数据分析过程中各个步骤中使用的工具

数据分析过程中各个步骤使用的工具
数据分析也好,统计分析也好,数据挖掘也好、商业智能也好,都需要在学习的时候掌握各种分析手段和技能,特别是要掌握分析软件工具!学习数据分析,一般是先学软件开始,再去应用,再学会理论和原理!没有软件的方法就不去学了,因为学了也不能做,除非你自己会编程序。
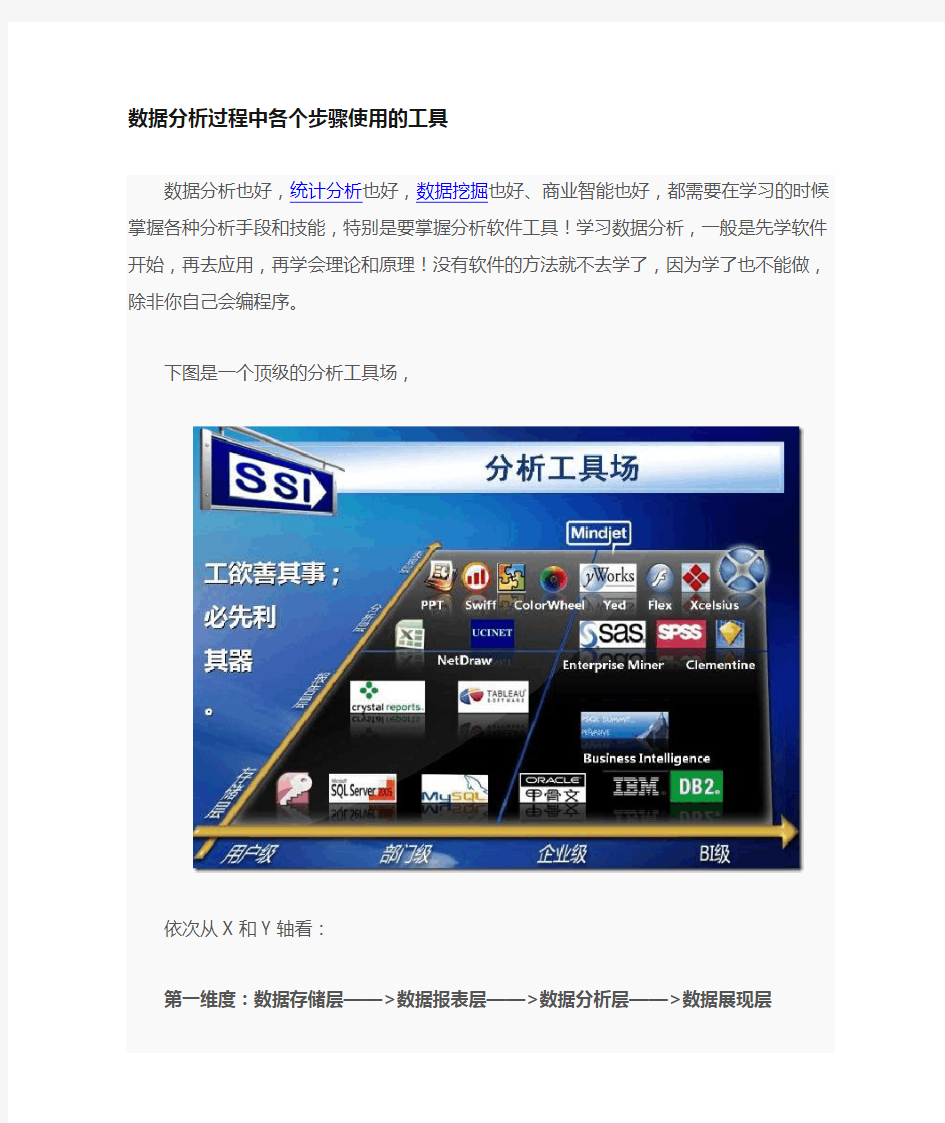
下图是一个顶级的分析工具场,
依次从X和Y轴看:
第一维度:数据存储层——>数据报表层——>数据分析层——>数据展现层
第二维度:用户级——>部门级——>企业级——>BI级
我结合上图和其他资料统计了我们可能用到的软件信息。具体的软件效果还需要进一步研究分析和实践。
1第一步:设计方案
可以考虑的软件工具:mind manager。
Mind manager(思维导图又叫心智图),是表达发射性思维的有效的图形思维工具,它简单却又极其有效,是一种革命性的思维工具。思维导图运用图文并重的技巧,把各级主题的关系用相互隶属与相关的层级图表现出来,把主题关键词与图像、颜色等建立记忆链接。思维导图充分运用左右脑的机能,利用记忆、阅读、思维的规律,协助人们在科学与艺术、逻辑与想象之间平衡发展,从而开启人类大脑的无限潜能。思维导图因此具有人类思维的强大功能。
思维导图是一种将放射性思考具体化的方法。我们知道放射性思考是人类大脑的自然思考方式,每一种进入大脑的资料,不论是感觉、记忆或是想法——包括文字、数字、符码、香气、食物、线条、颜色、意象、节奏、音符等,都可以成为一个思考中心,并由此中心向外发散出成千上万的关节点,每一个关节点代表与中心主题的一个连结,而每一个连结又可以成为另一个中心主题,再向外发散出成千上万的关节点,呈现出放射性立体结构,而这些关节的连结可以视为您的记忆,也就是您的个人数据库。
2第二步:数据采集
可以考虑的工具软件:word、excel、access、oracle、mysql。
2.1Word、Excel和Access等
有关office软件的内容,我们就不介绍了。
2.2Oracl e Database
又名Oracle RDBMS,或简称Oracle。是甲骨文公司的一款关系数据库管理系统。它是在数据库领域一直处于领先地位的产品。可以说Oracle数据库系统是目前世界上流行的关系数据库管理系统,系统可移植性好、使用方便、功能强,适用于各类大、中、小、微机环境。它是一种高效率、可靠性好的适应高吞吐量的数据库解决方案。
介绍:
https://www.360docs.net/doc/9718321035.html,/picture/1685727/1685727/0/f31fbe096b63f6241b74d9268544ebf81a4ca3
ee.html?fr=lemma&ct=single#aid=0&pic=f31fbe096b63f6241b74d9268544ebf81a4ca3ee
2.3MySQL
(发音为"my ess cue el",不是"my sequel")是一种开放源代码的关系型数据库管理系统(RDBMS),MySQL数据库系统使用最常用的数据库管理语言--结构化查询语言(SQL)进行数据库管理。
这个也不做过多介绍。
3第三步:数据处理
可以考虑的工具软件:Epidata、excel、SPSS、ETL。
3.1EpiData工具
是一个既可以用于创建数据结构文档,也可以用于数据定量分析一组应用工具的集合。EpiData协会于1999年在丹麦成立。EpiData采用Pascal开发。在允许的情况下,尽可能地使用开放标准(如HTML)。
介绍:
https://www.360docs.net/doc/9718321035.html,/link?url=9z2e0tvF9yh7a59W-0sYFNf8sZzjpqL4u11Glxxj4J1HBMtSl8eS JMSTeUZxEMcMlMGo8LnZQCforWxTqwPPda
下载地址:
https://www.360docs.net/doc/9718321035.html,/thread-386685-1-1.html
3.2Excel工具
有关Office软件的信息不做介绍
3.3SPSS工具
(Statistical Product and Service Solutions),“统计产品与服务解决方案”软件。最初软件全称为“社会科学统计软件包”(SolutionsStatistical Package for the Social Sciences),
但是随着SPSS产品服务领域的扩大和服务深度的增加,SPSS公司已于2000年正式将英文全称更改为“统计产品与服务解决方案”,标志着SPSS的战略方向正在做出重大调整。为IBM公司推出的一系列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软件产品及相关服务的总称SPSS,有Windows和Mac OS X等版本。
百度百科介绍:
https://www.360docs.net/doc/9718321035.html,/link?url=Sx6UNQj33qC5igpst8Lz2PZl494sD0FAG8fcCYgrVy0_jlSPvvBFmrH EngsfG5ou233d9aAxvgrrlw-NqSiZoa
下载地址:
https://www.360docs.net/doc/9718321035.html,/softdown/10039.htm
备注:安装需要注册码
3.4ETL模式
是英文Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
ETL是构建数据仓库的重要一环,用户从数据源抽取出所需的数据,经过数据清洗,最终按照预先定义好的数据仓库模型,将数据加载到数据仓库中去。
目前,ETL工具的典型代表有:Informatica、Datastage、OWB、微软DTS、Beeload、Kettle……开源的工具有eclipse的etl插件。cloveretl.
