如何用ImageJ测量染色体长度

细胞生物学有一个实验叫做小鼠骨髓细胞染色体的制备和组型分析,实验报告中,老师要求要用ImageJ这个软件对所得的染色体图像进行测量及配对,下面将对ImageJ的使用进行简单的介绍。
首先打开ImageJ软件,选择File—open,找到你的染色体图,这里建议先将染色体那一块裁剪下来。下一步便是对染色体进行标号,选择Text tool工具(就是那个A ),在要标的染色体旁单击,输入数字,再按Ctrl+D结束标记。然后就这样慢慢的标记完40条染色体吧。本人用过PS和Flash进行标记的,Flash比较快,但个人还是推荐PS,Flash不普及。
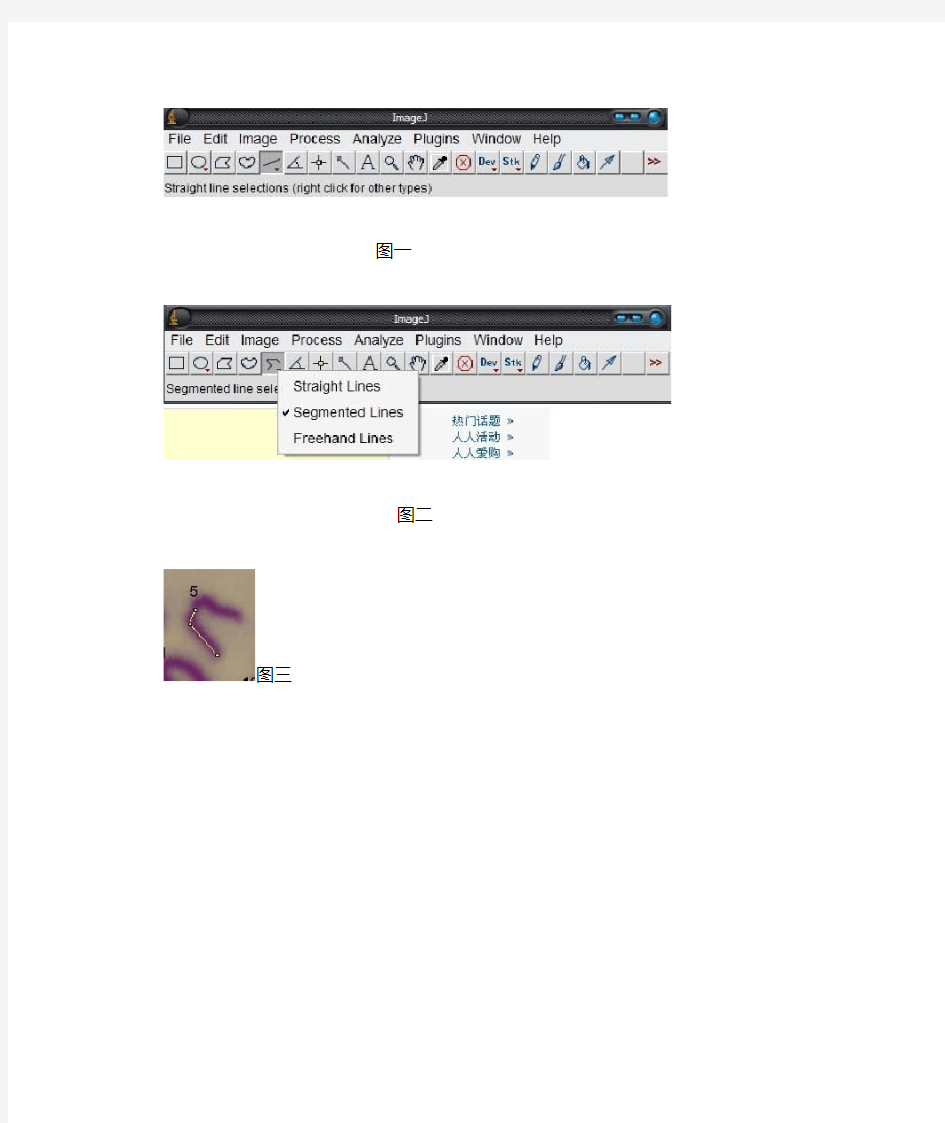
开始测量染色体的长度了,首先说一下ImageJ中默认的单位是pixel(像素),如果要设置可以在Analyze—Set Scale进行修改。本人觉得修改了也没有意思,你照片上根本就没有标尺。现在开始测量了,首先选择Straight line工具,(如图一),然后点击右键,选择Segmented line工具(如图二)。焦点移到图上面,左键单击起始点,鼠标移到转折点,再单击左键,最后移到终点,单击右键结束。(如图三)选择工具栏的Analyze—Measure(Ctrl+M也行),弹出了Results对话框,里面的length即为所测染色体长度。就这样一个一个的量吧,Results不要关了,你测量一次他里面的数据就会多一个的。量完40条染色体后焦点移到Results对话框上,选择File—Save as ...。就这样数据就存为一个EXCEL表格了。在量的过程中不免要对染色体进行放大,具体操作是选择图标像放大镜的那个工具,左键单击图像是放大,右键单击是缩小。
OK,这样你的染色体长度就量出来了,你会发现数据很不和谐,那么就多量几遍吧。
图一
图二
图三
遗传算法的流程图
一需求分析 1.本程序演示的是用简单遗传算法随机一个种群,然后根据所给的交叉率,变异率,世代数计算最大适应度所在的代数 2.演示程序以用户和计算机的对话方式执行,即在计算机终端上显示“提示信息”之后,由用户在键盘上输入演示程序中规定的命令;相应的输入数据和运算结果显示在其后。3.测试数据 输入初始变量后用y=100*(x1*x1-x2)*(x1*x2-x2)+(1-x1)*(1-x1)其中-2.048<=x1,x2<=2.048作适应度函数求最大适应度即为函数的最大值 二概要设计 1.程序流程图 2.类型定义 int popsize; //种群大小 int maxgeneration; //最大世代数 double pc; //交叉率 double pm; //变异率 struct individual
{ char chrom[chromlength+1]; double value; double fitness; //适应度 }; int generation; //世代数 int best_index; int worst_index; struct individual bestindividual; //最佳个体 struct individual worstindividual; //最差个体 struct individual currentbest; struct individual population[POPSIZE]; 3.