Hive入门

一、基础篇
1.1Hive的层次结构:
1.2进入Hive
●用自己的用户登陆网关机(172.16.213.223),运行命令hive,进入Hive Cli命令行:
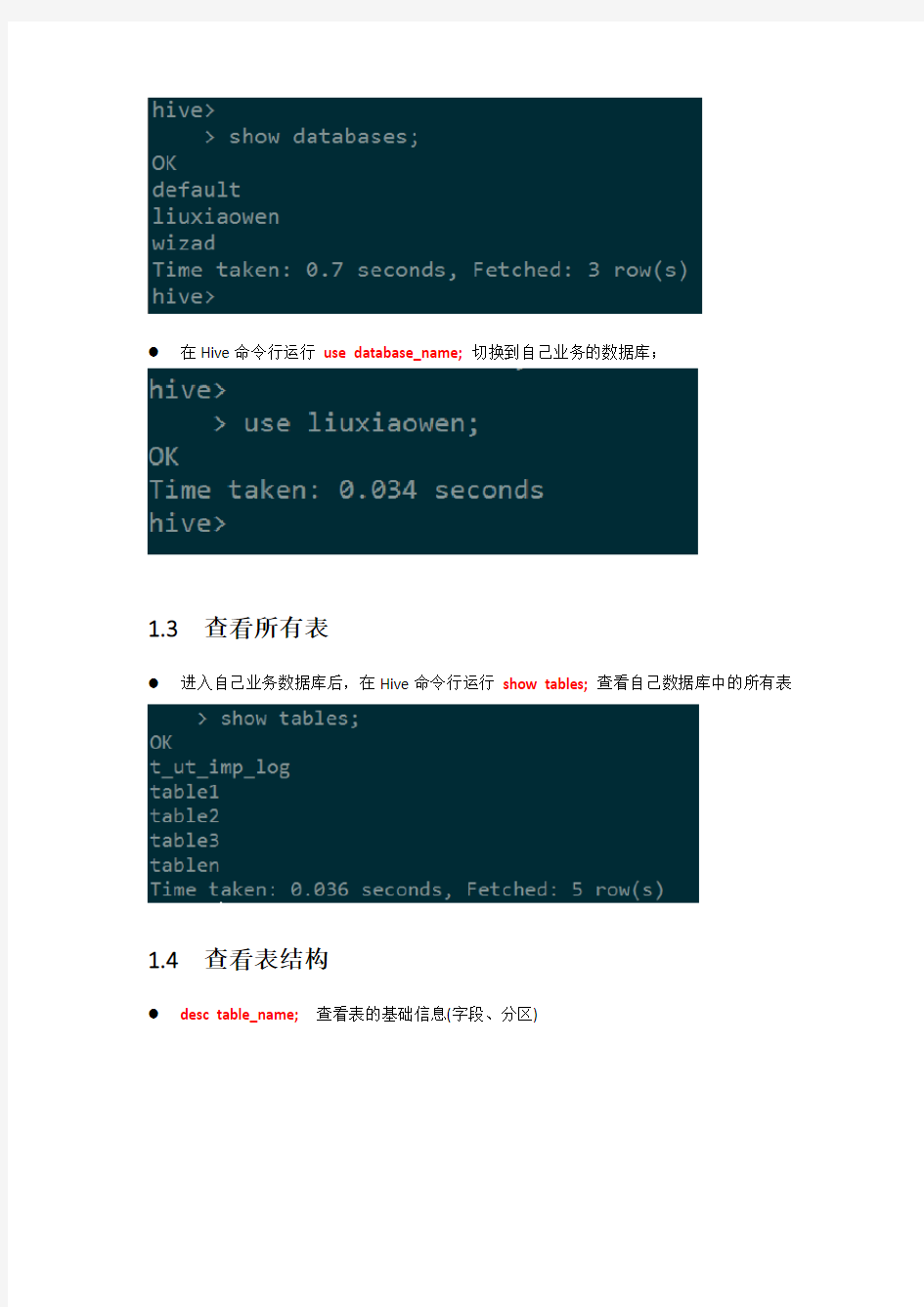
●在Hive命令行运行show databases;查看所有的数据库
●在Hive命令行运行use database_name;切换到自己业务的数据库;
1.3查看所有表
●进入自己业务数据库后,在Hive命令行运行show tables;查看自己数据库中的所有表
1.4查看表结构
●desctable_name;查看表的基础信息(字段、分区)
desc formatted table_name;查看表的详细信息(字段、分区、路径、格式等)
1.5基本数据类型
整型:
TINYINT、SMALLINT、INT、BIGINT
布尔型:
BOOLEAN
浮点型:
FLOAT、DOUBLE
字符型:
STRING
https://https://www.360docs.net/doc/9915139266.html,/confluence/display/Hive/Tutorial#Tutorial-TypeSystem 二、表
tab.xl sx
2.1内部表和外部表的区别
内部表删除时候会删除Hadoop上的数据;
外部表删除时候不会删除Hadoop上的数据;
2.2内部表
●适用场景:中间表,结果表,不需要从外部(如本地文件、HDFS上load数据)●创建语法:
CREATE TABLE tab (
column1 STRING,
column2 STRING,
column3 STRING,
column4 STRING,
columnN STRING
);
2.3外部表
●适用场景:源表,需要将外部数据映射到表中
●创建语法:
CREATE EXTERNAL TABLE tab (
column1 STRING,
column2 STRING,
column3 STRING,
column4 STRING,
columnN STRING
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
stored as textfile
location 'hdfs://namenode/tmp/liuxiaowen/tab/';
2.4分区
●对表按照一定的规则进行切分,如时间,每天(每小时)一个分区;
●适用场景:数据量非常大,按照时间或其他属性周期性维护和查询;
●创建分区语法:
CREATE TABLE tab (
column1 STRING,
columnN STRING
) partitioned BY (day STRING);
●内部表和外部表都可以创建分区;
●分区表必须在创建时候指定分区,对于一个已经创建好的非分区表,不能将其修改为分
区表;
●一个表可以有多个分区字段;
●查看表有哪些分区:
show partitions table_name;
●查看分区属性:
desc formatted t2 partition (pt = '2014-10-17');
●添加分区及数据:
ALTER TABLE tab ADD PARTITION (day = '2014-10-16')
location 'hdfs://namenode/tmp/liuxiaowen/tab/day=2014-10-16/';
ALTER TABLE tab ADD PARTITION (day = '2014-10-17')
location 'hdfs://namenode/tmp/liuxiaowen/tab/day=2014-10-17/';
●删除一个分区:
ALTER TABLE tab DROP PARTITION (day = '2014-10-16');
2.5修改表
●重命名
ALTER TABLE old_table_name RENAME TO new_table_name;
●添加字段
ALTER TABLE tab1 ADD COLUMNS (c1 INT, c2 STRING);
2.6删除表
●DROP TABLE tab;
三、加载数据
3.1 将本地(windows)上的文件上传至网关机(linux)
以linux终端工具SecureCRT为例,登陆网关机,点击SecureFX按钮:
弹出文件传输框,左侧为本地,右侧为网关机;
选择左侧和右侧目录,将左侧本地文件拖至右侧区域即可完成文件上传。
3.2 将网关机本地的文件上传至Hadoop
hadoop fs -put/tmp/f.txt/user/data/staging/page_view/
3.3 加载本地数据到外部表
创建时候指定location
CREATE EXTERNAL TABLE tab (
column1 STRING,
columnN STRING
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
stored as textfile
location 'hdfs://namenode/tmp/liuxiaowen/tab/';
●将网关机本地文件上传至指定的location
hadoop fs -put/tmp/f.txt hdfs://namenode/tmp/liuxiaowen/tab/
●文件格式要和表定义的格式一致
3.4 加载本地数据到内部表(分区)
●加载网关机本地文件到内部表
LOAD DATA LOCAL INPATH /tmp/f.txt INTO TABLE tab PARTITION (day = ‘2014-10-17’);
LOAD DATA LOCAL INPATH /tmp/f.txt OVERWRITEINTO TABLE tab PARTITION (day = ‘2014-10-17’);
* INTO 为追加,OVERWRITE INTO 为覆盖
●加载Hadoop文件到内部表
LOAD DATA INPATH '/tmp/liuxiaowen/tab/f.txt' INTO TABLE tab PARTITION (day = ‘2014-10-17’); LOAD DATA INPATH'/tmp/liuxiaowen/tab/f.txt' OVERWRITE INTO TABLE tab PARTITION (day = ‘2014-10-17’);
*LOAD DATA LOCAL INPATH 为网关机本地路径,LOAD DATA INPATH为Hadoop路径
●文件格式要和表定义的格式一致
3.5 从一个查询结果集加载数据(INSERT)