数据集成:快速实现ETL
百度百科介绍:
https://www.360docs.net/doc/9718321035.html,/link?url=EVl1pZdi9ZtCwa7yCH2LOM87LqVCE6XJVp68rJeB87v0hnvm6XXe
https://www.360docs.net/doc/9718321035.html,/soft/222228.htm
4第四步:数据分析
可以考虑的工具软件:SPSS、SAS、Matlab、Eviews、Stata、Excel、Weka、RapidMiner。
4.1SPSS
是一个综合类数据分析处理软件,前面介绍了,我们在这一部分就不再介绍。
4.2SAS
(全称STATISTICAL ANALYSIS SYSTEM,简称SAS)是全球最大的软件公司之一,是由美国NORTH CAROLINA州立大学1966年开发的统计分析软件。
百度百科介绍:
https://www.360docs.net/doc/9718321035.html,/link?url=JNRrNyC3ZhBPJXAL0HtQ2DGFBQP8RYeKWR81b6EtpF9PPuPPyC2 AiRgRT2t__cnqej3AFYNATem8OdaP-Cp5TDS_7cXwJMxjc_oNSocHgru
下载地址:
https://www.360docs.net/doc/9718321035.html,/thread-2114285-1-1.html
备注:安装需要虚拟光盘、sid等信息。也可以购买sid。
4.3Matlab
每个人都很了解,我就不做太多介绍了。
4.4Eviews
是Econometrics Views的缩写,直译为计量经济学观察,通常称为计量经济学软件包。
它的本意是对社会经济关系与经济活动的数量规律,采用计量经济学方法与技术进行“观察”。另外Eviews也是美国QMS公司研制的在Windows下专门从事数据分析、回归分析和预测的工具。使用Eviews可以迅速地从数据中寻找出统计关系,并用得到的关系去预测数据的未来值。Eviews的应用范围包括:科学实验数据分析与评估、金融分析、宏观经济预测、仿真、销售预测和成本分析等。
介绍:
https://www.360docs.net/doc/9718321035.html,/link?url=vLJW8XexwC-__vZ-7sL4zNWZQcCvN4oWReneCHa7mopZtK4VAv bdF2hUjNwbYIgngbqTQdcm7ApSfoTwTR4Ct_
下载地址:
https://www.360docs.net/doc/9718321035.html,/thread-752891-1-1.html
4.5Stata
是一套提供其使用者数据分析、数据管理以及绘制专业图表的完整及整合性统计软件。
它提供许许多多功能,包含线性混合模型、均衡重复反复及多项式普罗比模式。
Stata 其统计分析能力远远超过了SPSS ,在许多方面也超过了SAS !由于Stata 在分析时是将数据全部读入内存,在计算全部完成后才和磁盘交换数据,因此计算速度极快(一般来说,SAS 的运算速度要比SPSS 至少快一个数量级,而Stata 的某些模块和执行同样功能的SAS 模块比,其速度又比SAS 快将近一个数量级!)Stata 也是采用命令行方式来操作,但使用上远比SAS 简单。其生存数据分析、纵向数据(重复测量数据)分析等模块的功能甚至超过了SAS 。用Stata 绘制的统计图形相当精美,很有特色。
介绍:
下载:
https://www.360docs.net/doc/9718321035.html,/thread-714027-1-1.html
4.6weka
全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),是一款免费的,非商业化(与之对应的是SPSS公司商业数据挖掘产品--Clementine )的,基于JAVA环境下开源的机器学习(machine learning)以及数据挖掘(data minining)软件。它和它的源代码可在其官方网站下载。有趣的是,该软件的缩写WEKA也是New Zealand独有的一种鸟名,而Weka的主要开发者同时恰好来自New Zealand的the University of Waikato。
介绍:
https://www.360docs.net/doc/9718321035.html,/link?url=AR80v-BY2MUNu2j_JXqwBKDD6Df-hK7_LThpf_4vqUFYY5AIsOL4 7EwpChPhZi6tzJr8iIP8UQcablDhUj-MPK
下载:
https://www.360docs.net/doc/9718321035.html,/soft/17508.html
4.7RapidMiner
是世界领先的数据挖掘解决方案,在一个非常大的程度上有着先进技术。它数据挖
掘任务涉及范围广泛,包括各种数据艺术,能简化数据挖掘过程的设计和评价。
免费提供数据挖掘技术和库
100%用Java代码(可运行在大部分操作系统上)
数据挖掘过程简单,强大和直观
内部XML保证了标准化的格式来表示交换数据挖掘过程
可以用简单脚本语言自动进行大规模进程
多层次的数据视图,确保有效和透明的数据
图形用户界面的互动原型
命令行(批处理模式)自动大规模应用
Java API(应用编程接口)
简单的插件和推广机制
强大的可视化引擎,许多尖端的高维数据的可视化建模
值得一提的是,该工具在数据挖掘工具榜上位列榜首。
备注:下载需要注册帐号,并付费!
4.8Origin
为OriginLab公司出品的较流行的专业函数绘图软件,是公认的简单易学、操作灵活、功能强大的软件,既可以满足一般用户的制图需要,也可以满足高级用户数据分析、函数拟合的需要。
5第五步:数据呈现
可以考虑的工具软件:Excel、SAS、SPSS、Crystal Xcelsious、PPT、Swiff
Chart、Foxtable、Cognos、Tableau。
5.1Excel和PPT
5.2SAS和SPSS
这两类的情况在前面都有介绍,在这一部分也不做太多介绍。
5.3Crystal Xcelsius
是全球领先的商务智能软件商Business Objects的最新产品,中文名:“水晶易表”。
当我们需要向客户和同事展示商业数据,但听众却很容易被一大堆数据搞得疲倦和困惑。而且,即使人们希望通过增加图表和图形来增加展示的效果、来更好地表达意见,似乎也收效甚微。因为这些静止的、标准的表现形式看起来都是一样的。当今的市场竞争激烈,资源短缺,各种组织已经大量投资于科技手段以获得关于公司运营的数据,但人们很难快速的让这些数据变得有意义从而做出快速、准确的决策,并保持在竞争的前列。通过“如果—那么会(What i f)”分析来为公司未来的绩效进行建模,这项工作经常是由统计学家来完成,但他们不太了解当事人需要做出决策并改善业绩的前沿领域。随着Crystal Xcelsius的推出,以上问题都会得到解决!