函数声明 void generateinitialpopulation(); void generatenextpopulation(); void evaluatepopulation(); long decodechromosome(char *,int,int); void calculateobjectvalue(); void calculatefitnessvalue(); void findbestandworstindividual(); void performevolution(); void selectoperator(); void crossoveroperator(); void mutationoperator(); void input(); void outputtextreport(); 4.程序的各函数的简单算法说明如下: (1).void generateinitialpopulation ()和void input ()初始化种群和遗传算法参数。 input() 函数输入种群大小,染色体长度,最大世代数,交叉率,变异率等参数。 (2)void calculateobjectvalue();计算适应度函数值。 根据给定的变量用适应度函数计算然后返回适度值。 (3)选择函数selectoperator() 在函数selectoperator()中首先用rand ()函数产生0~1间的选择算子,当适度累计值不为零时,比较各个体所占总的适应度百分比的累计和与选择算子,直到达到选择算子的值那个个体就被选出,即适应度为fi的个体以fi/∑fk的概率继续存在; 显然,个体适应度愈高,被选中的概率愈大。但是,适应度小的个体也有可能被选中,以便增加下一代群体的多样性。 (4)染色体交叉函数crossoveroperator() 这是遗传算法中的最重要的函数之一,它是对个体两个变量所合成的染色体进行交叉,而不是变量染色体的交叉,这要搞清楚。首先用rand ()函数产生随机概率,若小于交叉概率,则进行染色体交叉,同时交叉次数加1。这时又要用rand()函数随机产生一位交叉位,把染色
基于遗传算法的染色体编码的分析
基于遗传算法的染色体编码的分析 第19卷第1期 2010年1月 重庆电子工程职业学院V o1.19NO.1 lan.2010oumalofChon£咽in£CoUe~eofElectronicEnl~ine 基于遗传算法的染色体编码的分析 吴焱岷 (重庆大学计算机学院,重庆400044;重庆电子工程职业学院,重庆401331) 摘要:遗传算法为解决复杂问题,特别是NP类问题提供了一种全新的思路,其编码方式也将在一定程 度上决定算法效率的高低和程序设计的复杂程度.需要针对想要解决问题类型的不同而采取不同的编码方式. 关键词:遗传算法;编码;值类型;事务类型 中图分类号:TP39文献标识码:A文章编号:1674—5787(2010)01一【)【】86一O2 遗传算法的概念最早是由BagleyJ.D在1967年提出 的.而开始遗传算法的理论和方法的系统性研究在1975 年开始.这一开创性工作是由Michigan大学的J.H. Holland所实行.遗传算法简称GA(GeneticAlgorithm),在 本质上是一种不依赖具体问题的直接搜索方法.其基本 思想是基于Darwin进化论和Mendel的遗传学说 Darwin进化论最重要的是适者生存原理它认为每 一 物种在发展中越来越适应环境.物种每个个体的基本 特征由后代所继承.但后代又会产生一些异于父代的新 变化. Mendel遗传学说最重要的是基因遗传原理它认为
