描述性统计与性能结果分析

描述性统计与性能结果分析——《LoadRunner 没有告诉你的》之一
发布时间: 2007-5-15 11:59 作者: 陈雷来源: cnblogs
LoadRunner中的90%响应时间是什么意思?这个值在进行性能分析时有什么作用?本文争取用最简洁的文字来解答这个问题,并引申出“描述性统计”方法在性能测试结果分析中的应用。
为什么要有90%用户响应时间?因为在评估一次测试的结果时,仅仅有平均事务响应时间是不够的。为什么这么说?你可以试着想想,是否平均事务响应时间满足了性能需求就表示系统的性能已经满足了绝大多数用户的要求?
假如有两组测试结果,响应时间分别是 {1,3,5,10,16} 和 {5,6,7,8,9},它们的平均值都是7,你认为哪次测试的结果更理想?
假如有一次测试,总共有100个请求被响应,其中最小响应时间为0.02秒,最大响应时间为110秒,平均事务响应时间为4.7秒,你会不会想到最小和最大响应时间如此大的偏差是否会导致平均值本身并不可信?
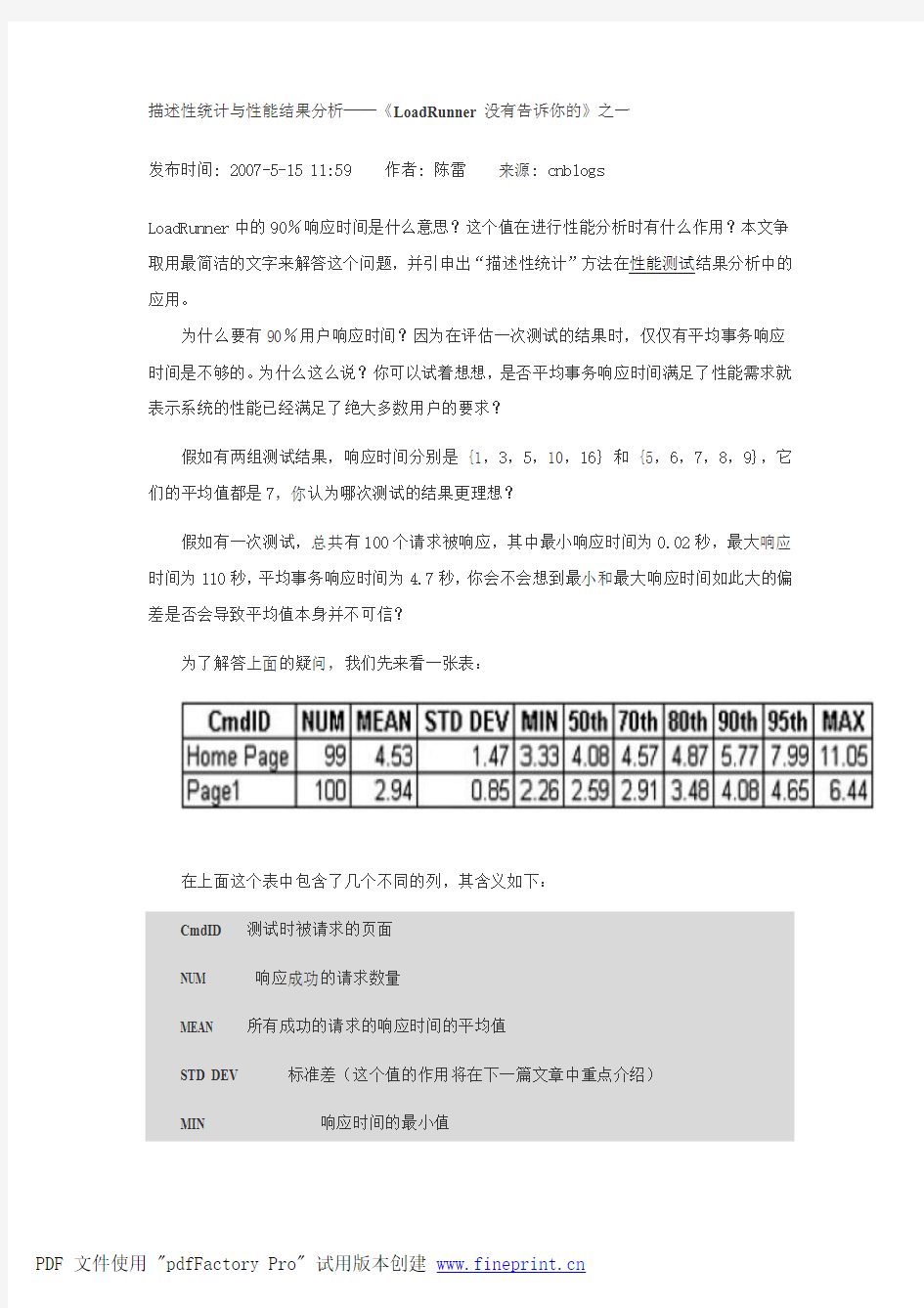
为了解答上面的疑问,我们先来看一张表:
在上面这个表中包含了几个不同的列,其含义如下:
CmdID测试时被请求的页面
NUM响应成功的请求数量
MEAN所有成功的请求的响应时间的平均值
STD DEV标准差(这个值的作用将在下一篇文章中重点介绍)
MIN响应时间的最小值
50 th(60/70/80/90/95 th)如果把响应时间从小到大顺序排序,那么50%的请求的响应时间在这个范围之内。后面的60/70/80/90/95 th 也是同样的含义MAX响应时间的最大值
我想看完了上面的这个表和各列的解释,不用多说大家也可以明白我的意思了。我把结论性的东西整理一下:
1. 90%用户响应时间在 LoadRunner中是可以设置的,你可以改为80%或95%;
2. 对于这个表,LoadRunner中是没有直接提供的,你可以把LR中的原始数据导
出到Excel中,并使用Excel中的PERCENTILE 函数很简单的算出不同百分比用户
请求的响应时间分布情况;
3. 从上面的表中来看,对于Home Page来说,平均事务响应时间(MEAN)只同70
%用户响应时间相一致。也就是说假如我们确定Home Page的响应时间应该在5秒
内,那么从平均事务响应时间来看是满足的,但是实际上有10-20%的用户请求的
响应时间是大于这个值的;对于Page 1也是一样,假如我们确定对于Page 1 的请
求应该在3秒内得到响应,虽然平均事务响应时间是满足要求的,但是实际上有
20-30%的用户请求的响应时间是超过了我们的要求的;
4. 你可以在95 th之后继续添加96/ 97/ 98/ 99/ 99.9/ 99.99 th,并利用Excel
的图表功能画一条曲线,来更加清晰表现出系统响应时间的分布情况。这时候你也
许会发现,那个最大值的出现几率只不过是千分之一甚至万分之一,而且99%的用
户请求的响应时间都是在性能需求所定义的范围之内的;
5. 如果你想使用这种方法来评估系统的性能,一个推荐的做法是尽可能让你的测
试场景运行的时间长一些,因为当你获得的测试数据越多,这个响应时间的分布曲
线就越接近真实情况;
6. 在确定性能需求时,你可以用平均事务响应时间来衡量系统的性能,也可以用
90%或95%用户响应时间来作为度量标准,它们并不冲突。实际上,在定义某些系
统的性能需求时,一定范围内的请求失败也是可以被接受的;
7. 上面提到的这些内容其实是与工具无关的,只要你可以得到原始的响应时间记
录,无论是使用LoadRunner还是JMeter或者OpenSTA,你都可以用这些方法和思路来评估你的系统的性能。
事实上,在性能测试领域中还有更多的东西是目前的商业测试工具或者开源测试工具都没有专门讲述的——换句话说,性能测试仅仅有工具是不够的。我们还需要更多其他领域的知识,例如数学和统计学,来帮助我们更好的分析性能数据,找到隐藏在那些数据之下的真相。
描述性统计与性能结果分析(续)——《LoadRunner 没有告诉你的》之二
发布时间: 2007-5-15 14:02 作者: 陈雷来源: cnblogs
数据统计分析的思路与分析结果的展示方式是同样重要的,有了好的分析思路,但是却不懂得如何更好的展示分析结果和数据来印证自己的分析,就像一个人满腹经纶却不知该如何一展雄才
一图胜千言,所以这次我会用两张图表来说明“描述性统计”在性能测试结果分析中的其他应用。
在这张图中,我们继续使用了上一篇文章——《描述性统计与结果分析》一文中的方法,对响应时间的分布情况来进行分析。上面这张图所使用的数据是通过对https://www.360docs.net/doc/a25374390.html, 首页进行测试得来的,在测试中分别使用10/25/50/75/100 几个不同级别的并发用户数量。通过这张图表,我们可以通过横向比较和纵向比较,更清晰的了解到被测应用在不同级别的负载下的响应能力。
这张图所使用的数据与第一张图一样,但是我们使用了另外一个视角来对数据进行展示。表中最左侧的2000/5000/10000/50000的单位是毫秒,分别表示了在整个测试过程中,响应时间在0-2000毫秒范围内的事务数量占成功的事务总数的百分比,响应时间在
2001-5000毫秒范围内的事务数量占成功的事务总数的百分比,响应时间在5001-10000毫秒范围内的事务数量占成功的事务总数的百分比,以及响应时间在10001-50000毫秒范围内的事务数量占成功的事务总数的百分比。
这几个时间范围的确定是参考了业内比较通行的“2-5-10原则”——当然你也可以为自己的测试制定其他标准,只要得到企业内的承认就可以。所谓的“2-5-10原则”,简单说,就是当用户能够在2秒以内得到响应时,会感觉系统的响应很快;当用户在2-5秒之间得到响应时,会感觉系统的响应速度还可以;当用户在5-10秒以内得到响应时,会感觉系统的响应速度很慢,但是还可以接受;而当用户在超过10秒后仍然无法得到响应时,会感
觉系统糟透了,或者认为系统已经失去响应,而选择离开这个Web站点,或者发起第二次请求。
那么从上面的图表中可以看到,当并发用户数量为10时,超过95%的用户都可以在5秒内得到响应;当并发用户数量达到25时,已经有80%的事务的响应时间处在危险的临界值,而且有相当数量的事务的响应时间超过了用户可以容忍的限度;随着并发用户数量的进一步增加,超过用户容忍限度的事务越来越多,当并发用户数到达75时,系统几乎已经无法为任何用户提供响应了。
这张图表也同样可以用于对不同负载下事务的成功、失败比例的比较分析。
Note:上面两个图表中的数据,主要通过Excel 中提供的FREQUENCY,AVERAGE,MAX,MIN 和PERCENTILE几个统计函数获得,具体的使用方法请参考Excel帮助手册。
理发店模型——《LoadRunner 没有告诉你的》之三
发布时间: 2007-5-15 14:06 作者: 陈雷来源: cnblogs
大概在一年前的一次讨论中,我的好友陈华第一次提到了这个模型的最初版本,经过几次讨论后,我们发现经过完善和扩展的“理发店模型”可以用来帮助我们理解很多性能测试的概念和理论,以及一些测试中遇到的问题。在最近的一次讨论后,我决定撰写一篇文章来专门讲述一下这个模型,希望可以帮助大家更好的理解性能测试有关的知识。