只需要简单的点击操作,Crystal Xcelsius就可以令静态的excel 电子表格充满生动的数据展示、动态表格、图像和可交互的可视化分析,我们还可以通过多种“如果---那么会”情景分析进行预测。最后,通过一键式整合,这些交互式的Crystal Xcelsius分析结果就可以轻松的嵌入到PowerPoint、Adobe PDF 文档、Outlook和网页上了。
下载地址:
https://www.360docs.net/doc/9718321035.html,/soft/17186.html
备注:破解注册:使用内存注册破解工具,点击"Patch",在安装目录下找到xcelsius.exe,确实,再使用下列序列号注册:
Crystal Xcelsius pro 4.X序列号:
Xcl4Pro-DLR8FHNM14FAMA2B9NDA
Xcl4Pro-DWQMAHB94R4G0A036AD6
Xcl4Pro-NYXA3BDF10R39AAQ12FD
Xcl4Pro-0TQW42AM01FA156ECARV
如果电脑上安装是精简版的office 2003等版本,可能会提示出错。
5.4Swiff Chart
主要可以帮你把商业或重要学术研究上的数据制成图表,并且利用参数或是加入“动作事件”而成为动态图表,完成之后更可以输出成为Flash (*.SFW) 格式,或是嵌入
Powerpoint 投影片中,不论用来放在网页上传播或是演示文稿使用都十分好用方便。
下载地址:
https://www.360docs.net/doc/9718321035.html,/design/homepage/detail-140588.html
5.5Foxtable
是广东狐表软件公司开发的软件。它将Excel、Access、Foxpro以及易表的优势融合在一起,无论是数据录入、查询、统计,还是报表生成,都前所未有的强大和易用,使得普通用户无需编写任何代码,即可轻松完成复杂的数据管理工作,真正做到拿来即用。
下载地址:
https://www.360docs.net/doc/9718321035.html,/soft/107521.html
5.6Cognos
是在BI核心平台之上,以服务为导向进行架构的一种数据模型,是唯一可以通过单一产品和在单一可靠架构上提供完整业务智能功能的解决方案。它可以提供无缝密合的报表、分析、记分卡、仪表盘等解决方案,通过提供所有的系统和资料资源,以简化公司各员工处理资讯的方法。作为一个全面、灵活的产品,Cognos业务智能解决方案可以容易地整合到现有的多系统和数据源架构中。
Cognos强大的报表制作和展示功能能够制作/展示任何形式的报表,其纯粹的Web界面使用方式又使得部署成本和管理成本降到最低。同时Cognos还可以同数据挖掘工具、统计分
析工具配合使用,增强决策分析功能。
百度百科介绍:
https://www.360docs.net/doc/9718321035.html,/link?url=fOyn8fqlKvz-e5Lu7BB4Zk8_QOwybATKpcUzVN8I1W3z_BwoF3fq hFdIEVNvxRPYTiQljUE-LT0V-V4hpqFJAK
下载地址:
https://www.360docs.net/doc/9718321035.html,/detail/gallopingturtle/4960051
5.7Tableau
是桌面系统中最简单的商业智能工具软件,Tableau 没有强迫用户编写自定义代码,新的控制台也可完全自定义配置。在控制台上,不仅能够监测信息,而且还提供完整的分析能力。Tableau控制台灵活,具有高度的动态性。
Tableau公司将数据运算与美观的图表完美地嫁接在一起。它的程序很容易上手,各公司可以用它将大量数据拖放到数字“画布”上,转眼间就能创建好各种图表。这一软件的理念是,界面上的数据越容易操控,公司对自己在所在业务领域里的所作所为到底是正确还是错误,就能了解得越透彻。但是不易使用和下载。
6第六步:报告撰写;
可以考虑的工具软件:Word、Excel、PPT、latex
1. 前三个都是我们常见的office工作软件,我们不做过多介绍。
2. latex是一个编译pdf的工具,可以很好的插入图片、表格等文件,同时latex中编译的
pdf文件的格式规范,且不能够改动。不会因为电脑的不同造成文件排版混乱的困扰。
LaTeX(L A T E X,音译“拉泰赫”)是一种基于ΤΕΧ的排版系统,由美国计算机学家莱斯利·兰伯特(Leslie Lamport)在20世纪80年代初期开发,利用这种格式,即使使用者没有排版和程序设计的知识也可以充分发挥由TeX所提供的强大功能,能在几天,甚至几小时内生成很多具有书籍质量的印刷品。对于生成复杂表格和数学公式,这一点表现得尤为突出。因此它非常适用于生成高印刷质量的科技和数学类文档。这个系统同样适用于生成从简单的信件到完整书籍的所有其他种类的文档。
百科介绍:
编译窗口:
结果呈现:
16种常用数据分析方法
一、描述统计描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:剔除法、均值法、最小邻居法、比率回归法、决策 树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W 检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A 单样本t检验:推断该样本来自的总体均数卩与已知的某一总体均数卩0 (常为理论值或标准值)有无差别; B 配对样本t 检验:当总体均数未知时,且两个样本可以配对,同对中的两者在可能会影响处理效果的各种条件方面扱为相似; C 两独立样本t 检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验 非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。 适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。 A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10 以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析检査测量的可信度,例如调查问卷的真实性。 分类: 1、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度 2、内在信度;每个量表是否测量到单一的概念,同时组成两表的内在体项一致性如何,常用方法分半信度。 四、列联表分析用于分析离散变量或定型变量之间是否存在相关。对于二维表,可进行卡 方检验,对于三维表,可作Mentel-Hanszel 分层分析列联表分析还包括配对计数资料的卡方检验、行列均为顺序变量的相关检验。 五、相关分析 研究现象之间是否存在某种依存关系,对具体有依存关系的现象探讨相关方向及相关程度。 1、单相关:两个因素之间的相关关系叫单相关,即研究时只涉及一个自变量和一个因变量; 2、复相关:三个或三个以上因素的相关关系叫复相关,即研究时涉及两个或两个以
大数据处理流程的主要环节
大数据处理流程的主要环节 大数据处理流程主要包括数据收集、数据预处理、数据存储、数据处理与分析、数据展示/数据可视化、数据应用等环节,其中数据质量贯穿于整个大数据流程,每一个数据处理环节都会对大数据质量产生影响作用。通常,一个好的大数据产品要有大量的数据规模、快速的数据处理、精确的数据分析与预测、优秀的可视化图表以及简练易懂的结果解释,本节将基于以上环节分别分析不同阶段对大数据质量的影响及其关键影响因素。 一、数据收集 在数据收集过程中,数据源会影响大数据质量的真实性、完整性数据收集、一致性、准确性和安全性。对于Web数据,多采用网络爬虫方式进行收集,这需要对爬虫软件进行时间设置以保障收集到的数据时效性质量。比如可以利用八爪鱼爬虫软件的增值API设置,灵活控制采集任务的启动和停止。 二、数据预处理 大数据采集过程中通常有一个或多个数据源,这些数据源包括同构或异构的数据库、文件系统、服务接口等,易受到噪声数据、数据值缺失、数据冲突等影响,因此需首先对收集到的大数据集合进行预处理,以保证大数据分析与预测结果的准确性与价值性。
