尽可能地相似,而不同类的中的对象之间尽可能地相异。这种聚类方法适用于中小数据集,对大规模的数据集进行聚类时需要作进一步的改进。 2.2层次法(hietarchicalmethods) 层次法对给定数据对象集合按层次进行分解,分解的结果形成一颗以数据子集为节点的聚类树,它表明类与类之间的相互关系。根据层次分解是自低向上还是自顶向下,可分为凝聚聚类法和分解聚类法:凝聚聚类法的主要思想是将每个对象作为一个单独的一个类,然后相继地合并相近的对象和类,直到所有的类合并为一个,或者符合预先给定的终止条件;分裂聚类法的主要思想是将所有的对象置于一个簇中,在迭代的每一步中,一个簇被分裂为更小的簇,直到最终每个对象在单独的一个簇中,或者符合预先给定的终止条件。在层次聚类法中,当数据对象集很大,且划分的类别数较少时,其速度较快,但是,该方法常常有这样的缺点:一个步骤(合并或分裂)完成,它就不能被取消,也就是说,开始错分的对象,以后无法再改变,从而使错分的对象不断增加,影响聚类的精度,此外,其抗“噪声”的能力也较弱,但是若把层次聚类和其他的聚类技术集成,形成多阶段聚类,聚类的效果有很大的提高。2.3基于密度的方法(density-basedmethods) 该方法的主要思想是只要临近区域的密度(对象或数据点的数目)超过某个阈值,就继续聚类。也就是说,对于给定的每个数据点,在一个给定范围的区域中必须至少包含某个数目的点。这样的方法就可以用来滤处"噪声"孤立点数据,发现任意形状的簇。2.4基于网格的方法(grid-basedmethods) 这种方法是把对象空间量化为有限数目的单元,形成一个网格结构。所有的聚类操作都在这个网格结构上进行。用这种方法进行聚类处理速度很快,其处理时间独立于数据对象的数目,只与量化空间中每一维的单元数目有关。 2.5基于模型的方法(model-basedmethod) 基于模型的方法为每个簇假定一个模型,寻找数据对给定模型的最佳拟合。该方法经常基于这样的假设:数据是根据潜在的概 收稿日期:2008-02-17 作者简介:黄利文(1979-),男,助教。
数据挖掘中聚类分析的研究_陈学进
收稿日期:2005-11-09 作者简介:陈学进(1972-),男,安徽六安人,讲师,硕士研究生,研究方向为计算机软件理论及数据挖掘;导师:胡学钢,博士,教授,研究方向为知识工程、数据挖掘、数据结构。 数据挖掘中聚类分析的研究 陈学进 (合肥工业大学计算机与信息学院,安徽合肥230009; 安徽工业大学计算机学院,安徽马鞍山243002) 摘 要:聚类分析是由若干个模式组成的,它在数据挖掘中的地位越来越重要。文中阐述了数据挖掘中聚类分析的概念、方法及应用,并通过引用一个用客户交易数据统计出每个客户的交易情况的例子,根据客户行为进行聚类。通过数据挖掘聚类分析,可以及时了解经营状况、资金情况、利润情况、客户群分布等重要的信息。对客户状态、交易行为、自然属性和其他信息进行综合分析,细分客户群,确定核心客户。采用不同的聚类方法,对于相同的记录集合可能有不同的划分结果对其进行关联分析,可为协助各种有效的方案,开展针对性的服务。关键词:数据挖掘;聚类分析;客户行为 中图分类号:T P311.13 文献标识码:A 文章编号:1673-629X (2006)09-0044-02 Research of Cluster Analysis in Data Mining CHEN Xue -jin (Computer and Information College of Hefei U niversity of T echnology ,Hefei 230009,China ; Computer College ,A nhui U niversity of T echnology ,M aanshan 243002,China ) Abstract :Cluster anal ysis is made up of patterns ,and becoming increasingly essential in data mining field .T his paper b riefly introduces the bas ic concept ,means and application of cluster anal ysis discussing about cluster analysis by using a case of customer trans action .In order to k now