遗漏解释变量检验在Eviews7.0中的实现步骤
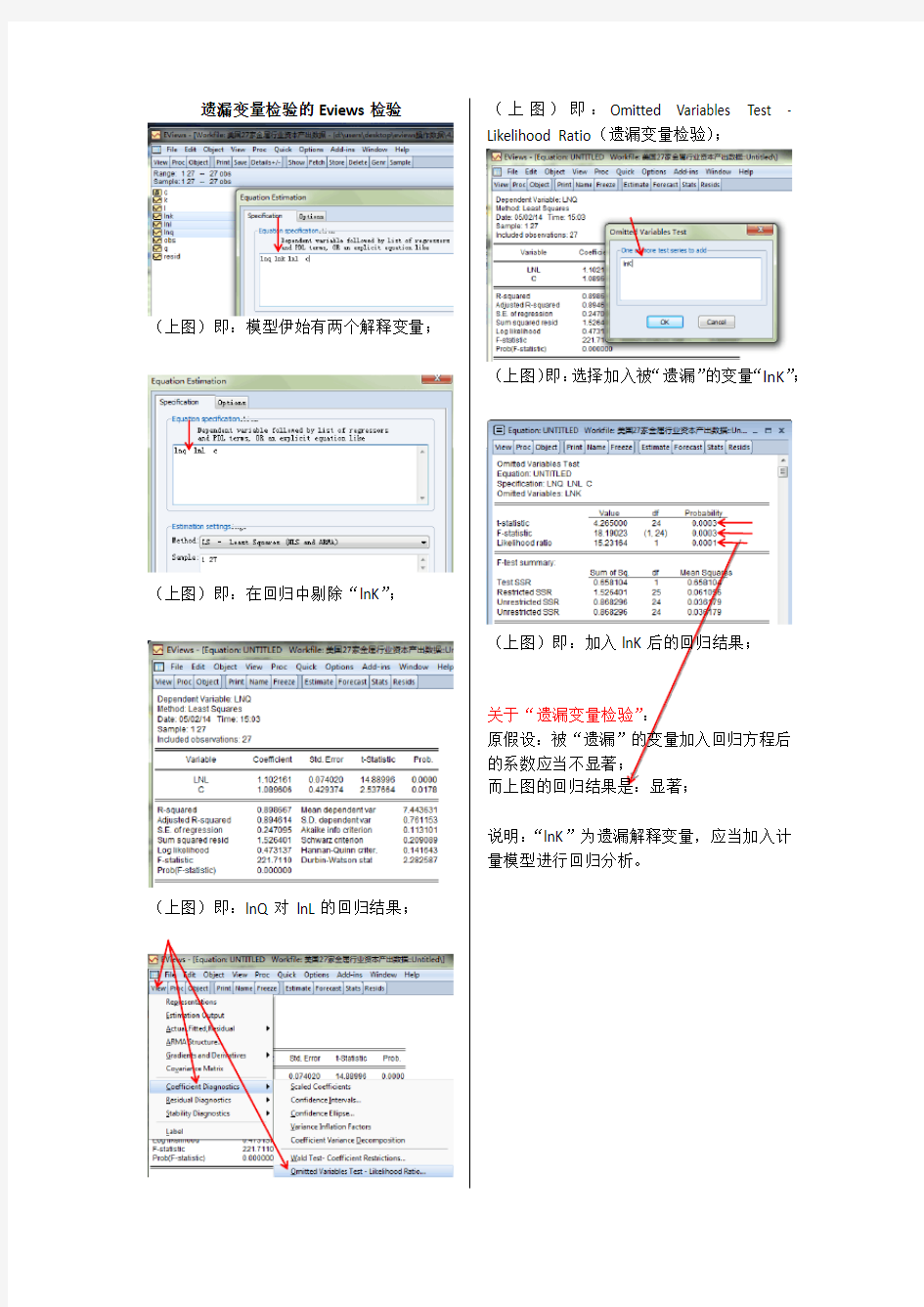
遗漏变量检验的Eviews 检验 (上图)即:模型伊始有两个解释变量;
(上图)即:在回归中剔除“lnK ”;
(上图)即:lnQ 对 lnL 的回归结果;
(上图)即:Omitted Variables Test -
Likelihood Ratio (遗漏变量检验);
(上图)即:选择加入被“遗漏”的变量“lnK ”; (上图)即:加入lnK 后的回归结果; 关于“遗漏变量检验”: 原假设:被“遗漏”的变量加入回归方程后的系数应当不显著; 而上图的回归结果是:显著; 说明:“lnK ”为遗漏解释变量,应当加入计量模型进行回归分析。
计量经济学第三版部分答案(第六章之后的)
第六章 1、答:给定显著水平α,依据样本容量n和解释变量个数k’,查D.W.表得d统计量的上界 du和下界dL,当0 简答题:1.选择工具变量的原则是什么:(1)工具变量必须与所替代的随机解释变量高度相关;(2)工具变量与随机误差项不相关(3)工具变量与其它解释变量不相关,避免出现多重共线性。 2.实际经济问题中的多重共线性 (1)经济变量的趋同性(2)滞后变量的引入(3)样本资料的限制 3.序列相关性产生的原因: (1)惯性;(2)模型设定误差;(3)蛛网现象;(4)数据加工。 4、随机解释变量问题及其解决方法。如果存在一个或多个随机变量作为解释变量,则称原模型出现随机解释变量问题。第一、随机解释变量与误差项相互独立;第二、随机解释变量与误差项同期无关,而异期相关;第三、随机解释变量与误差项同期相关;第四、解决方法为工具变量法。 5.随机解释变量产生的后果 1.若相互独立,则参数估计量仍然无偏一致。2 若同期相关,异期不相关,得到的参数估计有偏,但却是一致的3 若同期相关,则估计量有偏且非一致。 6.简述最小二乘估计量的性质:(1)线性性,即它是否是另一随机变量的线性函数;(2)无偏性,即它的均值或期望值是否等于总体的真实值;(3)有效性,即它是否在所有线性无偏估计量中具有最小方差。(4)渐近无偏性,即样本容量趋于无穷大时,是否它的均值序列趋于总体真值;(5)一致性,即样本容量趋于无穷大时,它是否依概率收敛于总体的真值;(6)渐近有效性,即样本容量趋于无穷大时,是否它在所有的一致估计量中具有最小的渐近方差。 7、虚拟变量的作用:(1)表现定性因素对被解释变量的影响(2)提高模型的说明能力与水平(3)季节变动分析。(4)方程差异性检验。 8、虚拟变量设置的原则:如果有定性因素共有个结果需要区别,那么至多引入m-1 个虚拟变量 9、实际经济问题中的多重共线性:(1)经济变量的趋同性(2)滞后变量的引入(3)样本资料的限制 10.引入随机误差形式为了:(1)代表未知的影响因素(2)代表残缺数据(3)代表众多细小的影响因素(4)代表数据观测误差(5)代表模型设定误差(6)变量的随机存在性 11. 12.回归分析的主要内容有:(1)根据样本观测值对经济计量模型参数进行估计,求得回归方程(2)对回归方程、参数估计值进行显著性检验(3)利用回归方程进行分析、评价及预测。 13.叙述原理:最小二乘法:当从模型总体随机抽取n组样本观测值后,最合理的参数估计量应该使得模型能最好的的拟合样本数据:最大似然法:当从模型的总体随机抽取n组样本观测值后,最合理的参数估计量应该使得从模型中抽取该n组样本观测值的概率最大。在满足一系列基本假设的情况下,模型结构参数的最大或然估计量与普通最小二乘估计量是相同的。 内生性问题与工具变量和两阶段最小二乘 一、背景 虽然在OLS 的大样本性质中,我们放宽了强外生性的假定,用弱外生条件来进行替代,即()0E x ε'=。但是,在实际的问题中,弱外生性的条件往往也是不容易满足的。也就是说,变量的内生性问题总是不可避免的。内生性引起的问题主要是引起参数估计的不一致。可以说,内生性问题是在实际应用中最经常遇到的问题。这个部分讨论的就是如何解决由内生性问题引起的参数估计的不一致。 二、知识要点 1、引起内生性的原因及其对参数估计的影响 2、代理变量法解决内生性问题 3、工具变量法和2SLS 的性质 三、要点细纲 1、引起内生性的原因及其对参数估计的影响 (1)模型设定偏误(遗漏变量) 这主要是因为实际的问题中,一个变量往往受到许多变量的影响,在实际建模过程中无法将解释变量全部列出。在这样的情况下,遗漏的变量的影响就被纳入了误差项中,在该遗漏变量与其他解释变量相关的情况下,就引起了内生性问题。即()0E x ε'≠。 (2)测量误差 关于测量误差引起内生性的问题要基于测量误差的假设。测量误差可能是对被解释变量y 的测量误差,也可能是由于对解释变量x 的测量误差。这两种情况引发的结果是不一样的。 A. 被解释变量y 的测量误差。 不妨假设y 的真实值是*y ,测量值为y ,则可以将测量误差表示成: *0e y y =-。假设理论的回归方程为: *011k k y x x βββε=+++ 将测量误差方程带入得到: 0110k k y x x e βββε=++++ 011k k x x v βββ=+++ 其中0v e ε=+是实际回归方程的残差。