INSERT INTO TABLE tab PARTITION (day = ‘2014-10-17’)
SELECT * FROM source_table;
INSERT OVERWRITE TABLE tab PARTITION (day = ‘2014-10-17’)
SELECT * FROM source_table;
●INTO 为追加,OVERWRITE为覆盖
四、下载数据
4.1 从Hadoop上下载文件到本地
hadoopfs –get/hivedata/warehouse/liuxiaowen/1.txt/home/liuxiaowen/data/
4.2 将一个查询结果集保存到本地文件
INSERT OVERWRITE LOCAL DIRECTORY '/home/liuxiaowen/data/'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
SELECT * FROM source_table;
五、查询
5.1 简单查询
SELECT *
FROM user
WHERE userid = ‘u1’;
SELECT https://www.360docs.net/doc/9915139266.html,erid,u.age,u.sex
FROM user u
WHERE userid = ‘u2’;
5.2 基于分区的查询
SELECT *
FROM user
WHERE userid = ‘u1’ AND day = ‘2014-10-17’;
SELECT https://www.360docs.net/doc/9915139266.html,erid,u.age,u.sex
FROM user u
WHERE userid = ‘u2’ AND u.day >= ‘2014-10-16’ AND u.day <= ‘2014-10-17’5.3 关联查询(JOIN)
用户表:
PV表:
SELECT https://www.360docs.net/doc/9915139266.html,erid,u.age,u.sex,p.pv
FROM user u JOIN pv p
ON (https://www.360docs.net/doc/9915139266.html,erid = https://www.360docs.net/doc/9915139266.html,erid)
WHERE p.day = '2014-10-17';
SELECT https://www.360docs.net/doc/9915139266.html,erid,u.age,u.sex,p.pv
FROM user u LEFT OUTER JOIN pv p
ON (https://www.360docs.net/doc/9915139266.html,erid = https://www.360docs.net/doc/9915139266.html,erid AND p.day = '2014-10-17');
SELECT https://www.360docs.net/doc/9915139266.html,erid,u.age,u.sex,IF(p.pv IS NULL,0,p.pv) FROM user u LEFT OUTER JOIN pv p
ON (https://www.360docs.net/doc/9915139266.html,erid = https://www.360docs.net/doc/9915139266.html,erid AND p.day = '2014-10-17');
5.4 聚合汇总
查询用户一段时间内的总PV:
SELECT userid,
SUM(pv)
FROM pv
WHERE day >= '2014-10-16' AND day <= '2014-10-17'
GROUP BY userid;
---------------------------------------------
u1 28
u2 15
u3 16
u4 20
●查询每一天的总PV
SELECT day,
SUM(pv)
FROM pv
GROUP BY day;
---------------------------------------------
2014-10-16 51
2014-10-17 28
https://https://www.360docs.net/doc/9915139266.html,/confluence/display/Hive/Tutorial#Tutorial-UsageandExamples
5.5 基于函数的复杂查询
●域名解析:
SELECT
a.t_ip,
regexp_extract(t_ip,'//(.*?)/',1),
parse_url(t_ip,'HOST')
FROM t_ut_imp_log a
WHERE a.pt = '2014-09-01'
AND t_ip LIKE 'http://%'
limit 10;
---------------------------------------------
https://www.360docs.net/doc/9915139266.html,/i/a21771,b200492904,c3527,i0,m202,h
https://www.360docs.net/doc/9915139266.html,
https://www.360docs.net/doc/9915139266.html,/imp/iv-5175/st-47/oi-183866/cr-2/adv-9/or-3271/pcon-0/ https://www.360docs.net/doc/9915139266.html,
https://www.360docs.net/doc/9915139266.html,/i/a21771,b200492904,c3527,i0,m202,h
https://www.360docs.net/doc/9915139266.html,
https://www.360docs.net/doc/9915139266.html,/imp/iv-4496/st-47/oi-183837/cr-2/adv-9/or-3271/pcon-0/ https://www.360docs.net/doc/9915139266.html,
访问路径、页面停留时间、是否新的SESSION
SELECT
cookieid,
SUM(1) OVER(PARTITION BY cookieid) AS pv,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS depth,
createtime,