不过,在这篇文章中,我将会尽量的只描述模型本身以及相关的一些扩展,而具体如何将这个模型完全同性能测试关联起来,我不会全部说破,留下足够的空间让大家继续思考和总结,最好也一起来对这个模型做进一步的完善和扩展,我相信,当大家在思考的过程中有所收获并有所突破时,那种快感和收获的喜悦才真的是让人倍感振奋而且终生难忘的。
当然,我要说明的是,这个模型仅仅是1个模型,它与大家实际工作中遇到的各式各样的情况未必都可以一一对应,但是大的方向和趋势应该是一致的。
相信大家都进过或见过理发店,一间或大或小的铺面,1个或几个理发师,几张理发用的椅子和供顾客等待的长条板凳。
在我们的这个理发店中,我们事先做了如下的假设:
1. 理发店共有3名理发师;
2. 每位理发师剪一个发的时间都是1小时;
3. 我们顾客们都是很有时间观念的人而且非常挑剔,他们对于每次光顾理发店时所能容忍的等待时间+剪发时间是3小时,而且等待时间越长,顾客的满意度越低。如果3个小时还不能剪完头发,我们的顾客会立马生气的走人。
通过上面的假设我们不难想象出下面的场景:
1. 当理发店内只有1位顾客时,只需要有1名理发师为他提供服务,其他两名理发师可能继续等着,也可能会帮忙打打杂。1小时后,这位顾客剪完头发出门走了。那么在这1个小时里,整个理发店只服务了1位顾客,这位顾客花费在这次剪发的时间是1小时;
2. 当理发店内同时有两位顾客时,就会同时有两名理发师在为顾客服务,另外1位发呆或者打杂帮忙。仍然是1小时后,两位顾客剪完头发出门。在这1小时里,理发店服务了两位顾客,这两位顾客花费在剪发的时间均为1小时;
3. 很容易理解,当理发店内同时有三位顾客时,理发店可以在1小时内同时服务三位顾客,每位顾客花费在这次剪发的时间仍然是均为1小时;
从上面几个场景中我们可以发现,在理发店同时服务的顾客数量从1位增加到3位的过程中,随着顾客数量的增多,理发店的整体工作效率在提高,但是每位顾客在理发店内所呆的时间并未延长。
当然,我们可以假设当只有1位顾客和2位顾客时,空闲的理发师可以帮忙打杂,使得其他理发师的工作效率提高,并使每位顾客的剪发时间小于1小时。不过即使根据这个假设,虽然随着顾客数量的增多,每位顾客的服务时间有所延长,但是这个时间始终还被控制在顾客可接受的范围之内,并且顾客是不需要等待的。
不过随着理发店的生意越来越好,顾客也越来越多,新的场景出现了。假设有一次顾客A、B、C刚进理发店准备剪发,外面一推门又进来了顾客D、E、F。因为A、B、C三位顾客先到,所以D、E、F三位只好坐在长板凳上等着。1小时后,A、B、C三位剪完头发走了,他们每个人这次剪发所花费的时间均为1小时。可是D、E、F三位就没有这么好运,因为他们要先等A、B、C三位剪完才能剪,所以他们每个人这次剪发所花费的时间均为2小时——包括等待1小时和剪发1小时。
通过上面这个场景我们可以发现,对于理发店来说,都是每小时服务三位顾客——第1
个小时是A、B、C,第二个小时是D、E、F;但是对于顾客D、E、F来说,“响应时间”延长了。如果你可以理解上面的这些场景,就可以继续往下看了。
在新的场景中,我们假设这次理发店里一次来了9位顾客,根据我们上面的场景,相信你不难推断,这9位顾客中有3位的“响应时间”为1小时,有3位的“响应时间”为2小时(等待1小时+剪发1小时),还有3位的“响应时间”为3小时(等待2小时+剪发1小时)——已经到达用户所能忍受的极限。假如在把这个场景中的顾客数量改为10,那么我们已经可以断定,一定会有1位顾客因为“响应时间”过长而无法忍受,最终离开理发店走了。
我想并不需要特别说明,大家也一定可以把上面的这些场景跟性能测试挂上钩了。如果你还是觉得比较抽象,继续看下面的这张图 ^_^
这张图中展示的是1个标准的软件性能模型。在图中有三条曲线,分别表示资源的利用情况(Utilization,包括硬件资源和软件资源)、吞吐量(Throughput,这里是指每秒事务数)以及响应时间(Response Time)。图中坐标轴的横轴从左到右表现了并发用户数(Number of Concurrent Users)的不断增长。
在这张图中我们可以看到,最开始,随着并发用户数的增长,资源占用率和吞吐量会相应的增长,但是响应时间的变化不大;不过当并发用户数增长到一定程度后,资源占用达到饱和,吞吐量增长明显放缓甚至停止增长,而响应时间却进一步延长。如果并发用户数继续增长,你会发现软硬件资源占用继续维持在饱和状态,但是吞吐量开始下降,响应时间明显的超出了用户可接受的范围,并且最终导致用户放弃了这次请求甚至离开。
根据这种性能表现,图中划分了三个区域,分别是Light Load(较轻的压力)、Heavy Load(较重的压力)和Buckle Zone(用户无法忍受并放弃请求)。在Light Load和Heavy Load 两个区域交界处的并发用户数,我们称为“最佳并发用户数(The Optimum Number of Concurrent Users)”,而Heavy Load和Buckle Zone两个区域交界处的并发用户数则称为“最大并发用户数(The Maximum Number of Concurrent Users)”。
当系统的负载等于最佳并发用户数时,系统的整体效率最高,没有资源被浪费,用户也不需要等待;当系统负载处于最佳并发用户数和最大并发用户数之间时,系统可以继续工作,但是用户的等待时间延长,满意度开始降低,并且如果负载一直持续,将最终会导致有些用户无法忍受而放弃;而当系统负载大于最大并发用户数时,将注定会导致某些用户无法忍受超长的响应时间而放弃。
对应到我们上面理发店的例子,每小时3个顾客就是这个理发店的最佳并发用户数,而每小时9个顾客则是它的最大并发用户数。当每小时都有3个顾客到来时,理发店的整体工作效率最高;而当每小时都有9个顾客到来时,前几个小时来的顾客还可以忍受,但是随着等待的顾客人数越来越多,等待时间越来越长,最终还是会有顾客无法忍受而离开。同时,随着理发店里顾客人数的增多和理发师工作时间的延长,理发师会逐渐产生疲劳,还要多花一些时间来清理环境和维持秩序,这些因素将最终导致理发师的工作效率随着顾客人数的增多和工作的延长而逐渐的下降,到最后可能要1.5小时甚至2个小时才能剪完1个发了。
当然,如果一开始就有10个顾客到来,则注定有1位顾客剪不到头发了。
进一步理解“最佳并发用户数”和“最大并发用户数”
在上一节中,我们详细的描述了并发用户数同资源占用情况、吞吐量以及响应时间的关系,并且提到了两个新的概念——“最佳并发用户数(The Optimum Number of Concurrent Users)”和“最大并发用户数(The Maximum Number of Concurrent Users)”。在这一
节中,我们将对“最佳并发用户数”和“最大并发用户数”的定义做更加清晰和明确的说明。
对于一个确定的被测系统来说,在某个具体的软硬件环境下,它的“最佳并发用户数”和“最大并发用户数”都是客观存在。以“最佳并发用户数”为例,假如一个系统的最佳并发用户数是50,那么一旦并发量超过这个值,系统的吞吐量和响应时间必然会“此消彼长”;如果系统负载长期大于这个数,必然会导致用户的满意度降低并最终达到一种无法忍受的地步。所以我们应该保证最佳并发用户数要大于系统的平均负载。
要补充的一点是,当我们需要对一个系统长时间施加压力——例如连续加压3-5天,来验证系统的可靠性或者说稳定性时,我们所使用的并发用户数应该等于或小于“最佳并发用户数”——大家也可以结合上面的讨论想想这是为什么。
而对于最大并发用户数的识别,需要考虑和鉴别一下以下两种情况:
1. 当系统的负载达到最大并发用户数后,响应时间超过了用户可以忍受的最大限度——这个限度应该来源于性能需求,例如:在某个级别的负载下,系统的响应时间应该小于5秒。这里容易疏忽的一点是,不要把顾客因为无法忍受而离开时店内的顾客数量作为理发店的“最大并发用户数”,因为这位顾客是在3小时前到达的,也就是说3小时前理发店内的顾客数量才是我们要找的“最大并发用户数”。而且,这位顾客的离开只是一个开始,可能有会更多的顾客随后也因为无法忍受超长的等待时间而离开;
2. 在响应时间还没有到达用户可忍受的最大限度前,有可能已经出现了用户请求的失败。以理发店模型为例,如果理发店只能容纳6位顾客,那么当7位顾客同时来到理发店时,虽然我们可以知道所有顾客都能在可容忍的时间内剪完头发,但是因为理发店容量有限,最终只好有一位顾客打道回府,改天再来。
对于一个系统来说,我们应该确保系统的最大并发用户数要大于系统需要承受的峰值负载。
如果你已经理解了上面提到的全部的概念,我想你可以展开进一步的思考,回头看一下自己以往做过的性能测试,看看是否可以对以往的工作产生新的理解。也欢迎大家在这里提出自己的心得或疑惑,继续讨论下去。
理发店模型的进一步扩展
这一节中我会提到一些对理发店模型的扩展,当然,我依然是只讲述现实中的理发店的故事,至于如何将这些扩展同性能测试以及性能解决方案等方面关联起来,就留给大家继续思考了。
扩展场景1:有些顾客已经是理发店的老顾客,他们和理发师已经非常熟悉,理发师可以不用花费太多时间沟通就知道这位顾客的想法。并且理发师对这位顾客的脑袋的形状也很熟悉,所以可以更快的完成一次理发的工作。
扩展场景2:理发店并不是只有剪发一种业务,还提供了烫发染发之类的业务,那么当顾客提出新的要求时,理发师服务一位顾客的时间可能会超过标准的1小时。而且这时如果要计算每位顾客的等待时间就变得复杂了很多,有些顾客的排队时间会比原来预计的延长,并最终导致他们因为无法忍受而离开。
扩展场景3:随着烫发和染发业务的增加,理发师们决定分工,两位专门剪发,一位专门负责烫发和染发。
扩展场景4:理发店的生意越来越好,理发师的数量和理发店的门面已经无法满足顾客的要求,于是理发店的老板决定在旁边再开一家店,并招聘一些工作能力更强的理发师。
扩展场景5:理发店的生意变得极为火爆了,两家店都无法满足顾客数量增长的需求,并且有些顾客开始反映到理发店的路途太远,到了以后又因为烫发和染发的人太多而等太久。可是理发店的老板也明白烫发和染发的收入要远远高于剪发阿,于是他脑筋一转,决定继续改变策略,在附近的几个大型小区租用小的铺面开设分店,专职剪发业务;再在市区的繁华路段开设旗舰店,专门为烫发、染发的顾客,以及VIP顾客服务。并增设800电话,当顾客想要剪发时,可以拨打这个电话,并由服务人员根据顾客的居住地点,将其指引到距离最近的一家分店去。
这篇文章就先写到这里了,希望大家在看完之后可以继续思考一下,也写出自己的心得体会或者新的想法,记下自己的不解和疑惑,让我们在不断的交流和讨论中走的更远。
性能测试相关术语的英文书写方法(不断更新ing)——知道了这些术语在英文中的正确书写方法之后,可以通过 Google 更加高效的获取到更多有用的资料。
理解性能——《LoadRunner 没有告诉你的》之四
发布时间: 2007-5-15 14:54 作者: 陈雷来源: cnblogs
本文是《LoadRunner没有告诉你的》系列文章的第四篇,在这篇短文中,我将尽可能用简洁清晰的文字写下我对“性能”的看法,并澄清几个容易混淆的概念,帮助大家更好的理解“性能”的含义。
如何评价性能的优劣: 用户视角 vs. 系统视角
对于最终用户(End-User)来说,评价系统的性能好坏只有一个字——“快”。最终用户并不需要关心系统当前的状态——即使系统这时正在处理着成千上万的请求,对于用户来说,由他所发出的这个请求是他唯一需要关心的,系统对用户请求的响应速度决定了用户对系统性能的评价。
而对于系统的运营商和开发商来说,期望的是能够让尽可能多的用户在任意时刻都拥有最好的体验,这就要确保系统能够在同一时间内处理更多的用户请求。正如在《理发店模型》一文中所描述的:系统的负载(并发用户数)与吞吐量(每秒事务数)、响应时间以及资源利用率(包括软硬件资源)之间存在着一个“此消彼长”的关系。因此,从系统的运营商和开发商的角度来看,所谓的“性能”是一个整体的概念,是系统的负载与吞吐量、可接受的响应时间以及资源利用率之间的平衡。
换句话说,“好的性能”意味着更大的最佳并发用户数(The Optimum Number of Concurrent Users)和最大并发用户数(The Maximum Number of Concurrent Users)。有关“最佳/最大并发用户数”的概念请参见《理发店模型》一文。
另外,从系统的视角来看,所需要关注的还包括三个与“性能”有关的属性:可靠性(Reliability),可伸缩性(Scalability)和可恢复性(Recoverability)——我将会在本系列文章的第五篇“无处不在的性能测试”中专门讨论这三个属性的含义和相关的实践经验。
响应时间
上面这张图引自段念兄的一份讲义,不过我略作了些修改。从图中我们可以清楚的看到一个请求的响应时间是由几部分时间组成的,包括
C1:用户请求发出前在客户端需要完成的预处理所需要的时间;
C2:客户端收到服务器返回的响应后,对数据进行处理并呈现所需要的时间;
A1:Web/App Server 对请求进行处理所需要的时间;
A2:DB Server 对请求进行处理所需的时间;
A3:Web/App Server 对 DB Server 返回的结果进行处理所需的时间;
N1:请求由客户端发出并到达Web/App Server 所需要的时间;
N2:如果需要进行数据库相关的操作,由Web/App Server 将请求发送至DB Server 所需要的时间;
N3:DB Server 完成处理并将结果返回Web/App Server 所需的时间;
N4:Web/App Server 完成处理并将结果返回给客户端所需的时间;
从用户的角度来看,响应时间=(C1+C2)+(A1+A2+A3)+(N1+N2+N3+N4);但是从系统的角度来看,响应时间只包括(A1+A2+A3)+(N1+N2+N3+N4)。
在理解了响应时间的组成之后,可以帮助我们通过对响应时间的分析来更好的识别和定位系统的性能瓶颈。
吞吐量
在不同的测试工具中,对于吞吐量(Throughput)会有不同的解释。例如,在LoadRunner中,这个指标是以字节数为单位来衡量网络吞吐量的,而在JMeter中则是以事务数/秒(TPS)为单位来衡量系统的响应能力的。不过在大多数英文的性能测试方面的书籍或资料中,吞吐量的定义使用的是后者。
并发用户数≠每秒请求数
这是两个容易让初学者混淆的概念。
简单说,当你在性能测试工具或者脚本中设置了100并发用户数后,并不能期望着一定会有每秒100个请求发给服务器。事实上,对于一个虚拟用户来说,每秒发出多少请求只跟服务器返回响应的速度有关。如果虚拟用户在0.5秒内就收到了响应,那么它会立即发出第二个请求;而如果要一直等待3秒才能得到响应,它将会一直等到收到响应后才发出第二个请求。也就是说,并发用户数的设置只是保证服务器在任一时刻都有100个请求需要处理,而并不一定是保证每秒中发送100个请求给服务器。
所以,只有当响应时间恰好是1秒时,并发用户数才会等于每秒请求数;否则,每秒请求数可能大于并发用户数或小于并发用户数。