显然,由于y 的测量误差0e 是与i x 相互独立的,所以实际回归方程的残差v 也与各解释变量相互独立(无关)。外生性条件满足。 B. 解释变量x 的测量误差 假设在回归式011k k y x x βββε=+++ 中,测量误差产生于k x ,即实际回归式为: *011k k y x x βββε=+++ 并有* k k k e x x =- 如果假设cov(,)0k k x e =,则将测量误差带入方程得到: 011k k k k y x x e βββεβ=++++ 011k k x x v βββ=+++ 显然,外生性条件满足。 如果假设* *2cov(,)0cov(,)cov(,)k k k k k k k e x e x e x e e σ=?=+=。该假设条件 称为Classical error-in-variables (CEV )假定。 由上述方程可以看出,此时测量误差会引起内生性问题。 ( 3) 双向交互影响(或者同时受其他变量的影响) 这种情况引起的内生性问题在现实中最为常见。其基本的原理可以阐述为,被解释变量y 和解释变量x 之间存在一个交互影响的过程。x 的数值大小会引起 y 取值的变换,但同时y 的变换又会反过来对x 构成影响。这样,在如下的回归 方程中: 011k k y x x βββε=+++ 如果残差项ε的冲击影响了y 的取值,而这样的影响会通过y 传导到x 上, 第四章 随机解释变量问题 1. 随机解释变量的来源有哪些? 答:随机解释变量的来源有:经济变量的不可控,使得解释变量观测值具有随机性;由于随机干扰项中包括了模型略去的解释变量,而略去的解释变量与模型中的解释变量往往是相关的;模型中含有被解释变量的滞后项,而被解释变量本身就是随机的。 2.随机解释变量有几种情形? 分情形说明随机解释变量对最小二乘估计的影响与后果? 答:随机解释变量有三种情形,不同情形下最小二乘估计的影响和后果也不同。(1)解释变量是随机的,但与随机干扰项不相关;这时采用OLS 估计得到的参数估计量仍为无偏估计量;(2)解释变量与随机干扰项同期无关、不同期相关;这时OLS 估计得到的参数估计量是有偏但一致的估计量;(3)解释变量与随机干扰项同期相关;这时OLS 估计得到的参数估计量是有偏且非一致的估计量。 3. 选择作为工具变量的变量必须满足那些条件? 答:选择作为工具变量的变量需满足以下三个条件:(1)与所替代的随机解释变量高度相关;(2)与随机干扰项不相关;(3)与模型中其他解释变量不相关,以避免出现多重共线性。 4.对模型 Y t =β0+β1X 1t +β2 X 2t +β3 Y t-1+μt 假设Y t-1与μt 相关。为了消除该相关性,采用工具变量法:先求Y t 关于X 1t 与 X 2t 回归,得到Y t ?,再做如下回归: Y t =β0+β1X 1t +β2 X 2t +β3Y t ?1 -+μt 试问:这一方法能否消除原模型中Y t-1与μt 的相关性? 为什么? 解答:能消除。在基本假设下,X 1t ,X 2t 与μt 应是不相关的,由此知,由X 1t 与X 2t 估计出的Y t ?应与μt 不相关。 5.对于一元回归模型 Y t =β0+β1X t *+μt 假设解释变量X t *的实测值X t 与之有偏误:X t = X t *+e t , 其中e t 是具有零均值、无序列相关,且与X t *及μt 不相关的随机变量。试问: (1) 能否将X t = X t *+e t 代入原模型,使之变换成Y t =β0+β1X t +νt 后进行估计? 其中,νt 为变换后模型的随机干扰项。 (2) 进一步假设μt 与e t 之间,以及它们与X t *之间无异期相关,那么E(X t-1νt )=0成立 吗?X t 与X t-1相关吗? (3) 由(2)的结论,你能寻找什么样的工具变量对变换后的模型进行估计? 解答:(1)不能。因为变换后的模型为 Y t =β0+β1X t +(μt -β 1e t ) 显然,由于 e t 与X t 同期相关,则说明变换后的模型中的随机干扰项νt =μt -β1e t 与X t 同 期相关。 (2) E(X t-1νt )=E[(X t-1* +e t-1)( μt -β1e t )] 内生性问题原因和处理 方法 Company number:【0089WT-8898YT-W8CCB-BUUT-202108】 内生性问题:就是模型中的一个或多个解释变量与随机扰动项相关的问题。变量的内生性问题总是不可避免的。内生性引起的问题主要是引起参数估计的不一致。 引起内生性问题的原因: (1)遗漏变量 这主要是因为实际的问题中,一个变量往往受到许多变量的影响,在实际建模过程中无法将解释变量全部列出。在这样的情况下,遗漏的变量的影响就被纳入了误差项中,在该遗漏变量与其他解释变量相关的情况下,就引起了内生性问题。 (2)测量误差 关于测量误差引起内生性的问题要基于测量误差的假设。测量误差可能是对被解释变量y 的测量误差,也可能是由于对解释变量x 的测量误差。这两种情况引发的结果是不一样的。 ( 3) 双向交互影响 这种情况引起的内生性问题在现实中最为常见。其基本的原理可以阐述为,被解释变量y 和解释变量x 之间存在一个交互影响的过程。x 的数值大小会引起y 取值的变换,但同时y 的变换又会反过来对x 构成影响。这样,在如下的回归方程中:011k k y x x βββε=+++,如果残差项ε的冲击影响了y 的取值,而这样的影响会通过y 传导到x 上,从而造成了x 和残差项ε的相关。也就是引起了内生性问题。 内生性问题处理方法: 1.工具变量法(IV ) 就是找到一个变量和内生化变量相关,但是和残差项不相关。在OLS的框架下同时有多个IV,这些工具变量被称为两阶段最小二乘(2SLS)估计量。具体的说,这种方法是找到影响内生变量的外生变量,连同其他已有的外生变量一起回归,得到内生变量的估计值,以此作为IV,放到原来的回归方程中进行回归。 2.代理变量法(Proxy) Proxy方法是将不可观测的变量用近似的变量进行替代,也就是说,是在残差项中提取出有用的信息,但是并没有对现有的解释变量进行处理。 3. 自然实验法 就是就是发生了某些外部突发事件,使得研究对象仿佛被随机分成了实验组或控制组。该事件只影响一部分样本,或者只影响解释变量而不影响被解释变量。 4. 双重差分法 倘若出现了一次外部冲击,这次冲击影响了一部分样本,对另一部分样本则无影响,双重差分法就是用来研究这次冲击的净效应的。其基本思想是,将受冲击的样本视作实验组,再按照一定标准在未受冲击的样本中寻求与实验组匹配的对照组,而后做差,做差剩下来的便是这次冲击的净效应。 第8章模型中的特殊解释变量 习题 一、单项选择题 1.对于一个含有截距项的计量经济模型,若某定性因素有m个互斥的类型,为将其引入模型中,则需要引入虚拟变量个数为() A. m B. m-1 C. m+1 D. m-k 2.在经济发展发生转折时期,可以通过引入虚拟变量方法来表示这种变化。例如,研究中国城镇居民消费函数时。1991年前后,城镇居民商品性实际支出Y 对实际可支配收入X的回归关系明显不同。现以1991年为转折时期,设虚拟变 量,数据散点图显示消费函数发生了结构性变化:基本消费部分下降了,边际消费倾向变大了。则城镇居民线性消费函数的理论方程可以写作() A. B. C. D. 3.对于有限分布滞后模型 在一定条件下,参数可近似用一个关于的阿尔蒙多项式表示(),其中多项式的阶数m必须满足() A. B. C. D. 4.对于有限分布滞后模型,解释变量的滞后长度每增加一期,可利用的样本数据就会( ) A. 增加1个 B. 减少1个 C. 增加2个 D. 减少2个 5.经济变量的时间序列数据大多存在序列相关性,在分布滞后模型中,这种序列相关性就转化为() A.异方差问题 B. 多重共线性问题 C.序列相关性问题 D. 设定误差问题 6.将一年四个季度对因变量的影响引入到模型中(含截距项),则需要引入虚 拟变量的个数为() A. 4 B. 3 C. 2 D. 1 7.若想考察某两个地区的平均消费水平是否存在显著差异,则下列那个模型比 较适合(Y代表消费支出;X代表可支配收入;D 2、D 3 表示虚拟变量)() A. B. C. D. 二、多项选择题 1.以下变量中可以作为解释变量的有() A. 外生变量 B. 滞后内生变量 C. 虚拟变量 D. 前定变量 E. 内生变量 2.关于衣着消费支出模型为:,其中 Y i 为衣着方面的年度支出;X i 为收入, 则关于模型中的参数下列说法正确的是() A.表示在保持其他条件不变时,女性比男性在衣着消费支出方面多支出(或少支出)差额 B.表示在保持其他条件不变时,大学毕业及以上比其他学历者在衣着消费支出方面多支出(或少支出)差额 C.表示在保持其他条件不变时,女性大学及以上文凭者比男性大学以下文凭者在衣着消费支出方面多支出(或少支出)差额 D. 表示在保持其他条件不变时,女性比男性大学以下文凭者在衣着消费支出方面多支出(或少支出)差额 E. 表示性别和学历两种属性变量对衣着消费支出的交互影响 三、判断题 1.通过虚拟变量将属性因素引入计量经济模型,引入虚拟变量的个数与样本容量大小有关。 2.虚拟变量的取值只能取0或1。 3.通过虚拟变量将属性因素引入计量经济模型,引入虚拟变量的个数与模型有无截距项无关。 四、问答题 1.Sen和Srivastava(1971)在研究贫富国之间期望寿命的差异时,利用101个国家的数据,建立了如下的回归模型(括号内的数值为对应参数估计值t值): 第7章 随机解释变量 单方程线性计量经济学模型假定解释变量是确定性变量,并且与随机误差项不相关,违背这一基本假设的问题被称为随机解释变量问题。本章介绍了随机解释变量问题的概念、产生的原因和后果、检验方法以及解决方法。 随机解释变量问题的概念 对于计量经济模型 n 21i i k i k i 22i 110 ,,, ββββ=+++++=u X X X Y i (7.1.1) 其中一个基本假设是解释变量k 21,,X X X 是确定性变量,即解释变量与随机扰动项不相关。