LAG(createtime) OVER(PARTITION BY cookieid ORDER BY createtime) AS last_view_time, LEAD(createtime) OVER(PARTITION BY cookieid ORDER BY createtime) AS next_view_time, uri,
FIRST_VALUE(uri) OVER(PARTITION BY cookieid ORDER BY createtime) AS landing_page FROM t_ut_imp_log
WHERE pt = '2014-09-01'
AND cookieid = '24D7776A00023753F1ACB9'
ORDER BY createtime;
---------------------------------------------
结果见前面的tab.xlsx
附录A
A.1 Hive基础教程
https://https://www.360docs.net/doc/9915139266.html,/confluence/display/Hive/Tutorial
A.2 Hive操作和函数
https://https://www.360docs.net/doc/9915139266.html,/confluence/display/Hive/LanguageManual+UDF
A.3 Hive DDL语法
DDL:数据定义语言。
创建、修改、删除(数据库、表、分区、列、视图、索引等数据库对象)。
https://https://www.360docs.net/doc/9915139266.html,/confluence/display/Hive/LanguageManual+DDL
A.4 Hive查询语法
https://https://www.360docs.net/doc/9915139266.html,/confluence/display/Hive/LanguageManual+Select A.5 Hive命令行使用说明
https://https://www.360docs.net/doc/9915139266.html,/confluence/display/Hive/LanguageManual+Cli
HIVE从入门到精通
HIVE从入门到精通 目录 HIVE介绍 (2) 二、hive的安装和配置 (8) 三、hive与hbase集成 (13) 四、HIVE创建目录和表 (16) 六、HIVE查询 (23) 七、HIVE视图 (29) 八、索引 (30) 九、hive schema (30) 十、Hive join (33) 十一、Hive基本语法 (37) 十二、Hive操作语句 (40) 十三、数据操作语句 (50) Hive 优化 (56)
HIVE介绍 主要介绍 背景及体系结构 1背景 应用于工业的商务智能收集分析所需的数据集正在大量增长,使 得传统的数据仓库解决方案变得过于昂贵。Hadoop 是一个流行的开源map-reduce实现,用于像yahoo, Facebook一类的公司。来存储和处 理商用硬件上的大范围数据集。然而map-reduce程序模型还是处于很 低级别,即需要开发者来书写客户程序,这些程序往往难于维护与重用。 用hbase做数据库,但由于hbase没有类sql查询方式,所以操作 和计算数据非常不方便,于是整合hive,让hive支撑在hbase数据库层面的hql查询。hive也叫做数据仓库。 2定义 Hive是基于Hadoop(HDFS, MapReduce)的一个数据仓库工具,可 以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。 本质是将SQL转换为MapReduce程序。 3体系结构 Hive本身建立在Hadoop的体系结构上,可以将结构化的数据文 件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语 句转换为MapReduce任务进行。并按照该计划生成MapReduce任务后 交给Hadoop集群处理,Hive的体系结构如图1-1所示:
Hive配置和基本操作
实验报告(四)
Hive 基础操作
Hive 基础(2):库、表、字段、交互式查询的基本操作目录[-] ?1、命令行操作 ?2、表操作 ?3、列操作 ?4、查看变量 ?5、一个完整的建库、表例子 ?6、常用语句示例 ?7、Refer: 1、命令行操作 (1)打印查询头,需要显示设置: sethive.cli.print.header=true; (2)加"--",其后的都被认为是注释,但CLI 不解析注释。带有注释的文件只能通过这种方式执行: hive -f script_name (3)-e后跟带引号的hive指令或者查询,-S去掉多余的输出: hive -S -e "select * FROM mytable LIMIT 3" > /tmp/myquery (4)遍历所有分区的查询将产生一个巨大的MapReduce作业,如果你的数据集和目录非常多, 因此建议你使用strict模型,也就是你存在分区时,必须指定where语句hive> set hive.mapred.mode=strict;
(5)显示当前使用数据库 set hive.cli.print.current.db=true; (6)设置Hive Job 优先级 setmapred.job.priority=VERY_HIGH | HIGH | NORMAL | LOW | V ERY_LOW (VERY_LOW=1,LOW=2500,NORMAL=5000,HIGH=7500,VERY _HIGH=10000) set mapred.job.map.capacity=M设置同时最多运行M个map 任务 set mapred.job.reduce.capacity=N设置同时最多运行N个red uce任务 (7)Hive 中的Mapper个数的是由以下几个参数确定的:mapred.min.split.size ,mapred.max.split.size ,dfs.block.siz e splitSize = Math.max(minSize, Math.min(maxSize, blockSiz e)); map个数还与inputfilles的个数有关,如果有2个输入文件,即使总大小小于blocksize,也会产生2个map mapred.reduce.tasks用来设置reduce个数。 2、表操作 (1)查看某个表所有分区 SHOW PARTITIONS ext_trackflow
基于Hive的分布式空间数据库的研究与优化