about much imoport information of running ,funds ,profits and customers .And anal yze state of cl ient ,bargaining action ,natu ral ess attribute and other information ,subdivide customer groups and fix on core client .By us ing various methods of cluster analysis ,it is effec -tive p roject to develop pertinence s ervice . Key words :data mining ;cluster analys is ;customer action 0 引 言 自20世纪60年代数据库系统诞生以来,数据库技术已经得到了飞速的发展,并且己经深入到社会生活的各个方面。现在,数据无处不在,可以存放在不同类型的数据库中,数据仓库技术可以将异构的数据库集成起来进行综合管理,从而提供更好的服务。 但是,随着科学技术的进步,新的数据采集和获取技术不断发展,使得数据库中所存储的数据量也随之急剧增长。另一方面,数据处理技术的发展却相对落后,数据库技术仍然停留在相对简单的录入、查询、统计、检索阶段,对数据库中的数据之间存在的关系和规则、数据的群体特征、数据集内部蕴涵的规律和趋势等,却缺少有效的技术手段将其提取出来,从而出现所谓的“被数据淹没,却饥渴于知识”(John Na isbett ,1997)的现象[1]。为了解决这种现象,科学家们于20世纪80年代末期创立了一个新的研究 领域,即数据挖掘(Data M ining ),或称数据挖掘和知识发 现(Data M ining and Know ledge Discovery ,DM KD )。这是在数据库技术、机器学习、人工智能、统计分析等基础上发展起来的一个交叉性的学科。区别于简单地从数据库管理系统检索和查询信息。数据挖掘是指“从数据中发现隐含的、先前不知道的、潜在有用的信息的非平凡过程”(Fra w le y ,1991),其目的是把大量的原始数据转换成有价值的、便于利用的知识。 自从数据挖掘和知识发现的概念于1989年8月首次出现在第11届国际联合人工智能学术会议以来,数据挖掘和知识发现领域的研究和应用均得到了长足的发展,形成了一些行之有效的理论和方法,并逐渐成为计算机信息处理领域的研究热点。 数据挖掘(Data M ining )是一个多学科交叉研究领域,它融合了数据库(Database )技术、人工智能(Artificial Intel -ligenc e )、机器学习(Machine Learning )、统计学(Statistics )、知识工程(Know ledge Engineering )、面向对象方法(Object -Oriented Method )、信息检索(Information Retrieval )、高性能计算(High -Perform ance Computing )以及数据可视化(Data Visualization )等最新技术的研究成果[2,3]。 第16卷 第9期2006年9月 计算机技术与发展COM PUTER TECHNOLOGY AND DEVELOPM ENT Vo l .16 N o .9Sep . 2006
聚类分析在经济中的应用
编号:201431120134 本科毕业论文 题目:方差分析在农业中的应用 院系:数学科学系 姓名:徐进辉 学号:1031120131 专业:信息与计算科学 年级:2011级 指导教师:陈敏 职称:助教 完成日期:2015年5月
摘要 近年来,河南省城镇由于商业,工农业,教育等方面的发展,带动了各城镇居民家庭消费支出.为探讨河南省城镇居民的消费结构,本文应用SPSS统计分析软件,对河南省18个地市级城市居民的消费结构进行了聚类分析,结果表明,河南省的18个城市按照消费结构的不同主要分为三大类:较高层次消费,中等层次消费,较低层次消费. 