遗传以密码方式存在细胞中.并以基因形式包含在染色 体内每个基因有特殊的位置并控制某种特殊性质,所 以.每个基因产生的个体对环境具有某种适应性.基因突变和基因杂交可产生更适应于环境的后代.经过存优去 劣的自然淘汰.适应性高的基因结构得以保存下来. 遗传算法最大的特点莫过于可以绕过复杂的数学推 导而采用最直接的方式在有限空间中搜索结果.例如求 函数f(x)=x*sin(10"n'x)+2在(一1,2)区间上的极大值,按照常规思路.需要对函数求导,找出函数的变化趋势和拐点.才能确定最大值的位置.对于相对简单的函数.采用 这些数学的方法还没有太高的难度.但是对于复杂的函数.则需要较为深厚的数学功底.同时也增加了程序设计的复杂程度 对于GA.采用一套全新的思路,首先任意给定一组 随机值x.由此开始进行演化.这些值就是代表一系列原 始生命.这些生命是否可以延续,取决于他们的适应程 度将这些随机值带入函数中进行运算,对得到的一系列 函数值进行排序.求最大值,可以认为值较大的函数值对应的x接近我们所需要的结论,这些结果可以保留;反之.对于另外一些函数值较小的x.则表明应该被淘汰. 第二步就是按照Mendel的基因理论.对这些将被淘 汰的X进行演化.演化分两步进行: (1)交叉.两个x值交换数据,类似生物界的交配,染 色体进行重新重组.交换基因以期得到新的品种,新品种可能更加适应环境而得到生存的机会.也可能向相反的 方向发展.从而失去生存的机会.因此通过某种方式得到新的X的值可以导致函数值增大.也可能导致减小,他们都将参加新一轮的竞争 (2)变异.单一的X值进行自身的调整,这类似于生
遗传算法的实验问题
遗传算法的实验问题 I.实验问题 对函数求解全局最大值。 II.实验目的 本实验的主要目的是通过MATLAB编程,使学生熟悉并掌握常用的MATLAB函数,同时对遗传算法有个初步的了解。 III.相关知识 遗传算法是进化算法中产生最早、影响最大、应用也比较广泛的一个研究方向和领域,其基本思想是由美国密执安大学的John H. Holland教授于1962年率先提出的。1975年,他出版了专著《自然与人工系统中的适应性行为》(Adaptation in Natural and Artificial Systems)[19],该书系统地阐述了遗传算法的基本理论和方法,确立了遗传算法的基本数学框架。此后,从事遗传算法研究的学者越来越多,使之成为一种通用于多领域中的优化算法。 遗传算法是一种基于生物的自然选择和群体遗传机理的搜索算法。它模拟了自然选择和自然遗传过程中发生的繁殖、交配和突变现象。它将每个可能的解看做是群体(所有可能解)中的一个个体,并将每个个体编码成字符串的形式,根据预定的目标函数对每个个体进行评价,给出一个适应度值。开始时总是随机地产生一些个体(即候选解),根据这些个体的适应度利用遗传算子对这些个体进行操作,得到一群新个体,这群新个体由于继承了上一代的一些优良性状,因而明显优于上一代,这样逐步朝着更优解的方向进化。遗传算法在每一代同时搜索参数空间的不同区域,然后把注意力集中到解空间中期望值最高的部分,从而使找到全局最优解的可能性大大增加。 作为进化算法的一个重要组成部分,遗传算法不仅包含了进化算法的基本形式和全部优点,同时还具备若干独特的性能: 1) 在求解问题时,遗传算法首先要选择编码方式,它直接处理的对象是参数的编码集而不是问题参数本身,搜索过程既不受优化函数连续性的约束,也没有函数导数必须存在的要求。通过优良染色体基因的重组,遗传算法可以有效地处理传统上非常复杂的优化函数求解问题。 