但是在现实经济生活中,这个假定不一定成立,这一方面是因为用于建模的经济变量的观测值一般会存在观测误差,另一方面是经济变量之间联系的普遍性使得解释变量可能在一定程度上依赖于应变量,即解释变量X 影响应变量Y ,而应变量Y 也会反过来影响解释变量X 。 模型中如果存在一个或多个随机变量作为解释变量,就称为模型出现了随机解释变量问题。其中k x 可能与随机误差项u 不相关,就是说,解释变量121,,-k x x x 都是外生的,但k x 有可能在方程(4.4.1)中是内生的,则称原模型存在随机解释变量问题。内生性可能源自于省略误差、测量误差,联立性等①。为讨论方便,我们假设中2X 为随机解释变量。 在模型()中,根据解释变量2X 与随机误差项的关系,可以分为三种类型: 1)随机解释变量与随机干扰项独立 )()(),(),(222===u E x E u x E u X Cov (7.1.2) 2)随机解释变量与随机干扰项同期无关但异期相关 n 21i 0),(),(i 2i 2 ,,, ===u x E u X Cov i i ① 具体详见《Econometric analysis of cross section and panal data 》(Jeffrey Wooldrige,2007 )。 内生性问题:就是模型中的一个或多个解释变量与随机扰动项相关的问题。变量的内生性问题总是不可避免的。内生性引起的问题主要是引起参数估计的不一致。 引起内生性问题的原因: (1)遗漏变量 这主要是因为实际的问题中,一个变量往往受到许多变量的影响,在实际建模过程中无法将解释变量全部列出。在这样的情况下,遗漏的变量的影响就被纳入了误差项中,在该遗漏变量与其他解释变量相关的情况下,就引起了内生性问题。 (2)测量误差 关于测量误差引起内生性的问题要基于测量误差的假设。测量误差可能是对被解释变量y 的测量误差,也可能是由于对解释变量x 的测量误差。这两种情况引发的结果是不一样的。 ( 3) 双向交互影响 这种情况引起的内生性问题在现实中最为常见。其基本的原理可以阐述为,被解释变量y 和解释变量x 之间存在一个交互影响的过程。x 的数值大小会引起y 取值的变换,但同时y 的变换又会反过来对x 构成影响。这样,在如下的回归方程中:011k k y x x βββε=+++,如果残差项ε的冲击影响了y 的取值,而这样的影响会通过y 传导到x 上,从而造成了x 和残差项ε的相关。也就是引起了内生性问题。 内生性问题处理方法: 1.工具变量法(IV) 就是找到一个变量和内生化变量相关,但是和残差项不相关。在OLS 的框架下同时有多个IV,这些工具变量被称为两阶段最小二乘(2SLS)估计量。具体的说,这种方法是找到影响内生变量的外生变量,连同其他已有的外生变量一起回归,得到内生变量的估计值,以此作为IV,放到原来的回归方程中进行回归。 2.代理变量法(Proxy) Proxy方法是将不可观测的变量用近似的变量进行替代,也就是说,是在残差项中提取出有用的信息,但是并没有对现有的解释变量进行处理。 3. 自然实验法 就是就是发生了某些外部突发事件,使得研究对象仿佛被随机分成了实验组或控制组。该事件只影响一部分样本,或者只影响解释变量而不影响被解释变量。 4. 双重差分法 倘若出现了一次外部冲击,这次冲击影响了一部分样本,对另一部分样本则无影响,双重差分法就是用来研究这次冲击的净效应的。其基本思想是,将受冲击的样本视作实验组,再按照一定标准在未受冲击的样本中寻求与实验组匹配的对照组,而后做差,做差剩下来的便是这次冲击的净效应。 第一学期期末考试试卷 《计量经济学》试卷 一、单项选择题(1分×20题=20分) 1.在回归分析中下列有关解释变量和被解释变量的说法中正确的是(c ) A. 被解释变量和解释变量均为随机变量 B. 被解释变量和解释变量均为非随机变量 C. 被解释变量为随机变量,解释变量为非随机变量 D. 被解释变量为非随机变量,解释变量为随机变量 2. 下面哪一个必定是错误的(a )。 A. 8.02.030^ =+=XY i r X Y B. 91.05.175^ =+=XY i r X Y C. 78.01.25^=-=XY i r X Y D. 96.05.312^ -=--=XY i r X Y 3.判断模型参数估计量的符号、大小、相互之间关系的合理性属于(b )准则。 A.计量经济 B.经济理论 C.统计 D.统计和经济理论 4. 判定系数r 2 =0.8,说明回归直线能解释被解释变量总变差的:( a ) A. 80% B. 64% C. 20% D. 89% 5.下图中“{”所指的距离是(b ) A. 随机误差项 B. 残差 C. i Y 的离差 D. i Y ?的离差 X 1?β+ i Y 6. 已知DW 统计量的值接近于2,则样本回归模型残差的一阶自相关系数ρ? 近似等于(a )。 A.0 B. -1 C.1 D. 0.5 7.已知含有截距项的三元线性回归模型估计的残差平方和为800e 2t =∑,估计用 样本容量为n=24,则随机误差项t ε的方差估计量为(b )。 A.33.3 B.40 C.38.09 D.36.36 8.反映由模型中解释变量所解释的那部分离差大小的是(b )。 A.总体平方和 B.回归平方和 C.