大数据的预处理环节主要包括数据清理、数据集成、数据归约与数据转换等内容,可以大大提高大数据的总体质量,是大数据过程质量的体现。数据清理技术包括对数据的不一致检测、噪声数据的识别、数据过滤与修正等方面,有利于提高大数据的一致性、准确性、真实性和可用性等方面的质量; 数据集成则是将多个数据源的数据进行集成,从而形成集中、统一的数据库、数据立方体等,这一过程有利于提高大数据的完整性、一致性、安全性和可用性等方面质量; 数据归约是在不损害分析结果准确性的前提下降低数据集规模,使之简化,包括维归约、数据归约、数据抽样等技术,这一过程有利于提高大数据的价值密度,即提高大数据存储的价值性。 数据转换处理包括基于规则或元数据的转换、基于模型与学习的转换等技术,可通过转换实现数据统一,这一过程有利于提高大数据的一致性和可用性。 总之,数据预处理环节有利于提高大数据的一致性、准确性、真实性、可用性、完整性、安全性和价值性等方面质量,而大数据预处理中的相关技术是影响大数据过程质量的关键因素 三、数据处理与分析 1、数据处理 大数据的分布式处理技术与存储形式、业务数据类型等相关,针对大数据处理的主要计算模型有MapReduce分布式计算框架、分布式内存计算系统、分布式流计算系统等。
试验数据统计分析步骤
试验数据统计分析教程
第一章:数据分析基本方法与步骤 §1-1:数据分类(定量资料和定性资料) 统计资料一般分为定量资料和定性资料两大类。 定量资料测定每个观察单位某项指标量的大小,所得的资料称为定量资料。定量资料又可细分为计量资料(可带度量单位和小数点,如:某人身高为1.173 m)和计数资料(一般只带度量单位,但不可带小数点,如:某人脉搏为73次/min) 。①计量资料在定量资料中,若指标的取值可以带度量衡单位,甚至可以带小数标志测量的精度的定量资料,就叫“ 计量资料” 。例如测得正常成年男子身高、体重、血红蛋白、总铁结合力等所得的资料。②计数资料在定量资料中,若指标的取值可以带度量衡单位,但不可以带小数即只能取整数,通常为正整数的定量资料,就叫“ 计数资料” 。例如测得正常成年男子脉搏数次、引体向上的次数次。 定性资料观测每个观察单位某项指标的状况,所得的资料称为定性资料。定性资料又可细分为名义资料(如血型分为:A、B、AB、O型)和有序资料(如疗效分为:治愈、显效、好转、无效、死亡) 。①名义资料在定性资料中,若指标的不同状况之间在本质上无数量大小或先后顺序之分的定性资料,就叫“ 名义资料” 。例如某单位全体员工按血型系统型、型、型、型来记录每个人的情况所得的资料;又例如某市全体员工按职业分为工人、农民、知识分子、军人等来记录每个人的情况所得的资料。②有序资料在定性资料中,若指标质的不同状况之间在本质上有数量大小或有先后顺序之分的定性资料,就叫“ 有序资料” 。例如某病患者按治疗后的疗效治愈、显效、好转、无效、死亡来划分所得的资料;又例如矽肺病患者按肺门密度级别来划分所得的资料。 判断资料性质的关键是把资料还原为基本观察单位的具体取值
常用数据分析方法详细讲解
常用数据分析方法详解 目录 1、历史分析法 2、全店框架分析法 3、价格带分析法 4、三维分析法 5、增长率分析法 6、销售预测方法 1、历史分析法的概念及分类 历史分析法指将与分析期间相对应的历史同期或上期数据进行收集并对比,目的是通过数据的共性查找目前问题并确定将来变化的趋势。 *同期比较法:月度比较、季度比较、年度比较 *上期比较法:时段比较、日别对比、周间比较、 月度比较、季度比较、年度比较 历史分析法的指标 *指标名称: 销售数量、销售额、销售毛利、毛利率、贡献度、交叉比率、销售占比、客单价、客流量、经营品数动销率、无销售单品数、库存数量、库存金额、人效、坪效 *指标分类: 时间分类 ——时段、单日、周间、月度、季度、年度、任意 多个时段期间 性质分类 ——大类、中类、小类、单品 图例 2框架分析法 又叫全店诊断分析法 销量排序后,如出现50/50、40/60等情况,就是什么都能卖一点但什么都不 好卖的状况,这个时候就要对品类设置进行增加或删减,因为你的门店缺少 重点,缺少吸引顾客的东西。 如果达到10/90,也是品类出了问题。 如果是20/80或30/70、30/80,则需要改变的是商品的单品。 *单品ABC分析(PSI值的概念) 销售额权重(0.4)×单品销售额占类别比+销售数量权重(0.3) × 单品销售数量占类别比+毛利额权重(0.3)单品毛利额占类别比 *类别占比分析(大类、中类、小类) 类别销售额占比、类别毛利额占比、 类别库存数量占比、类别库存金额占比、
类别来客数占比、类别货架列占比 表格例 3价格带及销售二维分析法 首先对分析的商品按价格由低到高进行排序,然后 *指标类型:单品价格、销售额、销售数量、毛利额 *价格带曲线分布图 *价格带与销售对数图 价格带及销售数据表格 价格带分析法 4商品结构三维分析法 *一种分析商品结构是否健康、平衡的方法叫做三维分析图。在三维空间坐标上以X、Y、Z 三个坐标轴分别表示品类销售占有率、销售成长率及利润率,每个坐标又分为高、低两段,这样就得到了8种可能的位置。 *如果卖场大多数商品处于1、2、3、4的位置上,就可以认为商品结构已经达到最佳状态。以为任何一个商品的品类销售占比率、销售成长率及利润率随着其商品生命周期的变化都会有一个由低到高又转低的过程,不可能要求所有的商品同时达到最好的状态,即使达到也不可能持久。因此卖场要求的商品结构必然包括:目前虽不能获利但具有发展潜力以后将成为销售主力的新商品、目前已经达到高占有率、高成长率及高利润率的商品、目前虽保持较高利润率但成长率、占有率趋于下降的维持性商品,以及已经决定淘汰、逐步收缩的衰退型商品。 *指标值高低的分界可以用平均值或者计划值。 图例 5商品周期增长率分析法 就是将一段时期的销售增长率与时间增长率的比值来判断商品所处生命周期阶段的方法。不同比值下商品所处的生命周期阶段(表示) 如何利用商品生命周期理论指导营运(图示) 6销售预测方法[/hide] 1.jpg (67.5 KB) 1、历史分析法
数据分析程序
数据分析程序流程图
数据分析程序 1 目的 确定收集和分析适当的数据,以证实质量管理体系的适宜性和有效性,评价和持续改进质量管理体系的有效性。 2 适用范围 本程序适用于烤烟生产服务全过程的数据分析。 3 工作职责 3.1 分管领导:负责数据分析结果的批准。 3.2 烟叶科:负责数据分析结果的审核。 3.3 相关部门:负责职责范围内数据的收集和分析。 4 工作程序 4.1 数据的分类 4.1.1 烟用物资采购发放数据:烟用物资盘点盘存、烟用物资需求、烟用物资采购、烟用物资发放、烟用物资分户发放、烟用物资供应商等相关数据。 4.1.2 烤烟生产收购销售数据。 4.1.3 烟叶挑选整理数据:烟叶挑选整理数据。 4.1.4 客户满意:烟厂(集团公司)和烟农满意度测量数据和其他反馈信息。 4.1.5 过程和质量监测数据:产购销过程各阶段检查数据及不合格项统计等。 4.1.6 持续改进数据。 4.2 数据的收集 4.2.1 烟用物资采购数据的收集 a) 烟草站于当年10月底对当年烟用物资使用情况进行收集,对库存情况进行盘点,并填写烟用物 资盘点情况统计表保存并送烟叶科; b) 储运科于当年10月底前将烟用物资库存情况进行盘点,送烟叶科; c) 储运站于当年挑选结束后对库存麻片、麻绳、缝口绳进行盘点,据次年生产需要,制定需求计 划表,送烟叶科。 d) 烟草站于当年10月底据次年生产需求填报烟用物资需求表,上报烟叶科,烟叶科据烟用物资需 求和库存盘点情况,拟定烟用物资需求计划,报公司烤烟生产分管领导批准; e) 烟叶科将物资采购情况形成汇总表,送财务科、报分管领导; f) 烟叶科形成烟用物资发放情况登记表,归档、备案; g) 烟草站形成烟用物资分户发放情况表,烟草站备案。 4.2.2 烤烟产购销数据的收集 a) 烟用物资采购数据收集完成后,由烟叶科填报《烟用物资采购情况汇总表》,于管理评审前上 报分管领导和经理。 b) 烤烟生产期间,烟草站每10天向烟叶科上报《烤烟生产情况统计表》,烟叶科汇总后定期上报 公司领导层。对所收集的进度报政府或上级部门时,必须由分管领导签字后才能送出。