2) 若遗传算法在每一代对群体规模为n的个体进行操作,实际上处理了大约O(n3)个模式,具有很高的并行性,因而具有明显的搜索效率。 3) 在所求解问题为非连续、多峰以及有噪声的情况下,能够以很大的概率收敛到最优解或满意解,因而具有较好的全局最优解求解能力。 4) 对函数的性态无要求,针对某一问题的遗传算法经简单修改即可适应于其他问题,或者加入特定问题的领域知识,或者与已有算法相结合,能够较好地解决一类复杂问题,因而具有较好的普适性和易扩充性。 5) 遗传算法的基本思想简单,运行方式和实现步骤规范,便于具体使用。 1.遗传算法对问题的描述 对于一个求函数最大值的优化问题(求函数最小值也雷同),一般可描述为下述数学规划模型: (1) 式中,X=[x1,x2,...,xn]T 为决策变量,f(X)为目标函数,和为约束条件,U是基本空间,R 是U的一个子集。集合R表示由所有满足约束条件的解所组成的一个集合,叫做可行解集合。它们的关系如图1所示。 图1 最优化问题的可行解及可行解集合 在遗传算法中,将n维决策向量X=[x1,x2,...,xn]T用n个记号Xi(i=1,2,...,n)
遗传算法
遗传算法是计算数学中用于解决最优化的搜索算法,是进化算法的一种。进化算法最初是借鉴了进化生物学中的一些现象而发展起来的,这些现象包括遗传、突变、自然选择以及杂交等。 遗传算法通常实现为一种计算机模拟。对于一个最优化问题,一定数量的候选解(称为个体)的抽象表示(称为染色体)的种群向更好的解进化。传统上,解用二进制表示(即0和1的串),但也可以用其他表示方法。进化从完全随机个体的种群开始,之后一代一代发生。在每一代中,整个种群的适应度被评价,从当前种群中随机地选择多个个体(基于它们的适应度),通过自然选择和突变产生新的生命种群,该种群在算法的下一次迭代中成为当前种群。 目录[隐藏] 1 遗传算法的机理 1.1 算法 1.2 GA参数 1.3 特点 2 变量 3 适用的问题 4 发展历史 5 应用领域 6 相关技术 7 参见 8 参考文献 9 外部链接 [编辑] 遗传算法的机理 在遗传算法里,优化问题的解被称为个体,它表示为一个参数列表,叫做染色体或者基因串。染色体一般被表达为简单的字符串或数字串,不过也有其他的表示方法适用,这一过程称为编码。一开始,算法随机生成一定数量的个体,有时候操作者也可以对这个随机产生过程进行干预,播下已经部分优化的种子。在每一代中,每一个个体都被评价,并通过计算适应度函数得到一个适应度数值。种群中的个体被按照适应度排序,适应度高的在前面。这里的“高”是相对于初始的种群的低适应度来说的。 下一步是产生下一代个体并组成种群。这个过程是通过选择和繁殖完成的,其中繁殖包括交配(crossover)和突变(mutation)。选择则是根据新个体的适应度进行的,适应度越高,被选择的机会越高,而适应度低的,被选择的机会就低。初始的数据可以通过这样的选择过程组成一个相对优化的群体。之后,被选择的个体进入交配过程。一般的遗传算法都有一个交配概率,范围一般是0.6~1,这个交配概率反映两个被选中的个体进行交配的概率。例如,交配概率为0.8,则80%的“夫妻”会生育后代。每两个个体通过交配产生两个新个体,代替原来的“老”个体,而不交配的个体则保持不变。交配父母的染色体相互交换,从而产生两个新的染色体,第一个个体前半段是父亲的染色体,后半段是母亲的,第二个个体则正好相反。不过这里的半段并不是真正的一半,这个位置叫做交配点,也是随机产生的,可以是染色体
遗传算法中的染色体基础知识