目录 摘要 ........................................................................................................................... I ABSTRACT............................................................................................................... III 1 绪论.. (1) 1.1研究背景及意义 (1) 1.2国内外研究现状 (3) 1.2.1分布式空间数据库技术的当前现状 (3) 1.2.2 Hive在分布式数据库的现状 (4) 1.3研究方法及内容 (4) 1.4论文组织结构 (5) 2 理论基础与关键技术 (7) 2.1空间数据库基础 (7) 2.1.1空间数据 (7) 2.1.2空间数据关系 (8) 2.1.3空间索引 (8) 2.1.4分布式空间数据库基础 (9) 2.2空间数据库模型 (10) 2.2.1空间数据库模型发展历程 (10) 2.2.2 Geodatabase空间数据模型 (11) 2.3基于Hadoop的分布式计算框架 (13) 2.3.1分布式文件系统HDFS (14) 2.3.2计算框架MapReduce (15) 2.3.3数据仓库工具Hive (15) 2.3.4 Hive、MapReduce、Hadoop之间的关系 (18) 2.4本章小结 (19) 3 扩展Hive的分布式空间数据库的分析与研究 (21) 3.1结构体系设计 (21) 3.1.1分布式空间系统的设计目标 (21) 3.1.2分布式空间计算系统DSQ总体架构 (21) 3.2空间数据管理 (22) 3.3关键字查询的优化 (23) 3.4本章小结 (24) 4 基于Hive的分布式空间查询扩展实现与优化 (25) 4.1 Hive框架的扩展 (25) 4.2 HIVE UDF的扩展支持 (27) 4.3针对基于Hive的查询框架的实现 (27) 4.4基于空间计算特点的性能调优 (29) 4.4.1 Hive的数据倾斜问题 (29) 4.4.2 bucket的大小划分 (30) 4.4.3合理化文件分布 (30) 4.5本章小结 (30) 5 实验验证 (33) V
Hive学习总结及应用
一、文档说明 熟悉Hive功能,了解基本开发过程,及在项目中的基本应用。 注意:本文档中但凡有hive库操作的语句,其后面的“;”是语句后面的,非文档格式需要。每个hive语句都要以“;”来结束,否则将视相邻两个分号“;”之间的所有语句为一条语句。 二、Hive(数据提取)概述 Hive是构建在HDFS 和Map/Reduce之上的可扩展的数据仓库。是对HADOOP的Map-Reduce进行了封装,类似于sql语句(hive称之为HQL)计算数据从而代替编写代码对mapreduce的操作,数据的来源还是HDFS上面的文件。 Hive中的表可以分为托管表和外部表,托管表的数据移动到数据仓库目录下,由Hive管理,外部表的数据在指定位置,不在Hive 的数据仓库中,只是在Hive元数据库中注册。创建外部表采用“create external tablename”方式创建,并在创建表的同时指定表的位置。 Hive本身是没有专门的数据存储格式,也没有为数据建立索引,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive就可以解析数据。所以往Hive表里面导入数据只是简单的将数据移动到表所在的目录中(如果数据是在HDFS上;但如果数据是在本地文件系统中,那么是将数据复制到表所在的目录中)。
三、Hive的元数据 Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。由于Hive的元数据需要不断的更新、修改,而HDFS系统中的文件是多读少改的,这显然不能将Hive的元数据存储在HDFS中。目前Hive将元数据存储在数据库中,如Mysql、Derby中。 Hive metastore 三种存储方式: Hive的meta 数据支持以下三种存储方式,其中两种属于本地存储,一种为远端存储。远端存储比较适合生产环境。 1、使用derby数据库存储元数据(内嵌的以本地磁盘作为存储),这称为“内嵌配置”。 这种方式是最简单的存储方式,只需要在或做如下配置便可。使用derby存储方式时,运行hive会在当前目录生成一个derby文件和一个metastore_db目录。这种存储方式的弊端是在同一个目录下同时只能有一个hive客户端能使用数据库,否则会提示如下错误(这是一个很常见的错误)。 2、使用本机mysql服务器存储元数据,这称为“本地metastore”。这种存储方式需要在本地运行一个mysql服务器, 3、使用远端mysql服务器存储元数据。这称为“远程metastore”。这种存储方式需要在远端服务器运行一个mysql服务器,并且需要在Hive服务器启动meta服务。
Hive简易操作入门
1Hive使用入门: 主要流程为: 1.运行putty等ssh客户端连接hive服务器; 2.运行hive命令进入hive shell环境; 3.执行HQL语句进行查询; 本流程中以putty为例,如果使用别的SSH客户端,界面上会不同,基本过程相似。 我们当前使用的hive版本为0.9.0。由于hive本身还在不断开发、升级中,不同版本的hive对各种语句、命令行参数等的支持均不同,请大家注意某个特性从哪一个版本开始支持。Hive官方网站上的教材中有些命令需要到0.10.0等更高版本才支持! 1.1安装ssh 客户端Putty 软件位置: \\cn1\ctrip\商业智能部\部门公用\SoftWare\putty.zip 解压所可以得到文件 Putty ssh客户端
1.2登录安装hive的机器 1.2.1运行putty 输入ip地址192.168.83.96 和端口号信息1022,如下图:注:一般默认的SSH端口是22,此处必须修改! 1.2.2登录linux 单击open按钮,按提示输入用户名,并回车,然后按提示输入密码,并回车,例如:
用户名为ppj 密码为HgeeGxR5 提示:可选中复制到剪贴板后,用鼠标右键粘贴 如果用户名、密码正确,则登录成功,顺利进入linux 的bash 环境。 注:此环境类似于运行windows的cmd进入的dos环境。 1.2.3输入hive,进入hive 的shell 环境:
1.2.4查询 执行如下查询语句: Use test_wqd; Select * from pageview limit 5; 屏幕输出即为查询语句的结果。 注意:hive的查询语句以分号作为各条命令的分隔符,结尾的分号不能省略。这一点和SQL Server的T-SQL差异比较大!