SPSS数据分析的主要步骤
欢迎阅读 SPSS 数据分析的主要步骤 利用SPSS 进行数据分析的关键在于遵循数据分析的一般步骤,但涉及的方面会相对较少。主要集中在以下几个阶段。 1.SPSS 数据的准备阶段 在该阶段应按照SPSS 的要求,利用SPSS 提供的功能准备SPSS 数据文件。其中包括在2.3.由于4.该阶段的主要任务是读懂SPSS 输出编辑窗口中的分析结果,明确其统计含义,并结合应用背景知识做出切合实际的合理解释。 数据分析必须掌握的分析术语 1、增长: 增长就是指连续发生的经济事实的变动,其意义就是考查对象数量的增多或减少。
百分点是指不同时期以百分数的形式表示的相对指标的变动幅度。 3、倍数与番数: 倍数:两个数字做商,得到两个数间的倍数。 4 5 6 例如:去年收入为23(其中增值业务3),今年收入为34(其中增值业务5),则增值业务拉动收入增长计算公式就为:(5-2)/23=(5-2)/(34-23)×(34-23)/23,解释3/(34-23)为数据业务增量的贡献,后面的(34-23)/23为增长率。 7、年均增长率: 即某变量平均每年的增长幅度。
平均数是指在一组数据中所有数据之和再除以数据的个数。它是反映数据集中趋势的一项指标。 公式为:总数量和÷总份数=平均数。 9、同比与环比 6 月比11 10 n 公式为:(现有价值/基础价值)^(1/年数)-1 如何用EXCEL进行数据分组 什么是交叉表 “交叉表”对象是一个网格,用来根据指定的条件返回值。数据显示在压缩行和列中。这种格式易于比较数据并辨别其趋势。它由三个元素组成:
?行 ?列 ?摘要字段 ?“交叉表”中的行沿水平方向延伸(从一侧到另一侧)。在上面的示例中,“手套”(Gloves) 是一行。 ?“交叉表”中的列沿垂直方向延伸(上下)。在上面的示例中,“美国”(USA) 是 ? 交叉“ ?/ ?每列的底部是该列的总计。在上面的例子中,该总计代表所有产品在一个国家/地区的销售量。“美国”一列底部的值是四,这是所有产品(手套、腰带和鞋子)在美国销售的总数。 注意:总计列可以出现在每一行的顶部。
业务流程图与数据流程图的比较知识讲解
业务流程图与数据流程图的比较
业务流程图与数据流程图的比较 一、业务流程图与数据流程图的区别 1. 描述对象不同 业务流程图的描述对象是某一具体的业务; 数据流程图的描述对象是数据流。 业务是指企业管理中必要且逻辑上相关的、为了完成某种管理功能的一系列相关的活动。在系统调研时, 通过了解组织结构和业务功能, 我们对系统的主要业务有了一个大概的认识。但由此我们得到的对业务的认识是静态的, 是由组织部门映射到业务的。而实际的业务是流动的, 我们称之为业务流程。一项完整的业务流程要涉及到多个部门和多项数据。例如, 生产业务要涉及从采购到财务, 到生产车间, 到库存等多个部门; 会产生从原料采购单, 应收付账款, 入库单等多项数据表单。因此, 在考察一项业务时我们应将该业务一系列的活动即整个过程为考察对象, 而不仅仅是某项单一的活动, 这样才能实现对业务的全面认识。将一项业务处理过程中的每一个步骤用图形来表示, 并把所有处理过程按一定的顺序都串起来就形成了业务流程图。如图 1 所示, 就是某公司物资管理的业务流程图。
数据流程图是对业务流程的进一步抽象与概括。抽象性表现在它完全舍去了具体的物质, 只剩下数据的流动、加工处理和存储; 概括性表现在它可以把各种不同业务处理过程联系起来,形成一个整体。从安东尼金字塔模型的角度来看, 业务流程图描述对象包括企业中的信息流、资金流和物流, 数据流程图则主要是对信息流的描述。此外, 数据流程图还要配合数据字典的说明, 对系统的逻辑模型进行完整和详细的描述。 2. 功能作用不同
业务流程图是一本用图形方式来反映实际业务处理过程的“流水帐”。绘制出这本流水帐对于开发者理顺和优化业务过程是很有帮助的。业务流程图的符号简单明了, 易于阅读和理解业务流程。绘制流程图的目的是为了分析业务流程, 在对现有业务流程进行分析的基础上进行业务流程重组, 产生新的更为合理的业务流程。通过除去不必要的、多余的业务环节; 合并重复的环节;增补缺少的必须的环节; 确定计算机系统要处理的环节等重要步骤, 在绘制流程图的过程中可以发现问题, 分析不足, 改进业务处理过程。 数据流程分析主要包括对信息的流动、传递、处理、存储等的分析。数据流程分析的目的就是要发现和解决数据流通中的问题, 这些问题有: 数据流程不畅, 前后数据不匹配, 数据处理过程不合理等。通过对这些问题的解决形成一个通畅的数据流程作为今后新系统的数据流程。数据流程图比起业务流程图更为抽象, 它舍弃了业务流程图中的一些物理实体, 更接近于信息系统的逻辑模型。对于较简单的业务, 我们可以省略其业务流程图直接绘制数据流程图。 3. 基本符号不同 (1)业务流程图的常用的基本符号有以下六种, 见图 2 所示。 (2)数据流程图的基本符号见图 3 所示
数据分析步骤
数据分析有极广泛的应用范围,这是一个扫盲贴。典型的数据分析可能包含以下三个步:[list]1、探索性数据分析,当数据刚取得时,可能杂乱无章,看不出规律,通过作图、造表、用各种形式的方程拟合,计算某些特征量等手段探索规律性的可能形式,即往什么方向和用何种方式去寻找和揭示隐含在数据中的规律性。2、模型选定分析,在探索性分析的基础上提出一类或几类可能的模型,然后通过进一步的分析从中挑选一定的模型。3、推断分析,通常使用数理统计方法对所定模型或估计的可靠程度和精确程度作出推断。数据分析过程实施数据分析过程的主要活动由识别信息需求、收集数据、分析数据、评价并改进数据分析的有效性组成。一、识别信息需求识别信息需求是确保数据分析过程有效性的首要条件,可以为收集数据、分析数据提供清晰的目标。识别信息需求是管理者的职责管理者应根据决策和过程控制的需求,提出对信息的需求。就过程控制而言,管理者应识别需求要利用那些信息支持评审过程输入、过程输出、资源配置的合理性、过程活动的优化方案和过程异常变异的发现。二、收集数据有目的的收集数据,是确保数据分析过程有效的基础。组织需要对收集数据的内容、渠道、方法进行策划。策划时应考虑:[list]①将识别的需求转化为具体的要求,如评价供方时,需要收集的数据可能包括其过程能力、测量系统不确定度等相关数据;②明确由谁在何时何处,通过何种渠道和方法收集数据;③记录表应便于使用;④采取有效措施,防止数据丢失和虚假数据对系统的干扰。三、分析数据分析数据是将收集的数据通过加工、整理和分析、使其转化为信息,通常用方法有:[list]老七种工具,即排列图、因果图、分层法、调查表、散步图、直方图、控制图;新七种工具,即关联图、系统图、矩阵图、KJ法、计划评审技术、PDPC法、矩阵数据图;四、数据分析过程的改进数据分析是质量管理体系的基础。组织的管理者应在适当时,通过对以下问题的分析,评估其有效性:[list]①提供决策的信息是否充分、可信,是否存在因信息不足、失准、滞后而导致决策失误的问题;②信息对持续改进质量管理体系、过程、产品所发挥的作用是否与期望值一致,是否在产品实现过程中有效运用数据分析;③收集数据的目的是否明确,收集的数据是否真实和充分,信息渠道是否畅通;④数据分析方法是否合理,是否将风险控制在可接受的范围;⑤数据分析所需资源是否得到保障。 数据分析是指通过建立审计分析模型对数据进行核对、检查、复算、判断等操作,将被审计单位数据的现实状态与理想状态进行比较,从而发现审计线索,搜集审计证据的过程。 数据分析过程的主要活动由识别信息需求、收集数据、分析数据、评价并改进数据分析的有效性组成。 一、识别信息需求 识别信息需求是确保数据分析过程有效性的首要条件,可以为收集数据、分析数据提供清晰的目标。识别信息需求是管理者的职责管理者应根据决策和过程控制的需求,提出对信息的需求。就过程控制而言,管理者应识别需求要利用那些信息支持评审过程输入、过程输出、资源配置的合理性、过程活动的优化方案和过程异常变异的发现。
手把手教你数据分析全流程