无所不在的性能测试——《LoadRunner 没有告诉你的》之五
发布时间: 2007-5-15 15:06 作者: 陈雷来源: cnblogs
提到性能测试,相信大家可以在网上找到很多种不同的定义、解释以及分类方法。不过归根结底,在大多数情况下,我们所要做的性能测试的目的是“观察系统在一个给定的环境和场景中的性能表现是否与预期目标一致,评判系统是否存在性能缺陷,并根据测试结果识别性能瓶颈,改善系统性能”。
本文是《LoadRunner没有告诉你的》系列的第五篇,在这篇文章中,我希望可以跟大家一起来探讨“如何将性能测试应用到软件开发过程的各个阶段中,如何通过尽早的开展性能测试来规避因为性能缺陷导致的损失”。
因此,本文的结构也将依据软件开发过程的不同阶段来组织。
另外,建议您在阅读本文前先阅读本系列文章的第三篇《理发店模型》和第四篇《理解性能》。
需求阶段
我们不可能将一辆设计载重为0.75吨的皮卡改装成载重15吨的大型卡车,如果你面对的正是这样的问题,那么恐怕你只能重做一辆,而且客户不会为你之前那辆付钱。对于一个已经完成的应用系统来说也是如此。
如果我们在系统结构确定之前就能够了解到系统的将要面对的压力,用户的使用习惯和使用频度,我们就可以更早也更有效的提前解决或预防可能发生的性能缺陷,也将会极大的减少后期返工和反复调优所带来的工作量。如果我们预期到系统的容量将会不断的增长,我们还可以给出相应的解决方案来低成本的解决这类问题,就像上面那辆皮卡,也许你可以有办法把20辆皮卡捆在一起,或者把15吨的东西分由20辆来运。
分析设计阶段
系统性能的优化并不是要等待整个系统全部集成后才能开始的,早在分析设计阶段,我们就可以开始考虑系统的技术架构和数据库部分的优化。
数据库通常位于整个系统的最底层,如果直到系统上线前才发现因为数据库设计不合理而导致性能极差,通常使用任何一种方法来优化都已经于事无补了。要避免这类问题,最常见的做法是在数据库结构确定后,通过工具或脚本向数据库中注入大量的数据,并模拟各种业务的数据库操作。根据对数据库性能的观察和分析,对数据库表结构和索引进行调整以优化数据库性能。
在系统的技术架构方面,要明白先进的技术并不是解决问题的唯一方法,过于强调技术的作用反而会将你带入歧途。例如:某些业务虽然经常面临着巨大的压力,并且业务本身的复杂性决定了通过算法的优化来提高系统的性能收效甚微。但是我们知道用户对于该业务的实时性要求并不高,并且返回结果对于不同用户来说是相同的。那么我们完全可以考虑将每次请求都动态生成返回结果的方式改为每次用户请求都返回一个定期更新的静态页面。
另外,所谓“先进技术”通常都会在带来某一方面改进的同时带来另一方面的问题,未经试验就盲目的在系统中加入各种流行元素未必是最好的选择。例如ORM可以提供一些方便,但是它生成的SQL是未经优化的,有时甚至比人工编写的SQL效率更低。
最后,要知道不同厂家的设备性能是不同的,而且不同的硬件设备搭载不同的操作系统、数据库、中间件以及应用服务器,表现出来的性能也是不同的。如果有足够的资源,应当考虑提前进行软硬件平台的对比选型;如果没有足够的资源,可以考虑通过一些专业的组织或网站来获取或购买相关的评估报告。
编码阶段
一片树叶在哪里最难被发现?——当这片树叶落在一堆树叶里面的时候。
如果你只是在系统测试完成后才开始性能测试,那么即使发现系统存在性能缺陷,并且已经有了几个可供怀疑的对象,但是当一段因为使用了不当的算法而导致执行效率很低的代码藏身于一个庞大的系统中时,找出它是非常困难的。避免这种情况出现的方法是尽早开始核心业务代码的性能测试,重点集中在对算法和实现方法的优化上。
另外,及早开始的测试也可以帮你更容易找到内存泄漏的问题。
测试阶段
产品终于交到我们手上了,搭建测试环境,设计测试场景,执行测试,找到系统的最佳并发用户数和最大并发用户数,将系统进行分类,评判系统的性能表现是否满足需求中定义的目标——如果有需求的话 ^_^
如果发现系统的性能表现与预期目标相去甚远,则需要根据执行测试过程中收集到的数据来分析和识别性能瓶颈,优化系统性能。
在这个阶段还有很多值得我们深入思考和讨论的东西,在本系列后续的文章中,我们将会更多的关注这一部分的内容。
维护阶段
维护阶段通常遇到的问题是需要在实验室中模拟客户环境,重现在客户那里发现的缺陷并修复缺陷。相比功能缺陷,性能缺陷与某一具体环境和场景的关联更加密切,所以在测试前需要检查生产环境中各服务器的资源利用率、系统访问日志、应用服务器的日志、数据库的日志。如果客户使用了专门的系统来监测各个服务器的软硬件资源使用情况的话,检查该系统
是否记录下了软硬件资源的异常或者警告。
与性能测试相关的其他测试
可靠性测试(Reliability Testing)对于一个运营商级的系统来说,能够保证提供7×24的连续稳定的服务是非常重要的。当然,你可以通过一些“高可用性(High Availability)”技术方案来增强系统的可靠性,但是对于系统本身的可靠性测试是不能被忽略的。
常用的测试方法是使用一定的负载长时间向服务器加压,并观察随着加压时间的延长,响应时间、吞吐量以及资源利用率的变化。要注意的是,所使用的负载应当是系统的最佳并并发用户数,而不是最大并发用户数。
可伸缩性测试(Scalability Testing)对于一个系统来说,在一个给定的环境下,它的最佳并发用户数和最大并发用户数是客观存在的,但是系统所面临的压力却有可能随上线时间的延长而增大。例如,一个在线购物站点,注册用户数量不断增多,访问站点查询商品信息和购买商品的人也不断的增多,我们应该用一种什么样的方案,在不影响系统继续为用户提供服务的前提下来实现系统的扩容?
一种常用的方案是使用负载均衡(Load Balance)和集群(Cluster)技术。但是在我们为客户提供这种方案之前,需要先自己进行测试,保证该技术的有效性——我们是否真的可以通过简单的增加服务器数据和修改某些参数配置,就能够使得系统的容量得到线性的增长?
可恢复性测试(Recoverability Testing)虽然我们已经可以准确的估算出系统上线后将要面对的压力,并且可以保证系统的最佳并发用户数和最大并发用户数是足以应对这些压力的,但是这个世界上总是有些事情上我们所无法预料到的——例如9.11事件发生后,AOL的网站访问量在短时间内增长到了平时的数十倍。
我们无法保证系统可以在任何情况下都能为用户正确无误的提供服务,但是我们需要确保当意外过去后,系统可以恢复到正常的状态,并继续后来的用户提供服务——就像从未发生过任何事情一样。
如果要实现“可恢复性测试”,我们可以借助于测试工具或脚本来逐渐的增大并发用户数,直至并发用户数已经超过了系统所能承受的最大并发用户数,并导致软硬件资源利用率饱
和,响应时间无限延长,大量的请求因为超过响应时间要求或无法获得响应而失败;之后,我们逐渐的减少并发用户数,并观察资源利用率、响应时间、吞吐量以及交易成功率的变化是否与预期目标一致。
当然,这一切的前提是在系统负载达到峰值前,Server一直在顽强的挣扎着而没有down掉
性能测试,并非网络应用专属
软件的性能和性能测试都是伴随着网络应用的兴起而逐渐被重视起来的,但是软件性能和性能测试却并非网络应用的专属名词,因为单机版的应用同样需要考虑性能问题。下面举几个简单的例子来方便大家的理解:
1. 当使用Word来编辑一个500多页,并包含了丰富图表、图片和各种格式、样式信息的文档时,是否每次对大段的文字或表格的修改、删除或重新排版,都要等待系统花几秒钟的时间进行处理?