残差平方和 D.离差和 9. 某企业的生产决策是由模型t t t u P S ++=10ββ描述(其中t S 为产量,t P 为价格),又知:如果该企业在1-t 期生产过剩,决策者会削减t 期的产量。由此判断上述模型存在(b )。 A. 异方差问题 B. 序列相关问题 C. 多重共线性问题 D. 随机解释变量问题 10.产量(X ,台)与单位产品成本(Y ,元/台)之间的回归方程为5X .1356Y ?-=,这说明(d )。 A.产量每增加一台,单位产品成本增加356元 B.产量每增加一台,单位产品成本减少1.5元 C.产量每增加一台,单位产品成本平均增加356元 D.产量每增加一台,单位产品成本平均减少1.5元 11.回归模型25,1i ,X Y i i 10i Λ=++=εββ,中,总体方差未知,检验0 :H 10=β时,所用的检验统计量) ?(S ?111βββ-服从(d )。 A.)2n (2 -χ B. )1n (t - C. )1n (2-χ D. )2n (t - 12.线性回归模型的参数估计量β?是随机变量i Y 的函数,即Y X )X X (?1''=-β。所以β?是(a )。 简答1、简述经济计量分析工作的程序设定模型、估计参数、检验模型、应用模型 2、简述回归分析与相关分析区别与联系两者都是研究相关关系的方法。但二者也有区别。相关分析关心的是变量之间的相关程度,但并不能反映变量之间的因果关系;而回归分析则要通过建立回归方程来估计解释变量与被解释变量之间的因果关系。此外,在回归分析中,定义被解释变量为随机变量,解释变量为非随机变量;而在相关分析中,把所考察的变量都看作是随机变量。 3、简述普通最小二乘法估计原理普通最小二乘法简称OLS,是应用最多的参数估计方法,也是从最小二乘原理出发的其他估计方法的基础。具有以下优良特性:残差平方和最小,无偏性和线性特征。 4、简述方差非齐性的后果参数的普通最小二乘估计虽然是无偏的,但却是非有效的。参数估计量的方差是有偏的,这将导致参数的假设检验失效,模型预测失效,是非有效的。 5、简述序列相关的后果当一个线性回归模型的随机误差项存在自相关时,就违背了线性回归方程的古典假定,如果仍然用普通最小二乘法估计参数,将 会产生严重后果。自相关产生的后果与异方差情形 类似。自相关影响OLS估计量的有效性,有效性不 再成立,存在比OLS模型更为有效的估计方法。存 在序列相关时,OLS方法下的各种检验失效,模型 预测失效。因为βi估计的方差不等于OLS方法下 计算的方差。 6、简述多重共线处理方法追加样本信息,使用非样 本先验信息,进行变量形式的转换,使用有偏估计 7、简述DW的局限性DW检验只适合一阶自回归形 式,而并不适用于检验高阶自回归形式或其它形式 的序列相关;模型中不含有滞后因变量。若届时变 量中有滞后变量,则DW检验将会失效;模型中含有 截距项;存在不能判定的区域。 8、简述方差非齐性的检验方法样本分段比较法; 残差回归检验法 9、简述发达市场经济国家模型特点建模依据各 流派经济理论;模型全面反映西方核算体系 10、简述经济计量模型评价的准则经济理论准 则;统计准则;经济计量准则 11、简述需求函数的特性非负性,可加性,零阶齐 次性,对称性,单调性 12、什么是内生变量是指模型要解释的变量。外 生变量决定内生变量,外生变量的变化回应其内生 变量的变化。具有一定概率分布的随机变量,它们 的数值是由模型自身决定的。 13、简述联立方程偏倚在结构式模型中,一些变 量可能在一个方程中作为解释变量,而在另一个方 程中又作为被解释变量,这就使得解释变量与随机 误差项之间存在相关关系,从而违背了最小二乘法 的一个重要假定,估计量因此是有偏的和非一致的。 14、简要说明格兰杰——恩格尔方法考察每个变 量的单整阶数;变量之间的长期均衡关系;误差修 正模型 15、什么是经济计量学它是在定性分析基础上, 专门探讨如何用经济数学模型方法定量描述具有随 机性特征的经济变量关系的边缘科学,或者说,它 是数理经济学和数理统计学的交叉科学。 16、什么是回归分析回归分析研究一个变量对于 一个或多个其它变量的依存关系,其目的在于根据 第七章 虚拟变量和随机解释变量 本章将讨论两种不同的模型:虚拟变量模型和随机解释变量模型,以及模型设定的其它问题。 第一节 虚拟变量模型 在我们以前考虑的模型中,解释变量都是定量变量(如成本、价格、收入、产出等),但在经济研究中,因变量经常受到一些定性变量的影响(如性别、种族、季节、不同历史时期等),我们把这类定性变量称为虚拟变量。习惯上用D表示虚拟变量,虚拟变量的取值通常为0和1。0表示变量具备某种属性,1表示变量不具备某种属性。 一、包含一个虚拟变量的模型 如果我们要研究的问题中解释变量只分为两类。则需引入一个模拟变量。 例9.1建立模型研究中国妇女在工作中是否受到歧视。 令Y=年薪,X=工作年限 ? ? ?