染色体是细胞核中载有遗传信息(基因)的物质,在显微镜下呈丝状或棒状,主要由脱氧核糖核酸和蛋白质组成,在细胞发生有丝分裂时期容易被碱性染料着色,因此而得名。在无性繁殖物种中,生物体内所有细胞的染色体数目都一样。而在有性繁殖物种中,生物体的体细胞染色体成对分布,称为二倍体。性细胞如精子、卵子等是单倍体,染色体数目只是体细胞的一半。[1]哺乳动物雄性个体细胞的性染色体对为XY;雌性则为XX。鸟类的性染色体与哺乳动物不同:雄性个体的是ZZ,雌性个体为ZW。 DNA[1]是一种长链聚合物,组成单位称为脱氧核苷酸(即A-腺嘌呤G-鸟嘌呤C-胞嘧啶T-胸腺嘧啶),而糖类与磷酸分子借由酯键相连,组成其长链骨架。每个糖分子都与
四种碱基里的其中一种相接,这些碱基沿着DNA长链所排列而成的序列,可组成遗传密码,是蛋白质氨基酸序列合成的依据。读取密码的过程称为转录,是以DNA双链中的一条为模板复制出一段称为RNA的核酸分子。多数RNA带有合成蛋白质的讯息,另有一些本身就拥有特殊功能,例如rRNA、snRNA与siRNA。在细胞内,DNA能组织成染色体结构,整组染色体则统称为基因组。染色体在细胞分裂之前会先行复制,此过程称为DNA复制。对真核生物,如动物、植物及真菌而言,染色体是存放于细胞核内;对于原核生物而言,如细菌,则是存放在细胞质中的类核里。染色体上的染色质蛋白,如组织蛋白,能够将DNA组织并压缩,以帮助DNA与其他蛋白质进行交互作用,进而调节基因的转录。 在脱氧核糖核酸和核糖核酸中,起配对作用的部分是含氮碱基。5种碱基都是杂环化合物,氮原子位于环上或取代氨基上,其中一部分(取代氨基,以及嘌呤环的1位氮、嘧啶环的3位氮)直接参与碱基配对。 碱基置换类型及缺失和插入突变示意图 碱基共有5种:胞嘧啶(缩写作C)、鸟嘌呤(G)、腺嘌呤(A)、胸腺嘧啶(T,DNA 专有)和尿嘧啶(U,RNA专有)。顾名思义,5种碱基中,腺嘌呤和鸟嘌呤属于嘌呤族(缩写作R),它们具有双环结构。胞嘧啶、尿嘧啶、胸腺嘧啶属于嘧啶族(Y),它们的环系是一个六元杂环。RNA中,尿嘧啶取代了胸腺嘧啶的位置。值得注意的是,胸腺嘧啶比尿嘧啶多一个5位甲基,这个甲基增大了遗传的准确性。 碱基通过共价键与核糖或脱氧核糖的1位碳原子相连而形成的化合物叫核苷。核苷再与磷酸结合就形成核苷酸,磷酸基接在五碳糖的5位碳原子上。 DNA(脱氧核糖核酸)的结构出奇的简单。DNA分子由两条很长的糖链结构构成骨架,通过碱基对结合在一起,就像梯子一样。整个分子环绕自身中轴形成一个双螺旋。两条链的空间是一定的,为2nm。 碱基
一种新的改进遗传算法及其性能分析外文翻译、中英文翻译、外文文献翻译
一种新的改进遗传算法及其性能分析外文翻译@中英文翻译 @外文文献翻译 摘要:虽然遗传算法以其全局搜索、并行计算、更好的健壮性以及在进化过程中不需要求导而著称,但是它仍然有一定的缺陷,比如收敛速度慢。本文根据几个基本定理,提出了一种使用变异染色体长度和交叉变异概率的改进遗传算法,它的主要思想是:在进化的开始阶段,我们使用短一些的变异染色体长度和高一些的交叉变异概率来解决,在全局最优解附近,使用长一些的变异染色体长度和低一些的交叉变异概率。最后,一些关键功能的测试表明,我们的解决方案可以显著提高遗传算法的收敛速度,其综合性能优于只保留最佳个体的遗传算法。 关键字:编译染色体长度;变异概率;遗传算法;在线离线性能 遗传算法是一种以自然界进化中的选择和繁殖机制为基础的自适应的搜索技术,它是由Holland 1975年首先提出的。它以其全局搜索、并行计算、更好的健壮性以及在进化过程中不需要求导而著称。