关键词:消费结构;相关分析;聚类分析 Abstract In recent years, due to the development of commercial, industrial and agricultural, and education and so on, the town of Henan province drives the consumption expenditure of urban households. In order to study the consumption structure of urban residents in Henan province, in this paper, we will use cluster analysis on 18 prefecture-level city residents' consumption structure of Henan province through SPSS statistical analysis software, and the results show that, according to the consumption structure, the 18 cities in Henan province can be divided into three different categories: high level consumption, moderate level consumption, low level consumption. Keywords: consumption structure; correlation analysis; cluster analysis
《数据挖掘》试题与标准答案
一、解答题(满分30分,每小题5分) 1. 怎样理解数据挖掘和知识发现的关系?请详细阐述之 首先从数据源中抽取感兴趣的数据,并把它组织成适合挖掘的数据组织形式;然后,调用相应的算法生成所需的知识;最后对生成的知识模式进行评估,并把有价值的知识集成到企业的智能系统中。 知识发现是一个指出数据中有效、崭新、潜在的、有价值的、一个不可忽视的流程,其最终目标是掌握数据的模式。流程步骤:先理解要应用的领域、熟悉相关知识,接着建立目标数据集,并专注所选择的数据子集;再作数据预处理,剔除错误或不一致的数据;然后进行数据简化与转换工作;再通过数据挖掘的技术程序成为模式、做回归分析或找出分类模型;最后经过解释和评价成为有用的信息。 2.时间序列数据挖掘的方法有哪些,请详细阐述之 时间序列数据挖掘的方法有: 1)、确定性时间序列预测方法:对于平稳变化特征的时间序列来说,假设未来行为与现在的行为有关,利用属性现在的值预测将来的值是可行的。例如,要预测下周某种商品的销售额,可以用最近一段时间的实际销售量来建立预测模型。 2)、随机时间序列预测方法:通过建立随机模型,对随机时间序列进行分析,可以预测未来值。若时间序列是平稳的,可以用自回归(Auto Regressive,简称AR)模型、移动回归模型(Moving Average,简称MA)或自回归移动平均(Auto Regressive Moving Average,简称ARMA)模型进行分析预测。 3)、其他方法:可用于时间序列预测的方法很多,其中比较成功的是神经网络。由于大量的时间序列是非平稳的,因此特征参数和数据分布随着时间的推移而变化。假如通过对某段历史数据的训练,通过数学统计模型估计神经网络的各层权重参数初值,就可能建立神经网络预测模型,用于时间序列的预测。
毕业设计总结的数据
毕业设计总结 此课题需要学生在选定题目的情况下,进行副标题的选配。一定要突出主题,做出特色餐饮空间。传统与现代文化的交融与对话等理念作为设计主题,强调空间形式上的叙述性、空间功能上的合理性、空间氛围的和睦性,并要求同学们在设计过程中深刻体会在现阶段对建筑环境的保护、合理利用这一现实问题。 本毕业设计(论文)课题的技术要求与数据(或论文主要内容): 一是以传统的低技术的方式建造,就地取材,更多关注的是文化的生态内涵,即指传统的本质内容如何地道地传承下去;二是建筑形态的生成要顾及到环境的、功能的、精神的各方面;三是建筑所生成的美和力量应是从它所处的环境中生长出来的,同时又完完全全地融合在它所处的环境中,有着强烈的地域文化环境。 随着经济的告诉发展,人们生活水平的提高,对餐饮空间的要求已经越来越多样化,有最初的纯粹解决就餐问题,发展为对空间氛围、格调、装饰、服务等软性要求日益增多,本设计通过本建筑环境及建筑内空间的设计,使学生从环境入手,建立起“环境—建筑—室内”完整的思维方式,创造出与自然和谐统一的地域性建筑室内外空间环境。并且从建筑性质要求角度,进行室内、外的空间分析、人流组织、造型等训练,加强学生通过设计语言表达情感的能力。 空间内容: 餐厅外立面,门厅、明档区、散座、雅间、厨房及储藏、卫生间 对本毕业设计(论文)课题成果的要求 1、设计说明(文字);要求不少于3000字,附有200字中英文摘要。 内容:结合调研的内容和一定的参考文献,分析方案设计的背景、设计的具体过程特点、室内外空间环境创造的构思创意、各功能流线的合理性等,要求主题明确、文笔流畅、图文并茂,提炼出一定的观点。论文格式严格按照统一模式。 2、总平面图; 3、主要室内空间平面布局图、顶平面图、立面图及重点造型详图、节点构造详图(A3,12张); 4、主要室内空间电脑彩色效果图(8张); 5、手绘外立面效果图(1张); 6、保留手绘设计构思草图(一草和二草的方案创意稿);