https://www.360docs.net/doc/9718321035.html,/ 手把手教你数据分析全流程 听到数据分析,很多竞价小编都会干到头很大有没有,正因为头大,所以我们才应该针对这方面去多种练习,一直练到什么时候拿到这个数据分析的任务感觉得心应手的时候正是我们成功的时候。 下图是某账户的营销数据。从你的角度看,你会觉得是哪里出了问题? 分析好之后,你便可以带着自己的答案看下去。 确定目的 一般情况下,我们进行数据分析是为了什么? 降低成本,增加对话、增加流量质量...等等。 但其实,最终我们都可以归结为一个目的:增加转化。
https://www.360docs.net/doc/9718321035.html,/ 那我们在分析时,便可以基于这个目的来出发。 发现问题 既然明确了目的,是增加转化,那便可先从结果出发。 从图中我们可以看出它的线索是逐步上升,但线索成本并没有下降。 那...从结果分析来看,我们的获客成本是较高的。 分析、确定问题 线索成本高,要么是因为我们的均价高,要么就是因为我们的对话率低。 但从对话率来看,它的数据我们可以接受,说明流量质量没问题;点击率略微下降,均价居高不下,所以导致对话成本也是处于一个较高的状态。 那,由此可以确定:对话成本高从而导致了一个线索成本的问题。 分解问题 确定了问题,我们就要分解问题。 建议像这种情况,我们可以在草稿或电脑上罗列出一个思维导图。 对话成本高,我们可以从两点来解决:
https://www.360docs.net/doc/9718321035.html,/ 1. 降低对话成本 2. 增加对话量 降低对话成本 降低对话成本,要么降低整体点击均价从而降低成本,要么提高对话率,以量取胜。 降低整体点击均价:我们可通过筛掉那些均价高、转化低的词来达到这一目的。 提高对话率:对话率往往和一个流量质量、转化引导有关系。那我们便可通过对以下四点进行分析,从而找到自身影响对话的一个薄弱之处。 抵达分析 承载分析 转化能力分析 流量质量分析 增加对话量 增加对话量,不过就是一个增加流量质量和流量数量的问题。 这就需要我们在增加流量数量的同时,筛选出垃圾流量。同样,我们可以通过分词来达到这一目的。 我们最初的目的是增加转化,那么便可先筛选出转化较好的词,然后进行分类。 均价高转化好:先加词,拓量之后优化创意,来控制流量。 均价低转化好:利用提价和放匹配相结合。 操作执行
大数据数据分析方法、数据处理流程实战案例
数据分析方法、数据处理流程实战案例 大数据时代,我们人人都逐渐开始用数据的眼光来看待每一个事情、事物。确实,数据的直观明了传达出来的信息让人一下子就能领略且毫无疑点,不过前提是数据本身的真实性和准确度要有保证。今天就来和大家分享一下关于数据分析方法、数据处理流程的实战案例,让大家对于数据分析师这个岗位的工作内容有更多的理解和认识,让可以趁机了解了解咱们平时看似轻松便捷的数据可视化的背后都是有多专业的流程在支撑着。 一、大数据思维 在2011年、2012年大数据概念火了之后,可以说这几年许多传统企业也好,互联网企业也好,都把自己的业务给大数据靠一靠,并且提的比较多的大数据思维。 那么大数据思维是怎么回事?我们来看两个例子: 案例1:输入法 首先,我们来看一下输入法的例子。 我2001年上大学,那时用的输入法比较多的是智能ABC,还有微软拼音,还有五笔。那时候的输入法比现在来说要慢的很多,许多时候输一个词都要选好几次,去选词还是调整才能把这个字打出来,效率是非常低的。 到了2002年,2003年出了一种新的输出法——紫光拼音,感觉真的很快,键盘没有按下去字就已经跳出来了。但是,后来很快发现紫光拼音输入法也有它的问题,比如当时互联网发展已经比较快了,会经常出现一些新的词汇,这些词汇在它的词库里没有的话,就很难敲出来这个词。
在2006年左右,搜狗输入法出现了。搜狗输入法基于搜狗本身是一个搜索,它积累了一些用户输入的检索词这些数据,用户用输入法时候产生的这些词的信息,将它们进行统计分析,把一些新的词汇逐步添加到词库里去,通过云的方式进行管理。 比如,去年流行一个词叫“然并卵”,这样的一个词如果用传统的方式,因为它是一个重新构造的词,在输入法是没办法通过拼音“ran bing luan”直接把它找出来的。然而,在大数据思维下那就不一样了,换句话说,我们先不知道有这么一个词汇,但是我们发现有许多人在输入了这个词汇,于是,我们可以通过统计发现最近新出现的一个高频词汇,把它加到司库里面并更新给所有人,大家在使用的时候可以直接找到这个词了。 案例2:地图 再来看一个地图的案例,在这种电脑地图、手机地图出现之前,我们都是用纸质的地图。这种地图差不多就是一年要换一版,因为许多地址可能变了,并且在纸质地图上肯定是看不出来,从一个地方到另外一个地方怎么走是最好的?中间是不是堵车?这些都是有需要有经验的各种司机才能判断出来。 在有了百度地图这样的产品就要好很多,比如:它能告诉你这条路当前是不是堵的?或者说能告诉你半个小时之后它是不是堵的?它是不是可以预测路况情况? 此外,你去一个地方它可以给你规划另一条路线,这些就是因为它采集到许多数据。比如:大家在用百度地图的时候,有GPS地位信息,基于你这个位置的移动信息,就可以知道路的拥堵情况。另外,他可以收集到很多用户使用的情况,可以跟交管局或者其他部门来采集一些其他摄像头、地面的传感器采集的车辆的数量的数据,就可以做这样的判断了。
运营必备的 15 个数据分析方法
提起数据分析,大家往往会联想到一些密密麻麻的数字表格,或是高级的数据建模手法,再或是华丽的数据报表。其实,“分析”本身是每个人都具备的能力;比如根据股票的走势决定购买还是抛出,依照每日的时间和以往经验选择行车路线;购买机票、预订酒店时,比对多家的价格后做出最终选择。 这些小型决策,其实都是依照我们脑海中的数据点作出判断,这就是简单分析的过程。对于业务决策者而言,则需要掌握一套系统的、科学的、符合商业规律的数据分析知识。 1.数据分析的战略思维 无论是产品、市场、运营还是管理者,你必须反思:数据本质的价值,究竟在哪里?从这些数据中,你和你的团队都可以学习到什么? 数据分析的目标 对于企业来讲,数据分析的可以辅助企业优化流程,降低成本,提高营业额,往往我们把这类数据分析定义为商业数据分析。商业数据分析的目标是利用大数据为所有职场人员做出迅捷、高质、高效的决策,提供可规模化的解决方案。商业数据分析的本质在于创造商业价值,驱动企业业务增长。 数据分析的作用 我们常常讲的企业增长模式中,往往以某个业务平台为核心。这其中,数据和数据分析,是不可或缺的环节。 通过企业或者平台为目标用户群提供产品或服务,而用户在使用产品或服务过程中产生的交互、交易,都可以作为数据采集下来。根据这些数据洞察,通过分析的手段反推客户的需求,创造更多符合需求的增值产品和服务,重新投入用户的使用,从而形成形成一个完整的业务闭环。这样的完整业务逻辑,可以真正意义上驱动业务的增长。 数据分析进化论 我们常常以商业回报比来定位数据分析的不同阶段,因此我们将其分为四个阶段。 阶段 1:观察数据当前发生了什么? 首先,基本的数据展示,可以告诉我们发生了什么。例如,公司上周投放了新的搜索引擎 A 的广告,想要
新手学习-一张图看懂数据分析流程
新手学习:一张图看懂数据分析流程? 1.数据采集 ? 2.数据存储 ? 3.数据提取 ? 4.数据挖掘 ? 5.数据分析 ? 6.数据展现 ? 7.数据应用 一个完整的数据分析流程,应该包括以下几个方面,建议收藏此图仔细阅读。完整的数据分析流程: 1、业务建模。 2、经验分析。 3、数据准备。 4、数据处理。 5、数据分析与展现。 6、专业报告。 7、持续验证与跟踪。
作为数据分析师,无论最初的职业定位方向是技术还是业务,最终发到一定阶段后都会承担数据管理的角色。因此,一个具有较高层次的数据分析师需要具备完整的知识结构。 1.数据采集 了解数据采集的意义在于真正了解数据的原始面貌,包括数据产生的时间、条件、格式、内容、长度、限制条件等。这会帮助数据分析师更有针对性的控制数据生产和采集过程,避免由于违反数据采集规则导致的数据问题;同时,对数据采集逻辑的认识增加了数据分析师对数据的理解程度,尤其是数据中的异常变化。比如:Omniture中的P rop变量长度只有100个字符,在数据采集部署过程中就不能把含有大量中文描述的文字赋值给Prop变量(超过的字符会被截断)。 在Webtrekk323之前的Pixel版本,单条信息默认最多只能发送不超过2K的数据。当页面含有过多变量或变量长度有超出限定的情况下,在保持数据收集的需求下,通常的解决方案是采用多个sendinfo方法分条发送;而在325之后的Pixel版本,单条信息默认最多可以发送7K数据量,非常方便的解决了代码部署中单条信息过载的问题。(W ebtrekk基于请求量付费,请求量越少,费用越低)。