HIVE安装使用说明
HIVE安装使用说明 一、Hive简介 1.1.Hive是什么 Hadoop作为分布式运算的基础架构设施,统计分析需要采用MapReduce编写程序后,放到Hadoop集群中进行统计分析计算,使用起来较为不便,Hive产品采用类似SQL的语句快速实现简单的MapReduce统计,很大程度降低了Hadoop的学习使用成本。 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供基础的SQL查询功能,可以将SQL 语句转换为MapReduce任务运行,而不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。 1.2.部署架构
Hive中的Driver为核心驱动部分,包括SQL语句的解释、编译为MapReduce任务,并进行优化、执行。 Hive用户访问包括4种运行和访问方式,一是CLI客户端;二是HiveServer2和Beeline方式;三是HCatalog/WebHCat方式;四是HWI 方式。 其中CLI、Beeline均为控制台命令行操作模式,区别在于CLI只能操作本地Hive服务,而Beeline可以通过JDBC连接远程服务。 HiveServer2为采用Thrift提供的远程调用接口,并提供标准的JDBC 连接访问方式。 HCatalog是Hadoop的元数据和数据表的管理系统,WebHCat则提供一条Restful的HCatalog远程访问接口,HCatalog的使用目前资料很少,尚未充分了解。 HWI是Hive Web Interface的简称,可以理解为CLI的WEB访问方式,因当前安装介质中未找到HWI对应的WAR文件,未能进行使用学习。 Hive在运行过程中,还需要提供MetaStore提供对元数据(包括表结构、表与数据文件的关系等)的保存,Hive提供三种形式的MetaStore:一是内嵌Derby方式,该方式一般用演示环境的搭建;二是采用第三方数据库进行保存,例如常用的MySQL等;三是远程接口方式,及由Hive自身提供远程服务,供其他Hive应用使用。在本安装示例中采用的第二种方式进行安装部署。 备注:在本文后续的安装和说明中,所有示例均以HiverServer2、
hive规则及常用语法
Hive规则及常用语法 一.hive介绍 hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。 二.Hive规则 1.建表规则 表名使用小写英文以字符串模块名称,项目以BI开头(数据集市以DM)以’_’分割主业务功能块名,然后详细业务名,最后以数据表类别结尾,数据表存放在相应的表空间 例如: 数据仓库层_业务大类_业务小类-*** 示例 dw_mobile_start_week dw_mobile_start_mon dw_mobile_start_day 1)在建立长期使用的表时,需要给每个字段Column填写Comment栏,加上中文注释方便查看。对于临时表在表名后加上temp; 2)对运算过程中临时使用的表,用完后即使删除,以便及时的回收空间。临时表如果只用来处理一天数据并且每天都要使用不要按时间建分区。避免造成临时表数据越来越大。 3)字段名应使用英文创建,字段类型尽量使用string.避免多表关联时关联字段类型不一致。 4)多表中存在关联关系的字段,名称,字段类型保持一致。方便直观看出关联关系及连接查询。 5)建表时能够划分分区的表尽量划分分区。 6)建表时为表指定表所在数据库中。 2.查询规则 1.多表执行join操作时,用户需保证连续查询中的表的大小从左到右是依次增加的。也 可以使用/*+STREAMTABLES(表别名)*/来标记大表。
hive语法和常用函数
Hive就是一个基于Hadoop分布式系统上的数据仓库,最早就是由Facebook公司开发的,Hive极大的推进了Hadoop ecosystem在数据仓库方面上的发展。 Facebook的分析人员中很多工程师比较擅长而SQL而不善于开发MapReduce程序,为此开发出Hive,并对比较熟悉SQL的工程师提供了一套新的SQL-like方言——Hive QL。 Hive SQL方言特别与MySQL方言很像,并提供了Hive QL的编程接口。Hive QL语句最终被Hive解析器引擎解析为MarReduce程序,作为job提交给Job Tracker运行。这对MapReduce框架就是一个很有力的支持。 Hive就是一个数据仓库,它提供了数据仓库的部分功能:数据ETL(抽取、转换、加载)工具,数据存储管理,大数据集的查询与分析能力。 由于Hive就是Hadoop上的数据仓库,因此Hive也具有高延迟、批处理的的特性,即使处理很小的数据也会有比较高的延迟。故此,Hive的性能就与居于传统数据库的数据仓库的性能不能比较了。 Hive不提供数据排序与查询的cache功能,不提供索引功能,不提供在线事物,也不提供实时的查询功能,更不提供实时的记录更性的功能,但就是,Hive能很好地处理在不变的超大数据集上的批量的分析处理功能。Hive就是基于hadoop平台的,故有很好的扩展性(可以自适应机器与数据量的动态变化),高延展性(自定义函数),良好的容错性,低约束的数据输入格式。 下面我们来瞧一下Hive的架构与执行流程以及编译流程:
用户提交的Hive QL语句最终被编译为MapReduce程序作为Job提交给Hadoop执行。 Hive的数据类型 Hive的基本数据类型有:TINYINT,SAMLLINT,INT,BIGINT,BOOLEAN,FLOAT,DOUBLE,STRING,TIMESTAMP(V0、8、0+)与BINARY(V0、8、0+)。 Hive的集合类型有:STRUCT,MAP与ARRAY。 Hive主要有四种数据模型(即表):(内部)表、外部表、分区表与桶表。 表的元数据保存传统的数据库的表中,当前hive只支持Derby与MySQL数据库。 内部表: Hive中的表与传统数据库中的表在概念上就是类似的,Hive的每个表都有自己的存储目录,除了外部表外,所有的表数据都存放在配置在hive-site、xml文件的${hive、metastore、warehouse、dir}/table_name目录下。 Java代码 1.CREATE TABLE IF NOT EXISTS students(user_no INT,name STRING,sex STRING, 2.grade STRING COMMOT '班级')COMMONT '学生表' 3.ROW FORMAT DELIMITED