聚类分析论文
聚类分析论文 TYYGROUP system office room 【TYYUA16H-TYY-TYYYUA8Q8-
聚类分析及其在新疆经济研究中的应用 孙鹿梅 (伊犁师范学院数学与统计学院新疆伊宁 835000) 摘要:本文论述聚类分析的基础理论和研究方法,包括系统聚类法和K-均值法,并以新疆十四个地州市2009的地区生产总值、人均 地区生产总值等十项综合经济指标为样本,利用SPSS软件,对他们 的综合发展水平进行类型划分及差异性程度分析. 关键词:聚类分析;SPSS软件;综合经济指标;新疆经济区划分 一、引言 聚类(clustering)是指根据“物以类聚”原理,将本身没有类别的样本聚集成不同的组,这样的一组数据对象的集合叫做簇,并且对每一个这样的簇进行描述的过程.它的目的是使得属于同一个簇的样本之间应该彼此相似,而不同簇的样本应该足够不相似.聚类技术正在蓬勃发展,涉及范围包括数据挖掘、统计学、机器学习、空间数据库技术、生物学以及经济学等各个领域,聚类分析已经成为数据挖掘研究领域中一个非常活跃的研究课题.聚类分析可用于对某省各地区经济发展划分为各个经济区、也可用于市场细分、目标客户定位、业绩评估等多方面. 在社会经济研究中,经常需要对所研究的区域进行经济区划分,以便进行分类指导.如何进行经济区划分呢?利用世界着名统计软件SPSS (Statistical Program for Social Science)的聚类分析功能,效果比较理想.聚类分析包含的内容很广泛,可以有系统聚类法、动态聚类法、分裂法、最优分割法、模糊聚类法、图论聚类法、聚类预报等多种方法,其中应用最为广泛的是系统聚类法和K-均值法. 由于西部发开发战略的实施和援疆工作的展开,新疆经济的发展迅速,但由于新疆地广,各地区之间的经济差异很大,要让新疆经济均衡发展,就要对新疆各地区的不同实施不同的经济政策.我分别用了SPSS的聚类分析中的系统聚类法和K-均值法对新疆各地区的进行经济区划分,以对新疆各地区实施不同的经济政策做依据.
毕业生就业数据分析系统开发毕业设计
毕业生就业数据分析系统开发
毕业设计(论文)原创性声明和使用授权说明 原创性声明 本人郑重承诺:所呈交的毕业设计(论文),是我个人在指导教师的指导下进行的研究工作及取得的成果。尽我所知,除文中特别加以标注和致谢的地方外,不包含其他人或组织已经发表或公布过的研究成果,也不包含我为获得及其它教育机构的学位或学历而使用过的材料。对本研究提供过帮助和做出过贡献的个人或集体,均已在文中作了明确的说明并表示了谢意。 作者签名:日期: 指导教师签名:日期: 使用授权说明 本人完全了解大学关于收集、保存、使用毕业设计(论文)的规定,即:按照学校要求提交毕业设计(论文)的印刷本和电子版本;学校有权保存毕业设计(论文)的印刷本和电子版,并提供目录检索与阅览服务;学校可以采用影印、缩印、数字化或其它复制手段保存论文;在不以赢利为目的前提下,学校可以公布论文的部分或全部内容。 作者签名:日期:
学位论文原创性声明 本人郑重声明:所呈交的论文是本人在导师的指导下独立进行研究所取得的研究成果。除了文中特别加以标注引用的内容外,本论文不包含任何其他个人或集体已经发表或撰写的成果作品。对本文的研究做出重要贡献的个人和集体,均已在文中以明确方式标明。本人完全意识到本声明的法律后果由本人承担。 作者签名:日期:年月日 学位论文版权使用授权书 本学位论文作者完全了解学校有关保留、使用学位论文的规定,同意学校保留并向国家有关部门或机构送交论文的复印件和电子版,允许论文被查阅和借阅。本人授权大学可以将本学位论文的全部或部分内容编入有关数据库进行检索,可以采用影印、缩印或扫描等复制手段保存和汇编本学位论文。 涉密论文按学校规定处理。 作者签名:日期:年月日 导师签名:日期:年月日
SPSS聚类分析和判别分析论文