当用户在离线状态下使用APP时,数据由于无法联网而发出,导致正常时间内的数据统计分析延迟。直到该设备下次联网时,数据才能被发出并归入当时的时间。这就产生了不同时间看相同历史时间的数据时会发生数据有出入。 在数据采集阶段,数据分析师需要更多的了解数据生产和采集过程中的异常情况,如此才能更好的追本溯源。另外,这也能很大程度上避免“垃圾数据进导致垃圾数据出”的问题。 2.数据存储 无论数据存储于云端还是本地,数据的存储不只是我们看到的数据库那么简单。比如: 数据存储系统是MySql、Oracle、SQL Server还是其他系统。 数据仓库结构及各库表如何关联,星型、雪花型还是其他。 生产数据库接收数据时是否有一定规则,比如只接收特定类型字段。 生产数据库面对异常值如何处理,强制转换、留空还是返回错误。 生产数据库及数据仓库系统如何存储数据,名称、含义、类型、长度、精度、是否可为空、是否唯一、字符编码、约束条件规则是什么。 接触到的数据是原始数据还是ETL后的数据,ETL规则是什么。 数据仓库数据的更新更新机制是什么,全量更新还是增量更新。
大数据分析和处理的方法步骤
大数据处理数据时代理念的三大转变:要全体不要抽样,要效率不要绝对精确,要相关不要因果。具体的大数据处理方法其实有很多,但是根据长时间的实践,天互数据总结了一个基本的大数据处理流程,并且这个流程应该能够对大家理顺大数据的处理有所帮助。整个处理流程可以概括为四步,分别是采集、导入和预处理、统计和分析,以及挖掘。 采集 大数据的采集是指利用多个数据库来接收发自客户端的数据,并且用户可以通过这些数据库来进行简单的查询和处理工作。比如,电商会使用传统的关系型数据库MySQL和Oracle等来存储每一笔事务数据,除此之外,Redis和MongoDB 这样的NoSQL数据库也常用于数据的采集。 在大数据的采集过程中,其主要特点和挑战是并发数高,因为同时有可能会有成千上万的用户来进行访问和操作,比如火车票售票网站和淘宝,它们并发的访问量在峰值时达到上百万,所以需要在采集端部署大量数据库才能支撑。并且如何在这些数据库之间进行负载均衡和分片的确是需要深入的思考和设计。 统计/分析 统计与分析主要利用分布式数据库,或者分布式计算集群来对存储于其内的海量数据进行普通的分析和分类汇总等,以满足大多数常见的分析需求,在这方面,一些实时性需求会用到EMC的GreenPlum、Oracle的Exadata,以及基于MySQL 的列式存储Infobright等,而一些批处理,或者基于半结构化数据的需求可以使用Hadoop。统计与分析这部分的主要特点和挑战是分析涉及的数据量大,其对系统资源,特别是I/O会有极大的占用。 导入/预处理 虽然采集端本身会有很多数据库,但是如果要对这些海量数据进行有效的分析,还是应该将这些来自前端的数据导入到一个集中的大型分布式数据库,或者分布式存储集群,并且可以在导入基础上做一些简单的清洗和预处理工作。也有一些用户会在导入时使用来自Twitter的Storm来对数据进行流式计算,来满足
大数据分析的流程浅析之一:大数据采集过程分析
大数据分析的流程浅析之一:大数据采集过程分析 数据采集,就是使用某种技术或手段,将数据收集起来并存储在某种设备上,这种设备可以是磁盘或磁带。区别于普通的数据分析,大数据分析的数据采集在数据收集和存储技术上都是不同的。具体情况如下: 1.大数据收集过程 在收集阶段,大数据分析在时空两个方面都有显著的不同。在时间维度上,为了获取更多的数据,大数据收集的时间频度大一些,有时也叫数据采集的深度。在空间维度上,为了获取更准确的数据,数据采集点设置得会更密一些。 以收集一个面积为100 平方米的葡萄园的平均温度 为例。小数据时代,由于成 本的原因,葡萄园主只能在 葡萄园的中央设置一个温度 计用来计算温度,而且每一 小时观测一次,这样一天就 只有24个数据。而在大数据 时代,在空间维度上,可以 设置100个温度计,即每个 1平方米一个温度计;在时间维度上,每隔1分钟就观测一次,这
样一天就有144000个数据,是原来的6000倍。 有了大量的数据,我们就可以更准确地知道葡萄园的平均温度,如果加上时间刻度的话,还可以得出一个时间序列的曲线,结果看起来使人很神往。 2.大数据的存储技术 通过增加数据采集的深度和广度,数据量越来越大,数据存储问题就凸现。原来1TB的数据,可以使用一块硬盘就可以实现数据的存储,而现在变成了6000TB,也就是需要6000块硬盘来存放数据,而且这个数据是每天都是增加的。这个时候计算机技术中的分布式计算开始发挥优势,它可以将6000台甚至更多的计算机组合在一起,让它们的硬盘组合成一块巨大的硬盘,这样人们就不用再害怕大数据了,大数据再大,增加计算机就可以了。实现分布式计算的软件有很多,名气最大的,目前市场上应用最广的,就是hadoop技术了,更精确地说应该是叫hadoop框架。 hadoop框架由多种功能性软件组成,其自身只是搭建一个和操作系统打交道的平台。其中最核心的软件有两个,一个是hdfs分布式文件系统,另一个是mapreduce分布式计算。hdfs分布式文件系统完成的功能就是将6000台计算机组合在一起,使它们的硬盘组合成一块巨大的硬盘,至于数据如何在硬盘上存放和读取,这件事由hadoop和hdfs共同完成,不用我们操心,这就如我们在使用一台计算机时只管往硬盘上存放数据,而数据存放在硬盘上的哪个磁道,我们是不用关心的。
业务流程图与数据流程图的比较(1)
业务流程图与数据流程图的比较 一、业务流程图与数据流程图的区别 1. 描述对象不同 业务流程图的描述对象是某一具体的业务; 数据流程图的描述对象是数据流。 业务是指企业管理中必要且逻辑上相关的、为了完成某种管理功能的一系列相关的活动。在系统调研时, 通过了解组织结构和业务功能, 我们对系统的主要业务有了一个大概的认识。但由此我们得到的对业务的认识是静态的, 是由组织部门映射到业务的。而实际的业务是流动的, 我们称之为业务流程。一项完整的业务流程要涉及到多个部门和多项数据。例如, 生产业务要涉及从采购到财务, 到生产车间, 到库存等多个部门; 会产生从原料采购单, 应收付账款, 入库单等多项数据表单。因此, 在考察一项业务时我们应将该业务一系列的活动即整个过程为考察对象, 而不仅仅是某项单一的活动, 这样才能实现对业务的全面认识。将一项业务处理过程中的每一个步骤用图形来表示, 并把所有处理过程按一定的顺序都串起来就形成了业务流程图。如图 1 所示, 就是某公司物资管理的业务流程图。 数据流程图是对业务流程的进一步抽象与概括。抽象性表现在它完全舍去了具体的物
质, 只剩下数据的流动、加工处理和存储; 概括性表现在它可以把各种不同业务处理过程联系起来,形成一个整体。从安东尼金字塔模型的角度来看, 业务流程图描述对象包括企业中的信息流、资金流和物流, 数据流程图则主要是对信息流的描述。此外, 数据流程图还要配合数据字典的说明, 对系统的逻辑模型进行完整和详细的描述。 2. 功能作用不同 业务流程图是一本用图形方式来反映实际业务处理过程的“流水帐”。绘制出这本流水帐对于开发者理顺和优化业务过程是很有帮助的。业务流程图的符号简单明了, 易于阅读和理解业务流程。绘制流程图的目的是为了分析业务流程, 在对现有业务流程进行分析的基础上进行业务流程重组, 产生新的更为合理的业务流程。通过除去不必要的、多余的业务环节; 合并重复的环节;增补缺少的必须的环节; 确定计算机系统要处理的环节等重要步骤, 在绘制流程图的过程中可以发现问题, 分析不足, 改进业务处理过程。 数据流程分析主要包括对信息的流动、传递、处理、存储等的分析。数据流程分析的目的就是要发现和解决数据流通中的问题, 这些问题有: 数据流程不畅, 前后数据不匹配, 数据处理过程不合理等。通过对这些问题的解决形成一个通畅的数据流程作为今后新系统的数据流程。数据流程图比起业务流程图更为抽象, 它舍弃了业务流程图中的一些物理实体, 更接近于信息系统的逻辑模型。对于较简单的业务, 我们可以省略其业务流程图直接绘制数据流程图。 3. 基本符号不同 (1)业务流程图的常用的基本符号有以下六种, 见图 2 所示。 (2)数据流程图的基本符号见图 3 所示 对数据流程图的基本符号解释如下: 外部实体表示数据流的始发点或终止点。原则上讲, 它不属于数据流程图的核心部分, 只是数据流程图的外围环境部分。在实际问题中它可能是人员、计算机外设、系统外部的文件等。