然而它也有一些缺点,如本地搜索不佳,过早收敛,以及收敛速度慢。近些年,这个问题被广泛地进行了研究。 本文提出了一种使用变异染色体长度和交叉变异概率的改进遗传算法。一些关键功能的测试表明,我们的解决方案可以显著提高遗传算法的收敛速度,其综合性能优于只保留最佳个体的遗传算法。 在第一部分,提出了我们的新算法。第二部分,通过几个优化例子,将该算法和只保留最佳个体的遗传算法进行了效率的比较。第三部分,就是所得出的结论。最后,相关定理的证明过程可见附录。 1. 算法的描述 1.1 一些定理 在提出我们的算法之前,先给出一个一般性的定理(见附件),如下:我们假设有一个变量(多变量可以拆分成多个部分,每一部分是一个变量)x ∈[ a, b ] , x ∈R,二进制的染色体编码是1. 定理1 染色体的最小分辨率是 s = 定理2 染色体的第i位的权重值是
遗传算法
遗传算法 摘要:遗传算法(Genetic Algorithm)是一类借鉴生物界的进化规律(适者生存,优胜劣汰遗传机制)演化而来的随机化搜索方法。它是由美国的J.Holland教授1975年首先提出,其主要特点是直接对结构对象进行操作,不存在求导和函数连续性的限定;具有内在的隐并行性和更好的全局寻优能力;采用概率化的寻优方法,能自动获取和指导优化的搜索空间,自适应地调整搜索方向,不需要确定的规则。遗传算法的这些性质,已被人们广泛地应用于组合优化、机器学习、信号处理、自适应控制和人工生命等领域。它是现代有关智能计算中的关键技术。遗传算法经过不断的发展和改进,又发展出许多新的进化算法,如模拟退火算法,免疫遗传算法,粒子群优化算法等等。 关键字:遗传算法;进化率;寻优方法;组合优化 1、遗传算法的发展及历史 遗传算法(Genetic Algorithm,简称GA)起源于对生物系统所进行的计算机模拟研究。美国Michigan大学的Ho11and教授及其学生受到生物模拟技术的启发,创造出了一种基于生物遗传和进化机制的适合于复杂系统优化的自适应概率优化技术——遗传算法。 1967年,Holland的学生Bagley在其博士论文中首次提出了“遗传算法”一词,他发展了复制、交叉、变异、显性、倒位等遗传算子,在个体编码上使用双倍体的编码方法。Holland教授用遗传算法的思想对自然和人工自适应系统进行了研究,提出了遗传算法的基本定理——模式定理(Schcma Theorem),并于1975年出版了第一本系统论述遗传算法和人工自适应系统的专著《Adaptation in Natural and Artificial Systems》。 20世纪80年代,Holland教授实现了第一个基于遗传算法的机器学习系统,开创了遗传算法的机器学习的新概念。1975年DeJong基于遗传算法的思想在计算机上进行了大量的纯数值函数优化计算实验,建立了遗传算法的工作框架,得到了一些重要且具有指导意义的结论。1989年Goldberg出版了专著《Genetic Algorithm in Search Optimization and Machine Learning》,系统地总结了遗传算法的主要研究成果,全面完整地论述了遗传算法的基本原理及其应用。 1991年,Davis出版了《Handbook of Genetic Algorithms》一书,介绍了遗传算法在科学计算、工程技术和社会经济中的大量实例。 1992年,Koza将遗传算法应用于计算机程序的优化设计及自动生成,提出了遗传编程(Genetic Programming,简称GP)的概念。 