S P S S聚类分析和判别分析 论文 Prepared on 22 November 2020
基于聚类分析的我国城镇居民消费结构实证分析摘要:近年来,我国城镇居民的整体消费水平逐渐提高,但各地区间的消费结构仍存在较大差别。文章选用8个城镇居民消费结构统计指标,采用欧式距离平方和离差平方和法,对我国31个省、直辖市及自治区的2013年城镇居民消费结构进行聚类分析和比较研究。这不仅从总体上掌握了我国消费结构类型的地区分布,而且系统分析了我国各地区消费结构的特点及产生原因,为国家制定消费政策提供了决策依据。 关键词:消费结构;聚类分析;判别分析;政策建议; 一、引言 近年来,随着我国经济的快速发展,城镇居民的收入不断增加,并且在国家连续出台住房、教育、医疗等各项改革措施和实施“刺激消费、扩大内需、拉动经济增长”经济政策的影响下,我国各地区城镇居民的消费支出也强劲增长,消费结构发生了巨大的变化,结构不合理现象也得到了一定程度的调整。但是,由于各地区的经济发展不平衡及原有经济基础的差异,使各地区的消费结构仍存在着明显差别。为了进一步改善消费结构,正确引导消费,提高我国城市居民的消费水平和生活质量,有必要考察我国各地区城镇居民的消费结构之间的异同并进行比较研究,以期发现特点和规律,从宏观上把握各地区城镇居民的消费现状和不同地区消费水平的差异,为提高我国各地区消费水平和谐增长提供决策依据。 二、消费结构的数据分析 消费结构指居民在生活消费过程中,不同类型消费的比例及其相互之间的配合、替代、制约的关系。就其数量关系来看,消费结构是指在消费过程中不同商品或劳务消费支出占居民总消费支出的比重,反映了一定社会经济条件下人们对各类商品及劳务的需求结构,体现一国或各地区的经济发展水平和居民生活状况。 (一)数据来源 为了更加深入地了解我国城镇居民消费结构,先利用2013年全国数据(如表1所示),对全国31个省、直辖市、自治区进行聚类分析。分析采用选用了城镇居民食品、衣着、居住、家庭用品及服务设备、医疗保健、交通和通信、教育文化娱乐服务、其它商品和服务八项指标,分别用来反映较高、中等、较低居民消费结构。
网络数据包的协议分析程序的设计开发—毕业设计论文
毕业设计(论文)网络数据包的协议分析程序的设计开发 论文作者姓名: 申请学位专业: 申请学位类别: 指导教师姓名(职称): 论文提交日期:
网络数据包的协议分析程序的设计开发 摘要 本文设计与实现了一个基于Linux下Libpcap库函数的网络数据包协议分析程序。程序的主要功能包括网络数据包捕获和常用网络协议分析。程序由输入/输出模块、规则匹配模块、数据捕获模块、协议分析模块组成。其中数据捕获模块和协议分析模块是本程序最关键、最主要的模块。 本文的主要内容如下:首先介绍了网络数据包协议分析程序的背景和概念。其次进行了程序的总体设计:确定了程序的功能,给出了程序的结构图和层次图,描述了程序的工作流程,对实现程序的关键技术做出了分析。接着,介绍完数据包捕获的相关背景和Libpcap函数库后,阐述了如何利用Libpcap函数库实现网络数据包捕获模块。然后对协议分析流程进行了详细的讲解,分析了常用网络协议。最后进行了程序的测试与运行:测试了程序能否按照预期的效果正确执行,印证了预期结果。 关键词:Libpcap;Linux;数据包捕获;应用层;协议识别
The Design and Development of Network Packet Protocol Analyzing Program Abstract The thesis is an attempt to introduce an implementation of network protocol analyzing program which is based on Libpcap, a famous network packet capture library on Linux. It has a rich feature set which includes capturing network packets and analyzing popular network protocols on Internet. The program is made up of an input/output module, a rules matching module, a packet capturing module and a protocol analyzing module. And the last