采购数据分析的8个流程与常用7个思路
【采购】采购数据分析的8个流程与常用7 个思路 在采购过程中,数据分析具有极其重要的战略意义,是优化供应链和采购决策的核心大脑。因此做好数据分析,是采购过程中最重要的环节之一。 那么如何做好数据分析呢?以下梳理出数据分析的8步流程,以及常见的7种分析思路。在启动数据分析前,最好跟主管或数据经验较丰富的童鞋确认每一步的分析流程。 一、数据分析八流程: 1、为什么分析? 首先,你得知道为什么分析?弄清楚此次数据分析的目的。比如,什么类型的 客户交货期总是拖延。你所有的分析都的围绕这个为什么来回答。避免不符合 目标反复返工,这个过程会很痛苦。 2、分析目标是谁? 要牢记清楚的分析因子,统计维度是金额,还是产品,还是供应商行业竞争趋势,还是供应商规模等等。避免把金额当产品算,把产品当金额算,算出的结 果是差别非常大的。 3、想达到什么效果? 通过分析各个维度产品类型,公司采购周期,采购条款,找到真正的问题。例 如这次分析的薄弱环节供应商,全部集中采购,和保持现状,都不符合利益最 大化原则。通过分析,找到真正的问题根源,发现精细化采购管理已经非常必 要了。
4、需要哪些数据? 采购过程涉及的数据,很多,需要哪些源数据?采购总额?零部件行业竞争度?货款周期?采购频次?库存备货数?客户地域因子?客户规模?等等列一个表。避免不断增加新的因子。 5、如何采集? 数据库中供应商信息采集,平时供应商各种信息录入,产品特性录入等,做数据分析一定要有原料,否则巧妇难为无米之炊。 6、如何整理? 整理数据是门技术活。不得不承认EXCEL是个强大工具,数据透视表的熟练使 用和技巧,作为支付数据分析必不可少,各种函数和公式也需要略懂一二,避 免低效率的数据整理。Spss也是一个非常优秀的数据处理工具,特别在数据量 比较大,而且当字段由特殊字符的时候,比较好用。 7、如何分析? 整理完毕,如何对数据进行综合分析,相关分析?这个是很考验逻辑思维和推 理能力的。同时分析推理过程中,需要对产品了如指掌,对供应商很了解,对 采购流程很熟悉。看似一个简单的数据分析,其实是各方面能力的体现。首先 是技术层面,对数据来源的抽取-转换-载入原理的理解和认识;其实是全局观,对季节性、公司等层面的业务有清晰的了解;最后是专业度,对业务的流程、设计等了如指掌。练就数据分析的洪荒之力并非一朝一夕之功,而是在实 践中不断成长和升华。一个好的数据分析应该以价值为导向,放眼全局、立足 业务,用数据来驱动增长。 8、如何展现和输出?
大数据分析过程遇到的13个问题
大数据分析遇到的13个问题 1、最早的数据分析可能就报表 目前很多数据分析后的结果,展示的形式很多,有各种图形以及报表,最早的应该是简单的几条数据,然后搞个web页面,展示一下数据。早期可能数据量也不大,随便搞个数据库,然后SQL搞一下,数据报表就出来了。但是数据量大 起来怎么分析呢?数据分析完了怎么做传输呢?这么大的数据量怎么做到实时呢?分析的结果数据如果不是很大还行,如果分析的结果数据还是很大改怎么办呢?这些问题在这篇文章中都能找到答案,下面各个击破。 2、要做数据分析,首先要有数据 这个标题感觉有点废话,不过要做饭需要食材一样。有些数据时业务积累的,像交易订单的数据,每一笔交易都会有一笔订单,之后再对订单数据作分析。但是有些场景下,数据没法考业务积累,需要依赖于外部,这个时候外部如果有现成的数据最好了,直接join过来,但是有时候是需要自己获取的,例如搞个爬虫爬取网页的数据,有时候单台机器搞爬虫可能还爬不完,这个时候可能就开始考虑单机多线程爬取或者分布式多线程爬取数据,中间涉及到一个步骤,就是在线的业务数据,需要每天晚上导入到离线的系统中,之后才可以进行分析。3、有了数据,咋分析呢? 先将数据量小的情况下,可能一个复杂的SQL就可以搞出来,之后搞个web 服务器,页面请求的时候,执行这个SQL,然后展示数据,好了,一个最简单的数据分析,严格意义上讲是统计的分析。这种情况下,分析的数据源小,分析的脚本就是在线执行的SQL,分析的结果不用传输,结果的展示就在页面上, 整个流程一条龙。 4、数据量大了,无法在线分析了,咋办呢? 这个时候,数据量已经大的无法用在线执行SQL的形式进行统计分析了。这个时候顺应时代的东西产生了(当然还有其他的,我就知道这个呵呵),数据离线数据工具hadoop出来了。这个时候,你的数据以文件的形式存在,可能各个属性是逗号分隔的,数据条数有十几个亿。这时候你可能需要构建一个hadoop
常用数据分析方法详解
. 常用数据分析方法详解 目录 1、历史分析法 2、全店框架分析法 3、价格带分析法 4、三维分析法 5、增长率分析法 6、销售预测方法 1、历史分析法的概念及分类 历史分析法指将与分析期间相对应的历史同期或上期数据进行收集并对比,目的是通过数据的共性查找目前问题并确定将来变化的趋势。 *同期比较法:月度比较、季度比较、年度比较 *上期比较法:时段比较、日别对比、周间比较、 月度比较、季度比较、年度比较 历史分析法的指标 *指标名称: 销售数量、销售额、销售毛利、毛利率、贡献度、交叉比率、销售占比、客单价、客流量、经营品数动销率、无销售单品数、库存数量、库存金额、人效、坪效*指标分类: 时间分类 ——时段、单日、周间、月度、季度、年度、任意 多个时段期间 性质分类 ——大类、中类、小类、单品 图例 2框架分析法 又叫全店诊断分析法 销量排序后,如出现50/50、40/60等情况,就是什么都能卖一点但什么都不 好卖的状况,这个时候就要对品类设置进行增加或删减,因为你的门店缺少 重点,缺少吸引顾客的东西。 如果达到10/90,也是品类出了问题。 如果是20/80或30/70、30/80,则需要改变的是商品的单品。 *单品ABC分析(PSI值的概念) 销售额权重(0.4)×单品销售额占类别比+销售数量权重(0.3) ×单品销售数量占类别比+毛利额权重(0.3)单品毛利额占类别比
*类别占比分析(大类、中类、小类) 类别销售额占比、类别毛利额占比、 类别库存数量占比、类别库存金额占比、 . . 类别来客数占比、类别货架陈列占比 表格范例 3价格带及销售二维分析法 首先对分析的商品按价格由低到高进行排序,然后 *指标类型:单品价格、销售额、销售数量、毛利额 *价格带曲线分布图 *价格带与销售对数图 价格带及销售数据表格 价格带分析法 4商品结构三维分析法 *一种分析商品结构是否健康、平衡的方法叫做三维分析图。在三维空间坐标上以X、Y、Z三个坐标轴分别表示品类销售占有率、销售成长率及利润率,每个坐标又分为高、低两段,这样就得到了8种可能的位置。 *如果卖场大多数商品处于1、2、3、4的位置上,就可以认为商品结构已经达到最佳状态。以为任何一个商品的品类销售占比率、销售成长率及利润率随着其商品生命周期的变化都会有一个由低到高又转低的过程,不可能要求所有的商品同时达到最好的状态,即使达到也不可能持久。因此卖场要求的商品结构必然包括:目前虽不能获利但具有发展潜力以后将成为销售主力的新商品、目前已经达到高占有率、高成长率及高利润率的商品、目前虽保持较高利润率但成长率、占有率趋于下降的维持性商品,以及已经决定淘汰、逐步收缩的衰退型商品。 *指标值高低的分界可以用平均值或者计划值。 图例 5商品周期增长率分析法 就是将一段时期的销售增长率与时间增长率的比值来判断商品所处生命周期阶段的方法。 不同比值下商品所处的生命周期阶段(表示) 如何利用商品生命周期理论指导营运(图示) 6销售预测方法[/hide] 1.jpg (67.5 KB) 1、历史分析法 . .