在控制系统的离线设计方面遗传算法被众多的使用者证明是有效的策略。例如,Krishnakumar和Goldberg以及Bramlette和Cusin已证明使用遗传优化方法在太空应用中导出优异的控制器结构比使用传统方法如LQR和Powell(鲍威尔)的增音机设计所用的时间要少(功能评估)。Porter和Mohamed展示了使用本质结构分派任务的多变量飞行控制系统的遗传设计方案。与此同时,另一些人证明了遗传算法如何在控制器结构的选择中使用。 从遗传算法的整个发展过程来看,20世纪70年代是兴起阶段,20世纪80年代是发展阶段,20世纪90年代是高潮阶段。遗传算法作为一种实用、高效、鲁棒性强的优化技术,发展极为迅速,已引起国内外学者的高度重视。 2、遗传算法的计算步骤及关键 2.1 需求分析
遗传算法笔记——4
第四章遗传算法的高级实现技术 4.1 倒位算子 4.1.1 倒位操作 所渭倒位操作(Iwerse〔)Per班ion)是指颠倒个体编码串中随机指定的二个基因座之间的基因排列顺序,从而形成一个新的染色体。倒位操作的具体过程是: [1]在个体编码串中随机指定二个基因座之后的铰胃为倒位点; (2)以倒位概率入颠倒这二个例位点之间的基因排列顺序。 4.2 二倍体与显性操作算于 4.2.1 二倍体结构的生物基础 一是二倍体的记亿能力,它使得生物能够记忆以前所经历过的环境及变化,使得生物的遗传进化过程能够快速地适应环境的变化。这个特点在遗传算法中的应用意义就在于.使用二倍体结构的遗传算法能够解决动态环境下的复杂系统优化问题.而常规的遗传算法却不能很好地应川于动态环境,它难于跟踪环境的动态变化过程。 二是显性操作的鲁棒性.它使得即使随机选择了适应度不高的个体,而在显性操作的作用下,能够用其另一同派染色体对其进行校正,从而避免这个有害选择所带来的不利之处。这个持点应用于遗传算法中.能有利于提高遗传算法的运算效率,维护好的搜索群体。 4.2.2 二倍体结构在遗传算法中的实现方案 这样,使用双倍体的遗传算法可描述如下; 1.初始化.并设置进化代数计数器初值。 2.随机产生具有二倍体结构的初始群体P(t)。 3.对初姑群体P(t)进行显性操作。 4.评价韧姑群钵P(t)中各个个体的适应度。 5.交叉操作:由每两个随机配对的2个体进行交又操作时,共可产生四个单倍休个体 6.变异操作:在对群体中的各个个体进行变异操作时*需要考虑隐性基因的作用。 7.对群体P”(t)进行显性操作。 8.评价群体P”(t)中各个个体的适应度。 9.个体选择、复制操作:。 10.终止条件判断。若不满足终上条件,则:转到第5步,继续进行进化操作过程;苦 满足终止条件,则:输出当前最优个体,算法结束。 应用实践表明,对于静态优化问题,与使用单倍体的遗传韵法相比,使用双倍体的遗传算法并不能改善多少求解性能。但对于动态系统的优化问题,使用单倍体的遗传算法很难达到优化要求,因为它跟踪不了动态环境的变化过程,此时,使用双倍体的遗传算法却能表现出较好的应用效果。 4.3 变氏度染色体遗传算法 4.3.1 变长度染色体遗传算法的编码与解码 对变长度染色体进行解码处理时,在正常指定情况下,将变长度染色体遗传算法中的个体基因型转换为常规遗传算法中的个体基因型时不会有什么问题,而在过剩指定或缺省指定时,就会产生描述过剩或描述不足的问题,此时可按下述规则来进行解码处理: (1)描述过剩时的解码方法。此时,常规遗传算法中的一个基内座可能在变长度染 色体个同时有几个对应的::元组,规定取最左边的二元组来进行解码。 2)捞述不足时的解码方法。此时,常规遗传算法中有些基因座上的基因值未被在变 长度染色体中明确地指定,这时可规定它们取某—顶先设定的标难值(或缺省值)。 4.3.2 切断算子与拼接算子 变长度染色体遗传算法除F使用常规遗传算法中的选择其子和变异算子之外,