two modules are key modules. The research work was described as followed. firstly, we introduce the background and concepts about network protocol analyzing programs; and we make an integrated design on the program, define functions of it, figure out its structure and hierarchical graphs, describe the workflow of it, and analyze the key techniques used in it; Secondly, after elaborating on the background of packet capture and the Libpcap library, we state a approach to implement a packet capture module with Libpcap; Thirdly, we explain the workflow about protocol analysis, and analyze common network protocols; Finally, we test our program to see whether it works as expected, fortunately, it does. Key words: Libpcap; Linux; Network packet capturing; Application layer; Protocol identification
聚类分析、数据挖掘、关联规则这几个概念的关系
聚类分析和关联规则属于数据挖掘这个大概念中的两类挖掘问题, 聚类分析是无监督的发现数据间的聚簇效应。 关联规则是从统计上发现数据间的潜在联系。 细分就是 聚类分析与关联规则是数据挖掘中的核心技术; 从统计学的观点看,聚类分析是通过数据建模简化数据的一种方法。传统的统计聚类分析方法包括系统聚类法、分解法、加入法、动态聚类法、有序样品聚类、有重叠聚类和模糊聚类等。采用k-均值、k-中心点等算法的聚类分析工具已被加入到许多著名的统计分析软件包中,如SPSS、SAS等。 从机器学习的角度讲,簇相当于隐藏模式。聚类是搜索簇的无监督学习过程。与分类不同,无监督学习不依赖预先定义的类或带类标记的训练实例,需要由聚类学习算法自动确定标记,而分类学习的实例或数据对象有类别标记。聚类是观察式学习,而不是示例式的学习。 聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。聚类分析所使用方法的不同,常常会得到不同的结论。不同研究者对于同一组数据进行聚类分析,所得到的聚类数未必一致。 从实际应用的角度看,聚类分析是数据挖掘的主要任务之一。而且聚类能够作为一个独立的工具获得数据的分布状况,观察每一簇数据的特征,集中对特定的聚簇集合作进一步地分析。聚类分析还可以作为其他算法(如分类和定性归纳算法)的预处理步骤。 关联规则挖掘过程主要包含两个阶段:第一阶段必须先从资料集合中找出所有的高频项目组(FrequentItemsets),第二阶段再由这些高频项目组中产生关联规则(AssociationRules)。 关联规则挖掘的第一阶段必须从原始资料集合中,找出所有高频项目组(LargeItemsets)。高频的意思是指某一项目组出现的频率相对于所有记录而言,必须达到某一水平。 关联规则挖掘的第二阶段是要产生关联规则(AssociationRules)。从高频项目组产生关联规则,是利用前一步骤的高频k-项目组来产生规则,在最小信赖度(MinimumConfidence)的条件门槛下,若一规则所求得的信赖度满足最小信赖度,称此规则为关联规则。
聚类分析论文