=,女性,男性 101D 可以建立如下模型: i i i i u D B X B B Y +++=210 )1.9( 与一般的回归模型一样,假定0)(=i u E 男性就业者的平均年薪: i i i i X B B D X Y E 10)0,(+== )2.9( 女性就业者的平均年薪: 210)1,(B X B B D X Y E i i i i ++== )3.9( 如果B 2=0则说明不存在性别歧视,如果02 如果随着工龄增加,男性与女性的年薪差距也发生变化,则模型(9.1)就变为 i i i i i u X D B X B B Y +++=210 )4.9( 图9.2描绘了男性年薪增加较快的情况。 我们称虚拟变量只影响斜率而不影响截距的模型为乘法模型如(9.4) 如果男性与女性的初始年薪和年薪增加速度都有差异,我们可以将加法模型和乘法模型 结合起来,得到如下模型 i i i i i i u D B X D B X B B Y ++++=3210 )5.9( 模型(9.5)可以用来表示截距和斜率都发生变化的模型。其图形如图9.3所示。 我们还可以用加法模型与乘法模型相结合的方式建立模型来拟合经济发展出现转折的 情况。例如,进口商品消费支出Y主要取决于国民生产总值X(作为收入的替代变量)的多少。我们改革开放前后,由于国家政策的变化,及改革开放后外资的大量引入等因素的影响,1978年前后,Y 对X 的回归关系明显不同。以t *=1978年为转折点,1978年的国民生产总值X *t 为临界值。设虚拟变量 相关分析:主要研究随机变量间的相关形式及相关程度。 回归分析:研究一个变量关于另一个变量的依赖关系的计算方法和理论。 高斯马尔科夫定理:普通最小二乘估计量具有线性性、无偏性和有效性等优良性质,是最佳线性无偏估计量。 高斯马尔科夫假定:(1)模型设立正确 (2)无完全共线性 (3)可识别性 (4) 零均值、同方差。无序列相关假定(5) 解释变量与随机项不相关 计量经济学模型:揭示经济活动中各种因素之间的定量关系,用随机性的数学方程加以描述。广义计量经济学:利用经济理论、统计学和数学定量研究经济现象的经济计量方法的统称,包括回归分析方法、投入产出分析方法、时间序列分析方法等。 狭义计量经济学:以揭示经济现象中的因果关系为目的,在数学上主要应用回归分析方法。计量经济学: 是经济学的一个分支学科,是以揭示经济活动中的客观存在的数量关系为内容的分支学科。 计量经济学模型成功的三要素:理论、方法和数据。 滞后变量模型:把过去时期的,具有滞后作用的变量叫做滞后变量,含有滞后变量的模型称为滞后变量模型。 多重共线性:如果某两个或多个解释变量之间出现了相关性,则称为存在多重共线性。 多重共线性的后果:(1)完全共线性下参数估计量不存在(2)近似共线性下普通最小二乘法参数估计量的方差变大(3)参数估计量经济含义不合理(4)变量的显著性检验和模型的预测功能失去意义。 多重共线性的检验:(1)检验多重共线性是否存在(2)判明存在多重共线性的范围。 克服多重共线性的方法:(1)排出引起共线性的变量(2)差分法(3)减小参数估计量的方差。完全共线性:对于多元线性回归模型,其基本假设之一是解释变量,,…,是相互独立的,如果存在,i=1,2,…,n,其中c不全为0,即某一个解释变量可以用其他解释变量的线性组合表示,则称为完全共线性。 异方差性:对于不同的样本点,随机干扰项的方差不再是常数,而是互不相同,则认为出现了异方差性。 异方差性的后果:(1)参数估计量非有效(2)变量的显著性检验失去意义(3)模型的预测失效异方差性的检验方法:(1)图示检验法(2)帕克检验和戈里瑟检验(3)G-Q检验(4)怀特检验。异方差性的修正:最常用的方法是加权最小二乘法,即对原模型加权,使之变成一个新的不存在异方差的模型,然后采用OLS法估计其参数。 序列相关性:多元线形回归模型的基本假设之一是模型的随机干扰项相互独立或不相关。如果模型的随机干扰项违背了相互独立的基本假设,称为存在序列相关性。 序列相关性的后果:(1)参数估计量非有效(2)变量的显著性检验失去意义(3)模型的预测失败。 序列相关性的检验方法:(1)图示法(2)回归检验法(3)杜宾—瓦森检验法(4)拉格朗日乘法检验。 序列相关性的补救:(1)广义最小二乘法(2)广义差分法(3)随机干扰项相关系数的估计(4)广义差分法在计量经济学软件中的实现。 最小二乘估计量的性质:(1)线形性(2)无偏性(3)有效性(4)渐近无偏性(5)一致性(6)渐进有效性。 最小样本容量:即从最小二乘原理和最大似然原理出发,欲得到参数估计量,不管其质量如何,所要求的样本容量的下限。 随机干扰项:即随机误差项,是一个随机变量,是针对总体回归函数而言的。 无偏性:是指参数估计量的均值(期望)等于模型的参数值。 