2. 当在Excel中使用嵌套的统计和数学函数对几万行记录进行统计分析时,是否每次都要两三分钟才能看到结果?
3. 杀毒软件是否每次都要花费两个小时才能完成一次对所有的分区的扫描?
4. 是否每次在手机的通讯簿中根据姓名搜索某个人的联系方式都要三四秒钟才有响应?
如果大家有兴趣,也可以通过Google搜索到更多的有关单机应用性能测试的资料。
点击这里了解整个系列的创作进度,查看文章目录,或浏览已经完成的文章。
获取有效的性能需求——《LoadRunner 没有告诉你的》之六
发布时间: 2007-5-15 15:07 作者: 陈雷来源: cnblogs
本文是《LoadRunner没有告诉你的》系列的第六篇,我将继续保持“无废话”的原则,用尽可能简洁、明确的语句来表述我对性能测试的看法和经验。在这篇文章中,我们要讨论的是如何获取“有效的”性能需求。
一个实际的例子
为了便于大家的理解,我们先来看一个性能需求的例子,让大家有一个感性的认识,本文后面的讨论也会再次提到这个例子。
这是一个证券行业系统中某个业务的“实际需求”——实际上是我根据通过网络搜集到的数据杜撰出来的,不过看起来像是真实的 ^_^
系统总容量达到日委托6000万笔,成交9000万笔
系统处理速度每秒7300笔,峰值处理能力达到每秒10000笔
实际股东帐号数3000万
SAS数据的描述性统计分析答案
实验一数据的描述性统计分析 一、选择题 1、以下( B )语句对变量进行分组,在使用前需按分组变量进行排序? 以下( C )语句可对变量进行分类,在使用前不必按分类变量进行排序? 用( A )语句可以选择输入数据集的一个行子集来进行分析? (A)WHERE语句(B)BY语句(C)CLASS语句(D)FREQ语句2、排序过程步中必须用什么语句对变量进行排序?( A ) (A)BY语句(B)CLASS语句(C)WHERE语句 3、如果要对数据集中的数据进行正态性检验,需要使用哪个过程?( B )(A)MEANS (B)UNIV ARIATE (C)FREQ 4、用UNIV ARIATE过程进行数据分析,要求此过程输出茎叶图、正态概率图等,应在语句中加上什么选项?(plot ) 5、用UNIV ARIATE过程进行数据分析,在输出结果中哪个统计量是对样本均值 为零的T检验的概率值?( A ) (A)T: Mean (B)Prob>|S| (C)Sgn Rank (D)Prob>|T| 二、假设某校100名女生的血清总蛋白含量(g/L)服从均值为75,标准差为3的正态分布,试产生样本数据,并利用SAS软件解决下面问题: 1、计算样本均值、方差、标准差、极差、四分位极差、变异系数、偏度、峰度; 2、画出直方图(垂直条形图); 3、画出茎叶图、盒形图和正态概率图; 4、试进行正态性检验。 Data N; DO i=1to100; x=75+3*normal(12345); output; end; proc print; run; proc univariate data=N; var x; run; proc gchart data=N; block x; run; proc univariate data=N plot; var x;
描述性统计分析报告--Descriptive Statistics菜单详解
第六章:描述性统计分析-- Descriptive Statistics菜单详解 描述性统计分析是统计分析的第一步,做好这第一步是下面进行正确统计推断的先决条件。SPSS的许多模块均可完成描述性分析,但专门为该目的而设计的几个模块则集中在Descriptive Statistics菜单中,最常用的是列在最前面的四个过程:Frequencies过程的特色是产生频数表;Descriptives过程则进行一般性的统计描述;Explore过程用于对数据概况不清时的探索性分析;Crosstabs 过程则完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。 本章讲述的四个过程在9.0及以前版本中被放置在Summarize菜单中。 §6.1 Frequencies过程 频数分布表是描述性统计中最常用的方法之一,Frequencies过程就是专门为产生频数表而设计的。它不仅可以产生详细的频数表,还可以按要求给出某百分位点的数值,以及常用的条图,圆图等统计图。 和国内常用的频数表不同,几乎所有统计软件给出的均是详细频数表,即并 不按某种要求确定组段数和组距,而是按照数值精确列表。如果想用Frequencies过程得到我们所熟悉的频数表,请先用第二章学过的Recode过程产生一个新变量来代表所需的各组段。 6.1.1 界面说明 Frequencies对话框的界面如下所示:
该界面在SPSS中实在太普通了,无须多言,重点介绍一下各部分的功能如下:【Display frequency tables复选框】 确定是否在结果中输出频数表。 【Statistics钮】 单击后弹出Statistics对话框如下,用于定义需要计算的其他描述统计量。 现将各部分解释如下:
描述性统计量分析
实验报告课程名称:sas
附录 1、直接从sas的Import data那,从桌面导入数据lwh; 2、在数据表lwh中增设sum变量形成新的数据表aa;从数据表aa剔除那些没有交易的股 票。 data lwh; set lwh; sum=average_price*volume; run; data lwh; set lwh; if price>0; run; 3、Tabulate过程输出统计量表 proc tabulate data=lwh; class region; var sum price; table region, (sum price)*(mean var); run; 运行结果: 图1 4、Gplot过程输出统计图表 proc gplot data=lwh; symbol1i=join v=+ color=red; symbol2i=rq v=& color=black; plot speed*low Level_Change*high/overlay; run; proc gplot data=lwh; symbol i=rqcli95 v=* color=blue; plot (Level_Change speed)*(low high); run;
运行结果: 图2 涨速和最低价、换手率和最高价的叠加散点图 图3 换手率和最低价的散点图
图4 涨速和最低价的散点图 5、输出现价的直方图程序: proc gchart data=lwh; vbar price/levels=18 modpoints=5791113151719212325272931 34384255; run; 运行结果:
05.第五讲 描述性统计分析评价方法
第五讲描述性统计分析评价方法——综合指标 实际上,从这一讲开始的教学内容都是介绍教育评价技术中的重要方法——教育统计分析方法,也即是分析资料的方法。其中包括描述性统计分析方法和推断性统计分析方法两大部分。 一、描述性统计分析评价方法的主要特点。对数据资料计算综合指标,然后根据综合指标值对教育客观事物给予评价。所谓综合指标指的是从数量方面综合说明事物特征的指标。常用的综合指标有绝对数、相对数、平均数和标准差。重点介绍后面两种。 二、综合指标的计算及解释 (一)绝对数(规模) (二)相对数(程度) (三)平均数(水平) 通常可用符号表示平均数 1.算术平均数(未经分类汇总的测量数据资料)计算方法见p62的(4.1)公式。 2.加权平均数(已经分类汇总的资料)
①组距数列平均数(对测量数据分组统计人数)例如P63表4-1的资料。计算方法如P63的(4.2)公式及83名教师平均年龄的计算。 * 为了减少计算的麻烦,在此介绍计算器统计功能的使用: A、操作步骤 计算器的统计功能的计算只能得到如下六个统计结果:n(数据个数)、(数据和)、(数据平方和)、(平均数)、(总体标准差)和S(样本标准差)。操作步骤如下:1)显示统计状态:2ndF STAT(或SD) 2)输入数据:每输入一个数据按DATA 3)取出统计结果:这时六个统计结果均处于待取状态,可根据需要取出其中的结果。 B、注意事项 1)若需继续进行第二组数据的统计运算时,需取消统计状态,再按上述步骤操作。按2ndF STAT即可取消统计的状态。 2)若不需要计算、、、、和S时(即进行 其他一般运算时),也应取消统计状态)。
利用Excel进行数据整理和描述性统计分析
实训一利用Excel进行数据整理和描述性统计分析 一、实训目的 目的有三:(1)掌握Excel中基本的数据处理方法;(2)学会使用Excel进行统计分组;(3)学会使用Excel计算各种描述性统计指标,能以此方式独立完成相关作业。 二、实训要求 1、已学习教材相关内容,理解数据整理中的统计计算问题;理解描述性统计指标中的统计计算问题;已阅读本次实训指导书,了解Excel中相关的计算工具。 2、准备好一个统计分组问题、准备好一个或几个描述性统计指标计算问题及相应数据(可用本实训所提供问题与数据)。 3、以Word文件形式(其中的统计表和统计图用Excel制作)提交实训报告(含:实训过程记录、疑难问题发现与解决记录(可选))。此条为所有实训所要求。 三、实训内容和操作步骤 (一)问题与数据 有顾客反映某家航空公司售票处售票的速度太慢。为此,航空公司收集了解100位顾客购票所花费时间的样本数据(单位:分钟),结果如下表。