聚类分析及其在新疆经济研究中的应用 孙鹿梅 (伊犁师范学院数学与统计学院新疆伊宁 835000) 摘要:本文论述聚类分析的基础理论和研究方法,包括系统聚类法和K-均值法,并以新疆十四个地州市2009的地区生产总值、人均地区生产总值等十项综合经济指标为样本,利用SPSS软件,对他们的综合发展水平进行类型划分及差异性程度分析. 关键词:聚类分析;SPSS软件;综合经济指标;新疆经济区划分 一、引言 聚类(clustering)是指根据“物以类聚”原理,将本身没有类别的样本聚集成不同的组,这样的一组数据对象的集合叫做簇,并且对每一个这样的簇进行描述的过程.它的目的是使得属于同一个簇的样本之间应该彼此相似,而不同簇的样本应该足够不相似.聚类技术正在蓬勃发展,涉及范围包括数据挖掘、统计学、机器学习、空间数据库技术、生物学以及经济学等各个领域,聚类分析已经成为数据挖掘研究领域中一个非常活跃的研究课题.聚类分析可用于对某省各地区经济发展划分为各个经济区、也可用于市场细分、目标客户定位、业绩评估等多方面. 在社会经济研究中,经常需要对所研究的区域进行经济区划分,以便进行分类指导.如何进行经济区划分呢?利用世界著名统计软件SPSS(Statistical Program for Social Science)的聚类分析功能,效果比较理想.聚类分析包含的内容很广泛,可以有系统聚类法、动态聚类法、分裂法、最优分割法、模糊聚类法、图论聚类法、聚类预报等多种方法,其中应用最为广泛的是系统聚类法和K-均值法. 由于西部发开发战略的实施和援疆工作的展开,新疆经济的发展迅速,但由于新疆地广,各地区之间的经济差异很大,要让新疆经济均衡发展,就要对新疆各地区的不同实施不同的经济政策.我分别用了SPSS的聚类分析中的系统聚类法和K-均值法对新疆各地区的进行经济区划分,以对新疆各地区实施不同的经济政策做依据. 二、基础知识
数据挖掘实验报告三
实验三 一、实验原理 K-Means算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。 在数据挖掘中,K-Means算法是一种cluster analysis的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。 算法原理: (1) 随机选取k个中心点; (2) 在第j次迭代中,对于每个样本点,选取最近的中心点,归为该类; (3) 更新中心点为每类的均值; (4) j<-j+1 ,重复(2)(3)迭代更新,直至误差小到某个值或者到达一定的迭代步 数,误差不变. 空间复杂度o(N) 时间复杂度o(I*K*N) 其中N为样本点个数,K为中心点个数,I为迭代次数 二、实验目的: 1、利用R实现数据标准化。 2、利用R实现K-Meams聚类过程。 3、了解K-Means聚类算法在客户价值分析实例中的应用。 三、实验内容 依据航空公司客户价值分析的LRFMC模型提取客户信息的LRFMC指标。对其进行标准差标准化并保存后,采用k-means算法完成客户的聚类,分析每类的客户特征,从而获得每类客户的价值。编写R程序,完成客户的k-means聚类,获得聚类中心与类标号,并统计每个类别的客户数
四、实验步骤 1、依据航空公司客户价值分析的LRFMC模型提取客户信息的LRFMC指标。
2、确定要探索分析的变量 3、利用R实现数据标准化。 4、采用k-means算法完成客户的聚类,分析每类的客户特征,从而获得每类客户的价值。
五、实验结果 客户的k-means聚类,获得聚类中心与类标号,并统计每个类别的客户数 六、思考与分析 使用不同的预处理对数据进行变化,在使用k-means算法进行聚类,对比聚类的结果。 kmenas算法首先选择K个初始质心,其中K是用户指定的参数,即所期望的簇的个数。 这样做的前提是我们已经知道数据集中包含多少个簇. 1.与层次聚类结合 经常会产生较好的聚类结果的一个有趣策略是,首先采用层次凝聚算法决定结果
访客登记系统__毕业设计
访客管理系统的开发 1.1系统概述 应用背景与系统功能 随着计算机技术的不断发展,公司、企业和机关的计算机化管理已经逐渐普及,计算机技术已经深入到企业管理的各个方面。例如本章中所要设计的访客管理系统、利用它就可以安全、可靠的管理公司、企业的访客记录,不仅可以保障公司安全更可以提高公司的管理水平和形象。本系统是一个小型访客管理系统,Visual Basic开发来进行数据库操作、系统开发的,总体任务是实现访客的登记、查询和本管理系统的用户权限维护和使用记录。本系统主要完成的功能有:
记录访客的基本资料,包括访客姓名、性别、来访时间、访问理由等,井将访客的资料存入访客资料数据表中。用户数据的维护,即维护用户数据表,完成各种对用户的操作,如用户登录、添加用户、更改密码和查看用户资料等。 用户使用.如查看访客资料,查看用户资料(依用户权限杳着,可以按姓名、性别、来访时间、来访原因查看)等。 用户操作记录,记录每个用户的访问时间,以及用户进行的操作。 用户权限管理,按照数据表里记录的权限,允许其执行相应的功能。 1.2 系统预览 用户成功登陆成功后进入系统的主界面,如图1-1所示