需求函数的零阶齐次性:消费者收入、商品价格和相关商品价格均增长 倍时,商品的需 实验八内生解释变量问题 【实验目的】 掌握工具变量法、两阶段最小二乘法的使用以及内生性检验与过度识别约束检验【实验内容】 利用美国各州的数据为样本观测值,建立香烟需求模型(见教材138页例4.3.4)【实验步骤】 地区 人均香烟消费Q (盒) 人均收入Y (千美元) 香烟平均销售价格P (美分/盒) 香烟平均消费税Tax (美分/盒) 香烟平均的特别消费税Taxs (美分/盒) SD 97.22 13.02 110.26 30.84 4.24 TN 122.32 14.30 109.62 24.28 8.12 TX 73.08 14.12 130.05 42.65 7.36 UT 49.27 12.37 118.75 33.14 5.65 VA 105.39 16.05 109.36 17.39 5.21 VT 122.33 14.02 115.25 28.87 5.49 WA 65.53 15.67 156.90 52.82 10.26 WI 92.47 14.81 132.14 40.68 6.29 WV 115.57 11.75 109.26 26.90 6.18 WY 112.24 14.12 104.03 23.62 0.00 根据商品需求函数理论,对香烟的人均消费需求Q 与居民的收入水平Y 及香烟的销售价格P 有关;虑到在市场均衡时香烟的销售价格也同时受香烟的需求量的影响,则Q 与P 之间存在着双向因果关系,P 为内生解释变量,考虑到香烟价格中包含政府对烟草的课税,而香烟的人均消费量本身不会直接影响政府对香烟的课税政策,因此香烟的消费税可能是价格的一个适当的工具变量。 一、建立对数线性模型:012ln ln ln Q Y P βββμ=+++ 对原模型做回归分析结果如下: 从结果可以看出,价格确实是影响人均香烟消费的重要因素,其弹性为-1.4,特别大。怀疑P 具有内生性。 二、工具变量法 利用消费税作为P 的工具变量,重新对原模型进行回归 把lnQ lnY lnP 作为一个组打开,选择Proc/Make Equation/Method 中的Tsls,点击确定 影响我国居民消费因素分析 班级: 组员: 一、提出问题: 1、原因: 居民消费水平是按国民收入或国内生产总值的使用总量中用于居民消费的总额除以年平均人口计算的,它反映一个国家或一个地区居民的一般消费水平。居民消费水平是GDP中一个重要组成部分,是拉动经济增长的三驾马车之一,在拉动经济增长的三架马车中,最终消费对经济影响的最大,是拉动经济增长最重要最稳定的因素。我国经济正逐渐由投资拉动型增长向消费拉动型增长转变,居民消费一直是经济学家关注的焦点和研究的热门领域。居民消费对经济的发展和社会的进歩有着重要的引导作用,居民消费的结构、质量和增长趋势如何,在很大程度上决定着经济、社会的发展情况。 要充分发挥消费对经济的拉动作用,关键问题是如何保证居民的消费水平。在人均国民生产总值为一千美元时,世界各国的居民消费率一般为60%左右。而我国的人均国民生产总值早已超过了一千美元,但2013年全国居民的消费率仅36%,严重低于正常水平。消费需求的偏低导致消费对经济增长的拉动作用也偏弱,因此提高居民消费率,增加居民消费对经济增长的贡献 度,是一项重要工作。 通过对历年我国居民消费水平的分析,我们可以对消费水平发展有一个清晰的画面,并且能透过数据的表象来分析更深层次的国家调控手段和战略使用。 2、研究立场:政策制定者 二、文献综述: 根据国外相关研究成果,主要有恩格尔的理论、绝对收入、相对收入、持久收入和生命周期消费理论等。Caballero (1990)指出,当期劳动收入发生变化表明未来的收入发生变化的可能性比较大,为维持未来消费的稳定性,需要进行预防性储蓄,从而会降低当期消费,使得长期的消费得到"平滑"。 国内研究得出的消费率的影响因素主要包括:居民收入占比,收入分配差距,不确定性,流动性约束和房价。齐吴珍认为居民消费的主要影响因素有:居民收入的增长率、收入分配差距、不确定性、流动性约束和房价等。 目前,多数学者通过建立消费与收入的模型或者消费分别与城乡居民收入建立模型进行分析,结果显示:1、收入是决定居民消费水平的主要因素,收入增加的快慢是影响居民消费需求变化的重要原因。 2、农村居民收入、财政支出水平、城市化水平、农村社会保障制度均对农村居民消费需求起正向作用,城乡居民收入差距起负向作用,农村内部收入分配差距与消费需求不存在显著相关关系。 3、收入的不确定性、以及出于预防动机,我国居民储蓄率高,在一定程度上影响 第六章内生增长理论 前面三章对经济增长的核心问题给出了满意的回答,得到的主要结论是:如果资本的报酬是资本对产出的贡献的反映,并且资本在总收入中的比例不大的话,那么资本积累既不能说明经济的长期增长,也不能说明国家之间收入水平的差异。但收入的决定性因素——有效劳动,却没有得到解释,它在模型中是一个神秘变量,我们既不知道它的具体含义,更不知道它是如何确定的,模型只把它作为外生变量看待,由经济的外部力量决定。这一点正是前三章建立的模型和理论的不足所在。因此,本章和下一章将要克服这一不足,把知识的增长纳入经济的内部因素之中,从更深的层次上来研究经济增长的基本问题。 本章要阐述的观点,是认为知识增长是经济增长的推动力量。这同第三章中索洛的观点是一致的:资本积累不是经济增长的源泉。但本章在分析知识进化和用知识解释有效劳动时,与前三章做法大为不同。本章要以明确的方式建立知识积累模型,并要研究知识如何产生,资源如何配置到知识的生产中去等问题。 第一节技术进步的影响因素 我们可以把知识或技术进步想象为一大堆的发现和发明,比如DNA结构的发现,转基因的发明,原子核反应的发现等等。