航空公司认为,为一位顾客办理一次售票业务所需的时间在五分钟之内就是合理的。上面的数据是否支持航空公司的说法顾客提出的意见是否合理请你对上面的数据进行适当的分析,回答下列问题。 (1)对数据进行等距分组,整理成频数分布表,并绘制频数分布图(直方图、折线图、饼图)。 (2)根据分组后的数据,计算中位数、众数、算术平均数和标准差。 (3)分析顾客提出的意见是否合理为什么 (4)使用哪一个平均指标来分析上述问题比较合理 答:(1): 2:
从表中我们可以得到中位数为众数为1平均数为标准差为 (3):合理,虽然他的平均数是<5属于正常范围,但是依旧有将近20%的购票时间>5分钟属于超过正常范围,那就是速度太慢了。平均数不能代表一切。 所以顾客提出的理由是正确的,购票太慢的现象确实存在。 (4):平均数比较合理,它能较好的反映购票的大概时间。比较有代表性! 实训二用Excel数据分析功能进行统计整理 和计算描述性统计指标 一、实训目的 学会使用Excel数据分析功能进行统计整理和计算各种描述性统计指标,能以此方式独立完成相关作业。 二、实训要求 1、已学习教材相关内容,理解统计整理和描述性统计指标中的统计计算问题;已阅读本次实验导引,了解Excel中相关的计算工具。 2、准备好一个统计分组问题、准备好一个或几个数字特征计算问题及相应数据(可用本实验导引所提供问题与数据)。 3、以Word文件形式(其中的统计表和统计图用Excel制作)提交实训报告(含:实训过程记录、疑难问题发现与解决记录(可选))。此条为所有实训所要求。 三、实训内容和操作步骤
描述性统计分析-Eviews
主讲人:刘莎莎 第三讲 描述性统计分析
一、 序列窗口下的描述性统计分析
知识点 1:如何以建立组对象的方式将数据导入到 Eviews 中去(第二种导入数 据的方式) 。 知识点 2:如何在序列窗口下实现简单描述性统计量和直方图,将直方图和正态 分布曲线叠加在一起,从而更直观地观察数据的分布特征。 (如何将 EViews 图形 复制粘贴到 word 中) 知识点 3:如何在序列窗口下实现描述性统计量的假设检验 知识点 4:如何实现将单序列按某一变量分类后再进行描述性统计分析(本案例 的分类变量是该天是星期几) 知识点 5:如何实现将单序列按某一变量分类后再进行假设检验 知识点 6:如何画上证综指日对数收益率的 QQ 图 知识点 7:如何估计数据的经验分布函数的参数 案例数据说明:2003 年 1 月 6 日-2009 年 6 月 26 日上证综指日对数收益率。
二、序列组窗口下的描述性统计分析
知识点 1:如何通过打开 excel 文件的方式将数据导入到 Eviews 中去。 (第三种 导入数据的方式) 。 知识点 2:如何实现多变量的描述性统计量 知识点 3:如何实现多变量描述性统计量的假设检验 案例数据说明:国家统计调查队分别在两个地区调查了 10 个家庭的收入 知识点 4:如何计算当前序列组的相关系数矩阵,协方差矩阵
主讲人:刘莎莎
案例数据说明:1983-2000 年我国粮食生产与相关投入的数据,变量包括粮食产 量(单位:万吨)、农业化肥施用量(单位:万千克)、粮食播种面积(单位: 公顷)
附注:描述性统计量的计算公式
标准差(Std.Dev.)的计算公式是:
s=
2 ( y ? y ) ∑ t t =1
T
T ?1
其中,
yt 是观测值, y 是样本平均数。
偏度(Skewness)的计算公式是:
1 T yt ? y 3 S = ∑( ) T t =1 s
其中,
yt 是观测值, y 是样本平均数,s 是样本标准差,T 是样本容量。对
称分布的偏度是零,比如正态分布。
峰度(Kurtosis)的计算公式是:
1 T yt ? y 4 S = ∑( ) T t =1 s
其中,
yt 是观测值, y 是样本平均数,s 是样本标准差,T 是样本容量。
正态分布的峰度值是 3。
多组和分类数据的描述性统计分析
§3.2多组和分类数据的描述性统计分析17 ?盒子图 盒子图能够直观简洁地展现数据分布的主要特征.我们在R 中使用boxplot()函数作盒子图.在盒子图中,上下四分位数分别确定中间箱体的顶部和底部,箱体中间的粗线是中位数所在的位置.由箱体向上下伸出的垂直部分为“触须”(whiskers),表示数据的散布范围,其为1.5倍四分位间距内距四分位点最远的数据点.超出此范围的点可看作为异常点(outlier). §3.2多组和分类数据的描述性统计分析 在对于多组数据的描述性统计量的计算和图形表示方面,前面所介绍的部分方法不能够有效地使用,例如许多函数都不能直接对数据框进行操作.这时我们需要一些其他的函数配合使用. 1.图形表示: ?散点图:前面介绍的plot,可直接对数据框操作.此时将绘出数据框中所对应的所有变量两两之间的散点图.所做图框中第一行的散点图是以第一个变量为纵坐标,分别以第二、三...个变量为横坐标的散点图.这里数据举例说明. library(DAAG);plot(hills) ?盒子图:前面介绍的boxplot,亦可直接对数据框操作,其在同一个作图区域内画出各组数的盒子图.但是注意,此时由于不同组数据的尺度可能差别很大,这样的盒子图很多时候表达出来不是很有意义.boxplot(faithful).因此这样做比较适合多组数据具有同样意义或近似尺度的情形.例如,我们想做某一数值变量在某个因子变量的不同水平下的盒子图.我们可采用类似如下的命令: boxplot(skullw ~age,data=possum),亦可加上参数horizontal=T,将该盒子图横向放置. boxplot(possum$skullw ~possum$sex,horizontal=T) ?条件散点图:当数据集中含有一个或多个因子变量时,我们可使用条件散点图函数coplot()作出因子变量不同水平下的多个散点图,当然该方法也适用于各种给定条件或限制情形下的作图.其调用格式为 coplot(formula,data)比如coplot(possum[[9]]~possum[[7]] possum[[4]]),或 coplot(skullw ~taill age,data=possum); coplot(skullw ~taill age+sex,data=possum)
描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。
一、描述统计 描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:剔除法、均值法、最小邻居法、比率回归法、决策树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A 单样本t检验:推断该样本来自的总体均数μ与已知的某一总体均数μ0 (常为理论值或标准值)有无差别; B 配对样本t检验:当总体均数未知时,且两个样本可以配对,同对中的两者在可能会影响处理效果的各种条件方面扱为相似; C 两独立样本t检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验 非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。 适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。
A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析 检査测量的可信度,例如调查问卷的真实性。 分类: 1、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度 2、内在信度;每个量表是否测量到单一的概念,同时组成两表的内在体项一致性如 何,常用方法分半信度。 四、列联表分析 用于分析离散变量或定型变量之间是否存在相关。 对于二维表,可进行卡方检验,对于三维表,可作Mentel-Hanszel分层分析。列联表分析还包括配对计数资料的卡方检验、行列均为顺序变量的相关检验。 五、相关分析 研究现象之间是否存在某种依存关系,对具体有依存关系的现象探讨相关方向及相关程度。 1、单相关:两个因素之间的相关关系叫单相关,即研究时只涉及一个自变量和一个因变量; 2、复相关:三个或三个以上因素的相关关系叫复相关,即研究时涉及两个或两个以上的自变量和因变量相关; 3、偏相关:在某一现象与多种现象相关的场合,当假定其他变量不变时,其中两个变量之间的相关关系称为偏相关。 六、方差分析
描述性统计分析