图1-1 系统主界面-访客登记 系统的主界面主要包括以下几部分:1)菜单2)工具栏3)当前用户状态说明4)程序主窗口 1.2 系统设计 1.2.1系统设计思想 本系统主要完成访客资料的记录和查询,为此,系统必须能够维护一个记录访客洋细资料的数据表,对该表进行写入和读出数据的操作。与此同时本系统还要给护用户权限,这样系统必须维护用户资料数据表,管理用户ID,密码和用户权限类型。系统还要能够记录和查询用户的一个操作。记录用户操作的数据表。记录用户lD 、所进行的操作类型.以及该操作的具体时间等 首先用户登录系统时,程序要从己有的用户资料数据表
数据挖掘层次聚类算法研究综述
数据挖掘层次聚类算法研究综述 摘要聚类问题是数据挖掘中的重要问题之一,是一种非监督的学习方法。分层聚类技 术在图像处理、入侵检测和生物信息学等方面有着极为重要的应用,是数据挖掘领域的研究热点之一。本文总结了分层聚类算法技术的研究现状,分析算法性能的主要差异,并指出其今后的发展趋势。 关键词层次聚类,数据挖掘,聚类算法 Review of hierarchical clustering algorithm in Data Mining Abstract Clustering problem of data mining is one of important issues, it is a kind of unsupervised learning methods. Stratified cluster technology in image processing, intrusion detection and bioinformatics has extremely important application and is data mining area of research one of the hotspots. This paper summarizes the layered clustering algorithm technology research, analyzes the main difference arithmetic performance, and pointed out the future development trend. Keywords Hierarchical clustering,Data mining,Clustering algorithm 1引言 随着计算机技术的发展,信息数据越来越多,如何从海量数据中提取对人们有价值的信息已经成为一个非常迫切的问题。由此产生了数据挖掘技术,它是一门新兴的交叉学科,汇集了来自机器学习、模式识别、数据库、统计学、人工智能等各领域的研究成果。聚类分析是数据挖掘中的一个重要研究领域。它在图像处理、入侵检测和生物信息学等方面有着极为重要的应用。数据挖掘是从大量数据中提取出可信、新颖、有效并能被人理解的模式的高级处理过程。其目标是从数据库中发现隐含的、有意义的知识。聚类分析作为一个独立的工具来获得数据分布的情况,是数据挖掘的一个重要研究分支。 在数据挖掘领域,研究工作己经集中在为大型数据库的有效和实际的聚类分析寻找适当的方法。活跃的主题集中在聚类方法的可伸缩性,方法对聚类复杂形状和类型的数据的有效性,高维聚类分析技术,以及针对大型数据库中混合数值和分类数据的聚类方法。迄今为止,人们己经提出了很多聚类算法,它们可以分为如下几类:划分方法、层次方法、基于密度的方法、基于网格的方法和基于模型的方法,这些算法对于不同的研究对象各有优缺点。在聚类算法当中,划分方法和层次方法是最常见的两类聚类技术,其中划分方法具有较高的执行效率,而层次方法在算法上比较符合数据的特性,所以相对于划分方法聚类的效果比较好。[1] 层次聚类算法和基于划分的K-Means聚类算法是实际应用中聚类分析的支柱,算法简单、快速而且能有效地处理大数据集。层次聚类方法是通过将数据组织为若干组并形成一个相应的树来进行聚类的。根据层是自底而上还是自顶而下形成。一个完全层次聚类的质量由于无法对己经做的合并或分解进行调整而受到影响。但是层次聚类算法没有使用准则函数,它所潜含的对数据结构的假设更少,所以它的通用性更强。 2 基于层次的聚类算法 2.1 凝聚的和分裂的层次聚类 层次聚类是聚类问题研究中一个重要的组成部分。分层聚类的基本原则可以表述为:如