其实,这些新发现和新发明都是科学研究的成果,当然也有一定的机遇因素,但不是经济力量作用的结果。然而在现代经济社会中,大多数技术进步却要归功于企业的研究开发(research and development,简称R&D)活动。我们在第二章第一节中提到的五个OECD国家,它们的工业性研究开发支出大约占它们的GDP的2%到3%左右。美国约有100万名科学家和研究人员,他们当中的75%都是企业雇用的,从事企业的研究开发活动。美国企业的研究开发支出占到企业总投资的20%以上,占到企业净投资的60%以上。毋庸置疑,企业在研究开发上的支出多少完全是从经济方面考虑的,是企业对研究开发的成本与收益进行权衡的结果。 (一) R&D决策与专利法 企业要在研究开发上进行支出,其理由同企业购置新机器或新建工厂是一样的,都是为了提高预期利润。在企业决定是否要购买新机器时,企业要把购买新机器后所能产生的预期利润的现值同购买和安装新机器所需的支出进行比较,如果预期利润的现值大于支出,则决定投资去购买新机器;否则,就不进行这项投资。同样,企业在进行R&D决策时,也要考虑投资于R&D所能取得的预期利润的现值与R&D支出的比较。企业增加R&D支出,意味着提高了企业发现和开发出新产品的可能性。如果新产品能够获得市场成功,那么企业的未来利润将上升。如果预期利润的现值超过研究开发的预期支出,那么企业就会上马新的R&D项目,进行R&D投资;否则,企业就不会这么做。 然而,研究开发投资与普通投资(比如购买新机器、新建工厂等)又有着重要的区别。像购买新机器这类普通投资只有内部效益,没有外部效益。一台机器被这家企业购买后,其他企业就不能再使用这台机器了,新机器只给它的拥有者提供效益(这就是内部效益),而不向其他企业提供效益(即没有外部效益)。但研究开发投资就不同了,研究开发的成果多是一些新思想,而这种思想一旦公开,就不但能被发现它的人和企业使用,而且能被社会广泛使 1.什么是计量经济学? 答: 计量经济学是以经济理论和经济数据的事实为依据,运用数学和统计学的方法,通过建立数学模型来研究经济数量关系和规律的一门经济学科。 2.什么是总体回归函数和样本回归函数?他们之间的区别是什么? 答:假如已知所研究的经济现象的总体的被解释变量Y和解释变量X的每个观测值有规律的变化(通常这是不可能的!),那么,可以计算出总体被解释变量Y的条件期望E(Y|Xi) 并将其表现为解释变量X的某种函数E(Y|Xi) =f(Xi) ,这个函数称为总体回归函数。 如果把被解释变量Y的样本条件均值表示为解释变量X的某种函数,这个函数称为样本回归函数。Y^i=β^1+β2Xi 区别:(1)总体回归线是未知,但它是确定的;样本回归线随抽样波动而变化,可以有许多条。 (2)总体回归函数的参数虽未知,但是确定的常数;样本回归函数的回归系数可估计,但是随抽样而变化的随机变量; (3)总体回归函数中的随机误差项ut 是不可直接观测的;而样本回归函数中的残差et 是只要估计出样本回归估计值就可以计算的数值。 3.对随机误差扰动项的假设? 答:(1)、随机误差项是一个期望值或平均值为0的随机变量; (2)、对于解释变量的所有观测值,随机误差项有相同的方差; (3)、随机误差项彼此不相关; (4)、解释变量是确定性变量,不是随机变量,与随机误差项彼此之间相互独立; (5)、随机误差项服从正态分布。 4.ols估计量的统计性质与对模型的基本假定的关系是什么? 1.多元回归的基本假设是什么,与简单线性回归的基本假设有什么区别? 答:1:零均值假定2.同方差和无自相关假定3随机扰动项与解释变量不相关4.无多重共线性假定5.正态性假定 区别:多元的基本假设比简单的多了一个无多重共线性假定。 2.F检验,是检验什么的?t检验,检验什么? 答:T检验是对回归参数的检验。 F检验是对多元线性回归模型中所有解释变量之间的线性关系在整体上是否显著的检验。 3.可决系数的显著性是通过什么来检验的? 答:可决系数可以作为综合度量回归模型对样本观测值拟合优度的度量指标。可决系数的计算式: 回归平方和(ESS)在总变差(TSS)中所占的比重称为多重可决系数,介于0和1之间,越接近于1,拟合程度越好。可决系数可以作为综合度量回归模型对样本观测值拟合优度的度量指标。可决系数越大,说明在总变差中由模型作出了解释的部分占的比重越大,模型拟合优度越好。反之可决系数小,说明模型对样本观测值的拟合程度越差。 4.TSS,ESS,RSS的自由度各是多少?TSS,ESS,RSS,自由度和与其对应的方差之间对应的关系是什么? 答:先定义一下:n为样本容量,K为为待估参数个数,也为解释变量+1(如果将常数项视作一个解释变量,也可以说是解释变量的总个数) (1)TSS的自由度为n-1,计量经济学简答
内生性问题
随机解释变量问题
内生性问题原因和处理方法
计量经济学题库第8章模型中的特殊解释变量
第7章 随机解释变量
(完整word版)内生性问题原因和处理方法
计量经济学期末试卷
计量经济学简答
第七章 虚拟变量和随机解释变量 (2)
计量经济学名词解释与简答
实验八内生解释变量问题.doc
计量经济学,多重共线性异方差虚拟变量随机解释变量大作业
第六章 内生增长理论
计量经济学简答题