《Hadoop大数据技术与应用》-Hive-常用操作
《Hadoop大数据技术与应用》 实验报告 Hive-常用操作
一、实验目的 掌握Hive的使用 二、实验环境 Hadoop2.7.3 Hive2.3.3 源数据:dept.csv,emp.csv 三、实验内容与实验过程及分析(写出详细的实验步骤,并分析实验结果) 实验内容: 1.启动Hadoop,用jps查看进程 2.在桌面打开命令行窗口,通过以下命令,将数据文件dept.csv和emp.csv下载到本地桌面上待用。 wget -P ~ /home/ubuntu/Desktop http://10.90.3.2/HUP/Hadoop/dept.csv 3.将上面两个表拷贝到hdfs的/027/hive目录下,然后查看是否拷贝成功。 hdfs dfs -mkdir -p /027/hive hdfs dfs -put dept.csv /027/hive hdfs dfs -put emp.csv /027/hive hdfs dfs -ls /027/hive 4.创建员工表
create table emp001(empno int,ename string,job string,mgr int,hiredate string,sal int,comm int,deptno int) row format delimited fields terminated by ','; 5.创建部门表 create table dept001(deptno int,dname string,loc string) row format delimited fields terminated by ','; 6.导入数据 load data inpath '/001/hive/emp.csv' into table emp001; load data inpath '/001/hive/dept.csv' into table dept001; 7.根据员工的部门号创建分区,表名为emp_part027 create table emp_part001(empno int,ename string,job string,mgr int,hiredate string,sal int,comm int)partitioned by (deptno int)row format delimited fields terminated by ','; 往分区表中插入数据:指明导入的数据的分区 insert into table emp_part001 partition(deptno=10) select empno,ename,job,mgr,hiredate,sal,comm from emp001 where deptno=10; insert into table emp_part001 partition(deptno=20) select empno,ename,job,mgr,hiredate,sal,comm from emp001 where deptno=20; insert into table emp_part001 partition(deptno=30) select empno,ename,job,mgr,hiredate,sal,comm from emp001 where deptno=30; 8.创建一个桶表,表名为emp_bucket027 create table emp_bucket001(empno int,ename string,job string,mgr int,hiredate string,sal int,comm int,deptno int)clustered by (job) into 4 buckets row format delimited fields terminated by ','; 通过子查询插入数据 insert into emp_bucket027 select * from emp001; 9.查询所有的员工信息
hive常用优化方法大全
hive常用优化方法大全 hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以通过类SQL语句快速实现简单的MapReduce统计,十分适合数据仓库的统计分析。 在使用hive的过程中,可以进行hive优化,以下是常用的hive优化方法: 1. join连接时的优化:当三个或多个以上的表进行join操作时,如果每个on使用相同的字段连接时只会产生一个mapreduce; 2. join连接时的优化:当多个表进行查询时,从左到右表的大小顺序应该是从小到大,原因是hive在对每行记录操作时会把其他表先缓存起来,直到扫描最后的表进行计算; 3. 在where字句中增加分区过滤器; 4. 当可以使用left semi join 语法时不要使用inner join,前者效率更高,原因是对于左表中指定的一条记录,一旦在右表中找到立即停止扫描; 5. 如果所有表中有一张表足够小,则可置于内存中,这样在和其他表进行连接的时候就能完成匹配,省略掉reduce过程,设置属性即可实现,set hive.auto.covert.join=true; 用户可以配置希望被优化的小表的大小 set hive.mapjoin.smalltable.size=2500000; 如果需要使用这两个配置可置入$HOME/.hiverc文件中; 6. 同一种数据的多种处理:从一个数据源产生的多个数据聚合,无需每次聚合都需要重新扫描一次; 7. limit调优:limit语句通常是执行整个语句后返回部分结果,set
hive.limit.optimize.enable=true; 8. 开启并发执行:某个job任务中可能包含众多的阶段,其中某些阶段没有依赖关系可以并发执行,开启并发执行后job任务可以更快的完成,设置属性:set hive.exec.parallel=true; 9. hive提供的严格模式,禁止3种情况下的查询模式: a:当表为分区表时,where字句后没有分区字段和限制时,不允许执行; b:当使用order by语句时,必须使用limit字段,因为order by 只会产生一个reduce任务。 c:限制笛卡尔积的查询; 10. 合理的设置map和reduce数量; 11. jvm重用。可在hadoop的mapred-site.xml中设置jvm被重用的次数。 除此之外,还有很多其他的优化方式,感兴趣的可以深入学习一下,相信不断的学习和积累,必定能熟练掌握大数据知识,成为高级大数据工程师!
hive的基本操作