遗传算法中的染色体基础知识
染色体(Chromosome )是细胞内具有遗传性质的物体,易被碱性染料染成深色,所以叫染色体(染色质);其本质是脱氧核甘酸,是细胞核内由组成、能用碱性染料染色、有结构的线状体,是遗传物质基因的。 染色体是中载有()的物质,在下呈丝状或棒状,主要由和组成,在细胞发生时期容易被着色,因此而得名。在物种中,生物体内所有细胞的染色体数目都一样。而在物种中,生物体的体细胞染色体成对分布,称为。性细胞如、等是,染色体数目只是体细胞的一半。[1]哺乳动物雄性个体细胞的性染色体对为XY;则为XX。鸟类的性染色体与不同:雄性个体的是ZZ,雌性个体为ZW。 脱氧核糖核酸(英语:Deoxyribonucleic acid,缩写为DNA)又称去氧核糖核酸,是一种,可组成遗传指令,以引导生物发育与生命机能运作。主要功能是长期性的资讯储存,可比喻为“蓝图”或“食谱”。其中包含的指令,是建构内其他的,如与所需。带有遗传讯息的DNA片段称为,其他的DNA序列,有些直接以自身构造发挥作用,有些则参与调控遗传讯息的表现。 DNA[1]是一种长链,组成单位称为脱氧核苷酸(即A-G-C-T-),而与磷酸分子借由酯键相连,组成其长链骨架。每个糖分子都与四种里的其中一种相接,这些碱基沿着DNA 长链所排列而成的序列,可组成,是序列合成的依据。读取密码的过程称为转录,是以
DNA双链中的一条为模板复制出一段称为RNA的核酸分子。多数带有合成蛋白质的讯息,另有一些本身就拥有特殊功能,例如rRNA、snRNA与siRNA。在细胞内,DNA 能组织成结构,整组染色体则统称为。染色体在细胞分裂之前会先行复制,此过程称为DNA复制。对真核生物,如动物、植物及真菌而言,染色体是存放于细胞核内;对于而言,如细菌,则是存放在细胞质中的类核里。染色体上的蛋白,如组织蛋白,能够将DNA组织并压缩,以帮助DNA与其他蛋白质进行交互作用,进而调节基因的转录。在脱氧核糖核酸和核糖核酸中,起配对作用的部分是含氮碱基。5种碱基都是杂环化合物,氮原子位于环上或取代氨基上,其中一部分(取代氨基,以及嘌呤环的1位氮、嘧啶环的3位氮)直接参与碱基配对。 碱基置换类型及缺失和插入突变示意图 碱基共有5种:(缩写作C)、(G)、(A)、(T,DNA专有)和(U,RNA专有)。顾名思义,5种碱基中,腺嘌呤和鸟嘌呤属于嘌呤族(缩写作R),它们具有双环结构。胞嘧啶、尿嘧啶、胸腺嘧啶属于嘧啶族(Y),它们的环系是一个六元杂环。RNA中,尿嘧啶取代了胸腺嘧啶的位置。值得注意的是,胸腺嘧啶比尿嘧啶多一个5位甲基,这个甲基增大了遗传的准确性。 碱基通过共价键与核糖或脱氧核糖的1位碳原子相连而形成的化合物叫核苷。核苷再与磷酸结合就形成核苷酸,磷酸基接在五碳糖的5位上。 DNA(脱氧核糖核酸)的结构出奇的简单。DNA分子由两条很长的糖链结构构成骨架,通过碱基对结合在一起,就像梯子一样。整个分子环绕自身中轴形成一个双螺旋。两条链的空间是一定的,为2nm。 碱基 在形成稳定螺旋结构的碱基对中共有4种不同碱基。根据它们英文名称的首字母分别称之为A(ADENINE 腺嘌呤)、T(THYMINE 胸腺嘧啶)、C(CYTOSINE 胞嘧啶)、
遗传算法及其在机构参数优化中应用
11.1遗传算法及其在机构参数优化中地应用 基于进化规律地遗传算法