07 描述统计量 N 极小值极大值均值标准差 员工人数12 9390.00 447519.00 128633.7500 164594.68556 业务及管理费12 57.60 876.31 285.7252 295.70362 存款利息投入12 351.00 6190.60 2467.5333 2106.81170 非利息收入12 12.09 296.92 111.9029 116.65440 利息收入12 112.47 2244.65 781.5745 792.37162 有效的 N (列表状态)12 08 描述统计量 N 极小值极大值均值标准差 员工人数12 11109.00 441883.00 133190.0833 163139.78332 业务及管理费12 72.92 991.93 380.5942 371.88382 存款利息投入12 86.37 3224.30 1307.1217 960.74201 非利息收入12 30.27 626.06 143.8101 191.94540 利息收入12 134.92 3051.58 946.5858 974.79290 有效的 N (列表状态)12 09 描述统计量 N 极小值极大值均值标准差 员工人数12 12301.00 440830.00 136322.0833 163373.41681 业务及管理费12 76.88 1017.03 409.1125 380.84033 存款利息投入12 963.28 16254.08 7076.2133 6108.27179 非利息收入12 13.22 733.17 238.9600 266.07660 利息收入12 158.07 2458.21 891.2656 848.13433 有效的 N (列表状态)12 10 描述统计量 N 极小值极大值均值标准差 员工人数12 14304.00 444447.00 143473.5000 164723.77709 业务及管理费12 106.27 1165.78 480.6733 431.78391 存款利息投入12 1859.44 13902.87 6008.6475 4474.67915 非利息收入12 17.19 770.72 193.6858 262.19946 利息收入12 227.60 3037.49 1226.6899 1125.16190 有效的 N (列表状态)12
数据的描述性统计分析
统计分析往往是从了解数据的基本特征开始的。描述数据分布特征的统计量可分为两类:一类表示数量的中心位置,另一类表示数量的变异程度(或称离散程度)。两者相互补充,共同反映数据的全貌。 这些内容可以通过SPSS中的“Descriptive Statistics”菜单中的过程来完成。 1 频数分析 (Descriptive Statistics - Frequencies) 频数分布分析主要通过频数分布表、条形图和直方图,以及集中趋势和离散趋势的各 种统计量来描述数据的分布特征。 下面我们通过例子来学习单变量频数分析操作。 1) 输入分析数据 在数据编辑器窗口打开“data1-2.sav”数据文件。 2)调用分析过程 在主菜单栏单击“Analyze”,在出现的下拉菜单里移动鼠标至“Descriptive Statistics”项上,在出现的次菜单里单击“Frequencies”项,打开如图3-4所示的对话框。 图3-4 “Frequencies” 对话框 3)设置分析变量 从左则的源变量框里选择一个和多个变量进入“Variable(s):”框里。在这里我们选“三化 螟蚁螟[虫口数]”变量进入“Variable(s):”框。 4)输出频数分布表
Display frequency tables,选中显示。 5)设置输出的统计量 单击“Statistics”按钮,打开图3-5所示的对话框,该对话框用于选择统计量: 图3-5 “Statistics”对话框 ①选择百分位显示“Percentiles Values”栏: Quartiles:四分位数,显示25%、50%和75%的百分位数。 Cut points for 10 equal groups:将数据平分为输入的10个等份。 Percentile(s)::用户自定义百分位数,输入值0—100之间。选中此项后,可以利用“Add”、“Change”和 “Remove”按钮设置多个百分位数。 ②选择变异程度的统计量“Dispersion”:(离散趋势) Std.deviation标准差 Minimum 最小值 Variance 方差 Maximum 最大值 Range 极差 S.E.mean均值标准误 ③选择表示数据中心位置的统计量“Central Tendency”:(集中趋势) Mean 均值 Median 中位数 Mode 众数 Sum 算术和
描述性统计分析
第六章描述性统计分析-- Descriptive Statistics菜单详解 6.1 Frequencies过程 6.1.1 界面说明 6.1.2 分析实例 6.1.3 结果解释 6.2 Descriptives过程 6.2.1 界面说明 6.2.2 结果解释 6.3 Explore过程 6.3.1 界面说明 6.3.2 结果解释 6.4 Crosstabs过程 6.4.1 界面说明 6.4.2 分析实例 6.4.3 结果解释 描述性统计分析是统计分析的第一步,做好这第一步是下面进行正确统计推断的先决条件。SPSS的许多模块均可完成描述性分析,但专门为该目的而设计的几个模块则集中在Descriptive Statistics菜单中,最常用的是列在最前面的四个过程:Frequencies过程的特色是产生频数表;Descriptives过程则进行一般性的统计描述;Explore过程用于对数据概况不清时的探索性分析;Crosstabs 过程则完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。 §6.1 Frequencies过程 频数分布表是描述性统计中最常用的方法之一,Frequencies过程就是专门为产生频数表而设计的。它不仅可以产生详细的频数表,还可以按要求给出某百分位点的数值,以及常用的条图,圆图等统计图。 和国内常用的频数表不同,几乎所有统计软件给出的均是详细频数表,即并不按某种要求确定组段数和组距,而是按照数值精确列表。如果想用Frequencies过程得到我们所熟悉的频数表,请先用第二章学过的Recode过程产生一个新变量来代表所需的各组段。 6.1.1 界面说明
关于描述性统计分析
关于描述性统计分析 作者:记忆de&#…文章来源:csdn blog 点击数:156 更新时间:2007-2-12 在数据分析的时候,一般首先要对数据进行描述性统计分析(Descriptive Anal ysis),以发现其内在的规律,再选择进一步分析的方法。描述性统计分析要对调查总体所有变量的有关数据做统计性描述,主要包括数据的频数分析、数据的集中趋势分析、数据离散程度分析、数据的分布、以及一些基本的统计图形。 (1)数据的频数分析:在数据的预处理部分,我们曾经提到利用频数分析和交叉频数分析来检验异常值。此外,频数分析也可以发现一些统计规律。比如说,收入低的被调查者用户满意度比收入高的被调查者高,或者女性的用户满意度比男性低等。不过这些规律只是表面的特征,在后面的分析中还要经过检验。 (2)数据的集中趋势分析:数据的集中趋势分析是用来反映数据的一般水平,常用的指标有平均值、中位数和众数等。各指标的具体意义如下: 平均值:是衡量数据的中心位置的重要指标,反映了一些数据必然性的特点,包括算术平均值、加权算术平均值、调和平均值和几何平均值。 中位数:是另外一种反映数据的中心位置的指标,其确定方法是将所有数据以由小到大的顺序排列,位于中央的数据值就是中位数。 众数:是指在数据中发生频率最高的数据值。 如果各个数据之间的差异程度较小,用平均值就有较好的代表性;而如果数据之
间的差异程度较大,特别是有个别的极端值的情况,用中位数或众数有较好的代表性。 (3)数据的离散程度分析:数据的离散程度分析主要是用来反映数据之间的差异程度,常用的指标有方差和标准差。方差是标准差的平方,根据不同的数据类型有不同的计算方法。 (4)数据的分布:在统计分析中,通常要假设样本的分布属于正态分布,因此需要用偏度和峰度两个指标来检查样本是否符合正态分布。偏度衡量的是样本分布的偏斜方向和程度;而峰度衡量的是样本分布曲线的尖峰程度。一般情况下,如果样本的偏度接近于0,而峰度接近于3,就可以判断总体的分布接近于正态分布。 (5)绘制统计图:用图形的形式来表达数据,比用文字表达更清晰、更简明。在SPSS软件里,可以很容易的绘制各个变量的统计图形,包括条形图、饼图和折线图等。 示例SIM手机描述性统计分析 为简化起见,我们只分析SIM手机用户满意调查中的两个变量:“总体感知质量”和“总体满意度”变量。 (1)数据的频数分析 用SPSS软件的频数分析可以很容易地画出两个变量的频数图:
描述性统计分析
描述性统计分析 作者:清华大学中国企业研究中心阅读次数:24704次发布日期:2005-07-04 在数据分析的时候,一般首先要对数据进行描述性统计分析(Descriptive Analysis),以发现其内在的规律,再选择进一步分析的方法。描述性统计分析要对调查总体所有变量的有关数据做统计性描述,主要包括数据的频数分析、数据的集中趋势分析、数据离散程度分析、数据的分布、以及一些基本的统计图形。 (1)数据的频数分析:在数据的预处理部分,我们曾经提到利用频数分析和交叉频数分析来检验异常值。此外,频数分析也可以发现一些统计规律。比如说,收入低的被调查者用户满意度比收入高的被调查者高,或者女性的用户满意度比男性低等。不过这些规律只是表面的特征,在后面的分析中还要经过检验。 (2)数据的集中趋势分析:数据的集中趋势分析是用来反映数据的一般水平,常用的指标有平均值、中位数和众数等。各指标的具体意义如下: 平均值:是衡量数据的中心位置的重要指标,反映了一些数据必然性的特点,包括算术平均值、加权算术平均值、调和平均值和几何平均值。 中位数:是另外一种反映数据的中心位置的指标,其确定方法是将所有数据以由小到大的顺序排列,位于中央的数据值就是中位数。 众数:是指在数据中发生频率最高的数据值。 如果各个数据之间的差异程度较小,用平均值就有较好的代表性;而如果数据之