使用某个数据库 Hive>use test_db; 创建表: hive> CREATE TABLE pokes (foo INT, bar STRING); Creates a table called pokes with two columns, the first being an integer and the other a string 创建一个新表,结构与其他一样 hive> create table new_table like records; 创建分区表: hive> create table logs(ts bigint,line string) partitioned by (dt String,country String); 加载分区表数据: hive> load data local inpath '/home/hadoop/input/hive/partitions/file1' into table logs partition (dt='2001-01-01',country='GB'); 展示表中有多少分区: hive> show partitions logs; 展示所有表: hive> SHOW TABLES; lists all the tables hive> SHOW TABLES '.*s'; lists all the table that end with 's'. The pattern matching follows Java regular expressions. Check out this link for documentation 显示表的结构信息 hive> DESCRIBE invites; shows the list of columns 更新表的名称: hive> ALTER TABLE source RENAME TO target; 添加新一列 hive> ALTER TABLE invites ADD COLUMNS (new_col2 INT COMMENT 'a comment'); 删除表: hive> DROP TABLE records; 删除表中数据,但要保持表的结构定义 hive> dfs -rmr /user/hive/warehouse/records;
(1)Hive的作用
Hive的作用与特征 1.Hadoop家族产品 Apache Hadoop:是Apache开源组织的一个分布式计算开源框架,提供了一个分布式文件系统子项目(HDFS)和支持MapReduce分布式计算的软件架构。 截止到2013年,根据统计,Hadoop家族产品已经达到20个。 2.Hive的定义 Apache Hive:是基于Hadoop的一个数据仓库工具,它提供了一系列的工具,可以将结构化的数据文件映射为一张数据库表,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop 中的大规模数据的机制。 Hive 定义了简单的类SQL 查询语言,称为HQL,它允许熟悉SQL 的用户查询数据。通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。同时,这个语言也允许熟悉MapReduce 开发者的开发自定义的mapper 和reducer 来处理内建的mapper 和reducer 无法完成的复杂的分析工作。 Hive最大的特点就是提供了类SQL的语法,封装了底层的MapReduce过程,让有SQL基础的业务人员,也可以直接利用Hadoop进行大数据的操作,就是这一特点,解决了原数据分析人员对于大数据分析的瓶颈。 3.设计特征 Hive 是一种底层封装了Hadoop 的数据仓库处理工具,使用类SQL 的HiveQL 语言实现数据查询,所有Hive 的数据都存储在Hadoop 兼容的文件系统(例如,Amazon S3、HDFS)中。Hive 在加载数据过程中不会对数据进行
任何的修改,只是将数据移动到HDFS 中Hive 设定的目录下,因此,Hive 不支持对数据的改写和添加,所有的数据都是在加载的时候确定的。Hive 的设计特点如下。 ● 支持索引,加快数据查询。 ● 不同的存储类型,例如,纯文本文件、HBase 中的文件。 ● 将元数据保存在关系数据库中,大大减少了在查询过程中执行语义检查的时间。 ● 可以直接使用存储在Hadoop 文件系统中的数据。 ● 内置大量用户函数UDF 来操作时间、字符串和其他的数据挖掘工具,支持用户扩展UDF 函数来完成内置函数无法实现的操作。 ● 类SQL 的查询方式,将SQL 查询转换为MapReduce 的job 在Hadoop 集群上执行。 4.Hive的体系结构 主要分为以下几个部分: 用户接口 用户接口主要有三个:CLI,Client 和WUI。其中最常用的是CLI,Cli 启动的时候,会同时启动一个Hive 副本。Client 是Hive 的客户端,用户连接至Hive Server。在启动Client 模式的时候,需要指出Hive Server 所在节点,并且在该节点启动Hive Server。WUI 是通过浏览器访问Hive。 元数据存储 Hive 将元数据存储在数据库中,如mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。 解释器、编译器、优化器、执行器 解释器、编译器、优化器完成HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS 中,并在随后由MapReduce 调用执行。 下图列出了Hive的知识点。
Hive常用的SQL命令操作
Hive提供了很多的函数,可以在命令行下show functions罗列所有的函数,你会发现这些函数名与mysql的很相近,绝大多数相同的,可通过describe function functionName 查看函数使用方法。 hive支持的数据类型很简单就INT(4 byte integer),BIGINT(8 byte integer),FLOAT(single precision),DOUBLE(double precision),BOOLEAN,STRING等原子类型,连日期时间类型也不支持,但通过to_date、unix_timestamp、date_diff、date_add、date_sub等函数就能完成mysql 同样的时间日期复杂操作。 如下示例: select * from tablename where to_date(cz_time) > to_date('2050-12-31'); select * from tablename where unix_timestamp(cz_time) > unix_timestamp('2050-12-31 15:32:28'); 分区 hive与mysql分区有些区别,mysql分区是用表结构中的字段来分区(range,list,hash等),而hive不同,他需要手工指定分区列,这个列是独立于表结构,但属于表中一列,在加载数据时手动指定分区。 创建表 hive> CREATE TABLE pokes (foo INT, bar STRING COMMENT 'This is bar'); 创建表并创建索引字段ds hive> CREATE TABLE invites (foo INT, bar STRING) PARTITIONED BY (ds STRING); 显示所有表 hive> SHOW TABLES; 按正条件(正则表达式)显示表, hive> SHOW TABLES '.*s'; 表添加一列