间的差异程度较大,特别是有个别的极端值的情况,用中位数或众数有较好的代表性。
(3)数据的离散程度分析:数据的离散程度分析主要是用来反映数据之间的差异程度,常用的指标有方差和标准差。方差是标准差的平方,根据不同的数据类型有不同的计算方法。 (4)数据的分布:在统计分析中,通常要假设样本的分布属于正态分布,因此需要用偏度和峰度两个指标来检查样本是否符合正态分布。偏度衡量的是样本分布的偏斜方向和程度;而峰度衡量的是样本分布曲线的尖峰程度。一般情况下,如果样本的偏度接近于0,而峰度接近于3,就可以判断总体的分布接近于正态分布。 (5)绘制统计图:用图形的形式来表达数据,比用文字表达更清晰、更简明。在SPSS软件里,可以很容易的绘制各个变量的统计图形,包括条形图、饼图和折线图等。 示例SIM手机描述性统计分析 为简化起见,我们只分析SIM手机用户满意调查中的两个变量:“总体感知质量”和“总体满意度”变量。 (1)数据的频数分析 用SPSS软件的频数分析可以很容易地画出两个变量的频数图:
描述性统计分析--Descriptive-Statistics
描述性统计分析--Descriptive-Statistics菜单详解
第六章:描述性统计分析-- Descriptive Statistics菜单详解 描述性统计分析是统计分析的第一步,做好这第一步是下面进行正确统计推断的先决条件。SPSS的许多模块均可完成描述性分析,但专门为该目的而设计的几个模块则集中在Descriptive Statistics菜单中,最常用的是列在最前面的四个过程:Frequencies过程的特色是产生频数表;Descriptives过程则进行一般性的统计描述;Explore过程用于对数据概况不清时的探索性分析;Crosstabs过程则完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。 本章讲述的四个过程在9.0及以前版本中被放置在Summarize菜单中。 §6.1 Frequencies过程 频数分布表是描述性统计中最常用的方法之一,Frequencies过程就是专门为产生频数表而设计的。它不仅可以产生详细的频数表,还可以按要求给出某百分位点的数值,以及常用的条图,圆图等统计图。 和国内常用的频数表不同,几乎所有统计软件给出的均是详细频数表,即并 不按某种要求确定组段数和组距,而是按照数值精确列表。如果想用Frequencies过程得到我们所熟悉的频数表,请先用第二章学过的Recode过程产生一个新变量来代表所需的各组段。 6.1.1 界面说明 Frequencies对话框的界面如下所示:
该界面在SPSS中实在太普通了,无须多言,重点介绍一下各部分的功能如下:【Display frequency tables复选框】 确定是否在结果中输出频数表。 【Statistics钮】 单击后弹出Statistics对话框如下,用于定义需要计算的其他描述统计量。 现将各部分解释如下:
matlab在统计数据描述性分析的应用
统计数据的描述性分析 一、实验目的 熟悉在matlab中实现数据的统计描述方法,掌握基本统计命令:样本均值、样本中位数、样本标准差、样本方差、概率密度函数pdf、概率分布函数df、随机数生成rnd。 二、实验内容 1 、频数表和直方图 数据输入,将你班的任意科目考试成绩输入 >> data=[91 78 90 88 76 81 77 74]; >> [N,X]=hist(data,5) N = 3 1 1 0 3 X = 75.7000 79.1000 82.5000 85.9000 89.3000 >> hist(data,5)
2、基本统计量 1) 样本均值 语法: m=mean(x) 若x 为向量,返回结果m是x 中元素的均值; 若x 为矩阵,返回结果m是行向量,它包含x 每列数据的均值。 2) 样本中位数 语法: m=median(x) 若x 为向量,返回结果m是x 中元素的中位数; 若x 为矩阵,返回结果m是行向量,它包含x 每列数据的中位数3) 样本标准差 语法:y=std(x) 若x 为向量,返回结果y 是x 中元素的标准差; 若x 为矩阵,返回结果y 是行向量,它包含x 每列数据的标准差
std(x)运用n-1 进行标准化处理,n是样本的个数。 4) 样本方差 语法:y=var(x); y=var(x,1) 若x 为向量,返回结果y 是x 中元素的方差; 若x 为矩阵,返回结果y 是行向量,它包含x 每列数据的方差 var(x)运用n-1 进行标准化处理(满足无偏估计的要求),n 是样本的个数。var(x,1)运用n 进行标准化处理,生成关于样本均值的二阶矩。 5) 样本的极差(最大之和最小值之差) 语法:z= range(x) 返回结果z是数组x 的极差。 6) 样本的偏度 语法:s=skewness(x) 说明:偏度反映分布的对称性,s>0 称为右偏态,此时数据位于均值右边的比左边的多;s<0,情况相反;s 接近0 则可认为分布是对称的。 7) 样本的峰度 语法:k= kurtosis(x) 说明:正态分布峰度是3,若k 比3 大得多,表示分布有沉重的尾巴,即样本中含有较多远离均值的数据,峰度可以作衡量偏离正态分布的尺度之一。 >> mean(data) ,
excel与描述性统计分析
用Excel进行数据分析:描述性统计分析 郑来轶发表于2013-04-14 22:03 来源:本站原创 在数据分析的时候,一般首先要对数据进行描述性统计分析(Descriptive Analysis),以发现其内在的规律,再选择进一步分析的方法。描述性统计分析要对调查总体所有变量的有关数据做统计性描述,主要包括数据的频数分析、数据的集中趋势分析、数据离散程度分析、数据的分布、以及一些基本的统计图形,常用的指标有均值、中位数、众数、方差、标准差等等。 接下来我们讲讲在Excel2007中完成描述性统计分析。 一、案例场景 某网站的专题活动积累了一定访问数据后,需要统计流量的的均值、区间,以及给出该专题访问量差异的量化标准,借此来作为分析每天访问量的价值、参差不齐、此起彼伏一个衡量的依据。要求得到均值、区间、众数、方差、标准差等统计数据。 二、操作步骤 1、打开数据表格,这个案例中用的数据无特殊要求,只是一列数值就可以了。 2、选择“工具”——“数据分析”——“描述统计”后,出现属性设置框
注:本功能需要使用Excel扩展功能,如果您的Excel尚未安装数据分析,可以参考上一篇文章《用Excel进行数据分析:数据分析工具在哪里?》。 3、依次选择 选项有2方面,输入和输出选项 输入区域:原始数据区域,选中多个行或列,选择相应的分组方式逐行/逐列;
如果数据有标志,勾选“标志位于第一行”;如果输入区域没有标志项,该复选框将被清除,Excel 将在输出表中生成适宜的数据标志; 输出区域可以选择本表、新工作表或是新工作簿; 汇总统计:包括有平均值、标准误差(相对于平均值)、中值、众数、标准偏差、方差、峰值、偏斜度、极差、最小值、最大值、总和、总个数、最大值、最小值和置信度等相关项目。第K大(小)值:输出表的某一行中包含每个数据区域中的第k 个最大(小)值。 平均数置信度:数值95% 可用来计算在显著性水平为5% 时的平均值置信度
用Excel进行数据分析:描述性统计分析
在数据分析的时候,一般首先要对数据进行描述性统计分析(Descriptive Analysis),以发现其内在的规律,再选择进一步分析的方法。描述性统计分析要对调查总体所有变量的有关数据做统计性描述,主要包括数据的频数分析、数据的集中趋势分析、数据离散程度分析、数据的分布、以及一些基本的统计图形,常用的指标有均值、中位数、众数、方差、标准差等等。 接下来我们讲讲在Excel2007中完成描述性统计分析。一、案例场景 某网站的专题活动积累了一定访问数据后,需要统计流量的的均值、区间,以及给出该专题访问量差异的量化标准,借此来作为分析每天访问量的价值、参差不齐、此起彼伏一个衡量的依据。要求得到均值、区间、众数、方差、标准差等统计数据。 二、操作步骤 1、打开数据表格,这个案例中用的数据无特殊要求,只是一列数值就可以了。 2、选择“工具”——“数据分析”——“描述统计”后,出现属性设置框
注:本功能需要使用Excel扩展功能,如果您的Excel尚未安装数据分析,可以参考上一篇文章《用Excel进行数据分析:数据分析工具在哪里?》。 3、依次选择 选项有2方面,输入和输出选项 输入区域:原始数据区域,选中多个行或列,选择相应的分组方式逐行/逐列;
如果数据有标志,勾选“标志位于第一行”;如果输入区域没有标志项,该复选框将被清除,Excel 将在输出表中生成适宜的数据标志; 输出区域可以选择本表、新工作表或是新工作簿; 汇总统计:包括有平均值、标准误差(相对于平均值)、中值、众数、标准偏差、方差、峰值、偏斜度、极差、最小值、最大值、总和、总个数、最大值、最小值和置信度等相关项目。 第K大(小)值:输出表的某一行中包含每个数据区域中的第 k 个最大(小)值。 平均数置信度:数值 95% 可用来计算在显著性水平为 5% 时的平均值置信度。