hive使用
创建表: hive> CREATE TABLE pokes (foo INT, bar STRING); Creates a table called pokes with two columns, the first being an integer and the other a string 创建一个新表,结构与其他一样 hive> create table new_table like records; 创建分区表: hive> create table logs(ts bigint,line string) partitioned by (dt String,country String); 加载分区表数据: hive> load data local inpath '/home/hadoop/input/hive/partitions/file1' into table logs partition (dt='2001-01-01',country='GB'); 展示表中有多少分区: hive> show partitions logs; 展示所有表: hive> SHOW TABLES; lists all the tables hive> SHOW TABLES '.*s'; lists all the table that end with 's'. The pattern matching follows Java regular expressions. Check out this link for documentation 显示表的结构信息 hive> DESCRIBE invites; shows the list of columns 更新表的名称: hive> ALTER TABLE source RENAME TO target; 添加新一列 hive> ALTER TABLE invites ADD COLUMNS (new_col2 INT COMMENT 'a comment'); 删除表: hive> DROP TABLE records; 删除表中数据,但要保持表的结构定义 hive> dfs -rmr /user/hive/warehouse/records; 从本地文件加载数据: hive> LOAD DATA LOCAL INPATH '/home/hadoop/input/ncdc/micro-tab/sample.txt' OVERWRITE INTO TABLE records; 显示所有函数: hive> show functions; 查看函数用法: hive> describe function substr;
Hive 开发中使用变量的两种方法
Hive 开发中使用变量的两种方法 hive的SQL中传入参数的方法: 准备测试表和测试数据 第一步先准备测试表和测试数据用于后续测试: hive> create database test; OK Time taken: 2.606 seconds 然后建个student.sql 和testdata_student文件 放入Linux系统任意目录下(eg: /usr/mrli) student.sql内容如下 use test; --学生信息表 create table IF NOT EXISTS student( sno bigint comment '学号' , sname string comment '姓名' , sage bigint comment '年龄' , pdate string comment '入学日期' ) COMMENT '学生信息表’ ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t’ LINES TERMINATED BY '\n' STORED AS TEXTFILE; LOAD DATA LOCAL INPATH '/usr/mrli/testdata_student' INTO TABLE student; testdata_student测试数据如下 1 name1 21 20130901 2 name2 22 20130901 3 name3 23 20130901 4 name4 24 20130901 5 name5 25 20130902 6 name6 26 20130902 7 name7 27 20130902 8 name8 28 20130902 9 name9 29 20130903 10 name10 30 20130903 11 name11 31 20130903 12 name12 32 20130904 13 name13 33 20130904 执行 在usr/mrli 目录下执行 hive -f student.sql 方法1:
Hive常用命令
Hive常用命令: 1、查看数据库 show databases; //查看已经存在的数据库 describe database test; //查看某个已经存在的数据库 2、创建数据库 create database test; create database if not exists test; create database test2 location '/user/hadoop/temp'; //制定数据库创建的目录 3、删除数据库 drop database if exists test1 cascade; 4、切换当前工作的数据库 use test2; 5、查看数据库中的表 show tables; //查看当前工作的数据库中的表 show tables in test3; //查看数据库test3中的表 6、创建表 create table if not exists test.student( name string comment 'student name', age int comment 'student age', course array